
آ
م€€è¯´هˆ°هˆ†ه¸ƒه¼ڈه¼€هڈ‘Zookeeperوک¯ه؟…é،»ن؛†è§£ه’ŒوژŒوڈ،çڑ„,هˆ†ه¸ƒه¼ڈو¶ˆوپ¯وœچهٹ،kafka م€پhbase هˆ°hadoopç‰هˆ†ه¸ƒه¼ڈه¤§و•°وچ®ه¤„çگ†éƒ½ن¼ڑ用هˆ°Zookeeper,و‰€ن»¥هœ¨و¤ه°†Zookeeperن½œن¸؛هں؛ç،€و¥è®²è§£م€‚
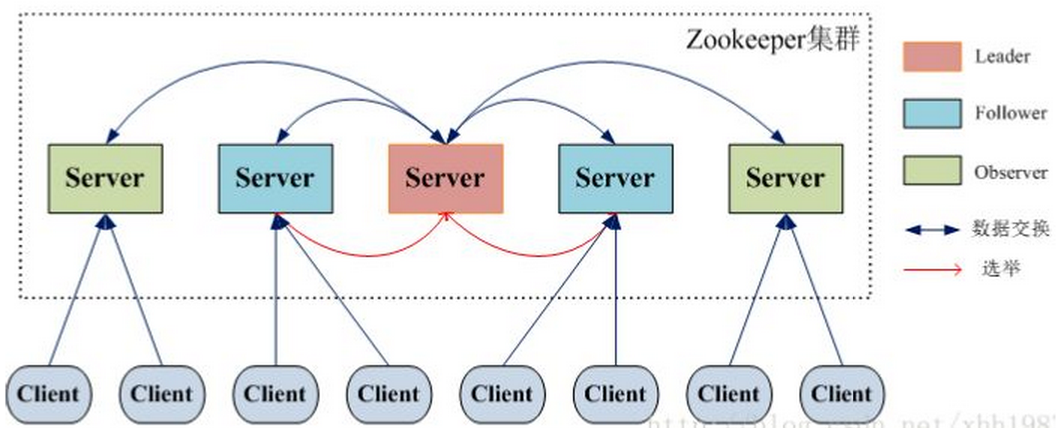
آ م€€م€€Zookeeper وک¯هˆ†ه¸ƒه¼ڈوœچهٹ،و،†و¶ï¼Œن¸»è¦پوک¯ç”¨و¥è§£ه†³هˆ†ه¸ƒه¼ڈه؛”用ن¸ç»ڈه¸¸éپ‡هˆ°çڑ„ن¸€ن؛›و•°وچ®ç®،çگ†é—®é¢ک,ه¦‚ï¼ڑç»ںن¸€ه‘½هگچوœچهٹ،م€پçٹ¶و€پهگŒو¥وœچهٹ،م€پ集群ç®،çگ†م€پهˆ†ه¸ƒه¼ڈه؛”用é…چç½®é،¹çڑ„ç®،çگ†ç‰ç‰م€‚
م€€م€€Zookeeper çڑ„و ¸ه؟ƒوک¯ه¹؟و’,è؟™ن¸ھوœ؛هˆ¶ن؟è¯پن؛†هگ„ن¸ھServerن¹‹é—´çڑ„هگŒو¥م€‚ه®çژ°è؟™ن¸ھوœ؛هˆ¶çڑ„هچڈè®®هڈ«هپڑZabهچڈè®®م€‚
م€€م€€Zabهچڈè®®وœ‰ن¸¤ç§چو¨،ه¼ڈ,ه®ƒن»¬هˆ†هˆ«وک¯وپ¢ه¤چو¨،ه¼ڈ(选ن¸»ï¼‰ه’Œه¹؟و’ و¨،ه¼ڈ(هگŒو¥ï¼‰م€‚ه½“وœچهٹ،هگ¯هٹ¨وˆ–者هœ¨é¢†ه¯¼è€…ه´©و؛ƒهگژ,Zabه°±è؟›ه…¥ن؛†وپ¢ه¤چو¨،ه¼ڈ,ه½“领ه¯¼è€…被选ن¸¾ه‡؛و¥ï¼Œن¸”ه¤§ه¤ڑو•°Serverه®Œوˆگن؛†ه’Œleaderçڑ„çٹ¶و€پهگŒو¥ن»¥هگژ, وپ¢ه¤چو¨،ه¼ڈه°±ç»“وںن؛†م€‚
م€€م€€çٹ¶و€پهگŒو¥ن؟è¯پن؛†leaderه’ŒServerه…·وœ‰ç›¸هگŒçڑ„ç³»ç»ںçٹ¶و€پم€‚ن¸؛ن؛†ن؟è¯پن؛‹هٹ،çڑ„é،؛ه؛ڈن¸€è‡´و€§ï¼Œzookeeper采用ن؛†é€’ه¢çڑ„ن؛‹هٹ،idهڈ· (zxid)و¥و ‡è¯†ن؛‹هٹ،م€‚
م€€م€€و‰€وœ‰çڑ„وڈگ议(proposal)都هœ¨è¢«وڈگه‡؛çڑ„و—¶ه€™هٹ ن¸ٹن؛†zxidم€‚ه®çژ°ن¸zxidوک¯ن¸€ن¸ھ64ن½چçڑ„و•°ه—,ه®ƒé«ک32ن½چوک¯epoch用 و¥و ‡è¯†leaderه…³ç³»وک¯هگ¦و”¹هڈک,و¯ڈو¬،ن¸€ن¸ھleader被选ه‡؛و¥ï¼Œه®ƒéƒ½ن¼ڑوœ‰ن¸€ن¸ھو–°çڑ„epoch,و ‡è¯†ه½“ه‰چه±ن؛ژé‚£ن¸ھleaderçڑ„ç»ںو²»و—¶وœںم€‚ن½ژ32ن½چ用ن؛ژ递 ه¢è®،و•°م€‚
م€€م€€و¯ڈن¸ھServerهœ¨ه·¥ن½œè؟‡ç¨‹ن¸وœ‰ن¸‰ç§چçٹ¶و€پï¼ڑ
م€€م€€LOOKINGï¼ڑه½“ه‰چServerن¸چçں¥éپ“leaderوک¯è°پ,و£هœ¨وگœه¯»م€‚
م€€م€€LEADINGï¼ڑه½“ه‰چServerهچ³ن¸؛选ن¸¾ه‡؛و¥çڑ„leaderم€‚
م€€م€€FOLLOWINGï¼ڑleaderه·²ç»ڈ选ن¸¾ه‡؛و¥ï¼Œه½“ه‰چServerن¸ژن¹‹هگŒو¥م€‚
آ
م€€م€€ZooKeeperçڑ„ه®‰è£…و¨،ه¼ڈهˆ†ن¸؛ن¸‰ç§چ,هˆ†هˆ«ن¸؛ï¼ڑهچ•وœ؛و¨،ه¼ڈم€پ集群و¨،ه¼ڈه’Œé›†ç¾¤ن¼ھهˆ†ه¸ƒو¨،ه¼ڈ
çژ¯ه¢ƒ
م€€م€€CentOS7.0 آ (windowsن¸ن½؟用ه°±ن½؟用zkServer.cmd)
م€€م€€ZooKeeperوœ€و–°ç‰ˆوœ¬
م€€م€€ç”¨root用وˆ·ه®‰è£…(ه¦‚وœç”¨ن؛ژhbaseو—¶ه°†و‰€وœ‰و–‡ن»¶وƒé™گو”¹ن¸؛hadoop用وˆ·ï¼‰
آ آ آ Javaçژ¯ه¢ƒï¼Œوœ€ه¥½وک¯وœ€و–°ç‰ˆوœ¬çڑ„م€‚
م€€م€€هˆ†ه¸ƒه¼ڈو—¶ه¤ڑوœ؛é—´è¦پç،®ن؟能و£ه¸¸é€ڑ讯,ه…³é—éک²çپ«ه¢™وˆ–让و¶‰هڈٹهˆ°çڑ„端هڈ£é€ڑè؟‡م€‚
ن¸‹è½½
م€€م€€هژ»ه®ک网ن¸‹è½½ ï¼ڑhttp://zookeeper.apache.org/releases.html#download
م€€م€€ن¸‹è½½هگژو”¾è؟›CentOSن¸çڑ„/usr/local/ و–‡ن»¶ه¤¹ن¸ï¼Œه¹¶è§£هژ‹هˆ°ه½“ه‰چو–‡ن»¶ن¸ /usr/local/zookeeper(و€ژن¹ˆè§£هژ‹هڈ¯هڈ‚考ن¹‹ه‰چçڑ„Haproxyçڑ„ه®‰è£…و–‡ç« )
