
摘要: 随着云计算和IoT的发展,时间序列数据的数据量急剧膨胀,高效的分析时间序列数据,使之产生业务价值成为一个热门话题。阿里巴巴数据库事业部的HiTSDB团队为您分享时间序列数据的计算分析的一般方法以及优化手段。
演讲嘉宾简介:钟宇(悠你) 阿里巴巴 数据库高级专家,时间序列数据库HiTSDB的研发负责人。在数据库、操作系统、函数式编程等方面有丰富的经验。
本次分享主要分为以下几个方面:
1. 时序数据库的应用场景
2. 面向分析的时序数据存储
3. 时序数据库的时序计算
4. 时序数据库的计算引擎
5. 时序数据库展望
一,时序数据库的应用场景
时序数据就是在时间上分布的一系列数值。生活中常见的时序数据包括,股票价格、广告数据、气温变化、网站的PV/UV、个人健康数据、工业传感器数据、服务器系统监控数据(比如CPU和内存占用率)、车联网等。
下面介绍IoT领域中的时间序列数据案例。IoT给时序数据处理带来了很大的挑战。这是由于IoT领域带来了海量的时间序列数据:
1. 成千上万的设备
2. 数以百万计的传感器
3. 每秒产生百万条数据
4. 24×7全年无休(区别于电商数据,电商数据存在高峰和低谷,因此可以利用低谷的时间段进行数据库维护,数据备份等工作)
5. 多维度查询/聚合
6. 最新数据实时可查
IoT中的时间序列数据处理主要包括以下四步:
1. 采样
2. 传输
3. 存储
4. 分析
二,面向分析的时序数据存储
下面介绍时间序列数据的一个例子。这是一个新能源风力发电机的例子。每个风力发电机上有两个传感器,一个是功率,一个是风速,并定时进行采样。三个设备,一共会产生六个时间序列。每个发电机都有多种标签,这就会产生多个数据维度。比如,基于生产厂商这个维度,对功率做聚合。或基于风场,对风速做聚合等。现在的时序数据库底层存储一般用的是单值模型。因为多值模型也可以一对一的映射到单值模型,但这个过程可能会导致性能损失。但是,在对外提供服务时,单值模型和多值模型都有应用。比如,OpenTSDB就是用单值模型对外提供服务的,而influxDB则是多值模型。但这两种数据库的底层存储用的都是单值模型。
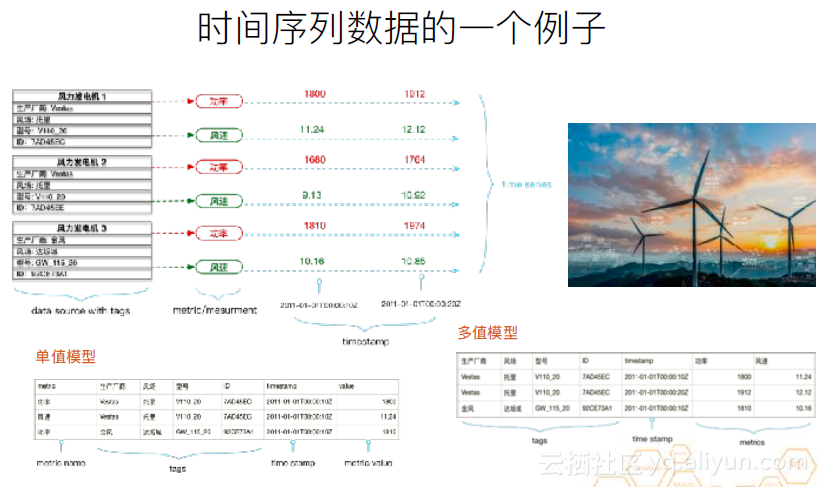
现实中的应用案例事实上会更复杂。像风力发电机这样的案例,它的设备和传感器的数量,我们可以认为是稳中有增的,不会发生特别剧烈的改变。它的数据采样的周期也是严格的定期采样。下图是一个工业案例,以滴滴这样的运营商为例。由于其业务特性,其车辆数量的增长和下降会出现暴涨暴跌。

总体而言,现实世界的复杂之处在于:
1. 未必是总是定时采样。
2. 时间线可能是高度发散。以互联网广告为例,在对广告进行采样时,新广告的增长和老广告的下线速度很快,时间线就很有可能时高度发散的。
