жҲ‘们йғҪзҹҘйҒ“esжҳҜдёҖдёӘеҲҶеёғејҸзҡ„еӯҳеӮЁе’ҢжЈҖзҙўзі»з»ҹпјҢеңЁеӯҳеӮЁзҡ„ж—¶еҖҷй»ҳи®ӨжҳҜж №жҚ®жҜҸжқЎи®°еҪ•зҡ„_idеӯ—ж®өеҒҡи·Ҝз”ұеҲҶеҸ‘зҡ„пјҢиҝҷж„Ҹе‘ізқҖesжңҚеҠЎз«ҜжҳҜеҮҶзЎ®зҹҘйҒ“жҜҸдёӘdocumentеҲҶеёғеңЁйӮЈдёӘshardдёҠзҡ„гҖӮ
зӣёеҜ№жҜ”дәҺCURDдёҠж“ҚдҪңпјҢsearchдёҖдёӘжҜ”иҫғеӨҚжқӮзҡ„жү§иЎҢжЁЎејҸпјҢеӣ дёәжҲ‘们дёҚзҹҘйҒ“йӮЈдәӣdocumentдјҡиў«еҢ№й…ҚеҲ°пјҢд»»дҪ•дёҖдёӘshardдёҠйғҪжңүеҸҜиғҪпјҢжүҖд»ҘдёҖдёӘsearchиҜ·жұӮеҝ…йЎ»жҹҘиҜўдёҖдёӘзҙўеј•жҲ–еӨҡдёӘзҙўеј•йҮҢйқўзҡ„жүҖжңүshardжүҚиғҪе®Ңж•ҙзҡ„жҹҘиҜўеҲ°жҲ‘们жғіиҰҒзҡ„з»“жһңгҖӮ
жүҫеҲ°жүҖжңүеҢ№й…Қзҡ„з»“жһңжҳҜжҹҘиҜўзҡ„第дёҖжӯҘпјҢжқҘиҮӘеӨҡдёӘshardдёҠзҡ„ж•°жҚ®йӣҶеңЁеҲҶйЎөиҝ”еӣһеҲ°е®ўжҲ·з«Ҝзҡ„д№ӢеүҚдјҡиў«еҗҲ并еҲ°дёҖдёӘжҺ’еәҸеҗҺзҡ„listеҲ—иЎЁпјҢз”ұдәҺйңҖиҰҒз»ҸиҝҮдёҖжӯҘеҸ–top Nзҡ„ж“ҚдҪңпјҢжүҖд»ҘsearchйңҖиҰҒиҝӣиҝҮдёӨдёӘйҳ¶ж®өжүҚиғҪе®ҢжҲҗпјҢеҲҶеҲ«жҳҜqueryе’ҢfetchгҖӮ
пјҲдёҖпјүqueryпјҲжҹҘиҜўйҳ¶ж®өпјү
еҪ“дёҖдёӘsearchиҜ·жұӮеҸ‘еҮәзҡ„ж—¶еҖҷпјҢиҝҷдёӘqueryдјҡиў«е№ҝж’ӯеҲ°зҙўеј•йҮҢйқўзҡ„жҜҸдёҖдёӘshardпјҲдё»shardжҲ–еүҜжң¬shardпјүпјҢжҜҸдёӘshardдјҡеңЁжң¬ең°жү§иЎҢжҹҘиҜўиҜ·жұӮеҗҺдјҡз”ҹжҲҗдёҖдёӘе‘Ҫдёӯж–ҮжЎЈзҡ„дјҳе…Ҳзә§йҳҹеҲ—гҖӮ
иҝҷдёӘйҳҹеҲ—жҳҜдёҖдёӘжҺ’еәҸеҘҪзҡ„top Nж•°жҚ®зҡ„еҲ—иЎЁпјҢе®ғзҡ„sizeзӯүдәҺfrom+sizeзҡ„е’ҢпјҢд№ҹе°ұжҳҜиҜҙеҰӮжһңдҪ зҡ„fromжҳҜ10пјҢsizeжҳҜ10пјҢйӮЈд№ҲиҝҷдёӘйҳҹеҲ—зҡ„sizeе°ұжҳҜ20пјҢжүҖд»Ҙиҝҷд№ҹжҳҜдёәд»Җд№Ҳж·ұеәҰеҲҶйЎөдёҚиғҪз”Ёfrom+sizeиҝҷз§Қж–№ејҸпјҢеӣ дёәfromи¶ҠеӨ§пјҢжҖ§иғҪе°ұи¶ҠдҪҺгҖӮ
