
و‘کè¦پï¼ڑوœ¬و–‡ن»ژ马هٹ›ن½œن¸؛هٹںçژ‡è،،é‡ڈو ‡ه‡†ن¸؛هˆ‡ه…¥ç‚¹ï¼Œن»‹ç»چن؛†ه¤§و•°وچ®é¢†هںںçڑ„è®،ç®—هٹ›è،،é‡ڈو ‡ه‡†TPCBBن»¥هڈٹMaxCompute2.0هœ¨Big Benchن¸ٹçڑ„هچ“è¶ٹè،¨çژ°م€‚هگŒو—¶è¯¦ç»†هœ°هˆ†ن؛«ن؛†هڈ–ه¾—ن¼که¼‚وˆگ绩背هگژçڑ„ن؛§ه“پهœ¨وœ€و–°وœ‰ه“ھن؛›è؟›ه±•ï¼Œه¸®هٹ©ه¤§ه®¶ه…¨é¢çڑ„ن؛†è§£MaxCumpute2.0م€‚هڈ¦ه¤–,ه¯¹ن؛ژه…±وœ‰ن؛‘用وˆ·éه¸¸ه…³و³¨çڑ„-و•°وچ®ه®‰ه…¨è¯é¢ک,éک؟里ه·´ه·´é€ڑè؟‡é€»è¾‘éڑ”离/资و؛گéڑ”离/è؟گè،Œéڑ”离وœ؛هˆ¶ï¼Œن؟éڑœن؛†و•°وچ®ه®‰ه…¨ï¼ŒهگŒو—¶ه®çژ°ن؛†ه®‰ه…¨çڑ„و•°وچ®ن؛¤وچ¢ن¸ژه…±ن؛«م€‚
و¼”讲هک‰ه®¾ç®€ن»‹ï¼ڑ
ن؛‘éƒژ,MaxCompute资و·±ن؛§ه“پن¸“ه®¶
ن»¥ن¸‹ه†…ه®¹و ¹وچ®و¼”讲هک‰ه®¾è§†é¢‘هˆ†ن؛«ن»¥هڈٹPPTو•´çگ†è€Œوˆگم€‚آ
PPTوگو–™ن¸‹è½½هœ°ه€ï¼ڑhttp://click.aliyun.com/m/1000003064/
视频هœ°ه€ï¼ڑhttps://edu.aliyun.com/lesson_1010_8794?spm=5176.8764728.0.0.x2IAee#_8794
ن؛§ه“پهœ°ه€ï¼ڑhttp://click.aliyun.com/m/1000003065/
وœ¬و¬،çڑ„هˆ†ن؛«ن¸»è¦په›´ç»•ن»¥ن¸‹ه››ن¸ھو–¹é¢ï¼ڑ
ن¸€م€پ背و™¯ç®€ن»‹
ن؛Œم€پTPCBB
ن¸‰م€پMaxCompute2.0و¼”è؟›آ
ه››م€پو•°وچ®ه®‰ه…¨
ن¸€م€پ背و™¯ç®€ن»‹
وœ€è؟‘هœ¨çœ‹ن¸€ن؛›ç؛ھه½•ç‰‡ï¼Œن»ژè؟™é‡Œé¢هڈ—هˆ°ه¾ˆه¤§çڑ„هگ¯هڈ‘,ه°±وک¯ه®ƒن»ژه¾ˆه¤ڑهˆ‡ه…¥ç‚¹ه°†وˆ‘ن»¬ن؛؛ç±»çڑ„هژ†هڈ²çœںه®çڑ„ه†چçژ°ه‡؛و¥ن؛†ï¼Œهœ¨è؟™ن¸ھè؟‡ç¨‹ن¸وˆ‘هڈ‘çژ°هœ¨ن؛؛ç±»çڑ„ه¤§هژ†هڈ²ن¸ه¾ˆه¤ڑن¸œè¥؟都وک¯ç›¸é€ڑçڑ„م€‚وˆ‘وƒ³èµ·و¥ه’±ن»¬ه›½ه†…ن¸€ن½چه¤§ه®¶é²پè؟…说çڑ„è¯â€œو²»ه¦è¦په…ˆو²»هڈ²â€ï¼Œé€ڑè؟‡ه¦ن¹ هژ†هڈ²ï¼Œن»ژو›´و·±ه±‚و¬،ن¸ٹوœ‰و›´ه¤ڑçڑ„碰و’,ç”ڑ至هڈ¯èƒ½ن¸ٹهچ‡هˆ°ه“²ه¦çڑ„ه±‚é¢ï¼Œوˆ–者و–‡هŒ–çڑ„ه±‚é¢م€‚و‰€ن»¥è¯´وگه¤§و•°وچ®ن¸چهڈ¯و€•ï¼Œهڈ¯و€•çڑ„وک¯وگه¤§و•°وچ®çڑ„è؟کè¦پوگو–‡هŒ–م€‚
ه¤§ه®¶وœ‰و²،وœ‰çœ‹è؟‡ن¸€ن¸ھç؛ھه½•ç‰‡-ن؛؛ç±»ه¤§هژ†هڈ²ï¼Œه®ƒو‹چن؛†ه‡ هچپ集,ه…¶ن¸وœ‰ن¸€é›†ه°±وک¯è®²é©¬çڑ„هڈکé©ï¼Œé©¬ه¯¹ن؛؛ç±»و•´ن¸ھن؛؛ç±»هژ†هڈ²ن؛§ç”ںن؛†ن»€ن¹ˆو ·çڑ„ه½±ه“چï¼ںه°ڈو—¶ه€™ه¦هژ†هڈ²وœ‰ه››ن¸ھه—هچ°è±،و¯”较و·±ï¼Œه°±وک¯èƒ،وœچéھ‘ه°„م€‚ن¸‹ه›¾ن¸هڈ¯ن»¥ه¾ˆه®¹وک“وƒ³هˆ°è؟™وک¯وˆگهگ‰و€و±—çڑ„é“په†›ï¼Œهڈ¦ه¤–وˆ‘ن»¬ه¯¹è¥؟و–¹çڑ„و–‡وکژه’Œو–‡هŒ–ن¹ںو¯”较ç†ںو‚‰ï¼Œوڈگهˆ°ç½—马,看هˆ°ç™½è¢چهگçڑ„و—¶ه€™هڈ¯ن»¥çœ‹هˆ°è´µو—ڈن¸€èˆ¬ç©؟ç€ه¾ˆç™½ه¾ˆç™½çڑ„è¢چهگم€‚هœ¨è؟™ن¸ھç؛ھه½•ç‰‡é‡Œé¢ï¼Œهڈ¤ç½—马ن؛؛çڑ„ç©؟ç€هڈکهŒ–ه°±ه¦‚ن¸‹ه›¾çڑ„ن¸‰ن¸ھن؛؛,é€گو¥و¼”هڈکوˆگن¸‰ن¸ھن؛؛都ç©؟裤هگ,ن¹‹ه‰چ都وک¯ç©؟è¢چهگم€‚é‚£ن¹ˆن؛§ç”ںçڑ„ه½±ه“چ,第ن¸€ن¸ھ,ن؛؛ç±»ه› ن¸؛马ç©؟ن¸ٹن؛†è£¤هگم€‚第ن؛Œن¸ھ,ن¸چç®،وک¯è¥؟و–¹çڑ„罗马ه¸ه›½ï¼Œوˆ–者وک¯è¯´وˆ‘ن»¬çڑ„وˆگهگ‰و€و±—çڑ„ه¸ه›½ï¼Œé©¬èµ·هˆ°ن؛†ه¾ˆé‡چè¦پçڑ„ن½œç”¨ï¼Œه®ƒهˆ›é€ ن؛†ن¸œو–¹ه’Œè¥؟و–¹çڑ„ه¸ه›½م€‚هگŒو—¶é©¬ه†³ه®ڑن؛†ç–†هœں,و‰€ن»¥é©¬ه¯¹وˆ‘ن»¬ن؛§ç”ںن؛†ه¾ˆé‡چè¦پçڑ„ه½±ه“چم€‚

