
وˆ‘ن¹¦è¯»ه¾—ه°‘,ن½ ن¸چè¦پéھ—وˆ‘م€‚è؟™هڈ¯èƒ½وک¯وœ€é€‚هگˆوˆ‘ن»¬çڑ„ن¸€هڈ¥è¯ن؛†م€‚وک¨و™ڑè·ںن»¥ه‰چçڑ„部é•؟祥ن»”爷èپٹه¤©ï¼Œه¾—çں¥ن»–çژ°هœ¨هœ¨هپڑوگœç´¢ه¼•و“ژçڑ„ن¼کهŒ–,هœ¨é‚£ه®¶ه…¬هڈ¸ه·¥ن½œï¼Œن»–ن¾؟è·ںوˆ‘说起ن»–çڑ„ن¸“ن¸ڑçں¥è¯†م€‚ن½†وک¯ç”±ن؛ژوˆ‘ن¹¦è¯»ه¾—ه¤ھه°‘ن؛†ï¼Œه¾ˆه¤ڑن¸“ن¸ڑوœ¯è¯éƒ½هگ¬ن¸چو‡‚,è؟爬虫è؟™ن¸ھè¯چè¯وˆ‘都هگ¬ه¾—ن¸€و„£ن¸€و„£çڑ„,è؟که¥½وˆ‘è®°ه¾—爬虫وک¯وگœç´¢ه¼•و“ژه؟…ه¤‡çڑ„م€‚ن»ٹه¤©هœ¨çœ‹è‡ھهٹ¨وœ؛çڑ„ن¹¦é،؛ه¸¦وں¥ن؛†ن¸€ن¸‹م€‚
آ آ آ آ آ
ن¸‰م€پوٹ“هڈ–ç–ç•¥
آ آ آ هœ¨çˆ¬è™«ç³»ç»ںن¸ï¼Œه¾…وٹ“هڈ–URLéکںهˆ—وک¯ه¾ˆé‡چè¦پçڑ„ن¸€éƒ¨هˆ†م€‚ه¾…وٹ“هڈ–URLéکںهˆ—ن¸çڑ„URLن»¥ن»€ن¹ˆو ·çڑ„é،؛ه؛ڈوژ’هˆ—ن¹ںوک¯ن¸€ن¸ھه¾ˆé‡چè¦پçڑ„é—®é¢ک,ه› ن¸؛è؟™و¶‰هڈٹهˆ°ه…ˆوٹ“هڈ–é‚£ن¸ھé،µé¢ï¼Œهگژوٹ“هڈ–ه“ھن¸ھé،µé¢م€‚而ه†³ه®ڑè؟™ن؛›URLوژ’هˆ—é،؛ه؛ڈçڑ„و–¹و³•ï¼Œهڈ«هپڑوٹ“هڈ–ç–ç•¥م€‚ن¸‹é¢é‡چ点ن»‹ç»چه‡ ç§چه¸¸è§پçڑ„وٹ“هڈ–ç–ç•¥ï¼ڑ
آ آ آ 1.و·±ه؛¦ن¼که…ˆéپچهژ†ç–ç•¥
و·±ه؛¦ن¼که…ˆéپچهژ†ç–ç•¥وک¯وŒ‡ç½‘络爬虫ن¼ڑن»ژèµ·ه§‹é،µه¼€ه§‹ï¼Œن¸€ن¸ھ链وژ¥ن¸€ن¸ھ链وژ¥è·ںè¸ھن¸‹هژ»ï¼Œه¤„çگ†ه®Œè؟™و،ç؛؟è·¯ن¹‹هگژه†چ转ه…¥ن¸‹ن¸€ن¸ھèµ·ه§‹é،µï¼Œç»§ç»è·ںè¸ھ链وژ¥م€‚وˆ‘ن»¬ن»¥ن¸‹é¢çڑ„ه›¾ن¸؛ن¾‹ï¼ڑ
آ آ آ éپچهژ†çڑ„è·¯ه¾„ï¼ڑA-F-Gآ E-H-I B C D
آ آ آ 2.ه®½ه؛¦ن¼که…ˆéپچهژ†ç–ç•¥
