
’╝łµ£¼µ¢ćµ£ĆÕłØńö▒µ£¼õ║║ķ╗äµ¢ćµĄĘÕÅæĶĪ©Õ£©InfoQõĖŁµ¢ćń½ÖõĖŖ’╝Ühttp://www.infoq.com/cn’╝ē
1ŃĆü ÕēŹĶ©Ć
volatileÕģ│ķö«ÕŁŚÕÅ»ĶāĮµś»JavaÕ╝ĆÕÅæõ║║ÕæśŌĆ£ń夵éēĶĆīÕÅłķÖīńö¤ŌĆØńÜäõĖĆõĖ¬Õģ│ķö«ÕŁŚŃĆéµ£¼µ¢ćÕ░åõ╗ÄvolatileÕģ│ķö«ÕŁŚńÜäõĮ£ńö©ŃĆüÕ╝ĆķöĆÕÆīÕģĖÕ×ŗÕ║öńö©Õ£║µÖ»õ╗źÕÅŖJavaĶÖܵŗ¤µ£║Õ»╣volatileÕģ│ķö«ÕŁŚńÜäÕ«×ńÄ░Ķ┐ÖÕćĀõĖ¬µ¢╣ķØóõĖ║Ķ»╗ĶĆģÕģ©ķØóµĘ▒ÕģźÕē¢µ×ÉvolatileÕģ│ķö«ÕŁŚŃĆé
volatileÕŁŚķØóõĖŖµ£ēŌĆ£µīźÕÅæµĆ¦ńÜä’╝īõĖŹń©│Õ«ÜńÜäŌĆصäŵĆØ’╝īÕ«āµś»ńö©õ║Äõ┐«ķź░ÕÅ»ÕÅśÕģ▒õ║½ÕÅśķćÅ’╝łMutable Shared Variable’╝ēńÜäõĖĆõĖ¬Õģ│ķö«ÕŁŚŃĆéµēĆĶ░ōŌĆ£Õģ▒õ║½ŌĆصś»µīćõĖĆõĖ¬ÕÅśķćÅĶāĮÕż¤Ķó½ÕżÜõĖ¬ń║┐ń©ŗĶ«┐ķŚ«’╝łÕīģµŗ¼Ķ»╗/ÕåÖ’╝ē’╝īµēĆĶ░ōŌĆ£ÕÅ»ÕÅśŌĆصś»µīćÕÅśķćÅńÜäÕĆ╝ÕÅ»õ╗źÕÅæńö¤ÕÅśÕī¢ŃĆ鵏óĶĆīĶ©Ćõ╣ŗ’╝īvolatileÕģ│ķö«ÕŁŚńö©õ║Äõ┐«ķź░ÕżÜõĖ¬ń║┐ń©ŗÕ╣ČÕÅæĶ«┐ķŚ«ńÜäÕÉīõĖĆõĖ¬ÕÅśķćÅ’╝īĶ┐Öõ║øń║┐ń©ŗõĖŁĶć│Õ░æµ£ēõĖĆõĖ¬ń║┐ń©ŗõ╝ܵø┤µ¢░Ķ┐ÖõĖ¬ÕÅśķćÅńÜäÕĆ╝ŃĆ鵳æõ╗¼ń¦░volatileõ┐«ķź░ńÜäÕÅśķćÅõĖ║volatileÕÅśķćÅŃĆ鵳æõ╗¼ń¤źķüōķöüńÜäõĮ£ńö©Õīģµŗ¼õ┐ØķÜ£ÕÄ¤ÕŁÉµĆ¦ŃĆüõ┐ØķÜ£ÕÅ»Ķ¦üµĆ¦õ╗źÕÅŖõ┐ØķÜ£µ£ēÕ║ÅµĆ¦ŃĆévolatileÕĖĖĶó½ń¦░õĖ║ŌĆ£ĶĮ╗ķćÅń║¦ķöüŌĆØ’╝īÕģČõĮ£ńö©õĖÄķöüµ£ēń▒╗õ╝╝ńÜäÕ£░µ¢╣ŌĆöŌĆövolatileõ╣¤ĶāĮÕż¤õ┐ØķÜ£ÕÄ¤ÕŁÉµĆ¦’╝łõ╗ģõ┐ØķÜ£long/doubleÕ×ŗÕÅśķćÅĶ«┐ķŚ«µōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦’╝ēŃĆüõ┐ØķÜ£ÕÅ»Ķ¦üµĆ¦õ╗źÕÅŖõ┐ØķÜ£µ£ēÕ║ÅµĆ¦ŃĆé
µ£¼µ¢ćµēƵÅÉÕÅŖńÜäŌĆ£JavaĶÖܵŗ¤µ£║ŌĆØÕ”éµŚĀńē╣Õł½Ķ»┤µśÄ’╝īÕØćńē╣µīćOracleÕģ¼ÕÅĖńÜäHotSpot JavaĶÖܵŗ¤µ£║ŃĆé
2. õ┐ØķÜ£long/doubleÕ×ŗÕÅśķćÅĶ«┐ķŚ«µōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦
õĖŹÕÅ»ÕłåÕē▓ńÜäµōŹõĮ£Ķó½ń¦░õĖ║ÕÄ¤ÕŁÉµōŹõĮ£’╝łAtomic Operation’╝ēŃĆéµēĆĶ░ōõĖŹÕÅ»ÕłåÕē▓’╝łIndivisible’╝ēµś»µīćõĖĆõĖ¬µōŹõĮ£õ╗ÄÕģȵē¦ĶĪīń║┐ń©ŗõ╗źÕż¢ńÜäÕģČõ╗¢ń║┐ń©ŗń£ŗµØź’╝īĶ»źµōŹõĮ£Ķ”üõ╣łÕĘ▓ń╗ÅÕ«īµłÉĶ”üõ╣łÕ░ܵ£¬Õ╝ĆÕ¦ŗ’╝īõ╣¤Õ░▒µś»Ķ»┤ÕģČõ╗¢ń║┐ń©ŗõĖŹõ╝Üń£ŗÕł░Ķ»źµōŹõĮ£ńÜäõĖŁķŚ┤ń╗ōµ×£ŃĆéÕ”éµ×£õĖĆõĖ¬µōŹõĮ£µś»ÕÄ¤ÕŁÉµōŹõĮ£’╝īķéŻõ╣łµłæõ╗¼Õ░▒ń¦░Ķ»źµōŹõĮ£Õģʵ£ēÕÄ¤ÕŁÉµĆ¦’╝łAtomicity’╝ēŃĆé
JavaĶ»ŁĶ©ĆĶ¦äĶīā’╝łJava Language Specification’╝īJLS’╝ēĶ¦äÕ«Ü’╝īJavaĶ»ŁĶ©ĆõĖŁķÆłÕ»╣long/doubleÕ×ŗõ╗źÕż¢ńÜäõ╗╗õĮĢÕÅśķćÅ’╝łÕīģµŗ¼Õ¤║ńĪĆń▒╗Õ×ŗÕÅśķćÅÕÆīÕ╝Ģńö©Õ×ŗÕÅśķćÅ’╝ēĶ┐øĶĪīńÜäĶ»╗ŃĆüÕåÖµōŹõĮ£ķāĮµś»ÕÄ¤ÕŁÉµōŹõĮ£’╝īÕŹ│JavaĶ»ŁĶ©ĆĶ¦äĶīāµ£¼Ķ║½Õ╣ČõĖŹĶ¦äÕ«ÜķÆłÕ»╣long/doubleÕ×ŗÕÅśķćÅĶ┐øĶĪīĶ»╗ŃĆüÕåÖµōŹõĮ£Õģʵ£ēÕÄ¤ÕŁÉµĆ¦ŃĆéõĖĆõĖ¬long/doubleÕ×ŗÕÅśķćÅńÜäĶ»╗/ÕåÖµōŹõĮ£Õ£©32õĮŹJavaĶÖܵŗ¤µ£║õĖŗÕÅ»ĶāĮõ╝ÜĶó½ÕłåĶ¦ŻõĖ║õĖżõĖ¬ÕŁÉµŁźķ¬ż’╝łµ»öÕ”éÕģłÕåÖõĮÄ32õĮŹ’╝īÕåŹÕåÖķ½ś32õĮŹ’╝ēµØźÕ«×ńÄ░’╝īĶ┐ÖÕ░▒Õ»╝Ķć┤õĖĆõĖ¬ń║┐ń©ŗÕ»╣long/doubleÕ×ŗÕÅśķćÅĶ┐øĶĪīńÜäÕåÖµōŹõĮ£ńÜäõĖŁķŚ┤ń╗ōµ×£ÕÅ»õ╗źĶó½ÕģČõ╗¢ń║┐ń©ŗµēĆĶ¦éÕ»¤Õł░’╝īÕŹ│µŁżµŚČķÆłÕ»╣long/doubleÕ×ŗÕÅśķćÅńÜäĶ«┐ķŚ«µōŹõĮ£õĖŹµś»ÕÄ¤ÕŁÉµōŹõĮ£ŃĆéµĖģÕŹĢ1µēĆńż║ńÜäÕ«×ķ¬īÕ▒Ģńż║õ║åĶ┐Öńé╣ŃĆé
µĖģÕŹĢ1 long/doubleÕ×ŗÕÅśķćÅÕåÖµōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦ķŚ«ķóśDemo
/**
*
* µ£¼DemoÕ┐ģķĪ╗õĮ┐ńö©32õĮŹJavaĶÖܵŗ¤µ£║µēŹĶāĮń£ŗÕł░ķØ×ÕÄ¤ÕŁÉµōŹõĮ£ńÜäµĢłµ×£. <br>
* Ķ┐ÉĶĪīµ£¼DemoµŚČõ╣¤ÕÅ»õ╗źµīćÕ«ÜĶÖܵŗ¤µ£║ÕÅéµĢ░ŌĆ£-clientŌĆØ
* @author Viscent Huang
*
*/
public class NonAtomicAssignmentDemo implements Runnable {
static long value = 0;
private final long valueToSet;
public NonAtomicAssignmentDemo(long valueToSet) {
this.valueToSet = valueToSet;
}
public static void main(String[] args) {
// ń║┐ń©ŗupdateThread1Õ░ådataµø┤µ¢░õĖ║0
Thread updateThread1 = new Thread(new NonAtomicAssignmentDemo(0L));
// ń║┐ń©ŗupdateThread2Õ░ådataµø┤µ¢░õĖ║-1
Thread updateThread2 = new Thread(new NonAtomicAssignmentDemo(-1L));
updateThread1.start();
updateThread2.start();
// õĖŹĶ┐øĶĪīÕ«×ķÖģĶŠōÕć║ńÜäOutputStream
final DummyOutputStream dos = new DummyOutputStream();
try (PrintStream dummyPrintSteam = new PrintStream(dos);) {
// Õģ▒õ║½ÕÅśķćÅvalueńÜäÕ┐½ńģ¦’╝łÕŹ│ń×¼ķŚ┤ÕĆ╝’╝ē
long snapshot;
while (0 == (snapshot = value) || -1 == snapshot) {
// õĖŹĶ┐øĶĪīÕ«×ķÖģńÜäĶŠōÕć║’╝īõ╗ģõ╗ģµś»õĖ║õ║åķś╗µŁóJITń╝¢Ķ»æÕÖ©ÕüÜÕŠ¬ńÄ»õĖŹÕÅśĶĪ©ĶŠŠÕ╝ÅÕż¢µÅÉõ╝śÕī¢
dummyPrintSteam.print(snapshot);
}
System.err.printf("Unexpected data: %d(0x%016x)", snapshot,
snapshot);
}
System.exit(0);
}
static class DummyOutputStream extends OutputStream {
@Override
public void write(int b) throws IOException {
// õĖŹÕ«×ķÖģĶ┐øĶĪīĶŠōÕć║
}
}
@Override
public void run() {
for (;;) {
value = valueToSet;
}
}
}
õĮ┐ńö©32õĮŹ’╝łĶĆīõĖŹµś»64õĮŹ’╝ēJavaĶÖܵŗ¤µ£║Ķ┐ÉĶĪīµĖģÕŹĢ1µēĆńż║ńÜäDemoµłæõ╗¼ÕÅ»õ╗źń£ŗÕł░Ķ»źń©ŗÕ║ÅńÜäĶŠōÕć║µś»’╝Ü
Unexpected data: 4294967295(0x00000000ffffffff)
µł¢ĶĆģ’╝ī
Unexpected data: -4294967296(0xffffffff00000000)
ÕÅ»Ķ¦ü’╝īmainń║┐ń©ŗĶ»╗ÕÅ¢Õł░Õģ▒õ║½ÕÅśķćÅvalueńÜäÕĆ╝ÕÅ»ĶāĮµŚóõĖŹµś»0’╝łÕ»╣Õ║öµŚĀń¼”ÕÅĘ16Ķ┐øÕłČµĢ░0x0000000000000000’╝ēõ╣¤õĖŹµś»-1’╝łÕ»╣Õ║öµŚĀń¼”ÕÅĘ16Ķ┐øÕłČµĢ░0xffffffffffffffff’╝ē’╝īĶĆīµś»ÕģČõ╗¢õĖżõĖ¬ń║┐ń©ŗµø┤µ¢░valueµŚČńÜäŌĆ£õĖŁķŚ┤ń╗ōµ×£ŌĆØŌĆöŌĆö4294967295’╝łÕ»╣Õ║öµŚĀń¼”ÕÅĘ16Ķ┐øÕłČµĢ░0x00000000ffffffff’╝ēµł¢ĶĆģ-4294967296’╝łÕ»╣Õ║öµŚĀń¼”ÕÅĘ16Ķ┐øÕłČµĢ░0xffffffff00000000’╝ē’╝īÕŹ│õĖĆõĖ¬ń║┐ń©ŗÕ»╣valueÕÅśķćÅńÜäõĮÄ’╝łLower’╝ē32õĮŹ’╝ł4õĖ¬ÕŁŚĶŖé’╝ēµø┤µ¢░õĖÄÕÅ”Õż¢õĖĆõĖ¬ń║┐ń©ŗÕ»╣valueÕÅśķćÅńÜäķ½ś’╝łHigher’╝ē32õĮŹ’╝ł4õĖ¬ÕŁŚĶŖé’╝ēµø┤µ¢░µēĆŌĆ£µĘĘÕÉłŌĆØÕć║µØźńÜäõĖĆõĖ¬ķØ×ķóäµ£¤ńÜäķöÖĶ»»ń╗ōµ×£ŃĆéÕøĀµŁż’╝īõĖŖĶ┐░DemoÕ»╣Õģ▒õ║½ÕÅśķćÅvalueńÜäÕåÖµōŹõĮ£Õ╣ČķØ×õĖĆõĖ¬ÕÄ¤ÕŁÉµōŹõĮ£ŃĆéĶ┐Öµś»ńö▒õ║Ä’╝ÜJavaÕ╣│ÕÅ░õĖŁ’╝īlong/doubleÕ×ŗÕÅśķćÅõ╝ÜÕŹĀńö©64õĮŹ’╝ł8õĖ¬ÕŁŚĶŖé’╝ēńÜäÕŁśÕé©ń®║ķŚ┤’╝īĶĆī32õĮŹńÜäJavaĶÖܵŗ¤µ£║Õ»╣Ķ┐Öń¦ŹÕÅśķćÅńÜäÕåÖµōŹõĮ£ÕÅ»ĶāĮõ╝ÜĶó½ÕłåĶ¦ŻõĖ║õĖżõĖ¬ÕŁÉµŁźķ¬żµØźÕ«×µ¢Į’╝īµ»öÕ”éÕģłÕåÖõĮÄ32õĮŹ’╝īÕåŹÕåÖķ½ś32õĮŹŃĆéķéŻõ╣ł’╝īÕżÜõĖ¬ń║┐ń©ŗĶ»ĢÕøŠÕģ▒õ║½ÕÉīõĖĆõĖ¬Ķ┐ÖµĀĘńÜäÕÅśķćŵŚČÕ░▒ÕÅ»ĶāĮÕć║ńÄ░õĖĆõĖ¬ń║┐ń©ŗÕ£©ÕåÖķ½ś32õĮŹńÜ䵌ČÕĆÖ’╝īÕÅ”Õż¢õĖĆõĖ¬ń║┐ń©ŗµü░ÕźĮµŁŻÕ£©ÕåÖõĮÄ32õĮŹ’╝īĶĆīµŁżÕł╗ń¼¼õĖēõĖ¬ń║┐ń©ŗĶ»╗ÕÅ¢Ķ┐ÖõĖ¬ÕÅśķćŵŚČµēĆĶ»╗ÕÅ¢Õł░ńÜäÕÅśķćÅÕĆ╝õ╗ģõ╗ģµś»ÕģČõ╗¢õĖżõĖ¬ń║┐ń©ŗµø┤µ¢░Ķ┐ÖõĖ¬ÕÅśķćÅńÜäõĖŁķŚ┤ń╗ōµ×£ŃĆé
32õĮŹĶÖܵŗ¤µ£║õĖŗ’╝īõĖĆõĖ¬long/doubleÕ×ŗÕÅśķćÅĶ»╗µōŹõĮ£ÕÉīµĀĘõ╣¤ÕÅ»ĶāĮõ╝ÜĶó½ÕłåĶ¦ŻõĖ║õĖżõĖ¬ÕŁÉµŁźķ¬żµØźÕ«×ńÄ░’╝īµ»öÕ”éÕģłĶ»╗ÕÅ¢õĮÄ32õĮŹÕł░Õ»äÕŁśÕÖ©õĖŁ’╝īÕåŹĶ»╗ÕÅ¢ķ½ś32õĮŹÕł░Õ»äÕŁśÕÖ©õĖŁŃĆéĶ┐Öń¦ŹÕ«×ńÄ░ÕÉīµĀĘõ╣¤õ╝ÜÕ»╝Ķć┤õĖÄõĖŖĶ┐░DemoµēĆÕ▒Ģńż║ńÜäńøĖõ╝╝ńÜäµĢłµ×£’╝īÕŹ│õĖĆõĖ¬ń║┐ń©ŗÕÅ»õ╗źĶ»╗ÕÅ¢Õł░ÕģČõ╗¢ń║┐ń©ŗÕ»╣long/doubleÕ×ŗÕÅśķćÅÕåÖµōŹõĮ£ńÜäõĖŁķŚ┤ń╗ōµ×£ŃĆéÕøĀµŁż’╝īÕ£©Ķ┐Öń¦ŹJavaĶÖܵŗ¤µ£║Õ«×ńÄ░õĖŗ’╝īlong/doubleÕ×ŗÕÅśķćÅĶ»╗µōŹõĮ£ÕÉīµĀĘõ╣¤õĖŹµś»ÕÄ¤ÕŁÉµōŹõĮ£ŃĆé
õĖŖĶ┐░Demoµø┤ÕżÜńÜ䵜»õ╗Äń│╗ń╗¤’╝łJavaĶÖܵŗ¤µ£║’╝ēÕ▒éķØóÕ▒Ģńż║ÕÄ¤ÕŁÉµĆ¦ķŚ«ķóśŃĆéķéŻõ╣ł’╝īÕ£©õĖÜÕŖĪÕ▒éķØóµłæõ╗¼µś»ÕÉ”õ╣¤ÕÅ»ĶāĮķüćÕł░ń▒╗õ╝╝õĖŖĶ┐░ńÜäÕÄ¤ÕŁÉµĆ¦ķŚ«ķóśÕæó’╝¤Õ”éµĖģÕŹĢ2µēĆńż║’╝īÕüćĶ«Šń║┐ń©ŗT1ķĆÜĶ┐ćµē¦ĶĪīupdateHostInfoµ¢╣µ│ĢµØźµø┤µ¢░õĖ╗µ£║õ┐Īµü»’╝łHostInfo’╝ē’╝īń║┐ń©ŗT2ÕłÖķĆÜĶ┐ćµē¦ĶĪīconnectToHostµ¢╣µ│ĢµØźĶ»╗ÕÅ¢õĖ╗µ£║õ┐Īµü»’╝īÕ╣ȵŹ«µŁżõĖÄńøĖÕ║öńÜäõĖ╗µ£║Õ╗║ń½ŗńĮæń╗£Ķ┐׵ğŃĆéķéŻõ╣ł’╝īupdateHostInfoµ¢╣µ│ĢõĖŁńÜäµōŹõĮ£’╝łµø┤µ¢░õĖ╗µ£║IPÕ£░ÕØĆÕÆīń½»ÕÅŻÕÅĘ’╝ēÕ┐ģķĪ╗µś»õĖĆõĖ¬ÕÄ¤ÕŁÉµōŹõĮ£’╝īÕŹ│Ķ┐ÖõĖ¬µōŹõĮ£Õ┐ģķĪ╗µś»ŌĆ£õĖŹÕÅ»ÕłåÕē▓ŌĆØńÜäŃĆéÕÉ”ÕłÖ’╝īÕÅ»ĶāĮÕć║ńÄ░Ķ┐ÖµĀĘńÜäµāģÕĮó’╝ÜÕüćĶ«ŠhostInfońÜäÕłØÕ¦ŗÕĆ╝ĶĪ©ńż║ńÜ䵜»IPÕ£░ÕØĆõĖ║ŌĆ£192.168.1.101ŌĆØŃĆüń½»ÕÅŻÕÅĘõĖ║8081ńÜäõĖ╗µ£║’╝īT1µē¦ĶĪīupdateHostInfoµ¢╣µ│ĢĶ»ĢÕøŠÕ░åhostInfoµø┤µ¢░õĖ║IPÕ£░ÕØĆõĖ║ŌĆ£192.168.1.100ŌĆØŃĆüń½»ÕÅŻÕÅĘõĖ║8080ńÜäõĖ╗µ£║ńÜ䵌ČÕĆÖ’╝īT2ÕÅ»ĶāĮÕłÜÕźĮµē¦ĶĪīconnectToHostµ¢╣µ│Ģ’╝īķéŻõ╣łµŁżµŚČńö▒õ║ÄT1ÕÅ»ĶāĮÕłÜÕłÜµē¦ĶĪīÕ«īĶ»ŁÕÅźŌæĀĶĆīµ£¬Õ╝ĆÕ¦ŗĶ»ŁÕÅźŌæĪ’╝łÕŹ│ÕŬµø┤µ¢░Õ«īIPÕ£░ÕØĆĶĆīÕ░ܵ£¬µø┤µ¢░ń½»ÕÅŻÕÅĘ’╝ē’╝īÕøĀµŁżT2ÕÅ»ĶāĮĶ»╗ÕÅ¢Õł░IPÕ£░ÕØĆõĖ║ŌĆ£192.168.1.100ŌĆØŃĆüĶĆīń½»ÕÅŻÕÅĘÕŹ┤õ╗ŹńäČõĖ║8081ńÜäõĖ╗µ£║õ┐Īµü»’╝īÕŹ│T2Ķ»╗ÕÅ¢Õł░õ║åõĖĆõĖ¬ķöÖĶ»»ńÜäõĖ╗µ£║õ┐Īµü»’╝łIPÕ£░ÕØĆõĖ║ŌĆ£192.168.1.100ŌĆØńÜäõĖ╗µ£║õĖŖķØóÕ╣ȵ▓Īµ£ēÕ╝ĆÕÉ»õŠ”Õɼń½»ÕÅŻ8081’╝īÕ«āÕ╝ĆÕÉ»ńÜä8080’╝ēõ╗ÄĶĆīµŚĀµ│ĢÕ╗║ń½ŗńĮæń╗£Ķ┐׵ğ’╝üĶ┐ÖķćīńÜäķöÖĶ»»µś»ńö▒õ║ÄupdateHostInfoµ¢╣µ│ĢõĖŁńÜäµōŹõĮ£õĖŹµś»ÕÄ¤ÕŁÉµōŹõĮ£’╝łõĖŹÕģĘÕżćŌĆ£õĖŹÕÅ»ÕłåÕē▓ŌĆØńÜäńē╣µĆ¦’╝ēĶĆīõĮ┐ÕģČõ╗¢ń║┐ń©ŗĶ»╗ÕÅ¢õ║åĶäŵĢ░µŹ«’╝łķöÖĶ»»ńÜäõĖ╗µ£║õ┐Īµü»’╝ēÕ»╝Ķć┤ńÜäŃĆé
µĖģÕŹĢ2 õĖÜÕŖĪÕ▒éķØóńÜäÕÄ¤ÕŁÉµōŹõĮ£ķŚ«ķóśDemo
public class AtomicityExample {
private HostInfo hostInfo;
public void updateHostInfo(String ip, int port) {
// õ╗źõĖŗµōŹõĮ£õĖŹµś»ÕÄ¤ÕŁÉµōŹõĮ£
hostInfo.setIp(ip);// Ķ»ŁÕÅźŌæĀ
hostInfo.setPort(port);// Ķ»ŁÕÅźŌæĪ
}
public void connectToHost() {
String ip = hostInfo.getIp();
int port = hostInfo.getPort();
connectToHost(ip, port);
}
private void connectToHost(String ip, int port) {
// ...
