
ж‘ҳиҰҒпјҡВ еңЁKubernetesжңҚеҠЎеҢ–гҖҒж—Ҙеҝ—еӨ„зҗҶе®һж—¶еҢ–д»ҘеҸҠж—Ҙеҝ—йӣҶдёӯејҸеӯҳеӮЁи¶ӢеҠҝдёӢпјҢKubernetesж—Ҙеҝ—еӨ„зҗҶдёҠд№ҹйҒҮеҲ°зҡ„ж–°жҢ‘жҲҳпјҢеҢ…жӢ¬пјҡе®№еҷЁеҠЁжҖҒйҮҮйӣҶгҖҒеӨ§жөҒйҮҸжҖ§иғҪ瓶йўҲгҖҒж—Ҙеҝ—и·Ҝз”ұз®ЎзҗҶзӯүй—®йўҳгҖӮжң¬ж–Үд»Ӣз»ҚдәҶвҖңLogtail + ж—Ҙеҝ—жңҚеҠЎ + з”ҹжҖҒвҖқжһ¶жһ„пјҢд»Ӣз»ҚдәҶпјҡLogtailе®ўжҲ·з«ҜеңЁKubernetesж—Ҙеҝ—йҮҮйӣҶеңәжҷҜдёӢзҡ„дјҳеҠҝпјӣж—Ҙеҝ—жңҚеҠЎдҪңдёәеҹәзЎҖи®ҫж–ҪдёҖз«ҷејҸи§ЈеҶіе®һж—¶иҜ»еҶҷгҖҒHTAPдёӨеӨ§ж—Ҙеҝ—ејәйңҖжұӮпјӣж—Ҙеҝ—жңҚеҠЎж•°жҚ®зҡ„ејҖж”ҫжҖ§д»ҘеҸҠдёҺдә‘дә§е“ҒгҖҒејҖжәҗзӨҫеҢәзӣёз»“еҗҲпјҢеңЁе®һж—¶и®Ўз®—гҖҒеҸҜи§ҶеҢ–гҖҒйҮҮйӣҶдёҠдёәз”ЁжҲ·жҸҗдҫӣзҡ„дё°еҜҢйҖүжӢ©гҖӮ
Kubernetesж—Ҙеҝ—еӨ„зҗҶзҡ„и¶ӢеҠҝдёҺжҢ‘жҲҳ
Kubernetesзҡ„servelessеҢ–
Kubernetesе®№еҷЁжҠҖжңҜдҝғиҝӣдәҶжҠҖжңҜж Ҳзҡ„еҺ»иҖҰеҗҲпјҢйҖҡиҝҮеј•е…Ҙж Ҳзҡ„еҲҶеұӮдҪҝеҫ—ејҖеҸ‘иҖ…еҸҜд»ҘжӣҙеҠ е…іжіЁиҮӘиә«зҡ„еә”з”ЁзЁӢеәҸе’ҢдёҡеҠЎеңәжҷҜгҖӮд»ҺKubernetesжң¬иә«жқҘзңӢпјҢиҝҷдёӘжҠҖжңҜи§ЈиҖҰд№ҹеңЁжӣҙиҝӣдёҖжӯҘеҸ‘еұ•пјҢе®№еҷЁеҢ–зҡ„дёҖдёӘеҸ‘еұ•зҡ„и¶ӢеҠҝжҳҜпјҡиҝҷдәӣе®№еҷЁйғҪе°ҶдјҡеңЁж— жңҚеҠЎеҷЁзҡ„еҹәзЎҖи®ҫж–ҪдёҠиҝҗиЎҢгҖӮ
и°ҲеҲ°еҹәзЎҖи®ҫж–ҪпјҢйҰ–е…ҲеҸҜд»ҘиҒ”жғіеҲ°дә‘пјҢзӣ®еүҚеңЁAWSгҖҒйҳҝйҮҢдә‘гҖҒAzureзҡ„дә‘дёҠйғҪжҸҗдҫӣдәҶж— жңҚеҠЎеҷЁеҢ–зҡ„KubernetesжңҚеҠЎгҖӮеңЁserverless KubernetesдёҠпјҢжҲ‘们е°ҶдёҚеҶҚе…іеҝғйӣҶзҫӨдёҺжңәеҷЁпјҢеҸӘйңҖиҰҒеЈ°жҳҺе®№еҷЁзҡ„й•ңеғҸгҖҒCPUгҖҒеҶ…еӯҳгҖҒеҜ№еӨ–жңҚеҠЎж–№ејҸе°ұеҸҜд»ҘеҗҜеҠЁеә”з”ЁгҖӮ
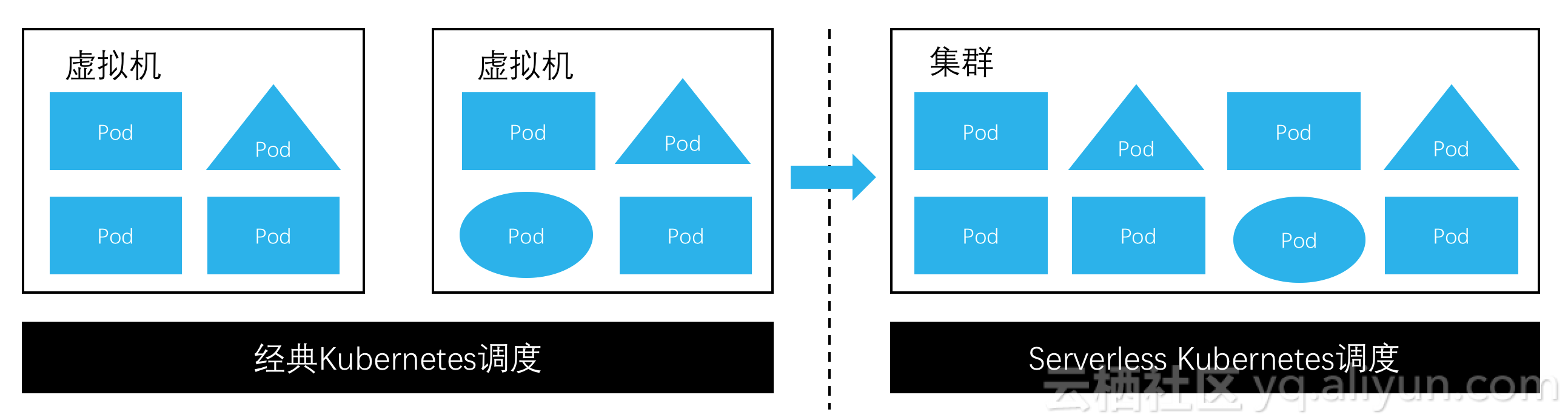
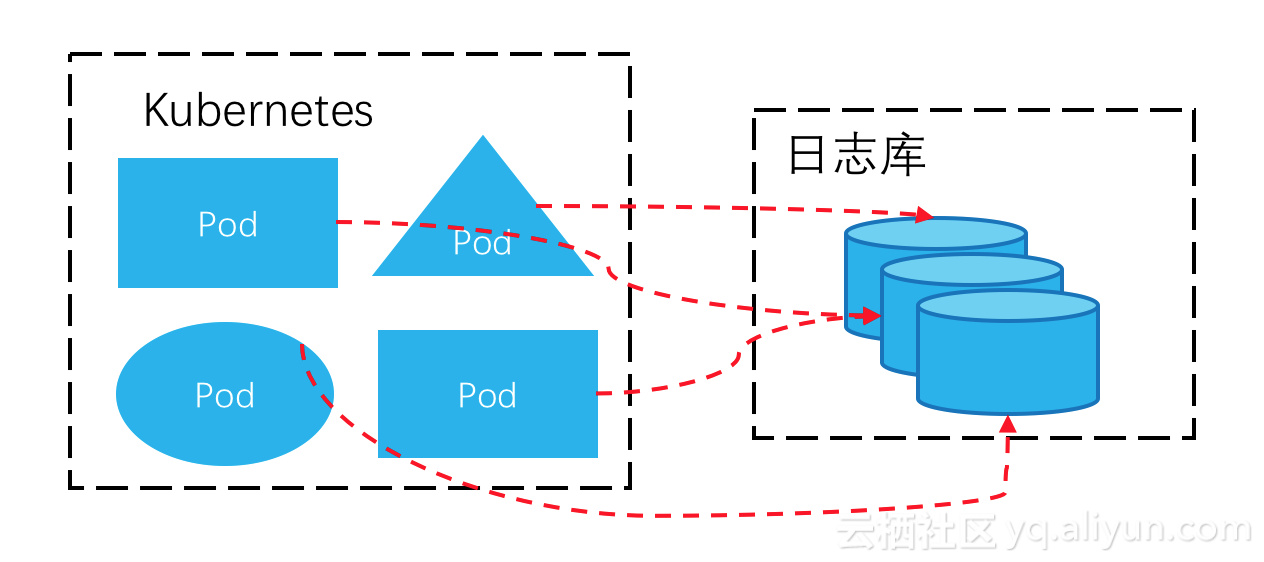
еҰӮдёҠеӣҫпјҢе·ҰеҸідёӨиҫ№еҲҶеҲ«жҳҜз»Ҹе…ёKubernetesгҖҒserverless Kubernetesзҡ„еҪўжҖҒгҖӮеңЁд»Һе·Ұеҗ‘еҸіеҸ‘еұ•зҡ„иҝҮзЁӢдёӯпјҢж—Ҙеҝ—йҮҮйӣҶд№ҹеҸҳеҫ—еӨҚжқӮпјҡ
- еңЁдёҖдёӘKubernetes nodeдёҠпјҢеҸҜиғҪдјҡиҝҗиЎҢжӣҙеӨ§и§„жЁЎйҮҸзә§зҡ„podпјҢжҜҸдёӘpodдёҠйғҪеҸҜиғҪжңүж—Ҙеҝ—жҲ–зӣ‘жҺ§жҢҮж ҮйҮҮйӣҶйңҖжұӮпјҢж„Ҹе‘ізқҖеҚ•nodeдёҠзҡ„ж—Ҙеҝ—йҮҸдјҡжӣҙеӨ§гҖӮ
- дёҖдёӘKubernetes nodeдёҠеҸҜиғҪдјҡиҝҗиЎҢжӣҙеӨҡз§Қзұ»зҡ„podпјҢж—Ҙеҝ—йҮҮйӣҶжқҘжәҗеҸҳеҫ—еӨҡж ·еҢ–пјҢеҗ„зұ»ж—Ҙеҝ—зҡ„з®ЎзҗҶгҖҒжү“ж ҮйңҖжұӮи¶ҠжқҘи¶Ҡиҝ«еҲҮгҖӮ
ж—Ҙеҝ—е®һж—¶жҖ§йңҖжұӮи¶ҠжқҘи¶Ҡејә
йҰ–е…ҲиҰҒејәи°ғзҡ„жҳҜпјҢ并йқһжүҖжңүж—Ҙеҝ—йғҪйңҖиҰҒе®һж—¶еӨ„зҗҶпјҢеҪ“еүҚеҫҲеӨҡ"T+1"ж—¶ж•Ҳзҡ„ж—Ҙеҝ—дәӨд»ҳдҫқ然йқһеёёйҮҚиҰҒпјҢжҜ”еҰӮпјҡеҒҡBIеҸҜиғҪеӨ©зә§еҲ«е»¶иҝҹи¶іеӨҹпјҢctrйў„дј°еҸҜиғҪ1е°Ҹ时延иҝҹзҡ„ж—Ҙеҝ—д№ҹеҸҜд»ҘгҖӮ
дҪҶжҳҜпјҢеңЁжңүдәӣеңәжҷҜдёӢпјҢз§’зә§жҲ–жӣҙй«ҳж—¶ж•ҲжҖ§зҡ„ж—Ҙеҝ—жҳҜеҝ…еӨҮеүҚжҸҗжқЎд»¶пјҢдёӢеӣҫжЁӘеқҗж Үд»Һе·ҰеҲ°еҸізҡ„еҜ№жҜ”еұ•зӨәдәҶж•°жҚ®е®һж—¶жҖ§еҜ№дәҺеҶізӯ–зҡ„йҮҚиҰҒжҖ§гҖӮ
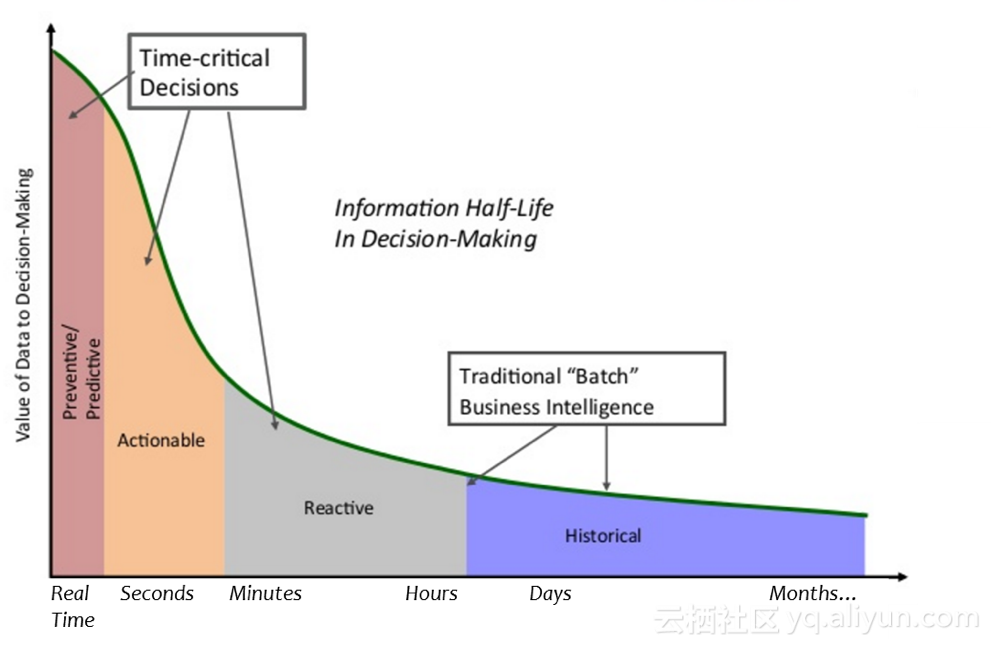
дёҫдёӨдёӘеңәжҷҜжқҘи°ҲдёҖдёӢе®һж—¶ж—Ҙеҝ—еҜ№дәҺеҶізӯ–зҡ„йҮҚиҰҒжҖ§пјҡ
- е‘ҠиӯҰеӨ„зҗҶгҖӮжҗһdevopsеҗҢеӯҰйғҪж·ұжңүдҪ“дјҡпјҢзәҝдёҠй—®йўҳи¶Ҡж—©еҸ‘зҺ°гҖҒи¶Ҡж—©еӨ„зҗҶжҲ‘们е°ұеҸҜд»Ҙжӣҙж·Ўе®ҡпјҢеӨ„зҗҶж—¶й—ҙжӢ–еҫ—д№…дәҶж•…йҡңе°ұеҸҜиғҪи·ҹзқҖеҚҮзә§гҖӮе®һж—¶ж—Ҙеҝ—её®еҠ©жҲ‘们жӣҙеҝ«еҸ‘зҺ°зі»з»ҹзҡ„ејӮеёёжҢҮж ҮпјҢи§ҰеҸ‘еә”жҖҘеӨ„зҗҶжөҒзЁӢгҖӮ
- AIOpsгҖӮзӣ®еүҚе·Із»ҸжңүдёҖдәӣз®—жі•еҹәдәҺж—Ҙеҝ—еҒҡејӮеёёзӮ№жЈҖжөӢгҖҒи¶ӢеҠҝйў„жөӢпјҡж №жҚ®ж—Ҙеҝ—зҡ„patternеҸҳеҢ–жҖҒеҠҝеҸ‘зҺ°жӯЈеёёе’ҢејӮеёёжғ…еҶөдёӢеҗ„зұ»еһӢж—Ҙеҝ—еҮәзҺ°зҡ„еҲҶеёғпјӣй’ҲеҜ№ITдёҡеҠЎзі»з»ҹпјҢз»ҷе®ҡеҸӮж•°еӣ еӯҗгҖҒеҸҳйҮҸеҜ№иҜёеҰӮзЎ¬зӣҳж•…йҡңзӯүй—®йўҳиҝӣиЎҢе»әжЁЎпјҢеҠ д»Ҙе®һж—¶ж—Ҙеҝ—жқҘе®һзҺ°ж•…йҡңдәӢ件预иӯҰгҖӮ
ж—Ҙеҝ—зҡ„йӣҶдёӯејҸеӯҳеӮЁ
