
参考地址: https://dzone.com/articles/software-architecture-the-5-patterns-you-need-to-k?edition=383283&utm_source=Daily%20Digest&utm_medium=email&utm_campaign=Daily%20Digest%202018-07-02
【注意】附件有该内容的pdf。
Whether you're a software architect or a developer, it always pays to know the patterns used in a given architecture. Here are five of the most important ones.
When I was attending night school to become a programmer, I learned several design patterns: singleton, repository, factory, builder, decorator, etc. Design patterns give us a proven solution to existing and recurring problems. What I didn’t learn was that a similar mechanism exists on a higher level: software architecture patterns. These are patterns for the overall layout of your application or applications. They all have advantages and disadvantages. And they all address specific issues.
Layered Pattern
The layered pattern is probably one of the most well-known software architecture patterns. Many developers use it, without really knowing its name. The idea is to split up your code into “layers”, where each layer has a certain responsibility and provides a service to a higher layer.
There isn’t a predefined number of layers, but these are the ones you see most often:
- Presentation or UI layer
- Application layer
- Business or domain layer
- Persistence or data access layer
- Database layer
The idea is that the user initiates a piece of code in the presentation layer by performing some action (e.g. clicking a button). The presentation layer then calls the underlying layer, i.e. the application layer. Then we go into the business layer and finally, the persistence layer stores everything in the database. So higher layers are dependent upon and make calls to the lower layers.

You will see variations of this, depending on the complexity of the applications. Some applications might omit the application layer, while others add a caching layer. It’s even possible to merge two layers into one. For example, the ActiveRecord pattern combines the business and persistence layers.
Layer Responsibility
As mentioned, each layer has its own responsibility. The presentation layer contains the graphical design of the application, as well as any code to handle user interaction. You shouldn’t add logic that is not specific to the user interface in this layer.
The business layer is where you put the models and logic that is specific to the business problem you are trying to solve.
The application layer sits between the presentation layer and the business layer. On the one hand, it provides an abstraction so that the presentation layer doesn’t need to know the business layer. In theory, you could change the technology stack of the presentation layer without changing anything else in your application (e.g. change from WinForms to WPF). On the other hand, the application layer provides a place to put certain coordination logic that doesn’t fit in the business or presentation layer.
Finally, the persistence layer contains the code to access the database layer. The database layer is the underlying database technology (e.g. SQL Server, MongoDB). The persistence layer is the set of code to manipulate the database: SQL statements, connection details, etc.
Advantages
- Most developers are familiar with this pattern.
- It provides an easy way of writing a well-organized and testable application.
Disadvantages
- It tends to lead to monolithic applications that are hard to split up afterward.
- Developers often find themselves writing a lot of code to pass through the different layers, without adding any value in these layers. If all you are doing is writing a simple CRUD application, the layered pattern might be overkill for you.
Ideal for
- Standard line-of-business apps that do more than just CRUD operations
Microkernel
The microkernel pattern, or plug-in pattern, is useful when your application has a core set of responsibilities and a collection of interchangeable parts on the side. The microkernel will provide the entry point and the general flow of the application, without really knowing what the different plug-ins are doing.
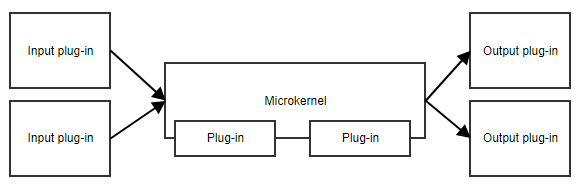
An example is a task scheduler. The microkernel could contain all the logic for scheduling and triggering tasks, while the plug-ins contain specific tasks. As long as the plug-ins adhere to a predefined API, the microkernel can trigger them without needing to know the implementation details.
Another example is a workflow. The implementation of a workflow contains concepts like the order of the different steps, evaluating the results of steps, deciding what the next step is, etc. The specific implementation of the steps is less important to the core code of the workflow.
Advantages
- This pattern provides great flexibility and extensibility.
- Some implementations allow for adding plug-ins while the application is running.
