
жСШи¶БпЉЪ¬†еЬ®2018еєі3жЬИ13жЧ•дЇСж†Цз§ЊеМЇпЉМжЭ•иЗ™еУИе∞Фжї®еЈ•дЄЪе§Іе≠¶зЪДж≤ИдњК敆еИЖдЇЂдЇЖеЕЄеЮЛж®°еЉП-жЈ±еЇ¶з•ЮзїПзљСзїЬеЕ•йЧ®гАВжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖеЕ≥дЇОжЈ±еЇ¶з•ЮзїПзљСзїЬзЪДеПСе±ХеОЖз®ЛпЉМеєґиѓ¶зїЖдїЛзїНдЇЖеРДдЄ™йШґжЃµж®°еЮЛзЪДзїУжЮДеПКзЙєзВєгАВ
еУИе∞Фжї®еЈ•дЄЪе§Іе≠¶зЪДж≤ИдњК敆еИЖдЇЂдЇЖеЕЄеЮЛж®°еЉП-жЈ±еЇ¶з•ЮзїПзљСзїЬеЕ•йЧ®гАВжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖеЕ≥дЇОжЈ±еЇ¶з•ЮзїПзљСзїЬзЪДеПСе±ХеОЖз®ЛпЉМеєґиѓ¶зїЖдїЛзїНдЇЖеРДдЄ™йШґжЃµж®°еЮЛзЪДзїУжЮДеПКзЙєзВєгАВ
зЫіжТ≠еЫЮй°ЊиѓЈзВєеЗї
дї•дЄЛжШѓз≤Њељ©иІЖйҐСеЖЕеЃєжХізРЖпЉЪ
йЧЃйҐШеЉХеЗЇ
е≠¶дє†зЯ•иѓЖдїОйЧЃйҐШеЉХеЗЇеЕ•жЙЛжШѓдЄАдЄ™еЊИе•љзЪДжЦєж≥ХпЉМжЙАдї•жЬђжЦЗе∞ЖеПѓдї•еЫізїХдЄЛйЭҐдЄЙдЄ™йЧЃйҐШжЭ•е±ХеЉАпЉЪ
1.DNNеТМCNNжЬЙдїАдєИдЄНеРМпЉЯжЬЙдїАдєИеЕ≥з≥їпЉЯе¶ВдљХеЃЪдєЙпЉЯ
2.дЄЇдїАдєИDNNзО∞еЬ®ињЩдєИзБЂпЉМеЃГзїПеОЖжАОдєИдЄАдЄ™еПСе±ХеОЖз®ЛпЉЯ
3.DNNзЪДзїУжЮДеЊИе§НжЭВпЉМжАОдєИиГљеЃЮйЩЕеЕ•йЧ®иѓХдЄАдЄЛеСҐпЉЯ
жЬђжЦЗжАЭзїіеѓЉеЫЊе¶ВдЄЛпЉЪ
еПСе±ХеОЖз®Л
DNN-еЃЪдєЙеТМж¶Вењµ
еЬ®еНЈзІѓз•ЮзїПзљСзїЬдЄ≠пЉМеНЈзІѓжУНдљЬеТМ汆еМЦжУНдљЬжЬЙжЬЇзЪДе†ЖеП†еЬ®дЄАиµЈпЉМдЄАиµЈзїДжИРдЇЖCNNзЪДдЄїеє≤гАВ
еРМж†ЈжШѓеПЧеИ∞зМХзМіиІЖзљСиЖЬдЄОиІЖиІЙзЪЃе±ВдєЛйЧіе§Ъе±ВзљСзїЬзЪДеРѓеПСпЉМжЈ±еЇ¶з•ЮзїПзљСзїЬжЮґжЮДжЮґжЮДеЇФињРиАМзФЯпЉМдЄФеПЦеЊЧдЇЖиЙѓе•љзЪДжАІиГљгАВеПѓдї•иѓіпЉМDNNеЕґеЃЮжШѓдЄАзІНжЮґжЮДпЉМжШѓжМЗжЈ±еЇ¶иґЕињЗеЗ†дЄ™зЫЄдЉЉе±ВзЪДз•ЮзїПзљСзїЬзїУжЮДпЉМдЄАиИђиГље§ЯиЊЊеИ∞еЗ†еНБе±ВпЉМжИЦиАЕзФ±дЄАдЇЫе§НжЭВзЪДж®°еЭЧзїДжИРгАВ
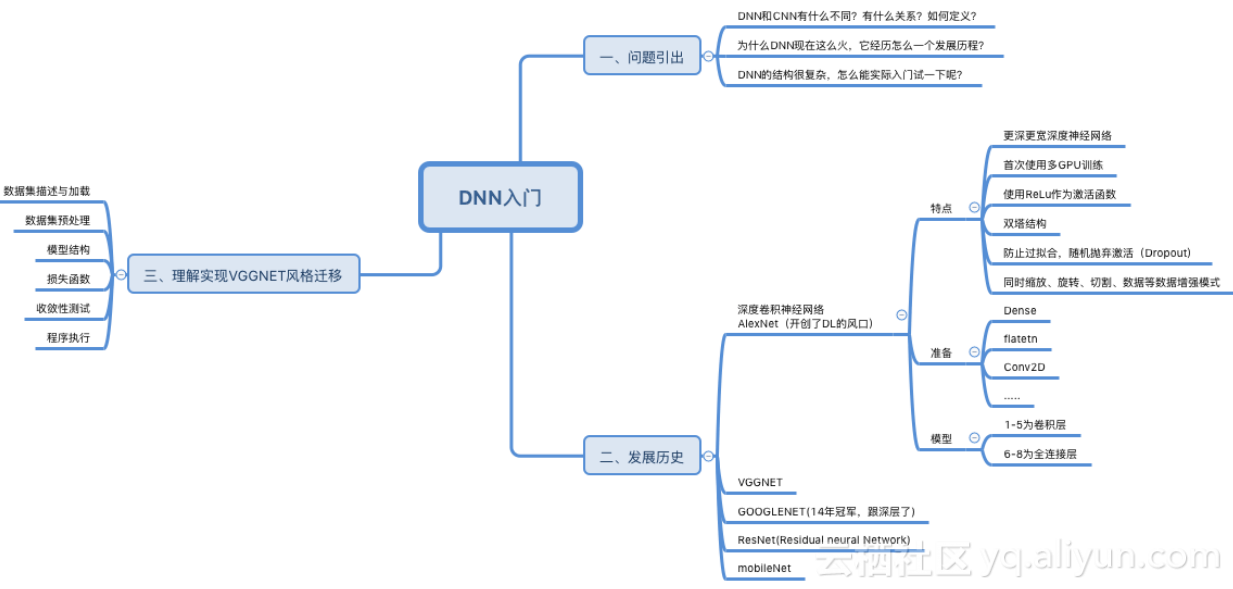
ILSVRC(ImageNetе§ІиІДж®°иІЖиІЙиѓЖеИЂжМСжИШиµЫ)жѓПеєійГљдЄНжЦ≠襀棱寶е≠¶дє†еИЈж¶ЬпЉМйЪПзЭАж®°еЮЛеПШеЊЧиґКжЭ•иґКжЈ±пЉМTop-5зЪДйФЩиѓѓзОЗдєЯиґКжЭ•иґКдљОпЉМзЫЃеЙНйЩНдљОеИ∞дЇЖ3.5%йЩДињСпЉМиАМдЇЇз±їеЬ®ImageNetжХ∞жНЃйЫЖеРИдЄКзЪДиЊ®иѓЖйФЩиѓѓзОЗе§Іж¶ВеЬ®5.1%пЉМдєЯе∞±жШѓзЫЃеЙНзЪДжЈ±еЇ¶е≠¶дє†ж®°еЮЛиѓЖеИЂиГљеКЫеЈ≤зїПиґЕињЗдЇЖдЇЇз±їгАВ
дїОAlexNetеИ∞MobileNet
Alexnet
