
еҺҹж–Үй“ҫжҺҘВ http://www.cnblogs.com/xinzhao/p/5644175.htmlВ
В
HashMapе’ҢHashTableжңүд»Җд№ҲдёҚеҗҢпјҹеңЁйқўиҜ•е’Ңиў«йқўиҜ•зҡ„иҝҮзЁӢдёӯпјҢжҲ‘й—®иҝҮд№ҹиў«й—®иҝҮиҝҷдёӘй—®йўҳпјҢд№ҹи§ҒиҝҮдәҶдёҚе°‘еӣһзӯ”пјҢд»ҠеӨ©еҶіе®ҡеҶҷдёҖеҶҷиҮӘе·ұеҝғзӣ®дёӯзҡ„зҗҶжғізӯ”жЎҲгҖӮ
д»Јз ҒзүҲжң¬
JDKжҜҸдёҖзүҲжң¬йғҪеңЁж”№иҝӣгҖӮжң¬ж–Үи®Ёи®әзҡ„HashMapе’ҢHashTableеҹәдәҺJDK 1.7.0_67гҖӮжәҗз Ғи§ҒиҝҷйҮҢ
1. ж—¶й—ҙ
HashTableдә§з”ҹдәҺJDK 1.1пјҢиҖҢHashMapдә§з”ҹдәҺJDK 1.2гҖӮд»Һж—¶й—ҙзҡ„з»ҙеәҰдёҠжқҘзңӢпјҢHashMapиҰҒжҜ”HashTableеҮәзҺ°еҫ—жҷҡдёҖдәӣгҖӮ
2. дҪңиҖ…
д»ҘдёӢжҳҜHashTableзҡ„дҪңиҖ…пјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTable
* @author Arthur van Hoff
* @author Josh Bloch
* @author Neal Gafterд»ҘдёӢжҳҜHashMapзҡ„дҪңиҖ…пјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashMap
* @author Doug Lea
* @author Josh Bloch
* @author Arthur van Hoff
* @author Neal GafterеҸҜд»ҘзңӢеҲ°HashMapзҡ„дҪңиҖ…еӨҡдәҶеӨ§зҘһDoug LeaгҖӮдёҚдәҶи§ЈDoug Leaзҡ„пјҢеҸҜд»ҘзңӢиҝҷйҮҢгҖӮ
3. еҜ№еӨ–зҡ„жҺҘеҸЈпјҲAPIпјү
HashMapе’ҢHashTableйғҪжҳҜеҹәдәҺе“ҲеёҢиЎЁжқҘе®һзҺ°й”®еҖјжҳ е°„зҡ„е·Ҙе…·зұ»гҖӮи®Ёи®ә他们зҡ„дёҚеҗҢпјҢжҲ‘们йҰ–е…ҲжқҘзңӢдёҖдёӢ他们жҡҙйңІеңЁеӨ–зҡ„APIжңүд»Җд№ҲдёҚеҗҢгҖӮ
3.1 Public Method
дёӢйқўдёӨеј еӣҫпјҢжҲ‘з”»еҮәдәҶHashMapе’ҢHashTableзҡ„зұ»з»§жүҝдҪ“зі»пјҢ并еҲ—еҮәдәҶиҝҷдёӨдёӘзұ»зҡ„еҸҜдҫӣеӨ–йғЁи°ғз”Ёзҡ„е…¬ејҖж–№жі•гҖӮ
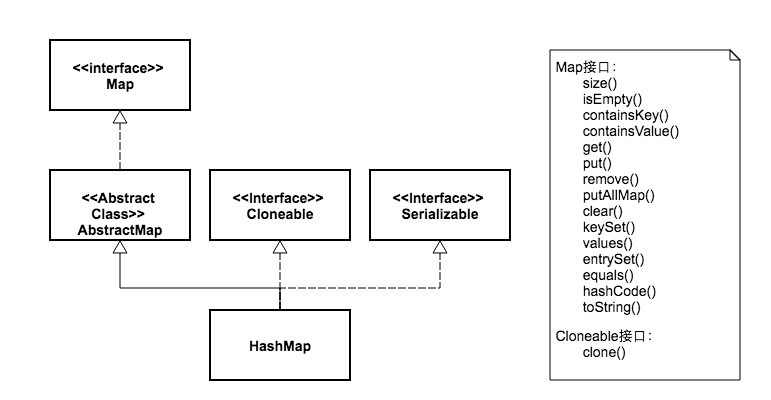
В
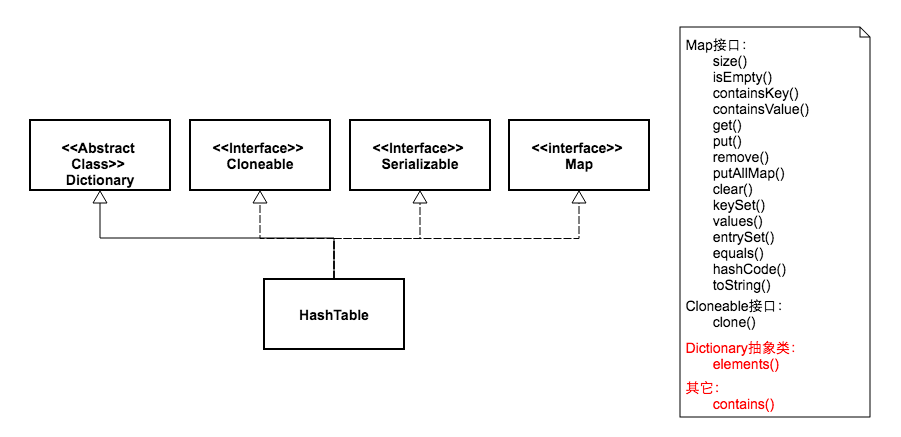
В
д»ҺеӣҫдёӯеҸҜд»ҘзңӢеҮәпјҢдёӨдёӘзұ»зҡ„继жүҝдҪ“зі»жңүдәӣдёҚеҗҢгҖӮиҷҪ然йғҪе®һзҺ°дәҶMapгҖҒCloneableгҖҒSerializableдёүдёӘжҺҘеҸЈгҖӮдҪҶжҳҜHashMap继жүҝиҮӘжҠҪиұЎзұ»AbstractMapпјҢиҖҢHashTable继жүҝиҮӘжҠҪиұЎзұ»DictionaryгҖӮе…¶дёӯDictionaryзұ»жҳҜдёҖдёӘе·Із»Ҹиў«еәҹејғзҡ„зұ»пјҢиҝҷдёҖзӮ№жҲ‘们еҸҜд»Ҙд»Һе®ғд»Јз Ғзҡ„жіЁйҮҠдёӯзңӢеҲ°пјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.Dictionary
* <strong>NOTE: This class is obsolete. New implementations should
