
Ā Ā Apache FlumeęÆäøäøŖååøå¼ēćåÆé ēćé«ęēę„åæę°ę®ę¶éē»ä»¶ļ¼ę们éåøøä½æēØFlumeå°åę£åØéē¾¤äøå¤äøŖServersēlogę件ļ¼ę±éå°äø央å¼ēę°ę®å¹³å°äøļ¼ä»„č§£å³āä»ē¦»ę£ēę„åæę件äøę„ēćē»č®”ę°ę®å°é¾āēé®é¢ćå½ē¶ļ¼Flumeäøä» ä» åÆ仄ę¶élogę件ļ¼å®ä¹ęÆęęÆå¦TCPćUDPēę¶ęÆę°ę®ēę¶éļ¼ę č®ŗå¦ä½ļ¼ę们ęē»č§£å³ēé®é¢å°±ęÆāå°ē¦»ę£ēę°ę®čæč”ę¶éāćę们å ęčæ°å äøŖę¦åæµļ¼
Ā Ā 1ćEventļ¼ę¶ęÆļ¼äŗ件ļ¼åØFlumeäøę°ę®ä¼ č¾ēåä½ęÆāeventāļ¼Flumeå°č§£ęēę„åæę°ę®ćę„ę¶å°ēTCPę°ę®ēåč£ ęeventsåØå éØFlowäøä¼ éć
Ā Ā 2ćAgentļ¼äø“čæę°ę®ęŗļ¼ęÆå¦logsę件ļ¼ēćéØē½²åØå®æäø»ęŗåØäøēFlumečæēØļ¼éåøøēØäŗę¶éćčæ껤ćåę£ę°ę®ļ¼Flume Agentéåøøéč¦åƹęŗę°ę®čæč”āäæ®é„°āåč½¬åē»čæē«ÆēCollectorć
Ā Ā 3ćCollectorļ¼å¦äøē§FlumečæēØļ¼Agentļ¼ļ¼å®ēØäŗę„ę¶Flume agentsåéēę¶ęÆļ¼ēøåƹäŗAgentļ¼Collectorāę¶éāēę¶ęÆéåøøę„čŖå¤äøŖServerļ¼å®ēä½ēØå°±ęÆåƹę¶ęÆčæč”āčåāćāęø ę“āćāåē±»āćāčæ껤āēļ¼å¹¶č“č“£äæååč½¬åē»downstreamć
Ā Ā 4ćSourceļ¼Flumeå éØē»ä»¶ä¹äøļ¼ēØäŗč§£ęåå§ę°ę®å¹¶å°č£ ęeventćęč ęÆę„ę¶Clientē«ÆåéēFlume Eventsļ¼åƹäŗFlumečæēØččØļ¼sourceęÆę“äøŖę°ę®ęµļ¼Data Flowļ¼ēęåē«Æļ¼ēØäŗāäŗ§ēāeventsćļ¼čÆ»ļ¼
Ā Ā 5ćChannelļ¼Flumeå éØē»ä»¶ä¹äøļ¼ēØäŗāä¼ č¾āeventsēééļ¼Channeléåøøå ·å¤āē¼åāę°ę®ćāęµéę§å¶āēē¹ę§ļ¼Channelēupstreamē«ÆęÆSourceļ¼downstreamäøŗSinkļ¼å¦ęä½ ēępipelineęØ”å¼ēęµę°ę®ęØ”åļ¼čæäøŖę¦åæµåŗčÆ„éåøø容ęēč§£ć
Ā Ā 6ćSinkļ¼Flumeå éØē»ä»¶ä¹äøļ¼ēØäŗå°å éØēeventséčæåéēåč®®åéē»ē¬¬äøę¹ē»ä»¶ļ¼ęÆå¦SinkåÆ仄å°eventsåå „ę¬å°ē£ēę件ćåŗäŗAvroåč®®éčæTCPę¹å¼åē»å ¶ä»Flumeļ¼åÆ仄åē»kafkaēå ¶ä»ę°ę®ååØå¹³å°ēļ¼Sinkęē»å°eventsä»å éØę°ę®ęµäøē§»é¤ćļ¼åļ¼
Ā
Ā Ā ē»ä»¶å éØé¾ę„å ³ē³»ļ¼
Ā Ā 1ćäøäøŖSourceåÆ仄å°eventsä¼ éē»äøäøŖęč å¤äøŖChannelļ¼éåøøäøäøŖSourceåƹåŗäøäøŖChannelļ¼å¦ęäøäøŖSourceå°eventåē»å¤äøŖChannelsę¶ļ¼éč¦ä½æēØāselectorāęŗå¶ļ¼č§äøęļ¼ć
Ā Ā 2ćChannelä½äøŗFlowå ³čēčē¹ļ¼å ¶upstreamäøŗSourceļ¼downstreamäøŗSinkćäøäøŖChannelåÆ仄ę„å „å¤äøŖSourcesļ¼å³å¤äøŖSourcesåÆ仄å°eventsåē»äøäøŖChannelćåę¶å¤äøŖSinksåÆ仄ä»äøäøŖChanneläøę¶č“¹ę¶ęÆļ¼éč¦ä½æēØSink Processoręŗå¶ļ¼č§äøęļ¼ć
Ā Ā 3ćSinkēäøęøøäøŗChannelļ¼äøäøŖSinkåŖč½ä»äøäøŖChanneläøę¶č“¹ę¶ęÆć
Ā Ā 4ćSourceå°ę¶ęÆä¼ éē»Channelļ¼ä»„åSinkä»Channeläøę¶č“¹ę¶ęÆļ¼åäøŗåØå éØēäŗå”äøčæč”ćChannelēå®ē°éåøøäøŗęēēBlockingQueueļ¼å¦ęChannelęŗ¢ę»”ļ¼é£ä¹Sourceēputęä½å°ä¼č¢«ęē»äøå¼åøøčæåļ¼ēØåéčÆļ¼å¦ęChanneläøŗē©ŗļ¼é£ä¹Sinkå°äøč½č·åę¶ęÆć
Ā
äøćę¶ę
Ā Ā 1ćę°ę®ęµęØ”å
Ā Ā ęÆäøŖFlume Eventē±ābyte payloadāåäøē»åÆéēstringå±ę§ęęļ¼å¦ęä½ ēęJMSē¼ēØļ¼é£ä¹åÆ仄认äøŗābyte payloadāå°±ęÆEventēbodyļ¼ē±äøåŗååčę°ē»ęęļ¼ęÆę¶ęÆēå 容äø»ä½ļ¼é¤ę¤ä¹å¤ļ¼Eventčæęäøäŗheadersęęļ¼K-Vē»ęļ¼ēØäŗäæåę¤eventēäøäŗå±ę§ć
Ā Ā Flume AgentčæēØļ¼JVMļ¼å éØęå¤äøŖē»ä»¶ęęļ¼åÆ仄å°ęŗę°ę®č§£ęęevent并å°å ¶éčæē¹å®ēFlowä»sourceč½¬åē»å ¶ä»ē®ēå°ļ¼hopļ¼ć
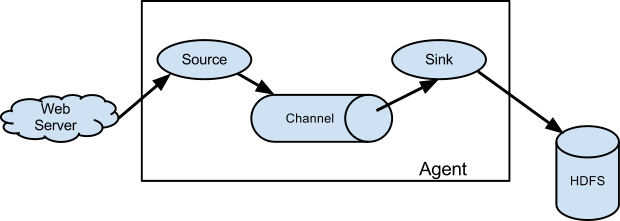
