http://m635674608.iteye.com/blog/2222487
 
 
Flume дљЬдЄЇ cloudera еЉАеПСзЪДеЃЮжЧґжЧ•ењЧжФґйЫЖз≥їзїЯпЉМеПЧеИ∞дЇЖдЄЪзХМзЪДиЃ§еПѓдЄОеєњж≥ЫеЇФзФ®гАВFlume еИЭеІЛзЪДеПСи°МзЙИжЬђзЫЃеЙН襀зїЯзІ∞дЄЇ Flume OGпЉИoriginal generationпЉЙпЉМе±ЮдЇО clouderaгАВдљЖйЪПзЭА FLume еКЯиГљзЪДжЙ©е±ХпЉМFlume OG дї£з†БеЈ•з®ЛиЗГиВњгАБж†ЄењГзїДдїґиЃЊиЃ°дЄНеРИзРЖгАБж†ЄењГйЕНзљЃдЄНж†ЗеЗЖз≠ЙзЉЇзВєжЪійЬ≤еЗЇжЭ•пЉМе∞§еЕґжШѓеЬ® Flume OG зЪДжЬАеРОдЄАдЄ™еПСи°МзЙИжЬђ 0.94.0 дЄ≠пЉМжЧ•ењЧдЉ†иЊУдЄНз®≥еЃЪзЪДзО∞и±°е∞§дЄЇдЄ•йЗНпЉМдЄЇдЇЖиІ£еЖ≥ињЩдЇЫйЧЃйҐШпЉМ2011 еєі 10 жЬИ 22 еПЈпЉМcloudera еЃМжИРдЇЖ Flume-728пЉМеѓє Flume ињЫи°МдЇЖйЗМз®ЛзҐСеЉПзЪДжФєеК®пЉЪйЗНжЮДж†ЄењГзїДдїґгАБж†ЄењГйЕНзљЃдї•еПКдї£з†БжЮґжЮДпЉМйЗНжЮДеРОзЪДзЙИжЬђзїЯзІ∞дЄЇ Flume NGпЉИnext generationпЉЙпЉЫжФєеК®зЪДеП¶дЄАеОЯеЫ†жШѓе∞Ж Flume зЇ≥еЕ• apache жЧЧдЄЛпЉМcloudera Flume жФєеРНдЄЇ Apache FlumeгАВIBM зЪДињЩзѓЗжЦЗзЂ†пЉЪгАКFlume NGпЉЪFlume еПСе±ХеП≤дЄКзЪДзђђдЄАжђ°йЭ©еСљгАЛпЉМдїОеЯЇжЬђзїДдїґдї•еПКзФ®жИЈдљУй™МзЪДиІТеЇ¶йШРињ∞ Flume OG еИ∞ Flume NG еПСзФЯзЪДйЭ©еСљжАІеПШеМЦгАВжЬђжЦЗе∞±дЄНеЖНиµШињ∞еРДзІНзїЖжЮЭжЬЂиКВдЇЖпЉМдЄНињЗињЩйЗМињШжШѓзЃАи¶БжПРдЄЛ Flume NG пЉИ1.x.xпЉЙзЪДдЄїи¶БеПШеМЦпЉЪ
- sourcesеТМsinks дљњзФ®channels ињЫи°МйУЊжО•
- дЄ§дЄ™дЄїи¶Бchannel гАВ1пЉМ ¬†in-memory channel ¬†йЭЮжМБдєЕжАІжФѓжМБпЉМйАЯеЇ¶ењЂгАВ2 пЉМ JDBC-based channel жМБдєЕжАІжФѓжМБгАВ
- дЄНеЖНеМЇеИЖйАїиЊСеТМзЙ©зРЖnodeпЉМжЙАжЬЙзЙ©зРЖиКВзВєзїЯзІ∞дЄЇ вАЬagentsвАЭ,жѓПдЄ™agents йГљиГљињРи°М0дЄ™жИЦе§ЪдЄ™sources еТМsinks
- дЄНеЖНйЬАи¶БmasterиКВзВєеТМеѓєzookeeperзЪДдЊЭиµЦпЉМйЕНзљЃжЦЗдїґзЃАеНХеМЦгАВ
- жПТдїґеМЦпЉМдЄАйГ®еИЖйЭҐеѓєзФ®жИЈпЉМеЈ•еЕЈжИЦз≥їзїЯеЉАеПСдЇЇеСШгАВ
- дљњзФ®ThriftгАБAvro Flume sources еПѓдї•дїОflume0.9.4 еПСйАБ events ¬†еИ∞flume 1.x
ж≥®пЉЪжЬђжЦЗжЙАдљњзФ®зЪД Flume зЙИжЬђдЄЇ flume-1.4.0-cdh4.7.0пЉМдЄНйЬАи¶БйҐЭе§ЦзЪДеЃЙи£ЕињЗз®ЛпЉМиІ£еОЛзЉ©еН≥еПѓзФ®гАВ¬†
1гАБFlume зЪДдЄАдЇЫж†ЄењГж¶ВењµпЉЪ
 
