
TF-IDFпјҲterm frequencyвҖ“inverse document frequencyпјүжҳҜдёҖз§Қз”ЁдәҺиө„и®ҜжЈҖзҙўдёҺиө„и®ҜжҺўеӢҳзҡ„еёёз”ЁеҠ жқғжҠҖжңҜ, TFIDFзҡ„дё»иҰҒжҖқжғіжҳҜпјҡеҰӮжһңжҹҗдёӘиҜҚжҲ–зҹӯиҜӯеңЁдёҖзҜҮж–Үз« дёӯеҮәзҺ°зҡ„йў‘зҺҮTFй«ҳпјҢ并且еңЁе…¶д»–ж–Үз« дёӯеҫҲе°‘еҮәзҺ°пјҢеҲҷи®ӨдёәжӯӨиҜҚжҲ–иҖ…зҹӯиҜӯе…·жңүеҫҲеҘҪзҡ„зұ»еҲ«еҢәеҲҶиғҪеҠӣпјҢйҖӮеҗҲз”ЁжқҘеҲҶзұ»гҖӮTFIDFе®һйҷ…дёҠжҳҜпјҡTF * IDFпјҢTFиҜҚйў‘(Term Frequency)пјҢIDFеҸҚж–ҮжЎЈйў‘зҺҮ(Inverse Document Frequency)гҖӮTFиЎЁзӨәиҜҚжқЎеңЁж–ҮжЎЈdдёӯеҮәзҺ°зҡ„йў‘зҺҮгҖӮ
In information retrieval, tfвҖ“idf, short for term frequencyвҖ“inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus.[1] It is often used as a weighting factor in information retrieval, text mining, and user modeling. The tf-idf value increases proportionally to the number of times a word appears in the document, but is offset by the frequency of the word in the corpus, which helps to adjust for the fact that some words appear more frequently in general. Nowadays, tf-idf is one of the most popular term-weighting schemes. For instance, 83% of text-based recommender systems in the domain of digital libraries use tf-idf[2].
Variations of the tfвҖ“idf weighting scheme are often used by search engines as a central tool in scoring and ranking a document's relevance given a user query. tfвҖ“idf can be successfully used for stop-words filtering in various subject fields including text summarization and classification.
One of the simplest ranking functions is computed by summing the tfвҖ“idf for each query term; many more sophisticated ranking functions are variants of this simple model.
В
В
В
Term frequency
Suppose we have a set of English text documents and wish to determine which document is most relevant to the query "the brown cow". A simple way to start out is by eliminating documents that do not contain all three words "the", "brown", and "cow", but this still leaves many documents. To further distinguish them, we might count the number of times each term occurs in each document and sum them all together; the number of times a term occurs in a document is called its term frequency.
The first form of term weighting is due to Hans Peter Luhn (1957) and is based on the Luhn Assumption:
The weight of a term that occurs in a document is simply proportional to the term frequency.В
В
Inverse document frequency
Because the term "the" is so common, term frequency will tend to incorrectly emphasize documents which happen to use the word "the" more frequently, without giving enough weight to the more meaningful terms "brown" and "cow". The term "the" is not a good keyword to distinguish relevant and non-relevant documents and terms, unlike the less common words "brown" and "cow". Hence an inverse document frequency factor is incorporated which diminishes the weight of terms that occur very frequently in the document set and increases the weight of terms that occur rarely.