Ā Ā Flume SourceēØäŗę¶č“¹ē±å¤éØę°ę®ęŗåē»å®ēeventsļ¼å¤éØę°ę®ęŗå°ę¶ęÆåē»Flume agentļ¼ä»„Flume SourceęÆęēę ¼å¼ćęÆå¦ļ¼Flume Avro SourceåÆ仄ēØę„ę„ę¶Avro Clientęč å ¶ä»Flume Avro Sinkåéēę¶ęÆćå½ē¶ļ¼ē±»ä¼¼ēFlume Thrift SourceåÆ仄ę„ę¶Thrift Clientęč å ¶ä»Flume Thrift Sinkåéēę¶ęÆćå½Flume Sourceę„ę¶å°ę¶ęÆ仄åļ¼å®åÆ仄å°ę¶ęÆäæåļ¼storeļ¼åØäøäøŖęč å¤äøŖChannelsäøćChannelęÆäøäøŖč¢«åØå¼ļ¼passiveļ¼ååØļ¼ēØäŗäæåę¶ęÆē“å°Flume Sinkę¶č“¹ļ¼ęÆå¦FileChannelļ¼å®åŗäŗę¬å°ēę件ē³»ē»ļ¼å°ę¶ęÆäæååØę¬å°ę件äøļ¼appendļ¼ćåƹäŗSinkččØļ¼å®ä»Channeläøē§»é¤ę¶ęÆļ¼ē¶åå°ę¶ęÆåéē»ē¬¬äøę¹ļ¼å¤éØļ¼ēååØå¹³å°ļ¼ęÆå¦HDFS Sinkļ¼å°ę¶ęÆäæååØHDFSē³»ē»äøļ¼ęč å°ę¶ęÆč½¬åē»äøäøēŗ§Flume Agentļ¼next hopļ¼ēFlume Sourceļ¼å¤ēŗ§ę¶ęäøļ¼ćåØAgentå éØļ¼sourceåsinkåäøŗå¼ę„ēę¹å¼ćę¹éęä½Channeläøēę¶ęÆćļ¼ēØååŗäŗęŗē ļ¼čÆ¦č§£åäøŖē»ä»¶ēå·„ä½åēļ¼
Ā
Ā Ā 2ćå¤åęµļ¼Complex Flowsļ¼
Ā Ā Flumeå č®øå¼åč ęå»ŗå¤ēŗ§ļ¼multi-hopļ¼ēFlowsęØ”åļ¼ę¶ęÆåØå°č¾¾ęē»ē®ēå°ä¹ååÆ仄ē»čæå¤äøŖFlume Agentsļ¼å®ä¹å č®øęå»ŗęÆå¦fan-inļ¼ęå „ļ¼ćfan-outļ¼ęåŗļ¼ē»ęēFlowsļ¼ä»„åäøäøęč·Æē±ćFailoveręØ”å¼ēęØ”åć
Ā
Ā Ā 3ćåÆé ę§ļ¼Reliabilityļ¼
Ā Ā ę¶ęÆļ¼ę¹éļ¼éčæęÆäøŖAgentēchannelļ¼ē¶ååéē»äøäøäøŖAgentęč ęē»ēååØå¹³å°ćåŖęå½äøäøäøŖagentęč ęē»ēååØå¹³å°ę„ę¶å¹¶äæååļ¼ęä¼ä»Channeläøē§»é¤ćčæä¹ęÆFlumeļ¼åč·³ļ¼single-hopļ¼ä¼ éčÆä¹äøå¦ä½ęä¾ē«Æåƹē«Æēę°ę®ęµåÆé ę§ēć
Ā Ā Flumeä½æēØäŗå”ę¹å¼ę„äæčÆę¶ęÆä¼ č¾ēåÆé ę§ļ¼čæäøē¹éåøøéč¦ļ¼ćSourcesåSinksåØååØćę£ē“¢ēęä½é½ä¼åå«åč£ åØē±Channelęä¾ēäŗå”äøļ¼čæåÆ仄ē”®äæäøē»ę¶ęÆåØFlowå éØē¹åƹē¹ä¼ éēåÆé ę§ļ¼source->channel->sinkļ¼ćå³ä½æåØå¤ēŗ§FlowsęØ”å¼äøļ¼äøäøēŗ§ēsinkåäøäøēŗ§ēsourceä¹é“ēę°ę®ä¼ č¾ä¹čæč”åØåčŖēäŗå”äøļ¼ä»„ē”®äæę°ę®åÆ仄å®å Øēč¢«ååØåØäøäøēŗ§ēchanneläøć
Ā
Ā Ā 4ćę¢å¤č½å
Ā Ā FlumeęÆęęä¹ ē±»åēFileChannelļ¼å³Channelēę¶ęÆåÆä»„č¢«äæååØę¬å°ēę件ē³»ē»äøļ¼čæē§ChannelęÆęę°ę®ę¢å¤ćę¤å¤ļ¼čæęÆęMemoryChannelļ¼å®ęÆåŗäŗå åēéåļ¼ęēå¾é«ä½ęÆå½AgentčæēØ失ęåļ¼é£äŗéēåØChanneläøēę¶ęÆå°ä¼äø¢å¤±ļ¼čę ę³ę¢å¤ļ¼ć
Ā
äŗćå®č£ äøä½æēØ
Ā Ā 1ćFlumeęÆJAVAå¼åļ¼ę仄éč¦åØå®æäø»ęŗåØäøé¦å å®č£ JDKļ¼å»ŗč®®1.7+ēę¬ļ¼å®č£ Flumeę¬čŗ«å¹¶äøå¤ęļ¼åŖéč¦åå¤äøäøŖflumeé ē½®ę件å³åÆļ¼é ē½®ę件äø声ęļ¼sourcećchannelćsinkēåčŖēå±ę§ļ¼ä»„åå®ä»¬ä¹é“ēFlowå ³čć
Ā Ā 2ćFlowäøēęÆäøŖē»ä»¶ļ¼sourcećchannelćsinkļ¼é½ęnamećtypeļ¼ä»„åäøē»ē¹å®ēé ē½®é锹ćęÆå¦Avro sourceéč¦ęå®ē»å®ēhostname仄åę¬å°ēē«Æå£ļ¼memory channeléč¦ęå®å®¹éē大å°ļ¼HDFS Sinkéč¦å£°ęHDFS URIåę件ēpathēć
Ā Ā 3ćē»ä»¶å ³ē³»
Ā Ā ęē»ļ¼Agentéč¦ē„éåäøŖē»ä»¶ä¹é“ēå ³ē³»ļ¼ä»„ęå»ŗFlowęØ”åćåØę们声ęsourcesćchannelsćsinksēåäøŖē»ä»¶ēé ē½®ē¹ę§ä¹åļ¼ē¶åäøŗchannelsęå®sinksåsourcesēčæę„å ³ē³»ļ¼å³sourceså°ä½æēØåŖäŗchannelsäæåę¶ęÆļ¼ä»„åsinkså°ä»åŖäŗchannelsäøč·åę¶ęÆć
Ā
Ā Ā 4ćåÆåØAgent
Ā Ā åØbinē®å½äøęäøäøŖflume-ngčę¬ļ¼åÆ仄ēØę„åÆåØagentļ¼äøčæåØåÆåØflumeä¹åļ¼ę们éåøøä¼č°ę“JVMēēøå ³åę°ļ¼åÆ仄éčæåØflume-env.shäøå¢å ēøå ³é ē½®ļ¼ęÆå¦ļ¼
xport JAVA_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=5445 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -verbose:gc -server -Xms512M -Xmx512M -XX:NewRatio=3 -XX:SurvivorRatio=8 -XX:MaxMetaspaceSize=128M -XX:+UseConcMarkSweepGC -XX:CompressedClassSpaceSize=128M -XX:MaxTenuringThreshold=5 -XX:CMSInitiatingOccupancyFraction=70 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/opt/flume/logs/server-gc.log.$(date +%Y%m%d%H%M) -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=64M"
Ā
Ā Ā ę¤åļ¼ę们åØconfē®å½äøåå»ŗäøäøŖflume-conf.propertiesę件ļ¼ēØäŗ声ęflumeē»ä»¶ļ¼ē¤ŗä¾å¦äøļ¼