ه®‰è£…
هچ•وœ؛و¨،ه¼ڈ
م€€م€€è؟›ه…¥zookeeperç›®ه½•ن¸‹çڑ„confهگç›®ه½•, é‡چه‘½هگچ zoo_sample.cfgو–‡ن»¶ï¼ŒZookeeper هœ¨هگ¯هٹ¨و—¶ن¼ڑو‰¾è؟™ن¸ھو–‡ن»¶ن½œن¸؛é»ک认é…چç½®و–‡ن»¶:
mv /usr/local/zookeeper/conf/zoo_sample.cfg آ zoo.cfg
م€€م€€é…چç½®zoo.cfgهڈ‚و•°

# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/usr/local/zookeeper/data dataLogDir=/usr/local/zookeeper/log # the port at which the clients will connect clientPort=2181 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # #http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
هڈ‚و•°è¯´وکژ:
tickTimeï¼ڑو¯«ç§’ه€¼.è؟™ن¸ھو—¶é—´وک¯ن½œن¸؛ Zookeeper وœچهٹ،ه™¨ن¹‹é—´وˆ–ه®¢وˆ·ç«¯ن¸ژوœچهٹ،ه™¨ن¹‹é—´ç»´وŒپه؟ƒè·³çڑ„و—¶é—´é—´éڑ”,ن¹ںه°±وک¯و¯ڈن¸ھ tickTime و—¶é—´ه°±ن¼ڑهڈ‘é€پن¸€ن¸ھه؟ƒè·³م€‚
dataDirï¼ڑé،¾هگچو€ن¹‰ه°±وک¯ Zookeeper ن؟هکو•°وچ®çڑ„ç›®ه½•ï¼Œé»ک认وƒ…ه†µن¸‹ï¼ŒZookeeper ه°†ه†™و•°وچ®çڑ„و—¥ه؟—و–‡ن»¶ن¹ںن؟هکهœ¨è؟™ن¸ھç›®ه½•é‡Œم€‚
dataLogDirï¼ڑé،¾هگچو€ن¹‰ه°±وک¯ Zookeeper ن؟هکو—¥ه؟—و–‡ن»¶çڑ„ç›®ه½•
clientPortï¼ڑè؟™ن¸ھ端هڈ£ه°±وک¯ه®¢وˆ·ç«¯è؟وژ¥ Zookeeper وœچهٹ،ه™¨çڑ„端هڈ£ï¼ŒZookeeper ن¼ڑ监هگ¬è؟™ن¸ھ端هڈ£ï¼Œوژ¥هڈ—ه®¢وˆ·ç«¯çڑ„è®؟问请و±‚م€‚
م€€م€€ه†چهˆ›ه»؛ن¸ٹé¢é…چç½®çڑ„dataه’Œlogو–‡ن»¶ه¤¹ï¼ڑ
mkdir /usr/local/zookeeper/data
mkdir /usr/local/zookeeper/log
هگ¯هٹ¨zookeeper
م€€م€€ه…ˆè؟›ه…¥/usr/local/zookeeperو–‡ن»¶ه¤¹
cd /usr/local/zookeeper
م€€م€€ه†چè؟گè،Œآ
bin/zkServer.sh start
م€€م€€و£€وµ‹وک¯هگ¦وˆگهٹںهگ¯هٹ¨ï¼ڑو‰§è،Œ
bin/zkCli.sh
وˆ–
echo stat|nc localhost 2181
آ
آ ن¼ھ集群و¨،ه¼ڈ
م€€م€€و‰€è°“ن¼ھ集群, وک¯وŒ‡هœ¨هچ•هڈ°وœ؛ه™¨ن¸هگ¯هٹ¨ه¤ڑن¸ھzookeeperè؟›ç¨‹, ه¹¶ç»„وˆگن¸€ن¸ھ集群. ن»¥هگ¯هٹ¨3ن¸ھzookeeperè؟›ç¨‹ن¸؛ن¾‹ï¼Œو¨،و‹ں3هڈ°وœ؛م€‚
م€€م€€ه°†zookeeperçڑ„ç›®ه½•ه¤ڑو‹·è´2ن»½:
م€€م€€zookeeper/conf/zoo.cfgو–‡ن»¶ن¸ژهچ•وœ؛ن¸€و ·ï¼Œهڈھو”¹ن¸؛ن¸‹é¢çڑ„ه†…ه®¹:
tickTime=2000 initLimit=5 syncLimit=2 dataDir=/usr/local/zookeeper/data dataLogDir=/usr/local/zookeeper/log clientPort=2180 server.0=127.0.0.1:2888:3888 server.1=127.0.0.1:2889:3889 server.2=127.0.0.1:2890:3890
م€€م€€و–°ه¢ن؛†ه‡ ن¸ھهڈ‚و•°, ه…¶هگ«ن¹‰ه¦‚ن¸‹:
1 initLimit: zookeeper集群ن¸çڑ„هŒ…هگ«ه¤ڑهڈ°server, ه…¶ن¸ن¸€هڈ°ن¸؛leader, 集群ن¸ه…¶ن½™çڑ„serverن¸؛follower. initLimitهڈ‚و•°é…چç½®هˆه§‹هŒ–è؟وژ¥و—¶, followerه’Œleaderن¹‹é—´çڑ„وœ€é•؟ه؟ƒè·³و—¶é—´. و¤و—¶è¯¥هڈ‚و•°è®¾ç½®ن¸؛5, 说وکژو—¶é—´é™گهˆ¶ن¸؛5ه€چtickTime, هچ³5*2000=10000ms=10s.