Karen SpГӨrck Jones (1972) conceived a statistical interpretation of term specificity called Inverse Document Frequency (IDF), which became a cornerstone of term weighting:
The specificity of a term can be quantified as an inverse function of the number of documents in which it occurs.В
В
IDFзҡ„дё»иҰҒжҖқжғіжҳҜпјҡеҰӮжһңеҢ…еҗ«иҜҚжқЎtзҡ„ж–ҮжЎЈи¶Ҡе°‘пјҢд№ҹе°ұжҳҜnи¶Ҡе°ҸпјҢIDFи¶ҠеӨ§пјҢеҲҷиҜҙжҳҺиҜҚжқЎtе…·жңүеҫҲеҘҪзҡ„зұ»еҲ«еҢәеҲҶиғҪеҠӣгҖӮеҰӮжһңжҹҗдёҖзұ»ж–ҮжЎЈCдёӯеҢ…еҗ«иҜҚжқЎtзҡ„ж–ҮжЎЈж•°дёәmпјҢиҖҢе…¶е®ғзұ»еҢ…еҗ«tзҡ„ж–ҮжЎЈжҖ»ж•°дёәkпјҢжҳҫ然жүҖжңүеҢ…еҗ«tзҡ„ж–ҮжЎЈж•°n=m + kпјҢеҪ“mеӨ§зҡ„ж—¶еҖҷпјҢnд№ҹеӨ§пјҢжҢүз…§IDFе…¬ејҸеҫ—еҲ°зҡ„IDFзҡ„еҖјдјҡе°ҸпјҢе°ұиҜҙжҳҺиҜҘиҜҚжқЎtзұ»еҲ«еҢәеҲҶиғҪеҠӣдёҚејәгҖӮдҪҶжҳҜе®һйҷ…дёҠпјҢеҰӮжһңдёҖдёӘиҜҚжқЎеңЁдёҖдёӘзұ»зҡ„ж–ҮжЎЈдёӯйў‘з№ҒеҮәзҺ°пјҢеҲҷиҜҙжҳҺиҜҘиҜҚжқЎиғҪеӨҹеҫҲеҘҪд»ЈиЎЁиҝҷдёӘзұ»зҡ„ж–Үжң¬зҡ„зү№еҫҒпјҢиҝҷж ·зҡ„иҜҚжқЎеә”иҜҘз»ҷе®ғ们иөӢдәҲиҫғй«ҳзҡ„жқғйҮҚпјҢ并йҖүжқҘдҪңдёәиҜҘзұ»ж–Үжң¬зҡ„зү№еҫҒиҜҚд»ҘеҢәеҲ«дёҺе…¶е®ғзұ»ж–ҮжЎЈгҖӮиҝҷе°ұжҳҜIDFзҡ„дёҚи¶ід№ӢеӨ„.
В
жЎҲдҫӢпјҡеҒҮеҰӮдёҖзҜҮж–Ү件зҡ„жҖ»иҜҚиҜӯж•°жҳҜ100дёӘпјҢиҖҢиҜҚиҜӯвҖңжҜҚзүӣвҖқеҮәзҺ°дәҶ3ж¬ЎпјҢйӮЈд№ҲвҖңжҜҚзүӣвҖқдёҖиҜҚеңЁиҜҘж–Ү件дёӯзҡ„иҜҚйў‘е°ұжҳҜ3/100=0.03гҖӮдёҖдёӘи®Ўз®—ж–Ү件频зҺҮ (DF) зҡ„ж–№жі•жҳҜжөӢе®ҡжңүеӨҡе°‘д»Ҫж–Ү件еҮәзҺ°иҝҮвҖңжҜҚзүӣвҖқдёҖиҜҚпјҢ然еҗҺйҷӨд»Ҙж–Ү件йӣҶйҮҢеҢ…еҗ«зҡ„ж–Ү件жҖ»ж•°гҖӮжүҖд»ҘпјҢеҰӮжһңвҖңжҜҚзүӣвҖқдёҖиҜҚеңЁ1,000д»Ҫж–Ү件еҮәзҺ°иҝҮпјҢиҖҢж–Ү件жҖ»ж•°жҳҜ10,000,000д»Ҫзҡ„иҜқпјҢе…¶йҖҶеҗ‘ж–Ү件频зҺҮе°ұжҳҜ lg(10,000,000 / 1,000)=4гҖӮжңҖеҗҺзҡ„TF-IDFзҡ„еҲҶж•°дёә0.03 * 4=0.12гҖӮ