agent.channels=ch-spooling agent.sources=src-spooling agent.sinks=sink-avro-spooling ##spooling agent.channels.ch-spooling.type=file agent.channels.ch-spooling.checkpointDir=/opt/flume/.flume/file-channel/ch-spooling/checkpoint agent.channels.ch-spooling.dataDirs=/opt/flume/.flume/file-channel/ch-spooling/data agent.channels.ch-spooling.capacity=1000000 agent.channels.ch-spooling.transactionCapacity=10000 agent.sources.src-spooling.type=spooldir agent.sources.src-spooling.channels=ch-spooling agent.sources.src-spooling.spoolDir=/opt/deploy/tomcat/order-center/logs agent.sources.src-spooling.deletePolicy=immediate #agent.sources.src-spooling.deletePolicy=never agent.sources.src-spooling.includePattern=((access)|(order-center)).*\.log.+ agent.sources.src-spooling.ignorePattern=^.*\.gz$ agent.sources.src-spooling.consumeOrder=oldest agent.sources.src-spooling.recursiveDirectorySearch=false agent.sources.src-spooling.batchSize=1000 agent.sources.src-spooling.inputCharset=UTF-8 agent.sources.src-spooling.decodeErrorPolicy=IGNORE agent.sinks.sink-avro-spooling.channel=ch-spooling agent.sinks.sink-avro-spooling.type=avro agent.sinks.sink-avro-spooling.hostname=10.0.1.100 agent.sinks.sink-avro-spooling.port=9011 agent.sinks.sink-avro-spooling.batch-size=1000 agent.sinks.sink-avro-spooling.compression-type=deflate
Ā
Ā Ā ē¶åę们åÆ仄éčæå¦äøę¹å¼åÆåØflumeļ¼
bin/flume-ng agent --conf /opt/flume/conf --conf-file /opf/flume/conf/flume-conf.properties --name agent -Dflume.root.logger=INFO,LOGFILE -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=true
Ā Ā
Ā Ā äøčæ°é ē½®ę件ļ¼å£°ęäŗagentåē§°äøŗāagentāļ¼å³ęęé ē½®åēåē¼éč¦ä»„agentåē§°å¼å¤“ļ¼ēØäŗéå®é ē½®ēāå½åē©ŗé“āļ¼äøäøŖé ē½®ę件äøåÆ仄声ęå¤äøŖagentćę¤é ē½®ę件äøļ¼åå«å£°ęäøäøŖsourcećchannelåsinkć
Ā Ā ę们åØåÆåØę¶ļ¼éčæā--conf-fileāę„ęå®é ē½®ę件ēč·Æå¾ļ¼éčæā--nameāę„ęå®éč¦å č½½ēagentēåē§°ć
Ā
Ā Ā 5ćåØlogäøč¾åŗåå§ę°ę®
Ā Ā å¾å¤ę¶åļ¼ē¹å«ęÆåØå¼åęµčÆęé“ļ¼ę们éåøøéč¦ę£ęµFlumeäøę°ę®ēäæ”ęÆļ¼
Ā Ā 1ļ¼éčæęå®ā-Dorg.apache.flume.log.printconfig=trueāļ¼åÆ仄åØåÆåØę„åæäøę„ēflumeēé ē½®äæ”ęÆć
Ā Ā 2ļ¼éčæā-Dorg.apache.flume.log.rawdata=trueāļ¼åÆ仄ę„ēflumeäøę¶ęÆēåå§ę°ę®ļ¼å ę¬headersåbodyå 容ć
Ā Ā 3ļ¼éčæā-Dflume.root.logger=DEBUG,consoleāļ¼äøč¬ēäŗ§ēÆå¢äøŗINFO,LOGFILEļ¼ļ¼åÆ仄声ęloggerēēŗ§å«ä»„åęå°ēč¾åŗē»ē«Æć
Ā
Ā Ā 6ćåŗäŗzookeeperé ē½®ē®”ēļ¼
Ā Ā éåøøę åµäøļ¼flumeēé ē½®ę件äæååØagentę¬å°ļ¼å¦ęä½ ēflumeéē¾¤ęÆč¾åŗ大ļ¼å½éč¦č°ę“é ē½®ę¶å°ęÆč¾éŗ»ē¦ļ¼ę们åÆ仄å°flumeēé ē½®äæååØzookeeperäøļ¼é£ä¹åØåÆåØflumeę¶ęå®zookeeperå°ååpathå³åÆļ¼
bin/flume-ng agent -conf /opt/flume/conf -z zk1:2181,zk2:2181 -p /flume -name agent
Ā
Ā Ā ęäøŖäŗŗ认äøŗļ¼ēØzookeeperäæåFlumeé ē½®å¢å äŗē®”ēēå¤ęåŗ¦ļ¼ęÆē«ęä½zookeeperä¹éč¦äøå®ēęęÆéØę§ļ¼ę们åÆ仄åŗäŗājenkins + é ē½®äøę§āę¹å¼ę„č§£å³ę¤é®é¢ļ¼å³å°flumeé ē½®ę¾åØé ē½®äøę§ęŗäøļ¼ä½æēØjenkinsē»äøéØē½²flumeļ¼åØéØē½²åÆåØflumeä¹åļ¼å°é ē½®ę件éčæsshēę¹å¼åę„å°flume agentęŗåØäøļ¼ē¶åååÆåØćļ¼ē®åę¬äŗŗéēØēå°±ęÆę¤ę¹å¼ļ¼
Ā
Ā Ā 7ćē¬¬äøę¹ę件ęč ä¾čµåŗ
