
声明:本文内容和涉及到的代码仅限于个人学习,任何人不得作为商业用途。
本文将介绍我最近在学习Python过程中写的一个爬虫程序,将力争做到不需要有任何Python基础的程序员都能读懂。读者也可以先跳到文章末尾看最终收集的数据效果和完整代码。
1. 确立目标需求
本次练习Python爬虫的目标需求为以下两点:
1) 收集huajiao.com上的人气主播信息:每位主播的关注数,粉丝数,赞数,经验值等数据
2) 收集每位人气主播的直播历史数据,包括每次直播的开播时间,观看人数,赞数等数据
2. 确立逻辑步骤
首先通过浏览器查看www.huajiao.com网站上的各个页面,分析它的网站结构。得到如下信息:
1) 每一个导航项列出的都是直播列表,而非主播的个人主页列表
以“热门推荐”为例,如下图,每个直播页面的url格式为http://www.huajiao.com/l/liveId, 这里的liveId唯一标识一个直播,比如http://www.huajiao.com/l/52860333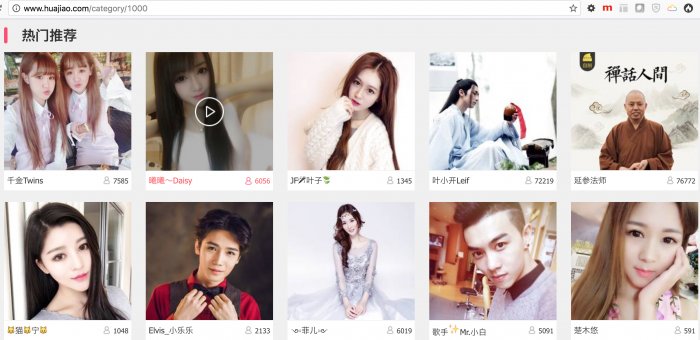
2) 在直播页上有主播的用户ID和昵称等信息
通过点击用户昵称可以进入主播的个人主页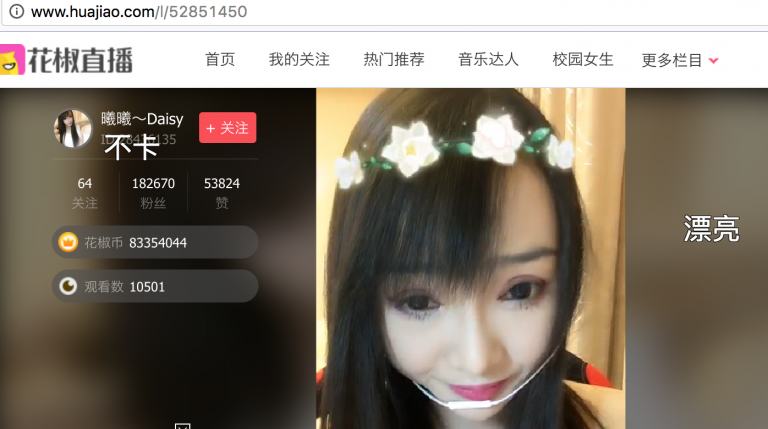
3) 在主播个人主页上有更加完整的个人信息
更加完整的个人信息包括关注数,粉丝数,赞数,经验值等数据;也有主播的直播历史数据,如下图,每个主播个人主页的url格式为http://www.huajiao.com/user/userId, 这里的userId唯一标识一个主播用户,比如http://www.huajiao.com/user/50647288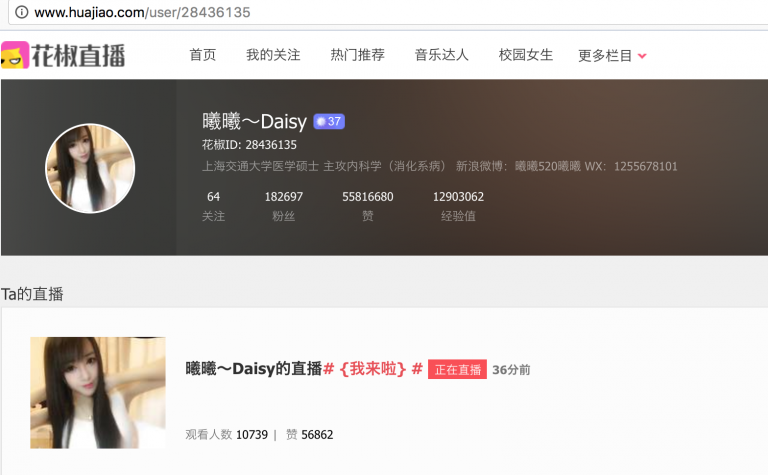
4) 程序逻辑
通过以上的分析,爬虫可以从直播列表页入手,获取到所有的直播url中的直播id,即上文提到的liveId;
拿到直播id后就可以进入直播页获取用户id,即前面提到的userId,
有了userId后就可以进入主播个人主页,在个人主页上有主播完整的个人信息和直播历史信息。
具体步骤如下:
- a):抓取直播列表页的html, 我选取的是”热门推荐”页面http://www.huajiao.com/category/1000
- b):从获取到的“热门推荐”页面的html中过滤出所有的直播地址,http://www.huajiao.com/l/liveId
- c):通过直播id抓取直播页面的html, 并过滤出主播的userId