ж—Ҙеҝ—жқҘжәҗжңүеҫҲеӨҡпјҢеёёи§Ғзҡ„жңүпјҡж–Ү件пјҢж•°жҚ®еә“audit logпјҢзҪ‘з»ңж•°жҚ®еҢ…зӯүзӯүгҖӮ并且пјҢй’ҲеҜ№еҗҢдёҖд»Ҫж•°жҚ®пјҢеҜ№дәҺдёҚеҗҢзҡ„дҪҝз”ЁиҖ…пјҲдҫӢеҰӮпјҡејҖеҸ‘гҖҒиҝҗз»ҙгҖҒиҝҗиҗҘзӯүпјүгҖҒдёҚеҗҢзҡ„з”ЁйҖ”пјҲдҫӢеҰӮпјҡе‘ҠиӯҰгҖҒж•°жҚ®жё…жҙ—гҖҒе®һж—¶жЈҖзҙўгҖҒжү№йҮҸи®Ўз®—зӯүпјүпјҢеӯҳеңЁдҪҝз”ЁеӨҡз§Қж–№ејҸйҮҚеӨҚж¶Ҳиҙ№ж—Ҙеҝ—ж•°жҚ®зҡ„жғ…еҶөгҖӮ
еңЁж—Ҙеҝ—ж•°жҚ®зҡ„зі»з»ҹйӣҶжҲҗдёҠпјҢд»Һж•°жҚ®жәҗеҲ°еӯҳеӮЁиҠӮзӮ№еҶҚеҲ°и®Ўз®—иҠӮзӮ№пјҢеҸҜд»Ҙе®ҡд№үдёәдёҖдёӘpipelineгҖӮеҰӮдёӢеӣҫпјҢд»ҺдёҠеҲ°дёӢзҡ„еҸҳеҢ–жҳҜпјҡж—Ҙеҝ—еӨ„зҗҶжӯЈеңЁд»ҺO(N^2) pipelinesеҗ‘O(N) pipelinesжј”иҝӣгҖӮ
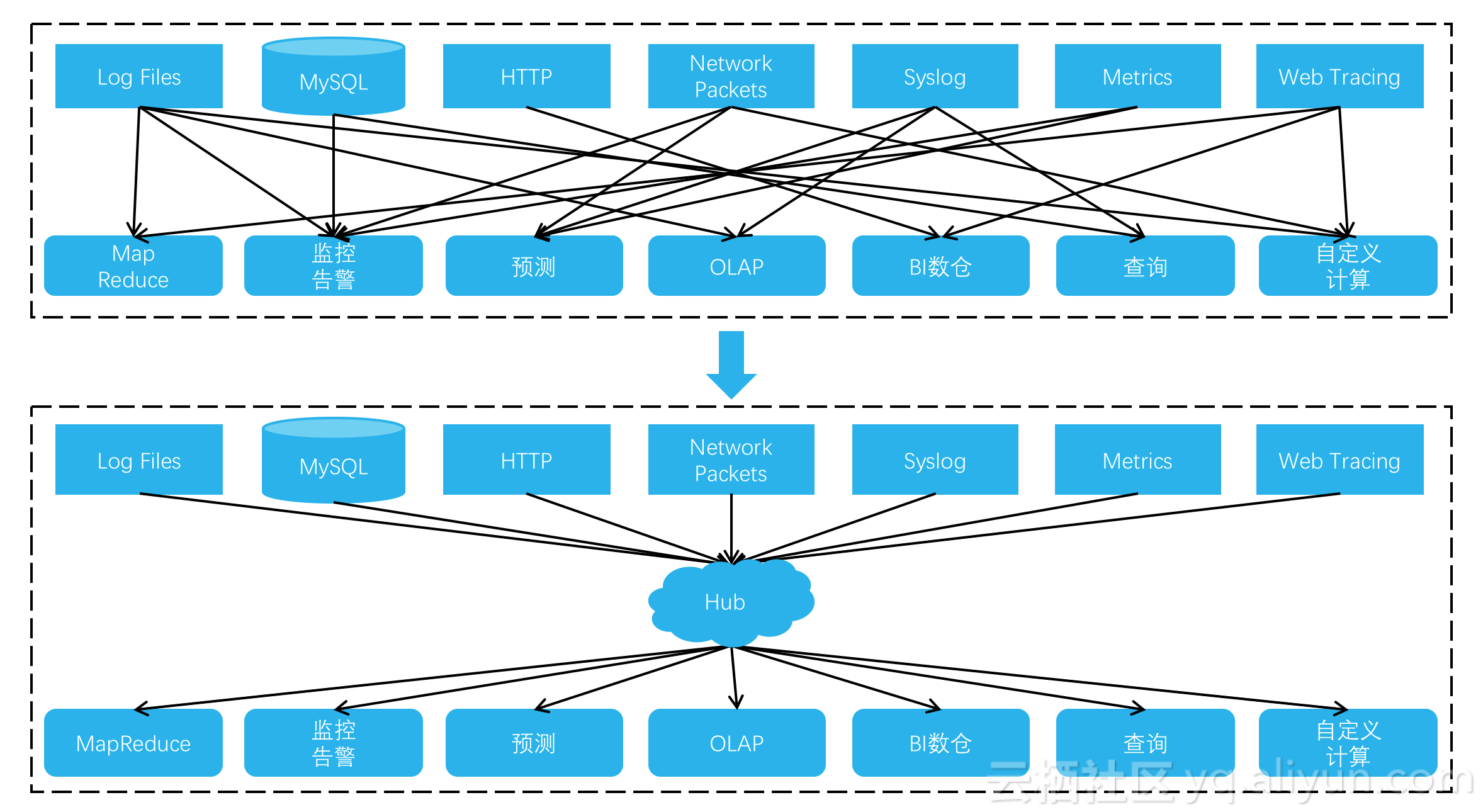
еңЁиҝҮеҺ»пјҢеҗ„зұ»ж—Ҙеҝ—з”Ёзү№е®ҡзҡ„ж–№ејҸжқҘеӯҳеӮЁпјҢйҮҮйӣҶеҲ°и®Ўз®—й“ҫи·ҜдёҚе…·иў«йҖҡз”Ёе’ҢеӨҚз”ЁжқЎд»¶пјҢpipelineйқһеёёеӨҚжқӮпјҢж•°жҚ®еӯҳеӮЁд№ҹеҸҜиғҪйҮҚеӨҚеҶ—дҪҷгҖӮеҪ“еүҚж—Ҙеҝ—ж•°жҚ®йӣҶжҲҗдёҠпјҢйҖҡиҝҮдҫқиө–дёҖдёӘдёӯжһўпјҲHubпјүжқҘз®ҖеҢ–ж—Ҙеҝ—жһ¶жһ„зҡ„еӨҚжқӮеәҰгҖҒдјҳеҢ–еӯҳеӮЁеҲ©з”ЁзҺҮгҖӮиҝҷдёӘеҹәзЎҖи®ҫж–Ҫзә§еҲ«зҡ„HubйқһеёёйҮҚиҰҒпјҢйңҖиҰҒж”ҜжҢҒе®һж—¶pub/subпјҢиғҪеӨҹеӨ„зҗҶй«ҳ并еҸ‘зҡ„еҶҷе…ҘгҖҒиҜ»еҸ–иҜ·жұӮпјҢжҸҗдҫӣжө·йҮҸзҡ„еӯҳеӮЁз©әй—ҙгҖӮ
Kubernetesж—Ҙеҝ—йҮҮйӣҶж–№жЎҲзҡ„жј”иҝӣ
еүҚйқўдёҖиҠӮжҖ»з»“дәҶKubernetesж—Ҙеҝ—еӨ„зҗҶдёҠзҡ„и¶ӢеҠҝпјҢйӮЈд№Ҳ家дёӢжқҘдјҡзӣҳзӮ№дёҖдёӢKubernetesдёҠеҮ з§Қеёёи§Ғж—Ҙеҝ—йҮҮйӣҶзҡ„еҒҡжі•гҖӮ
е‘Ҫд»ӨиЎҢе·Ҙе…·
KubernetesйӣҶзҫӨдёҠиҰҒзңӢж—Ҙеҝ—пјҢжңҖеҹәзЎҖзҡ„еҒҡжі•е°ұжҳҜзҷ»жңәеҷЁпјҢиҝҗиЎҢkubectl logsе°ұеҸҜд»ҘзңӢеҲ°е®№еҷЁеҶҷеҮәзҡ„stdout/stderrгҖӮ
еҹәзЎҖзҡ„ж–№жЎҲжІЎжі•ж»Ўи¶іжӣҙеӨҡйңҖжұӮпјҡ
- еҸӘж”ҜжҢҒж ҮеҮҶиҫ“еҮә
- ж•°жҚ®дёҚиғҪжҢҒд№…еҢ–
- йҷӨдәҶзңӢеҒҡдёҚдәҶеҲ«зҡ„дәӢ
иҠӮзӮ№ж—Ҙеҝ—ж–Ү件иҗҪзӣҳ
еңЁKubernetes nodeз»ҙеәҰеҺ»еӨ„зҗҶж—Ҙеҝ—пјҢdocker engineе°Ҷе®№еҷЁзҡ„stdout/stderrйҮҚе®ҡеҗ‘еҲ°logdriverпјҢ并且еңЁlogdriverдёҠеҸҜд»Ҙй…ҚзҪ®еӨҡз§ҚеҪўејҸеҺ»жҢҒд№…еҢ–ж—Ҙеҝ—пјҢжҜ”еҰӮд»Ҙjsonж јејҸдҝқеӯҳж–Ү件еҲ°жң¬ең°еӯҳеӮЁгҖӮ
е’Ңkubectlе‘Ҫд»ӨиЎҢзӣёжҜ”пјҢжӣҙиҝӣдёҖжӯҘжҳҜжҠҠж—Ҙеҝ—еҒҡеҲ°дәҶжң¬ең°еҢ–еӯҳеӮЁгҖӮеҸҜд»Ҙз”Ёgrep/awkиҝҷдәӣLinuxе·Ҙе…·еҺ»еҲҶжһҗж—Ҙеҝ—ж–Ү件еҶ…е®№гҖӮ
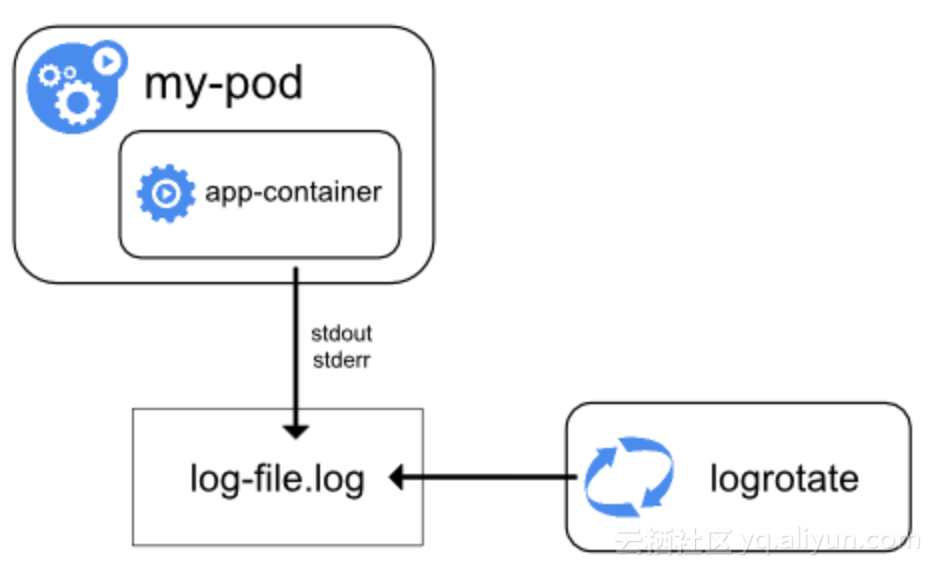
иҝҷдёӘж–№жЎҲзӣёеҪ“дәҺеӣһеҲ°дәҶзү©зҗҶжңәж—¶д»ЈпјҢдҪҶд»Қ然еӯҳеңЁеҫҲеӨҡй—®йўҳжІЎжңүи§ЈеҶіпјҡ
- еҹәдәҺdocker engineе’ҢlogdriverпјҢйҷӨдәҶй»ҳи®Өзҡ„ж ҮеҮҶиҫ“еҮәпјҢдёҚж”ҜжҢҒеә”з”ЁзЁӢеәҸзҡ„ж—Ҙеҝ—
- ж—Ҙеҝ—ж–Ү件rotateеӨҡж¬ЎжҲ–иҖ…Kubernetes nodeиў«й©ұйҖҗеҗҺж•°жҚ®дјҡдёўеӨұ
- жІЎжі•и·ҹејҖжәҗзӨҫеҢәгҖҒдә‘дёҠзҡ„ж•°жҚ®еҲҶжһҗе·Ҙе…·йӣҶжҲҗ
еҹәдәҺиҝҷдёӘж–№жЎҲзҡ„дёҖдёӘиҝӣеҢ–зүҲжң¬жҳҜеңЁnodeдёҠйғЁзҪІж—Ҙеҝ—йҮҮйӣҶе®ўжҲ·з«ҜпјҢе°Ҷж—Ҙеҝ—дёҠдј еҲ°дёӯеҝғеҢ–ж—Ҙеҝ—еӯҳеӮЁзҡ„и®ҫж–ҪдёҠеҺ»гҖӮзӣ®еүҚиҝҷд№ҹжҳҜжҺЁиҚҗзҡ„жЁЎејҸпјҢдјҡеңЁдёӢдёҖиҠӮеҶҚеҒҡд»Ӣз»ҚгҖӮ
sidecarжЁЎејҸж—Ҙеҝ—е®ўжҲ·з«ҜйҮҮйӣҶ
дёҖз§Қдјҙз”ҹжЁЎејҸпјҢеңЁдёҖдёӘpodеҶ…пјҢйҷӨдәҶдёҡеҠЎе®№еҷЁеӨ–пјҢиҝҳжңүдёҖдёӘж—Ҙеҝ—е®ўжҲ·з«Ҝе®№еҷЁгҖӮиҝҷдёӘж—Ҙеҝ—е®ўжҲ·з«Ҝе®№еҷЁиҙҹиҙЈйҮҮйӣҶpodеҶ…е®№еҷЁзҡ„ж ҮеҮҶиҫ“еҮәгҖҒж–Ү件гҖҒmetricж•°жҚ®дёҠжҠҘжңҚеҠЎз«ҜгҖӮ
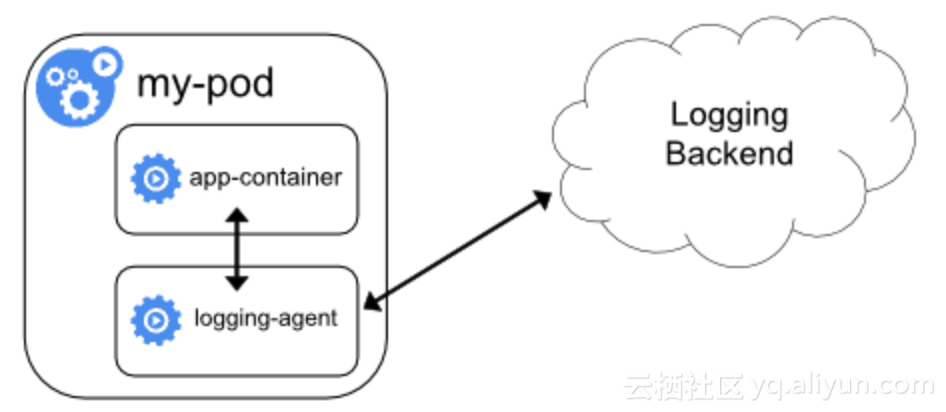
иҝҷдёӘж–№жЎҲи§ЈеҶідәҶж—Ҙеҝ—жҢҒд№…еҢ–еӯҳеӮЁзӯүеҹәжң¬зҡ„еҠҹиғҪйңҖжұӮпјҢдҪҶдёӨдёӘең°ж–№жңүеҫ…жҸҗеҚҮпјҡ
- дёҖдёӘиҠӮзӮ№дёҠеҰӮжһңиҝҗиЎҢдәҶNдёӘpodпјҢе°ұж„Ҹе‘ізқҖдјҡеҗҢж—¶иҝҗиЎҢзқҖNдёӘж—Ҙеҝ—е®ўжҲ·з«ҜпјҢйҖ жҲҗCPUгҖҒеҶ…еӯҳгҖҒз«ҜеҸЈзӯүиө„жәҗзҡ„жөӘиҙ№гҖӮ
- KubernetesдёӢйңҖиҰҒдёәжҜҸдёӘpodеҚ•зӢ¬иҝӣиЎҢйҮҮйӣҶй…ҚзҪ®пјҲйҮҮйӣҶж—Ҙеҝ—зӣ®еҪ•пјҢйҮҮйӣҶ规еҲҷпјҢеӯҳеӮЁзӣ®ж ҮзӯүпјүпјҢдёҚжҳ“з»ҙжҠӨгҖӮ
ж—Ҙеҝ—зӣҙеҶҷ
зӣҙеҶҷж–№жЎҲдёҖиҲ¬жҳҜйҖҡиҝҮдҝ®ж”№еә”з”ЁзЁӢеәҸжң¬иә«жқҘе®һзҺ°пјҢеңЁзЁӢеәҸеҶ…йғЁз»„з»ҮеҮ жқЎж—Ҙеҝ—пјҢ然еҗҺи°ғз”Ёзұ»дјјHTTP APIе°Ҷж•°жҚ®еҸ‘йҖҒеҲ°ж—Ҙеҝ—еӯҳеӮЁеҗҺз«ҜгҖӮ