}
public static class HostInfo {
private String ip;
private int port;
public HostInfo(String ip, int port) {
this.ip = ip;
this.port = port;
}
// ...
}
}
ÕĮōńäČ’╝īõĖŖĶ┐░ÕÄ¤ÕŁÉµĆ¦ķŚ«ķóśķāĮÕÅ»õ╗źķĆÜĶ┐ćÕŖĀķöüĶ¦ŻÕå│ŃĆéõĖŹĶ┐ć’╝īJavaĶ»ŁĶ©ĆĶ¦äĶīāńē╣Õł½Õ£░Ķ¦äÕ«ÜķÆłÕ»╣volatileõ┐«ķź░ńÜälong/doubleÕ×ŗÕÅśķćÅĶ┐øĶĪīńÜäĶ»╗ŃĆüÕåÖµōŹõĮ£õ╣¤Õģʵ£ēÕÄ¤ÕŁÉµĆ¦ŃĆ鵏óĶĆīĶ©Ćõ╣ŗ’╝īvolatileÕģ│ķö«ÕŁŚĶāĮÕż¤õ┐ØķÜ£long/doubleÕ×ŗÕÅśķćÅĶ«┐ķŚ«µōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦ŃĆéķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īvolatileÕ»╣ÕÄ¤ÕŁÉµĆ¦ńÜäõ┐ØķÜ£õ╗ģķÖÉõ║ÄÕģ▒õ║½ÕÅśķćÅÕåÖÕÆīĶ»╗µōŹõĮ£µ£¼Ķ║½ŃĆéÕ»╣Õģ▒õ║½ÕÅśķćÅĶ┐øĶĪīńÜäĶĄŗÕĆ╝µōŹõĮ£Õ«×ķÖģõĖŖÕŠĆÕŠĆµś»õĖĆõĖ¬ÕżŹÕÉłµōŹõĮ£’╝īvolatileÕ╣ČõĖŹĶāĮõ┐ØķÜ£Ķ┐Öõ║øĶĄŗÕĆ╝µōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦ŃĆéõŠŗÕ”é’╝īÕ”éõĖŗķÆłÕ»╣volatileÕÅśķćÅcounter1ĶĄŗÕĆ╝Ķ»ŁÕÅź’╝Ü
volatile counter1 = counter2 + 1;
Õ”éµ×£counter2µś»õĖĆõĖ¬Õ▒Ćķā©ÕÅśķćÅ’╝īķéŻõ╣łõĖŖĶ┐░ĶĄŗÕĆ╝Ķ»ŁÕÅźÕ«×ķÖģõĖŖÕ░▒µś»ķÆłÕ»╣counter1ńÜäÕåÖµōŹõĮ£’╝īÕøĀµŁżÕ£©volatileÕģ│ķö«ÕŁŚńÜäõĮ£ńö©õĖŗõĖŖĶ┐░ĶĄŗÕĆ╝µōŹõĮ£Õģʵ£ēÕÄ¤ÕŁÉµĆ¦ŃĆéÕ”éµ×£counter2õ╣¤µś»õĖĆõĖ¬Õģ▒õ║½ÕÅśķćÅ’╝īķéŻõ╣łõĖŖĶ┐░ĶĄŗÕĆ╝Ķ»ŁÕÅźÕ░▒õĖŹÕģʵ£ēÕÄ¤ÕŁÉµĆ¦ŃĆéĶ┐Öµś»ńö▒õ║ĵŁżµŚČõĖŖĶ┐░Ķ»ŁÕÅźÕ«×ķÖģõĖŖÕÅ»õ╗źĶó½ÕłåĶ¦ŻõĖ║Õ”éõĖŗÕćĀõĖ¬ÕŁÉµōŹõĮ£’╝łõ╝¬õ╗ŻńĀüĶĪ©ńż║’╝ē’╝Ü
r1 = counter2; //ÕŁÉµōŹõĮ£ŌæĀ’╝ÜÕ░åÕģ▒õ║½ÕÅśķćÅcounter2ńÜäÕĆ╝ÕŖĀĶĮĮÕł░Õ»äÕŁśÕÖ©r1
r1 = r1 + 1;//ÕŁÉµōŹõĮ£ŌæĪ’╝ÜÕ░åÕ»äÕŁśÕÖ©r1ńÜäÕĆ╝Õó×ÕŖĀ1
counter1 = r1;//ÕŁÉµōŹõĮ£Ōæó’╝ÜÕ░åÕ»äÕŁśÕÖ©r1ńÜäÕĆ╝ÕåÖÕģźÕģ▒õ║½ÕÅśķćÅcounter1’╝łÕåģÕŁś’╝ē
volatileÕģ│ķö«ÕŁŚÕ╣ČõĖŹÕāÅķöüķ鯵ĀĘÕģʵ£ēµÄÆõ╗¢µĆ¦’╝īÕ£©ÕåÖµōŹõĮ£µ¢╣ķØó’╝īÕģČÕ»╣ÕÄ¤ÕŁÉµĆ¦ńÜäõ┐ØķÜ£õ╣¤õ╗ģõ╗ģõĮ£ńö©õ║ÄõĖŖĶ┐░ńÜäÕŁÉµōŹõĮ£Ōæó’╝łÕÅśķćÅÕåÖµōŹõĮ£’╝ēŃĆéÕøĀµŁż’╝īõĖĆõĖ¬ń║┐ń©ŗÕ£©µē¦ĶĪīÕł░ÕŁÉµōŹõĮ£ŌæóńÜ䵌ČÕĆÖ’╝īÕģČõ╗¢ń║┐ń©ŗÕÅ»ĶāĮÕĘ▓ń╗ŵø┤µ¢░õ║åÕģ▒õ║½ÕÅśķćÅcounter2ńÜäÕĆ╝’╝īĶ┐ÖÕ░▒õĮ┐ÕŠŚÕŁÉµōŹõĮ£ŌæóńÜäµē¦ĶĪīń║┐ń©ŗÕ«×ķÖģõĖŖµś»ÕÉæÕģ▒õ║½ÕÅśķćÅcounter1ÕåÖÕģźõ║åõĖĆõĖ¬µŚ¦ÕĆ╝ŃĆé
ÕøĀµŁż’╝īÕ»╣volatileÕÅśķćÅńÜäĶĄŗÕĆ╝µōŹõĮ£ÕģČĶĪ©ĶŠŠÕ╝ÅÕÅ│ĶŠ╣õĖŹĶāĮÕīģÕɽõ╗╗õĮĢÕģ▒õ║½ÕÅśķćÅ’╝łÕīģµŗ¼Ķó½ĶĄŗÕĆ╝ńÜävolatileÕÅśķćŵ£¼Ķ║½’╝ēŃĆé
õŠØńģ¦JavaĶ»ŁĶ©ĆĶ¦äĶīā’╝īÕ»╣volatileõ┐«ķź░ńÜälong/doubleÕ×ŗÕÅśķćÅńÜäĶ┐øĶĪīńÜäĶ»╗µōŹõĮ£õ╣¤Õģʵ£ēÕÄ¤ÕŁÉµĆ¦ŃĆéÕøĀµŁż’╝īµłæõ╗¼Ķ»┤volatileĶāĮÕż¤õ┐ØķÜ£long/doubleÕ×ŗÕÅśķćÅĶ«┐ķŚ«µōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦ŃĆé
3. õ┐ØķÜ£ÕÅ»Ķ¦üµĆ¦
ÕÅ»Ķ¦üµĆ¦’╝łVisibility’╝ēµś»µīćõĖĆõĖ¬ń║┐ń©ŗ’╝łĶ»╗ń║┐ń©ŗ’╝ēµś»ÕÉ”µł¢ĶĆģÕ£©õ╗Ćõ╣łµāģÕåĄõĖŗĶāĮÕż¤Ķ»╗ÕÅ¢Õł░ÕģČõ╗¢ń║┐ń©ŗ’╝łÕåÖń║┐ń©ŗ’╝ēÕ»╣Õģ▒õ║½ÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░ŃĆéńö▒õ║ÄĶĮ»õ╗ČŃĆüńĪ¼õ╗ČńÜäÕĤÕøĀ’╝īõĖĆõĖ¬ń║┐ń©ŗ’╝łÕåÖń║┐ń©ŗ’╝ēÕ»╣Õģ▒õ║½ÕÅśķćÅĶ┐øĶĪīµø┤µ¢░õ╣ŗÕÉÄ’╝īÕģČõ╗¢ń║┐ń©ŗ’╝łĶ»╗ń║┐ń©ŗ’╝ēÕåŹµØźĶ»╗ÕÅ¢Ķ»źÕÅśķćÅńÜ䵌ČÕĆÖ’╝īĶ┐Öõ║øĶ»╗ń║┐ń©ŗÕÅ»ĶāĮµŚĀµ│ĢĶ»╗ÕÅ¢Õł░ÕåÖń║┐ń©ŗÕ»╣Õģ▒õ║½ÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░’╝īµĖģÕŹĢ3Õ▒Ģńż║õ║åĶ┐Öńé╣ŃĆé
µĖģÕŹĢ3 ÕÅ»Ķ¦üµĆ¦ķŚ«ķóśDemo
public class VisibilityDemo {
public static void main(String[] args) throws InterruptedException {
CountingThread backgroundThread = new CountingThread();
backgroundThread.start();
Thread.sleep(1000);
backgroundThread.cancel();
backgroundThread.join();
System.out.printf("count:%s", backgroundThread.count);
}
}
class CountingThread extends Thread {
// ń║┐ń©ŗÕü£µŁóµĀćÕ┐Ś
private boolean ready = false;
public int count = 0;
@Override
public void run() {
while (!ready) {
count++;
}
}
public void cancel() {
ready = true;
}
}
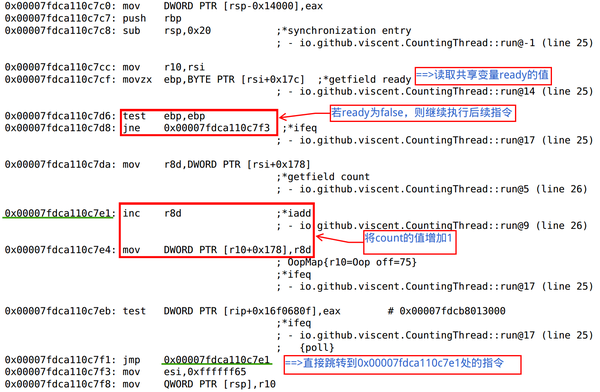
Ķ»źDemoõĖŁ’╝īµłæõ╗¼õĖ║ÕŁÉń║┐ń©ŗbackgroundThread’╝łń▒╗Õ×ŗõĖ║CountingThread’╝ēĶ«ŠńĮ«õ║åõĖĆõĖ¬Õü£µŁóµĀćĶ«░readyŃĆéÕĮōreadyÕĆ╝õĖ║trueµŚČ’╝īÕŁÉń║┐ń©ŗķĆÜĶ┐ćõĮ┐ÕģČrunµ¢╣µ│ĢĶ┐öÕø×ĶĆīÕ«×ńÄ░ń║┐ń©ŗńÜäń╗łµŁóŃĆéńäČĶĆī’╝īõĮ┐ńö©JavaĶÖܵŗ¤µ£║ńÜäserverµ©ĪÕ╝ÅĶ┐ÉĶĪīõĖŖĶ┐░Demo’╝īµłæõ╗¼ÕÅ»õ╗źÕÅæńÄ░Ķ»źDemoõĖŁńÜäÕŁÉń║┐ń©ŗÕ╣ȵ▓Īµ£ēÕāŵłæõ╗¼ķóäµ£¤ńÜäķ鯵ĀĘÕ£©1ń¦ÆķƤõ╣ŗÕÉÄń╗łµŁóĶĆīµś»õĖĆńø┤Õ£©Ķ┐ÉĶĪī’╝üńö▒µŁżÕÅ»Ķ¦ü’╝īõĖ╗ń║┐ń©ŗ’╝łmainń║┐ń©ŗ’╝ēÕ»╣Õģ▒õ║½ÕÅśķćÅreadyµēĆÕüÜńÜäµø┤µ¢░’╝łÕ░åreadyĶ«ŠńĮ«õĖ║true’╝ēÕ╣ȵ▓Īµ£ēĶó½ÕŁÉń║┐ń©ŗbackgroundThreadµēĆĶ»╗ÕÅ¢Õł░ŃĆéń®ČÕģČÕĤÕøĀ’╝īĶ┐Öµś»HotSpotĶÖܵŗ¤µ£║ńÜäC2ń╝¢Ķ»æÕÖ©’╝łJust In Timeń╝¢Ķ»æÕÖ©’╝ēÕ£©Õ░åÕŁŚĶŖéńĀüÕŖ©µĆüń╝¢Ķ»æõĖ║µ£¼Õ£░µ£║ÕÖ©ńĀüńÜäĶ┐ćń©ŗõĖŁµē¦ĶĪīÕŠ¬ńÄ»õĖŹÕÅśķćÅÕż¢µÅÉ’╝ł Loop-invariant code motion’╝ēõ╝śÕī¢ńÜäń╗ōµ×£’╝Üńö▒õ║ÄĶ»źDemoõĖŁńÜäÕģ▒õ║½ÕÅśķćÅreadyÕ╣ȵ▓Īµ£ēķććńö©volatileõ┐«ķź░’╝īÕøĀµŁżC2ń╝¢Ķ»æÕÖ©õ╝ÜĶ«żõĖ║Ķ»źÕÅśķćÅÕ╣ČõĖŹõ╝ÜĶó½ÕżÜõĖ¬ń║┐ń©ŗĶ«┐ķŚ«’╝łÕ«×ķÖģõĖŖµ£ēÕżÜõĖ¬ń║┐ń©ŗĶ«┐ķŚ«Ķ»źÕÅśķćÅ’╝ē’╝īõ║ĵś»C2ń╝¢Ķ»æÕÖ©õĖ║õ║åµÅÉÕŹćõ╗ŻńĀüµē¦ĶĪīµĢłńÄćĶĆīÕ░åCountingThread.run()õĖŁńÜäwhileÕŠ¬ńÄ»Ķ»ŁÕÅźõ╝śÕī¢õĖ║õĖÄÕ”éõĖŗõ╝¬õ╗ŻńĀüńŁēµĢłńÜäµ£║ÕÖ©ńĀü’╝Ü
if (!ready) {// Õ»╣ÕÅśķćÅreadyńÜäÕłżµ¢ŁĶó½µÅÉÕŹćÕł░ÕŠ¬ńÄ»Ķ»ŁÕÅźõ╣ŗÕż¢
while (true) {
count++;
}
}
Ķ┐Öń¦Źõ╝śÕī¢ÕÅ»õ╗źķĆÜĶ┐浤źń£ŗC2ń╝¢Ķ»æÕÖ©µēĆõ║¦ńö¤ńÜäµ▒ćń╝¢õ╗ŻńĀüµØźńĪ«Ķ«ż’╝īÕ”éÕøŠ1µēĆńż║ŃĆéõĖŹÕ╣ĖńÜ䵜»’╝īĶ┐Öń¦Źõ╝śÕī¢Õ»╝Ķć┤õ║åµŁ╗ÕŠ¬ńÄ»’╝ü
ÕøŠ1 C2ń╝¢Ķ»æÕÖ©ÕŠ¬ńÄ»õĖŹÕÅśķćÅÕż¢µÅÉõ╝śÕī¢µēĆõ║¦ńö¤ńÜäµ▒ćń╝¢õ╗ŻńĀü
┬Ā
Õ”éµ×£µłæõ╗¼ķććńö©volatileõ┐«ķź░õĖŖĶ┐░DemoõĖŁńÜäreadyÕÅśķćÅ’╝īķéŻõ╣łC2ń╝¢Ķ»æÕÖ©õŠ┐õ╝ÜŌĆ£µäÅĶ»åŌĆØÕł░readyµś»õĖĆõĖ¬Õģ▒õ║½ÕÅśķćÅ’╝īÕøĀµŁżÕ░▒õĖŹõ╝ÜÕ»╣CountingThread.run()õĖŁńÜäwhileÕŠ¬ńÄ»Ķ»ŁÕÅźµē¦ĶĪīÕŠ¬ńÄ»õĖŹÕÅśķćÅÕż¢µÅÉõ╝śÕī¢õ╗ÄĶĆīķü┐ÕģŹõ║åµŁ╗ÕŠ¬ńÄ»ŃĆé
ÕĮōńäČ’╝īńĪ¼õ╗ČńÜäÕøĀń┤Āõ╣¤ÕÅ»ĶāĮÕ»╝Ķć┤ÕÅ»Ķ¦üµĆ¦ķŚ«ķóśŃĆéÕżäńÉåÕÖ©õĖ║õ║åµÅÉķ½śÕåģÕŁśÕåÖµōŹõĮ£ńÜäµĢłńÄćĶĆīÕ╝ĢÕģźńÜäńĪ¼õ╗Čķā©õ╗ČÕåÖń╝ōÕå▓ÕÖ©’╝łStore Buffer’╝ēÕÆīµŚĀµĢłÕī¢ķś¤ÕłŚ’╝łInvalidate Queue’╝ēķāĮÕÅ»ĶāĮÕ»╝Ķć┤õĖĆõĖ¬ń║┐ń©ŗÕ»╣Õģ▒õ║½ÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░µŚĀµ│ĢĶó½ÕÉÄń╗Łń║┐ń©ŗµēĆĶ»╗ÕÅ¢Õł░ŃĆé
JavaĶ»ŁĶ©ĆĶ¦äĶīāĶ¦äÕ«Ü’╝īÕ»╣õ║ÄÕÉīõĖĆõĖ¬volatileÕÅśķćÅ’╝īõĖĆõĖ¬ń║┐ń©ŗ’╝łÕåÖń║┐ń©ŗ’╝ēÕ»╣Ķ»źÕÅśķćÅĶ┐øĶĪīµø┤µ¢░’╝īÕģČõ╗¢ń║┐ń©ŗ’╝łĶ»╗ń║┐ń©ŗ’╝ēķÜÅÕÉÄÕ»╣Ķ»źÕÅśķćÅĶ┐øĶĪīĶ»╗ÕÅ¢’╝īĶ┐Öõ║øń║┐ń©ŗµĆ╗µś»ÕÅ»õ╗źĶ»╗ÕÅ¢Õł░ÕåÖń║┐ń©ŗÕ»╣Ķ»źÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░ŃĆ鵏óĶĆīĶ©Ćõ╣ŗ’╝īÕåÖń║┐ń©ŗµø┤µ¢░õĖĆõĖ¬volatileÕÅśķćÅ’╝īĶ»╗ń║┐ń©ŗķÜÅÕÉÄµØźĶ»╗ÕÅ¢Ķ»źÕÅśķćÅ’╝īķéŻõ╣łĶ┐Öõ║øĶ»╗ń║┐ń©ŗĶāĮÕż¤Ķ»╗ÕÅ¢Õł░ÕåÖń║┐ń©ŗÕ»╣Ķ»źÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░Ķ┐ÖõĖĆńé╣µś»µ£ēõ┐ØķÜ£ńÜä’╝łĶĆīõĖŹµś»ńó░Ķ┐ɵ░ö’╝ü’╝ēŃĆéõĖŹĶ┐ć’╝īńö▒õ║ÄvolatileÕ╣ČõĖŹÕģʵ£ēķöüķ鯵ĀĘńÜäµÄÆõ╗¢µĆ¦’╝īÕøĀµŁżvolatileÕ╣ČõĖŹĶāĮÕż¤õ┐ØķÜ£Ķ»╗ń║┐ń©ŗµēĆĶ»╗ÕÅ¢Õł░ÕÅśķćÅÕĆ╝µś»Õģ▒õ║½ÕÅśķćÅńÜäµ£Ćµ¢░ÕĆ╝’╝ÜĶ»╗ń║┐ń©ŗÕ£©Ķ»╗ÕÅ¢õĖĆõĖ¬volatileÕÅśķćÅńÜäķéŻõĖĆÕł╗’╝īÕģČõ╗¢ń║┐ń©ŗ’╝łÕåÖń║┐ń©ŗ’╝ēÕÅ»ĶāĮÕÅłµü░ÕźĮµø┤µ¢░õ║åĶ»źÕÅśķćÅ’╝īÕøĀµŁżĶ»╗ń║┐ń©ŗµēĆĶ»╗ÕÅ¢Õł░Õģ▒õ║½ÕÅśķćÅÕĆ╝õ╗ģõ╗ģµś»õĖĆõĖ¬ńøĖÕ»╣µ¢░ÕĆ╝’╝īÕŹ│ÕģČõ╗¢ń║┐ń©ŗµø┤µ¢░Ķ┐ćńÜäÕĆ╝’╝łõĖŹõĖĆիܵś»µ£Ćµ¢░ÕĆ╝’╝ēŃĆé