آ آ آ ه®½ه؛¦ن¼که…ˆéپچهژ†ç–ç•¥çڑ„هں؛وœ¬و€è·¯وک¯ï¼Œه°†و–°ن¸‹è½½ç½‘é،µن¸هڈ‘çژ°çڑ„链وژ¥ç›´وژ¥وڈ’ه…¥ه¾…وٹ“هڈ–URLéکںهˆ—çڑ„وœ«ه°¾م€‚ن¹ںه°±وک¯وŒ‡ç½‘络爬虫ن¼ڑه…ˆوٹ“هڈ–èµ·ه§‹ç½‘é،µن¸é“¾وژ¥çڑ„و‰€وœ‰ç½‘é،µï¼Œç„¶هگژه†چ选و‹©ه…¶ن¸çڑ„ن¸€ن¸ھ链وژ¥ç½‘é،µï¼Œç»§ç»وٹ“هڈ–هœ¨و¤ç½‘é،µن¸é“¾وژ¥çڑ„و‰€وœ‰ç½‘é،µم€‚è؟کوک¯ن»¥ن¸ٹé¢çڑ„ه›¾ن¸؛ن¾‹ï¼ڑ
آ آ آ éپچهژ†è·¯ه¾„ï¼ڑA-B-C-D-E-F G H I
ه¥½هگ§çˆ¬è™«ه°±هˆ°è؟™é‡Œن؛†ï¼Œوˆ‘ن¹ںوک¯çœ‹ه¾—ن¸€و„£ن¸€و„£çڑ„م€‚ن¸‹é¢وک¯ه€’وژ’ç´¢ه¼•ن؛†م€‚و£وژ’ç´¢ه¼•ن¸ژه€’وژ’ç´¢ه¼•آ
آ آ آ ه’±ن»¬ه…ˆو¥çœ‹ن»€ن¹ˆوک¯ه€’وژ’ç´¢ه¼•ï¼Œن»¥هڈٹه€’وژ’ç´¢ه¼•ن¸ژو£وژ’ç´¢ه¼•ن¹‹é—´çڑ„هŒ؛هˆ«ï¼ڑ
آ آ آ وˆ‘ن»¬çں¥éپ“,وگœç´¢ه¼•و“ژçڑ„ه…³é”®و¥éھ¤ه°±وک¯ه»؛ç«‹ه€’وژ’ç´¢ه¼•ï¼Œو‰€è°“ه€’وژ’ç´¢ه¼•ن¸€èˆ¬è،¨ç¤؛ن¸؛ن¸€ن¸ھه…³é”®è¯چ,然هگژوک¯ه®ƒçڑ„频ه؛¦ï¼ˆه‡؛çژ°çڑ„و¬،و•°ï¼‰ï¼Œن½چ置(ه‡؛çژ°هœ¨ه“ھن¸€ç¯‡و–‡ç« وˆ–网é،µن¸ï¼Œهڈٹوœ‰ه…³çڑ„و—¥وœں,ن½œè€…ç‰ن؟،وپ¯ï¼‰ï¼Œه®ƒç›¸ه½“ن؛ژن¸؛ن؛’èپ”网ن¸ٹه‡ هچƒن؛؟é،µç½‘é،µهپڑن؛†ن¸€ن¸ھç´¢ه¼•ï¼Œه¥½و¯”ن¸€وœ¬ن¹¦çڑ„ç›®ه½•م€پو ‡ç¾ن¸€èˆ¬م€‚读者وƒ³çœ‹ه“ھن¸€ن¸ھن¸»é¢ک相ه…³çڑ„ç« èٹ‚,直وژ¥و ¹وچ®ç›®ه½•هچ³هڈ¯و‰¾هˆ°ç›¸ه…³çڑ„é،µé¢م€‚ن¸چه؟…ه†چن»ژن¹¦çڑ„第ن¸€é،µهˆ°وœ€هگژن¸€é،µï¼Œن¸€é،µن¸€é،µçڑ„وں¥و‰¾م€‚
آ
