
жСШи¶БпЉЪ¬†2018зђђдєЭе±КдЄ≠еЫљжХ∞жНЃеЇУжКАжЬѓе§ІдЉЪпЉМйШњйЗМдЇСйЂШзЇІжКАжЬѓдЄУеЃґгАБжЮґжЮДеЄИе∞Бз•ЮпЉИжЫєйЊЩпЉЙеЄ¶жЭ•йҐШдЄЇе§ІжХ∞жНЃжЧґдї£жХ∞жНЃеЇУ-дЇСHBaseжЮґжЮД&зФЯжАБ&еЃЮиЈµзЪДжЉФиЃ≤гАВдЄїи¶БеЖЕеЃєжЬЙдЄЙдЄ™жЦєйЭҐпЉЪй¶ЦеЕИдїЛзїНдЇЖдЄЪеК°жМСжИШеЄ¶жЭ•зЪДжЮґжЮДжЉФињЫпЉМеЕґжђ°еИЖжЮРдЇЖApsaraDB HBaseеПКзФЯжАБпЉМжЬАеРОеИЖдЇЂдЇЖе§ІжХ∞жНЃжХ∞жНЃеЇУзЪДеЃЮйЩЕж°ИдЊЛгАВ
2018зђђдєЭе±КдЄ≠еЫљжХ∞жНЃеЇУжКАжЬѓе§ІдЉЪпЉМйШњйЗМдЇСйЂШзЇІжКАжЬѓдЄУеЃґгАБжЮґжЮДеЄИе∞Бз•ЮпЉИжЫєйЊЩпЉЙеЄ¶жЭ•йҐШдЄЇе§ІжХ∞жНЃжЧґдї£жХ∞жНЃеЇУ-дЇСHBaseжЮґжЮД&зФЯжАБ&еЃЮиЈµзЪДжЉФиЃ≤гАВдЄїи¶БеЖЕеЃєжЬЙдЄЙдЄ™жЦєйЭҐпЉЪй¶ЦеЕИдїЛзїНдЇЖдЄЪеК°жМСжИШеЄ¶жЭ•зЪДжЮґжЮДжЉФињЫпЉМеЕґжђ°еИЖжЮРдЇЖApsaraDB HBaseеПКзФЯжАБпЉМжЬАеРОеИЖдЇЂдЇЖе§ІжХ∞жНЃжХ∞жНЃеЇУзЪДеЃЮйЩЕж°ИдЊЛгАВ
зЫіжТ≠иІЖйҐСеЫЮй°Њ
PPTдЄЛиљљиѓЈзВєеЗї
дї•дЄЛжШѓз≤Њељ©иІЖйҐСеЖЕеЃєжХізРЖпЉЪ
дЄЪеК°зЪДжМСжИШ
е≠ШеВ®йЗПп•Њ/еєґеПСиЃ°зЃЧеҐЮе§І
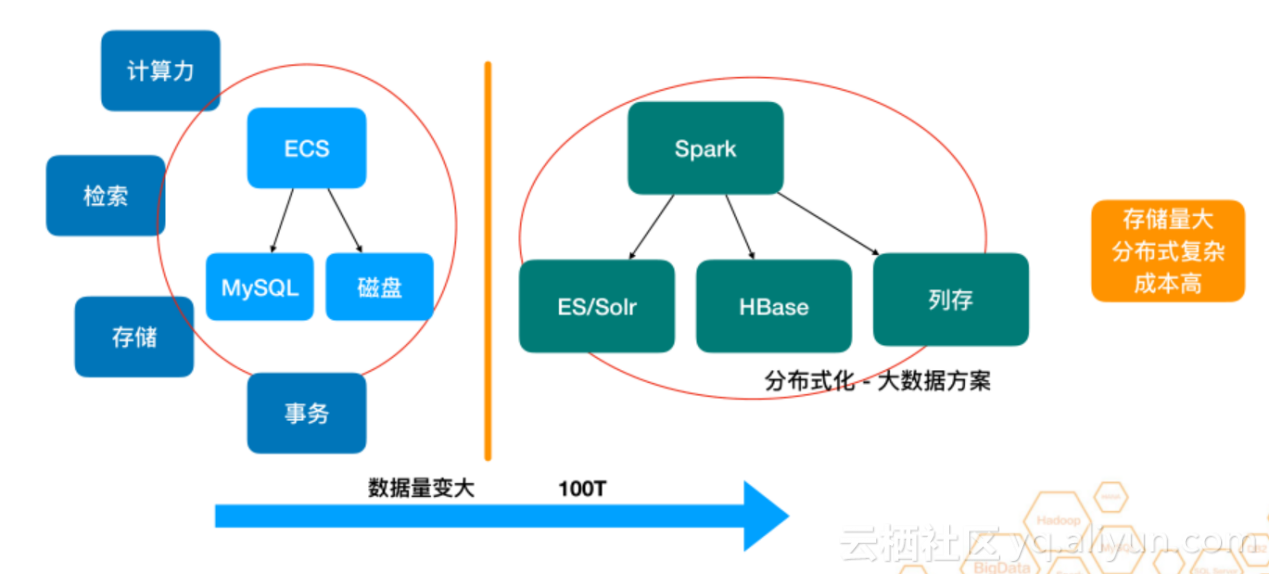
зО∞е¶ВдїКе§ІйЗПзЪДдЄ≠е∞ПеЮЛеЕђеПЄеєґж≤°жЬЙе§ІиІДж®°зЪДжХ∞жНЃпЉМе¶ВжЮЬдЄАеЃґеЕђеПЄзЪДжХ∞жНЃйЗПиґЕињЗ100TпЉМдЄФиГљйАЪињЗжХ∞жНЃдЇІзФЯжЦ∞зЪДдїЈеАЉпЉМеЯЇжЬђеПѓдї•иѓіжШѓе§ІжХ∞жНЃеЕђеПЄдЇЖ гАВиµЈеИЭпЉМдЄАдЄ™еИЫдЄЪеЕђеПЄзЪДеЯЇжЬђжАЭиЈѓе∞±жШѓй¶ЦеЕИжЮґжЮДдЄАдЄ™жИЦиАЕеЗ†дЄ™ECSпЉМеРОйЭҐеК†еЕ•MySQL,е¶ВжЮЬжЬЙеЫЊзЙЗйЬАж±ВињШеПѓеК†еЕ•з£БзЫШпЉМиѓ•жЮґжЮДзЪДеЯЇжЬђиГљеКЫеМЕжЛђдЇЛеК°гАБе≠ШеВ®гАБ糥еЉХеТМиЃ°зЃЧеКЫгАВйЪПзЭАеЕђеПЄзЪДжЕҐжЕҐеПСе±ХпЉМжХ∞жНЃйЗПеЬ®дЄНжЦ≠еЬ∞еҐЮе§ІпЉМеЕґйАЪињЗMySQLеПКз£БзЫШеЯЇжЬђжЧ†ж≥Хжї°иґ≥йЬАж±ВпЉМеП™жЬЙеИЖеЄГеЉПеМЦгАВ ињЩдЄ™жЧґеАЩMySQLеПШжИРдЇЖHBase,ж£А糥еПШжИРдЇЖSolr/ESпЉМеЖНECSжПРдЊЫзЪДиЃ°зЃЧеКЫеПШжИРдЇЖSparkгАВдљЖињЩдєЯдЉЪйЭҐдЄіе≠ШеВ®йЗПе§ІдЄФе≠ШеВ®жИРжЬђйЂШз≠ЙйЧЃйҐШгАВ
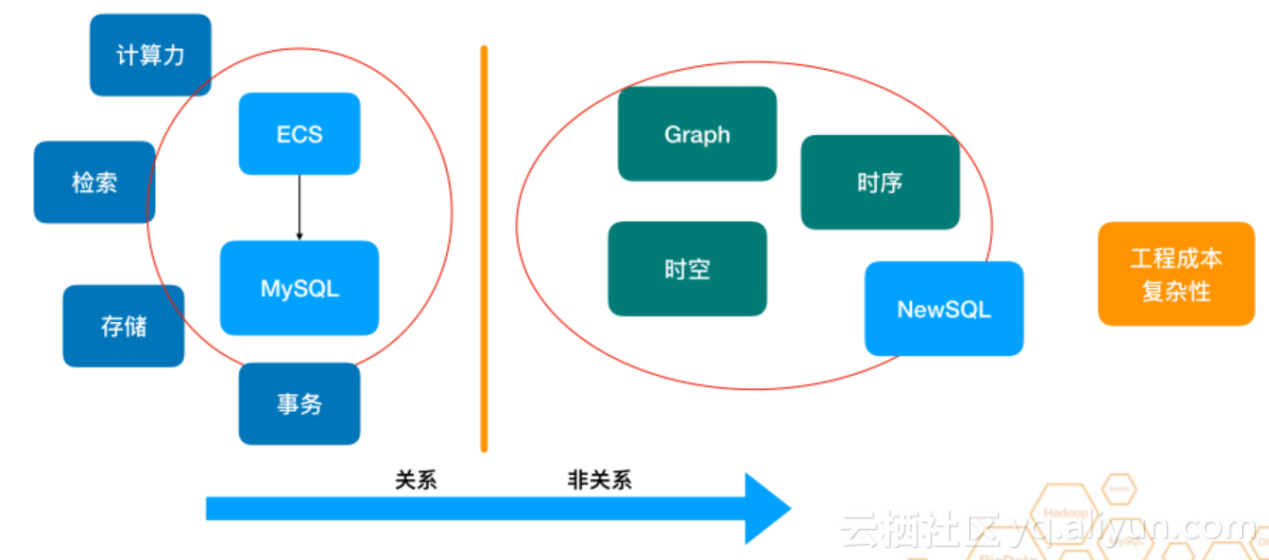