4. Õ░Åń╗ō
õ╗źõĖŖµłæõ╗¼õ╗ŗń╗Źõ║åvolatileÕģ│ķö«ÕŁŚÕ»╣long/doubleÕ×ŗÕÅśķćÅĶ«┐ķŚ«µōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦õ┐ØķÜ£õ╗źÕÅŖÕ»╣ÕÅ»Ķ¦üµĆ¦ńÜäõ┐ØķÜ£ŃĆéµÄźõĖŗµØźµłæõ╗¼Õ░åõ╗ŗń╗ŹvolatileÕ»╣µ£ēÕ║ÅµĆ¦ńÜäõ┐ØķÜ£’╝īÕ╣ČķĆÜĶ┐ćõ╗ŗń╗ŹJavaÕåģÕŁśµ©ĪÕ×ŗõĖŁńÜäHappens-beforeÕģ│ń│╗Ķ┐ÖõĖƵ”éÕ┐ĄµØźµĘ▒ÕģźńÉåĶ¦ŻvolatileÕ»╣ÕÅ»Ķ¦üµĆ¦ÕÆīµ£ēÕ║ÅµĆ¦ńÜäõ┐ØķÜ£ŃĆé
5. õ┐ØķÜ£µ£ēÕ║ÅµĆ¦
õĖĆõĖ¬ÕżäńÉåÕÖ©õĖŖńÜäń║┐ń©ŗµēƵē¦ĶĪīńÜäõĖĆń╗äµōŹõĮ£Õ£©ÕģČõ╗¢ÕżäńÉåÕÖ©õĖŖńÜäń║┐ń©ŗń£ŗµØźÕÅ»ĶāĮµś»õ╣▒Õ║ÅńÜä’╝łOut-of-order’╝ē’╝īÕŹ│Ķ┐Öõ║øń║┐ń©ŗÕ»╣Ķ┐Öń╗äµōŹõĮ£õĖŁńÜäÕÉäõĖ¬µōŹõĮ£ńÜäµä¤ń¤źķĪ║Õ║Å’╝łĶ¦éÕ»¤Õł░ńÜäķĪ║Õ║Å’╝ēõĖÄń©ŗÕ║ÅķĪ║Õ║Å’╝łńø«µĀćõ╗ŻńĀüõĖŁµīćÕ«ÜńÜäķĪ║Õ║Å’╝ēõĖŹõĖĆĶć┤ŃĆé
õĖŗķØóµłæõ╗¼ń£ŗõĖĆõĖ¬õ╣▒Õ║ÅÕ«×ķ¬ī’╝īÕ”éµĖģÕŹĢ4µēĆńż║ŃĆé
µĖģÕŹĢ4 JITń╝¢Ķ»æÕÖ©µīćõ╗żķ揵ÄÆÕ║ÅDemo
/**
*
* ÕåŹńÄ░JITµīćõ╗żķ揵ÄÆÕ║ÅńÜäDemo
*
*
*
* @author Viscent Huang
*
*/
@ConcurrencyTest(iterations = 200000)
public class JITReorderingDemo {
private int externalData = 1;
private Helper helper;
@Actor
public void createHelper() {
helper = new Helper(externalData);
}
@Observer({
@Expect(desc = "Helper is null", expected = -1),
@Expect(desc = "Helper is not null,but it is not initialized",
expected = 0),
@Expect(desc = "Only 1 field of Helper instance was initialized",
expected = 1),
@Expect(desc = "Only 2 fields of Helper instance were initialized",
expected = 2),
@Expect(desc = "Only 3 fields of Helper instance were initialized",
expected = 3),
@Expect(desc = "Helper instance was fully initialized", expected = 4) })
public int consume() {
int sum = 0;
/*
*
* ńö▒õ║ĵłæõ╗¼µ£¬Õ»╣Õģ▒õ║½ÕÅśķćÅhelperĶ┐øĶĪīõ╗╗õĮĢÕżäńÉå’╝łµ»öÕ”éķććńö©volatileÕģ│ķö«ÕŁŚõ┐«ķź░Ķ»źÕÅśķćÅ’╝ē’╝ī
*
* ÕøĀµŁż’╝īĶ┐ÖķćīÕÅ»ĶāĮÕŁśÕ£©ÕÅ»Ķ¦üµĆ¦ķŚ«ķóś’╝īÕŹ│ÕĮōÕēŹń║┐ń©ŗĶ»╗ÕÅ¢Õł░ńÜäÕÅśķćÅÕĆ╝ÕÅ»ĶāĮõĖ║nullŃĆé
*
*/
final Helper observedHelper = helper;
if (null == observedHelper) {
sum = -1;
} else {
sum = observedHelper.payloadA + observedHelper.payloadB
+ observedHelper.payloadC + observedHelper.payloadD;
}
return sum;
}
static class Helper {
int payloadA;
int payloadB;
int payloadC;
int payloadD;
public Helper(int externalData) {
this.payloadA = externalData;
this.payloadB = externalData;
this.payloadC = externalData;
this.payloadD = externalData;
}
}
public static void main(String[] args) throws InstantiationException,
IllegalAccessException {
// Ķ░āńö©µĄŗĶ»ĢÕĘźÕģĘĶ┐ÉĶĪīµĄŗĶ»Ģõ╗ŻńĀü
TestRunner.runTest(JITReorderingDemo.class);
}
}
µĖģÕŹĢ4õĖŁńÜäń©ŗÕ║ÅķØ×ÕĖĖń«ĆÕŹĢ’╝łĶ»╗ĶĆģÕÅ»õ╗źÕ┐ĮńĢźÕģČõĖŁńÜäµ│©Ķ¦Ż’╝īÕøĀõĖ║ķ鯵ś»ń╗ÖµĄŗĶ»ĢÕĘźÕģĘńö©ńÜä’╝ē’╝ÜcreateHelperµ¢╣µ│Ģõ╝ÜÕ░åÕ«×õŠŗÕÅśķćÅhelperµø┤µ¢░õĖ║õĖĆõĖ¬µ¢░ÕłøÕ╗║ńÜäHelperÕ«×õŠŗ’╝øconsumeµ¢╣µ│Ģõ╝ÜĶ»╗ÕÅ¢helperµēĆÕ╝Ģńö©ńÜäHelperÕ«×õŠŗ’╝īÕ╣ČĶ«Īń«ŚĶ»źÕ«×õŠŗńÜäµēƵ£ēÕŁŚµ«Ą’╝łpayloadA~payloadD’╝ēńÜäÕĆ╝õ╣ŗÕÆīõĮ£õĖ║ÕģČĶ┐öÕø×ÕĆ╝ŃĆéĶ»źń©ŗÕ║ÅńÜämainµ¢╣µ│ĢĶ░āńö©µĄŗĶ»ĢÕĘźÕģĘTestRunnerńÜärunTestµ¢╣µ│ĢńÜäõĮ£ńö©µś»Ķ«®µĄŗĶ»ĢÕĘźÕģĘÕ«ēµÄÆõĖĆõ║øń║┐ń©ŗÕ╣ČÕÅæÕ£░µē¦ĶĪīcreateHelperµ¢╣µ│ĢÕÆīconsumeµ¢╣µ│Ģ’╝īÕ╣Čń╗¤Ķ«Īconsumeµ¢╣µ│ĢÕżÜµ¼Īµē¦ĶĪīńÜäĶ┐öÕø×ÕĆ╝ŃĆéńö▒õ║ÄcreateHelperµ¢╣µ│ĢÕłøÕ╗║HelperÕ«×õŠŗńÜ䵌ČÕĆÖõĮ┐ńö©ńÜäµ×äķĆĀÕÖ©ÕÅéµĢ░externalDataÕĆ╝õĖ║1’╝īÕøĀµŁżĶ┐ÖµĀĘń£ŗµØźconsumeµ¢╣µ│ĢńÜäĶ┐öÕø×ÕĆ╝õ╝╝õ╣ÄŌĆ£ńÉåµēĆÕĮōńäČŌĆØÕ£░Õ║öĶ»źµś»4ŃĆéńäČĶĆī’╝īõ║ŗÕ«×ÕŹ┤Õ╣ČõĖŹµĆ╗µś»Õ”鵣żŃĆéõĮ┐ńö©Õ”éõĖŗÕæĮõ╗żõ╗źserverµ©ĪÕ╝ÅÕ╣ČĶ«ŠńĮ«JavaĶÖܵŗ¤µ£║ÕÅéµĢ░ŌĆ£-XX:-UseCompressedOopsŌĆØĶ┐ÉĶĪīµĖģÕŹĢ4µēĆńż║ńÜäń©ŗÕ║Å[1]’╝Ü
java -server -XX:-UseCompressedOops JITReorderingDemo
µłæõ╗¼ÕÅ»õ╗źń£ŗÕł░ń▒╗õ╝╝Õ”éõĖŗńÜäĶŠōÕć║[2]’╝Ü
expected:-1 occurrences:8 ==>Helper is null
expected:0 occurrences:2 ==>Helper is not null,but it is not initialized
expected:1 occurrences:0 ==>Only 1 field of Helper instance was initialized
expected:2 occurrences:1 ==>Only 2 fields of Helper instance were initialized
expected:3 occurrences:4 ==>Only 3 fields of Helper instance were initialized
expected:4 occurrences:199985 ==>Helper instance was fully initialized
õĖŖķØóńÜäĶŠōÕć║õĖŁ’╝īexpectedÕÉÄķØóńÜäµĢ░ÕŁŚĶĪ©ńż║consumeµ¢╣µ│ĢńÜäĶ┐öÕø×ÕĆ╝’╝īńøĖÕ║öńÜäoccurrencesĶĪ©ńż║Õć║ńÄ░ńøĖÕ║öĶ┐öÕø×ÕĆ╝ńÜäµ¼ĪµĢ░ŃĆé
õĖŹķÜŠń£ŗÕć║Ķ┐Öµ¼Īń©ŗÕ║ÅĶ┐ÉĶĪīµŚČ’╝īµ£ēÕćĀµ¼Īconsumeµ¢╣µ│ĢńÜäĶ┐öÕø×ÕĆ╝Õ╣ČõĖŹõĖ║4’╝ܵ£ēńÜäõĖ║3’╝łÕć║ńÄ░4µ¼Ī’╝ēŃĆüµ£ēńÜäõĖ║2’╝łÕć║ńÄ░1µ¼Ī’╝ē’╝īńöÜĶć│Ķ┐śµ£ēńÜäõĖ║0’╝łÕć║ńÄ░2µ¼Ī’╝ē’╝üĶ┐ÖĶ»┤µśÄconsumeµ¢╣µ│ĢńÜäµē¦ĶĪīń║┐ń©ŗµ£ēµŚČÕĆÖĶ»╗ÕÅ¢Õł░õ║åõĖĆõĖ¬µ£¬ÕłØÕ¦ŗÕī¢Õ«īµ»Ģ’╝łµł¢ĶĆģµŁŻÕ£©ÕłØÕ¦ŗÕī¢’╝ēńÜäHelperÕ«×õŠŗ’╝ÜHelperÕ«×õŠŗõĖŹõĖ║null’╝īõĮåµś»ÕģČķā©ÕłåÕ«×õŠŗÕŁŚµ«ĄńÜäÕŁŚµ«ĄÕĆ╝õ╗ŹńäČõĖ║ÕģČķ╗śĶ«żÕĆ╝ĶĆīķØ×Helperń▒╗ńÜäµ×äķĆĀÕÖ©õĖŁµīćÕ«ÜńÜäÕłØÕ¦ŗÕĆ╝ŃĆéõĖŗķØóµłæõ╗¼Õłåµ×ÉÕģČõĖŁńÜäÕĤÕøĀŃĆé
µłæõ╗¼ń¤źķüō’╝īcreateHelperµ¢╣µ│ĢõĖŁńÜäÕö»õĖĆõĖƵØĪĶ»ŁÕÅź’╝Ü
helper = new Helper(externalData);
ÕÅ»õ╗źÕłåĶ¦ŻõĖ║õ╗źõĖŗÕćĀõĖ¬ÕŁÉµōŹõĮ£’╝łõ╝¬õ╗ŻńĀüĶĪ©ńż║’╝ē’╝Ü
objRef = allocate(Helper.class);//ÕŁÉµōŹõĮ£ŌæĀ’╝ÜÕłåķģŹHelperÕ«×õŠŗµēĆķ£ĆńÜäÕåģÕŁśń®║ķŚ┤’╝īÕ╣ČĶÄĘÕŠŚõĖĆõĖ¬µīćÕÉæĶ»źń®║ķŚ┤ńÜäÕ╝Ģńö©
inovkeConstructor(objRef)’╝ø//ÕŁÉµōŹõĮ£ŌæĪ’╝ÜĶ░āńö©Helperń▒╗ńÜäµ×äķĆĀÕÖ©ÕłØÕ¦ŗÕī¢objRefÕ╝Ģńö©µīćÕÉæńÜäHelperÕ«×õŠŗ
helper = objRef’╝ø//ÕŁÉµōŹõĮ£Ōæó’╝ÜÕ░åHelperÕ«×õŠŗÕ╝Ģńö©objRefĶĄŗÕĆ╝ń╗ÖÕ«×õŠŗÕÅśķćÅhelper
ķĆÜĶ┐浤źń£ŗJavaÕŁŚĶŖéńĀüõĖŹķÜŠÕÅæńÄ░createHelperµ¢╣µ│ĢõĖŁµīćÕ«ÜńÜäń©ŗÕ║ÅķĪ║Õ║ÅÕ░▒µś»õĖŖĶ┐░ńÜäÕģłÕłØÕ¦ŗÕī¢HelperÕ«×õŠŗ’╝łÕŁÉµōŹõĮ£ŌæĪ’╝ēÕåŹÕ░åńøĖÕ║öńÜäÕ«×õŠŗńÜäÕ╝Ģńö©ĶĄŗÕĆ╝ń╗ÖÕ«×õŠŗÕÅśķćÅhelper’╝łÕŁÉµōŹõĮ£Ōæó’╝ēŃĆéńäČĶĆī’╝īconsumeµ¢╣µ│ĢńÜäµē¦ĶĪīń║┐ń©ŗÕŹ┤Ķ¦éÕ»¤Õł░õ║åµ£¬ÕłØÕ¦ŗÕī¢Õ«īµ»ĢńÜäHelperÕ«×õŠŗ’╝īĶ┐ÖĶ»┤µśÄĶ»źń║┐ń©ŗÕ»╣createHelperµ¢╣µ│ĢµēƵē¦ĶĪīńÜäµōŹõĮ£ńÜäµä¤ń¤źķĪ║Õ║ÅõĖÄĶ»źµ¢╣µ│ĢµēƵīćÕ«ÜńÜäń©ŗÕ║ÅķĪ║Õ║ÅõĖŹõĖĆĶć┤’╝īÕŹ│õ║¦ńö¤õ║åõ╣▒Õ║ÅŃĆé