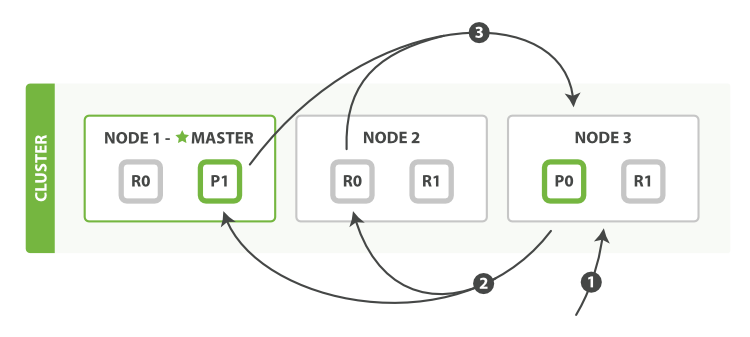
esйҮҢйқўеҲҶеёғејҸsearchзҡ„жҹҘиҜўжөҒзЁӢеҰӮдёӢпјҡ
````
1пјҢе®ўжҲ·з«ҜеҸ‘йҖҒдёҖдёӘsearchиҜ·жұӮеҲ°Node 3дёҠпјҢ然еҗҺNode 3дјҡеҲӣе»әдёҖдёӘдјҳе…Ҳзә§йҳҹеҲ—е®ғзҡ„еӨ§е°Ҹ=from+size
2пјҢжҺҘзқҖNode 3иҪ¬еҸ‘иҝҷдёӘsearchиҜ·жұӮеҲ°зҙўеј•йҮҢйқўжҜҸдёҖдёӘдё»shardжҲ–иҖ…еүҜжң¬shardдёҠпјҢжҜҸдёӘshardдјҡеңЁжң¬ең°жҹҘиҜўз„¶еҗҺж·»еҠ з»“жһңеҲ°жң¬ең°зҡ„жҺ’еәҸеҘҪзҡ„дјҳе…Ҳзә§йҳҹеҲ—йҮҢйқўгҖӮ
3пјҢжҜҸдёӘshardиҝ”еӣһdocIdе’ҢжүҖжңүеҸӮдёҺжҺ’еәҸеӯ—ж®өзҡ„еҖјдҫӢеҰӮ_scoreеҲ°дјҳе…Ҳзә§йҳҹеҲ—йҮҢйқўпјҢ然еҗҺеҶҚиҝ”еӣһз»ҷcoordinatingиҠӮзӮ№д№ҹе°ұжҳҜNode 3пјҢ然еҗҺNode 3иҙҹиҙЈе°ҶжүҖжңүshardйҮҢйқўзҡ„ж•°жҚ®з»ҷеҗҲ并еҲ°дёҖдёӘе…ЁеұҖзҡ„жҺ’еәҸзҡ„еҲ—иЎЁгҖӮ
````
дёҠйқўжҸҗеҲ°дёҖдёӘжңҜиҜӯеҸ«coordinating nodeпјҢиҝҷдёӘиҠӮзӮ№жҳҜеҪ“searchиҜ·жұӮйҡҸжңәиҙҹиҪҪзҡ„еҸ‘йҖҒеҲ°дёҖдёӘиҠӮзӮ№дёҠпјҢ然еҗҺиҝҷдёӘиҠӮзӮ№е°ұдјҡжҲҗдёәдёҖдёӘcoordinating nodeпјҢе®ғзҡ„иҒҢиҙЈжҳҜе№ҝж’ӯsearchиҜ·жұӮеҲ°жүҖжңүзӣёе…ізҡ„shardдёҠпјҢ然еҗҺеҗҲ并他们зҡ„е“Қеә”з»“жһңеҲ°дёҖдёӘе…ЁеұҖзҡ„жҺ’еәҸеҲ—иЎЁдёӯ然еҗҺиҝӣиЎҢ第дәҢдёӘfetchйҳ¶ж®өпјҢжіЁж„ҸиҝҷдёӘз»“жһңйӣҶд»…д»…еҢ…еҗ«docIdе’ҢжүҖжңүжҺ’еәҸзҡ„еӯ—ж®өеҖјпјҢsearchиҜ·жұӮеҸҜд»Ҙиў«дё»shardжҲ–иҖ…еүҜжң¬shardеӨ„зҗҶпјҢиҝҷд№ҹжҳҜдёәд»Җд№ҲжҲ‘们иҜҙеўһеҠ еүҜжң¬зҡ„дёӘж•°е°ұиғҪеўһеҠ жҗңзҙўеҗһеҗҗйҮҸзҡ„еҺҹеӣ пјҢcoordinatingиҠӮзӮ№е°ҶдјҡйҖҡиҝҮround-robinзҡ„ж–№ејҸиҮӘеҠЁиҙҹиҪҪеқҮиЎЎгҖӮ