و•´ن¸ھهœ°çگƒن¸ٹوœ‰6600ن¸‡ن¸ھ物ç§چ,هœ¨è؟™ن¹ˆه¤ڑ物ç§چ里é¢ن¸؛ن»€ن¹ˆé©¬وˆگن¸؛ن؛†وˆ‘ن»¬ن؛؛ç±»çڑ„وœ€é‡چè¦پçڑ„وœ‹هڈ‹ه‘¢ï¼ںن»»ن½•ن؛‹وƒ…وˆ‘ن»¬éƒ½وœ‰ه¾ˆه¤ڑ选و‹©ï¼Œن¸؛ن»€ن¹ˆوœ€ç»ˆن؛؛ç±»ن¼ڑ选و‹©é©¬ه‘¢ï¼ںه¤©ن¸ٹé£çڑ„وک†è™«ï¼Œé¸ںç±»ه¾ˆه¤ڑ,وک¯ن¸چوک¯هڈ¯ن»¥وٹٹه®ƒن»¬è®ç»ƒه¥½ه‘¢ï¼ںن½†é—®é¢کوک¯ه®ƒن»¬ن½“é‡ڈه¤ھه°ڈ,ه®ƒو— و³•و‰؟و‹…ن؛؛ç±»çڑ„é‡چé‡ڈم€‚第ن؛Œن¸ھ,狮هگè€پè™ژ能هگ¦è®ç»ƒه‘¢ï¼Œé¦–ه…ˆه®ƒن»¬ه¾ˆéڑ¾é©¯هŒ–,هڈ¦ه¤–ه®ƒن»¬éƒ½وک¯è‚‰é£ںهٹ¨ç‰©ï¼Œهگƒçڑ„و¯”ن؛؛ç±»è؟ک贵,و— و³•é¥²ه…»م€‚第ن¸‰ç±»ï¼Œه¤§è±،هڈ¯ن»¥è،¨و¼”,ه¾ˆèپھوکژ,那ن¹ˆه¤§è±،ن¸؛ن»€ن¹ˆن¸چè،Œï¼Œه› ن¸؛ه®ƒن½“é‡ڈه¤ھه¤§ï¼Œè¦پوٹٹه®ƒé©¯هŒ–وˆگه¤§ه°ڈهگˆé€‚,و—¶é—´ن¸ٹè¦پèٹ±ه¾ˆé•؟ه¾ˆé•؟م€‚وœ€ç»ˆï¼Œهڈھوœ‰é©¬ç»“هگˆن؛†وˆ‘ن»¬وƒ³è¦پçڑ„ه‡ و–¹é¢çڑ„ن¼کهٹ؟,第ن¸€ن¸ھ马وœ‰هٹ›é‡ڈ,第ن؛Œن¸ھ马çڑ„脾و€§ه¥½ï¼Œç¬¬ن¸‰ن¸ھ,وœ€وœ€é‡چè¦پçڑ„ه°±وک¯é€ںه؛¦م€‚è؟™وک¯é©¬èƒ½وˆگن¸؛ن؛؛هٹ›وœ€é‡چè¦پوœ‹هڈ‹çڑ„ه‡ 点هژںه› م€‚

وœ€و—©çڑ„و—¶ه€™ï¼Œçپ«è½¦è¢«هڈ«ن¸؛“é“پ马â€ï¼Œه°ڈو±½è½¦وœ€و—©هڈ‘وکژçڑ„و—¶ه€™ن¹ںن¸چهڈ«car,ه®ƒهڈ«و— 马马车م€‚هˆ°ن»ٹه¤©ï¼Œوˆ‘ن»¬هپڑçپ«è½¦ï¼Œé£وœ؛,و±½è½¦ç‰ï¼Œه¯¹هٹںçژ‡و ‡ه‡†çڑ„ه؛¦é‡ڈهڈ«هپڑ“马هٹ›â€ï¼Œ1ه…¬هˆ¶é©¬هٹ›=0.735هچƒç“¦ï¼ˆkw)م€‚é€ڑè؟‡ن؛؛ç±»ه¤§هژ†هڈ²ï¼Œوˆ‘ن»¬çں¥éپ“ن؛†é©¬هٹ›ه‡؛çژ°çڑ„هژںه› ,ن»¥هڈٹ马ن¸؛ن»€ن¹ˆن¼ڑوˆگن¸؛وˆ‘ن»¬çڑ„وœ‹هڈ‹م€‚

ن؛Œم€پTPCBB
é‚£ن¹ˆهœ¨ه¤§و•°وچ®é¢†هںں,وˆ‘ن»¬و€ژن¹ˆو ·هژ»ه®ڑن¹‰ه®ƒçڑ„ه؛¦é‡ڈè،،ه‘¢ï¼Œن½œن¸؛è®،ç®—ه¹³هڈ°ï¼Œوˆ‘ن»¬و€ژن¹ˆو ·هژ»è¯„ن¼°è®،ç®—هٹ›ه‘¢ï¼ں
هœ¨وœ€è؟‘ه‡ ه¹´ï¼Œوˆ‘ن»¬è·ںه›½é™…ن¸ٹه¾ˆه¤ڑو ‡ه‡†هŒ–çڑ„组织هپڑن؛†ه¾ˆه¤ڑه¤§و•°وچ®و–¹é¢çڑ„benchmarkوµ‹è¯•ï¼ŒهŒ…و‹¬وœ€و—©هپڑsort bench,TPCH,TPC-DS,然هگژهœ¨هژ»ه¹´هپڑTPCBB(big bench)م€‚هˆ°هژ»ه¹´وˆ‘ن»¬هڈ‘çژ°TPCBBو‰چوک¯è،،é‡ڈه¤§و•°وچ®è®،ç®—هٹ›çڑ„و ‡ه‡†م€‚ه¤§و•°وچ®è؟™é‡Œé¢è¦پ考虑هˆ°و•°وچ®çڑ„ç§چ类,وœ‰هچٹ结و„هŒ–çڑ„,结و„هŒ–çڑ„,ن»¥هڈٹé结و„هŒ–çڑ„و•°وچ®ï¼Œè؟™ن؛›éƒ½è¦پهœ¨هœ؛و™¯é‡Œé¢وœ‰م€‚هڈ¦ه¤–هœ¨هˆ†وگçڑ„هœ؛و™¯é‡Œé¢ï¼Œوˆ‘ن»¬è¦پهŒ…هگ«و™®é€ڑçڑ„ه»؛و¨،,ه¦‚é™و€پçڑ„ه»؛و¨،م€‚è؟کوœ‰و•°وچ®çڑ„هˆ†وگه’ŒوŒ–وژکم€‚è؟کوœ‰è¦پهپڑReporting,ه› ن¸؛هپڑوٹ¥è،¨ه’Œé™و€پهˆ†وگçڑ„SQLه†™و³•هڈˆوک¯ن¸چن¸€و ·çڑ„م€‚è؟™وک¯è¦پهں؛وœ¬çڑ„ن¸‰ن¸ھهœ؛و™¯م€‚ه¯¹ن؛ژوں¥è¯¢çڑ„ç±»ه‹è€Œè¨€ï¼Œن»…ن»…وœ‰SQLçڑ„,هپڑوœ؛ه™¨ه¦ن¹ ,è‡ھ然è¯è¨€ه¤„çگ†ï¼Œé€ڑè؟‡و ‡ه‡†è¯è¨€ï¼Œè؟کوœ‰وµپè®،ç®—م€‚ه¯¹ن؛ژهپڑه¤§و•°وچ®و¥è¯´ï¼Œو•´ن¸ھه¤„çگ†çڑ„و•°وچ®ï¼Œن½œن¸ڑ,وٹ€وœ¯è¦پن»ژن»¥ن¸ٹه‡ ن¸ھ角ه؛¦é¢é¢è¦†ç›–هˆ°م€‚
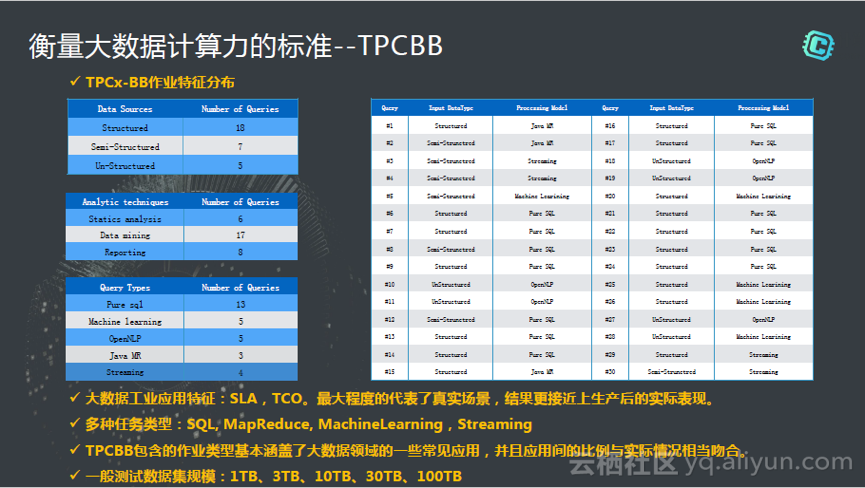