* implement the Map interface, rather than extending thisclass.</strong>еҗҢж—¶жҲ‘们зңӢеҲ°HashTableжҜ”HashMapеӨҡдәҶдёӨдёӘе…¬ејҖж–№жі•гҖӮдёҖдёӘжҳҜelementsпјҢиҝҷжқҘиҮӘдәҺжҠҪиұЎзұ»DictionaryпјҢйүҙдәҺиҜҘзұ»е·Із»ҸеәҹејғпјҢжүҖд»ҘиҝҷдёӘж–№жі•д№ҹе°ұжІЎд»Җд№Ҳз”ЁеӨ„дәҶгҖӮеҸҰдёҖдёӘеӨҡеҮәжқҘзҡ„ж–№жі•жҳҜcontainsпјҢиҝҷдёӘеӨҡеҮәжқҘзҡ„ж–№жі•д№ҹжІЎд»Җд№Ҳз”ЁпјҢеӣ дёәе®ғи·ҹcontainsValueж–№жі•еҠҹиғҪжҳҜдёҖж ·зҡ„гҖӮд»Јз ҒдёәиҜҒпјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTablepublicsynchronizedbooleancontains(Object value) {
if (value == null) {
throw new NullPointerException();
}
Entry tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
publicbooleancontainsValue(Object value) {
return contains(value);
}жүҖд»Ҙд»Һе…¬ејҖзҡ„ж–№жі•дёҠжқҘзңӢпјҢиҝҷдёӨдёӘзұ»жҸҗдҫӣзҡ„пјҢжҳҜдёҖж ·зҡ„еҠҹиғҪгҖӮйғҪжҸҗдҫӣй”®еҖјжҳ е°„зҡ„жңҚеҠЎпјҢеҸҜд»ҘеўһгҖҒеҲ гҖҒжҹҘгҖҒж”№й”®еҖјеҜ№пјҢеҸҜд»ҘеҜ№е»әгҖҒеҖјгҖҒй”®еҖјеҜ№жҸҗдҫӣйҒҚеҺҶи§ҶеӣҫгҖӮж”ҜжҢҒжө…жӢ·иҙқпјҢж”ҜжҢҒеәҸеҲ—еҢ–гҖӮ
3.2 Null Key & Null Value
HashMapжҳҜж”ҜжҢҒnullй”®е’ҢnullеҖјзҡ„пјҢиҖҢHashTableеңЁйҒҮеҲ°nullж—¶пјҢдјҡжҠӣеҮәNullPointerExceptionејӮеёёгҖӮиҝҷ并дёҚжҳҜеӣ дёәHashTableжңүд»Җд№Ҳзү№ж®Ҡзҡ„е®һзҺ°еұӮйқўзҡ„еҺҹеӣ еҜјиҮҙдёҚиғҪж”ҜжҢҒnullй”®е’ҢnullеҖјпјҢиҝҷд»…д»…жҳҜеӣ дёәHashMapеңЁе®һзҺ°ж—¶еҜ№nullеҒҡдәҶзү№ж®ҠеӨ„зҗҶпјҢе°Ҷnullзҡ„hashCodeеҖје®ҡдёәдәҶ0пјҢд»ҺиҖҢе°Ҷе…¶еӯҳж”ҫеңЁе“ҲеёҢиЎЁзҡ„第0дёӘbucketдёӯгҖӮжҲ‘们дёҖputж–№жі•дёәдҫӢпјҢзңӢдёҖзңӢд»Јз Ғзҡ„з»ҶиҠӮпјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTablepublicsynchronized V put(K key, V value) {
// еҰӮжһңvalueдёәnullпјҢжҠӣеҮәNullPointerException
if (value == null) {
throw new NullPointerException();
}
// еҰӮжһңkeyдёәnullпјҢеңЁи°ғз”Ёkey.hashCode()ж—¶жҠӣеҮәNullPointerException
// ...
}
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HasMappublic V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// еҪ“keyдёәnullж—¶пјҢи°ғз”ЁputForNullKeyзү№ж®ҠеӨ„зҗҶ
if (key == null)
return putForNullKey(value);
// ...