Ā Ā Flumeę¬čŗ«å·²ē»ęÆęäŗęÆč¾äø°åÆēē»ä»¶ļ¼ä½ęÆę们åØå¾å¤ę åµäøļ¼ęč®øéč¦ę©å±å®ēē¹ę§ļ¼ęÆå¦čŖäø»å¼åFlumeēę¦ęŖåØćSinkēļ¼ę¤åę们éč¦å°čŖå·±ējarę¾åØFlumeēCLASSPATHäøćåØflumeēāplugins.dāē®å½äøļ¼åÆä»„ę ¹ę®ä½ ēē»ä»¶ē¹ę§åå»ŗåē®å½ļ¼ęÆäøŖåē®å½äøéč¦å ·å¤å¦äøäøäøŖåē®å½ļ¼ęÆå¦ļ¼plugins.d/my-ext/ļ¼
Ā Ā 1ļ¼libļ¼ę¤ę件ējarć
Ā Ā 2ļ¼libextļ¼ę¤ę件ä¾čµējarć
Ā Ā 3ļ¼nativeļ¼ę¤ę件ä¾čµēę¬å°åŗļ¼ęÆå¦ā.soāę件ć
Ā
äøćå¤ęč®¾č®”
Ā Ā 1ćMulti-agent
Ā Ā Ā 
Ā
Ā Ā äøŗäŗå®ē°ę¶ęÆåÆ仄éčæå¤äøŖagentsęč hopsļ¼åäøäøŖagentēsinkåå½åagentēsourceéč¦ä½æēØavro RPCļ¼äø¤č ä¹é“éč¦åå®hostnameļ¼IPļ¼åportć
Ā
Ā Ā 2ćę°ę®å并ļ¼Consolidationļ¼
Ā Ā äøäøŖęÆč¾éēØēåŗęÆęÆļ¼å¤äøŖäŗ§ēę„åæēClientsåéę°ę®ē»å äøŖå ³čå°ååØē³»ē»ēagentsļ¼ęÆå¦agentsä»ę°ē¾äøŖweb serversäøę¶éę„åæļ¼ē¶ååē»å äøŖagents并ęå®ä»¬åå „HDFSéē¾¤ć
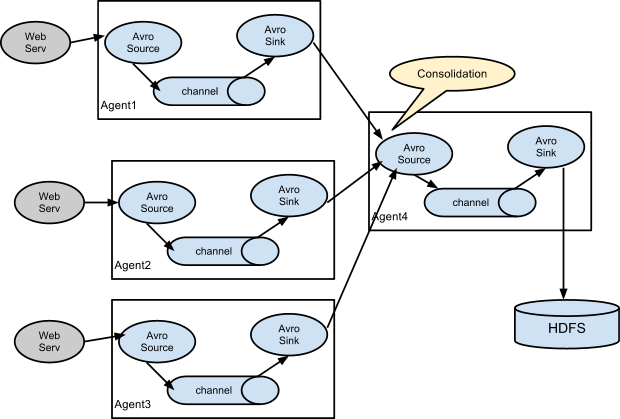
Ā Ā čæē§å¤å±ļ¼multi-tierļ¼ēę¶ęäøļ¼ē¬¬äøå±ēFlume Agentsä½æēØAvro sinkļ¼å¹¶é½ęåčæē«ÆēäøäøŖagentēAvro sourceļ¼ē®åēę¬äøļ¼ä½ å¤äøŖagentsä¹é“ä¹åÆ仄ä½æēØThrift sink + Thrift sourceļ¼ćē¬¬äŗå±AgentēsourcåÆ仄å°ę¶å°ēå¤äøŖagentsēę¶ęÆå并å°äøäøŖchanneläøļ¼ē¶åę¤channelåÆä»„č¢«å½åagentēsinkę¶č“¹å¹¶åå „ē®ę ååØå¹³å°ćļ¼ę们äøŗä»ä¹éēØå¤ēŗ§ę¶ęļ¼čäøęÆęÆäøŖagentē“ę„åå „ē®ę ååØļ¼čÆ·åēļ¼ļ¼
Ā
Ā Ā 3ćMultiplexing the flowļ¼å¤č·Æå¤ēØęµļ¼
Ā Ā FlumeęÆęå°ę¶ęÆęµå¤å¶å°äøäøŖęč å¤äøŖē®ēå°ļ¼åÆ仄éčæ声ęFlow å¤ēØåØäøŗreplicatećęč ęÆéę©ę§å°ę¶ęÆč·Æē±å°äøäøŖęč å¤äøŖchannelsäøć
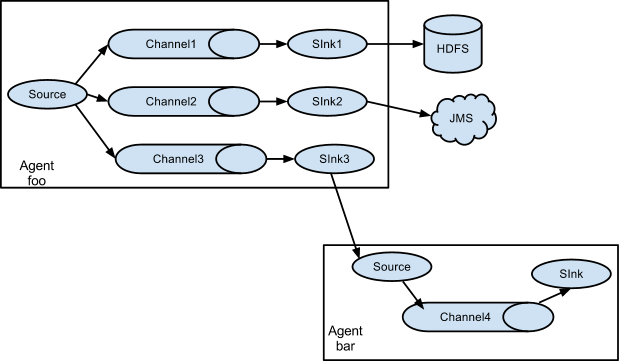
Ā Ā äøčæ°ä¾åäøļ¼agent āfooāēsourceå°ę¶ęÆęµāęåŗāå°äøäøŖäøåēchannelsäøļ¼čæē§ęåŗåÆ仄äøŗāreplicatingāćāmultiplexingāćåØreplicatingę åµäøļ¼ęÆäøŖeventé½ä¼č¢«åē»äøäøŖchannelsćåƹäŗmultiplexingļ¼ä»»ä½eventå°ä¼ę ¹ę®é ē½®äøēå¹é ę¹å¼åē»ęļ¼č¢«ä¼ éē»åÆēØchannelsäøēäøäøŖåéļ¼ęÆå¦eventęäøŖå±ę§äøŗātxnTypeā ļ¼å½å¼äøŗācustomerāę¶å®åŗčÆ„å°āchannel1āåāchannel3āļ¼å½å¼äøŗāvendorāę¶åŗčÆ„å°āchannel2āļ¼å¦åå ¶ä»å¼ę¶åŗčÆ„å°āchannel3āļ¼čæē§å¼å¹é ēę å°å ³ē³»åÆ仄é ē½®ę件äøęå®ć
Ā
åćé ē½®ļ¼ē®čæ°ļ¼
Ā Ā ä»äøčæ°ä¾åäøę们已ē»ē„éļ¼é ē½®ę件äøéč¦å£°ęāsourceāćāchannelāćāsinkāäøē§ē»ä»¶ēē¹ę§ļ¼ęÆäøŖē»ä»¶é½éč¦ä»„agent åē§°ä½äøŗåē¼ļ¼ęÆå¦āagentāć
<agent-name>.sources=<source1> <source2> ##å¤äøŖå¼ä¹é“仄ē©ŗę ¼é“é <agent-name>.channels=<channel1> <channel2> <agent-name>.sinks=<sink1> <sink2> ##éäøŖ声ęē»ä»¶ēå±ę§ <agent-name>.sources.<source-name>.type=<type> ... ##声ęē»ä»¶ēFlowčæę„å ³ē³» <agent-name>.sources.<source-name>.channels=<channel1> <channel2> ... <agent-name>.sinks.<sink-name>.channel=<channel> ##éč¦ē¹å«å¼ŗč°ļ¼ęÆäøŖsinkåŖč½ę„å „äøäøŖchannel ##ęÆäøŖsourcesåÆä»„ę ¹ę®āå¤ēØāę åµļ¼ä¼ č¾å°å¤äøŖchannels
Ā
Ā Ā å ³äŗāęåŗāęµļ¼
Ā Ā å¦äøęčæ°ļ¼FlumeęÆęå°ę¶ęÆęµä»sourceäøęåŗå°å¤äøŖchannelsćę2ē§ęåŗēęØ”åļ¼replicatingćmultiplexingļ¼āreplicatingāęØ”å¼äøļ¼ę¶ęÆå°ä¼åē»ęęēęå®ēchannelsļ¼å¤å¶ļ¼ļ¼åØmultiplexingęØ”å¼äøļ¼ę ¹ę®å¹é åę å°å ³ē³»ļ¼ę¶ęÆä» ä¼åē»ē¬¦åč¦ę±ēchannelsćäøŗäŗå®ē°ęåŗļ¼éč¦åØsourceäøęå®channelsēåč”Øåęåŗēēē„ćåÆ仄éčæåØchanneläøęå®āselectorāå±ę§äøŗāreplicatingāęč āmultiplexingāļ¼ē¶ååęå®éę©åØēč§åćé»č®¤ę åµäøļ¼āselectorāē±»åäøŗāreplicatingāļ¼
<agent-name>.sources.<source1>.channels=<channel1> <channel2> <agent-name>.sources.<source1>.selector.type=replicating ##multiplexing <agent-name>.sinks.<sink1>.channel=<channel1> ...