3. 主键和schema修改。前面例子中提到的Tag,可以对应数据库的schema,在实际业务中可能会频繁改动。现在一般的时序数据库中,主键是会默认生成的,即所有tag的组合。因此,在新增tag时,主键就会改变,则变为了另一个对象。
4. 分布式系统和片键。由于数据量很大,因此需要对数据进行分片,片键的选择也是一个难以抉择的问题。
5. 数据类型。以刚才提到的单值模型为例。假设有一个三维的加速度传感器,同一时间点上会产生三个关联的数据,这时的数据类型就应该是一个维度为3的矢量,即一个新的数据类型。
6. 需要对每个数据点的值做过滤。假设每辆车上都装有GPS传感器,假设要统计某一时间段内,一公里内,出现了哪些车辆,分别由哪些厂商生产。此时需要对地理位置进行过滤。
下图是过去提出利用HiTSDB对时序问题的解决方案。在这种方案中,未解决发散问题,较高维数据和值过滤问题。用倒排索引来存储设备信息,并把时间点上的数据存在高压缩比缓存中。这两者结合,实际上将逻辑上的一个表分成了两个表,用以解决多维度查询和聚合的问题。但使用这种方案依然有很多问题无法解决。

下面是HiTSDB的一些优势和不足:
1. 优势:
倒排索引可以很方便的筛选设备;
高压缩比缓存具有很高的写入和读取能力
方便的时间切片
无schema,灵活方便支持各种数据模型
2. 不足:
在非定时采样场景下可能导致数据稀疏
值没有索引,因此值过滤只能线性过滤
Schema改动导致时间线变动
广播查限制了QPS
在此基础上,进行了演进,如下图。
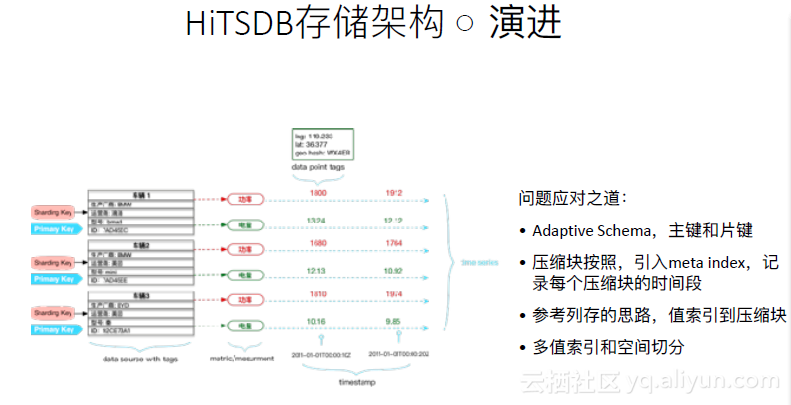
1. 引入了Adaptive schema,即如果未指定一个数据表的schema,则认为写入的第一条数据中包含的TagKV即是片键也是主键,用以确定唯一性以及数据会被分片到哪一个节点上。
2. 压缩块也不再是按固定的时间切片了,引入了meta index,用以查询每个数据块的开始和结束时间。在一个时间段内攒够了足够的数据后,把整个数据块进行压缩。
3. 参考列存的思路,值索引到压缩块。值索引不再像传统数据库那样索引到行。
4. 多值索引和空间切分。
三,时序数据库的时序算法
上面所述的存储结构主要是为了方便进行时序数据的加工和分析。时序有一些特殊算法。
1. 降采样和插值:传感器采样出的点可能特别密集,在分析趋势时,会希望进行过滤。通过降采样可以利用一段时间内的最小值/最大值/平均值来替代。
降采样算法:min/max/avg。
插值算法:补零/线性/贝塞尔曲线
2. 聚合计算:由于采样是精确到每个传感器的,但有时需要的数据并不仅是精确到某个传感器的。比如,希望比较两个不同厂商的发电机,哪个在风场中产生了更多的电。那么就需要对传感器数据进行聚合。
逻辑聚合:min/max
算术聚合:sum/count/avg
统计:histogram/percentile/Standard Deviation
3. 时间轴计算
变化率:rate