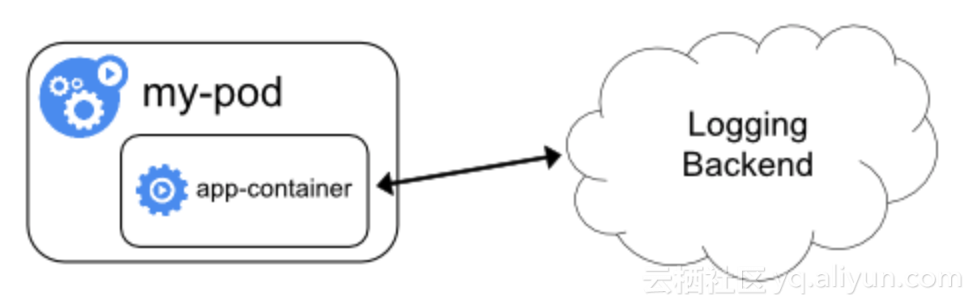
еёҰжқҘзҡ„еҘҪеӨ„жҳҜпјҡж—Ҙеҝ—ж јејҸеҸҜд»ҘжҢүйңҖDIYпјҢж—Ҙеҝ—жәҗе’Ңзӣ®ж Үзҡ„и·Ҝз”ұеҸҜд»Ҙд»»ж„Ҹй…ҚзҪ®гҖӮ
д№ҹеҸҜд»ҘзңӢеҲ°дҪҝз”ЁдёҠзҡ„йҷҗеҲ¶пјҡ
- дҫөе…Ҙд»Јз ҒдјҡеҜ№дёҡеҠЎж”№йҖ жңүзӣҙжҺҘзҡ„дҫқиө–пјҢжҺЁеҠЁдёҡеҠЎж”№йҖ дёҖиҲ¬жҜ”иҫғжј«й•ҝгҖӮ
- еә”з”ЁзЁӢеәҸеңЁеҸ‘ж•°жҚ®еҲ°иҝңз«ҜйҒҮеҲ°ејӮеёёпјҲжҜ”еҰӮзҪ‘з»ңжҠ–еҠЁпјҢжҺҘ收жңҚеҠЎз«ҜеҶ…йғЁй”ҷиҜҜпјүж—¶пјҢйңҖиҰҒеңЁжңүйҷҗеҶ…еӯҳдёӯзј“еӯҳж•°жҚ®еҒҡйҮҚиҜ•пјҢжңҖз»ҲиҝҳжҳҜжңүжҰӮзҺҮйҖ жҲҗж•°жҚ®дёўеӨұгҖӮ
Kubernetesж—Ҙеҝ—еӨ„зҗҶжһ¶жһ„
жқҘиҮӘзӨҫеҢәзҡ„жһ¶жһ„
зӣ®еүҚи§ҒеҲ°жҜ”иҫғеӨҡзҡ„жһ¶жһ„дёӯпјҢйҮҮйӣҶе·ҘдҪңйҖҡиҝҮжҜҸдёӘKubernetes nodeдёҠе®үиЈ…дёҖдёӘж—Ҙеҝ—е®ўжҲ·з«Ҝе®ҢжҲҗпјҡ
- Kubernetesе®ҳж–№жҺЁиҚҗзҡ„жҳҜtreasure dataе…¬еҸёејҖжәҗзҡ„fluentdпјҢе®ғзҡ„жҖ§иғҪзҺ°гҖҒжҸ’件丰еҜҢеәҰжҜ”иҫғеқҮиЎЎгҖӮ
- зӨҫеҢәжңүд№ҹдёҚе°‘еңЁдҪҝз”Ёelasticе…¬еҸёејҖжәҗзҡ„beatsзі»еҲ—пјҢжҖ§иғҪдёҚй”ҷпјҢжҸ’件ж”ҜжҢҒз•Ҙе°‘дёҖдәӣгҖӮй’ҲеҜ№дёҖз§Қж•°жҚ®йңҖиҰҒйғЁзҪІзү№е®ҡзҡ„е®ўжҲ·з«ҜзЁӢеәҸпјҢжҜ”еҰӮж–Үжң¬ж–Ү件йҖҡиҝҮfilebeatsжқҘйҮҮйӣҶгҖӮ
- д№ҹжңүдәӣжһ¶жһ„еңЁдҪҝз”ЁlogstashпјҢETLж”ҜжҢҒйқһеёёдё°еҜҢпјҢдҪҶжҳҜJRubyе®һзҺ°еҜјиҮҙжҖ§иғҪеҫҲе·®гҖӮ
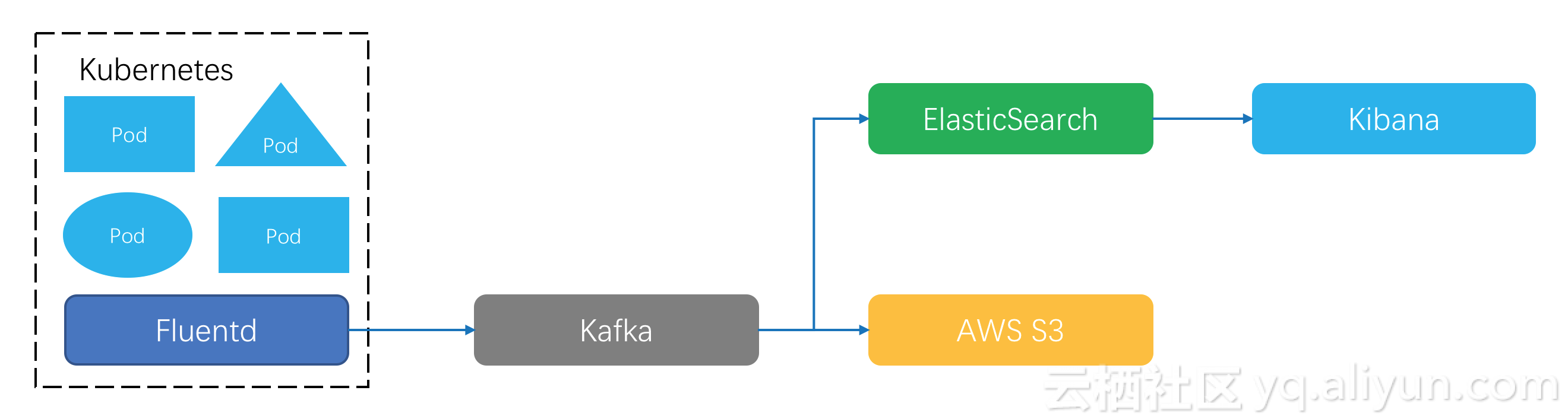
ж—Ҙеҝ—е®ўжҲ·з«ҜжҠҠж•°жҚ®ж јејҸеҢ–еҘҪд№ӢеҗҺз”ЁжҢҮе®ҡеҚҸи®®дёҠдј еҲ°еӯҳеӮЁз«ҜпјҢеёёи§Ғзҡ„йҖүжӢ©жңүKafkaгҖӮKafkaж”ҜжҢҒе®һж—¶и®ўйҳ…гҖҒйҮҚеӨҚж¶Ҳиҙ№пјҢеҗҺжңҹеҸҜд»ҘеҶҚж №жҚ®дёҡеҠЎйңҖиҰҒжҠҠж•°жҚ®еҗҢжӯҘеҲ°е…¶е®ғзі»з»ҹеҺ»пјҢжҜ”еҰӮпјҡдёҡеҠЎж—Ҙеҝ—еҲ°Elastic SearchеҒҡе…ій”®иҜҚжҹҘиҜўпјҢз»“еҗҲKibanaеҒҡж—Ҙеҝ—еҸҜи§ҶеҢ–еҲҶжһҗпјӣйҮ‘иһҚеңәжҷҜж—Ҙеҝ—иҰҒй•ҝжңҹз•ҷеӯҳпјҢеҸҜд»ҘйҖүжӢ©жҠ•йҖ’Kafkaж•°жҚ®еҲ°AWS S3иҝҷж ·зҡ„й«ҳжҖ§д»·жҜ”еӯҳеӮЁдёҠгҖӮ
иҝҷдёӘжһ¶жһ„зңӢиө·жқҘз®ҖжҙҒжңүж•ҲпјҢдҪҶеңЁKubernetesдёӢи·қзҰ»е®ҢзҫҺиҝҳжңүдәӣз»ҶиҠӮй—®йўҳиҰҒи§ЈеҶіпјҡ
- йҰ–е…ҲпјҢиҝҷжҳҜдёҖдёӘж ҮеҮҶзҡ„иҠӮзӮ№зә§йҮҮйӣҶж–№жЎҲпјҢKubernetesдёӢfluentdзӯүе®ўжҲ·з«Ҝзҡ„зЁӢеәҸйғЁзҪІгҖҒйҮҮйӣҶй…ҚзҪ®з®ЎзҗҶжҳҜдёӘйҡҫйўҳпјҢеңЁж—Ҙеҝ—йҮҮйӣҶи·Ҝз”ұгҖҒж•°жҚ®жү“ж ҮгҖҒе®ўжҲ·з«Ҝй…ҚзҪ®зӯүй—®йўҳжІЎжңүй’ҲеҜ№жҖ§дјҳеҢ–гҖӮ
- е…¶ж¬ЎпјҢеңЁж—Ҙеҝ—зҡ„ж¶Ҳиҙ№дёҠпјҢиҷҪ然Kafkaзҡ„иҪҜ件з”ҹжҖҒи¶іеӨҹдё°еҜҢпјҢдҪҶжҳҜд»Қ然йңҖиҰҒдё“дёҡдәәе‘ҳжқҘз»ҙжҠӨпјҢиҰҒеҒҡдёҡеҠЎи§„еҲ’гҖҒиҖғиҷ‘жңәеҷЁж°ҙдҪҚгҖҒеӨ„зҗҶ硬件жҚҹеқҸгҖӮеҰӮжһңиҰҒжҹҘиҜўеҲҶжһҗж—Ҙеҝ—пјҢиҝҳйңҖиҰҒжңүеҜ№Elastic Searchзі»з»ҹжңүи¶іеӨҹдәҶи§ЈгҖӮжҲ‘们зҹҘйҒ“еңЁPBзә§ж•°жҚ®еңәжҷҜдёӢпјҢеҲҶеёғејҸзі»з»ҹзҡ„жҖ§иғҪгҖҒиҝҗз»ҙй—®йўҳејҖе§ӢеҮёжҳҫпјҢиҖҢй©ҫй©ӯиҝҷдәӣејҖжәҗзі»з»ҹйңҖиҰҒеҫҲејәзҡ„дё“дёҡиғҪеҠӣгҖӮ
ж—Ҙеҝ—жңҚеҠЎзҡ„Kubernetesж—Ҙеҝ—жһ¶жһ„е®һи·ө
жҲ‘们жҸҗеҮәеҹәдәҺйҳҝйҮҢдә‘ж—Ҙеҝ—жңҚеҠЎзҡ„Kubernetesж—Ҙеҝ—еӨ„зҗҶжһ¶жһ„пјҢз”Ёд»ҘиЎҘе……зӨҫеҢәзҡ„ж–№жЎҲпјҢжқҘе°қиҜ•и§ЈеҶіKubernetesеңәжҷҜдёӢж—Ҙеҝ—еӨ„зҗҶзҡ„дёҖдәӣз»ҶиҠӮдҪ“йӘҢй—®йўҳгҖӮиҝҷдёӘжһ¶жһ„еҸҜд»ҘжҖ»з»“дёәпјҡвҖңLogtail + ж—Ҙеҝ—жңҚеҠЎ + з”ҹжҖҒвҖқгҖӮ
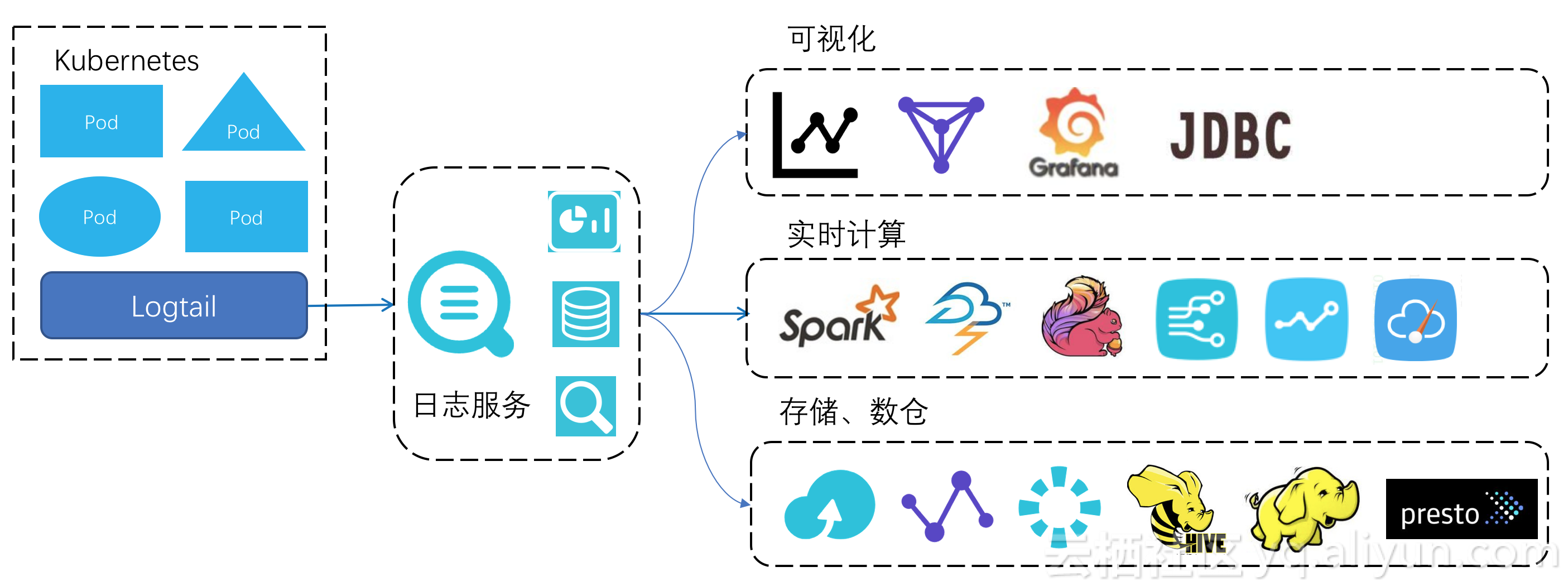
йҰ–е…ҲпјҢLogtailжҳҜж—Ҙеҝ—жңҚеҠЎзҡ„ж•°жҚ®йҮҮйӣҶе®ўжҲ·з«ҜпјҢй’ҲеҜ№KubernetesеңәжҷҜдёӢзҡ„дёҖдәӣз—ӣзӮ№еҒҡдәҶй’ҲеҜ№жҖ§и®ҫи®ЎгҖӮд№ҹжҳҜжҢүз…§Kubernetesе®ҳж–№е»әи®®зҡ„ж–№ејҸпјҢеңЁжҜҸдёӘnodeдёҠеҸӘйғЁзҪІдёҖдёӘLogtailе®ўжҲ·з«ҜпјҢиҙҹиҙЈиҝҷдёӘnodeдёҠжүҖжңүзҡ„podж—Ҙеҝ—йҮҮйӣҶгҖӮ
е…¶ж¬ЎпјҢй’ҲеҜ№е…ій”®иҜҚжҗңзҙўе’ҢSQLз»ҹи®ЎиҝҷдёӨдёӘеҹәжң¬зҡ„ж—Ҙеҝ—йңҖжұӮпјҡж—Ҙеҝ—жңҚеҠЎжҸҗдҫӣдәҶеҹәзЎҖзҡ„LogHubеҠҹиғҪпјҢж”ҜжҢҒж•°жҚ®зҡ„е®һж—¶еҶҷе…ҘгҖҒи®ўйҳ…пјӣеңЁLogHubеӯҳеӮЁзҡ„еҹәзЎҖдёҠпјҢеҸҜд»ҘйҖүжӢ©ејҖеҗҜж•°жҚ®зҡ„зҙўеј•еҲҶжһҗеҠҹиғҪпјҢејҖеҗҜзҙўеј•еҗҺеҸҜд»Ҙж”ҜжҢҒж—Ҙеҝ—е…ій”®иҜҚжҹҘиҜўд»ҘеҸҠSQLиҜӯжі•еҲҶжһҗгҖӮ