В
IDFзҡ„дё»иҰҒжҖқжғіжҳҜпјҡеҰӮжһңеҢ…еҗ«иҜҚжқЎtзҡ„ж–ҮжЎЈи¶Ҡе°‘пјҢд№ҹе°ұжҳҜnи¶Ҡе°ҸпјҢIDFи¶ҠеӨ§пјҢеҲҷиҜҙжҳҺиҜҚжқЎtе…·жңүеҫҲеҘҪзҡ„зұ»еҲ«еҢәеҲҶиғҪеҠӣгҖӮеҰӮжһңжҹҗдёҖзұ»ж–ҮжЎЈCдёӯеҢ…еҗ«иҜҚжқЎtзҡ„ж–ҮжЎЈж•°дёәmпјҢиҖҢе…¶е®ғзұ»еҢ…еҗ«tзҡ„ж–ҮжЎЈжҖ»ж•°дёәkпјҢжҳҫ然жүҖжңүеҢ…еҗ«tзҡ„ж–ҮжЎЈж•°n=m+kпјҢеҪ“mеӨ§зҡ„ж—¶еҖҷпјҢnд№ҹеӨ§пјҢжҢүз…§IDFе…¬ејҸеҫ—еҲ°зҡ„IDFзҡ„еҖјдјҡе°ҸпјҢе°ұиҜҙжҳҺиҜҘиҜҚжқЎtзұ»еҲ«еҢәеҲҶиғҪеҠӣдёҚејәгҖӮдҪҶжҳҜе®һйҷ…дёҠпјҢеҰӮжһңдёҖдёӘиҜҚжқЎеңЁдёҖдёӘзұ»зҡ„ж–ҮжЎЈдёӯйў‘з№ҒеҮәзҺ°пјҢеҲҷиҜҙжҳҺиҜҘиҜҚжқЎиғҪеӨҹеҫҲеҘҪд»ЈиЎЁиҝҷдёӘзұ»зҡ„ж–Үжң¬зҡ„зү№еҫҒпјҢиҝҷж ·зҡ„иҜҚжқЎеә”иҜҘз»ҷе®ғ们иөӢдәҲиҫғй«ҳзҡ„жқғйҮҚпјҢ并йҖүжқҘдҪңдёәиҜҘзұ»ж–Үжң¬зҡ„зү№еҫҒиҜҚд»ҘеҢәеҲ«дёҺе…¶е®ғзұ»ж–ҮжЎЈгҖӮиҝҷе°ұжҳҜIDFзҡ„дёҚи¶ід№ӢеӨ„. еңЁдёҖд»Ҫз»ҷе®ҡзҡ„ж–Ү件йҮҢпјҢиҜҚйў‘пјҲterm frequencyпјҢTFпјүжҢҮзҡ„жҳҜжҹҗдёҖдёӘз»ҷе®ҡзҡ„иҜҚиҜӯеңЁиҜҘж–Ү件дёӯеҮәзҺ°зҡ„йў‘зҺҮгҖӮиҝҷдёӘж•°еӯ—жҳҜеҜ№иҜҚж•°(term count)зҡ„еҪ’дёҖеҢ–пјҢд»ҘйҳІжӯўе®ғеҒҸеҗ‘й•ҝзҡ„ж–Ү件гҖӮпјҲеҗҢдёҖдёӘиҜҚиҜӯеңЁй•ҝж–Ү件йҮҢеҸҜиғҪдјҡжҜ”зҹӯж–Ү件жңүжӣҙй«ҳзҡ„иҜҚж•°пјҢиҖҢдёҚз®ЎиҜҘиҜҚиҜӯйҮҚиҰҒдёҺеҗҰгҖӮпјүеҜ№дәҺеңЁжҹҗдёҖзү№е®ҡж–Ү件йҮҢзҡ„иҜҚиҜӯВ 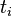 В жқҘиҜҙпјҢе®ғзҡ„йҮҚиҰҒжҖ§еҸҜиЎЁзӨәдёәпјҡ
В жқҘиҜҙпјҢе®ғзҡ„йҮҚиҰҒжҖ§еҸҜиЎЁзӨәдёәпјҡ
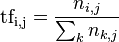
д»ҘдёҠејҸеӯҗдёӯВ  В жҳҜиҜҘиҜҚеңЁж–Ү件