пјҲдәҢпјүfetchпјҲиҜ»еҸ–йҳ¶ж®өпјү
queryйҳ¶ж®өж ҮиҜҶдәҶйӮЈдәӣж–ҮжЎЈж»Ўи¶ідәҶиҜҘж¬Ўзҡ„searchиҜ·жұӮпјҢдҪҶжҳҜжҲ‘们д»Қ然йңҖиҰҒжЈҖзҙўеӣһdocumentж•ҙжқЎж•°жҚ®пјҢиҝҷдёӘйҳ¶ж®өз§°дёәfetch
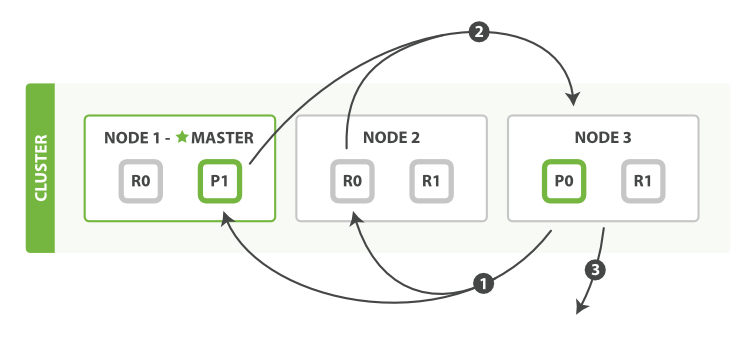
жөҒзЁӢеҰӮдёӢпјҡ
````
1пјҢcoordinating иҠӮзӮ№ж ҮиҜҶдәҶйӮЈдәӣdocumentйңҖиҰҒиў«жӢүеҸ–еҮәжқҘпјҢ并еҸ‘йҖҒдёҖдёӘжү№йҮҸзҡ„mutil getиҜ·жұӮеҲ°зӣёе…ізҡ„shardдёҠ
2пјҢжҜҸдёӘshardеҠ иҪҪзӣёе…іdocumentпјҢеҰӮжһңйңҖиҰҒ他们е°Ҷдјҡиў«иҝ”еӣһеҲ°coordinating иҠӮзӮ№дёҠ
3пјҢдёҖж—ҰжүҖжңүзҡ„documentиў«жӢүеҸ–еӣһжқҘпјҢcoordinatingиҠӮзӮ№е°Ҷдјҡиҝ”еӣһз»“жһңйӣҶеҲ°е®ўжҲ·з«ҜдёҠгҖӮ
````
иҝҷйҮҢйңҖиҰҒжіЁж„ҸпјҢcoordinatingиҠӮзӮ№жӢүеҸ–зҡ„ж—¶еҖҷеҸӘжӢүеҸ–йңҖиҰҒиў«жӢүеҸ–зҡ„ж•°жҚ®пјҢжҜ”еҰӮfrom=90пјҢsize=10пјҢйӮЈд№ҲfetchеҸӘдјҡиҜ»еҸ–йңҖиҰҒиў«иҜ»еҸ–зҡ„10жқЎж•°жҚ®пјҢиҝҷ10жқЎж•°жҚ®еҸҜиғҪеңЁдёҖдёӘshardдёҠпјҢд№ҹеҸҜиғҪеңЁеӨҡдёӘshardдёҠжүҖд»Ҙ
coordinatingиҠӮзӮ№дјҡжһ„е»әдёҖдёӘmulti-getиҜ·жұӮ并еҸ‘йҖҒеҲ°жҜҸдёҖдёӘshardдёҠпјҢжҜҸдёӘshardдјҡж №жҚ®йңҖиҰҒд»Һ_sourceеӯ—ж®өйҮҢйқўиҺ·еҸ–ж•°жҚ®пјҢдёҖж—ҰжүҖжңүзҡ„ж•°жҚ®иҝ”еӣһпјҢcoordinatingиҠӮзӮ№дјҡз»„иЈ…ж•°жҚ®иҝӣе…ҘеҚ•дёӘresponseйҮҢйқўз„¶еҗҺе°Ҷе…¶иҝ”еӣһз»ҷжңҖз»Ҳзҡ„clientгҖӮ