зїДдїґ еКЯиГљ
| Agent |
дљњзФ®JVM ињРи°МFlumeгАВжѓПеП∞жЬЇеЩ®ињРи°МдЄАдЄ™agentпЉМдљЖжШѓеПѓдї•еЬ®дЄАдЄ™agentдЄ≠еМЕеРЂе§ЪдЄ™sourcesеТМsinksгАВ |
| Client |
зФЯдЇІжХ∞жНЃпЉМињРи°МеЬ®дЄАдЄ™зЛђзЂЛзЪДзЇњз®ЛгАВ |
| Source |
дїОClientжФґйЫЖжХ∞жНЃпЉМдЉ†йАТзїЩChannelгАВ |
| Sink |
дїОChannelжФґйЫЖжХ∞жНЃпЉМињРи°МеЬ®дЄАдЄ™зЛђзЂЛзЇњз®ЛгАВ |
| Channel |
ињЮжО• sources еТМ sinks пЉМињЩдЄ™жЬЙзВєеГПдЄАдЄ™йШЯеИЧгАВ |
| Events |
еПѓдї•жШѓжЧ•ењЧиЃ∞ељХгАБ avro еѓєи±°з≠ЙгАВ |
1.1 жХ∞жНЃжµБж®°еЮЛ
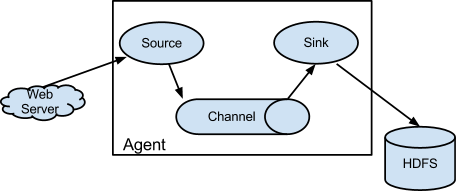
Flumeдї•agentдЄЇжЬАе∞ПзЪДзЛђзЂЛињРи°МеНХдљНгАВдЄАдЄ™agentе∞±жШѓдЄАдЄ™JVMгАВеНХagentзФ±SourceгАБSinkеТМChannelдЄЙе§ІзїДдїґжЮДжИРпЉМе¶ВдЄЛеЫЊпЉЪ
 ¬† еЫЊдЄА
¬† еЫЊдЄА
FlumeзЪДжХ∞жНЃжµБзФ±дЇЛдїґ(Event)иіѓз©њеІЛзїИгАВдЇЛдїґжШѓFlumeзЪДеЯЇжЬђжХ∞жНЃеНХдљНпЉМеЃГжРЇеЄ¶жЧ•ењЧжХ∞жНЃ(е≠ЧиКВжХ∞зїД嚥еЉП)еєґдЄФжРЇеЄ¶жЬЙе§ідњ°жБѓпЉМињЩдЇЫEventзФ±Agentе§ЦйГ®зЪДSourceпЉМжѓФе¶ВдЄКеЫЊдЄ≠зЪДWeb ServerзФЯжИРгАВељУSourceжНХиОЈдЇЛдїґеРОдЉЪињЫи°МзЙєеЃЪзЪДж†ЉеЉПеМЦпЉМзДґеРОSourceдЉЪжККдЇЛдїґжО®еЕ•(еНХдЄ™жИЦе§ЪдЄ™)ChannelдЄ≠гАВдљ†еПѓдї•жККChannelзЬЛдљЬжШѓдЄАдЄ™зЉУеЖ≤еМЇпЉМеЃГе∞ЖдњЭе≠ШдЇЛдїґзЫіеИ∞Sinkе§ДзРЖеЃМиѓ•дЇЛдїґгАВSinkиіЯиі£жМБдєЕеМЦжЧ•ењЧжИЦиАЕжККдЇЛдїґжО®еРСеП¶дЄАдЄ™SourceгАВ
еЊИзЫізЩљзЪДиЃЊиЃ°пЉМеЕґдЄ≠еАЉеЊЧж≥®жДПзЪДжШѓпЉМFlumeжПРдЊЫдЇЖе§ІйЗПеЖЕзљЃзЪДSourceгАБChannelеТМSinkз±їеЮЛгАВдЄНеРМз±їеЮЛзЪДSource,ChannelеТМSinkеПѓдї•иЗ™зФ±зїДеРИгАВзїДеРИжЦєеЉПеЯЇдЇОзФ®жИЈиЃЊзљЃзЪДйЕНзљЃжЦЗдїґпЉМйЭЮеЄЄзБµжіїгАВжѓФе¶ВпЉЪChannelеПѓдї•жККдЇЛдїґжЪВе≠ШеЬ®еЖЕе≠ШйЗМпЉМдєЯеПѓдї•жМБдєЕеМЦеИ∞жЬђеЬ∞з°ђзЫШдЄКгАВSinkеПѓдї•жККжЧ•ењЧеЖЩеЕ•HDFS, HBaseпЉМзФЪиЗ≥жШѓеП¶е§ЦдЄАдЄ™Sourceз≠Йз≠ЙгАВ
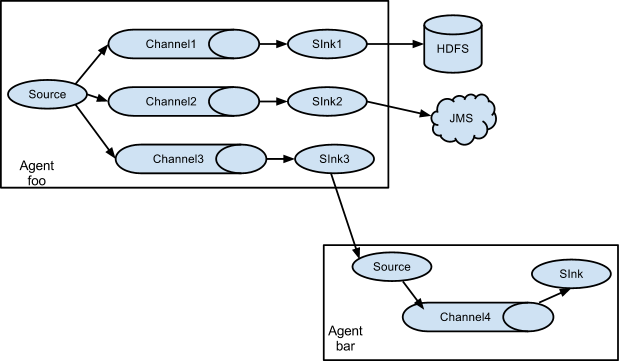
е¶ВжЮЬдљ†дї•дЄЇFlumeе∞±ињЩдЇЫиГљиАРйВ£е∞±е§ІйФЩзЙєйФЩдЇЖгАВFlumeжФѓжМБзФ®жИЈеїЇзЂЛе§ЪзЇІжµБпЉМдєЯе∞±жШѓиѓіпЉМе§ЪдЄ™agentеПѓдї•еНПеРМеЈ•дљЬпЉМеєґдЄФжФѓжМБFan-inгАБFan-outгАБContextual RoutingгАБBackup RoutesгАВе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ
1.2 йЂШеПѓйЭ†жАІ
дљЬдЄЇзФЯдЇІзОѓеҐГињРи°МзЪДиљѓдїґпЉМйЂШеПѓйЭ†жАІжШѓењЕй°їзЪДгАВ
дїОеНХagentжЭ•зЬЛпЉМFlumeдљњзФ®еЯЇдЇОдЇЛеК°зЪДжХ∞жНЃдЉ†йАТжЦєеЉПжЭ•дњЭиѓБдЇЛдїґдЉ†йАТзЪДеПѓйЭ†жАІгАВSourceеТМSink襀е∞Би£ЕињЫдЄАдЄ™дЇЛеК°гАВдЇЛ俴襀е≠ШжФЊеЬ®ChannelдЄ≠зЫіеИ∞иѓ•дЇЛ俴襀е§ДзРЖпЉМChannelдЄ≠зЪДдЇЛдїґжЙНдЉЪ襀粿йЩ§гАВињЩжШѓFlumeжПРдЊЫзЪДзВєеИ∞зВєзЪДеПѓйЭ†жЬЇеИґгАВ
дїОе§ЪзЇІжµБжЭ•зЬЛпЉМеЙНдЄАдЄ™agentзЪДsinkеТМеРОдЄАдЄ™agentзЪДsourceеРМж†ЈжЬЙеЃГдїђзЪДдЇЛеК°жЭ•дњЭйЪЬжХ∞жНЃзЪДеПѓйЭ†жАІгАВ
1.3 еПѓжБҐе§НжАІ
ињШжШѓйЭ†ChannelгАВжО®иНРдљњзФ®FileChannelпЉМдЇЛдїґжМБдєЕеМЦеЬ®жЬђеЬ∞жЦЗдїґз≥їзїЯйЗМ(жАІиГљиЊГеЈЃ)гАВ
2гАБFlume жХідљУжЮґжЮДдїЛзїН
FlumeжЮґжЮДжХідљУдЄКзЬЛе∞±жШѓ¬†source-->channel-->sink¬†зЪДдЄЙе±ВжЮґжЮДпЉИеПВиІБжЬАдЄКйЭҐзЪД еЫЊдЄАпЉЙпЉМз±їдЉЉзФЯжИРиАЕеТМжґИиієиАЕзЪДжЮґжЮДпЉМдїЦдїђдєЛйЧійАЪињЗqueueпЉИchannelпЉЙдЉ†иЊУпЉМиІ£иА¶гАВ
Source:еЃМжИРеѓєжЧ•ењЧжХ∞жНЃзЪДжФґйЫЖпЉМеИЖжИР transtion еТМ event жЙУеЕ•еИ∞channelдєЛдЄ≠гАВ¬†
Channel:дЄїи¶БжПРдЊЫдЄАдЄ™йШЯеИЧзЪДеКЯиГљпЉМеѓєsourceжПРдЊЫдЄ≠зЪДжХ∞жНЃињЫи°МзЃАеНХзЪДзЉУе≠ШгАВ¬†
Sink:еПЦеЗЇChannelдЄ≠зЪДжХ∞жНЃпЉМињЫи°МзЫЄеЇФзЪДе≠ШеВ®жЦЗдїґз≥їзїЯпЉМжХ∞жНЃеЇУпЉМжИЦиАЕжПРдЇ§еИ∞ињЬз®ЛжЬНеК°еЩ®гАВ¬†
еѓєзО∞жЬЙз®ЛеЇПжФєеК®жЬАе∞ПзЪДдљњзФ®жЦєеЉПжШѓдљњзФ®жШѓзЫіжО•иѓїеПЦз®ЛеЇПеОЯжЭ•иЃ∞ељХзЪДжЧ•ењЧжЦЗдїґпЉМеЯЇжЬђеПѓдї•еЃЮзО∞жЧ†зЉЭжО•еЕ•пЉМдЄНйЬАи¶БеѓєзО∞жЬЙз®ЛеЇПињЫи°МдїїдљХжФєеК®гАВ¬†
еѓєдЇОзЫіжО•иѓїеПЦжЦЗдїґSource, дЄїи¶БжЬЙдЄ§зІНжЦєеЉПпЉЪ¬†
2.1 Exec source
еПѓйАЪињЗеЖЩUnix commandзЪДжЦєеЉПзїДзїЗжХ∞жНЃпЉМжЬАеЄЄзФ®зЪДе∞±жШѓtail -F [file]гАВ
еПѓдї•еЃЮзО∞еЃЮжЧґдЉ†иЊУпЉМдљЖеЬ®flumeдЄНињРи°МеТМиДЪжЬђйФЩиѓѓжЧґпЉМдЉЪдЄҐжХ∞жНЃпЉМдєЯдЄНжФѓжМБжЦ≠зВєзї≠дЉ†еКЯиГљгАВеЫ†дЄЇж≤°жЬЙиЃ∞ељХдЄКжђ°жЦЗдїґиѓїеИ∞зЪДдљНзљЃпЉМдїОиАМж≤°еКЮж≥ХзЯ•йБУпЉМдЄЛжђ°еЖНиѓїжЧґпЉМдїОдїАдєИеЬ∞жЦєеЉАеІЛиѓїгАВзЙєеИЂжШѓеЬ®жЧ•ењЧжЦЗдїґдЄАзЫіеЬ®еҐЮеК†зЪДжЧґеАЩгАВflumeзЪДsourceжМВдЇЖгАВз≠ЙflumeзЪДsourceеЖНжђ°еЉАеРѓзЪДињЩжЃµжЧґйЧіеЖЕпЉМеҐЮеК†зЪДжЧ•ењЧеЖЕеЃєпЉМе∞±ж≤°еКЮж≥Х襀sourceиѓїеПЦеИ∞дЇЖгАВдЄНињЗflumeжЬЙдЄАдЄ™execStreamзЪДжЙ©е±ХпЉМеПѓдї•иЗ™еЈ±еЖЩдЄАдЄ™зЫСжОІжЧ•ењЧеҐЮеК†жГЕеЖµпЉМжККеҐЮеК†зЪДжЧ•ењЧпЉМйАЪињЗиЗ™еЈ±еЖЩзЪДеЈ•еЕЈжККеҐЮеК†зЪДеЖЕеЃєпЉМдЉ†йАБзїЩflumeзЪДnodeгАВеЖНдЉ†йАБзїЩsinkзЪДnodeгАВи¶БжШѓиГљеЬ®tailз±їзЪДsourceдЄ≠иГљжФѓжМБпЉМеЬ®nodeжМВжОЙињЩжЃµжЧґйЧізЪДеЖЕеЃєпЉМз≠ЙдЄЛжђ°nodeеЉАеРѓеРОеЬ®зїІзї≠дЉ†йАБпЉМйВ£е∞±жЫіеЃМзЊОдЇЖгАВ
2.2 Spooling Directory Source
SpoolSource:жШѓзЫСжµЛйЕНзљЃзЪДзЫЃељХдЄЛжЦ∞еҐЮзЪДжЦЗдїґпЉМеєґе∞ЖжЦЗдїґдЄ≠зЪДжХ∞жНЃиѓїеПЦеЗЇжЭ•пЉМеПѓеЃЮзО∞еЗЖеЃЮжЧґгАВйЬАи¶Бж≥®жДПдЄ§зВєпЉЪ1гАБжЛЈиіЭеИ∞spoolзЫЃељХдЄЛзЪДжЦЗдїґдЄНеПѓдї•еЖНжЙУеЉАзЉЦиЊСгАВ2гАБspoolзЫЃељХдЄЛдЄНеПѓеМЕеРЂзЫЄеЇФзЪДе≠РзЫЃељХгАВеЬ®еЃЮйЩЕдљњзФ®зЪДињЗз®ЛдЄ≠пЉМеПѓдї•зїУеРИlog4jдљњзФ®пЉМдљњзФ®log4jзЪДжЧґеАЩпЉМе∞Жlog4jзЪДжЦЗдїґеИЖеЙ≤жЬЇеИґиЃЊдЄЇ1еИЖйТЯдЄАжђ°пЉМе∞ЖжЦЗдїґжЛЈиіЭеИ∞spoolзЪДзЫСжОІзЫЃељХгАВlog4jжЬЙдЄАдЄ™TimeRollingзЪДжПТдїґпЉМеПѓдї•жККlog4jеИЖеЙ≤зЪДжЦЗдїґеИ∞spoolзЫЃељХгАВеЯЇжЬђеЃЮзО∞дЇЖеЃЮжЧґзЪДзЫСжОІгАВFlumeеЬ®дЉ†еЃМжЦЗдїґдєЛеРОпЉМе∞ЖдЉЪдњЃжФєжЦЗдїґзЪДеРОзЉАпЉМеПШдЄЇ.COMPLETEDпЉИеРОзЉАдєЯеПѓдї•еЬ®йЕНзљЃжЦЗдїґдЄ≠зБµжіїжМЗеЃЪпЉЙ¬†
ExecSourceпЉМSpoolSourceеѓєжѓФпЉЪExecSourceеПѓдї•еЃЮзО∞еѓєжЧ•ењЧзЪДеЃЮжЧґжФґйЫЖпЉМдљЖжШѓе≠ШеЬ®FlumeдЄНињРи°МжИЦиАЕжМЗдї§жЙІи°МеЗЇйФЩжЧґпЉМе∞ЖжЧ†ж≥ХжФґйЫЖеИ∞жЧ•ењЧжХ∞жНЃпЉМжЧ†ж≥ХдљХиѓБжЧ•ењЧжХ∞жНЃзЪДеЃМжХіжАІгАВSpoolSourceиЩљзДґжЧ†ж≥ХеЃЮзО∞еЃЮжЧґзЪДжФґйЫЖжХ∞жНЃпЉМдљЖжШѓеПѓдї•дљњзФ®дї•еИЖйТЯзЪДжЦєеЉПеИЖеЙ≤жЦЗдїґпЉМиґЛињСдЇОеЃЮжЧґгАВе¶ВжЮЬеЇФзФ®жЧ†ж≥ХеЃЮзО∞дї•еИЖйТЯеИЗеЙ≤жЧ•ењЧжЦЗдїґзЪДиѓЭпЉМеПѓдї•дЄ§зІНжФґйЫЖжЦєеЉПзїУеРИдљњзФ®гАВ¬†
ChannelжЬЙе§ЪзІНжЦєеЉПпЉЪжЬЙMemoryChannel, JDBC Channel, MemoryRecoverChannel, FileChannelгАВMemoryChannelеПѓдї•еЃЮзО∞йЂШйАЯзЪДеРЮеРРпЉМдљЖжШѓжЧ†ж≥ХдњЭиѓБжХ∞жНЃзЪДеЃМжХіжАІгАВMemoryRecoverChannelеЬ®еЃШжЦєжЦЗж°£зЪДеїЇиЃЃдЄКеЈ≤зїПеїЇдєЙдљњзФ®FileChannelжЭ•жЫњжНҐгАВFileChannelдњЭиѓБжХ∞жНЃзЪДеЃМжХіжАІдЄОдЄАиЗіжАІгАВеЬ®еЕЈдљУйЕНзљЃFileChannelжЧґпЉМеїЇиЃЃFileChannelиЃЊзљЃзЪДзЫЃељХеТМз®ЛеЇПжЧ•ењЧжЦЗдїґдњЭе≠ШзЪДзЫЃељХиЃЊжИРдЄНеРМзЪДз£БзЫШпЉМдї•дЊњжПРйЂШжХИзОЗгАВ¬†
SinkеЬ®иЃЊзљЃе≠ШеВ®жХ∞жНЃжЧґпЉМеПѓдї•еРСжЦЗдїґз≥їзїЯдЄ≠пЉМжХ∞жНЃеЇУдЄ≠пЉМhadoopдЄ≠еВ®жХ∞жНЃпЉМеЬ®жЧ•ењЧжХ∞жНЃиЊГе∞СжЧґпЉМеПѓдї•е∞ЖжХ∞жНЃе≠ШеВ®еЬ®жЦЗдїґз≥їдЄ≠пЉМеєґдЄФиЃЊеЃЪдЄАеЃЪзЪДжЧґйЧійЧійЪФдњЭе≠ШжХ∞жНЃгАВеЬ®жЧ•ењЧжХ∞жНЃиЊГе§ЪжЧґпЉМеПѓдї•е∞ЖзЫЄеЇФзЪДжЧ•ењЧжХ∞жНЃе≠ШеВ®еИ∞HadoopдЄ≠пЉМдЊњдЇОжЧ•еРОињЫи°МзЫЄеЇФзЪДжХ∞жНЃеИЖжЮРгАВ¬†
3гАБеЄЄзФ®жЮґжЮДгАБеКЯиГљйЕНзљЃз§ЇдЊЛ
3.1 еЕИжЭ•дЄ™зЃАеНХзЪДпЉЪеНХиКВзВє Flume йЕНзљЃ
 