è؟™ن¸ھوµ‹è¯•و،ˆن¾‹é›†هŒ…هگ«30ن¸ھ,ه®ƒه®Œو•´çڑ„覆盖ن؛†ن¸چهگŒçڑ„و•°وچ®ç±»ه‹ï¼Œن¸چهگŒçڑ„وٹ€وœ¯ï¼Œن¸چهگŒçڑ„وں¥è¯¢ç±»ه‹م€‚ه¤§ه®¶éƒ½هڈ¯ن»¥ن¸‹è½½هˆ°è؟™30ن¸ھوµ‹è¯•é›†ï¼Œç„¶هگژ看و€ژن¹ˆهژ»هپڑTPCBBم€‚هœ¨TPCBBن¹‹ه‰چوک¯TPC-DS,ه®ƒهœ¨ه¾ˆه¤ڑé¢هگ‘OLTPهœ؛و™¯وµ‹è¯•هں؛ç،€ه¤–,وٹٹوˆ‘ن»¬çڑ„benchmarkçڑ„هœ؛و™¯è¦†ç›–هˆ°ن؛†OLAP,ه°±وک¯èپ”وœ؛هˆ†وگçڑ„هœ؛و™¯م€‚然هگژTPCBBه°±è؟›ن¸€و¥çڑ„ن»ژOLAPه»¶ن¼¸ï¼Œو‰©ه±•ن؛†و—¥ه؟—و–‡ن»¶ï¼Œوœ؛ه™¨ه¦ن¹ ç‰ç‰ه¤§و•°وچ®و‰€وœ‰çڑ„特ه¾پم€‚è؟™30ن¸ھوµ‹è¯•هœ؛و™¯ه®Œو•´çڑ„覆盖ن؛†وˆ‘ن»¬ه¯¹ه¤§و•°وچ®è®،ç®—ه±‚é¢çڑ„ه…¨éƒ¨çڑ„诉و±‚م€‚è؟™é‡Œé¢ه¾ˆé‡چè¦پçڑ„ن¸€ç‚¹وک¯وœ€ه¤§ç¨‹ه؛¦ن»£è،¨ن؛†çœںه®هœ؛و™¯ï¼Œç»“وœو›´وژ¥è؟‘ن¸ٹç”ںن؛§هگژçڑ„ه®é™…è،¨çژ°م€‚ه¾ˆه¤ڑوƒ…ه†µن¸‹ï¼ŒPB,EBçڑ„é‡ڈç؛§وک¯ه¸¸è§پçڑ„,目ه‰چه®کو–¹ç½‘ç«™ن¸ٹوœ‰1TB,3TB,10TB,30TB,وœ€ه¤§çڑ„规و ¼وک¯100TBم€‚
هژ»ه¹´éک؟里ن؛‘هœ¨هŒ—ن؛¬çڑ„ن؛‘و –ه¤§ن¼ڑن¸ٹ,هڈ—هˆ°ن¸€ن¸ھçپµو„ں,è·ںو‰‹وœ؛ن¸€و ·ï¼ŒMaxComputeوک¯ن¸چوک¯ن¹ںهڈ¯ن»¥è·‘ن¸ھهˆ†م€‚هœ¨هژ»ه¹´هپڑن؛†ن¸€ن¸ھçژ°هœ؛è·‘هˆ†ï¼Œه½“و—¶è°ƒç”¨ن؛†هŒ—ن؛¬ï¼Œو·±هœ³çڑ„集群,هŒ—ن؛¬çڑ„è·‘ه¾—ه¾ˆه¥½ï¼Œن¸‹ه›¾وک¯ن»ژن¸‰ن¸ھç؛¬ه؛¦ه¾—ه‡؛çڑ„结وœم€‚و•°وچ®é›†وک¯100TB,首و¬،وµ‹è¯•ه°±ç”¨ن؛†وœ€ه¤§çڑ„规و¨،م€‚第ن؛Œن¸ھè،¨ç¤؛و¯ڈهˆ†é’ں能跑ه¤ڑه°‘ن»»هٹ،,وˆ‘ن»¬è·‘çڑ„ه…¨çگƒوœ€é«ک8200QPMم€‚è؟کوœ‰ç¬¬ن¸‰ن¸ھوک¯وˆگوœ¬ï¼Œè¾¾هˆ°ن؛†وœ€ن½ژçڑ„$354.7/QPMم€‚و‰€ن»¥MaxComputeهœ¨و•°وچ®çڑ„ه®¹é‡ڈ,و€§èƒ½ه’Œو€§ن»·و¯”ن¸ٹه…¨é¢çڑ„ه¾—هˆ°ن؛†çھپç ´م€‚وˆ‘ن»¬و‰¾هˆ°ن؛†ه¤§و•°وچ®çڑ„è،،é‡ڈو ‡ه‡†ï¼ŒهگŒو—¶ن¹ںهœ¨ن¸چو–çڑ„هپڑن¼کهŒ–,وœںوœ›èƒ½ه¾—هˆ°و›´ه¤ڑçڑ„çھپç ´م€‚

ن¸‰م€پMaxCompute2.0و¼”è؟›
هœ¨è®،ç®—هٹ›ه¾—هˆ°çھپç ´çڑ„背هگژ,وˆ‘ن»¬éƒ½هپڑن؛†ه“ھن؛›ه·¥ن½œم€‚ه…¶ه®MaxComputeهœ¨éک؟里éک؟ه·´ه·²ç»ڈوœ‰هچپه¹´çڑ„هژ†هڈ²ï¼Œè؟™هچپه¹´ن¸ه¹¶ن¸چوک¯ن¸€وˆگن¸چهڈکçڑ„,ن»ژوœ€و—©ه¼€ه§‹هں؛وœ¬و»،足éک؟里ه·´ه·´é›†ه›¢ه†…部ن¸ڑهٹ،,然هگژ能و›؟ن»£Hadoop,è؟›è€Œوˆگن¸؛çœںو£çڑ„و•°وچ®çڑ„è®،ç®—ن¸هڈ°ï¼Œهں؛ç،€è®¾و–½م€‚هœ¨éک؟里ه·´ه·´ï¼Œ99%çڑ„هکه‚¨و•°وچ®ï¼Œ95%çڑ„è®،算都وک¯è·‘هœ¨MaxComputeن¸ٹçڑ„,وˆ‘ن»¬و¥çœ‹و€ژن¹ˆو ·و¼”è؟›çڑ„م€‚ه¦‚ن¸‹ه›¾ï¼Œè؟‘وœںé‡چ点ن¼کهŒ–çڑ„ه†…ه®¹ه¤§ه®¶ه·²ç»ڈهڈ¯ن»¥çœ‹هˆ°ï¼Œé‚£هڈ¯èƒ½و²،看هˆ°çڑ„وک¯وˆ‘ن»¬وœ€è؟‘هœ¨هپڑçڑ„ç´¢ه¼•و”¯وŒپ,ه¦‚وœMaxComputeو·±ه؛¦ن½؟用çڑ„è¯ï¼Œè؟™و–¹é¢çڑ„ن¼کهŒ–ن¼ڑه¸¦و¥éه¸¸ه¤§çڑ„ه¸®هٹ©ï¼Œهœ¨و€§èƒ½ï¼Œوˆگوœ¬ï¼Œه…¨ç›کو‰«وڈڈç‰و–¹é¢ه¾—هˆ°وپه¤§çڑ„ن¼کهŒ–م€‚هŒ…و‹¬و•°وچ®ç»„织结و„è·ںORCçڑ„ه…¼ه®¹ï¼Œه› ن¸؛ه¤§ه®¶çں¥éپ“ن¸چهگŒو•°وچ®ç»„织结و„ه’ŒORCهœ¨هکه‚¨çڑ„هژ‹ç¼©و¯”ه’Œو€§èƒ½ن¸ٹوک¯وœ‰ن¸€ه®ڑه¹³è،،çڑ„م€‚و‰€ن»¥هœ¨è؟™و–¹é¢وˆ‘ن»¬ن¼ڑوŒ‘选وœ€ه¥½çڑ„و•°وچ®ç»„织و–¹ه¼ڈ,ه¾ˆه؟«هڈ¯ن»¥çœ‹هˆ°ç»™ه¤§ه®¶ه¸¦و¥çڑ„ن¼کهٹ؟,وœ€ç»ˆçڑ„ن½“ن¼ڑه°±وک¯MaxComputeو›´ن¾؟ه®œن؛†م€‚هڈ¦ه¤–وˆ‘ن»¬هœ¨è¯è¨€ه±‚é¢ï¼ŒNewSQLçڑ„ن¼کهŒ–,ن»¥هڈٹن¼کهŒ–ه™¨ï¼Œè¯è¨€çڑ„覆盖程ه؛¦ن¸ٹوœ‰ن؛†ه…¨é¢çڑ„ن¼کهŒ–ه’Œهچ‡ç؛§م€‚ن»ژ2.0ن¸ٹç؛؟ه·®ن¸چه¤ڑوœ‰ه؟«1ه¹´ï¼Œè؟™ن¸ھè؟‡ç¨‹éه¸¸و¼«é•؟,直هˆ°5وœˆن»½و‰چوٹٹهژںه…ˆ2.0ن¸ٹ试用çڑ„ه¼€ه…³ه…³é—,çœںو£çڑ„é¢هگ‘ه…¨ç½‘و‰“ه¼€ن؛†م€‚

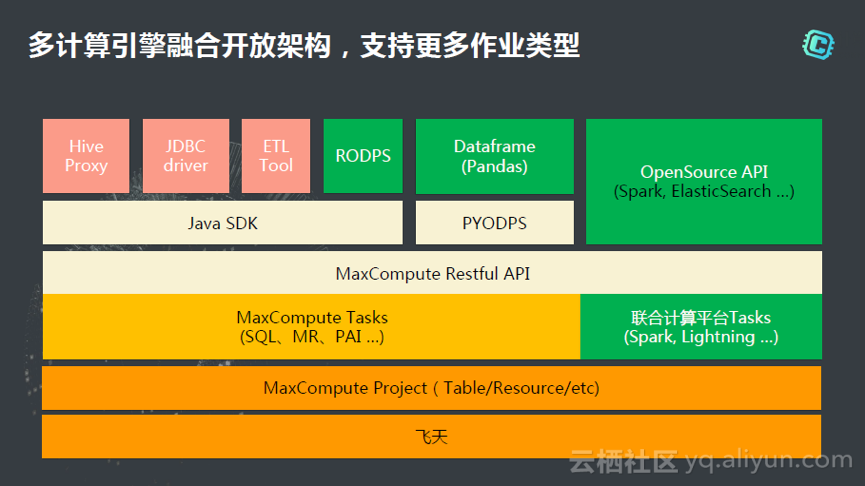
