
A high-throughput distributed messaging system.
--Apache Kafka
Kafka作为时下最流行的开源消息系统,被广泛地应用在数据缓冲、异步通信、汇集日志、系统解耦等方面。相比较于RocketMQ等其他常见消息系统,Kafka在保障了大部分功能特性的同时,还提供了超一流的读写性能。
本文将针对Kafka性能方面进行简单分析,首先简单介绍一下Kafka的架构和涉及到的名词:
-
Topic:用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上。
-
Partition:是Kafka中横向扩展和一切并行化的基础,每个Topic都至少被切分为1个Partition。
-
Offset:消息在Partition中的编号,编号顺序不跨Partition。
-
Consumer:用于从Broker中取出/消费Message。
-
Producer:用于往Broker中发送/生产Message。
-
Replication:Kafka支持以Partition为单位对Message进行冗余备份,每个Partition都可以配置至少1个Replication(当仅1个Replication时即仅该Partition本身)。
-
Leader:每个Replication集合中的Partition都会选出一个唯一的Leader,所有的读写请求都由Leader处理。其他Replicas从Leader处把数据更新同步到本地,过程类似大家熟悉的MySQL中的Binlog同步。
-
Broker:Kafka中使用Broker来接受Producer和Consumer的请求,并把Message持久化到本地磁盘。每个Cluster当中会选举出一个Broker来担任Controller,负责处理Partition的Leader选举,协调Partition迁移等工作。
-
ISR(In-Sync Replica):是Replicas的一个子集,表示目前Alive且与Leader能够“Catch-up”的Replicas集合。由于读写都是首先落到Leader上,所以一般来说通过同步机制从Leader上拉取数据的Replica都会和Leader有一些延迟(包括了延迟时间和延迟条数两个维度),任意一个超过阈值都会把该Replica踢出ISR。每个Partition都有它自己独立的ISR。
以上几乎是我们在使用Kafka的过程中可能遇到的所有名词,同时也无一不是最核心的概念或组件,感觉到从设计本身来说,Kafka还是足够简洁的。这次本文围绕Kafka优异的吞吐性能,逐个介绍一下其设计与实现当中所使用的各项“黑科技”。
