到目前为止Kubernetes对基于cpu使用率的水平pod自动伸缩支持比较良好,但根据自定义metrics的HPA支持并不完善,并且使用起来也不方便。
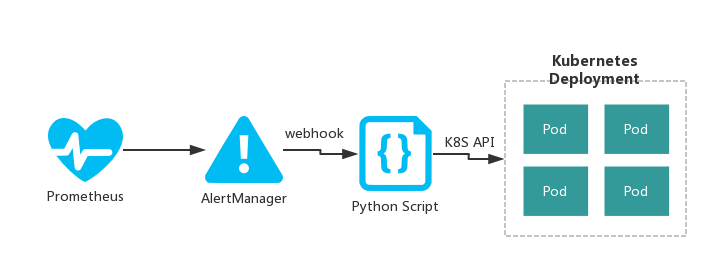
下面介绍一个基于Prometheus和Alertmanager实现Kubernetes Pod 自动伸缩的方案,该方案支持任意自定义metrics。思路比较简单:由Prometheus负责收集需要的性能指标(如:当前链接的并发数,当前cpu的使用率等),根据定义好的告警规则生成告警事件,然后将告警事件传递给Alertmanager,由alertmanager触发webhook来实现最终的pod伸缩功能,如下图所示:
Prometheus中Alert rules的配置示例:
ALERT HpaTrigger
IF app_active_task_count > 30
FOR 30m
LABELS {serverity = "page",trigger="hpa",action = "scale-out",value = "{{$value}}", deployment="test", namespace = "{{$labels.namespace}}"}
ANNOTATIONS {
summary = "Instance {{$labels.namespace}}: scale-out",
description = "{{$labels.namespace}} auto scale-out"
}
上述规则表示应用的活动任务数持续30分钟都大于30的话,就需要创建新的pod以应对过多的任务数。但此处并不会直接触发水平Pod自动伸缩功能,prometheus根据告警规则只会生成一个告警事件,并将该事件传递给alertmanager,由alertmanager决定如何处理该告警。
Alertmanager配置示例:
global:
route:
receiver: 'email' #全局配置,默认将收到的告警事件路由给email接收器
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
routes:
- receiver: 'auto-hpa' #将trigger=hpa的告警路由给auto-hpa
match:
trigger: hpa
receivers:
- name: 'email'
email_configs:
- to: ops@test.com
from: monitor@test.com
smarthost: smtpserver:port
auth_username: "username"
auth_identity: "username"
auth_password: "password"
require_tls: true
- name: "auto-hpa"
webhook_configs:
- url: 'http://YOUR_WEBHOOK_IP:PORT/hpa' #自定义webhook url地址。
send_resolved: true
Alertmanager接受到相应的告警之后,会将获取到的具体metics值(此处metric name为app_active_task_count)和在告警规则中定义的LABELS信息合并为一个json数据,以POST方式发送给我我们定义好的webhook url。
webhook Python脚本示例:
from flask import Flask,request
import json
app = Flask(__name__)
@app.route("/hpa",methods=["POST"])
def hpa():
content = request.get_json()
#分析content字段,提取相关数据,调用k8s api实现水平pod自动伸缩的功能
#.......
#.......
print content
if __name__ == "__main__":
app.run("0.0.0.0")
这里我省略了具体调用k8s api实现pod伸缩的逻辑。Alertmanager将所有的信息以json格式post给我们自定义的脚本了,具体怎么处理,就看业务需求了。





相关推荐
### 基于Prometheus和Zabbix实现容器云平台整体监控方案—最佳实践 #### 一、背景介绍 随着云计算的普及以及企业数字化转型的深入,容器化技术因其高效的资源利用、灵活的服务编排能力而成为了当前IT领域的热门...
Prometheus Operator可以简化Prometheus的部署和管理,自动处理配置更新和扩展。 2. `prometheus-k8s.yaml`:这将定义Prometheus服务器的配置,包括服务发现规则、目标抓取配置和存储设置。 3. `grafana.yaml`:...
该项目的目的是简化和自动化针对Kubernetes集群的基于Prometheus的监视堆栈的配置。 Prometheus运算符包括但不限于以下功能: Kubernetes自定义资源:使用Kubernetes自定义资源来部署和管理Prometheus,Alert...
