
1. Kettle的简单介绍
Kettle(现名Data Integration)是一款使用Java编写的功能强大的ETL(Extract Transform and Load)工具,支持关系型数据库(PostgreSQL、MySQL、Oracle等)、非关系型数据库(MongoDB、ElasticSearch等)以及文件之间的大规模数据迁移。
2. 常用组件
Kettle提供了极为丰富的组件库,下面列举的是它的一些常用组件,以及对组件的常用参数进行简单介绍,详细的参数说明可参考Kettle的帮助文档。
2.1 Table input
指定数据库表作为输入。
-
Step name: 步骤名称,Kettle的每一个组件即一个步骤,可为该步骤取一个别名 -
Connection: 指定数据库连接 -
SQL: 编写SQL,从该数据库表中筛选出符合条件的数据
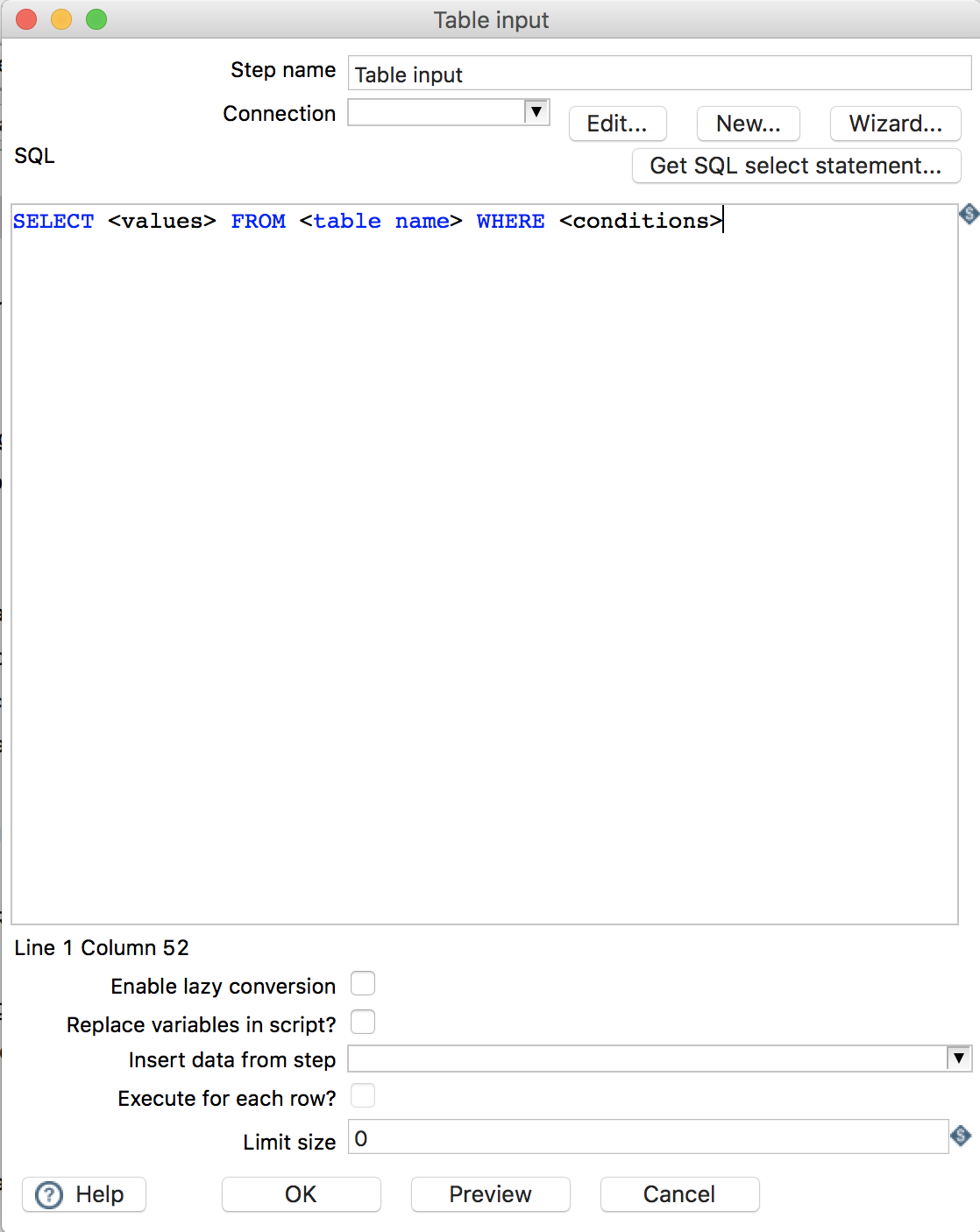
2.2 Table output
指定数据库表作为输出
-
Step name: 步骤名称 -
Connection: 指定数据库连接 -
Target schema: 输出的数据库表模式 -
Target table: 指定输出的数据库表 -
Use batch update for inserts: 是否使用批处理进行插入 -
Database fields: 配置字段映射关系-