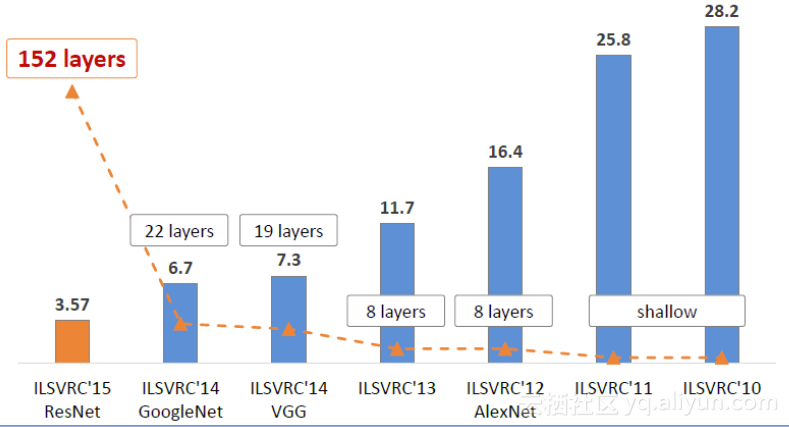
AlexNetжШѓй¶Цжђ°жККеНЈзІѓз•ЮзїПзљСзїЬеЉХеЕ•иЃ°зЃЧжЬЇиІЖиІЙйҐЖеЯЯеєґеПЦеЊЧз™Бз†іжАІжИРзї©зЪДж®°еЮЛгАВ
AlexNetжЬЙAlex KrizhevskyгАБllya SutskeverгАБGeoff HintonжПРеЗЇпЉМиОЈеЊЧдЇЖILSVRC 2012еєізЪДеЖ†еЖЫпЉМеЖНtop-5й°єзЫЃдЄ≠йФЩиѓѓзОЗдїЕдїЕ15.3%пЉМзЫЄеѓєдЇОдљњзФ®дЉ†зїЯжЦєж≥ХзЪДдЇЪеЖЫ26.2%зЪДжИРзї©дЉШиЙѓйЗНе§Із™Бз†ігАВ
зЫЄжѓФдєЛеЙНзЪДLeNetпЉМAlexNetйАЪињЗе†ЖеП†еНЈзІѓе±ВдљњеЊЧж®°еЮЛжЫіжЈ±жЫіеЃљпЉМеРМжЧґеАЯеК©GPUдљњеЊЧиЃ≠зїГеЖНеПѓжО•еПЧзЪДжЧґйЧіиМГеЫіеЖЕеЊЧеИ∞зїУжЮЬпЉМжО®еК®дЇЖеНЈзІѓз•ЮзїПзљСзїЬзФЪиЗ≥жШѓжЈ±еЇ¶е≠¶дє†зЪДеПСе±ХгАВ
дЄЛйЭҐжШѓAlexNetзЪДжЮґжЮДпЉЪ
AlexNetзЪДзЙєзВєжЬЙпЉЪ
1.еАЯеК©жЛ•жЬЙ1500дЄЗж†Зз≠ЊгАБ22000еИЖз±їзЪДImageNetжХ∞жНЃйЫЖжЭ•иЃ≠зїГж®°еЮЛпЉМжО•ињСзЬЯеЃЮдЄЦзХМдЄ≠зЪДе§НжЭВеЬЇжЩѓгАВ
2.дљњзФ®жЫіжЈ±жЫіеЃљзЪДCNNжЭ•жПРйЂШе≠¶дє†еЃєйЗПгАВ
3.зБµжіїињРзФ®ReLUдљЬдЄЇжњАжіїеЗљжХ∞пЉМзЫЄеѓєSigmoidе§ІеєЕеЇ¶жПРйЂШдЇЖиЃ≠зїГйАЯеЇ¶гАВ
4.дљњзФ®е§ЪеЭЧGPUжПРйЂШж®°еЮЛзЪДеЃєйЗПгАВ
5.йАЪињЗLRNеЉХеЕ•з•ЮзїПеЕГдєЛйЧізЪДзЂЮдЇЙдї•еЄЃеК©ж≥ЫеМЦпЉМжПРйЂШж®°еЮЛжАІиГљгАВ
6.йАЪињЗDropoutйЪПжЬЇењљзХ•йГ®еИЖз•ЮзїПеЕГпЉМйБњеЕНињЗжЛЯеРИгАВ
7.йАЪињЗзЉ©жФЊгАБзњїиљђгАБеИЗеЙ≤з≠ЙжХ∞жНЃеҐЮеЉЇжЦєеЉПйБњеЕНињЗжЛЯеРИгАВ
дї•дЄКдЄЇеЕЄеЮЛзЪДжЈ±еЇ¶з•ЮзїПзљСзїЬињРзФ®зЪДжЦєж≥ХгАВ
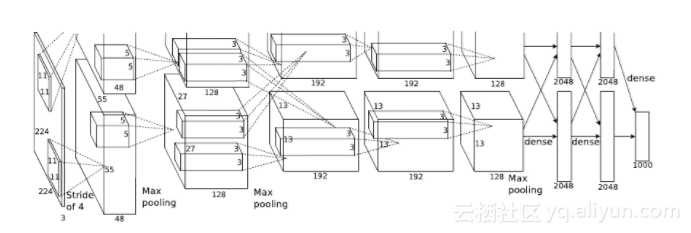
AlexNetеЬ®з†ФеПСзЪДжЧґеАЩпЉМдљњзФ®зЪДGTX580дїЕжЬЙ3GBзЪДжШЊе≠ШпЉМжЙАдї•еИЫйА†жАІзЪДжККж®°еЮЛжЛЖиІ£еЬ®дЄ§еЉ†жШЊеН°дЄ≠пЉМжЮґжЮДе¶ВдЄЛпЉЪ
1.зђђдЄАе±ВжШѓеНЈзІѓе±ВпЉМйТИеѓє224x224x3зЪДиЊУеЕ•еЫЊзЙЗињЫи°МеНЈзІѓжУНдљЬпЉМеПВжХ∞дЄЇпЉЪеНЈзІѓж†Є11x11x3пЉМжХ∞йЗП96пЉМж≠•йХњ4пЉМLRNж≠£жАБеМЦеРОињЫи°М2x2зЪДжЬА姲汆еМЦгАВ
2.зђђдЇМе±ВжШѓеНЈзІѓе±ВпЉМдїЕдЄОеРМдЄАдЄ™GPUеЖЕзЪДзђђдЄАе±ВиЊУеЗЇињЫи°МеНЈзІѓпЉМеПВжХ∞дЄЇпЉЪеНЈзІѓж†Є5x5x48пЉМзЦПжЬЧ256пЉМLRNж≠£жАБеМЦеРОињЫи°М2x2зЪДжЬА姲汆еМЦгАВ
3.зђђдЄЙе±ВжШѓеНЈзІѓе±ВпЉМдЄОзђђдЇМе±ВжЙАжЬЙиЊУеЗЇињЫи°МеНЈзІѓпЉМеПВжХ∞дЄЇпЉЪ3x3x256пЉМжХ∞йЗП384.