Broker
不同于Redis和MemcacheQ等内存消息队列,Kafka的设计是把所有的Message都要写入速度低容量大的硬盘,以此来换取更强的存储能力。实际上,Kafka使用硬盘并没有带来过多的性能损失,“规规矩矩”的抄了一条“近道”。
首先,说“规规矩矩”是因为Kafka在磁盘上只做Sequence I/O,由于消息系统读写的特殊性,这并不存在什么问题。关于磁盘I/O的性能,引用一组Kafka官方给出的测试数据(Raid-5,7200rpm):
Sequence I/O: 600MB/s
Random I/O: 100KB/s
所以通过只做Sequence I/O的限制,规避了磁盘访问速度低下对性能可能造成的影响。
接下来我们再聊一聊Kafka是如何“抄近道的”。
首先,Kafka重度依赖底层操作系统提供的PageCache功能。当上层有写操作时,操作系统只是将数据写入PageCache,同时标记Page属性为Dirty。当读操作发生时,先从PageCache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。同时如果有其他进程申请内存,回收PageCache的代价又很小,所以现代的OS都支持PageCache。
使用PageCache功能同时可以避免在JVM内部缓存数据,JVM为我们提供了强大的GC能力,同时也引入了一些问题不适用与Kafka的设计。
• 如果在Heap内管理缓存,JVM的GC线程会频繁扫描Heap空间,带来不必要的开销。如果Heap过大,执行一次Full GC对系统的可用性来说将是极大的挑战。
• 所有在在JVM内的对象都不免带有一个Object Overhead(千万不可小视),内存的有效空间利用率会因此降低。
• 所有的In-Process Cache在OS中都有一份同样的PageCache。所以通过将缓存只放在PageCache,可以至少让可用缓存空间翻倍。
• 如果Kafka重启,所有的In-Process Cache都会失效,而OS管理的PageCache依然可以继续使用。
PageCache还只是第一步,Kafka为了进一步的优化性能还采用了Sendfile技术。在解释Sendfile之前,首先介绍一下传统的网络I/O操作流程,大体上分为以下4步。
-
OS 从硬盘把数据读到内核区的PageCache。
-
用户进程把数据从内核区Copy到用户区。
-
然后用户进程再把数据写入到Socket,数据流入内核区的Socket Buffer上。
-
OS 再把数据从Buffer中Copy到网卡的Buffer上,这样完成一次发送。