}
private V putForNullKey(V value) {
// keyдёәnullж—¶пјҢж”ҫеҲ°table[0]д№ҹе°ұжҳҜ第0дёӘbucketдёӯ
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}4. е®һзҺ°еҺҹзҗҶ
жң¬иҠӮи®Ёи®әHashMapе’ҢHashTableеңЁж•°жҚ®з»“жһ„е’Ңз®—жі•еұӮйқўпјҢжңүд»Җд№ҲдёҚеҗҢгҖӮ
4.1 ж•°жҚ®з»“жһ„
HashMapе’ҢHashTableйғҪдҪҝз”Ёе“ҲеёҢиЎЁжқҘеӯҳеӮЁй”®еҖјеҜ№гҖӮеңЁж•°жҚ®з»“жһ„дёҠжҳҜеҹәжң¬зӣёеҗҢзҡ„пјҢйғҪеҲӣе»әдәҶдёҖдёӘ继жүҝиҮӘMap.Entryзҡ„з§Ғжңүзҡ„еҶ…йғЁзұ»EntryпјҢжҜҸдёҖдёӘEntryеҜ№иұЎиЎЁзӨәеӯҳеӮЁеңЁе“ҲеёҢиЎЁдёӯзҡ„дёҖдёӘй”®еҖјеҜ№гҖӮ
EntryеҜ№иұЎе”ҜдёҖиЎЁзӨәдёҖдёӘй”®еҖјеҜ№пјҢжңүеӣӣдёӘеұһжҖ§пјҡ
-K key й”®еҜ№иұЎ
-V value еҖјеҜ№иұЎ
-int hash й”®еҜ№иұЎзҡ„hashеҖј
-Entry<k, v="" style="margin: 0px; padding: 0px;">В entry жҢҮеҗ‘й“ҫиЎЁдёӯдёӢдёҖдёӘEntryеҜ№иұЎпјҢеҸҜдёәnullпјҢиЎЁзӨәеҪ“еүҚEntryеҜ№иұЎеңЁй“ҫиЎЁе°ҫйғЁ
еҸҜд»ҘиҜҙпјҢжңүеӨҡе°‘дёӘй”®еҖјеҜ№пјҢе°ұжңүеӨҡе°‘дёӘEntryеҜ№иұЎпјҢйӮЈд№ҲеңЁHashMapе’ҢHashTableдёӯжҳҜжҖҺд№ҲеӯҳеӮЁиҝҷдәӣEntryеҜ№иұЎпјҢд»Ҙж–№дҫҝжҲ‘们еҝ«йҖҹжҹҘжүҫе’Ңдҝ®ж”№зҡ„е‘ўпјҹиҜ·зңӢдёӢеӣҫгҖӮ
В

дёҠеӣҫз”»еҮәзҡ„жҳҜдёҖдёӘжЎ¶ж•°йҮҸдёә8пјҢеӯҳжңү5дёӘй”®еҖјеҜ№зҡ„HashMap/HashTableзҡ„еҶ…еӯҳеёғеұҖжғ…еҶөгҖӮеҸҜд»ҘзңӢеҲ°HashMap/HashTableеҶ…йғЁеҲӣе»әжңүдёҖдёӘEntryзұ»еһӢзҡ„еј•з”Ёж•°з»„пјҢз”ЁжқҘиЎЁзӨәе“ҲеёҢиЎЁпјҢж•°з»„зҡ„й•ҝеәҰпјҢеҚіжҳҜе“ҲеёҢжЎ¶зҡ„ж•°йҮҸгҖӮиҖҢж•°з»„зҡ„жҜҸдёҖдёӘе…ғзҙ йғҪжҳҜдёҖдёӘEntryеј•з”ЁпјҢд»ҺEntryеҜ№иұЎзҡ„еұһжҖ§йҮҢпјҢд№ҹеҸҜд»ҘзңӢеҮәе…¶жҳҜй“ҫиЎЁзҡ„иҠӮзӮ№пјҢжҜҸдёҖдёӘEntryеҜ№иұЎеҶ…йғЁеҸҲеҗ«жңүеҸҰдёҖдёӘEntryеҜ№иұЎзҡ„еј•з”ЁгҖӮ
иҝҷж ·е°ұеҸҜд»Ҙеҫ—еҮәз»“и®әпјҢHashMap/HashTableеҶ…йғЁз”ЁEntryж•°з»„е®һзҺ°е“ҲеёҢиЎЁпјҢиҖҢеҜ№дәҺжҳ е°„еҲ°еҗҢдёҖдёӘе“ҲеёҢжЎ¶пјҲж•°з»„зҡ„еҗҢдёҖдёӘдҪҚзҪ®пјүзҡ„й”®еҖјеҜ№пјҢдҪҝз”ЁEntryй“ҫиЎЁжқҘеӯҳеӮЁ(и§ЈеҶіhashеҶІзӘҒ)гҖӮ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTable
/** * The hash table data. */
private transient Entry<K,V>[] table;
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashMap
/** * The table, resized as necessary. Length MUST Always be a power of two. */
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;д»Һд»Јз ҒеҸҜд»ҘзңӢеҲ°пјҢеҜ№дәҺе“ҲеёҢжЎ¶зҡ„еҶ…йғЁиЎЁзӨәпјҢдёӨдёӘзұ»зҡ„е®һзҺ°жҳҜдёҖиҮҙзҡ„гҖӮ
4.2 з®—жі•
дёҠдёҖе°ҸиҠӮе·Із»ҸиҜҙдәҶз”ЁжқҘиЎЁзӨәе“ҲеёҢиЎЁзҡ„еҶ…йғЁж•°жҚ®з»“жһ„гҖӮHashMap/HashTableиҝҳйңҖиҰҒжңүз®—жі•жқҘе°Ҷз»ҷе®ҡзҡ„й”®keyпјҢжҳ е°„еҲ°зЎ®е®ҡзҡ„hashжЎ¶пјҲж•°з»„дҪҚзҪ®пјүгҖӮйңҖиҰҒжңүз®—жі•еңЁе“ҲеёҢжЎ¶еҶ…зҡ„й”®еҖјеҜ№еӨҡеҲ°дёҖе®ҡзЁӢеәҰж—¶пјҢжү©е……е“ҲеёҢиЎЁзҡ„еӨ§е°ҸпјҲж•°з»„зҡ„еӨ§е°ҸпјүгҖӮжң¬е°ҸиҠӮжҜ”иҫғиҝҷдёӨдёӘзұ»еңЁз®—жі•еұӮйқўжңүе“ӘдәӣдёҚеҗҢгҖӮ
еҲқе§Ӣе®№йҮҸеӨ§е°Ҹе’ҢжҜҸж¬Ўжү©е……е®№йҮҸеӨ§е°Ҹзҡ„дёҚеҗҢгҖӮе…ҲзңӢд»Јз Ғпјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTable
// е“ҲеёҢиЎЁй»ҳи®ӨеҲқе§ӢеӨ§е°Ҹдёә11
public Hashtable() {
this(11, 0.75f);
}
protectedvoidrehash() {
int oldCapacity = table.length;
Entry<K,V>[] oldMap = table;
// жҜҸж¬Ўжү©е®№дёәеҺҹжқҘзҡ„2n+1
int newCapacity = (oldCapacity << 1) + 1;
// ...
