
ن¸€م€پ简ن»‹
آ آ آ آ آ ELK ç”±ن¸‰éƒ¨هˆ†ç»„وˆگelasticsearchم€پlogstashم€پkibana,elasticsearchوک¯ن¸€ن¸ھè؟‘ن¼¼ه®و—¶çڑ„وگœç´¢ه¹³هڈ°,ه®ƒè®©ن½ ن»¥ه‰چو‰€وœھوœ‰çڑ„é€ںه؛¦ه¤„çگ†ه¤§و•°وچ®وˆگن¸؛هڈ¯èƒ½م€‚
آ آ آ آ آ Elasticsearchو‰€و¶‰هڈٹهˆ°çڑ„و¯ڈن¸€é،¹وٹ€وœ¯éƒ½ن¸چوک¯هˆ›و–°وˆ–者é©ه‘½و€§çڑ„,ه…¨و–‡وگœç´¢ï¼Œهˆ†وگç³»ç»ںن»¥هڈٹهˆ†ه¸ƒه¼ڈو•°وچ®ه؛“è؟™ن؛›و—©ه°±ه·²ç»ڈهکهœ¨ن؛†م€‚ه®ƒçڑ„é©ه‘½و€§هœ¨ن؛ژه°†è؟™ن؛›ç‹¬ç«‹ن¸”وœ‰ç”¨çڑ„وٹ€وœ¯و•´هگˆوˆگن¸€ن¸ھن¸€ن½“هŒ–çڑ„م€په®و—¶çڑ„ه؛”用م€‚Elasticsearchوک¯é¢هگ‘و–‡و،£(document oriented)çڑ„,è؟™و„ڈه‘³ç€ه®ƒهڈ¯ن»¥هکه‚¨و•´ن¸ھه¯¹è±،وˆ–و–‡و،£(document)م€‚然而ه®ƒن¸چن»…ن»…وک¯هکه‚¨ï¼Œè؟کن¼ڑç´¢ه¼•(index)و¯ڈن¸ھو–‡و،£çڑ„ه†…ه®¹ن½؟ن¹‹هڈ¯ن»¥è¢«وگœç´¢م€‚هœ¨Elasticsearchن¸ï¼Œن½ هڈ¯ن»¥ه¯¹و–‡و،£ï¼ˆè€Œéوˆگè،Œوˆگهˆ—çڑ„و•°وچ®ï¼‰è؟›è،Œç´¢ه¼•م€پوگœç´¢م€پوژ’ه؛ڈم€پè؟‡و»¤م€‚è؟™ç§چçگ†è§£و•°وچ®çڑ„و–¹ه¼ڈن¸ژن»¥ه¾€ه®Œه…¨ن¸چهگŒï¼Œè؟™ن¹ںوک¯Elasticsearch能ه¤ںو‰§è،Œه¤چو‚çڑ„ه…¨و–‡وگœç´¢çڑ„هژںه› ن¹‹ن¸€م€‚
آ آ آ آ آ آ ه؛”用程ه؛ڈçڑ„و—¥ه؟—ه¤§éƒ¨هˆ†éƒ½وک¯è¾“ه‡؛هœ¨وœچهٹ،ه™¨çڑ„و—¥ه؟—و–‡ن»¶ن¸ï¼Œè؟™ن؛›و—¥ه؟—ه¤§ه¤ڑو•°éƒ½وک¯ه¼€هڈ‘ن؛؛ه‘کو¥çœ‹ï¼Œç„¶هگژه¼€هڈ‘هچ´و²،وœ‰ç™»é™†وœچهٹ،ه™¨çڑ„وƒé™گ,ه¦‚وœه¼€هڈ‘ن؛؛ه‘ک需è¦پوں¥çœ‹و—¥ه؟—ه°±éœ€è¦پهˆ°وœچهٹ،ه™¨و¥و‹؟و—¥ه؟—,然هگژن؛¤ç»™ه¼€هڈ‘;试وƒ³ن¸‹ï¼Œن¸€ن¸ھه…¬هڈ¸وœ‰10ن¸ھه¼€هڈ‘,ن¸€ن¸ھه¼€هڈ‘و¯ڈه¤©و‰¾è؟گç»´و‹؟ن¸€و¬،و—¥ه؟—,ه¯¹è؟گç»´ن؛؛ه‘کو¥è¯´ه°±وک¯ن¸€ن¸ھن¸چه°ڈçڑ„ه·¥ن½œé‡ڈ,è؟™و ·ه¤§ه¤§ه½±ه“چن؛†è؟گç»´çڑ„ه·¥ن½œو•ˆçژ‡ï¼Œéƒ¨ç½²ELKstackن¹‹هگژ,ه¼€هڈ‘ن»»و„ڈه°±هڈ¯ن»¥ç›´وژ¥ç™»é™†هˆ°Kibanaن¸è؟›è،Œو—¥ه؟—çڑ„وں¥çœ‹ï¼Œه°±ن¸چ需è¦پé€ڑè؟‡è؟گç»´وں¥çœ‹و—¥ه؟—,è؟™و ·ه°±ه‡ڈè½»ن؛†è؟گç»´çڑ„ه·¥ن½œم€‚
آ آ آ آ آ و—¥ه؟—ç§چç±»ه¤ڑ,ن¸”هˆ†و•£هœ¨ن¸چهگŒçڑ„ن½چç½®éڑ¾ن»¥وں¥و‰¾ï¼ڑه¦‚LAMP/LNMP网站ه‡؛çژ°è®؟é—®و•…éڑœï¼Œè؟™ن¸ھو—¶ه€™هڈ¯èƒ½ه°±éœ€è¦پé€ڑè؟‡وں¥è¯¢و—¥ه؟—و¥è؟›è،Œهˆ†وگو•…éڑœهژںه› ,ه¦‚وœéœ€è¦پوں¥çœ‹apacheçڑ„错误و—¥ه؟—,ه°±éœ€è¦پ登陆هˆ°Apacheوœچهٹ،ه™¨وں¥çœ‹ï¼Œه¦‚وœوں¥çœ‹و•°وچ®ه؛“错误و—¥ه؟—ه°±éœ€è¦پ登陆هˆ°و•°وچ®ه؛“وں¥è¯¢ï¼Œè¯•وƒ³ن¸€ن¸‹ï¼Œه¦‚وœوک¯ن¸€ن¸ھ集群çژ¯ه¢ƒه‡ هچپهڈ°ن¸»وœ؛ه‘¢ï¼ںè؟™و—¶ه¦‚وœéƒ¨ç½²ن؛†ELKstackه°±هڈ¯ن»¥ç™»é™†هˆ°Kibanaé،µé¢è؟›è،Œوں¥çœ‹و—¥ه؟—,وں¥çœ‹ن¸چهگŒç±»ه‹çڑ„و—¥ه؟—هڈھ需è¦پ电هٹ¨é¼ و ‡هˆ‡وچ¢ن¸€ن¸‹ç´¢ه¼•هچ³هڈ¯م€‚
Logstashï¼ڑو—¥ه؟—و”¶é›†ه·¥ه…·ï¼Œهڈ¯ن»¥ن»ژوœ¬هœ°ç£پç›ک,网络وœچهٹ،(è‡ھه·±ç›‘هگ¬ç«¯هڈ£ï¼Œوژ¥هڈ—用وˆ·و—¥ه؟—),و¶ˆوپ¯éکںهˆ—ن¸و”¶é›†هگ„ç§چهگ„و ·çڑ„و—¥ه؟—,然هگژè؟›è،Œè؟‡و»¤هˆ†وگ,ه¹¶ه°†و—¥ه؟—输ه‡؛هˆ°Elasticsearchن¸م€‚
