
е Ҷ(heap)зҡ„ж•°жҚ®з»“жһ„жҳҜе®Ңе…ЁдәҢеҸүж ‘
ж–°еўһзӨәж„Ҹеӣҫ
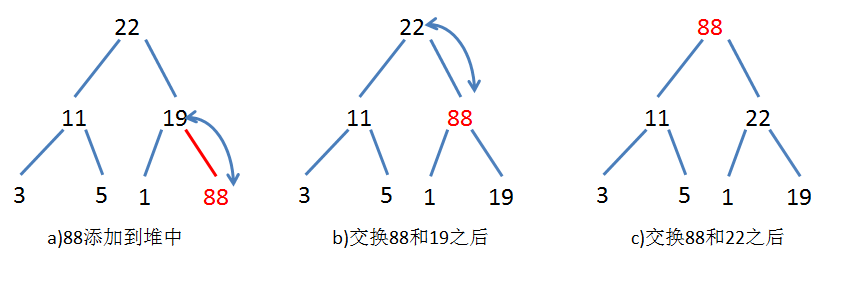
еҲ йҷӨзӨәж„Ҹеӣҫ
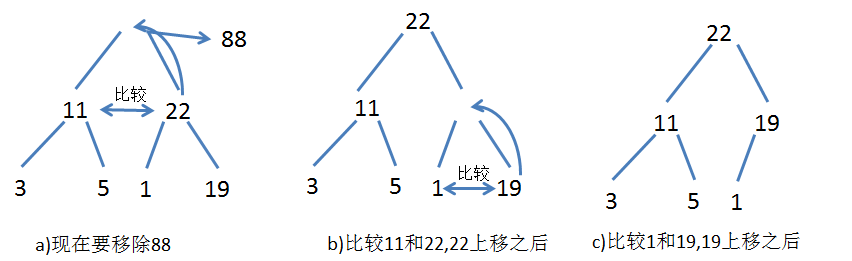
е…Ҳиҝӣе…ҲеҮәпјҢиҝҷз§Қз»“жһ„йҖӮеҗҲеҒҡеӯҳеӮЁгҖӮ
е ҶжҳҜеӯҳеӮЁзҡ„еҚ•дҪҚпјҢиҖҢж ҲжҳҜиҝҗиЎҢж—¶зҡ„еҚ•дҪҚгҖӮ
ж Ҳ(stack)жҳҜеҗҺиҝӣе…ҲеҮәпјҢеӯҳеӮЁиҝҗиЎҢж—¶зҡ„еҸҳйҮҸпјҢеҚіж–№жі•дёӯзҡ„еҸҳйҮҸ
д»Јз ҒдёӯпјҢи¶ҠйҮҢеұӮзҡ„еҸҳйҮҸпјҢдҪңз”Ёеҹҹи¶Ҡе°ҸпјҢз”Ёе®Ңе°ұйҮҠж”ҫпјҢйҖӮеҗҲж Ҳиҝҷз§Қж•°жҚ®з»“жһ„

В
ж Ҳи§ЈеҶізЁӢеәҸзҡ„иҝҗиЎҢй—®йўҳпјҢеҚізЁӢеәҸеҰӮдҪ•жү§иЎҢпјҢжҲ–иҖ…иҜҙеҰӮдҪ•еӨ„зҗҶж•°жҚ®пјӣе Ҷи§ЈеҶізҡ„жҳҜж•°жҚ®еӯҳеӮЁзҡ„й—®йўҳпјҢеҚіж•°жҚ®жҖҺд№Ҳ
ж”ҫгҖҒж”ҫеңЁе“Әе„ҝгҖӮ
В
ж Ҳеӣ дёәжҳҜиҝҗиЎҢеҚ•дҪҚпјҢеӣ жӯӨйҮҢйқўеӯҳеӮЁзҡ„дҝЎжҒҜйғҪжҳҜи·ҹеҪ“еүҚзәҝзЁӢпјҲжҲ–зЁӢеәҸпјүзӣёе…ідҝЎжҒҜзҡ„гҖӮеҢ…жӢ¬еұҖйғЁеҸҳйҮҸгҖҒзЁӢеәҸиҝҗиЎҢзҠ¶жҖҒгҖҒж–№жі•иҝ”еӣһеҖјзӯүзӯүпјӣиҖҢе ҶеҸӘиҙҹиҙЈеӯҳеӮЁеҜ№иұЎдҝЎжҒҜгҖӮ
В
йқўеҗ‘еҜ№иұЎзҡ„еј•е…ҘпјҢдҪҝеҫ—еҜ№еҫ…й—®йўҳзҡ„жҖқиҖғж–№ејҸеҸ‘з”ҹдәҶж”№еҸҳпјҢиҖҢжӣҙжҺҘиҝ‘дәҺиҮӘ然方ејҸзҡ„жҖқиҖғгҖӮеҪ“жҲ‘们жҠҠеҜ№иұЎжӢҶејҖпјҢдҪ дјҡеҸ‘зҺ°пјҢеҜ№иұЎзҡ„еұһжҖ§е…¶е®һе°ұжҳҜж•°жҚ®пјҢеӯҳж”ҫеңЁе ҶдёӯпјӣиҖҢеҜ№иұЎзҡ„иЎҢдёәпјҲж–№жі•пјүпјҢе°ұжҳҜиҝҗиЎҢйҖ»иҫ‘пјҢж”ҫеңЁж ҲдёӯгҖӮ
В
е Ҷдёӯеӯҳзҡ„жҳҜеҜ№иұЎгҖӮж Ҳдёӯеӯҳзҡ„жҳҜеҹәжң¬ж•°жҚ®зұ»еһӢе’Ңе ҶдёӯеҜ№иұЎзҡ„еј•з”ЁгҖӮ
В
зЁӢеәҸиҝҗиЎҢж°ёиҝңйғҪжҳҜеңЁж ҲдёӯиҝӣиЎҢзҡ„пјҢеӣ иҖҢеҸӮж•°дј йҖ’ж—¶пјҢеҸӘеӯҳеңЁдј йҖ’еҹәжң¬зұ»еһӢе’ҢеҜ№иұЎеј•з”Ёзҡ„й—®йўҳгҖӮдёҚдјҡзӣҙжҺҘ
дј еҜ№иұЎжң¬иә«гҖӮ
В
В
JavaдёӯпјҢж Ҳзҡ„еӨ§е°ҸйҖҡиҝҮ-XssжқҘи®ҫзҪ®пјҢеҪ“ж ҲдёӯеӯҳеӮЁж•°жҚ®жҜ”иҫғеӨҡж—¶пјҢйңҖиҰҒйҖӮеҪ“и°ғеӨ§иҝҷдёӘеҖјпјҢеҗҰеҲҷдјҡеҮәзҺ°
java.lang.StackOverflowErrorејӮеёёгҖӮеёёи§Ғзҡ„еҮәзҺ°иҝҷдёӘејӮеёёзҡ„жҳҜж— жі•иҝ”еӣһзҡ„йҖ’еҪ’пјҢеӣ дёәжӯӨж—¶ж Ҳдёӯдҝқеӯҳзҡ„дҝЎжҒҜйғҪжҳҜж–№жі•иҝ”еӣһзҡ„и®°еҪ•зӮ№гҖӮ
В
е ҶпјҢйЎәеәҸйҡҸж„ҸгҖӮж ҲпјҢеҗҺиҝӣе…ҲеҮә(Last-In/First-Out)гҖӮ
е ҶпјҲж“ҚдҪңзі»з»ҹпјүпјҡ дёҖиҲ¬з”ұзЁӢеәҸе‘ҳеҲҶй…ҚйҮҠж”ҫпјҢ иӢҘзЁӢеәҸе‘ҳдёҚйҮҠж”ҫпјҢзЁӢеәҸз»“жқҹж—¶еҸҜиғҪз”ұOSеӣһ收пјҢеҲҶй…Қж–№ејҸеҖ’жҳҜзұ»дјјдәҺй“ҫиЎЁгҖӮ
е ҶеҲҷжҳҜеӯҳж”ҫеңЁдәҢзә§зј“еӯҳдёӯпјҢз”ҹе‘Ҫе‘Ёжңҹз”ұиҷҡжӢҹжңәзҡ„еһғеңҫеӣһ收算法жқҘеҶіе®ҡпјҲ并дёҚжҳҜдёҖж—ҰжҲҗдёәеӯӨе„ҝеҜ№иұЎе°ұиғҪиў«еӣһ收пјүгҖӮжүҖд»Ҙи°ғз”ЁиҝҷдәӣеҜ№иұЎзҡ„йҖҹеәҰиҰҒзӣёеҜ№жқҘеҫ—дҪҺдёҖдәӣ
В
В
В
В
1.heapжҳҜе ҶпјҢstackжҳҜж ҲгҖӮ
2.stackзҡ„з©әй—ҙз”ұж“ҚдҪңзі»з»ҹиҮӘеҠЁеҲҶй…Қе’ҢйҮҠж”ҫпјҢheapзҡ„з©әй—ҙжҳҜжүӢеҠЁз”іиҜ·е’ҢйҮҠж”ҫзҡ„пјҢheapеёёз”Ёnewе…ій”®еӯ—жқҘеҲҶй…ҚгҖӮ
3.stackз©әй—ҙжңүйҷҗпјҢheapзҡ„з©әй—ҙжҳҜеҫҲеӨ§зҡ„иҮӘз”ұеҢәгҖӮ
еңЁJavaдёӯпјҢ
иӢҘеҸӘжҳҜеЈ°жҳҺдёҖдёӘеҜ№иұЎпјҢеҲҷе…ҲеңЁж ҲеҶ…еӯҳдёӯдёәе…¶еҲҶй…Қең°еқҖз©әй—ҙпјҢ
иӢҘеҶҚnewдёҖдёӢпјҢе®һдҫӢеҢ–е®ғпјҢеҲҷеңЁе ҶеҶ…еӯҳдёӯдёәе…¶еҲҶй…Қең°еқҖгҖӮ
4.дёҫдҫӢпјҡ
ж•°жҚ®зұ»еһӢ еҸҳйҮҸеҗҚпјӣиҝҷж ·е®ҡд№үзҡ„дёңиҘҝеңЁж ҲеҢәгҖӮ
еҰӮпјҡObject a =null; еҸӘеңЁж ҲеҶ…еӯҳдёӯеҲҶй…Қз©әй—ҙ
new ж•°жҚ®зұ»еһӢ();жҲ–иҖ…malloc(й•ҝеәҰ);В В В иҝҷж ·е®ҡд№үзҡ„дёңиҘҝе°ұеңЁе ҶеҢә
еҰӮпјҡObject b =new Object(); еҲҷеңЁе ҶеҶ…еӯҳдёӯеҲҶй…Қз©әй—ҙ