В жҳҜиҜҘиҜҚеңЁж–Ү件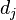 дёӯзҡ„еҮәзҺ°ж¬Ўж•°пјҢиҖҢеҲҶжҜҚеҲҷжҳҜеңЁж–Ү件дёӯжүҖжңүеӯ—иҜҚзҡ„еҮәзҺ°ж¬Ўж•°д№Ӣе’ҢгҖӮ
дёӯзҡ„еҮәзҺ°ж¬Ўж•°пјҢиҖҢеҲҶжҜҚеҲҷжҳҜеңЁж–Ү件дёӯжүҖжңүеӯ—иҜҚзҡ„еҮәзҺ°ж¬Ўж•°д№Ӣе’ҢгҖӮ
йҖҶеҗ‘ж–Ү件频зҺҮпјҲinverse document frequencyпјҢIDFпјүжҳҜдёҖдёӘиҜҚиҜӯжҷ®йҒҚйҮҚиҰҒжҖ§зҡ„еәҰйҮҸгҖӮжҹҗдёҖзү№е®ҡиҜҚиҜӯзҡ„IDFпјҢеҸҜд»Ҙз”ұжҖ»ж–Ү件数зӣ®йҷӨд»ҘеҢ…еҗ«иҜҘиҜҚиҜӯд№Ӣж–Ү件зҡ„ж•°зӣ®пјҢеҶҚе°Ҷеҫ—еҲ°зҡ„е•ҶеҸ–еҜ№ж•°еҫ—еҲ°пјҡ
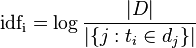
е…¶дёӯ
- |D|пјҡиҜӯж–ҷеә“дёӯзҡ„ж–Ү件жҖ»ж•°
-
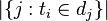 пјҡеҢ…еҗ«иҜҚиҜӯзҡ„ж–Ү件数зӣ®пјҲеҚі
пјҡеҢ…еҗ«иҜҚиҜӯзҡ„ж–Ү件数зӣ®пјҲеҚі зҡ„ж–Ү件数зӣ®пјүеҰӮжһңиҜҘиҜҚиҜӯдёҚеңЁиҜӯж–ҷеә“дёӯпјҢе°ұдјҡеҜјиҮҙиў«йҷӨж•°дёәйӣ¶пјҢеӣ жӯӨдёҖиҲ¬жғ…еҶөдёӢдҪҝз”Ё
зҡ„ж–Ү件数зӣ®пјүеҰӮжһңиҜҘиҜҚиҜӯдёҚеңЁиҜӯж–ҷеә“дёӯпјҢе°ұдјҡеҜјиҮҙиў«йҷӨж•°дёәйӣ¶пјҢеӣ жӯӨдёҖиҲ¬жғ…еҶөдёӢдҪҝз”Ё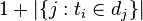
然еҗҺ

жҹҗдёҖзү№е®ҡж–Ү件еҶ…зҡ„й«ҳиҜҚиҜӯйў‘зҺҮпјҢд»ҘеҸҠиҜҘиҜҚиҜӯеңЁж•ҙдёӘж–Ү件йӣҶеҗҲдёӯзҡ„дҪҺж–Ү件频зҺҮпјҢеҸҜд»Ҙдә§з”ҹеҮәй«ҳжқғйҮҚзҡ„TF-IDFгҖӮеӣ жӯӨпјҢTF-IDFеҖҫеҗ‘дәҺиҝҮж»ӨжҺүеёёи§Ғзҡ„иҜҚиҜӯпјҢдҝқз•ҷйҮҚиҰҒзҡ„иҜҚиҜӯгҖӮ
В
еҺҹеҲӣдёҚжҳ“пјҢж¬ўиҝҺжү“иөҸ,иҜ·и®ӨеҮҶжӯЈзЎ®ең°еқҖпјҢи°ЁйҳІеҒҮеҶ’

В
В

В



зӣёе…іжҺЁиҚҗ
гҖҠLDAдёҺTF-IDFз®—жі•пјҡж·ұеәҰжҺўи®ЁдёҺеә”з”ЁгҖӢ еңЁдҝЎжҒҜжЈҖзҙўе’ҢиҮӘ然иҜӯиЁҖеӨ„зҗҶйўҶеҹҹпјҢLDAпјҲLatent Dirichlet Allocationпјүе’ҢTF-IDFпјҲTerm Frequency-Inverse Document FrequencyпјүжҳҜдёӨз§ҚиҮіе…ійҮҚиҰҒзҡ„з®—жі•пјҢе®ғ们еңЁж–Үжң¬еҲҶжһҗгҖҒж–ҮжЎЈеҲҶзұ»...