µ¤źń£ŗõĖŖĶ┐░ń©ŗÕ║ÅĶ┐ÉĶĪīĶ┐ćń©ŗõĖŁJITń╝¢Ķ»æÕÖ©ÕŖ©µĆüńö¤µłÉńÜäµ▒ćń╝¢õ╗ŻńĀü’╝łńøĖÕĮōõ║ĵ£║ÕÖ©ńĀü’╝ē’╝īÕ”éÕøŠ2µēĆńż║’╝īµłæõ╗¼ÕÅ»õ╗źÕÅæńÄ░JITń╝¢Ķ»æÕÖ©ń╝¢Ķ»æÕŁŚĶŖéńĀüńÜ䵌ČÕĆÖÕ╣ČõĖŹµś»µ»Åµ¼ĪķāĮµīēńģ¦õĖŖĶ┐░µ║Éõ╗ŻńĀüķĪ║Õ║Å’╝łĶ┐ÖķćīÕÉīµŚČõ╣¤µś»ń©ŗÕ║ÅķĪ║Õ║Å’╝ēńö¤µłÉńøĖÕ║öńÜäµ£║ÕÖ©ńĀü’╝łµ▒ćń╝¢õ╗ŻńĀü’╝ē’╝ÜJITń╝¢Ķ»æÕÖ©Õ░åÕŁÉµōŹõĮ£ŌæóńøĖÕ║öńÜäµīćõ╗żķ揵ÄÆÕł░ÕŁÉµōŹõĮ£ŌæĪńøĖÕ║öńÜäµīćõ╗żõ╣ŗÕēŹ’╝īÕŹ│JITń╝¢Ķ»æÕÖ©Õ£©ÕłØÕ¦ŗÕī¢HelperÕ«×õŠŗõ╣ŗÕēŹÕÅ»ĶāĮÕĘ▓ń╗ÅÕ░åÕ»╣Ķ»źÕ«×õŠŗńÜäÕ╝Ģńö©ÕåÖÕģźhelperÕ«×õŠŗÕÅśķćÅŃĆéĶ┐ÖÕ░▒Õ»╝Ķć┤õ║åÕģČõ╗¢ń║┐ń©ŗ’╝łconsumeµ¢╣µ│ĢńÜäµē¦ĶĪīń║┐ń©ŗ’╝ēń£ŗÕł░helperÕ«×õŠŗÕÅśķćÅ’╝łõĖŹõĖ║null’╝ēńÜ䵌ČÕĆÖ’╝īĶ»źÕ«×õŠŗÕÅśķćŵēĆÕ╝Ģńö©ńÜäÕ»╣Ķ▒ĪÕÅ»ĶāĮĶ┐śµ▓Īµ£ēĶó½ÕłØÕ¦ŗÕī¢µł¢ĶĆģµ£¬ÕłØÕ¦ŗÕī¢Õ«īµ»Ģ’╝łÕŹ│ńøĖÕ║öµ×äķĆĀÕÖ©õĖŁńÜäõ╗ŻńĀüµ£¬µē¦ĶĪīń╗ōµØ¤’╝ēŃĆéĶ┐ÖÕ░▒Ķ¦ŻķćŖõ║åõĖ║õ╗Ćõ╣łµłæõ╗¼Õ£©Ķ┐ÉĶĪīõĖŖĶ┐░ń©ŗÕ║ÅńÜ䵌ČÕĆÖ’╝īconsumeµ¢╣µ│ĢńÜäĶ┐öÕø×ÕĆ╝µ£ēµŚČÕĆÖÕ╣ČõĖŹµś»4ŃĆé
ÕøŠ2 JITń╝¢Ķ»æÕÖ©ķ揵ÄÆÕ║ÅDemoõĖŁńÜäµ▒ćń╝¢õ╗ŻńĀüńē浫Ą
┬Ā
ĶÖĮńäČõ╣▒Õ║ŵ£ēÕł®õ║ÄÕģģÕłåÕÅæµīźÕżäńÉåÕÖ©ńÜäµīćõ╗żµē¦ĶĪīµĢłńÄć’╝īõĮåµś»µŁŻÕ”éõĖŖĶ┐░Õ«×ķ¬īµēĆÕ▒Ģńż║ńÜä’╝īÕ«āõ╣¤ÕÅ»ĶāĮÕ»╝Ķć┤ń©ŗÕ║ŵŁŻńĪ«µĆ¦ńÜäķŚ«ķóśŃĆéµēĆõ╗ź’╝īõĖ║õ║åõ┐ØķÜ£ń©ŗÕ║ÅńÜ䵣ŻńĪ«µĆ¦’╝īµ£ēµŚČÕĆÖµłæõ╗¼ķ£ĆĶ”üńĪ«õ┐Øń║┐ń©ŗÕ»╣õĖĆń╗äµōŹõĮ£ńÜäµä¤ń¤źķĪ║Õ║ÅõĖÄĶ┐Öń╗äµōŹõĮ£ńÜäń©ŗÕ║ÅķĪ║Õ║Åõ┐صīüõĖĆĶć┤’╝īÕŹ│õ┐ØķÜ£Ķ┐Öń╗äµōŹõĮ£ńÜäµ£ēÕ║ÅµĆ¦ŃĆéõĖŖĶ┐░Õ«×ķ¬īõĖŁ’╝īõĖ║õ║åńĪ«õ┐Øconsumeµ¢╣µ│ĢńÜäµē¦ĶĪīń║┐ń©ŗń£ŗÕł░ńÜäHelperÕ«×õŠŗµĆ╗µś»ÕłØÕ¦ŗÕī¢Õ«īµ»ĢńÜä’╝īµłæõ╗¼ķ£ĆĶ”üńĪ«õ┐ØcreateHelperµ¢╣µ│ĢµēƵē¦ĶĪīńÜäµōŹõĮ£ńÜäµ£ēÕ║ÅµĆ¦ŃĆéõĖ║µŁż’╝īµłæõ╗¼ÕŬķ£ĆĶ”üńö©volatileÕģ│ķö«ÕŁŚµØźõ┐«ķź░Õ«×õŠŗÕÅśķćÅhelperÕŹ│ÕÅ»’╝īĶĆīµŚĀķ£ĆÕƤÕŖ®ķöüŃĆéĶ┐Öķćī’╝īvolatileÕģ│ķö«ÕŁŚµēĆĶĄĘńÜäõĮ£ńö©µś»ķĆÜĶ┐ćń”üµŁóÕŁÉµōŹõĮ£ŌæĪĶó½JITń╝¢Ķ»æÕÖ©õ╗źÕÅŖÕżäńÉåÕÖ©ķ揵ÄÆÕ║Å’╝łµīćõ╗żķ揵ÄÆÕ║ÅŃĆüÕåģÕŁśķ揵ÄÆÕ║Å’╝ēÕł░ÕŁÉµōŹõĮ£Ōæóõ╣ŗÕÉÄ’╝īõ╗ÄĶĆīõ┐ØķÜ£õ║åµ£ēÕ║ÅµĆ¦ŃĆé
JavaĶ»ŁĶ©ĆĶ¦äĶīāĶ¦äÕ«Ü’╝īÕ»╣õ║ÄĶ«┐ķŚ«’╝łĶ»╗ŃĆüÕåÖ’╝ēÕÉīõĖĆõĖ¬volatileÕÅśķćÅńÜäÕżÜõĖ¬ń║┐ń©ŗĶĆīĶ©Ć’╝īõĖĆõĖ¬ń║┐ń©ŗ’╝łÕåÖń║┐ń©ŗ’╝ēÕ£©ÕåÖvolatileÕÅśķćÅÕēŹµēƵē¦ĶĪīńÜäÕåģÕŁśĶ»╗ŃĆüÕåÖµōŹõĮ£Õ£©ķÜÅÕÉÄĶ»╗ÕÅ¢Ķ»źvolatileÕÅśķćÅńÜäÕģČõ╗¢ń║┐ń©ŗ’╝łĶ»╗ń║┐ń©ŗ’╝ēń£ŗµØźµś»µ£ēÕ║ÅńÜäŃĆéĶ«ŠXŃĆüYµś»µÖ«ķĆÜ’╝łķØ×volatile’╝ēÕģ▒õ║½ÕÅśķćÅ’╝īÕģČÕłØÕ¦ŗÕĆ╝ÕØćõĖ║0’╝īVµś»volatileÕÅśķćÅ’╝īÕģČÕłØÕ¦ŗÕĆ╝õĖ║false’╝īr1ŃĆür2µś»Õ▒Ćķā©ÕÅśķćÅ’╝īń║┐ń©ŗT1ÕÆīT2ÕģłÕÉÄĶ«┐ķŚ«V’╝īÕ”éÕøŠ3µēĆńż║ŃĆéķéŻõ╣ł’╝īT1Õ»╣VńÜäµø┤µ¢░õ╗źÕÅŖµø┤µ¢░VÕēŹµēƵē¦ĶĪīńÜäµōŹõĮ£Õ£©T2ń£ŗµØźµś»µ£ēÕ║ÅńÜä’╝ÜÕ£©T2ń£ŗµØźT1Õ»╣XŃĆüYÕÆīVńÜäÕåÖµōŹõĮ£Õ░▒Õāŵś»Õ«īÕģ©õŠØńģ¦ń©ŗÕ║ÅķĪ║Õ║ŵē¦ĶĪīńÜäŃĆ鵏óĶĆīĶ©Ćõ╣ŗ’╝īÕ”éµ×£T2Ķ»╗ÕÅ¢Õł░VńÜäÕĆ╝õĖ║true’╝īķéŻõ╣łĶ»źń║┐ń©ŗµēĆĶ»╗ÕÅ¢Õł░ńÜäXÕÆīYńÜäÕĆ╝Õ┐ģńäČõĖ║ÕłåÕł½õĖ║1ÕÆī2ŃĆéńøĖÕÅŹ’╝īÕ”éµ×£VõĖŹµś»volatileÕÅśķćÅ’╝īķéŻõ╣łõĖŖĶ┐░Ķ┐Öń¦Źõ┐ØĶ»üÕ░▒õĖŹÕŁśÕ£©’╝īÕŹ│T2Ķ»╗ÕÅ¢Õł░VńÜäÕĆ╝õĖ║trueµŚČ’╝īT2µēĆĶ»╗ÕÅ¢Õł░XÕÆīYńÜäÕĆ╝ÕÅ»ĶāĮÕ╣ČķØ×1ÕÆī2ŃĆé
ÕøŠ3 volatileÕģ│ķö«ÕŁŚńÜäµ£ēÕ║ÅµĆ¦õ┐ØķÜ£ńż║õŠŗõ╗ŻńĀü

┬Ā
õĖŖĶ┐░õŠŗÕŁÉõĖŁ’╝īµłæõ╗¼ÕüćĶ«ŠÕŬµ£ēõĖĆõĖ¬ń║┐ń©ŗµø┤µ¢░V’╝łÕÅ”Õż¢õĖĆõĖ¬ń║┐ń©ŗĶ»╗ÕÅ¢V’╝ē’╝īÕ”éµ×£µ£ēµø┤ÕżÜńÜäń║┐ń©ŗÕ╣ČÕÅæµø┤µ¢░V’╝īķéŻõ╣łńö▒õ║ÄvolatileÕ╣ČõĖŹÕģʵ£ēµÄÆõ╗¢µĆ¦’╝īÕøĀµŁżÕ£©T2Ķ»╗ÕÅ¢VńÜ䵌ČÕĆÖT1õ╣ŗÕż¢ńÜäÕģČõ╗¢ń║┐ń©ŗÕÅ»ĶāĮÕĘ▓ń╗ÅÕÅłµø┤µ¢░õ║åÕģ▒õ║½ÕÅśķćÅXŃĆüY’╝īĶ┐ÖÕ░▒õĮ┐ÕŠŚT2Õ£©ÕģČĶ»╗ÕÅ¢Õł░VńÜäÕĆ╝õĖ║trueńÜäµāģÕåĄõĖŗ’╝īÕģČĶ»╗ÕÅ¢Õł░XÕÆīYńÜäÕĆ╝ÕÅ»ĶāĮõĖŹµś»1ÕÆī2ŃĆéõĖŹĶ┐ć’╝īĶ┐Öń¦ŹńÄ░Ķ▒Īµś»µĢ░µŹ«ń½×õ║ēńÜäń╗ōµ×£’╝īĶ┐ÖõĖÄvolatileĶāĮÕż¤õ┐ØķÜ£µ£ēÕ║ÅµĆ¦µ£¼Ķ║½Õ╣ČõĖŹń¤øńøŠŃĆé
6. Happens-beforeÕģ│ń│╗
õ║åĶ¦ŻJavaÕåģÕŁśµ©ĪÕ×ŗ’╝łJava Memory Model’╝ēõĖŁńÜäÕ«Üõ╣ēńÜäHappens-beforeÕģ│ń│╗’╝łHappens-before Relationship’╝ēĶ┐ÖõĖƵ”éÕ┐Ąµ£ēÕŖ®õ║ĵłæõ╗¼Ķ┐øõĖƵŁźńÉåĶ¦ŻvolatileÕÅśķćÅÕ»╣ÕÅ»Ķ¦üµĆ¦ÕÆīµ£ēÕ║ÅµĆ¦ńÜäõ┐ØķÜ£ŃĆé
JavaÕåģÕŁśµ©ĪÕ×ŗÕ«Üõ╣ēõ║åõĖĆõ║øÕŖ©õĮ£’╝łAction’╝ēŃĆéĶ┐Öõ║øÕŖ©õĮ£Õīģµŗ¼ÕÅśķćÅńÜäĶ»╗/ÕåÖŃĆüķöüńÜäńö│Ķ»Ę’╝łlock’╝ēõĖÄķćŖµöŠ’╝łunlock’╝ēõ╗źÕÅŖń║┐ń©ŗńÜäÕÉ»ÕŖ©’╝łThread.start()Ķ░āńö©’╝ēÕÆīÕŖĀÕģź’╝łThread.join()Ķ░āńö©’╝ēńŁēŃĆéÕ”éµ×£ÕŖ©õĮ£AÕÆīÕŖ©õĮ£Bõ╣ŗķŚ┤ÕŁśÕ£©Happens-beforeÕģ│ń│╗’╝īķéŻõ╣łÕŖ©õĮ£AńÜäµē¦ĶĪīń╗ōµ×£Õ»╣ÕŖ©õĮ£BÕÅ»Ķ¦üŃĆéÕÅŹõ╣ŗ’╝īÕ”éµ×£ÕŖ©õĮ£AÕÆīÕŖ©õĮ£Bõ╣ŗķŚ┤õĖŹÕŁśÕ£©Happens-beforeÕģ│ń│╗’╝īķéŻõ╣łÕŖ©õĮ£AńÜäµē¦ĶĪīń╗ōµ×£Õ»╣BµØźĶ»┤õĖŹõĖĆիܵś»ÕÅ»Ķ¦üńÜäŃĆéõĖŗµ¢ćµłæõ╗¼ńö©ŌĆ£ŌåÆŌĆØµØźĶĪ©ńż║Happens-beforeÕģ│ń│╗’╝īõŠŗÕ”éŌĆ£AŌåÆBŌĆØĶĪ©ńż║ÕŖ©õĮ£AõĖÄÕŖ©õĮ£BÕŁśÕ£©Happens-beforeÕģ│ń│╗ŃĆé
JavaÕåģÕŁśµ©ĪÕ×ŗõĖŁńÜävolatileÕÅśķćÅĶ¦äÕłÖ’╝łVolatile Variable Rule’╝ēĶ¦äÕ«Ü’╝īÕ»╣õĖĆõĖ¬volatileÕÅśķćÅńÜäÕåÖµōŹõĮ£happens-beforeÕÉÄń╗Ł’╝łSubsequent’╝ēµ»ÅõĖĆõĖ¬ķÆłÕ»╣Ķ»źÕÅśķćÅńÜäĶ»╗µōŹõĮ£ŃĆéĶ┐Öķćīµ£ēõĖżńé╣ķ£ĆĶ”üµ│©µäÅ’╝Üķ”¢Õģł’╝īķÆłÕ»╣ÕÉīõĖĆõĖ¬volatileÕÅśķćÅńÜäÕåÖŃĆüĶ»╗µōŹõĮ£õ╣ŗķŚ┤µēŹµ£ēhappens-beforeÕģ│ń│╗’╝īõĖŹÕÉīvolatileÕÅśķćÅõ╣ŗķŚ┤ńÜäÕåÖŃĆüĶ»╗µōŹõĮ£Õ╣ȵŚĀhappens-beforeÕģ│ń│╗’╝øÕģȵ¼Ī’╝īķÆłÕ»╣ÕÉīõĖĆõĖ¬volatileÕÅśķćÅńÜäÕåÖŃĆüĶ»╗µōŹõĮ£Õ┐ģķĪ╗Õģʵ£ēµŚČķŚ┤õĖŖńÜäÕģłÕÉÄÕģ│ń│╗’╝īÕŹ│õĖĆõĖ¬ń║┐ń©ŗÕģłÕåÖÕÅ”Õż¢õĖĆõĖ¬ń║┐ń©ŗÕåŹµØźĶ»╗Ķ┐ÖµĀĘĶ┐ÖõĖżõĖ¬ÕŖ©õĮ£õ╣ŗķŚ┤µēŹĶāĮÕż¤µ£ēhappens-beforeÕģ│ń│╗ŃĆéÕøĀµŁż’╝īÕ»╣õ║ÄÕøŠ2ÕÅ»µ£ēwVŌåÆrV’╝īÕŹ│ÕŖ©õĮ£wV’╝łÕåÖvolatileÕÅśķćÅV’╝ēńÜäń╗ōµ×£Õ»╣rV’╝łĶ»╗volatileÕÅśķćÅV’╝ēÕÅ»Ķ¦üŃĆé
JavaÕåģÕŁśµ©ĪÕ×ŗõĖŁń©ŗÕ║ÅķĪ║Õ║ÅĶ¦äÕłÖ’╝łProgram Order Rule’╝ēĶ¦äÕ«ÜÕÉīõĖĆõĖ¬ń║┐ń©ŗõĖŁńÜäµ»ÅõĖĆõĖ¬ÕŖ©õĮ£ķāĮhappens-beforeĶ»źń║┐ń©ŗõĖŁń©ŗÕ║ÅķĪ║Õ║ÅõĖŖµÄÆÕ£©Ķ»źÕŖ©õĮ£õ╣ŗÕÉÄńÜäµ»ÅõĖĆõĖ¬ÕŖ©õĮ£ŃĆéÕøĀµŁż’╝īÕ»╣õ║ÄÕøŠ3ÕÅ»µ£ēÕ”éõĖŗńÜähappens-beforeÕģ│ń│╗’╝Ü
wXŌåÆwY ’╝łhb1’╝ē
wYŌåÆwV’╝łhb2’╝ē
rVŌåÆrX ’╝łhb3’╝ē
rXŌåÆrY’╝łhb4’╝ē
Happens-beforeÕģ│ń│╗Õģʵ£ēõ╝ĀķĆÆµĆ¦’╝īÕŹ│Õ”éµ×£AŌåÆB’╝īBŌåÆC’╝īķéŻõ╣łÕ░▒µ£ēAŌåÆCŃĆéÕøĀµŁż’╝īńö▒hb1ÕÆīhb2ÕŻՊŚÕć║õ╗źõĖŗhappens-beforeÕģ│ń│╗’╝Ü
wXŌåÆwV’╝łhb5’╝ē
ÕåŹµĀ╣µŹ«volatileÕÅśķćÅĶ¦äÕłÖ’╝īÕÅ»µ£ēhappens-beforeÕģ│ń│╗’╝Ü
wVŌåÆrV’╝łhb6’╝ē
Ķ┐øõĖƵŁźµĀ╣µŹ«happens-beforeÕģ│ń│╗ńÜäõ╝ĀķĆÆµĆ¦ńö▒hb5ÕÆīhb6ÕŻՊŚÕć║õ╗źõĖŗhappens-beforeÕģ│ń│╗’╝Ü
wXŌåÆrV’╝łhb7’╝ē
ÕÉīµĀʵĀ╣µŹ«happens-beforeÕģ│ń│╗ńÜäõ╝ĀķĆÆµĆ¦ńö▒hb7ÕÆīhb3ÕŻՊŚÕć║õ╗źõĖŗhappens-beforeÕģ│ń│╗’╝Ü
wXŌåÆrX’╝łhb8’╝ē
ÕÉīńÉå’╝īµłæõ╗¼õ╣¤ÕÅ»õ╗źµÄ©µ¢ŁÕć║õ╗źõĖŗhappens-beforeÕģ│ń│╗’╝Ü
wYŌåÆrY’╝łhb9’╝ē
ńö▒µŁżÕÅ»Ķ¦ü’╝īń║┐ń©ŗT1Õ»╣µÖ«ķĆÜÕģ▒õ║½ÕÅśķćÅXÕÆīYµēĆÕüÜńÜäµø┤µ¢░Õ»╣ń║┐ń©ŗT2µØźĶ»┤ķāĮµś»ÕÅ»Ķ¦üńÜäŃĆéĶ┐Öń¦ŹÕÅ»Ķ¦üµĆ¦µś»Õ£©volatileÕÅśķćÅĶ¦äÕłÖŃĆüń©ŗÕ║ÅķĪ║Õ║ÅĶ¦äÕłÖõ╗źÕÅŖhappens-beforeÕģ│ń│╗ńÜäõ╝ĀķĆÆµĆ¦ńÜäÕģ▒ÕÉīõĮ£ńö©õĖŗÕŠŚõ╗źõ┐ØķÜ£ńÜäŃĆéÕøĀµŁż’╝īµłæõ╗¼Ķ»┤volatileÕģ│ķö«ÕŁŚõĖŹõ╗ģõ╗ģõ┐ØķÜ£ÕåÖń║┐ń©ŗÕ»╣volatileÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░ńÜäÕÅ»Ķ¦üµĆ¦’╝łhb6’╝ē’╝īÕ«āĶ┐śõ┐ØķÜ£õ║åÕåÖń║┐ń©ŗÕ£©ÕåÖvolatileÕÅśķćÅÕēŹÕ»╣ÕģČõ╗¢ķØ×volatileÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░ńÜäÕÅ»Ķ¦üµĆ¦’╝łhb8ÕÆīhb9’╝ēŃĆé
