
概述
kubernetes中pods是平凡的,可创建可销毁而且不可再生。 ReplicationControllers可以动态的创建&销毁pods(如扩容 or 缩容 or 更新)。虽然pods有他们单独的ip,但是他们的ip并不能得到稳定的保证,这将会导致一个问题,如果在kubernetes集群中,有一些pods(backends)为另一些pods(frontend)提供一些功能,如何能保证frontend能够找到&链接到backends。
引入Services。
kubernetes services是一个抽象的概念,定义了如何和一组pods相关联—— 有时候叫做“micro-service”。一个service通过Label Selector来筛选出一组pods(下文会说明什么情况下不需要selector)。
举个栗子,设想一个拥有三个节点的图片处理backend,这三个节点都可以随时替代——frontend并不关系链接的是哪一个。即使组成backend的pods发生了变动,frontend也不必关心连接到哪个backend。services将frontend和backend的链接关系解耦。
对于kubernetes本身的应用来说,kubernetes提供了一个简单的endpoint 的api,对于非kubernetes本身的应用,kubernetes为servicet提供了一个解决方案,通过一个设定vip的bridge来链接pods。
定义一个service
在kubernetes中,services和pods一样都是一个REST对象。同其他的REST对象一样,通过POST来创建一个service。比如,有一组pods,每个pod对外暴露9376端口 他们的label为“app=MyApp”:
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"protocol": "TCP",
"port": 80,
"targetPort": 9376
}
]
}
}
上述的json将会做以下事情:创建一个叫“my-service”的service,它映射了label为“app=MyApp”的pods端口9376,这个service将会被分配一个ip(cluster ip),service用这个ip作为代理,service的selector将会一直对pods进行筛选,并将起pods结果放入一个也焦作“my-service”的Endpoints中。
注意,一个service可能将流量引入到任何一个targetPost,默认targetPort字段和port字段是相同的。有趣的是targetPort 也可以是一个string,可以设定为是一组pods所映射port的name。在每个pod中,这个name所对应的真实port都可以不同。这为部署& 升级service带来了很大的灵活性,比如 可以在
kubernetes services支持TCP & UDP协议,默认为tcp。
Services without selectors
kubernetes service通常是链接pods的一个抽象层,但是service也可以作用在其他类型的backend。比如:
- 在生产环境中你想使用一个外部的database集群,在测试环境中使用自己的database;
- 希望将一个service指向另一个namespace中的service 或者 指向另外一个集群;
- 希望将非kubernetes的工作代码环境迁移到kubernetes中;
在以上任意一个情景中,都可以使用到不指定selector的service:
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"ports": [
{
"protocol": "TCP",
"port": 80,
"targetPort": 9376
}
]
}
}
在这个例子中,因为没有使用到selector,因此没有一个明确的Endpoint对象被创建。 因此需要手动的将service映射到对应的endpoint:
{
"kind": "Endpoints",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"subsets": [
{
"addresses": [
{ "IP": "1.2.3.4" }
],
"ports": [
{ "port": 80 }
]
}
]
}
无论有没有selector都不会影响这个service,其router指向了这个endpoint(在本例中为1.2.3.4:80)。
虚IP & service代理(Virtual IPs and service proxies)