Table field: 输出的数据库表字段 -
Stream field: 流字段(流入该组件的数据字段)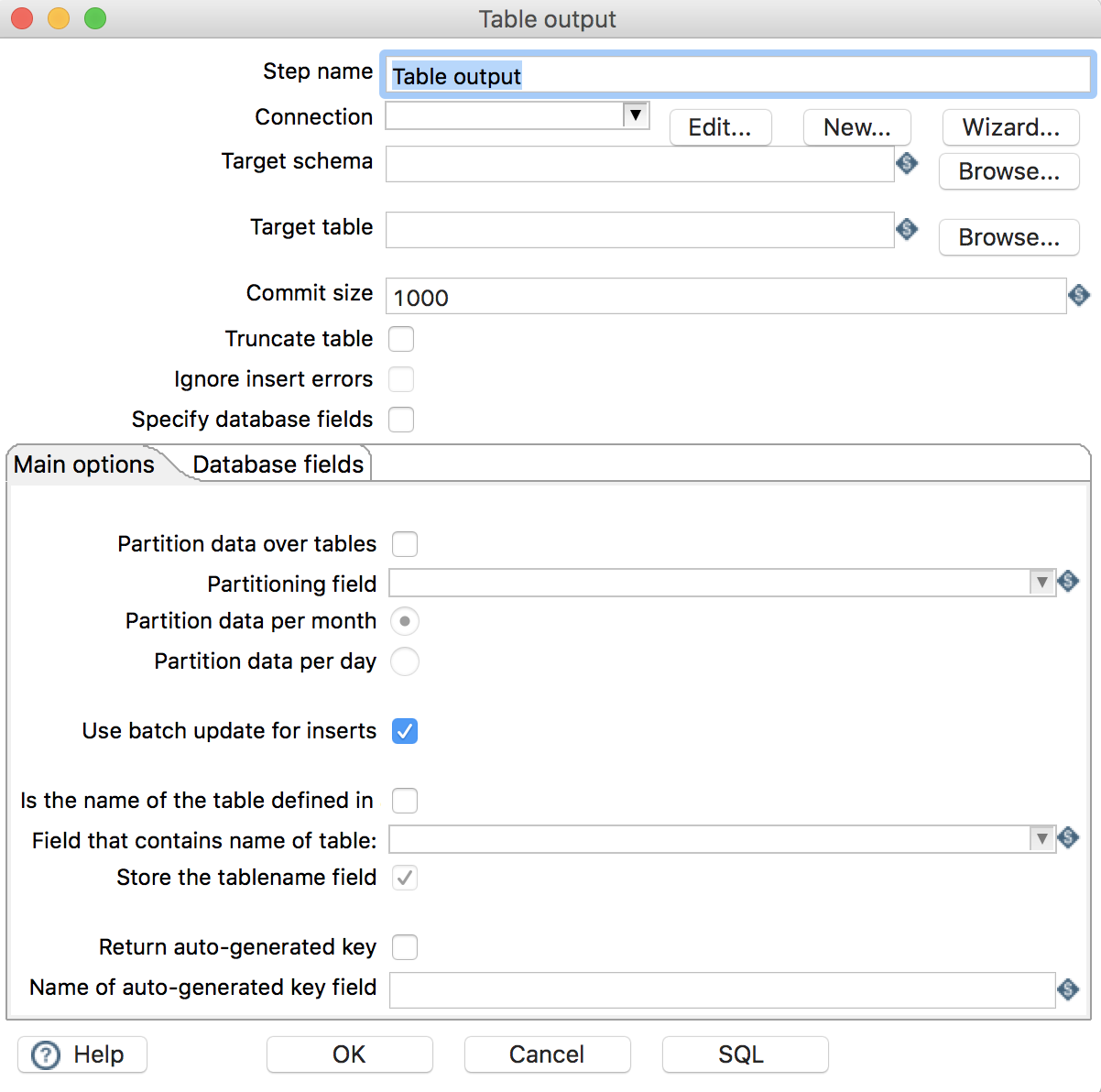
-
2.3 Sort rows
按照某字段进行排序
-
Step name: 步骤名称 -
Fields:-
Fieldname: 排序的字段名 -
Ascending: 排序方式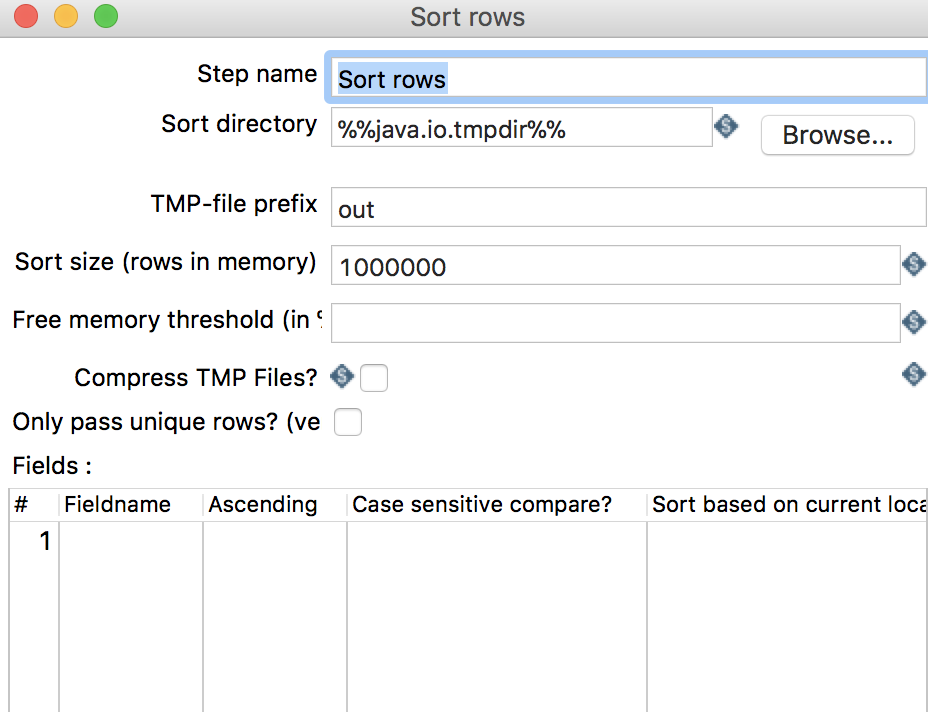
-
2.4 Merge join
将不同来源数据进行融合,类似于
SQL中的join,注意: 该组件接收的数据必须按照join字段按照相同规则进行排序,否则join后的数据会有丢失。
-
Step name: 步骤名称 -
First Step: 需要融合的一组数据 -
Second Step: 需要融合的另一组数据 -
Join Type: 融合的类型 -
Keys for 1st step:First Step中进行融合的字段 -
Keys for 2nd step:Second Step中进行融合的字段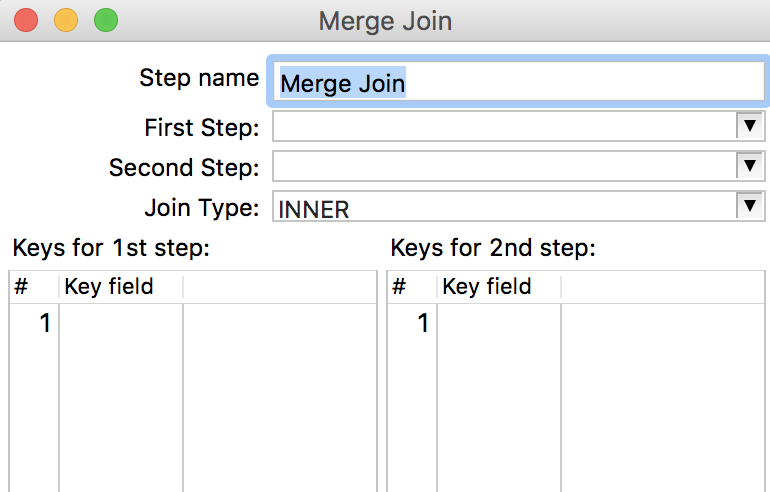
2.5 Add sequence
读取指定的序列值
-
Step name: 步骤名称 -
Name of value: 序列值别名 -
Use DB to get sequence: 是否使用数据库序列 -