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
 
a1.sources = r1
a1.sinks = k1
a1.channels = c1
 
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
 
a1.sinks.k1.type = logger
 
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
 
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
е∞ЖдЄКињ∞йЕНзљЃе≠ШдЄЇпЉЪexample.conf
зДґеРОжИСдїђе∞±еПѓдї•еРѓеК® Flume дЇЖпЉЪ
 
|
1
|
bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
|
PSпЉЪ-Dflume.root.logger=INFO,console дїЕдЄЇ debug дљњзФ®пЉМиѓЈеЛњзФЯдЇІзОѓеҐГзФЯжРђз°ђе•ЧпЉМеР¶еИЩе§ІйЗПзЪДжЧ•ењЧдЉЪињФеЫЮеИ∞зїИзЂѓгАВгАВгАВ
-c/--conf еРОиЈЯйЕНзљЃзЫЃељХпЉМ-f/--conf-file¬†еРОиЈЯеЕЈдљУзЪДйЕНзљЃжЦЗдїґпЉМ-n/--name¬†жМЗеЃЪagentзЪДеРНзІ∞
зДґеРОжИСдїђеЖНеЉАдЄАдЄ™ shell зїИзЂѓз™ЧеП£пЉМtelnet дЄКйЕНзљЃдЄ≠дЊ¶еРђзЪДзЂѓеП£пЉМе∞±еПѓдї•еПСжґИжБѓзЬЛеИ∞жХИжЮЬдЇЖпЉЪ
 
|
1
2
3
4
5
6
|
$ telnet localhost 44444
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
Hello world! <ENTER>
OK
|
Flume зїИзЂѓз™ЧеП£ж≠§жЧґдЉЪжЙУеН∞еЗЇе¶ВдЄЛдњ°жБѓпЉМе∞±и°®з§ЇжИРеКЯдЇЖпЉЪ
 
|
1
2
3
|
12/06/19 15:32:19 INFO source.NetcatSource: Source starting
12/06/19 15:32:19 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
12/06/19 15:32:34 INFO sink.LoggerSink: Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D          Hello world!. }
|
иЗ≥ж≠§пЉМеТ±дїђзЪДзђђдЄАдЄ™ Flume Agent зЃЧжШѓйГ®зљ≤жИРеКЯдЇЖпЉБ
3.2¬†еНХиКВзВє Flume¬†зЫіжО•еЖЩеЕ• HDFS
 
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
agent1.channels.ch1.type = memory
agent1.channels.ch1.capacity = 100000
agent1.channels.ch1.transactionCapacity = 100000
agent1.channels.ch1.keep-alive = 30
 
 
agent1.sources.avro-source1.type = exec
agent1.sources.avro-source1.shell = /bin/bash -c
agent1.sources.avro-source1.command = tail -n +0 -F /home/storm/tmp/id.txt
agent1.sources.avro-source1.channels = ch1
agent1.sources.avro-source1.threads = 5
 
agent1.sinks.log-sink1.channel = ch1
agent1.sinks.log-sink1.type = hdfs
agent1.sinks.log-sink1.hdfs.path = hdfs://192.168.1.111:8020/flumeTest
agent1.sinks.log-sink1.hdfs.writeFormat = Text
agent1.sinks.log-sink1.hdfs.fileType = DataStream
agent1.sinks.log-sink1.hdfs.rollInterval = 0
agent1.sinks.log-sink1.hdfs.rollSize = 1000000
agent1.sinks.log-sink1.hdfs.rollCount = 0
agent1.sinks.log-sink1.hdfs.batchSize = 1000
agent1.sinks.log-sink1.hdfs.txnEventMax = 1000
agent1.sinks.log-sink1.hdfs.callTimeout = 60000
agent1.sinks.log-sink1.hdfs.appendTimeout = 60000
 
agent1.channels = ch1
agent1.sources = avro-source1
agent1.sinks = log-sink1
|
еРѓеК®е¶ВдЄЛеСљдї§пЉМе∞±еПѓдї•еЬ® hdfs дЄКзЬЛеИ∞жХИжЮЬдЇЖгАВ
../bin/flume-ng agent --conf ../conf/ -f flume_directHDFS.conf -n agent1 -Dflume.root.logger=INFO,console
PSпЉЪеЃЮйЩЕзОѓеҐГдЄ≠жЬЙињЩж†ЈзЪДйЬАж±ВпЉМйАЪињЗеЬ®е§ЪдЄ™agentзЂѓtailжЧ•ењЧпЉМеПСйАБзїЩcollectorпЉМcollectorеЖНжККжХ∞жНЃжФґйЫЖпЉМзїЯдЄАеПСйАБзїЩHDFSе≠ШеВ®иµЈжЭ•пЉМељУHDFSжЦЗдїґе§Іе∞ПиґЕињЗдЄАеЃЪзЪДе§Іе∞ПжИЦиАЕиґЕињЗеЬ®иІДеЃЪзЪДжЧґйЧійЧійЪФдЉЪзФЯжИРдЄАдЄ™жЦЗдїґгАВ
Flume еЃЮзО∞дЇЖдЄ§дЄ™TriggerпЉМеИЖеИЂдЄЇSizeTrigerпЉИеЬ®и∞ГзФ®HDFSиЊУеЗЇжµБеЖЩзЪДеРМжЧґпЉМcountиѓ•жµБеЈ≤зїПеЖЩеЕ•зЪДе§Іе∞ПжАїеТМпЉМиЛ•иґЕињЗдЄАеЃЪе§Іе∞ПпЉМеИЩеИЫеїЇжЦ∞зЪДжЦЗдїґеТМиЊУеЗЇжµБпЉМеЖЩеЕ•жУНдљЬжМЗеРСжЦ∞зЪДиЊУеЗЇжµБпЉМеРМжЧґcloseдї•еЙНзЪДиЊУеЗЇжµБпЉЙеТМTimeTrigerпЉИеЉАеРѓеЃЪжЧґеЩ®пЉМељУеИ∞иЊЊиѓ•зВєжЧґпЉМиЗ™еК®еИЫеїЇжЦ∞зЪДжЦЗдїґеТМиЊУеЗЇжµБпЉМжЦ∞зЪДеЖЩеЕ•йЗНеЃЪеРСеИ∞иѓ•жµБдЄ≠пЉМеРМжЧґcloseдї•еЙНзЪДиЊУеЗЇжµБпЉЙгАВ
3.3 жЭ•дЄАдЄ™еЄЄиІБжЮґжЮДпЉЪе§Ъ agent ж±ЗиБЪеЖЩеЕ• HDFS
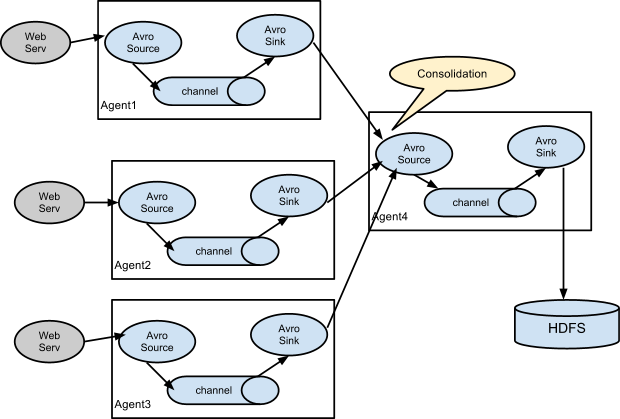
 
3.3.1 еЬ®еРДдЄ™webservжЧ•ењЧжЬЇдЄКйЕНзљЃ Flume Client
 
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
clientMainAgent.channels = c1
clientMainAgent.sources  = s1
clientMainAgent.sinks    = k1 k2
clientMainAgent.sinkgroups = g1
clientMainAgent.sources.s1.type = spooldir
clientMainAgent.sources.s1.spoolDir  =/dsap/rawdata/
clientMainAgent.sources.s1.fileHeader = true
clientMainAgent.sources.s1.deletePolicy =immediate
clientMainAgent.sources.s1.batchSize =1000
clientMainAgent.sources.s1.channels =c1
clientMainAgent.sources.s1.deserializer.maxLineLength =1048576
clientMainAgent.channels.c1.type = file
clientMainAgent.channels.c1.checkpointDir = /var/flume/fchannel/spool/checkpoint
clientMainAgent.channels.c1.dataDirs = /var/flume/fchannel/spool/data
clientMainAgent.channels.c1.capacity = 200000000
clientMainAgent.channels.c1.keep-alive = 30
clientMainAgent.channels.c1.write-timeout = 30
clientMainAgent.channels.c1.checkpoint-timeout=600
clientMainAgent.sinks.k1.channel = c1
clientMainAgent.sinks.k1.type = avro
clientMainAgent.sinks.k1.hostname = flume115
clientMainAgent.sinks.k1.port = 41415
clientMainAgent.sinks.k2.channel = c1
clientMainAgent.sinks.k2.type = avro
clientMainAgent.sinks.k2.hostname = flume116
clientMainAgent.sinks.k2.port = 41415
clientMainAgent.sinkgroups.g1.sinks = k1 k2
clientMainAgent.sinkgroups.g1.processor.type = load_balance
clientMainAgent.sinkgroups.g1.processor.backoff   = true
clientMainAgent.sinkgroups.g1.processor.selector  = random
|
../bin/flume-ng agent --conf ../conf/ -f flume_Consolidation.conf -n clientMainAgent -Dflume.root.logger=DEBUG,console
3.3.2 еЬ®ж±ЗиБЪиКВзВєйЕНзљЃ Flume server
 