Stack.В В ThisВ В livesВ В inВ В theВ В generalВ В RAMВ В (random-accessВ В memory)В В area,В В butВ В hasВ В directВ В supportВ В fromВ В theВ В processorВ В viaВ В itsВ В stackВ В pointer.В В TheВ В stackВ В pointerВ В isВ В movedВ В downВ В toВ В createВ В newВ В memoryВ В andВ В movedВ В upВ В toВ В releaseВ В thatВ В memory.В В ThisВ В isВ В anВ В extremelyВ В fastВ В andВ В efficientВ В wayВ В toВ В allocateВ В storage,В В secondВ В onlyВ В toВ В registers.В В TheВ В JavaВ В compilerВ В mustВ В know,В В whileВ В itВ В isВ В creatingВ В theВ В program,В В theВ В exactВ В sizeВ В andВ В lifetimeВ В ofВ В allВ В theВ В dataВ В thatВ В isВ В storedВ В onВ В theВ В stack,В В becauseВ В itВ В mustВ В generateВ В theВ В codeВ В toВ В moveВ В theВ В stackВ В pointerВ В upВ В andВ В down.В В ThisВ В constraintВ В placesВ В limitsВ В onВ В theВ В flexibilityВ В ofВ В yourВ В programs,В В soВ В whileВ В someВ В JavaВ В storageВ В existsВ В onВ В theВ В stackВ В ?inВ В particular,В В objectВ В handlesВ В ?JavaВ В objectsВ В areВ В notВ В placedВ В onВ В theВ В stack.В В В
Heap.В В ThisВ В isВ В aВ В general-purposeВ В poolВ В ofВ В memoryВ В (alsoВ В inВ В theВ В RAMВ В area)В В whereВ В allВ В JavaВ В objectsВ В live.В В TheВ В niceВ В thingВ В aboutВ В theВ В heapВ В isВ В that,В В unlikeВ В theВ В stack,В В theВ В compilerВ В doesn 'tВ В needВ В toВ В knowВ В howВ В muchВ В storageВ В itВ В needsВ В toВ В allocateВ В fromВ В theВ В heapВ В orВ В howВ В longВ В thatВ В storageВ В mustВ В stayВ В onВ В theВ В heap.В В Thus,В В there 'sВ В aВ В greatВ В dealВ В ofВ В flexibilityВ В inВ В usingВ В storageВ В onВ В theВ В heap.В В WheneverВ В youВ В needВ В toВ В createВ В anВ В object,В В youВ В simplyВ В writeВ В theВ В codeВ В toВ В createВ В itВ В usingВ В newВ В andВ В theВ В storageВ В isВ В allocatedВ В onВ В theВ В heapВ В whenВ В thatВ В codeВ В isВ В executed.В В AndВ В ofВ В courseВ В there 'sВ В aВ В priceВ В youВ В payВ В forВ В thisВ В flexibility:В В itВ В takesВ В moreВ В timeВ В toВ В allocateВ В heapВ В storage.В В
Javaдёӯе ҶеҶ…еӯҳдёҺж ҲеҶ…еӯҳеҲҶй…Қжө…жһҗ
http://www.iteye.com/topic/941682
JavaжҠҠеҶ…еӯҳеҲ’еҲҶжҲҗдёӨз§ҚпјҡдёҖз§ҚжҳҜж ҲеҶ…еӯҳпјҢеҸҰдёҖз§ҚжҳҜе ҶеҶ…еӯҳгҖӮеңЁеҮҪж•°дёӯе®ҡд№үзҡ„дёҖдәӣеҹәжң¬зұ»еһӢзҡ„еҸҳйҮҸе’ҢеҜ№иұЎзҡ„еј•з”ЁеҸҳйҮҸйғҪжҳҜеңЁеҮҪж•°зҡ„ж ҲеҶ…еӯҳдёӯеҲҶй…ҚпјҢеҪ“еңЁдёҖж®өд»Јз Ғеқ—е®ҡд№үдёҖдёӘеҸҳйҮҸж—¶пјҢJavaе°ұеңЁж ҲдёӯдёәиҝҷдёӘеҸҳйҮҸеҲҶй…ҚеҶ…еӯҳз©әй—ҙпјҢеҪ“и¶…иҝҮеҸҳйҮҸзҡ„дҪңз”ЁеҹҹеҗҺпјҢJava дјҡиҮӘеҠЁйҮҠж”ҫжҺүдёәиҜҘеҸҳйҮҸеҲҶй…Қзҡ„еҶ…еӯҳз©әй—ҙпјҢиҜҘеҶ…еӯҳз©әй—ҙеҸҜд»Ҙз«ӢеҚіиў«еҸҰдҪңе®ғз”ЁгҖӮВ
гҖҖгҖҖе ҶеҶ…еӯҳз”ЁжқҘеӯҳж”ҫз”ұ new еҲӣе»әзҡ„еҜ№иұЎе’Ңж•°з»„пјҢеңЁе ҶдёӯеҲҶй…Қзҡ„еҶ…еӯҳпјҢз”ұ Java иҷҡжӢҹжңәзҡ„иҮӘеҠЁеһғеңҫеӣһ收еҷЁжқҘз®ЎзҗҶгҖӮеңЁе Ҷдёӯдә§з”ҹдәҶдёҖдёӘж•°з»„жҲ–иҖ…еҜ№иұЎд№ӢеҗҺпјҢиҝҳеҸҜд»ҘеңЁж Ҳдёӯе®ҡд№үдёҖдёӘзү№ж®Ҡзҡ„еҸҳйҮҸпјҢи®©ж Ҳдёӯзҡ„иҝҷдёӘеҸҳйҮҸзҡ„еҸ–еҖјзӯүдәҺж•°з»„жҲ–еҜ№иұЎеңЁе ҶеҶ…еӯҳдёӯзҡ„йҰ–ең°еқҖпјҢж Ҳдёӯзҡ„иҝҷдёӘеҸҳйҮҸе°ұжҲҗдәҶж•°з»„жҲ–еҜ№иұЎзҡ„еј•з”ЁеҸҳйҮҸпјҢд»ҘеҗҺе°ұеҸҜд»ҘеңЁзЁӢеәҸдёӯдҪҝз”Ёж Ҳдёӯзҡ„еј•з”ЁеҸҳйҮҸжқҘи®ҝй—®е Ҷдёӯзҡ„ж•°з»„жҲ–иҖ…еҜ№иұЎпјҢеј•з”ЁеҸҳйҮҸе°ұзӣёеҪ“дәҺжҳҜдёәж•°з»„жҲ–иҖ…еҜ№иұЎиө·зҡ„дёҖдёӘеҗҚз§°гҖӮеј•з”ЁеҸҳйҮҸжҳҜжҷ®йҖҡзҡ„еҸҳйҮҸпјҢе®ҡд№үж—¶еңЁж ҲдёӯеҲҶй…ҚпјҢеј•з”ЁеҸҳйҮҸеңЁзЁӢеәҸиҝҗиЎҢеҲ°е…¶дҪңз”Ёеҹҹд№ӢеӨ–еҗҺиў«йҮҠж”ҫгҖӮиҖҢж•°з»„е’ҢеҜ№иұЎжң¬иә«еңЁе ҶдёӯеҲҶй…ҚпјҢеҚідҪҝзЁӢеәҸиҝҗиЎҢеҲ°дҪҝз”Ё new дә§з”ҹж•°з»„жҲ–иҖ…еҜ№иұЎзҡ„иҜӯеҸҘжүҖеңЁзҡ„д»Јз Ғеқ—д№ӢеӨ–пјҢж•°з»„е’ҢеҜ№иұЎжң¬иә«еҚ жҚ®зҡ„еҶ…еӯҳдёҚдјҡиў«йҮҠж”ҫпјҢж•°з»„е’ҢеҜ№иұЎеңЁжІЎжңүеј•з”ЁеҸҳйҮҸжҢҮеҗ‘е®ғзҡ„ж—¶еҖҷпјҢжүҚеҸҳдёәеһғеңҫпјҢдёҚиғҪеңЁиў«дҪҝз”ЁпјҢдҪҶд»Қ然еҚ жҚ®еҶ…еӯҳз©әй—ҙдёҚж”ҫпјҢеңЁйҡҸеҗҺзҡ„дёҖдёӘдёҚзЎ®е®ҡзҡ„ж—¶й—ҙиў«еһғеңҫеӣһ收еҷЁж”¶иө°(йҮҠж”ҫжҺү)гҖӮВ