Connnection: 数据库连接 -
Schema name: 数据库模式名称 -
Sequence name: 序列名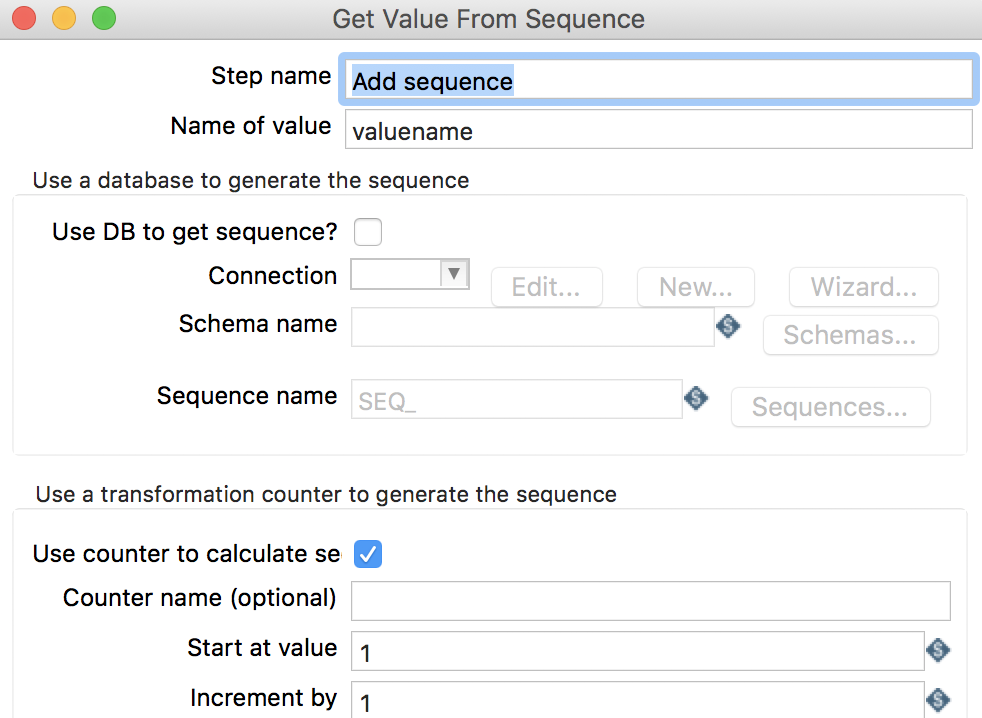
2.6 Modified Java Script Value
支持编写
JavaScript脚本,用于实现必要的业务逻辑
-
Step name: 步骤名称 -
Java script functions: 提供了一些JavaScript函数 -
Java script: 脚本编辑窗口 -
Fields: 可将脚本中的定义的变量映射出去
3. 在实际场景中的应用
在软件开发中,经常会遇到这样的场景: 新开发的系统即将替换老系统,而老系统庞大的数据需迁移到新系统中,但数据结构与新系统不完全兼容,下面通过一个简单的例子来介绍
Kettle是如何处理这些老数据,完成数据迁移任务的。
3.1 老数据结构
-
company公司表:
-
district区域表:
该表存储了省市区,通过parent_id进行关联
-
company_district公司区域表:
-
employee员工表:
-
employee_company员工公司表:
3.2 新数据结构
-
company公司表: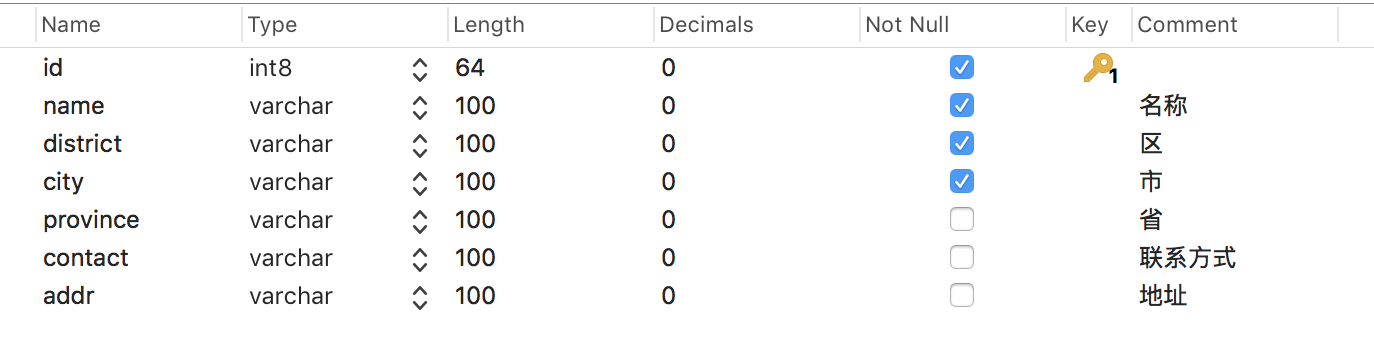
对比老数据