- Microkernel and plug-ins can be developed by separate teams.
Disadvantages
- It can be difficult to decide what belongs in the microkernel and what doesn’t.
- The predefined API might not be a good fit for future plug-ins.
Ideal for
- Applications that take data from different sources, transform that data and writes it to different destinations
- Workflow applications
- Task and job scheduling applications
CQRS
CQRS is an acronym for Command and Query Responsibility Segregation. The central concept of this pattern is that an application has read operations and write operations that must be totally separated. This also means that the model used for write operations (commands) will differ from the read models (queries). Furthermore, the data will be stored in different locations. In a relational database, this means there will be tables for the command model and tables for the read model. Some implementations even store the different models in totally different databases, e.g. SQL Server for the command model and MongoDB for the read model.
This pattern is often combined with event sourcing, which we’ll cover below.
How does it work exactly? When a user performs an action, the application sends a command to the command service. The command service retrieves any data it needs from the command database, makes the necessary manipulations and stores that back in the database. It then notifies the read service so that the read model can be updated. This flow can be seen below.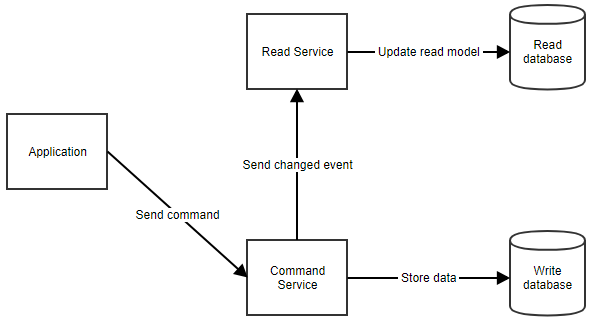
When the application needs to show data to the user, it can retrieve the read model by calling the read service, as shown below.
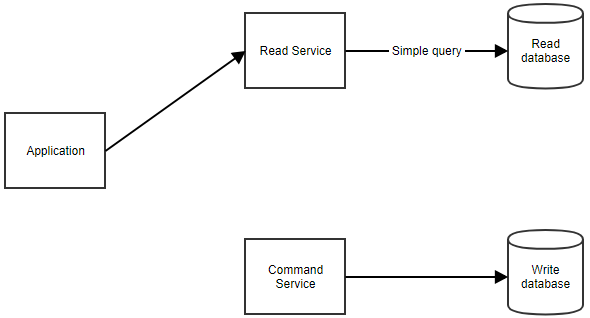 Advantages
Advantages
- Command models can focus on business logic and validation while read models can be tailored to specific scenarios.
- You can avoid complex queries (e.g. joins in SQL) which makes the reads more performant.
Disadvantages
- Keeping the command and the read models in sync can become complex.
Ideal for
- Applications that expect a high amount of reads
- Applications with complex domains
Event Sourcing
As I mentioned above, CQRS often goes hand in hand with event sourcing. This is a pattern where you don’t store the current state of your model in the database, but rather the events that happened to the model. So when the name of a customer changes, you won’t store the value in a “Name” column. You will store a “NameChanged” event with the new value (and possibly the old one too).
When you need to retrieve a model, you retrieve all its stored events and reapply them on a new object. We call this rehydrating an object.
A real-life analogy of event sourcing is accounting. When you add an expense, you don’t change the value of the total. In accounting, a new line is added with the operation to be performed. If an error was made, you simply add a new line. To make your life easier, you could calculate the total every time you add a line. This total can be regarded as the read model. The example below should make it more clear.

You can see that we made an error when adding Invoice 201805. Instead of changing the line, we added two new lines: first, one to cancel the wrong line, then a new and correct line. This is how event sourcing works. You never remove events, because they have undeniably happened in the past. To correct situations, we add new events.
Also, note how we have a cell with the total value. This is simply a sum of all values in the cells above. In Excel, it automatically updates so you could say it synchronizes with the other cells. It is the read model, providing an easy view for the user.