}
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashMap
// е“ҲеёҢиЎЁй»ҳи®ӨеҲқе§ӢеӨ§е°Ҹдёә2^4=16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
voidaddEntry(int hash, K key, V value, int bucketIndex) {
// жҜҸж¬Ўжү©е……дёәеҺҹжқҘзҡ„2n
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
}еҸҜд»ҘзңӢеҲ°HashTableй»ҳи®Өзҡ„еҲқе§ӢеӨ§е°Ҹдёә11пјҢд№ӢеҗҺжҜҸж¬Ўжү©е……дёәеҺҹжқҘзҡ„2n+1гҖӮHashMapй»ҳи®Өзҡ„еҲқе§ӢеҢ–еӨ§е°Ҹдёә16пјҢд№ӢеҗҺжҜҸж¬Ўжү©е……дёәеҺҹжқҘзҡ„2еҖҚгҖӮиҝҳжңүжҲ‘жІЎеҲ—еҮәд»Јз Ғзҡ„дёҖзӮ№пјҢе°ұжҳҜеҰӮжһңеңЁеҲӣе»әж—¶з»ҷе®ҡдәҶеҲқе§ӢеҢ–еӨ§е°ҸпјҢйӮЈд№ҲHashTableдјҡзӣҙжҺҘдҪҝз”ЁдҪ з»ҷе®ҡзҡ„еӨ§е°ҸпјҢиҖҢHashMapдјҡе°Ҷе…¶жү©е……дёә2зҡ„е№Ӯж¬Ўж–№еӨ§е°ҸгҖӮ
д№ҹе°ұжҳҜиҜҙHashTableдјҡе°ҪйҮҸдҪҝз”Ёзҙ ж•°гҖҒеҘҮж•°гҖӮиҖҢHashMapеҲҷжҖ»жҳҜдҪҝз”Ё2зҡ„е№ӮдҪңдёәе“ҲеёҢиЎЁзҡ„еӨ§е°ҸгҖӮжҲ‘们зҹҘйҒ“еҪ“е“ҲеёҢиЎЁзҡ„еӨ§е°Ҹдёәзҙ ж•°ж—¶пјҢз®ҖеҚ•зҡ„еҸ–жЁЎе“ҲеёҢзҡ„з»“жһңдјҡжӣҙеҠ еқҮеҢҖпјҲе…·дҪ“иҜҒжҳҺпјҢи§ҒиҝҷзҜҮж–Үз« пјүпјҢжүҖд»ҘеҚ•д»ҺиҝҷдёҖзӮ№дёҠзңӢпјҢHashTableзҡ„е“ҲеёҢиЎЁеӨ§е°ҸйҖүжӢ©пјҢдјјд№Һжӣҙй«ҳжҳҺдәӣгҖӮдҪҶеҸҰдёҖж–№йқўжҲ‘们еҸҲзҹҘйҒ“пјҢеңЁеҸ–жЁЎи®Ўз®—ж—¶пјҢеҰӮжһңжЁЎж•°жҳҜ2зҡ„е№ӮпјҢйӮЈд№ҲжҲ‘们еҸҜд»ҘзӣҙжҺҘдҪҝз”ЁдҪҚиҝҗз®—жқҘеҫ—еҲ°з»“жһңпјҢж•ҲзҺҮиҰҒеӨ§еӨ§й«ҳдәҺеҒҡйҷӨжі•гҖӮжүҖд»Ҙд»Һhashи®Ўз®—зҡ„ж•ҲзҺҮдёҠпјҢеҸҲжҳҜHashMapжӣҙиғңдёҖзӯ№гҖӮ
жүҖд»ҘпјҢдәӢе®һе°ұжҳҜHashMapдёәдәҶеҠ еҝ«hashзҡ„йҖҹеәҰпјҢе°Ҷе“ҲеёҢиЎЁзҡ„еӨ§е°Ҹеӣәе®ҡдёәдәҶ2зҡ„е№ӮгҖӮеҪ“然иҝҷеј•е…ҘдәҶе“ҲеёҢеҲҶеёғдёҚеқҮеҢҖзҡ„й—®йўҳпјҢжүҖд»ҘHashMapдёәи§ЈеҶіиҝҷй—®йўҳпјҢеҸҲеҜ№hashз®—жі•еҒҡдәҶдёҖдәӣж”№еҠЁгҖӮе…·дҪ“жҲ‘们жқҘзңӢзңӢпјҢеңЁиҺ·еҸ–дәҶkeyеҜ№иұЎзҡ„hashCodeд№ӢеҗҺпјҢHashTableе’ҢHashMapеҲҶеҲ«жҳҜжҖҺж ·е°Ҷ他们hashеҲ°зЎ®е®ҡзҡ„е“ҲеёҢжЎ¶пјҲEntryж•°з»„дҪҚзҪ®пјүдёӯзҡ„гҖӮ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTable
// hash дёҚиғҪи¶…иҝҮInteger.MAX_VALUE жүҖд»ҘиҰҒеҸ–е…¶жңҖе°Ҹзҡ„31дёӘbit
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
// зӣҙжҺҘи®Ўз®—key.hashCode()
privateinthash(Object k) {
// hashSeed will be zero if alternative hashing is disabled.