company表,新的company表中新增了district、city、province字段,他们可以从老数据company_district表和district表中取得;contact字段对应tel字段;addr对应address。 -
employee员工表: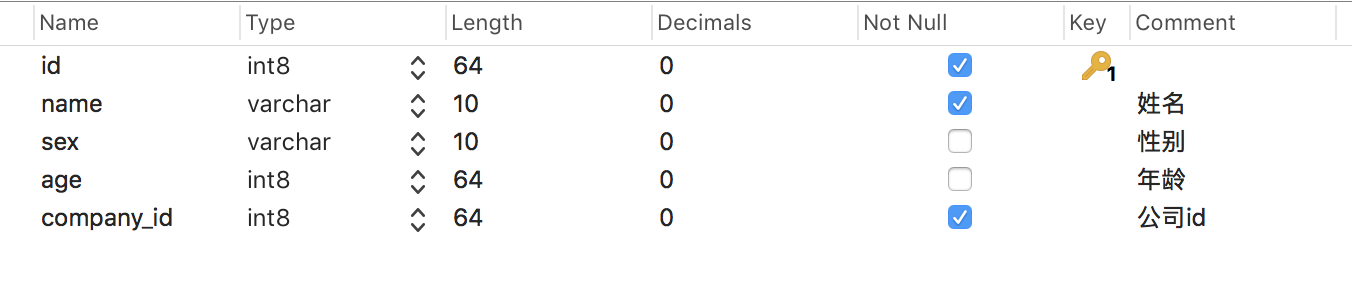
对比老数据
employee表,新的employee表中新增company_id字段且有外键约束;sex字段由原来的1、2变更为男、女
3.3 数据迁移
由于
employee有外键关联company,因此先迁移company表数据,新的company表需新增old_id字段来保存老的company表的id,用于员工关联公司。
3.3.1 company表
数据迁移前的分析:
company表数据来源于三张表:company、company_district、district,因此需要三个Table input组件。company和company_district需进行join,join的结果还需和district进行join,因此需要两个Merge Join组件。- 使用
Merge join组件之前需进行排序,因此需要三个Sort rows组件- 新的
company表的id来源于自增长序列,因此需要一个Add sequence组件。- 最后将结果导入新的
company表,因此需要一个Table output组件。
- 打开
