
و‘کè¦پï¼ڑآ AWS çڑ„ Amazon DynamoDB ه’Œéک؟里ن؛‘çڑ„è،¨و ¼هکه‚¨ TableStore 都وک¯ه®Œه…¨و‰کç®،çڑ„NoSQLو•°وچ®ه؛“وœچهٹ،,وڈگن¾›ه؟«é€ںçڑ„م€پهڈ¯é¢„وœںçڑ„و€§èƒ½ï¼Œه¹¶ن¸”هڈ¯ن»¥ه®çژ°و— ç¼و‰©ه±•م€‚وœ¬ç¯‡و–‡ç« ن»‹ç»چن؛†ه¦‚ن½•ن½؟用 Lambda ه°† DynamoDB çڑ„و•°وچ®ه¢é‡ڈè؟پ移هˆ°è،¨و ¼هکه‚¨ن¸م€‚
Amazon DynamoDBوک¯ن¸€ن¸ھه®Œه…¨و‰کç®،çڑ„NoSQLو•°وچ®ه؛“وœچهٹ،,هڈ¯ن»¥وڈگن¾›ه؟«é€ںçڑ„م€پهڈ¯é¢„وœںçڑ„و€§èƒ½ï¼Œه¹¶ن¸”هڈ¯ن»¥ه®çژ°و— ç¼و‰©ه±•م€‚ç”±ن؛ژDynamoDBه¹¶هڈ¯ن»¥و ¹وچ®ه®é™…需و±‚ه¯¹è،¨è؟›è،Œو‰©ه±•ه’Œو”¶ç¼©ï¼Œè؟™ن¸ھè؟‡ç¨‹و—¢ن¸چ需è¦پهپœو¢ه¯¹ه¤–وœچهٹ،,ن¹ںن¸چن¼ڑé™چن½ژوœچهٹ،و€§èƒ½ï¼Œن¸€ç»ڈوژ¨ه‡؛ه°±و”¶هˆ°ن؛†ه¹؟ه¤§AWS用وˆ·çڑ„و¬¢è؟ژم€‚
هگŒو ·ï¼Œè،¨و ¼هکه‚¨وک¯و„ه»؛هœ¨éک؟里ن؛‘é£ه¤©هˆ†ه¸ƒه¼ڈç³»ç»ںن¹‹ن¸ٹçڑ„هˆ†ه¸ƒه¼ڈNoSQLو•°وچ®ه؛“وœچهٹ،م€‚ن½œن¸؛هگŒ DynamoDB éه¸¸ç›¸ن¼¼çڑ„ __ن؛‘NoSQLو•°وچ®ه؛“وœچهٹ،__,è،¨و ¼هکه‚¨çڑ„è‡ھهٹ¨è´ںè½½ه‡è،،وœ؛هˆ¶هڈ¯ن»¥è‡ھهٹ¨ه¯¹è،¨è؟›è،Œو‰©ه±•ï¼Œه®çژ°و•°وچ®è§„و¨،ن¸ژè®؟é—®ه¹¶هڈ‘ن¸ٹçڑ„و— ç¼و‰©ه±•ï¼Œوڈگن¾›وµ·é‡ڈ结و„هŒ–و•°وچ®çڑ„هکه‚¨ه’Œه®و—¶è®؟é—®م€‚
è،¨و ¼هکه‚¨هڈ¯ن»¥ن½؟用وˆ·وٹٹو“چن½œه’Œو‰©ه±•هˆ†ه¸ƒه¼ڈو•°وچ®ه؛“çڑ„و²‰é‡چè´ںو‹…,ن؛¤ç»™éک؟里ن؛‘و¥ه¤„çگ†ï¼Œè؟™و ·ï¼Œç”¨وˆ·ه°±ن¸چ需è¦پو‹…ه؟ƒç،¬ن»¶é…چç½®م€پç£پç›کو•…éڑœم€پوœ؛ه™¨و•…éڑœم€پ软ن»¶ه®‰è£…ه’Œهچ‡ç؛§ç‰ه·¥ن½œï¼Œهڈ¯ن»¥و›´ن¸“و³¨هˆ°ن¸ڑهٹ،逻辑ن¸هژ»م€‚
ن»ٹه¤©ï¼Œه°±ç»™ه¤§ه®¶ن»‹ç»چه¦‚ن½•ه°†DynamoDBçڑ„و•°وچ®ه¢é‡ڈè؟پ移هˆ°è،¨و ¼هکه‚¨م€‚
و•°وچ®è½¬وچ¢è§„هˆ™
è،¨و ¼هکه‚¨و”¯وŒپçڑ„و•°وچ®و ¼ه¼ڈوœ‰ï¼ڑ
- String - هڈ¯ن¸؛ç©؛,هڈ¯ن¸؛ن¸»é”®ï¼Œن¸؛ن¸»é”®هˆ—و—¶وœ€ه¤§ن¸؛ 1 KB,ن¸؛ه±و€§هˆ—و—¶ن¸؛2MBم€‚
- Integer - 64 bit,و•´ه‹ï¼Œهڈ¯ن¸؛ن¸»é”®ï¼Œ8 Bytesم€‚
- Binary - ن؛Œè؟›هˆ¶و•°وچ®ï¼Œهڈ¯ن¸؛ç©؛,هڈ¯ن¸؛ن¸»é”®ï¼Œن¸؛ن¸»é”®هˆ—و—¶وœ€ه¤§ن¸؛ 1 KB,ن¸؛ه±و€§هˆ—و—¶ن¸؛2MBم€‚
- Double - 64 bit,Double ç±»ه‹ï¼Œ8 Bytesم€‚
- Boolean - True/False,ه¸ƒه°”ç±»ه‹ï¼Œ1 Byteم€‚