TF-IDFдёҺдҪҷејҰзӣёдјјжҖ§зҡ„еә”з”Ё TF-IDFпјҲTerm Frequency-Inverse Document FrequencyпјүжҳҜдёҖз§Қеёёз”Ёзҡ„е…ій”®иҜҚжҸҗеҸ–з®—жі•пјҢеә”з”ЁдәҺиҮӘеҠЁе…ій”®иҜҚжҸҗеҸ–гҖҒдҝЎжҒҜжЈҖзҙўзӯүйўҶеҹҹгҖӮиҜҘз®—жі•зҡ„дјҳзӮ№жҳҜз®ҖеҚ•еҝ«йҖҹпјҢз»“жһңжҜ”иҫғз¬ҰеҗҲе®һйҷ…жғ…еҶөгҖӮTF-IDF з®—жі•...
### дҪҝз”ЁTF-IDFзЎ®е®ҡж–ҮжЎЈжҹҘиҜўдёӯзҡ„иҜҚзӣёе…іжҖ§ еңЁеҪ“д»Ҡж•°жҚ®й©ұеҠЁзҡ„дё–з•ҢдёӯпјҢд»ҺеӨ§йҮҸж–Үжң¬дҝЎжҒҜдёӯй«ҳж•Ҳең°жЈҖзҙўзӣёе…ідҝЎжҒҜжҳҜдёҖйЎ№иҮіе…ійҮҚиҰҒзҡ„жҠҖиғҪгҖӮжң¬ж–ҮжҺўи®ЁдәҶеҰӮдҪ•еә”з”ЁTF-IDFпјҲTerm Frequency-Inverse Document FrequencyпјүжқҘзЎ®е®ҡж–ҮжЎЈ...
TF-IDFпјҲTerm Frequency-Inverse Document FrequencyпјүжҳҜдёҖз§ҚеңЁдҝЎжҒҜжЈҖзҙўе’Ңж–Үжң¬жҢ–жҺҳйўҶеҹҹе№ҝжіӣдҪҝз”Ёзҡ„жқғйҮҚи®Ўз®—ж–№жі•пјҢз”ЁдәҺиҜ„дј°дёҖдёӘиҜҚеңЁж–ҮжЎЈдёӯзҡ„йҮҚиҰҒжҖ§гҖӮиҝҷдёӘжҰӮеҝөеҹәдәҺдёӨдёӘдё»иҰҒеӣ зҙ пјҡиҜҚйў‘пјҲTerm Frequency, TFпјүе’ҢйҖҶж–ҮжЎЈ...
еңЁиҝҷдёӘдё»йўҳдёӯпјҢ"NLPпјҡеҹәдәҺTF-IDFзҡ„дёӯж–Үе…ій”®иҜҚжҸҗеҸ–"жҳҜдёҖдёӘйЎ№зӣ®пјҢе®ғеҲ©з”ЁTF-IDFз®—жі•жқҘд»Һдёӯж–Үж–Үжң¬дёӯжҸҗеҸ–е…·жңүд»ЈиЎЁжҖ§зҡ„е…ій”®иҜҚгҖӮTF-IDFжҳҜдёҖз§Қз»Ҹе…ёзҡ„ж–Үжң¬зү№еҫҒжқғйҮҚи®Ўз®—ж–№жі•пјҢе№ҝжіӣеә”з”ЁдәҺдҝЎжҒҜжЈҖзҙўгҖҒж–ҮжЎЈеҲҶзұ»е’Ңе…ій”®иҜҚжҸҗеҸ–зӯүйўҶеҹҹ...
### еҹәдәҺTF-IDFз®—жі•жҠҪеҸ–ж–Үз« е…ій”®иҜҚ #### дёҖгҖҒеј•иЁҖ TF-IDFпјҲTerm Frequency-Inverse Document FrequencyпјүжҳҜдёҖз§Қе№ҝжіӣеә”з”ЁдәҺдҝЎжҒҜжЈҖзҙўдёҺж–Үжң¬жҢ–жҺҳйўҶеҹҹзҡ„з»ҹи®Ўж–№жі•пјҢз”ЁдәҺиҜ„дј°еҚ•иҜҚеҜ№дәҺдёҖдёӘж–ҮжЎЈйӣҶжҲ–иҖ…иҜӯж–ҷеә“дёӯеҚ•дёӘж–ҮжЎЈзҡ„...