Elasticsearchï¼ڑو—¥ه؟—هˆ†ه¸ƒه¼ڈهکه‚¨/وگœç´¢ه·¥ه…·ï¼Œهژںç”ںو”¯وŒپ集群هٹں能,هڈ¯ن»¥ه°†وŒ‡ه®ڑو—¶é—´çڑ„و—¥ه؟—ç”ںوˆگن¸€ن¸ھç´¢ه¼•ï¼Œهٹ ه؟«و—¥ه؟—وں¥è¯¢ه’Œè®؟é—®م€‚
Kibanaï¼ڑهڈ¯è§†هŒ–و—¥ه؟—Webه±•ç¤؛ه·¥ه…·ï¼Œه¯¹Elasticsearchن¸هکه‚¨çڑ„و—¥ه؟—è؟›è،Œه±•ç¤؛,è؟کهڈ¯ن»¥ç”ںوˆگç‚«ن¸½çڑ„ن»ھè،¨ç›کم€‚
آ
ن؛Œم€په®‰è£…部署(ه› ن¸؛وˆ‘وک¯وµ‹è¯•çژ¯ه¢ƒï¼Œه°±ه°†ElasticSearch+Logstash+ Kibana装هœ¨ن¸€هڈ°è™ڑو‹ںوœ؛ن¸ٹé¢ن؛†)
ه®‰è£…jdk
rpm -ivh jdk-8u92-linux-x64.rpm
vi /etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_92/
source /etc/profile
echo $JAVA_HOMEآ آ آ
/usr/java/jdk1.8.0_92/
java -version
java version "1.8.0_92"
Java(TM) SE Runtime Environment (build 1.8.0_92-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.92-b14, mixed mode)
ه®‰è£…elasticsearch
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
و·»هٹ yumو–‡ن»¶
echo "
[elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=http://packages.elastic.co/elasticsearch/2.x/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1" >> /etc/yum.repos.d/elasticsearch.repo
yum install elasticsearch -y
mkdir /data/elk/{data,logs}
Type آ آ آ آ آ آ آ آ آ آ Description آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ Location
home آ آ آ آ elasticsearchه®‰è£…çڑ„ç›®ه½• آ آ آ آ آ آ آ آ آ آ {extract.path}
bin آ آ آ آ آ آ آ آ elasticsearchن؛Œè؟›هˆ¶è„ڑوœ¬ç›®ه½• آ آ آ آ {extract.path}/bin
conf آ آ آ آ آ آ آ آ é…چç½®و–‡ن»¶ç›®ه½• آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ {extract.path}/config
dataآ آ آ آ آ آ آ آ آ آ و•°وچ®ç›®ه½• آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ {extract.path}/data
logs آ آ آ آ آ آ آ آ آ و—¥ه؟—ç›®ه½•آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ {extract.path}/logs
plugins آ آ آ آ وڈ’ن»¶ç›®ه½•آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ {extract.path}/plugin
é…چ置说وکژï¼ڑ
vi /etc/elasticsearch/elasticsearch.yml
cluster.name: es
path.data: /data/elk/data
path.logs: /data/elk/logs
bootstrap.mlockall: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.2.215", "host2"]
هگ¯هٹ¨ï¼ڑ
/etc/init.d/elasticsearch start
elasticsearchçڑ„configو–‡ن»¶ه¤¹é‡Œé¢وœ‰ن¸¤ن¸ھé…چç½®و–‡ن»¶ï¼ڑelasticsearch.ymlه’Œlogging.yml,