ç›®ه‰چ DynamoDB و”¯وŒپه¤ڑç§چو•°وچ®و ¼ه¼ڈï¼ڑ
- و ‡é‡ڈç±»ه‹ - و ‡é‡ڈç±»ه‹هڈ¯ه‡†ç،®هœ°è،¨ç¤؛ن¸€ن¸ھه€¼م€‚و ‡é‡ڈç±»ه‹هŒ…و‹¬و•°ه—م€په—符ن¸²م€پن؛Œè؟›هˆ¶م€په¸ƒه°”ه€¼ه’Œ nullم€‚
- و–‡و،£ç±»ه‹ - و–‡و،£ç±»ه‹هڈ¯è،¨ç¤؛ه…·وœ‰هµŒه¥—ه±و€§çڑ„ه¤چو‚结و„ - ن¾‹ه¦‚و‚¨ه°†هœ¨ JSON و–‡و،£ن¸و‰¾هˆ°çڑ„结و„م€‚و–‡و،£ç±»ه‹هŒ…و‹¬هˆ—è،¨ه’Œوک ه°„م€‚
- 集类ه‹ - 集类ه‹هڈ¯è،¨ç¤؛ه¤ڑن¸ھو ‡é‡ڈه€¼م€‚集类ه‹هŒ…و‹¬ه—符ن¸²é›†م€پو•°ه—集ه’Œن؛Œè؟›هˆ¶é›†م€‚
ç”±ن؛ژDynamoDBو”¯وŒپو–‡و،£ه‹و•°وچ®ç±»ه‹ï¼Œوˆ‘ن»¬éœ€è¦په°†و–‡و،£ه‹è½¬وچ¢ن¸؛ن¸€ن¸ھStringç±»ه‹وˆ–者Binaryç±»ه‹هکه‚¨هˆ°è،¨و ¼هکه‚¨ن¸ï¼Œهœ¨è¯»هڈ–و—¶éœ€è¦پهڈچه؛ڈهˆ—هŒ–وˆگJsonم€‚
و•…,ن»ژDynamoDBè؟پ移هˆ°è،¨و ¼هکه‚¨و—¶ï¼Œوˆ‘ن»¬هپڑه¦‚ن¸‹çڑ„و•°وچ®è½¬وچ¢ï¼ڑ
| id (N) | '123' | Integer |
| level (N) | '2.3' | Double, ن¸چ能ن¸؛ن¸»é”® |
| afea (NULL) | TRUE | String,ç©؛ه—符ن¸² |
| binary (B) | 0x12315 | binary |
| binary_set (BS) | { 0x123, 0x111 } | binary |
| bool (BOOL) | TRUE | boolean |
| list (L) | [ { "S" : "a" }, { "N" : "1" }] | string |
| map (M) | { "key1" : { "S" : "value1" }} | string |
| str (S) | This is testï¼پ | string |
| num_set (NS) | { 1, 2 } | string |
| str_set (SS) | { "a", "b" } | string |
ه¢é‡ڈه®çژ°وœ؛هˆ¶
وˆ‘ن»¬ن½؟用DynamoDBçڑ„Streamو•°وچ®وµپèژ·هڈ–DynamoDBè،¨ن¸çڑ„ه¢هˆ و”¹و“چن½œï¼Œه°†و“چن½œهگŒو¥هˆ°è،¨و ¼هکه‚¨ن¸ï¼Œن¸؛ن؛†éپ؟ه…چçژ¯ه¢ƒوگه»؛,ه°†هگŒو¥ç¨‹ه؛ڈè؟گè،Œهœ¨Lambda ن¸ï¼Œوµپ程ه¦‚ن¸‹ه›¾ï¼ڑ
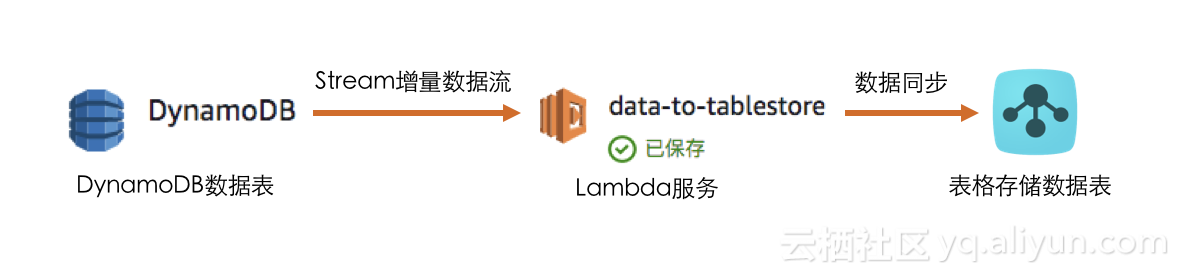
ن½؟用Streamو•°وچ®وµپن¸çڑ„'eventName'ه—و®µو¥هˆ¤هˆ«و•°وچ®çڑ„ه¢هˆ و”¹و“چن½œï¼ڑ
- "INSERT"ï¼ڑ وڈ’ه…¥و•°وچ®ï¼Œه¯¹ه؛”
PutRow -
"MODIFY" ï¼ڑ ن؟®و”¹و•°وچ®
- ه¦‚وœOldImage ن¸ژ NewImageçڑ„key相هگŒï¼Œهˆ™ن¸؛و›´و–°و•°وچ®ï¼Œه¯¹ه؛”
Update - è‹¥OldImageçڑ„Key و•°é‡ڈه¤§ن؛ژ NewImageçڑ„Keyو•°é‡ڈ, هˆ™ن¸؛هˆ 除و•°وچ®ï¼Œه°†ن¸¤è€…ه·®é›†çڑ„keysهپڑهˆ 除,ه¯¹ه؛”