return hashSeed ^ k.hashCode();
}
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashMap
int hash = hash(key);
int i = indexFor(hash, table.length);
// еңЁи®Ўз®—дәҶkey.hashCode()д№ӢеҗҺпјҢеҒҡдәҶдёҖдәӣдҪҚиҝҗз®—жқҘеҮҸе°‘е“ҲеёҢеҶІзӘҒ
finalinthash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// еҸ–жЁЎдёҚеҶҚйңҖиҰҒеҒҡйҷӨжі•
staticintindexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}жӯЈеҰӮжҲ‘们жүҖиЁҖпјҢHashMapз”ұдәҺдҪҝз”ЁдәҶ2зҡ„е№Ӯж¬Ўж–№пјҢжүҖд»ҘеңЁеҸ–жЁЎиҝҗз®—ж—¶дёҚйңҖиҰҒеҒҡйҷӨжі•пјҢеҸӘйңҖиҰҒдҪҚзҡ„дёҺиҝҗз®—е°ұеҸҜд»ҘдәҶгҖӮдҪҶжҳҜз”ұдәҺеј•е…Ҙзҡ„hashеҶІзӘҒеҠ еү§й—®йўҳпјҢHashMapеңЁи°ғз”ЁдәҶеҜ№иұЎзҡ„hashCodeж–№жі•д№ӢеҗҺпјҢеҸҲеҒҡдәҶдёҖдәӣдҪҚиҝҗз®—еңЁжү“ж•Јж•°жҚ®гҖӮе…ідәҺиҝҷдәӣдҪҚи®Ўз®—дёәд»Җд№ҲеҸҜд»Ҙжү“ж•Јж•°жҚ®зҡ„й—®йўҳпјҢжң¬ж–ҮдёҚеҶҚеұ•ејҖдәҶгҖӮж„ҹе…ҙи¶Јзҡ„еҸҜд»ҘзңӢиҝҷйҮҢгҖӮ
еҰӮжһңдҪ жңүз»ҶеҝғиҜ»д»Јз ҒпјҢиҝҳеҸҜд»ҘеҸ‘зҺ°дёҖзӮ№пјҢе°ұжҳҜHashMapе’ҢHashTableеңЁи®Ўз®—hashж—¶йғҪз”ЁеҲ°дәҶдёҖдёӘеҸ«hashSeedзҡ„еҸҳйҮҸгҖӮиҝҷжҳҜеӣ дёәжҳ е°„еҲ°еҗҢдёҖдёӘhashжЎ¶еҶ…зҡ„EntryеҜ№иұЎпјҢжҳҜд»Ҙй“ҫиЎЁзҡ„еҪўејҸеӯҳеңЁзҡ„пјҢиҖҢй“ҫиЎЁзҡ„жҹҘиҜўж•ҲзҺҮжҜ”иҫғдҪҺпјҢжүҖд»ҘHashMap/HashTableзҡ„ж•ҲзҺҮеҜ№е“ҲеёҢеҶІзӘҒйқһеёёж•Ҹж„ҹпјҢжүҖд»ҘеҸҜд»ҘйўқеӨ–ејҖеҗҜдёҖдёӘеҸҜйҖүhashпјҲhashSeedпјүпјҢд»ҺиҖҢеҮҸе°‘е“ҲеёҢеҶІзӘҒгҖӮеӣ дёәиҝҷжҳҜдёӨдёӘзұ»зӣёеҗҢзҡ„дёҖзӮ№пјҢжүҖд»Ҙжң¬ж–ҮдёҚеҶҚеұ•ејҖдәҶпјҢж„ҹе…ҙи¶Јзҡ„зңӢиҝҷйҮҢгҖӮдәӢе®һдёҠпјҢиҝҷдёӘдјҳеҢ–еңЁJDK 1.8дёӯе·Із»ҸеҺ»жҺүдәҶпјҢеӣ дёәJDK 1.8дёӯпјҢжҳ е°„еҲ°еҗҢдёҖдёӘе“ҲеёҢжЎ¶пјҲж•°з»„дҪҚзҪ®пјүзҡ„EntryеҜ№иұЎпјҢдҪҝз”ЁдәҶзәўй»‘ж ‘жқҘеӯҳеӮЁпјҢд»ҺиҖҢеӨ§еӨ§еҠ йҖҹдәҶе…¶жҹҘжүҫж•ҲзҺҮгҖӮ
5. зәҝзЁӢе®үе…Ё
жҲ‘们иҜҙHashTableжҳҜеҗҢжӯҘзҡ„пјҢHashMapдёҚжҳҜпјҢд№ҹе°ұжҳҜиҜҙHashTableеңЁеӨҡзәҝзЁӢдҪҝз”Ёзҡ„жғ…еҶөдёӢпјҢдёҚйңҖиҰҒеҒҡйўқеӨ–зҡ„еҗҢжӯҘпјҢиҖҢHashMapеҲҷдёҚиЎҢгҖӮйӮЈд№ҲHashTableжҳҜжҖҺд№ҲеҒҡеҲ°зҡ„е‘ўпјҹ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTablepublicsynchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
public Set<K> keySet() {
if (keySet == null)
keySet = Collections.synchronizedSet(new KeySet(), this);
return keySet;
}еҸҜд»ҘзңӢеҲ°пјҢд№ҹжҜ”иҫғз®ҖеҚ•пјҢе°ұжҳҜе…¬ејҖзҡ„ж–№жі•жҜ”еҰӮgetйғҪдҪҝз”ЁдәҶsynchronizedжҸҸиҝ°з¬ҰгҖӮиҖҢйҒҚеҺҶи§ҶеӣҫжҜ”еҰӮkeySetйғҪдҪҝз”ЁдәҶCollections.synchronizedXXXиҝӣиЎҢдәҶеҗҢжӯҘеҢ…иЈ…гҖӮ
6. д»Јз ҒйЈҺж ј
д»ҺжҲ‘зҡ„е“ҒдҪҚжқҘзңӢпјҢHashMapзҡ„д»Јз ҒиҰҒжҜ”HashTableж•ҙжҙҒеҫҲеӨҡгҖӮдёӢйқўиҝҷж®өHashTableзҡ„д»Јз ҒпјҢжҲ‘е°ұи§үзқҖжңүзӮ№ж··д№ұпјҢдёҚеӨӘиғҪжҺҘеҸ—иҝҷз§Қд»Јз ҒеӨҚз”Ёзҡ„ж–№ејҸгҖӮ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTable
/** * A hashtable enumerator class. This class implements both the * Enumeration and Iterator interfaces, but individual instances * can be created with the Iterator methods disabled. This is necessary * to avoid unintentionally increasing the capabilities granted a user * by passing an Enumeration. */
private class Enumerator<T> implements Enumeration<T>, Iterator<T> {
Entry[] table = Hashtable.this.table;
int index = table.length;
Entry<K,V> entry = null;
Entry<K,V> lastReturned = null;
int type;
/** * Indicates whether this Enumerator is serving as an Iterator * or an Enumeration. (true -> Iterator). */
boolean iterator;
/** * The modCount value that the iterator believes that the backing * Hashtable should have. If this expectation is violated, the iterator * has detected concurrent modification. */
protected int expectedModCount = modCount;
Enumerator(int type, boolean iterator) {
this.type = type;
this.iterator = iterator;
}
//...