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
collectorMainAgent.channels = c2
collectorMainAgent.sources  = s2
collectorMainAgent.sinks    =k1 k2
collectorMainAgent.sources.s2.type = avro
collectorMainAgent.sources.s2.bind = flume115
collectorMainAgent.sources.s2.port = 41415
collectorMainAgent.sources.s2.channels = c2
 
collectorMainAgent.channels.c2.type = file
collectorMainAgent.channels.c2.checkpointDir =/opt/var/flume/fchannel/spool/checkpoint
collectorMainAgent.channels.c2.dataDirs = /opt/var/flume/fchannel/spool/data,/work/flume/fchannel/spool/data
collectorMainAgent.channels.c2.capacity = 200000000
collectorMainAgent.channels.c2.transactionCapacity=6000
collectorMainAgent.channels.c2.checkpointInterval=60000
collectorMainAgent.sinks.k2.type = hdfs
collectorMainAgent.sinks.k2.channel = c2
collectorMainAgent.sinks.k2.hdfs.path = hdfs://db-cdh-cluster/flume%{dir}
collectorMainAgent.sinks.k2.hdfs.filePrefix =k2_%{file}
collectorMainAgent.sinks.k2.hdfs.inUsePrefix =_
collectorMainAgent.sinks.k2.hdfs.inUseSuffix =.tmp
collectorMainAgent.sinks.k2.hdfs.rollSize = 0
collectorMainAgent.sinks.k2.hdfs.rollCount = 0
collectorMainAgent.sinks.k2.hdfs.rollInterval = 240
collectorMainAgent.sinks.k2.hdfs.writeFormat = Text
collectorMainAgent.sinks.k2.hdfs.fileType = DataStream
collectorMainAgent.sinks.k2.hdfs.batchSize = 6000
collectorMainAgent.sinks.k2.hdfs.callTimeout = 60000
collectorMainAgent.sinks.k1.type = hdfs
collectorMainAgent.sinks.k1.channel = c2
collectorMainAgent.sinks.k1.hdfs.path = hdfs://db-cdh-cluster/flume%{dir}
collectorMainAgent.sinks.k1.hdfs.filePrefix =k1_%{file}
collectorMainAgent.sinks.k1.hdfs.inUsePrefix =_
collectorMainAgent.sinks.k1.hdfs.inUseSuffix =.tmp
collectorMainAgent.sinks.k1.hdfs.rollSize = 0
collectorMainAgent.sinks.k1.hdfs.rollCount = 0
collectorMainAgent.sinks.k1.hdfs.rollInterval = 240
collectorMainAgent.sinks.k1.hdfs.writeFormat = Text
collectorMainAgent.sinks.k1.hdfs.fileType = DataStream
collectorMainAgent.sinks.k1.hdfs.batchSize = 6000
collectorMainAgent.sinks.k1.hdfs.callTimeout = 60000
|
../bin/flume-ng agent --conf ../conf/ -f flume_Consolidation.conf -n collectorMainAgent -Dflume.root.logger=DEBUG,console
дЄКйЭҐйЗЗзФ®зЪДе∞±жШѓз±їдЉЉ cs жЮґжЮДпЉМеРДдЄ™ flume agent иКВзВєеЕИе∞ЖеРДеП∞жЬЇеЩ®зЪДжЧ•ењЧж±ЗжАїеИ∞¬†Consolidation иКВзВєпЉМзДґеРОеЖНзФ±ињЩдЇЫиКВзВєзїЯдЄАеЖЩеЕ• HDFSпЉМеєґдЄФйЗЗзФ®дЇЖиіЯиљљеЭЗи°°зЪДжЦєеЉПпЉМдљ†ињШеПѓдї•йЕНзљЃйЂШеПѓзФ®зЪДж®°еЉПз≠Йз≠ЙгАВ
4гАБеПѓиГљйБЗеИ∞зЪДйЧЃйҐШпЉЪ
4.1 OOM¬†йЧЃйҐШпЉЪ
|
1
2
3
4
5
|
flume жК•йФЩпЉЪ
java.lang.OutOfMemoryError: GC overhead limit exceeded
жИЦиАЕпЉЪ
java.lang.OutOfMemoryError: Java heap space
Exception in thread "SinkRunner-PollingRunner-DefaultSinkProcessor" java.lang.OutOfMemoryError: Java heap space
|
Flume еРѓеК®жЧґзЪДжЬАе§Іе†ЖеЖЕе≠Ше§Іе∞ПйїШиЃ§жШѓ 20MпЉМзЇњдЄКзОѓеҐГеЊИеЃєжШУ OOMпЉМеЫ†ж≠§йЬАи¶Бдљ†еЬ® flume-env.sh¬†дЄ≠жЈїеК† JVM еРѓеК®еПВжХ∞:¬†
|
1
|
JAVA_OPTS="-Xms8192m -Xmx8192m -Xss256k -Xmn2g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-UseGCOverheadLimit"
|
зДґеРОеЬ®еРѓеК® agent зЪДжЧґеАЩдЄАеЃЪи¶БеЄ¶дЄК¬†-c conf йАЙй°єпЉМеР¶еИЩ¬†flume-env.sh йЗМйЕНзљЃзЪДзОѓеҐГеПШйЗПдЄНдЉЪ襀еК†иљљзФЯжХИгАВ
еЕЈдљУеПВиІБпЉЪ
http://stackoverflow.com/questions/1393486/error-java-lang-outofmemoryerror-gc-overhead-limit-exceeded
http://marc.info/?l=flume-user&m=138933303305433&w=2
4.2 JDK зЙИжЬђдЄНеЕЉеЃєйЧЃйҐШпЉЪ
 
|
1
2
3
4
5
6
7
|
2014-07-07 14:44:17,902 (agent-shutdown-hook) [WARN - org.apache.flume.sink.hdfs.HDFSEventSink.stop(HDFSEventSink.java:504)] Exception while closing hdfs:
java.lang.UnsupportedOperationException: This is supposed to be overridden by subclasses.
        at com.google.protobuf.GeneratedMessage.getUnknownFields(GeneratedMessage.java:180)
        at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$GetFileInfoRequestProto.getSerializedSize(ClientNamenodeProtocolProtos.java:30108)
        at com.google.protobuf.AbstractMessageLite.toByteString(AbstractMessageLite.java:49)
        at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.constructRpcRequest(ProtobufRpcEngine.java:149)
        at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:193)
|
жККдљ†зЪД jdk7 жНҐжИР jdk6 иѓХиѓХгАВ
4.3 е∞ПжЦЗдїґеЖЩеЕ• HDFS еїґжЧґзЪДйЧЃйҐШ
еЕґеЃЮдЄКйЭҐ 3.2 дЄ≠еЈ≤жЬЙиѓіжШОпЉМflume зЪД sink еЈ≤зїПеЃЮзО∞дЇЖеЗ†зІНжЬАдЄїи¶БзЪДжМБдєЕеМЦиІ¶еПСеЩ®пЉЪ
жѓФе¶ВжМЙе§Іе∞ПгАБжМЙйЧійЪФжЧґйЧігАБжМЙжґИжБѓжЭ°жХ∞з≠Йз≠ЙпЉМйТИеѓєдљ†зЪДжЦЗдїґињЗе∞ПињЯињЯж≤°ж≥ХеЖЩеЕ• HDFS жМБдєЕеМЦзЪДйЧЃйҐШпЉМ
йВ£жШѓеЫ†дЄЇдљ†ж≠§жЧґињШж≤°жЬЙжї°иґ≥жМБдєЕеМЦзЪДжЭ°дїґпЉМжѓФе¶Вдљ†зЪДи°МжХ∞ињШж≤°жЬЙиЊЊеИ∞йЕНзљЃзЪДйШИеАЉжИЦиАЕе§Іе∞ПињШж≤°иЊЊеИ∞з≠Йз≠ЙпЉМ
еПѓдї•йТИеѓєдЄКйЭҐ 3.2 е∞ПиКВзЪДйЕНзљЃеЊЃи∞ГдЄЛпЉМдЊЛе¶ВпЉЪ
 
|
1
|
agent1.sinks.log-sink1.hdfs.rollInterval = 20
|
ељУињЯињЯж≤°жЬЙжЦ∞жЧ•ењЧзФЯжИРзЪДжЧґеАЩпЉМе¶ВжЮЬдљ†жГ≥еЊИењЂзЪД flushпЉМйВ£дєИиЃ©еЃГжѓПйЪФ 20s flush жМБдєЕеМЦдЄАдЄЛпЉМagent дЉЪж†єжНЃе§ЪдЄ™жЭ°дїґпЉМдЉШеЕИжЙІи°Мжї°иґ≥жЭ°дїґзЪДиІ¶еПСеЩ®гАВ
дЄЛйЭҐиіідЄАдЇЫеЄЄиІБзЪДжМБдєЕеМЦиІ¶еПСеЩ®пЉЪ
 
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
agent.sinks.sink.hdfs.rollInterval=600
 
