
дЄАгАБKafkaжХ∞жНЃжФґйЫЖжЬЇеИґ
KafkaйЫЖзЊ§дЄ≠зФ±producerиіЯиі£жХ∞жНЃзЪДдЇІзФЯпЉМеєґеПСйАБеИ∞еѓєеЇФзЪДTopicпЉЫProducerйАЪињЗpushзЪДжЦєеЉПе∞ЖжХ∞жНЃеПСйАБеИ∞еѓєеЇФTopicзЪДеИЖеМЇ
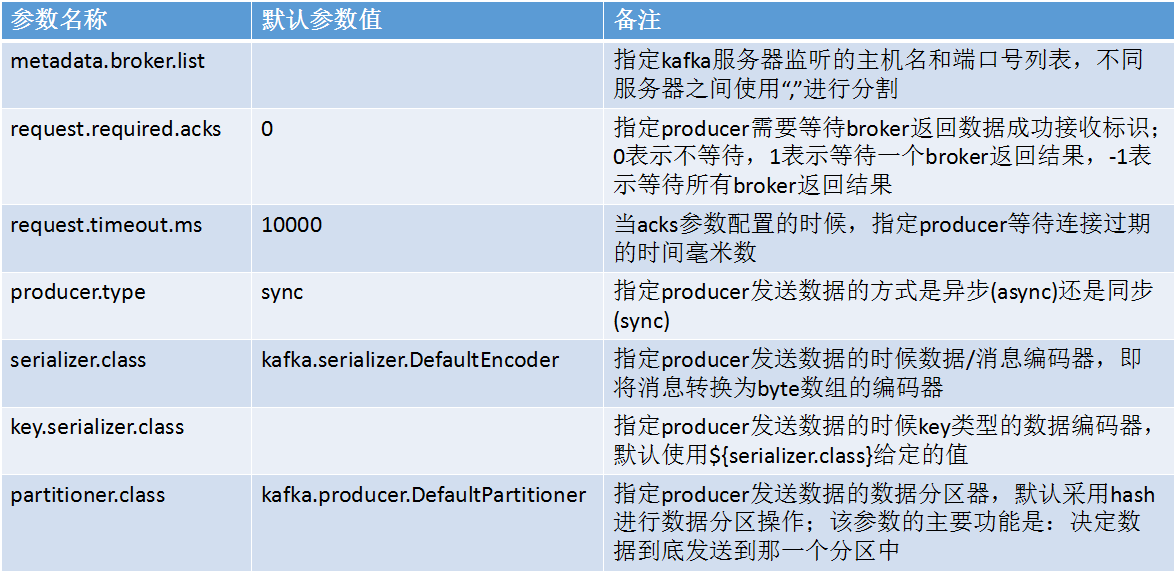
ProducerеПСйАБеИ∞TopicзЪДжХ∞жНЃжШѓжЬЙkey/valueйФЃеАЉеѓєзїДжИРзЪДпЉМKafkaж†єжНЃkeyзЪДдЄНеРМзЪДеАЉеЖ≥еЃЪжХ∞жНЃеПСйАБеИ∞дЄНеРМзЪДPartitionпЉМйїШиЃ§йЗЗзФ®HashзЪДжЬЇеИґеПСйАБжХ∞жНЃеИ∞еѓєеЇФTopicзЪДдЄНеРМPartitionдЄ≠пЉМйЕНзљЃеПВжХ∞дЄЇ{partitioner.class}
ProducerеПСйАБжХ∞жНЃзЪДжЦєеЉПеИЖдЄЇsync(еРМж≠•)еТМasync(еЉВж≠•)дЄ§зІНпЉМйїШиЃ§дЄЇеРМж≠•жЦєеЉПпЉМзФ±еПВжХ∞{producer.type}еЖ≥еЃЪпЉЫељУдЄЇеЉВж≠•еПСйАБж®°еЉПзЪДжЧґеАЩProducerжПРдЊЫйЗНиѓХжЬЇеИґпЉМйїШ聧姱賕йЗНиѓХеПСйАБ3жђ°
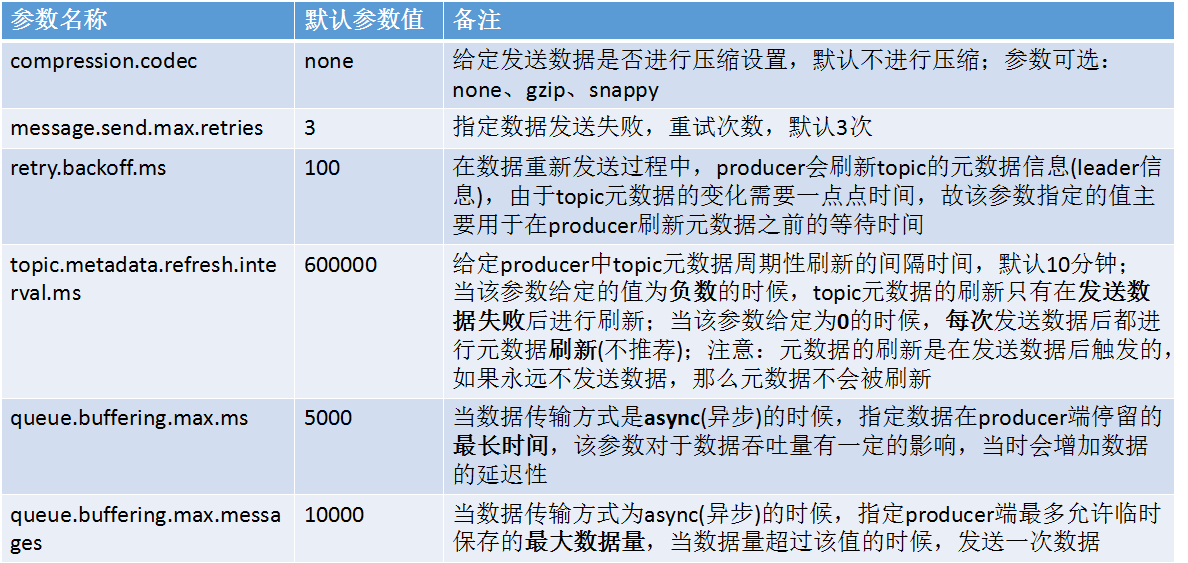