- d):通过userId抓取主播的个人主页,过滤出关注数,粉丝数,赞数,经验值;过滤出直播历史数据。
- e):将用户数据和直播历史数据写入mysql保存
以上是根据观察网站页面,直观上得出的一个爬虫逻辑,但实际在开发过程中,还要考虑更多,比如:
- a)爬虫要定时执行,对于已经采集到的数据,采取何种更新策略
- b)直播历史数据需要请求相应的ajax接口,对收到的数据进行json解码分析
- c)主播昵称包含emoji表情,如果数据库使用常用的编码”utf8″则会写入报错
- d)过滤直播地址来获取直播id时,需要使用到正则匹配,我使用的是Python库”re”
- e)分析html,我使用的是”BeautifulSoup”
- f)读写mysql,我使用的是”pymysql”
如上逻辑步骤分析清楚后,就是编码了,利用Python来实现以上的逻辑步骤。
3. Python编码
1) 数据表设计
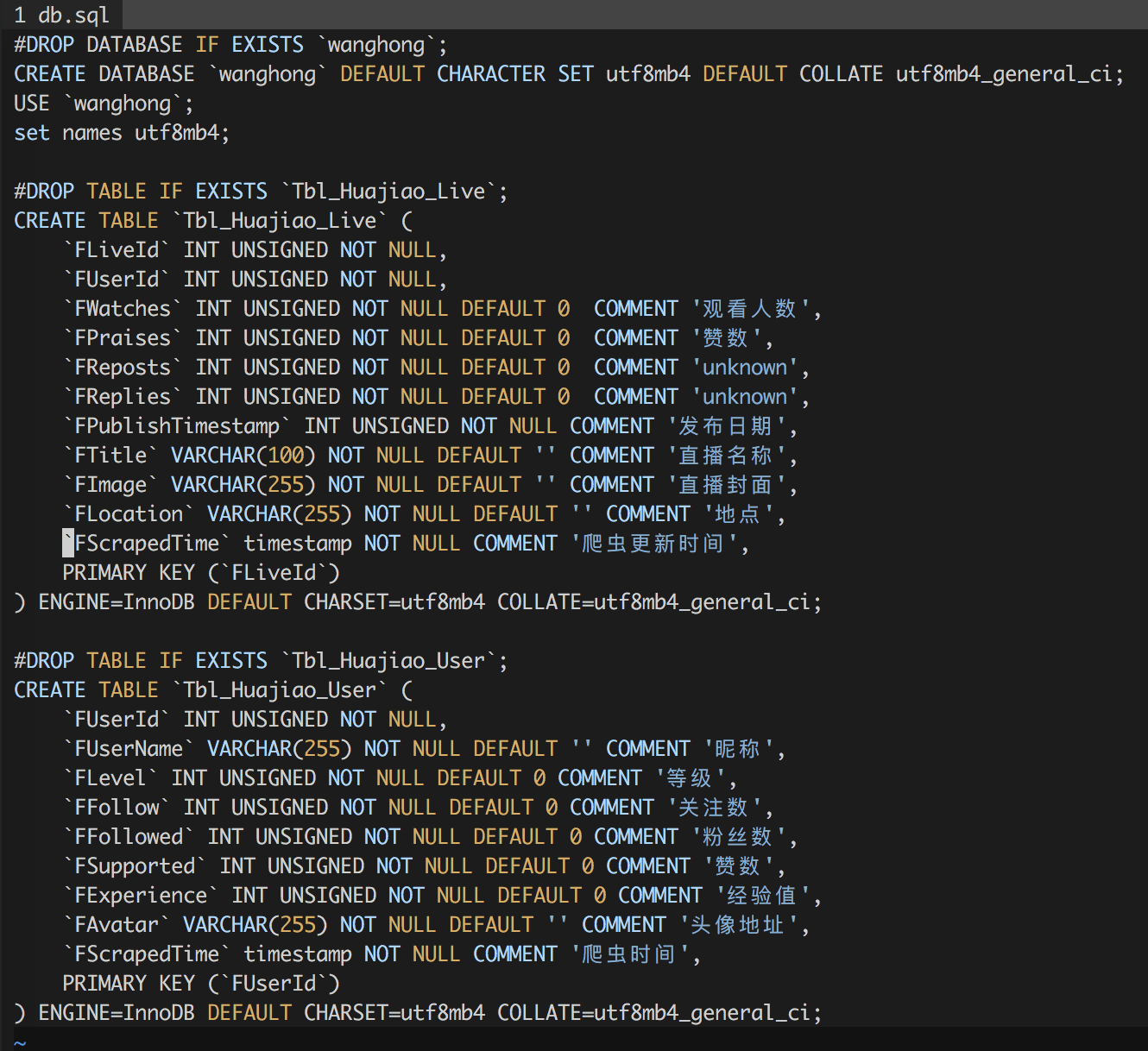
其中Tbl_Huajiao_User用于存储主播的个人数据,Tbl_Huajiao_Live用于存储主播的历史直播数据,其中字段FScrapedTime是每次记录更新的时间,依靠此字段可以实现简单的更新策略。
2) 从直播列表页过滤出直播Id列表
# filter out live ids from a url
def filterLiveIds(url):
html = urlopen(url)
liveIds = set()
bsObj = BeautifulSoup(html, "html.parser")
for link in bsObj.findAll("a", href=re.compile("^(/l/)")):
if 'href' in link.attrs:
newPage = link.attrs['href']
liveId = re.findall("[0-9]+", newPage)
liveIds.add(liveId[0])
return liveIds
关于python中如何定义函数,直接看以上代码就可以了,使用”def”和冒号,没有大括号。其中urlopen(url)是python的库函数,需要做import, 如下:
from urllib.request import urlopen