agent.sinks.sink.hdfs.rollSize = 268435456
 
agent.sinks.sink.hdfs.rollCount = 0
 
agent.sinks.sink.hdfs.idleTimeout = 3600
 
agent.sinks.HDFS.hdfs.batchSize = 1000
|
жЫіе§ЪеЕ≥дЇО sink зЪДиІ¶еПСжЬЇеИґдЄОеПВжХ∞йЕНзљЃиѓЈеПВиІБпЉЪ¬†http://flume.apache.org/FlumeUserGuide.html#hdfs-sink
http://stackoverflow.com/questions/20638498/flume-not-writing-to-hdfs-unless-killed
ж≥®жДПпЉЪеѓєдЇО HDFS жЭ•иѓіеЇФељУзЂ≠еКЫйБњеЕНе∞ПжЦЗдїґйЧЃйҐШпЉМжЙАдї•иѓЈжЕОйЗНеѓєеЊЕдљ†йЕНзљЃзЪДжМБдєЕеМЦиІ¶еПСжЬЇеИґгАВ
4.4 жХ∞жНЃйЗНе§НеЖЩеЕ•гАБ䪥姱йЧЃйҐШ
FlumeзЪДHDFSsinkеЬ®жХ∞жНЃеЖЩеЕ•/иѓїеЗЇChannelжЧґпЉМйГљжЬЙTranscationзЪДдњЭиѓБгАВељУTransaction姱賕жЧґпЉМдЉЪеЫЮжїЪпЉМзДґеРОйЗНиѓХгАВдљЖзФ±дЇОHDFSдЄНеПѓдњЃжФєжЦЗдїґзЪДеЖЕеЃєпЉМеБЗиЃЊжЬЙ1дЄЗи°МжХ∞жНЃи¶БеЖЩеЕ•HDFSпЉМиАМеЬ®еЖЩеЕ•5000и°МжЧґпЉМзљСзїЬеЗЇзО∞йЧЃйҐШеѓЉиЗіеЖЩеŕ姱賕пЉМTransactionеЫЮжїЪпЉМзДґеРОйЗНеЖЩињЩ10000жЭ°иЃ∞ељХжИРеКЯпЉМе∞±дЉЪеѓЉиЗізђђдЄАжђ°еЖЩеЕ•зЪД5000и°МйЗНе§НгАВињЩдЇЫйЧЃйҐШжШѓ HDFS жЦЗдїґз≥їзїЯиЃЊиЃ°дЄКзЪДзЙєжАІзЉЇйЩЈпЉМеєґдЄНиГљйАЪињЗзЃАеНХзЪДBugfixжЭ•иІ£еЖ≥гАВжИСдїђеП™иГљеЕ≥йЧ≠жЙєйЗПеЖЩеЕ•пЉМеНХжЭ°дЇЛеК°дњЭиѓБпЉМжИЦиАЕеРѓзФ®зЫСжОІз≠ЦзХ•пЉМдЄ§зЂѓеѓєжХ∞гАВ
MemoryеТМexecзЪДжЦєеЉПеПѓиГљдЉЪжЬЙжХ∞ж́䪥姱пЉМfile жШѓ end to end зЪДеПѓйЭ†жАІдњЭиѓБзЪДпЉМдљЖжШѓжАІиГљиЊГеЙНдЄ§иАЕи¶БеЈЃгАВ
end to endгАБstore on failure жЦєеЉП ACK з°ЃиЃ§жЧґйЧіиЃЊзљЃињЗзЯ≠пЉИзЙєеИЂжШѓйЂШе≥∞жЧґйЧіпЉЙдєЯжЬЙеПѓиГљеЉХеПСжХ∞жНЃзЪДйЗНе§НеЖЩеЕ•гАВ
4.5 tail жЦ≠зВєзї≠дЉ†зЪДйЧЃйҐШпЉЪ
еПѓдї•еЬ® tail дЉ†зЪДжЧґеАЩиЃ∞ељХи°МеПЈпЉМдЄЛжђ°еЖНдЉ†зЪДжЧґеАЩпЉМеПЦдЄКжђ°иЃ∞ељХзЪДдљНзљЃеЉАеІЛдЉ†иЊУпЉМз±їдЉЉпЉЪ
 
|
1
|
agent1.sources.avro-source1.command = /usr/local/bin/tail¬† -n +$(tail -n1 /home/storm/tmp/n) --max-unchanged-stats=600 -F¬† /home/storm/tmp/id.txt | awk 'ARNGIND==1{i=$0;next}{i++; if($0~/жЦЗдїґеЈ≤жИ™жЦ≠/)i=0; print i >> "/home/storm/tmp/n";print $1"---"i}' /home/storm/tmp/n -
|
йЬАи¶Бж≥®жДПе¶ВдЄЛеЗ†зВєпЉЪ
пЉИ1пЉЙжЦЗ俴襀 rotation зЪДжЧґеАЩпЉМйЬАи¶БеРМж≠•жЫіжЦ∞дљ†зЪДжЦ≠зВєиЃ∞ељХвАЬжМЗйТИвАЭпЉМ
пЉИ2пЉЙйЬАи¶БжМЙжЦЗдїґеРНжЭ•ињљиЄ™жЦЗдїґпЉМ
пЉИ3пЉЙflume жМВжОЙеРОйЬАи¶БзіѓеК†жЦ≠зВєзї≠дЉ†вАЬжМЗйТИвАЭ
пЉИ4пЉЙflume жМВжОЙеРОпЉМе¶ВжЮЬжБ∞е•љжЦЗ俴襀 rotationпЉМйВ£дєИдЉЪжЬЙдЄҐжХ∞жНЃзЪДй£ОйЩ©пЉМ
¬† ¬† ¬† ¬†еП™иГљзЫСжОІе∞љењЂжЛЙиµЈжИЦиАЕеК†йАїиЊСеИ§жЦ≠жЦЗдїґе§Іе∞ПйЗНзљЃжМЗйТИгАВ
пЉИ5пЉЙtail ж≥®жДПдљ†зЪДзЙИжЬђпЉМиѓЈжЫіжЦ∞¬†coreutils еМЕеИ∞жЬАжЦ∞гАВ
4.6 еЬ® Flume дЄ≠е¶ВдљХдњЃжФєгАБдЄҐеЉГгАБжМЙйҐДеЃЪдєЙиІДеИЩеИЖз±їе≠ШеВ®жХ∞жНЃпЉЯ
ињЩйЗМдљ†йЬАи¶БеИ©зФ® Flume жПРдЊЫзЪДжЛ¶жИ™еЩ®пЉИInterceptorпЉЙжЬЇеИґжЭ•жї°иґ≥дЄКињ∞зЪДйЬАж±ВдЇЖпЉМеЕЈдљУиѓЈеПВиАГдЄЛйЭҐеЗ†дЄ™йУЊжО•пЉЪ
пЉИ1пЉЙFlume-NGжЇРз†БйШЕиѓїдєЛInterceptor(еОЯеИЫ) ¬†
http://www.cnblogs.com/lxf20061900/p/3664602.html
пЉИ2пЉЙFlume-NGиЗ™еЃЪдєЙжЛ¶жИ™еЩ®
http://sep10.com/posts/2014/04/15/flume-interceptor/
пЉИ3пЉЙFlume-ngзФЯдЇІзОѓеҐГеЃЮиЈµпЉИеЫЫпЉЙеЃЮзО∞logж†ЉеЉПеМЦinterceptor
http://blog.csdn.net/rjhym/article/details/8450728
пЉИ4пЉЙflume-ngе¶ВдљХж†єжНЃжЇРжЦЗдїґеРНиЊУеЗЇеИ∞HDFSжЦЗдїґеРН
http://abloz.com/2013/02/19/flume-ng-output-according-to-the-source-file-name-to-the-hdfs-file-name.html
5гАБReferпЉЪ
пЉИ1пЉЙscribeгАБchukwaгАБkafkaгАБflumeжЧ•ењЧз≥їзїЯеѓєжѓФ ¬†
http://www.ttlsa.com/log-system/scribe-chukwa-kafka-flume-log-system-contrast/
пЉИ2пЉЙеЕ≥дЇОFlume-ngйВ£дЇЫдЇЛ ¬†http://www.ttlsa.com/?s=flume
¬† ¬† ¬† ¬† ¬†еЕ≥дЇОFlume-ngйВ£дЇЫдЇЛпЉИдЄЙпЉЙпЉЪеЄЄиІБжЮґжЮДжµЛиѓХ ¬†http://www.ttlsa.com/log-system/about-flume-ng-3/
пЉИ3пЉЙFlume 1.4.0 User Guide
http://archive.cloudera.com/cdh4/cdh/4/flume-ng-1.4.0-cdh4.7.0/FlumeUserGuide.html
пЉИ4пЉЙflumeжЧ•ењЧйЗЗйЫЖ ¬†http://blog.csdn.net/sunmeng_007/article/details/9762507
пЉИ5пЉЙFlume-NG + HDFS + HIVE жЧ•ењЧжФґйЫЖеИЖжЮР
http://eyelublog.wordpress.com/2013/01/13/flume-ng-hdfs-hive-%E6%97%A5%E5%BF%97%E6%94%B6%E9%9B%86%E5%88%86%E6%9E%90/
пЉИ6пЉЙгАРTwitter Stormз≥їеИЧгАСflume-ng+Kafka+Storm+HDFS еЃЮжЧґз≥їзїЯжР≠еїЇ
http://blog.csdn.net/weijonathan/article/details/18301321
пЉИ7пЉЙFlume-NG + HDFS + PIG жЧ•ењЧжФґйЫЖеИЖжЮР
http://hi.baidu.com/life_to_you/item/a98e2ec3367486dbef183b5e
flume з§ЇдЊЛдЄАжФґйЫЖtomcatжЧ•ењЧ ¬†http://my.oschina.net/88sys/blog/71529
flume-ng е§ЪиКВзВєйЫЖзЊ§з§ЇдЊЛ ¬†http://my.oschina.net/u/1401580/blog/204052
иѓХзФ®flume-ng 1.1¬†¬†http://heipark.iteye.com/blog/1617995
пЉИ8пЉЙFlafka: Apache Flume Meets Apache Kafka for Event Processing
http://blog.cloudera.com/blog/2014/11/flafka-apache-flume-meets-apache-kafka-for-event-processing/
пЉИ9пЉЙFlume-ngзЪДеОЯзРЖеТМдљњзФ®
http://segmentfault.com/blog/javachen/1190000002532284
пЉИ10пЉЙеЯЇдЇОFlumeзЪДзЊОеЫҐжЧ•ењЧжФґйЫЖз≥їзїЯ(дЄА)жЮґжЮДеТМиЃЊиЃ°
http://tech.meituan.com/mt-log-system-arch.html
пЉИ11пЉЙеЯЇдЇОFlumeзЪДзЊОеЫҐжЧ•ењЧжФґйЫЖз≥їзїЯ(дЇМ)жФєињЫеТМдЉШеМЦ
http://tech.meituan.com/mt-log-system-optimization.html
пЉИ12пЉЙHow-to: Do Real-Time Log Analytics with Apache Kafka, Cloudera Search, and Hue
http://blog.cloudera.com/blog/2015/02/how-to-do-real-time-log-analytics-with-apache-kafka-cloudera-search-and-hue/
пЉИ13пЉЙReal-time analytics in Apache Flume - Part 1
http://jameskinley.tumblr.com/post/57704266739/real-time-analytics-in-apache-flume-part-1
 http://my.oschina.net/leejun2005/blog/288136 
 
 
 
 
 
-------------------------------------дї•дЄЛдЄЇеП¶дЄАзѓЗжЦЗзЂ†--------------------------------------------
http://blog.csdn.net/code52/article/details/51173196
 
1гАБ еЕИжЭ•дЄ™зЃАеНХзЪДпЉЪеНХиКВзВє Flume йЕНзљЃ
telnet:example.conf
./bin/flume-ng agent --conf conf --conf-file ./conf/example.conf --name a1 -Dflume.root.logger=INFO,console
PSпЉЪ-Dflume.root.logger=INFO,console дїЕдЄЇ debug дљњзФ®пЉМиѓЈеЛњзФЯдЇІзОѓеҐГзФЯжРђз°ђе•ЧпЉМеР¶еИЩе§ІйЗПзЪДжЧ•ењЧдЉЪињФеЫЮеИ∞зїИзЂѓгАВгАВгАВ
-c/--conf еРОиЈЯйЕНзљЃзЫЃељХпЉМ-f/--conf-file еРОиЈЯеЕЈдљУзЪДйЕНзљЃжЦЗдїґпЉМ-n/--name жМЗеЃЪagentзЪДеРНзІ∞
 
еЉАдЄАдЄ™ shell зїИзЂѓз™ЧеП£пЉМtelnet дЄКйЕНзљЃдЄ≠дЊ¶еРђзЪДзЂѓеП£пЉМе∞±еПѓдї•еПСжґИжБѓзЬЛеИ∞жХИжЮЬдЇЖ:
[root@10.10.73.58]$ telnet localhost 44444
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
hello word
OK
 