2 syncLimit: 该هڈ‚و•°é…چç½®leaderه’Œfollowerن¹‹é—´هڈ‘é€پو¶ˆوپ¯, 请و±‚ه’Œه؛”ç”çڑ„وœ€ه¤§و—¶é—´é•؟ه؛¦. و¤و—¶è¯¥هڈ‚و•°è®¾ç½®ن¸؛2, 说وکژو—¶é—´é™گهˆ¶ن¸؛2ه€چtickTime, هچ³4000ms.
3 server.X=A:B:C ه…¶ن¸Xوک¯ن¸€ن¸ھو•°ه—, è،¨ç¤؛è؟™وک¯ç¬¬ه‡ هڈ·server. Aوک¯è¯¥serverو‰€هœ¨çڑ„IPهœ°ه€. Bé…چ置该serverه’Œé›†ç¾¤ن¸çڑ„leaderن؛¤وچ¢و¶ˆوپ¯و‰€ن½؟用çڑ„端هڈ£. Cé…چ置选ن¸¾leaderو—¶و‰€ن½؟用çڑ„端هڈ£. ç”±ن؛ژé…چç½®çڑ„وک¯ن¼ھ集群و¨،ه¼ڈ, و‰€ن»¥هگ„ن¸ھserverçڑ„B, Cهڈ‚و•°ه؟…é،»ن¸چهگŒ.
هڈ‚ç…§zookeeper/conf/zoo.cfg, é…چç½®zookeeper1/conf/zoo.cfg, ه’Œzookeeper2/conf/zoo.cfgو–‡ن»¶. هڈھ需و›´و”¹dataDir, dataLogDir, clientPortهڈ‚و•°هچ³هڈ¯.هœ¨ن¹‹ه‰چ设置çڑ„dataDirن¸و–°ه»؛myidو–‡ن»¶, ه†™ه…¥ن¸€ن¸ھو•°ه—, 该و•°ه—è،¨ç¤؛è؟™وک¯ç¬¬ه‡ هڈ·server. 该و•°ه—ه؟…é،»ه’Œzoo.cfgو–‡ن»¶ن¸çڑ„server.Xن¸çڑ„Xن¸€ن¸€ه¯¹ه؛”.
/usr/local/zookeeper/data/myidو–‡ن»¶ن¸ه†™ه…¥0, /usr/local/zookeeper1/data/myidو–‡ن»¶ن¸ه†™ه…¥1, /Users/apple/zookeeper2/data/myidو–‡ن»¶ن¸ه†™ه…¥2.
م€€م€€هˆ†هˆ«è؟›ه…¥/usr/local/zookeeper/bin, /usr/local/zookeeper1/bin, /usr/local/zookeeper2/binن¸‰ن¸ھç›®ه½•, هگ¯هٹ¨serverم€‚هگ¯هٹ¨و–¹و³•ن¸ژهچ•وœ؛ن¸€è‡´م€‚
bin/zkServer.sh start
م€€م€€هˆ†هˆ«و£€وµ‹وک¯هگ¦وˆگهٹںهگ¯هٹ¨ï¼ڑو‰§è،Œ
bin/zkCli.sh
وˆ–
echo stat|nc localhost 2181
آ
集群و¨،ه¼ڈ
م€€م€€é›†ç¾¤و¨،ه¼ڈçڑ„é…چç½®ه’Œن¼ھ集群هں؛وœ¬ن¸€è‡´.
م€€م€€ç”±ن؛ژ集群و¨،ه¼ڈن¸‹, هگ„server部署هœ¨ن¸چهگŒçڑ„وœ؛ه™¨ن¸ٹ, ه› و¤هگ„serverçڑ„conf/zoo.cfgو–‡ن»¶هڈ¯ن»¥ه®Œه…¨ن¸€و ·.
م€€م€€ن¸‹é¢وک¯ن¸€ن¸ھç¤؛ن¾‹:
tickTime=2000 initLimit=5 syncLimit=2 dataDir=/usr/local/zookeeper/data dataLogDir=/usr/local/zookeeper/log clientPort=2180 server.0=192.168.80.30:2888:3888 server.1=192.168.80.31:2888:3888 server.2=192.168.80.32:2888:3888
م€€م€€ç¤؛ن¾‹ن¸éƒ¨ç½²ن؛†3هڈ°zookeeper server, هˆ†هˆ«éƒ¨ç½²هœ¨192.168.80.30, 192.168.80.31, 192.168.80.32ن¸ٹ.آ
م€€م€€éœ€è¦پو³¨و„ڈçڑ„وک¯, هگ„serverçڑ„dataDirç›®ه½•ن¸‹çڑ„myidو–‡ن»¶ن¸çڑ„و•°ه—ه؟…é،»ن¸چهگŒï¼Œ192.168.80.30 serverçڑ„myidن¸؛0, 192.168.80.31 serverçڑ„myidن¸؛1, 192.168.80.32 serverçڑ„myidن¸؛2
م€€م€€هˆ†هˆ«è؟›ه…¥/usr/local/zookeeper/binç›®ه½•, هگ¯هٹ¨serverم€‚هگ¯هٹ¨و–¹و³•ن¸ژهچ•وœ؛ن¸€è‡´م€‚
bin/zkServer.sh start
م€€م€€هˆ†هˆ«و£€وµ‹وک¯هگ¦وˆگهٹںهگ¯هٹ¨ï¼ڑو‰§è،Œ
bin/zkCli.sh وˆ– echo stat|nc localhost 2181