其中BeautifulSoup是一个第三方Python库,通过它就可以方便的解析html代码了,通过它的findAll()方法找出所有的a标签,并且这个方法支持正则,所以在它的参数里我传入了一个正则re.compile(“^(/l/)”)来表示寻找一”/l/”开头的所有链接地址,bsObj.findAll(“a”, href=re.compile(“^(/l/)”))的结果是一个列表,故使用for循环来遍历列表内的元素,在遍历过程中通过使用正则re.findall(“[0-9]+”, newPage)匹配出liveId, 并临时保存在liveIds中,并将liveIds返回给调用者。
3) 从直播页过滤出主播id
# get user id from live page
def getUserId(liveId):
html = urlopen("http://www.huajiao.com/" + "l/" + str(liveId))
bsObj = BeautifulSoup(html, "html.parser")
text = bsObj.title.get_text()
res = re.findall("[0-9]+", text)
return res[0]
这里还是使用BeautifulSoup分析直播页的html结构,使用bsObj.title.get_text()获取到主播Id的文本信息后,通过正则获取到最终的userId
4) 通过userId进入主播个人主页获取个人信息
#get user data from user page
def getUserData(userId):
html = urlopen("http://www.huajiao.com/user/" + str(userId))
bsObj = BeautifulSoup(html, "html.parser")
data = dict()
try:
userInfoObj = bsObj.find("div", {"id":"userInfo"})
data['FAvatar'] = userInfoObj.find("div", {"class": "avatar"}).img.attrs['src']
userId = userInfoObj.find("p", {"class":"user_id"}).get_text()
data['FUserId'] = re.findall("[0-9]+", userId)[0]
tmp = userInfoObj.h3.get_text('|', strip=True).split('|')
#print(tmp[0].encode("utf-8"))
data['FUserName'] = tmp[0]