Kettle,点击File->new->Transformation,新建一个转换流程 - 点击左侧
DesignTab页,将Table input组件拖拽至右侧转换流程窗口,在组件上右键点击edit,弹出该组件的编辑窗口,设置步骤名称、数据库连接和SQL语句,如下图所示: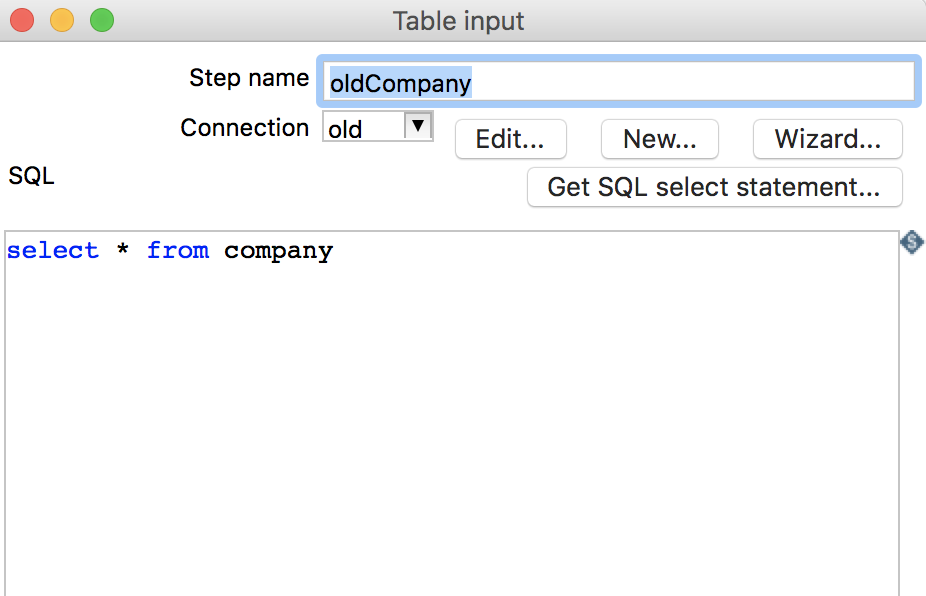
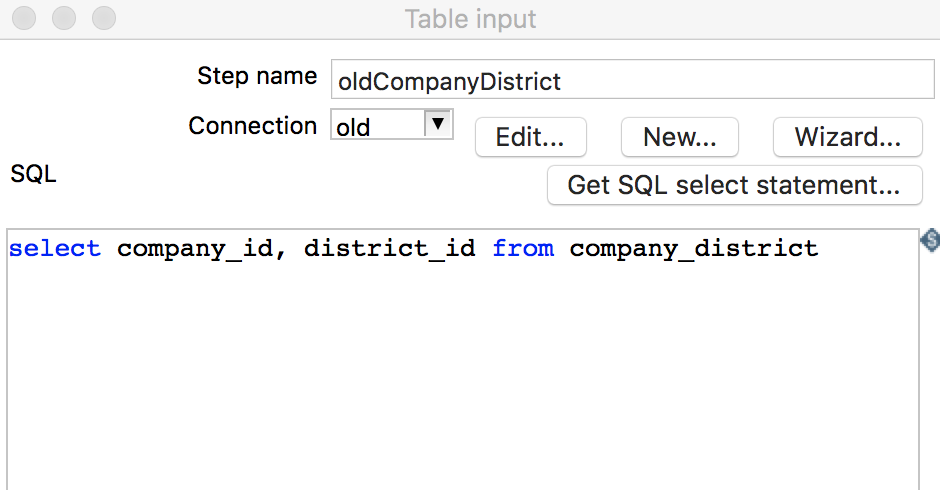

-
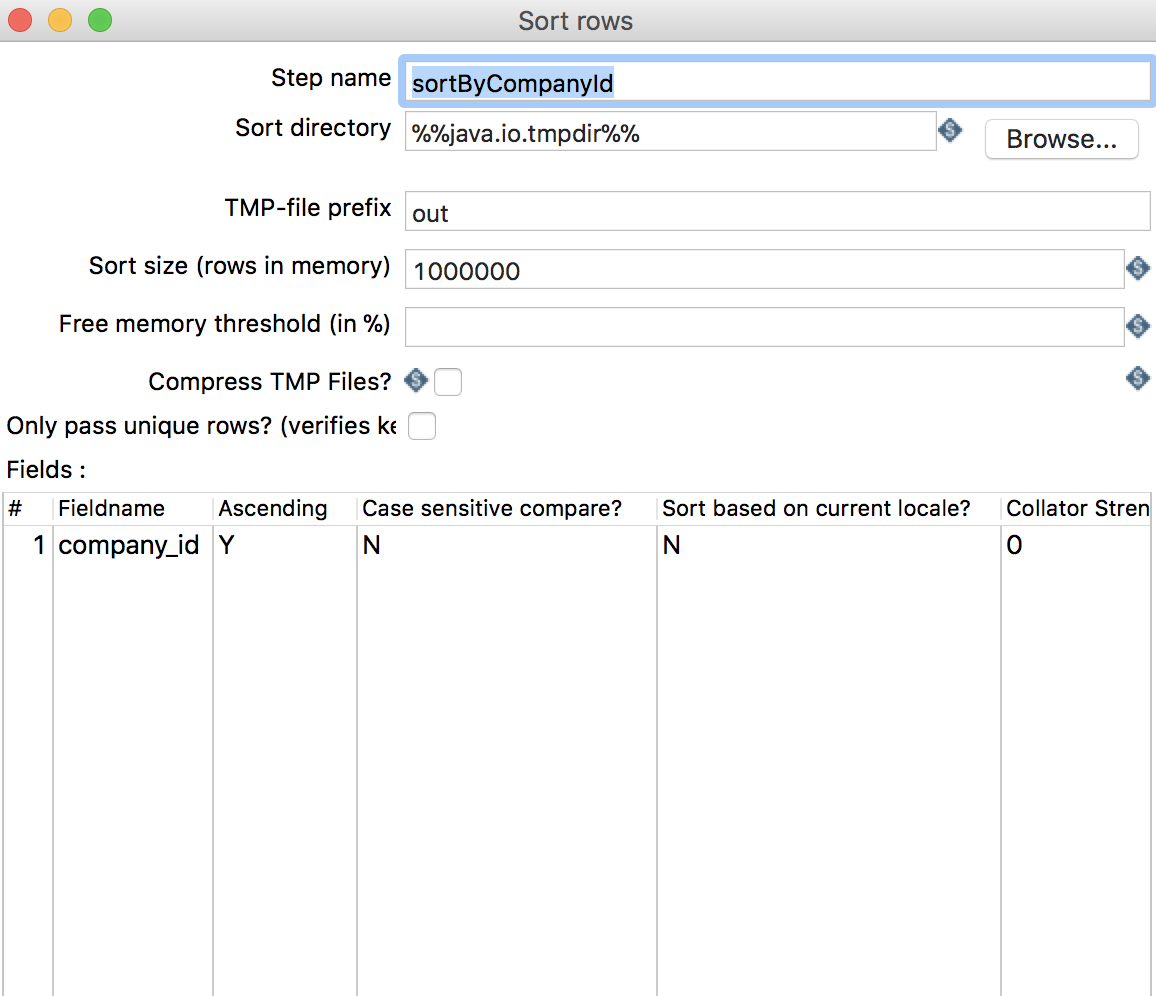
将
company和company_district数据进行left join,join之前需按照join字段排序,将Sort rows组件拖拽至右侧转换流程窗口,并进行编辑,如下图所示: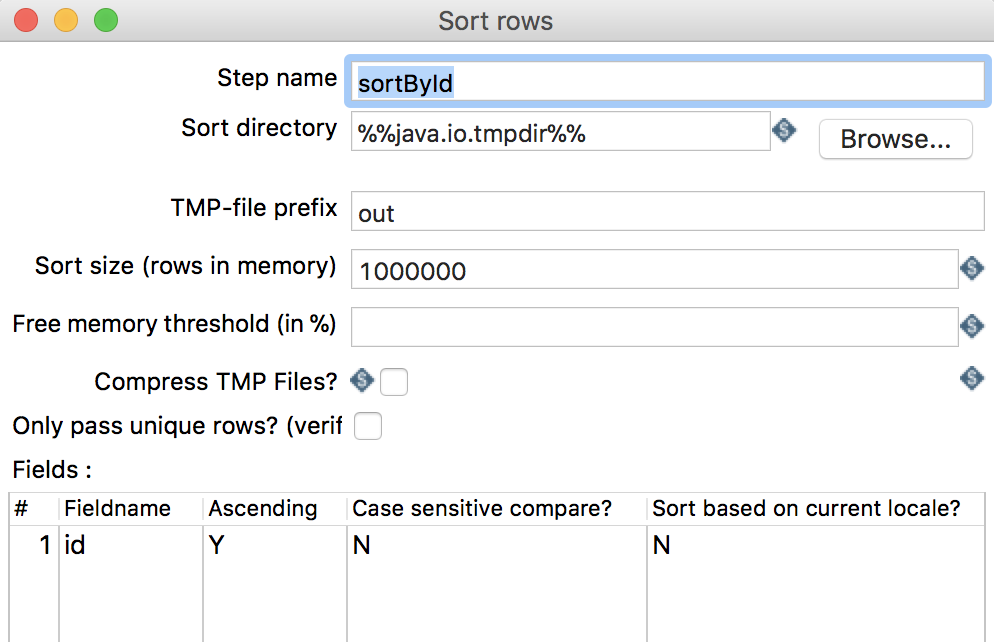
-
将
Merge Join组件拖拽至右侧,并进行编辑,如下图所示: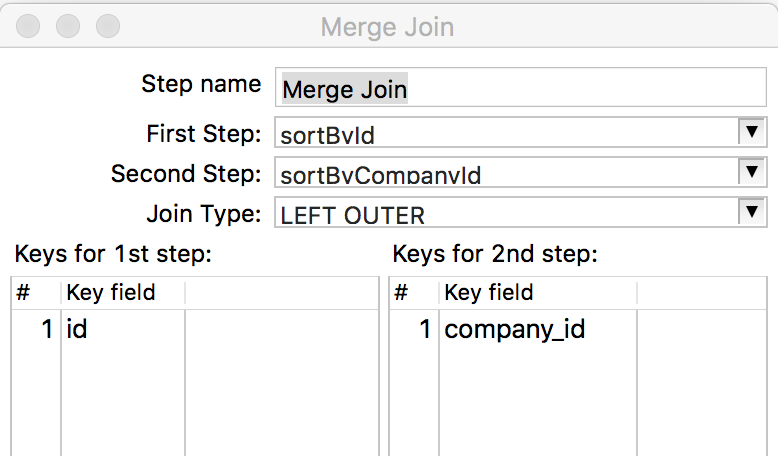
-
将
company和company_districtMerge Join的结果和district数据分别进行排序,同上面步骤 -
将两者进行
join,同上面步骤 -
添加
Add sequence组件,并进行编辑,如下图所示: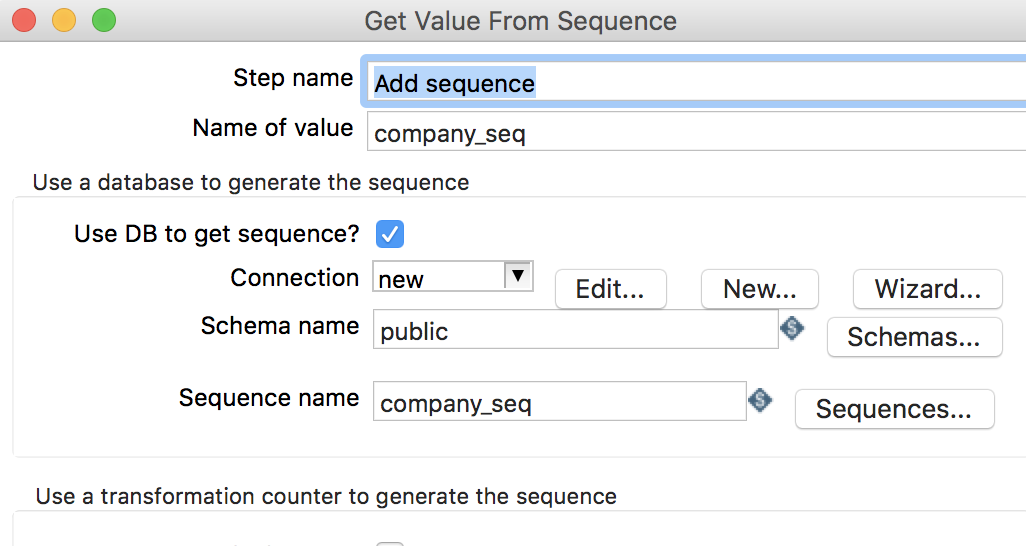
-
添加