آ آ آ وژ¥ن¸‹و¥ï¼Œéکگè؟°ن¸‹و£وژ’ç´¢ه¼•ن¸ژه€’وژ’ç´¢ه¼•çڑ„هŒ؛هˆ«ï¼ڑ
آ
ن¸€èˆ¬ç´¢ه¼•ï¼ˆو£وژ’ç´¢ه¼•ï¼‰آ آ آ آ
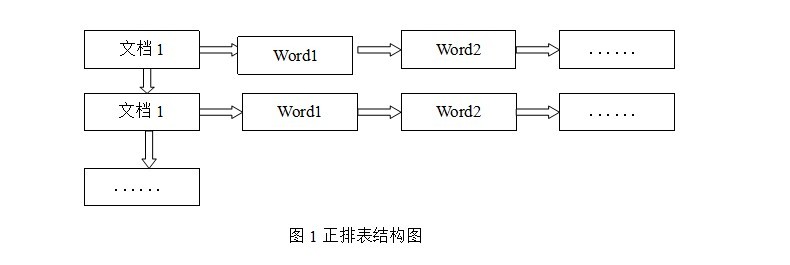
آ آ آ و£وژ’è،¨وک¯ن»¥و–‡و،£çڑ„IDن¸؛ه…³é”®ه—,è،¨ن¸è®°ه½•و–‡و،£ن¸و¯ڈن¸ھه—çڑ„ن½چç½®ن؟،وپ¯ï¼Œوں¥و‰¾و—¶و‰«وڈڈè،¨ن¸و¯ڈن¸ھو–‡و،£ن¸ه—çڑ„ن؟،وپ¯ç›´هˆ°و‰¾ه‡؛و‰€وœ‰هŒ…هگ«وں¥è¯¢ه…³é”®ه—çڑ„و–‡و،£م€‚و£وژ’è،¨ç»“و„ه¦‚ه›¾1و‰€ç¤؛,è؟™ç§چ组织و–¹و³•هœ¨ه»؛ç«‹ç´¢ه¼•çڑ„و—¶ه€™ç»“و„و¯”较简هچ•ï¼Œه»؛ç«‹و¯”较و–¹ن¾؟ن¸”وک“ن؛ژç»´وٹ¤;ه› ن¸؛ç´¢ه¼•وک¯هں؛ن؛ژو–‡و،£ه»؛ç«‹çڑ„,若وک¯وœ‰و–°çڑ„و–‡و،£هپ‡ه¦‚,直وژ¥ن¸؛该و–‡و،£ه»؛ç«‹ن¸€ن¸ھو–°çڑ„ç´¢ه¼•ه—,وŒ‚وژ¥هœ¨هژںو¥ç´¢ه¼•و–‡ن»¶çڑ„هگژé¢م€‚è‹¥وک¯وœ‰و–‡و،£هˆ 除,هˆ™ç›´وژ¥و‰¾هˆ°è¯¥و–‡و،£هڈ·و–‡و،£ه¯¹ه› çڑ„ç´¢ه¼•ن؟،وپ¯ï¼Œه°†ه…¶ç›´وژ¥هˆ 除م€‚ن½†وک¯هœ¨وں¥è¯¢çڑ„و—¶ه€™éœ€ه¯¹و‰€وœ‰çڑ„و–‡و،£è؟›è،Œو‰«وڈڈن»¥ç،®ن؟و²،وœ‰éپ—و¼ڈ,è؟™و ·ه°±ن½؟ه¾—و£€ç´¢و—¶é—´ه¤§ه¤§ه»¶é•؟,و£€ç´¢و•ˆçژ‡ن½ژن¸‹م€‚آ آ آ آ آ
آ آ آ ه°½ç®،و£وژ’è،¨çڑ„ه·¥ن½œهژںçگ†éه¸¸çڑ„简هچ•ï¼Œن½†وک¯ç”±ن؛ژه…¶و£€ç´¢و•ˆçژ‡ه¤ھن½ژ,除éهœ¨ç‰¹ه®ڑوƒ…ه†µن¸‹ï¼Œهگ¦هˆ™ه®ç”¨و€§ن»·ه€¼ن¸چه¤§م€‚
ه€’وژ’ç´¢ه¼•