TF-IDFпјҲTerm Frequency-Inverse Document FrequencyпјүжҳҜдёҖз§ҚеңЁдҝЎжҒҜжЈҖзҙўе’Ңж–Үжң¬жҢ–жҺҳйўҶеҹҹе№ҝжіӣдҪҝз”Ёзҡ„жқғйҮҚи®Ўз®—ж–№жі•пјҢз”ЁдәҺиҜ„дј°дёҖдёӘиҜҚеңЁж–ҮжЎЈдёӯзҡ„йҮҚиҰҒжҖ§гҖӮиҝҷдёӘжҰӮеҝөеҹәдәҺдёӨдёӘеҺҹеҲҷпјҡиҜҚйў‘пјҲTerm Frequency, TFпјүе’ҢйҖҶж–ҮжЎЈйў‘зҺҮ...
еңЁ"tf-idf-keyword-master"иҝҷдёӘеҺӢзј©еҢ…ж–Ү件дёӯпјҢеҫҲеҸҜиғҪеҢ…еҗ«дәҶе®һзҺ°TF-IDFе…ій”®иҜҚжҸҗеҸ–зҡ„д»Јз ҒжЎҶжһ¶жҲ–иҖ…зӨәдҫӢгҖӮз”ЁжҲ·еҸҜиғҪйңҖиҰҒиҝӣдёҖжӯҘдәҶи§Јд»Јз Ғз»“жһ„пјҢеӯҰд№ еҰӮдҪ•еҠ иҪҪзү№е®ҡиҜӯж–ҷеә“пјҢеҰӮдҪ•иҝӣиЎҢйў„еӨ„зҗҶпјҢеҰӮдҪ•и®Ўз®—TF-IDFеҖјпјҢд»ҘеҸҠеҰӮдҪ•иҫ“еҮәе’Ң...
TF-IDFпјҲTerm Frequency-Inverse Document FrequencyпјүжҳҜдёҖз§ҚеңЁдҝЎжҒҜжЈҖзҙўе’ҢиҮӘ然иҜӯиЁҖеӨ„зҗҶдёӯе№ҝжіӣдҪҝз”Ёзҡ„з»ҹи®Ўж–№жі•пјҢз”ЁдәҺиҜ„дј°дёҖдёӘиҜҚеңЁж–ҮжЎЈдёӯзҡ„йҮҚиҰҒжҖ§гҖӮиҝҷдёӘж–№жі•еҹәдәҺдёӨдёӘж ёеҝғжҰӮеҝөпјҡиҜҚйў‘пјҲTerm Frequency, TFпјүе’ҢйҖҶж–ҮжЎЈйў‘зҺҮ...
жңәеҷЁеӯҰд№ ж–Үжң¬еҲҶзұ»еҹәдәҺTF-IDF+жңҙзҙ иҙқеҸ¶ж–Ҝж–Үжң¬ж•°жҚ®зҡ„еҲҶзұ»дёҺеҲҶжһҗжәҗз ҒпјҲй«ҳеҲҶеӨ§дҪңдёҡпјү.zipжң¬иө„жәҗдёӯзҡ„жәҗз ҒйғҪжҳҜз»ҸиҝҮжң¬ең°зј–иҜ‘иҝҮеҸҜиҝҗиЎҢзҡ„пјҢиҜ„е®ЎеҲҶиҫҫеҲ°95еҲҶд»ҘдёҠгҖӮиө„жәҗйЎ№зӣ®зҡ„йҡҫеәҰжҜ”иҫғйҖӮдёӯпјҢеҶ…е®№йғҪжҳҜз»ҸиҝҮеҠ©ж•ҷиҖҒеёҲе®Ўе®ҡиҝҮзҡ„иғҪеӨҹ...
TF-IDFпјҲTerm Frequency-Inverse Document FrequencyпјүжҳҜдёҖз§ҚеңЁдҝЎжҒҜжЈҖзҙўе’ҢиҮӘ然иҜӯиЁҖеӨ„зҗҶдёӯе№ҝжіӣдҪҝз”Ёзҡ„з»ҹи®Ўж–№жі•пјҢз”ЁдәҺиҜ„дј°дёҖдёӘиҜҚеңЁж–ҮжЎЈйӣҶеҗҲдёӯзҡ„йҮҚиҰҒжҖ§гҖӮеңЁJavaзј–зЁӢзҺҜеўғдёӢпјҢTF-IDFеҸҜд»Ҙеё®еҠ©жҲ‘们жҸҗеҸ–ж–Үжң¬зҡ„е…ій”®дҝЎжҒҜпјҢзҗҶи§Ј...