4.зђђеЫЫе±ВжШѓеНЈзІѓе±ВпЉМдїЕдЄОеРМдЄАдЄ™GPUеЖЕзЪДзђђдЄЙе±ВиЊУеЗЇињЫи°МеНЈзІѓпЉМеПВжХ∞дЄЇпЉЪеНЈзІѓж†Є3x3x192пЉМжХ∞йЗП384гАВ
5.зђђдЇФе±ВжШѓеНЈзІѓе±ВпЉМдїЕдЄОеРМдЄАдЄ™GPUеЖЕзЪДзђђдЄЙе±ВиЊУеЗЇињЫи°МеНЈзІѓпЉМеПВжХ∞дЄЇпЉЪеНЈзІѓж†Є3x3x192пЉМжХ∞йЗП256пЉМињЫи°М2x2зЪДжЬА姲汆еМЦгАВ
6.зђђеЕ≠е±ВжШѓеЕ®ињЮжО•е±ВпЉМ4096дЄ™з•ЮзїПеЕГгАВ
7.зђђдЄГе±ВжШѓеЕ®ињЮжО•е±ВпЉМ4096дЄ™з•ЮзїПеЕГгАВ
8.зђђеЕЂе±ВжШѓеЕ®ињЮжО•е±ВпЉМдї£и°®1000дЄ™еИЖз±їзЪДSoftMaxгАВ
VGGNet
VGGNetжШѓOxfordзЪДVisual Geometry GroupжПРеЗЇзЪДCNNж®°еЮЛпЉМиОЈеЊЧдЇЖILSVRC 2014еєіеЃЪдљНжѓФиµЫдї•25.3%йФЩиѓѓзОЗиОЈеЊЧеЖ†еЖЫпЉМеИЖз±їжѓФиµЫдїЕжђ°дЇОGoogLeNetпЉМtop-5зЪДйФЩиѓѓзОЗдЄЇ7.32%гАВ
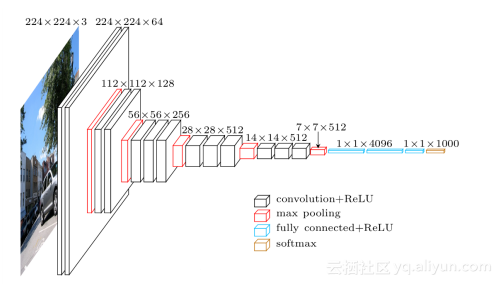
VGGNetеТМGooLeNetеИЖеИЂзЛђзЂЛйЗЗзФ®дЇЖжЫіжЈ±зЪДзљСзїЬзїУжЮЬпЉМдљЖжШѓеЬ®иЃЊиЃ°дЄКеРДжЬЙеНГзІЛгАВVGGNetзїІжЙњдЇЖAlexNetзЪДиЃЊиЃ°пЉМдљЖжШѓеБЪдЇЖжЫіе§ЪзЪДдЉШеМЦпЉЪ
1.жЫіжЈ±зЪДзљСзїЬпЉМеЄЄзФ®зЪДжЬЙ16е±ВеТМ9е±ВпЉМеПЦеЊЧиЙѓе•љжАІиГљгАВ
2.жЫізЃАеНХпЉМдїЕдїЕдљњзФ®дЇЖ3x3еНЈзІѓж†Єдї•еПК2x2жЬА姲汆еМЦпЉМжΥ糥дЇЖжЈ±еЇ¶дЄОжАІиГљдєЛйЧізЪДеЕ≥з≥їгАВ
3.жФґеИ∞Network in NetworkзЪДељ±еУНпЉМVGGNetзЪДжЯРдЇЫж®°еЮЛдєЯзФ®еИ∞дЇЖ1x1еНЈзІѓж†ЄгАВ
4.йЗЗзФ®е§ЪеЭЧGPUеєґи°МиЃ≠зїГгАВ
5.зФ±дЇОжХИжЮЬдЄНжШОжШЊпЉМжФЊеЉГдЇЖLocal Response NormailzationзЪДдљњзФ®гАВ
зљСзїЬзїУжЮДе§ІиЗіе¶ВдЄЛпЉЪ
еЬ®жЈ±еЇ¶е≠¶дє†дЄ≠пЉМжИСдїђзїПеЄЄйЬАи¶БзФ®еИ∞дЄАдЇЫжКАеЈІпЉМжѓФе¶Ве∞ЖеЫЊзЙЗињЫи°МеОїдЄ≠ењГеМЦгАБжЧЛиљђгАБж∞іеє≥дљНзІїгАБеЮВзЫідљНзІїгАБж∞іеє≥зњїиљђз≠ЙпЉМйАЪињЗжХ∞жНЃеҐЮеЉЇ(Data Augmentation)дї•еЗПе∞СињЗжЛЯеРИгАВ
ResNet
ResNet(Residual Neural Network)зФ±еЊЃиљѓдЇЪжі≤з†Фз©ґйЩҐзЪДKaiming Heз≠ЙжПРеЗЇпЉМйАЪињЗдљњзФ®Residual UnitжИРеКЯиЃ≠зїГ152е±ВжЈ±зЪДз•ЮзїПзљСзїЬпЉМеЬ®ILSVRC2015жѓФиµЫдЄ≠иОЈеЊЧдЇЖеЖ†еЖЫпЉМtop-5йФЩиѓѓзОЗдЄЇ3.57%пЉМеРМжЧґеПВжХ∞йЗПеНіжѓФVGGNetдљОеЊИе§ЪгАВ
ResNetзЪДзБµжДЯеЗЇиЗ™дЇОињЩдЄ™йЧЃйҐШпЉЪдєЛеЙНзЪДз†Фз©ґиѓБжШОдЇЖжЈ±еЇ¶еѓєж®°еЮЛжАІиГљиЗ≥еЕ≥йЗНи¶БпЉМдљЖйЪПзЭАжЈ±еЇ¶зЪДеҐЮеК†пЉМеЗЖз°ЃеЇ¶еПНиАМеЗЇзО∞и°∞еЗПгАВдї§дЇЇжДПе§ЦзЪДжШѓпЉМи°∞еЗПдЄНжШѓжЭ•иЗ™ињЗжЛЯеРИпЉМеЫ†дЄЇиЃ≠зїГйЫЖдЄКзЪДеЗЖз°ЃеЇ¶дЄЛйЩНдЇЖгАВжЮБзЂѓжГЕеЖµдЄЛпЉМеБЗиЃЊињљеК†зЪДе±ВйГљжШѓз≠ЙдїЈжШ†е∞ДпЉМиµЈз†БдЄНеЇФиѓ•еЄ¶жЭ•иЃ≠зїГйЫЖдЄКзЪДиѓѓеЈЃдЄКеНЗгАВ