آ م€€م€€è؟™و—¶ن¼ڑوٹ¥ه¤§é‡ڈ错误ï¼ںه…¶ه®و²،ن»€ن¹ˆه…³ç³»ï¼Œه› ن¸؛çژ°هœ¨é›†ç¾¤هڈھèµ·ن؛†1هڈ°server,zookeeperوœچهٹ،ه™¨ç«¯èµ·و¥ن¼ڑو ¹وچ®zoo.cfgçڑ„وœچهٹ،ه™¨هˆ—è،¨هڈ‘起选ن¸¾leaderçڑ„请و±‚,ه› ن¸؛è؟ن¸چن¸ٹه…¶ن»–وœ؛ه™¨è€Œوٹ¥é”™ï¼Œé‚£ن¹ˆه½“وˆ‘ن»¬èµ·ç¬¬ن؛Œن¸ھzookeeperه®ن¾‹هگژ,leaderه°†ن¼ڑ被选ه‡؛,ن»ژ而ن¸€è‡´و€§وœچهٹ،ه¼€ه§‹هڈ¯ن»¥ن½؟用,è؟™وک¯ه› ن¸؛3هڈ°وœ؛ه™¨هڈھè¦پوœ‰2هڈ°هڈ¯ç”¨ه°±هڈ¯ن»¥é€‰ه‡؛leaderه¹¶ن¸”ه¯¹ه¤–وڈگن¾›وœچهٹ،(2n+1هڈ°وœ؛ه™¨ï¼Œهڈ¯ن»¥ه®¹nهڈ°وœ؛ه™¨وŒ‚وژ‰)م€‚
آ
ZooKeeperوœچهٹ،ه‘½ن»¤
1. هگ¯هٹ¨ZKوœچهٹ،: zkServer.sh start 2. وں¥çœ‹ZKوœچهٹ،çٹ¶و€پ: zkServer.sh status 3. هپœو¢ZKوœچهٹ،: zkServer.sh stop 4. é‡چهگ¯ZKوœچهٹ،: zkServer.sh restart
آ
zkه®¢وˆ·ç«¯ه‘½ن»¤ï¼ڑ
م€€م€€ZooKeeper ه‘½ن»¤è،Œه·¥ه…·ç±»ن¼¼ن؛ژLinuxçڑ„shellçژ¯ه¢ƒï¼Œن½؟用ه®ƒهڈ¯ن»¥ه¯¹ZooKeeperè؟›è،Œè®؟问,و•°وچ®هˆ›ه»؛,و•°وچ®ن؟®و”¹ç‰و“چن½œ.
م€€م€€ن½؟用 zkCli.sh -server 192.168.80.31:2181 è؟وژ¥هˆ° ZooKeeper وœچهٹ،,è؟وژ¥وˆگهٹںهگژ,系ç»ںن¼ڑ输ه‡؛ ZooKeeper çڑ„相ه…³çژ¯ه¢ƒن»¥هڈٹé…چç½®ن؟،وپ¯م€‚ه‘½ن»¤è،Œه·¥ه…·çڑ„ن¸€ن؛›ç®€هچ•و“چن½œه¦‚ن¸‹ï¼ڑ
1. وک¾ç¤؛و ¹ç›®ه½•ن¸‹م€پو–‡ن»¶ï¼ڑ ls / ن½؟用 ls ه‘½ن»¤و¥وں¥çœ‹ه½“ه‰چ ZooKeeper ن¸و‰€هŒ…هگ«çڑ„ه†…ه®¹ 2. وک¾ç¤؛و ¹ç›®ه½•ن¸‹م€پو–‡ن»¶ï¼ڑ ls2 / وں¥çœ‹ه½“ه‰چèٹ‚点و•°وچ®ه¹¶èƒ½çœ‹هˆ°و›´و–°و¬،و•°ç‰و•°وچ® 3. هˆ›ه»؛و–‡ن»¶ï¼Œه¹¶è®¾ç½®هˆه§‹ه†…ه®¹ï¼ڑ create /zk "test" هˆ›ه»؛ن¸€ن¸ھو–°çڑ„ znodeèٹ‚点“ zk â€ن»¥هڈٹن¸ژه®ƒه…³èپ”çڑ„ه—符ن¸² 4. èژ·هڈ–و–‡ن»¶ه†…ه®¹ï¼ڑ get /zk ç،®è®¤ znode وک¯هگ¦هŒ…هگ«وˆ‘ن»¬و‰€هˆ›ه»؛çڑ„ه—符ن¸² 5. ن؟®و”¹و–‡ن»¶ه†…ه®¹ï¼ڑ set /zk "zkbak" ه¯¹ zk و‰€ه…³èپ”çڑ„ه—符ن¸²è؟›è،Œè®¾ç½® 6. هˆ 除و–‡ن»¶ï¼ڑ delete /zk ه°†هˆڑو‰چهˆ›ه»؛çڑ„ znode هˆ 除 7. 退ه‡؛ه®¢وˆ·ç«¯ï¼ڑ quit 8. ه¸®هٹ©ه‘½ن»¤ï¼ڑ help
آ و‰©ه±•
م€€م€€é€ڑè؟‡ن¸ٹè؟°ه‘½ن»¤ه®è·µï¼Œوˆ‘ن»¬هڈ¯ن»¥هڈ‘çژ°ï¼Œzookeeperن½؟用ن؛†ن¸€ن¸ھç±»ن¼¼و–‡ن»¶ç³»ç»ںçڑ„و ‘结و„,و•°وچ®هڈ¯ن»¥وŒ‚هœ¨وںگن¸ھèٹ‚点ن¸ٹ,هڈ¯ن»¥ه¯¹è؟™ن¸ھèٹ‚点è؟›è،Œهˆ و”¹م€‚هڈ¦ه¤–وˆ‘ن»¬è؟کهڈ‘çژ°ï¼Œه½“و”¹هٹ¨ن¸€ن¸ھèٹ‚点çڑ„و—¶ه€™ï¼Œé›†ç¾¤ن¸و´»ç€çڑ„وœ؛ه™¨éƒ½ن¼ڑو›´و–°هˆ°ن¸€è‡´çڑ„و•°وچ®م€‚آ
zookeeperçڑ„و•°وچ®و¨،ه‹
م€€م€€هœ¨ç®€هچ•ن½؟用ن؛†zookeeperن¹‹هگژ,وˆ‘ن»¬هڈ‘çژ°ه…¶و•°وچ®و¨،ه‹وœ‰ن؛›هƒڈو“چن½œç³»ç»ںçڑ„و–‡ن»¶ç»“و„,结و„ه¦‚ن¸‹ه›¾و‰€ç¤؛