Kafka ProducerзЫЄеЕ≥еПВжХ∞пЉЪ

 
 
 
дЇМгАБKafkaжХ∞жНЃжґИиієжЬЇеИґ
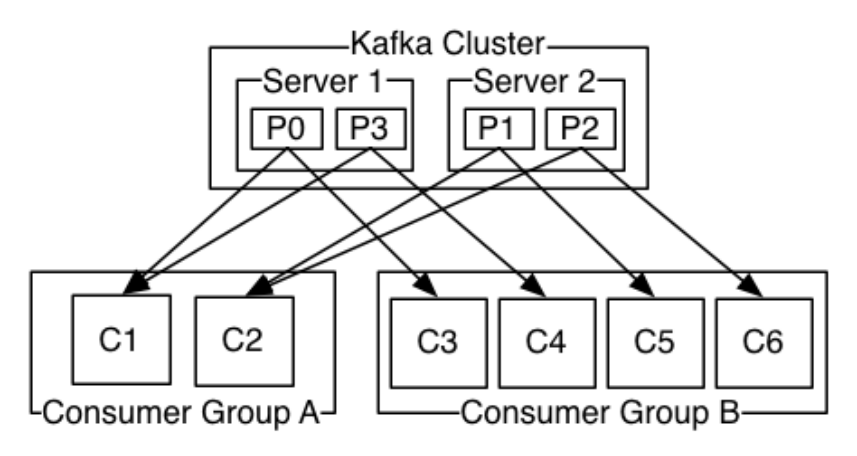
KafkaжЬЙдЄ§зІНж®°еЉПжґИиієжХ∞жНЃпЉЪйШЯеИЧеТМеПСеЄГиЃҐйШЕпЉЫеЬ®йШЯеИЧж®°еЉПдЄЛпЉМдЄАжЭ°жХ∞жНЃеП™дЉЪеПСйАБзїЩcustomer groupдЄ≠зЪДдЄАдЄ™customerињЫи°МжґИиієпЉЫеЬ®еПСеЄГиЃҐйШЕж®°еЉПдЄЛпЉМдЄАжЭ°жХ∞жНЃдЉЪеПСйАБзїЩе§ЪдЄ™customerињЫи°МжґИиіє
KafkaзЪДCustomerеЯЇдЇОoffsetеѓєkafkaдЄ≠зЪДжХ∞жНЃињЫи°МжґИиієпЉМеѓєдЇОдЄАдЄ™customer groupдЄ≠зЪДжЙАжЬЙcustomerеЕ±дЇЂдЄАдЄ™offsetеБПзІїйЗП
KafkaдЄ≠йАЪињЗжОІеИґCustomerзЪДеПВжХ∞{group.id}жЭ•еЖ≥еЃЪkafkaжШѓдїАдєИжХ∞жНЃжґИиієж®°еЉПпЉМе¶ВжЮЬжЙАжЬЙжґИиієиАЕзЪДиѓ•еПВжХ∞еАЉжШѓзЫЄеРМзЪДпЉМйВ£дєИж≠§жЧґзЪДkafkaе∞±жШѓз±їдЉЉдЇОйШЯеИЧж®°еЉПпЉМжХ∞жНЃеП™дЉЪеПСйАБеИ∞дЄАдЄ™customerпЉМж≠§жЧґKafkaз±їдЉЉдЇОиіЯиљљеЭЗи°°пЉЫеР¶еИЩе∞±жШѓеПСеЄГиЃҐйШЕж®°еЉПпЉЫ еЬ®йШЯеИЧж®°еЉПдЄЛпЉМеПѓиГљдЉЪиІ¶еПСKafkaзЪДConsumer Rebalance
KafkaзЪДжХ∞жНЃжШѓжМЙзЕІеИЖеМЇињЫи°МжОТеЇПзЪД(жПТеЕ•зЪДй°ЇеЇП)пЉМдєЯе∞±жШѓжѓПдЄ™еИЖеМЇдЄ≠зЪДжХ∞жНЃжШѓжЬЙеЇПзЪДгАВеЬ®ConsumerињЫи°МжХ∞жНЃжґИиієзЪДжЧґеАЩпЉМдєЯжШѓеѓєеИЖеМЇзЪДжХ∞жНЃињЫи°МжЬЙеЇПзЪДжґИиієзЪДпЉМдљЖжШѓдЄНдњЭиѓБжЙАжЬЙжХ∞жНЃзЪДжЬЙеЇПжАІ(е§ЪдЄ™еИЖеМЇдєЛйЧі)
Consumer RebalanceпЉЪељУдЄАдЄ™consumer groupзїДдЄ≠зЪДжґИиієиАЕжХ∞йЗПеТМеѓєеЇФTopicзЪДеИЖеМЇжХ∞йЗПдЄАиЗізЪДжЧґеАЩпЉМж≠§жЧґдЄАдЄ™ConsumerжґИиієдЄАдЄ™PartitionзЪДжХ∞жНЃпЉЫе¶ВжЮЬдЄНдЄАиЗіпЉМйВ£дєИеПѓиГљеЗЇзО∞дЄАдЄ™ConsumerжґИиієе§ЪдЄ™PartitionзЪДжХ∞жНЃжИЦиАЕдЄНжґИиієжХ∞жНЃзЪДжГЕеЖµпЉМињЩдЄ™жЬЇеИґжШѓж†єжНЃConsumerеТМPartitionзЪДжХ∞йЗПеК®жАБеПШеМЦзЪД
