
1.场景
我们在生产环境中需要对系统的各种日志进行采集、查询和分析。本例演示使用Fluentd进行日志采集,Elasticsearch进行日志存储,Kibana进行日志查询分析。
2.安装
2.1 创建dashboard用户
sa.yml:
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: dashboard
roleRef:
kind: ClusterRole
name: view
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: dashboard
namespace: kube-system
2.2 创建PersistentVolume
创建PersistentVolume用作Elasticsearch存储所用的磁盘:
pv.yml:
apiVersion: v1
kind: PersistentVolume
metadata:
name: elk-log-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
nfs:
path: /opt/data/kafka0
server: 192.168.1.140
readOnly: false
2.3 fluentd的配置(configmap)
若无此步的话,fluentd-es镜像会有下面的错误:
2018-03-07 08:35:18 +0000 [info]: adding filter pattern="kubernetes.**" type="kubernetes_metadata"
2018-03-07 08:35:19 +0000 [error]: config error file="/etc/td-agent/td-agent.conf" error="Invalid Kubernetes API v1 endpoint https://172.21.0.1:443/api: SSL_connect returned=1 errno=0 state=error: certificate verify failed"
2018-03-07 08:35:19 +0000 [info]: process finished code=256
所以需要配置configmap:
cm.yml:
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-conf
namespace: kube-system
data:
td-agent.conf: |
<match fluent.**>
type null
</match>
# Example:
# {"log":"[info:2016-02-16T16:04:05.930-08:00] Some log text here\n","stream":"stdout","time":"2016-02-17T00:04:05.931087621Z"}
<source>
type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
tag kubernetes.*
format json
read_from_head true
</source>
<filter kubernetes.**>
type kubernetes_metadata
verify_ssl false
</filter>
<source>
type tail
format syslog
path /var/log/messages
pos_file /var/log/messages.pos
tag system
</source>
<match **>
type elasticsearch
user "#{ENV['FLUENT_ELASTICSEARCH_USER']}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD']}"
log_level info
include_tag_key true
host elasticsearch-logging
port 9200
logstash_format true
# Set the chunk limit the same as for fluentd-gcp.
buffer_chunk_limit 2M
# Cap buffer memory usage to 2MiB/chunk * 32 chunks = 64 MiB
buffer_queue_limit 32
flush_interval 5s
# Never wait longer than 5 minutes between retries.
max_retry_wait 30
# Disable the limit on the number of retries (retry forever).
disable_retry_limit
# Use multiple threads for processing.
num_threads 8
</match>
2.4 整体配置
logging.yml:
apiVersion: v1
kind: ReplicationController
metadata:
name: elasticsearch-logging-v1
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
replicas: 2
selector:
k8s-app: elasticsearch-logging
version: v1
template:
metadata:
labels:
k8s-app: elasticsearch-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
serviceAccount: dashboard
containers:
- image: registry.cn-hangzhou.aliyuncs.com/google-containers/elasticsearch:v2.4.1-1
name: elasticsearch-logging
resources:
# need more cpu upon initialization, therefore burstable class
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: es-persistent-storage
mountPath: /data
env:
- name: "NAMESPACE"
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumes:
- name: es-persistent-storage
persistentVolumeClaim:
claimName: elk-log
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: elk-log
namespace: kube-system
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
#selector:
# matchLabels:
# release: "stable"
# matchExpressions:
# - {key: environment, operator: In, values: [dev]}
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-logging
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "Elasticsearch"
spec:
ports:
- port: 9200
protocol: TCP
targetPort: db
selector:
k8s-app: elasticsearch-logging
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: fluentd-es-v1.22
namespace: kube-system
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
version: v1.22
spec:
template:
metadata:
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
version: v1.22
# This annotation ensures that fluentd does not get evicted if the node
# supports critical pod annotation based priority scheme.
# Note that this does not guarantee admission on the nodes (#40573).
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
scheduler.alpha.kubernetes.io/tolerations: '[{"key": "node.alpha.kubernetes.io/ismaster", "effect": "NoSchedule"}]'
spec:
serviceAccount: dashboard
containers:
- name: fluentd-es
image: registry.cn-hangzhou.aliyuncs.com/google-containers/fluentd-elasticsearch:1.22
command:
- '/bin/sh'
- '-c'
- '/usr/sbin/td-agent 2>&1 >> /var/log/fluentd.log'
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
- name: config-volume
mountPath: /etc/td-agent/
readOnly: true
#nodeSelector:
# alpha.kubernetes.io/fluentd-ds-ready: "true"
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: config-volume
configMap:
name: fluentd-conf
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: kibana-logging
namespace: kube-system
labels:
k8s-app: kibana-logging
kubernetes.io/cluster-service: "true"
spec:
replicas: 1
selector:
matchLabels:
k8s-app: kibana-logging
template:
metadata:
labels:
k8s-app: kibana-logging
spec:
containers:
- name: kibana-logging
image: registry.cn-hangzhou.aliyuncs.com/google-containers/kibana:v4.6.1-1
resources:
# keep request = limit to keep this container in guaranteed class
limits:
cpu: 100m
requests:
cpu: 100m
env:
- name: "ELASTICSEARCH_URL"
value: "http://elasticsearch-logging:9200"
- name: "KIBANA_BASE_URL"
value: "/api/v1/proxy/namespaces/kube-system/services/kibana-logging"
ports:
- containerPort: 5601
name: ui
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: kibana-logging
namespace: kube-system
labels:
k8s-app: kibana-logging
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "Kibana"
spec:
ports:
- port: 5601
protocol: TCP
targetPort: ui
selector:
k8s-app: kibana-logging
type: ClusterIP
2.5 安装
kubectl apply -f sa.yml
kubectl apply -f cm.yml
kubectl apply -f pv.yml
kubectl apply -f logging.yml
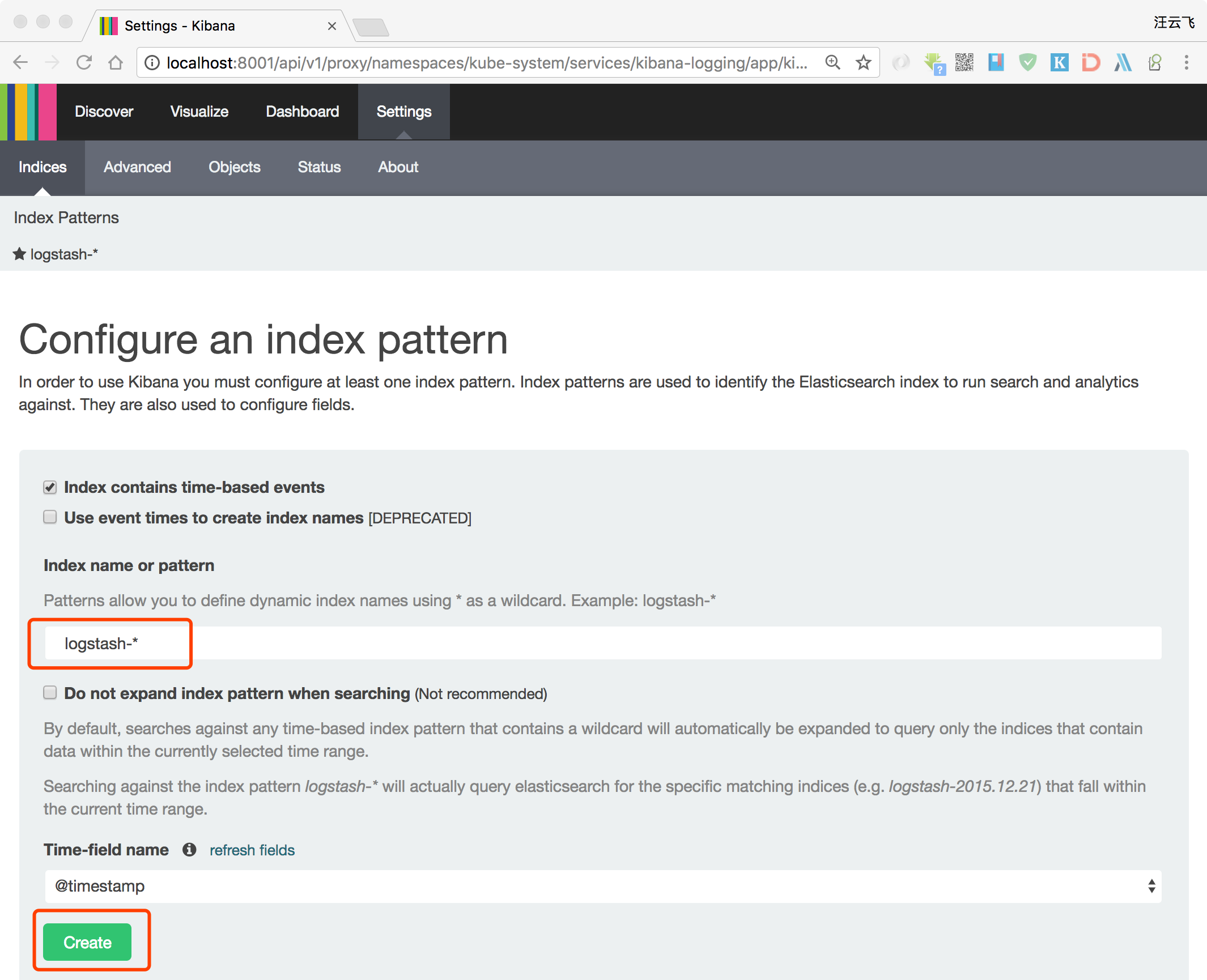
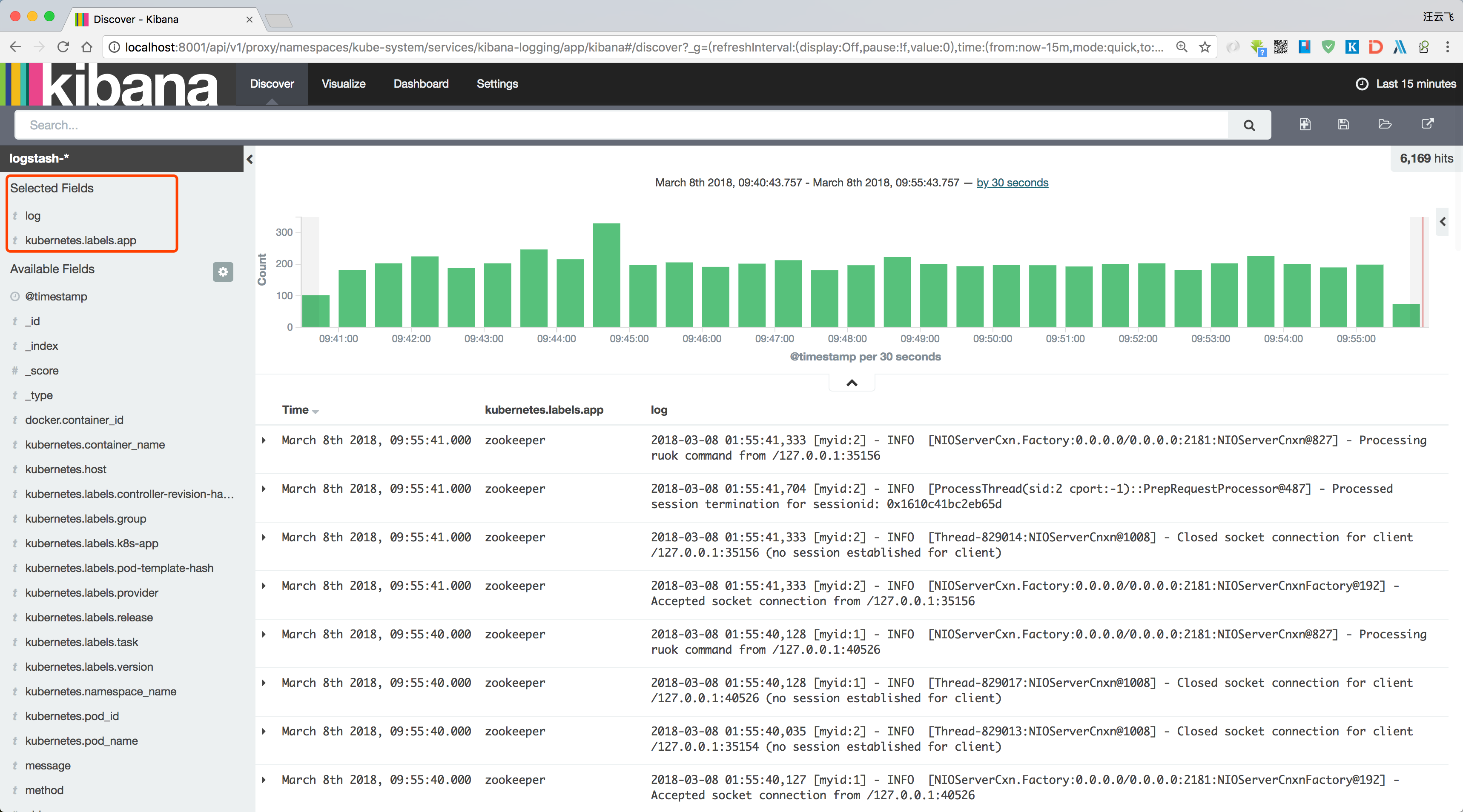
2.6 验证
-
上步完成后要等待相当长的时间,请耐心等待。
-
查看
kibana与Elasticsearch访问地址:kubectl cluster-infoKubernetes master is running at https://Master-IP:6443 Elasticsearch is running at https://Master-IP:6443/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy Heapster is running at https://Master-IP:6443/api/v1/namespaces/kube-system/services/heapster/proxy Kibana is running at https://Master-IP:6443/api/v1/namespaces/kube-system/services/kibana-logging/proxy KubeDNS is running at https://Master-IP:6443/api/v1/namespaces/kube-system/services/kube-dns/proxy monitoring-influxdb is running at https://Master-IP:6443/api/v1/namespaces/kube-system/services/monitoring-influxdb/proxy -
启动客户端代理
kubectl proxy,访问:http://localhost:8001/api/v1/namespaces/kube-system/services/kibana-logging/proxy



相关推荐
Kubernetes日志采集面临诸多挑战,包括多环境动态性、使用负担、服务动态迁移、缺乏中心化配置管理、多种日志格式、集群动态伸缩以及监控困难等。针对这些痛点,可以采用一些解决方案,如Logtail这样的日志采集工具...
除了集群管理和资源调度,Kubernetes还提供了一套完备的监控和日志系统,这对于发现和定位问题至关重要。Kubernetes允许使用者对Kafka集群和Topic进行有效的监控,及时发现并处理问题。 不过,在实施基于Kubernetes...
【标题】:“Linux-基于Kubernetes的全开源端到端DevOps工具链”是指在Linux操作系统环境下,利用Kubernetes作为核心容器编排平台,构建一套完整的、开源的DevOps工具链,以实现从代码开发、构建、测试到部署的自动...
7. **监控与日志**:Prometheus、Grafana、ELK Stack(Elasticsearch、Logstash、Kibana)等工具用于收集、分析和可视化系统性能和日志,以便及时发现并解决问题。 8. **安全性**:Istio、Kubernetes Network ...
基于日志服务的Kubernetes日志方案实践则提出了在Kubernetes集群中直接使用日志服务的架构。比如使用Elasticsearch、Kibana、Fluentd、Kafka和AWS S3等组合,或者是使用阿里云提供的Logtail日志服务。阿里云日志服务...