Table output组件,并进行编辑,如下图所示: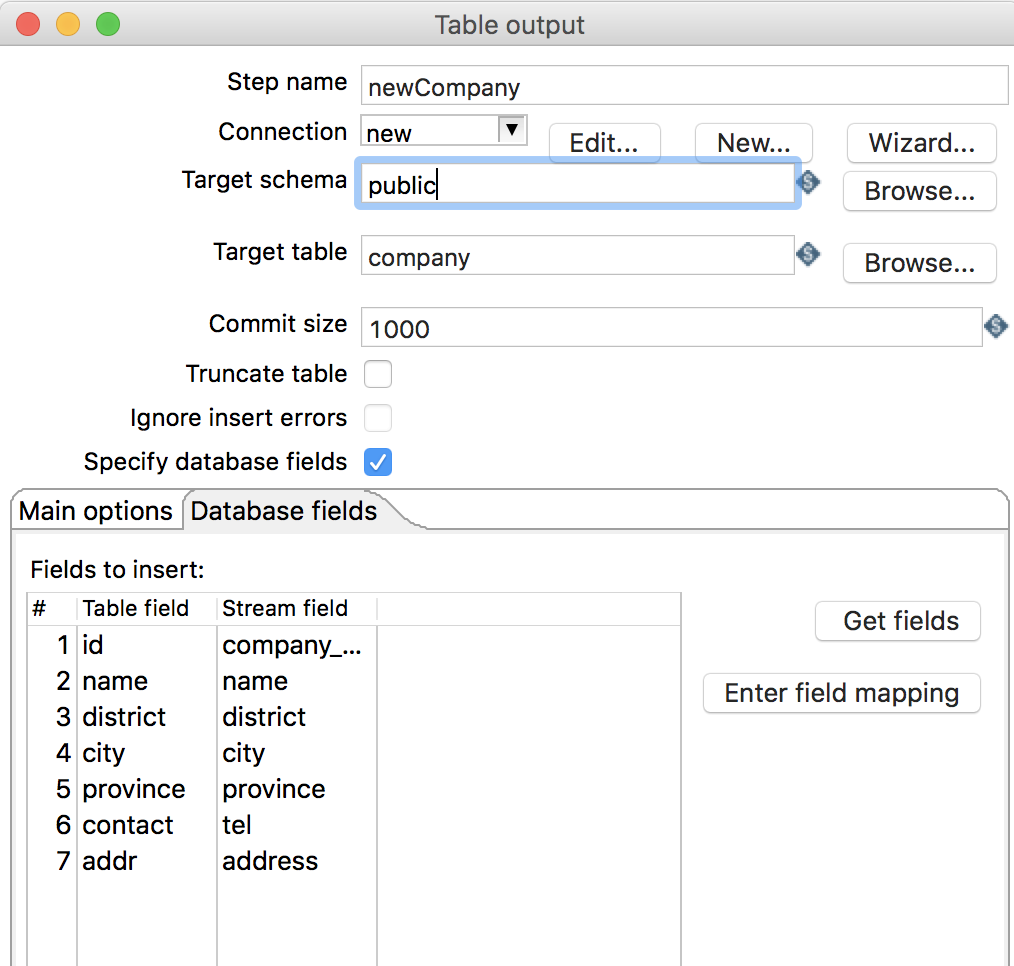
-
整体流程如下图所示:
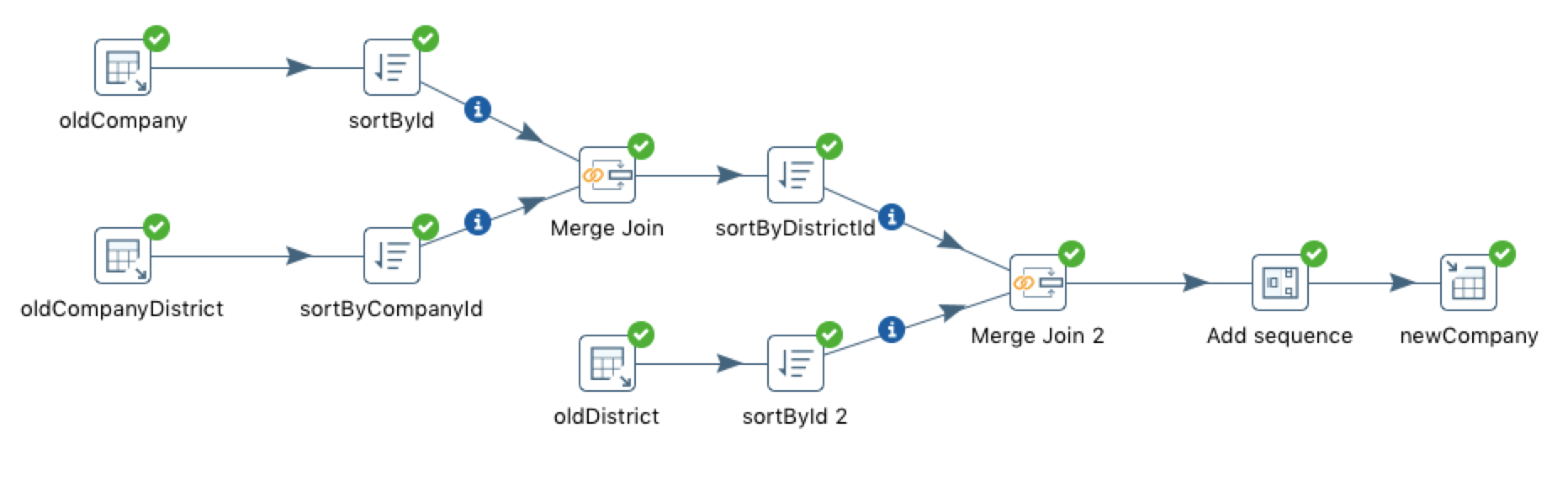
-
点击启动按钮执行整个流程,直至所有步骤右上角出现绿色的箭头,
company表便完成了迁移。
3.3.2 employee表
数据迁移前的分析:
employee表数据来源三张表: 老的employee、老的employee_company和新的company,因此需要三个Table input组件- 老的
employee和employee_company需进行join,join的结果还需和新的company进行join,因此需要两个Merge join组件和三个Sort rows组件。- 新的
employee表的id来源于自增长序列,因此需要一个Add sequence组件。- 新的
employee表的sex字段存储的是'男/女',而不是'1/2',因此需要一个Modified Java Script Value组件进行简单处理。- 最后将结果导入新的
employee表,因此需要一个Table output组件。
- 与
company的数据迁移类似,添加三个Table input组件,并进行编辑 - 分别将
employee和employee_company按照join字段进行统一排序 - 将排序的结果进行