еП¶е§ЦдЄАдЄ™иґЛеКње∞±жШѓйЭЮзїУжЮДеМЦзЪДжХ∞жНЃиґКжЭ•иґКе§ЪпЉМжХ∞жНЃзїУжЮДзЪДж®°еЉПдЄНдїЕдїЕжШѓSQLпЉМжЧґеЇПгАБжЧґз©ЇгАБgraphж®°еЉПдєЯиґКжЭ•иґКе§ЪпЉМйЬАи¶БдЄАдЇЫжЦ∞зЪДе≠ШеВ®зїУжЮДжИЦжЦ∞зЪДзЃЧж≥ХеОїиІ£еЖ≥ињЩз±їйЧЃйҐШпЉМдєЯжДПеС≥зЭАжЙАйЬАи¶БеБЪзЪДеЈ•з®ЛйЗПе∞±дЉЪзЫЄеѓєиЊГйЂШгАВ
еЉХеЕ•жЫіе§ЪзЪДжХ∞жНЃ
еѓєдЇОжХ∞жНЃе§ДзРЖе§ІиЗіеПѓељТз±їдЄЇеЫЫдЄ™жЦєйЭҐпЉМеИЖеИЂжШѓе§НжЭВжАІгАБзБµжіїжАІгАБеїґињЯ<иѓї,еЖЩ>еТМеИЖеЄГеЉПпЉМеЕґдЄ≠еИЖеЄГеЉПиВѓеЃЪжШѓдЄНеПѓе∞СзЪДпЉМдЄАжЧ¶зЉЇе∞СеИЖеЄГеЉПе∞±жЧ†ж≥ХиІ£еЖ≥е§ІиІДж®°йЧЃйҐШ гАВзБµжіїжАІзЪДжДПжАЭжШѓдЄЪеК°еПѓдї•дїїжДПжФєеПШзЪДпЉЫе§НжЭВжАІе∞±жШѓињРи°МдЄАжЭ°SQLиГље§ЯиЃњйЧЃе§Ъе∞СжХ∞жНЃжИЦиАЕиѓіSQLжШѓеР¶е§НжЭВпЉЫеїґињЯдєЯеПѓеИЖдЄЇиѓїдЄОеЖЩзЪДеїґињЯгАВHadoop & SparkеПѓдї•иІ£еЖ≥иЃ°зЃЧе§НжЭВжАІеТМзБµжіїжАІпЉМдљЖжШѓиІ£еЖ≥дЄНдЇЖеїґињЯзЪДйЧЃйҐШпЉЫHBase&еИЖеЄГеЉП糥еЉХгАБеИЖеЄГеЉПжХ∞жНЃеЇУеПѓдї•иІ£еЖ≥зБµжіїжАІдЄОеїґињЯзЪДйЧЃйҐШпЉМдљЖзФ±дЇОеЃГж≤°жЬЙеЊИе§ЪиЃ°зЃЧиКВзВєпЉМжЙАдї•иІ£еЖ≥дЄНдЇЖиЃ°зЃЧе§НжЭВжАІзЪДйЧЃйҐШгАВKylin(жї°иґ≥иѓїеїґињЯ)еЬ®иЃ°зЃЧе§НжЭВжАІдЄОеїґињЯдєЛйЧіжЙЊдЇЖдЄАдЄ™еє≥и°°зВєпЉМињЩдЄ™еє≥и°°зВєе∞±жШѓжАОж†ЈењЂйАЯеЗЇжК•и°®пЉМдљЖеѓєдЇОињЩдЄ™зїУжЮЬзЪДиЊУеЕ•жЧґйЧіжИСдїђеєґдЄНеЕ≥ењГпЉМеѓєдЇОе§ІйГ®еИЖзЪДжК•и°®з±їзЪДйЬАж±Ве∞±жШѓињЩж†ЈзЪДгАВжѓПдЄ™еЉХжУОйГљжШѓдЄАеЃЪзЪДдЊІйЗНпЉМж≤°жЬЙйУґеЉєпЉБ
ApsaraDB HBaseдЇІеУБжЮґжЮДеПКжФєињЫ
еЇФеѓєзЪДеКЮж≥Х
жИСдїђдєЯдЄНиГљиІ£еЖ≥жЙАжЬЙзЪДйЧЃйҐШпЉМжИСдїђеП™жШѓиІ£еЖ≥еЕґдЄ≠е§ІйГ®еИЖзЪДйЧЃйҐШгАВе¶ВдљХжЙЊеИ∞дЄАдЄ™еЬ®еЈ•з®ЛдЄКиГље§ЯиІ£еЖ≥е§ІйГ®еИЖйЧЃйҐШзЪДжЦєж°ИиЗ≥еЕ≥йЗНи¶БпЉМеЇФеѓєеКЮж≥ХпЉЪ
- еИЖеЄГеЉПпЉЪжПРдЊЫжЙ©е±ХжАІ
- иЃ°зЃЧеКЫеїґдЉЄпЉЪзЃЧе≠Р+SQLпЉМдїОECSеИ∞SparkеЕґжЬђиі®еЕґеЃЮе∞±жШѓдЄАзІНиЃ°зЃЧеКЫзЪДеїґдЉЄ
- еИЖе±ВиЃЊиЃ°пЉЪйЩНдљОе§НжЭВжАІпЉМжПРдЊЫе§Ъж®°еЉПзЪДе≠ШеВ®ж®°еЮЛ
- дЇСеМЦпЉЪе§НзФ®иµДжЇР&еЉєжАІпЉМйЩНдљОжИРжЬђ
еЯЇжЬђжЮДжЮґ
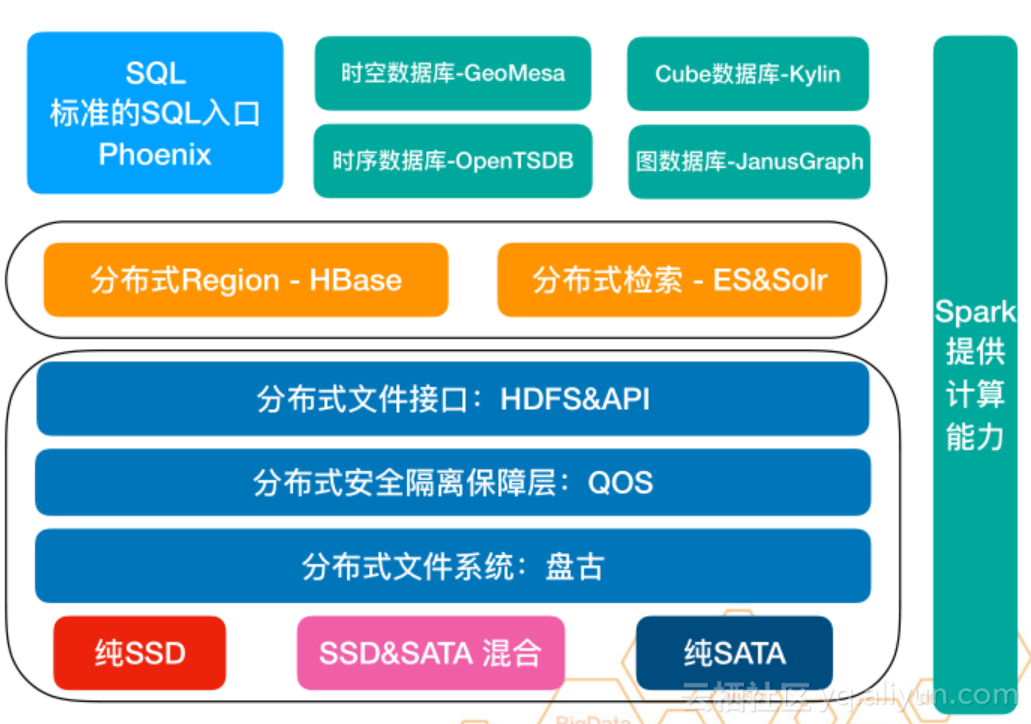
й¶ЦеЕИеМЕеРЂдЇЖдЄ§дЄ™еИЖз¶ї
- еИЖеИЂжШѓHDFSдЄОеИЖеЄГеЉПRegionеИЖеЄГеЉПж£А糥еИЖз¶ї
- SQLжЧґз©ЇеЫЊжЧґеЇПCubeдЄОеИЖеЄГеЉПRegionж£А糥еИЖз¶ї