жңҖеҗҺпјҢж—Ҙеҝ—жңҚеҠЎзҡ„ж•°жҚ®жҳҜејҖж”ҫзҡ„гҖӮзҙўеј•ж•°жҚ®еҸҜд»ҘйҖҡиҝҮJDBCеҚҸи®®дёҺ第дёүж–№зі»з»ҹеҜ№жҺҘпјҢSQLжҹҘиҜўз»“жһңдёҺиҜёеҰӮйҳҝйҮҢдә‘DataVгҖҒејҖжәҗзӨҫеҢәзҡ„Grafanaзі»з»ҹеҫҲж–№дҫҝең°йӣҶжҲҗпјӣж—Ҙеҝ—жңҚеҠЎзҡ„й«ҳеҗһеҗҗзҡ„е®һж—¶иҜ»еҶҷиғҪеҠӣж”Ҝж’‘дәҶдёҺжөҒи®Ўз®—зі»з»ҹзҡ„еҜ№жҺҘпјҢspark streamingгҖҒblinkгҖҒjstormзӯүжөҒи®Ўз®—зі»з»ҹдёҠйғҪжңүconnectorж”ҜжҢҒпјӣз”ЁжҲ·иҝҳеҸҜд»ҘйҖҡиҝҮе…Ёжүҳз®Ўзҡ„жҠ•йҖ’еҠҹиғҪжҠҠж•°жҚ®еҶҷе…ҘеҲ°йҳҝйҮҢдә‘зҡ„еҜ№иұЎеӯҳеӮЁOSSпјҢжҠ•йҖ’ж”ҜжҢҒиЎҢеӯҳпјҲcsvгҖҒjsonпјүгҖҒеҲ—еӯҳпјҲparquetпјүж јејҸпјҢиҝҷдәӣж•°жҚ®еҸҜд»Ҙз”ЁдҪңй•ҝжңҹдҪҺжҲҗжң¬еӨҮд»ҪпјҢжҲ–иҖ…жҳҜйҖҡиҝҮвҖңOSSеӯҳеӮЁ+E-MapReduceи®Ўз®—вҖқжһ¶жһ„жқҘе®һзҺ°ж•°жҚ®д»“еә“гҖӮ
ж—Ҙеҝ—жңҚеҠЎзҡ„дјҳеҠҝ
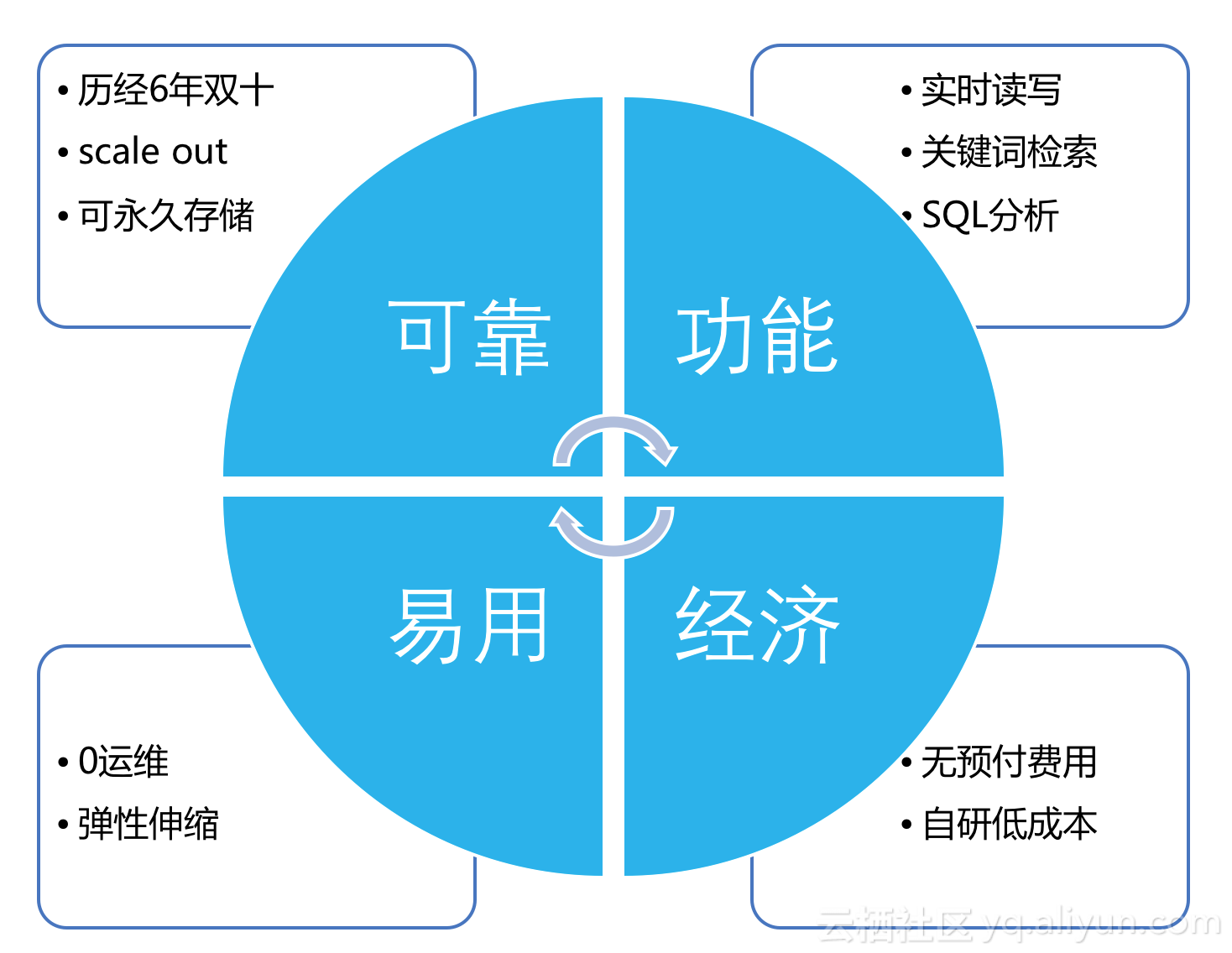
д»ҺеӣӣдёӘзӮ№дёҠжқҘжҸҸиҝ°ж—Ҙеҝ—жңҚеҠЎзҡ„зү№зӮ№пјҡ
- еңЁеҸҜйқ жҖ§е’ҢзЁіе®ҡжҖ§дёҠпјҢе®ғж”Ҝж’‘дәҶйҳҝйҮҢйӣҶеӣўе’ҢиҡӮиҡҒйҮ‘жңҚеӨҡж¬ЎеҸҢеҚҒдёҖе’ҢеҸҢеҚҒдәҢзҡ„еӨ§дҝғгҖӮ
- еңЁеҠҹиғҪдёҠдёҖз«ҷејҸиҰҶзӣ–дәҶKafka + ElasticSearchеӨ§йғЁеҲҶеңәжҷҜгҖӮ
- дҪңдёәдә‘дёҠзҡ„еҹәзЎҖи®ҫж–ҪеҸҜд»Ҙж–№дҫҝең°е®һзҺ°еј№жҖ§дјёзј©пјҢеҜ№дәҺз”ЁжҲ·жқҘиҜҙпјҢеӨ§дҝғж—¶дёҚйңҖиҰҒж“Қеҝғд№°жңәеҷЁжү©е®№гҖҒжҜҸеӨ©еқҸдёҠж•°еҚҒдёӘзӣҳйңҖиҰҒз»ҙдҝ®зӯүй—®йўҳгҖӮ
- ж—Ҙеҝ—жңҚеҠЎд№ҹеҗҢж ·е…·еӨҮдә‘зҡ„0йў„д»ҳжҲҗжң¬гҖҒжҢүйңҖд»ҳиҙ№зҡ„зү№зӮ№пјҢ并且зӣ®еүҚжҜҸжңҲжңү500MBзҡ„е…Қиҙ№йўқеәҰгҖӮ
еӣһйЎҫ第дёҖиҠӮдёӯжҸҗеҲ°зҡ„Kubernetesж—Ҙеҝ—еӨ„зҗҶзҡ„и¶ӢеҠҝдёҺжҢ‘жҲҳпјҢиҝҷйҮҢжҖ»з»“дәҶж—Ҙеҝ—жңҚеҠЎзҡ„дёүдёӘдјҳеҠҝпјҡ
- дҪңдёәж—Ҙеҝ—еҹәзЎҖи®ҫж–ҪпјҢи§ЈеҶідәҶеҗ„з§Қж—Ҙеҝ—ж•°жҚ®йӣҶдёӯеҢ–еӯҳеӮЁй—®йўҳгҖӮ
- жңҚеҠЎеҢ–зҡ„дә§е“ҒеёҰз»ҷз”ЁжҲ·жӣҙеӨҡзҡ„жҳ“з”ЁжҖ§пјҢдёҺKubernetesеңЁserverlessзҡ„зӣ®ж ҮдёҠд№ҹжҳҜеҘ‘еҗҲзҡ„гҖӮ
- еҠҹиғҪдёҠеҗҢж—¶ж»Ўи¶іе®һж—¶иҜ»еҶҷгҖҒHTAPйңҖжұӮпјҢз®ҖеҢ–дәҶж—Ҙеҝ—еӨ„зҗҶзҡ„жөҒзЁӢдёҺжһ¶жһ„гҖӮ
ж—Ҙеҝ—жңҚеҠЎз»“еҗҲзӨҫеҢәеҠӣйҮҸиҝӣиЎҢKubernetesж—Ҙеҝ—еҲҶжһҗ
KubernetesжәҗиҮӘзӨҫеҢәпјҢдҪҝз”ЁејҖжәҗиҪҜ件иҝӣиЎҢKubernetesж—Ҙеҝ—зҡ„еӨ„зҗҶд№ҹжҳҜдёҖдәӣеңәжҷҜдёӢзҡ„жӯЈзЎ®йҖүжӢ©гҖӮ
ж—Ҙеҝ—жңҚеҠЎдҝқиҜҒж•°жҚ®зҡ„ејҖж”ҫжҖ§пјҢдёҺејҖжәҗзӨҫеҢәеңЁйҮҮйӣҶгҖҒи®Ўз®—гҖҒеҸҜи§ҶеҢ–зӯүж–№йқўиҝӣиЎҢеҜ№жҺҘпјҢеё®еҠ©з”ЁжҲ·дә«еҸ—еҲ°зӨҫеҢәжҠҖжңҜжҲҗжһңгҖӮ

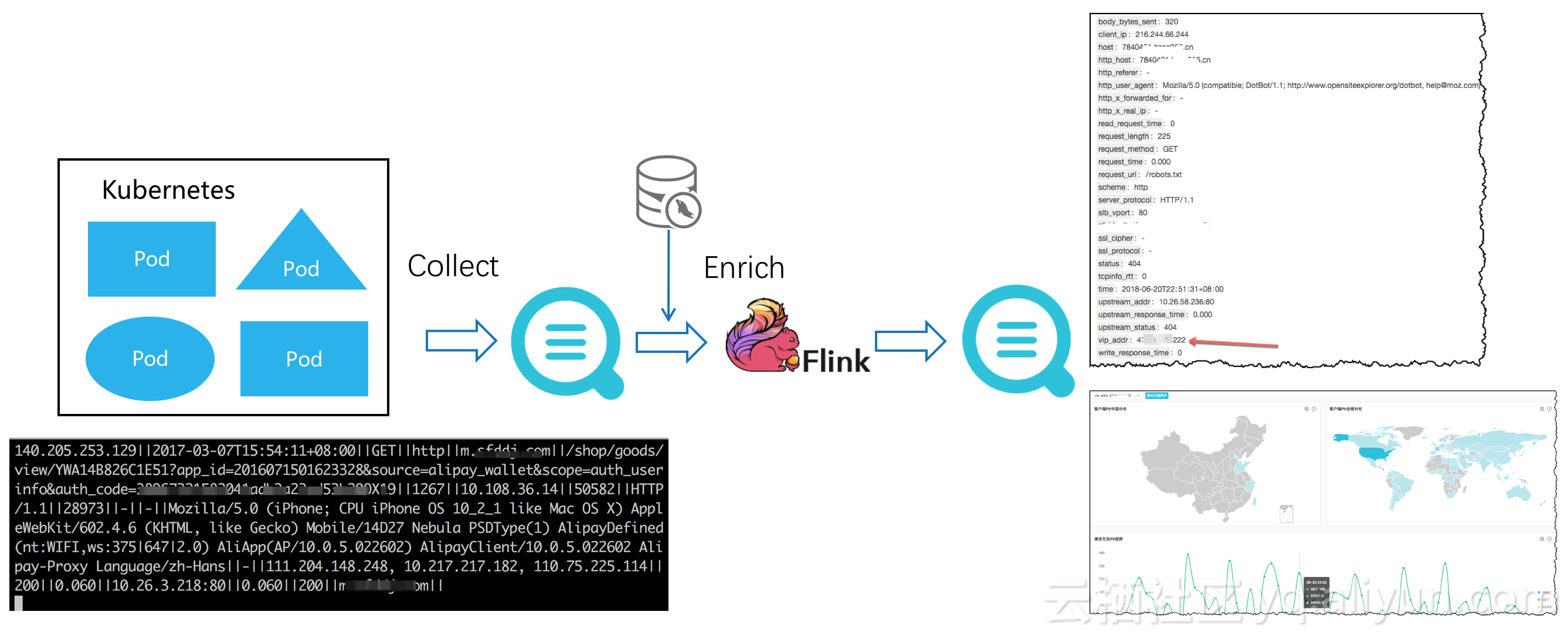
еҰӮдёӢеӣҫпјҢдёҫдёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗпјҡдҪҝз”ЁжөҒи®Ўз®—еј•ж“Һflinkе®һж—¶ж¶Ҳиҙ№ж—Ҙеҝ—жңҚеҠЎзҡ„ж—Ҙеҝ—еә“ж•°жҚ®пјҢжәҗж—Ҙеҝ—еә“зҡ„shard并еҸ‘дёҺflink taskе®һзҺ°еҠЁжҖҒиҙҹиҪҪеқҮиЎЎпјҢеңЁе®ҢжҲҗдёҺMySQLзҡ„metaе®ҢжҲҗж•°жҚ®joinеҠ е·ҘеҗҺпјҢеҶҚйҖҡиҝҮconnectorжөҒејҸеҶҷе…ҘеҸҰдёҖдёӘж—Ҙеҝ—жңҚеҠЎж—Ҙеҝ—еә“еҒҡеҸҜи§ҶеҢ–жҹҘиҜўгҖӮ
LogtailеңЁKubernetesж—Ҙеҝ—йҮҮйӣҶеңәжҷҜдёӢзҡ„и®ҫи®Ў
еңЁжң¬ж–Ү第дәҢиҠӮжҲ‘们еӣһйЎҫдәҶKubernetesж—Ҙеҝ—йҮҮйӣҶж–№жЎҲжј”иҝӣиҝҮзЁӢдёӯйҒҮеҲ°зҡ„й—®йўҳпјҢ第дёүиҠӮд»Ӣз»ҚдәҶеҹәдәҺйҳҝйҮҢдә‘ж—Ҙеҝ—жңҚеҠЎзҡ„еҠҹиғҪгҖҒз”ҹжҖҒгҖӮеңЁиҝҷдёҖиҠӮдјҡйҮҚзӮ№еҜ№LogtailйҮҮйӣҶз«Ҝзҡ„и®ҫи®Ўе’ҢдјҳеҢ–е·ҘдҪңеҒҡдёҖдәӣд»Ӣз»ҚпјҢз»Ҷж•°LogtailеҰӮдҪ•и§ЈеҶіKubernetesж—Ҙеҝ—йҮҮйӣҶдёҠзҡ„з—ӣзӮ№гҖӮ
KubernetesйҮҮйӣҶзҡ„йҡҫзӮ№
-
йҮҮйӣҶзӣ®ж ҮеӨҡж ·еҢ–
- е®№еҷЁstdout/stderr
- е®№еҷЁеә”з”Ёж—Ҙеҝ—
- е®ҝдё»жңәж—Ҙеҝ—
- ејҖж”ҫеҚҸи®®пјҡSyslogгҖҒHTTPзӯү
-
йҮҮйӣҶеҸҜйқ жҖ§
- жҖ§иғҪдёҠйңҖиҰҒж»Ўи¶іеҚ•nodeдёҠеӨ§жөҒйҮҸж—Ҙеҝ—еңәжҷҜпјҢеҗҢж—¶е…јйЎҫйҮҮйӣҶзҡ„е®һж—¶жҖ§
- и§ЈеҶіе®№еҷЁж—Ҙеҝ—жҳ“еӨұжҖ§й—®йўҳ
- еңЁеҗ„з§Қжғ…еҶөдёӢе°ҪйҮҸдҝқиҜҒйҮҮйӣҶж•°жҚ®зҡ„е®Ңж•ҙжҖ§
-
еҠЁжҖҒдјёзј©еёҰжқҘзҡ„жҢ‘жҲҳ
- е®№еҷЁжү©гҖҒзј©е®№еҜ№иҮӘеҠЁеҸ‘зҺ°зҡ„иҰҒжұӮ