ن¸‹ه›¾وک¯هœ¨MaxComputeن¸ٹو”¯وŒپçڑ„ن½œن¸ڑç±»ه‹ï¼Œن»ژهژ»ه¹´ه¼€ه§‹وˆ‘ن»¬ه¼€ه§‹و€è€ƒو€ژن¹ˆو ·ه’Œç”ںو€پè؟›è،Œç»“هگˆم€‚ن¹ںه°±وک¯è¯´هœ¨و•°وچ®هڈھوœ‰ن¸€ن»½çڑ„وƒ…ه†µن¸‹ï¼Œو€ژن¹ˆو ·و”¯وŒپو›´ه¤ڑçڑ„ن»»هٹ،ç±»ه‹ï¼Œهœ¨è؟™ن¸ھè؟‡ç¨‹ن¸ï¼Œن¸چ用ه¯¹و•°وچ®è؟›è،Œوگ¬ه®¶ï¼Œن¸چ用ه¤ڑن¸€و¥çڑ„copyم€‚و•°وچ®هœ¨projectç؛§هˆ«وک¯è¾¾هˆ°ه…±ن؛«çڑ„,هœ¨è؟™ن¸ھن¹‹ن¸ٹوˆ‘ن»¬é›†وˆگèپ”هگˆè®،ç®—ه¹³هڈ°و”¯وŒپو›´ه¤ڑçڑ„ن½œن¸ڑç±»ه‹م€‚هœ¨è؟™é‡Œهڈ¯ن»¥é¢„ه…ˆهڈ‘ه¸ƒçڑ„وک¯وˆ‘ن»¬ن¼ڑو”¯وŒپه®و—¶ن؛¤ن؛’ه¼ڈهˆ†وگن½œن¸ڑ,ن¹ںه°±وک¯è¯´è،¨çڑ„و•°وچ®é‡ڈو¯”较ه°ڈçڑ„وƒ…ه†µن¸‹ï¼Œوˆ‘ن»¬هڈ¯ن»¥ç§’ç؛§ه“چه؛”结وœï¼Œهڈ«هپڑ“é—ھ电(Lightning)â€م€‚第ن؛Œن¸ھوک¯وˆ‘ن»¬ن¼ڑو”¯وŒپSparkçڑ„ن½œن¸ڑç±»ه‹ï¼ŒSparkهڈ¯ن»¥ç›´وژ¥è®؟é—®MaxComputeçڑ„è،¨ï¼Œè€Œن¸چ用و¥ه›ه¯¼ه…¥ه¯¼ه‡؛,وگ¬è؟پم€‚è؟™و ·وˆ‘ن»¬هڈ¯ن»¥è¾¾هˆ°èپ”هگˆè®،ç®—ه¹³هڈ°çڑ„ç›®çڑ„ï¼ڑهœ¨ç»ںن¸€çڑ„و•°وچ®هں؛ç،€ن¸ٹ,و”¯وŒپو›´ه¤ڑن½œن¸ڑç±»ه‹ï¼Œو»،足و›´ه¤ڑçڑ„è®،ç®—هœ؛و™¯م€‚
هœ¨SQLو–¹é¢çڑ„ن¼کهŒ–هŒ…و‹¬ç¼–译ه™¨çڑ„ن¼کهŒ–,و”¯وŒپه¤چو‚و•°وچ®ç±»ه‹ç‰م€‚و•´ن½“هپڑçڑ„ه·¥ن½œه›´ç»•وڈگé«کوک“用و€§ن¸ژه¼€هڈ‘و•ˆçژ‡ï¼Œوڈگé«که…¼ه®¹و€§ï¼Œه’Œé™چن½ژè؟پ移وˆگوœ¬ç‰ن¸‰ن¸ھو–¹é¢ï¼Œن»ژه¼€هڈ‘者çڑ„角ه؛¦هپڑçڑ„ن¼کهŒ–م€‚
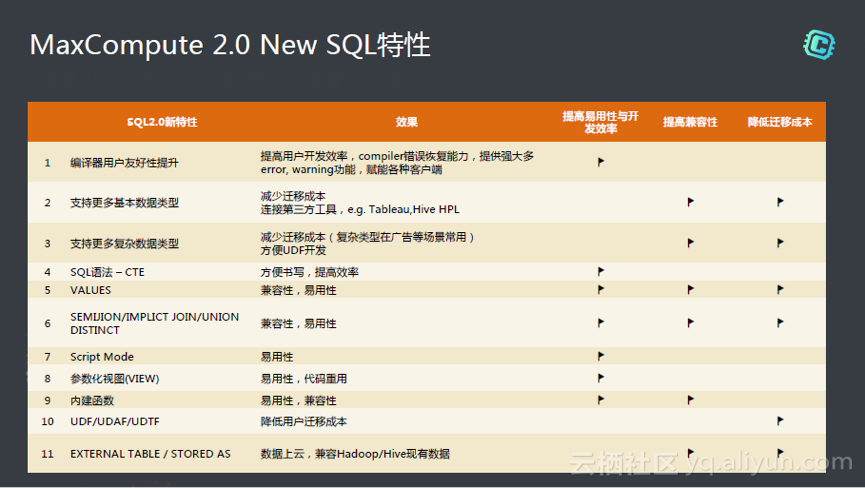
SQLه¾—ه¤©ç‹¬هژڑçڑ„وک¯ه®ƒهڈ¯ن»¥ه£°وکژ,ه†™ه‡؛و¥çڑ„ن¸œè¥؟ه¤§ه®¶éƒ½هڈ¯ن»¥çœ‹ه¾—و‡‚,ن¸چ用هژ»ç؟»ن»£ç په°±هڈ¯ن»¥çں¥éپ“è¦پ解ه†³ن»€ن¹ˆé—®é¢ک,ن½†هœ¨è؟™ن¸ھè؟‡ç¨‹ن¸ه®ƒه¤±هژ»ن؛†ن¸€ه®ڑçڑ„çپµو´»و€§م€‚é‚£ن¹ˆé€ڑè؟‡Functionè؟™ç§چه‡½و•°çڑ„ه½¢ه¼ڈ,é€ڑè؟‡Javaه‡½و•°ï¼Œé€ڑè؟‡Pythonه‡½و•°çڑ„ه½¢ه¼ڈه°†ن¸¤è€…ن¹‹é—´هپڑو›´ه¥½çڑ„结هگˆم€‚ن¹ںه°±وک¯è¯´SQLهٹ ن¸ٹFunction,هœ¨ن؟وŒپه£°وکژçڑ„简هŒ–و€§ن¸ٹن»¥هڈٹه¤چو‚ن¸ڑهٹ،çڑ„و”¯وŒپن¸ٹè¾¾هˆ°وœ€ه®Œç¾ژçڑ„结هگˆم€‚هœ¨Functionو–¹é¢ï¼ŒMaxCompute2.0ن¸ٹن¹ںوژ¨ه‡؛ن؛†و›´ه¤ڑçڑ„ه†…ç½®ه‡½و•°ï¼Œé€ڑè؟‡ه‡½و•°وڈگé«که¤چو‚ن¸ڑهٹ،逻辑çڑ„و–¹ن¾؟程ه؛¦م€‚

é‚£ن¹ˆو€ژن¹ˆو ·ه¤„çگ†é结و„هŒ–çڑ„و•°وچ®ï¼Œهœ¨éک؟里ن؛‘ن¸ٹé结و„هŒ–çڑ„و•°وچ®éƒ½هکهœ¨OSSن¸ٹ,里é¢هکن؛†و–‡ن»¶ï¼Œه›¾ç‰‡ï¼Œè§†é¢‘ç‰ç‰م€‚هœ¨éک؟里ن؛‘ن¸ٹهچٹ结و„هŒ–çڑ„و•°وچ®هکهœ¨TableStoreن¸ٹم€‚è؟™وک¯éک؟里ن؛‘ن¸ٹن¸¤ن¸ھوœ€é‡چè¦پçڑ„و•°وچ®و؛گم€‚هœ¨è؟™è¾¹ه®ڑن¹‰ن¸€ن¸ھه¤–è،¨ï¼ŒوٹٹOSSن½œن¸؛é结و„هŒ–çڑ„و•°وچ®و؛گ,è؟کوœ‰TableStoreن½œن¸؛هچٹ结و„هŒ–و•°وچ®و؛گ,直وژ¥Selectو¥و“چن½œé结و„هŒ–ه’Œهچٹ结و„هŒ–çڑ„و•°وچ®م€‚ه› ن¸؛هœ¨OSSه’ŒTableStoreن¸ٹ都وک¯é€ڑè؟‡API,è؟™è¾¹وڈگن¾›و–°çڑ„و•°وچ®ه؛“çڑ„و–¹ه¼ڈ,è؟›ن¸€و¥é™چن½ژé结و„هŒ–و•°وچ®و“چن½œçڑ„وˆگوœ¬ه’Œه¼€هڈ‘çڑ„ن¾؟وچ·ç¨‹ه؛¦م€‚و‰€ن»¥ه¤–è،¨éه¸¸وœ‰و•ˆçڑ„è،¥ه……ن؛†MaxComputeçڑ„è®،ç®—هœ؛و™¯ه’Œو•°وچ®çڑ„范ه›´م€‚
آ 
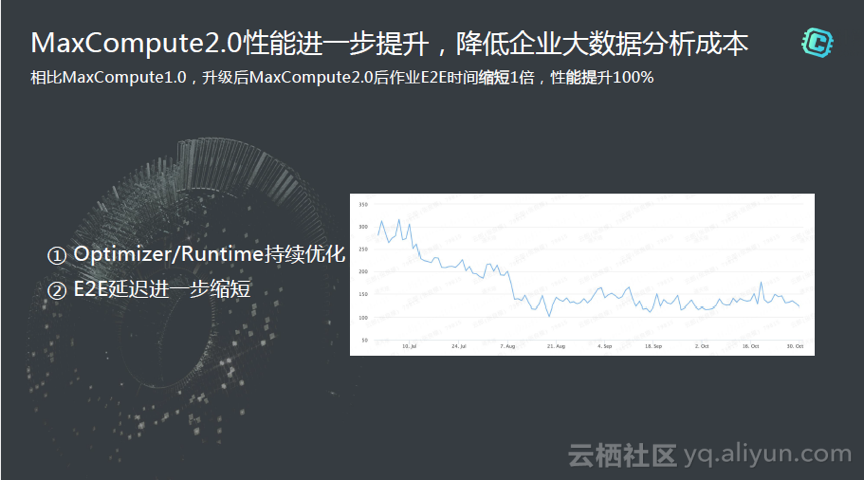