ńÉåĶ¦Żõ║åHappens-beforeÕģ│ń│╗Ķ┐ÖõĖƵ”éÕ┐Ąõ╣ŗÕÉÄ’╝īµłæõ╗¼ÕÅ»õ╗źµĆØĶĆāĶ┐ÖµĀĘõĖĆõĖ¬ķŚ«ķóś’╝ÜvolatileÕģ│ķö«ÕŁŚÕ»╣ÕÅ»Ķ¦üµĆ¦ÕÆīµ£ēÕ║ÅµĆ¦ńÜäõ┐ØķÜ£µś»ÕÉ”ķĆéńö©õ║ĵĢ░ń╗äÕæó’╝¤õŠŗÕ”é’╝īÕ»╣õ║Ävolatileõ┐«ķź░ńÜäõĖĆõĖ¬intµĢ░ń╗ävArr’╝īń║┐ń©ŗAµē¦ĶĪīŌĆ£vArr[0]=1;ŌĆØ’╝īµÄźńØĆ’╝īń║┐ń©ŗBÕåŹµØźĶ»╗ÕÅ¢vArrńÜäń¼¼1õĖ¬Õģāń┤Ā’╝īķéŻõ╣łµŁżµŚČń║┐ń©ŗBµēĆĶ»╗ÕÅ¢Õł░Õģāń┤ĀÕĆ╝µś»ÕÉ”õĖĆիܵś»ŌĆ£1ŌĆØÕæó’╝łĶ┐Öķćīµłæõ╗¼ÕüćĶ«ŠÕŬµ£ēń║┐ń©ŗAÕÆīń║┐ń©ŗBĶ┐ÖõĖżõĖ¬ń║┐ń©ŗĶ«┐ķŚ«vArr’╝ē’╝¤ńŁöµĪłµś»ŌĆ£õĖŹõĖĆÕ«ÜŌĆØ’╝ܵŁżµŚČń║┐ń©ŗAÕÆīń║┐ń©ŗBõ╗ÄvolatileÕģ│ķö«ÕŁŚńÜäĶ¦ÆÕ║”µØźń£ŗķāĮÕŬµś»Ķ»╗ń║┐ń©ŗ’╝łĶ»╗ÕÅ¢volatileÕÅśķćÅvArr’╝ē’╝īÕŹ│Ķ┐ÖõĖżõĖ¬ń║┐ń©ŗõ╣ŗķŚ┤Õ╣ČõĖŹÕŁśÕ£©Happens-beforeÕģ│ń│╗’╝īÕøĀµŁżń║┐ń©ŗAÕ»╣vArrń¼¼1õĖ¬Õģāń┤ĀńÜäµø┤µ¢░Õ»╣ń║┐ń©ŗBµØźĶ»┤õĖŹõĖĆիܵś»ÕÅ»Ķ¦üńÜäŃĆéĶ┐ÖõĖ¬õŠŗÕŁÉõĖŁ’╝īĶ”üõ┐ØķÜ£Õ»╣µĢ░ń╗äÕģāń┤ĀńÜäµø┤µ¢░ńÜäÕÅ»Ķ¦üµĆ¦’╝īµłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©java.util.concurrent.atomic.AtomicIntegerArrayń▒╗ŃĆé
7. Õ░Åń╗ō
õĖŖķØóõ╗ŗń╗Źõ║åvolatileÕ»╣µ£ēÕ║ÅµĆ¦ńÜäõ┐ØķÜ£’╝īÕ╣ČķĆÜĶ┐ćõ╗ŗń╗ŹJavaÕåģÕŁśµ©ĪÕ×ŗõĖŁńÜäHappens-beforeÕģ│ń│╗Ķ┐ÖõĖƵ”éÕ┐ĄµØźĶ┐øõĖƵŁźõ╗ŗń╗ŹvolatileÕ»╣ÕÅ»Ķ¦üµĆ¦ÕÆīµ£ēÕ║ÅµĆ¦ńÜäõ┐ØķÜ£ŃĆéķĆÜĶ┐ćÕēŹķØóńÜäõ╗ŗń╗Ź’╝īµłæõ╗¼ń¤źķüōvolatileÕģ│ķö«ÕŁŚńÜäõĮ£ńö©Õīģµŗ¼õ┐ØķÜ£long/doubleÕ×ŗÕÅśķćÅĶ«┐ķŚ«µōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦ŃĆüõ┐ØķÜ£ÕÅ»Ķ¦üµĆ¦ÕÆīõ┐ØķÜ£µ£ēÕ║ÅµĆ¦ŃĆéµÄźõĖŗµØźÕ░åõ╗ŗń╗ŹJavaĶÖܵŗ¤µ£║Õ»╣volatileÕģ│ķö«ÕŁŚńÜäÕ«×ńÄ░’╝īvolatileÕģ│ķö«ÕŁŚńÜäÕ╝ĆķöĆõ╗źÕÅŖvolatileńÜäÕģĖÕ×ŗÕ║öńö©Õ£║µÖ»ŃĆé
8. JavaĶÖܵŗ¤µ£║Õ»╣volatileńÜäÕ«×ńÄ░
µ£¼ĶŖéõ╝ܵČēÕÅŖĶŠāÕżÜńÜäµ£»Ķ»Ł’╝īÕ”éĶĪ©1µēĆńż║ŃĆé
ĶĪ©1 µ£¼ĶŖéµ£»Ķ»Ł

JavaĶÖܵŗ¤µ£║Õ»╣long/doubleÕ×ŗÕÅśķćÅĶ«┐ķŚ«µōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦õ┐ØķÜ£µś»ķĆÜĶ┐ćõĮ┐ńö©ÕÄ¤ÕŁÉµīćõ╗ż’╝łµ£¼Ķ║½Õ░▒Õģʵ£ēÕÄ¤ÕŁÉµĆ¦ńÜäÕżäńÉåÕÖ©µīćõ╗ż’╝ēÕ«×ńÄ░ńÜäŃĆéõĖŗķØóķĆÜĶ┐ćõĖĆõĖ¬Õ«×ķ¬īµØźĶ┐øõĖƵŁźõ╗ŗń╗ŹĶ┐Öńé╣’╝īĶ»źÕ«×ķ¬īµēĆķ£ĆńÜäJavaõ╗ŻńĀüÕ”éµĖģÕŹĢ6µēĆńż║ŃĆé
µĖģÕŹĢ6 JavaĶÖܵŗ¤µ£║Õ»╣volatileĶ»Łõ╣ēńÜäÕ«×ńÄ░Õ«×ķ¬īJavaõ╗ŻńĀü
public class AtomicJVMImpl {
static long normalLong = 0L;
static volatile long volatileLong = 0L;
public static void main(String[] args) {
long v1 = 0, v2 = 0;
for (int i = 0; i < 100100; i++) {
normalWrite(i);
volatileWrite(i);
v1 = normalRead() + i;
v2 = volatileRead();
}
System.out.println(v1 + "," + v2);
}
public static void normalWrite(long value) {
normalLong = value;
}
public static void volatileWrite(long value) {
volatileLong = value;
}
public static long volatileRead() {
return volatileLong;
}
public static long normalRead() {
return normalLong;
}
}
32õĮŹJavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēµē¦ĶĪī’╝łÕŖ©µĆüń╝¢Ķ»æ’╝ēnormalWriteµ¢╣µ│ĢõĖŁńÜäµÖ«ķĆÜlong/doubleÕ×ŗÕÅśķćÅÕåÖµōŹõĮ£µŚČõĮ┐ńö©ńÜäµ£║ÕÖ©ńĀü’╝łx86µ▒ćń╝¢Ķ»ŁĶ©ĆĶĪ©ńż║’╝ēÕ”éÕøŠ4µēĆńż║ŃĆé
ÕøŠ4 32õĮŹJavaĶÖܵŗ¤µ£║x86ÕżäńÉåÕÖ©õĖŗÕ»╣µÖ«ķĆÜlong/doubleÕ×ŗÕÅśķćÅÕåÖµōŹõĮ£ńÜäÕ«×ńÄ░
┬Ā
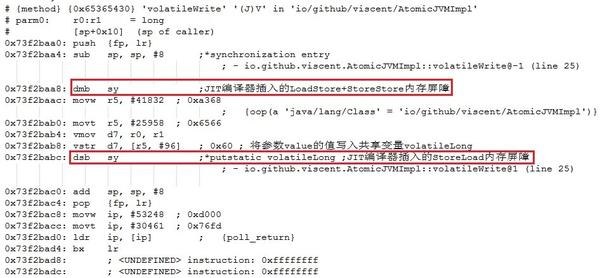
ÕÅ»Ķ¦ü’╝ī32õĮŹJavaĶÖܵŗ¤µ£║Õ£©x86ÕżäńÉåÕÖ©Õ╣│ÕÅ░õĖŗÕ»╣µÖ«ķĆÜlong/doubleÕ×ŗÕÅśķćÅ’╝łĶ┐Öķćīµś»longÕ×ŗÕÅśķćÅ’╝ēńÜäÕåÖµōŹõĮ£µś»ķĆÜĶ┐ćõĖżõĖ¬ÕŁÉµōŹõĮ£ŌĆöŌĆöÕģłÕåÖõĮÄ32õĮŹÕåŹÕåÖķ½ś32õĮŹÕ«×ńÄ░ńÜäŃĆé32õĮŹJavaĶÖܵŗ¤µ£║Õ£©µ¤Éõ║øÕżäńÉåÕÖ©Õ╣│ÕÅ░õĖŗÕÅ»ĶāĮõ╗ŹńäČõĮ┐ńö©õĖƵØĪµīćõ╗ż’╝łµ»öÕ”éÕ£©ARMÕżäńÉåÕÖ©Õ╣│ÕÅ░õĖŗõĮ┐ńö©strdµīćõ╗ż’╝ēµØźÕ«×ńÄ░µÖ«ķĆÜlong/doubleÕ×ŗÕÅśķćÅńÜäÕåÖµōŹõĮ£’╝īõĮåµś»Ķ┐ÖµØĪµīćõ╗żÕÅ»ĶāĮõĖŹµś»ÕÄ¤ÕŁÉµīćõ╗ż’╝īÕøĀµŁżÕ£©JavaĶ»ŁĶ©ĆĶ┐ÖõĖĆÕ▒éµ¼ĪµØźĶ¦éÕ»¤’╝īµŁżµŚČńÜäµÖ«ķĆÜlong/doubleÕ×ŗÕÅśķćÅÕåÖµōŹõĮ£ÕÉīµĀĘõ╣¤õĖŹµś»ÕÄ¤ÕŁÉµōŹõĮ£ŃĆé32õĮŹJavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēÕ£©x86ÕżäńÉåÕÖ©Õ╣│ÕÅ░õĖŗÕ«×ńÄ░volatileWriteµ¢╣µ│ĢõĖŁńÜävolatile long/doubleÕ×ŗÕÅśķćÅÕåÖµōŹõĮ£µŚČõĮ┐ńö©ńÜ䵜»õĖĆõĖ¬ÕÄ¤ÕŁÉµīćõ╗ż’╝łvmovsd’╝ē’╝īÕ”éÕøŠ5µēĆńż║ŃĆé
ÕøŠ5 32õĮŹJavaĶÖܵŗ¤µ£║x86ÕżäńÉåÕÖ©õĖŗÕ»╣volatile long/doubleÕ×ŗÕÅśķćÅÕåÖµōŹõĮ£ńÜäÕ«×ńÄ░
┬Ā
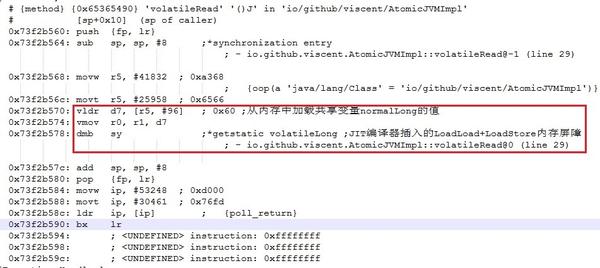
ń▒╗õ╝╝ńÜä’╝īJavaĶÖܵŗ¤µ£║Õ»╣long/doubleÕ×ŗÕÅśķćÅĶ»╗µōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦õ┐ØķÜ£õ╣¤µś»ķĆÜĶ┐ćõĮ┐ńö©ÕÄ¤ÕŁÉµīćõ╗żÕ«×ńÄ░ńÜäŃĆéõŠŗÕ”é’╝ī32õĮŹJavaĶÖܵŗ¤µ£║Õ£©x86Õ╣│ÕÅ░õĖŗõ╝ÜõĮ┐ńö©vmovsdĶ┐ÖõĖ¬ÕÄ¤ÕŁÉµīćõ╗żµØźÕ«×ńÄ░volatileõ┐«ķź░ńÜälong/doubleÕ×ŗÕÅśķćÅńÜäĶ»╗µōŹõĮ£’╝īĶĆīÕ»╣µÖ«ķĆÜlong/doubleÕ×ŗÕÅśķćÅńÜäĶ»╗µōŹõĮ£ÕłÖµś»õĮ┐ńö©2µØĪmovµīćõ╗żÕ«×ńÄ░ŃĆé
JavaĶÖܵŗ¤µ£║Õ»╣ÕÅ»Ķ¦üµĆ¦ÕÆīµ£ēÕ║ÅµĆ¦ńÜäõ┐ØķÜ£ÕłÖµś»ķĆÜĶ┐ćõĮ┐ńö©ÕåģÕŁśÕ▒ÅķÜ£Õ«×ńÄ░ńÜäŃĆé
ÕżäńÉåÕÖ©Õ£©Õģȵē¦ĶĪīÕåģÕŁśÕåÖµōŹõĮ£ńÜ䵌ČÕĆÖ’╝īÕŠĆÕŠĆµś»ÕģłÕ░åµĢ░µŹ«ÕåÖÕģźÕģČÕåÖń╝ōÕå▓ÕÖ©õĖŁ’╝īĶĆīõĖŹµś»ńø┤µÄźÕåÖÕģźķ½śķƤń╝ōÕŁśŃĆéńö▒õ║ÄõĖĆõĖ¬ÕżäńÉåÕÖ©õĖŖńÜäÕåÖń╝ōÕå▓ÕÖ©õĖŁńÜäÕåģÕ«╣µŚĀµ│ĢĶó½ÕģČõ╗¢ÕżäńÉåÕÖ©µēĆĶ»╗ÕÅ¢’╝īÕøĀµŁżÕåÖń║┐ń©ŗÕ┐ģķĪ╗ńĪ«õ┐ØÕģČÕ»╣volatileÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░õ╗źÕÅŖÕģȵø┤µ¢░volatileÕÅśķćÅÕēŹÕ»╣ÕģČõ╗¢Õģ▒õ║½ÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░’╝łõ╗źõĖŗń╗¤ń¦░õĖ║Õ»╣Õģ▒õ║½ÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░’╝ēÕł░ĶŠŠĶ»źÕżäńÉåÕÖ©ńÜäķ½śķƤń╝ōÕŁś’╝łĶĆīõĖŹµś»õ╗ŹńäČÕü£ńĢÖÕ£©ÕåÖń╝ōÕå▓ÕÖ©õĖŁ’╝ēŃĆéĶ┐ÖµĀĘ’╝īÕåÖń║┐ń©ŗńÜäĶ┐Öõ║øµø┤µ¢░ķĆÜĶ┐ćń╝ōÕŁśõĖĆĶć┤µĆ¦ÕŹÅĶ««Ķó½ÕģČõ╗¢ÕżäńÉåÕÖ©õĖŖńÜäń║┐ń©ŗµēĆĶ»╗ÕÅ¢µēŹµłÉõĖ║ÕÅ»ĶāĮŃĆéõĖ║µŁż’╝īJavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēõ╝ÜÕ£©volatileÕÅśķćÅÕåÖµōŹõĮ£õ╣ŗÕÉĵÅÆÕģźõĖĆõĖ¬StoreLoadÕåģÕŁśÕ▒ÅķÜ£ŃĆéĶ┐ÖõĖ¬ÕåģÕŁśÕ▒ÅķÜ£ńÜäÕģČõĖŁõĖĆõĖ¬õĮ£ńö©Õ░▒µś»Õ░åÕģȵē¦ĶĪīÕżäńÉåÕÖ©ńÜäÕåÖń╝ōÕå▓ÕÖ©õĖŁńÜäÕĮōÕēŹÕåģÕ«╣ÕåÖÕģźķ½śķƤń╝ōÕŁśŃĆé
ńö▒õ║ĵŚĀµĢłÕī¢ķś¤ÕłŚńÜäÕŁśÕ£©’╝īÕżäńÉåÕÖ©õ╗ÄÕģČķ½śķƤń╝ōÕŁśõĖŁĶ»╗ÕÅ¢Õł░ńÜäÕģ▒õ║½ÕÅśķćÅÕĆ╝ÕÅ»ĶāĮµś»Ķ┐浌ČńÜäŃĆéÕøĀµŁż’╝īõĖ║õ║åńĪ«õ┐ØĶ»╗ń║┐ń©ŗĶāĮÕż¤Ķ»╗ÕÅ¢Õł░ÕåÖń║┐ń©ŗÕ»╣Õģ▒õ║½ÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░’╝łÕīģµŗ¼volatileÕÅśķćÅ’╝ē’╝īĶ»╗ń║┐ń©ŗńÜäµē¦ĶĪīÕżäńÉåÕÖ©Õ┐ģķĪ╗Õ£©Ķ»╗ÕÅ¢volatileÕÅśķćÅÕēŹńĪ«õ┐صŚĀµĢłÕī¢ķś¤ÕłŚõĖŁÕåģÕ«╣Ķó½Õ║öńö©Õł░Ķ»źÕżäńÉåÕÖ©ńÜäķ½śķƤń╝ōÕŁśõĖŁ’╝īÕŹ│µĀ╣µŹ«µŚĀµĢłÕī¢ķś¤ÕłŚõĖŁńÜäÕåģÕ«╣Õ░åĶ»źÕżäńÉåÕÖ©õĖŁńøĖÕ║öńÜäń╝ōÕŁśĶĪīĶ«ŠńĮ«õĖ║µŚĀµĢł’╝īõ╗ÄĶĆīõĮ┐ÕåÖń║┐ń©ŗÕ»╣Õģ▒õ║½ÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░ĶāĮÕż¤Ķó½ÕÅŹµśĀÕł░Ķ»źÕżäńÉåÕÖ©ńÜäķ½śķƤń╝ōÕŁśõĖŖŃĆéõĖ║µŁż’╝īJavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēõ╝ÜÕ£©volatileÕÅśķćÅĶ»╗µōŹõĮ£ÕēŹµÅÆÕģźõĖĆõĖ¬LoadLoadÕåģÕŁśÕ▒ÅķÜ£ŃĆéµ£ēńÜäÕżäńÉåÕÖ©’╝łõŠŗÕ”éx86ÕżäńÉåÕÖ©ÕÆīARMÕżäńÉåÕÖ©’╝ēÕ╣ȵ▓Īµ£ēÕ╝ĢÕģźµŚĀµĢłÕī¢ķś¤ÕłŚ’╝īÕøĀµŁżÕ£©Ķ┐Öõ║øÕżäńÉåÕÖ©õĖŖõĖŖĶ┐░LoadLoadÕåģÕŁśÕ▒ÅķÜ£Õ░▒õĖŹÕåŹĶó½ķ£ĆĶ”üŃĆé
ÕÅ»Ķ¦ü’╝īvolatileÕģ│ķö«ÕŁŚÕ»╣ÕÅ»Ķ¦üµĆ¦ńÜäõ┐ØķÜ£µś»ķĆÜĶ┐ćJavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēÕ£©ÕåÖń║┐ń©ŗÕÆīĶ»╗ń║┐ń©ŗõĖŁķģŹÕ»╣Õ£░õĮ┐ńö©ÕåģÕŁśÕ▒ÅķÜ£Õ«×ńÄ░ńÜä’╝īÕ”éÕøŠ6µēĆńż║ŃĆé
ÕøŠ6 JavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēõĖ║Õ«×ńÄ░volatileĶ»Łõ╣ēĶĆīµÅÆÕģźńÜäÕåģÕŁśÕ▒ÅķÜ£