- йҷҚдҪҺKubernetesйғЁзҪІзҡ„еӨҚжқӮеәҰ
-
йҮҮйӣҶй…ҚзҪ®жҳ“з”ЁжҖ§
- йҮҮйӣҶй…ҚзҪ®жҖҺд№ҲйғЁзҪІгҖҒз®ЎзҗҶ
- дёҚеҗҢз”ЁйҖ”зҡ„podж—Ҙеҝ—йңҖиҰҒеҲҶй—ЁеҲ«зұ»еӯҳеӮЁпјҢж•°жҚ®и·Ҝз”ұжҖҺд№ҲеҺ»з®ЎзҗҶ
Logtailй«ҳеҸҜйқ йҮҮйӣҶ
Logtailж”ҜжҢҒиҮіе°‘at-least-onceйҮҮйӣҶзҡ„иҜӯд№үдҝқиҜҒпјҢйҖҡиҝҮж–Ү件е’ҢеҶ…еӯҳдёӨз§Қзә§еҲ«зҡ„checkpointжңәеҲ¶жқҘдҝқиҜҒеңЁе®№еҷЁйҮҚеҗҜеңәжҷҜдёӢзҡ„ж–ӯзӮ№з»ӯдј гҖӮ
ж—Ҙеҝ—йҮҮйӣҶиҝҮзЁӢдёӯеҸҜиғҪйҒҮеҲ°еҗ„з§Қеҗ„ж ·зҡ„жқҘиҮӘзі»з»ҹжҲ–з”ЁжҲ·й…ҚзҪ®зҡ„й”ҷиҜҜпјҢдҫӢеҰӮж—Ҙеҝ—ж јејҸеҢ–и§ЈжһҗеҮәй”ҷж—¶жҲ‘们йңҖиҰҒеҸҠж—¶и°ғж•ҙи§Јжһҗ规еҲҷгҖӮLogtailжҸҗдҫӣдәҶйҮҮйӣҶзӣ‘жҺ§еҠҹиғҪпјҢеҸҜд»Ҙе°ҶејӮеёёе’Ңз»ҹи®ЎдҝЎжҒҜдёҠжҠҘж—Ҙеҝ—еә“并ж”ҜжҢҒжҹҘиҜўгҖҒе‘ҠиӯҰгҖӮ
дјҳеҢ–и®Ўз®—жҖ§иғҪи§ЈеҶіеҚ•иҠӮзӮ№еӨ§и§„жЁЎж—Ҙеҝ—йҮҮйӣҶй—®йўҳпјҢLogtailеңЁдёҚеҒҡж—Ҙеҝ—еӯ—ж®өж јејҸеҢ–зҡ„жғ…еҶөпјҲsinglelineжЁЎејҸпјүдёӢеҒҡеҲ°еҚ•cpuж ё100MB/sе·ҰеҸізҡ„еӨ„зҗҶжҖ§иғҪгҖӮй’ҲеҜ№зҪ‘з»ңеҸ‘йҖҒзҡ„ж…ўIOж“ҚдҪңпјҢе®ўжҲ·з«Ҝе°ҶеӨҡжқЎж—Ҙеҝ—batch commitеҲ°жңҚеҠЎз«ҜеҒҡжҢҒд№…еҢ–пјҢе…јйЎҫдәҶйҮҮйӣҶзҡ„е®һж—¶жҖ§дёҺй«ҳеҗһеҗҗиғҪеҠӣгҖӮ
еңЁйҳҝйҮҢйӣҶеӣўеҶ…йғЁпјҢLogtailзӣ®еүҚжңүзҷҫдёҮзә§и§„жЁЎзҡ„е®ўжҲ·з«ҜйғЁзҪІпјҢзЁіе®ҡжҖ§жҳҜдёҚй”ҷзҡ„гҖӮ
дё°еҜҢзҡ„ж•°жҚ®жәҗж”ҜжҢҒ
еә”еҜ№KubernetesзҺҜеўғдёӢеӨҚжқӮеӨҡж ·зҡ„йҮҮйӣҶйңҖжұӮпјҢLogtailеңЁйҮҮйӣҶжәҗеӨҙдёҠеҸҜд»Ҙж”ҜжҢҒпјҡstdout/stderrпјҢе®№еҷЁгҖҒе®ҝдё»жңәж—Ҙеҝ—ж–Ү件пјҢsyslogгҖҒlumberjackзӯүејҖж”ҫеҚҸи®®ж•°жҚ®йҮҮйӣҶгҖӮ
е°ҶдёҖжқЎж—Ҙеҝ—жҢүз…§иҜӯд№үеҲҮеҲҶдёәеӨҡдёӘеӯ—ж®өе°ұеҸҜд»Ҙеҫ—еҲ°еӨҡдёӘkey-valueеҜ№пјҢз”ұжӯӨе°ҶдёҖжқЎж—Ҙеҝ—жҳ е°„еҲ°tableжЁЎеһӢдёҠпјҢиҝҷдёӘе·ҘдҪңдҪҝеҫ—еңЁжҺҘдёӢжқҘзҡ„ж—Ҙеҝ—еҲҶжһҗиҝҮзЁӢдёӯдәӢеҚҠеҠҹеҖҚгҖӮLogtailж”ҜжҢҒд»ҘдёӢдёҖдәӣж—Ҙеҝ—ж јејҸеҢ–ж–№ејҸпјҡ
- еӨҡиЎҢи§ЈжһҗгҖӮжҜ”еҰӮJava stack traceж—Ҙеҝ—жҳҜз”ұеӨҡдёӘиҮӘ然иЎҢз»„жҲҗзҡ„пјҢйҖҡиҝҮиЎҢйҰ–жӯЈеҲҷиЎЁиҫҫејҸзҡ„и®ҫзҪ®жқҘе®һзҺ°ж—Ҙеҝ—жҢүйҖ»иҫ‘иЎҢеҲҮеҲҶгҖӮ
- иҮӘжҸҸиҝ°и§ЈжһҗгҖӮж”ҜжҢҒcsvгҖҒjsonзӯүж јејҸпјҢиҮӘеҠЁжҸҗеҸ–еҮәж—Ҙеҝ—еӯ—ж®өгҖӮ
- йҖҡиҝҮжӯЈеҲҷгҖҒиҮӘе®ҡд№үжҸ’件方ејҸж»Ўи¶іжӣҙеӨҡзү№е®ҡйңҖжұӮгҖӮ
- еҜ№дәҺдёҖдәӣе…ёеһӢзҡ„ж—Ҙеҝ—жҸҗдҫӣеҶ…зҪ®и§Јжһҗ规еҲҷгҖӮжҜ”еҰӮпјҢз”ЁжҲ·еҸӘйңҖиҰҒеңЁwebжҺ§еҲ¶еҸ°дёҠйҖүжӢ©ж—Ҙеҝ—зұ»еҲ«жҳҜNginxи®ҝй—®ж—Ҙеҝ—пјҢLogtailе°ұеҸҜд»ҘиҮӘеҠЁжҠҠдёҖжқЎи®ҝй—®ж—Ҙеҝ—жҢүз…§Nginxзҡ„log formatй…ҚзҪ®жҠҪеҸ–еҮәclient_ipгҖҒuriзӯүзӯүеӯ—ж®өгҖӮ
еә”еҜ№иҠӮзӮ№зә§е®№еҷЁеҠЁжҖҒдјёзј©
е®№еҷЁеӨ©з”ҹдјҡеҒҡеёёжҖҒеҢ–жү©е®№гҖҒзј©е®№пјҢж–°жү©е®№зҡ„е®№еҷЁж—Ҙеҝ—йңҖиҰҒеҸҠж—¶иў«йҮҮйӣҶеҗҰеҲҷе°ұдјҡдёўеӨұпјҢиҝҷиҰҒжұӮе®ўжҲ·з«ҜжңүиғҪеҠӣеҠЁжҖҒж„ҹзҹҘеҲ°йҮҮйӣҶжәҗпјҢдё”йғЁзҪІгҖҒй…ҚзҪ®йңҖиҰҒеҒҡеҲ°и¶іеӨҹзҡ„жҳ“з”ЁжҖ§гҖӮLogtailд»Һд»ҘдёӢдёӨдёӘз»ҙеәҰжқҘи§ЈеҶіж•°жҚ®йҮҮйӣҶзҡ„е®Ңж•ҙжҖ§й—®йўҳпјҡ
-
йғЁзҪІ
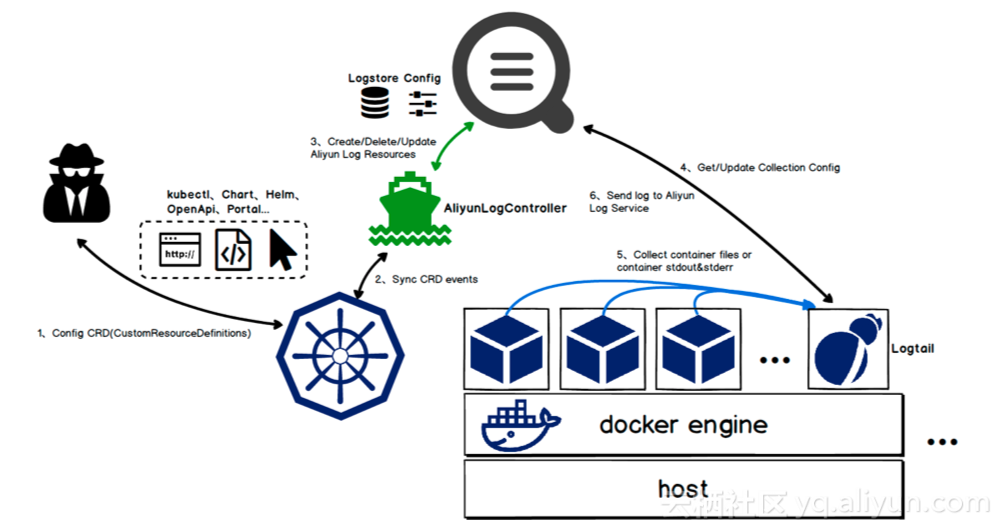
- йҖҡиҝҮDaemonSetж–№ејҸжқҘеҝ«йҖҹйғЁзҪІLogtailеҲ°дёҖдёӘKubernetes nodeдёҠпјҢдёҖжқЎжҢҮд»Өе°ұеҸҜд»Ҙе®ҢжҲҗпјҢдёҺK8Sеә”з”ЁеҸ‘еёғйӣҶжҲҗд№ҹеҫҲж–№дҫҝгҖӮ
- Logtailе®ўжҲ·з«ҜйғЁзҪІеҲ°nodeдёҠд»ҘеҗҺпјҢйҖҡиҝҮdomain socketдёҺdocker engineйҖҡдҝЎжқҘеӨ„зҗҶиҜҘиҠӮзӮ№дёҠзҡ„е®№еҷЁеҠЁжҖҒйҮҮйӣҶгҖӮеўһйҮҸжү«жҸҸеҸҜд»ҘеҸҠж—¶ең°еҸ‘зҺ°nodeдёҠзҡ„е®№еҷЁеҸҳеҢ–пјҢеҶҚеҠ дёҠе®ҡжңҹе…ЁйҮҸжү«йқўжңәеҲ¶жқҘдҝқиҜҒдёҚдјҡдёўеӨұжҺүд»»дҪ•дёҖдёӘе®№еҷЁжӣҙж”№дәӢ件пјҢиҝҷдёӘеҸҢйҮҚдҝқйҡңзҡ„и®ҫи®ЎдҪҝеҫ—еңЁе®ўжҲ·з«ҜдёҠеҸҜд»ҘеҸҠж—¶гҖҒе®Ңж•ҙеҸ‘зҺ°еҖҷйҖүзҡ„зӣ‘жҺ§зӣ®ж ҮгҖӮ
-
йҮҮйӣҶй…ҚзҪ®з®ЎзҗҶ
