
本篇文章内容来自2016年TOP100summitWalmartLabs实验室广告平台首席工程师、架构师粟迪夫的案例分享。
编辑:Cynthia
粟迪夫:WalmartLabs实验室广告平台首席工程师、架构师
在大数据平台架构设计、消息中间件、分布式系统等领域有丰富经验。
作为技术负责人,帮助多家企业搭建了大数据平台和分布式系统。
目前主导WMX大数据平台、广告效益分析系统和实时数据管道的开发。
导读:作为世界上最大的商品零售商,沃尔玛每天都投放大量的广告、产生大量的商品交易,生成大量数据,需要分析这些数据的关系以衡量广告活动的效果,并以此为依据制定广告活动的策略,帮助广告主有效地投放广告以促进商品销售。本文结合测度FACEBOOK广告效果这一具体案例,讲述沃尔玛WMX团队如何利用开源技术开发WMX广告效益分析平台,支持快速算法迭代,持续更新大数据技术以提升系统性能和运行效率,提高软件质量,以及提高团队的知识水平。
一.问题的提出
沃尔玛拥有众多零售商店和网上销售渠道。当顾客购买商品,交易和顾客的信息就会记录下来。其中顾客的信息经过整理分类就形成沃尔玛的用户背景资料,例如住址、性别、年龄、信用卡、教育、婚姻、爱好、消费习惯。通过用户分析,我们可以把用户的真实身份和网络身份联系起来,还可以生成个体用户、家庭用户等有用信息。
为了帮助供货商促销商品,沃尔玛进行广告推广活动。在广告推广活动中,针对某些商品,根据用户背景资料选取合适的用户作为受众,制作广告,投放到选定的广告渠道上,如手机APP、电邮、沃尔玛网站、社交媒体、搜索引擎、新闻网站等。
可见,广告推广活动的数据是高维度的,例如:
● 用户数据 :地址、收入、支出、教育、婚姻、性别、年龄
● 广告数据 :图文格式、尺寸、可否点击、位置
● 商品数据 :商品类型、属性、促销、折扣
● 发布渠道数据 :URL、网站、App
● 展示数据 :时间、设备、地理位置
在生成效益分析报告、衡量广告推广活动的效果时,我们需要按任意维度的组合选取受众和聚合销售收入的信息。
衡量广告推广活动的效果,常用的办法是A/B测试。即把用户分成A组和B组,A组用户是广告推广活动的受众,B组用户不是受众。比较A、B两组用户的交易金额可以得到广告推广活动的效果。
效益分析报告的生成有三个难点。
● 一是高维度的数据导致数据连接时产生的大量数据。
● 二是按任意维度聚集会产生大量报表。
● 三是广告推广活动和交易的匹配算法不是唯一的,需要进行算法测试和迭代以选取最优算法。
原有的系统主要依靠HiveQL把大量数据连接起来,然后过滤,针对每一种聚集方式都产生一个报表;每个报表都重新运行一遍整个流程。这种做法复杂、低效,不能复用中间结果,难以改进。
这要求我们开发一个广告效益分析平台以克服上述缺点,能够高效地生成按任意维度聚合的效益分析报告,快速地进行算法迭代。
二.系统架构及技术演进
本节结合Facebook广告案例讲解系统架构的设计及技术演进。
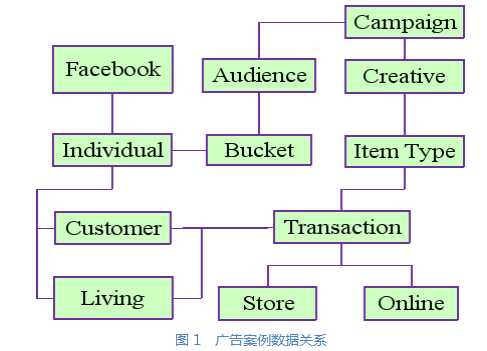
沃尔玛在Facebook上的广告推广活动数据关系如图1所示。一个广告推广活动首先为商品(Item Type)创建广告(Creative)。广告推广活动(Campaign)始于按要求选取合适的沃尔玛个人用户(Individual)作为受众(Audience)。受众分为A/B两组(Bucket),进行AB测试。首先把用户资料上载到Facebook,Facebook展示广告后,下载Facebook的广告展示数据(Facebook User)。
沃尔玛个人用户分成两类:
● Customer在线上商店(Online)完成交易(Transaction);Living Unit在实体商店(Store)完成交易。
商品交易和广告推广活动通过用户、商品以及时间关联起来。
我们结合广告展示数据和交易数据生成广告效益分析报告:对比A/B两组受众的商品交易总金额。广告效益分析报告生成的数据处理流程是:
● 用户映射:找到Facebook User、Individual、Customer、Living Unit、Audience、Bucket之间的对应关系。
● 数据连接:连接广告推广活动、受众、用户、商品、交易,生成大数据表。
● 交易归属(attribution):分析广告推广活动和交易之间的关系,把交易归属于某个广告推广活动。
● 分组聚合 :按要求分组数据计算交易金额。
其中的难点是:
● 数据连接生成大数据表时会产生大量的数据,必须及时过滤数据。
● 交易归属不是唯一的。一个交易有可能与多个广告推广活动相关,我们需要测试多种算法优化交易归属。
● 我们需要按任意维度进行分组聚合,生成高维度报表。高维度的分组组合数目太多,每种组合都生成一个报表不现实。
针对上述要求和难点,我们设计了一个新的系统架构:可动态扩展的模块化数据管道。基于这个新的系统架构,Facebook广告效益分析系统如图2所示。
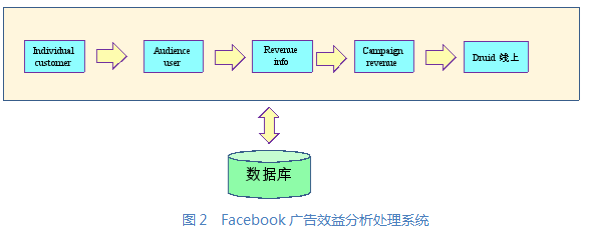
整个广告系统由三个部分构成:数据收集系统、广告效益分析系统和报表查询系统。我们关注的是广告效益分析系统。
广告效益分析系统从数据收集系统读取数据,生成广告效益分析报表,客户通过报表查询系统查询广告效益分析报表。我们把图2抽象扩展成为一个平台,就是图3所示的可动态扩展的模块化数据管道。

可动态扩展的模块化数据管道由多个MapReduce模块连接而成;与微服务架构类似,把一个复杂的数据处理分解为多个步骤。每个模块从数据库中读取数据,把处理的结果存储到数据库中。上一个模块的处理结果就是下一个模块的输入。
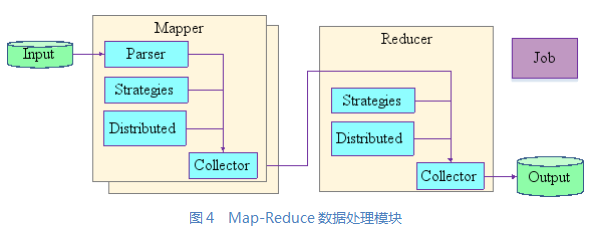
一个MapReduce模块的结构如图4所示。它由一个Job、多个Mapper和一个Reducer三个部分组成。
● Job负责配置模块的组成和控制;
● Mapper的Parser负责读取数据;
● Strategies由多个处理单元组成,数据依次由这些单元处理,完成数据过滤、添加、校正、转换等任务;
● 辅助数据存储在Distributed Cache中;
● Collector把处理结果序列化输出给Reducer使用。
● 每一个Mapper对一个数据源作处理,多个数据源就需要多个Mapper作处理。
● Reducer的Strategies象Mapper的一样,由多个数据处理单元构成,完成对数据的连接、聚集、计算等任务;
● Collector把处理结果存储到数据库中。
可动态扩展的模块化数据管道把复杂的数据处理分配到多个数据处理模块中完成,每个模块完成一个独立的逻辑功能处理,并把结果存储在数据库中。模块单一的逻辑功能有利于我们发现系统瓶颈并进行优化。这样的架构使得一个系统可以多技术并存。我们能够针对每一个模块处理的数据量和速度要求,为每个模块选取最合适的技术。
例如,一个数据量小的模块,我们可以选取Spark作为处理技术,快速处理。而对于大数据处理模块,我们可以用Hadoop的MapReduce作精细的数据过滤处理。每个模块内部的Strategies是可配置的,我们只需要替换不同的Attribution算法就能快速地完成算法迭代。由于中间结果存储在数据库中,它们可以被方便地复用。模块化的另一个好处是我们可以方便地测试新的大数据技术,加快技术演进的进程。
沃尔玛的大数据基础设施包括Hadoop、MapReduce、Spark、HDFS、S3、Cassandra、Hive、Kafka、Pig、Logstash。其中:
● 并行处理的计算平台是Hadoop,在Hadoop之上提供了HiveQL、MapReduce和Spark等界面;
● HiveQL提供了类SQL的数据查询和存取,但是效率比较低;MapReduce提供精细的编程控制功能;
● Spark提供面向集合的处理功能和数据流处理能力,它的数据主要存储在内存中,所以处理的速度比基于Hadoop的MapReduce要快很多。