Event sourcing is often combined with CQRS because rehydrating an object can have a performance impact, especially when there are a lot of events for the instance. A fast read model can significantly improve the response time of the application.
Advantages
- This software architecture pattern can provide an audit log out of the box. Each event represents a manipulation of the data at a certain point in time.
Disadvantages
- It requires some discipline because you can’t just fix wrong data with a simple edit in the database.
- It’s not a trivial task to change the structure of an event. For example, if you add a property, the database still contains events without that data. Your code will need to handle this missing data graciously.
Ideal for applications that
- Need to publish events to external systems
- Will be built with CQRS
- Have complex domains
- Need an audit log of changes to the data
Microservices
When you write your application as a set of microservices, you’re actually writing multiple applications that will work together. Each microservice has its own distinct responsibility and teams can develop them independently of other microservices. The only dependency between them is the communication. As microservices communicate with each other, you will have to make sure messages sent between them remain backwards-compatible. This requires some coordination, especially when different teams are responsible for different microservices.
A diagram can explain.
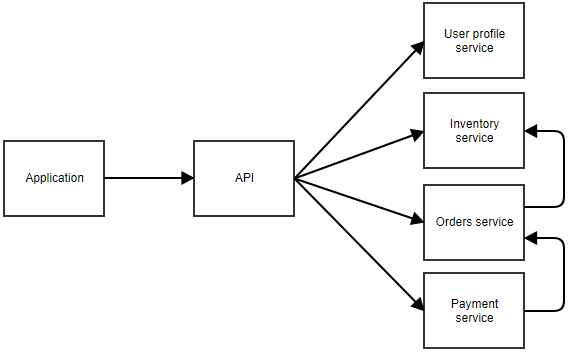 In the above diagram, the application calls a central API that forwards the call to the correct microservice. In this example, there are separate services for the user profile, inventory, orders, and payment. You can imagine this is an application where the user can order something. The separate microservices can call each other too. For example, the payment service may notify the orders service when a payment succeeds. The orders service could then call the inventory service to adjust the stock.
In the above diagram, the application calls a central API that forwards the call to the correct microservice. In this example, there are separate services for the user profile, inventory, orders, and payment. You can imagine this is an application where the user can order something. The separate microservices can call each other too. For example, the payment service may notify the orders service when a payment succeeds. The orders service could then call the inventory service to adjust the stock.
There is no clear rule of how big a microservice can be. In the previous example, the user profile service may be responsible for data like the username and password of a user, but also the home address, avatar image, favorites, etc. It could also be an option to split all those responsibilities into even smaller microservices.
Advantages
- You can write, maintain, and deploy each microservice separately.
- A microservices architecture should be easier to scale, as you can scale only the microservices that need to be scaled. There’s no need to scale the less frequently used pieces of the application.
- It’s easier to rewrite pieces of the application because they’re smaller and less coupled to other parts.
Disadvantages
- Contrary to what you might expect, it’s actually easier to write a well-structured monolith at first and split it up into microservices later. With microservices, a lot of extra concerns come into play: communication, coordination, backward compatibility, logging, etc. Teams that miss the necessary skill to write a well-structured monolith will probably have a hard time writing a good set of microservices.
- A single action of a user can pass through multiple microservices. There are more points of failure, and when something does go wrong, it can take more time to pinpoint the problem.
Ideal for:
- Applications where certain parts will be used intensively and need to be scaled
- Services that provide functionality to several other applications
- Applications that would become very complex if combined into one monolith
- Applications where clear bounded contexts can be defined
Combine
I’ve explained several software architecture patterns, as well as their advantages and disadvantages. But there are more patterns than the ones I’ve laid out here. It is also not uncommon to combine several of these patterns. They aren’t always mutually exclusive. For example, you could have several microservices and have some of them use the layered pattern, while others use CQRS and event sourcing.
The important thing to remember is that there isn’t one solution that works everywhere. When we ask the question of which pattern to use for an application, the age-old answer still applies: “it depends.” You should weigh in on the pros and cons of a solution and make a well-informed decision.