Ā
Ā Ā åƹäŗāmultiplexingāčæéč¦å ¶ä»ēé ē½®é”¹ļ¼eventå±ę§äøchannelēę å°å ³ē³»ęÆåæ é”»é ē½®ēćselectorä¼ę£ęµevent headersäøé ē½®ēå±ę§ļ¼å¦ęå¼å¹é ļ¼åä¼å°ę¤ę¶ęÆåē»ēøåŗēchannelsäøļ¼å¦åå°ä¼åéå°é ē½®äøęå®ēdefaultēchannelļ¼
<agent-name>.sources.<source1>.selector.type=multiplexing <agent-name>.sources.<source1>.selector.header=<someHeader> <agent-name>.sources.<source1>.selector.mapping.<value1>=<channel1> ##å½someHeaderēå¼äøŗvalue1ę¶ļ¼ę¶ęÆåē»channel1 <agent-name>.sources.<source1>.selector.mapping.<value2>=<channel2> <channel3> <agent-name>.sources.<source1>.selector.mapping.default=<channel1> ##å¦ęę²”ęå¹é ęåļ¼åä½æēØdefaultęå®ēchannelć ##éč¦ē¹å«ę³Øęļ¼eventäøåæ é”»å å«ę¤headerļ¼äøå¼äøč½äøŗnullļ¼å¦åä¼åƼč“ę ę³å¹é ä»»ä½channelć
Ā
äŗćFlume Sourcesļ¼ē®čæ°ļ¼
Ā Ā Sourceē»ä»¶åÆ仄ę„ę¶ę„čŖTCPčæę„ēę°ę®ćęč č§£ęę¬å°ę件ēę„åæę”ē®ļ¼ē¶åå°ę°ę®å°č£ ęeventsļ¼å¹¶å°eventsä¼ éē»å éØēchannelsļ¼SourceęÆFlume agentäøę°ę®ęµēęåē«Æćē®åFlumeå ē½®ēęÆč¾åøøēØēsourceē±»åęļ¼
Ā Ā 1ļ¼Avro Sourceļ¼åŗäŗTCPćAvroę°ę®åč®®ļ¼ę¤sourceä½äøŗAvro RPCēserverē«Æļ¼ēØäŗę„ę¶ClientåéēAvroę°ę®ć
Ā Ā 2ļ¼Thrift Sourceļ¼åŗäŗTPCćThriftę°ę®åč®®ļ¼ę¤sourceä½äøŗThrift RPCēserverē«Æļ¼ēØäŗę„ę¶Client åéēThriftę°ę®ć
Ā Ā 3ļ¼Spooling Directory Sourceļ¼ę£ęµę¬å°ę件ē®å½äøę件ļ¼å¹¶å°ē°ęļ¼ęę°å¢ļ¼ęä»¶č§£ęęeventsćčæē§sourceéåøøēØę„ę¶éāåå²ę„åæę件āļ¼ęÆå¦ęÆ天ę°å¢ēę„åæę件ēć
Ā Ā 4ļ¼Taildir Sourceļ¼ē±»ä¼¼äŗātailāę令ļ¼ę£ęµęå®ę件ęÆå¦ęę°å¢ļ¼appendļ¼ēę°ę®ļ¼å°ę°å¢ēę°ę®å°č£ ęeventsļ¼ęÆꬔęä½é½ä¼č®°å½å½åę件已ē»å¤ēēpositionļ¼äøäøꬔęä½å°ä»positionå¤ē»§ē»čæč”ćčæåƹę们ę¶éāå®ę¶ę„åæāéåøøęēØć
Ā Ā 5ļ¼kafka sourceļ¼ä½äøŗkafkaēconsumerļ¼ęå®kafkaēTopicsåč”Øļ¼ä»kafkaäøę¶č“¹ę¶ęÆć
Ā Ā 6ļ¼čæęå ¶ä»ēsourcesļ¼ęÆå¦ļ¼SyslogćNetCatćHTTPēć
Ā
å ćFlume Sinksļ¼ē®čæ°ļ¼
Ā Ā 1ļ¼HDFS Sinkļ¼å°ę¶ęÆåå „å°HDFSę件ē³»ē»äøļ¼ęÆępathčŖåØåå»ŗćę件ååēē¹ę§ć
Ā Ā 2ļ¼Avro Sinkļ¼ęåøøēØSinkä¹äøļ¼å°ę¶ęÆéčæAvro RPCę¹å¼ä¼ éē»čæē«ÆServerćéåøøēØåØmulti-tierę¶ęäøļ¼ęÆFlume ęØčēSinkć
Ā Ā 3ļ¼Thrift Sinkļ¼åäøć
Ā Ā 4ļ¼File Roll Sinkļ¼å°ę¶ęÆåå „ę¬å°ę件ē³»ē»ļ¼ęÆęęē §ę¶é“ååļ¼ęÆęčŖå®ä¹ēpathē®”ēćļ¼å¾å¤ę¶åę们éč¦ę©å±å®ļ¼
Ā Ā 5ļ¼Null Sinkļ¼ęäŗåŗęÆéåøøęēØļ¼ē“ę„äø¢å¼ę¶ęÆć
Ā Ā 6ļ¼Kafka Sinkļ¼å°ę¶ęÆåå „Kafkaļ¼ęåøøēØēSinkä¹äøļ¼ę¤Sinkä½äøŗkafkaēproducerē«Æć
Ā
äøćFlume Channelsļ¼ē®čæ°ļ¼
Ā Ā 1ļ¼Memory Channelļ¼å°EventsäæååØå åäøļ¼äøäøŖBlockqingQueueļ¼čæęÆę°ę®åÆé ę§č¾å¼±ćä½ęÆęēęé«ēChannelćéåøøéēØäŗå®ę¶ę°ę®ä¼ č¾ć
Ā Ā 2ļ¼File Channelļ¼å°EventsäæååØę¬å°ēFileäøļ¼ę°ę®åÆé ę§č¾é«ćä½ęÆęēč¾ä½ēChannelļ¼éåøøēØäŗä¼ č¾é£äŗåÆé ę§č¦ę±č¾é«ēę°ę®ć
Ā Ā 3ļ¼å ¶ä»ļ¼ęÆå¦JDBC Channelćkafka Channelļ¼čæęå®éŖę§ēSpillable Memory Channelļ¼åŗäŗMemoryåFileļ¼
Ā
å «ćFlume Selectorsļ¼éę©åØļ¼
Ā Ā åØäøęäøę们已ē»ęå°Selectorēęŗå¶ļ¼å³ēØäŗSourceäøę¶ęÆēč·Æē±ļ¼éčæäøå®ēę”件å°äøäøŖSourceäøēeventsä¼ éē»ēøåŗēChannelćē®åęÆęäø¤ē§selectorļ¼replicatingåmultiplexingļ¼é»č®¤äøŗāreplicatingāć
Ā Ā 1ćreplicatingļ¼å¤å¶ļ¼å³ęÆäøŖeventé½å°ä»„āå¤å¶āēę¹å¼ä¼ éē»å¤äøŖchannelsć
agent.sources=s1 agent.channels=c1 c2 c3 agent.sources.s1.selector.type=replicating agent.sources.s1.channels=c1 c2 c3 agent.sources.s1.selector.optional=c3
Ā