data['FLevel'] = tmp[1]
tmp = userInfoObj.find("ul", {"class":"clearfix"}).get_text('|', strip=True).split('|')
data['FFollow'] = tmp[0]
data['FFollowed'] = tmp[2]
data['FSupported'] = tmp[4]
data['FExperience'] = tmp[6]
return data
except AttributeError:
#traceback.print_exc()
print(str(userId) + ":html parse error in getUserData()")
return 0
以上使用了python的try-except的异常处理机制,因为在使用BeautifulSoup分析html数据时,有时候会因为没有某个对象而报错,对于这种报错需要处理,否则整个程序就会停止执行,这里我们打印出了日志,在日志中记录了相应的userId。当然这里还是主要用到了BeautifulSoup便捷的功能,比如其中的get_text()方法,能够将多个标签的文本抽取出来并且能够制定文本的分隔符,和对空格等字符进行过滤。
5) 将获取的个人信息写入mysql
# update user data
def replaceUserData(data):
conn = getMysqlConn()
cur = conn.cursor()
try:
cur.execute("USE wanghong")
cur.execute("set names utf8mb4")
cur.execute("REPLACE INTO Tbl_Huajiao_User(FUserId,FUserName, FLevel, FFollow,FFollowed,FSupported,FExperience,FAvatar,FScrapedTime) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s)", (int(data['FUserId']), data['FUserName'],int(data['FLevel']),int(data['FFollow']),int(data['FFollowed']), int(data['FSupported']), int(data['FExperience']), data['FAvatar'],getNowTime())