kubernetes中的每个node都会运行一个kube-proxy。他为每个service都映射一个本地port,任何连接这个本地port的请求都会转到backend后的随机一个pod,service中的字段SessionAffinity决定了使用backend的哪个pod,最后在本地建立一些iptables规则,这样访问service的cluster ip以及对应的port时,就能将请求映射到后端的pod中。
最终的结果就是,任何对service的请求都能被映射到正确的pod中,而client不需要关心kubernetes、service或pod的其他信息。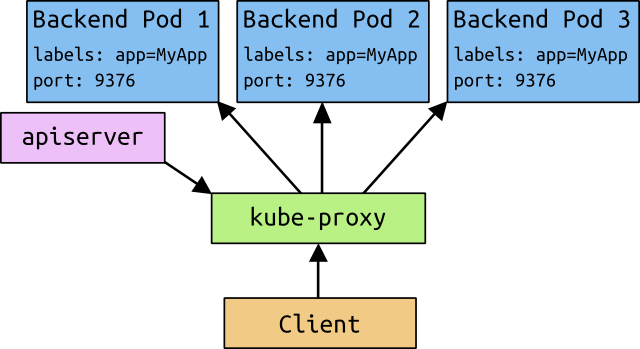
在kubernetes中,service是基于三层(TCP/UDP over IP)的架构,目前还没有提供专门作用于七层(http)的services。
Multi-Port Services
在很多情况下,一个service需要对多个port做映射。下面举个这样的例子,注意,使用multi-port时,必须为每个port设定name,如:
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"name": "http",
"protocol": "TCP",
"port": 80,
"targetPort": 9376
},
{
"name": "https",
"protocol": "TCP",
"port": 443,
"targetPort": 9377
}
]
}
}
Choosing your own IP address
用户可以为service指定自己的cluster ip,通过字段spec.clusterIP来实现。用户设定的ip必须是一个有效的ip,必须符合service_cluster_ip_range 范围,如果ip不合符上述规定,apiserver将会返回422。
Why not use round-robin DNS?
有一个问题会时不时的出现,为什么不用一个DNS轮询来替换vip?有如下几个理由:
- 已经拥有很长历史的DNS库不会太注意DNS TTL 并且会缓存name lookup的结果;
- 许多应用只做一次name lookup并且将结果缓存;
- 即使app和dns库做了很好的解决,client对dns做一遍又一遍的轮询将会增加管理的复杂度;
我们做这些避免用户做哪些作死的行为,但是,如果真有那么多用户要求,我们会提供这样的选择。
Discovering services
对于每个运行的pod,kubelet将为其添加现有service的全局变量,支持Docker links compatible变量 以及 简单的{SVCNAME}_SERVICE_HOST and {SVCNAME}_SERVICE_PORT变量。
比如,叫做”redis-master“的service,对外映射6379端口,已经被分配一个ip,10.0.0.11,那么将会产生如下的全局变量:
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
这意味着一个顺序依赖——service要想被pod使用,必须比pod先建立,否则这些service环境变量不会构建在pod中。DNS没有这些限制。
DNS
一个可选的扩展(强烈建议)是DNS server。DNS server通过kubernetes api server来观测是否有新service建立,并为其建立对应的dns记录。如果集群已经enable DNS,那么pod可以自动对service做name解析。
举个栗子,有个叫做”my-service“的service,他对应的kubernetes namespace为”my-ns“,那么会有他对应的dns记录,叫做”my-service.my-ns“。那么在my-ns的namespace中的pod都可以对my-service做name解析来轻松找到这个service。在其他namespace中的pod解析”my-service.my-ns“来找到他。解析出来的结果是这个service对应的cluster ip。
Headless services
有时候你不想做负载均衡 或者 在意只有一个cluster ip。这时,你可以创建一个”headless“类型的service,将spec.clusterIP字段设置为”None“。对于这样的service,不会为他们分配一个ip,也不会在pod中创建其对应的全局变量。DNS则会为service 的name添加一系列的A记录,直接指向后端映射的pod。此外,kube proxy也不会处理这类service ,没有负载均衡也没有请求映射。endpoint controller则会依然创建对应的endpoint。
这个操作目的是为了用户想减少对kubernetes系统的依赖,比如想自己实现自动发现机制等等。Application可以通过api轻松的结合其他自动发现系统。