е§ІиЗізЪДеИЖе±ВжЬЇжЮДе¶ВдЄЛпЉЪ - зђђдЄАе±ВпЉЪдїЛиі®е±ВпЉМзГ≠SSDдїЛиі®гАБжЄ©SSD&SATA жЈЈеРИгАБеЖЈзЇѓSATA(еБЪEC)
- зђђдЇМе±ВпЉЪеИЖеЄГеЉПжЦЗдїґз≥їзїЯпЉМдєЯе∞±жШѓзЫШеП§гАВдЇЛеЃЮдЄКиґКжШѓеЇХе±ВиґКеЃєжШУеБЪе∞Би£ЕдЉШеМЦгАВ
- зђђдЄЙе±ВпЉЪеИЖеЄГеЉПеЃЙеЕ®йЪФз¶їдњЭйЪЬе±ВQOSпЉМе¶ВжЮЬжИСдїђеБЪе≠ШеВ®иЃ°зЃЧеИЖз¶їпЉМе∞±жДПеС≥зЭАеЇХе±ВзЪДдЄЙдЄ™йЫЖзЊ§йЬАи¶БеЄГдЄЙе•ЧпЉМињЩж†ЈжѓПдЄ™йЫЖзЊ§е∞±дЉЪжЬЙеЗ†еНБеП∞зФЪиЗ≥еЗ†зЩЊеП∞зЪДиКВзВєпЉМж≠§жЧґе≠ШеВ®еКЫжШѓзФ±е§ІеЃґжЭ•еЭЗжСКзЪДпЉМињЩе∞±жДПеС≥зЭАеИЖеЄГеЉПеЃЙеЕ®йЪФз¶їдњЭйЪЬе±Ви¶БеБЪе•љйЪФз¶їжАІпЉМеЉХеЕ•QOSе∞±жДПеС≥зЭАдЉЪеҐЮеК†еїґињЯпЉМж≠§жЧґдЉЪеЉХеЕ•дЄАдЇЫжЦ∞зЪДз°ђдїґ(жѓФе¶ВRDMA)еОїе∞љеПѓиГљзЪДеЗПе∞ПеїґињЯгАВ
- зђђеЫЫе±ВпЉЪеИЖеЄГеЉПжЦЗдїґжО•еП£пЉЪHDFS & API(ж≠§е±ВзЬЛжГЕеЖµеПѓжЬЙеПѓжЧ†)
- зђђдЇФе±ВпЉЪжИСдїђжПРдЊЫдЇЖдЄ§дЄ™зїДдїґпЉМеИЖеЄГеЉПRegion-HBaseдЄОеИЖеЄГеЉПж£А糥-SolrпЉМеЬ®з†Фз©ґеИЖеЄГ糥еЉХзЪДжЧґеАЩеПСзО∞еНХжܯ糥еЉХжШѓзЫЄеѓєзЃАеНХзЪДпЉМжИСдїђжПРдЊЫйТИеѓєдЇМ篲糥еЉХйЗЗеПЦеЖЕзљЃзЪДеИЖеЄГеЉПRegionзЪДеИЖеЄГеЉПжЮґжЮДпЉМйТИеѓєеЕ®жЦЗ糥еЉХйЗЗеПЦе§ЦзљЃSolrеИЖеЄГеЉП糥еЉХжЦєж°И
- зђђеЕ≠е±ВпЉЪеїЇиЃЊеЬ®еИЖеЄГеЉПKVдєЛдЄКпЉМжЬЙNewSQLе•ЧдїґгАБжЧґз©Їе•ЧдїґгАБжЧґеЇПе•ЧдїґгАБеЫЊе•ЧдїґеПКCubeе•Чдїґ
еП¶е§ЦпЉМеПѓдї•еЉХеЕ•sparkжЭ•еИЖжЮРпЉМињЩдЄ™дєЯжШѓз§ЊеМЇзЫЃеЙНйАЪзФ®зЪДжЦєж°И
иІ£еЖ≥жИРжЬђзЪДжЦєж°И
еѓєдЇОиІ£еЖ≥жИРжЬђзЪДжЦєж°ИзЃАеНХдїЛзїНе¶ВдЄЛпЉЪ
- еИЖзЇІе≠ШеВ®пЉЪSSDдЄОSATAзЪДдїЈж†ЉзЫЄеЈЃеЊИе§ЪпЉМеЬ®еЖЈжХ∞жНЃдЄКпЉМжИСдїђеїЇиЃЃзЫіжО•йЗЗеПЦеЖЈе≠ШеВ®зЪДжЦєеЉП пЉМеПѓдї•иКВзЇ¶500%зЪДжИРжЬђ
- йЂШеОЛзЉ©жѓФпЉЪеЬ®еИЖзЇІе≠ШеВ®дЄКжЬЙдЄАдЄ™иЊГе•љзЪДеОЛзЉ©пЉМе∞§еЕґжШѓеЬ®еЖЈжХ∞жНЃпЉМжИСдїђеПѓдї•жПРйЂШеОЛзЉ©жѓФдЊЛпЉМеП¶е§ЦеИЖеЄГеЉПжЦЗдїґз≥їзїЯеПѓдї•йЗЗеПЦECињЫдЄАж≠•йЩНдљОе≠ШеВ®жИРжЬђпЉМиКВзЇ¶100%зЪДжИРжЬђ
- еЯЇз°АиЃЊжЦљеЕ±дЇЂпЉЪеЇУе≠ШеОЛп¶КеИЖжЛЕпЉМдЇСеє≥еП∞еПѓдї•йЗКжФЊзЇҐеИ©зїЩеЃҐжИЈ
- е≠ШеВ®дЄОиЃ°зЃЧеИЖз¶їпЉЪжМЙйЬАиЃ°иіє
