
一:History日志聚合的配置
1.介绍
Spark的日志聚合功能不是standalone模式独享的,是所有运行模式下都会存在的情况
默认情况下历史日志是保存到tmp文件夹中的
2.参考官网的知识点位置

3.修改spark-defaults.conf

4.修改env.sh

5.在HDFS上新建/spark-history
bin/hdfs dfs -mkdir /spark-history
6.启动历史服务
sbin/start-history-server.sh

7.测试
webUI: http://192.168.187.146:18080/
local模式:bin/spark-shell
standalone模式:bin/spark-shell --master spark://linux-hadoop3.ibeifeng.com:7070
8.local模式的测试
bin/spark-shell
然后输入程序。
在

9.standalone模式
bin/spark-shell --master spark://linux-hadoop3.ibeifeng.com:7070
输入程序
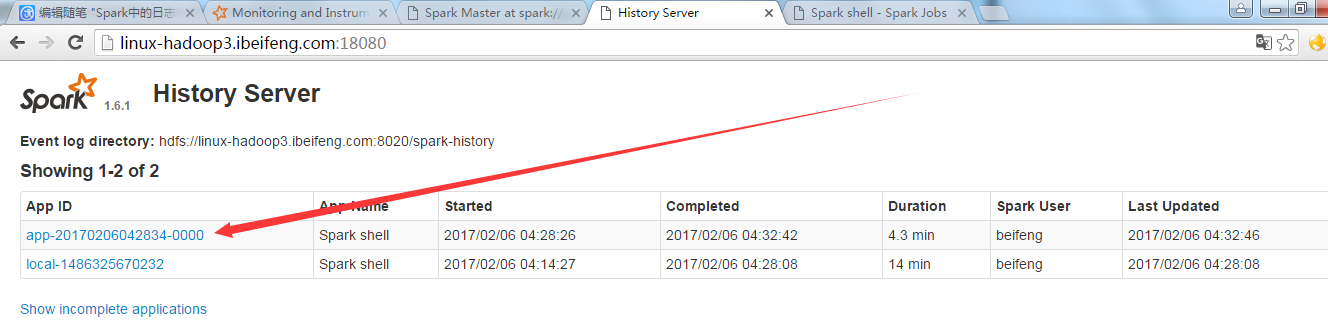
二:RestApi
返回应用程序的执行结果。
1.关于RestApi的官网
也是属于monitor的部分

2.介绍
专门用于获取历史应用的执行结果
用法: http://<server-url>:18080/api/v1
3.使用
http://linux-hadoop3.ibeifeng.com:18080/api/v1/applications

4.进一步使用
http://linux-hadoop3.ibeifeng.com:18080/api/v1/applications/app-20170206042834-0000/jobs

http://www.cnblogs.com/juncaoit/p/6379006.html



相关推荐
在本例中,描述提到的是一个专用于收集日志的 Kafka 插件,这可能是为了实现日志聚合、分析或者实时监控。 **二、Kafka Connector 的架构** Kafka Connect 由两部分组成:Connector 和 Worker。Connector 负责定义...
ELK stack是一套流行的开源日志分析解决方案,其名称由 Elasticsearch、Logstash 和 Kibana 三个软件的...通过本指南,你可以了解到ELK stack在海量日志分析中的作用,以及如何搭建和使用这一强大的日志处理解决方案。
- `log4j-api-2.7.jar`:日志框架Log4j的API部分,Elasticsearch使用Log4j记录和管理日志信息。 - `jackson-dataformat-cbor-2.8.11.jar`:Jackson库的一个模块,用于处理CBOR( Concise Binary Object ...
9. **Flume**:Cloudera开发的数据收集系统,可高效、可靠地收集、聚合和移动大量日志数据。 10. **Oozie**:工作流管理系统,用于调度和监控Hadoop作业,确保集群作业的顺利执行。 11. **Solr**:基于Lucene的...
【Apache Knox】是一个安全网关,提供REST API的统一访问入口。 【Apache Ranger】是权限管理框架,用于管理Hadoop生态系统的复杂数据权限。 【Slider】是YARN应用,用于在YARN上部署和管理现有的分布式应用。 ...
Kafka提供了Java和Scala的生产者和消费者API,以及基于HTTP的REST Proxy接口,方便不同语言的应用接入。 **五、部署与配置** Kafka集群的部署涉及到broker配置、Zookeeper配置、安全性设置等,需要根据实际需求...
Elasticsearch是一种分布式、RESTful搜索和分析引擎,用于实时全文检索、日志聚合和分析。结合Kafka,我们可以实现数据的实时流转,确保数据的快速索引和查询。 实现这一过程通常分为以下步骤: 1. **设置环境**:...
在IT领域,数据聚合是常见的需求,特别是在大数据分析、实时监控和日志管理等场景中。"赫鲁库"可能是项目作者或开发者的名字,也可能是一个特定的术语或组件,但由于信息有限,无法进一步明确其具体含义。...
6. **监控与日志**:为了保证系统的稳定运行,可能会使用Prometheus和Grafana进行性能监控,ELK Stack(Elasticsearch, Logstash, Kibana)或Logback进行日志收集和分析。 7. **持续集成/持续部署(CI/CD)**:...
它被广泛应用于日志分析、监控系统、信息检索、商业智能等领域。Elasticsearch的核心功能包括全文搜索、结构化搜索、聚合分析以及实时数据分析。 3. **JavaScript**:JavaScript是一种轻量级的解释型编程语言,主要...