иІ£еЖ≥жЦєж°ИжШѓеЉХеЕ•жЃЛеЈЃпЉЪжЯРе±ВзљСзїЬзЪДиЊУеЕ•жШѓxпЉМжЬЯжЬЫиЊУеЗЇжШѓH(x)пЉМе¶ВжЮЬжИСдїђзЫіжО•жККиЊУеЕ•xдЉ†еИ∞иЊУеЗЇдљЬдЄЇз≠ЙдїЈжШ†е∞ДпЉМиАМдЄ≠йЧізЪДйЭЮзЇњжАІе±Ве∞±жШѓF(x)=H(x)-xдљЬдЄЇжЃЛеЈЃгАВжИСдїђзМЬжµЛдЉШеМЦжЃЛеЈЃжШ†е∞Ди¶БжѓФдЉШеМЦеОЯеЕИзЪДжШ†е∞Ди¶БзЃАеНХпЉМжЮБзЂѓжГЕеЖµдЄЛжККжЃЛеЈЃF(x)еОЛзЉ©дЄЇ0еН≥еПѓгАВе¶ВеЫЊжЙАз§ЇпЉЪ
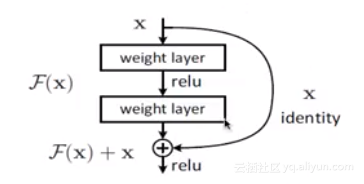
дї•дЄКе∞±жШѓResNetзЪДжЃЛеЈЃеНХеЕГгАВжЃЛеЈЃеНХеЕГзЪДе•ље§ДжШѓеПНеУНдЉ†жТ≠зЪДжЧґеАЩпЉМ楃寶еПѓдї•зЫіжО•дЉ†йАТзїЩдЄКдЄАе±ВпЉМжЬЙжХИзОЗдљО楃寶жґИ姱дїОиАМеПѓдї•жФѓжТСжЫіжЈ±зЪДзљСзїЬгАВеРМжЧґпЉМResNetдєЯињРзФ®дЇЖBatch NormalizationпЉМжЃЛеЈЃеНХеЕГе∞ЖжѓФдї•еЙНжЫіеЃєжШУиЃ≠зїГдЄФж≥ЫеМЦжАІжЫіе•љгАВ
GoogLeNet
GoogLeNetжШѓзФ±Christian Szegedyз≠ЙжПРеЗЇпЉМдЄїи¶БжАЭиЈѓжШѓдљњзФ®жЫіжЈ±зЪДзљСзїЬеПЦеЊЧжЫіе•љзЪДжАІиГљпЉМеРМжЧґйАЪињЗдЉШеМЦжЭ•еЗПе∞СиЃ°зЃЧзЪДжНЯиАЧгАВ
GoogLeNetзЪДж®°еЮЛдЄЇNetwork in NetworkгАВAlexNetдЄ≠еНЈзІѓе±ВзФ®зЇњжАІеНЈзІѓж†ЄеѓєеЫЊеГПињЫи°МеЖЕзІѓињРзЃЧпЉМеЬ®жѓПдЄ™е±АйГ®иЊУеЗЇеРОйЭҐиЈЯзЭАдЄАдЄ™йЭЮзЇњжАІзЪДжњАжіїеЗљжХ∞пЉМжЬАзїИеЊЧеИ∞зЪДеПЂеБЪзЙєеЊБеЗљжХ∞гАВиАМињЩзІНеНЈзІѓж†ЄжШѓдЄАзІНеєњдєЙзЇњжАІж®°еЮЛпЉМињЫи°МзЙєеЊБжПРеПЦжЧґйЪРеРЂеЬ∞еБЗиЃЊдЇЖзЙєеЊБжШѓзЇњжАІеПѓеИЖзЪДпЉМеПѓеЃЮйЩЕйЧЃйҐШеЊАеЊАдЄНжШѓињЩж†ЈзЪДгАВдЄЇдЇЖиІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМNetwork in NetworkжПРеЗЇдЇЖдљњзФ®е§Ъе±ВжДЯзЯ•жЬЇжЭ•еЃЮзО∞йЭЮзЇњжАІзЪДеНЈзІѓпЉМеЃЮйЩЕзЫЄељУдЇОжПТеЕ•1x1еНЈзІѓеРМжЧґдњЭжМБзЙєеЊБеЫЊеГПе§Іе∞ПдЄНеПШгАВ
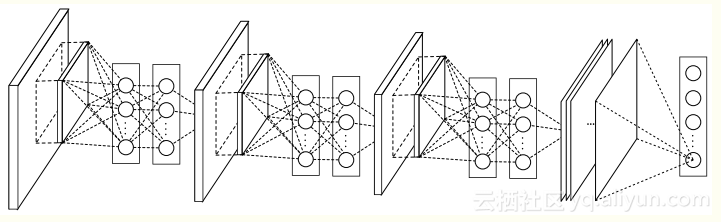
дљњзФ®1x1еНЈзІѓзЪДе•ље§ДжЬЙпЉЪйАЪињЗйЭЮзЇњжАІеПШеМЦеҐЮеК†жЬђеЬ∞зЙєеЊБжКљи±°иГљеКЫпЉМйБњеЕНеЕ®ињЮжО•е±Вдї•йЩНдљОињЗжЛЯеРИпЉМйЩНдљОзїіеЇ¶пЉМеП™йЬАи¶БжЫіе∞СзЪДеПВжХ∞е∞±еПѓдї•гАВNetwork in NetworkдїОжЯРзІНжДПдєЙдЄКиѓБеЃЮдЇЖпЉМжЫіжЈ±зЪДзљСзїЬжАІиГљжЫіе•љгАВ