- дЉШеМЦжАІиГљпЉЪеЖНжККжАІиГљжПРеНЗ1еАНеЈ¶еП≥
дЇСжХ∞жНЃеЇУеЯЇжЬђйГ®зљ≤зїУжЮД
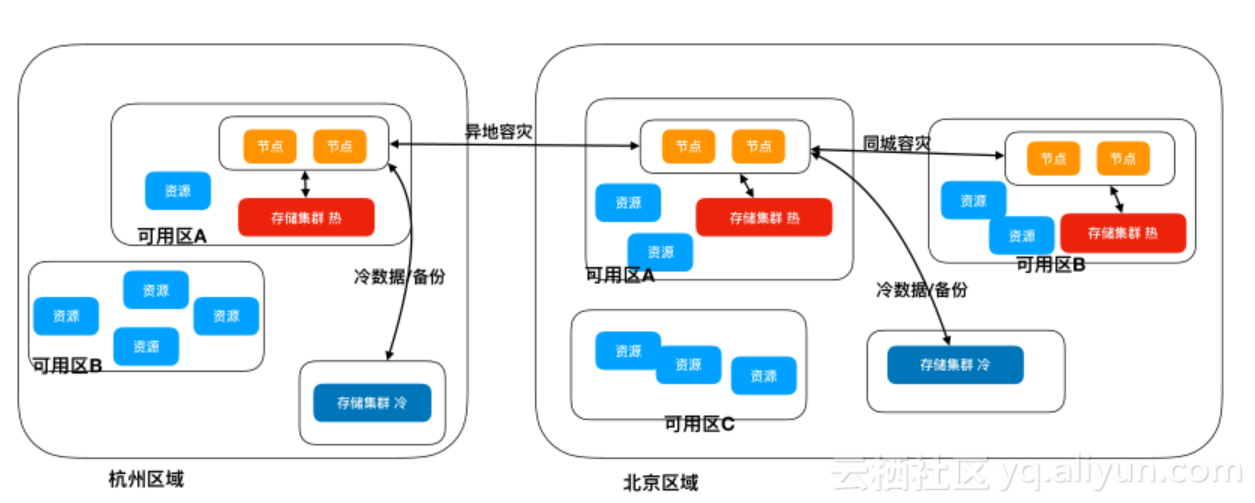
еБЗиЃЊеЬ®еМЧдЇђжЬЙдЄЙдЄ™жЬЇжИњеПѓзФ®еМЇAгАБBеТМC,жИСдїђдЉЪеЬ®еПѓзФ®еМЇAдЄ≠йГ®зљ≤дЄАдЄ™зГ≠зЪДе≠ШеВ®йЫЖзЊ§пЉМеЬ®еМЧдЇђжХідљУеМЇеЯЯйГ®дЄАдЄ™еЖЈзЪДе≠ШеВ®йЫЖзЊ§пЉМеЃЮйЩЕдЄКжЬЙеЗ†дЄ™еПѓзФ®еМЇе∞±еПѓдї•жЬЙеЗ†дЄ™зГ≠йЫЖзЊ§пЉМдЄїи¶БжШѓдњЭйЪЬеїґињЯзЪДпЉЫеЖЈйЫЖзЊ§еѓєеїґињЯзЫЄеѓєдЄНжХПжДЯпЉМеПѓдї•еЬ∞еЯЯеНХзЛђйГ®зљ≤пЉМеП™и¶БдЇ§жНҐжЬЇжї°иґ≥еЖЈйЫЖзЊ§жЙАйЬАзЪДеЄ¶еЃљеН≥еПѓгАВињЩж†ЈзЪДе•ље§ДжШѓдЄЙдЄ™еМЇеЕ±дЇЂдЄАдЄ™еЖЈйЫЖзЊ§пЉМе∞±жДПеС≥зЭАеПѓдї•еЕ±дЇЂеЇУе≠ШгАВ
ApsaraDB HBaseдЇІеУБиГљеКЫ
жИСдїђжПРдЊЫдЄ§дЄ™зЙИжЬђпЉМдЄАжШѓеНХиКВзВєзЙИпЉМеЕґзЙєзВєжШѓзїЩеЉАеПСжµЛиѓХзФ®жИЦиАЕеПѓзФ®жАІдЄНйЂШпЉМжХ∞жНЃйЗПдЄНе§ІзЪДеЬЇжЩѓгАВдЇМжШѓйЫЖзЊ§зЙИжЬђеЕґзЙєзВєжШѓйЂШиЗ≥5000w QPSпЉМе§ЪиЊЊ10Pе≠ШеВ®дЄОйЂШеПѓйЭ†дљОеїґињЯз≠ЙгАВ
- жХ∞жНЃеПѓйЭ†жАІпЉЪ99.99999999%пЉЪдєЛжЙАдї•еПѓйЭ†жАІеПѓдї•иЊЊеИ∞е¶Вж≠§дєЛйЂШпЉМеЕґж†ЄењГзЪДеОЯеЫ†е∞±жШѓе≠ШеВ®йЫЖзЊ§жШѓеНХзЛђйГ®зљ≤зЪДпЉМеЕґдЉЪж†єжНЃжЬЇжЮґз≠ЙињЫи°МеЙѓжЬђжФЊзљЃдЉШеМЦ
- жЬНеК°еПѓзФ®жАІпЉЪеНХйЫЖзЊ§99.9% еПМйЫЖзЊ§99.99%гАВ
- жЬНеК°дњЭйЪЬпЉЪжЬНеК°жЬ™жї°иґ≥SLAиµФдїШгАВ
- жХ∞жНЃе§ЗдїљеПКжБҐе§НгАВ
- жХ∞жНЃзГ≠еЖЈеИЖз¶їеИЖзЇІе≠ШеВ®гАВ
- дЉБдЄЪзЇІеЃЙеЕ®пЉЪиЃ§иѓБжОИжЭГеПКеК†еѓЖгАВ
- жПРдЊЫж£А糥еПКдЇМ篲糥еЉХеПКNewSQLиГљеКЫгАВ
- жПРдЊЫжЧґеЇП/еЫЊ/жЧґз©Ї/CubeзЫЄеЕ≥иГљеКЫгАВ
- дЄОSparkжЧ†зЉЭйЫЖжИРпЉМжПРдЊЫAPиГљеКЫгАВ
жХ∞жНЃе§ЗдїљеПКжБҐе§Н
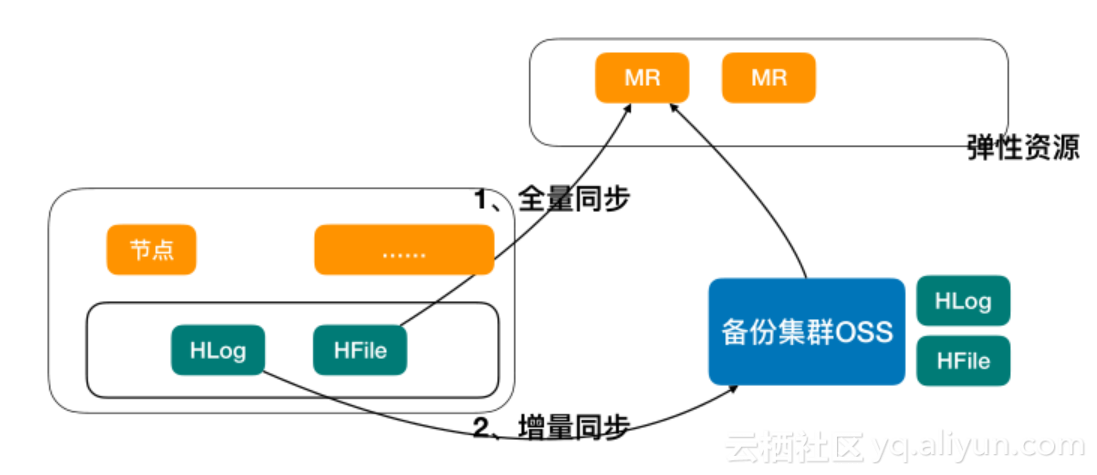
е§ЗдїљеИЖдЄЇеЕ®йЗПе§ЗдїљHFileдЄО еҐЮйЗПп•Ње§ЗдїљHLogпЉЫжБҐе§НеИЖдЄЇHLogиљђеМЦдЄЇHFileеТМBulkLoadеК†иљљгАВйШњйЗМдЇСйЫЖеЫҐињДдїКдЄЇж≠ҐеЈ≤зїПжЬЙдЄАдЄЗдЄ§еНГе§ЪеП∞зЪДHBase,е§ІйГ®еИЖйГљжШѓдЄїе§ЗйЫЖзЊ§зЪДпЉМеЬ®дЇСдЄКзФ±дЇОеЃҐжИЈжИРжЬђзЪДеОЯеЫ†пЉМе§ІйГ®еИЖдЄНйАЙжЛ©дЄїе§ЗпЉМжЙАдї•йЬАи¶БеѓєжХ∞жНЃињЫи°Ме§ЗдїљгАВеЕґйЪЊзВєеЬ®дЇОе§ЗдїљйЬАи¶БеЉХеЕ•иЃ°зЃЧиµДжЇРпЉМжИСдїђйЬАи¶БеЉХеЕ•еЉєжАІзЪДиЃ°зЃЧиµДжЇРжЭ•е§ДзРЖе§ЗдїљзЪДзЫЄеЕ≥иЃ°зЃЧдїїеК°
Compaction з¶їзЇњCompaction(з†Фз©ґдЄ≠)
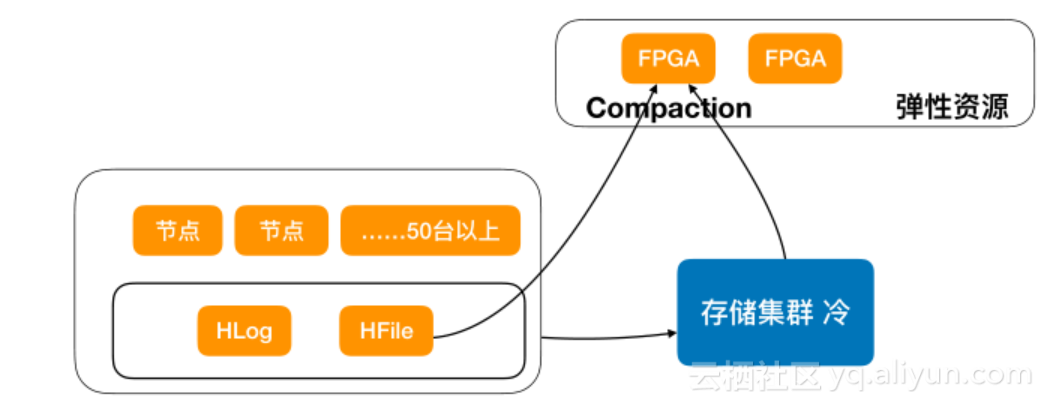
жИСдїђеЬ®еЖЕйГ®з†Фз©ґе¶ВдљХйАЪFPGAеѓєCompactionињЫи°МеК†йАЯпЉМињЩдЉЪдљњеЊЧйЫЖзЊ§ињРи°МжѓФиЊГеє≥зЉУпЉМзЙєеИЂжШѓеѓєиЃ°зЃЧиµДжЇРе∞СпЉМе≠ШеВ®йЗПе§ІзЪДжГЕеЖµдЄЛпЉМеПѓдї•йАЪињЗз¶їзЇњзЪДдљЬдЄЪе§ДзРЖCompactionгАВ
зїДдїґе±В
жИСдїђжЬЙ5дЄ≠зїДдїґпЉМNewSQL(Phoenix)гАБжЧґеЇПOpenTSDBгАБжЧґз©ЇGeoMesaгАБеЫЊJanusGraphеПКCubeзЪДKylinпЉМеПКжПРдЊЫHTAPиГљеКЫзЪДSparkгАВињЩйЗМзЃАеНХжППињ∞еЗ†дЄ™пЉМе¶ВдЄЛпЉЪ
NewSQL-Phoenix
еЃҐжИЈињШжШѓжѓФиЊГеЦЬ搥зФ®SQLзЪД,PhoenixдЉЪжФѓжМБSQLеПКдЇМ篲糥еЉХпЉМеЬ®иґЕињЗ1TзЪДжХ∞жНЃйЗПзЪДжГЕеЖµдЄЛпЉМеѓєдЇЛеК°зЪДйЬАж±Ве∞±еЊИе∞СпЉИжЙАдї•жИСдїђеєґж≤°жЬЙжФѓжМБдЇЛеК°пЉЙпЉЫдЇМ篲糥еЉХжШѓйАЪињЗеЖНжЦ∞еїЇдЄАеЉ†HBaseи°®жЭ•еЃЮзО∞зЪДгАВеЬ®еСљдЄ≠糥еЉХзЪДжГЕеЖµдЄЛпЉМдЄЗдЇњзЇІеИЂзЪДиЃњйЧЃеЯЇжЬђеЬ®жѓЂзІТзЇІеИЂпЉМдљЖзФ±дЇОPhoenixиБЪеРИзВєеЬ®дЄАдЄ™иКВзВєпЉМжЙАдї•п•ІиГљеБЪShuffleз±їдЉЉзЪДдЇЛжГЕпЉМеРМжЧґдєЯе∞±п•ІиГље§ДзРЖе§НжЭВзЪДиЃ°зЃЧпЉМжЙАдї•дїїдљХиѓіжИСжШѓHTAPжЮґжЮДзЪДпЉМе¶ВжЮЬдЄНиГљеБЪShuffleпЉМе∞±еЯЇжЬђдЄНиГљеБЪе§НжЭВзЪДиЃ°зЃЧгАВ
HTAP-Spark
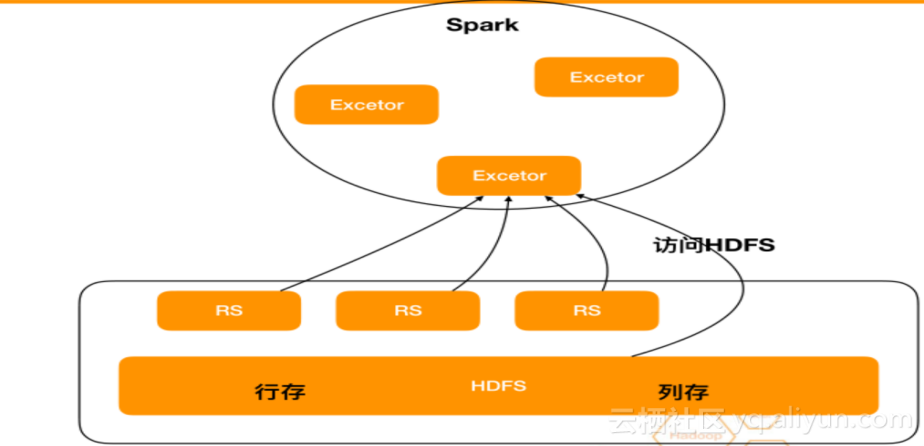
еЬ®HTAP-SparkињЩйГ®еИЖдЄїи¶БдїЛзїНдЄАдЄЛRDD APIгАБ SQLгАБзЫіжО•иЃњйЧЃHFileпЉМеЃГдїђзЪДзЙєзВєе¶ВдЄЛпЉЪ
- RDD APIеЕЈжЬЙзЃАеНХжЦєдЊњпЉМйїШиЃ§жФѓжМБзЪДзЙєзВєпЉМдљЖйЂШеєґеПСscanе§Іи°®дЉЪељ±еУНз®≥еЃЪжАІпЉЫ
- SQLжФѓжМБзЃЧе≠РдЄЛжО®гАБschemaжШ†е∞ДгАБеРДзІНеПВжХ∞и∞ГдЉШпЉМйЂШеєґеПСscanе§Іи°®дЉЪељ±еУНз®≥еЃЪжАІпЉЫ
- зЫіжО•иЃњйЧЃHFileпЉМзЫіжО•иЃњйЧЃе≠ШеВ®дЄНзїПињЗиЃ°зЃЧпЉМе§ІжЙєйЗПп•ЊиЃњйЧЃжАІиГљжЬАе•љпЉМйЬАи¶БsnapshotеѓєйљРжХ∞жНЃгАВ
жЧґеЇП-OpenTSDB & HiTSDB
TSDж≤°жЬЙзКґжАБпЉМеПѓдї•еК®жАБеК†еЗПиКВзВєпЉМеєґжМЙзЕІжЧґеЇПжХ∞жНЃзЪДзЙєзВєиЃЊиЃ°и°®зїУжЮДпЉМеЕґеЖЕзљЃйТИеѓєжµЃзВєзЪДйЂШеОЛзЉ©жѓФзЪДзЃЧж≥ХпЉМжИСдїђдЇСдЄКдЄУдЄЪзЙИзЪДHiTSDBеҐЮеК†еАТжОТз≠ЙиГљеКЫпЉМеєґиГље§ЯйТИеѓєжЧґеЇПеҐЮеК†жПТеАЉгАБйЩНз≤ЊеЇ¶з≠ЙдЉШеМЦгАВ