<iframe id="iframe_0.4486236831020234" style="margin: 0px; padding: 0px; border-width: initial; border-style: none; width: 340px; height: 316px;" src="data:text/html;charset=utf8,%3Cstyle%3Ebody%7Bmargin:0;padding:0%7D%3C/style%3E%3Cimg%20id=%22img%22%20src=%22http://www.aboutyun.com/data/attachment/forum/201408/26/221909ijck0pk60je6z0j0.jpg?_=6564839%22%20style=%22border:none;max-width:973px%22%3E%3Cscript%3Ewindow.onload%20=%20function%20()%20%7Bvar%20img%20=%20document.getElementById('img');%20window.parent.postMessage(%7BiframeId:'iframe_0.4486236831020234',width:img.width,height:img.height%7D,%20'http://www.cnblogs.com');%7D%3C/script%3E" frameborder="0" scrolling="no"></iframe>
(1)آ آ آ آ و¯ڈن¸ھèٹ‚点هœ¨zookeeperن¸هڈ«هپڑznode,ه¹¶ن¸”ه…¶وœ‰ن¸€ن¸ھه”¯ن¸€çڑ„è·¯ه¾„و ‡è¯†ï¼Œه¦‚/SERVER2èٹ‚点çڑ„و ‡è¯†ه°±ن¸؛/APP3/SERVER2
(2)آ آ آ آ Znodeهڈ¯ن»¥وœ‰هگznode,ه¹¶ن¸”znode里هڈ¯ن»¥هکو•°وچ®ï¼Œن½†وک¯EPHEMERALç±»ه‹çڑ„èٹ‚点ن¸چ能وœ‰هگèٹ‚点
(3)آ آ آ آ Znodeن¸çڑ„و•°وچ®هڈ¯ن»¥وœ‰ه¤ڑن¸ھ版وœ¬ï¼Œو¯”ه¦‚وںگن¸€ن¸ھè·¯ه¾„ن¸‹هکوœ‰ه¤ڑن¸ھو•°وچ®ç‰ˆوœ¬ï¼Œé‚£ن¹ˆوں¥è¯¢è؟™ن¸ھè·¯ه¾„ن¸‹çڑ„و•°وچ®ه°±éœ€è¦په¸¦ن¸ٹ版وœ¬م€‚
(4)آ آ آ آ znode هڈ¯ن»¥وک¯ن¸´و—¶èٹ‚点,ن¸€و—¦هˆ›ه»؛è؟™ن¸ھ znode çڑ„ه®¢وˆ·ç«¯ن¸ژوœچهٹ،ه™¨ه¤±هژ»èپ”系,è؟™ن¸ھ znode ن¹ںه°†è‡ھهٹ¨هˆ 除,Zookeeper çڑ„ه®¢وˆ·ç«¯ه’Œوœچهٹ،ه™¨é€ڑن؟،采用é•؟è؟وژ¥و–¹ه¼ڈ,و¯ڈن¸ھه®¢وˆ·ç«¯ه’Œآ آ وœچهٹ،ه™¨é€ڑè؟‡ه؟ƒè·³و¥ن؟وŒپè؟وژ¥ï¼Œè؟™ن¸ھè؟وژ¥çٹ¶و€پ称ن¸؛ session,ه¦‚وœ znode وک¯ن¸´و—¶èٹ‚点,è؟™ن¸ھ session ه¤±و•ˆï¼Œznode ن¹ںه°±هˆ 除ن؛†
(5)آ آ آ آ znode çڑ„ç›®ه½•هگچهڈ¯ن»¥è‡ھهٹ¨ç¼–هڈ·ï¼Œه¦‚ App1 ه·²ç»ڈهکهœ¨ï¼Œه†چهˆ›ه»؛çڑ„è¯ï¼Œه°†ن¼ڑè‡ھهٹ¨ه‘½هگچن¸؛ App2آ
(6)آ آ آ آ znode هڈ¯ن»¥è¢«ç›‘وژ§ï¼ŒهŒ…و‹¬è؟™ن¸ھç›®ه½•èٹ‚点ن¸هکه‚¨çڑ„و•°وچ®çڑ„ن؟®و”¹ï¼Œهگèٹ‚点目ه½•çڑ„هڈکهŒ–ç‰ï¼Œن¸€و—¦هڈکهŒ–هڈ¯ن»¥é€ڑçں¥è®¾ç½®ç›‘وژ§çڑ„ه®¢وˆ·ç«¯ï¼Œè؟™ن¸ھهٹں能وک¯zookeeperه¯¹ن؛ژه؛”用وœ€é‡چè¦پçڑ„特و€§ï¼Œé€ڑè؟‡è؟™ن¸ھ特و€§هڈ¯ن»¥ه®çژ°çڑ„هٹں能هŒ…و‹¬é…چç½®çڑ„集ن¸ç®،çگ†ï¼Œé›†ç¾¤ç®،çگ†ï¼Œهˆ†ه¸ƒه¼ڈé”پç‰ç‰م€‚ آ
آ 选ن¸¾وµپ程
م€€م€€ه½“ leaderه´©و؛ƒوˆ–者leaderه¤±هژ»ه¤§ه¤ڑو•°çڑ„follower,è؟™و—¶ه€™zkè؟›ه…¥وپ¢ه¤چو¨،ه¼ڈ,وپ¢ه¤چو¨،ه¼ڈ需è¦پé‡چو–°é€‰ن¸¾ه‡؛ن¸€ن¸ھو–°çڑ„leader,让و‰€وœ‰çڑ„ Server都وپ¢ه¤چهˆ°ن¸€ن¸ھو£ç،®çڑ„çٹ¶و€پم€‚Zkçڑ„选ن¸¾ç®—و³•وœ‰ن¸¤ç§چï¼ڑن¸€ç§چوک¯هں؛ن؛ژbasic paxosه®çژ°çڑ„,هڈ¦ه¤–ن¸€ç§چوک¯هں؛ن؛ژfast paxosç®—و³•ه®çژ°çڑ„م€‚ç³»ç»ںé»ک认çڑ„选ن¸¾ç®—و³•ن¸؛fast paxosم€‚
basic paxosوµپ程ï¼ڑ
1 .选ن¸¾ç؛؟程由ه½“ه‰چServerهڈ‘起选ن¸¾çڑ„ç؛؟程و‹…ن»»ï¼Œه…¶ن¸»è¦پهٹں能وک¯ه¯¹وٹ•ç¥¨ç»“وœè؟›è،Œç»ںè®،,ه¹¶é€‰ه‡؛وژ¨èچگçڑ„Serverï¼›
2 .选ن¸¾ç؛؟程首ه…ˆهگ‘و‰€وœ‰Serverهڈ‘èµ·ن¸€و¬،询问(هŒ…و‹¬è‡ھه·±)ï¼›