гҖҖгҖҖиҝҷд№ҹжҳҜJavaжҜ”иҫғеҚ еҶ…еӯҳзҡ„еҺҹеӣ пјҢе®һйҷ…дёҠпјҢж Ҳдёӯзҡ„еҸҳйҮҸжҢҮеҗ‘е ҶеҶ…еӯҳдёӯзҡ„еҸҳйҮҸпјҢиҝҷе°ұжҳҜ Java дёӯзҡ„жҢҮй’Ҳ!В
гҖҖгҖҖjavaдёӯеҶ…еӯҳеҲҶй…Қзӯ–з•ҘеҸҠе Ҷе’Ңж Ҳзҡ„жҜ”иҫғВ
гҖҖгҖҖ1 еҶ…еӯҳеҲҶй…Қзӯ–з•ҘВ
гҖҖгҖҖжҢүз…§зј–иҜ‘еҺҹзҗҶзҡ„и§ӮзӮ№,зЁӢеәҸиҝҗиЎҢж—¶зҡ„еҶ…еӯҳеҲҶй…Қжңүдёүз§Қзӯ–з•Ҙ,еҲҶеҲ«жҳҜйқҷжҖҒзҡ„,ж ҲејҸзҡ„,е’Ңе ҶејҸзҡ„.В
гҖҖгҖҖйқҷжҖҒеӯҳеӮЁеҲҶй…ҚжҳҜжҢҮеңЁзј–иҜ‘ж—¶е°ұиғҪзЎ®е®ҡжҜҸдёӘж•°жҚ®зӣ®ж ҮеңЁиҝҗиЎҢж—¶еҲ»зҡ„еӯҳеӮЁз©әй—ҙйңҖжұӮ,еӣ иҖҢеңЁзј–иҜ‘ж—¶е°ұеҸҜд»Ҙз»ҷ他们еҲҶй…Қеӣәе®ҡзҡ„еҶ…еӯҳз©әй—ҙ.иҝҷз§ҚеҲҶй…Қзӯ–з•ҘиҰҒжұӮзЁӢеәҸд»Јз ҒдёӯдёҚе…Ғи®ёжңүеҸҜеҸҳж•°жҚ®з»“жһ„(жҜ”еҰӮеҸҜеҸҳж•°з»„)зҡ„еӯҳеңЁ,д№ҹдёҚе…Ғи®ёжңүеөҢеҘ—жҲ–иҖ…йҖ’еҪ’зҡ„з»“жһ„еҮәзҺ°,еӣ дёәе®ғ们йғҪдјҡеҜјиҮҙзј–иҜ‘зЁӢеәҸж— жі•и®Ўз®—еҮҶзЎ®зҡ„еӯҳеӮЁз©әй—ҙйңҖжұӮ.В
гҖҖгҖҖж ҲејҸеӯҳеӮЁеҲҶй…Қд№ҹеҸҜз§°дёәеҠЁжҖҒеӯҳеӮЁеҲҶй…Қ,жҳҜз”ұдёҖдёӘзұ»дјјдәҺе Ҷж Ҳзҡ„иҝҗиЎҢж ҲжқҘе®һзҺ°зҡ„.е’ҢйқҷжҖҒеӯҳеӮЁеҲҶй…ҚзӣёеҸҚ,еңЁж ҲејҸеӯҳеӮЁж–№жЎҲдёӯ,зЁӢеәҸеҜ№ж•°жҚ®еҢәзҡ„йңҖжұӮеңЁзј–иҜ‘ж—¶жҳҜе®Ңе…ЁжңӘзҹҘзҡ„,еҸӘжңүеҲ°иҝҗиЎҢзҡ„ж—¶еҖҷжүҚиғҪеӨҹзҹҘйҒ“,дҪҶжҳҜ规е®ҡеңЁиҝҗиЎҢдёӯиҝӣе…ҘдёҖдёӘзЁӢеәҸжЁЎеқ—ж—¶,еҝ…йЎ»зҹҘйҒ“иҜҘзЁӢеәҸжЁЎеқ—жүҖйңҖзҡ„ж•°жҚ®еҢәеӨ§е°ҸжүҚиғҪеӨҹдёәе…¶еҲҶй…ҚеҶ…еӯҳ.е’ҢжҲ‘们еңЁж•°жҚ®з»“жһ„жүҖзҶҹзҹҘзҡ„ж ҲдёҖж ·,ж ҲејҸеӯҳеӮЁеҲҶй…ҚжҢүз…§е…ҲиҝӣеҗҺеҮәзҡ„еҺҹеҲҷиҝӣиЎҢеҲҶй…ҚгҖӮВ
гҖҖгҖҖйқҷжҖҒеӯҳеӮЁеҲҶй…ҚиҰҒжұӮеңЁзј–иҜ‘ж—¶иғҪзҹҘйҒ“жүҖжңүеҸҳйҮҸзҡ„еӯҳеӮЁиҰҒжұӮ,ж ҲејҸеӯҳеӮЁеҲҶй…ҚиҰҒжұӮеңЁиҝҮзЁӢзҡ„е…ҘеҸЈеӨ„еҝ…йЎ»зҹҘйҒ“жүҖжңүзҡ„еӯҳеӮЁиҰҒжұӮ,иҖҢе ҶејҸеӯҳеӮЁеҲҶй…ҚеҲҷдё“й—ЁиҙҹиҙЈеңЁзј–иҜ‘ж—¶жҲ–иҝҗиЎҢж—¶жЁЎеқ—е…ҘеҸЈеӨ„йғҪж— жі•зЎ®е®ҡеӯҳеӮЁиҰҒжұӮзҡ„ж•°жҚ®з»“жһ„зҡ„еҶ…еӯҳеҲҶй…Қ,жҜ”еҰӮеҸҜеҸҳй•ҝеәҰдёІе’ҢеҜ№иұЎе®һдҫӢ.е Ҷз”ұеӨ§зүҮзҡ„еҸҜеҲ©з”Ёеқ—жҲ–з©әй—Іеқ—з»„жҲҗ,е Ҷдёӯзҡ„еҶ…еӯҳеҸҜд»ҘжҢүз…§д»»ж„ҸйЎәеәҸеҲҶй…Қе’ҢйҮҠж”ҫ.В
гҖҖгҖҖ2 е Ҷе’Ңж Ҳзҡ„жҜ”иҫғВ
гҖҖгҖҖдёҠйқўзҡ„е®ҡд№үд»Һзј–иҜ‘еҺҹзҗҶзҡ„ж•ҷжқҗдёӯжҖ»з»“иҖҢжқҘ,йҷӨйқҷжҖҒеӯҳеӮЁеҲҶй…Қд№ӢеӨ–,йғҪжҳҫеҫ—еҫҲе‘Ҷжқҝе’Ңйҡҫд»ҘзҗҶи§Ј,дёӢйқўж’ҮејҖйқҷжҖҒеӯҳеӮЁеҲҶй…Қ,йӣҶдёӯжҜ”иҫғе Ҷе’Ңж Ҳ:В
гҖҖгҖҖд»Һе Ҷе’Ңж Ҳзҡ„еҠҹиғҪе’ҢдҪңз”ЁжқҘйҖҡдҝ—зҡ„жҜ”иҫғ,е Ҷдё»иҰҒз”ЁжқҘеӯҳж”ҫеҜ№иұЎзҡ„пјҢж Ҳдё»иҰҒжҳҜз”ЁжқҘжү§иЎҢзЁӢеәҸзҡ„.иҖҢиҝҷз§ҚдёҚеҗҢеҸҲдё»иҰҒжҳҜз”ұдәҺе Ҷе’Ңж Ҳзҡ„зү№зӮ№еҶіе®ҡзҡ„:В
гҖҖгҖҖеңЁзј–зЁӢдёӯпјҢдҫӢеҰӮC/C++дёӯпјҢжүҖжңүзҡ„ж–№жі•и°ғз”ЁйғҪжҳҜйҖҡиҝҮж ҲжқҘиҝӣиЎҢзҡ„,жүҖжңүзҡ„еұҖйғЁеҸҳйҮҸ,еҪўејҸеҸӮж•°йғҪжҳҜд»Һж ҲдёӯеҲҶй…ҚеҶ…еӯҳз©әй—ҙзҡ„гҖӮе®һйҷ…дёҠд№ҹдёҚжҳҜд»Җд№ҲеҲҶй…Қ,еҸӘжҳҜд»Һж ҲйЎ¶еҗ‘дёҠз”Ёе°ұиЎҢ,е°ұеҘҪеғҸе·ҘеҺӮдёӯзҡ„дј йҖҒеёҰ(conveyor belt)дёҖж ·,Stack PointerдјҡиҮӘеҠЁжҢҮеј•дҪ еҲ°ж”ҫдёңиҘҝзҡ„дҪҚзҪ®,дҪ жүҖиҰҒеҒҡзҡ„еҸӘжҳҜжҠҠдёңиҘҝж”ҫдёӢжқҘе°ұиЎҢ.йҖҖеҮәеҮҪж•°зҡ„ж—¶еҖҷпјҢдҝ®ж”№ж ҲжҢҮй’Ҳе°ұеҸҜд»ҘжҠҠж Ҳдёӯзҡ„еҶ…е®№й”ҖжҜҒ.иҝҷж ·зҡ„жЁЎејҸйҖҹеәҰжңҖеҝ«, еҪ“然иҰҒз”ЁжқҘиҝҗиЎҢзЁӢеәҸдәҶ.йңҖиҰҒжіЁж„Ҹзҡ„жҳҜ,еңЁеҲҶй…Қзҡ„ж—¶еҖҷ,жҜ”еҰӮдёәдёҖдёӘеҚіе°ҶиҰҒи°ғз”Ёзҡ„зЁӢеәҸжЁЎеқ—еҲҶй…Қж•°жҚ®еҢәж—¶,еә”дәӢе…ҲзҹҘйҒ“иҝҷдёӘж•°жҚ®еҢәзҡ„еӨ§е°Ҹ,д№ҹе°ұиҜҙжҳҜиҷҪ然еҲҶй…ҚжҳҜеңЁзЁӢеәҸиҝҗиЎҢж—¶иҝӣиЎҢзҡ„,дҪҶжҳҜеҲҶй…Қзҡ„еӨ§е°ҸеӨҡе°‘жҳҜзЎ®е®ҡзҡ„,дёҚеҸҳзҡ„,иҖҢиҝҷдёӘ"еӨ§е°ҸеӨҡе°‘"жҳҜеңЁзј–иҜ‘ж—¶зЎ®е®ҡзҡ„,дёҚжҳҜеңЁиҝҗиЎҢж—¶.В