Ā Ā selectoręäø¤äøŖå±ę§ātypeāåāoptionalāļ¼å ¶äøtypeēØäŗęå®éę©åØēē±»åļ¼åæ é”»äøŗāreplicatingāćå ¶äøāoptionalāč”Øē¤ŗåÆéēchannelļ¼å³channlesäø声ęēāc1 c2 c3āļ¼å ¶äøę¶ęÆåØāc1 c2āåå „å¤±č“„ę¶å°ä¼åƼč“äŗå”ęä½å¤±č“„ļ¼å äøŗc3äøŗoptionalļ¼é£ä¹åå „c3å¤±č“„ēę¶ęÆå°ä¼č¢«åæ½ē„ć
Ā
Ā Ā 2ćmultiplexingļ¼å¤ēØļ¼å³ę¶ęÆę ¹ę®äøå®ēēē„ļ¼åē»Channelsåč”ØäøęäøŖchannelļ¼eventså¤ēØčæäŗChannelsć
agent.sources=s1 agent.channels=c1 c2 c3 c4 agent.sources.s1.selector.type=multiplexing agent.sources.s1.selector.header=state agent.sources.s1.selector.mapping.CZ=c1 agent.sources.s1.selector.mapping.US=c2 c3 agent.sources.s1.selector.default=c4
Ā
Ā Ā ę¤ē§ē±»åēselectoråƹę¶ęÆēč·Æē±ļ¼éč¦å£°ęmappingćéčæāheaderāęå®éč¦å¹é ēheaderļ¼å¦ęheaderēå¼äømappingåč”Øäøå¹é ļ¼ę¶ęÆå°ä¼ä¼ éē»mappingåƹåŗēchannelļ¼å¦ęåę å¹é ļ¼åä¼ éē»ādefaultāęå®ēchannelćåØę¤éč¦ę³Øęļ¼eventäøåæ é”»ååØę¤heeaderļ¼äøå¼äøč½äøŗnullļ¼å¦åå°åƼč“ę¶ęÆę ę³ä¼ éć
Ā
ä¹ćFlume Sink Processorsļ¼å¤ēåØļ¼
Ā Ā é«ēŗ§ē¹ę§ļ¼Sink groupsåÆ仄å°å¤äøŖsinksä½äøŗäøäøŖę“ä½ļ¼åƹäøäøŖgroupäøēå¤äøŖsinkså®ē°ęÆå¦āload balancingāęč āfailoverāē¹ę§ćē®åęÆęäø¤ē§processorsļ¼load_balancećfailoverć
agent.sinkgroups=g1 agent.sinkgroups.g1.sinks=sink1 sink2 agent.sinkgroups.g1.processor.type=load_balance
Ā
Ā Ā 1) Failover Sink Processor
Ā Ā åØgroupäø声ęå¤äøŖsinksļ¼åŖč¦ęäøäøŖsinkęęļ¼ę¶ęÆé½å°č¢«å¤ēåä¼ éćå®ēåēęÆč¾ē®åļ¼å½äøäøŖsinkę¶ęÆåéåŗē°å¼åøøåļ¼ę¤sinkå°č¢«ę č®°äøŗāfailā并å°å ¶ę·»å å°failSinksåč”Øäøļ¼å¹¶ä»aliveSinksåč”Øäøéę©äøäøŖpriorityå¼ęé«ēsinkę„ę„ē®”ļ¼å¹¶č“č“£ę¤åēę¶ęÆåéļ¼ē“å°å®åŗē°å¼åøøäøŗę¢ćé£äŗę č®°äøŗfailēsinkļ¼å°ä¼é“ęę§ēę£ęµå®ä»¬ēē¶ęļ¼éåfailSinksåč”Øļ¼éäøŖ让å®ä»¬å°čÆåéę¶ęÆļ¼å¦ęåéęååå°ę¤sinkę·»å å°aliveSinksäøćļ¼ēØåå°åŗäŗęŗē č§£éå éØåēļ¼
Ā Ā åØä»»ä½ę¶å»ļ¼sinksåč”ØäøåŖęäøäøŖsinkč“č“£ę¶ęÆä¼ éļ¼å ¶ä»sinksåŖåābackupāļ¼čæē¬¦åfailoverēčÆä¹ć
agent.sinkgroups=g1 agent.sinkgroups.g1.sinks=sink1 sink2 agent.sinkgroups.g1.processor.type=failover agent.sinkgroups.g1.processor.priority.sink1=5 agent.sinkgroups.g1.processor.priority.sink2=10 ##åƹäŗfailed sinksļ¼backoffēęéæę¶é“ļ¼ęÆ«ē§ļ¼ļ¼č¶ ę¶åå°ä¼ ##å°čÆ让å®ä»¬åéę¶ęÆļ¼ä»„éŖčÆę“»ę§ć agent.sinkgroups.g1.processor.maxpenalty=10000
Ā
Ā Ā 2ļ¼Load balanceing Sink Processor
Ā Ā ęÆęåØå¤äøŖSinksä¹é“č“č½½åč””ļ¼sinkēéę©ęŗå¶åäøŗārandomāåāround_robināļ¼é»č®¤äøŗāround_robināćåØå¤ēę¶ęÆę¶ļ¼éę©åØę ¹ę®é ē½®ēéę©ęŗå¶ļ¼ä»sinksåč”Øäøéę©äøäøŖsinkļ¼å¹¶ä½æēØę¤sinkę¶č“¹ę¶ęÆļ¼ä»Channeläøč·åę¶ęÆļ¼ļ¼å¦ęę¤sinkę ę³ä¼ éę¶ęÆļ¼éę©åØå°ä¼éę°éę©sinkļ¼å¦ęęęēsinksé½ę ę³ä¼ éļ¼é£ä¹ęē»å°ęåŗå¼åøøć
Ā Ā å¦ęå¼åÆäŗbackoffļ¼é£äŗfailedSinkå°č¢«ę·»å å°āé»ååāäøļ¼å¹¶āäæēāäøꮵę¶é“ļ¼č¶ ę¶åļ¼ę¤failed SinkåÆä»„č¢«éę°ę·»å å°éę©åč”Øäøļ¼ęč®øę¤ę¶å®ä»ē¶äøåÆēØļ¼å¦ęåꬔäøåÆēØļ¼å®ētimeoutę¶é“å°ä¼å¢éæļ¼ęéæäøŗmaxTimeoutļ¼ćéę©åØåØęÆꬔéę©sinkę¶ļ¼é£äŗåØāé»ååāäøēsinkå°äøåäøć
agent.singroups=g1 agent.sinkgroups.g1.sinks=s1 s2 ##åæ é”»äøŗload_balance agent.sinkgroups.g1.processor.type=load_balance ##å¼åÆbackoff agent.sinkgroups.g1.processor.backoff=true ##éę©ęŗå¶ļ¼randomćround_robin agent.sinkgroups.g1.processor.selector=random ##backoffęéæę¶é“ļ¼ęÆ«ē§ agent.sinkgroups.g1.processor.selector.maxTimeout=30000
Ā
Ā åćEvent Serializersļ¼ę¶ęÆåŗååļ¼