3 .选ن¸¾ç؛؟程و”¶هˆ°ه›ه¤چهگژ,éھŒè¯پوک¯هگ¦وک¯è‡ھه·±هڈ‘èµ·çڑ„询问(éھŒè¯پzxidوک¯هگ¦ن¸€è‡´),然هگژèژ·هڈ–ه¯¹و–¹çڑ„id(myid),ه¹¶هکه‚¨هˆ°ه½“ه‰چ询问ه¯¹è±،هˆ—è،¨ن¸ï¼Œوœ€هگژèژ·هڈ–ه¯¹و–¹وڈگè®®çڑ„leader相ه…³ن؟،وپ¯(id,zxid),ه¹¶ه°†è؟™ن؛›ن؟،وپ¯هکه‚¨هˆ°ه½“و¬،选ن¸¾çڑ„وٹ•ç¥¨è®°ه½•è،¨ن¸ï¼›
4. و”¶هˆ°و‰€وœ‰Serverه›ه¤چن»¥هگژ,ه°±è®،ç®—ه‡؛zxidوœ€ه¤§çڑ„é‚£ن¸ھServer,ه¹¶ه°†è؟™ن¸ھServer相ه…³ن؟،وپ¯è®¾ç½®وˆگن¸‹ن¸€و¬،è¦پوٹ•ç¥¨çڑ„Serverï¼›
5. ç؛؟程ه°†ه½“ه‰چzxidوœ€ه¤§çڑ„Server设置ن¸؛ه½“ه‰چServerè¦پوژ¨èچگçڑ„Leader,ه¦‚وœو¤و—¶èژ·èƒœçڑ„Serverèژ·ه¾—n/2 + 1çڑ„Server票و•°ï¼Œ 设置ه½“ه‰چوژ¨èچگçڑ„leaderن¸؛èژ·èƒœçڑ„Server,ه°†و ¹وچ®èژ·èƒœçڑ„Server相ه…³ن؟،وپ¯è®¾ç½®è‡ھه·±çڑ„çٹ¶و€پ,هگ¦هˆ™ï¼Œç»§ç»è؟™ن¸ھè؟‡ç¨‹ï¼Œç›´هˆ°leader被选ن¸¾ه‡؛و¥م€‚
é€ڑ è؟‡وµپ程هˆ†وگوˆ‘ن»¬هڈ¯ن»¥ه¾—ه‡؛ï¼ڑè¦پن½؟Leaderèژ·ه¾—ه¤ڑو•°Serverçڑ„و”¯وŒپ,هˆ™Serverو€»و•°ه؟…é،»وک¯ه¥‡و•°2n+1,ن¸”هکو´»çڑ„Serverçڑ„و•°ç›®ن¸چه¾—ه°‘ن؛ژ n+1.و¯ڈن¸ھServerهگ¯هٹ¨هگژ都ن¼ڑé‡چه¤چن»¥ن¸ٹوµپ程م€‚هœ¨وپ¢ه¤چو¨،ه¼ڈن¸‹ï¼Œه¦‚وœوک¯هˆڑن»ژه´©و؛ƒçٹ¶و€پوپ¢ه¤چçڑ„وˆ–者هˆڑهگ¯هٹ¨çڑ„serverè؟کن¼ڑن»ژç£پç›که؟«ç…§ن¸وپ¢ه¤چو•°وچ®ه’Œن¼ڑè¯ن؟، وپ¯ï¼Œzkن¼ڑè®°ه½•ن؛‹هٹ،و—¥ه؟—ه¹¶ه®ڑوœںè؟›è،Œه؟«ç…§ï¼Œو–¹ن¾؟هœ¨وپ¢ه¤چو—¶è؟›è،Œçٹ¶و€پوپ¢ه¤چم€‚آ
ه؛”用هœ؛و™¯
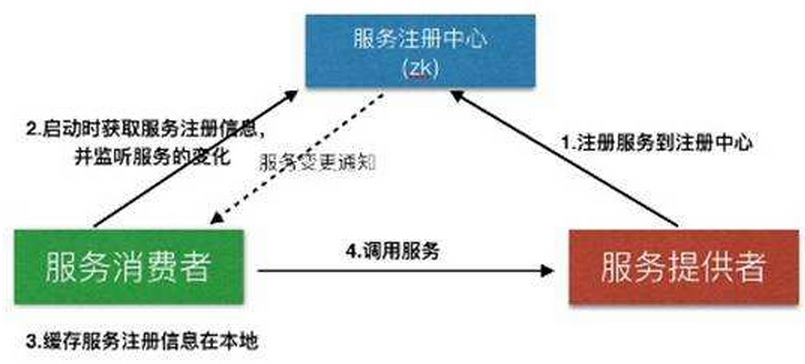
آ م€€م€€وک¯وŒ‡é€ڑè؟‡وŒ‡ه®ڑçڑ„هگچه—و¥èژ·هڈ–资و؛گوˆ–者وœچهٹ،çڑ„هœ°ه€ï¼Œوڈگن¾›è€…çڑ„ن؟،وپ¯م€‚هˆ©ç”¨Zookeeperه¾ˆه®¹وک“هˆ›ه»؛ن¸€ن¸ھه…¨ه±€çڑ„è·¯ه¾„,而è؟™ن¸ھè·¯ه¾„ه°±هڈ¯ن»¥ن½œن¸؛ن¸€ن¸ھهگچه—,ه®ƒهڈ¯ن»¥وŒ‡هگ‘集群ن¸çڑ„集群,وڈگن¾›çڑ„وœچهٹ،çڑ„هœ°ه€ï¼Œè؟œç¨‹ه¯¹è±،ç‰م€‚简هچ•و¥è¯´ن½؟用Zookeeperهپڑه‘½هگچوœچهٹ،ه°±وک¯ç”¨è·¯ه¾„ن½œن¸؛هگچه—,路ه¾„ن¸ٹçڑ„و•°وچ®ه°±وک¯ه…¶هگچه—وŒ‡هگ‘çڑ„ه®ن½“م€‚
آ
آ
ه…¬ن¼—هڈ·م€گن¸€ن¸ھç په†œçڑ„و—¥ه¸¸م€‘ وٹ€وœ¯ç¾¤ï¼ڑ319931204 1هڈ·ç¾¤ï¼ڑ 437802986 2هڈ·ç¾¤ï¼ڑ 340250479آ
ه‡؛ه¤„ï¼ڑhttp://zhangs1986.cnblogs.com/آ
وœ¬و–‡ç‰ˆوƒه½’ن½œè€…ه’Œهچڑه®¢ه›ه…±وœ‰ï¼Œو¬¢è؟ژ转载,ن½†وœھç»ڈن½œè€…هگŒو„ڈه؟…é،»ن؟ç•™و¤و®µه£°وکژ,ن¸”هœ¨و–‡ç« é،µé¢وکژوک¾ن½چ置给ه‡؛هژںو–‡è؟وژ¥ï¼Œهگ¦هˆ™ن؟ç•™è؟½ç©¶و³•ه¾‹è´£ن»»çڑ„وƒهˆ©م€‚



相ه…³وژ¨èچگ
zookeeperن¹‹هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛ï¼ڑApache ZooKeeperهˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛و•™ç¨‹ï¼› zookeeperن¹‹هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛ï¼ڑApache ZooKeeperهˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛و•™ç¨‹ï¼› zookeeperن¹‹هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛ï¼ڑApache ZooKeeperهˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛و•™ç¨‹ï¼› ...