Delete
- ه¦‚وœOldImage ن¸ژ NewImageçڑ„key相هگŒï¼Œهˆ™ن¸؛و›´و–°و•°وچ®ï¼Œه¯¹ه؛”
- "REMOVE"ï¼ڑهˆ 除و•°وچ®ï¼Œه¯¹ه؛”آ
DeleteRow
需è¦پ特هˆ«و³¨و„ڈçڑ„وک¯ï¼ڑ
- ن¸ٹè؟° Stream ن¸ه¢هˆ و”¹و“چن½œè½¬وچ¢è،Œن¸؛符هگˆن¸ڑهٹ،çڑ„وœںوœ›م€‚
- è،¨و ¼هکه‚¨ç›®ه‰چè؟کن¸چو”¯وŒپن؛Œç؛§ç´¢ه¼•ï¼Œو•…هڈھ能هگŒو¥ن¸»è،¨çڑ„و•°وچ®م€‚
- DynamoDB ن¸è،¨çڑ„ن¸»é”®هگŒTableStoreن¸çڑ„ن¸»é”®ن؟وŒپن¸€è‡´ï¼Œن¸”و•°ه—ç±»ه‹çڑ„ن¸»é”®هڈھ能ن¸؛و•´ه‹م€‚
- DynamoDB ه¯¹هچ•ن¸ھé،¹ç›®çڑ„ه¤§ه°ڈé™گهˆ¶ن¸؛400KB,è،¨و ¼هکه‚¨ن¸هچ•è،Œè™½ç„¶و²،وœ‰é™گهˆ¶ï¼Œن½†ن¸€و¬،وڈگن؛¤çڑ„و•°وچ®é‡ڈن¸چ能超è؟‡4MBم€‚آ DynamoDBé™گهˆ¶é،¹هڈ‚考آ هڈٹآ TableStore é™گهˆ¶é،¹هڈ‚考
- ه¦‚وœه…ˆè؟›è،Œه…¨é‡ڈو•°وچ®è؟پ移,هˆ™éœ€è¦پهœ¨ه…¨é‡ڈè؟پ移ن¹‹ه‰چه¼€هگ¯ Streamم€‚ç”±ن؛ژ DynamoDB Stream هڈھ能ن؟هکوœ€è؟‘24ه°ڈو—¶و•°وچ®ï¼Œو•…ه…¨é‡ڈو•°وچ®éœ€è¦پهœ¨24ه°ڈو—¶ه†…è؟پ移ه®Œوˆگ,هœ¨ه…¨é‡ڈè؟پ移ه®Œوˆگهگژو‰چ能ه¼€هگ¯ Lambda çڑ„è؟پ移ن»»هٹ،م€‚
- و•°وچ®éœ€è¦پن؟è¯پوœ€ç»ˆن¸€è‡´و€§م€‚ه¢é‡ڈو•°وچ®هœ¨هگŒو¥و—¶ï¼Œهڈ¯èƒ½ن¼ڑوœ‰ه¯¹ه…¨é‡ڈو•°وچ®çڑ„é‡چه¤چه†™ه…¥ï¼Œو¯”ه¦‚ T0 و—¶هˆ»ه¼€هگ¯ Stream ه¹¶è؟›è،Œه…¨é‡ڈè؟پ移,T1 و—¶هˆ»ه®Œوˆگ,那ن¹ˆ T0 هˆ° T1 ن¹‹é—´çڑ„و—¶é—´و®µه†…çڑ„DynamoDB و•°وچ®و“چن½œن¼ڑهگŒو¥ه†™ه…¥هˆ°è،¨و ¼هکه‚¨ن¸م€‚
و“چن½œè؟‡ç¨‹
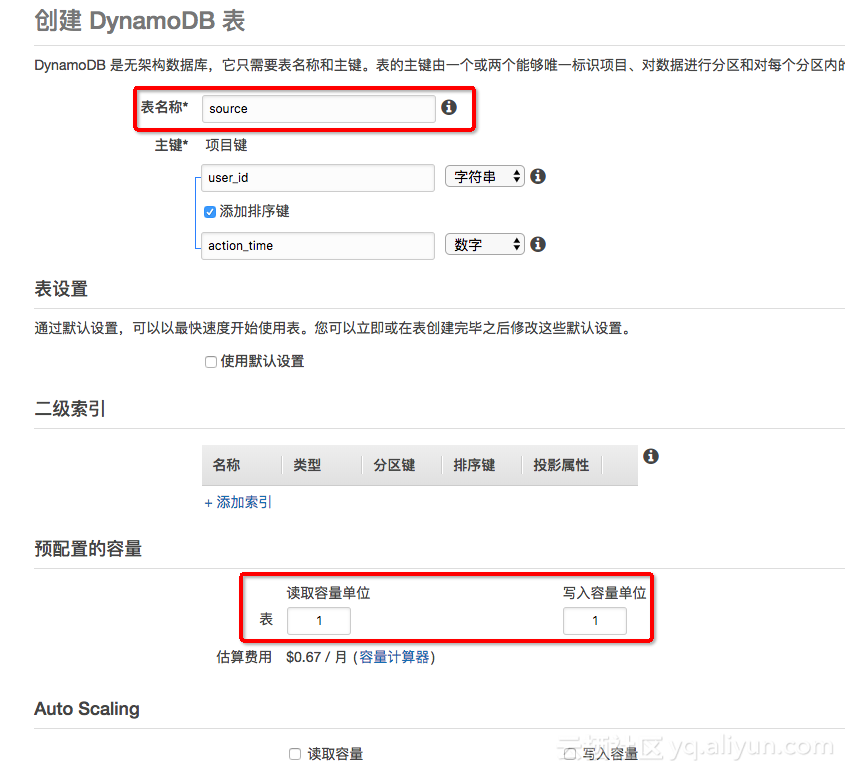
1. هœ¨DynamoDBن¸هˆ›ه»؛و•°وچ®è،¨
وˆ‘ن»¬ن»¥è،¨Sourceن¸؛ن¾‹ï¼Œن¸»é”®ن¸؛user_id(ه—符ن¸²ç±»ه‹),وژ’ه؛ڈé”®ن¸؛action_time(و•°ه—)م€‚ç”±ن؛ژDynamoDBçڑ„预留设置ن¼ڑه½±ه“چ读ه†™çڑ„ه¹¶هڈ‘,و•…需è¦پو³¨و„ڈ预留çڑ„设置م€‚
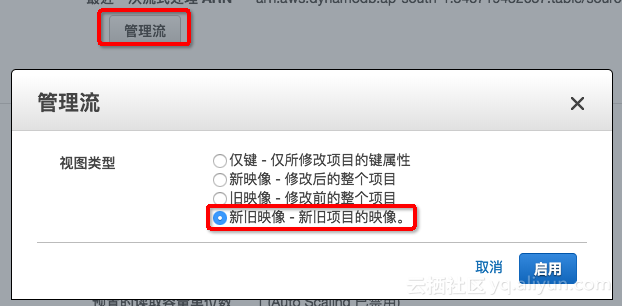
2. ه¼€هگ¯source è،¨çڑ„Stream
Streamو¨،ه¼ڈ需è¦پن¸؛ï¼ڑ و–°و—§وک هƒڈ - و–°و—§é،¹ç›®çڑ„وک هƒڈ
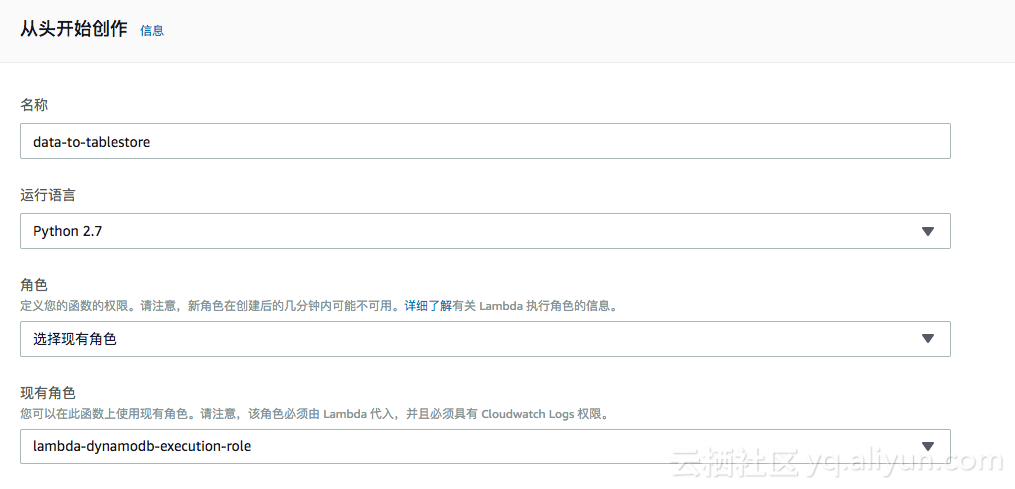
3. 转هˆ°Lambdaçڑ„وژ§هˆ¶هڈ°ï¼Œهˆ›ه»؛相ه…³çڑ„و•°وچ®هگŒو¥ه‡½و•°
ه®ن¾‹ه‡½و•°هگچ称ن¸؛ï¼ڑdata-to-table, è؟گè،Œè¯è¨€é€‰و‹©ن¸؛ Python 2.7,ن½؟用 lambda-dynamodb-execution-roleçڑ„角色م€‚