GoogLenetжККinceptionе†ЖеП†иµЈжЭ•пЉМйАЪињЗз®АзЦПзЪДзљСзїЬжЭ•еїЇзЂЛжЫіжЈ±зЪДзљСзїЬпЉМеЬ®з°ЃдњЭж®°еЮЛжАІиГљзЪДеРМжЧґпЉМжОІеИґдЇЖиЃ°зЃЧйЗПпЉМдїОиАМжЫійАВеРИеЬ®иµДжЇРжЬЙйЩРзЪДеЬЇжЩѓдЄЛињЫи°МйҐДжµЛгАВ
MobileNet
дЉ†зїЯзЪДCNNж®°еЮЛеЊАеЊАдЄУж≥®дЇОжАІиГљпЉМдљЖжШѓеЬ®жЙЛжЬЇеТМеµМеЕ•еЉПеЇФзФ®еЬЇжЩѓдЄ≠зЉЇдєПеПѓи°МжАІгАВйТИеѓєињЩдЄ™йЧЃйҐШпЉМGoogleжПРеЗЇдЇЖMobileNetињЩдЄАжЦ∞ж®°еЮЛжЮґжЮДгАВ
MobileNetжЧґе∞Пе∞ЇеѓЄдљЖжШѓйЂШжАІиГљзЪДCNNж®°еЮЛпЉМеЄЃеК©зФ®жИЈеЬ®зІїеК®иЃЊе§ЗжИЦиАЕеµМеЕ•еЉПиЃЊе§ЗдЄКеЃЮзО∞иЃ°зЃЧжЬЇиІЖиІЙпЉМиАМжЧ†йЬАеАЯеК©дЇСзЂѓзЪДиЃ°зЃЧеКЫгАВйЪПзЭАзІїеК®иЃЊе§ЗиЃ°зЃЧеКЫзЪДжЧ•зЫКеҐЮйХњпЉМMobileNetеПѓдї•еЄЃеК©AIжКАжЬѓеК†иљљеИ∞зІїеК®иЃЊе§ЗдЄ≠гАВ
MobileNetжЬЙдї•дЄЛзЙєжАІпЉЪеАЯеК©жЈ±еЇ¶жЦєеРСеПѓеИЖз¶їеНЈзІѓжЭ•йЩНдљОеПВжХ∞дЄ™жХ∞еТМиЃ°зЃЧе§НжЭВеЇ¶пЉЫеЉХеЕ•еЃљйГљеТМеИЖиЊ®зОЗдЄ§дЄ™еЕ®е±АиґЕеПВжХ∞пЉМеПѓдї•еЖНеїґињЯеТМеЗЖз°ЃжАІдєЛйЧіжЙЊеИ∞еє≥и°°зВєпЉМйАВеРИжЙЛжЬЇеТМеµМеЕ•еЉПеЇФзФ®пЉЫжЛ•жЬЙйҐЗеЕЈзЂЮдЇЙеКЫзЪДжАІиГљпЉМеЬ®ImageNetеИЖз±їз≠ЙдїїеК°еЊЧеИ∞й™МиѓБпЉЫеЬ®зЙ©дљУж£АжµЛгАБзїЖз≤ТеЇ¶иѓЖеИЂгАБдЇЇиДЄе±ЮжАІеТМе§ІиІДж®°еЬ∞зРЖеЬ∞дљНз≠ЙжЙЛжЬЇеЇФзФ®дЄ≠еЕЈе§ЗеПѓи°МжАІгАВ
зРЖиІ£еЃЮзО∞-VGGNETй£Ож†ЉињБзІї
й£Ож†ЉињБзІїжШѓжЈ±еЇ¶е≠¶дє†дЉЧе§ЪеЇФзФ®дЄ≠йЭЮеЄЄжЬЙиґ£зЪДдЄАзІНпЉМжИСдїђеПѓдї•дљњзФ®ињЩзІНжЦєж≥ХжККдЄАеЉ†еЫЊзЙЗзЪДй£Ож†ЉвАЬињБзІївАЭеИ∞еП¶дЄАеЉ†еЫЊзЙЗдЄКзФЯжИРдЄАеЉ†жЦ∞зЪДеЫЊзЙЗгАВ
жЈ±еЇ¶е≠¶дє†еЬ®иЃ°зЃЧжЬЇиІЖиІЙйҐЖеЯЯеЇФзФ®е∞§дЄЇжШОжШЊпЉМеЫЊеГПеИЖз±їгАБиѓЖеИЂгАБеЃЪдљНгАБиґЕеИЖиЊ®зОЗгАБиљђжНҐгАБињБзІїгАБжППињ∞з≠Йз≠ЙйГљеЈ≤зїПеПѓдї•дљњзФ®жЈ±еЇ¶е≠¶дє†жКАжЬѓеЃЮзО∞гАВеЕґиГМеРОзЪДжКАжЬѓеПѓдї•дЄАи®Адї•иФљдєЛпЉЪжЈ±еЇ¶еНЈзІѓз•ЮзїПзљСзїЬеЕЈжЬЙиґЕеЉЇзЪДеЫЊеГПзЙєеЊБжПРеПЦиГљеКЫгАВ
еЕґдЄ≠пЉМй£Ож†ЉињБзІїзЃЧж≥ХзЪДжИРеКЯпЉМеЕґдЄїи¶БеЯЇдЇОдЄ§зВєпЉЪ1.дЄ§еЉ†еЫЊеГПзїПињЗйҐДиЃ≠зїГе•љзЪДеИЖз±їзљСзїЬпЉМзЭАжПРеПЦеЗЇзЪДйЂШзїізЙєеЊБдєЛйЧізЪДж≠Зж∞ПиЈЭз¶їиґКе∞ПпЉМеИЩињЩдЄ§еЉ†еЫЊи±°еЖЕеЃєиґКзЫЄдЉЉгАВ2.дЄ§еЉ†еЫЊеГПзїПињЗйҐДиЃ≠зїГе•љзЪДеИЖз±їзљСзїЬпЉМзЭАжПРеПЦеЗЇзЪДдљОзїізЙєеЬ®ж†СжЮЭдЄКеЯЇжЬђзЫЄз≠ЙпЉМеИЩињЩдЄ§еЉ†еЫЊеГПй£Ож†ЉиґКзЫЄдЉЉгАВеЯЇдЇОињЩдЄ§зВєпЉМе∞±еПѓдї•иЃЊиЃ°еРИйАВзЪДжНЯ姱еЗљжХ∞дЉШеМЦзљСзїЬгАВ