Flume зїИзЂѓз™ЧеП£ж≠§жЧґдЉЪжЙУеН∞еЗЇе¶ВдЄЛдњ°жБѓпЉМе∞±и°®з§ЇжИРеКЯдЇЖпЉЪ
2016-02-29 20:12:00,719 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.Java:150)] Source starting
2016-02-29 20:12:00,735 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:164)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
2016-02-29 20:12:22,744 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 64 0D                hello word. }
2гАБеНХиКВзВє Flume¬†зЫіжО•еЖЩеЕ• HDFS
# Define a memory channel called ch1 on agent1
agent1.channels.ch1.type = memory
agent1.channels.ch1.capacity = 100000
agent1.channels.ch1.transactionCapacity = 100000
agent1.channels.ch1.keep-alive = 30
 
# Define an Avro source called avro-source1 on agent1 and tell it
# to bind to 0.0.0.0:41414. Connect it to channel ch1.
#agent1.sources.avro-source1.channels = ch1
#agent1.sources.avro-source1.type = avro
#agent1.sources.avro-source1.bind = 127.0.0.1
#agent1.sources.avro-source1.port = 44444
#agent1.sources.avro-source1.threads = 5
 
#define source monitor a file
agent1.sources.avro-source1.type = exec
agent1.sources.avro-source1.shell = /bin/bash -c
agent1.sources.avro-source1.command = tail -n +0 -F /home/storm/tmp/id.txt
agent1.sources.avro-source1.channels = ch1
agent1.sources.avro-source1.threads = 5
 
# Define a logger sink that simply logs all events it receives
# and connect it to the other end of the same channel.
agent1.sinks.log-sink1.channel = ch1
agent1.sinks.log-sink1.type = hdfs
agent1.sinks.log-sink1.hdfs.path = hdfs://192.168.1.111:8020/flumeTest
agent1.sinks.log-sink1.hdfs.writeFormat = Text
agent1.sinks.log-sink1.hdfs.fileType = DataStream
agent1.sinks.log-sink1.hdfs.rollInterval = 0
agent1.sinks.log-sink1.hdfs.rollSize = 1000000
agent1.sinks.log-sink1.hdfs.rollCount = 0
agent1.sinks.log-sink1.hdfs.batchSize = 1000
agent1.sinks.log-sink1.hdfs.txnEventMax = 1000
agent1.sinks.log-sink1.hdfs.callTimeout = 60000
agent1.sinks.log-sink1.hdfs.appendTimeout = 60000
 
# Finally, now that we've defined all of our components, tell
# agent1 which ones we want to activate.
agent1.channels = ch1
agent1.sources = avro-source1
agent1.sinks = log-sink1
еРѓеК®е¶ВдЄЛеСљдї§пЉМе∞±еПѓдї•еЬ® hdfs дЄКзЬЛеИ∞жХИжЮЬдЇЖгАВ
../bin/flume-ng agent --conf ../conf/ -f flume_directHDFS.conf -n agent1 -Dflume.root.logger=INFO,console
PSпЉЪеЃЮйЩЕзОѓеҐГдЄ≠жЬЙињЩж†ЈзЪДйЬАж±ВпЉМйАЪињЗеЬ®е§ЪдЄ™agentзЂѓtailжЧ•ењЧпЉМеПСйАБзїЩcollectorпЉМcollectorеЖНжККжХ∞жНЃжФґйЫЖпЉМзїЯдЄАеПСйАБзїЩHDFSе≠ШеВ®иµЈжЭ•пЉМељУHDFSжЦЗдїґе§Іе∞ПиґЕињЗдЄАеЃЪзЪДе§Іе∞ПжИЦиАЕиґЕињЗеЬ®иІДеЃЪзЪДжЧґйЧійЧійЪФдЉЪзФЯжИРдЄАдЄ™жЦЗдїґгАВ
Flume еЃЮзО∞дЇЖдЄ§дЄ™TriggerпЉМеИЖеИЂдЄЇSizeTrigerпЉИеЬ®и∞ГзФ®HDFSиЊУеЗЇжµБеЖЩзЪДеРМжЧґпЉМcountиѓ•жµБеЈ≤зїПеЖЩеЕ•зЪДе§Іе∞ПжАїеТМпЉМиЛ•иґЕињЗдЄАеЃЪе§Іе∞ПпЉМеИЩеИЫеїЇжЦ∞зЪДжЦЗдїґеТМиЊУеЗЇжµБпЉМеЖЩеЕ•жУНдљЬжМЗеРСжЦ∞зЪДиЊУеЗЇжµБпЉМеРМжЧґcloseдї•еЙНзЪДиЊУеЗЇжµБпЉЙеТМTimeTrigerпЉИеЉАеРѓеЃЪжЧґеЩ®пЉМељУеИ∞иЊЊиѓ•зВєжЧґпЉМиЗ™еК®еИЫеїЇжЦ∞зЪДжЦЗдїґеТМиЊУеЗЇжµБпЉМжЦ∞зЪДеЖЩеЕ•йЗНеЃЪеРСеИ∞иѓ•жµБдЄ≠пЉМеРМжЧґcloseдї•еЙНзЪДиЊУеЗЇжµБпЉЙгАВ
3гАБжЭ•дЄАдЄ™еЄЄиІБжЮґжЮДпЉЪе§Ъ agent ж±ЗиБЪеЖЩеЕ• HDFS
 
4гАБеЬ®еРДдЄ™webserverжЧ•ењЧжЬЇдЄКйЕНзљЃ Flume Client
# clientMainAgent
clientMainAgent.channels = c1
clientMainAgent.sources  = s1
clientMainAgent.sinks    = k1 k2
# clientMainAgent sinks group
clientMainAgent.sinkgroups = g1
# clientMainAgent Spooling Directory Source
clientMainAgent.sources.s1.type = spooldir
clientMainAgent.sources.s1.spoolDir  =/dsap/rawdata/
clientMainAgent.sources.s1.fileHeader = true
clientMainAgent.sources.s1.deletePolicy =immediate
clientMainAgent.sources.s1.batchSize =1000
clientMainAgent.sources.s1.channels =c1
clientMainAgent.sources.s1.deserializer.maxLineLength =1048576
# clientMainAgent FileChannel
clientMainAgent.channels.c1.type = file
clientMainAgent.channels.c1.checkpointDir = /var/flume/fchannel/spool/checkpoint
clientMainAgent.channels.c1.dataDirs = /var/flume/fchannel/spool/data
clientMainAgent.channels.c1.capacity = 200000000
clientMainAgent.channels.c1.keep-alive = 30
clientMainAgent.channels.c1.write-timeout = 30
clientMainAgent.channels.c1.checkpoint-timeout=600
 
# clientMainAgent Sinks
# k1 sink
clientMainAgent.sinks.k1.channel = c1
clientMainAgent.sinks.k1.type = avro
# connect to CollectorMainAgent
clientMainAgent.sinks.k1.hostname = flume115
clientMainAgent.sinks.k1.port = 41415
# k2 sink
clientMainAgent.sinks.k2.channel = c1
clientMainAgent.sinks.k2.type = avro
 
# connect to CollectorBackupAgent
clientMainAgent.sinks.k2.hostname = flume116
clientMainAgent.sinks.k2.port = 41415
# clientMainAgent sinks group
clientMainAgent.sinkgroups.g1.sinks = k1 k2
# load_balance type
clientMainAgent.sinkgroups.g1.processor.type = load_balance
clientMainAgent.sinkgroups.g1.processor.backoff   = true
clientMainAgent.sinkgroups.g1.processor.selector  = random
 
../bin/flume-ng agent --conf ../conf/ -f flume_Consolidation.conf -n clientMainAgent -Dflume.root.logger=DEBUG,console
5гАБеЬ®ж±ЗиБЪиКВзВєйЕНзљЃ Flume server
# collectorMainAgent
collectorMainAgent.channels = c2
collectorMainAgent.sources  = s2
collectorMainAgent.sinks    =k1 k2
# collectorMainAgent AvroSource
#
collectorMainAgent.sources.s2.type = avro
collectorMainAgent.sources.s2.bind = flume115
collectorMainAgent.sources.s2.port = 41415
collectorMainAgent.sources.s2.channels = c2
 
# collectorMainAgent FileChannel
#
collectorMainAgent.channels.c2.type = file
collectorMainAgent.channels.c2.checkpointDir =/opt/var/flume/fchannel/spool/checkpoint
collectorMainAgent.channels.c2.dataDirs = /opt/var/flume/fchannel/spool/data,/work/flume/fchannel/spool/data
collectorMainAgent.channels.c2.capacity = 200000000
collectorMainAgent.channels.c2.transactionCapacity=6000
collectorMainAgent.channels.c2.checkpointInterval=60000
# collectorMainAgent hdfsSink
collectorMainAgent.sinks.k2.type = hdfs
collectorMainAgent.sinks.k2.channel = c2
collectorMainAgent.sinks.k2.hdfs.path = hdfs://db-cdh-cluster/flume%{dir}
collectorMainAgent.sinks.k2.hdfs.filePrefix =k2_%{file}
collectorMainAgent.sinks.k2.hdfs.inUsePrefix =_
collectorMainAgent.sinks.k2.hdfs.inUseSuffix =.tmp
collectorMainAgent.sinks.k2.hdfs.rollSize = 0
collectorMainAgent.sinks.k2.hdfs.rollCount = 0
collectorMainAgent.sinks.k2.hdfs.rollInterval = 240
collectorMainAgent.sinks.k2.hdfs.writeFormat = Text
collectorMainAgent.sinks.k2.hdfs.fileType = DataStream
collectorMainAgent.sinks.k2.hdfs.batchSize = 6000
collectorMainAgent.sinks.k2.hdfs.callTimeout = 60000
 
collectorMainAgent.sinks.k1.type = hdfs
collectorMainAgent.sinks.k1.channel = c2
collectorMainAgent.sinks.k1.hdfs.path = hdfs://db-cdh-cluster/flume%{dir}
collectorMainAgent.sinks.k1.hdfs.filePrefix =k1_%{file}
collectorMainAgent.sinks.k1.hdfs.inUsePrefix =_
collectorMainAgent.sinks.k1.hdfs.inUseSuffix =.tmp
collectorMainAgent.sinks.k1.hdfs.rollSize = 0
collectorMainAgent.sinks.k1.hdfs.rollCount = 0
collectorMainAgent.sinks.k1.hdfs.rollInterval = 240
collectorMainAgent.sinks.k1.hdfs.writeFormat = Text
collectorMainAgent.sinks.k1.hdfs.fileType = DataStream
collectorMainAgent.sinks.k1.hdfs.batchSize = 6000
collectorMainAgent.sinks.k1.hdfs.callTimeout = 60000
../bin/flume-ng agent --conf ../conf/ -f flume_Consolidation.conf -n collectorMainAgent -Dflume.root.logger=DEBUG,console
дЄКйЭҐйЗЗзФ®зЪДе∞±жШѓз±їдЉЉ cs жЮґжЮДпЉМеРДдЄ™ flume agent иКВзВєеЕИе∞ЖеРДеП∞жЬЇеЩ®зЪДжЧ•ењЧж±ЗжАїеИ∞¬†Consolidation иКВзВєпЉМзДґеРОеЖНзФ±ињЩдЇЫиКВзВєзїЯдЄАеЖЩеЕ• HDFSпЉМеєґдЄФйЗЗзФ®дЇЖиіЯиљљеЭЗи°°зЪДжЦєеЉПпЉМдљ†ињШеПѓдї•йЕНзљЃйЂШеПѓзФ®зЪДж®°еЉПз≠Йз≠ЙгАВ
6гАБдљњзФ®log4jеПСйАБlogеИ∞flume
1пЉЙflumeйЕНзљЃпЉЪ
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
 