join - 分别将新的
company和join之后的结果按照join字段进行统一排序 - 将排序的结果进行
join - 编写脚本,转换
sex字段
- 读取新的
employee序列值 - 输出到新的
employee表中 -
整体流程如下图所示:
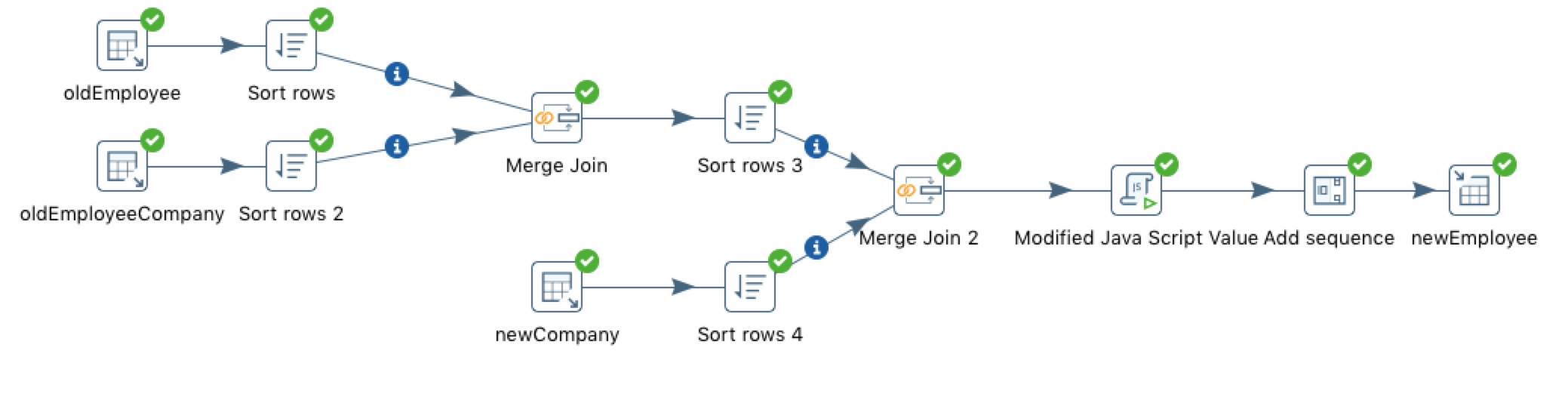
-
点击启动按钮执行整个流程,直至所有步骤右上角出现绿色的箭头,
employee表便完成了迁移。
3.4 结果
-
company表
-
employee表
至此,便完成了老数据的迁移。
4. 遇到的问题
在
Kettle使用过程中会发现,当需要进行迁移的数据量较为庞大时(千万级),常常会出现内存溢出的问题,解决方法是将Kettle内存调高些: 打开spoon.sh文件,找到PENTAHO_DI_JAVA_OPTIONS="-Xms1024m -Xmx2048m -XX:MaxPermSize=256m",将其修改为PENTAHO_DI_JAVA_OPTIONS="-Xms16384m -Xmx32768m -XX:MaxPermSize=16384m",重启即可。



相关推荐
- **从各种数据源提取数据**:包括遗留系统、数据库、文件等。 - **转换数据**:优化数据结构,使其更适合报告和分析,同步来自不同数据库的数据,并进行数据清洗以消除错误。 - **加载数据到数据仓库**:将处理后的...