ConsumerйАЪињЗpollзЪДжЦєеЉПдЄїеК®дїОKafkaйЫЖзЊ§дЄ≠иОЈеПЦжХ∞жНЃ
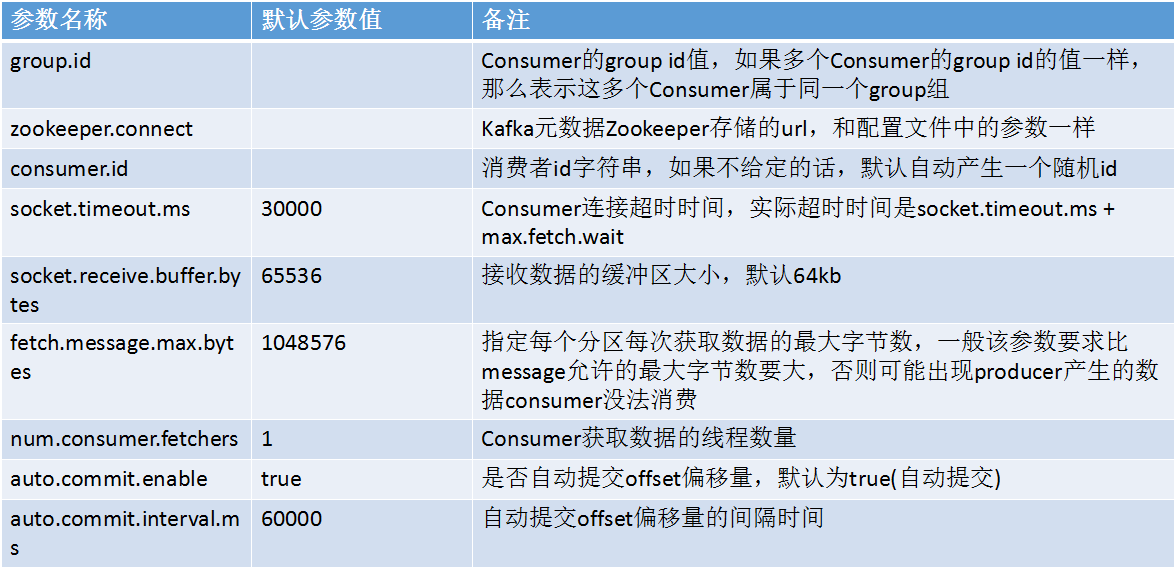
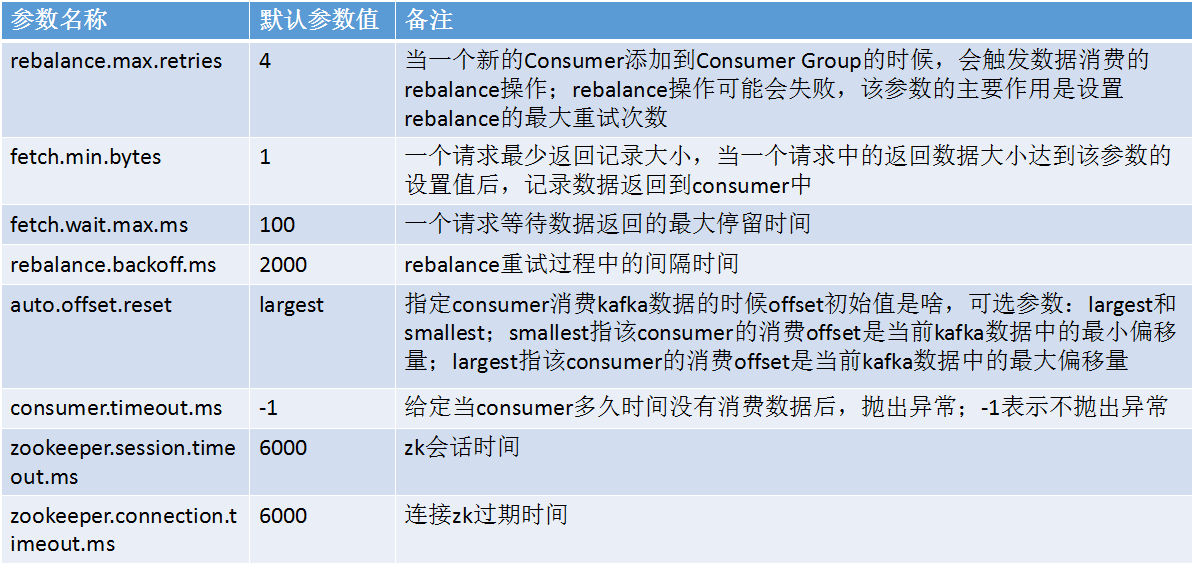
Kafka ConsumerзЫЄеЕ≥еПВжХ∞иѓіжШОпЉЪ



зЫЄеЕ≥жО®иНР
3. **жМБдєЕеМЦ**пЉЪжґИжБѓе≠ШеВ®еЬ®з£БзЫШдЄКпЉМжПРдЊЫдЇЖдЄАзІНжМБдєЕеМЦзЪДжХ∞жНЃе≠ШеВ®жЦєеЉПпЉМињЩдљњеЊЧKafkaиГље§ЯйХњжЬЯдњЭзХЩжХ∞жНЃпЉМзЫіеИ∞襀жґИиієиАЕжґИиієжИЦињЗжЬЯгАВ 4. **еПѓжЙ©е±ХжАІ**пЉЪKafkaзЪДиЃЊиЃ°еЕБиЃЄеЕґж∞іеє≥жЙ©е±ХпЉМеПѓдї•йАЪињЗеҐЮеК†жЫіе§ЪзЪДиКВзВєжЭ•жПРйЂШе§ДзРЖиГљеКЫ...
3. **жМБдєЕжАІ**пЉЪжґИжБѓжМБдєЕеМЦеИ∞з£БзЫШпЉМжФѓжМБйХњжЧґйЧізЪДжХ∞жНЃдњЭзХЩгАВ 4. **еПѓжЙ©е±ХжАІ**пЉЪKafkaйЫЖзЊ§жФѓжМБж∞іеє≥жЙ©е±ХпЉМеПѓдї•ж†єжНЃйЬАи¶БиљїжЭЊжЈїеК†жЫіе§ЪиКВзВєгАВ #### зїУиЃЇ KafkaеЗ≠еАЯеЕґзЛђзЙєзЪДиЃЊиЃ°жАЭжГ≥еТМжКАжЬѓеЃЮзО∞пЉМеЬ®жґИжБѓдЉ†йАТйҐЖеЯЯеЕЈжЬЙжШЊиСЧзЪД...
### Kafkaз†Фз©ґеТМжЦЗж°£жХізРЖ #### дЄАгАБKafkaж¶Вињ∞дЄОжЮґжЮД KafkaжШѓдЄАзІНеИЖеЄГеЉПзЪДгАБйЂШеРЮеРР...йАЪињЗжЈ±еЕ•зРЖиІ£ињЩдЇЫеЕ≥йФЃж¶ВењµеТМжКАжЬѓзВєпЉМеПѓдї•жЫіе•љеЬ∞еИ©зФ®KafkaзЪДеЉЇе§ІеКЯиГљжЭ•иІ£еЖ≥еЃЮйЩЕйЧЃйҐШпЉМе¶ВжЮДеїЇйЂШжХИеПѓйЭ†зЪДжХ∞жНЃзЃ°йБУгАБжЧ•ењЧжФґйЫЖз≥їзїЯз≠ЙгАВ
KafkaзЪДе§НеИґжЬЇеИґз°ЃдњЭдЇЖжґИжБѓзЪДйЂШеПѓзФ®жАІеТМжХЕйЪЬжБҐе§НиГљеКЫгАВељУйЫЖзЊ§дЄ≠зЪДдЄАдЄ™BrokerиКВзº姱賕жЧґпЉМеЕґдїЦиКВзВєдЄКзЪДеЙѓжЬђеПѓдї•жПРдЊЫзЫЄеРМзЪДжХ∞жНЃпЉМдїОиАМдњЭиѓБжЬНеК°дЄНдЉЪдЄ≠жЦ≠гАВж≠§е§ЦпЉМKafkaињШжПРдЊЫдЇЖжХ∞жНЃеОЛзЉ©еКЯиГљпЉМињЩиГље§ЯйЩНдљОе≠ШеВ®еТМеЄ¶еЃљзЪДдљњзФ®...