- **日志监控**:收集系统运行过程中的各类日志信息。 - **方法监控**:监测应用程序内部的方法执行情况,如执行时间、调用频率等。 - **JVM监控**:跟踪Java虚拟机的运行状态,包括内存使用情况、垃圾回收等。 - **...
**Go-kail:一款简单的Kubernetes日志查看器** 在Kubernetes集群中,管理与查看Pod的日志是一项常见的任务,而Go-kail正是为了解决这个问题而设计的工具。Go-kail是一个用Go语言编写的轻量级日志查看器,它能够帮助...
Kubernetes监控与日志.pdf kubernetes容器云平台实践-李志伟v1.0.pdf Kubernetes生态系统现状报告.pdf Kubernetes下API网关的微服务实践 长虹集团-李玮演讲PPT.pdf Kubernetes与EcOS的碰撞结合 成都精灵云-张行才...
### 从OpenStack到Kubernetes:云平台日志监控的新挑战 #### 一、引言 随着云计算技术的发展,从传统的虚拟化管理平台OpenStack到更先进的容器编排平台Kubernetes,云基础设施经历了显著的变化。这些变化不仅影响...
综上所述,基于kubernetes的云上自动化运维能够显著提升运维效率,降低错误率,同时通过精细的监控和管理,确保系统的稳定性和可扩展性。然而,实施kubernetes自动化运维需要深入理解其原理和最佳实践,以充分发挥其...
Kubernetes是一个强大的开源容器编排系统,能够自动化容器的部署、扩展和管理,提高了应用部署的速度和灵活性。借助K8s,用户可以快速部署应用、轻松扩展、无缝对接新功能,并优化硬件资源利用。随着K8s社区的发展,...
总结来说,基于Kubernetes的58同城深度学习算法平台是通过先进的云计算技术实现AI算法开发和运行的现代化平台,它整合了资源管理、任务调度、模型部署和监控等多个关键环节,提升了整个AI生态系统的效率和稳定性。
总结,基于Kubernetes的容器服务提供了全面的解决方案,涵盖了从镜像管理、应用部署到监控运维的各个环节,为企业构建了一套高效、灵活、可扩展的云上应用管理框架。通过360私有云平台HULK的实践,我们可以看到...
此外,他还可能讨论监控和日志管理,如使用Prometheus和Grafana进行性能监控,以及使用Elasticsearch和Logstash进行日志收集和分析。 在微服务架构方面,高欣可能会分享如何利用Kubernetes来管理和扩展微服务,包括...
惠普的私有云平台实践可能还包括自定义的管理工具、监控和日志收集、安全策略以及自动化运维流程。通过这些工具,企业能够更有效地管理和运营自己的容器化应用,提高开发效率,同时确保系统的稳定性和安全性。 此外...
这个生态系统包括了各种软件、插件和工具,旨在提升Kubernetes的易用性、自动化程度、网络管理、集群监控以及安全性等方面。下面我们将详细探讨这些关键领域的工具。 ### 1. 容器运行时 容器运行时是Kubernetes的...
3. **日志与监控**:集成 Kubernetes 日志和监控数据,方便用户查看 Pod 的运行日志和性能指标。 4. **用户权限管理**:支持 RBAC(Role-Based Access Control),精细化控制不同用户对集群资源的访问权限。 5. **...
基于Kubernetes的CI/CD流程通常包括代码仓库、自动化测试、镜像构建、版本管理、部署和监控等环节。 6. 监控与日志管理:为了保障容器云平台的稳定运行,易宝支付必须实施全面的监控策略,实时追踪系统状态、性能...
- **监控和日志**:集成监控和日志系统,实时了解容器和服务状态,便于故障排查和性能优化。 总结来说,基于Kubernetes和Docker的企业级容器云平台方案为企业带来了资源优化、敏捷开发和高效运维的可能。通过容器...
本实践案例主要围绕"360私有云平台基于Kubernetes的容器服务实践"展开,深入探讨了如何利用Kubernetes这一强大的容器编排系统来构建和管理私有云环境。Kubernetes(简称K8s)是Google开源的容器集群管理系统,旨在...