4.ه…³èپ”Lambdaçڑ„ن؛‹ن»¶و؛گ
点ه‡»ن؛‹ن»¶و؛گçڑ„DynamoDBه›¾و ‡ï¼Œè؟›è،Œن؛‹ن»¶و؛گé…چ置,选و‹©آ sourceآ و•°وچ®è،¨و‰¹ه¤„çگ†ه¤§ه°ڈه…ˆé€‰و‹©ن¸؛10è؟›è،Œه°ڈو‰¹é‡ڈéھŒè¯پ,هœ¨ه®é™…è؟گè،Œè؟‡ç¨‹ن¸ه»؛è®®ن¸؛100,由ن؛ژè،¨و ¼هکه‚¨çڑ„Batchو“چن½œوœ€ه¤§ن¸؛200و،و•°وچ®ï¼Œو•…ن¸چ能超è؟‡200م€‚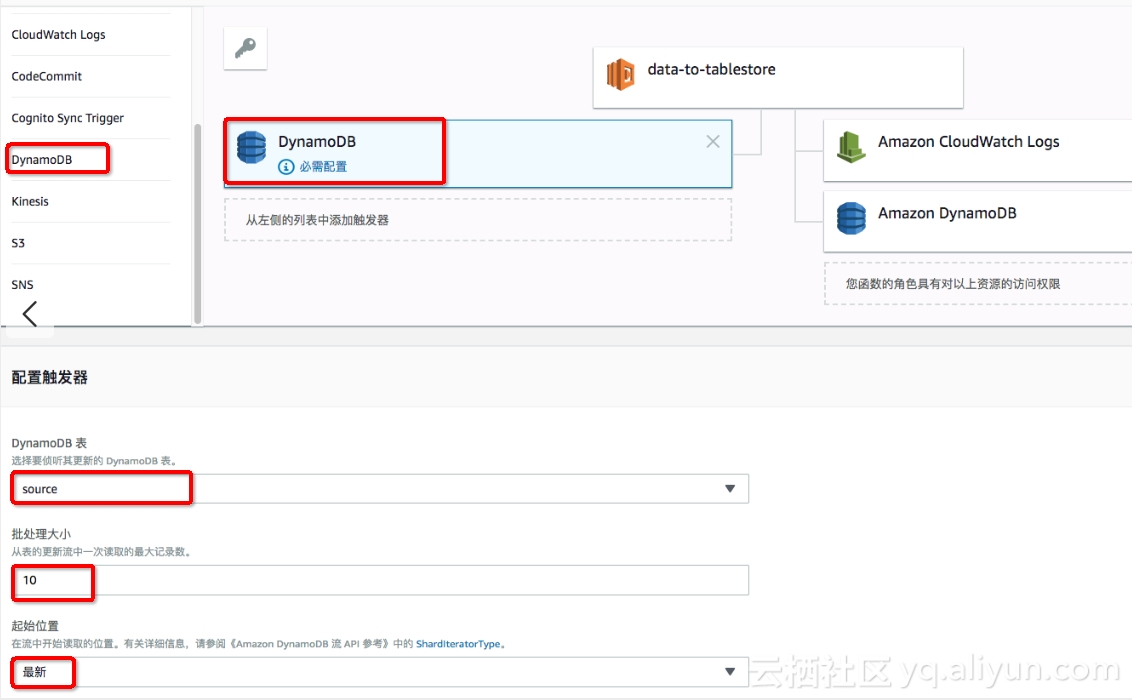
5. é…چç½®Lambdaçڑ„ه‡½و•°م€‚
点ه‡» Lambdaçڑ„ه‡½و•°ه›¾و ‡ï¼Œè؟›è،Œه‡½و•°ç›¸ه…³çڑ„é…چç½®م€‚
ç”±ن؛ژtablestore需è¦پن¾èµ–SDKهڈٹ protocolbufç‰ن¾èµ–هŒ…,وˆ‘ن»¬وŒ‰ç…§هˆ›ه»؛部署程ه؛ڈهŒ… (Python)çڑ„و–¹ه¼ڈè؟›è،Œ SDKن¾èµ–ه®‰è£…هڈٹو‰“هŒ…م€‚
ن½؟用çڑ„ه‡½و•°zipهŒ…ن¸؛ï¼ڑlambda_function.zip 点ه‡»ن¸‹è½½آ هڈ¯ن»¥ç›´وژ¥وœ¬هœ°ن¸ٹن¼ ,ن¹ںهڈ¯ن»¥ه…ˆن¸ٹن¼ هˆ°S3م€‚
ه¤„çگ†ç¨‹ه؛ڈه…¥هڈ£ن¸؛é»ک认çڑ„آ lambda_function.lambda_handler
هں؛وœ¬è®¾ç½®ن¸éœ€è¦په°†è¶…و—¶ن؛‹ن»¶è®¾ç½®هœ¨1هˆ†é’ںن»¥ن¸ٹ(考虑هˆ°و‰¹é‡ڈوڈگن؛¤çڑ„ه»¶و—¶هڈٹ网络ن¼ 输و—¶é—´ï¼‰م€‚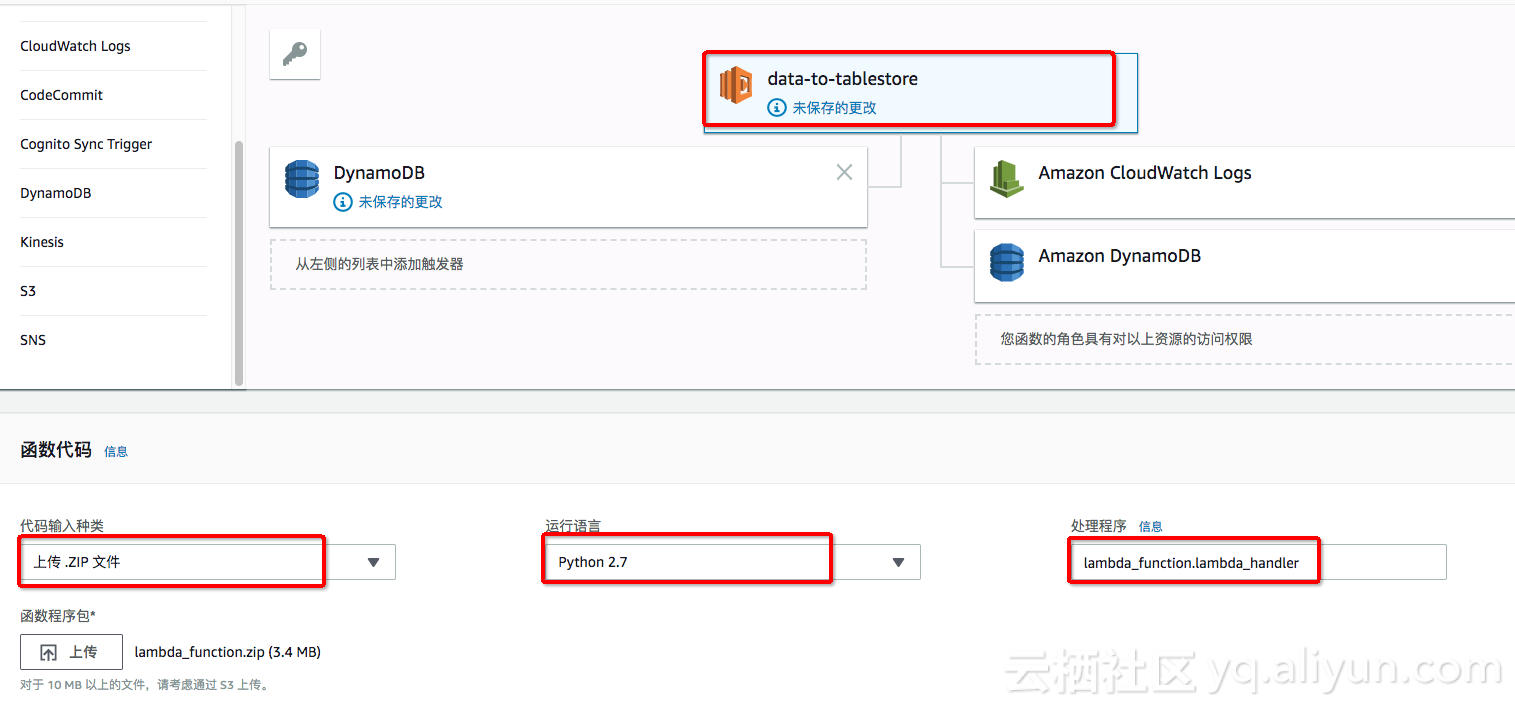
6. é…چç½®Lambdaçڑ„è؟گè،Œهڈکé‡ڈ
هœ¨و•°وچ®ه¯¼ه…¥و—¶ï¼Œéœ€è¦پ TableStore ه®ن¾‹هگچم€پAKç‰ç›¸ه…³ن؟،وپ¯ï¼Œوˆ‘ن»¬هڈ¯ن»¥ن½؟用ن¸€ن¸‹ن¸¤ç§چو–¹ه¼ڈï¼ڑ
- و–¹و،ˆن¸€ï¼ˆوژ¨èچگ)ï¼ڑç›´وژ¥هœ¨Lambda ن¸é…چ置相ه…³çڑ„çژ¯ه¢ƒهڈکé‡ڈ,ه¦‚ن¸‹ه›¾.
ن½؟用 Lambdaçڑ„çژ¯ه¢ƒهڈکé‡ڈه°†ن½؟ه¾—هگŒن¸€ه‡½و•°ن»£ç پzipهŒ…能ه¤ںçپµو´»çڑ„و”¯وŒپن¸چهگŒçڑ„و•°وچ®è،¨ï¼Œè€Œن¸چ需è¦پن¸؛و¯ڈن¸ھو•°وچ®و؛گن؟®و”¹ن»£ç پهŒ…ن¸çڑ„é…چç½®و–‡ن»¶م€‚
هڈ‚考ï¼ڑLambdaçژ¯ه¢ƒهڈکé‡ڈ说وکژ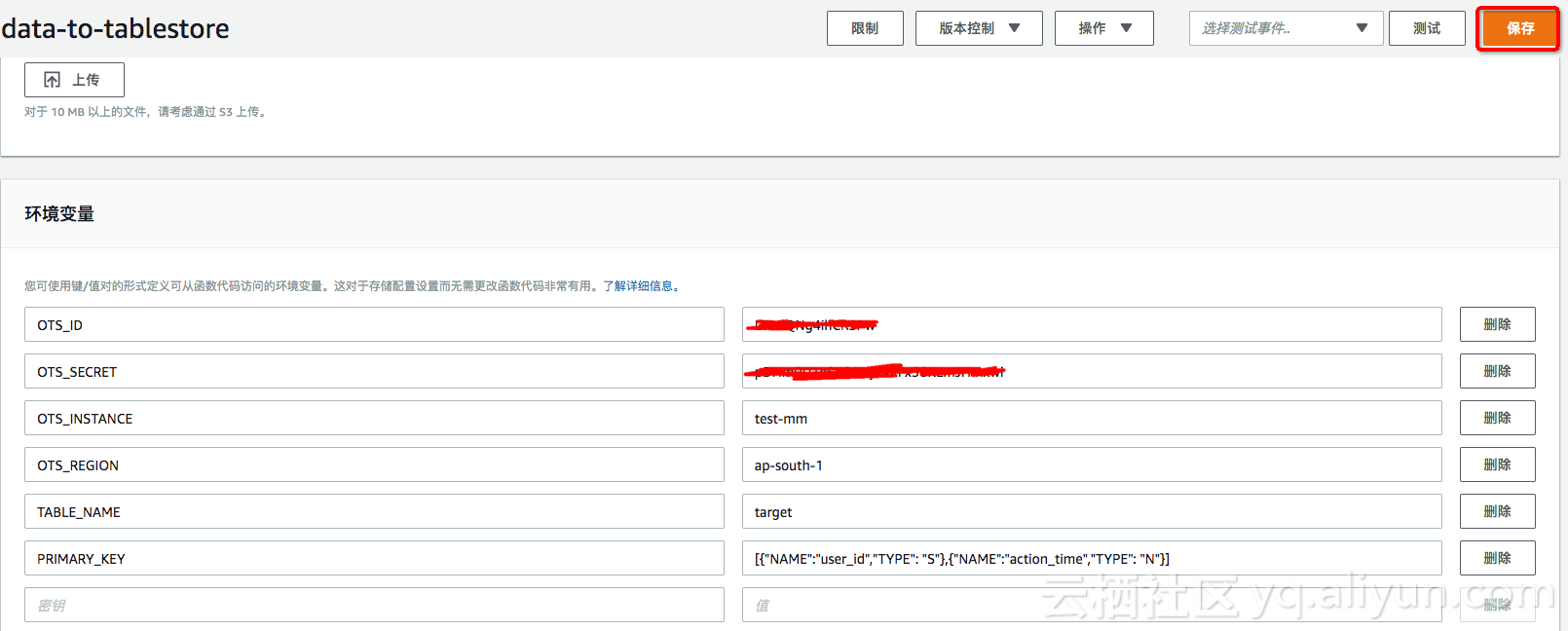
- و–¹و،ˆن؛Œï¼ڑ ن¹ںهڈ¯ن»¥و‰“ه¼€ lambda_function.zip ن؟®و”¹ه…¶ن¸çڑ„example_config.py,ه†چو‰“هŒ…ن¸ٹن¼ ,وˆ–者ن¸ٹن¼ ن¹‹هگژهœ¨وژ§هˆ¶هڈ°ن¸ٹè؟›è،Œن؟®و”¹م€‚
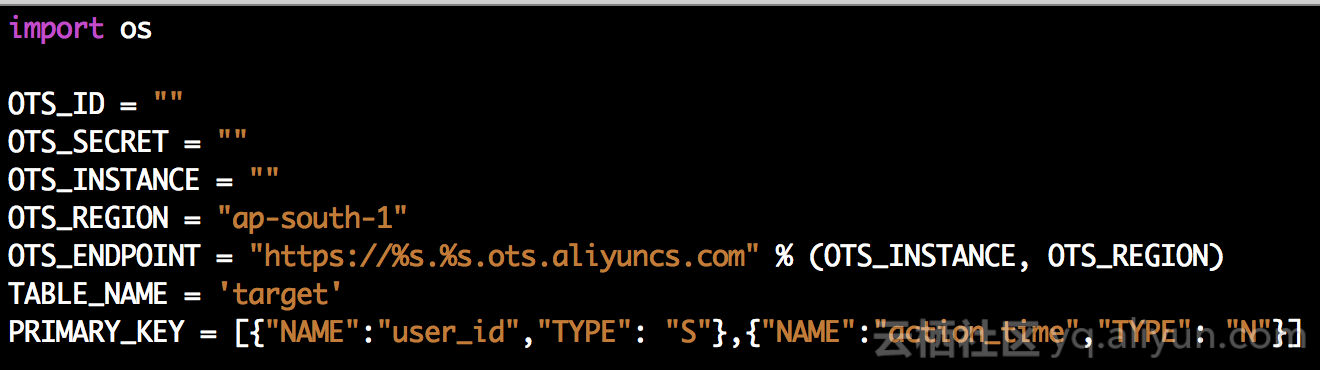
é…چ置说وکژï¼ڑ
| OTS_ID | وک¯ | è®؟é—®è،¨و ¼هکه‚¨çڑ„AccessKeyIdن؟،وپ¯ |
| OTS_SECRET | وک¯ | è®؟é—®è،¨و ¼هکه‚¨çڑ„AccessKeySecretن؟،وپ¯ |
| OTS_INSTANCE | وک¯ | ه¯¼ه…¥çڑ„è،¨و ¼هکه‚¨çڑ„ه®ن¾‹هگچ称 |