- Logtailд»Һи®ҫи®Ўд№ӢеҲқе°ұйҖүжӢ©дәҶжңҚеҠЎз«ҜйӣҶдёӯејҸйҮҮйӣҶй…ҚзҪ®з®ЎзҗҶпјҢдҝқиҜҒйҮҮйӣҶжҢҮд»ӨеҸҜд»Ҙд»ҺжңҚеҠЎз«Ҝжӣҙй«ҳж•Ҳең°дј иҫҫз»ҷе®ўжҲ·з«ҜгҖӮиҝҷдёӘй…ҚзҪ®з®ЎзҗҶеҸҜд»ҘжҠҪиұЎдёә"жңәеҷЁз»„+йҮҮйӣҶй…ҚзҪ®"жЁЎеһӢпјҢеҜ№дәҺдёҖдёӘйҮҮйӣҶй…ҚзҪ®пјҢеңЁжңәеҷЁз»„еҶ…зҡ„Logtailе®һдҫӢеҸҜд»ҘеҚіж—¶иҺ·еҸ–еҲ°жңәеҷЁз»„дёҠжүҖе…іиҒ”зҡ„йҮҮйӣҶй…ҚзҪ®пјҢеҺ»ејҖеҗҜйҮҮйӣҶд»»еҠЎгҖӮ
- й’ҲеҜ№KubernetesеңәжҷҜпјҢLogtailи®ҫи®ЎдәҶиҮӘе®ҡд№үж ҮиҜҶж–№ејҸжқҘз®ЎзҗҶжңәеҷЁгҖӮдёҖзұ»podеҸҜд»ҘеЈ°жҳҺдёҖдёӘеӣәе®ҡзҡ„жңәеҷЁж ҮиҜҶпјҢLogtailдҪҝз”ЁиҝҷдёӘжңәеҷЁж ҮиҜҶеҗ‘жңҚеҠЎз«ҜжұҮжҠҘеҝғи·іпјҢеҗҢж—¶жңәеҷЁз»„дҪҝз”ЁиҝҷдёӘиҮӘе®ҡд№үж ҮиҜҶжқҘз®ЎзҗҶLogtailе®һдҫӢгҖӮеҪ“KubernetesиҠӮзӮ№жү©е®№ж—¶пјҢLogtailдёҠжҠҘpodеҜ№еә”зҡ„иҮӘе®ҡд№үжңәеҷЁж ҮиҜҶеҲ°жңҚеҠЎз«ҜпјҢжңҚеҠЎз«Ҝе°ұдјҡжҠҠиҝҷдёӘжңәеҷЁз»„дёҠзҡ„жҢӮиҪҪзҡ„йҮҮйӣҶй…ҚзҪ®дёӢеҸ‘з»ҷLogtailгҖӮзӣ®еүҚеңЁејҖжәҗйҮҮйӣҶе®ўжҲ·з«ҜдёҠпјҢеёёи§Ғзҡ„еҒҡжі•жҳҜдҪҝз”ЁжңәеҷЁipжҲ–hostnameжқҘж ҮиҜҶе®ўжҲ·з«ҜпјҢиҝҷж ·еңЁе®№еҷЁдјёзј©ж—¶пјҢйңҖиҰҒеҸҠж—¶еҺ»еўһеҲ жңәеҷЁз»„еҶ…зҡ„жңәеҷЁipжҲ–hostnameпјҢеҗҰеҲҷе°ұдјҡеҜјиҮҙж•°жҚ®йҮҮйӣҶзҡ„зјәеӨұпјҢйңҖиҰҒеӨҚжқӮзҡ„жү©е®№жөҒзЁӢдҝқиҜҒгҖӮ
и§ЈеҶійҮҮйӣҶй…ҚзҪ®з®ЎзҗҶйҡҫйўҳ
LogtailжҸҗдҫӣдёӨз§ҚйҮҮйӣҶй…ҚзҪ®зҡ„з®ЎзҗҶж–№ејҸпјҢз”ЁжҲ·ж №жҚ®иҮӘе·ұзҡ„е–ңеҘҪд»»йҖүжқҘж“ҚдҪңпјҡ
- CRDгҖӮдёҺKubernetesз”ҹжҖҒж·ұеәҰйӣҶжҲҗпјҢйҖҡиҝҮеңЁе®ўжҲ·з«ҜдёҠдәӢ件зӣ‘еҗ¬еҸҜд»ҘиҒ”еҠЁеҲӣе»әж—Ҙеҝ—жңҚеҠЎдёҠзҡ„ж—Ҙеҝ—еә“гҖҒйҮҮйӣҶй…ҚзҪ®гҖҒжңәеҷЁз»„зӯүиө„жәҗгҖӮ
- WEBжҺ§еҲ¶еҸ°гҖӮдёҠжүӢеҝ«пјҢеҸҜи§ҶеҢ–ж–№ејҸжқҘй…ҚзҪ®ж—Ҙеҝ—ж јејҸеҢ–и§Јжһҗ规еҲҷпјҢйҖҡиҝҮwizardе®ҢжҲҗйҮҮйӣҶй…ҚзҪ®дёҺжңәеҷЁз»„зҡ„е…іиҒ”гҖӮз”ЁжҲ·еҸӘйңҖиҰҒжҢүз…§д№ жғҜжқҘи®ҫзҪ®дёҖдёӘе®№еҷЁзҡ„ж—Ҙеҝ—зӣ®еҪ•пјҢLogtailеңЁдёҠејҖеҗҜйҮҮйӣҶж—¶дјҡиҮӘеҠЁжёІжҹ“жҲҗе®ҝдё»жңәдёҠзҡ„е®һйҷ…ж—Ҙеҝ—зӣ®еҪ•гҖӮ
жҲ‘们е°Ҷж—Ҙеҝ—д»ҺжәҗеҲ°зӣ®ж ҮпјҲж—Ҙеҝ—еә“пјүе®ҡд№үдёәдёҖдёӘйҮҮйӣҶи·Ҝз”ұгҖӮдҪҝз”Ёдј з»ҹж–№жЎҲе®һзҺ°дёӘжҖ§еҢ–йҮҮйӣҶи·Ҝз”ұеҠҹиғҪйқһеёёйә»зғҰпјҢйңҖиҰҒеңЁе®ўжҲ·з«Ҝжң¬ең°й…ҚзҪ®пјҢжҜҸдёӘpodе®№еҷЁеҶҷжӯ»иҝҷдёӘйҮҮйӣҶи·Ҝз”ұпјҢеҜ№дәҺе®№еҷЁйғЁзҪІгҖҒз®ЎзҗҶдјҡжңүејәдҫқиө–гҖӮLogtailи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„зӘҒз ҙзӮ№жҳҜеҜ№зҺҜеўғеҸҳйҮҸзҡ„еә”з”ЁпјҢKubernetesзҡ„envжҳҜз”ұеӨҡдёӘkey-valueз»„жҲҗпјҢеңЁйғЁзҪІе®№еҷЁж—¶еҸҜд»ҘиҝӣиЎҢenvи®ҫзҪ®гҖӮLogtailзҡ„йҮҮйӣҶй…ҚзҪ®дёӯи®ҫи®ЎдәҶIncludeEnvе’ҢExcludeEnvй…ҚзҪ®йЎ№пјҢз”ЁдәҺеҠ е…ҘжҲ–жҺ’йҷӨйҮҮйӣҶжәҗгҖӮеңЁдёӢйқўзҡ„еӣҫдёӯпјҢpodдёҡеҠЎе®№еҷЁеҗҜеҠЁж—¶и®ҫзҪ®log_typeзҺҜеўғеҸҳйҮҸпјҢеҗҢж—¶LogtailйҮҮйӣҶй…ҚзҪ®дёӯе®ҡд№үдәҶIncludeEnv: log_type=nginx_access_logпјҢжқҘжҢҮе®ҡ收йӣҶnginxзұ»з”ЁйҖ”зҡ„podж—Ҙеҝ—еҲ°зү№е®ҡж—Ҙеҝ—еә“гҖӮ
жүҖжңүеңЁKubernetesдёҠйҮҮйӣҶеҲ°зҡ„ж•°жҚ®пјҢLogtailйғҪиҮӘеҠЁиҝӣиЎҢдәҶpod/namesapce/contanier/imageз»ҙеәҰзҡ„жү“ж ҮпјҢж–№дҫҝеҗҺз»ӯзҡ„ж•°жҚ®еҲҶжһҗгҖӮ
ж—Ҙеҝ—дёҠдёӢж–ҮжҹҘиҜўзҡ„и®ҫи®Ў
дёҠдёӢж–ҮжҹҘиҜўжҳҜжҢҮпјҡз»ҷе®ҡдёҖжқЎж—Ҙеҝ—пјҢжҹҘзңӢиҜҘж—Ҙеҝ—еңЁеҺҹжңәеҷЁгҖҒж–Ү件дҪҚзҪ®зҡ„дёҠдёҖжқЎжҲ–дёӢдёҖжқЎж—Ҙеҝ—пјҢзұ»дјјдәҺLinuxдёҠзҡ„grep -A -BгҖӮ
еңЁdevopsзӯүдёҖдәӣеңәжҷҜдёӢпјҢйҖ»иҫ‘жҖ§ејӮеёёйңҖиҰҒиҝҷдёӘж—¶еәҸжқҘиҫ…еҠ©е®ҡдҪҚпјҢжңүдәҶдёҠдёӢж–ҮжҹҘзңӢеҠҹиғҪдјҡдәӢеҚҠеҠҹеҖҚгҖӮ然еҗҺеңЁеҲҶеёғејҸзі»з»ҹдёӢпјҢеңЁжәҗе’Ңзӣ®ж ҮдёҠйғҪеҫҲйҡҫдҝқиҜҒеҺҹе…Ҳзҡ„ж—Ҙеҝ—йЎәеәҸпјҡ
- еңЁйҮҮйӣҶе®ўжҲ·з«ҜеұӮйқўпјҢKubernetesеҸҜиғҪдә§з”ҹеӨ§йҮҸж—Ҙеҝ—пјҢж—Ҙеҝ—йҮҮйӣҶиҪҜ件йңҖиҰҒеҲ©з”ЁжңәеҷЁзҡ„еӨҡдёӘcpuж ёеҝғи§ЈжһҗгҖҒйў„еӨ„зҗҶж—Ҙеҝ—пјҢ并йҖҡиҝҮеӨҡзәҝзЁӢ并еҸ‘жҲ–иҖ…еҚ•зәҝзЁӢејӮжӯҘеӣһи°ғзҡ„ж–№ејҸеӨ„зҗҶзҪ‘з»ңеҸ‘йҖҒзҡ„ж…ўIOй—®йўҳгҖӮиҝҷдҪҝеҫ—ж—Ҙеҝ—ж•°жҚ®дёҚиғҪжҢүз…§жңәеҷЁдёҠзҡ„дәӢ件дә§з”ҹйЎәеәҸдҫқж¬ЎеҲ°иҫҫжңҚеҠЎз«ҜгҖӮ