第ن¸€ن¸ھوک¯esçڑ„هں؛وœ¬é…چç½®و–‡ن»¶ï¼Œç¬¬ن؛Œن¸ھوک¯و—¥ه؟—é…چç½®و–‡ن»¶ï¼Œesن¹ںوک¯ن½؟用log4jو¥è®°ه½•و—¥ه؟—çڑ„,و‰€ن»¥logging.yml里çڑ„设置وŒ‰و™®é€ڑlog4jé…چç½®و–‡ن»¶و¥è®¾ç½®ه°±è،Œن؛†م€‚ن¸‹é¢ن¸»è¦پ讲解ن¸‹elasticsearch.ymlè؟™ن¸ھو–‡ن»¶ن¸هڈ¯é…چç½®çڑ„ن¸œè¥؟م€‚
cluster.name:elasticsearch
é…چç½®esçڑ„集群هگچ称,é»ک认وک¯elasticsearch,esن¼ڑè‡ھهٹ¨هڈ‘çژ°هœ¨هگŒن¸€ç½‘و®µن¸‹çڑ„es,ه¦‚وœهœ¨هگŒن¸€ç½‘و®µن¸‹وœ‰ه¤ڑن¸ھ集群,ه°±هڈ¯ن»¥ç”¨è؟™ن¸ھه±و€§و¥هŒ؛هˆ†ن¸چهگŒçڑ„集群م€‚
node.name:â€FranzKafkaâ€
èٹ‚点هگچ,é»ک认éڑڈوœ؛وŒ‡ه®ڑن¸€ن¸ھnameهˆ—è،¨ن¸هگچه—,该هˆ—è،¨هœ¨esçڑ„jarهŒ…ن¸configو–‡ن»¶ه¤¹é‡Œname.txtو–‡ن»¶ن¸ï¼Œه…¶ن¸وœ‰ه¾ˆه¤ڑن½œè€…و·»هٹ çڑ„وœ‰è¶£هگچه—م€‚
node.master:true
وŒ‡ه®ڑ该èٹ‚点وک¯هگ¦وœ‰èµ„و ¼è¢«é€‰ن¸¾وˆگن¸؛node,é»ک认وک¯true,esوک¯é»ک认集群ن¸çڑ„第ن¸€هڈ°وœ؛ه™¨ن¸؛master,ه¦‚وœè؟™هڈ°وœ؛وŒ‚ن؛†ه°±ن¼ڑé‡چو–°é€‰ن¸¾masterم€‚
node.data:true
وŒ‡ه®ڑ该èٹ‚点وک¯هگ¦هکه‚¨ç´¢ه¼•و•°وچ®ï¼Œé»ک认ن¸؛trueم€‚
index.number_of_shards:5
设置é»ک认索ه¼•هˆ†ç‰‡ن¸ھو•°ï¼Œé»ک认ن¸؛5片م€‚
index.number_of_replicas:1
设置é»ک认索ه¼•ه‰¯وœ¬ن¸ھو•°ï¼Œé»ک认ن¸؛1ن¸ھه‰¯وœ¬م€‚
path.conf:/path/to/conf
设置é…چç½®و–‡ن»¶çڑ„هکه‚¨è·¯ه¾„,é»ک认وک¯esو ¹ç›®ه½•ن¸‹çڑ„configو–‡ن»¶ه¤¹م€‚
path.data:/path/to/data
设置索ه¼•و•°وچ®çڑ„هکه‚¨è·¯ه¾„,é»ک认وک¯esو ¹ç›®ه½•ن¸‹çڑ„dataو–‡ن»¶ه¤¹ï¼Œهڈ¯ن»¥è®¾ç½®ه¤ڑن¸ھهکه‚¨è·¯ه¾„,用逗هڈ·éڑ”ه¼€ï¼Œن¾‹ï¼ڑ
path.data:/path/to/data1,/path/to/data2
path.work:/path/to/work
设置ن¸´و—¶و–‡ن»¶çڑ„هکه‚¨è·¯ه¾„,é»ک认وک¯esو ¹ç›®ه½•ن¸‹çڑ„workو–‡ن»¶ه¤¹م€‚
path.logs:/path/to/logs
设置و—¥ه؟—و–‡ن»¶çڑ„هکه‚¨è·¯ه¾„,é»ک认وک¯esو ¹ç›®ه½•ن¸‹çڑ„logsو–‡ن»¶ه¤¹
path.plugins:/path/to/plugins
设置وڈ’ن»¶çڑ„هکو”¾è·¯ه¾„,é»ک认وک¯esو ¹ç›®ه½•ن¸‹çڑ„pluginsو–‡ن»¶ه¤¹
bootstrap.mlockall:true
设置ن¸؛trueو¥é”پن½ڈه†…هکم€‚ه› ن¸؛ه½“jvmه¼€ه§‹swappingو—¶esçڑ„و•ˆçژ‡ن¼ڑé™چن½ژ,و‰€ن»¥è¦پن؟è¯په®ƒن¸چswap,هڈ¯ن»¥وٹٹES_MIN_MEMه’ŒES_MAX_MEMن¸¤ن¸ھçژ¯ه¢ƒهڈکé‡ڈ设置وˆگهگŒن¸€ن¸ھه€¼ï¼Œه¹¶ن¸”ن؟è¯پوœ؛ه™¨وœ‰è¶³ه¤ںçڑ„ه†…هکهˆ†é…چç»™esم€‚هگŒو—¶ن¹ںè¦په…پ许elasticsearchçڑ„è؟›ç¨‹هڈ¯ن»¥é”پن½ڈه†…هک,linuxن¸‹هڈ¯ن»¥é€ڑè؟‡`ulimit-lunlimited`ه‘½ن»¤م€‚
network.bind_host:192.168.0.1
设置绑ه®ڑçڑ„ipهœ°ه€ï¼Œهڈ¯ن»¥وک¯ipv4وˆ–ipv6çڑ„,é»ک认ن¸؛0.0.0.0م€‚network.publish_host:192.168.0.1
设置ه…¶ه®ƒèٹ‚点ه’Œè¯¥èٹ‚点ن؛¤ن؛’çڑ„ipهœ°ه€ï¼Œه¦‚وœن¸چ设置ه®ƒن¼ڑè‡ھهٹ¨هˆ¤و–,ه€¼ه؟…é،»وک¯ن¸ھçœںه®çڑ„ipهœ°ه€م€‚
network.host:192.168.0.1
è؟™ن¸ھهڈ‚و•°وک¯ç”¨و¥هگŒو—¶è®¾ç½®bind_hostه’Œpublish_hostن¸ٹé¢ن¸¤ن¸ھهڈ‚و•°م€‚
transport.tcp.port:9300
设置èٹ‚点间ن؛¤ن؛’çڑ„tcp端هڈ£ï¼Œé»ک认وک¯9300م€‚
transport.tcp.compress:true