铅笔头识别数据集,1692张原始训练图,640*640分辨率,91.1%的正确识别率,标注支持coco json格式
高校网络教学的体系规划与创建.docx
SpringBoot的学生心理咨询评估系统,你看这篇就够了(附源码)
内容概要:本文详细介绍了如何使用遗传算法优化BP神经网络,以提高交通流量预测的准确性。文中首先解释了BP神经网络的基本结构及其局限性,即容易陷入局部最优解的问题。随后,作者展示了遗传算法的工作原理,并将其应用于优化BP神经网络的权重和偏置。通过定义适应度函数、选择、交叉和变异等步骤,实现了对BP神经网络的有效改进。实验结果显示,优化后的BP神经网络在交通流量预测中的精度显著高于传统的BP神经网络,特别是在处理复杂的非线性问题时表现出色。 适用人群:对机器学习、深度学习以及交通流量预测感兴趣的科研人员和技术开发者。 使用场景及目标:适用于需要进行精确交通流量预测的应用场景,如智能交通系统、城市规划等领域。主要目标是通过遗传算法优化BP神经网络,解决其易陷入局部最优的问题,从而提高预测精度和稳定性。 其他说明:文中提供了详细的Python代码实现,帮助读者更好地理解和实践这一优化方法。同时,强调了遗传算法在全局搜索方面的优势,以及其与BP神经网络结合所带来的性能提升。此外,还讨论了一些具体的实施技巧,如适应度函数的设计、交叉和变异操作的选择等。 标签1,标签2,标签3,标签4,标签5
内容概要:本文详细介绍了H5U框架在PLC与触摸屏集成方面的应用,特别是在总线伺服控制和跨平台移植方面。文章首先解析了伺服控制的核心代码,如使能模块和绝对定位指令,强调了标准化控制流程的优势。接着讨论了触摸屏交互,通过直接映射PLC的DB块地址简化了数据处理。然后介绍了总线配置,尤其是EtherCAT总线初始化及其容错设计。此外,文章还探讨了框架的移植性和报警处理设计,展示了其在不同PLC品牌间的易用性和高效的故障恢复能力。 适合人群:从事工业自动化领域的工程师和技术人员,特别是有PLC编程经验和需要进行伺服控制系统开发的人群。 使用场景及目标:①快速搭建和调试基于PLC和触摸屏的自动化控制系统;②提高多轴设备的调试效率;③实现跨平台的无缝移植;④优化报警管理和故障恢复机制。 其他说明:该框架不仅提供了详细的代码示例和注释,还包含了丰富的实战经验和最佳实践,使得新手能够快速上手,而资深工程师可以在此基础上进一步创新。
内容概要:本文档《UE5开发.txt》全面介绍了Unreal Engine 5(UE5)的基本概念、安装配置、项目创建、文件结构及常用功能。UE5是一款强大的游戏引擎,支持实时渲染、蓝图创作、C++编程等功能。文档详细描述了UE5的安装步骤,包括硬件要求和环境配置;项目创建过程,涵盖项目模板选择、质量预设、光线追踪等设置;文件结构解析,重点介绍了Config、Content和.uproject文件的重要性。此外,文档深入讲解了蓝图编辑器的使用,包括变量、数组、集合、字典等数据类型的操作,以及事件、函数、宏和事件分发器的应用。蓝图作为一种可视化脚本工具,使开发者无需编写C++代码即可快速创建逻辑,适用于快速开发和迭代。 适合人群:具备一定编程基础的游戏开发者、设计师和对游戏开发感兴趣的初学者,尤其是希望深入了解UE5引擎及其蓝图系
餐馆点菜系统概要设计说明书.doc
5+1档轿车手动变速箱设计说明书.doc
1万吨自来水厂详细设计说明书.doc
wordpress外贸电商企业产品主题 页面展示图https://i-blink.csdnimg.cn/direct/e45b2e2e8e27423eb79bda5f4c1216d7.png
低效林改造作业设计说明书.doc
西门子200smart编程软件V2.8.2.1
135调速器操纵手柄 设计说明书.doc
内容概要:本文档为蓝桥杯全国软件和信息技术专业人才竞赛提供了全面的指导,涵盖竞赛概述、流程与规则、核心考点与备赛策略、实战技巧与避坑指南以及备赛资源推荐。蓝桥杯竞赛由工信部人才交流中心主办,涉及算法设计、软件开发、嵌入式系统、电子设计等领域。文档详细介绍了参赛流程(报名、省赛、国赛、国际赛),并针对软件类和电子类竞赛分别阐述了高频考点和备赛建议。对于软件类,强调了算法与数据结构的重要性,如排序、动态规划、图论等;对于电子类,则侧重于硬件基础和开发工具的使用。此外,还提供了详细的答题策略、常见陷阱规避方法及工具调试技巧。; 适合人群:高校本专科生、研究生,尤其是对算法设计、软件开发、嵌入式系统等领域感兴趣的计算机科学及相关专业的学生。; 使用场景及目标:①帮助参赛选手熟悉竞赛流程和规则,明确各阶段任务;②提供系统的备赛策略,包括高频考点的学习和专项突破;③指导选手掌握实战技巧,避免常见错误,提高答题效率和准确性。; 阅读建议:此文档不仅提供了理论知识,还包含了大量实战经验和备赛资源推荐,建议读者结合自身情况制定个性化的备赛计划,充分利用提供的资源进行练习和准备。
基于行块抽取正文内容的java版本的改进算法.zip
内容概要:本文详细介绍了基于西门子S7-200 PLC和MCGS组态软件的快递分拣系统的设计与实现方法。首先阐述了硬件配置的关键要点,包括IO分配表的具体设置以及传感器和执行机构的连接方式。接着深入解析了PLC程序中的梯形图逻辑,涵盖主传送带的连锁保护、机械臂动作的自保持逻辑和安全复位机制等核心部分。同时探讨了MCGS组态画面的应用,展示了如何通过脚本实现动态效果和数据统计功能。此外,文中还分享了一些调试经验和常见问题的解决方案,如防止传感器抖动、优化数据传输效率等。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是对PLC编程和组态软件有一定了解的人群。 使用场景及目标:适用于需要构建高效可靠的快递分拣系统的物流企业或相关项目开发者。目标是帮助读者掌握从硬件选型到软件编程的一整套实施流程,确保系统能够稳定运行并达到预期性能指标。 其他说明:文章不仅提供了理论指导,还结合实际案例进行了详细的步骤讲解,有助于读者更好地理解和应用于实践中。
该资源为joblib-0.12.5-py2.py3-none-any.whl,欢迎下载使用哦!
内容概要:本文详细介绍了三种经典的机器学习分类算法——决策树、随机森林和KNN分类器,在Python的sklearn库中的具体实现方法。首先,通过加载鸢尾花数据集进行数据准备,并将其划分为训练集和测试集。接着分别实现了决策树、随机森林和KNN分类器,展示了每种算法的关键参数配置及其对模型性能的影响。对于决策树,重点讨论了max_depth参数的作用以及如何通过可视化工具理解其分裂过程;随机森林部分强调了n_estimators参数的选择和特征重要性的评估;而KNN分类器则着重于特征标准化的重要性和n_neighbors参数的优化。此外,文中还提供了关于模型选择的指导,帮助读者根据不同应用场景选择合适的算法。 适合人群:对机器学习感兴趣的初学者和有一定编程基础的研发人员。 使用场景及目标:①理解并掌握决策树、随机森林和KNN分类器的工作原理;②学会使用sklearn库快速构建和评估分类模型;③能够根据具体问题特点选择最适合的分类算法。 其他说明:本文不仅提供了详细的代码示例,还分享了许多实践经验,如参数调优技巧、模型评估方法等,有助于读者更好地理解和应用这些算法。
带式输送机传动装置设计课程设计说明书.doc