жҖ»з»“пјҡ
жң¬ж–Үд»Ӣз»ҚдәҶesзҡ„еҲҶеёғејҸsearchзҡ„жҹҘиҜўжөҒзЁӢеҲҶдёәqueryе’ҢfetchдёӨдёӘйҳ¶ж®өпјҢеңЁqueryйҳ¶ж®өдјҡд»ҺжүҖжңүзҡ„shardдёҠиҜ»еҸ–зӣёе…іdocumentзҡ„docIdеҸҠзӣёе…ізҡ„жҺ’еәҸеӯ—ж®өеҖјпјҢ并жңҖз»ҲеңЁcoordinatingиҠӮзӮ№дёҠ收йӣҶжүҖжңүзҡ„з»“жһңж•°иҝӣе…ҘдёҖдёӘе…ЁеұҖзҡ„жҺ’еәҸеҲ—иЎЁеҗҺпјҢ然еҗҺиҺ·еҸ–ж №жҚ®from+sizeжҢҮе®ҡpageйЎөзҡ„ж•°жҚ®пјҢиҺ·еҸ–иҝҷдәӣdocIdеҗҺеҶҚжһ„е»әдёҖдёӘmulti-getиҜ·жұӮеҸ‘йҖҒзӣёе…ізҡ„shardдёҠд»Һ_sourceйҮҢйқўиҺ·еҸ–йңҖиҰҒеҠ иҪҪзҡ„ж•°жҚ®пјҢжңҖз»ҲеҶҚиҝ”еӣһз»ҷclientз«ҜпјҢиҮіжӯӨж•ҙдёӘsearchиҜ·жұӮжөҒзЁӢжү§иЎҢе®ҢжҜ•пјҢиҮідәҺдёәд»Җд№ҲesиҰҒйҖҡиҝҮдёӨдёӘйҳ¶ж®өжқҘе®ҢжҲҗдёҖж¬ЎsearchиҜ·жұӮиҖҢдёҚжҳҜдёҖж¬Ўжҗһе®ҡпјҢж¬ўиҝҺеӨ§е®¶еңЁиҜ„и®әеҢәз•ҷиЁҖи®Ёи®әгҖӮ
жңүд»Җд№Ҳй—®йўҳеҸҜд»Ҙжү«з Ғе…іжіЁеҫ®дҝЎе…¬дј—еҸ·пјҡжҲ‘жҳҜж”»еҹҺеёҲ(woshigcs)пјҢеңЁеҗҺеҸ°з•ҷиЁҖе’ЁиҜўгҖӮ жҠҖжңҜеҖәдёҚиғҪж¬ пјҢеҒҘеә·еҖәжӣҙдёҚиғҪж¬ пјҢ жұӮйҒ“д№Ӣи·ҜпјҢдёҺеҗӣеҗҢиЎҢгҖӮ 
еҲҶдә«еҲ°пјҡ









зӣёе…іжҺЁиҚҗ
1. **Elasticsearch (ES)**пјҡElasticsearchжҳҜдёҖдёӘеҹәдәҺLuceneзҡ„еҲҶеёғејҸгҖҒе…Ёж–Үжҗңзҙўе’ҢеҲҶжһҗеј•ж“ҺгҖӮе®ғз”ЁдәҺеӯҳеӮЁгҖҒжҗңзҙўе’ҢеҲҶжһҗеӨ§йҮҸз»“жһ„еҢ–е’Ңйқһз»“жһ„еҢ–ж•°жҚ®пјҢе№ҝжіӣеә”з”ЁдәҺж—Ҙеҝ—еҲҶжһҗгҖҒе®һж—¶еҲҶжһҗгҖҒдҝЎжҒҜжЈҖзҙўзӯүйўҶеҹҹгҖӮ 2. **ChromeжөҸи§ҲеҷЁ...