对时序数据进行加工的分析的重要目的是发现异常。下面介绍在异常检测中如何定义问题。从异常检测的角度来看时间序列数据,分为三个维度:time, object, metric。
1. 固定两个维度,只考虑一个维度的数据。
·T: only consider time dim,单一对象单一metric即单个时间序列):spikes & dips、趋势变化、范围变化。
·M: only consider metric,找出不符合metric之间相互关系的数据。
·O: only consider object,找出与众不同的对象。
2. 固定一个维度,只考虑两个维度的数据。
·MT:固定对象,考虑多个时间序列(每个对应一个metric),并找出其相互变化方式不同的作为异常。
·MO:不考虑时间特性,考虑多个对象且每个对象都可以用多个metric表示,如何从中找出不同的对象。
·TO:多个对象单一metric,找出变化趋势不同的对象。
在异常检测中,面向问题有如下计算方法:
1. 内置函数
·高压缩比缓存直接作为窗口缓存
·对于满足数据局部性的问题,直接在高压缩比缓存上运行
·结果直接写回
·定时调度 vs 数据触发
2. 外置计算
·定时查询 vs 流式读取
·使用同样的查询语言执行查询或定义数据源
·数据库内置时间窗口
·数据流的触发机制
针对时序数据,又可以将计算分为预计算和后计算。

预计算:事先将结果计算完并存储。这是流计算中常用的方式。其特点如下:
·数据存储量低
·查询性能高
·需要手工编写计算过程
·新的计算无法立即查看结果
·灵活性差
·不保存原始数据
后计算:先存数据,需要时进行计算。这是数据库中常用的方式。其特点如下:
·数据存储量大
·查询/聚合性能瓶颈
·任何查询都可以随时获得结果
·使用DSL进行查询
·灵活性好
·保存原始数据
四,时序数据库的计算引擎
基于两种计算的特点,在时序数据处理中,我们使用的是一种混合架构。有数据进来时,有预聚合规则,如果符合规则就进行预聚合,把数据写入数据库中。在查询时,如果符合预聚合规则,就可以很快得到结果。对于不满足预聚合规则的数据,会将其从数据库中读出,进行后聚合。中间的聚合引擎是一种类似流式计算的架构,数据库或者数据源都可以作为数据源。数据源的来源对于引擎是不可见的,它的功能是接收数据,计算并产生结果。因此,预计算和后计算都可以利用这一种逻辑进行,并放在同一个运行环境中。
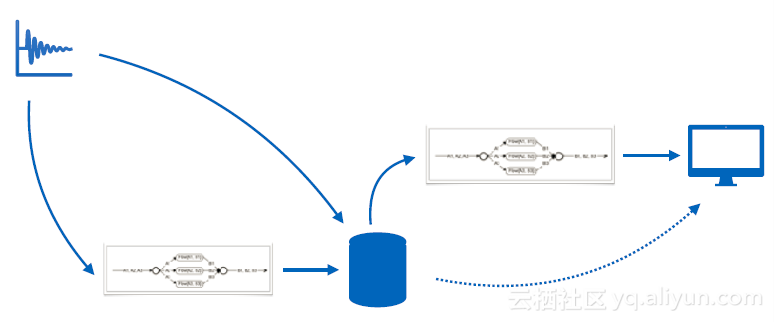
在逻辑上,上图是可行的。但实际上,如果要用这种方式进行流计算,由于数据源可能出现乱序等问题,就必须要利用窗口函数,将数据放入时间窗口中整理好,但这种缓存的效率其实并不高,实际情况下,是按照下图这种逻辑进行的。数据会被写进数据库,由于数据库有高压缩比缓存,是专门针对时序数据的。当一个时间窗口结束时,利用持续查询来进行预计算。它会将高压缩比缓存中的数据拿一部分出来做预聚合再写回数据库中。这样,这个缓存机制就替代了原来的时间窗口,节省了很多内存,降低了很多计算开销。