)
conn.commit()
except pymysql.err.InternalError as e:
print(e)
这里使用了Python第三方库pymysql进行mysql的读写操作,而指定编码utf8mb4,也就是为了避免文章开始提到的一个问题,关于emoji表情符,如果数据库使用常用的编码”CHARSET=utf8 COLLATE=utf8_general_ci”则会写入报错,注意上面sql语句里也声明了utf8mb4字符集和编码。
这里没有使用mysql的“INSERT”,而是使用了“REPLACE”,是当包含同样的FUserId的一条记录被写入时将替换原来的记录,这样能够保证爬虫定时更新到最新的数据。
6) 获取某主播的直播历史数据
#get user history lives
def getUserLives(userId):
try:
url = "http://webh.huajiao.com/User/getUserFeeds?fmt=json&uid=" + str(userId)
html = urlopen(url).read().decode('utf-8')
jsonData = json.loads(html)
if jsonData['errno'] != 0:
print(str(userId) + "error occured in getUserFeeds for: " + jsonData['msg'])
return 0
return jsonData['data']['feeds']
except Exception as e:
print(e)
return 0
前面说到,获取直播历史数据是通过直接请求ajax接口地址的,代码中的url即为接口地址,这是通过浏览器的调试工具获得的。这里用到了json的解码。
7) 将主播的直播历史数据写入Mysql
这里和以上第5项类似,就不详述了,读者可以在文章末尾的github地址获取完整的代码
8) 定义骨架函数
#spider user ids
def spiderUserDatas():
for liveId in getLiveIdsFromRecommendPage():
userId = getUserId(liveId)
userData = getUserData(userId)
if userData:
replaceUserData(userData)
return 1
#spider user lives