- еңЁеҲҶеёғејҸзі»з»ҹзҡ„жңҚеҠЎз«ҜеұӮйқўпјҢз”ұдәҺж°ҙе№іжү©еұ•зҡ„еӨҡжңәиҙҹиҪҪеқҮиЎЎжһ¶жһ„пјҢдҪҝеҫ—еҗҢдёҖе®ўжҲ·з«ҜжңәеҷЁзҡ„ж—Ҙеҝ—дјҡеҲҶж•ЈеңЁеӨҡеҸ°еӯҳеӮЁиҠӮзӮ№дёҠгҖӮеңЁеҲҶж•ЈеӯҳеӮЁзҡ„ж—Ҙеҝ—еҹәзЎҖдёҠеҶҚжҒўеӨҚжңҖеҲқзҡ„йЎәеәҸжҳҜеӣ°йҡҫзҡ„гҖӮ
дј з»ҹдёҠдёӢж–ҮжҹҘиҜўж–№жЎҲпјҢдёҖиҲ¬жҳҜж №жҚ®ж—Ҙеҝ—еҲ°иҫҫжңҚеҠЎз«Ҝж—¶й—ҙгҖҒж—Ҙеҝ—дёҡеҠЎж—¶й—ҙеӯ—ж®өеҒҡдёӨж¬ЎжҺ’еәҸгҖӮиҝҷеңЁеӨ§ж•°жҚ®еңәжҷҜдёӢеӯҳеңЁпјҡжҺ’еәҸжҖ§иғҪй—®йўҳгҖҒж—¶й—ҙзІҫеәҰдёҚи¶ій—®йўҳпјҢж— жі•зңҹе®һиҝҳеҺҹдәӢ件зҡ„зңҹе®һж—¶еәҸгҖӮ
LogtailдёҺж—Ҙеҝ—жңҚеҠЎпјҲе…ій”®иҜҚжҹҘиҜўеҠҹиғҪпјүзӣёз»“еҗҲжқҘи§ЈеҶіиҝҷдёӘй—®йўҳпјҡ
дёҖдёӘе®№еҷЁж–Ү件зҡ„ж—Ҙеҝ—еңЁйҮҮйӣҶдёҠдј ж—¶пјҢе…¶ж•°жҚ®еҢ…жҳҜз”ұдёҖжү№зҡ„еӨҡжқЎж—Ҙеҝ—з»„жҲҗпјҢеӨҡжқЎж—Ҙеҝ—еҜ№еә”зү№е®ҡж–Ү件зҡ„дёҖдёӘblockпјҢжҜ”еҰӮ512KBгҖӮеңЁиҝҷдёҖдёӘж•°жҚ®еҢ…зҡ„еӨҡжқЎж—Ҙеҝ—жҳҜжҢүз…§жәҗж–Ү件зҡ„ж—Ҙеҝ—еәҸжҺ’еҲ—пјҢд№ҹе°ұж„Ҹе‘ізқҖжҹҗж—Ҙеҝ—зҡ„дёӢдёҖжқЎеҸҜиғҪжҳҜеңЁеҗҢдёҖдёӘж•°жҚ®еҢ…йҮҢд№ҹеҸҜиғҪеңЁдёӢдёҖдёӘж•°жҚ®еҢ…йҮҢгҖӮ
LogtailеңЁйҮҮйӣҶж—¶дјҡз»ҷиҝҷдёӘж•°жҚ®еҢ…и®ҫзҪ®е”ҜдёҖзҡ„ж—Ҙеҝ—жқҘжәҗsourceIdпјҢ并еңЁдёҠдј зҡ„ж•°жҚ®еҢ…йҮҢи®ҫзҪ®еҢ…иҮӘеўһIdпјҢеҸ«еҒҡpackageIDгҖӮжҜҸдёӘpackageеҶ…пјҢд»»ж„ҸдёҖжқЎж—Ҙеҝ—жӢҘжңүеҢ…еҶ…зҡ„дҪҚ移offsetгҖӮ
иҷҪ然数жҚ®еҢ…еңЁжңҚеҠЎз«ҜеҗҺеӯҳеӮЁеҸҜиғҪжҳҜж— еәҸзҠ¶жҖҒпјҢдҪҶж—Ҙеҝ—жңҚеҠЎжңүзҙўеј•еҸҜд»ҘеҺ»зІҫзЎ®seekжҢҮе®ҡsourceIdе’ҢpackageIdзҡ„ж•°жҚ®еҢ…гҖӮ
еҪ“жҲ‘们жҢҮе®ҡе®№еҷЁAзҡ„еәҸеҸ·2ж—Ҙеҝ—пјҲsource_id:AпјҢpackage_id:NпјҢoffset:MпјүжҹҘзңӢе…¶дёӢж–Үж—¶пјҢе…ҲеҲӨж–ӯж—Ҙеҝ—еңЁеҪ“еүҚж•°жҚ®еҢ…зҡ„offsetжҳҜеҗҰдёәж•°жҚ®еҢ…зҡ„жң«е°ҫпјҲеҢ…зҡ„ж—Ҙеҝ—жқЎж•°е®ҡд№үдёәLпјҢжң«е°ҫзҡ„offsetдёәL-1пјүпјҡеҰӮжһңoffset Mе°ҸдәҺ(L-1)пјҢеҲҷиҜҙжҳҺе®ғзҡ„дёӢдёҖжқЎж—Ҙеҝ—дҪҚзҪ®жҳҜпјҡsource_id:AпјҢpackage_id:NпјҢoffset:M+1пјӣиҖҢеҰӮжһңеҪ“еүҚж—Ҙеҝ—жҳҜж•°жҚ®еҢ…зҡ„жңҖеҗҺдёҖжқЎпјҢеҲҷе…¶дёӢдёҖжқЎж—Ҙеҝ—зҡ„дҪҚзҪ®жҳҜпјҡsource_id:AпјҢpackage_id:N+1пјҢoffset:0гҖӮ
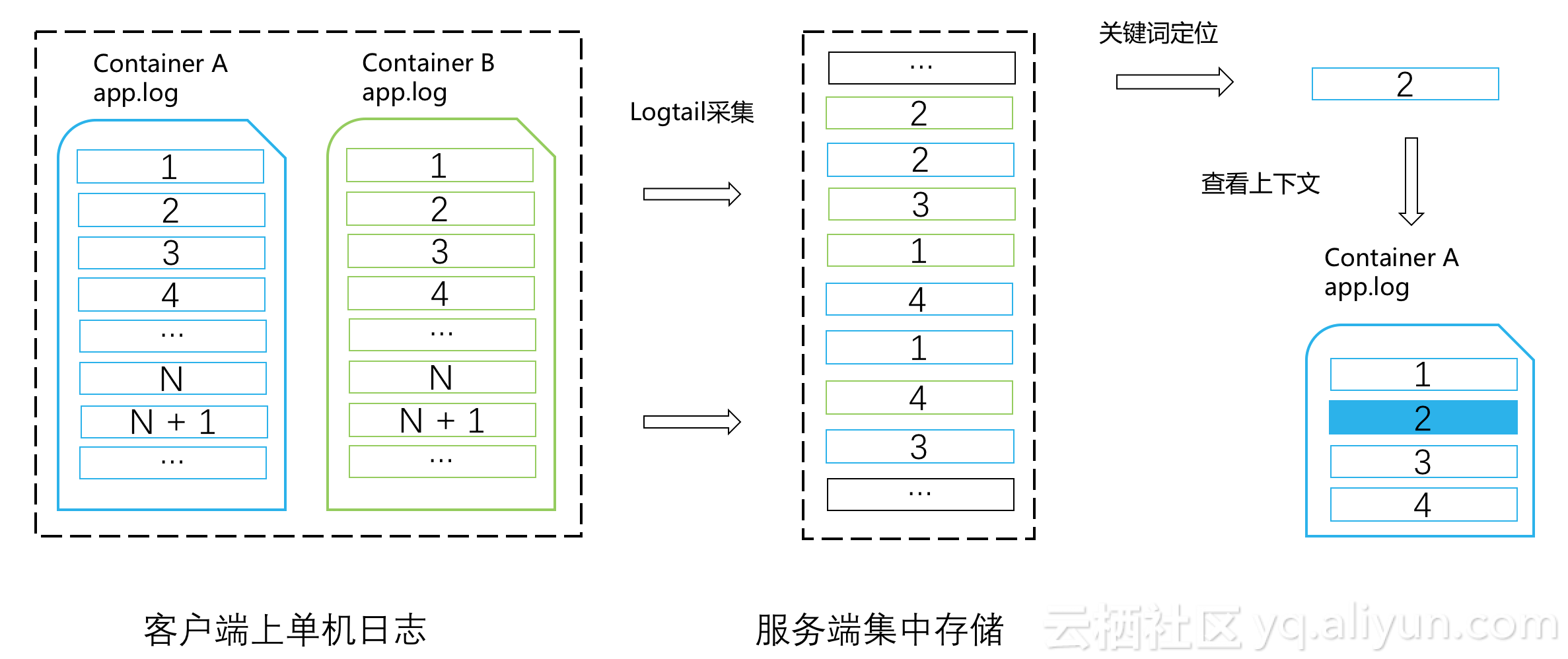
еңЁеӨ§йғЁеҲҶеңәжҷҜдёӢпјҢеҲ©з”Ёе…ій”®иҜҚйҡҸжңәжҹҘиҜўиҺ·еҸ–еҲ°зҡ„дёҖдёӘpackageпјҢеҸҜд»Ҙж”ҜжҢҒеҪ“еүҚеҢ…й•ҝеәҰLж¬Ўж•°зҡ„дёҠдёӢж–Үзҝ»йЎөпјҢеңЁжҸҗеҚҮжҹҘиҜўжҖ§иғҪеҗҢж—¶д№ҹеӨ§еӨ§йҷҚдҪҺзҡ„еҗҺеҸ°жңҚеҠЎйҡҸжңәIOзҡ„ж¬Ўж•°гҖӮ
В



зӣёе…іжҺЁиҚҗ
еңЁжң¬з”өеҺӢиЎЁзҡ„и®ҫи®ЎдёӯпјҢйҖҡиҝҮFPGAе®һзҺ°зҡ„дёІеҸЈйҖҡдҝЎжҺ§еҲ¶жЁЎеқ—иғҪеӨҹе°ҶеӨ„зҗҶеҗҺзҡ„з”өеҺӢж•°жҚ®еҸ‘йҖҒз»ҷLC1602жҳҫзӨәжЁЎеқ—пјҢжҲ–дёҺе…¶д»–и®ҫеӨҮиҝӣиЎҢж•°жҚ®дәӨжҚўгҖӮ LC1602жҳҫзӨәжЁЎеқ—жҳҜдёҖз§Қеёёз”Ёзҡ„еӯ—з¬ҰеһӢж¶Іжҷ¶жҳҫзӨәжЁЎеқ—пјҢиғҪеӨҹжё…жҷ°ең°жҳҫзӨәж•°еӯ—е’Ңеӯ—з¬ҰдҝЎжҒҜгҖӮеңЁ...
еҹәдәҺFPGAзҡ„з”өеҺӢиЎЁLC1602жҳҫзӨәзі»з»ҹпјҡFPGAж ёеҝғжҺ§еҲ¶жЁЎеқ—дёҺTLC549дҝЎеҸ·йҮҮйӣҶзҡ„дёІеҸЈйҖҡдҝЎе…Ёи§ЈгҖӮ,еҹәдәҺFPGAзҡ„з”өеҺӢиЎЁLC1602жҳҫзӨәдёҺдёІеҸЈйҖҡдҝЎпјҡTLC549жЁЎжӢҹдҝЎеҸ·йҮҮйӣҶж ёеҝғжҺ§еҲ¶зЁӢеәҸдёҺж“ҚдҪңжҢҮеҚ—,еҹәдәҺFPGAзҡ„з”өеҺӢиЎЁLC1602жҳҫзӨәдёІеҸЈйҖҡдҝЎпјҢдҪҝз”Ё...
4. **йҹіиҙЁ**пјҡе°Ҫз®ЎйҷҚдҪҺдәҶзј–з ҒеӨҚжқӮеәҰпјҢLC3 Plusд»ҚиғҪжҸҗдҫӣжҺҘиҝ‘CDзә§еҲ«зҡ„йҹіиҙЁпјҢе…¶йҮҮз”Ёзҡ„й«ҳзә§йҹійў‘еӨ„зҗҶжҠҖжңҜпјҢеҰӮиҮӘйҖӮеә”йҮҸеҢ–гҖҒеҷӘеЈ°жҠ‘еҲ¶е’Ңйў‘еёҰжү©еұ•пјҢзЎ®дҝқдәҶеңЁеҗ„з§ҚжҜ”зү№зҺҮдёӢйғҪиғҪдҝқжҢҒиҫғеҘҪзҡ„еҗ¬ж„ҹгҖӮ 5. **иө„жәҗж•ҲзҺҮ**пјҡиҖғиҷ‘еҲ°еөҢе…ҘејҸ...
4. **еҜ„еӯҳеҷЁ**: LC-3жңүдёүдёӘйҖҡз”ЁеҜ„еӯҳеҷЁпјҢR0-R2пјҢд»ҘеҸҠдёҖдёӘзЁӢеәҸи®Ўж•°еҷЁPCпјҢз”ЁдәҺеӯҳеӮЁдёӢдёҖжқЎиҰҒжү§иЎҢзҡ„жҢҮд»Өең°еқҖгҖӮR0йҖҡеёёдҪңдёәйӣ¶еҜ„еӯҳеҷЁпјҢе…¶еҖје§Ӣз»Ҳдёә0гҖӮ 5. **зЁӢеәҸз»“жһ„**: дёҖдёӘе…ёеһӢзҡ„LC3зЁӢеәҸз”ұж•°жҚ®еҢәгҖҒд»Јз ҒеҢәе’Ңж ҲеҢәз»„жҲҗгҖӮж•°жҚ®...