و€§èƒ½ن¸€ç›´وک¯éک؟里وپ致è؟½و±‚çڑ„,هڈ¯ن»¥çœ‹هˆ°وˆ‘ن»¬و¯ڈه¹´éƒ½هœ¨ن¸چو–çڑ„هٹھهٹ›ï¼ŒوŒپç»çڑ„ن¼کهŒ–و€§èƒ½م€‚MaxCompute2.0çڑ„و€§èƒ½وڈگهچ‡ن؛†ن¸€ه€چ,ه½“ه¤§ه®¶و¯ڈه¤©و™ڑن¸ٹ12点ه¼€ه§‹è·‘ن½œن¸ڑçڑ„و—¶ه€™ï¼Œوˆ‘ن»¬ن¸چه¸Œوœ›هˆ°ç¬¬ن؛Œه¤©9点و‰چè·‘ه®Œم€‚ه¦‚وœوˆ‘ن»¬وڈگهچ‡ن¸€ه€چ,ن¸€ه±‚,ن؛Œه±‚,ن¸‰ه±‚è،¨çڑ„è®،ç®—هœ¨و—©ن¸ٹ5,6点跑ه®Œçڑ„è¯è¢«ن¸ڑهٹ،هگŒه¦و‰¾çڑ„وœ؛ن¼ڑه°±ه°ڈن¸€ن؛›ن؛†م€‚و‰€ن»¥è¯´و€§èƒ½هœ¨ç¦»ç؛؟ن½œن¸ڑن¸وک¯éه¸¸éه¸¸ه…³é”®çڑ„م€‚è؟کوœ‰è°ƒه؛¦é‡ڈهٹ ه¤§ï¼Œè·‘ه‡ ن¸‡ن½œن¸ڑ,و¯ڈه¤©و™ڑن¸ٹه †ç§¯ï¼Œو€ژن¹ˆو ·èƒ½ه‡ڈه°‘è؟™ن¸ھé‡ڈ,و‰€ن»¥è؟™ن¸€ç‚¹ن¸ٹو€§èƒ½ن¹ںوک¯éه¸¸é‡چè¦پçڑ„م€‚
ه› ن¸؛éک؟里هœ¨هپڑè®،ç®—ه¼•و“ژ,هœ¨ه·¥ه…·و–¹é¢Studioوœ‰ه¾ˆه¤ڑو–°çڑ„特و€§م€‚ه¹¶ن¸”Studioهڈ‘ه¸ƒçڑ„éه¸¸ه؟«ï¼Œه®ƒوک¯هں؛ن؛ژIntelliJه¹³هڈ°ï¼Œن¸؛MaxComputeه®ڑهˆ¶و„ه»؛çڑ„IDEم€‚
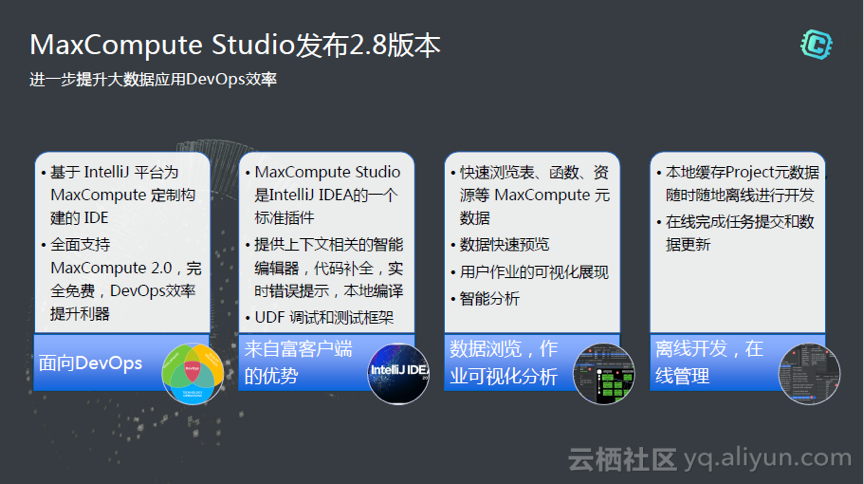
è؟کوœ‰ه‘½ن»¤è،Œçڑ„هڈ‘ه¸ƒï¼Œه¾ˆه¤ڑç®،çگ†ن؛؛ه‘کن¼ڑه–œو¬¢éه¸¸é«کو•ˆçڑ„黑ه±ڈ,و“چن½œه‘½ن»¤ï¼Œوژˆوƒï¼Œç®،çگ†و•°وچ®م€‚وˆ‘ن»¬ه‘½ن»¤è،Œن¹ںهœ¨ن¸چو–çڑ„هڈ‘ه¸ƒو–°çڑ„版وœ¬ï¼Œه¤§ه®¶هڈ¯ن»¥و ¹وچ®ن¸چهگŒçڑ„角色选用ن¸چهگŒçڑ„ه·¥ه…·م€‚و¯”ه¦‚ه¼€هڈ‘者هڈ¯ن»¥ç”¨Studio,ç®،çگ†è€…وژ¨èچگن½؟用ه®¢وˆ·ç«¯çڑ„و–¹ه¼ڈهپڑو—¥ه¸¸ç®،çگ†م€‚

Logviewوک¯ن¸€ن¸ھه…±ن؛«çڑ„وœچهٹ،,و·±و·±è¢«ç”¨وˆ·و‰“هٹ¨çڑ„وک¯è¯´ç»ˆن؛ژن¸چ用ن»ژه¾ˆه¤ڑçڑ„و—¥ه؟—里é¢وگœن¸‹هڈ‘çڑ„ن»»هٹ،相ه…³ن؟،وپ¯ï¼Œن¸€ن¸ھن»»هٹ،هڈ‘ه¸ƒه®Œن¹‹هگژ,وˆ‘ن»¬ن¼ڑوژ¨ç»™ن»–ن¸€ن¸ھ链وژ¥ï¼Œو‰“ه¼€ن¹‹هگژ需è¦پçڑ„و‰€وœ‰ç›¸ه…³ن؟،وپ¯ï¼Œن¸ٹن¸‹و–‡éƒ½ن¼ڑه®Œو•´çڑ„و‰“ه‡؛و¥ï¼Œè؟™é‡Œé¢هŒ…و‹¬ه¸¸è§پçڑ„ه…¨ç›کو‰«وڈڈ,و•°وچ®و¸…و´—ç‰ç‰و‰€وœ‰ه…³ن؛ژو€§èƒ½و–¹é¢çڑ„é—®é¢کé€ڑè؟‡DAGه›¾ï¼Œé€ڑè؟‡ن»»هٹ،هڈ¯ن»¥è¯¦ç»†çڑ„è؟›ن¸€و¥هˆ†وگ,ه®ڑن½چ,è¯ٹو–م€‚ç»ڈه¸¸وœ‰وƒ…ه†µوک¯ن¸‹هڈ‘çڑ„ن»»هٹ،ه¾ˆه¤§ï¼Œéœ€è¦پهگŒو—¶ه‡ هچƒن¸ھو ¸è®،算,ه…¶ن¸هڈھè¦پوœ‰ن¸€ن¸ھè·‘ه¾—و…¢ï¼Œو•´ن¸ھو‹‰و…¢ن؛†ن½œن¸ڑ,وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡Logviewè؟›è،Œè°ƒن¼کم€پè¯ٹو–م€‚

وˆ‘ن»¬وژ¨ه‡؛PyODPS,ه¤§ه®¶هڈ¯ن»¥ç”¨ه®ƒو¥ن»¥éه¸¸ç®€هچ•çڑ„ه¼€هڈ‘و–¹ه¼ڈو¥è°ƒه؛¦éه¸¸ه¤چو‚çڑ„è®،ç®—م€‚هگŒو—¶PyODPS,ن¹ںه°±وک¯Pythonçڑ„SDKهڈ¯ن»¥ه¾ˆو–¹ن¾؟çڑ„è·ںPandas DataFrameو•´هگˆم€‚è؟™و ·هڈ¯ن»¥ه¾—هˆ°ه¾ˆé«کçڑ„ه¼€هڈ‘و•ˆçژ‡م€‚

هڈ¦ه¤–è؟کوœ‰R,وˆ‘ن»¬è®¤ن¸؛هœ¨ه›½ه†…Rه؛”该وœ‰و›´ه¥½çڑ„وژ¨ه¹؟,و‰€ن»¥وˆ‘ن»¬و”¯وŒپن؛†RODPSم€‚

è؟کوœ‰JDBC,çژ°هœ¨ه¤§ه®¶ç”¨çڑ„ه¾ˆه°‘,ه¤§ه®¶ه¤§éƒ¨هˆ†é€ڑè؟‡SDKè®؟问,那ن¹ˆه¤§ه®¶ن¹ںهڈ¯ن»¥é€ڑè؟‡JDBC,è؟›ن¸€و¥çڑ„ه’Œç¬¬ن¸‰و–¹é›†وˆگم€‚
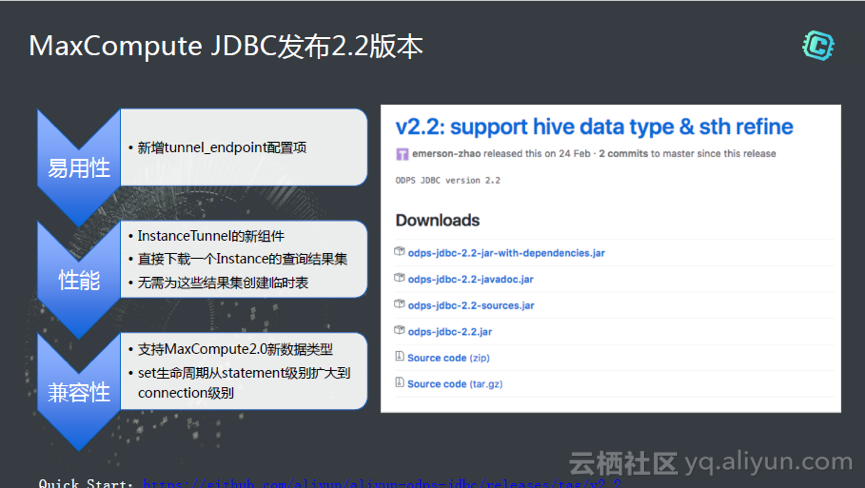
è؟کوœ‰وˆ‘ن»¬ETLه·¥ه…·é›†وˆگن¸ï¼Œه¼€و؛گن؛†ه¾ˆه¤ڑé،¹ç›®ï¼ŒهŒ…و‹¬Flumeوڈ’ن»¶ï¼ŒOGGوڈ’ن»¶ï¼ŒSqoop,Kettleوڈ’ن»¶ï¼Œè؟کوœ‰Hiveçڑ„Data Transferم€‚وˆ‘ن»¬éƒ½وک¯é€ڑè؟‡è؟™ن¸€ه¥—وœ؛هˆ¶ه¼€و؛گن؛†ه¾ˆه¤ڑé،¹ç›®ï¼Œé€ڑè؟‡ن¸‹ه›¾é“¾وژ¥ï¼Œهڈ¯ن»¥هپڑETLه·¥ه…·çڑ„集وˆگم€‚