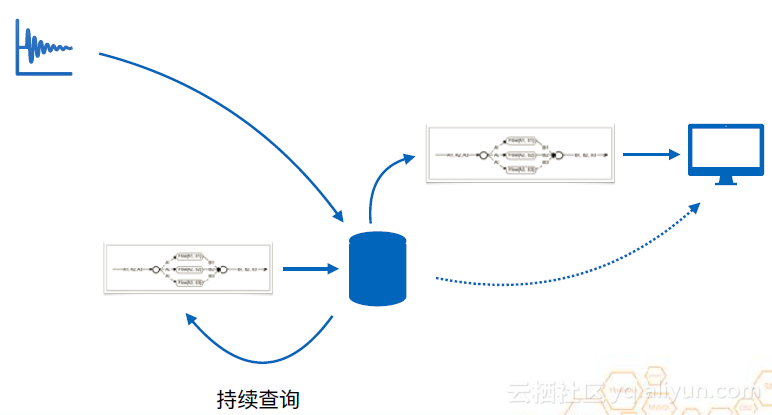
使用类似于流的架构的好处是可以将其很快的接入异构计算的环境中。正如大家熟知的,流计算可以转化为一个DAG。结合前面提到的降采样和聚合的例子。以一个加法为例,可以把数据切成三片放入不同的工作节点上计算,计算完后再进行一次聚合输出数据。工作节点既可能是CPU也可能是GPU。接入异构计算的环境中,可以加速数据的计算。
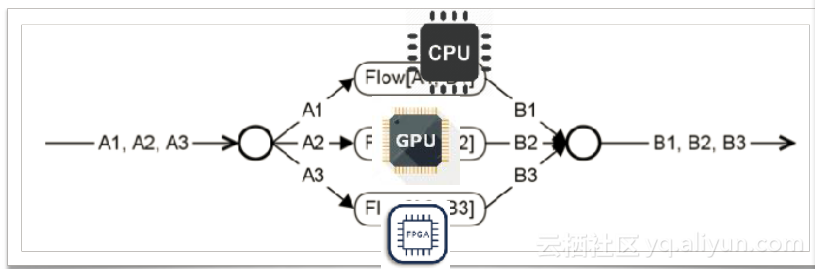
五,时序数据库展望
下图是对未来架构的展望。
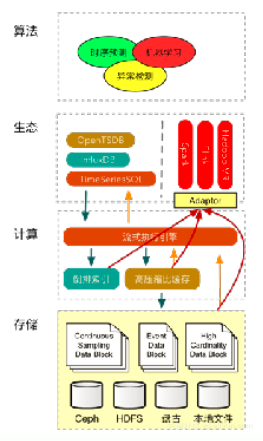
1. 存储层
·类似lambda架构,基于一系列不可修改的文件
·针对不同的场景提供不同的存储格式
2. 计算层
·流式架构,基于内存的异构计算,自动填充热数据
·数据分片,支持高QPS读取
3. 索引
·全局的索引 vs 文件局部索引
4. 大数据
·可以直接在大量的文件上跑MR,也可以通过高压缩比缓存以流的方式订阅数据
未来,这个数据库将会演化成时序数据平台。它可以兼容SQL生态,一系列大数据平台,以及融合边缘计算。在部署时可以在云和边缘部署一整套的管理架构,同时把用SQL描述的规则下放到云板和边缘板上,形成一整套数据处理方案。

POLARDB:https://www.aliyun.com/product/polardb?spm=5176.8142029.388261.347.62136d3etcPz5x
HBASE: https://www.aliyun.com/product/hbase?spm=5176.155538.765261.355.57227e0dLAlXGl
云数据库RDS PPAS 版 :https://www.aliyun.com/product/rds/ppas?spm=5176.54432.765261.351.6e1e28f5UFqADw



相关推荐
标题提及的“网络游戏-一种基于动态网络图分析的时间序列数据处理方法”正是这样一种创新技术,它将动态网络图分析与时间序列数据处理相结合,旨在解决网络游戏中的复杂问题。 动态网络图是一种表示系统中各个元素...
1、资源内容:基于Matlab实现时间序列数据处理(源码+数据+说明文档).rar 2、适用人群:计算机,电子信息工程、数学等专业的大学生课程设计、期末大作业或毕业设计,作为“参考资料”使用。 3、解压说明:本资源...
这种网络结构在处理时间序列数据、文本分类、音频信号分析等方面表现出色。本文将深入探讨1D CNN的工作原理、应用场景以及如何用Python实现。 1D CNN的核心思想是利用卷积核对一维数据进行滑动窗口操作,提取特征。...