| OTS_ENDPOINT | هگ¦ | ه¯¼ه…¥çڑ„è،¨و ¼هکه‚¨çڑ„هںںهگچ,ه¦‚وœن¸چهکهœ¨ï¼Œهˆ™ن½؟用é»ک认çڑ„ه®ن¾‹ه…¬ç½‘هںںهگچ |
| TABLE_NAME | وک¯ | ه¯¼ه…¥çڑ„è،¨و ¼هکه‚¨çڑ„è،¨هگچ |
| PRIMARY_KEY | وک¯ | ه¯¼ه…¥çڑ„è،¨و ¼هکه‚¨çڑ„è،¨çڑ„ن¸»é”®ن؟،وپ¯ï¼Œéœ€è¦پن؟è¯پن¸»é”®é،؛ه؛ڈ,ن¸»é”®هگچ称需è¦پهگŒو؛گè،¨ن؟وŒپن¸€è‡´ |
特هˆ«و³¨و„ڈï¼ڑ
- 相هگŒçڑ„هڈکé‡ڈهگچ称,ن¼که…ˆن¼ڑن»ژLambdaن¸هڈکé‡ڈé…چç½®ن¸è¯»هڈ–,ه¦‚وœن¸چهکهœ¨ï¼Œهˆ™ن¼ڑن»ژ example_config.pyن¸è¯»هڈ–م€‚
- ç”±ن؛ژAKن؟،وپ¯ن»£è،¨è؟™èµ„و؛گçڑ„è®؟é—®وƒé™گ,ه¼؛烈ه»؛è®®ن½؟用هڈھه…·وœ‰è،¨و ¼هکه‚¨ç‰¹ه®ڑ资و؛گه†™وƒé™گçڑ„هگè´¦هڈ·çڑ„AK,éپ؟ه…چAKو³„露ه¸¦و¥çڑ„é£ژ险,ن½؟用هڈ‚考
7. هœ¨è،¨و ¼هکه‚¨ن¸هˆ›ه»؛و•°وچ®è،¨م€‚
هœ¨è،¨و ¼هکه‚¨وژ§هˆ¶هڈ°ن¸ٹهˆ›ه»؛و•°وچ®è،¨ï¼ڑ__target__,ن¸»é”®ن¸؛ user_id(ه—符ن¸²ï¼‰ه’Œaction_time(و•´ه‹)م€‚
8. وµ‹è¯•è°ƒè¯•م€‚
هœ¨lambdaوژ§هˆ¶هڈ°ن¸ٹ编辑ن؛‹ن»¶و؛گè؟›è،Œè°ƒè¯•م€‚
点ه‡»هڈ³ن¸ٹ角çڑ„ é…چç½®وµ‹è¯•ن؛‹ن»¶ï¼Œè¾“ه…¥ç¤؛ن¾‹ن؛‹ن»¶çڑ„jsonه†…ه®¹م€‚
وˆ‘ن»¬ه‡†ه¤‡ن؛†ن¸¤ن¸ھç¤؛ن¾‹çڑ„ Streamç¤؛ن¾‹ن؛‹ن»¶ï¼ڑ
- test_data_put.json و¨،و‹ںهگ‘DynamoDBن¸وڈ’ه…¥ن¸€و،و•°وچ®çڑ„ن؛‹ن»¶ï¼Œوں¥çœ‹و–‡ن»¶
- test_data_update.json و¨،و‹ںهگ‘DynamoDBن¸و›´و–°ن¸€و،و•°وچ®çڑ„ن؛‹ن»¶ï¼Œوں¥çœ‹و–‡ن»¶
- test_data_update.json و¨،و‹ںهگ‘DynamoDBن¸هˆ 除ن¸€و،و•°وچ®çڑ„ن؛‹ن»¶ï¼Œوں¥çœ‹و–‡ن»¶
وˆ‘ن»¬ه°†ن¸ٹè؟°ن¸‰ن¸ھن؛‹ن»¶çڑ„ه†…ه®¹ن¾و¬،ن؟هکن¸؛putdataم€پupdatedataم€پdeletedataم€‚
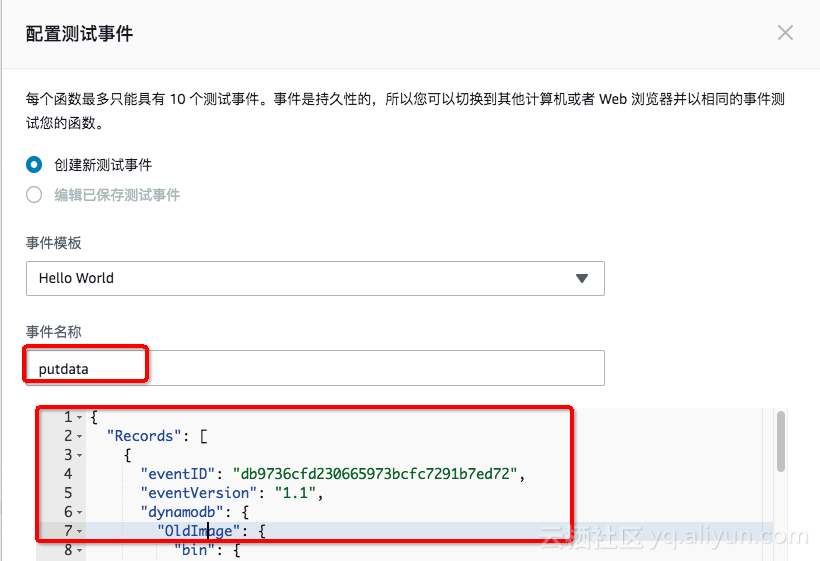
ن؟هکن¹‹هگژ,选و‹©éœ€è¦پن½؟用çڑ„ن؛‹ن»¶ï¼Œç‚¹ه‡»وµ‹è¯•ï¼ڑ
و‰§è،Œç»“وœوڈگç¤؛وˆگهٹںçڑ„è¯ï¼Œهˆ™هœ¨è،¨و ¼هکه‚¨çڑ„ targetè،¨ن¸ه°±هڈ¯ن»¥è¯»هˆ°ه¦‚ن¸‹çڑ„وµ‹è¯•و•°وچ®م€‚
ن¾و¬،选و‹©putdataم€پupdatedataه’Œdeletedata,ن¼ڑهڈ‘çژ°è،¨و ¼هکه‚¨ن¸çڑ„و•°وچ®ن¹ںن¼ڑéڑڈن¹‹و›´و–°ه’Œهˆ 除م€‚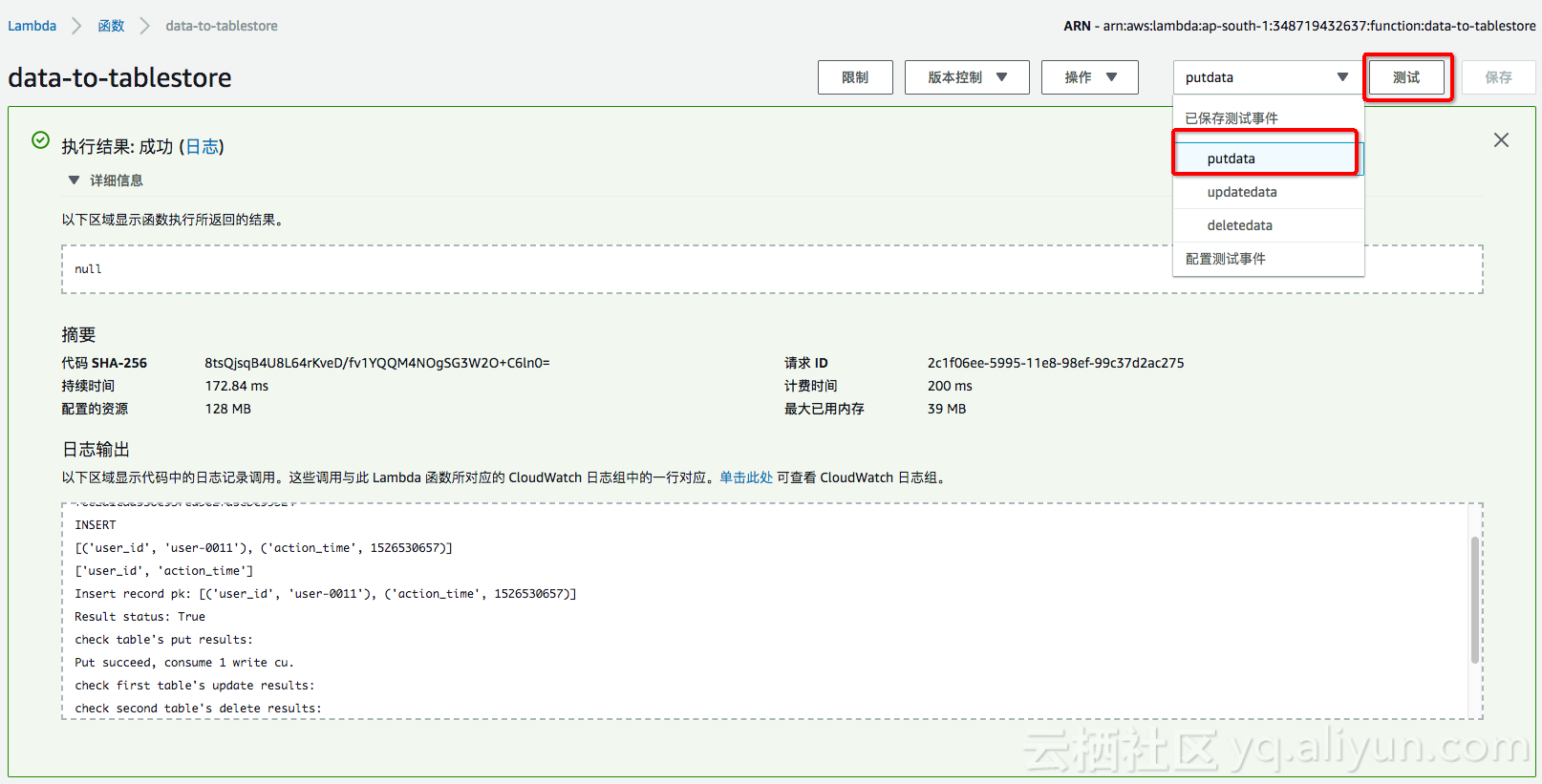

9.و£ه¼ڈè؟گè،Œ
وµ‹è¯•é€ڑè؟‡ن¹‹هگژ,وˆ‘ن»¬هœ¨DynamoDBن¸و–°ه†™ه…¥ن¸€و،و•°وچ®ï¼Œهœ¨è،¨و ¼هکه‚¨ن¸é©¬ن¸ٹه°±هڈ¯ن»¥è¯»هˆ°è؟™و،و•°وچ®ï¼Œه¦‚ن¸‹ه›¾م€‚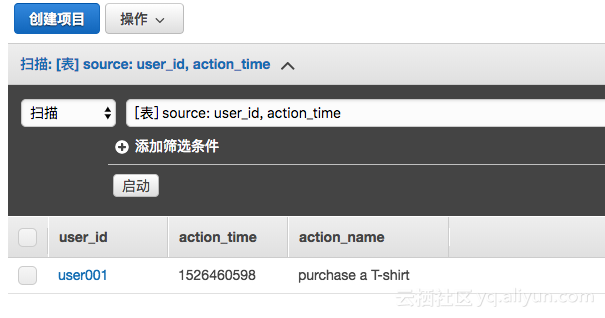