еңЁжң¬ж–ҮдёӯпјҢжҲ‘们е°Ҷж·ұе…ҘжҺўи®ЁеҰӮдҪ•дҪҝз”ЁSpring BootдёҺElasticsearch 7.6.2иҝӣиЎҢеҹәжң¬ж“ҚдҪңпјҢеҢ…жӢ¬еҲӣе»әзҙўеј•гҖҒж·»еҠ ...и®°дҪҸпјҢElasticsearchзҡ„ејәеӨ§иҝҳеңЁдәҺе®ғзҡ„иҒҡеҗҲеҲҶжһҗгҖҒең°зҗҶдҪҚзҪ®жҗңзҙўзӯүй«ҳзә§зү№жҖ§пјҢиҝҷдәӣйғҪжҳҜиҝӣдёҖжӯҘжҸҗеҚҮеә”з”ЁжҖ§иғҪзҡ„е…ій”®гҖӮ
иҝҷдёҖзӮ№еҜ№дәҺдҪҝз”ЁKettleдҪңдёәж•°жҚ®йӣҶжҲҗи§ЈеҶіж–№жЎҲзҡ„дјҒдёҡжқҘиҜҙжҳҜдёҖдёӘйҮҚиҰҒзҡ„йҮҢзЁӢзў‘пјҢеӣ дёәе®ғж„Ҹе‘ізқҖ他们зҺ°еңЁеҸҜд»Ҙж— зјқең°е°ҶElasticsearch 7ж•ҙеҗҲеҲ°д»–们зҡ„ж•°жҚ®еӨ„зҗҶжөҒзЁӢдёӯгҖӮ Elasticsearch 7дёҺElasticsearch 8еңЁеҠҹиғҪе’Ңжһ¶жһ„дёҠжңүжүҖ...
Elasticsearch HeadжҸ’件дёәElasticsearchзҡ„з®ЎзҗҶе’Ңзӣ‘жҺ§жҸҗдҫӣдәҶзӣҙи§Ӯзҡ„еӣҫеҪўз•ҢйқўпјҢжһҒеӨ§ең°з®ҖеҢ–дәҶж“ҚдҪңжөҒзЁӢпјҢе°Өе…¶йҖӮеҗҲеҲқеӯҰиҖ…е’ҢејҖеҸ‘иҖ…дҪҝз”ЁгҖӮеңЁеӨ§ж•°жҚ®иғҢжҷҜдёӢпјҢжҺҢжҸЎиҝҷж¬ҫе·Ҙе…·еҜ№дәҺжҸҗеҚҮж•°жҚ®еӨ„зҗҶж•ҲзҺҮе’ҢдјҳеҢ–дёҡеҠЎжөҒзЁӢе…·жңүйҮҚиҰҒж„Ҹд№үгҖӮ...
**и°·жӯҢжөҸи§ҲеҷЁElasticsearch...жҖ»зҡ„жқҘиҜҙпјҢиҝҷдёӘи°·жӯҢжөҸи§ҲеҷЁElasticsearchжҹҘиҜўж•°жҚ®жү©еұ•з»„件з®ҖеҢ–дәҶеҜ№Elasticsearchе®һдҫӢзҡ„и®ҝй—®жөҒзЁӢпјҢжҸҗй«ҳдәҶе·ҘдҪңж•ҲзҺҮпјҢеҜ№дәҺйңҖиҰҒйў‘з№ҒиҝӣиЎҢElasticsearchж“ҚдҪңзҡ„з”ЁжҲ·жқҘиҜҙпјҢжҳҜдёҖдёӘйқһеёёе®һз”Ёзҡ„е·Ҙе…·гҖӮ
10. **еӨ§ж•°жҚ®еӨ„зҗҶ**: дҪңдёәеӨ§ж•°жҚ®е·Ҙе…·пјҢElasticsearchж”ҜжҢҒеӨ„зҗҶжө·йҮҸж•°жҚ®пјҢеҸҜд»Ҙеҝ«йҖҹе“Қеә”еӨҚжқӮзҡ„жҹҘиҜўпјҢ并йҖҡиҝҮжЁӘеҗ‘жү©еұ•еўһеҠ еӨ„зҗҶиғҪеҠӣгҖӮ еңЁе®һйҷ…еә”з”ЁдёӯпјҢз”ЁжҲ·еҸҜиғҪйңҖиҰҒз»“еҗҲKibanaпјҲз”ЁдәҺж•°жҚ®еҸҜи§ҶеҢ–пјүгҖҒLogstashпјҲж•°жҚ®ж”¶йӣҶе’Ң...