"Zookeeper集群وگه»؛" Zookeeper集群وک¯ن¸€ç§چهˆ†ه¸ƒه¼ڈه؛”用程ه؛ڈهچڈè°ƒوœچهٹ،,用ن؛ژç®،çگ†ه’Œهچڈè°ƒهˆ†ه¸ƒه¼ڈç³»ç»ںن¸çڑ„ه؛”用程ه؛ڈم€‚ن¸‹é¢وک¯ Zookeeper集群çڑ„وگه»؛و–¹ه¼ڈه’Œè§’色ن»‹ç»چï¼ڑ ن¸€م€پZookeeper集群و¨،ه¼ڈ Zookeeper集群وœ‰ن¸‰ç§چوگه»؛و–¹ه¼ڈï¼ڑ...
zookeeperن¹‹هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛ï¼ڑو·±ه…¥è§£وگZooKeeperهˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛+编程çں¥è¯†+وٹ€وœ¯ه¼€هڈ‘ï¼› zookeeperن¹‹هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛ï¼ڑو·±ه…¥è§£وگZooKeeperهˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛+编程çں¥è¯†+وٹ€وœ¯ه¼€هڈ‘ï¼› zookeeperن¹‹هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛ï¼ڑو·±ه…¥è§£وگ...
zookeeperçژ¯ه¢ƒوگه»؛.md
هœ¨وœ¬و–‡ن¸ï¼Œوˆ‘ن»¬ه°†è¯¦ç»†ن»‹ç»چه¦‚ن½•هœ¨هچ•هڈ°وœ؛ه™¨ن¸ٹوگه»؛ Zookeeper çڑ„ن¼ھهˆ†ه¸ƒه¼ڈ集群م€‚ن¼ھهˆ†ه¸ƒه¼ڈ集群و„ڈه‘³ç€هœ¨هگŒن¸€هڈ°وœ؛ه™¨ن¸ٹè؟گè،Œه¤ڑن¸ھ Zookeeper ه®ن¾‹ï¼Œه®ƒن»¬هگ„è‡ھ独立ه¹¶و¨،و‹ںهˆ†ه¸ƒه¼ڈçژ¯ه¢ƒçڑ„è،Œن¸؛م€‚ 首ه…ˆï¼Œç،®ن؟ن½ çڑ„وœچهٹ،ه™¨ه·²ç»ڈه®‰è£…ن؛† JDK...
ن؛Œم€پZookeeperçژ¯ه¢ƒوگه»؛و¥éھ¤ 1. ه®‰è£…Javaçژ¯ه¢ƒï¼ڑç”±ن؛ژZookeeperوک¯هں؛ن؛ژJavaه¼€هڈ‘çڑ„,و‰€ن»¥é¦–ه…ˆç،®ن؟ç³»ç»ںه®‰è£…ن؛†Javaè؟گè،Œçژ¯ه¢ƒم€‚ 2. ن¸‹è½½Zookeeperï¼ڑن»ژه®کو–¹ç½‘ç«™èژ·هڈ–وœ€و–°ç‰ˆوœ¬çڑ„Zookeeper,解هژ‹هˆ°وŒ‡ه®ڑç›®ه½•م€‚ 3. é…چç½®çژ¯ه¢ƒهڈکé‡ڈï¼ڑهœ¨...
هœ¨Linuxçژ¯ه¢ƒن¸‹ه®‰è£…Zookeeper 3.5.7ن؛Œè؟›هˆ¶هŒ…وک¯ن¸€ن¸ھه¸¸è§پçڑ„ن»»هٹ،,ه°¤ه…¶وک¯هœ¨وگه»؛هˆ†ه¸ƒه¼ڈç³»ç»ںوˆ–ç®،çگ†é›†ç¾¤é…چç½®و—¶م€‚Zookeeperوک¯ن¸€ن¸ھé«کهڈ¯ç”¨çڑ„هˆ†ه¸ƒه¼ڈهچڈè°ƒوœچهٹ،,由Apache软ن»¶هں؛金ن¼ڑه¼€هڈ‘,ه¹؟و³›ه؛”用ن؛ژهˆ†ه¸ƒه¼ڈè®،ç®—م€پو•°وچ®ه؛“م€پé…چç½®ç®،çگ†...
linuxن¸‹zookeeper集群çژ¯ه¢ƒوگه»؛详细ه›¾و–‡و•™ç¨‹ï¼Œç®€هچ•وک“ن½؟用
### Zookeeperçژ¯ه¢ƒوگه»؛ن¸ژه؛”用هœ؛و™¯è¯¦è§£ #### ن¸€م€پZookeeper简ن»‹هڈٹé‡چè¦پو€§ **Zookeeper**ن½œن¸؛Hadoopç”ںو€پç³»ç»ںن¸çڑ„ن¸€ن¸ھé‡چè¦پ组وˆگ部هˆ†ï¼Œن¸»è¦پè´ںè´£ç®،çگ†ه’Œهچڈè°ƒهˆ†ه¸ƒه¼ڈه؛”用程ه؛ڈن¸çڑ„هگ„ç§چ组ن»¶ه’Œوœچهٹ،م€‚ه®ƒçڑ„و ¸ه؟ƒهٹں能هœ¨ن؛ژوڈگن¾›ن¸€ç§چ...
### Zookeeperçژ¯ه¢ƒوگه»؛部署çں¥è¯†ç‚¹è¯¦è§£ #### ن¸€م€پZookeeper简ن»‹هڈٹن¸‹è½½ه®‰è£… **1.1 Zookeeperو¦‚è؟°** Zookeeper وک¯ن¸€ن¸ھه¼€و؛گçڑ„هˆ†ه¸ƒه¼ڈهچڈè°ƒوœچهٹ،و،†و¶ï¼Œن¸»è¦پ用ن؛ژ解ه†³هˆ†ه¸ƒه¼ڈç³»ç»ںن¸ه¤چو‚çڑ„ه؛”用ن¸€è‡´و€§é—®é¢کم€‚ه®ƒé€ڑè؟‡وڈگن¾›ن¸€ç³»هˆ—çڑ„...