External services
对于你应用的某些部分(比如frontend),你可能希望将service开放到公网ip,kubernetes提供两种方式来实现,NodePort and LoadBalancer。
每个service都有个type字段,值可以有以下几种:
- ClusterIP: 使用集群内的私有ip —— 这是默认值。
- NodePort: 除了使用cluster ip外,也将service的port映射到每个node的一个指定内部port上,映射的每个node的内部port都一样。
- LoadBalancer: 使用一个ClusterIP & NodePort,但是会向cloud provider申请映射到service本身的负载均衡。
注意:NodePort支持TCP/UDP,LoadBalancer只支持TCP。
Type = NodePort
如果将type字段设置为NodePort,kubernetes master将会为service的每个对外映射的port分配一个”本地port“,这个本地port作用在每个node上,且必须符合定义在配置文件中的port范围(为--service-node-port-range)。这个被分配的”本地port“定义在service配置中的spec.ports[*].nodePort字段,如果为这个字段设定了一个值,系统将会使用这个值作为分配的本地port 或者 提示你port不符合规范。
这样就方便了开发者使用自己的负载均衡方案。
Type = LoadBalancer
如果在一个cloud provider中部署使用service,将type地段设置为LoadBalancer将会使service使用人家提供的负载均衡。这样会异步的来创建service的负载均衡,在service配置的status.loadBalancer字段中,描述了所使用被提供负载均衡的详细信息,如:
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"protocol": "TCP",
"port": 80,
"targetPort": 9376,
"nodePort": 30061
}
],
"clusterIP": "10.0.171.239",
"type": "LoadBalancer"
},
"status": {
"loadBalancer": {
"ingress": [
{
"ip": "146.148.47.155"
}
]
}
}
}
这样外部的负载均衡方案将会直接作用在后端的pod上。
Shortcomings
通过iptables和用户控件映射可以很好的为中小型规模服务,但是并不适用于拥有数千个service的集群。详情请看” the original design proposal for portals“。
使用kube-proxy不太可能看到访问的源ip,这样使得某些类型防火墙实效。
LoadBalancers 只支持TCP.
type字段被设计成嵌套的结构,每一层都被增加到了前一层。很多云方案提供商支持的并不是很好(如,gce没有必要分配一个NodePort来使LoadBalancer正常工作,但是AWS需要),但是当前的API需要。
Future work
The gory details of virtual IPs
以上的信息应该足够用户来使用service。但是还是有许多东西值得大家来深入理解。 (懒得翻了,大家自己看吧,最后贴上最后一个图)
Avoiding collisions
IPs and VIPs
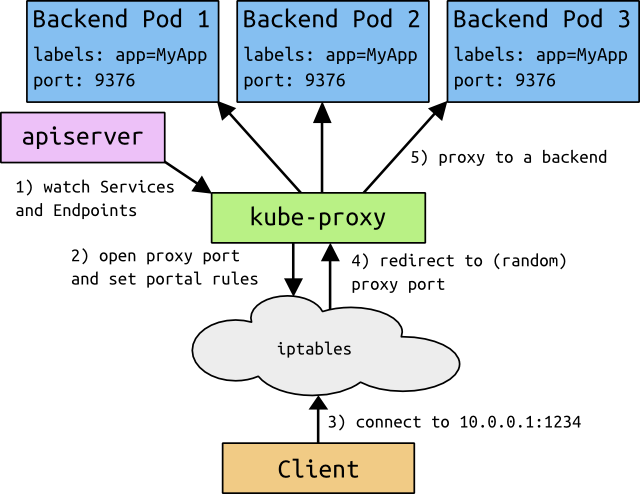
https://segmentfault.com/a/1190000002892825



相关推荐
在K8S中部署Blackbox Exporter通常涉及创建一个Deployment和一个Service。Deployment定义了Blackbox Exporter的Pod规格,包括使用的镜像、端口暴露等信息;Service则用来让集群内部其他组件可以访问Blackbox ...
三、部署Prometheus in k8s 1. 准备资源 在部署Prometheus前,我们需要准备以下资源: - Prometheus的yaml配置文件:定义了Prometheus服务器、服务发现、目标规则等。 - Alertmanager的yaml配置文件(可选):如果...
《Kubernetes in Action》是关于Kubernetes(简称K8s)的权威学习教程,它针对的是K8s的新版本,因此对于想要深入了解和掌握最新Kubernetes技术的人来说,是一本不可多得的指南。Kubernetes是一种开源容器编排系统,...