ElasticsearchжҳҜдёҖж¬ҫејҖжәҗзҡ„е…Ёж–Үжҗңзҙўеј•ж“ҺпјҢе№ҝжіӣеә”з”ЁдәҺж—Ҙеҝ—еҲҶжһҗгҖҒе®һж—¶ж•°жҚ®еҲҶжһҗгҖҒзҪ‘з«ҷжҗңзҙўзӯүеӨҡдёӘйўҶеҹҹгҖӮе®ғеҹәдәҺLuceneеә“пјҢдҪҶжҸҗдҫӣдәҶжӣҙй«ҳзә§еҲ«зҡ„жҠҪиұЎе’ҢеҲҶеёғејҸзү№жҖ§пјҢдҪҝеҫ—ж•°жҚ®зҡ„еӯҳеӮЁгҖҒзҙўеј•е’ҢжЈҖзҙўеҸҳеҫ—жӣҙеҠ з®ҖеҚ•й«ҳж•ҲгҖӮиҝҷд»Ҫй«ҳжё…...
2. **жөҒзЁӢжҗңзҙў**пјҡйҖҡиҝҮElasticsearchпјҢз”ЁжҲ·еҸҜд»Ҙеҝ«йҖҹжҗңзҙўеҺҶеҸІжөҒзЁӢе®һдҫӢпјҢжҹҘиҜўзү№е®ҡд»»еҠЎзҡ„жү§иЎҢжғ…еҶөжҲ–жүҫеҲ°з¬ҰеҗҲзү№е®ҡжқЎд»¶зҡ„жөҒзЁӢе®һдҫӢгҖӮ 3. **жҷәиғҪжҺЁиҚҗ**пјҡз»“еҗҲжңәеҷЁеӯҰд№ пјҢElasticsearchеҸҜд»Ҙж №жҚ®еҺҶеҸІжөҒзЁӢж•°жҚ®йў„жөӢжңӘжқҘеҸҜиғҪзҡ„...
Elasticsearchж•°жҚ®еҜјеҮәе·Ҙе…·жҳҜдёҖз§Қй«ҳж•Ҳе®һз”Ёзҡ„и§ЈеҶіж–№жЎҲпјҢе®ғе…Ғи®ёз”ЁжҲ·ж–№дҫҝең°д»ҺElasticsearchпјҲESпјүйӣҶзҫӨдёӯжҠҪеҸ–ж•°жҚ®пјҢ并е°Ҷе…¶еҜјеҮәеҲ°дёҚеҗҢзҡ„зӣ®ж ҮпјҢеҰӮMySQLж•°жҚ®еә“жҲ–жң¬ең°ж–Ү件系з»ҹгҖӮиҝҷж¬ҫе·Ҙе…·е°Өе…¶йҖӮз”ЁдәҺйңҖиҰҒиҝӣиЎҢж•°жҚ®иҝҒ移гҖҒеӨҮд»ҪжҲ–...
жҖ»з»“пјҢElasticsearch 8.1.2жҳҜйҖӮз”ЁдәҺWindows x86_64зҺҜеўғзҡ„еӨ§ж•°жҚ®жҗңзҙўе’ҢеҲҶжһҗеј•ж“ҺпјҢе…¶ејәеӨ§зҡ„еҠҹиғҪе’Ңжҳ“з”ЁжҖ§дҪҝе…¶жҲҗдёәеӨ§ж•°жҚ®йўҶеҹҹзҡ„зғӯй—ЁйҖүжӢ©гҖӮжӯЈзЎ®е®үиЈ…е’Ңй…ҚзҪ®ElasticsearchпјҢз»“еҗҲе…¶д»–Elastic Stack组件пјҢеҸҜд»Ҙеё®еҠ©дјҒдёҡй«ҳж•Ҳ...