}7. HashTableе·Із»Ҹиў«ж·ҳжұ°дәҶпјҢдёҚиҰҒеңЁд»Јз ҒдёӯеҶҚдҪҝз”Ёе®ғгҖӮ
д»ҘдёӢжҸҸиҝ°жқҘиҮӘдәҺHashTableзҡ„зұ»жіЁйҮҠпјҡ
If a thread-safe implementation is not needed, it is recommended to use HashMap in place of Hashtable. If a thread-safe highly-concurrent implementation is desired, then it is recommended to use java.util.concurrent.ConcurrentHashMap in place of Hashtable.
з®ҖеҚ•жқҘиҜҙе°ұжҳҜпјҢеҰӮжһңдҪ дёҚйңҖиҰҒзәҝзЁӢе®үе…ЁпјҢйӮЈд№ҲдҪҝз”ЁHashMapпјҢеҰӮжһңйңҖиҰҒзәҝзЁӢе®үе…ЁпјҢйӮЈд№ҲдҪҝз”ЁConcurrentHashMapгҖӮHashTableе·Із»Ҹиў«ж·ҳжұ°дәҶпјҢдёҚиҰҒеңЁж–°зҡ„д»Јз ҒдёӯеҶҚдҪҝз”Ёе®ғгҖӮ
8. жҢҒз»ӯдјҳеҢ–
иҷҪ然HashMapе’ҢHashTableзҡ„е…¬ејҖжҺҘеҸЈеә”иҜҘдёҚдјҡж”№еҸҳпјҢжҲ–иҖ…иҜҙж”№еҸҳдёҚйў‘з№ҒгҖӮдҪҶжҜҸдёҖзүҲжң¬зҡ„JDKпјҢйғҪдјҡеҜ№HashMapе’ҢHashTableзҡ„еҶ…йғЁе®һзҺ°еҒҡдјҳеҢ–пјҢжҜ”еҰӮдёҠж–ҮжӣҫжҸҗеҲ°зҡ„JDK 1.8зҡ„зәўй»‘ж ‘дјҳеҢ–гҖӮжүҖд»ҘпјҢе°ҪеҸҜиғҪзҡ„дҪҝз”Ёж–°зүҲжң¬зҡ„JDKеҗ§пјҢйҷӨдәҶйӮЈдәӣзӮ«й…·зҡ„ж–°еҠҹиғҪпјҢжҷ®йҖҡзҡ„APIд№ҹдјҡжңүжҖ§иғҪдёҠжңүжҸҗеҚҮгҖӮ
дёәд»Җд№ҲHashTableе·Із»Ҹж·ҳжұ°дәҶпјҢиҝҳиҰҒдјҳеҢ–е®ғпјҹеӣ дёәжңүиҖҒзҡ„д»Јз ҒиҝҳеңЁдҪҝз”Ёе®ғпјҢжүҖд»ҘдјҳеҢ–дәҶе®ғд№ӢеҗҺпјҢиҝҷдәӣиҖҒзҡ„д»Јз Ғд№ҹиғҪиҺ·еҫ—жҖ§иғҪжҸҗеҚҮгҖӮ



зӣёе…іжҺЁиҚҗ
з»јдёҠжүҖиҝ°пјҢ`HashMap`е’Ң`HashTable`еңЁеӨҡдёӘж–№йқўеӯҳеңЁе·®ејӮгҖӮйҖүжӢ©е“ӘдёҖдёӘеҸ–еҶідәҺзү№е®ҡзҡ„еә”з”ЁеңәжҷҜе’ҢйңҖжұӮпјҡ - еҰӮжһңйңҖиҰҒзәҝзЁӢе®ү全并且иғҪеӨҹжҺҘеҸ—дёҖе®ҡзҡ„жҖ§иғҪжҚҹиҖ—пјҢеҸҜд»ҘйҖүжӢ©`HashTable`гҖӮ - еҰӮжһңиҝҪжұӮжӣҙй«ҳзҡ„жҖ§иғҪдё”еҸҜд»ҘиҮӘе·ұеӨ„зҗҶзәҝзЁӢ...
жҖ»дҪ“жқҘиҜҙпјҢ`HashMap` е’Ң `HashTable` еңЁи®ҫи®ЎдёҠжңүжҳҫи‘—дёҚеҗҢпјҢйҖүжӢ©е“ӘдёҖдёӘеҸ–еҶідәҺе…·дҪ“зҡ„еә”з”ЁеңәжҷҜгҖӮеҰӮжһңдёҚйңҖиҰҒзәҝзЁӢе®үе…ЁпјҢ并且еҸҜиғҪж¶үеҸҠ `null` й”®жҲ–еҖјзҡ„жғ…еҶөдёӢпјҢе»әи®®дҪҝз”Ё `HashMap`пјӣеҰӮжһңйңҖиҰҒзәҝзЁӢе®үе…ЁпјҢжҲ–иҖ…еёҢжңӣдҪҝз”Ёж—©жңҹзҡ„ ...