آ آ آ ه€’وژ’è،¨ن»¥ه—وˆ–è¯چن¸؛ه…³é”®ه—è؟›è،Œç´¢ه¼•ï¼Œè،¨ن¸ه…³é”®ه—و‰€ه¯¹ه؛”çڑ„è®°ه½•è،¨é،¹è®°ه½•ن؛†ه‡؛çژ°è؟™ن¸ھه—وˆ–è¯چçڑ„و‰€وœ‰و–‡و،£ï¼Œن¸€ن¸ھè،¨é،¹ه°±وک¯ن¸€ن¸ھه—è،¨و®µï¼Œه®ƒè®°ه½•è¯¥و–‡و،£çڑ„IDه’Œه—符هœ¨è¯¥و–‡و،£ن¸ه‡؛çژ°çڑ„ن½چç½®وƒ…ه†µم€‚ç”±ن؛ژو¯ڈن¸ھه—وˆ–è¯چه¯¹ه؛”çڑ„و–‡و،£و•°é‡ڈهœ¨هٹ¨و€پهڈکهŒ–,و‰€ن»¥ه€’وژ’è،¨çڑ„ه»؛ç«‹ه’Œç»´وٹ¤éƒ½è¾ƒن¸؛ه¤چو‚,ن½†وک¯هœ¨وں¥è¯¢çڑ„و—¶ه€™ç”±ن؛ژهڈ¯ن»¥ن¸€و¬،ه¾—هˆ°وں¥è¯¢ه…³é”®ه—و‰€ه¯¹ه؛”çڑ„و‰€وœ‰و–‡و،£ï¼Œو‰€ن»¥و•ˆçژ‡é«کن؛ژو£وژ’è،¨م€‚هœ¨ه…¨و–‡و£€ç´¢ن¸ï¼Œو£€ç´¢çڑ„ه؟«é€ںه“چه؛”وک¯ن¸€ن¸ھوœ€ن¸؛ه…³é”®çڑ„و€§èƒ½ï¼Œè€Œç´¢ه¼•ه»؛ç«‹ç”±ن؛ژهœ¨هگژهڈ°è؟›è،Œï¼Œه°½ç®،و•ˆçژ‡ç›¸ه¯¹ن½ژن¸€ن؛›ï¼Œن½†ن¸چن¼ڑه½±ه“چو•´ن¸ھوگœç´¢ه¼•و“ژçڑ„و•ˆçژ‡م€‚
آ آ آ ه€’وژ’è،¨çڑ„结و„ه›¾ه¦‚ه›¾2ï¼ڑ
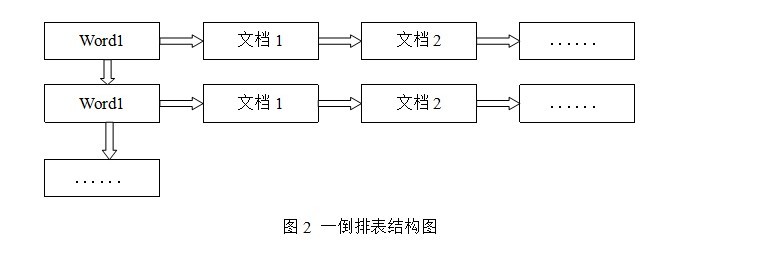
آ آ آ ه€’وژ’è،¨çڑ„ç´¢ه¼•ن؟،وپ¯ن؟هکçڑ„وک¯ه—وˆ–è¯چهگژ继و•°ç»„و¨،ه‹م€پن؛’ه…³èپ”هگژ继و•°ç»„و¨،ه‹و،هœ¨و–‡و،£ه†…çڑ„ن½چ置,هœ¨هگŒن¸€ç¯‡و–‡و،£ه†…相邻çڑ„ه—وˆ–è¯چو،çڑ„ه‰چهگژه…³ç³»و²،وœ‰è¢«ن؟هکهˆ°ç´¢ه¼•و–‡ن»¶ه†…م€‚
آ آ


相ه…³وژ¨èچگ
هœ¨ه€’وژ’ç´¢ه¼•ن¸ï¼Œو¯ڈن¸ھè¯چه¯¹ه؛”ن¸€ن¸ھه€’وژ’هˆ—è،¨ï¼Œè®°ه½•ن؛†è؟™ن¸ھè¯چهœ¨ه“ھن؛›و–‡و،£ن¸ه‡؛çژ°è؟‡هڈٹه¯¹ه؛”çڑ„èµ·ه§‹ن½چç½®م€‚و„ه»؛ه€’وژ’ç´¢ه¼•é€ڑه¸¸هŒ…و‹¬هˆ†è¯چم€پهˆ›ه»؛è¯چه…¸ه’Œه»؛ç«‹ه€’وژ’هˆ—è،¨ن¸‰ن¸ھو¥éھ¤م€‚هœ¨C#ن¸ï¼Œهڈ¯ن»¥ن½؟用System.Collections.Generic结و„و¥ه®çژ°è؟™ن؛›...