# Describe/configure the source
a1.sources.r1.type = avro
#a1.sources.r1.type = netcat
a1.sources.r1.bind=10.10.73.58
a1.sources.r1.port=44446
 
# Describe the sink
a1.sinks.k1.type = logger
 
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
 
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
 
2пЉЙеРѓеК®
./bin/flume-ng agent --conf conf --conf-file ./conf/flume-conf.properties --name a1 -Dflume.root.logger=INFO,LOGFILE
 
3пЉЙlog4jйЕНзљЃпЉЪ
log4j.propertiesпЉМдєЯеПѓдї•дљњзФ®дљњзФ®log4j.xml
### set log levels ###
log4j.rootLogger=INFO ,Console, file, flume
log4j.logger.per.flume=INFO
 
#Console
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.Target=System.out
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
#log4j.appender.Console.layout.ConversionPattern=%m%n
log4j.logger.com.test=Console
#log4j.logger.com.gongpb.framework.exception=Console
 
### flume ###
log4j.appender.flume=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.layout=org.apache.log4j.PatternLayout
log4j.appender.flume.Hostname=10.10.73.58
log4j.appender.flume.Port=44446
 
### file ###
log4j.appender.file=org.apache.log4j.DailyRollingFileAppender
log4j.appender.file.Threshold=INFO
log4j.appender.file.File=/opt/logs/test.log
log4j.appender.file.Append=true
log4j.appender.file.DatePattern='.'yyyy-MM-dd
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %c{1} [%p] %m%n
 
4пЉЙеПСйАБз®ЛеЇПпЉЪ
package com.test.flume;
import java.util.Date;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
 
public class WriteLog {
protected static final Logger logger = LoggerFactory.getLogger(WriteLog.class);
 
    public static void main(String[] args) throws Exception {
//     String configFile = WriteLog.class.getResource("/").getPath() + "/log4j.properties";
// PropertyConfigurator.configure(configFile);
        while (true) {
            logger.info(String.valueOf(new Date().getTime()));
            Thread.sleep(1000);
        }
    }    
}
7гАБеПѓиГљйБЗеИ∞зЪДйЧЃйҐШ
1пЉЙOOM¬†йЧЃйҐШпЉЪ
flume жК•йФЩпЉЪ
java.lang.OutOfMemoryError: GC overhead limit exceeded
жИЦиАЕпЉЪ
java.lang.OutOfMemoryError: Java heap space
Exception in thread"SinkRunner-PollingRunner-DefaultSinkProcessor" java.lang.OutOfMemoryError: Java heap space
Flume¬†еРѓеК®жЧґзЪДжЬАе§Іе†ЖеЖЕе≠Ше§Іе∞ПйїШиЃ§жШѓ¬†20MпЉМзЇњдЄКзОѓеҐГеЊИеЃєжШУOOMпЉМеЫ†ж≠§йЬАи¶Бдљ†еЬ®flume-env.sh¬†дЄ≠жЈїеК†JVM¬†еРѓеК®еПВжХ∞:¬†
JAVA_OPTS="-Xms8192m -Xmx8192m -Xss256k -Xmn2g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-UseGCOverheadLimit"
зДґеРОеЬ®еРѓеК®¬†agent¬†зЪДжЧґеАЩдЄАеЃЪи¶БеЄ¶дЄК¬†-c confйАЙй°єпЉМеР¶еИЩ¬†flume-env.shйЗМйЕНзљЃзЪДзОѓеҐГеПШйЗПдЄНдЉЪ襀еК†иљљзФЯжХИгАВ
 
2пЉЙJDK зЙИжЬђдЄНеЕЉеЃєйЧЃйҐШпЉЪ
2014-07-07 14:44:17,902 (agent-shutdown-hook) [WARN - org.apache.flume.sink.hdfs.HDFSEventSink.stop(HDFSEventSink.java:504)] Exception while closing hdfs://192.168.1.111:8020/flumeTest/FlumeData. Exception follows.
java.lang.UnsupportedOperationException: This is supposed to be overridden by subclasses.
        at com.google.protobuf.GeneratedMessage.getUnknownFields(GeneratedMessage.java:180)
        at org.apache.Hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$GetFileInfoRequestProto.getSerializedSize(ClientNamenodeProtocolProtos.java:30108)
        at com.google.protobuf.AbstractMessageLite.toByteString(AbstractMessageLite.java:49)
        at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.constructRpcRequest(ProtobufRpcEngine.java:149)
        at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:193)
жККдљ†зЪД jdk7 жНҐжИР jdk6 иѓХиѓХгАВ
3пЉЙе∞ПжЦЗдїґеЖЩеЕ• HDFS еїґжЧґзЪДйЧЃйҐШ
еЕґеЃЮдЄКйЭҐ 3.2 дЄ≠еЈ≤жЬЙиѓіжШОпЉМflume зЪД sink еЈ≤зїПеЃЮзО∞дЇЖеЗ†зІНжЬАдЄїи¶БзЪДжМБдєЕеМЦиІ¶еПСеЩ®пЉЪ
жѓФе¶ВжМЙе§Іе∞ПгАБжМЙйЧійЪФжЧґйЧігАБжМЙжґИжБѓжЭ°жХ∞з≠Йз≠ЙпЉМйТИеѓєдљ†зЪДжЦЗдїґињЗе∞ПињЯињЯж≤°ж≥ХеЖЩеЕ• HDFS жМБдєЕеМЦзЪДйЧЃйҐШпЉМ
йВ£жШѓеЫ†дЄЇдљ†ж≠§жЧґињШж≤°жЬЙжї°иґ≥жМБдєЕеМЦзЪДжЭ°дїґпЉМжѓФе¶Вдљ†зЪДи°МжХ∞ињШж≤°жЬЙиЊЊеИ∞йЕНзљЃзЪДйШИеАЉжИЦиАЕе§Іе∞ПињШж≤°иЊЊеИ∞з≠Йз≠ЙпЉМ
еПѓдї•йТИеѓєдЄКйЭҐ 3.2 е∞ПиКВзЪДйЕНзљЃеЊЃи∞ГдЄЛпЉМдЊЛе¶ВпЉЪ
agent1.sinks.log-sink1.hdfs.rollInterval = 20
 
ељУињЯињЯж≤°жЬЙжЦ∞жЧ•ењЧзФЯжИРзЪДжЧґеАЩпЉМе¶ВжЮЬдљ†жГ≥еЊИењЂзЪД flushпЉМйВ£дєИиЃ©еЃГжѓПйЪФ 20s flush жМБдєЕеМЦдЄАдЄЛпЉМagent дЉЪж†єжНЃе§ЪдЄ™жЭ°дїґпЉМдЉШеЕИжЙІи°Мжї°иґ≥жЭ°дїґзЪДиІ¶еПСеЩ®гАВ
дЄЛйЭҐиіідЄАдЇЫеЄЄиІБзЪДжМБдєЕеМЦиІ¶еПСеЩ®пЉЪ
# Number of seconds to wait before rolling current file (in 600 seconds)
agent.sinks.sink.hdfs.rollInterval=600
# File size to trigger roll, in bytes (256Mb)
agent.sinks.sink.hdfs.rollSize = 268435456
# never roll based on number of events
agent.sinks.sink.hdfs.rollCount = 0
# Timeout after which inactive files get closed (in seconds)
agent.sinks.sink.hdfs.idleTimeout = 3600
agent.sinks.HDFS.hdfs.batchSize = 1000
4пЉЙжХ∞жНЃйЗНе§НеЖЩеЕ•гАБ䪥姱йЧЃйҐШ
FlumeзЪДHDFSsinkеЬ®жХ∞жНЃеЖЩеЕ•/иѓїеЗЇChannelжЧґпЉМйГљжЬЙTranscationзЪДдњЭиѓБгАВељУTransaction姱賕жЧґпЉМдЉЪеЫЮжїЪпЉМзДґеРОйЗНиѓХгАВдљЖзФ±дЇОHDFSдЄНеПѓдњЃжФєжЦЗдїґзЪДеЖЕеЃєпЉМеБЗиЃЊжЬЙ1дЄЗи°МжХ∞жНЃи¶БеЖЩеЕ•HDFSпЉМиАМеЬ®еЖЩеЕ•5000и°МжЧґпЉМзљСзїЬеЗЇзО∞йЧЃйҐШеѓЉиЗіеЖЩеŕ姱賕пЉМTransactionеЫЮжїЪпЉМзДґеРОйЗНеЖЩињЩ10000жЭ°иЃ∞ељХжИРеКЯпЉМе∞±дЉЪеѓЉиЗізђђдЄАжђ°еЖЩеЕ•зЪД5000и°МйЗНе§НгАВињЩдЇЫйЧЃйҐШжШѓHDFS¬†жЦЗдїґз≥їзїЯиЃЊиЃ°дЄКзЪДзЙєжАІзЉЇйЩЈпЉМеєґдЄНиГљйАЪињЗзЃАеНХзЪДBugfixжЭ•иІ£еЖ≥гАВжИСдїђеП™иГљеЕ≥йЧ≠жЙєйЗПеЖЩеЕ•пЉМеНХжЭ°дЇЛеК°дњЭиѓБпЉМжИЦиАЕеРѓзФ®зЫСжОІз≠ЦзХ•пЉМдЄ§зЂѓеѓєжХ∞гАВ
MemoryеТМexecзЪДжЦєеЉПеПѓиГљдЉЪжЬЙжХ∞ж́䪥姱пЉМfileжШѓ¬†end to endзЪДеПѓйЭ†жАІдњЭиѓБзЪДпЉМдљЖжШѓжАІиГљиЊГеЙНдЄ§иАЕи¶БеЈЃгАВ
end to endгАБstore on failureжЦєеЉП¬†ACKз°ЃиЃ§жЧґйЧіиЃЊзљЃињЗзЯ≠пЉИзЙєеИЂжШѓйЂШе≥∞жЧґйЧіпЉЙдєЯжЬЙеПѓиГљеЉХеПСжХ∞жНЃзЪДйЗНе§НеЖЩеЕ•гАВ
5пЉЙtail жЦ≠зВєзї≠дЉ†зЪДйЧЃйҐШпЉЪ
еПѓдї•еЬ® tail дЉ†зЪДжЧґеАЩиЃ∞ељХи°МеПЈпЉМдЄЛжђ°еЖНдЉ†зЪДжЧґеАЩпЉМеПЦдЄКжђ°иЃ∞ељХзЪДдљНзљЃеЉАеІЛдЉ†иЊУпЉМз±їдЉЉпЉЪ
agent1.sources.avro-source1.command = /usr/local/bin/tail ¬†-n +$(tail -n1 /home/storm/tmp/n) --max-unchanged-stats=600 -F ¬†/home/storm/tmp/id.txt | awk 'ARNGIND==1{i=$0;next}{i++; if($0~/жЦЗдїґеЈ≤жИ™жЦ≠/)i=0; print i >> "/home/storm/tmp/n";print $1"---"i}' /home/storm/tmp/n -
 