网盘文件永久链接 目录 1.Kubernetes-组件个招ra量 2.Kubernetes-基础念.at 3.Kubernetes-集群安装at 4.Kubernetes-室源清单rar 5、Kubernetes-资源控器at ...12.Kubernetes-高可用的K8S集群构建rar
k8s 上部署高可用的 service mesh 监控 Old-school monitoring Solving issues in a new way Monitoring your service mesh
2. **K8S 重新初始化Master节点**:文件"K8S 重新初始化master节点(初始化master节点报错Port 6443 is in use).docx"可能涉及在遇到特定错误,如端口冲突时,如何正确地重新初始化Master节点,确保所有服务能够正常...
### CentOS 7.5 安装 K8S v1.11.0 集群部署 #### 一、概述 随着容器技术的发展,越来越多的企业选择使用容器化部署应用程序以提高资源利用率和应用的可移植性。Kubernetes(简称 K8S)作为目前最流行的容器编排...
而Kubernetes(简称k8s)则是一个领先的容器编排系统,用于自动化容器化应用程序的部署、扩展和管理。本教程将详细介绍如何使用Ansible来安装和配置Kubernetes集群,版本为1.25。 首先,我们需要确保所有服务器节点...
K8S CKS 1.24 EXAM 练习备考必备 Kubernetes Security Specialist certification is a highly respected certification in the field of container orchestration and cloud computing. This certification aims to...
本篇文章将深入探讨如何使用Python脚本来自动生成K8S的YAML文件,以`service.yaml`和`deployment.yaml`为例。 ### 1. 生成`service.yaml` #### 1.1 YAML转JSON 首先,我们需要一个基础的`service.yaml`模板,它...
源码包"k8s-msa-in-action.zip"包含了该课程的所有实例代码和相关资源,帮助学习者通过实践理解Kubernetes在微服务场景中的应用。 在Kubernetes中,微服务实践涉及到多个关键知识点: 1. **Kubernetes基本概念**:...
readinessProbe: 指示容器是否准备好服务请求。如果就绪探针失败,端点控制器将从...[root@k8s-master01 k8s-test]# cat readiness.yaml apiVersion: v1 kind: Pod metadata: name: readiness-httpget-pod namespace
在IT行业中,Kubernetes(简称K8s)是目前最流行的容器编排系统,用于自动化容器化应用的部署、扩展和管理。而Ansible则是一款强大的自动化工具,它通过简单的YAML语法,使得配置管理、应用部署和任务执行等工作变得...
"docker_pdf.rar"这个压缩包显然包含了与k8s全栈(all-in-one)集群安装、管理和问题解决相关的资料。以下是基于这些文件名所推测出的知识点详细解析: 1. **Kubernetes全栈集群安装**:k8s allinone指的是在单个...
Kubernetes(简称K8s)是由Google开源的项目,旨在自动化容器化应用程序的部署、扩展和管理,现已成为云原生计算领域的核心组件。 这本书详细介绍了Kubernetes的基础概念和架构,包括Pod、Service、Deployment、...
在构建 Kubernetes (K8s) 云平台的过程中,etcd 是一个至关重要的组件。etcd 是一个分布式的、一致性的键值存储系统,用于共享配置和服务发现,它为 Kubernetes 提供了数据持久化和一致性保证。在本篇内容中,我们将...
Kubernetes的部署模式包括IaaS(Infrastructure-as-a-Service)、PaaS(Platform-as-a-Service)和SaaS(Software-as-a-Service)。IaaS如Amazon Web Services的EC2和S3提供了底层的云基础设施;PaaS如Google App ...
《Kubernetes in Action》这本书是深入理解并掌握Kubernetes(K8s)这一现代容器编排系统的宝贵资源。Kubernetes,通常简称为K8s,是Google开源的一个用于自动化容器化应用部署、扩展和管理的平台,它已经成为云计算...