TF-IDFпјҲTerm Frequency-Inverse Document FrequencyпјүжҳҜдёҖз§ҚеңЁдҝЎжҒҜжЈҖзҙўе’ҢиҮӘ然иҜӯиЁҖеӨ„зҗҶдёӯе№ҝжіӣдҪҝз”Ёзҡ„ж–Үжң¬зү№еҫҒиЎЁзӨәж–№жі•гҖӮе®ғиғҪеӨҹиЎЎйҮҸдёҖдёӘиҜҚеңЁж–ҮжЎЈдёӯзҡ„йҮҚиҰҒжҖ§пјҢйҖӮз”ЁдәҺж–ҮжЎЈйӣҶеҗҲзҡ„зү№еҫҒжҸҗеҸ–пјҢеё®еҠ©жҲ‘们зҗҶи§Јж–ҮжЎЈзҡ„дё»йўҳе’ҢеҢәеҲҶ...
еҹәдәҺ TF-IDF ж–Үжң¬еҗ‘йҮҸеҢ–зҡ„ SQL жіЁе…Ҙж”»еҮ»жЈҖжөӢ SQL жіЁе…Ҙж”»еҮ»жҳҜжңҖеёёи§Ғзҡ„ Web еә”з”ЁзЁӢеәҸж”»еҮ»жүӢж®өпјҢеҲ©з”ЁжңәеҷЁеӯҰд№ жЈҖжөӢ SQL жіЁе…Ҙж”»еҮ»е·ІжҲҗдёәдёҖз§Қи¶ӢеҠҝгҖӮиҜҘи®әж–ҮжҸҗеҮәдәҶеҹәдәҺ TF-IDF ж–Үжң¬еҗ‘йҮҸеҢ–зҡ„ SQL жіЁе…Ҙж”»еҮ»жЈҖжөӢж–№жі•пјҢж—ЁеңЁжҸҗй«ҳ...
жҲ‘зҡ„еҚҡе®ўпјҡTF-IDFеҺҹзҗҶеҸҠз®—жі•е®һзҺ°...иҜҘиө„жәҗжҳҜжңүе…ідёӯж–Үж–Үз« зҡ„ж•°жҚ®йӣҶпјҢйҖӮеҗҲиҝӣиЎҢTF-IDFиҜҚйў‘еҲҶжһҗпјҢж•°жҚ®йӣҶдёӯзҡ„иҜҚе·Із»Ҹз”ЁеҲҶиҜҚе·Ҙе…·жҢүз©әж јеҲҮеүІиҝҮпјҢеҸҜд»ҘзӣҙжҺҘдҪҝз”ЁпјҢд»Јз Ғе®һзҺ°йғЁеҲҶеңЁеҚҡе®ўдёӯжңүеҶҷ
TF-IDFз®—жі•жҳҜдёҖз§ҚеңЁж–Үжң¬еҲҶжһҗе’ҢдҝЎжҒҜжЈҖзҙўйўҶеҹҹе№ҝжіӣеә”з”Ёзҡ„е…ій”®еӯ—жҸҗеҸ–жҠҖжңҜгҖӮе®ғзҡ„дё»иҰҒзӣ®ж ҮжҳҜиҜ„дј°дёҖдёӘиҜҚеҜ№дәҺдёҖдёӘж–ҮжЎЈйӣҶеҗҲжҲ–иҜӯж–ҷеә“дёӯзҡ„жҹҗдёҖдёӘж–ҮжЎЈзҡ„йҮҚиҰҒжҖ§гҖӮTF-IDFз®—жі•з»“еҗҲдәҶиҜҚйў‘пјҲTerm Frequency, TFпјүе’ҢйҖҶж–ҮжЎЈйў‘зҺҮ...