监控体系的设计基于联邦模式的部署,意味着可以通过多个Prometheus实例来分散数据采集的负载,并实现跨集群的监控。这种设计有助于避免中心节点成为瓶颈或单点故障,提升系统的可用性和可靠性。 文档还提到,为了...
本文将深入探讨基于Linux的NetApp exporter及其与Prometheus的集成。 首先,让我们理解Prometheus。Prometheus是一个强大的时间序列数据库和监控系统,由Google设计并开源。它支持灵活的查询语言、多维度数据模型...
Prometheus和Grafana是两种广泛用于监控Kubernetes集群的开源工具。Prometheus是一个功能强大的时间序列数据库和监视系统,而Grafana则是一个可视化工具,可以将Prometheus收集的数据以直观的图表形式展示出来。这个...
Prometheus+Grafana监控Kubernetes-配套yaml.zip grafana.yaml、Kubernetes Pod Resources.json、namespace.yaml、node-exporter.yaml、prometheus.yaml
第五章“prometheus基于k8s的服务发现”深入讨论了Prometheus如何在Kubernetes中自动发现服务。Prometheus通过服务发现机制,可以动态地获取到Kubernetes集群中的Pod和服务信息,实现对这些组件的监控。 第九章...
- 第02阶段:持续交付方法 - 在这个阶段,可能会讨论如何利用持续集成/持续部署(CI/CD)实践,如Jenkins或GitLab CI,结合Docker和Kubernetes实现自动化构建、测试和部署流程。 综合以上信息,我们可以期待这个...
Kubernetes的API Server可以作为Prometheus的服务发现机制,使得Prometheus能自动发现并监控新的Pod。这需要配置Prometheus的Service Discovery规则来识别Kubernetes的Endpoint。 3. **Target Exporters** 为了...
Kubernetes提供了一种强大而灵活的方式来管理和运行分布式系统,特别适合在云环境中实现自动化运维。 1. **自动化运维关键因素** - **完善运维设备**:自动化运维平台如kubernetes的运行依赖于高性能的硬件设备。...
6. **弹性伸缩与性能监控**:讨论如何使用 Kubernetes 的 Horizontal Pod Autoscaler (HPA) 功能自动调整服务实例数量,以及如何通过 Prometheus、Grafana 等工具监控微服务性能。 7. **故障恢复与容错**:讲解如何...
标题 "K8S之HPA基于内存指标实现pod自动扩缩容测试用例" 涉及的关键知识点是 Kubernetes(K8S)的水平自动扩展(Horizontal Pod Autoscaler, HPA)以及如何根据内存指标来调整Pod的副本数量。在这个测试用例中,我们...
综上所述,Prometheus在Kubernetes环境中的应用是多方面的,从基础组件到应用服务,再到告警和自动伸缩,它提供了全面且灵活的监控解决方案。通过深入理解这些知识点,开发者和运维人员能够更好地维护和优化...
基于Prometheus+Grafana搭建JMeter性能测试监控平台.docx 做性能测试,如果没有养成良好的保存结果习惯,那么一个业务指标监控平台就必不可少,不仅可以在线监控,还可以用于报告总结,数据持久化的好处就是让人眼前...
本文将详细介绍基于Prometheus的GPU服务器运维监控系统,涵盖了系统的设计、实现和应用等方面的知识点。 一、GPU服务器监控的需求 随着人工智能技术的快速发展,对系统部署和监控能力也提出更高的要求。服务器运维...
本文涵盖了Prometheus Operator在Kubernetes集群上的安装流程和一些关键操作,展现了如何通过CRDs实现Prometheus实例的自动化管理。熟练掌握Prometheus Operator将帮助运维人员更有效地监控Kubernetes环境,确保系统...
例如,可能需要配置K8s的服务发现规则,让Prometheus自动发现并监控K8s集群中的所有Pod。 2. **Alertmanager配置部署**: Alertmanager是Prometheus的一部分,负责接收警报并根据预设的规则发送通知。配置Alert...
Prometheus是目前非常流行的开源监控系统,特别是在 Kubernetes 集群中广泛应用。它以其强大的时间序列数据收集和处理能力,以及灵活的警报管理和丰富的可视化工具而受到赞誉。本课程聚焦于 Prometheus 在 ...
总的来说,k8s-prom-hpa是Kubernetes环境中实现基于Prometheus自定义指标的水平Pod自动缩放的关键组件。通过这种方式,我们可以根据业务需求进行更智能、更精细的资源管理,提高系统的响应性和效率。