HashMapе’ҢHashTableеә•еұӮеҺҹзҗҶд»ҘеҸҠеёёи§ҒйқўиҜ•йўҳ HashMapе’ҢHashTableжҳҜJavaдёӯдёӨдёӘеёёз”Ёзҡ„ж•°жҚ®з»“жһ„пјҢйғҪжҳҜеҹәдәҺе“ҲеёҢиЎЁе®һзҺ°зҡ„пјҢдҪҶе®ғ们д№Ӣй—ҙеӯҳеңЁзқҖдёҖдәӣе…ій”®зҡ„еҢәеҲ«гҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁHashMapе’ҢHashTableзҡ„еә•еұӮеҺҹзҗҶпјҢ并жҖ»з»“еёёи§Ғзҡ„...
HashMapе’ҢHashTableзҡ„еҢәеҲ«пјҹдҪҶжҳҜеҰӮжһңжғізәҝзЁӢе®үе…Ёжңүжғіж•ҲзҺҮй«ҳпјҹ
еңЁJavaйӣҶеҗҲжЎҶжһ¶дёӯпјҢ`HashMap`, `HashTable` е’Ң `HashSet` жҳҜдёүдёӘйҮҚиҰҒзҡ„ж•°жҚ®з»“жһ„пјҢе®ғ们еҲҶеҲ«е®һзҺ°дәҶ`Map`жҺҘеҸЈе’Ң`Set`жҺҘеҸЈпјҢжҸҗдҫӣдәҶдёҚеҗҢзҡ„еҠҹиғҪжқҘж»Ўи¶ідёҚеҗҢзҡ„зј–зЁӢйңҖжұӮгҖӮжң¬ж–Үе°ҶйҮҚзӮ№еҲҶжһҗиҝҷдёүз§Қж•°жҚ®з»“жһ„д№Ӣй—ҙзҡ„еҢәеҲ«пјҢзү№еҲ«жҳҜй’ҲеҜ№...
JavaйӣҶеҗҲдё“йўҳжҖ»з»“пјҡHashMapе’ҢHashTableжәҗз ҒеӯҰд№ е’ҢйқўиҜ•жҖ»з»“ жң¬ж–ҮжҖ»з»“дәҶJavaйӣҶеҗҲдё“йўҳдёӯзҡ„HashMapе’ҢHashTableпјҢж¶өзӣ–дәҶе®ғ们зҡ„жәҗз ҒеӯҰд№ е’ҢйқўиҜ•жҖ»з»“гҖӮHashMapжҳҜдёҖз§ҚеҹәдәҺе“ҲеёҢиЎЁзҡ„йӣҶеҗҲзұ»пјҢе®ғзҡ„еӯҳеӮЁз»“жһ„жҳҜдёҖдёӘж•°з»„пјҢжҜҸдёӘе…ғзҙ ...
`HashMap`е’Ң`HashTable`еҗ„жңүдјҳеҠҝпјҢеңЁйҖүжӢ©дҪҝз”Ёе“Әз§Қж•°жҚ®з»“жһ„ж—¶пјҢйңҖиҰҒж №жҚ®е…·дҪ“зҡ„еә”з”ЁеңәжҷҜжқҘеҶіе®ҡгҖӮеҰӮжһңзЁӢеәҸиҝҗиЎҢеңЁеҚ•зәҝзЁӢзҺҜеўғдёӯжҲ–иҖ…иғҪеӨҹйҖҡиҝҮе…¶д»–ж–№ејҸдҝқиҜҒзәҝзЁӢе®үе…ЁпјҢйӮЈд№ҲдҪҝз”Ё`HashMap`еҸҜд»ҘиҺ·еҫ—жӣҙеҘҪзҡ„жҖ§иғҪпјӣиҖҢеңЁеӨҡзәҝзЁӢзҺҜеўғ...
еңЁJavaзј–зЁӢиҜӯиЁҖдёӯпјҢ`HashMap`е’Ң`Hashtable`жҳҜдёӨз§ҚйқһеёёйҮҚиҰҒзҡ„ж•°жҚ®з»“жһ„пјҢе®ғ们йғҪз”ЁдәҺеӯҳеӮЁй”®еҖјеҜ№гҖӮ然иҖҢпјҢеңЁе®һйҷ…еә”з”ЁиҝҮзЁӢдёӯпјҢиҝҷдёӨз§Қж•°жҚ®з»“жһ„жңүзқҖжң¬иҙЁзҡ„дёҚеҗҢпјҢдёӢйқўе°ҶиҜҰз»Ҷд»Ӣз»Қиҝҷдәӣе·®ејӮгҖӮ #### 1. еҺҶеҸІиғҢжҷҜеҸҠе®һзҺ°еҺҹзҗҶ - **...
HashMapгҖҒHashtableе’ҢTreeMapйғҪжҳҜJavaдёӯе®һзҺ°MapжҺҘеҸЈзҡ„зұ»пјҢе®ғ们用дәҺеӯҳеӮЁй”®еҖјеҜ№ж•°жҚ®пјҢдҪҶеҗ„иҮӘе…·жңүдёҚеҗҢзҡ„зү№зӮ№е’ҢдҪҝз”ЁеңәжҷҜгҖӮ HashMapжҳҜжңҖеёёз”Ёзҡ„Mapе®һзҺ°пјҢе®ғйҖҡиҝҮе“ҲеёҢиЎЁпјҲж•ЈеҲ—иЎЁпјүе®һзҺ°пјҢжҸҗдҫӣеҝ«йҖҹзҡ„жҸ’е…ҘгҖҒжҹҘжүҫе’ҢеҲ йҷӨж“ҚдҪңпјҢ...