Ā Ā åŗååļ¼å³åØsinkå°Eventä¼ éę¶å¦ä½åŗååEventćåŗååäøååŗåååƹåŗļ¼ę仄å½åsinkēåŗåååŗčÆ„äøremoteē«Æēååŗååäŗēøåƹåŗć
Ā Ā 1ćBody Text Serializer
Ā Ā å«åļ¼ē®åļ¼ļ¼textļ¼ē“ę„å°Event body仄ęµēę¹å¼åå „ļ¼eventēheaderséØåå°ä¼č¢«åæ½ē„ć
Ā
agent.sinks=s1 agent.sinks.s1.type=file_roll ##å°eventåå „ę¬å°ē£ē agent.sinks.s1.directory=/logs/flume agent.sinks.s1.serializer=text agent.sinks.s1.serializer.appendNewline=trueĀ
Ā
Ā Ā ę¤åŗåååŖęäøäøŖå±ę§āappendNewlineāļ¼å³ęÆå¦åØbodyę°ę®åå „å®ęÆä¹åčæ½å äøäøŖāę¢č”ē¬¦āć
Ā
Ā Ā 2ćAvro Event Serializer
Ā Ā åƹäŗAvroSinkļ¼ęč å°event åå „Avroåŗååę件ę¶ļ¼åÆ仄ä½æēØę¤åŗååę¹å¼ć
Ā
åäøćFlume Interceptorsļ¼ę¦ęŖåØļ¼
Ā Ā éåøøéč¦ēē¹ę§ļ¼ę们åÆ仄ä½æēØę¦ęŖåØå®ē°åƹeventsēäæ®ę¹åäø¢å¼ļ¼modify/dropļ¼ļ¼flumeęÆęé¾å¼ēę¦ęŖåØļ¼å³å¤äøŖę¦ęŖåØå°ę ¹ę®å ¶åØé ē½®äø声ęēé”ŗåŗä¾ę¬”ę§č”ļ¼eventsļ¼éåøøęÆę¹éļ¼å°ä¾ę¬”ē»čæęÆäøŖę¦ęŖåØćę们åØę¦ęŖåØäøļ¼åÆ仄äæ®ę¹eventēheadersēč³bodyļ¼å¦ęę¦ęŖåØå³å®äø¢å¼ęäøŖeventļ¼åŖéč¦åØčæåēeventsåč”Øäøäøå å«å®å³åÆļ¼å¦ęę³ę¾å¼ęęļ¼åŖéč¦čæåē©ŗēlistå³åÆć
Ā
agent.sources=s1 agent.channels=c1 agent.sources.s1.interceptors=i1 i2 agent.sources.s1.interceptors.i1.type=host agent.sources.s1.interceptors.i2=timestampĀ
Ā
Ā Ā ę³Øęļ¼åŖęsourceē»ä»¶ęÆęę¦ęŖåØļ¼å³eventsåØä¼ éē»channelä¹åļ¼å č®øä½æēØę¦ęŖåØåƹeventsčæč”č°ę“ćåƹäŗčŖå®ä¹ēę¦ęŖåØļ¼éč¦åØātypeāå±ę§äø声ęē±»ēå Øåļ¼ęÆå¦ļ¼com.test.flume.interceptors.MyInterceptor$Builderļ¼ļ¼čŖå®ä¹ēinterceptoréč¦å®ē°āorg.apache.flume.interceptor.Interceptorāę„å£ļ¼éč¦ę³ØęāBuilderāéč¦åØinterceptoräø声ęć
Ā
Ā Ā 1ćTimstamp ę¦ęŖåØ
Ā Ā åØeventēheadersäøę·»å äøäøŖheaderļ¼å ¶å¼äøŗeventč¢«å¤ēēę¶é“ę³ćå¦ęeventäøå·²ē»ååØę¤headerļ¼ęÆå¦äøäøēŗ§agentå·²ē»åØheadersäøę·»å äŗļ¼ļ¼åÆ仄éčæāpreserveExistingāę„å³å®ęÆå¦äæēåå¼ćę¤ę¦ęŖåØēē®åäøŗļ¼timestampć
Ā
Ā Ā 2ćHostę¦ęŖåØ
Ā Ā åØeventēheadersäøę·»å äøäøŖheaderļ¼å ¶å¼äøŗagentęåØęŗåØēhostnameęč IPļ¼ę¤ę¦ęŖåØē®åäøŗļ¼host
Ā Ā
Ā Ā 3ćStaticę¦ęŖåØ
Ā Ā åØheadersäøę·»å äøäøŖåøøéļ¼ē®åäøŗļ¼staticć
Ā
agent.sources.s1.interceptors.i1.type=static agent.sources.s1.interceptors.i1.key=project agent.sources.s1.interceptors.i1.value=order_center
Ā
Ā
Ā Ā 4ćUUIDę¦ęŖåØļ¼äøŗeventę·»å äøäøŖå Øå±åÆäøēUUID headerļ¼ē®åäøŗļ¼UUIDć
Ā Ā 5ćRegexčæ껤ę¦ęŖåØļ¼éčæę£åč”Øč¾¾å¼å¹é bodyå 容ļ¼åÆä»„ę ¹ę®å¹é ē»ęę„å³å®ęÆå¦å å«ęč äø¢å¼ę¤eventć



ēøå ³ęØč
flume1.7ētaildiręÆęwindows,flume1.7ētaildiręÆęwindows
### Windows äø Flume 1.7 ēä½æēØęå #### Apache Flume ę¦čæ° Apache Flume ęÆäøäøŖååøå¼ēćåÆé ēäøé«åÆēØēē³»ē»ļ¼ēØäŗä»äøåēę°ę®ęŗę¶éćę±ę»åä¼ č¾å¤§éēę„åæę°ę®å°éäøå¼ēę°ę®ååØäøåæćFlume ēč®¾č®”ē®ē...
Apache Flume ęÆäøäøŖååøå¼ćåÆé äøåÆēØäŗęęę¶éćčååē§»åØ大éę„åæę°ę®ēē³»ē»ćå®å ·ęé«åÆēØę§ć容éę§ååÆę©å±ę§ļ¼å¹æę³åŗēØäŗ大ę°ę®å¤ēé¢åćFlume 1.7.0 ęÆčÆ„č½Æ件ēäøäøŖēę¬ļ¼å å«äŗå®ę“ēęŗ代ē ļ¼ä¾æäŗ...
### Apache Flume 1.7 ēØę·ęåę øåæē„čÆē¹ #### äøćå¼čØäøę¦čæ° - **Apache Flume** ęÆäøäøŖååøå¼ćåÆé äøåÆēØēē³»ē»ļ¼äø»č¦ēØäŗé«ęå°ę¶éćčå并ē§»åØ大éēę„åæę°ę®ļ¼čæäŗę°ę®ę„čŖäøåēęŗ并ęē»ååØå°éäøå¼...
#### 1.2 Flumeē¹ę§ - **åÆé ę§**ļ¼Flumeē”®äæę°ę®ä¼ č¾čæēØäøę°ę®ēå®ę“ę§ļ¼å³ä½æåØē½ē»äøēسå®ēę åµäøä¹č½ęå°åę°ę®äø¢å¤±ēé£é©ć - **åÆę©å±ę§**ļ¼éēę°ę®ęŗę°éēå¢å ļ¼FlumeåÆ仄éčæę·»å ę“å¤ēčē¹ę„č½»ę¾ę©å±å ¶...