相关推荐
5. 场景视图(Scenario View):场景视图并非独立的视图,而是通过用例或场景来串联其他四个视图,它体现了系统在特定情境下的行为。场景视图帮助验证架构决策是否满足了需求,例如,用户登录过程可能涉及到逻辑视图...
面向模式的软件架构(Pattern-Oriented Software Architecture, POSA)系列是一套经典的软件设计与架构书籍,由著名计算机科学家弗兰克·巴斯(Frank Buschmann)、雷纳德·莫尔内(Reinhard Koenig)、丹尼斯·里奇...
5. 验证:升级完成后,重启开发环境,检查J-Link是否能够正常工作,不再弹出"The connected J-Link is defective"的错误。 通过以上步骤,开发者可以有效地解决由于固件版本不匹配导致的J-Link连接问题。同时,保持...
#### 5. 内存管理与跟踪 - **内存分配**:探讨内核如何管理内存资源,包括页式管理、物理内存管理等。 - **内存跟踪**:提供内存泄露检测的方法和技术,帮助开发者提高内核的健壮性。 #### 6. I/O 交互与文件系统 -...
**藏经阁-LEAN APP Instagram Architectur.pdf** 这篇文档主要探讨了Instagram Android应用程序的设计与优化策略,特别是如何构建一个轻量级(Lean)的应用。在阿里巴巴云的背景下,这种优化对于处理大规模用户基础...
### IA-32 Intel Architecture Software Developer’s Manual Volume 1: Basic Architecture #### 一、概述 《IA-32 Intel Architecture Software Developer’s Manual Volume 1: Basic Architecture》是一本详细...
5. **内存分配和跟踪**:详细介绍了内存管理,包括动态内存分配、释放和内存泄漏的预防。 6. **追踪子系统行为**:提供了理解和调试内核行为的手段。 7. **I/O交互**:涵盖了设备驱动程序和I/O子系统的接口,以及...
5. 现在,你可以使用这个连接执行SQL查询、事务管理等数据库操作了。 总之,cx_Oracle是Python连接Oracle数据库的关键工具,而oci.dll及其相关的Oracle Instant Client组件则是其正常工作的前提。当遇到oci.dll缺失...
There are two general approaches to developing artificial general intelligence (AGI)1: computer-science-oriented and neuroscience-oriented. Because of the fundamental differences in their ...
ZK® is the most proven Ajax + Mobile framework designed to maximize enterprise operation efficiency and minimize the development cost by its groundbreaking Direct RIA architectur
5. 性能评估:在图像处理和机器学习中,性能评估是至关重要的一个方面。文章提到了对公共图像集进行评估的技术,这些技术用于确定不同方法在精确度和效率方面的能力。 6. 细粒度定位和尺度不变性:这两个问题是在...
Architecture ...architectur The architecture diagram completely shows the execution process of the tool. From the figure, the tool has gone through five modules: Parameter parser. Parse
5. **浮点运算优化**:针对浮点运算密集型应用,如科学计算和图形处理,优化浮点指令的使用,包括使用SSE和AVX指令集。 6. **编译器选项**:了解如何使用编译器优化标志,如GCC的-O选项,调整代码生成以适应特定的...
计算机系统架构是IT领域中的核心课程,主要探讨计算机硬件、软件以及它们之间的交互方式。它涉及处理器设计、内存系统、I/O设备、总线结构、并行计算等多个方面。VIT Computer Science专业的"计算机系统架构"课程...
java查看底层源码快捷键 MVVMFrame MVVMFrame for Android 是一个基于Google官方推出的Architecture Components dependencies(现在叫JetPack){ Lifecycle,LiveData,ViewModel,Room } 构建的快速开发框架。...
It is intended to show how the different SCSI standards are inter-related. The main concepts and terminology of the SCSI architectural model are: Only the externally observable behavior is defined...
SODA,全称为Small Object Directory Architecture,是一个设计用于管理和组织小型对象的开源软件系统。它的灵感来源于Novell NDS(Network Directory Service),一个在早期网络环境中广泛使用的目录服务技术,用于...