def spiderUserLives():
userIds = selectUserIds(100)
for userId in userIds:
liveDatas = getUserLives(userId[0])
for liveData in liveDatas:
liveData['feed']['FUserId'] = userId[0]
replaceUserLive(liveData['feed'])
return 1
所谓的骨架函数,就是控制单个小的功能函数,实现循环逻辑,一页一页的去采集数据。
spiderUserDatas()的逻辑:拿到liveId列表后,循环遍历的去取每一个liveId对应的userId,进而渠道userData并写入mysql;
spiderUserLives()的逻辑:从mysql中选出上次爬虫时间最晚的100个userId, 循环遍历地去取每一个user的直播历史数据并写入mysql;
9) 定义入口函数和命令行参数
def main(argv):
if len(argv) < 2:
print("Usage: python3 huajiao.py [spiderUserDatas|spiderUserLives]")
exit()
if (argv[1] == 'spiderUserDatas'):
spiderUserDatas()
elif (argv[1] == 'spiderUserLives'):
spiderUserLives()
elif (argv[1] == 'getUserCount'):
print(getUserCount())
elif (argv[1] == 'getLiveCount'):
print(getLiveCount())
else:
print("Usage: python3 huajiao.py [spiderUserDatas|spiderUserLives|getUserCount|getLiveCount]")
if __name__ == '__main__':
main(sys.argv)
首先,要命名python在命令行模式下如何接收参数,通过sys.argv;
再有__name__的含义,如果文件被执行,则__name__的值为”__main__”;
这样通过以上代码就可以实现命令行调用和参数处理了。
比如要爬取主播的个人信息,则执行:
python3 huajiao.py spiderUserDatas
比如查看爬取了多少条用户数据信息,则执行:
python3 huajiao.py getUserCount
10) 加入crontab
*/1 * * * * python3 /root/PythonPractice/spiderWanghong/huajiao.py spiderUserDatas >> /tmp/huajiao.py_spiderUserDatas.log */1 * * * * python3 /root/PythonPractice/spiderWanghong/huajiao.py spiderUserLives >> /tmp/huajiao.py_spiderUserLives.log
4. 目标需求达成
主播数据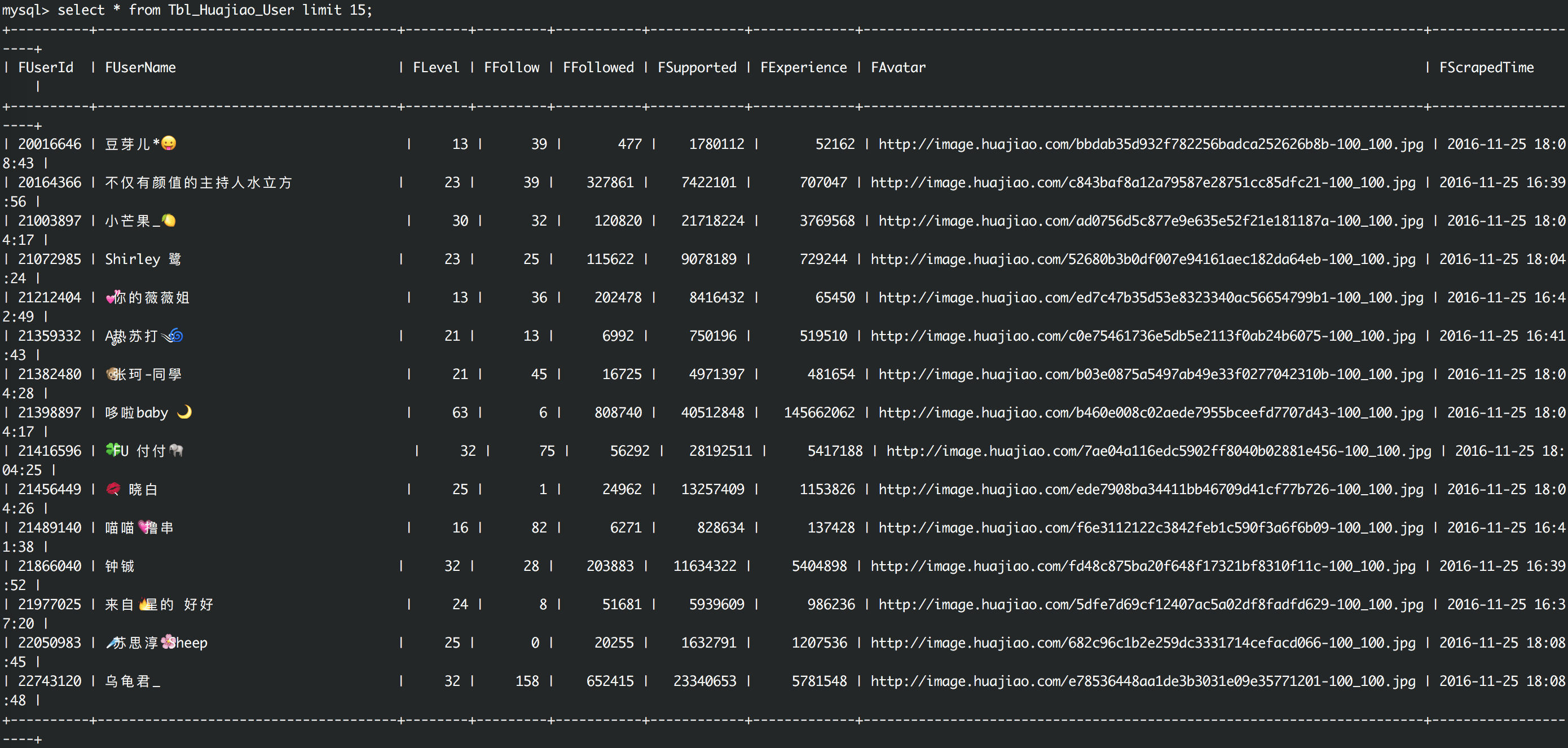
直播历史数据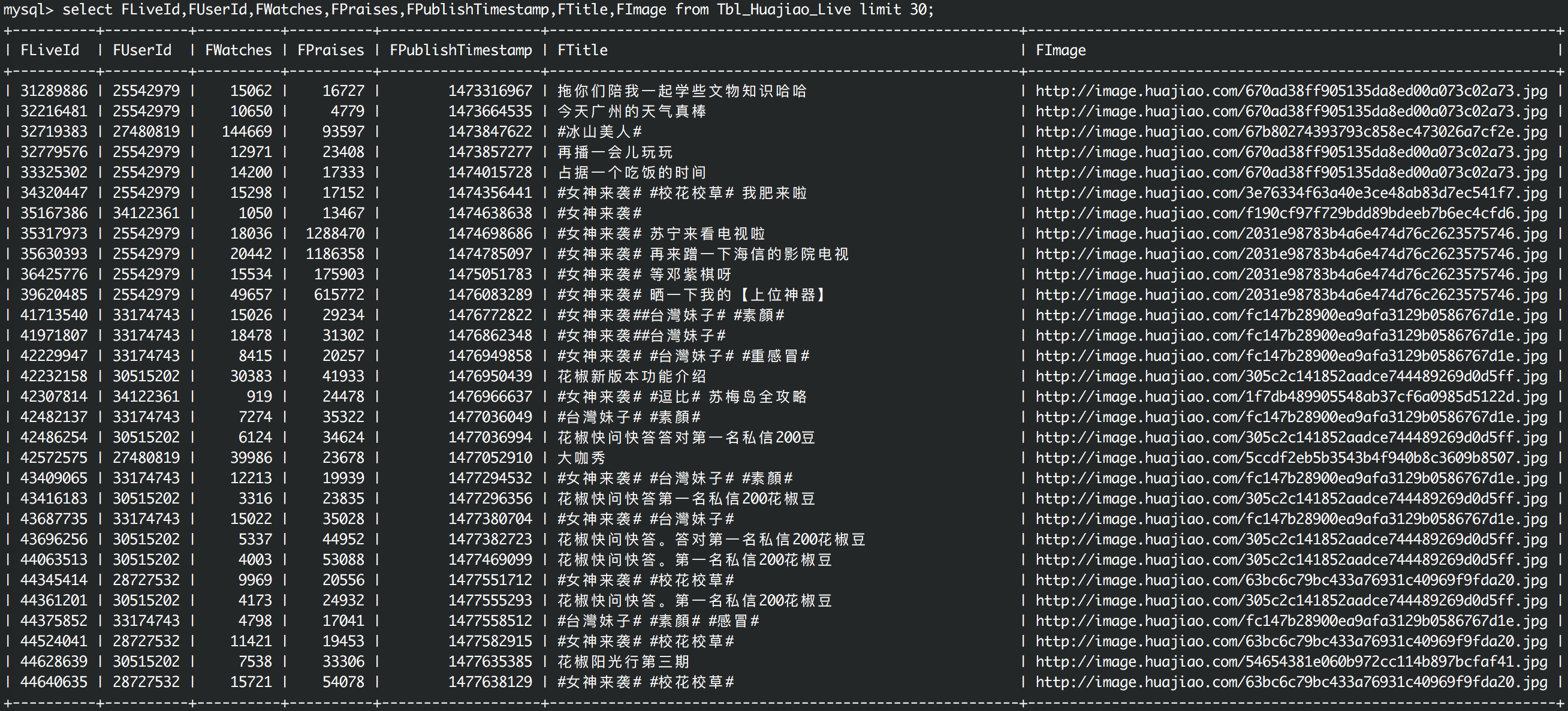
5. 待改进项和后续计划
对mysql的读写部分进行优化,现在写的比较臃肿
对其他直播网站进行分析并收集数据
将各个直播网站的数据进行聚合
6. 代码地址
https://github.com/octans/PythonPractice/tree/master/spiderWanghong




相关推荐
本书从Python的安装开始,详细讲解了Python从简单程序延伸到Python网络爬虫的全过程。本书从实战出发,根据不同的需求...适合Python网络爬虫初学者、数据分析与挖掘技术初学者,以及高校及培训学校相关专业的师生阅读。
它的设计哲学强调代码的可读性和简洁的语法,使得Python成为初学者和高级程序员的理想选择。Python的独特之处在于它是一种解释型、编译性、互动性和面向对象的脚本语言,这使得它在开发过程中无需编译,可以直接通过...
本篇文章《Python入门网络爬虫之精华版》主要介绍了Python网络爬虫的基础知识,从抓取、分析到存储的三个主要方面,以及如何应对一些常见的反爬虫机制。此外,还提及了Scrapy这一流行的爬虫框架,并提供了一个参考...
3. Portia框架:面向非程序员,采用可视化方式设计爬虫,操作简单,适合初学者和快速原型开发。 4. newspaper框架:专注于新闻和文章的抓取与分析,提供文章内容提取、元信息解析等功能。 5. Python-goose框架:专门...
《Python 3开发网络爬虫》是一本专为Python初学者和有志于网络爬虫技术的开发者编写的书籍。本书旨在通过实例介绍如何利用Python 3语言进行高效的网络数据抓取,涵盖了一系列网络爬虫的基础知识和进阶技巧。 在...