з”өеҠЁжұҪиҪҰиёҸжқҝжөӢиҜ•жңәLabviewжәҗз Ғи§ЈжһҗеҸҠе®һз”ЁжЎҶжһ¶пјҡж•°жҚ®йҮҮйӣҶдёҺжҺ§еҲ¶жҠҖжңҜеә”з”Ёе®һи·өпјҢйҷ„иҘҝй—ЁеӯҗPLCжҺ§еҲ¶дёҺеҠҹиғҪеӨҚз”Ёж”»з•Ҙ,з”өеҠЁжұҪиҪҰиёҸжқҝжөӢиҜ•жңәLabviewжәҗз ҒпјҢз»Ҹе…ёжЎҶжһ¶пјҢз ”еҚҺиҝҗеҠЁжҺ§еҲ¶еҚЎ1220Uе’Ңж•°жҚ®йҮҮйӣҶеҚЎ1716LеҸҠиҘҝй—ЁеӯҗP LcпјҢж•°жҚ®...
LC-3жЁЎжӢҹеҷЁжҳҜеӯҰд№ е’ҢзҗҶи§Ји®Ўз®—жңә硬件дёҺиҪҜ件дәӨдә’зҡ„дёҖдёӘејәеӨ§е·Ҙе…·пјҢе®ғе…Ғи®ёз”ЁжҲ·зј–еҶҷгҖҒиҝҗиЎҢе’Ңи°ғиҜ•LC-3жұҮзј–иҜӯиЁҖзЁӢеәҸпјҢиҖҢж— йңҖе®һйҷ…зҡ„зү©зҗҶи®ҫеӨҮгҖӮ LC-3жЁЎжӢҹеҷЁзҡ„ж ёеҝғеҠҹиғҪеҢ…жӢ¬пјҡ 1. **зЁӢеәҸзј–иҫ‘еҷЁ**пјҡжӯӨжЁЎжӢҹеҷЁжҸҗдҫӣдәҶдёҖдёӘеҶ…зҪ®зҡ„...
LC-3 жЁЎжӢҹеҷЁе…Ғи®ёз”ЁжҲ·еңЁжІЎжңүе®һйҷ…硬件зҡ„жғ…еҶөдёӢиҝҗиЎҢе’ҢжөӢиҜ• LC-3 зЁӢеәҸгҖӮжң¬жҢҮеҚ—дё»иҰҒйқўеҗ‘дҪҝз”Ё Windows ж“ҚдҪңзі»з»ҹзҡ„з”ЁжҲ·пјҢи®Іи§ЈеҰӮдҪ•дҪҝз”Ё LC-3 жЁЎжӢҹеҷЁе’Ң LC3Edit зј–иҫ‘еҷЁгҖӮ йҰ–е…ҲпјҢLC-3 жЁЎжӢҹеҷЁзҡ„йҮҚиҰҒжҖ§еңЁдәҺе®ғжҸҗдҫӣдәҶеҜ№ LC-3 ISA...
LC3жҳҜдёҖз§Қз®ҖеҚ•зҡ„иҷҡжӢҹи®Ўз®—жңәзі»з»ҹпјҢеёёз”ЁдәҺж•ҷеӯҰе’ҢеӯҰд№ жұҮзј–иҜӯиЁҖгҖӮLC3жұҮзј–иҜӯиЁҖжҳҜдёәиҝҷдёӘзі»з»ҹи®ҫи®Ўзҡ„пјҢе®ғжҳҜдёҖз§Қ...йҖҡиҝҮе®һи·өзј–еҶҷе’Ңи°ғиҜ•LC3жұҮзј–д»Јз ҒпјҢдёҚд»…еҸҜд»Ҙж·ұе…ҘзҗҶи§ЈжұҮзј–иҜӯиЁҖпјҢиҝҳиғҪеўһејәеҜ№и®Ўз®—жңә硬件е’Ңж“ҚдҪңзі»з»ҹжү§иЎҢжңәеҲ¶зҡ„зҗҶи§ЈгҖӮ
3. **Logback**пјҡз”ұLog4jзҡ„еҲӣе§ӢдәәCeki GГјlcГји®ҫи®ЎпјҢдҪңдёәLog4jзҡ„жӣҝд»Је“ҒпјҢLogbackжҸҗдҫӣдәҶжӣҙй«ҳзҡ„жҖ§иғҪе’Ңж–°зҡ„зү№жҖ§пјҢжҜ”еҰӮејӮжӯҘж—Ҙеҝ—и®°еҪ•гҖӮе®ғеҗҢж—¶ж”ҜжҢҒSLF4JжҺҘеҸЈпјҢдҪҝеҫ—дёҺSLF4Jе…је®№зҡ„еә“еҸҜд»Ҙж— зјқйӣҶжҲҗгҖӮ 4. **JavaеҶ…зҪ®ж—Ҙеҝ—API**...
жҖ»з»“пјҢGC-MSе’ҢLC-MSеңЁж•°жҚ®йҮҮйӣҶдёҺеӨ„зҗҶдёӯж¶үеҸҠж ·е“ҒеүҚеӨ„зҗҶгҖҒд»ӘеҷЁж“ҚдҪңгҖҒж•°жҚ®и§ЈжһҗзӯүеӨҡдёӘзҺҜиҠӮпјҢеҜ№дәҺзҗҶи§Је’Ңиҝҗз”ЁиҝҷдәӣжҠҖжңҜпјҢйңҖиҰҒж·ұе…ҘеӯҰд№ е№¶дёҚж–ӯе®һи·өгҖӮиҝҷд»ҪеҗҚдёәвҖңGC-MSе’ҢLC-MSж•°жҚ®йҮҮйӣҶд»ҘеҸҠеӨ„зҗҶвҖқзҡ„иө„ж–ҷпјҢж— з–‘жҳҜж•ҷиӮІе·ҘдҪңиҖ…е’ҢеӯҰз”ҹ...
AAC.rar жҳҜдёҖдёӘеҢ…еҗ«жңүе…ійҹійў‘зј–з ҒжҠҖжңҜзҡ„еҺӢзј©еҢ…пјҢдё»иҰҒе…іжіЁAACпјҲAdvanced Audio Codingпјүзј–з ҒпјҢзү№еҲ«жҳҜAAC-LCпјҲLow Complexityпјүеӯҗж јејҸгҖӮAACжҳҜдёҖз§Қй«ҳж•Ҳзҡ„еЈ°йҹіеҺӢзј©ж ҮеҮҶпјҢе№ҝжіӣеә”з”ЁдәҺж•°еӯ—йҹійў‘е№ҝж’ӯгҖҒжөҒеӘ’дҪ“жңҚеҠЎд»ҘеҸҠ移еҠЁи®ҫеӨҮ...
- **зҒөжҙ»жҖ§**: LC3 еҸҜд»ҘеңЁжҒ’е®ҡжҜ”зү№зҺҮжЁЎејҸдёӢиҝҗиЎҢпјҢд№ҹеҸҜд»ҘеңЁеӨ–жҺ§еҲ¶зҡ„еҸҜеҸҳжҜ”зү№зҺҮжЁЎејҸдёӢиҝҗиЎҢпјҢиҝҷдҪҝеҫ— LC3 еңЁдёҚеҗҢеә”з”ЁеңәжҷҜдёӢе…·жңүеҫҲй«ҳзҡ„йҖӮеә”жҖ§гҖӮ ##### 4. й«ҳиҙЁйҮҸйҹійў‘ - **дјҳеҠҝ**: LC3 жҸҗдҫӣдәҶдјҳз§Җзҡ„йҹіиҙЁпјҢзү№еҲ«жҳҜеңЁиҫғдҪҺ...
3. **иҜӯд№үеҲҶжһҗ**пјҡжӯӨйҳ¶ж®өжЈҖжҹҘзЁӢеәҸзҡ„йҖ»иҫ‘жӯЈзЎ®жҖ§пјҢдҫӢеҰӮзұ»еһӢеҢ№й…ҚгҖҒеҸҳйҮҸеЈ°жҳҺзӯүпјҢ并ејҖе§Ӣз”ҹжҲҗдёҺLC-3жһ¶жһ„е…је®№зҡ„дёӯй—ҙиЎЁзӨәгҖӮеңЁCиҜӯиЁҖдёӯпјҢеҰӮ`int a = 5;`дјҡиў«иҪ¬жҚўдёәLC-3зҡ„еҶ…еӯҳеҲҶй…Қе’Ңж•°жҚ®еҠ иҪҪжҢҮд»ӨгҖӮ 4. **зӣ®ж Үд»Јз Ғз”ҹжҲҗ**пјҡжңҖеҗҺ...
йЈҺе…үеӮЁи¶…зә§з”өе®№ж··еҗҲеӮЁиғҪзі»з»ҹдёүзӣёLC并зҪ‘д»ҝзңҹз ”з©¶пјҡжһ„жҲҗгҖҒдјҳеҢ–дёҺ并зҪ‘зӯ–з•ҘжҺўи®Ё,йЈҺе…үеӮЁи¶…зә§з”өе®№ж··еҗҲеӮЁиғҪзі»з»ҹдёүзӣёLC并зҪ‘д»ҝзңҹз ”з©¶пјҡж··еҗҲеӮЁиғҪзі»з»ҹдјҳеҢ–дёҺ并зҪ‘йҖҶеҸҳжҠҖжңҜжҺўи®Ё,йЈҺе…үеӮЁи¶…зә§з”өе®№ж··еҗҲеӮЁиғҪHESSдёүзӣёLC并зҪ‘д»ҝзңҹзі»з»ҹжһ„жҲҗ...
### LC3еҫ®жһ¶жһ„иҜҰи§Ј #### дёҖгҖҒжҰӮиҝ° LC3жҳҜдёҖз§ҚеҚ•жҖ»зәҝејҖжәҗCPUпјҢе…¶и®ҫи®Ўз®ҖжҙҒдё”жҳ“дәҺзҗҶи§ЈпјҢиҝҷдҪҝеҫ—е®ғ...йҖҡиҝҮз ”з©¶LC3пјҢеӯҰд№ иҖ…еҸҜд»ҘжӣҙеҘҪең°зҗҶи§Јеҫ®жһ¶жһ„жҳҜеҰӮдҪ•е®һзҺ°жҢҮд»ӨйӣҶжһ¶жһ„зҡ„пјҢ并且иғҪеӨҹжҙһеҜҹеҲ°дёҚеҗҢи®ҫи®ЎеҶізӯ–иғҢеҗҺзҡ„еҺҹзҗҶе’ҢжҠҖжңҜжҢ‘жҲҳгҖӮ
е®үиЈ…lc3tools жҗӯй…ҚдҪҝз”Ёbrew tap dennis97519/lc3toolsbrew install lc3toolsе®үиЈ…еҗҺпјҢжӮЁеҸҜд»ҘзӣҙжҺҘеңЁз»Ҳз«ҜдёӯдҪҝз”Ёlc3convertпјҢlc3asпјҢlc3simе’Ңlc3sim-tkгҖӮеӨҚжқӮиҝҳж·»еҠ дәҶз”ЁдәҺжӣҝд»ЈLC3д»ҝзңҹеҷЁе®үиЈ…и„ҡжң¬гҖӮ GUIд»ҝзңҹеҷЁзңӢиө·жқҘеҘҪеӨҡдәҶ...
"LC301.exe"жҳҜLC3жЁЎжӢҹеҷЁзҡ„е®үиЈ…зЁӢеәҸпјҢе®ғжҸҗдҫӣдәҶдёҖдёӘеңЁWindowsзҺҜеўғдёӢиҝҗиЎҢLC3зЁӢеәҸзҡ„е№іеҸ°гҖӮз”ЁжҲ·еҸҜд»ҘйҖҡиҝҮзј–еҶҷе’ҢиҝҗиЎҢLC3жұҮзј–д»Јз ҒпјҢи§ӮеҜҹзЁӢеәҸжү§иЎҢзҡ„иҝҮзЁӢпјҢиҝҷеҜ№дәҺеӯҰд№ жұҮзј–иҜӯиЁҖе’Ңи®Ўз®—жңәдҪ“зі»з»“жһ„йқһеёёжңүеё®еҠ©гҖӮеңЁе®үиЈ…иҝҮзЁӢдёӯпјҢйңҖиҰҒ...
LC3и“қзүҷзј–з ҒеҠҹиғҪжҳҜдёҖз§ҚеҹәдәҺеқ—зҡ„иҪ¬жҚўйҹійў‘зј–и§Јз ҒжҠҖжңҜпјҢе®ҡд№үдәҶеә”з”ЁдәҺйҹійў‘й…ҚзҪ®ж–Ү件зҡ„жңүж•Ҳи“қзүҷйҹійў‘зј–и§Јз ҒеҷЁгҖӮиҜҘзј–и§Јз ҒеҷЁеҸҜйҖҡиҝҮеӨҡз§ҚжҜ”зү№зҺҮеҜ№иҜӯйҹіе’Ңйҹід№җиҝӣиЎҢзј–з ҒпјҢ并且еҸҜд»ҘеҗҲ并еҲ°д»»дҪ•и“қзүҷйҹійў‘й…ҚзҪ®ж–Ү件дёӯгҖӮ LC3зҡ„еҹәжң¬жҰӮиҝ°пјҡ...
жң¬ж¬Ўе®һйӘҢжҳҜеҹәдәҺи®Ўз®—жңәзі»з»ҹиҜҫзЁӢдёӯзҡ„第еӣӣж¬Ўе®һи·өд»»еҠЎпјҢзӣ®ж ҮжҳҜдҪҝз”ЁLC-3пјҲLittle Computer 3пјүжЁЎжӢҹеҷЁжқҘи®ҫи®ЎдёҖдёӘз®Җжҳ“зүҲзҡ„еӣӣеӯҗжЈӢжёёжҲҸгҖӮLC-3жҳҜдёҖз§Қз®ҖеҚ•зҡ„еҫ®еӨ„зҗҶеҷЁжЁЎеһӢпјҢеёёз”ЁдәҺж•ҷиӮІзӣ®зҡ„пјҢи®©еӯҰз”ҹзҗҶи§Је’ҢеӯҰд№ и®Ўз®—жңәзі»з»ҹзҡ„еә•еұӮ...
еҚ•зӣёLCеһӢйҖҶеҸҳеҷЁгҖҒеҚ•зӣёLCLеһӢйҖҶеҸҳеҷЁгҖҒдёүзӣёLCLйҖҶеҸҳеҷЁгҖҒдёүзӣёLCйҖҶеҸҳеҷЁпјҡд»»ж„ҸеҠҹзҺҮгҖҒз”өеҺӢгҖҒйў‘зҺҮи®ҫи®Ў.pdf