TF-IDFпјҲTerm Frequency-Inverse Document FrequencyпјүжҳҜдёҖз§ҚеңЁдҝЎжҒҜжЈҖзҙўе’Ңж–Үжң¬жҢ–жҺҳйўҶеҹҹе№ҝжіӣдҪҝз”Ёзҡ„з»ҹи®Ўж–№жі•пјҢз”ЁдәҺиҜ„дј°дёҖдёӘиҜҚеңЁж–ҮжЎЈдёӯзҡ„йҮҚиҰҒжҖ§гҖӮе®ғеҹәдәҺдёӨдёӘжҰӮеҝөпјҡиҜҚйў‘пјҲTerm Frequency, TFпјүе’ҢйҖҶж–ҮжЎЈйў‘зҺҮпјҲInverse ...
TF-IDFпјҢе…Ёз§°дёәTerm Frequency-Inverse Document FrequencyпјҢжҳҜдёҖз§ҚеңЁдҝЎжҒҜжЈҖзҙўе’Ңж–Үжң¬жҢ–жҺҳйўҶеҹҹе№ҝжіӣеә”з”Ёзҡ„з»ҹи®Ўж–№жі•пјҢз”ЁдәҺиҜ„дј°дёҖдёӘиҜҚеңЁж–ҮжЎЈйӣҶжҲ–иҜӯж–ҷеә“дёӯзҡ„йҮҚиҰҒжҖ§гҖӮе®ғз»“еҗҲдәҶиҜҚйў‘пјҲTerm Frequency, TFпјүе’ҢйҖҶж–ҮжЎЈйў‘зҺҮ...
жң¬ж–Үд»Ӣз»ҚдәҶдёҖз§ҚеҹәдәҺж”№иҝӣTF-IDFз®—жі•зҡ„зүӣз–ҫз—…жҷәиғҪиҜҠж–ӯзі»з»ҹгҖӮдј з»ҹзҡ„TF-IDFз®—жі•еӯҳеңЁдёҖдәӣзјәйҷ·пјҢдҫӢеҰӮж— жі•еҗҲзҗҶең°д»ЈиЎЁжҹҗз–ҫз—…зҡ„з—ҮзҠ¶пјҢйҷҚдҪҺжҷәиғҪиҜҠж–ӯзі»з»ҹзҡ„жҖ§иғҪгҖӮдёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢжң¬ж–ҮжҸҗеҮәдәҶдёҖдёӘж”№иҝӣзҡ„TF-IDFз®—жі•пјҢ并е°Ҷе…¶еә”з”Ё...
ж №жҚ®жҸҗдҫӣзҡ„ж–Ү件дҝЎжҒҜпјҢиҜҘж–ҮжЎЈиҜҰз»ҶжҸҸиҝ°дәҶеҰӮдҪ•дҪҝз”ЁMapReduceжЎҶжһ¶жқҘе®һзҺ°TF-IDFпјҲTerm Frequency-Inverse Document Frequencyпјүз®—жі•гҖӮTF-IDFжҳҜдёҖз§Қз»ҹи®Ўж–№жі•пјҢз”ЁдәҺиҜ„дј°дёҖдёӘиҜҚиҜӯеңЁдёҖдёӘж–ҮжЎЈйӣҶеҗҲдёӯзҡ„йҮҚиҰҒжҖ§гҖӮе®ғе№ҝжіӣеә”з”ЁдәҺдҝЎжҒҜ...
еңЁд»Ӣз»ҚTF-IDFз®—жі•д№ӢеүҚпјҢйңҖиҰҒе…ҲдәҶи§ЈдёҖдёӢж–Үжң¬еҲҶзұ»е’Ңз©әй—ҙеҗ‘йҮҸжЁЎеһӢпјҲVSMпјүгҖӮж–Үжң¬еҲҶзұ»жҳҜе°Ҷж–Үжң¬ж•°жҚ®жҢүз…§е…¶еҶ…е®№е’Ңзү№жҖ§еҲҶй…ҚеҲ°дёҖдёӘжҲ–еӨҡдёӘзұ»еҲ«дёӯзҡ„иҝҮзЁӢгҖӮз©әй—ҙеҗ‘йҮҸжЁЎеһӢжҳҜж–Үжң¬иЎЁзӨәзҡ„дёҖз§Қж–№жі•пјҢе®ғйҖҡиҝҮе°Ҷж–ҮжЎЈиЎЁзӨәдёәеҗ‘йҮҸз©әй—ҙдёӯзҡ„зӮ№...