Elasticsearch 7.8.0 жҳҜдёҖдёӘй«ҳеәҰеҸҜжү©еұ•зҡ„ејҖжәҗе…Ёж–Үжҗңзҙўеј•ж“ҺпјҢе№ҝжіӣеә”з”ЁдәҺж•°жҚ®еҲҶжһҗгҖҒж—Ҙеҝ—иҒҡеҗҲе’Ңе®һж—¶жҗңзҙўеңәжҷҜгҖӮиҝҷдёӘеҺӢзј©еҢ…еҢ…еҗ«дәҶдёӨдёӘдёҚеҗҢж“ҚдҪңзі»з»ҹзҡ„зүҲжң¬пјҡLinux е’Ң WindowsпјҢеҲҶеҲ«жҳҜ `elasticsearch-7.8.0-linux-x86_64....
ElasticsearchжҳҜдёҖж¬ҫејәеӨ§зҡ„ејҖжәҗжҗңзҙўеј•ж“ҺпјҢе°Өе…¶йҖӮз”ЁдәҺе®һж—¶ж•°жҚ®еҲҶжһҗе’ҢеӨ§и§„жЁЎж•°жҚ®жЈҖзҙўгҖӮиҝҷдёӘеҺӢзј©еҢ…"elasticsearch-7.8.1-windows-x86_64.zip"жҳҜдё“дёәWindows 64дҪҚзі»з»ҹи®ҫи®Ўзҡ„жңҖж–°зүҲжң¬пјҢжҸҗдҫӣдәҶеңЁWindowsзҺҜеўғдёӢиҝҗиЎҢElastic...
3. **SQL ж”ҜжҢҒ**пјҡElasticsearch 6.4.0 еј•е…ҘдәҶеҜ№ SQL жҹҘиҜўиҜӯжі•зҡ„ж”ҜжҢҒпјҢдҪҝеҫ—зҶҹжӮү SQL зҡ„з”ЁжҲ·иғҪжӣҙе®№жҳ“ең°дёҺ Elasticsearch дәӨдә’пјҢжҸҗй«ҳдәҶејҖеҸ‘ж•ҲзҺҮгҖӮ 4. **жңәеҷЁеӯҰд№ еҠҹиғҪ**пјҡиҜҘзүҲжң¬иҝӣдёҖжӯҘеўһејәдәҶеҶ…зҪ®зҡ„жңәеҷЁеӯҰд№ еҠҹиғҪпјҢеҸҜд»Ҙ...
Elasticsearch жҳҜдёҖдёӘејҖжәҗзҡ„е…Ёж–Үжҗңзҙўеј•ж“ҺпјҢеҹәдәҺ Lucene еә“пјҢжҸҗдҫӣеҲҶеёғејҸгҖҒе®һж—¶гҖҒеҸҜжү©еұ•зҡ„ж•°жҚ®жҗңзҙўе’ҢеҲҶжһҗиғҪеҠӣгҖӮеңЁ7.6.0зүҲжң¬дёӯпјҢе®ғ继з»ӯејәеҢ–дәҶе…¶ж ёеҝғеҠҹиғҪпјҢеҢ…жӢ¬жӣҙеҝ«зҡ„жҗңзҙўйҖҹеәҰгҖҒжӣҙй«ҳзҡ„зҙўеј•жҖ§иғҪд»ҘеҸҠжӣҙејәеӨ§зҡ„ж•°жҚ®еҲҶжһҗиғҪеҠӣ...
**Elasticsearch ж•°жҚ®жҹҘиҜў SQL зҹҘиҜҶзӮ№иҜҰи§Ј** еңЁеӨ§ж•°жҚ®ж—¶д»ЈпјҢElasticsearch дҪңдёәдёҖж¬ҫй«ҳжҖ§иғҪгҖҒеҸҜ...йҖҡиҝҮзҶҹз»ғжҺҢжҸЎ Elasticsearch SQLпјҢејҖеҸ‘иҖ…еҸҜд»ҘжӣҙеҘҪең°еҲ©з”Ё Elasticsearch зҡ„ејәеӨ§еҠҹиғҪпјҢи§ЈеҶіеҗ„з§Қж•°жҚ®жҹҘиҜўе’ҢеҲҶжһҗзҡ„йңҖжұӮгҖӮ
Elasticsearch 5.4.0 жҳҜдёҖдёӘжөҒиЎҢзҡ„ејҖжәҗжҗңзҙўеј•ж“Һе’ҢеҲҶжһҗеј•ж“ҺпјҢе№ҝжіӣеә”з”ЁдәҺеӨ§ж•°жҚ®еӨ„зҗҶгҖҒж—Ҙеҝ—еҲҶжһҗгҖҒе®һж—¶жҗңзҙўе’Ңзӣ‘жҺ§зӯүеңәжҷҜгҖӮе®ғеҹәдәҺ Lucene еә“жһ„е»әпјҢжҸҗдҫӣдәҶеҲҶеёғејҸгҖҒеҸҜжү©еұ•гҖҒиҝ‘е®һж—¶зҡ„жҗңзҙўдёҺеҲҶжһҗеҠҹиғҪгҖӮMaven жҳҜ Java йЎ№зӣ®з®ЎзҗҶ...