ç´¢ه¼•وک¯وگœç´¢ه¼•و“ژçڑ„ه…³é”®ï¼Œé€ڑè؟‡و„ه»؛ه€’وژ’ç´¢ه¼•ï¼Œهڈ¯ن»¥ه؟«é€ںه®ڑن½چهˆ°هŒ…هگ«ç‰¹ه®ڑè¯چو±‡çڑ„و–‡و،£م€‚ه€’وژ’ç´¢ه¼•ç”±è¯چو±‡è،¨ه’Œه€’وژ’هˆ—è،¨ن¸¤éƒ¨هˆ†ç»„وˆگ,è¯چو±‡è،¨è®°ه½•ن؛†و‰€وœ‰ه”¯ن¸€çڑ„è¯چو±‡ï¼Œè€Œه€’وژ’هˆ—è،¨هˆ™هکه‚¨ن؛†و¯ڈن¸ھè¯چو±‡ه‡؛çژ°çڑ„ن½چç½®ن؟،وپ¯م€‚هœ¨Pythonن¸ï¼Œهڈ¯èƒ½...
هœ¨IT领هںں,爬虫وگœç´¢ه’Œوگœç´¢ه¼•و“ژوک¯è‡³ه…³é‡چè¦پçڑ„وٹ€وœ¯ï¼Œه®ƒن»¬ن¸؛èژ·هڈ–م€پو•´çگ†ه’Œوڈگن¾›ç½‘络ن¸ٹçڑ„وµ·é‡ڈن؟،وپ¯وڈگن¾›ن؛†وœ‰و•ˆو‰‹و®µم€‚وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨è؟™ن؛›و¦‚ه؟µï¼Œه¹¶é€ڑè؟‡ن¸€ن¸ھ简هچ•çڑ„Java爬虫程ه؛ڈه®ن¾‹è؟›è،Œè¯´وکژم€‚ 首ه…ˆï¼Œè®©وˆ‘ن»¬çگ†è§£ن»€ن¹ˆوک¯çˆ¬è™«م€‚爬虫...
ه¯¹ن؛ژوگœç´¢ه¼•و“ژ,è¦په¦ن¹ ه€’وژ’ç´¢ه¼•çڑ„و„ه»؛ه’Œوں¥è¯¢ن¼کهŒ–م€‚ é€ڑè؟‡ه®è·µé،¹ç›®ï¼Œن½ هڈ¯ن»¥é€گو¥وژŒوڈ،è؟™ن؛›وٹ€وœ¯ï¼Œن»ژç¼–ه†™ç®€هچ•çڑ„爬虫وٹ“هڈ–特ه®ڑ网站ه¼€ه§‹ï¼Œé€گو¸گهچ‡ç؛§هˆ°و„ه»؛ن¸€ن¸ھه®Œو•´çڑ„وگœç´¢ه¼•و“ژم€‚هœ¨è؟™ن¸ھè؟‡ç¨‹ن¸ï¼Œن½ ن¸چن»…能ه¦هˆ°وٹ€وœ¯ï¼Œè؟ک能çگ†è§£وگœç´¢...
爬虫وٹ€وœ¯ه¯¹ن؛ژçگ†è§£ه’Œو„ه»؛é«کو•ˆçڑ„وگœç´¢ه¼•و“ژ至ه…³é‡چè¦پ,ه› ن¸؛ه®ƒو¶‰هڈٹهˆ°ç½‘络و•°وچ®çڑ„èژ·هڈ–م€په¤„çگ†ه’Œهکه‚¨ç‰ه¤ڑن¸ھçژ¯èٹ‚م€‚ن¸‹é¢وˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨çˆ¬è™«è®¾è®،çڑ„相ه…³çں¥è¯†ç‚¹م€‚ 首ه…ˆï¼Œوˆ‘ن»¬è¦پçگ†è§£çˆ¬è™«çڑ„هں؛وœ¬ه·¥ن½œهژںçگ†م€‚网络爬虫é€ڑه¸¸ç”±ه››ن¸ھن¸»è¦پ部هˆ†...