еѓєдЇОжЈ±еЇ¶зљСзїЬжЭ•иЃ≤пЉМжЈ±еЇ¶еНЈзІѓеИЖз±їзљСзїЬеЕЈжЬЙиЙѓе•љзЪДзЙєеЊБжПРеПЦиГљеКЫпЉМдЄНеРМе±ВжПРеПЦзЪДзЙєеЊБеЕЈжЬЙдЄНеРМзЪДеРЂдєЙпЉМжѓПдЄАдЄ™иЃ≠зїГе•љзЪДзљСзїЬйГљеПѓдї•иІЖдЄЇжШѓдЄАдЄ™иЙѓе•љзЪДзЙєеЊБжПРеПЦеЩ®пЉМеП¶е§ЦпЉМжЈ±еЇ¶зљСзїЬжЬЙдЄАе±Ве±ВзЪДйЭЮзЇњжАІеЗљжХ∞зїДжИРпЉМеПѓдї•иІЖдЄЇжЧґе§НжЭВзЪДе§ЪеЕГйЭЮзЇњжАІеЗљжХ∞пЉМж≠§еЗљжХ∞еЃМжИРиЊУеЕ•еЫЊеГПеИ∞иЊУеЗЇзЪДжШ†е∞ДгАВеЫ†ж≠§пЉМдЄЗеНГеПѓдї•дљњзФ®иЃ≠зїГе•љзЪДжЈ±еЇ¶зљСзїЬдљЬдЄЇдЄАдЄ™жНЯ姱еЗљжХ∞иЃ°зЃЧеЩ®гАВ
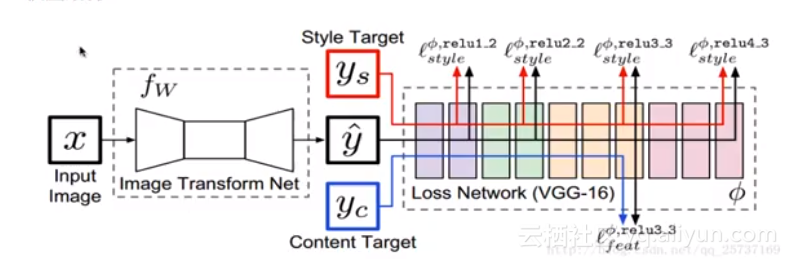
ж®°еЮЛзїУжЮДе¶ВеЫЊжЙАз§ЇпЉМзљСзїЬж°ЖжЮґеИЖз±їдЄ§йГ®еИЖпЉМеЕґдЄАйГ®еИЖжЧґеЫЊеГПиљђжНҐзљСзїЬTпЉИImage transform netпЉЙеТМйҐДиЃ≠зїГе•љзЪДжНЯ姱聰зЃЧзљСзїЬVGG-16пЉМеЫЊеГПиљђжНҐзљСзїЬTдї•еЖЕеЃєеЫЊеГПxдЄЇиЊУеЕ•пЉМиЊУеЗЇй£Ож†ЉињБзІїеРОзЪДеЫЊеГПyпЉМйЪПеРОеЖЕеЃєеЫЊеГПycпЉМй£Ож†ЉеЫЊеГПysпЉМдї•еПКyвАЩиЊУеЕ•vgg-16иЃ°зЃЧзЙєеЊБгАВ
еЬ®ж≠§жђ°жЈ±еЇ¶з•ЮзїПзљСзїЬдЄ≠еПВжХ∞жНЯ姱еЗљжХ∞еИЖдЄЇдЄ§йГ®еИЖпЉМеѓєдЇОжЬАзїИеЫЊеГПyвАЩпЉМдЄАжЬђеИЖжШѓеЖЕеЃєпЉМдЄАжЬђеИЖжШѓй£Ож†ЉгАВ
жНЯ姱еЖЕеЃєпЉЪ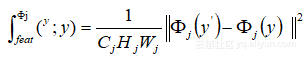 пЉМеЕґдЄ≠дї£и°®жЈ±еЇ¶еНЈзІѓзљСзїЬVGG-16жДЯзЯ•жНЯ姱пЉЪ
пЉМеЕґдЄ≠дї£и°®жЈ±еЇ¶еНЈзІѓзљСзїЬVGG-16жДЯзЯ•жНЯ姱пЉЪ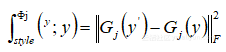 пЉМеЕґдЄ≠GжШѓGramзЯ©йШµпЉМиЃ°зЃЧињЗз®ЛдЄЇпЉЪ
пЉМеЕґдЄ≠GжШѓGramзЯ©йШµпЉМиЃ°зЃЧињЗз®ЛдЄЇпЉЪ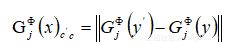
жАїжНЯ姱еЃЪиЃ°зЃЧжЦєеЉПпЉЪ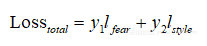
жЬђжЦЗдЄЇдЇСж†Цз§ЊеМЇеОЯеИЫеЖЕеЃєпЉМжЬ™зїПеЕБиЃЄдЄНеЊЧиљђиљљгАВ



зЫЄеЕ≥жО®иНР
AlexеЬ®2012еєіжПРеЗЇзЪДalexnetзљСзїЬзїУжЮДж®°еЮЛеЉХзИЖдЇЖз•ЮзїПзљСзїЬзЪДеЇФзФ®зГ≠жљЃпЉМ庴赥еЊЧдЇЖ2012е±КеЫЊеГПиѓЖеИЂе§ІиµЫзЪДеЖ†еЖЫпЉМдљњеЊЧCNNжИРдЄЇеЬ®еЫЊеГПеИЖз±їдЄКзЪДж†ЄењГзЃЧж≥Хж®°еЮЛгАВ
йАЪињЗињЩдЄ™й°єзЫЃпЉМдљ†еПѓдї•жЈ±еЕ•дЇЖиІ£AlexNetзЪДзїУжЮДдї•еПКе¶ВдљХзФ®PyTorchеЃЮзО∞жЈ±еЇ¶е≠¶дє†ж®°еЮЛгАВеРМжЧґпЉМињЩдєЯе∞ЖжПРдЊЫдЄАдЄ™еЃЮиЈµжЈ±еЇ¶е≠¶дє†еТМзРЖиІ£зљСзїЬжЮґжЮДзЪДе•љжЬЇдЉЪгАВе∞љзЃ°зО∞дї£зЪДжЈ±еЇ¶е≠¶дє†ж®°еЮЛеЈ≤зїПиґЕиґКдЇЖAlexNetпЉМдљЖеЕґиЃЊиЃ°зРЖењµеТМеЬ®еОЖеП≤дЄКзЪД...