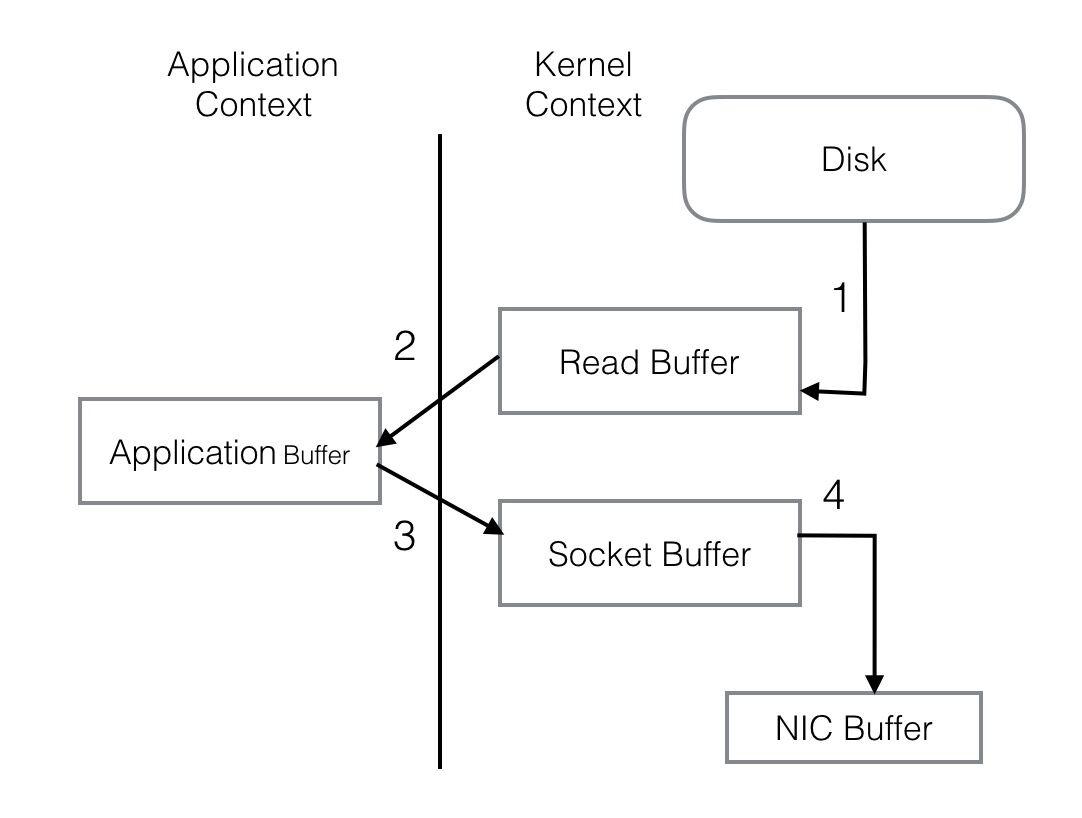
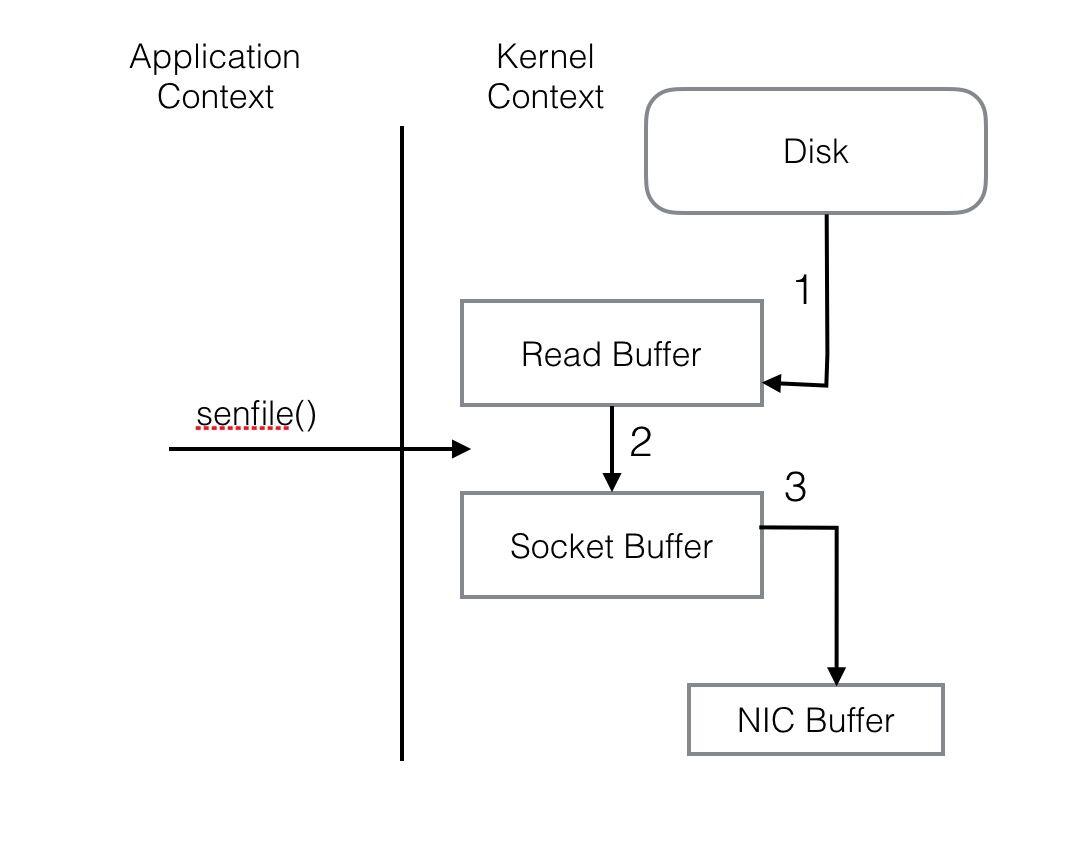
整个过程共经历两次Context Switch,四次System Call。同一份数据在内核Buffer与用户Buffer之间重复拷贝,效率低下。其中2、3两步没有必要,完全可以直接在内核区完成数据拷贝。这也正是Sendfile所解决的问题,经过Sendfile优化后,整个I/O过程就变成了下面这个样子。
通过以上的介绍不难看出,Kafka的设计初衷是尽一切努力在内存中完成数据交换,无论是对外作为一整个消息系统,或是内部同底层操作系统的交互。如果Producer和Consumer之间生产和消费进度上配合得当,完全可以实现数据交换零I/O。这也就是我为什么说Kafka使用“硬盘”并没有带来过多性能损失的原因。下面是我在生产环境中采到的一些指标。
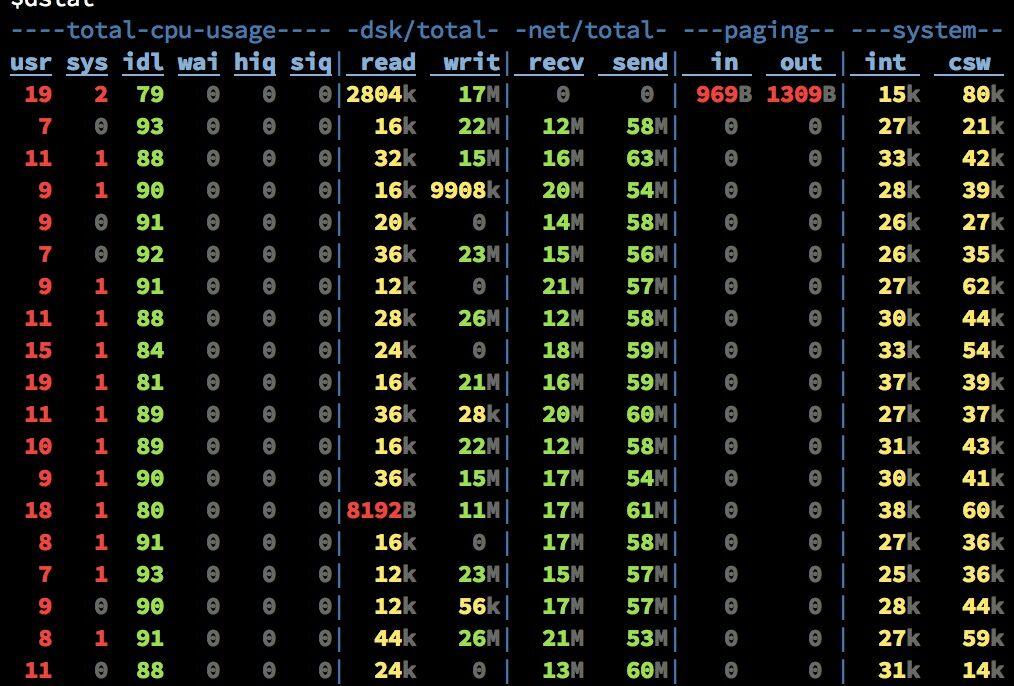
(20 Brokers, 75 Partitions per Broker, 110k msg/s)
此时的集群只有写,没有读操作。10M/s左右的Send的流量是Partition之间进行Replicate而产生的。从recv和writ的速率比较可以看出,写盘是使用Asynchronous+Batch的方式,底层OS可能还会进行磁盘写顺序优化。而在有Read Request进来的时候分为两种情况,第一种是内存中完成数据交换。
Send流量从平均10M/s增加到了到平均60M/s,而磁盘Read只有不超过50KB/s。PageCache降低磁盘I/O效果非常明显。

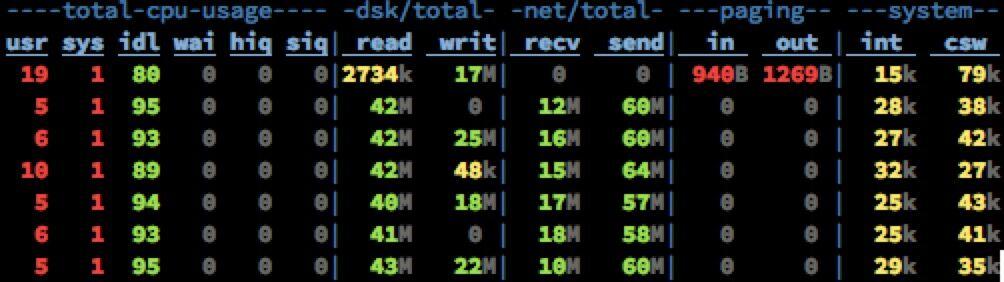
接下来是读一些收到了一段时间,已经从内存中被换出刷写到磁盘上的老数据。
其他指标还是老样子,而磁盘Read已经飚高到40+MB/s。此时全部的数据都已经是走硬盘了(对硬盘的顺序读取OS层会进行Prefill PageCache的优化)。依然没有任何性能问题。
Tips
-
Kafka官方并不建议通过Broker端的log.flush.interval.messages和log.flush.interval.ms来强制写盘,认为数据的可靠性应该通过Replica来保证,而强制Flush数据到磁盘会对整体性能产生影响。
-
可以通过调整/proc/sys/vm/dirty_background_ratio和/proc/sys/vm/dirty_ratio来调优性能。
-
脏页率超过第一个指标会启动pdflush开始Flush Dirty PageCache。