┬Ā
volatileÕģ│ķö«ÕŁŚÕ»╣µ£ēÕ║ÅµĆ¦ńÜäõ┐ØķÜ£õ╣¤µś»ķĆÜĶ┐ćJavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēÕ£©ÕåÖń║┐ń©ŗÕÆīĶ»╗ń║┐ń©ŗõĖŁķģŹÕ»╣Õ£░õĮ┐ńö©ÕåģÕŁśÕ▒ÅķÜ£Õ«×ńÄ░ńÜäŃĆéõĖ║õ║åõĮ┐ÕåÖń║┐ń©ŗÕ»╣Õģ▒õ║½ÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░Õ£©Ķ»╗ń║┐ń©ŗń£ŗµØźµś»µ£ēÕ║ÅńÜä’╝łÕŹ│µä¤ń¤źķĪ║Õ║ÅõĖÄń©ŗÕ║ÅķĪ║Õ║Åõ┐صīüõĖĆĶć┤’╝ē’╝īJavaĶÖܵŗ¤µ£║ķ”¢ÕģłÕ┐ģķĪ╗õ┐ØĶ»üÕåÖń║┐ń©ŗń©ŗÕ║ÅķĪ║Õ║ÅõĖŖµÄÆÕ£©ÕåÖvolatileÕÅśķćÅõ╣ŗÕēŹńÜäÕ»╣ÕģČõ╗¢Õģ▒õ║½ÕÅśķćÅńÜäµø┤µ¢░Õģłõ║ÄÕ»╣volatileÕÅśķćÅńÜäµø┤µ¢░ÕÅŹµśĀÕł░Ķ»źń║┐ń©ŗµēĆÕ£©ńÜäÕżäńÉåÕÖ©ńÜäķ½śķƤń╝ōÕŁśõĖŖŃĆ鵏óĶĆīĶ©Ćõ╣ŗ’╝īJavaĶÖܵŗ¤µ£║Õ┐ģķĪ╗ńĪ«õ┐Øń©ŗÕ║ÅķĪ║Õ║ÅõĖŖµÄÆÕ£©volatileÕÅśķćÅÕåÖµōŹõĮ£õ╣ŗÕēŹńÜäÕģČõ╗¢ÕåÖµōŹõĮ£õĖŹĶāĮÕż¤Ķó½ń╝¢Ķ»æÕÖ©/ÕżäńÉåÕÖ©ķĆÜĶ┐ćµīćõ╗żķ揵ÄÆÕ║ÅÕÆī’╝łµł¢’╝ēÕåģÕŁśķ揵ÄÆÕ║ÅĶó½ķ揵ÄÆÕ║ÅÕł░Ķ»źvolatileÕÅśķćÅÕåÖµōŹõĮ£õ╣ŗÕÉÄŃĆéõĖ║µŁż’╝īJavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēõ╝ÜÕ£©volatileÕÅśķćÅÕåÖµōŹõĮ£õ╣ŗÕēŹµÅÆÕģźLoadStore+StoreStoreÕåģÕŁśÕ▒ÅķÜ£’╝īĶ┐ÖõĖ¬ń╗äÕÉłÕåģÕŁśÕ▒ÅķÜ£ń”üµŁóõ║åvolatileÕÅśķćÅÕåÖµōŹõĮ£õĖÄĶ»źµōŹõĮ£õ╣ŗÕēŹńÜäõ╗╗õĮĢĶ»╗ŃĆüÕåÖµōŹõĮ£õ╣ŗķŚ┤ńÜäķ揵ÄÆÕ║Å’╝łÕīģµŗ¼µīćõ╗żķ揵ÄÆÕ║ÅÕÆīÕåģÕŁśķ揵ÄÆÕ║Å’╝ēŃĆéÕģȵ¼Ī’╝īJavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēÕ┐ģķĪ╗ńĪ«õ┐ØĶ»╗ń║┐ń©ŗÕ£©Ķ»╗ÕÅ¢Õ«īÕåÖń║┐ń©ŗÕ»╣volatileÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░õ╣ŗÕÉĵēŹÕ╝ĆÕ¦ŗĶ»╗ÕÅ¢ÕåÖń║┐ń©ŗÕ£©µø┤µ¢░Ķ»źvolatileÕÅśķćÅÕēŹÕ»╣ÕģČõ╗¢Õģ▒õ║½ÕÅśķćŵēĆÕüÜńÜäµø┤µ¢░ŃĆ鵏óĶĆīĶ©Ćõ╣ŗ’╝īJavaĶÖܵŗ¤µ£║Õ┐ģķĪ╗ńĪ«õ┐Øń©ŗÕ║ÅķĪ║Õ║ÅõĖŖµÄÆÕ£©volatileÕÅśķćÅĶ»╗µōŹõĮ£õ╣ŗÕÉÄńÜäÕģČõ╗¢Õģ▒õ║½ÕÅśķćÅńÜäĶ»╗ŃĆüÕåÖµōŹõĮ£õĖŹĶāĮÕż¤Ķó½ń╝¢Ķ»æÕÖ©/ÕżäńÉåÕÖ©ķĆÜĶ┐ćµīćõ╗żķ揵ÄÆÕ║ÅÕÆī’╝łµł¢’╝ēÕåģÕŁśķ揵ÄÆÕ║ÅĶó½ķ揵ÄÆÕ║ÅÕł░Ķ»źvolatileÕÅśķćÅĶ»╗µōŹõĮ£õ╣ŗÕēŹŃĆéõĖ║µŁż’╝īJavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēõ╝ÜÕ£©volatileÕÅśķćÅĶ»╗µōŹõĮ£õ╣ŗÕÉĵÅÆÕģźõĖĆõĖ¬LoadLoad+LoadStoreÕåģÕŁśÕ▒ÅķÜ£’╝īĶ┐ÖõĖ¬ń╗äÕÉłÕåģÕŁśÕ▒ÅķÜ£ń”üµŁóõ║åvolatileÕÅśķćÅĶ»╗µōŹõĮ£õĖÄĶ»źµōŹõĮ£õ╣ŗÕÉÄńÜäõ╗╗õĮĢĶ»╗ŃĆüÕåÖµōŹõĮ£õ╣ŗķŚ┤ńÜäķ揵ÄÆÕ║Å’╝łÕīģµŗ¼µīćõ╗żķ揵ÄÆÕ║ÅÕÆīÕåģÕŁśķ揵ÄÆÕ║Å’╝ēŃĆéÕÅ»Ķ¦ü’╝īJavaĶÖܵŗ¤µ£║µś»ķĆÜĶ┐ćõĮ┐ÕåÖń║┐ń©ŗÕÆīĶ»╗ń║┐ń©ŗķģŹÕ»╣Õ£░õĮ┐ńö©ÕåģÕŁśÕ▒ÅķÜ£µØźÕ«×ńÄ░volatileÕ»╣µ£ēÕ║ÅµĆ¦ńÜäõ┐ØķÜ£ńÜä’╝īÕ”éÕøŠ6µēĆńż║ŃĆé
ÕøŠ7ÕÆīÕøŠ8Õ▒Ģńż║õ║åJavaĶÖܵŗ¤µ£║’╝ł32õĮŹ’╝ēÕ£©ARMÕżäńÉåÕÖ©Õ╣│ÕÅ░õĖŗÕ»╣µĖģÕŹĢ1õĖŁńÜävolatileWriteŃĆüvolatileReadµ¢╣µ│ĢĶ┐øĶĪīJITń╝¢Ķ»æµŚČµÅÆÕģźńÜäÕåģÕŁśÕ▒ÅķÜ£µāģÕåĄŃĆé
ÕøŠ7 JavaĶÖܵŗ¤µ£║Õ£©ARMÕżäńÉåÕÖ©Õ╣│ÕÅ░õĖŗÕ£©volatileÕÅśķćÅÕåÖµōŹõĮ£ÕēŹÕÉĵÅÆÕģźńÜäÕåģÕŁśÕ▒ÅķÜ£
┬Ā
┬Ā
ÕøŠ7õĖŁ’╝īJITń╝¢Ķ»æÕÖ©Õ£©volatileÕåÖµōŹõĮ£’╝łŌĆ£vstr d7, [r5, #96]ŌĆصīćõ╗ż’╝ēÕēŹµÅÆÕģźńÜäŌĆ£dmb syŌĆصīćõ╗żńøĖÕĮōõ║ÄLoadStore+StoreStoreÕåģÕŁśÕ▒ÅķÜ£ŃĆéJITń╝¢Ķ»æÕÖ©Õ£©volatileÕåÖµōŹõĮ£ÕÉĵÅÆÕģźńÜäŌĆ£dsb syŌĆصīćõ╗żńøĖÕĮōõ║ÄStoreLoadÕåģÕŁśÕ▒ÅķÜ£ŃĆé
ÕøŠ8 JavaĶÖܵŗ¤µ£║Õ£©ARMÕżäńÉåÕÖ©Õ╣│ÕÅ░õĖŗÕ£©volatileÕÅśķćÅĶ»╗µōŹõĮ£ÕÉĵÅÆÕģźńÜäÕåģÕŁśÕ▒ÅķÜ£
┬Ā
┬Ā
ÕøŠ8õĖŁ’╝īJITń╝¢Ķ»æÕÖ©Õ£©volatileĶ»╗µōŹõĮ£’╝łŌĆ£vldr d7, [r5, #96]ŌĆصīćõ╗ż’╝ēÕÉĵÅÆÕģźńÜäŌĆ£dmb syŌĆصīćõ╗żńøĖÕĮōõ║ÄLoadStore+LoadLoadÕåģÕŁśÕ▒ÅķÜ£ŃĆéńö▒õ║ÄARMÕżäńÉåÕÖ©Õ╣ȵ▓Īµ£ēõĮ┐ńö©µŚĀµĢłÕī¢ķś¤ÕłŚ’╝īÕøĀµŁżJITń╝¢Ķ»æÕÖ©Õ£©volatileĶ»╗µōŹõĮ£ÕēŹÕ╣ČõĖŹķ£ĆĶ”üµÅÆÕģźLoadLoadÕåģÕŁśÕ▒ÅķÜ£ŃĆé
9. volatileńÜäÕ╝ĆķöĆ
õĖŖõĖĆĶŖ鵳æõ╗¼Ķ«▓Õł░JavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēõ╝ÜÕ£©volatileÕÅśķćÅÕåÖµōŹõĮ£õ╣ŗÕÉĵÅÆÕģźõĖĆõĖ¬StoreLoadÕåģÕŁśÕ▒ÅķÜ£ŃĆéStoreLoadÕåģÕŁśÕ▒ÅķÜ£µś»õĖĆõĖ¬Õģ©ĶāĮÕ×ŗÕåģÕŁśÕ▒ÅķÜ£’╝īÕ«āµś»ÕåģÕŁśÕ▒ÅķÜ£õĖŁÕŖ¤ĶāĮµ£ĆÕ╝║Õż¦Õ╝ĆķöĆõ╣¤µ£ĆÕż¦ńÜäõĖĆõĖ¬ÕåģÕŁśÕ▒ÅķÜ£ŃĆéĶ»źÕåģÕŁśÕ▒ÅķÜ£ķÖżõ║åĶāĮÕż¤Õ░åÕåÖń╝ōÕå▓ÕÖ©õĖŁµØĪńø«ÕåÖÕģźķ½śķƤń╝ōÕŁśõ╣ŗÕż¢’╝īĶ┐śĶāĮÕż¤Õ░åµŚĀµĢłÕī¢ķś¤ÕłŚõĖŁńÜäÕåģÕ«╣Õ║öńö©Õł░ķ½śķƤń╝ōÕŁśõĖŁŃĆéĶĆīĶ┐ÖõĖżõĖ¬µōŹõĮ£ńÜäÕ╝ĆķöĆĶŠāÕż¦’╝īÕ£©µ¤Éõ║øÕżäńÉåÕÖ©õĖŖ’╝łõŠŗÕ”éARMÕżäńÉåÕÖ©’╝ēĶ»źÕåģÕŁśÕ▒ÅķÜ£ÕÅ»ĶāĮĶ┐śõ╝ÜÕ»╝Ķć┤ÕżäńÉåÕÖ©µĄüµ░┤ń║┐’╝łPipeline’╝ēÕü£ķĪ┐ŃĆéńö▒õ║ÄJavaĶÖܵŗ¤µ£║Õ╣ČõĖŹķ£ĆĶ”üÕ£©µÖ«ķĆÜÕÅśķćÅÕåÖµōŹõĮ£õ╣ŗÕÉĵÅÆÕģźÕåģÕŁśÕ▒ÅķÜ£’╝īĶĆīõĖ┤ńĢīÕī║õĖŁńÜäÕåÖµōŹõĮ£ķÖżõ║åµ£ēÕåģÕŁśÕ▒ÅķÜ£ńÜäÕ╝ĆķöĆõ╣ŗÕż¢’╝īĶ┐śµ£ēķöüńÜäńö│Ķ»ĘõĖÄķćŖµöŠńÜäÕ╝ĆķöĆ’╝īÕøĀµŁżvolatileÕÅśķćÅÕåÖµōŹõĮ£ńÜäÕ╝ĆķöĆõ╗ŗõ║ĵ֫ķĆÜÕÅśķćÅÕåÖµōŹõĮ£ÕÆīõĖ┤ńĢīÕī║õĖŁńÜäÕåÖµōŹõĮ£õ╣ŗķŚ┤ŃĆé
Õ”éµ×£ÕżäńÉåÕÖ©Õ╝ĢÕģźõ║åµŚĀµĢłÕī¢ķś¤ÕłŚ’╝īķéŻõ╣łJavaĶÖܵŗ¤µ£║ķ£ĆĶ”üÕ£©volatileÕÅśķćÅĶ»╗µōŹõĮ£ÕēŹµÅÆÕģźõĖĆõĖ¬LoadLoadÕåģÕŁśÕ▒ÅķÜ£ŃĆéÕÅ”Õż¢’╝īJavaĶÖܵŗ¤µ£║’╝łJITń╝¢Ķ»æÕÖ©’╝ēÕ£©volatileÕÅśķćÅĶ»╗µōŹõĮ£õ╣ŗÕÉĵÅÆÕģźńÜäLoadLoad+LoadStoreÕåģÕŁśÕ▒ÅķÜ£õ╝Üķś╗µŁóÕżäńÉåÕÖ©µē¦ĶĪīµ¤Éõ║øõ╝śÕī¢’╝łµ»öÕ”éķ揵ÄÆÕ║ÅÕÆīķóäÕģłÕŖĀĶĮĮµĢ░µŹ«’╝ēŃĆéĶĆīõĖ┤ńĢīÕī║õĖŁńÜäĶ»╗µōŹõĮ£õĖŹõ╗ģõ╗ģµ£ēÕåģÕŁśÕ▒ÅķÜ£ńÜäÕ╝ĆķöĆ’╝īĶ┐śµ£ēķöüńÜäńö│Ķ»ĘõĖÄķćŖµöŠńÜäÕ╝ĆķöĆŃĆéÕøĀµŁż’╝īvolatileÕÅśķćÅĶ»╗µōŹõĮ£ńÜäÕ╝ĆķöĆõ╗ŗõ║ĵ֫ķĆÜÕÅśķćÅĶ»╗µōŹõĮ£ÕÆīõĖ┤ńĢīÕī║õĖŁńÜäĶ»╗µōŹõĮ£õ╣ŗķŚ┤ŃĆé
µÖ«ķĆÜÕģ▒õ║½ÕÅśķćÅńÜäÕĆ╝ÕÅ»ĶāĮõ╝ÜĶó½JITń╝¢Ķ»æÕÖ©ń╝ōÕŁśÕł░Õ»äÕŁśÕÖ©õĖŁ’╝īÕŹ│Õ»╣õ║Äõ╗╗µäÅõĖĆõĖ¬ń║┐ń©ŗ’╝īĶ»źń║┐ń©ŗń¼¼õĖƵ¼ĪĶ»╗ÕÅ¢µ¤ÉõĖ¬µÖ«ķĆÜÕģ▒õ║½ÕÅśķćŵś»õĖƵ¼ĪÕåģÕŁśĶ»╗µōŹõĮ£’╝łµ»öÕ”éx86ÕżäńÉåÕÖ©õĖŖńÜämovµīćõ╗ż’╝ē’╝īķÜÅÕÉÄķćŹÕżŹĶ»╗ÕÅ¢Ķ┐ÖõĖ¬Õģ▒õ║½ÕÅśķćÅÕłÖµś»õ╗ÄÕ»äÕŁśÕÖ©õĖŁĶ»╗ÕÅ¢ŃĆéµĀ╣µŹ«volatileÕģ│ķö«ÕŁŚńÜäĶ»Łõ╣ē’╝īvolatileÕÅśķćŵś»õĖŹĶāĮÕż¤Ķó½ń╝ōÕŁśÕł░Õ»äÕŁśÕÖ©õĖŁ’╝īÕŹ│µ»ÅõĖ¬volatileÕÅśķćÅĶ»╗µōŹõĮ£ķāĮµś»õĖƵ¼ĪÕåģÕŁśĶ»╗µōŹõĮ£’╝īÕÉīõĖĆõĖ¬ń║┐ń©ŗÕŹ│õĮ┐µś»Ķ┐×ń╗ŁÕżÜµ¼ĪĶ»╗ÕÅ¢ÕÉīõĖĆõĖ¬volatileÕÅśķćÅ’╝īĶ┐ÖÕĮōõĖŁńÜ䵻ŵ¼ĪĶ»╗ÕÅ¢µōŹõĮ£ķāĮµś»õ╗ÄÕåģÕŁśõĖŁĶ»╗ÕÅ¢ńÜäŃĆéÕøĀµŁż’╝īõ╗ĵĢ┤õĮōõĖŖń£ŗ’╝īvolatileÕÅśķćÅńÜäĶ»╗ÕÅ¢Õ╝ĆķöĆĶ”üµ»öµÖ«ķĆÜÕģ▒õ║½ÕÅśķćÅńÜäÕ╝ĆķöĆĶ”üÕż¦ŃĆé
10. volatileńÜäÕģĖÕ×ŗÕ║öńö©Õ£║µÖ»
10.1ŃĆü ķŚ┤µÄźõ┐ØķÜ£ÕżŹÕÉłµōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦õĖÄÕÅ»Ķ¦üµĆ¦
Õ»╣õ║ĵĖģÕŹĢ2õĖŁńÜäÕÅ»Ķ¦üµĆ¦ÕÆīÕÄ¤ÕŁÉµĆ¦ķŚ«ķóś’╝īĶÖĮńäȵłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćÕ»╣updateHostInfoµ¢╣µ│ĢÕÆīconnectToHostµ¢╣µ│ĢĶ┐øĶĪīÕŖĀķöüµØźÕŖĀõ╗źĶ¦ŻÕå│’╝īõĮåµś»ÕƤÕŖ®volatileÕģ│ķö«ÕŁŚµłæõ╗¼µŚóÕÅ»õ╗źõ┐ØķÜ£ÕÅ»Ķ¦üµĆ¦ÕÆīÕÄ¤ÕŁÉµĆ¦ÕÅłÕÅ»õ╗źķü┐ÕģŹķöüńÜäÕ╝ĆķöĆ’╝īÕ”éµĖģÕŹĢ7µēĆńż║ŃĆé
µĖģÕŹĢ7 õĮ┐ńö©volatileķŚ┤µÄźõ┐ØķÜ£ÕżŹÕÉłµōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦õĖÄÕÅ»Ķ¦üµĆ¦Õ«×õŠŗ
public class AtomicityExample1 {
private volatile HostInfo hostInfo;
public void updateHostInfo(String ip, int port) {
HostInfo newHostInfo = new HostInfo(ip, port);
this.hostInfo = newHostInfo;
}
public void connectToHost() {
String ip = hostInfo.getIp();
int port = hostInfo.getPort();
connectToHost(ip, port);
}
private void connectToHost(String ip, int port) {
// ...