е§ІжХ∞жНЃжХ∞жНЃеЇУзЪДеЃЮйЩЕж°ИдЊЛ
дї•дЄЛзЃАеНХдїЛзїНеЗ†дЄ™еЃҐжИЈзЪДж°ИдЊЛпЉМзЫЃеЙНеЈ≤зїПеЬ®дЇСдЄКApsaraDB HBaseињРи°МпЉМжХ∞жНЃйЗПеЯЇжЬђеЬ®10Tдї•дЄКпЉЪ
жЯРиљ¶иБФзљСеЕђеПЄ
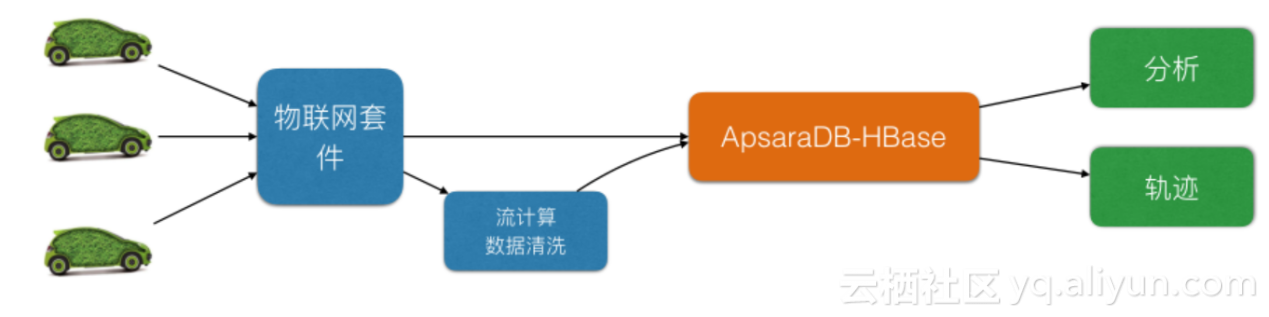
ињЩжШѓдЄАдЄ™иљ¶иБФзљСзЪДеЃҐжИЈпЉМжЬЙ100дЄЗиљ¶пЉМжѓПиЊЖиљ¶жѓП10зІТдЄКдЉ†дЄАжђ°пЉМжѓПжђ°1KBпЉМињЩж†ЈдЄАеєіе∞±жЬЙ300TжХ∞жНЃпЉМеЕ≠дЄ™жЬИдї•дЄКжШѓжХ∞жНЃдљОйҐСиЃњйЧЃпЉМжЙАдї•дїЦи¶БеБЪеИЖзЇІе≠ШеВ®пЉМжККеЖЈжХ∞жНЃжФЊеИ∞дљОдїЛиі®дЄК
жЯРе§ІжХ∞жНЃжОІеЕђеПЄ
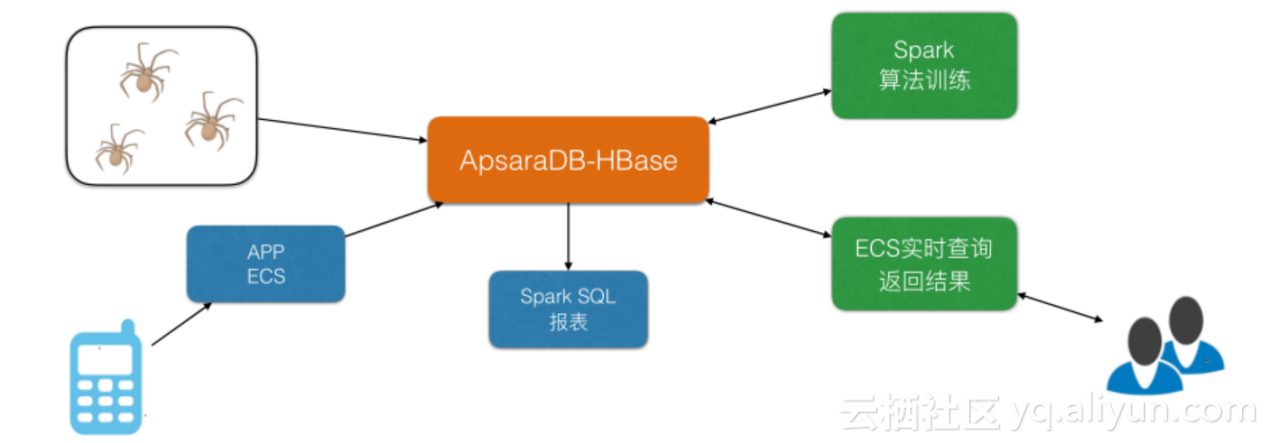
ињЩжШѓдЄАдЄ™е§ІжХ∞жНЃжОІеЕђеПЄпЉМеЃГе§ІзЇ¶жЬЙ200T+зЪДжХ∞жНЃйЗПпЉМе∞ЖHBaseжХ∞жНЃ (еЬ®зЇњеЃЮжЧґе§ІжХ∞жНЃе≠ШеВ®)дљЬдЄЇдЄїжХ∞жНЃеЇУпЉМеЕИзФ®HBaseеБЪзЃЧж≥ХиЃ≠зїГпЉМеЖНзФ®HBase SQLеЗЇжК•и°®пЉМеП¶е§ЦеБЪдЇЖдЄАе•ЧECSињЫи°МеЃЮжЧґжЯ•дї•дЊњдЄОеЃҐжИЈдєЛйЧіињЫи°МжХ∞жНЃдЇ§жНҐгАВ
жЯРз§ЊдЇ§еЕђеПЄ
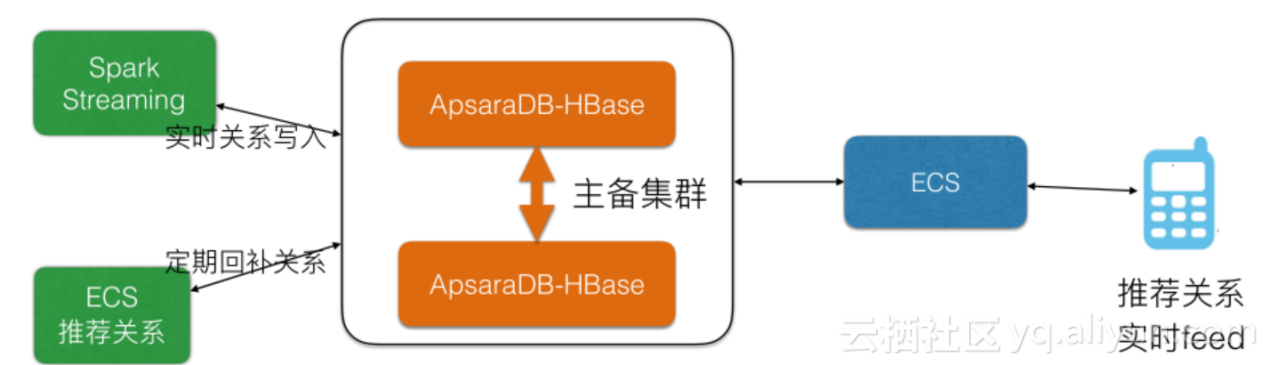
з§ЊдЇ§дЉЪжЬЙе§ІйЗПзЪДжО®иНРпЉМжЙАдї•SLAи¶Бж±ВйЂШиЊЊ99.99пЉМеєґйЗЗзФ®еПМйЫЖзЊ§дњЭйЪЬпЉМеНХйЫЖзЊ§иѓїеЖЩйЂШе≥∞QPS еПѓдї•иЊЊеИ∞1000w+пЉМжХ∞жНЃйЗПеЬ®30TеЈ¶еП≥гАВ
жЯРеЯЇйЗСеЕђеПЄ

ињЩжШѓдЄАдЄ™йЗСиЮНеЕђеПЄпЉМеЃГжЬЙ10000дЇњдї•дЄКзЪДдЇ§жШУжХ∞жНЃпЉМзЫЃеЙНзФ®е§ЪдЄ™дЇМ篲糥еЉХжФѓжМБжѓЂзІТзЇІеИЂзЪДжߕ胥пЉМжХ∞жНЃйЗПеЬ®100TеЈ¶еП≥
жЯРеЕђеПЄжК•и°®з≥їзїЯ
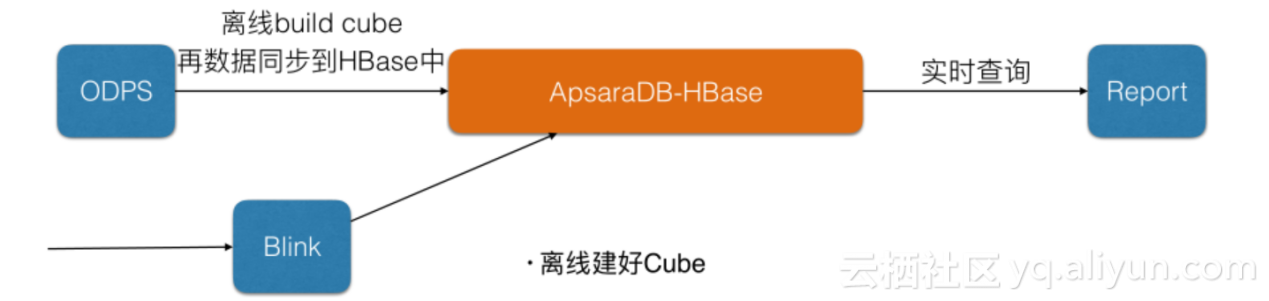
еЕИз¶їзЇњеїЇе•љCubeеЖНжККжХ∞жНЃеРМж≠•еИ∞HBaseдЄ≠пЉМеЃЮжЧґжХ∞жНЃйАЪињЗBlinkеѓєжО•ињЫи°МжЫіжЦ∞пЉМжХ∞жНЃйЗПеЬ®еПѓиЊЊ20TеЈ¶еП≥гАВ



зЫЄеЕ≥жО®иНР
гАРе§ІжХ∞жНЃжЧґдї£жХ∞жНЃеЇУ-дЇСHBaseжЮґжЮД&зФЯжАБ&еЃЮиЈµгАСйШњйЗМдЇСзЪДйЂШзЇІжКАжЬѓдЄУеЃґе∞Бз•ЮпЉИжЫєйЊЩпЉЙеЬ®DTCC2018е§ІдЉЪдЄКеИЖдЇЂдЇЖеЕ≥дЇОе§ІжХ∞жНЃжХ∞жНЃеЇУзЪДжЬАжЦ∞еЃЮиЈµпЉМзЙєеИЂжШѓиБЪзД¶дЇОдЇСHBaseзЪДжЮґжЮДгАБзФЯжАБеПКеЕґеЬ®еЃЮйЩЕдЄЪеК°дЄ≠зЪДеЇФзФ®гАВдЇСHBaseдљЬдЄЇе§ІжХ∞жНЃе≠ШеВ®...