-
脏页率超过第二个指标会阻塞所有的写操作来进行Flush。
-
根据不同的业务需求可以适当的降低dirty_background_ratio和提高dirty_ratio。
Partition
Partition是Kafka可以很好的横向扩展和提供高并发处理以及实现Replication的基础。
扩展性方面。首先,Kafka允许Partition在集群内的Broker之间任意移动,以此来均衡可能存在的数据倾斜问题。其次,Partition支持自定义的分区算法,例如可以将同一个Key的所有消息都路由到同一个Partition上去。 同时Leader也可以在In-Sync的Replica中迁移。由于针对某一个Partition的所有读写请求都是只由Leader来处理,所以Kafka会尽量把Leader均匀的分散到集群的各个节点上,以免造成网络流量过于集中。
并发方面。任意Partition在某一个时刻只能被一个Consumer Group内的一个Consumer消费(反过来一个Consumer则可以同时消费多个Partition),Kafka非常简洁的Offset机制最小化了Broker和Consumer之间的交互,这使Kafka并不会像同类其他消息队列一样,随着下游Consumer数目的增加而成比例的降低性能。此外,如果多个Consumer恰巧都是消费时间序上很相近的数据,可以达到很高的PageCache命中率,因而Kafka可以非常高效的支持高并发读操作,实践中基本可以达到单机网卡上限。
不过,Partition的数量并不是越多越好,Partition的数量越多,平均到每一个Broker上的数量也就越多。考虑到Broker宕机(Network Failure, Full GC)的情况下,需要由Controller来为所有宕机的Broker上的所有Partition重新选举Leader,假设每个Partition的选举消耗10ms,如果Broker上有500个Partition,那么在进行选举的5s的时间里,对上述Partition的读写操作都会触发LeaderNotAvailableException。
再进一步,如果挂掉的Broker是整个集群的Controller,那么首先要进行的是重新任命一个Broker作为Controller。新任命的Controller要从Zookeeper上获取所有Partition的Meta信息,获取每个信息大概3-5ms,那么如果有10000个Partition这个时间就会达到30s-50s。而且不要忘记这只是重新启动一个Controller花费的时间,在这基础上还要再加上前面说的选举Leader的时间 -_-!!!!!!