**Python在金融大数据领域的应用:第四讲 - 金融时间序列数据处理与分析** 在金融行业中,数据处理和分析是至关重要的任务,而Python作为一种强大的编程语言,已经成为了金融数据分析的首选工具。本教程将深入探讨...
时间序列数据处理是数据分析领域的重要组成部分,特别是在物联网(IoT)和数据库管理中。时间序列数据是由一系列在特定时间点上记录的数值组成,如股票价格、广告数据、气温变化、网站流量、个人健康数据、工业...
在遥感和气象学中,时间序列数据常用来追踪和分析某一地区的长期变化,如海平面、温度或降水量的变化。 3. **时间序列**:时间序列分析是统计学的一个分支,专门处理按时间顺序排列的数据。它用于检测趋势、周期性...
时间序列数据处理是指对随时间变化而记录下的数据序列进行分析和管理的一系列技术。这些数据具有时间的顺序性、连续性和时效性等特点。在云计算领域,尤其以物联网(IoT)为代表的场景中,时间序列数据的处理变得尤为...
多元时间序列数据集是数据挖掘领域中的重要资源,它们包含了多个不同时间点上的观测值,这些观测值可以对应于各种不同的变量或特征。在本数据集中,我们可以找到多个具有特定特性的数据集,如AUSLAN、WalkvsRun、...
5. **时间序列数据处理**: - **定义日期**:在SPSS中,需要通过“Data→Define Dates”定义数据的时间属性,以便正确处理时间序列数据。 - **时间序列图绘制**:选择合适的变量和时间轴标签绘制时间序列图,帮助...
redistimeseries.so redistimeseries.so redistimeseries.so redistimeseries.so redistimeseries.soredistimeseries.so redistimeseries.so redistimeseries.so redistimeseries.so redistimeseries.
在时间序列分析方面,Python提供了多种工具和库,如Pandas、NumPy、Matplotlib、Statsmodels等,这些库极大地简化了时间序列数据处理和分析的过程。 ##### Pandas:高效的数据处理 - **DataFrame对象**:Pandas的...
本篇内容主要探讨了时间序列数据处理的关键概念和方法,包括随机过程、平稳性原理以及平稳性检验。 首先,随机过程是描述一系列依赖于时间的随机变量的集合。在时间序列分析中,样本观测值被视为随机过程的一部分。...
总结来说,"第五讲-时间序列数据分析"涵盖了Python中进行时间序列数据处理和预测的核心概念和方法,包括数据读取、预处理、可视化、平滑、分解、建模和评估。通过学习和实践这些技术,你将能够对各种时间序列数据...
UCR(University of California, Riverside)单变量时间序列数据集是一系列专门用于时间序列分类任务的数据集合,由UCR时间序列分类档案馆提供。这个数据集包含了128个不同的子数据集,每个子数据集都代表一类特定的...
在这个案例中,我们关注的是一个名为“时间序列示例的数据集.rar”的压缩包文件,其中包含了一个或多个时间序列数据文件,这些文件通常用于教学、研究或实际应用中的预测模型构建。 首先,我们要理解时间序列数据的...
除此之外,基于小波分解的平稳时间序列分析法也被提出并应用于非平稳时间序列数据处理中。小波分析在处理非平稳时间序列方面具有独特的优势,它能够将信号分解到不同的频率层面上,各个层面上的信号近似为平稳信号,...
GRU是一种特殊的循环神经网络(RNN),被设计来处理序列数据,如时间序列数据,通过捕捉序列中的时间动态特征来进行预测或分类。数据文档是一个天气时间序列数据集,它由德国耶拿的马克思 • 普朗克生物地球化学研究...
多变量输入意味着模型不仅考虑单一的时间序列数据,还同时考虑多个相关变量来预测目标变量,这样可以提供更全面的信息,提高预测准确性。而单变量输入可能只基于一个特征进行预测,这在某些场景下可能是足够的,例如...
GIMMS NDVI数据ENVI裁剪和R语言时间序列处理...8. 时间序列处理分析:时间序列处理分析是指对时间序列数据进行处理和分析,以了解数据的变化趋势和规律。可以使用R语言中的相关函数和 packages 实现时间序列处理分析。