дҪҝз”ЁKettleиҝһжҺҘESжҸ’件зҡ„дјҳеҠҝеңЁдәҺпјҢе®ғе…Ғи®ёдҪ еңЁETLжөҒзЁӢдёӯзҒөжҙ»ең°еӨ„зҗҶж•°жҚ®иҪ¬жҚўпјҢеҰӮж•°жҚ®жё…жҙ—гҖҒж јејҸиҪ¬жҚўзӯүпјҢ然еҗҺеҶҚжү№йҮҸеҜје…ҘеҲ°ElasticsearchгҖӮиҝҷдҪҝеҫ—KettleиғҪеӨҹе……еҲҶеҸ‘жҢҘе…¶ж•°жҚ®еӨ„зҗҶиғҪеҠӣпјҢ并дёҺElasticsearchзҡ„ејәеӨ§жҗңзҙўе’ҢеҲҶжһҗ...
жң¬йЎ№зӣ®жҳҜй’ҲеҜ№Elasticsearch 5.xзүҲжң¬зҡ„Javaе·Ҙе…·зұ»пјҢж—ЁеңЁз®ҖеҢ–дёҺSpringBootйӣҶжҲҗж—¶зҡ„ејҖеҸ‘жөҒзЁӢпјҢйҖҡиҝҮе°ҒиЈ…еёёз”ЁAPIе’ҢиҮӘе®ҡд№үжіЁи§ЈпјҢе®һзҺ°ејҖз®ұеҚіз”Ёзҡ„еҠҹиғҪгҖӮ йҰ–е…ҲпјҢи®©жҲ‘们ж·ұе…ҘзҗҶи§ЈElasticsearchзҡ„Java APIгҖӮElasticsearchжҸҗдҫӣдәҶ...
4. **еӨҚжқӮжҹҘиҜў**: еҲ©з”ЁElasticsearchзҡ„й«ҳзә§жҹҘиҜўеҠҹиғҪпјҢе®һзҺ°з”ЁжҲ·иҫ“е…Ҙзҡ„еӨҡж ·еҢ–жҹҘиҜўйңҖжұӮгҖӮ 5. **жҺЁиҚҗз”ҹжҲҗ**: Sparkзҡ„MLlibжЁЎеқ—еҸҜд»Ҙи®ӯз»ғжҺЁиҚҗжЁЎеһӢпјҢж №жҚ®з”ЁжҲ·еҺҶеҸІиЎҢдёәе’ҢеҒҸеҘҪз”ҹжҲҗдёӘжҖ§еҢ–жҺЁиҚҗгҖӮ 6. **з»“жһңиһҚеҗҲ**: з»“еҗҲжҗңзҙўз»“жһң...
еңЁжҗңзҙўеј•ж“Һе’Ңж–Үжң¬еҲҶжһҗйўҶеҹҹпјҢElasticsearchпјҲз®Җз§°ESпјүжҳҜдёҖдёӘе№ҝжіӣдҪҝз”Ёзҡ„ејҖжәҗи§ЈеҶіж–№жЎҲпјҢе®ғжҸҗдҫӣдәҶејәеӨ§зҡ„е…Ёж–ҮжЈҖзҙўгҖҒе®һж—¶еҲҶжһҗд»ҘеҸҠй«ҳеҸҜз”ЁжҖ§гҖӮдёәдәҶжӣҙеҘҪең°еӨ„зҗҶдёӯж–Үж–ҮжЎЈпјҢElasticsearch жҸҗдҫӣдәҶеӨҡз§ҚжҸ’件пјҢе…¶дёӯжңҖи‘—еҗҚзҡ„е°ұжҳҜ IK ...