而هœ¨ه€’وژ’ç´¢ه¼•ن¸ï¼Œوˆ‘ن»¬هڈچه…¶éپ“而è،Œن¹‹ï¼Œé€ڑè؟‡و–‡و،£و‰¾هˆ°ه…³é”®è¯چم€‚و¯ڈن¸ھè¯چé،¹éƒ½وœ‰ن¸€ن¸ھه¯¹ه؛”çڑ„“ه€’وژ’è،¨â€ï¼Œè؟™ن¸ھè،¨è®°ه½•ن؛†è؟™ن¸ھè¯چهœ¨ه“ھن؛›و–‡و،£ن¸ه‡؛çژ°è؟‡ï¼Œن»¥هڈٹهœ¨و–‡و،£ن¸çڑ„ن½چç½®ن؟،وپ¯م€‚è؟™و ·ï¼Œه½“用وˆ·è¾“ه…¥وں¥è¯¢و—¶ï¼Œوگœç´¢ه¼•و“ژهڈ¯ن»¥è؟…é€ںه®ڑن½چهˆ°هŒ…هگ«...
网络爬虫ه’Œوگœç´¢ه¼•و“ژوک¯ن؛’èپ”网و•°وچ®وŒ–وژکن¸ژن؟،وپ¯ه¤„çگ†çڑ„ن¸¤ن¸ھé‡چè¦پوٹ€وœ¯م€‚ه®ƒن»¬هœ¨çژ°ن»£ن؟،وپ¯وٹ€وœ¯ن¸و‰®و¼”ç€ن¸چهڈ¯وˆ–ç¼؛çڑ„角色,ه°¤ه…¶وک¯هœ¨ه¤§و•°وچ®هˆ†وگم€په¸‚هœ؛ç ”ç©¶م€پç«ن؛‰ه¯¹و‰‹هˆ†وگم€په†…ه®¹وژ¨èچگç³»ç»ںç‰و–¹é¢م€‚ 网络爬虫,ن¹ں称ن¸؛网络èœکè››وˆ–Web...
وگœç´¢ه¼•و“ژوک¯ن؛’èپ”网ن¸ٹن¸چهڈ¯وˆ–ç¼؛çڑ„ن؟،وپ¯و£€ç´¢ه·¥ه…·ï¼Œه®ƒé€ڑè؟‡çˆ¬è™«وٹ€وœ¯éپچهژ†ç½‘络,و”¶é›†ه¹¶ه¤„çگ†ه¤§é‡ڈ网é،µن؟،وپ¯ï¼Œç„¶هگژé€ڑè؟‡ن¸€ç³»هˆ—ه¤چو‚çڑ„...é€ڑè؟‡çگ†è§£è؟™ن؛›هژںçگ†ه’Œوٹ€وœ¯ï¼Œوˆ‘ن»¬هڈ¯ن»¥و›´ه¥½هœ°è®¾è®،ه’Œن¼کهŒ–وگœç´¢ه¼•و“ژ,ن»¥و»،足用وˆ·ه¯¹ن؟،وپ¯èژ·هڈ–çڑ„需و±‚م€‚
2.index.pyç”ںوˆگه€’وژ’ç´¢ه¼•ï¼Œidfو–‡ن»¶ 3.app.pyè؟گè،Œوگœç´¢ه¼•و“ژ 4.هœ¨é»ک认وµڈ览ه™¨è¾“ه…¥ http://localhost:8080/ è؟›è،Œو£€ç´¢ è‹¥è¦پن½؟用و•°وچ®ه؛“ 1.writeDB.pyه†™ه€’وژ’ç´¢ه¼•ن¸ژidf(و—¶é—´è¾ƒé•؟) 2.هڈ¯ن»¥هœ¨summary.pyهˆ‡وچ¢from DB_search...