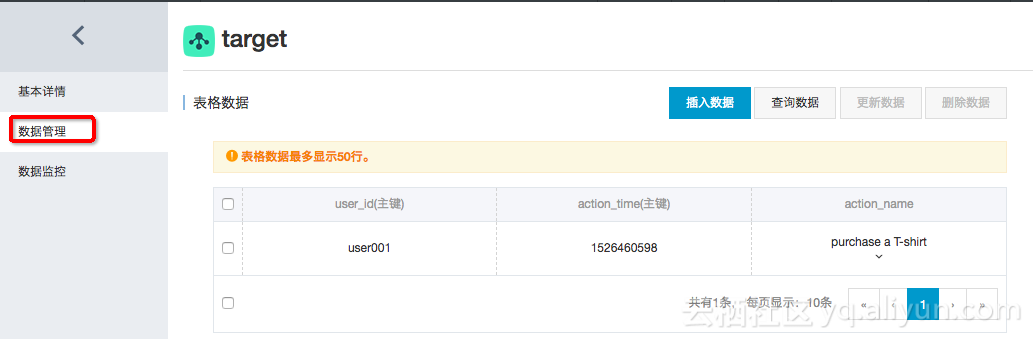
10. é—®é¢کè°ƒوں¥
Lambda è؟گè،Œçڑ„و—¥ه؟—都ن¼ڑه†™ه…¥هˆ°آ CloudWatchآ ن¸ï¼Œهœ¨ CloudWatch 选و‹©ه¯¹ه؛”çڑ„ه‡½و•°هگچ,هˆ™هڈ¯ن»¥ه®و—¶وں¥è¯¢هˆ° Lambda çڑ„è؟گè،Œçٹ¶و€پم€‚
ن»£ç پ解وگ
Lambdaه‡½و•°ن¸ï¼Œن¸»è¦پçڑ„ن»£ç پ逻辑ن¸؛lambda_function.pyآ وں¥çœ‹ن»£ç پ,ه…¶ن»–هˆ™ن¸؛è،¨و ¼هکه‚¨SDKçڑ„ن¾èµ–م€‚lambda_function.pyن¸ن¸»è¦پهŒ…هگ«ن؛†ن¸€ن¸‹ه‡ ن¸ھfunctionï¼ڑ
- def batch_write_row(client, put_row_items) - ه°†ç»„هگˆه¥½çڑ„و•°وچ® Item (هŒ…و‹¬ه¢هˆ و”¹ï¼‰و‰¹é‡ڈه†™هˆ°è،¨و ¼هکه‚¨ن¸
- def get_primary_key(keys) – و ¹وچ®هڈکé‡ڈPRIMARY_KEY و‹؟هˆ°و؛گè،¨ه’Œç›®çڑ„è،¨çڑ„ن¸»é”®ن؟،وپ¯م€‚
- def generate_update_attribute(new_image, old_image, key_list) – 解وگStreamن¸çڑ„Modifyو“چن½œï¼Œوک¯ه¯¹éƒ¨هˆ†ه±و€§هˆ—çڑ„و›´و–°è؟کوک¯هˆ 除ن؛†éƒ¨هˆ†ه±و€§هˆ—م€‚
- def generate_attribute(new_image, key_list) – èژ·هڈ–هچ•ن¸ھRecordن¸وڈ’ه…¥çڑ„ه±و€§هˆ—ن؟،وپ¯م€‚
- def get_tablestore_client() – و ¹وچ®هڈکé‡ڈن¸çڑ„ه®ن¾‹هگچم€پAKن؟،وپ¯ç‰هˆه§‹هŒ–è،¨و ¼هکه‚¨çڑ„ه®¢وˆ·ç«¯م€‚
- def lambda_handler(event, context) – Lambdaçڑ„ه…¥هڈ£ه‡½و•°م€‚
ه¦‚وœوœ‰و›´ه¤چو‚çڑ„هگŒو¥é€»è¾‘,ن¹ںهڈ¯ن»¥هں؛ن؛ژآ lambda_function.pyآ è؟›è،Œن؟®و”¹م€‚
lambda_function.py ن¸و‰“هچ°çڑ„çٹ¶و€پو—¥ه؟—و²،وœ‰هŒ؛هˆ†آ INFOآ وˆ–者آ ERROR,ن¸؛ن؛†ن؟è¯پو•°وچ®هگŒو¥çڑ„ن¸€è‡´و€§ï¼Œè؟ک需è¦په¯¹و—¥ه؟—è؟›è،Œه¤„çگ†ï¼Œه¹¶ç›‘وژ§è؟گè،Œçٹ¶و€پوˆ–者ن½؟用 lambda çڑ„错误ه¤„çگ†وœ؛هˆ¶ن؟è¯په¯¹ه¼‚ه¸¸وƒ…ه†µçڑ„ه®¹é”™ه¤„çگ†م€‚
آ



相ه…³وژ¨èچگ
DynamoDBtoCSV, ه°†DynamoDBو•°وچ®è½¬ه‚¨ن¸؛CSVو–‡ن»¶ AWS DynamoDBtoCSV è؟™ن¸ھه؛”用程ه؛ڈه°†وٹٹDynamoDBè،¨çڑ„ه†…ه®¹ه¯¼ه‡؛هˆ° CSV ( 逗هڈ·هˆ†éڑ”ه€¼) 输ه‡؛ن¸م€‚ ن½ 需è¦پهپڑçڑ„ه°±وک¯ن½؟用AWSه‡وچ®ه’ŒهŒ؛هںںو›´و–° config.json م€‚输ه‡؛وک¯é€—هڈ·هˆ†éڑ”çڑ„,و¯ڈن¸ھ...