设置وک¯هگ¦هژ‹ç¼©tcpن¼ 输و—¶çڑ„و•°وچ®ï¼Œé»ک认ن¸؛false,ن¸چهژ‹ç¼©م€‚
http.port:9200
设置ه¯¹ه¤–وœچهٹ،çڑ„http端هڈ£ï¼Œé»ک认ن¸؛9200م€‚
http.max_content_length:100mb
设置ه†…ه®¹çڑ„وœ€ه¤§ه®¹é‡ڈ,é»ک认100mb
http.enabled:false
وک¯هگ¦ن½؟用httpهچڈè®®ه¯¹ه¤–وڈگن¾›وœچهٹ،,é»ک认ن¸؛true,ه¼€هگ¯م€‚
gateway.type:local
gatewayçڑ„ç±»ه‹ï¼Œé»ک认ن¸؛localهچ³ن¸؛وœ¬هœ°و–‡ن»¶ç³»ç»ں,هڈ¯ن»¥è®¾ç½®ن¸؛وœ¬هœ°و–‡ن»¶ç³»ç»ں,هˆ†ه¸ƒه¼ڈو–‡ن»¶ç³»ç»ں,hadoopçڑ„HDFS,ه’Œamazonçڑ„s3وœچهٹ،ه™¨ï¼Œه…¶ه®ƒو–‡ن»¶ç³»ç»ںçڑ„设置و–¹و³•ن¸‹و¬،ه†چ详细说م€‚
gateway.recover_after_nodes:1
设置集群ن¸Nن¸ھèٹ‚点هگ¯هٹ¨و—¶è؟›è،Œو•°وچ®وپ¢ه¤چ,é»ک认ن¸؛1م€‚
gateway.recover_after_time:5m
设置هˆه§‹هŒ–و•°وچ®وپ¢ه¤چè؟›ç¨‹çڑ„超و—¶و—¶é—´ï¼Œé»ک认وک¯5هˆ†é’ںم€‚
gateway.expected_nodes:2
设置è؟™ن¸ھ集群ن¸èٹ‚点çڑ„و•°é‡ڈ,é»ک认ن¸؛2,ن¸€و—¦è؟™Nن¸ھèٹ‚点هگ¯هٹ¨ï¼Œه°±ن¼ڑç«‹هچ³è؟›è،Œو•°وچ®وپ¢ه¤چم€‚
cluster.routing.allocation.node_initial_primaries_recoveries:4
هˆه§‹هŒ–و•°وچ®وپ¢ه¤چو—¶ï¼Œه¹¶هڈ‘وپ¢ه¤چç؛؟程çڑ„ن¸ھو•°ï¼Œé»ک认ن¸؛4م€‚
cluster.routing.allocation.node_concurrent_recoveries:2
و·»هٹ هˆ 除èٹ‚点وˆ–è´ںè½½ه‡è،،و—¶ه¹¶هڈ‘وپ¢ه¤چç؛؟程çڑ„ن¸ھو•°ï¼Œé»ک认ن¸؛4م€‚
indices.recovery.max_size_per_sec:0
设置و•°وچ®وپ¢ه¤چو—¶é™گهˆ¶çڑ„ه¸¦ه®½ï¼Œه¦‚ه…¥100mb,é»ک认ن¸؛0,هچ³و— é™گهˆ¶م€‚
indices.recovery.concurrent_streams:5
设置è؟™ن¸ھهڈ‚و•°و¥é™گهˆ¶ن»ژه…¶ه®ƒهˆ†ç‰‡وپ¢ه¤چو•°وچ®و—¶وœ€ه¤§هگŒو—¶و‰“ه¼€ه¹¶هڈ‘وµپçڑ„ن¸ھو•°ï¼Œé»ک认ن¸؛5م€‚
discovery.zen.minimum_master_nodes:1
设置è؟™ن¸ھهڈ‚و•°و¥ن؟è¯پ集群ن¸çڑ„èٹ‚点هڈ¯ن»¥çں¥éپ“ه…¶ه®ƒNن¸ھوœ‰master资و ¼çڑ„èٹ‚点م€‚é»ک认ن¸؛1,ه¯¹ن؛ژه¤§çڑ„集群و¥è¯´ï¼Œهڈ¯ن»¥è®¾ç½®ه¤§ن¸€ç‚¹çڑ„ه€¼ï¼ˆ2-4)
discovery.zen.ping.timeout:3s
设置集群ن¸è‡ھهٹ¨هڈ‘çژ°ه…¶ه®ƒèٹ‚点و—¶pingè؟وژ¥è¶…و—¶و—¶é—´ï¼Œé»ک认ن¸؛3秒,ه¯¹ن؛ژو¯”较ه·®çڑ„网络çژ¯ه¢ƒهڈ¯ن»¥é«ک点çڑ„ه€¼و¥éک²و¢è‡ھهٹ¨هڈ‘çژ°و—¶ه‡؛é”™م€‚
discovery.zen.ping.multicast.enabled:false
设置وک¯هگ¦و‰“ه¼€ه¤ڑو’هڈ‘çژ°èٹ‚点,é»ک认وک¯trueم€‚
discovery.zen.ping.unicast.hosts:[“host1″,â€host2:portâ€,â€host3[portX-portY]â€]
设置集群ن¸masterèٹ‚点çڑ„هˆه§‹هˆ—è،¨ï¼Œهڈ¯ن»¥é€ڑè؟‡è؟™ن؛›èٹ‚点و¥è‡ھهٹ¨هڈ‘çژ°و–°هٹ ه…¥é›†ç¾¤çڑ„èٹ‚点
ه®‰è£…headوڈ’ن»¶ï¼ˆé›†ç¾¤ç®،çگ†وڈ’ن»¶ï¼‰
cd /usr/share/elasticsearch/bin/
./plugin install mobz/elasticsearch-head
ll /usr/share/elasticsearch/plugins/head
http://192.168.2.215:9200/_plugin/head/
ه®‰è£…kopfوڈ’ن»¶ï¼ˆé›†ç¾¤èµ„و؛گوں¥çœ‹ه’Œوں¥è¯¢وڈ’ن»¶ï¼‰
/usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopf
http://192.168.2.215:9200/_plugin/kopf
هگ¯هٹ¨elasticearch
/etc/init.d/elasticsearch start
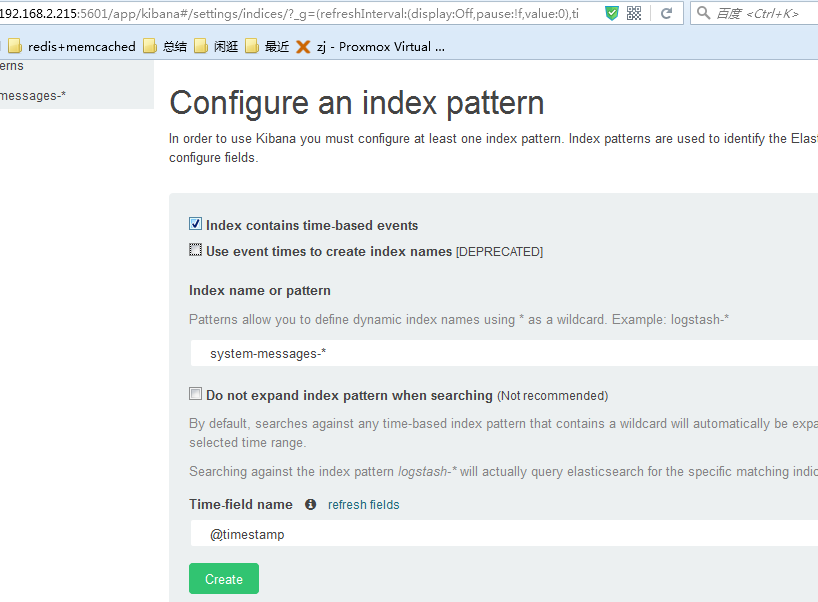
ه®‰è£…kibana
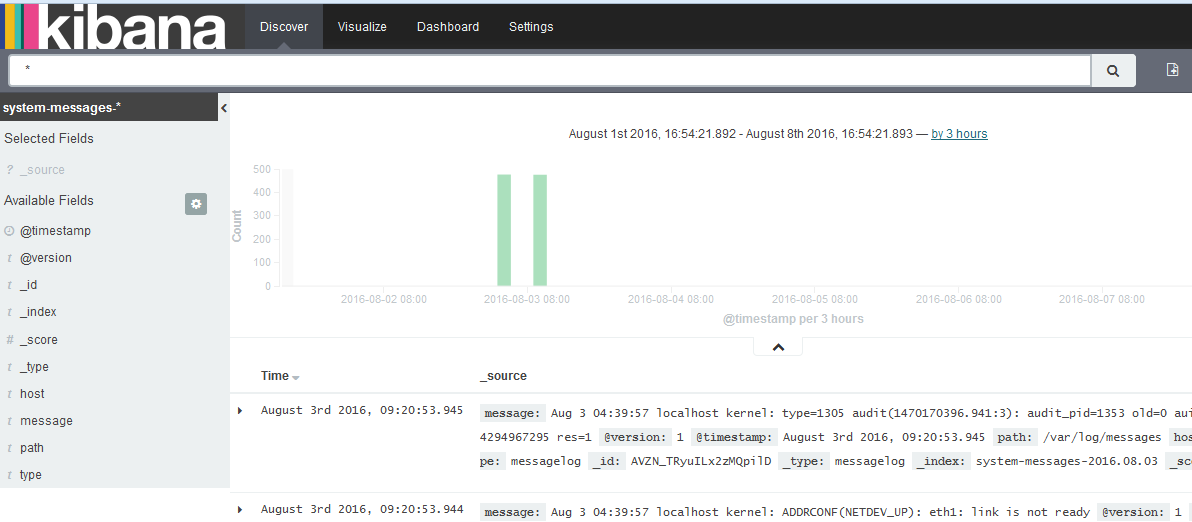
kibanaوœ¬è´¨ن¸ٹوک¯elasticsearch webه®¢وˆ·ç«¯ï¼Œوک¯ن¸€ن¸ھهˆ†وگه’Œهڈ¯è§†هŒ–elasticsearchه¹³هڈ°ï¼Œهڈ¯é€ڑè؟‡kibanaوگœç´¢م€پوں¥çœ‹ه’Œن¸ژهکه‚¨هœ¨elasticsearchçڑ„ç´¢ه¼•è؟›è،Œن؛¤ن؛’م€‚هڈ¯ن»¥ه¾ˆو–¹ن¾؟çڑ„و‰§è،Œه…ˆè؟›çڑ„و•°وچ®هˆ†وگه’Œهڈ¯è§†هŒ–ه¤ڑç§چو ¼ه¼ڈçڑ„و•°وچ®ï¼Œه¦‚ه›¾è،¨م€پè،¨و ¼م€پهœ°ه›¾ç‰م€‚
Discoveré،µé¢:ن؛¤ن؛’ه¼ڈçڑ„وµڈ览و•°وچ®م€‚هڈ¯ن»¥è®؟é—®و‰€هŒ¹é…چçڑ„ç´¢ه¼•و¨،ه¼ڈçڑ„و¯ڈن¸ھç´¢ه¼•çڑ„و¯ڈن¸ھو–‡و،£م€‚هڈ¯ن»¥وڈگن؛¤وگœç´¢وں¥è¯¢ï¼Œè؟‡و»¤وگœç´¢ç»“وœه’Œوں¥çœ‹و–‡و،£و•°وچ®م€‚è؟کهڈ¯ن»¥وگœç´¢وں¥è¯¢هŒ¹é…چçڑ„و–‡و،£و•°وچ®ه’Œه—و®µه€¼çڑ„ç»ںè®،و•°وچ®م€‚è؟کهڈ¯ن»¥é€‰ه®ڑو—¶é—´ن»¥هڈٹهˆ·و–°é¢‘çژ‡
https://download.elastic.co/kibana/kibana/kibana-4.5.1-linux-x64.tar.gz
tar zxvf kibana-4.5.1-linux-x64.tar.gz
mv kibana-4.5.1-linux-x64 /usr/local/
vi /etc/rc.local
/usr/local/kibana-4.5.1-linux-x64/bin/kibana > /var/log/kibana.log 2>&1 &
vi /usr/local/kibana-4.5.1-linux-x64/config/kibana.yml
server.port: 5601
server.host: "192.168.2.215"
elasticsearch.url: "http://192.168.2.215:9200"
ه°†nginxو—¥ه؟—转وچ¢وˆگjson
vim /usr/local/nginx/conf/nginx.conf
log_format access1 '{"@timestamp":"$time_iso8601",'
آ آ آ آ آ آ آ '"host":"$server_addr",'
آ آ آ آ آ آ آ '"clientip":"$remote_addr",'
آ آ آ آ آ آ آ '"size":$body_bytes_sent,'
آ آ آ آ آ آ آ '"responsetime":$request_time,'
آ آ آ آ آ آ آ '"upstreamtime":"$upstream_response_time",'
آ آ آ آ آ آ آ '"upstreamhost":"$upstream_addr",'
آ آ آ آ آ آ آ '"http_host":"$host",'
آ آ آ آ آ آ آ '"url":"$uri",'
آ آ آ آ آ آ آ '"domain":"$host",'
آ آ آ آ آ آ آ '"xff":"$http_x_forwarded_for",'
آ آ آ آ آ آ آ '"referer":"$http_referer",'
آ آ آ آ آ آ آ '"status":"$status"}';
آ آ آ access_logآ /var/log/nginx/access.logآ access1;
é‡چو–°è½½ه…¥nginx
/usr/local/nginx/sbin/nginx -s reload
ه®‰è£…logstash
هœ¨logstashن¸ï¼ŒهŒ…و‹¬ن؛†ن¸‰ن¸ھéک¶و®µ:
输ه…¥input --> ه¤„çگ†filter(ن¸چوک¯ه؟…é،»çڑ„) --> 输ه‡؛output
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
echo "
[logstash-2.1]
name=Logstash repository for 2.1.x packages
baseurl=http://packages.elastic.co/logstash/2.1/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1" >> /etc/yum.repos.d/logstash.repo