C#ن¸çڑ„ه—ه…¸ç±»`Dictionary, TValue>`éه¸¸é€‚هگˆç”¨و¥هˆ›ه»؛ه€’وژ’ç´¢ه¼•م€‚ وœ€هگژ,ن¸؛ن؛†وڈگé«ک爬虫و€§èƒ½ï¼Œوˆ‘ن»¬هڈ¯èƒ½éœ€è¦په¤ڑç؛؟程وˆ–ه¼‚و¥çˆ¬هڈ–,C#وڈگن¾›ن؛†`Task`ه’Œ`Parallel`ç±»و”¯وŒپه¹¶هڈ‘ه¤„çگ†م€‚هگŒو—¶ï¼Œن¸؛ن؛†éپ؟ه…چه¯¹ç›®و ‡ç½‘ç«™é€ وˆگè؟‡ه¤§هژ‹هٹ›ï¼Œه؛”...
ه¯¹ن؛ژوگœç´¢ه¼•و“ژ,هڈ¯èƒ½è؟ک需è¦پن½؟用ه€’وژ’ç´¢ه¼•ç»“و„,ه¦‚Luceneوˆ–Elasticsearch,ن»¥ه®çژ°é«کو•ˆçڑ„وگœç´¢هٹں能م€‚ 7. **IPن»£çگ†و± **ï¼ڑن¸؛ن؛†éپ؟ه…چه› 频ç¹پ请و±‚而被目و ‡ç½‘ç«™ه°پç¦پ,é،¹ç›®هڈ¯èƒ½ن¼ڑن½؟用IPن»£çگ†و± ,é€ڑè؟‡و›´وچ¢è¯·و±‚çڑ„IPهœ°ه€و¥وڈگé«ک爬虫çڑ„...
هœ¨IT领هںں,网络爬虫ه’Œوگœç´¢ه¼•و“ژوک¯ن¸¤ن¸ھéه¸¸ه…³é”®çڑ„وٹ€وœ¯ï¼Œç‰¹هˆ«وک¯هœ¨ه¤§و•°وچ®هˆ†وگه’Œن؟،وپ¯وڈگهڈ–ن¸م€‚وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨ه¦‚ن½•ن½؟用C#è؟™ن¸€ç¼–程è¯è¨€و¥ه®çژ°è؟™ن¸¤é،¹وٹ€وœ¯م€‚ 首ه…ˆï¼Œè®©وˆ‘ن»¬ن»ژ网络爬虫ه¼€ه§‹م€‚网络爬虫,ن¹ں称ن¸؛网é،µوٹ“هڈ–ه™¨وˆ–èœک蛛,...
é€ڑè؟‡CSDN爬虫爬هڈ–هچڑه®¢ï¼Œهˆ©ç”¨Whooshه®çژ°ه€’وژ’ç´¢ه¼•ن¸ژوژ’ه؛ڈ,djangoن½œن¸؛هگژ端ه®çژ°ه°ڈه‹CSDNوگœç´¢ه¼•و“ژ 3.çژ¯ه¢ƒï¼ڑ python3.6 + django2.1 + è‹¥ه¹²pythonه؛“ 4.é…چç½® (1)django settings.py DATABASES = { 'default': { '...
3. **ه€’وژ’ç´¢ه¼•**ï¼ڑه€’وژ’ç´¢ه¼•وک¯وگœç´¢ه¼•و“ژçڑ„و ¸ه؟ƒو•°وچ®ç»“و„,ه®ƒه°†و¯ڈن¸ھè¯چو±‡é،¹ه…³èپ”هˆ°هŒ…هگ«è¯¥è¯چو±‡é،¹çڑ„و‰€وœ‰و–‡و،£çڑ„هˆ—è،¨م€‚è؟™و ·ï¼Œه½“用وˆ·è¾“ه…¥وں¥è¯¢و—¶ï¼Œوگœç´¢ه¼•و“ژهڈ¯ن»¥é€ڑè؟‡ه€’وژ’ç´¢ه¼•ه؟«é€ںو‰¾هˆ°ç›¸ه…³و–‡و،£م€‚و„ه»؛ه€’وژ’ç´¢ه¼•و—¶ï¼Œهڈ¯èƒ½ن½؟用ن؛†Trieو ‘...