гҖҖгҖҖе ҶжҳҜеә”з”ЁзЁӢеәҸеңЁиҝҗиЎҢзҡ„ж—¶еҖҷиҜ·жұӮж“ҚдҪңзі»з»ҹеҲҶй…Қз»ҷиҮӘе·ұеҶ…еӯҳпјҢз”ұдәҺд»Һж“ҚдҪңзі»з»ҹз®ЎзҗҶзҡ„еҶ…еӯҳеҲҶй…Қ,жүҖд»ҘеңЁеҲҶй…Қе’Ңй”ҖжҜҒж—¶йғҪиҰҒеҚ з”Ёж—¶й—ҙпјҢеӣ жӯӨз”Ёе Ҷзҡ„ж•ҲзҺҮйқһеёёдҪҺ.дҪҶжҳҜе Ҷзҡ„дјҳзӮ№еңЁдәҺ,зј–иҜ‘еҷЁдёҚеҝ…зҹҘйҒ“иҰҒд»Һе ҶйҮҢеҲҶй…ҚеӨҡе°‘еӯҳеӮЁз©әй—ҙпјҢд№ҹдёҚеҝ…зҹҘйҒ“еӯҳеӮЁзҡ„ж•°жҚ®иҰҒеңЁе ҶйҮҢеҒңз•ҷеӨҡй•ҝзҡ„ж—¶й—ҙ,еӣ жӯӨ,з”Ёе Ҷдҝқеӯҳж•°жҚ®ж—¶дјҡеҫ—еҲ°жӣҙеӨ§зҡ„зҒөжҙ»жҖ§гҖӮдәӢе®һдёҠ,йқўеҗ‘еҜ№иұЎзҡ„еӨҡжҖҒжҖ§,е ҶеҶ…еӯҳеҲҶй…ҚжҳҜеҝ…дёҚеҸҜе°‘зҡ„,еӣ дёәеӨҡжҖҒеҸҳйҮҸжүҖйңҖзҡ„еӯҳеӮЁз©әй—ҙеҸӘжңүеңЁиҝҗиЎҢж—¶еҲӣе»әдәҶеҜ№иұЎд№ӢеҗҺжүҚиғҪзЎ®е®ҡ.еңЁC++дёӯпјҢиҰҒжұӮеҲӣе»әдёҖдёӘеҜ№иұЎж—¶пјҢеҸӘйңҖз”Ё newе‘Ҫд»Өзј–еҲ¶зӣёе…ізҡ„д»Јз ҒеҚіеҸҜгҖӮжү§иЎҢиҝҷдәӣд»Јз Ғж—¶пјҢдјҡеңЁе ҶйҮҢиҮӘеҠЁиҝӣиЎҢж•°жҚ®зҡ„дҝқеӯҳ.еҪ“然пјҢдёәиҫҫеҲ°иҝҷз§ҚзҒөжҙ»жҖ§пјҢеҝ…然дјҡд»ҳеҮәдёҖе®ҡзҡ„д»Јд»·:еңЁе ҶйҮҢеҲҶй…ҚеӯҳеӮЁз©әй—ҙж—¶дјҡиҠұжҺүжӣҙй•ҝзҡ„ж—¶й—ҙ!иҝҷд№ҹжӯЈжҳҜеҜјиҮҙжҲ‘们еҲҡжүҚжүҖиҜҙзҡ„ж•ҲзҺҮдҪҺзҡ„еҺҹеӣ ,зңӢжқҘеҲ—е®ҒеҗҢеҝ—иҜҙзҡ„еҘҪ,дәәзҡ„дјҳзӮ№еҫҖеҫҖд№ҹжҳҜдәәзҡ„зјәзӮ№,дәәзҡ„зјәзӮ№еҫҖеҫҖд№ҹжҳҜдәәзҡ„дјҳзӮ№(жҷ•~).В
гҖҖгҖҖ3 JVMдёӯзҡ„е Ҷе’Ңж ҲВ
гҖҖгҖҖJVMжҳҜеҹәдәҺе Ҷж Ҳзҡ„иҷҡжӢҹжңә.JVMдёәжҜҸдёӘж–°еҲӣе»әзҡ„зәҝзЁӢйғҪеҲҶй…ҚдёҖдёӘе Ҷж Ҳ.д№ҹе°ұжҳҜиҜҙ,еҜ№дәҺдёҖдёӘJavaзЁӢеәҸжқҘиҜҙпјҢе®ғзҡ„иҝҗиЎҢе°ұжҳҜйҖҡиҝҮеҜ№е Ҷж Ҳзҡ„ж“ҚдҪңжқҘе®ҢжҲҗзҡ„гҖӮе Ҷж Ҳд»Ҙеё§дёәеҚ•дҪҚдҝқеӯҳзәҝзЁӢзҡ„зҠ¶жҖҒгҖӮJVMеҜ№е Ҷж ҲеҸӘиҝӣиЎҢдёӨз§Қж“ҚдҪң:д»Ҙеё§дёәеҚ•дҪҚзҡ„еҺӢж Ҳе’ҢеҮәж Ҳж“ҚдҪңгҖӮВ
гҖҖгҖҖжҲ‘们зҹҘйҒ“,жҹҗдёӘзәҝзЁӢжӯЈеңЁжү§иЎҢзҡ„ж–№жі•з§°дёәжӯӨзәҝзЁӢзҡ„еҪ“еүҚж–№жі•.жҲ‘们еҸҜиғҪдёҚзҹҘйҒ“,еҪ“еүҚж–№жі•дҪҝз”Ёзҡ„её§з§°дёәеҪ“еүҚеё§гҖӮеҪ“зәҝзЁӢжҝҖжҙ»дёҖдёӘJavaж–№жі•,JVMе°ұдјҡеңЁзәҝзЁӢзҡ„ Javaе Ҷж ҲйҮҢж–°еҺӢе…ҘдёҖдёӘеё§гҖӮиҝҷдёӘеё§иҮӘ然жҲҗдёәдәҶеҪ“еүҚеё§.еңЁжӯӨж–№жі•жү§иЎҢжңҹй—ҙ,иҝҷдёӘеё§е°Ҷз”ЁжқҘдҝқеӯҳеҸӮж•°,еұҖйғЁеҸҳйҮҸ,дёӯй—ҙи®Ўз®—иҝҮзЁӢе’Ңе…¶д»–ж•°жҚ®.иҝҷдёӘеё§еңЁиҝҷйҮҢе’Ңзј–иҜ‘еҺҹзҗҶдёӯзҡ„жҙ»еҠЁзәӘеҪ•зҡ„жҰӮеҝөжҳҜе·®дёҚеӨҡзҡ„.В
гҖҖгҖҖд»ҺJavaзҡ„иҝҷз§ҚеҲҶй…ҚжңәеҲ¶жқҘзңӢ,е Ҷж ҲеҸҲеҸҜд»Ҙиҝҷж ·зҗҶи§Ј:е Ҷж Ҳ(Stack)жҳҜж“ҚдҪңзі»з»ҹеңЁе»әз«ӢжҹҗдёӘиҝӣзЁӢж—¶жҲ–иҖ…зәҝзЁӢ(еңЁж”ҜжҢҒеӨҡзәҝзЁӢзҡ„ж“ҚдҪңзі»з»ҹдёӯжҳҜзәҝзЁӢ)дёәиҝҷдёӘзәҝзЁӢе»әз«Ӣзҡ„еӯҳеӮЁеҢәеҹҹпјҢиҜҘеҢәеҹҹе…·жңүе…ҲиҝӣеҗҺеҮәзҡ„зү№жҖ§гҖӮВ
гҖҖгҖҖжҜҸдёҖдёӘJavaеә”з”ЁйғҪе”ҜдёҖеҜ№еә”дёҖдёӘJVMе®һдҫӢпјҢжҜҸдёҖдёӘе®һдҫӢе”ҜдёҖеҜ№еә”дёҖдёӘе ҶгҖӮеә”з”ЁзЁӢеәҸеңЁиҝҗиЎҢдёӯжүҖеҲӣе»әзҡ„жүҖжңүзұ»е®һдҫӢжҲ–ж•°з»„йғҪж”ҫеңЁиҝҷдёӘе Ҷдёӯ,并з”ұеә”з”ЁжүҖжңүзҡ„зәҝзЁӢе…ұдә«.и·ҹC/C++дёҚеҗҢпјҢJavaдёӯеҲҶй…Қе ҶеҶ…еӯҳжҳҜиҮӘеҠЁеҲқе§ӢеҢ–зҡ„гҖӮJavaдёӯжүҖжңүеҜ№иұЎзҡ„еӯҳеӮЁз©әй—ҙйғҪжҳҜеңЁе ҶдёӯеҲҶй…Қзҡ„пјҢдҪҶжҳҜиҝҷдёӘеҜ№иұЎзҡ„еј•з”ЁеҚҙжҳҜеңЁе Ҷж ҲдёӯеҲҶй…Қ,д№ҹе°ұжҳҜиҜҙеңЁе»әз«ӢдёҖдёӘеҜ№иұЎж—¶д»ҺдёӨдёӘең°ж–№йғҪеҲҶй…ҚеҶ…еӯҳпјҢеңЁе ҶдёӯеҲҶй…Қзҡ„еҶ…еӯҳе®һйҷ…е»әз«ӢиҝҷдёӘеҜ№иұЎпјҢиҖҢеңЁе Ҷж ҲдёӯеҲҶй…Қзҡ„еҶ…еӯҳеҸӘжҳҜдёҖдёӘжҢҮеҗ‘иҝҷдёӘе ҶеҜ№иұЎзҡ„жҢҮй’Ҳ(еј•з”Ё)иҖҢе·ІгҖӮВ
гҖҖгҖҖJava дёӯзҡ„е Ҷе’Ңж ҲВ
гҖҖгҖҖJavaжҠҠеҶ…еӯҳеҲ’еҲҶжҲҗдёӨз§ҚпјҡдёҖз§ҚжҳҜж ҲеҶ…еӯҳпјҢдёҖз§ҚжҳҜе ҶеҶ…еӯҳгҖӮВ
гҖҖгҖҖеңЁеҮҪж•°дёӯе®ҡд№үзҡ„дёҖдәӣеҹәжң¬зұ»еһӢзҡ„еҸҳйҮҸе’ҢеҜ№иұЎзҡ„еј•з”ЁеҸҳйҮҸйғҪеңЁеҮҪж•°зҡ„ж ҲеҶ…еӯҳдёӯеҲҶй…ҚгҖӮВ
гҖҖгҖҖеҪ“еңЁдёҖж®өд»Јз Ғеқ—е®ҡд№үдёҖдёӘеҸҳйҮҸж—¶пјҢJavaе°ұеңЁж ҲдёӯдёәиҝҷдёӘеҸҳйҮҸеҲҶй…ҚеҶ…еӯҳз©әй—ҙпјҢеҪ“и¶…иҝҮеҸҳйҮҸзҡ„дҪңз”ЁеҹҹеҗҺпјҢJavaдјҡиҮӘеҠЁйҮҠж”ҫжҺүдёәиҜҘеҸҳйҮҸжүҖеҲҶй…Қзҡ„еҶ…еӯҳз©әй—ҙпјҢиҜҘеҶ…еӯҳз©әй—ҙеҸҜд»Ҙз«ӢеҚіиў«еҸҰдҪңд»–з”ЁгҖӮВ