жҹҘзңӢ`HashTable`е’Ң`HashMap`зҡ„жәҗз ҒпјҢеҸҜд»ҘеҸ‘зҺ°дёӨиҖ…еңЁеҶ…йғЁе®һзҺ°дёҠд№ҹжңүжүҖдёҚеҗҢгҖӮ`HashTable`зӣҙжҺҘдҪҝз”ЁдәҶж•°з»„+й“ҫиЎЁзҡ„ж–№ејҸпјҢиҖҢ`HashMap`еңЁJava 8еҸҠд»ҘеҗҺзүҲжң¬еј•е…ҘдәҶзәўй»‘ж ‘дјҳеҢ–пјҢеҪ“й“ҫиЎЁй•ҝеәҰиҫҫеҲ°дёҖе®ҡйҳҲеҖјпјҲ8пјүж—¶пјҢдјҡиҪ¬жҚўдёәзәўй»‘...
hashmapе’Ңhashtableзҡ„еҢәеҲ«
еңЁJavaзј–зЁӢиҜӯиЁҖдёӯпјҢйӣҶеҗҲжЎҶжһ¶жҳҜеӨ„зҗҶеҜ№иұЎж•°з»„зҡ„йҮҚиҰҒе·Ҙе…·пјҢе…¶дёӯ`List`гҖҒ`ArrayList`гҖҒ`Vector`гҖҒ`HashTable`е’Ң`HashMap`жҳҜдә”дёӘе…ій”®зҡ„жҺҘеҸЈе’Ңзұ»пјҢе®ғ们еҗ„жңүдёҚеҗҢзҡ„зү№жҖ§е’Ңз”ЁйҖ”гҖӮд»ҘдёӢжҳҜиҝҷдәӣжҰӮеҝөзҡ„иҜҰз»Ҷи§ЈйҮҠпјҡ 1. **ListжҺҘеҸЈ**...
hashMapе’ҢHashtableзҡ„еҢәеҲ«1
HashMap е’Ң Hashtable жҳҜ Java йӣҶеҗҲжЎҶжһ¶дёӯдёӨдёӘйҮҚиҰҒзҡ„жҳ е°„ж•°жҚ®з»“жһ„пјҢе®ғ们йғҪе®һзҺ°дәҶ Map жҺҘеҸЈпјҢдҪҶе…·жңүжҳҫи‘—зҡ„е·®ејӮгҖӮд»ҘдёӢе°ҶиҜҰз»Ҷд»Ӣз»ҚиҝҷдёӨдёӘзұ»зҡ„дё»иҰҒеҢәеҲ«пјҡ 1. зәҝзЁӢе®үе…ЁжҖ§пјҡ - HashMap дёҚжҳҜзәҝзЁӢе®үе…Ёзҡ„пјҢиҝҷж„Ҹе‘ізқҖеңЁеӨҡзәҝзЁӢ...
е’Ң HashMap дёҚеҗҢзҡ„жҳҜпјҢHashtable дёҚе…Ғи®ё null й”®е’Ң null еҖјгҖӮжӯӨеӨ–пјҢHashtable зҡ„иЎҢдёәжӣҙжҺҘиҝ‘дәҺдј з»ҹж•°жҚ®еә“зҡ„иЎЁж јпјҢе®ғдёҚе…Ғи®ёз©әеј•з”ЁдҪңдёәй”®жҲ–еҖјпјҢеӣ жӯӨеңЁжҹҗдәӣеңәжҷҜдёӢеҸҜиғҪжӣҙдёҘи°ЁгҖӮ WeakHashMap зұ» WeakHashMap жҳҜ HashMap ...
йҷӨдәҶ `Hashtable` е’Ң `HashMap` д№ӢеӨ–пјҢJava иҝҳжҸҗдҫӣдәҶеӨҡз§ҚйӣҶеҗҲзұ»жқҘж»Ўи¶ідёҚеҗҢзҡ„йңҖжұӮпјҡ - **List**пјҡйЎәеәҸе®№еҷЁпјҢж”ҜжҢҒйҮҚеӨҚе…ғзҙ пјҢеҰӮ `ArrayList` е’Ң `LinkedList`гҖӮ - **Set**пјҡдёҚйҮҚеӨҚе…ғзҙ зҡ„йӣҶеҗҲпјҢеҰӮ `HashSet`гҖӮ - **...
11.HashMapе’ҢHashTableзҡ„еҢәеҲ«.avi
HashMapе’ҢHashtableзҡ„еҢәеҲ«JavaејҖеҸ‘Javaз»ҸйӘҢжҠҖе·§е…ұ2йЎө.pdf.zip
2. й”®е’ҢеҖјзҡ„ null еҖјпјҡHashMap зҡ„й”®е’ҢеҖјйғҪе…Ғи®ёжңү null еҖјеӯҳеңЁпјҢиҖҢ HashTable еҲҷдёҚиЎҢгҖӮ 3. ж•ҲзҺҮпјҡHashMap зҡ„ж•ҲзҺҮжҜ” HashTable зҡ„иҰҒй«ҳгҖӮ HashMap зҡ„еҶ…йғЁз»“жһ„ HashMap зҡ„еҶ…йғЁз»“жһ„жҳҜе“ҲеёҢиЎЁпјҢе…·жңүиҫғеҝ«зҡ„жҹҘиҜўйҖҹеәҰе’ҢзӣёеҜ№...
е…¶дёӯпјҢHashMap, HashTable, LinkedHashMap, TreeMap жҳҜеӣӣз§Қеёёз”Ёзҡ„ Map е®һзҺ°зұ»пјҢжҜҸз§Қзұ»йғҪжңүе…¶зү№зӮ№е’Ңз”ЁйҖ”гҖӮжң¬ж–Үе°ҶеҜ№иҝҷеӣӣз§Қ Map е®һзҺ°зұ»иҝӣиЎҢжҜ”иҫғе’ҢеҲҶжһҗгҖӮ HashMap HashMap жҳҜ Java дёӯжңҖеёёз”Ёзҡ„ Map е®һзҺ°зұ»пјҢе®ғж №жҚ®й”®зҡ„ ...