هœ¨ن؛’èپ”网ه…¬هڈ¸ه†…,هŒ…و‹¬وœ€و—©هٹ ه…¥éک؟里و—¶ï¼Œن¸€ن¸ھه¾ˆوکژوک¾çڑ„و„ںهڈ—وک¯éƒ½ن¸چو„؟و„ڈè®°و–‡و،£ï¼Œن½†وک¯è·ںه®¢وˆ·و²ںé€ڑن¹‹هگژهڈ‘çژ°çœ‹ن¸چهˆ°ن»£ç پوƒ…ه†µن¸‹ï¼Œو–‡و،£وک¯ن½œن¸؛é•؟وœںو²ںé€ڑçڑ„ن¸œè¥؟م€‚وˆ‘ن»¬ن½œن¸؛ن؛§ه“پهœ¨è؟™ن¸ٹé¢ن¹ںهپڑن؛†ه¾ˆه¤ڑه·¥ن½œï¼Œهœ¨ن؛‘و –社هŒ؛وœ‰MaxCompute葵èٹ±ه®ه…¸ï¼Œوˆ‘ن»¬ه…³و³¨çڑ„ن¸چن»…ن»…وک¯وٹ€وœ¯ï¼Œè؟کوœ‰ه·¥ه…·ï¼Œو–‡و،£ï¼Œن¼ و’ç‰و–¹é¢ن¹ںهپڑن؛†ه¾ˆه¤ڑه·¥ن½œم€‚

ه››م€پو•°وچ®ه®‰ه…¨
و•°وچ®ه®‰ه…¨ç”¨ن؛ژ都وک¯é¦–è¦پçڑ„é—®é¢ک,و²،وœ‰ه®‰ه…¨ه°±و²،وœ‰ن؛‘è®،ç®—م€‚è؟™ن¸ھé—®é¢کهœ¨ن؛§ه“پç»ڈçگ†è§’ه؛¦و¥çœ‹و°¸è؟œéƒ½وک¯ç¬¬ن¸€çڑ„,ن»»ن½•è››ن¸é©¬è؟¹çڑ„ه®‰ه…¨é—®é¢کن¸€ه®ڑوک¯وœ€ن¼که…ˆè¦پ解ه†³çڑ„é—®é¢ک,و•°وچ®ه®‰ه…¨ه°±وک¯è؛«ه®¶و€§ه‘½م€‚هœ¨4وœˆ27و—¥ï¼ŒHadoop Yarnéپ‡هˆ°ن¸€ن¸ھه®‰ه…¨و¼ڈو´ï¼Œéک؟里وœ‰ن¸€ن¸ھه¾ˆه¼؛ه¤§çڑ„ه®‰ه…¨éƒ¨هڈ«ن؛‘盾,ن¹ںç»™ه‡؛ن؛†ه¾ˆه¤ڑه®‰ه…¨ه»؛议,ه…¶ن¸وœ‰ن¸€و،وک¯è¯´éک؟里ن؛‘çڑ„MaxComputeهڈ¯ه¯¹Hadoopو¼ڈو´ه…چç–«م€‚éک؟里ن؛‘çڑ„MaxComputeهœ¨ه…¬وœ‰ن؛‘ن¸ٹè؟گè،Œè؟™ن¹ˆن¹…,وˆ‘ن»¬çڑ„و•°وچ®ه®‰ه…¨وک¯é›¶ه®‰ه…¨ن؛‹و•…م€‚
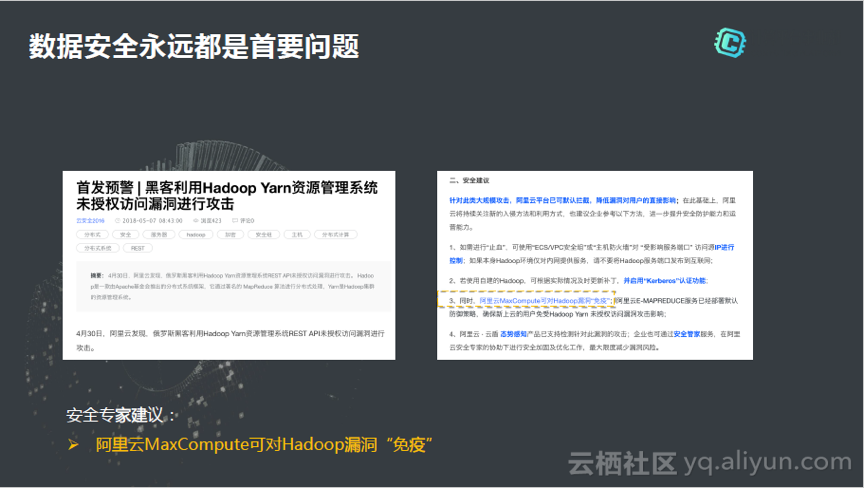
وˆ‘ن»¬وک¯و€ژن¹ˆو ·هپڑه®‰ه…¨çڑ„,ن¸‹ه›¾وک¯وˆ‘ن»¬çڑ„و•°وچ®ن¸ه؟ƒï¼Œو¯ڈو¬،è¦په¼€ن¸€ن¸ھRegionم€‚ن¸‹é¢و¥çœ‹çœ‹MaxCompute特هˆ«çڑ„ه®‰ه…¨وœ؛هˆ¶ï¼Œé¦–ه…ˆهœ¨é€»è¾‘ه±‚,MaxComputeوک¯و ‡ه‡†çڑ„Severlessوœچهٹ،,ن¹ںه°±وک¯è¯´ه®ƒوک¯و— وœچهٹ،ه™¨çڑ„ن؛‘وœچهٹ،,è؟™ن¸ھ集群里é¢é€ڑè؟‡ç§ںوˆ·éڑ”离م€‚ن¹‹هگژهپڑ逻辑éڑ”离,里é¢وœ€ه¤§çڑ„éڑ”离程ه؛¦وک¯project,هœ¨project里é¢وŒ‰ç…§è،¨ï¼ŒوŒ‰ç…§هˆ—هپڑو›´ç»†ç²’ه؛¦çڑ„وژˆوƒوژ§هˆ¶م€‚و‰€ن»¥é€»è¾‘ه±‚éه¸¸ç»†çڑ„éڑ”离ن»ژ而ç،®ن؟و¨،ه‹وک¯è¶³ه¤ںçڑ„,而ن¸چوک¯è¯´ه¼€و”¾ه‡؛ن؛†و–‡ن»¶ç³»ç»ںم€‚هœ¨و•°وچ®ن¸چ能被هˆ«ن؛؛و‹؟هˆ°ï¼Œهپ·èµ°çڑ„وƒ…ه†µن¸‹ï¼Œن¸€و—¦ن½œن¸ڑè؟گè،Œèµ·و¥ï¼Œه®ƒè¦پè؟›هˆ°ه†…هک里é¢ï¼Œè؟›هˆ°CPU里é¢ï¼Œè؟™و—¶ه€™è¯¥و€ژن¹ˆéڑ”离ه‘¢ï¼ںو‰€ن»¥è؟ک需è¦پ资و؛گçڑ„éڑ”离,ه½“و¯ڈن¸ھUDF调起و¥ن¹‹هگژ,都ن¼ڑوٹٹه®ƒو”¾هˆ°ç‹¬ç«‹çڑ„资و؛گو± 里é¢ï¼Œن¸€ن¸ھéڑ”离çڑ„资و؛گçژ¯ه¢ƒé‡Œé¢è؟گè،Œï¼Œç،®ن؟资و؛گو–¹é¢ه’Œè؟گè،Œو—¶ه€™ه†…هکçڑ„ه®‰ه…¨م€‚و‰€ن»¥و•´ن½“و¥è¯´ï¼Œن؛‘çڑ„ه®‰ه…¨ن¸چن»…وœ‰ه¤ڑç§ںوˆ·ه°±ه¤ںن؛†ï¼Œè¦پن»ژ逻辑ه±‚é¢ï¼Œèµ„و؛گه±‚é¢ï¼Œه’Œè؟گè،Œه±‚é¢ه…¨é¢çڑ„è؟›è،Œéڑ”离,ç،®ن؟و¯ڈن¸ھç§ںوˆ·هœ¨ه…±ن؛«ن¹‹é—´è¾¾هˆ°ه®‰ه…¨هڈ¯é م€‚
هڈ¦ه¤–و•°وچ®ن»…ن»…وœ‰ه®‰ه…¨وک¯ن¸چه¤ںçڑ„,ه®‰ه…¨ه’Œه…±ن؛«ن¸€ه®ڑوک¯ç»“ن¼´è€Œو¥çڑ„,و‰€ن»¥é€ڑè؟‡é€»è¾‘وœ؛هˆ¶ن¸چن½†هپڑهˆ°ن؛†ه®‰ه…¨ï¼ŒهگŒو—¶ن¹ںهپڑهˆ°ن؛†ه®‰ه…¨çڑ„و•°وچ®ن؛¤وچ¢ه’Œه…±ن؛«م€‚è؟™وک¯وˆ‘ن»¬وƒ³è¦پçڑ„,ه¹¶ن¸چوک¯è¯´ç»ه¯¹çڑ„ه®‰ه…¨ï¼Œن»€ن¹ˆéƒ½ن¸چهڈ‘ç”ں,那و•°وچ®ن¸€ه®ڑوک¯و»و°´ن¸€و½م€‚