гҖҖгҖҖе ҶеҶ…еӯҳз”ЁжқҘеӯҳж”ҫз”ұnewеҲӣе»әзҡ„еҜ№иұЎе’Ңж•°з»„гҖӮВ
гҖҖгҖҖеңЁе ҶдёӯеҲҶй…Қзҡ„еҶ…еӯҳпјҢз”ұJavaиҷҡжӢҹжңәзҡ„иҮӘеҠЁеһғеңҫеӣһ收еҷЁжқҘз®ЎзҗҶгҖӮВ
гҖҖгҖҖеңЁе Ҷдёӯдә§з”ҹдәҶдёҖдёӘж•°з»„жҲ–еҜ№иұЎеҗҺпјҢиҝҳеҸҜд»ҘеңЁж Ҳдёӯе®ҡд№үдёҖдёӘзү№ж®Ҡзҡ„еҸҳйҮҸпјҢи®©ж ҲдёӯиҝҷдёӘеҸҳйҮҸзҡ„еҸ–еҖјзӯүдәҺж•°з»„жҲ–еҜ№иұЎеңЁе ҶеҶ…еӯҳдёӯзҡ„йҰ–ең°еқҖпјҢж Ҳдёӯзҡ„иҝҷдёӘеҸҳйҮҸе°ұжҲҗдәҶж•°з»„жҲ–еҜ№иұЎзҡ„еј•з”ЁеҸҳйҮҸгҖӮВ
гҖҖгҖҖеј•з”ЁеҸҳйҮҸе°ұзӣёеҪ“дәҺжҳҜдёәж•°з»„жҲ–еҜ№иұЎиө·зҡ„дёҖдёӘеҗҚз§°пјҢд»ҘеҗҺе°ұеҸҜд»ҘеңЁзЁӢеәҸдёӯдҪҝз”Ёж Ҳдёӯзҡ„еј•з”ЁеҸҳйҮҸжқҘи®ҝй—®е Ҷдёӯзҡ„ж•°з»„жҲ–еҜ№иұЎгҖӮВ
гҖҖгҖҖе…·дҪ“зҡ„иҜҙпјҡВ
гҖҖгҖҖж ҲдёҺе ҶйғҪжҳҜJavaз”ЁжқҘеңЁRamдёӯеӯҳж”ҫж•°жҚ®зҡ„ең°ж–№гҖӮдёҺC++дёҚеҗҢпјҢJavaиҮӘеҠЁз®ЎзҗҶж Ҳе’Ңе ҶпјҢзЁӢеәҸе‘ҳдёҚиғҪзӣҙжҺҘең°и®ҫзҪ®ж ҲжҲ–е ҶгҖӮВ
гҖҖгҖҖJavaзҡ„е ҶжҳҜдёҖдёӘиҝҗиЎҢж—¶ж•°жҚ®еҢә,зұ»зҡ„(еҜ№иұЎд»ҺдёӯеҲҶй…Қз©әй—ҙгҖӮиҝҷдәӣеҜ№иұЎйҖҡиҝҮnewгҖҒnewarrayгҖҒanewarrayе’ҢmultianewarrayзӯүжҢҮд»Өе»әз«ӢпјҢе®ғ们дёҚйңҖиҰҒзЁӢеәҸд»Јз ҒжқҘжҳҫејҸзҡ„йҮҠж”ҫгҖӮе ҶжҳҜз”ұеһғеңҫеӣһ收жқҘиҙҹиҙЈзҡ„пјҢе Ҷзҡ„дјҳеҠҝжҳҜеҸҜд»ҘеҠЁжҖҒең°еҲҶй…ҚеҶ…еӯҳеӨ§е°ҸпјҢз”ҹеӯҳжңҹд№ҹдёҚеҝ…дәӢе…Ҳе‘ҠиҜүзј–иҜ‘еҷЁпјҢеӣ дёәе®ғжҳҜеңЁиҝҗиЎҢж—¶еҠЁжҖҒеҲҶй…ҚеҶ…еӯҳзҡ„пјҢJavaзҡ„еһғеңҫ收йӣҶеҷЁдјҡиҮӘеҠЁж”¶иө°иҝҷдәӣдёҚеҶҚдҪҝз”Ёзҡ„ж•°жҚ®гҖӮдҪҶзјәзӮ№жҳҜпјҢз”ұдәҺиҰҒеңЁиҝҗиЎҢж—¶еҠЁжҖҒеҲҶй…ҚеҶ…еӯҳпјҢеӯҳеҸ–йҖҹеәҰиҫғж…ўгҖӮВ
гҖҖгҖҖж Ҳзҡ„дјҳеҠҝжҳҜпјҢеӯҳеҸ–йҖҹеәҰжҜ”е ҶиҰҒеҝ«пјҢд»…ж¬ЎдәҺеҜ„еӯҳеҷЁпјҢж Ҳж•°жҚ®еҸҜд»Ҙе…ұдә«гҖӮдҪҶзјәзӮ№жҳҜпјҢеӯҳеңЁж Ҳдёӯзҡ„ж•°жҚ®еӨ§е°ҸдёҺз”ҹеӯҳжңҹеҝ…йЎ»жҳҜзЎ®е®ҡзҡ„пјҢзјәд№ҸзҒөжҙ»жҖ§гҖӮж Ҳдёӯдё»иҰҒеӯҳж”ҫдёҖдәӣеҹәжң¬зұ»еһӢзҡ„еҸҳйҮҸ(,int, short, long, byte, float, double, boolean, char)е’ҢеҜ№иұЎеҸҘжҹ„гҖӮВ
гҖҖгҖҖж ҲжңүдёҖдёӘеҫҲйҮҚиҰҒзҡ„зү№ж®ҠжҖ§пјҢе°ұжҳҜеӯҳеңЁж Ҳдёӯзҡ„ж•°жҚ®еҸҜд»Ҙе…ұдә«гҖӮеҒҮи®ҫжҲ‘们еҗҢж—¶е®ҡд№үпјҡВ
гҖҖгҖҖint a = 3;В
гҖҖгҖҖint b = 3;В
гҖҖгҖҖзј–иҜ‘еҷЁе…ҲеӨ„зҗҶint a = 3;йҰ–е…Ҳе®ғдјҡеңЁж ҲдёӯеҲӣе»әдёҖдёӘеҸҳйҮҸдёәaзҡ„еј•з”ЁпјҢ然еҗҺжҹҘжүҫж ҲдёӯжҳҜеҗҰжңү3иҝҷдёӘеҖјпјҢеҰӮжһңжІЎжүҫеҲ°пјҢе°ұе°Ҷ3еӯҳж”ҫиҝӣжқҘпјҢ然еҗҺе°ҶaжҢҮеҗ‘3гҖӮжҺҘзқҖеӨ„зҗҶint b = 3;еңЁеҲӣе»әе®Ңbзҡ„еј•з”ЁеҸҳйҮҸеҗҺпјҢеӣ дёәеңЁж Ҳдёӯе·Із»Ҹжңү3иҝҷдёӘеҖјпјҢдҫҝе°ҶbзӣҙжҺҘжҢҮеҗ‘3гҖӮиҝҷж ·пјҢе°ұеҮәзҺ°дәҶaдёҺbеҗҢж—¶еқҮжҢҮеҗ‘3зҡ„жғ…еҶөгҖӮиҝҷж—¶пјҢеҰӮжһңеҶҚд»Өa=4;йӮЈд№Ҳзј–иҜ‘еҷЁдјҡйҮҚж–°жҗңзҙўж ҲдёӯжҳҜеҗҰжңү4еҖјпјҢеҰӮжһңжІЎжңүпјҢеҲҷе°Ҷ4еӯҳж”ҫиҝӣжқҘпјҢ并д»ӨaжҢҮеҗ‘4;еҰӮжһңе·Із»ҸжңүдәҶпјҢеҲҷзӣҙжҺҘе°ҶaжҢҮеҗ‘иҝҷдёӘең°еқҖгҖӮеӣ жӯӨaеҖјзҡ„ж”№еҸҳдёҚдјҡеҪұе“ҚеҲ°bзҡ„еҖјгҖӮиҰҒжіЁж„Ҹиҝҷз§Қж•°жҚ®зҡ„е…ұдә«дёҺдёӨдёӘеҜ№иұЎзҡ„еј•з”ЁеҗҢж—¶жҢҮеҗ‘дёҖдёӘеҜ№иұЎзҡ„иҝҷз§Қе…ұдә«жҳҜдёҚеҗҢзҡ„пјҢеӣ дёәиҝҷз§Қжғ…еҶөaзҡ„дҝ®ж”№е№¶дёҚдјҡеҪұе“ҚеҲ°b, е®ғжҳҜз”ұзј–иҜ‘еҷЁе®ҢжҲҗзҡ„пјҢе®ғжңүеҲ©дәҺиҠӮзңҒз©әй—ҙгҖӮиҖҢдёҖдёӘеҜ№иұЎеј•з”ЁеҸҳйҮҸдҝ®ж”№дәҶиҝҷдёӘеҜ№иұЎзҡ„еҶ…йғЁзҠ¶жҖҒпјҢдјҡеҪұе“ҚеҲ°еҸҰдёҖдёӘеҜ№иұЎеј•з”ЁеҸҳйҮҸВ