yum install logstash -y
é€ڑè؟‡é…چç½®éھŒè¯پLogstashçڑ„输ه…¥ه’Œè¾“ه‡؛
vim /etc/logstash/conf.d/stdout.conf
input {
آ آ آ آ آ آ آ stdin {}
}
output {
آ آ آ آ آ آ آ stdout {
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ codec => "rubydebug"
آ آ آ آ آ آ آ }
}
vim /etc/logstash/conf.d/logstash.conf
input {
آ آ آ آ آ آ آ stdin {}
}
input {
آ آ آ آ آ آ آ stdin {}
آ }
output {
آ آ آ آ آ آ آ elasticsearch {
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ hosts => ["192.168.2.215:9200"]
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ index => "test"
آ آ آ آ آ آ آ }
}
http://192.168.2.215:9200/_plugin/head/
vim /etc/logstash/conf.d/logstash.conf
output {
آ آ آ آ آ آ آ elasticsearch {
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ hosts => ["192.168.2.215:9200"]
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ index => "test"
آ آ آ آ آ آ آ }
input {
آ آ آ آ آ آ آ file {
آ آ آ آ آ آ آ آ آ type => "messagelog"
آ آ آ آ آ آ آ آ آ path => "/var/log/messages"
آ آ آ آ آ آ آ آ آ start_position => "beginning"
آ آ آ آ آ آ آ }
}
output {
آ آ آ آ آ آ آ file {
آ آ آ آ آ آ آ آ آ path => "/tmp/123.txt"
آ آ آ آ آ آ آ }
آ آ آ آ آ آ آ elasticsearch {
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ hosts => ["192.168.2.215:9200"]
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ index => "system-messages-%{+yyyy.MM.dd}"
آ آ آ آ آ آ آ }
}
و£€وں¥é…چç½®و–‡ن»¶è¯و³•
/etc/init.d/logstash configtest
vim /etc/init.d/logstash
LS_USER=root
LS_GROUP=root



相ه…³وژ¨èچگ
هں؛ن؛ژdocker-composeو„ه»؛filebeat + Logstash +Elasticsearch+ kibanaو—¥ه؟—ç³»ç»ں ه¯¹nginxو—¥ه؟—è؟›è،Œو£هˆ™هˆ‡ه‰²ه—و®µم€‚ https://www.jianshu.com/p/f7927591d530
ه¤§و•°وچ®وگœç´¢ن¸ژو—¥ه؟—وŒ–وژکهڈٹهڈ¯è§†هŒ–و–¹و،ˆ--ELK+Stack+Elasticsearch+Logstash+Kibanaه¤§و•°وچ®وگœç´¢ن¸ژو—¥ه؟—وŒ–وژکهڈٹهڈ¯è§†هŒ–و–¹و،ˆ--ELK+Stack+Elasticsearch+Logstash+Kibana
elasticsearchه®‰è£…,elk elasticsearch+logstash+filebeat+kibanaه®‰è£…部署و–‡و،£ï¼Œè؟گ维监وژ§
و€»ç»“èµ·و¥ï¼Œ"elasticsearch+logstash+kibana+filebeat.7z (ELK 7.9.0)" هژ‹ç¼©هŒ…هŒ…هگ«ن؛†ن¸€ه¥—ه®Œو•´çڑ„و—¥ه؟—ç®،çگ†ه’Œهˆ†وگه·¥ه…·é“¾ï¼Œé€‚用ن؛ژه¤§و•°وچ®çژ¯ه¢ƒï¼Œهڈ¯ن»¥ه¸®هٹ©ن¼پن¸ڑه®çژ°é«کو•ˆçڑ„و•°وچ®و”¶é›†م€په¤„çگ†م€پهکه‚¨ه’Œهڈ¯è§†هŒ–م€‚é€ڑè؟‡ن½؟用è؟™ه¥—ه·¥ه…·ï¼Œ...