}
public static class HostInfo {
private String ip;
private int port;
public HostInfo(String ip, int port) {
this.ip = ip;
this.port = port;
}
public String getIp() {
return ip;
}
public int getPort() {
return port;
}
// ...
}
}
µĖģÕŹĢ7õĖŁńÜäupdateHostInfoµ¢╣µ│ĢĶ┐Éńö©õ║åõĖŹÕÅ»ÕÅśÕ»╣Ķ▒Ī’╝łImmutable Object’╝ēµ©ĪÕ╝Å’╝ÜÕ«āÕ£©µø┤µ¢░õĖ╗µ£║IPÕ£░ÕØĆÕÆīń½»ÕÅŻÕÅĘńÜ䵌ČÕĆÖÕ╣ČõĖŹĶ░āńö©HostInfoń▒╗ńÜäńøĖÕ║ösetµ¢╣µ│Ģ’╝īĶĆīµś»ÕģłÕłøÕ╗║µ¢░ńÜäHostInfoÕ«×õŠŗ’╝īÕåŹÕ░åĶ»źÕ«×õŠŗ’╝łńÜäÕ╝Ģńö©’╝ēĶĄŗÕĆ╝ń╗ÖÕ«×õŠŗÕÅśķćÅhostInfo’╝īńö▒µŁżÕ«×ńÄ░õ║åõĖ╗µ£║õ┐Īµü»ńÜäµø┤µ¢░ŃĆéńö▒õ║ÄĶ┐ÖõĖ¬ĶĄŗÕĆ╝µōŹõĮ£µ£¼Ķ║½Õ░▒µś»õĖĆõĖ¬ÕÄ¤ÕŁÉµōŹõĮ£’╝īÕøĀµŁżµłæõ╗¼ÕŬķ£ĆĶ”üÕåŹõĮ┐Ķ┐ÖõĖ¬ĶĄŗÕĆ╝µōŹõĮ£ńÜäń╗ōµ×£Õ»╣ÕģČõ╗¢ń║┐ń©ŗÕÅ»Ķ¦üÕŹ│ÕÅ»õ┐ØķÜ£ń║┐ń©ŗÕ«ēÕģ©ŃĆéõĖ║µŁż’╝īµłæõ╗¼ÕŬķ£ĆĶ”üÕ░åÕ«×õŠŗÕÅśķćÅhostInfoÕŻ░µśÄõĖ║volatileÕÅśķćÅÕŹ│ÕÅ»ŃĆé
10.2ŃĆü õ┐ØķÜ£Õ»╣Ķ▒ĪńÜäÕ«ēÕģ©ÕÅæÕĖā
volatileńÜäõĖĆõĖ¬ÕģĖÕ×ŗÕ║öńö©Õ░▒µś»ńö©õ║ĵŁŻńĪ«Õ£░Õ«×ńÄ░Õ¤║õ║ÄÕÅīķ揵ŻĆµ¤źķöüÕ«Ü’╝łDouble checked locking’╝ēµ│ĢńÜäÕŹĢõŠŗń▒╗’╝łSingleton’╝ē’╝īÕ”éµĖģÕŹĢ3µēĆńż║ŃĆéńö©ÕÅīķ揵ŻĆµ¤źķöüիܵ│ĢµØźÕ«×ńÄ░ÕŹĢõŠŗń▒╗ńÜäńø«ńÜäÕ£©õ║ĵŚóĶāĮÕż¤Õ«×ńÄ░Õ╗ČĶ┐¤ÕŖĀĶĮĮ’╝łLazy Load’╝īõ╗źÕćÅÕ░æõĖŹÕ┐ģĶ”üńÜäÕ╝ĆķöĆ’╝ēÕÅłĶāĮÕż¤Õ░ĮķćÅÕćÅÕ░æķöüńÜäÕ╝ĆķöĆŃĆéµĖģÕŹĢ8õĖŁ’╝īķććńö©volatileµØźõ┐«ķź░ķØÖµĆüÕÅśķćÅinstanceńø«ńÜäµ£ēõĖżõĖ¬’╝Üõ┐ØķÜ£ÕÅ»Ķ¦üµĆ¦ÕÆīõ┐ØķÜ£µ£ēÕ║ÅµĆ¦ŃĆéÕ░Įń«ĪÕ»╣instanceÕÅśķćÅńÜäĶĄŗÕĆ╝µś»Õ£©õĖĆõĖ¬õĖ┤ńĢīÕī║õĖŁĶ┐øĶĪīńÜä’╝īõĮåµś»ń¼¼1µ¼ĪµŻĆµ¤źńÜäifĶ»ŁÕÅźÕ╣ȵ▓Īµ£ēÕżäõ║ÄõĖ┤ńĢīÕī║õ╣ŗõĖŁŃĆéõ╣¤Õ░▒µś»Ķ»┤’╝īĶ»ŁÕÅźŌæóÕ»╣instanceńÜäÕåÖµōŹõĮ£õĖÄĶ»ŁÕÅźŌæĀÕ»╣instanceńÜäĶ»╗µōŹõĮ£Ķ┐ÖõĖżõĖ¬µōŹõĮ£õ╣ŗķŚ┤Õ╣ČõĖŹÕŁśÕ£©happens-beforeÕģ│ń│╗’╝īÕøĀµŁż’╝īĶ»ŁÕÅźŌæóńÜäµē¦ĶĪīń╗ōµ×£Õ»╣Ķ»ŁÕÅźŌæĀµØźĶ»┤õĖŹõĖĆիܵś»ÕÅ»Ķ¦üńÜäŃĆéõĖ║õ║åńĪ«õ┐ØĶ»ŁÕÅźŌæóÕ»╣instanceńÜäÕåÖµōŹõĮ£ńÜäń╗ōµ×£Õ»╣Ķ»ŁÕÅźŌæĀ’╝łń¼¼1µ¼ĪµŻĆµ¤ź’╝ēÕÅ»Ķ¦ü’╝īµłæõ╗¼ÕŬķ£ĆĶ”üķććńö©volatileµØźõ┐«ķź░instanceÕŹ│ÕÅ»ŃĆéõ╗ĵ£ēÕ║ÅµĆ¦ńÜäĶ¦ÆÕ║”µØźń£ŗ’╝īÕ£©µ▓Īµ£ēķććńö©volatileõ┐«ķź░instanceńÜäµāģÕåĄõĖŗ’╝īĶ»ŁÕÅźŌæĀńÜäµē¦ĶĪīń║┐ń©ŗÕŹ│õĮ┐Ķ»╗ÕÅ¢Õł░instanceõĖŹõĖ║null’╝łÕģČõ╗¢ń║┐ń©ŗµē¦ĶĪīĶ»ŁÕÅźŌæóńÜäń╗ōµ×£’╝ē’╝īķéŻõ╣łńö▒õ║Äķ揵ÄÆÕ║Å’╝łJITķ揵ÄÆÕ║ÅÕÆī/µ┤╗ÕåģÕŁśķ揵ÄÆÕ║Å’╝ēńÜäõĮ£ńö©’╝īinstanceµēĆÕ╝Ģńö©ńÜäÕ»╣Ķ▒Īõ╗ŹńäČÕÅ»ĶāĮµś»µ£¬ÕłØÕ¦ŗÕī¢Õ«īµ»ĢńÜä’╝īĶ┐ÖÕ░▒ÕÅ»ĶāĮÕ»╝Ķć┤ń©ŗÕ║ÅńÜ䵣ŻńĪ«µĆ¦ķŚ«ķóśŃĆéķććńö©volatileõ┐«ķź░instanceõ╣ŗÕÉÄ’╝īÕ£©volatileõ┐ØķÜ£µ£ēÕ║ÅµĆ¦ńÜäõĮ£ńö©õĖŗ’╝īĶ»ŁÕÅźŌæĀńÜäµē¦ĶĪīń║┐ń©ŗõĖƵŚ”ń£ŗÕł░instanceõĖŹõĖ║null’╝īķéŻõ╣łinstanceµēĆÕ╝Ģńö©ńÜäÕ»╣Ķ▒ĪÕ┐ģńäȵś»ÕłØÕ¦ŗÕī¢Õ«īµ»ĢńÜäŃĆ鵣żµŚČ’╝īµłæõ╗¼ń¦░instanceµēĆÕ╝Ģńö©ńÜäÕ»╣Ķ▒ĪĶó½Õ«ēÕģ©Õ£░ÕÅæÕĖāŃĆé
µĖģÕŹĢ8 õĮ┐ńö©volatileµŁŻńĪ«Õ«×ńÄ░Õ¤║õ║ÄÕÅīķ揵ŻĆµ¤źķöüիܵ│ĢńÜäÕŹĢõŠŗń▒╗
public class DCLSingleton {
private static volatile DCLSingleton instance;
// ń£üńĢźÕģČõ╗¢ÕŁŚµ«Ą
// ń¦üµ£ēµ×äķĆĀÕÖ©
private DCLSingleton() {
}
public DCLSingleton getInstance() {
if (null == instance) {// Ķ»ŁÕÅźŌæĀ’╝Ü ń¼¼1µ¼ĪµŻĆµ¤ź’╝īõĖŹÕŖĀķöü
synchronized (DCLSingleton.class) {
if (null == instance) {// Ķ»ŁÕÅźŌæĪ’╝Ü ń¼¼2µ¼ĪµŻĆµ¤ź’╝īÕŖĀķöü
instance = new DCLSingleton();// Ķ»ŁÕÅźŌæó’╝ÜÕ«×õŠŗÕī¢
}
}
}
return instance;
}
// ń£üńĢźÕģČõ╗¢publicµ¢╣µ│Ģ
}
11. µĆ╗ń╗ō
volatileÕģ│ķö«ÕŁŚńÜäõĮ£ńö©Õīģµŗ¼õ┐ØķÜ£long/doubleÕ×ŗÕÅśķćÅĶ«┐ķŚ«µōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦ŃĆüõ┐ØķÜ£ÕÅ»Ķ¦üµĆ¦õ╗źÕÅŖõ┐ØķÜ£µ£ēÕ║ÅµĆ¦ŃĆéJavaĶÖܵŗ¤µ£║Õ£©Õ«×ńÄ░volatileÕģ│ķö«ÕŁŚńÜäĶ»Łõ╣ēµŚČķĆÜÕĖĖõ╝ÜÕƤÕŖ®õĖĆõ║øńē╣µ«ŖńÜäÕżäńÉåÕÖ©µīćõ╗ż’╝łÕÄ¤ÕŁÉµīćõ╗żÕÆīÕåģÕŁśÕ▒ÅķÜ£’╝ēŃĆévolatileÕÅśķćÅĶ«┐ķŚ«ńÜäÕ╝ĆķöĆõ╗ŗõ║ĵ֫ķĆÜÕÅśķćÅĶ«┐ķŚ«ÕÆīÕ£©õĖ┤ńĢīÕī║õĖŁĶ┐øĶĪīńÜäÕÅśķćÅĶ«┐ķŚ«õ╣ŗķŚ┤ŃĆévolatileńÜäÕģĖÕ×ŗĶ┐Éńö©Õ£║µÖ»Õīģµŗ¼ķŚ┤µÄźõ┐ØķÜ£ÕżŹÕÉłµōŹõĮ£ńÜäÕÄ¤ÕŁÉµĆ¦ŃĆüõ┐ØķÜ£Õ»╣Ķ▒ĪńÜäÕ«ēÕģ©ÕÅæÕĖāńŁēŃĆé
’╝łÕŠ«õ┐ĪÕģ¼õ╝ŚÕÅĘ’╝ÜVChannel
http://weixin.qq.com/r/oUibg6-EUPIvrevg9x2z┬Ā(õ║īń╗┤ńĀüĶć¬ÕŖ©Ķ»åÕł½)
’╝ē
12. ÕÅéĶĆāĶĄäµ¢Ö
1ŃĆü ķ╗äµ¢ćµĄĘ.JavaÕżÜń║┐ń©ŗń╝¢ń©ŗÕ«×µłśµīćÕŹŚ’╝łµĀĖÕ┐āń»ć’╝ē.ńöĄÕŁÉÕĘźõĖÜÕć║ńēłńżŠ,2017
2ŃĆü ķ╗äµ¢ćµĄĘ.JavaÕżÜń║┐ń©ŗń╝¢ń©ŗÕ«×µłśµīćÕŹŚ’╝łĶ«ŠĶ«Īµ©ĪÕ╝Åń»ć’╝ē.ńöĄÕŁÉÕĘźõĖÜÕć║ńēłńżŠ,2015
3ŃĆü Brian GoetzńŁē.Java Concurrency In Practice.Addison-Wesley Professional,2006
4ŃĆü JavaĶ»ŁĶ©ĆĶ¦äĶīāń¼¼17ń½Ā’╝Ühttps://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html
5ŃĆü Managing volatility’╝Ühttps://www.ibm.com/developerworks/library/j-jtp06197/index.html
6ŃĆü JavaÕżÜń║┐ń©ŗń╝¢ń©ŗµ©ĪÕ╝ÅÕ«×µłśµīćÕŹŚ’╝łõ║ī’╝ē’╝ÜImmutable Objectµ©ĪÕ╝Å’╝Ühttp://www.infoq.com/cn/articles/java-multithreaded-programming-mode-immutable-object
7ŃĆü Java Memory Model From a Programmer's Point-of-View’╝Ühttps://dzone.com/articles/java-memory-model-programer%E2%80%99s
8ŃĆü The JSR-133 Cookbook for Compiler Writers’╝Ühttp://gee.cs.oswego.edu/dl/jmm/cookbook.html
9ŃĆü Memory Barriers: a Hardware View for Software Hackers’╝Ühttp://www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.07.23a.pdf
10ŃĆüMemory Barriers and JVM Concurrency:https://www.infoq.com/articles/memory_barriers_jvm_concurrency
[1] ĶÖܵŗ¤µ£║ÕÅéµĢ░ŌĆ£-XX:-UseCompressedOopsŌĆØ’╝Ühttps://docs.oracle.com/javase/8/docs/technotes/guides/vm/performance-enhancements-7.html#compressedOopŃĆé
[2] Ķ┐ÖõĖ¬ĶŠōÕć║ńøĖÕ║öńÜäµē¦ĶĪīńÄ»Õóāõ┐Īµü»ŌĆöŌĆöµōŹõĮ£ń│╗ń╗¤’╝ÜLinux’╝łx86_64ń│╗ń╗¤’╝ē’╝īJDKńēłµ£¼’╝ÜJDK 1.8.0_40’╝īÕżäńÉåÕÖ©Õ×ŗÕÅĘ’╝ÜIntel i5-3210MŃĆé



ńøĖÕģ│µÄ©ĶŹÉ
6. **ÕżÜń║┐ń©ŗ**’╝ÜJavaµÅÉõŠøõ║åõĖ░Õ»īńÜäAPIµö»µīüÕżÜń║┐ń©ŗń╝¢ń©ŗ’╝īÕ”éThreadń▒╗ŃĆüRunnableµÄźÕÅŻ’╝īõ╗źÕÅŖsynchronizedÕģ│ķö«ÕŁŚŃĆüvolatileÕģ│ķö«ÕŁŚńŁē’╝īńÉåĶ¦ŻÕ╣ČÕÅæń╝¢ń©ŗńÜäµ”éÕ┐ĄÕÆīÕ«×ĶĘĄµ¢╣µ│ĢÕ»╣õ║ÄÕ╝ĆÕÅæķ½śµĢłń©ŗÕ║ÅĶć│Õģ│ķćŹĶ”üŃĆé 7. **IOµĄü**’╝ÜJavańÜäIOµĄü...