зӣёе…іжҺЁиҚҗ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷйҳҗиҝ°дәҶC++зұ»зҡ„жһ„йҖ дёҺжһҗжһ„жңәеҲ¶пјҢи§ЈйҮҠдәҶиҝҷдёӨз§Қзү№ж®ҠжҲҗе‘ҳеҮҪж•°зҡ„е·ҘдҪңеҺҹзҗҶе’Ңеә”з”ЁеңәжҷҜпјҢж¶өзӣ–жһ„йҖ еҮҪж•°зҡ„зү№зӮ№гҖҒеҲҶзұ»дёҺи°ғз”Ёж–№ејҸгҖҒжһ„йҖ еҮҪж•°еҲқе§ӢеҢ–еҲ—иЎЁгҖҒд»ҘеҸҠжһҗжһ„еҮҪж•°зҡ„дҪңз”ЁгҖҒи°ғз”Ёж—¶жңәе’ҢжіЁж„ҸдәӢйЎ№гҖӮж–ҮдёӯиҝҳжҺўи®ЁдәҶеңЁC++зј–зЁӢдёӯеҰӮдҪ•иҝҗз”ЁиҝҷдәӣжңәеҲ¶е®һзҺ°й«ҳж•Ҳзҡ„иө„жәҗз®ЎзҗҶе’ҢеҶ…еӯҳе®үе…ЁпјҢзү№еҲ«жҳҜйҒөеҫӘRAIIеҺҹеҲҷгҖҒйҒҝе…Қеёёи§Ғй”ҷиҜҜпјҲеҰӮиө„жәҗжңӘйҮҠж”ҫгҖҒйҮҚеӨҚжһҗжһ„гҖҒејӮеёёе®үе…Ёй—®йўҳпјүгҖҒ并еңЁеӨҡзәҝзЁӢзҺҜеўғдёӯеҗҲзҗҶеӨ„зҗҶеҗҢжӯҘж“ҚдҪңгҖӮ йҖӮеҗҲдәәзҫӨпјҡе…·жңүеҹәзЎҖC++зј–зЁӢжҠҖиғҪзҡ„зЁӢеәҸе‘ҳпјҢе°Өе…¶жҳҜеёҢжңӣж·ұе…ҘдәҶи§ЈеҜ№иұЎз”ҹе‘Ҫе‘Ёжңҹз®ЎзҗҶе’Ңй«ҳзә§иө„жәҗз®ЎзҗҶжҠҖжңҜзҡ„дәәзҫӨгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ зҗҶи§Је’Ңеә”з”ЁC++зұ»зҡ„жһ„йҖ дёҺжһҗжһ„жңәеҲ¶жқҘзј–еҶҷй«ҳж•Ҳзҡ„д»Јз Ғпјӣв‘Ўйў„йҳІе’Ңдҝ®еӨҚз”ұдәҺиө„жәҗз®ЎзҗҶдёҚеҪ“еј•еҸ‘зҡ„еҗ„з§Қй”ҷиҜҜе’ҢжҖ§иғҪй—®йўҳпјӣв‘ўжҸҗй«ҳеҜ№йқўеҗ‘еҜ№иұЎзј–зЁӢзҡ„зҗҶи§ЈпјҢжҺҢжҸЎеңЁеӨҡзәҝзЁӢзҺҜеўғдёӢзҡ„иө„жәҗз®ЎзҗҶжҠҖе·§гҖӮ е…¶д»–иҜҙжҳҺпјҡйҖҡиҝҮе®һйҷ…жЎҲдҫӢж·ұе…ҘеҲҶжһҗC++дёӯжһ„йҖ еҮҪж•°е’Ңжһҗжһ„еҮҪж•°зҡ„еә”з”ЁпјҢејәи°ғRAIIпјҲResource Acquisition Is InitializationпјүеҺҹеҲҷзҡ„йҮҚиҰҒжҖ§гҖӮеҗҢж—¶д№ҹжҸҗеҸҠдәҶжңӘжқҘеӯҰд№ ж–№еҗ‘еҰӮжҷәиғҪжҢҮй’Ҳе’Ң移еҠЁиҜӯд№үзӯүеҶ…е®№пјҢеё®еҠ©ејҖеҸ‘иҖ…жӣҙеҘҪең°жҺҢжҸЎC++зј–зЁӢжҠҖе·§гҖӮ
жң¬ж–ҮдёәжҠӣз –еј•зҺүпјҡз®ҖеҚ•жҸҸиҝ°пјҢеҰӮйңҖж №жҚ®иҮӘиә«дёҡеҠЎиҜҰз»Ҷи®ҫи®ЎпјҢиҜ·йҡҸж—¶иҒ”зі»
зҷҫеҗҲжЈҖйӘҢиЎЁж ј(йЈҹе“ҒйҰҷиҫӣж–ҷиҙЁйҮҸйӘҢ收记еҪ•иЎЁ)жЈҖйӘҢиЎЁж ј(йЈҹе“ҒйҰҷиҫӣж–ҷиҙЁйҮҸйӘҢ收记еҪ•иЎЁ).docx
жңҖж–°PHPзӣІзӣ’е•ҶеҹҺзі»з»ҹжәҗз ҒThinkPHPжЎҶжһ¶
еҘҮејӮеҖјеҲҶи§ЈпјҲSingular Value DecompositionпјҢз®Җз§°SVDпјүжҳҜзәҝжҖ§д»Јж•°дёӯзҡ„дёҖз§ҚйҮҚиҰҒзҹ©йҳөеҲҶи§Јж–№жі•пјҢе№ҝжіӣеә”з”ЁдәҺж•°жҚ®еӨ„зҗҶе’ҢдҝЎеҸ·еҲҶжһҗгҖӮеңЁжң¬еңәжҷҜдёӯпјҢжҲ‘们关注зҡ„жҳҜеҰӮдҪ•еҲ©з”ЁSVDжқҘзЎ®е®ҡVMDпјҲVariable Modulation DecompositionпјҢеҸҜеҸҳи°ғеҲ¶еҲҶи§Јпјүзҡ„KеҖјгҖӮVMDжҳҜдёҖз§ҚдҝЎеҸ·еҲҶи§ЈжҠҖжңҜпјҢе®ғиғҪеӨҹе°ҶеӨҚжқӮдҝЎеҸ·еҲҶи§ЈдёәдёҖзі»еҲ—и°ғеҲ¶йў‘зҺҮжҲҗеҲҶпјҢеҜ№дәҺйқһе№ізЁідҝЎеҸ·зҡ„еҲҶжһҗе’ҢеӨ„зҗҶйқһеёёжңүз”ЁгҖӮ зҗҶи§ЈSVDзҡ„еҹәжң¬жҰӮеҝөпјҡд»»дҪ•mГ—nзҡ„е®һж•°жҲ–еӨҚж•°зҹ©йҳөAйғҪеҸҜд»ҘиЎЁзӨәдёәдёүдёӘзҹ©йҳөзҡ„д№ҳз§ҜпјҢеҚіA=UОЈV^TпјҢе…¶дёӯUжҳҜmГ—mзҡ„жӯЈдәӨзҹ©йҳөпјҢОЈжҳҜдёҖдёӘmГ—nзҡ„еҜ№и§’зҹ©йҳөпјҢе…¶еҜ№и§’зәҝе…ғзҙ жҳҜеҘҮејӮеҖјпјҢVжҳҜnГ—nзҡ„жӯЈдәӨзҹ©йҳөгҖӮеҘҮејӮеҖјПғ_iжҢүз…§йқһйҷҚеәҸжҺ’еҲ—пјҢе®ғ们еҸҚжҳ дәҶзҹ©йҳөAзҡ„дҝЎжҒҜйҮҸе’ҢйҮҚиҰҒжҖ§гҖӮ еңЁVMDдёӯпјҢеҘҮејӮеҖјеҲҶи§Јзҡ„дҪңз”ЁеңЁдәҺиҜҶеҲ«дҝЎеҸ·зҡ„дёҚеҗҢйў‘зҺҮжҲҗеҲҶгҖӮеҪ“еҜ№дҝЎеҸ·иҝӣиЎҢVMDж—¶пјҢзӣ®ж ҮжҳҜжүҫеҲ°жңҖдҪізҡ„KеҖјпјҢд»ҘдҪҝеҲҶи§ЈеҗҺзҡ„еӯҗеёҰдҝЎеҸ·е°ҪеҸҜиғҪзӢ¬з«Ӣдё”ж— дәӨеҸүгҖӮKеҖјд»ЈиЎЁдәҶеҲҶи§Јеҫ—еҲ°зҡ„и°ғеҲ¶жЁЎејҸж•°йҮҸпјҢжҜҸдёӘжЁЎејҸеҜ№еә”дёҖдёӘзү№е®ҡзҡ„йў‘зҺҮиҢғеӣҙгҖӮ дёәдәҶзЎ®е®ҡKеҖјпјҢжҲ‘们йңҖиҰҒеҲҶжһҗSVDзҡ„з»“жһңпјҢеҚіеҘҮејӮеҖјзҡ„еҲҶеёғгҖӮеҘҮејӮеҖјзҡ„еӨ§е°ҸеҸҚжҳ дәҶеҺҹе§ӢдҝЎеҸ·зҡ„з»“жһ„дҝЎжҒҜгҖӮйҖҡеёёпјҢдҝЎеҸ·дёӯзҡ„дё»иҰҒжҲҗеҲҶеҜ№еә”иҫғеӨ§зҡ„еҘҮејӮеҖјпјҢиҖҢеҷӘеЈ°жҲ–дёҚйҮҚиҰҒзҡ„жҲҗеҲҶеҜ№еә”иҫғе°Ҹзҡ„еҘҮејӮеҖјгҖӮеӣ жӯӨпјҢеҘҮејӮеҖјзҡ„дёӢйҷҚи¶ӢеҠҝеҸҜд»ҘдҪңдёәеҲӨж–ӯдҝЎеҸ·жҲҗеҲҶеҸҳеҢ–зҡ„дёҖдёӘжҢҮж ҮгҖӮ йҖҡиҝҮз»ҳеҲ¶еҘҮејӮеҖјзҡ„зҙҜз§ҜиҙЎзҢ®зҺҮжӣІзәҝпјҢжҲ‘们еҸҜд»Ҙи§ӮеҜҹеҲ°еҘҮејӮеҖјзҡ„жҳҫи‘—дёӢйҷҚзӮ№пјҢиҝҷдёӘзӮ№йҖҡеёёеҜ№еә”зқҖдҝЎеҸ·дё»иҰҒжҲҗеҲҶзҡ„з»“жқҹпјҢеҗҺз»ӯзҡ„еҘҮејӮеҖјеҸҜд»Ҙи§ҶдёәеҷӘеЈ°жҲ–ж¬ЎиҰҒжҲҗеҲҶгҖӮиҝҷдёӘжҳҫи‘—дёӢйҷҚзӮ№еҚідёәйҖүжӢ©KеҖјзҡ„дҫқжҚ®гҖӮдёҖиҲ¬жқҘиҜҙпјҢйҖүжӢ©еҘҮејӮеҖјжӣІзәҝеҮәзҺ°вҖңиҪ¬жҠҳвҖқжҲ–иҖ…вҖңе№іеҸ°вҖқзҡ„дҪҚзҪ®дҪңдёәKеҖјпјҢеҸҜд»ҘзЎ®дҝқдё»иҰҒдҝЎеҸ·жҲҗеҲҶиў«дҝқз•ҷпјҢеҗҢж—¶е°ҪеҸҜиғҪеҮҸе°‘еҷӘеЈ°зҡ„еҪұе“ҚгҖӮ е…·дҪ“е®һзҺ°жӯҘйӘӨеҰӮдёӢпјҡ 