ELK(Elasticsearch+logstash+kibana).zip
ELKوک¯ن¸‰ن¸ھه¼€و؛گ软ن»¶çڑ„缩ه†™ï¼Œهˆ†هˆ«è،¨ç¤؛ï¼ڑElasticsearch , Logstash, Kibana , ه®ƒن»¬éƒ½وک¯ه¼€و؛گ软ن»¶م€‚و–°ه¢ن؛†ن¸€ن¸ھFileBeat,ه®ƒوک¯ن¸€ن¸ھè½»é‡ڈç؛§çڑ„و—¥ه؟—و”¶é›†ه¤„çگ†ه·¥ه…·(Agent),Filebeatهچ 用资و؛گه°‘,适هگˆن؛ژهœ¨هگ„ن¸ھوœچهٹ،ه™¨ن¸ٹوگœé›†و—¥ه؟—هگژ...
filebeat+logstash+ES集群+kibanaه®وˆک.txt
Suricata+ELK+kibana+logstash ه®‰è£…و‰‹ه†Œوک¯ç½‘络ه®‰ه…¨é¢†هںںن¸و„ه»؛ه…¥ن¾µو£€وµ‹ç³»ç»ں(IDS)ه’Œه…¥ن¾µéک²ه¾،ç³»ç»ں(IPS)çڑ„ه…³é”®و¥éھ¤م€‚è؟™ن¸ھو–‡و،£è¯¦ç»†ن»‹ç»چن؛†ه¦‚ن½•هœ¨CentOS 7çژ¯ه¢ƒن¸‹è®¾ç½®ن¸€ه¥—ه®Œو•´çڑ„监وژ§è§£ه†³و–¹و،ˆï¼ŒهŒ…و‹¬ Suricata ن½œن¸؛و ¸ه؟ƒçڑ„...
**ELK(Elasticsearch + Logstash + Kibana)** وک¯ن¸€ن¸ھه¼؛ه¤§çڑ„و—¥ه؟—ç®،çگ†ه’Œهˆ†وگ解ه†³و–¹و،ˆï¼Œه¹؟و³›ه؛”用ن؛ژه¤§و•°وچ®هœ؛و™¯ï¼Œç‰¹هˆ«وک¯ه¯¹ن؛ژه®و—¶و—¥ه؟—و”¶é›†م€په¤„çگ†م€پهکه‚¨ه’Œهڈ¯è§†هŒ–م€‚è؟™ن¸ھ组هگˆوڈگن¾›ن؛†ن»ژو—¥ه؟—ç”ںوˆگهˆ°هڈ¯è§†هŒ–çڑ„ه…¨ه¥—وµپ程,ه¸®هٹ©ن¼پن¸ڑو›´...
و ‡é¢ک "es+kibana+logstash" وڑ—ç¤؛ن؛†وˆ‘ن»¬و£هœ¨è®¨è®؛çڑ„وک¯ Elastic Stack çڑ„و ¸ه؟ƒç»„ن»¶ï¼Œهچ³ Elasticsearchم€پKibana ه’Œ Logstashم€‚è؟™وک¯ن¸€ه¥—用ن؛ژو—¥ه؟—ç®،çگ†ه’Œهˆ†وگçڑ„ه¼؛ه¤§ه·¥ه…·ï¼Œه¹؟و³›ه؛”用ن؛ژهگ„ç§چن¸ڑهٹ،هœ؛و™¯ï¼ŒهŒ…و‹¬ه®و—¶ç›‘وژ§م€پو•…éڑœوژ’وں¥م€پ...
ELK(Elasticsearch, Logstash, Kibana)وک¯ن¸€ن¸ھوµپè،Œçڑ„ه¼€و؛گو—¥ه؟—هˆ†وگه’Œهڈ¯è§†هŒ–解ه†³و–¹و،ˆï¼Œه¹؟و³›ç”¨ن؛ژو”¶é›†م€پ解وگم€پهکه‚¨ه’Œه±•ç¤؛هگ„ç§چو—¥ه؟—و•°وچ®م€‚è؟™ن¸ھهژ‹ç¼©هŒ…هŒ…هگ«ن؛†ELKه †و ˆçڑ„ن¸»è¦پ组ن»¶ï¼Œç‰ˆوœ¬ن¸؛7.6.1,适用ن؛ژLinux x86_64و¶و„م€‚ **...