- ķĆÜĶ┐ćĶ┐ÖõĖ¬Ķ░£ķóś’╝īĶ»╗ĶĆģÕ░åõ║åĶ¦ŻvolatileÕģ│ķö«ÕŁŚńÜäõĮ£ńö©ÕÅŖÕģČÕ£©ÕżÜń║┐ń©ŗńÄ»ÕóāõĖŗńÜ䵣ŻńĪ«õĮ┐ńö©µ¢╣µ│ĢŃĆé #### ń╗ōĶ«║ ŃĆŖJava Puzzlers: Traps, Pitfalls, and Corner CasesŃĆŗõĖŹõ╗ģµś»õĖƵ£¼µ£ēĶČŻńÜäń╝¢ń©ŗõ╣”ń▒Ź’╝īµø┤µś»õĖƵ£¼Õ«ØĶ┤ĄńÜäÕÅéĶĆāµīćÕŹŚŃĆéķĆÜĶ┐ć...
Ķ┐Öõ║øÕĘźÕģĘÕ£©ÕżÜń║┐ń©ŗń╝¢ń©ŗõĖŁµ£ēńØĆÕ╣┐µ│øńÜäÕ║öńö©’╝īõ╣”õĖŁõ╝ÜĶ»”ń╗åõ╗ŗń╗ŹÕ«āõ╗¼ńÜäńö©µ│ĢÕÆīÕ║öńö©Õ£║µÖ»ŃĆé ķĆÜĶ┐ćķśģĶ»╗ŃĆŖJavaĶ¦Żµāæ’╝łõĖŁµ¢ć’╝ēŃĆŗ’╝īÕ╝ĆÕÅæĶĆģÕÅ»õ╗źÕ»╣Ķ┐Öõ║øÕģ│ķö«ń¤źĶ»åńé╣µ£ēµø┤µĘ▒Õł╗ńÜäńÉåĶ¦Ż’╝īµÅÉÕŹćń╝¢ń©ŗµŖĆÕʦ’╝īĶ¦ŻÕå│Õ«×ķÖģÕĘźõĮ£õĖŁķüćÕł░ńÜäķŚ«ķóś’╝īõ╗ÄĶĆīµłÉõĖ║µø┤...
2. **ÕżÜń║┐ń©ŗ**’╝ÜJavaµÅÉõŠøõ║åThreadń▒╗ÕÆīRunnableµÄźÕÅŻµØźµö»µīüÕżÜń║┐ń©ŗń╝¢ń©ŗ’╝īńÉåĶ¦Żń║┐ń©ŗÕÉīµŁź’╝łÕ”ésynchronizedÕģ│ķö«ÕŁŚŃĆüvolatileÕÅśķćÅŃĆüLockµÄźÕÅŻ’╝ēÕÆīÕ╣ČÕÅæÕĘźÕģĘń▒╗’╝łÕ”éSemaphoreŃĆüCountDownLatchŃĆüCyclicBarrier’╝ēĶāĮķü┐ÕģŹÕĖĖĶ¦üńÜäÕ╣ČÕÅæ...
µ£¼µ¢ćÕ░åÕø┤ń╗ĢJavaÕżÜń║┐ń©ŗÕ▒ĢÕ╝Ć’╝īĶ«▓Ķ¦ŻÕģȵĀĖÕ┐āµ”éÕ┐ĄŃĆüÕ«×ńÄ░µ¢╣Õ╝Åõ╗źÕÅŖķØóĶ»ĢõĖŁÕÅ»ĶāĮķüćÕł░ńÜäķŚ«ķóśŃĆé **õĖĆŃĆüÕżÜń║┐ń©ŗńÜäÕ¤║µ£¼µ”éÕ┐Ą** 1. **ń║┐ń©ŗõĖÄĶ┐øń©ŗ**’╝Üń║┐ń©ŗµś»Ķ┐øń©ŗÕåģķā©ńÜäµē¦ĶĪīÕŹĢÕģā’╝īµ»ÅõĖ¬Ķ┐øń©ŗĶć│Õ░æµ£ēõĖĆõĖ¬ń║┐ń©ŗ’╝īÕżÜõĖ¬ń║┐ń©ŗÕÅ»õ╗źÕģ▒õ║½ÕÉīõĖĆĶ┐øń©ŗńÜä...
6. **ÕżÜń║┐ń©ŗ** - **Threadń▒╗ÕÆīRunnableµÄźÕÅŻ**’╝ÜÕłøÕ╗║ń║┐ń©ŗńÜäõĖżń¦Źµ¢╣Õ╝ÅŃĆé - **ÕÉīµŁźµ£║ÕłČ**’╝ÜsynchronizedÕģ│ķö«ÕŁŚŃĆü volatileÕÅśķćÅÕÆīLockµÄźÕÅŻ’╝īńö©õ║Äõ┐ØĶ»üń║┐ń©ŗÕ«ēÕģ©ŃĆé 7. **I/OµĄü** - **ÕŁŚĶŖ鵥üõĖÄÕŁŚń¼”µĄü**’╝ÜńÉåĶ¦ŻÕÆīõĮ┐ńö©...
3. **ÕżÜń║┐ń©ŗ**’╝ÜJavaµÅÉõŠøõ║åõĖ░Õ»īńÜäÕżÜń║┐ń©ŗµö»µīü’╝īÕīģµŗ¼`Thread`ń▒╗ŃĆü`Runnable`µÄźÕÅŻŃĆü`ExecutorService`ÕÆī`Future`ńŁēŃĆéµĘ▒ÕģźńÉåĶ¦ŻÕ╣ČÕÅæÕĤńÉåÕÆīÕÉīµŁźµ£║ÕłČ’╝łÕ”é`synchronized`ŃĆü`volatile`Õģ│ķö«ÕŁŚŃĆü`Lock`µÄźÕÅŻ’╝ēÕ»╣õ║Äń╝¢ÕåÖķ½śµĢłÕ╣ČÕÅæ...
6. **ÕżÜń║┐ń©ŗ**’╝Üń║┐ń©ŗńÜäÕłøÕ╗║ŃĆüÕÉīµŁźŃĆüķĆÜõ┐Ī’╝īõ╗źÕÅŖThreadÕÆīRunnableµÄźÕÅŻńÜäõĮ┐ńö©ŃĆé 7. **ÕÅŹÕ░äµ£║ÕłČ**’╝ÜĶ┐ÉĶĪīµŚČÕŖ©µĆüÕŖĀĶĮĮń▒╗ŃĆüĶÄĘÕÅ¢ń▒╗õ┐Īµü»ŃĆüĶ░āńö©µ¢╣µ│ĢÕÆīµ×äķĆĀÕÖ©ńŁēŃĆé Õģȵ¼Ī’╝īõ╣”õĖŁńÜä"Ķ¦Żµāæ"ķā©ÕłåÕÅ»ĶāĮõ╝ܵĘ▒ÕģźÕł░õĖĆõ║øÕĖĖĶ¦üńÜäÕø░µāæÕÆīķÖĘķś▒’╝ī...
11. **Õ╣ČÕÅæń╝¢ń©ŗ**’╝ÜJavaÕ╣ČÕÅæÕ║ōµÅÉõŠøõ║åõĖĆÕźŚõĖ░Õ»īńÜäÕĘźÕģĘ’╝īÕ”éExecutorServiceŃĆüCountDownLatchŃĆüCyclicBarrierŃĆüSemaphoreńŁē’╝īÕĖ«ÕŖ®Õ╝ĆÕÅæĶĆģń╝¢ÕåÖķ½śµĢłńÜäÕżÜń║┐ń©ŗń©ŗÕ║ÅŃĆé 12. **LambdaĶĪ©ĶŠŠÕ╝ÅõĖÄÕćĮµĢ░Õ╝Åń╝¢ń©ŗ**’╝ÜJava 8Õ╝ĢÕģźõ║åLambda...
"JavaĶ¦Żµāæ"Ķ┐Öµ£¼õ╣”ń▒ŹµŚ©Õ£©ÕĖ«ÕŖ®ń©ŗÕ║ÅÕæśĶ¦ŻÕå│Õ£©Õ«×ķÖģń╝¢ń©ŗĶ┐ćń©ŗõĖŁķüćÕł░ńÜäÕø░µāæÕÆīķÜŠķóś’╝īķĆÜĶ┐ćµĘ▒ÕģźµĄģÕć║Õ£░Ķ¦ŻķćŖķéŻõ║øń£ŗõ╝╝Õć║õ╣ĵäŵ¢ÖńÜäõ╗ŻńĀüĶĪīõĖ║’╝īÕĖ«ÕŖ®Ķ»╗ĶĆģµÅÉÕŹćÕ»╣JavaĶ»ŁĶ©ĆńÜäńÉåĶ¦ŻŃĆé 1. **Õ╝éÕĖĖÕżäńÉå**’╝ÜJavaõĖŁńÜäÕ╝éÕĖĖÕżäńÉåµś»õĖĆõĖ¬ķćŹĶ”üńÜäµ”éÕ┐Ą’╝ī...
5. **ÕżÜń║┐ń©ŗ**’╝Üõ║åĶ¦Żń║┐ń©ŗńÜäÕłøÕ╗║µ¢╣Õ╝Å’╝łThreadń▒╗ŃĆüRunnableµÄźÕÅŻ’╝ēŃĆüń║┐ń©ŗÕÉīµŁźµ£║ÕłČ’╝łsynchronizedŃĆüvolatileŃĆüLockµÄźÕÅŻ’╝ē’╝īõ╗źÕÅŖń║┐ń©ŗµ▒ĀńÜäõĮ┐ńö©ŃĆé 6. **JVM**’╝ÜJVMńÜäÕĘźõĮ£ÕĤńÉå’╝īń▒╗ÕŖĀĶĮĮµ£║ÕłČ’╝łÕÅīõ║▓Õ¦öµ┤Šµ©ĪÕ×ŗ’╝ē’╝īÕŁŚĶŖéńĀüµē¦ĶĪīÕ╝ĢµōÄ...
Javań╝¢ń©ŗĶ»ŁĶ©ĆõĮ£õĖ║ĶĮ»õ╗ČÕ╝ĆÕÅæńÜäķćŹĶ”üÕĘźÕģĘ’╝īÕģČķØóĶ»ĢķóśµČĄńø¢õ║åÕ╣┐µ│øńÜäķóåÕ¤¤’╝īÕīģµŗ¼Õ¤║ńĪĆń¤źĶ»åŃĆüµĢ░µŹ«ń╗ōµ×äõĖÄń«Śµ│ĢŃĆüÕżÜń║┐ń©ŗŃĆüńĮæń╗£ń╝¢ń©ŗŃĆüÕ╝éÕĖĖÕżäńÉåŃĆüJVMõ╝śÕī¢ŃĆüķøåÕÉłµĪåµ×ČŃĆüĶ«ŠĶ«Īµ©ĪÕ╝ÅńŁēŃĆéõ╗źõĖŗµś»Õ»╣"JAVAķØóĶ»ĢķóśĶ¦Żµāæń│╗ÕłŚ"õĖŁÕÅ»ĶāĮµČēÕÅŖńÜäń¤źĶ»åńé╣ńÜä...
Ķ┐ÖķĆÜÕĖĖµČēÕÅŖÕł░JavańÜäµĀĖÕ┐āµ”éÕ┐ĄŃĆüķ½śń║¦ńē╣µĆ¦ŃĆüĶ«ŠĶ«Īµ©ĪÕ╝ÅŃĆüÕ╣ČÕÅæń╝¢ń©ŗŃĆüķøåÕÉłµĪåµ×ČŃĆüIO/NIOµĄüŃĆüÕ╝éÕĖĖÕżäńÉåŃĆüÕ×āÕ£ŠÕø×µöȵ£║ÕłČŃĆüÕżÜń║┐ń©ŗŃĆüJVMõ╝śÕī¢ńŁēÕżÜõĖ¬µ¢╣ķØóŃĆéÕ»╣õ║ÄJavaÕ╝ĆÕÅæĶĆģ’╝īÕ░żÕģȵś»ÕćåÕżćķØóĶ»Ģµł¢µÅÉÕŹćµŖƵ£»ĶāĮÕŖøńÜäõ║║µØźĶ»┤’╝īĶ┐Öõ║øķāĮµś»Ķć│Õģ│ķćŹĶ”ü...
2. **ÕżÜń║┐ń©ŗ**’╝ÜJavańÜäÕ╣ČÕÅæńē╣µĆ¦µś»ÕģČÕ╝║Õż¦ÕŖ¤ĶāĮõ╣ŗõĖĆ’╝īõĮåÕÉīµŚČõ╣¤ÕÅ»ĶāĮÕ»╝Ķć┤ÕżŹµØéķŚ«ķóśŃĆéõ╣”õĖŁÕÅ»ĶāĮµČĄńø¢ń║┐ń©ŗÕ«ēÕģ©ŃĆüµŁ╗ķöüŃĆüµ┤╗ķöüŃĆüķźźķź┐ńŁēķŚ«ķóś’╝īõ╗źÕÅŖÕ”éõĮĢõĮ┐ńö©`synchronized`ŃĆü`volatile`Õģ│ķö«ÕŁŚÕÆī`java.util.concurrent`ÕīģµØźĶ¦ŻÕå│Ķ┐Öõ║ø...
ķØóĶ»ĢÕ«śÕÅ»ĶāĮõ╝ÜĶ«ŠĶ«ĪķŚ«ķóśµØźµĄŗĶ»ĢÕĆÖķĆēõ║║Õ£©ÕżäńÉåÕżÜń║┐ń©ŗķŚ«ķ󜵌ČńÜäĶāĮÕŖø’╝īµ»öÕ”éµŁ╗ķöüŃĆüµ┤╗ķöüŃĆüķźźķź┐ńŁēķŚ«ķóśńÜäķóäķś▓ŃĆé µŁżÕż¢’╝īJavańÜäÕ╝éÕĖĖÕżäńÉåõ╣¤µś»ķØóĶ»ĢõĖŁńÜäÕĖĖĶ¦üķŚ«ķóśŃĆéõ║åĶ¦ŻõĮĢµŚČµŖøÕć║Õ╝éÕĖĖŃĆüÕ”éõĮĢµŹĢĶÄĘÕ╝éÕĖĖŃĆüfinallyÕØŚńÜäõĮ£ńö©’╝īõ╗źÕÅŖĶć¬Õ«Üõ╣ēÕ╝éÕĖĖ...
3. **ÕżÜń║┐ń©ŗ**’╝ÜJavaµÅÉõŠøõ║åõĖ░Õ»īńÜäÕżÜń║┐ń©ŗµö»µīü’╝īÕīģµŗ¼Threadń▒╗ÕÆīRunnableµÄźÕÅŻŃĆéńÉåĶ¦Żń║┐ń©ŗńÜäńö¤ÕæĮÕ橵£¤ŃĆüÕÉīµŁźµ£║ÕłČ’╝łÕ”ésynchronizedÕģ│ķö«ÕŁŚŃĆüvolatileÕÅśķćÅŃĆüLockµÄźÕÅŻ’╝ēõ╗źÕÅŖµŁ╗ķöüŃĆüµ┤╗ķöüÕÆīķźźķź┐ńŖȵĆü’╝īµś»ń╝¢ÕåÖķ½śµĢłÕ╣ČÕÅæń©ŗÕ║ÅńÜäÕ¤║ńĪĆŃĆé ...
Ķ░£ķóśÕ░åÕ▒Ģńż║Õ”éõĮĢµŁŻńĪ«õĮ┐ńö©synchronizedŃĆüvolatileÕģ│ķö«ÕŁŚ’╝īõ╗źÕÅŖÕ”éõĮĢńÉåĶ¦ŻÕÆīķü┐ÕģŹµŁ╗ķöüŃĆüµ┤╗ķöüŃĆüķźźķź┐ńŁēķŚ«ķóś’╝īńĪ«õ┐ØÕżÜń║┐ń©ŗńÄ»ÕóāõĖŗńÜäń©ŗÕ║ÅĶĪīõĖ║µś»ÕÅ»ķó䵥ŗÕÆīÕ«ēÕģ©ńÜäŃĆé õ╣”õĖŁĶ┐śµČĄńø¢õ║åJavańÜäIOÕÆīNIOń│╗ń╗¤’╝īĶ¦ŻķćŖõ║åµĄüńÜäõĮ┐ńö©ŃĆüµ¢ćõ╗ȵōŹõĮ£õ╗źÕÅŖ...
4. ÕżÜń║┐ń©ŗ’╝ÜÕ╣ČÕÅæń╝¢ń©ŗµś»JavaõĖŁńÜäõĖĆõĖ¬ķćŹĶ”üķóåÕ¤¤’╝īõ╣”õĖŁÕÅ»ĶāĮõ╝Üõ╗ŗń╗Źń║┐ń©ŗÕ«ēÕģ©ķŚ«ķóś’╝īÕ”ésynchronizedÕģ│ķö«ÕŁŚńÜäõĮ┐ńö©’╝īvolatileÕÅśķćÅńÜäõĮ£ńö©’╝īõ╗źÕÅŖµŁ╗ķöüŃĆüµ┤╗ķöüÕÆīķźźķź┐ńÄ░Ķ▒ĪńÜäķóäķś▓ŃĆé 5. Õ╝éÕĖĖÕżäńÉå’╝ÜJavańÜäÕ╝éÕĖĖÕżäńÉåµ£║ÕłČµś»õĖĆõĖ¬ķćŹĶ”üńÜäń¤źĶ»å...
ķĆÜĶ┐ćĶ┐Öõ╗ĮĶ»Šõ╗Č’╝īÕŁ”õ╣ĀĶĆģÕÅ»õ╗źń│╗ń╗¤Õ£░õ║åĶ¦ŻJavańÜäµĀĖÕ┐āĶ»Łµ│ĢŃĆüń▒╗õĖÄÕ»╣Ķ▒ĪŃĆüÕ╝éÕĖĖÕżäńÉåŃĆüÕżÜń║┐ń©ŗŃĆüķøåÕÉłµĪåµ×ČŃĆüIOµĄüŃĆüńĮæń╗£ń╝¢ń©ŗõ╗źÕÅŖJava Swingµł¢JavaFXńŁēGUIń╝¢ń©ŗµŖƵ£»ŃĆé Õ£©ŃĆɵÅÅĶ┐░ŃĆæõĖŁµÅÉÕł░ńÜäŌĆ£ÕŹÜµ¢ćķōŠµÄź’╝Ü...