本教程旨在帮助初学者和有一定基础的开发者深入理解和掌握Python网络爬虫技术,通过实际项目实战,提升技能水平。 一、Python爬虫基础 Python网络爬虫主要涉及以下核心概念和技术: 1. 请求与响应:网络爬虫首先...
对于进行网络爬虫开发的初学者来说,掌握Python的基础非常重要。这包括变量、数据类型、控制结构(比如if语句、for循环和while循环)、函数定义、模块使用以及异常处理等。只有具备了这些基础,才能灵活地使用Python...
这本书主要针对初学者,旨在帮助读者掌握Python的基本知识并应用到网络爬虫的实践中。通过学习这本书,读者可以了解到网络爬虫的原理、构建步骤以及在实际中的应用。 网络爬虫,又称网页抓取或数据抓取,是一种自动...
"Python初学者资料大全"这个压缩包文件显然是为了帮助那些刚刚接触Python的人提供一个全面的学习资源集合。 该压缩包可能包含以下内容: 1. **基础教程**:这些教程通常会从Python的基础语法开始,如变量、数据...
综上所述,这份压缩包为Python初学者提供了一条清晰的学习路径:首先通过《Python基础教程》建立语言基础,然后借助《Python网络数据采集》和《用Python写网络爬虫》深入学习网络爬虫的原理和实践。这些书籍将帮助...
本书会详细讲解Python的基础语法,包括变量、控制结构、函数等,以便初学者快速入门。同时,书中将深入探讨如何利用Python的requests库进行HTTP请求,获取网页数据,以及BeautifulSoup和PyQuery等库解析HTML和XML...
Python爬虫实战是一份Python爬虫实战指南,内容涵盖数据采集、处理和分析...这个实例具有详细的注释,方便初学者理解和学习。 根据文件名"HelloWorld",我们可以推测这可能是该项目的起始示例,类似于许多编程教程中常
根据提供的信息,《Python网络爬虫实战》是一本适合初学者使用的Python爬虫技术书籍,它不仅能够帮助读者巩固基础知识,还能够作为一本实用工具书在实际工作中发挥作用。下面将详细介绍该书中可能涵盖的关键知识点。...
Python是一种广泛使用的高级编程语言,以其易读性、简洁的语法和强大的功能而备受青睐,尤其适合初学者入门。"Python入门教程"是学习Python的第一步,它通常涵盖基础语法、数据类型(如整型、浮点型、字符串、列表、...
总的来说,《Python3网络爬虫实战》是一本全面覆盖网络爬虫基础知识和进阶技巧的书籍,无论你是编程初学者还是有一定经验的开发者,都能从中获益匪浅,提升自己的网络爬虫技术。通过阅读并实践书中的内容,你将能够...
### Python爬虫入门教程知识点详解 #### 一、理解网页结构 在进行Python爬虫开发之前,首先要了解网页...通过以上内容的学习,初学者可以快速掌握Python爬虫的基本操作和技术要点,为后续更深入的学习打下坚实的基础。
这个资源包包含了大量的实例,旨在帮助初学者和有一定基础的开发者从基础知识开始,逐步掌握到高级的网络爬虫应用。下面将详细阐述Python网络爬虫的核心知识点及其在实际开发中的应用。 一、Python基础 Python是...
【标题】"基于Python的百度云网盘...对于初学者来说,这是一个很好的实战项目,能够提升他们的编程和问题解决能力。同时,理解并运行这个项目也能帮助学习者更深入地了解网络爬虫的工作原理,以及如何应对反爬策略。
3. Portia:可视化爬虫框架,通过拖拽操作定义爬取规则,适合初学者。 4. newspaper和Python-goose:专注于新闻和文章内容的提取,提供元信息分析,适用于新闻聚合和文本挖掘。 五、数据爬取实战——豆瓣电影数据...