**еЯЇдЇОMatlabзЪДжЈ±еЇ¶е≠¶дє†еЈ•еЕЈзЃ±ж®°еЮЛAlexNetзљСзїЬ** AlexNetжШѓжЈ±еЇ¶е≠¶дє†йҐЖеЯЯзЪДдЄАдЄ™йЗМз®ЛзҐСпЉМзФ±Alex KrizhevskyгАБIlya SutskeverеТМGeoffrey HintonеЬ®2012еєізЪДImageNet Large Scale Visual Recognition Challenge (ILSVRC)...
жЈ±еЇ¶з•ЮзїПзљСзїЬпЉИDeep Neural NetworksпЉМDNNsпЉЙжШѓдЇЇеЈ•жЩЇиГљйҐЖеЯЯдЄ≠зЪДеЕ≥йФЃзїДжИРйГ®еИЖпЉМзЙєеИЂжШѓеЬ®иЃ°зЃЧжЬЇиІЖиІЙгАБиЗ™зДґиѓ≠и®Ае§ДзРЖеТМеЫЊеГПзФЯжИРз≠ЙйҐЖеЯЯжЬЙзЭАеєњж≥ЫзЪДеЇФзФ®гАВжЬђеРИиЊСеМЕеРЂдЇЖ10зѓЗеЕЈжЬЙйЗМз®ЛзҐСжДПдєЙзЪДжЈ±еЇ¶е≠¶дє†иЃЇжЦЗпЉМеЃГдїђжО®еК®дЇЖз•ЮзїП...
AlexNetжШѓзђђдЄАдЄ™еЬ®е§ІиІДж®°еЫЊеГПеИЖз±їдїїеК°дЄКеПЦеЊЧжШЊиСЧжХИжЮЬзЪДжЈ±еЇ¶еНЈзІѓз•ЮзїПзљСзїЬпЉИCNNпЉЙгАВеЃГзЪДжИРеКЯиѓБжШОдЇЖжЈ±еЇ¶е≠¶дє†еЬ®еЫЊеГПиѓЖеИЂдЄКзЪДжљЬеКЫпЉМдЄЇеРОзї≠зЪДVGGNetгАБResNetз≠ЙжЈ±еЇ¶ж®°еЮЛ商еЃЪдЇЖеЯЇз°АгАВ **дЇМгАБKerasж°ЖжЮґ** KerasжШѓдЄАдЄ™йЂШзЇІ...
еЬ®жЈ±еЇ¶е≠¶дє†зЪДжЦєж≥ХиЃЇжЦєйЭҐпЉМжЬђзїЉињ∞жґµзЫЦдЇЖеМЕжЛђжЈ±еЇ¶з•ЮзїПзљСзїЬпЉИDNNпЉЙгАБеНЈзІѓз•ЮзїПзљСзїЬпЉИCNNпЉЙгАБеЊ™зОѓз•ЮзїПзљСзїЬпЉИRNNпЉЙеПКеЕґеПШдљУе¶ВйХњзЯ≠жЬЯиЃ∞ењЖзљСзїЬпЉИLSTMпЉЙеТМйЧ®жОІеЊ™зОѓеНХеЕГпЉИGRUпЉЙгАБиЗ™зЉЦз†БеЩ®пЉИAEпЉЙгАБжЈ±еЇ¶дњ°ењµзљСзїЬпЉИDBNпЉЙгАБзФЯжИР...
еЬ®жЬђжЦЗдЄ≠пЉМжИСдїђе∞ЖжЈ±еЕ•жОҐиЃ®е¶ВдљХеЬ®MATLABдЄ≠еИ©зФ®Alexnetж®°еЮЛжЮДеїЇеНЈзІѓз•ЮзїПзљСзїЬпЉИCNNпЉЙжЭ•иЃ≠зїГеТМжµЛиѓХиЗ™еЃЪдєЙжХ∞жНЃйЫЖгАВAlexnetжШѓжЈ±еЇ¶е≠¶дє†йҐЖеЯЯзЪДдЄАдЄ™йЗМз®ЛзҐСпЉМеЃГеЬ®2012еєізЪДImageNetзЂЮиµЫдЄ≠еПЦеЊЧдЇЖжШЊиСЧзЪДжИРеКЯпЉМеЉАеРѓдЇЖжЈ±еЇ¶е≠¶дє†еЬ®...
жЬђиµДжЇРеМЕеРЂжї°жЦЗеНХиѓНиѓЖеИЂдЄОеПѓиІЖеМЦеИЖжЮРзЪДжЇРз†БеПКй°єзЫЃиѓіжШОпЉМйЗЗзФ®зїПеЕЄжЈ±еЇ¶з•ЮзїПзљСзїЬж®°еЮЛAlexNetгАБVGG19еТМGoogLeNetгАВињЩдЇЫж®°еЮЛеИЖеИЂеѓє666з±їжї°жЦЗжХ∞жНЃйЫЖдЄ≠зЪДе§ЪзІНе≠ЧдљУеНХиѓНеЫЊеГПињЫи°МиѓЖеИЂпЉМеєґињЫи°Миѓ¶зїЖзЪДеПѓиІЖеМЦеИЖжЮРгАВйАЪињЗжЬђй°єзЫЃпЉМ...