此外,在Broker端,对Producer和Consumer都使用了Buffer机制。其中Buffer的大小是统一配置的,数量则与Partition个数相同。如果Partition个数过多,会导致Producer和Consumer的Buffer内存占用过大。
Tips
-
Partition的数量尽量提前预分配,虽然可以在后期动态增加Partition,但是会冒着可能破坏Message Key和Partition之间对应关系的风险。
-
Replica的数量不要过多,如果条件允许尽量把Replica集合内的Partition分别调整到不同的Rack。
-
尽一切努力保证每次停Broker时都可以Clean Shutdown,否则问题就不仅仅是恢复服务所需时间长,还可能出现数据损坏或其他很诡异的问题。
Producer
Kafka的研发团队表示在0.8版本里用Java重写了整个Producer,据说性能有了很大提升。我还没有亲自对比试用过,这里就不做数据对比了。本文结尾的扩展阅读里提到了一套我认为比较好的对照组,有兴趣的同学可以尝试一下。
其实在Producer端的优化大部分消息系统采取的方式都比较单一,无非也就化零为整、同步变异步这么几种。
Kafka系统默认支持MessageSet,把多条Message自动地打成一个Group后发送出去,均摊后拉低了每次通信的RTT。而且在组织MessageSet的同时,还可以把数据重新排序,从爆发流式的随机写入优化成较为平稳的线性写入。
此外,还要着重介绍的一点是,Producer支持End-to-End的压缩。数据在本地压缩后放到网络上传输,在Broker一般不解压(除非指定要Deep-Iteration),直至消息被Consume之后在客户端解压。
当然用户也可以选择自己在应用层上做压缩和解压的工作(毕竟Kafka目前支持的压缩算法有限,只有GZIP和Snappy),不过这样做反而会意外的降低效率!!!! Kafka的End-to-End压缩与MessageSet配合在一起工作效果最佳,上面的做法直接割裂了两者间联系。至于道理其实很简单,压缩算法中一条基本的原理“重复的数据量越多,压缩比越高”。无关于消息体的内容,无关于消息体的数量,大多数情况下输入数据量大一些会取得更好的压缩比。
不过Kafka采用MessageSet也导致在可用性上一定程度的妥协。每次发送数据时,Producer都是send()之后就认为已经发送出去了,但其实大多数情况下消息还在内存的MessageSet当中,尚未发送到网络,这时候如果Producer挂掉,那就会出现丢数据的情况。
为了解决这个问题,Kafka在0.8版本的设计借鉴了网络当中的ack机制。如果对性能要求较高,又能在一定程度上允许Message的丢失,那就可以设置request.required.acks=0 来关闭ack,以全速发送。如果需要对发送的消息进行确认,就需要设置request.required.acks为1或-1,那么1和-1又有什么区别呢?这里又要提到前面聊的有关Replica数量问题。如果配置为1,表示消息只需要被Leader接收并确认即可,其他的Replica可以进行异步拉取无需立即进行确认,在保证可靠性的同时又不会把效率拉得很低。如果设置为-1,表示消息要Commit到该Partition的ISR集合中的所有Replica后,才可以返回ack,消息的发送会更安全,而整个过程的延迟会随着Replica的数量正比增长,这里就需要根据不同的需求做相应的优化。
Tips
-
Producer的线程不要配置过多,尤其是在Mirror或者Migration中使用的时候,会加剧目标集群Partition消息乱序的情况(如果你的应用场景对消息顺序很敏感的话)。
-
0.8版本的request.required.acks默认是0(同0.7)。
Consumer
Consumer端的设计大体上还算是比较常规的。
• 通过Consumer Group,可以支持生产者消费者和队列访问两种模式。
• Consumer API分为High level和Low level两种。前一种重度依赖Zookeeper,所以性能差一些且不自由,但是超省心。第二种不依赖Zookeeper服务,无论从自由度和性能上都有更好的表现,但是所有的异常(Leader迁移、Offset越界、Broker宕机等)和Offset的维护都需要自行处理。
• 大家可以关注下不日发布的0.9 Release。开发人员又用Java重写了一套Consumer。把两套API合并在一起,同时去掉了对Zookeeper的依赖。据说性能有大幅度提升哦~~
Tips
强烈推荐使用Low level API,虽然繁琐一些,但是目前只有这个API可以对Error数据进行自定义处理,尤其是处理Broker异常或由于Unclean Shutdown导致的Corrupted Data时,否则无法Skip只能等着“坏消息”在Broker上被Rotate掉,在此期间该Replica将会一直处于不可用状态。
扩展阅读
Sendfile: https://www.ibm.com/developerworks/cn/java/j-zerocopy/
So what’s wrong with 1975 programming: https://www.varnish-cache.org/trac/wiki/ArchitectNotes
Benchmarking: https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
https://segmentfault.com/a/1190000003985468



相关推荐
首先,硬盘方案的选择直接影响Kafka的性能,包括大容量存储、高IO吞吐量、快速扩容能力、数据安全性以及低冗余。常见的硬盘构建策略有单硬盘读写、多目录读写、硬盘阵列(如RAID0和RAID10)以及逻辑卷(LVM)等。 1...