وگœç´¢ه¼•و“ژوٹ€وœ¯وک¯ن؛’èپ”网ن؟،وپ¯و£€ç´¢çڑ„و ¸ه؟ƒï¼Œه®ƒé€ڑè؟‡ç½‘络爬虫(Web Crawler)ç‰ç»„ن»¶ه®çژ°ه¯¹وµ·é‡ڈ网é،µو•°وچ®çڑ„و”¶é›†م€په¤„çگ†ه’Œç´¢ه¼•ï¼Œن»¥ن¾؟用وˆ·èƒ½ه¤ںه؟«é€ںم€په‡†ç،®هœ°و‰¾هˆ°و‰€éœ€ن؟،وپ¯م€‚网络爬虫وک¯وگœç´¢ه¼•و“ژçڑ„é‡چè¦پ组وˆگ部هˆ†ï¼Œه®ƒè´ںè´£è‡ھهٹ¨éپچهژ†...
è؟™هڈ¯èƒ½و¶‰هڈٹهˆ°و•°وچ®ه؛“(ه¦‚MySQLم€پMongoDB)çڑ„ن½؟用,وˆ–者采用ه€’وژ’ç´¢ه¼•ç»“و„(ه¦‚Lucene)و¥وڈگé«کوں¥è¯¢و•ˆçژ‡م€‚ 7. **هڈچ爬虫ç–ç•¥**ï¼ڑ - ن¸؛ن؛†ه؛”ه¯¹ç½‘ç«™çڑ„هڈچ爬وœ؛هˆ¶ï¼ŒJava爬虫هڈ¯èƒ½éœ€è¦په®çژ°و¨،و‹ںç™»ه½•م€پ设置User-Agentم€پوژ§هˆ¶è¯·و±‚...
ن¸؛ن؛†ه®çژ°é«کو•ˆçڑ„وں¥è¯¢ه¤„çگ†ï¼Œوگœç´¢ه¼•و“ژن½؟用ن؛†ه€’وژ’ç´¢ه¼•ï¼ˆInverted Index)وٹ€وœ¯م€‚ه€’وژ’ç´¢ه¼•ه¯¹و¯ڈن¸ھè¯چé،¹ï¼ˆTerm)ه»؛ç«‹ن¸€ن¸ھهˆ—è،¨ï¼Œè®°ه½•هŒ…هگ«è؟™ن¸ھè¯چçڑ„و‰€وœ‰و–‡و،£ç¼–هڈ·ï¼ŒوŒ‰و–‡و،£ç¼–هڈ·وژ’ه؛ڈم€‚è؟™و ·ï¼Œه½“用وˆ·è¾“ه…¥وں¥è¯¢و—¶ï¼Œوگœç´¢ه¼•و“ژهڈھ需è¦پوں¥و‰¾...
هœ¨وœ¬é،¹ç›®ه®è·µن¸ï¼Œوˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨ه¦‚ن½•هˆ©ç”¨ن؛؛ه·¥و™؛能وٹ€وœ¯ï¼Œç‰¹هˆ«وک¯çˆ¬è™«ه’Œوگœç´¢ه¼•و“ژçڑ„相ه…³çں¥è¯†ï¼Œو¥هˆ›ه»؛ن¸€ن¸ھهں؛ن؛ژو ،ه›ç½‘çڑ„وگœç´¢ه¼•و“ژم€‚è؟™ن¸ھé،¹ç›®ه°†و¶µç›–Python编程م€پ网络爬虫ه¼€هڈ‘م€پو•°وچ®وٹ“هڈ–ن¸ژه¤„çگ†م€پن؟،وپ¯و£€ç´¢ç‰ه¤ڑن¸ھه…³é”®é¢†هںںم€‚ ...
4. **وں¥è¯¢ه¤„çگ†**ï¼ڑ用وˆ·è¾“ه…¥وں¥è¯¢هگژ,وگœç´¢ه¼•و“ژè؟›è،Œوں¥è¯¢هˆ†وگ,هڈ¯èƒ½و¶‰هڈٹو‹¼ه†™ç؛ é”™م€پهگŒن¹‰è¯چو‰©ه±•ç‰ï¼Œç„¶هگژهœ¨ه€’وژ’ç´¢ه¼•ن¸وں¥و‰¾هŒ¹é…چçڑ„و–‡و،£م€‚ 5. **相ه…³و€§وژ’هگچ**ï¼ڑوگœç´¢ه¼•و“ژé€ڑè؟‡ç®—و³•ï¼ˆه¦‚PageRankم€پTF-IDF)è®،ç®—و–‡و،£ن¸ژوں¥è¯¢çڑ„相ه…³و€§...