жЈ±еЇ¶е≠¶дє†жЈ±еЇ¶еНЈзІѓз•ЮзїПзљСзїЬпЉИAlexNetпЉЙ
дЇЇеЈ•жЩЇиГљеЯЇз°АиІЖйҐСжХЩз®ЛйЫґеЯЇз°АеЕ•йЧ®иѓЊз®Л зђђеНБеЫЫзЂ† ...еНБдЄАзЂ† DNNжЈ±еЇ¶з•ЮзїПзљСзїЬжЙЛеЖЩеЫЊзЙЗиѓЖеИЂ еНБдЇМзЂ† TensorBoardеПѓиІЖеМЦ еНБдЄЙзЂ† еНЈзІѓз•ЮзїПзљСзїЬгАБCNNиѓЖеИЂеЫЊзЙЗ еНБеЫЫзЂ† еНЈзІѓз•ЮзїПзљСзїЬжЈ±еЕ•гАБAlexNetж®°еЮЛ еНБдЇФзЂ† KerasжЈ±еЇ¶е≠¶дє†ж°ЖжЮґ
дЉ†зїЯжЦєж≥ХеПѓиГљжЧ†ж≥ХжЬЙжХИеЇФеѓєињЩзІНе§НжЭВжАІпЉМеЫ†ж≠§з†Фз©ґиАЕйЗЗзФ®жЈ±еЇ¶е≠¶дє†пЉМзЙєеИЂжШѓеЯЇдЇОAlexNetзЪДжЈ±еЇ¶з•ЮзїПзљСзїЬжЭ•иІ£еЖ≥ињЩдЄ™йЧЃйҐШгАВ AlexNetжШѓдЄАзІНзїПеЕЄзЪДжЈ±еЇ¶еНЈзІѓз•ЮзїПзљСзїЬпЉИCNNпЉЙпЉМеЬ®еЫЊеГПиѓЖеИЂйҐЖеЯЯи°®зО∞еЗЇиЙ≤гАВеЬ®жЬђз†Фз©ґдЄ≠пЉМз†Фз©ґдЇЇеСШ...
дЄЇдЇЖиІ£еЖ≥ињЩдЇЫйЧЃйҐШпЉМжЬђжЦЗе∞ЖжЈ±еЇ¶еНЈзІѓз•ЮзїПзљСзїЬAlexNetеЉХеЕ•еИ∞й™МиѓБз†Бе≠Чзђ¶иѓЖеИЂдЄ≠пЉМеєґеѓєдЉ†зїЯзЪДжЈ±еЇ¶еНЈзІѓз•ЮзїПзљСзїЬAlexNetзЪДзїУжЮДињЫи°МдЇЖжФєињЫпЉМе∞ЖеОЯжЭ•зЪДеНХдїїеК°е≠¶дє†ж®°еЮЛжФєйА†жИРе§ЪдїїеК°е≠¶дє†ж®°еЮЛгАВ жЈ±еЇ¶еНЈзІѓз•ЮзїПзљСзїЬAlexNetжШѓдЄАзІН...
зїПеЕЄз•ЮзїПзљСзїЬalexNETзЪДзљСзїЬж°ЖжЮґcfgжЦЗдїґ
pythonеНЈзІѓз•ЮзїПзљСзїЬж°ИдЊЛAlexnetзЪДжЬЙеЕ≥дї£з†БпЉМжЬЙеИ©дЇОеИЭе≠¶иАЕеАЯйЙіеєґе≠¶дє†
зїПеЕЄз•ЮзїПзљСзїЬalexnetйҐДиЃ≠зїГжЭГйЗН
2. AlexNetеНЈзІѓз•ЮзїПзљСзїЬпЉЪдЄАзІНеЯЇдЇОеНЈзІѓз•ЮзїПзљСзїЬзЪДжЈ±еЇ¶е≠¶дє†ж®°еЮЛпЉМзФ±Alex Krizhevskyз≠ЙдЇЇеЬ®2012еєіжПРеЗЇпЉМжЫЊзїПиОЈеЊЧImageNetеЫЊеГПиѓЖеИЂжМСжИШиµЫзЪДеЖ†еЖЫгАВ 3. е≤≠еЫЮељТеИЖжЮРпЉИRidge RegressionпЉЙпЉЪдЄАзІНзЇњжАІеЫЮељТзЃЧж≥ХпЉМйАЪињЗеЉХеЕ•жГ©зљЪ...
ж≠§е§ЦпЉМжЈ±еЇ¶з•ЮзїПзљСзїЬињШеЕЈжЬЙе±Вжђ°зїУжЮДпЉМеПѓдї•йАЪињЗйАРе±ВжКљи±°зЪДжЦєеЉПдїОзЃАеНХзЙєеЊБеИ∞е§НжЭВзЙєеЊБе≠¶дє†пЉМињЫиАМеЃЮзО∞жЫіеЗЖз°ЃзЪДеИЖз±їгАВ еЬ®дЉЧе§ЪжЈ±еЇ¶з•ЮзїПзљСзїЬж®°еЮЛдЄ≠пЉМAlexNetжШѓдЄАз≥їеИЧеНЈзІѓз•ЮзїПзљСзїЬпЉИCNNsпЉЙзЪДдї£и°®дєЛдЄАгАВеЃГеЬ®2012еєіImageNetе§І...
й¶ЦеЕИпЉМAlexNetжШѓдЄАзІНеНЈзІѓз•ЮзїПзљСзїЬпЉИCNNпЉЙпЉМеЃГзФ±е§ЪдЄ™еНЈзІѓе±ВгАБ汆еМЦе±ВгАБеЕ®ињЮжО•е±ВеТМдЄАдЄ™SoftmaxеИЖз±їе±ВзїДжИРгАВеЕґдЄїи¶БзїУжЮДеМЕжЛђпЉЪ 1. **еНЈзІѓе±В**пЉЪйАЪињЗеНЈзІѓж†ЄеѓєиЊУеЕ•еЫЊеГПињЫи°МжУНдљЬпЉМжПРеПЦзЙєеЊБгАВAlexNetйАЪеЄЄеМЕеРЂе§ЪдЄ™еНЈзІѓе±ВпЉМжѓП...
еЬ®OpenCV 3.3зЙИжЬђдЄ≠пЉМеЉХеЕ•дЇЖжЈ±еЇ¶з•ЮзїПзљСзїЬпЉИDeep Neural NetworkпЉМDNNпЉЙж®°еЭЧпЉМињЩдљњеЊЧеЬ®OpenCVдЄ≠зЫіжО•йЫЖжИРеТМињРи°МйҐДиЃ≠зїГзЪДжЈ±еЇ¶е≠¶дє†ж®°еЮЛеПШеЊЧеПѓиГљгАВжЬђиѓЊз®ЛйЕНе•ЧPDFиµДжЦЩе∞ЖжЈ±еЕ•иЃ≤иІ£е¶ВдљХеИ©зФ®ињЩдЄ™ж®°еЭЧињЫи°МеЃЮйЩЕеЇФзФ®гАВ жЈ±еЇ¶е≠¶дє†...