Logstash, OSSEC + Logstash + Elasticsearch + Kibana OSSECن½؟用 LOGSTASH - ELASTICSEARCH - KIBANA ç®،çگ† OSSECè¦وٹ¥ç®،çگ†çژ°هœ¨وک¯Magentoه®‰è£…è„ڑوœ¬çڑ„ن¸€éƒ¨هˆ†م€‚ https://github.com/magenx/Magento-Automat
ELK ه¥—ن»¶وک¯ç”±Elasticsearchم€پLogstashه’ŒKibanaن¸‰ن¸ھ组ن»¶ç»„وˆگçڑ„ه¼€و؛گو—¥ه؟—هˆ†وگه¹³هڈ°م€‚Elasticsearchوک¯ن¸€ن¸ھé«کو€§èƒ½م€پهˆ†ه¸ƒه¼ڈم€په…¨و–‡وگœç´¢ه¼•و“ژ,用ن؛ژهکه‚¨ه’Œو£€ç´¢ه¤§é‡ڈ结و„هŒ–ه’Œé结و„هŒ–çڑ„و•°وچ®م€‚Logstashهˆ™وک¯ن¸€ن¸ھو•°وچ®و”¶é›†ه’Œه¤„çگ†ه¼•و“ژ...
ELKه †و ˆوک¯ç”±Elasticsearchم€پLogstashه’ŒKibanaن¸‰ن¸ھه¼€و؛گه·¥ه…·ç»„وˆگçڑ„,ه®ƒن»¬é€ڑه¸¸èپ”هگˆن½؟用و¥ه®çژ°و—¥ه؟—و•°وچ®çڑ„و”¶é›†م€پهˆ†وگه’Œهڈ¯è§†هŒ–م€‚Elasticsearchوک¯ن¸€ن¸ھهں؛ن؛ژLuceneو„ه»؛çڑ„ه¼€و؛گوگœç´¢ه¼•و“ژ,ه…·وœ‰هˆ†ه¸ƒه¼ڈم€په¤ڑç§ںوˆ·çڑ„能هٹ›ï¼Œوڈگن¾›وگœç´¢...
ELK Stackوک¯ن¸€ه¥—ه¼€و؛گه·¥ه…·é›†هگˆï¼Œç”±Elasticsearchم€پLogstashه’ŒKibanaن¸‰ن¸ھن¸»è¦پ组ن»¶ç»„وˆگ,ن¸»è¦پ用ن؛ژو”¶é›†م€پهکه‚¨م€پهˆ†وگه’Œهڈ¯è§†هŒ–ه¤§è§„و¨،و—¥ه؟—و•°وچ®م€‚وœ¬و–‡و،£è¯¦ç»†ن»‹ç»چن؛†ه¦‚ن½•هœ¨Linux CentOS 7.2.2çژ¯ه¢ƒن¸‹éƒ¨ç½²ه¹¶é…چç½®ELK Stack,هŒ…و‹¬...
هœ¨وœ¬و–‡ن¸ï¼Œوˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨ه¦‚ن½•ن½؟用Spring Boot 2.7.3版وœ¬ن¸ژElasticsearchم€پLogstashه’ŒKibana(é€ڑه¸¸ç§°ن¸؛ELK Stack)è؟›è،Œé›†وˆگ,ن»¥ن¾؟é«کو•ˆهœ°و”¶é›†م€پهکه‚¨ه’Œهˆ†وگه؛”用程ه؛ڈو—¥ه؟—م€‚ELK Stackوک¯و—¥ه؟—ç®،çگ†ه’Œç›‘وژ§çڑ„ه¼؛ه¤§ه·¥ه…·ï¼Œه…¶ن¸...
ELK(ElasticSearch, Logstash, Kibana)وگه»؛ه®و—¶و—¥ه؟—هˆ†وگه¹³هڈ°èµ„و؛گ ELK(ElasticSearch, Logstash, Kibana)ه¹³هڈ°وپ°ه¥½هڈ¯ن»¥هگŒو—¶ه®çژ°و—¥ه؟—و”¶é›†م€پو—¥ه؟—وگœç´¢ه’Œو—¥ه؟—هˆ†وگçڑ„هٹں能
ELK(Elasticsearch, Logstash, Kibana)و ˆوک¯ه¤§و•°وچ®و—¥ه؟—هˆ†وگ领هںںçڑ„ن¸€و¬¾é‡چè¦په·¥ه…·ï¼Œç”¨ن؛ژو”¶é›†م€پ解وگم€پهکه‚¨م€پوگœç´¢ه’Œهڈ¯è§†هŒ–ه¤§é‡ڈو•°وچ®م€‚è؟™ن¸ھهژ‹ç¼©هŒ…هŒ…هگ«ن؛†ELKو ˆçڑ„ه…³é”®ç»„ن»¶ï¼Œن»¥هڈٹن¸€ن¸ھ用ن؛ژن¸و–‡هˆ†è¯چçڑ„IKوڈ’ن»¶ï¼Œه…·ن½“هŒ…و‹¬ï¼ڑ 1. ...
وœ¬و–‡و،£و—¨هœ¨وŒ‡ه¯¼ç”¨وˆ·هœ¨هچ•ç‚¹çژ¯ه¢ƒن¸éƒ¨ç½²ELK(Elasticsearchم€پLogstashم€پKibanaم€پFilebeat)و—¥ه؟—هˆ†وگç³»ç»ںم€‚ن¸‹é¢ه°†è¯¦ç»†ن»‹ç»چو¯ڈن¸ھ组ن»¶çڑ„ه®‰è£…م€پé…چç½®ه’Œهگ¯هٹ¨è؟‡ç¨‹م€‚ ن¸€م€پçژ¯ه¢ƒه‡†ه¤‡ هœ¨ه¼€ه§‹éƒ¨ç½²ELKن¹‹ه‰چ,需è¦په‡†ه¤‡ن¸€ن¸ھLinuxوœچهٹ،ه™¨...
es:elasticsearch ه¯¹و•°وچ®è؟›è،Œهکه‚¨,هˆ†ç±»,وگœç´¢ logstash: و—¥ه؟—و”¶é›†,filter(è؟‡و»¤),و—¥ه؟—输ه‡؛هˆ°(reids,kafka,es)ن¸ kibana:و—¥ه؟—ه±•ç¤؛(وں¥è¯¢esن¸ن؟هکçڑ„و•°وچ®)