7. **Kafka**:Kafka是一个高吞吐量的分布式消息系统,常用于实时数据管道和流处理。其架构解析和性能优化内容将帮助理解如何构建可靠且高效的实时数据流处理平台。 8. **数据中台建设**:数据中台是企业数据管理和...
内容概要:本文档详细介绍了如何利用Python实现鲸鱼优化算法(WOA)结合卷积神经网络(CNN)和门控循环单元(GRU)来进行多输入单输出回归预测。主要涵盖的内容包括:背景介绍、项目目标与意义、面临的挑战及其应对方法、项目的特点与创新之处、以及广泛的潜在应用领域(如金融、能源、气象、环保等)。通过对模型架构的具体阐述和示例代码演示,展示了该模型在处理复杂时间序列问题方面的优越性能。此外,还讨论了使用WOA优化CNN-GRU模型超参数的过程,从而提升模型在训练时的表现和准确性。 适用人群:面向有兴趣探索深度学习在时序数据处理中应用的专业人士,特别是那些希望深入了解并尝试将优化算法应用于深度学习架构的研发人员和技术爱好者。 使用场景及目标:此资源可用于指导开发人员在各类实际业务环境中实施高精度的时间序列预测系统,如金融市场预测、能源需求估计或者气候条件预测等。具体来说,它可以用来①改进现有模型以增加其准确性和鲁棒性;②加速模型迭代速度并降低成本;③促进跨学科交叉研究,推动技术创新。 其他说明:文中提供了从头搭建WOA-CNN-GRU框架所需的全部必要步骤,包括但不限于数据清理与标准化处理
Apache:Apache的安装与配置:14. Apache性能调优与安全加固.pdf
Comsol电弧冲击击穿模型:多相流模拟电弧产生与多物理场分布研究,Comsol电弧冲击击穿模型:多相流模拟电弧产生与多物理场分布研究,comsol电弧冲击击穿模型,采用多相流模拟电弧的产生,可以得到电弧温度场,流体场,电磁场分布, ,核心关键词:Comsol电弧冲击击穿模型; 多相流模拟; 电弧产生; 电弧温度场; 流体场; 电磁场分布;,COMSOL电弧冲击多相流模拟模型
粒子群算法优化光伏发电MPPT实现多峰值寻优,解决阴影遮蔽问题,基于MATLAB编程与S-function调用,粒子群算法(PSO)与阴影遮蔽在光伏发电中的MPPT多峰值寻优实现:突破局部最优,实现最大峰值功率输出,粒子群算法(PSO)光伏发电 MPPT实现多峰值寻优,阴影遮蔽光伏发电算法 使用s函数编写粒子群算法,阴影遮蔽,实现多峰值寻优,解决经典mppt算法会形成局部最优的问题,追踪到最大峰值功率输出。 粒子群算法使用matlab编程实现,再simulink中用S-function调用 ,PSO; 多峰值寻优; 阴影遮蔽; 光伏发电; MPPT算法; S-function; MATLAB编程; Simulink调用,粒子群算法优化MPPT:阴影遮蔽光伏发电多峰值寻优的MATLAB实现
项目工程资源经过严格测试运行并且功能上ok,可复现复刻,拿到资料包后可实现复刻出一样的项目,本人系统开发经验充足(全栈),有任何使用问题欢迎随时与我联系,我会及时为您解惑,提供帮助 【资源内容】:包含源码、工程文件、说明等。资源质量优质,放心下载使用!可实现复现;设计报告可借鉴此项目;该资源内项目代码都经过测试运行,功能ok 【项目价值】:可用在相关项目设计中,皆可应用在项目、毕业设计、课程设计、期末/期中/大作业、工程实训、大创等学科竞赛比赛、初期项目立项、学习/练手等方面,可借鉴此优质项目实现复刻,设计报告也可借鉴此项目,也可基于此项目来扩展开发出更多功能 【提供帮助】:有任何使用上的问题欢迎随时与我联系,及时抽时间努力解答解惑,提供帮助 【附带帮助】:若还需要相关开发工具、学习资料等,我会提供帮助,提供资料,鼓励学习进步 质量优质,放心下载使用。下载后请首先打开说明文件(如有);项目工程可实现复现复刻,如果基础还行,也可在此程序基础上进行修改,以实现其它功能。供开源学习/技术交流/学习参考,网络商品/电子资源资料具可复制性不支持退款,勿用于商业用途。质量优质,放心下载使用。