"е§ІжХ∞жНЃжЧґдї£жХ∞жНЃеЇУ-дЇСHBaseжЮґжЮДзФЯжАБеПКеЃЮиЈµ" еЬ®е§ІжХ∞жНЃжЧґдї£пЉМжХ∞жНЃеЇУйЭҐдЄізЭАеЈ®е§ІзЪДжМСжИШпЉМе¶ВдљХиІ£еЖ≥ињЩдЇЫжМСжИШжИРдЄЇжХ∞жНЃеЇУжЮґжЮДеЄИеТМеЉАеПСиАЕйЬАи¶БиІ£еЖ≥зЪДйЧЃйҐШгАВжЬђжЦЗе∞ЖдїОдЇСHBaseжЮґжЮДзФЯжАБеПКеЃЮиЈµиІТеЇ¶пЉМиЃ®иЃЇе§ІжХ∞жНЃжЧґдї£жХ∞жНЃеЇУзЪДжМСжИШеТМ...
жАїзїУжЭ•иѓіпЉМдЇСHBaseеЬ®е§ІжХ∞жНЃжЧґдї£жЙЃжЉФзЭАйЗНи¶БзЪДиІТиЙ≤пЉМеЕґеЉЇе§ІзЪДеИЖеЄГеЉПжЮґжЮДгАБдЄ∞еѓМзЪДзФЯжАБз≥їзїЯдї•еПКеєњж≥ЫзЪДеЇФзФ®еЃЮиЈµпЉМдљњеЊЧеЃГжИРдЄЇе§ДзРЖе§ІиІДж®°жХ∞жНЃзЪДй¶ЦйАЙеЈ•еЕЈгАВйАЪињЗдЄНжЦ≠зЪДжКАжЬѓеИЫжЦ∞еТМдЉШеМЦпЉМйШњйЗМдЇСзЪДдЇСHBaseе∞ЖжМБзї≠дЄЇеРДи°МдЄЪжПРдЊЫйЂШжХИ...
HBaseжШѓдЄАдЄ™еЯЇдЇОеИЧжЧПзЪДNoSQLжХ∞жНЃеЇУпЉМињРи°МеЬ®HadoopдєЛдЄКпЉМйАВзФ®дЇОе§ІжХ∞жНЃе≠ШеВ®гАВеЃГжПРдЊЫдЇЖеЃЮжЧґиѓїеЖЩеТМж∞іеє≥жЙ©е±ХзЪДиГљеКЫгАВ HiveжШѓеЯЇдЇОHadoopзЪДжХ∞жНЃдїУеЇУеЈ•еЕЈпЉМеЃГеЕБиЃЄзФ®жИЈдљњзФ®з±їSQLзЪДHQLиѓ≠и®АињЫи°МжХ∞жНЃжߕ胥еТМеИЖжЮРпЉМйАВеРИе§ДзРЖеТМзЃ°зРЖ...
гАКе§ІжХ∞жНЃдє¶з±Н-HbaseжЮґжЮДиЃЊиЃ°гАЛжШѓдЄАжЬђдЄУж≥®дЇОе§ІжХ∞жНЃйҐЖеЯЯдЄ≠еИЖеЄГеЉПжХ∞жНЃеЇУHbaseзЪДжЈ±еЇ¶иІ£жЮРдє¶з±НпЉМйАВеРИеѓєе§ІжХ∞жНЃжКАжЬѓе∞§еЕґжШѓHbaseжДЯеЕіиґ£зЪДз®ЛеЇПеСШеТМжХ∞жНЃеИЖжЮРеЄИгАВдє¶дЄ≠иѓ¶зїЖйШРињ∞дЇЖHbaseзЪДж†ЄењГеОЯзРЖгАБзФЯжАБзОѓеҐГдї•еПКеЬ®еЃЮйЩЕй°єзЫЃдЄ≠зЪД...
еЬ®е§ІжХ∞жНЃжКАжЬѓзФЯжАБдЄ≠пЉМHiveгАБHBaseеТМClickHouseжШѓдЄЙзІНеЄЄзФ®зЪДе§ДзРЖе§ІжХ∞жНЃзЪДеЈ•еЕЈгАВеЃГдїђеРДиЗ™жЬЙдЄНеРМзЪДзЙєзВєеТМеЇФзФ®еЬЇжЩѓпЉМеРМжЧґдєЯеЬ®дЄНжЦ≠еЬ∞еПСе±ХеТМеЃМеЦДдЄ≠гАВ HiveжШѓдЄАдЄ™еїЇзЂЛеЬ®HadoopдєЛдЄКзЪДжХ∞жНЃдїУеЇУеЯЇз°АжЮґжЮДпЉМеЃГжПРдЊЫдЇЖз±їSQLзЪДжߕ胥...
дЇСHbaseжХ∞жНЃеЇУеЬ®дЇњжЦєдЇСеЃЮиЈµдєЛиЈѓ жЬђжЦЗж°£дЄїи¶БдїЛзїНдЇЖдЇњжЦєдЇСзІСжКАCTOзОЛжИРеЖЫеЬ®йШњйЗМдЇСеє≥еП∞дЄКеЃЮзО∞дЇСHbaseжХ∞жНЃеЇУзЪДеЃЮиЈµзїПеОЖеТМзїПй™МгАВиѓ•еЃЮиЈµдЄїи¶БиІ£еЖ≥дЇЖдЇњжЦєдЇСзІСжКАеЬ®е§ІжХ∞жНЃе≠ШеВ®еТМе§ДзРЖжЦєйЭҐзЪДжМСжИШпЉМйАЪињЗдЇСHbaseжХ∞жНЃеЇУеЃЮзО∞дЇЖйЂШжХИгАБ...