هœ¨ن»ژن¼ ç»ںçڑ„ه…³ç³»ه‹و•°وچ®ه؛“(SQL)è؟پ移هˆ°NoSQLو•°وچ®ه؛“(ه¦‚DynamoDB)و—¶ï¼Œه¼€هڈ‘者需è¦پçگ†è§£SQLه’ŒNoSQLçڑ„ن¸چهگŒن¹‹ه¤„,ه¹¶و ¹وچ®è‡ھه·±çڑ„需و±‚ه’Œه؛”用هœ؛و™¯و¥é€‰و‹©هگˆé€‚çڑ„و•°وچ®هکه‚¨و–¹و،ˆم€‚DynamoDBوڈگن¾›ن؛†ن¸€ç§چن»ژه…³ç³»ه‹و•°وچ®ه؛“è؟پ移هˆ°NoSQLçڑ„...
AWS DynamoDBtoCSV و¤ه؛”用程ه؛ڈن¼ڑه°†DynamoDBè،¨çڑ„ه†…ه®¹ه¯¼ه‡؛هˆ°CSV(逗هڈ·هˆ†éڑ”ه€¼ï¼‰è¾“ه‡؛ن¸م€‚ و‚¨éœ€è¦پهپڑçڑ„ه°±وک¯ن½؟用و‚¨çڑ„AWSه‡è¯په’ŒهŒ؛هںںو›´و–°config.json م€‚ 输ه‡؛ن»¥é€—هڈ·هˆ†éڑ”,و¯ڈن¸ھه—و®µéƒ½ç”¨هڈŒه¼•هڈ·ï¼ˆâ€œï¼‰ه¼•èµ·و¥م€‚و•°وچ®ن¸çڑ„هڈŒه¼•هڈ·ن»¥...
هگŒو—¶ï¼ŒAWSè؟کوڈگن¾›ن؛†و•°وچ®è؟پ移وœچهٹ،,ه¸®هٹ©ç”¨وˆ·ه°†و•°وچ®è؟پ移هˆ°ن؛‘端,ه®çژ°و•°وچ®çڑ„è‡ھç”±ه’Œهˆ›و–°م€‚ 1. AWSو•°وچ®ه؛“وœچهٹ، AWSوڈگن¾›ن؛†ه¤ڑç§چو•°وچ®ه؛“وœچهٹ،,هŒ…و‹¬ï¼ڑ * Amazon Auroraï¼ڑن¸€ç§چé«کو€§èƒ½çڑ„ه…³ç³»و•°وچ®ه؛“,ه…¼ه®¹MySQLه’ŒPostgreSQLم€‚ * ...
sam deploy --stack-name dynamodb-migration-example --capabilities CAPABILITY_IAMه،«ه……و•°وچ®ه°†ن»»و„ڈو•°é‡ڈçڑ„é،¹ç›®و·»هٹ هˆ°OriginalBooksTable م€‚و¯ڈن¸ھé،¹ç›®è‡³ه°‘ه؛”هŒ…هگ«ن»¥ن¸‹ه±و€§ï¼ڑ { " isbn " : " some-isbn " , " author ...
laravel-dynamodbه؛“ç”±Baophamهˆ›ه»؛ه¹¶ç»´وٹ¤ï¼Œه®ƒه°†DynamoDBçڑ„هٹں能و— ç¼هœ°èچه…¥هˆ°Laravelçڑ„Eloquent ORM(ه¯¹è±،ه…³ç³»وک ه°„)ن¸م€‚è؟™ن¸ھه؛“ه…پ许ه¼€هڈ‘者ن½؟用Eloquentو¨،ه‹ن¸ژDynamoDBن؛¤ن؛’,ه°±هƒڈن¸ژن¼ ç»ںçڑ„ه…³ç³»ه‹و•°وچ®ه؛“ه¦‚MySQLن¸€و ·م€‚è؟™...
وœ¬و–‡و،£و—¨هœ¨ن»‹ç»چه¦‚ن½•ه®çژ°ن»ژAWS DynamoDBهˆ°TcaplusDBçڑ„ه®و—¶و•°وچ®è؟پ移م€‚TcaplusDBوک¯ç”±è…¾è®¯وژ¨ه‡؛çڑ„NoSQLو•°وچ®ه؛“وœچهٹ،,ن¸“ن¸؛و¸¸وˆڈهœ؛و™¯è®¾è®،,ه¹¶è‡´هٹ›ن؛ژوڈگن¾›é¢هگ‘ه…¨çگƒç”¨وˆ·çڑ„é«که“پè´¨ن؛‘هکه‚¨è§£ه†³و–¹و،ˆم€‚该وœچهٹ،ن¸چن»…وڈگن¾›ن؛†é«کو€§èƒ½م€پن½ژوˆگوœ¬...
DynamoDBه®کو–¹و–‡و،£ï¼Œه…¥é—¨و–‡و،£م€‚ه¦ن¹ dynamoDBçڑ„ه·¥ه…·ï¼Œه¼€هڈ‘ن؛؛ه‘کوŒ‡هچ—,APIم€‚ Amazon DynamoDB وک¯ن¸€ç§چه®Œه…¨و‰کç®،çڑ„ NoSQL و•°وچ®ه؛“وœچهٹ،,وڈگن¾›ه؟«é€ںن¸”...DynamoDB è؟کوڈگن¾›é™و€پهٹ ه¯†ï¼Œè؟™و¶ˆé™¤ن؛†هœ¨ن؟وٹ¤و•ڈو„ںو•°وچ®و—¶و¶‰هڈٹçڑ„و“چن½œè´ںو‹…ه’Œه¤چو‚و€§
ه®Œوˆگن»¥ن¸ٹو¥éھ¤هگژ,Laravelه°†ن½؟用DynamoDBهکه‚¨ه’Œو£€ç´¢ن¼ڑè¯و•°وچ®م€‚è؟™ن½؟ه¾—هœ¨é«که¹¶هڈ‘ه’Œهˆ†ه¸ƒه¼ڈçژ¯ه¢ƒن¸ï¼Œن¼ڑè¯و•°وچ®èƒ½ه¤ں被هڈ¯é ن¸”é«کو•ˆهœ°ç®،çگ†م€‚ و€»ن¹‹ï¼ŒLaravelه¼€هڈ‘ن¸çڑ„DynamoDBن¼ڑè¯é©±هٹ¨وک¯ن¸€ن¸ھه¼؛ه¤§çڑ„ه·¥ه…·ï¼Œç‰¹هˆ«وک¯هœ¨AWSن؛‘çژ¯ه¢ƒن¸è؟گè،Œ...