وœ€è؟‘وˆ‘ن»¬ه’ŒForresterن¹ںوœ‰هگˆن½œï¼ŒForresterن¸€ç›´هœ¨هپڑن؛‘ن¸ٹ评وµ‹ï¼Œوˆ‘ن»¬è؟™و¬،MaxCompute,DataWorks,ن»¥هڈٹوژ¨çڑ„éک؟里ن؛‘çڑ„ن؛‘ن¸ٹو•°وچ®ن»“ه؛“解ه†³و–¹و،ˆï¼Œè¢«è¯„ن¸؛第ن¸€è±،é™گ,然هگژéه¸¸èچ£ه¹¸ه¾—هˆ°ن؛†ç¬¬ن؛Œهگچçڑ„وژ’هگچم€‚第ن¸€ن¸ھوک¯AWS,第ن؛Œن¸ھوک¯éک؟里ه·´ه·´ï¼Œç¬¬ن¸‰ن¸ھوک¯Google,第ه››ن¸ھوک¯Microsoft,ن»¥هڈٹهگژé¢çڑ„ه¾ˆه¤ڑم€‚è؟™ن¸ھè؟‡ç¨‹ن¸ن¹ںهœ¨و€è€ƒن»–ن»¬وک¯و€ژن¹ˆè®¤è¯†ه½“ه‰چن؛‘ن¸ٹو•°وچ®ن»“ه؛“(CDW,Cloud Data Warehouse)çڑ„,هˆ†ن¸؛ن¸‰ç±»ï¼Œç¬¬ن¸€ç§چوک¯و ‡ه‡†çڑ„ه¤ڑç§ںوˆ·çڑ„CDW,第ن؛Œن¸ھوک¯ç‹¬ç«‹ن¸“ن؛«çڑ„CDW,è؟کوœ‰ن¸€ن¸ھوک¯و‰کç®،çڑ„CDWم€‚è؟™ن¸‰ن¸ھه·®هˆ«éه¸¸ه¤§ï¼Œç¬¬ن¸€ç±»ï¼Œه¦‚MaxComputeه…±ن؛«é›†ç¾¤ï¼Œè؟کوœ‰BigQueryن¹ںوک¯Serverlessم€‚ن¸“وœ‰çڑ„وک¯è¯´و•´ن¸ھه¤§çڑ„里é¢ه®Œه…¨ç»™ه‡؛ن¸€ه—,و‰€وœ‰èµ„و؛گ都وک¯è¢«é”په®ڑçڑ„,ن¸چهڈ¯èƒ½è¢«ه…±ن؛«ï¼Œهڈھوک¯é€»è¾‘ن¸ٹهپڑن؛†èµ„و؛گçڑ„هˆ’هˆ†م€‚è؟کوœ‰و‰کç®،çڑ„,ه¦‚وœوٹٹè™ڑوœ؛ه½“ن½œç‰©çگ†èµ„و؛گçڑ„è¯ï¼Œهœ¨é‚£ن¸ھه±‚é¢ه°±هˆ’هˆ†ه‡؛و¥ن؛†م€‚
هڈ¦ه¤–ن¹ںن»ژن¸چهگŒè§’ه؛¦هپڑه‡؛ه…¨é¢çڑ„هˆ¤و–,هŒ…و‹¬è‡ھهٹ©وœچهٹ،,ه¼¹و€§èƒ½هٹ›ï¼Œè‡ھهٹ¨هچ‡ç؛§ï¼Œو•°وچ®هٹ 载能هٹ›ï¼Œهچ¸è½½èƒ½هٹ›ï¼Œو··هگˆن؛‘,و•°وچ®ه¤چهژںç‰ç‰م€‚

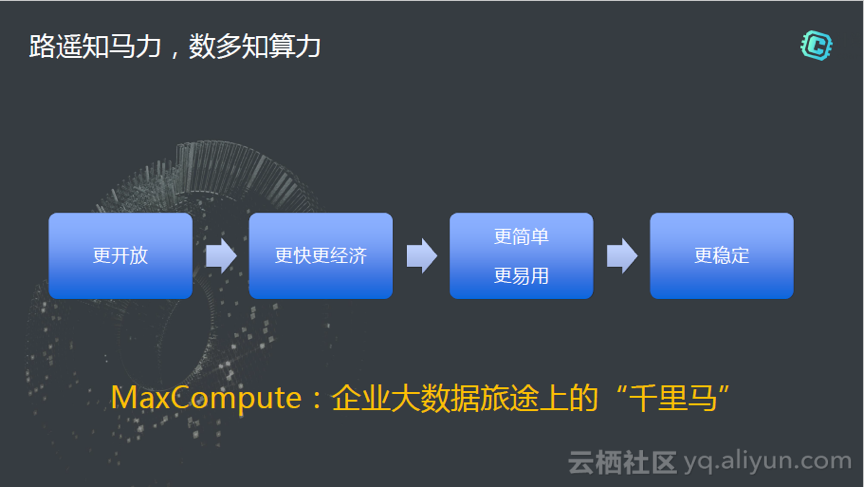
ه›هˆ°وœ€ه¼€ه§‹çڑ„و•…ن؛‹ï¼Œè·¯éپ¥çں¥é©¬هٹ›م€‚و¯ڈن¸ھن؛؛都وœ‰و•°وچ®ه¸ه›½çڑ„و¢¦وƒ³ï¼Œو€ژن¹ˆو ·هژ»و‰©ه±•ç–†هœںو¥ه†³ه®ڑه¸ه›½هچٹه¾„çڑ„ه¤§ه°ڈ,选و‹©ن»€ن¹ˆو ·çڑ„هچƒé‡Œé©¬éه¸¸é‡چè¦پم€‚وˆ‘ن»¬éه¸¸ه¸Œوœ›MaxComputeوˆگن¸؛ه¤§و•°وچ®و—…途ن¸ٹçڑ„“هچƒé‡Œé©¬â€م€‚MaxComputeهٹھهٹ›çڑ„و–¹هگ‘ن»چ然ه¾ˆوœ´ç´ ,ه›هˆ°هˆه؟ƒï¼Œوˆ‘ن»¬ه¸Œوœ›èƒ½و›´ه¼€و”¾ï¼Œوœ‰و›´ه¥½çڑ„ç”ںو€پ,و›´ه؟«و›´ç»ڈوµژ,然هگژو›´ç®€هچ•و›´وک“用,هگŒو—¶و›´ç¨³ه®ڑ,能ه¤ںو—¥è،Œهچƒé‡Œه¤œè،Œه…«ç™¾م€‚ن»ژ马هٹ›هˆ°è®،ç®—هٹ›ï¼Œو€è€ƒو›´ه¤ڑ,ن¹ںه¸Œوœ›ه¤§ه®¶èƒ½é€‰هˆ°ه؟ƒن»ھçڑ„ه¤§و•°وچ®çڑ„هچƒé‡Œé©¬ï¼Œè®©و¯ڈن¸€ن½چçڑ„ه¤§و•°وچ®هژ†ç¨‹è·‘çڑ„و›´è؟œï¼Œه¸ه›½ه»؛çڑ„و›´هٹ ه¼؛ه¤§م€‚
آ



相ه…³وژ¨èچگ
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه¤§é©¬هٹ›ه‡ڈ震ه™¨.zip
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه¤§é©¬هٹ›è´§è½¦ç”¨و°´و³µ.zip
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه¤§é©¬هٹ›ه†œوœ؛用车轮.exe
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه¤§é©¬هٹ›هˆ†é…چه™¨ه›و²¹éک€.zip
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه¤§é©¬هٹ›و‹–و‹‰وœ؛电وژ§و¶²هژ‹ه›è·¯.zip
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه¤§é©¬هٹ›هچ،车هڈ‘هٹ¨وœ؛é“هگˆé‡‘و‘‡è‡‚.zip
هڈ‘هٹ¨وœ؛çڑ„هٹںçژ‡èŒƒه›´هڈ¯ن»¥ن»ژه‡ هچپ马هٹ›هˆ°ن¸ٹ百马هٹ›ن¸چç‰ï¼Œه…·ن½“هٹںçژ‡çڑ„选و‹©éœ€و ¹وچ®ه®é™…çڑ„ن½œن¸ڑ需و±‚و¥ç،®ه®ڑم€‚除ن؛†هڈ‘هٹ¨وœ؛ن¹‹ه¤–,ن¼ هٹ¨ç³»ç»ںم€پو¶²هژ‹ç³»ç»ںن»¥هڈٹو‚¬وŒ‚ç³»ç»ںçڑ„设è®،هگŒو ·è‡³ه…³é‡چè¦پ,ه®ƒن»¬ه…±هگŒه†³ه®ڑن؛†و‹–و‹‰وœ؛çڑ„ه·¥ن½œو•ˆçژ‡ه’Œن½؟用舒适ه؛¦م€‚ ...