企业敏捷响应度是企业适应外部环境变化、迅速调整策略以抓住市场机遇和应对挑战的能力。这种能力在当今快速变化的市场环境中尤为重要,因为它直接关系到企业的竞争力和可持续发展。 本数据参考C刊《经济管理》范合君(2024)老师的做法,现代企业特别是上市公司重大决策是由董事会讨论做出的鉴于此,本文采用当期董事会会议次数测度企业敏捷响应度(测算结果为agility_1),次数越多,表明企业对外界变化的响应速度越快。此外,本文还采用企业当期召开的股东大会会议次数作为敏捷响应度的替代变量进行稳健性检验。(测算结果为agility_2) 数据名称:上市公司-企业敏捷响应度数据 数据年份:2001-2023年 参考文献:数字化转型、敏捷响应度与企业韧性[J].经济管理-范合君,潘宁宁. ## 02、相关数据 代码、年份、董事会会议次数、监事会会议次数、股东大会召开次数、agility_1、agility_2。
内容概要:本文档《ITSS-12-01备品备件控制程序》为企业提供了关于备品备件管理系统的详细规范,覆盖从供应商评估与选择到仓库管理和库存盘点的所有步骤。具体来说,文档明确了综合部门负责的各项管理任务,规定应急采购流程、常规入库与领用程序、备件返修操作和定期的安全库存检测机制。为了保障高效运作,该程序还强调了一系列的细节要求,如合格供方的标准确定和对重要事项如《供应商年度评价表》的周期性评审。 适用人群:适用于参与企业管理、运营和维护团队成员,尤其是那些关注备品备件供应链效率的人群。 使用场景及目标:主要用于确保企业能够通过规范化的方法来优化备品备件的存储和使用,降低不必要的开销。同时帮助企业管理人员更好地理解和应用具体的管理措施和技术手段,提高设备维修响应速度,并保障服务质量。这将有助于提高整个企业的运作效率,减少因设备故障带来的损失。 其他说明:该控制程序适用于特定企业环境,并包含了多项实际工作中使用的表格模板,如‘供应商选择’、‘备件领用单’等。
西门子S7-300系统甲醛生产线博途TIA STEP7与WINCC RT Advanced上位机编程案例:采用V15+博图软件与PLC 315系列,高效控制甲醛生产线,西门子S7-300系统甲醛生产线博途TIA STEP7与WINCC RT Advanced上位机编程案例:采用V15+博图软件与PLC 315系列控制程序实践,西门子S7-300系统甲醛生产线博途控制系统程序案例,编程软件采用西门子博途TIA STEP7和WINCC RT Advanced上位机画面程序例程,硬件PLC采用315系列。 博图版本V15及以上。 ,西门子S7-300系统; 甲醛生产线; 博途控制系统程序案例; TIA STEP7; WINCC RT Advanced; 硬件PLC 315系列; 博图版本V15及以上,西门子S7-300甲醛生产线博途V15控制程序案例:TIA STEP7与WINCC RT Advanced联控实践
ingress控制器
西门子S1500 PLC飞剪控制程序经典案例(含触摸屏编程)-博图V16打开,含注释适合学习参考,含S200smart追剪程序,西门子S1500 PLC飞剪程序及触摸屏实战案例,含注释,学习参考经典案例,含S200smart追剪程序,西门子S1500 PLC飞剪程序(含触摸屏程序) 程序有注释、非常适合用来学习西门子s1500飞剪控制,文件包括西门子plc程序和西门子触摸屏程序,程序用博图V16打开,是西门子S1500飞剪控制的借鉴和参考经典案列。 西门子S200smart PLC的追剪程序也有(含触摸屏程序) ,S1500 PLC飞剪程序; 注释; 博图V16; S1500飞剪控制案例; S200smart PLC追剪程序; 触摸屏程序。,西门子S1500飞剪控制与S200 Smart PLC追剪程序合集:经典案例与注释详解
技术选型 【后端】:Java 【框架】:springboot 【前端】:vue 【JDK版本】:JDK1.8 【数据库】:mysql 5.7+ 资源包含项目源码+数据库脚本+万字文档。 项目包含前后台完整源码,都经过本人调试,确保可以正常运行! 具体项目介绍可查看博主文章或私聊获取。 也可提供远程调试、二次开发、项目讲解服务,有意向可私聊。 助力学习实践,提升编程技能,快来获取这份宝贵的资源吧!