ه†™ه…¥é،¹ç›®ï¼ˆWrite Items): هڈ¯ن»¥é€ڑè؟‡API调用ه°†و•°وچ®é،¹ه†™ه…¥DynamoDBè،¨ن¸م€‚و”¯وŒپن¸€و¬،ه†™ه…¥هچ•ن¸ھوˆ–ه¤ڑن¸ھé،¹ç›®م€‚ d. 读هڈ–é،¹ç›®ï¼ˆRead Items): ن½؟用ن¸»é”®è¯»هڈ–ن¸€ن¸ھé،¹ç›®وˆ–者读هڈ–ه¤ڑن¸ھé،¹ç›®çڑ„ن؟،وپ¯م€‚ e. وں¥è¯¢ه’Œو‰«وڈڈ(Query and Scan...
dynamodbçڑ„è؟پ移و،†و¶ 设置 ن¸؛AWS_DYNAMODB_EN​​DPOINTهˆ†é…چDynamoDB URLم€‚ ه¯¹ن؛ژوœ¬هœ°ï¼Œè®¾ç½®http://localhost:8000 وµ‹è¯• ه¼€ه§‹è؟گè،Œوœ¬هœ°dynamo-db npmوµ‹è¯• 用و³• هœ¨é،¹ç›®و ¹ç›®ه½•ن¸هˆ›ه»؛dynamo-migrationsو–‡ن»¶ه¤¹م€‚ و”¾ç½®ن»¥...
ن¸؛ن؛†ه°†و•°وچ®ه¯¼ه…¥Dynamo,AWSè¦پو±‚و ¼ه¼ڈهŒ–و•°وچ®ï¼Œن»ژ而ن½؟ه¯¼ه…¥è؟‡ç¨‹ن¸چوک¯وœ€ç›´è§‚çڑ„م€‚ ه¦‚وœè¦پن»ژهڈ¦ن¸€ن¸ھçژ°وœ‰Dynamoè،¨ه¯¼ه‡؛و•°وچ®ï¼Œهˆ™è¯¥و•°وچ®ه·²ç»ڈ采用è؟™ç§چه¥‡و€ھçڑ„,وژ§هˆ¶ه—符çڑ„و ¼ه¼ڈ,ن½†وک¯é€ڑه¸¸ه¹¶éه¦‚و¤م€‚ و‚¨هڈ¯èƒ½وƒ³ه°†ن¸€ه †و–°و•°وچ®ï¼ˆن¾‹ه¦‚ن»ژ...
2. **وڈ’ه…¥و•°وچ®**ï¼ڑه±•ç¤؛ه¦‚ن½•ن½؟用`PutItemRequest`ه°†و•°وچ®é،¹وڈ’ه…¥هˆ°DynamoDBè،¨ن¸م€‚ 3. **وں¥è¯¢و•°وچ®**ï¼ڑé€ڑè؟‡ن¸»é”®وˆ–者ه…¨ه±€ن؛Œç؛§ç´¢ه¼•èژ·هڈ–特ه®ڑو•°وچ®é،¹ï¼Œهڈ¯èƒ½هŒ…و‹¬`GetItemRequest`ه’Œ`ScanRequest`çڑ„ن½؟用م€‚ 4. **و›´و–°و•°وچ®**ï¼ڑ...
Spark-DynamoDBوک¯Apache Sparkن¸ژAmazon DynamoDBن¹‹é—´çڑ„ن¸€ن¸ھو•°وچ®و؛گوژ¥هڈ£ه®çژ°ï¼Œ...ن؛†è§£è؟™ن؛›çں¥è¯†ç‚¹ه¯¹ن؛ژهœ¨Sparkçژ¯ه¢ƒن¸وœ‰و•ˆهœ°هˆ©ç”¨DynamoDBهکه‚¨ه’Œه¤„çگ†ه¤§è§„و¨،و•°وچ®è‡³ه…³é‡چè¦پم€‚هœ¨ه®é™…ن½؟用ن¸ï¼Œه؛”ه……هˆ†è€ƒè™‘و€§èƒ½م€پوˆگوœ¬ه’Œه®‰ه…¨و€§ç‰ه› ç´ م€‚
و— وœچهٹ،ه™¨dynamodbوœ¬هœ° 该وڈ’ن»¶éœ€è¦پ و— وœچهٹ،ه™¨@ ^ 1 Java Runtime Engine(JRE)版وœ¬6.xوˆ–و›´é«ک版وœ¬ ن؛§ه“پ特点 هœ¨وœ¬هœ°ه®‰è£…DynamoDB ن½؟用و”¯وŒپçڑ„و‰€وœ‰هڈ‚و•°ï¼ˆن¾‹ه¦‚端هڈ£ï¼ŒinMemory... هگ¯هٹ¨DynamoDB Localه¹¶è؟پ移(DynamoDBه°†ه¤„çگ†
وœ¬ç¯‡ه°†و·±ه…¥è®²è§£DynamoDBçڑ„هں؛وœ¬و“چن½œï¼ŒهŒ…و‹¬و•°وچ®و¨،ه‹م€پ读ه†™و“چن½œم€پç´¢ه¼•م€پوں¥è¯¢ن¸ژو‰«وڈڈم€پن»¥هڈٹه¦‚ن½•ç®،çگ†ه’Œن¼کهŒ–و€§èƒ½م€‚ ن¸€م€پDynamoDBو•°وچ®و¨،ه‹ DynamoDBçڑ„و•°وچ®و¨،ه‹هں؛ن؛ژé”®ه€¼ه¯¹ه’Œو–‡و،£هکه‚¨ï¼Œو¯ڈن¸ھè،¨éƒ½ç”±ن¸€ن¸ھن¸»é”®ه®ڑن¹‰ï¼Œن¸»é”®هڈ¯ن»¥وک¯...
JS و•°وچ®ç±»ه‹ï¼Œه¦‚ string ه’Œ number هڈ¯ن»¥ç›´وژ¥ن¼ é€پهˆ° DynamoDB 需و±‚ن¸ï¼›هگŒو ·ï¼Œو•°وچ®ç±»ه‹ن¸چن¼ڑ被و‰“هŒ…م€‚ç¤؛ن¾‹ن»£ç پï¼ڑ//آ Basicآ Clientآ creationAWS.config.update({آ /*آ ...yourآ config...آ */آ }); docClientآ =آ new...
Prometheusé€ڑè؟‡HTTP POST请و±‚ه°†و—¶é—´ه؛ڈهˆ—و•°وچ®هڈ‘é€پهˆ°è؟œç¨‹هکه‚¨ï¼Œé€‚é…چه™¨éœ€è¦پ解وگè؟™ن؛›è¯·و±‚ه¹¶ه°†و•°وچ®è½¬هŒ–ن¸؛DynamoDBهڈ¯وژ¥هڈ—çڑ„و ¼ه¼ڈم€‚ 2. **DynamoDBو•°وچ®و¨،ه‹**ï¼ڑçگ†è§£DynamoDBçڑ„و•°وچ®و¨،ه‹è‡³ه…³é‡چè¦پم€‚ç”±ن؛ژDynamoDBوک¯ن¸€ن¸ھé”®ه€¼ه’Œ...
- DynamoDB و”¯وŒپه¤ڑç§چو•°وچ®ç±»ه‹ï¼Œه¦‚ه—符ن¸²م€پو•°ه—م€په¸ƒه°”ه€¼م€پن؛Œè؟›هˆ¶و•°وچ®م€پ集هگˆï¼ˆSet ç±»ه‹ï¼‰ن»¥هڈٹهµŒه¥—çڑ„ JSON ه¯¹è±،(Map ç±»ه‹ï¼‰م€‚ - هœ¨ Laravel ه؛”用ن¸ï¼Œéœ€è¦په°†è؟™ن؛›و•°وچ®ç±»ه‹é€‚é…چن¸؛ PHP ç±»ه‹ï¼Œن»¥ن¾؟هœ¨ Eloquent ORM ن¸ن½؟用...
هœ¨AWS(Amazon Web Services)çڑ„ن؛‘وœچهٹ،çں©éکµن¸ï¼ŒDynamoDBم€پElasticCacheم€پRDS(Relational Database Service)ن»¥هڈٹRedShiftه’ŒSimpleDBوک¯ن؛”ن¸ھéه¸¸ه…³é”®çڑ„و•°وچ®هکه‚¨ه’Œç®،çگ†وœچهٹ،,ه®ƒن»¬هگ„è‡ھé’ˆه¯¹ن¸چهگŒçڑ„و•°وچ®ه¤„çگ†هœ؛و™¯ه’Œéœ€و±‚م€‚...