1. **äŗ件(Event)**ļ¼äŗ件ęÆFlumeę°ę®å¤ēēåŗę¬åä½ļ¼å å«äøäøŖåčę°ē»ēęęč“č½½ļ¼payloadļ¼ååÆéēheaderļ¼åē¬¦äø²å±ę§ļ¼ćäŗ件ä»ęŗ(Source)äŗ§ēļ¼éčæéé(Channel)ä¼ éļ¼ęē»ē±ę°“ę§½(Sink)å¤ēć 2. **ęŗ...
å¦ęä½ ēēÆå¢ęÆåŗäŗJDK 1.7ēļ¼ä½ éč¦åÆ»ę¾Flumeē1.7ēę¬ļ¼čæä¹ęÆęčæ°äøęå°ēć ęčæ°äøęåŗļ¼ē±äŗFlumeå®ē½ēäøč½½éåŗ¦åÆč½č¾ę ¢ļ¼ęä¾äŗäøäøŖå¤ēØēäøč½½é¾ę„ļ¼ę¹ä¾æēØę·č·åApache Flume 1.8.0ēēę¬ćę¤å¤ļ¼čµęŗäøčæ...
Flumeåŗę¬ēč®ŗäøå®č·µ FlumeęÆäøäøŖé«åÆēØēćååøå¼ēęµ·éę„åæééćčååä¼ č¾ēē³»ē»ļ¼ē±Clouderaęä¾ćå®åŗäŗęµå¼ę¶ęļ¼ēµę“»ē®åćFlumeäø»č¦ē±AgentćSourcećChannelćSinkåäøŖē»ä»¶ē»ęļ¼ęÆäøŖē»ä»¶é½ę®ę¼ēéč¦ē...
ę»ē»ļ¼FlumeęÆäøäøŖå¼ŗ大äøēµę“»ēę„åæē®”ēē³»ē»ļ¼å®ēååøå¼ē¹ę§ćåÆå®å¶ēę°ę®ęŗåååØ仄åé«åÆēØę§č®¾č®”ä½æå ¶åØ大ę°ę®ēÆå¢äøå¹æåę¬¢čæćéčæé čÆ»åēč§£å®ę¹ęę”£ļ¼ē»åå®é ēé ē½®åčæč”ē»éŖļ¼ę们åÆ仄å åå©ēØFlumeč§£å³å¤§...
1. **Flumeåŗę¬ę¶ę**ļ¼Flumeē±SourcećChannelåSinkäøéØåē»ęćSourceč“č“£ę„ę¶ę°ę®ļ¼Channelä½äøŗäø“ę¶ååØļ¼Sinkč“č“£å°ę°ę®åéå°ē®ēå°ļ¼å¦Elasticsearchć 2. **Flumeé ē½®**ļ¼äøŗäŗå°Flumečæę„å°Elasticsearchļ¼...
- **Event**ļ¼Event ęÆ Flume å¤ēēåŗę¬åä½ļ¼ē± Header å Body äø¤éØåē»ęćHeader å å«å ę°ę®äæ”ęÆļ¼Body åå å«äŗå®é ēę„åæę°ę®ć #### äøćFlume ēåÆé ę§äøåÆę¢å¤ę§ Flume ęä¾äŗå¤ē§ęŗå¶ę„ē”®äæę°ę®ēåÆé ...
Flume AgentęÆFlumeēåŗę¬å·„ä½åä½ļ¼å®ęÆäøäøŖē¬ē«ēJavačęęŗčæēØļ¼č“č“£ę§č”ę°ę®ęµå¤ēćAgentå éØå å«äŗSourcećChannelåSinkäøäøŖē»ä»¶ļ¼å®ä»¬åčŖęæę äøåēčč“£ļ¼ 1. Sourceļ¼SourceęÆę°ę®ēå „å£ļ¼č“č“£ä»åē§...
- **ē³»ē»č¦ę±ļ¼** å®č£ JDK1.7å仄äøēę¬ļ¼Flumeēę¬ęØčä½æēØ1.5.2ć - **éē¾¤éØē½²ļ¼** å»ŗč®®ęē §å®ę¹ęę”£ēęØčē»ęļ¼å³ä½æēØSource-Client/Channel-Client/Sink-Client仄åSource-Server/Channel-Server/Sink-Server...
ę¬ęå°ęåƼęØå®ę Flume-NG ēå®č£ ååŗę¬é ē½®ć å®č£ Flume-NG 1. å å³ę”件ļ¼Java JDK å®č£ åØå®č£ Flume-NG ä¹åļ¼éč¦å å®č£ Java JDKćęØåÆ仄ęē § JDK ēå®č£ ęåčæč”å®č£ ć 2. äøč½½ Flume-NG ä½æēØ wget å½ä»¤...
åØ大ę°ę®å®ę¶å¤ēé¢åļ¼FlumećKafka å Spark Streaming ęÆåøøēØēę°ę®ééćä¼ č¾äøå¤ēå·„å ·ćę¬å®éŖę„åčƦē»éčæ°äŗå¦ä½å°čæäøäøŖē»ä»¶ē»åä½æēØļ¼ęå»ŗäøäøŖé«ęēę°ę®ęµå¤ēē³»ē»ć äøćFlume äø Spark Streaming ē...
Agent ęÆäøäøŖ JVM čæēØļ¼å®ä»„äŗ件ēå½¢å¼å°ę°ę®ä»ęŗ夓éč³ē®ēå°ļ¼ęÆ Flume ę°ę®ä¼ č¾ēåŗę¬åå ćAgent äø»č¦ę 3 äøŖéØåē»ęļ¼SourcećChannel å Sinkć 1.2.2 Source Source ęÆč“č“£ę„ę¶ę°ę®å° Flume Agent ēē»ä»¶...
/opt/flume1.7/bin/flume-ng agent --conf /opt/flume1.7/conf/ --name a1 --conf-file /opt/flume1.7/job/flume-netcat-test01.conf -Dflume.root.logger=INFO,console ``` ä½æēØnetcatå·„å ·å55555ē«Æå£åéę°ę®ļ¼ `...
6. **Flumeēé«ēŗ§ē¹ę§**ļ¼ - **å¤ēŗ§å¤ē**ļ¼FlumeęÆęå¤ēŗ§ę°ę®å¤ēļ¼ä½ åÆ仄åå»ŗå¤äøŖęŗćééåę„ę¶åØēē»åę„å®ē°å¤ęēęµēØć - **容éę§**ļ¼Flumeä½æēØęä¹ åééļ¼å¦ę件ééļ¼ę„ē”®äæåØę éę¶äøä¼äø¢å¤±ę°ę®ć ...
2. **Event**ļ¼Flumeä¼ č¾ēåŗę¬åä½ļ¼ē±HeaderåBodyē»ęćHeaderå å«å ę°ę®äæ”ęÆļ¼BodyåęÆå®é ēę°ę®å 容ć 3. **Agent**ļ¼Flumeēę øåæē»ä»¶ļ¼ē±SourcećChannelåSinkēęęļ¼č“č“£å°Eventä»äøäøŖå°ę¹ä¼ č¾å°å¦äøäøŖ...
Flume ęÆ Apache Hadoop ēęē³»ē»äøēäøäøŖååøå¼ć...ēč§£ Flume ēåŗę¬ę¦åæµćé ē½®ä»„ååē§ē»ä»¶ēä½æēØļ¼ęÆå åå©ēØ Flume åč½ēå ³é®ćåØå®é åŗēØäøļ¼åÆä»„ę ¹ę®å ·ä½éę±č°ę“é ē½®ļ¼ä»„éåŗäøåēę°ę®ęŗåę°ę®å¤ēä»»å”ć