1. еҜ№дҝЎеҸ·иҝӣиЎҢSVDпјҢеҫ—еҲ°еҘҮејӮеҖјеәҸеҲ—гҖӮ 2. и®Ўз®—еҘҮејӮеҖјзҡ„зҙҜз§ҜиҙЎзҢ®зҺҮпјҢеҚіе°ҶеҘҮејӮеҖјжҢүйҷҚеәҸжҺ’еҲ—еҗҺпјҢжҜҸдёӘеҘҮејӮеҖјйҷӨд»ҘжүҖжңүеҘҮејӮеҖјзҡ„е’ҢпјҢ然еҗҺзҙҜеҠ гҖӮ 3. з»ҳеҲ¶зҙҜз§ҜиҙЎзҢ®зҺҮжӣІзәҝпјҢ并еҜ»жүҫжӣІзәҝзҡ„иҪ¬жҠҳзӮ№жҲ–иҖ…е№іеҸ°еҢәгҖӮ 4. е°ҶиҪ¬жҠҳзӮ№еҜ№еә”зҡ„еҘҮејӮеҖјдёӘж•°дҪңдёәVMDзҡ„KеҖјгҖӮ еңЁе®һйҷ…еә”з”ЁдёӯпјҢзЎ®е®ҡKеҖјиҝҳеҸҜд»Ҙз»“еҗҲе…¶д»–еҮҶеҲҷпјҢеҰӮдҝЎжҒҜзҶөгҖҒиғҪйҮҸйӣҶдёӯеәҰзӯүпјҢд»ҘзЎ®дҝқеҲҶи§Јзҡ„еҗҲзҗҶжҖ§е’ҢзЁіе®ҡжҖ§гҖӮжӯӨеӨ–пјҢдёҚеҗҢзҡ„дҝЎеҸ·е’Ңеә”з”ЁеңәжҷҜеҸҜиғҪйңҖиҰҒи°ғж•ҙKеҖјзҡ„йҖүжӢ©зӯ–з•ҘпјҢиҝҷйңҖиҰҒж №жҚ®е…·дҪ“й—®йўҳиҝӣиЎҢз»ҶиҮҙзҡ„з ”з©¶е’Ңе®һйӘҢйӘҢиҜҒгҖӮ жҖ»з»“жқҘиҜҙпјҢеҲ©з”ЁSVDзЎ®е®ҡVMDзҡ„KеҖјжҳҜйҖҡиҝҮеҜ№еҘҮејӮеҖјеҲҶеёғзҡ„еҲҶжһҗпјҢжүҫеҮәдҝЎеҸ·дё»иҰҒжҲҗеҲҶдёҺеҷӘеЈ°д№Ӣй—ҙзҡ„з•ҢйҷҗпјҢд»ҺиҖҢйҖүжӢ©дёҖдёӘеҗҲйҖӮзҡ„еҲҶи§ЈжЁЎејҸж•°йҮҸгҖӮиҝҷз§Қж–№жі•жңүеҠ©дәҺжҸҗеҸ–дҝЎеҸ·зҡ„е…ій”®зү№еҫҒпјҢжҸҗй«ҳVMDеҲҶи§Јзҡ„ж•ҲзҺҮе’ҢеҮҶзЎ®жҖ§гҖӮгҖӮеҶ…е®№жқҘжәҗдәҺзҪ‘з»ңеҲҶдә«пјҢеҰӮжңүдҫөжқғиҜ·иҒ”зі»жҲ‘еҲ йҷӨгҖӮ
еёёз”ЁжҠӨзҗҶжҠҖжңҜж“ҚдҪң规зЁӢ49йЎ№.docx
еұҖйғЁйҳҙеҪұйҒ®жҢЎпјҢзҒ°зӢјMPPTпјҢзҒ°зӢјз®—жі• зҒ°зӢјз®—жі•е®һзҺ°йғЁеҲҶйҒ®йҳҙзҡ„MPPTи·ҹиёӘпјҢеҢ…жӢ¬е…үз…§зӘҒеҸҳжғ…еҶөпјҢеҢ…жӢ¬зҒ°зӢјз®—жі•зЁӢеәҸе’Ңmatlab simulinkжЁЎеһӢзҡ„жҗӯе»әпјҢеҠҹзҺҮпјҢз”өеҺӢпјҢз”өжөҒжіўеҪўеӣҫе’ҢеҚ з©әжҜ”жіўеҪўеӣҫе…ҘеҰӮдёӢгҖӮ ,еұҖйғЁйҳҙеҪұйҒ®жҢЎ; зҒ°зӢјMPPT; зҒ°зӢјз®—жі•; е…үз…§зӘҒеҸҳ; жіўеҪўеӣҫ; зЁӢеәҸжҗӯе»ә; matlab simulinkжЁЎеһӢ,зҒ°зӢјз®—жі•MPPTи·ҹиёӘпјҢеұҖйғЁйҒ®йҳҙеҸҠзӘҒеҸҳжғ…еҶөз ”з©¶
XCPжҲ–иҖ…CCPж Үе®ҡпјҢA2Lж Үе®ҡж–Ү件пјҢеҹәдәҺmapж–Ү件иҮӘеҠЁжӣҙж–°A2Lзҡ„ең°еқҖе’Ңз»“жһ„дҪ“еҸҳйҮҸзҡ„ең°еқҖ жәҗз ҒеҹәдәҺCпјғйңҖиҰҒејҖеҸ‘пјҢзј–иҜ‘еҷЁдёәVS2022 ,XCP/CCPж Үе®ҡ; A2Lж Үе®ҡж–Ү件; ең°еӣҫж–Ү件иҮӘеҠЁжӣҙж–°; C#ејҖеҸ‘; VS2022зј–иҜ‘еҷЁ,еҹәдәҺC#ејҖеҸ‘зҡ„XCP/CCPж Үе®ҡзі»з»ҹпјҢиҮӘеҠЁжӣҙж–°A2Lж–Ү件ең°еқҖдёҺз»“жһ„дҪ“еҸҳйҮҸ
з»ҷйӮЈдәӣдҝ®ж”№kofзҡ„зҺ©е®¶з”Ёзҡ„е·Ҙе…·пјҢз®ҖеҚ•еҝ«жҚ·ж–№дҫҝпјҢйңҖиҰҒиҮӘеҸ–
s10207-024-00818-y.pdf
Screenshot_20250314_152955.jpg
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮжЎЈиҜҰз»Ҷд»Ӣз»ҚдәҶ FactSet е…¬еҸёжҺЁеҮәзҡ„ Truvalue V3 е№іеҸ°зҡ„еҶ…е®№йҮҮйӣҶдёҺеӨ„зҗҶжөҒзЁӢеҸҠе…¶иҜ„еҲҶж–№жі•гҖӮFactSet еҲ©з”Ёдәәе·ҘжҷәиғҪжҠҖжңҜе’ҢиҜӯд№үеӨ§ж•°жҚ®еӨ„зҗҶиғҪеҠӣ收йӣҶ并解жһҗжҜҸж—Ҙи¶…иҝҮ4000дёҮд»ҪжқҘиҮӘ20еӨҡдёҮдҝЎжәҗзҡ„е…ЁзҗғESGзӣёе…ідҝЎжҒҜгҖӮйҖҡиҝҮеҜ№иҝҷдәӣйқһз»“жһ„еҢ–ж–Үжң¬ж•°жҚ®зҡ„ж·ұеәҰеү–жһҗпјҢTruvalueе№іеҸ°иғҪеӨҹиҜҶеҲ«е…ій”®ESGдё»йўҳ并йҮҸеҢ–жғ…з»ӘеҖҫеҗ‘еәҰгҖӮе®ғдёҚд»…жҸҗдҫӣеҚ•зҜҮж–Үз« еұӮйқўзҡ„жғ…з»Әжү“еҲҶпјҲд»ҺжңҖж¶ҲжһҒ0еҲ°жңҖз§ҜжһҒ100пјүпјҢиҖҢдё”иҝҳз»јеҗҲиҜ„дј°е…¬еҸёй•ҝжңҹеҸ‘еұ•и¶ӢеҠҝд»ҘеҸҠзҹӯжңҹеёӮеңәиЎЁзҺ°гҖӮжӯӨеӨ–пјҢиҝҳи®Ёи®әдәҶеҠЁжҖҒйҮҚиҰҒжҖ§е’ҢйҮҚзӮ№дәӢ件жЈҖжөӢзӯүзү№еҫҒпјҢдҪҝеҲҶжһҗеёҲжӣҙе®№жҳ“жҚ•жҚүеҲ°дјҒдёҡжҙ»еҠЁиғҢеҗҺзҡ„жҪңеңЁжңәдјҡдёҺйЈҺйҷ©гҖӮ йҖӮз”ЁдәәзҫӨпјҡйҮ‘иһҚиЎҢдёҡд»ҺдёҡиҖ…еҰӮжҠ•иө„йЎҫй—®гҖҒеҹәйҮ‘з»ҸзҗҶд»ҘеҸҠе…¶д»–е…іжіЁдјҒдёҡеҸҜжҢҒз»ӯеҸ‘еұ•е’ҢзӨҫдјҡиҙЈд»»зҡ„дё“дёҡдәәеЈ«гҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮпјҡдёәжҠ•иө„иҖ…жҸҗдҫӣзІҫеҮҶзҡ„ж•°жҚ®ж”ҜжҢҒд»ҘиҝӣиЎҢиө„дә§й…ҚзҪ®еҶізӯ–пјӣиҫ…еҠ©з ”究е‘ҳеҜ№зү№е®ҡдјҒдёҡжҲ–иЎҢдёҡзҡ„ж·ұеәҰи°ғз ”е·ҘдҪңгҖӮ е…¶д»–иҜҙжҳҺпјҡжң¬ж–№жі•и®әзү№еҲ«ејәи°ғйҮҮз”ЁSASBж ҮеҮҶдҪңдёәиҜ„д»·еҹәеҮҶд№ӢдёҖпјҢ并解йҮҠдәҶеҮ з§ҚйҮҚиҰҒзҡ„еҫ—еҲҶи®Ўз®—е…¬ејҸпјҢеҰӮи„үжҗҸеҲҶж•°гҖҒжҙһеҜҹеҠӣеҲҶж•°еҸҠж—¶еҠҝеҠЁйҮҸжҢҮж Үзӯүзҡ„е…·дҪ“иҝҗдҪңжңәеҲ¶гҖӮеҗҢж—¶жҰӮиҝ°дәҶдёҖдәӣиҙЁйҮҸжҺ§еҲ¶жҺӘж–Ҫд»ҘзЎ®дҝқжүҖжҸҗдҫӣж•°жҚ®зҡ„жңүж•ҲжҖ§е’ҢеҮҶзЎ®жҖ§гҖӮ