Spark是新兴的大数据技术,性能还不够稳定,如果数据大小和内存不匹配容易造成任务中断。根据我们系统的架构,我们选取了MapReduce和Spark作为我们的主要支撑技术。数据量小的模块用Spark实现,数据量大的模块用MapReduce实现。
大数据的存储可以选择HDFS、S3、Cassandra、Hive。
● Cassandra提供快速的Key-Value存储,存取速度很快但是价格比较高,不适合每天几十TB的数据量需要;
● Hive是基于HDFS的SQL类数据库,可以用于MapReduce和Spark;
● S3能提供与HDFS同一量级的大数据存储;
我们最终选择HDFS和Hive存储格式。
可动态扩展的模块化数据管道生成一张高维度的表,没有分类聚集,而是把数据表交给Druid作索引处理。Druid是一个开源的数据存储和线上分析处理工具,能够快速完成任意维度的数据聚集查询。这个工具极大地减少了我们需要生成报表的数量。
三.以代码审查为中心的软件质量管理
在软件的开发中,我们希望提高软件质量、团队协作和开发效率。我们用到的开源软件开发技术有:Linux、Java、Scala、Python、Hadoop、Spark、Junit、Maven、代码共享管理工具Git、代码审查工具Gerrit、共享文档Confluence、CI工具Jenkins、项目管理工具Jira。我们采取Agile软件开发管理的方式,每个Spring两个星期,用Jira作为项目管理工具。主要编程语言是Java、Scala。
在项目的实施过程中比较有特色的是以代码审查为中心的软件开发。代码的开发流程是:编程、提交、审查、合并。如果审查不通过,需要再次编程、提交、审查。如果审查通过,就可以合并代码。
首先,我们以最小的逻辑功能单元组织代码。每次提交的代码都完成一项独立的逻辑功能。对于新功能,我们先开发控制框架,再开发每一个子功能。对于拥有公共模块的多个子模块,我们先开发广告模块,后应用公共模块实现子模块。对于Bug的修复,我们也是把一个Bug作逻辑划分。这样不仅在实现上逻辑清晰,减少了Bug的产生,而且有利于代码审查者理解代码和以后的代码维护。
我们使用Git管理代码共享,利用Gerrit来进行代码审查。代码提交后,相关开发人员会收到电邮通知进行审查。代码审查者可以给代码打-2至+2分。代码积累够+4分才可以合并。通常,对代码有任何疑问都可以提出问题,打-1分。代码提交者回答问题之后,审查者可以更改分数。
其次,我们强化了单元测试,除了某些难以测试的代码,我们要求测试达到100%的代码覆盖。代码在提交之前,必须成功地编译和单元测试。我们使用了Junit、Mockoti、Harmcrest、Truth、Jacoco等开源软件进行单元测试。通过单元测试,我们在开发阶段就排除了大量的Bug。
第三,我们尽可能复用软件,包括Apache、Hadoop、Guava、Protobuf等开源代码库,Walmartlabs的公共代码库,以及已测试代码。另外只要有可能,就抽取公共代码作为公共模块。这种方法减少了开发的工作量,提高了软件质量,减少了软件维护的工作量。
第四,我们利用Jenkin服务器进行持续集成。代码提交时自动触发持续集成。只有持续集成成功才能合并代码。
以代码审查为中心的软件开发改变了软件开发流程,迫使开发人员在编码之前就清晰要开发功能的逻辑。严格的代码审查使得大量的Bug在代码开发阶段就被排除,而且提高了代码的可读性和可维护性。系统的Bug减少到5%,平均Bug修复时间减少到1/5。同时,增加了团队的交流,提高了团队协作能力,有多人维护代码,也有利于技术交流和引进新技术 。
以代码审查为中心的软件开发改变了软件开发的时间分配,编程、测试、审查的时间比例为1:2:1。



相关推荐
【标题】"TOP100Summit2017 爆款"指的是在2017年举办的科技界盛事——TOP100SUMMIT。这个活动每年都会聚焦并表彰100个最具影响力的科技创新与研发管理案例,旨在推动科技行业的进步和发展。 【描述】"TOP100SUMMIT...