KafkaзЪДиЃЊиЃ°зЫЃж†ЗжШѓжПРдЊЫйЂШеРЮеРРйЗПзЪДжґИжБѓдЉ†йАТиГљеКЫпЉМзЫЄиЊГдЇОActiveMQгАБRabbitMQз≠ЙдЉ†зїЯжґИжБѓйШЯеИЧпЉМKafkaеЕЈе§ЗжЫійЂШзЪДжАІиГљгАБеЖЕзљЃзЪДеИЖеМЇжЬЇеИґгАБжґИжБѓе§НеИґдї•еПКеЃєйФЩжАІпЉМзЙєеИЂйАВеРИе§ІжХ∞жНЃйЗПзЪДеЃЮжЧґе§ДзРЖеТМеИЖжЮРеЇФзФ®гАВ KafkaзЪДж†ЄењГж¶Вењµ...
2. **дљњзФ®еЬЇжЩѓ (Use Cases)**пЉЪKafkaеЄЄзФ®дЇОжЧ•ењЧжФґйЫЖгАБзФ®жИЈи°МдЄЇињљиЄ™гАБжµБеЉПе§ДзРЖгАБжґИжБѓз≥їзїЯгАБзљСзЂЩжіїеК®зїЯиЃ°гАБињРиР•жМЗж†ЗжФґйЫЖгАБеЃЮжЧґеИЖжЮРз≠ЙгАВеЃГдєЯеЄЄдљЬдЄЇеЊЃжЬНеК°жЮґжЮДдЄ≠зЪДжґИжБѓдЄ≠йЧідїґпЉМжПРдЊЫжЬНеК°йЧізЪДиІ£иА¶еТМеЉВж≠•йАЪдњ°гАВ 3. **ењЂйАЯ...
йАЪињЗеИЖжЮР`kafka-2.2.1-src`жЇРз†БпЉМжИСдїђеПѓдї•жЫіжЈ±еЕ•еЬ∞зРЖиІ£KafkaзЪДеЖЕйГ®еЃЮзО∞пЉМдЊЛе¶ВжґИжБѓзЪДе≠ШеВ®гАБзљСзїЬйАЪдњ°гАБжґИиієиАЕењГиЈ≥жЬЇеИґгАБеИЖеМЇеИЖйЕНз≠ЦзХ•з≠ЙпЉМињЩеѓєдЇОеЉАеПСгАБињРзїіеТМдЉШеМЦKafkaз≥їзїЯеЕЈжЬЙйЗНи¶БзЪДеЃЮиЈµдїЈеАЉгАВеРМжЧґпЉМжЇРз†Бе≠¶дє†дєЯиГљеЄЃеК©...
йЭҐиѓХдЄ≠пЉМйЩ§дЇЖињЩдЇЫеЯЇз°АзЯ•иѓЖпЉМињШеПѓиГљжґЙеПКеИЖеЄГеЉПдЇЛеК°зЪДдЄАиЗіжАІдњЭиѓБгАБSpringCloudзЪДењГиЈ≥жЬЇеИґгАБEurekaзЪДзЉУе≠ШжЬЇеИґдї•еПКдЄНеРМжґИжБѓйШЯеИЧе¶ВRabbitMQгАБRocketMQгАБKafkaзЪДеѓєжѓФз≠ЙйЂШзЇІиѓЭйҐШгАВзРЖиІ£еєґиГљзБµжіїињРзФ®ињЩдЇЫзЯ•иѓЖе∞ЖжЬЙеК©дЇОеЬ®йЭҐиѓХдЄ≠...