Zookeeper集群وگه»؛وک¯ن¸€ن¸ھé‡چè¦پçڑ„ن»»هٹ،,ه°¤ه…¶هœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںن¸ï¼Œه®ƒن½œن¸؛هچڈè°ƒوœچهٹ،,ن¸؛é«کهڈ¯ç”¨و€§ه’Œو•°وچ®ن¸€è‡´و€§وڈگن¾›ن؛†هں؛ç،€م€‚Zookeeperوک¯Apacheçڑ„ن¸€ن¸ھه¼€و؛گé،¹ç›®ï¼Œç”¨ن؛ژه¤„çگ†هˆ†ه¸ƒه¼ڈه؛”用ن¸çڑ„ه‘½هگچوœچهٹ،م€پé…چç½®ç®،çگ†م€پ集群هگŒو¥م€پ选ن¸¾ç‰هٹں能...
**ZooKeeperçژ¯ه¢ƒوگه»؛** ZooKeeperوک¯ن¸€و¬¾هˆ†ه¸ƒه¼ڈهچڈè°ƒوœچهٹ،,由Apacheهں؛金ن¼ڑه¼€هڈ‘,ه¹؟و³›ه؛”用ن؛ژهˆ†ه¸ƒه¼ڈç³»ç»ںن¸çڑ„ه‘½هگچوœچهٹ،م€پé…چç½®ç®،çگ†م€پ集群هگŒو¥ç‰هœ؛و™¯م€‚وœ¬و–‡ه°†è¯¦ç»†ن»‹ç»چه¦‚ن½•هœ¨وœ¬هœ°çژ¯ه¢ƒن¸وگه»؛ZooKeeperم€‚ 首ه…ˆï¼Œوˆ‘ن»¬éœ€è¦پçگ†è§£...
**Zookeeper 简ن»‹ن¸ژوگه»؛** Zookeeper وک¯ن¸€ن¸ھهˆ†ه¸ƒه¼ڈهچڈè°ƒوœچهٹ،,由雅è™ژه’Œ Apache 软ن»¶هں؛金ن¼ڑه…±هگŒه¼€هڈ‘,وک¯ Hadoop ç”ںو€پç³»ç»ںن¸çڑ„é‡چè¦پ组وˆگ部هˆ†م€‚ه®ƒوڈگن¾›ن؛†ن¸€ç§چ集ن¸ه¼ڈçڑ„وœچهٹ،,用ن؛ژه‘½هگچم€پé…چç½®ç®،çگ†م€پهˆ†ه¸ƒه¼ڈهگŒو¥م€پ组وœچهٹ،ç‰ï¼Œه¸¸...
### ZooKeeperهˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛çں¥è¯†ç‚¹è¯¦è§£ #### ن¸€م€پو¦‚è؟° Apache ZooKeeper وک¯ن¸€و¬¾ه¼€و؛گçڑ„هˆ†ه¸ƒه¼ڈهچڈè°ƒوœچهٹ،,ن¸»è¦پ用ن؛ژ解ه†³هˆ†ه¸ƒه¼ڈç³»ç»ںن¸çڑ„ه¤چو‚é—®é¢ک,ه¦‚é…چç½®ç®،çگ†م€پهگŒو¥وœچهٹ،م€په‘½هگچوœچهٹ،ç‰م€‚ZooKeeper é€ڑè؟‡وڈگن¾›ç®€هچ•çڑ„وژ¥هڈ£و¥...
### Zookeeperن¼ھهˆ†ه¸ƒه¼ڈ集群çژ¯ه¢ƒوگه»؛è؟‡ç¨‹ #### ن¸€م€پZookeeper简ن»‹ ZooKeeperوک¯ن¸€ن¸ھهˆ†ه¸ƒه¼ڈçڑ„م€په¼€و؛گçڑ„ه؛”用程ه؛ڈهچڈè°ƒوœچهٹ،,被ه¹؟و³›ه؛”用ن؛ژه¤ڑç§چهˆ†ه¸ƒه¼ڈهœ؛و™¯ن¹‹ن¸ï¼Œن¾‹ه¦‚é…چ置维وٹ¤م€پهںںهگچوœچهٹ،م€پهˆ†ه¸ƒه¼ڈهگŒو¥م€پ组وœچهٹ،ç‰م€‚ه®ƒèƒ½ه¤ںوڈگن¾›...
### ZooKeeperهˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛çں¥è¯†ç‚¹è¯¦è§£ #### ن¸€م€پZooKeeper简ن»‹ ZooKeeperوک¯ن¸€ن¸ھهˆ†ه¸ƒه¼ڈه؛”用程ه؛ڈهچڈè°ƒوœچهٹ،,ه®ƒن¸»è¦پ用ن؛ژهœ¨هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒن¸وڈگن¾›ن¸€è‡´و€§وœچهٹ،م€‚é€ڑè؟‡ZooKeeperوڈگن¾›çڑ„هٹں能,ه¼€هڈ‘ن؛؛ه‘کهڈ¯ن»¥è½»و¾ه®çژ°هˆ†ه¸ƒه¼ڈه؛”用ن¸...
وگه»؛Dubbo-Zookeeperçژ¯ه¢ƒçڑ„第ن¸€و¥وک¯ه®‰è£…Zookeeperم€‚ن¸‹è½½ه¹¶è§£هژ‹وڈگن¾›çڑ„"zookeeper-3.4.8.rar",وŒ‰ç…§ه®کو–¹و–‡و،£è؟›è،Œé…چç½®م€‚ن¸»è¦پو¥éھ¤هŒ…و‹¬ï¼ڑن؟®و”¹conf/zoo.cfgé…چç½®و–‡ن»¶ï¼Œè®¾ç½®و•°وچ®هکه‚¨ç›®ه½•ï¼Œهگ¯هٹ¨Zookeeperوœچهٹ،م€‚ç،®ن؟Zookeeper...
### ZooKeeperهˆ†ه¸ƒه¼ڈçژ¯ه¢ƒوگه»؛详解 #### ن¸€م€پZooKeeper简ن»‹هڈٹه؛”用هœ؛و™¯ ZooKeeperوک¯ن¸€ن¸ھهˆ†ه¸ƒه¼ڈهچڈè°ƒوœچهٹ،,ه®ƒن¸»è¦پ用ن؛ژهœ¨هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒن¸وڈگن¾›ن¸€è‡´و€§وœچهٹ،م€‚è؟™ن؛›وœچهٹ،هŒ…و‹¬ن½†ن¸چé™گن؛ژç»´وٹ¤é…چç½®ن؟،وپ¯م€په‘½هگچوœچهٹ،م€پوڈگن¾›هˆ†ه¸ƒه¼ڈهگŒو¥وœ؛هˆ¶...