**TOP100 Summit** 是一个致力于挖掘和分享科技创新与研发管理最佳实践的重要平台。该盛会每年在全球范围内筛选出100个具有代表性的技术创新和研发管理案例,旨在通过这些真实案例的分享,为参会者提供宝贵的学习...
总的来说,《TOP100Summit2018-爆款架构》深入剖析了构建高可用、高性能互联网架构的关键技术和实践,对于从事IT行业的开发者和架构师来说,这些都是不可或缺的知识点,有助于提升系统设计和运维的能力。
标题与描述均聚焦于“Top100summit个性化的双11-个性化推荐技术的应用”,这明确指出了文章的核心议题在于探讨个性化推荐技术在天猫双11活动中的实际应用,特别是通过张奇(得福)这位天猫推荐算法团队成员的视角...
Top100summit全球软件案例研究峰会12月7-9日在北京九华山庄举行。大会分为5个专场:产品专场、团队专场、测试专场、开发专场、架构专场。大会主题以分享案例为主,从企业的研发管理设计案例出发,引用案例分享企业...
通过下载提供的"spark-summit-201806_iteblog"压缩包,你可以获取到大会的完整PPT资料,深入理解Spark技术的前沿动态。 1. **Apache Spark概述**:Apache Spark是目前最流行的大数据处理框架之一,以其高效、易用和...
TOP100SUMMIT是科技界一年一度的案例研究盛会,每年甄选有代表的100个技术创新/研发管理案例,旨在揭幕100件案例背后的思考、长尾价值,为 听众提炼最佳学习路径(或看点),帮助他人的项目或团队获得启示、成长,...
TOP100SUMMIT是科技界一年一度的案例研究盛会,每年甄选有代表的100个技术创新/研发管理案例,旨在揭幕100件案例背后的思考、长尾价值,为 听众提炼最佳学习路径(或看点),帮助他人的项目或团队获得启示、成长,...
spark-summit-north-america-2018-06 全部 PPT -part1部分。 spark-summit-north-america-2018-06 全部 PPT -part1部分
TOP100SUMMIT是科技界一年一度的案例研究盛会,每年甄选有代表的100个技术创新/研发管理案例,旨在揭幕100件案例背后的思考、长尾价值,为 听众提炼最佳学习路径(或看点),帮助他人的项目或团队获得启示、成长,...
### 大数据技术分享 Spark技术讲座 Apache Spark 2.3概述 #### 一、Apache Spark 2.3简介 在2018年的Spark Summit大会上,Sameer Agarwal介绍了Apache Spark 2.3版本的一些关键特性。作为Spark的Committer和2.3...
综上所述,“大数据技术分享 Spark技术讲座 Azure上的加速Spark和云中的可扩展硬件卸载 共51页.pdf”这份文档深入探讨了如何利用Azure云平台的RDMA技术和SparkRDMA Shuffle插件来加速Spark应用程序的执行。...
2021中国网络开源技术生态峰会PPT汇总,共21份。 轻量级k8s构建开放式边缘计算架构 白盒开放场景及研究探讨 大网网络操作系统+云网融合的智慧大脑 不断扩展的云网络边界和开源技术在其中的应用 网络操作系统-从开源...
标题"Maggies-Summit-2015---Summit-2015---Build-Enterprise-Apps-in-60-Minutes-Cordova-Light-Forms-App"指的是一个在2015年Maggies峰会上展示的议题,主题是“60分钟内构建企业级应用——Cordova轻量级表单应用...
Top100summit全球软件案例研究峰会12月7-9日在北京九华山庄举行。大会分为5个专场:产品专场、团队专场、测试专场、开发专场、架构专场。大会主题以分享案例为主,从企业的研发管理设计案例出发,引用案例分享企业...
ROS (Robot Operating System) 是一个开源操作系统,专为开发机器人应用而设计。它提供了一个框架,使得机器人硬件、传感器和算法能够以标准化的方式交互。在本案例中,我们关注的是"ros-melodic-summit-xl-common...
spark-summit-north-america-2018-06(Finished) 日程及 slides => 详情 => CSDN 下载地址 => 、 关注 iteblog_hadoop 公众号 或 及时获取大数据相关信息。
2021 Data & Cloud Summit 是由 Kyligence 主办的年度数据与云行业峰会,本次峰会以「云 · 数据·智能」为主题,面向所有关注大数据、云计算等领域的CIO、CDO、业务决策者、技术负责人、数据分析师、架构师、开发...
- **Summit:** 顶点,同样用于描述达到的最高点或最高成就。 ### 十一、Competitor **原词:** competitor(竞争者) **替换词:** - **Rival:** 对手,特别是在商业或体育等领域的直接竞争对手。 - **Opponent:** ...
在QCon Summit 2018上,eBay大数据架构师俞育才分享了关于如何将多处理器并行数据库管理系统(MPP DBMS)迁移至Apache Spark的经验,旨在提高数据仓库系统的灵活性、扩展性和成本效益。 **为什么要做迁移?** 1. **...