йЬАи¶Бж≥®жДПе¶ВдЄЛеЗ†зВєпЉЪ
пЉИ1пЉЙжЦЗ俴襀rotation¬†зЪДжЧґеАЩпЉМйЬАи¶БеРМж≠•жЫіжЦ∞дљ†зЪДжЦ≠зВєиЃ∞ељХвАЬжМЗйТИвАЭпЉМ
пЉИ2пЉЙйЬАи¶БжМЙжЦЗдїґеРНжЭ•ињљиЄ™жЦЗдїґпЉМ
пЉИ3пЉЙflumeжМВжОЙеРОйЬАи¶БзіѓеК†жЦ≠зВєзї≠дЉ†вАЬжМЗйТИвАЭ
пЉИ4пЉЙflumeжМВжОЙеРОпЉМе¶ВжЮЬжБ∞е•љжЦЗ俴襀¬†rotationпЉМйВ£дєИдЉЪжЬЙдЄҐжХ∞жНЃзЪДй£ОйЩ©пЉМ
¬† ¬† ¬† ¬†еП™иГљзЫСжОІе∞љењЂжЛЙиµЈжИЦиАЕеК†йАїиЊСеИ§жЦ≠жЦЗдїґе§Іе∞ПйЗНзљЃжМЗйТИгАВ
пЉИ5пЉЙtail¬†ж≥®жДПдљ†зЪДзЙИжЬђпЉМиѓЈжЫіжЦ∞¬†coreutilsеМЕеИ∞жЬАжЦ∞гАВ
 
6пЉЙеЬ® Flume дЄ≠е¶ВдљХдњЃжФєгАБдЄҐеЉГгАБжМЙйҐДеЃЪдєЙиІДеИЩеИЖз±їе≠ШеВ®жХ∞жНЃпЉЯ
ињЩйЗМдљ†йЬАи¶БеИ©зФ®¬†Flume¬†жПРдЊЫзЪДжЛ¶жИ™еЩ®пЉИInterceptorпЉЙжЬЇеИґжЭ•жї°иґ≥дЄКињ∞зЪДйЬАж±ВдЇЖгАВ
 




зЫЄеЕ≥жО®иНР
- **жХ∞жНЃеЇУеЕЉеЃєжАІ**пЉЪFlume-ng-sql-sourceйАЪеЄЄйЬАи¶БJDBCй©±еК®жЭ•ињЮжО•еРДзІНз±їеЮЛзЪДSQLжХ∞жНЃеЇУпЉМеЫ†ж≠§йЬАи¶Бз°ЃдњЭж≠£з°ЃеЃЙи£ЕеєґйЕНзљЃдЇЖзЫЄеЇФзЪДй©±еК®гАВ - **жߕ胥еЃЪеИґ**пЉЪзФ®жИЈеПѓдї•зЉЦеЖЩиЗ™еЃЪдєЙSQLжߕ胥жЭ•иОЈеПЦжЙАйЬАзЪДжХ∞жНЃпЉМдєЯеПѓдї•ж†єжНЃжЧґйЧіжИ≥...
1. **йЕНзљЃ**пЉЪйЕНзљЃflumeng-kafka-pluginжґЙеПКеИ∞иЃЊзљЃFlumeдї£зРЖзЪДйЕНзљЃжЦЗдїґпЉМеМЕжЛђKafkaжЬНеК°еЩ®зЪДеЬ∞еЭАгАБи¶БжґИиієжИЦеПСеЄГзЪДдЄїйҐШгАБдї•еПКиЃ§иѓБдњ°жБѓз≠ЙгАВ 2. **жАІиГљдЉШеМЦ**пЉЪиАГиЩСеИ∞FlumeеТМKafkaзЪДеРЮеРРйЗПпЉМжИСдїђеПѓиГљйЬАи¶Би∞ГжХізЉУеЖ≤еМЇе§Іе∞П...
- **йЕНзљЃprofile**пЉЪз°ЃдњЭдЄ§еП∞жЬЇеЩ®дЄКзЪДFlume-ngйЕНзљЃжЦЗдїґж≠£з°ЃжЧ†иѓѓгАВ #### еЫЫгАБFlumeйЫЖзЊ§йЕНзљЃз§ЇдЊЛ ##### 4.1 Netcatж®°еЉПйЕНзљЃ Netcatж®°еЉПжШѓдЄАзІНзЃАеНХзЪДзљСзїЬйАЪдњ°жЦєеЉПпЉМеПѓдї•зФ®жЭ•жµЛиѓХжХ∞жНЃдЉ†иЊУжШѓеР¶ж≠£еЄЄгАВеЬ®agentеТМcollect...
ињЩеПѓдї•йАЪињЗеЬ® Flume зЪДйЕНзљЃжЦЗдїґдЄ≠жМЗеЃЪ `lib` зЫЃељХжИЦиАЕдљњзФ® `flume-ng classloader.path` еПВжХ∞жЭ•еЃЮзО∞гАВ йАЪињЗињЩдЄ™еЃЮжИШпЉМжИСдїђеПѓдї•е≠¶дє†еИ∞е¶ВдљХеИ©зФ® Apache Flume еТМ Kafka еЃЮзО∞йЂШжХИзЪДжХ∞жНЃжµБе§ДзРЖгАВињЩдЄ™ињЗз®ЛеѓєдЇОеЃЮжЧґе§ІжХ∞жНЃ...
дїОFlumeзЪДзЙИжЬђжЫіињ≠жЭ•зЬЛпЉМFlumeNGжШѓеЬ®еОЯжЬЙFlume0.9xзЙИжЬђеЯЇз°АдЄКињЫи°МйЗНжЦ∞еЉАеПСзЪДзЙИжЬђпЉМдєЯе∞±жШѓжЦ∞дЄАдї£зЪДFlume(NG)пЉМеЃГдЄОиАБдЄАдї£зЙИжЬђ(OG)дЄНеЕЉеЃєгАВNGзЙИжЬђзЪДдЄїи¶БзЫЃж†ЗжШѓдЄЇдЇЖзЃАеМЦйЕНзљЃгАБзЃАеМЦйГ®зљ≤пЉИеПЦжґИдЇЖMasterиКВзВєпЉЙдї•еПКйЗНжЮДз®ЛеЇП...
10. **еЃЮжИШж°ИдЊЛдЄОжЬАдљ≥еЃЮиЈµ**: дљ†ињШдЉЪжЙЊеИ∞еЃЮйЩЕдљњзФ®FlumeзЪДж°ИдЊЛеИЖжЮРпЉМдЇЖиІ£е¶ВдљХеЬ®дЄНеРМеЬЇжЩѓдЄЛеЇФзФ®FlumeпЉМдї•еПКе¶ВдљХдЉШеМЦйЕНзљЃдї•жПРеНЗжАІиГљеТМеПѓйЭ†жАІгАВ йАЪињЗжЈ±еЕ•е≠¶дє†вАЬUsing Flume PDFвАЭпЉМдљ†е∞ЖеЕЈе§ЗиЃЊиЃ°гАБйЕНзљЃеТМзЃ°зРЖйЂШжХИгАБеПѓйЭ†...
ж≠§йЕНзљЃжЦЗдїґеРМж†ЈеЃЪдєЙдЇЖдЄАдЄ™Flume Agent `a1`пЉМдљЖињЩйЗМзЪДжЇР`r1`жШѓдЄАдЄ™AVROз±їеЮЛзЪДжЇРпЉМеєґдЄФеП™йЕНзљЃдЇЖдЄАдЄ™Loggerз±їеЮЛзЪДжО•жФґзЂѓ`k1`еТМдЄАдЄ™еЖЕе≠Шз±їеЮЛзЪДйАЪйБУ`c1`гАВињЩдЄ™йЕНзљЃжЦЗдїґзЪДдљЬзФ®жШѓдљЬдЄЇеЙНдЄАдЄ™йЕНзљЃжЦЗдїґдЄ≠йАЪйБУ`c1`еТМ`c2`зЪДжО•жФґ...
- **еРѓеК®Flume**пЉЪжЙІи°М`bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name a1 -Dflume.root.logger=INFO,console`еРѓеК®Flume AgentгАВ 2. **KafkaзОѓеҐГжЮДеїЇ**пЉЪ - **еЃЙи£ЕZookeeper**пЉЪKafkaдЊЭиµЦ...
4. **Flume-ng еТМ Flume++**пЉЪFlume-ngжШѓFlumeзЪДдЄЛдЄАдї£зЙИжЬђпЉМеЃГжПРдЊЫдЇЖжЫіеЉЇе§ІзЪДеКЯиГљеТМжЫізЃАжіБзЪДйЕНзљЃж®°еЮЛгАВFlume++еПѓиГљжМЗзЪДжШѓеЯЇдЇОFlume-ngзЪДйЂШзЇІзФ®ж≥ХжИЦжЙ©е±ХпЉМеЃГеПѓиГљеМЕеРЂдЇЖдЄАдЇЫдЉШеМЦз≠ЦзХ•пЉМе¶ВеК®жАБиіЯиљљеє≥и°°гАБиЗ™еК®жХЕйЪЬжБҐе§Нз≠Й...
Flume NG жШѓ Flume зЪДжЦ∞зЙИжЬђпЉМзЫЄжѓФжЧІзЙИпЉИFlume OGпЉЙжЫіеЉЇе§ІгАБжЫізБµжіїпЉМжФѓжМБжЫіе§ЪзЪДзЙєжАІеТМйЕНзљЃйАЙй°єгАВеЃГеЉХеЕ•дЇЖжЫідЄ∞еѓМзЪДжХ∞жНЃе§ДзРЖиГљеКЫпЉМзЃАеМЦдЇЖйЕНзљЃпЉМеєґжПРйЂШдЇЖжАІиГљеТМз®≥еЃЪжАІгАВ 7. **Flume еЬ®е§ІжХ∞жНЃеЉАеПСдЄ≠зЪДеЇФзФ®** еЬ®е§ІжХ∞жНЃ...
12-8 -йАЪињЗеЃЪжЧґи∞ГеЇ¶еЈ•еЕЈжѓПдЄАеИЖйТЯдЇІзФЯдЄАжЙєжХ∞жНЃ 1.еЬ®зЇњеЈ•еЕЈ ...crontab -e ¬†*/1 * * * * /hadoop/data/project/log_generator.sh е¶ВжЮЬи¶БеПЦжґИзФ®#ж≥®йЗКжОЙ 2.еѓєжО•pythonжЧ•ењЧдЇІзФЯеЩ®иЊУеЗЇ...streaming_project.confжЦЗдїґеЕЈдљУйЕНзљЃпЉЪ