жҜ•дёҡи®ҫи®Ў&иҜҫзЁӢи®ҫи®Ў еҹәдәҺSTM32еҚ•зүҮжңәзҡ„зү©иҒ”зҪ‘жҷәиғҪ家еәӯе®үйҳІзі»з»ҹпјҲиҪҜ件жәҗз Ғ+硬件иө„ж–ҷ+йғЁзҪІж•ҷзЁӢ+и®ҫи®Ўд»»еҠЎд№Ұ+жј”зӨәи§Ҷйў‘пјүпјҢй«ҳеҲҶйЎ№зӣ®пјҢејҖз®ұеҚіз”Ё йҡҸзқҖе…¬дј—е®үе…Ёж„ҸиҜҶзҡ„жҸҗй«ҳпјҢдәә们еҜ№е®¶еәӯе®үе…ЁйҳІжҺ§зҡ„йңҖжұӮж„ҲеҸ‘иҝ«еҲҮпјҢеҰӮдҪ•еҗҲзҗҶеә”з”ЁжҺ§еҲ¶гҖҒйҖҡдҝЎеҸҠзӣ‘жҺ§зӯүиҮӘеҠЁеҢ–жҠҖжңҜжүӢж®өпјҢжү“йҖ жҷәиғҪеҢ–家еәӯе®үйҳІзі»з»ҹжҲҗдёәз ”з©¶йҮҚзӮ№гҖӮеӣ жӯӨжҸҗеҮәдәҶеҹәдәҺзү©иҒ”зҪ‘зҡ„家еәӯе®үйҳІзі»з»ҹ,е®һзҺ°зӣ‘жөӢзҮғж°”жі„жјҸ并жҠҘиӯҰгҖҒзӣ‘жөӢзҒ«зҒҫзғҹйӣҫ并жҠҘиӯҰгҖҒжЈҖжөӢйқһжі•е…Ҙе®Ө并жҠҘиӯҰзӯүеҠҹиғҪпјҢжһҒеӨ§дҝқйҡң家еәӯеұ…дҪҸеңәжүҖзҡ„е®үе…ЁжҖ§гҖӮ з”ЁSTM32еҚ•зүҮжңәејҖеҸ‘пјҡ 1гҖҒзӣ‘жөӢзҮғж°”жі„жјҸ(MQ-5)гҖҒзӣ‘жөӢзҒ«зҒҫзғҹйӣҫ(DS18B20гҖҒMO-7)гҖҒжЈҖжөӢйқһжі•е…Ҙе®Ө(зәўеӨ–еҜ№з®Ў) 2гҖҒж¶Іжҷ¶жҳҫзӨәзҮғж°”жө“еәҰгҖҒзғҹйӣҫжө“еәҰгҖҒжё©еәҰгҖҒжҳҜеҗҰжңүдәәй—Ҝе…ҘгҖҒеёғйҳІзҠ¶жҖҒ 3гҖҒжҢүй”®еҸҜд»Ҙи®ҫзҪ®зҮғж°”гҖҒзғҹйӣҫгҖҒжё©еәҰзҡ„жҠҘиӯҰеҖјпјҢеӨ§дәҺж—¶еҖҷејҖеҗҜиңӮйёЈеҷЁжҠҘиӯҰд»ҘеҸҠеҜ№еә”зҡ„жҠҘиӯҰжҢҮзӨәзҒҜ 4гҖҒеҪ“зі»з»ҹејҖеҗҜеёғйҳІпјҢжңүдәәй—Ҝе…ҘпјҢејҖеҗҜиңӮйёЈеҷЁжҠҘиӯҰд»ҘеҸҠеҜ№еә”жҢҮзӨәзҒҜпјҢж’ӨйҳІж—¶пјҢдёҚжЈҖжөӢйқһжі•й—Ҝе…Ҙ 5гҖҒж•°жҚ®йҖҡиҝҮwIFIдёҠдј еҲ°жүӢжңәз«Ҝ 6гҖҒеҪ“жҠҘиӯҰж—¶еҖҷеҸ‘йҖҒжҠҘиӯҰзҹӯдҝЎпјҢзҹӯдҝЎеҢ…еҗ«и§ҰеҸ‘жҠҘиӯҰзҡ„жғ…еҶөпјҡеҰӮзҮғж°”жҠҘиӯҰеҸ‘йҖҒ:gas leakage жё©еәҰжҲ–иҖ…зғҹйӣҫжҠҘиӯҰеҸ‘йҖҒ:fire smoke alarm йқһжі•е…Ҙе®ӨеҸ‘йҖҒ:Illegal Entry
зҷҪиғЎжӨ’жЈҖйӘҢиЎЁж ј(йЈҹе“ҒйҰҷиҫӣж–ҷиҙЁйҮҸйӘҢ收记еҪ•иЎЁ)жЈҖйӘҢиЎЁж ј(йЈҹе“ҒйҰҷиҫӣж–ҷиҙЁйҮҸйӘҢ收记еҪ•иЎЁ).docx
зҹўйҮҸиҫ№з•ҢпјҢиЎҢж”ҝеҢәеҹҹиҫ№з•ҢпјҢзІҫзЎ®еҲ°д№Ўй•ҮиЎ—йҒ“пјҢеҸҜзӣҙжҺҘеҜје…ҘarcgisдҪҝз”Ё
c++еӨҡеӘ’дҪ“йҹіи§Ҷйў‘ж’ӯж”ҫеҷЁ
Adobe After Effects е…ЁеҘ—жҸ’件е®үиЈ…еҢ…
Flac3dеҮҪж•°еҪўејҸзҡ„еә”еҠӣиҫ№з•Ңж–ҪеҠ зј–зЁӢ flac3dеә”еҠӣиҫ№з•Ңзј–зЁӢеӨ„зҗҶ жң¬дёәжң¬дәәеҒҡзҡ„з®ҖеҚ•жЎҲдҫӢпјҡй’ҲеҜ№з«Ӣж–№дҪ“жЁЎеһӢпјҢеҗҢж—¶иҖғиҷ‘йҮҚеҠӣе’ҢдёҖдҫ§еә”еҠӣиҫ№з•ҢеҜ№жЁЎеһӢеә”еҠӣеҲҶеёғиҝӣиЎҢеҲҶжһҗгҖӮ зү№иүІпјҡеә”еҠӣеҮҪж•°еҸҜд»Ҙд»»ж„Ҹж”№еҸҳпјҢи°ғиҠӮз®ҖеҚ•еҝ«жҚ· д»Јз ҒиҜ·еүҚе’ЁиҜўдәҶи§Јжё…жҘҡпјҢдёҚж”ҜжҢҒ ж¬ҫ й’ҲеҜ№ең°еә”еҠӣеҸҚжј”гҖҒиө°ж»‘ж–ӯеұӮзӯүеҲҶжһҗдёӯзҡ„еә”еҠӣиҫ№з•ҢдҪҚ移иҫ№з•Ңй—®йўҳеҰӮжңүйңҖжұӮе®ҡеҲ¶ ,Flac3d;еә”еҠӣиҫ№з•Ңж–ҪеҠ ;зј–зЁӢеӨ„зҗҶ;з«Ӣж–№дҪ“жЁЎеһӢ;йҮҚеҠӣеҪұе“Қ;еә”еҠӣеҲҶеёғеҲҶжһҗ;еҮҪж•°еҪўејҸеә”еҠӣиҫ№з•Ң;ең°еә”еҠӣеҸҚжј”;иө°ж»‘ж–ӯеұӮ;дҪҚ移иҫ№з•Ңй—®йўҳгҖӮ,Flac3dзј–зЁӢпјҡеә”еҠӣиҫ№з•Ңж–ҪеҠ зҡ„з®Җжҳ“жЎҲдҫӢеҲҶжһҗ
еҹәдәҺmatlabзҡ„еҮқеңҹйҡҸжңәзҗғеҪўйӘЁж–ҷзҗғдҪ“и’ҷзү№еҚЎжҙӣйҡҸжңәеҲҶеёғжЁЎеһӢ дёүз§ҚзІ’еҫ„дёҚеҗҢзҡ„йӘЁж–ҷйҡҸжңәеҲҶеёғ жЁЎжӢҹж··еҮқеңҹжқҗж–ҷзҡ„иҝҮзЁӢпјҢзІ’еҫ„еҸҜиҮӘиЎҢе®ҡд№үпјҢеҸҜи®ҫзҪ®еӯ”йҡҷзҺҮ еҠЁз”»жҳҫзӨәе»әжЁЎиҝҮзЁӢ зЁӢеәҸе·Іи°ғйҖҡпјҢеҸҜзӣҙжҺҘиҝҗиЎҢ ,еҹәдәҺMatlab; еҮқеңҹйҡҸжңәзҗғеҪўйӘЁж–ҷ; зҗғдҪ“и’ҷзү№еҚЎжҙӣйҡҸжңәеҲҶеёғжЁЎеһӢ; дёҚеҗҢзІ’еҫ„йӘЁж–ҷйҡҸжңәеҲҶеёғ; жЁЎжӢҹж··еҮқеңҹжқҗж–ҷ; зІ’еҫ„еҸҜе®ҡд№ү; еӯ”йҡҷзҺҮеҸҜи®ҫзҪ®; еҠЁз”»жҳҫзӨәе»әжЁЎиҝҮзЁӢ; зЁӢеәҸе·Іи°ғйҖҡгҖӮ,еҹәдәҺMatlabзҡ„ж··еҮқеңҹйӘЁж–ҷйҡҸжңәеҲҶеёғжЁЎжӢҹзЁӢеәҸ
2008-2020е№ҙеҗ„зңҒжҜҸеҚҒдёҮдәәеҸЈй«ҳзӯүеӯҰж Ўе№іеқҮеңЁж Ўз”ҹж•°ж•°жҚ® 1гҖҒж—¶й—ҙпјҡ2008-2020е№ҙ 2гҖҒжқҘжәҗпјҡеӣҪ家з»ҹи®ЎjгҖҒз»ҹи®Ўnj 3гҖҒжҢҮж ҮпјҡиЎҢж”ҝеҢәеҲ’д»Јз ҒгҖҒең°еҢәеҗҚз§°гҖҒе№ҙд»ҪгҖҒжҜҸеҚҒдёҮдәәеҸЈй«ҳзӯүеӯҰж Ўе№іеқҮеңЁж Ўз”ҹж•° 4гҖҒиҢғеӣҙпјҡ31зңҒ