难得软件安全材料
2025年最新单页图床+最新完整版图床系统修复版,图床系统是一种用于存储和管理图片文件的在线服务。它允许用户上传图片文件,并生成相应的图片链接,从而方便用户在网页、社交媒体或其他平台上分享图片。 功能特点: 图片上传: 用户可以通过图床系统将本地图片文件上传到服务器上。 图片存储: 图床系统会将用户上传的图片文件存储在服务器上,确保图片文件的踩院涂煽啃浴� 图片链接生成: 每张上传的图片都会生成一个唯一的链接,用户可以通过该链接访问和分享图片。 图片管理: 用户可以在图床系统中管理上传的图片,包括查看、删除、编辑等操作。 批量上传: 支持用户一次性上传多张图片,提高上传效率。 图片预览: 提供图片预览功能,让用户在上传前能够查看图片内容。 响应式设计: 图床系统可以在不同设备上进行自适应,保证用户在各种屏幕大小下都能方便使用。
规划及控制算法深度解析:自动驾驶规划模块与多种控制算法比对,经验总结,助力求职季,规划及控制算法深度解析:自动驾驶规划模块与多种控制算法比对,经验总结(附带Apollo6.0 EMplanner分析与经验宝贵的控制算法实战应用),规划及控制算法理论分析, 涵盖详细的自动驾驶规划及控制模块的算法理论(规划大约有18页,控制大约有17页)。 其中规划模块主要围绕Apollo6.0实现的EMplanner展开,控制算法详细叙述了常用控制算法包括PID、模糊控制、LQR、MPC的算法原理并结合实际工程经验进行算法比对。 控制领域有句老话,做自动驾驶控制的人才是真正依靠经验积累出来的,经验无价。 同时正值biye季,希望这两份文档给需要人带来帮助。 实实在在的工作经验总结 ,核心关键词: 规划及控制算法理论; 自动驾驶规划模块; Apollo6.0实现的EMplanner; 控制算法; PID控制; 模糊控制; LQR; MPC; 经验积累; 工作经验总结。,深入剖析:Apollo6.0下的自动驾驶规划与控制算法理论
共赢天下互助平台理财源码 自适应PC WAP ThinkPHP内核,,自适应手机端可打包APP 带激活码+排单系统+自动匹配+奖金+经理人+分拆 功能还是比较齐全的一套互助系统,这类台子接触的不多,所以玩法我不是很熟悉,也就大概理解下字面意思,对互助众筹这类台子有接触或者感兴趣的兄弟可以研究研究 ,对于懂这类平台的兄弟话这套程序就是绝对的好东西。
风光出力场景生成与消减模拟技术详解:蒙特卡洛与拉丁超立方生成技术,结合快速削减方法!,风光出力场景生成与消减:蒙特卡洛模拟与拉丁超立方生成技术结合快速前推法与同步回代削减策略,风光出力场景生成与消减 可采用蒙特卡洛模拟和拉丁超立方生成光伏和风电出力场景,并采用快速前推法或同步回代消除法进行削减,可以对生成场景数和削减数据进行修改。 可增加负荷功率的场景生成与削减,根据需求进行修改-改进 ,风光出力场景生成与消减;蒙特卡洛模拟;拉丁超立方生成;快速前推法;同步回代消除法;负荷功率场景生成与削减。,风光出力场景生成与消减技术:蒙特卡洛模拟与优化策略研究
OpenDrive高精地图解析源码SDK:全网最全最轻量级,深入解析与工程项目移植的宝贵资源,OpenDrive高精地图解析源码SDK:全网最全,轻量级解析,深入了解内部机理与项目移植的宝贵资源,opendrive高精地图解析源码SDK , 毫不夸张的说这是全网最全最轻量级的opendrive高精地图解析源码,希望深入了解opendrive高精地图解析内部机理的朋友,又或者希望直接将该SDK移植到工程项目中的朋友,这个源码SDK不可多得。 实实在在的工作经验总结 ,核心关键词: opendrive高精地图解析源码SDK; 最全最轻量级; 内部机理; 移植工程项目; 工作经验总结,《全网最全OpenDrive高精地图解析源码SDK,助力项目实战经验分享》
技术选型 【后端】:Java 【框架】:springboot 【前端】:vue 【JDK版本】:JDK1.8 【数据库】:mysql 5.7+ 资源包含项目源码+数据库脚本+万字文档。 项目包含前后台完整源码,都经过本人调试,确保可以正常运行! 具体项目介绍可查看博主文章或私聊获取。 也可提供远程调试、二次开发、项目讲解服务,有意向可私聊。 助力学习实践,提升编程技能,快来获取这份宝贵的资源吧!