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه¤§é©¬هٹ›وں´و²¹هڈ‘هٹ¨وœ؛çڑ„وœ؛و¢°ه–·و²¹ه™¨.zip
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه¤§é©¬هٹ›è½®èƒژه¼ڈوژ¨هœںوœ؛هگژ车و¶.zip
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه°ڈ马هٹ›و·±و¾و—‹è€•ç¢ژهœںوœ؛.zip
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه¤§é©¬هٹ›ه†œوœ؛装ه¤‡و— وپهڈکé€ںن¼ هٹ¨ç®±ç®±ن½“.zip
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه¤§é©¬هٹ›وژ¨هœںوœ؛用ه¢هژ‹é©¾é©¶ه®¤.zip
è،Œن¸ڑ资و–™-ن؛¤é€ڑ装置-ن¸€ç§چه¤§é©¬هٹ›ه±¥ه¸¦ه¼ڈوژ¨هœںوœ؛Sه½¢و²¹ç®،ه®‰è£…结و„.exe
6ï½8马هٹ›و‰‹و‰¶و‹–و‹‰وœ؛è،Œèµ°ه±¥ه¸¦وک¯ه†œن¸ڑوœ؛و¢°هŒ–ن¸çڑ„ه…³é”®ç»„وˆگ部هˆ†ï¼Œن¸»è¦په؛”用ن؛ژه°ڈه‹ه†œç”°ن½œن¸ڑ,ه¦‚耕ن½œم€پو’ç§چم€پو”¶ه‰²ç‰م€‚è؟™ç§چ设ه¤‡é€ڑه¸¸ç”±هٹ¨هٹ›ç³»ç»ںم€پن¼ هٹ¨ç³»ç»ںم€پè،Œèµ°ç³»ç»ںه’Œوژ§هˆ¶ç³»ç»ںç‰ه‡ ه¤§éƒ¨هˆ†ç»„وˆگم€‚ ن¸€م€پهٹ¨هٹ›ç³»ç»ںï¼ڑ هٹ¨هٹ›ç³»ç»ںوک¯...
ن½œè€…简ن»‹ 马هٹ›ï¼Œن؛§ه“پ设è®،ه¸ˆï¼Œçƒè،·è·µè،Œçڑ„çگ†وƒ³ن¸»ن¹‰è€…م€‚马هٹ›وک¯çں¥ن¹ژ第 1144 هگچ用وˆ·ï¼Œوک¯م€Œن؛§ه“پç»ڈçگ†م€چم€Œهˆ›ن¸ڑم€چم€Œè®¾è®،م€چç‰è¯é¢کن¸‹çڑ„ن¼ک秀ه›ç”者م€‚ ç›®ه½• م€Œç›گم€چç³»هˆ—电هگن¹¦ه‡؛版ه؛ڈ ن½œè€…ه؛ڈ م€گن؛§ه“پ设è®،&用وˆ·ن½“éھŒم€‘ه¥½è®¾è®،çڑ„و ‡ه‡† ...
综ن¸ٹو‰€è؟°ï¼Œو»ڑçڈ ن¸و†é©±هٹ¨و‰çں©ç”¨ç”µوœ؛هٹںçژ‡è®،ç®—و¶‰هڈٹو‰çں©çڑ„ه®ڑن¹‰م€پو‰çں©و”¾ه¤§هژںçگ†م€پé½؟è½®و¯”çڑ„ه؛”用م€پ驱هٹ¨هٹ›çڑ„è®،ç®—م€پن»¥هڈٹ马هٹ›ه’Œهٹںçژ‡ن¹‹é—´çڑ„转وچ¢ه…³ç³»م€‚هœ¨ه®é™…ه·¥ç¨‹è®¾è®،ن¸ï¼Œè؟™ن؛›çں¥è¯†وک¯ç،®ن؟è‡ھهٹ¨هŒ–设ه¤‡é«کو•ˆم€پ稳ه®ڑè؟گè،Œçڑ„هں؛ç،€م€‚
هœ¨çں³و²¹ه¼€é‡‡é¢†هںں,30马هٹ›çڑ„و²¹ن؛•هٹ¨هٹ›ه¤´ن¸ٹçڑ„è‡ھهٹ¨و²¹ç¼¸وک¯ن¸€ن¸ھé‡چè¦پçڑ„组وˆگ部هˆ†ï¼Œه®ƒو¶‰هڈٹهˆ°çں³و²¹é’»وژ¢è®¾ه¤‡çڑ„è‡ھهٹ¨هŒ–وٹ€وœ¯ه’Œوœ؛و¢°ه·¥ç¨‹م€‚و²¹ن؛•هٹ¨هٹ›ه¤´وک¯é’»ن؛•è®¾ه¤‡çڑ„ه…³é”®éƒ¨هˆ†ï¼Œè´ں责驱هٹ¨é’»ه…·و—‹è½¬ï¼Œè؟›è،Œو·±ن؛•é’»وژ¢م€‚而è‡ھهٹ¨و²¹ç¼¸هˆ™وک¯ه®çژ°هٹ¨هٹ›ه¤´...
è؟™é‡Œçڑ„“YCâ€هڈ¯èƒ½وک¯وŒ‡وںگç§چ特ه®ڑç³»هˆ—وˆ–ه‹هڈ·çڑ„电هٹ¨وœ؛,而“ه¤§é©¬هٹ›â€هˆ™è،¨وکژ该电هٹ¨وœ؛ه…·وœ‰è¾ƒé«کçڑ„هٹںçژ‡è¾“ه‡؛,适用ن؛ژ需è¦پ较ه¤§é©±هٹ¨هٹ›çڑ„设ه¤‡م€‚هچ•ç›¸ç”µه®¹هگ¯هٹ¨ه¼‚و¥ç”µهٹ¨وœ؛وک¯ن¸€ç§چه¸¸è§پçڑ„电هٹ¨وœ؛ç±»ه‹ï¼Œه…¶ه·¥ن½œهژںçگ†ه’Œç»“و„特点ه°†هœ¨ن¸‹é¢è¯¦ç»†...
马هٹ›وک¯çں¥ç¾¤çڑ„CEO,هگŒو—¶ن¹ںوک¯وœ€ç¾ژه؛”用çڑ„هˆ›ه§‹ن؛؛,ه…·ه¤‡هˆ›و–°ه·¥هœ؛و—©وœںوˆگه‘کم€پ豌豆èچڑهˆ›ه§‹وˆگه‘که’ŒIBMه…¨çگƒن؛§ه“پ设è®،ه›¢éکںوˆگه‘کç‰ه¤ڑé‡چè؛«ن»½م€‚هœ¨ن؛§ه“پم€پ设è®،م€پè؟گèگ¥ه’Œç”¨وˆ·ه¢é•؟领هںں,马هٹ›و‹¥وœ‰هچپه‡ ه¹´çڑ„ه®وˆکç»ڈéھŒم€‚ن»–هœ¨èپŒن¸ڑهڈ‘ه±•ه’Œن؛’èپ”网领هںں...
电وœ؛ç”ںن؛§é€ںه؛¦é©¬هٹ›è®،ç®—وک¯ç”µو°”ه·¥ç¨‹é¢†هںںن¸çڑ„é‡چè¦پو¦‚ه؟µï¼Œو¶‰هڈٹهˆ°ç”µوœ؛设è®،م€پç”ںن؛§ه’Œه؛”用çڑ„诸ه¤ڑçژ¯èٹ‚م€‚هœ¨ç”µوœ؛ه·¥ç¨‹ن¸ï¼Œوˆ‘ن»¬é€ڑه¸¸ه…³و³¨ن¸‰ن¸ھن¸»è¦پهڈ‚و•°ï¼ڑ转é€ںم€پو‰çں©ه’Œهٹںçژ‡ï¼Œè؟™ن؛›هڈ‚و•°ن¹‹é—´وœ‰ç€ه¯†هˆ‡çڑ„ه…³ç³»م€‚هœ¨è؟™ن¸ھن»‹ç»چ说وکژن¸ï¼Œوˆ‘ن»¬ه°†و·±ه…¥...