3. **HBaseжЮґжЮДзїДдїґ**пЉЪ - **HMaster**пЉЪиіЯиі£жХідЄ™йЫЖзЊ§зЪДзЃ°зРЖпЉМеМЕжЛђRegionзЪДеИЖйЕНгАБиіЯиљљеЭЗи°°дї•еПКжХЕйЪЬжБҐе§Нз≠ЙгАВ - **HRegionServer**пЉЪжѓПдЄ™RegionServerжЙШзЃ°дЄАйГ®еИЖRegionпЉМеєґе§ДзРЖеѓєиѓ•йГ®еИЖRegionзЪДиѓїеЖЩиѓЈж±ВгАВ - **...
жЬђиµДжЇРдЄЇ"еЃМжХізЙИе§ІжХ∞жНЃиѓЊдїґйЫЖеРИ4-е§ІжХ∞жНЃеѓЉиЃЇ-зђђеЫЫзЂ†-еИЖеЄГеЉПжХ∞жНЃеЇУHBaseпЉИеЕ±71й°µпЉЙ.rar"пЉМеЃГжШѓдЄАдЄ™еОЛзЉ©еМЕжЦЗдїґпЉМеМЕеРЂдЇЖ71й°µеЕ≥дЇОе§ІжХ∞жНЃеѓЉиЃЇиѓЊз®ЛдЄ≠зђђеЫЫзЂ†вАФвАФеИЖеЄГеЉПжХ∞жНЃеЇУHBaseзЪДиѓ¶зїЖиЃ≤иІ£гАВHBaseжШѓе§ІжХ∞жНЃйҐЖеЯЯдЄ≠зЪДдЄАдЄ™...
зїЉдЄКжЙАињ∞пЉМHBase v1.7.2жШѓдЄАдЄ™йЂШжХИгАБеПѓжЙ©е±ХзЪДеИЖеЄГеЉПжХ∞жНЃеЇУз≥їзїЯпЉМеєњж≥ЫеЇФзФ®дЇОдЇТиБФзљСгАБзФµдњ°гАБйЗСиЮНз≠Йе§ЪдЄ™и°МдЄЪпЉМдЄЇе§ІжХ∞жНЃжЧґдї£зЪДжХ∞жНЃе≠ШеВ®еТМе§ДзРЖжПРдЊЫдЇЖеЉЇе§ІжФѓжМБгАВйАЪињЗе≠¶дє†еТМжОМжП°HBaseпЉМеЉАеПСиАЕиГље§ЯжЫіе•љеЬ∞еЇФеѓєе§ІжХ∞жНЃжМСжИШпЉМ...
6. **HadoopзФЯжАБзїДдїґ**пЉЪйЩ§дЇЖеЯЇжЬђзЪДHDFSеТМMapReduceпЉМHadoopзФЯжАБз≥їзїЯињШеМЕжЛђHiveпЉИжХ∞жНЃдїУеЇУеЈ•еЕЈпЉЙгАБPigпЉИжХ∞жНЃеИЖжЮРеЈ•еЕЈпЉЙгАБHBaseпЉИNoSQLжХ∞жНЃеЇУпЉЙгАБSparkпЉИењЂйАЯжХ∞жНЃе§ДзРЖж°ЖжЮґпЉЙз≠ЙгАВзРЖиІ£ињЩдЇЫзїДдїґзЪДеКЯиГљеТМзЫЄдЇТеЕ≥з≥їжШѓеЕ®йЭҐ...
йАЪињЗеѓєHBaseзЪДеИЖеЄГеЉПзЙєжАІгАБеЃЮжЧґиѓїеЖЩгАБжХ∞жНЃж®°еЮЛгАБ糥еЉХз≠ЦзХ•гАБAPIдљњзФ®еПКдЄОHadoopзФЯжАБз≥їзїЯзЪДйЕНеРИз≠ЙжЦєйЭҐзЪДзРЖиІ£пЉМиѓїиАЕеПѓдї•жЫіе•љеЬ∞жОМжП°ињЩдЄАеЉЇе§ІзЪДNoSQLжХ∞жНЃеЇУпЉМеєґе∞ЖеЕґеЇФзФ®дЇОеРДзІНе§ІжХ∞жНЃиІ£еЖ≥жЦєж°ИдЄ≠гАВеѓєдЇОе≠¶дє†иАЕиАМи®АпЉМињЩдЄ™ж°ИдЊЛ...
4. **HadoopзФЯжАБ**пЉЪеМЕжЛђHBaseпЉИеИЖеЄГеЉПжХ∞жНЃеЇУпЉЙгАБHiveпЉИжХ∞жНЃдїУеЇУеЈ•еЕЈпЉЙгАБPigпЉИжХ∞жНЃеИЖжЮРеЈ•еЕЈпЉЙз≠ЙпЉМеЃГдїђдЄОHadoopе¶ВдљХеНПеРМжПРдЊЫе§ІжХ∞жНЃиІ£еЖ≥жЦєж°ИгАВ 5. **HadoopйЕНзљЃ**пЉЪе¶ВдљХиЃЊзљЃHadoopзЪДйЕНзљЃжЦЗдїґпЉМе¶В`core-site.xml`гАБ`...
HadoopзФЯжАБеМЕжЛђдЉЧе§ЪзЫЄеЕ≥й°єзЫЃпЉМе¶ВHBaseпЉИеИЖеЄГеЉПNoSQLжХ∞жНЃеЇУпЉЙгАБHiveпЉИжХ∞жНЃдїУеЇУеЈ•еЕЈпЉЙгАБPigпЉИйЂШзЇІжХ∞жНЃе§ДзРЖиѓ≠и®АпЉЙгАБSparkпЉИењЂйАЯгАБйАЪзФ®зЪДе§ІжХ∞жНЃе§ДзРЖеЉХжУОпЉЙз≠ЙгАВињЩдЇЫеЈ•еЕЈдЄОHadoopеНПеРМеЈ•дљЬпЉМжПРдЊЫжЫіеЕ®йЭҐзЪДе§ІжХ∞жНЃиІ£еЖ≥жЦєж°ИгАВ ...
1. е§ІжХ∞жНЃеЯЇз°АпЉЪй¶ЦеЕИпЉМжХЩжЭРдЉЪдїЛзїНе§ІжХ∞жНЃзЪДеЯЇжЬђж¶ВењµпЉМеМЕжЛђе§ІжХ∞жНЃзЪД4VзЙєеЊБпЉИVolumeгАБVelocityгАБVarietyгАБValueпЉЙдї•еПКе§ІжХ∞жНЃжЮґжЮДзЪДеЯЇз°АпЉМе¶ВHadoopзФЯжАБз≥їзїЯдЄ≠зЪДHDFSгАБMapReduceеТМYARNгАВ 2. HadoopињРзїіпЉЪжЈ±еЕ•иЃ≤иІ£Hadoop...
жЬђзѓЗжЦЗзЂ†е∞Жиѓ¶зїЖдїЛзїНWhaleAIжПРдЊЫзЪДPythonиЗ™еК®еМЦHBaseйГ®зљ≤жЦєж°ИпЉМдї•еПКе¶ВдљХеИ©зФ®еЃГжЭ•дЄУж≥®дЇОдЇЇеЈ•жЩЇиГљеТМе§ІжХ∞жНЃзЪДеЃЮиЈµгАВ й¶ЦеЕИпЉМиЃ©жИСдїђдЇЖиІ£HBaseзЪДеЯЇжЬђж¶ВењµгАВHBaseжШѓдЄЇе§ДзРЖPBзЇІжХ∞жНЃиЃЊиЃ°зЪДпЉМеЕґж†ЄењГзЙєжАІеМЕжЛђпЉЪеЉЇдЄАиЗіжАІгАБж∞іеє≥...
3. **HBaseжЮґжЮД**пЉЪHBaseзЪДжЮґжЮДеЯЇдЇОHDFSпЉИHadoop Distributed File SystemпЉЙпЉМеєґйЗЗзФ®Region ServerеТМMaster ServerзЪДиЃЊиЃ°пЉМдњЭиѓБдЇЖжХ∞жНЃзЪДеИЖеЄГеТМйЂШеПѓзФ®жАІгАВRegion ServerиіЯиі£жХ∞жНЃе≠ШеВ®еТМжߕ胥пЉМMaster ServerеИЩиіЯиі£еЕ®е±А...