
آ
آ access pattern in spark storage

آ
آ 
آ
آ
آ [1]
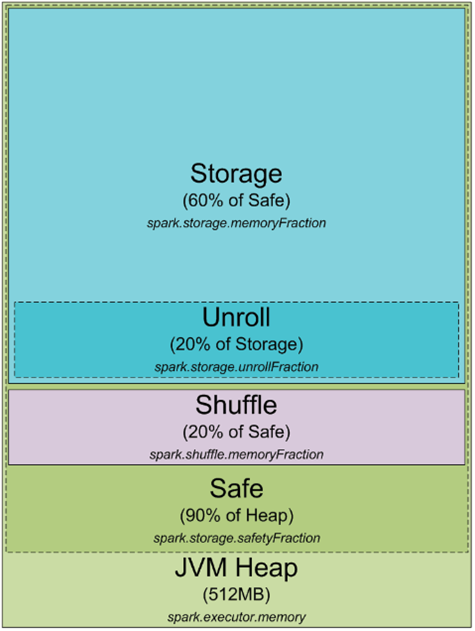
هˆ°ç›®ه‰چن¸؛و¢ï¼Œوˆ‘ن»¬ه·²ç»ڈن؛†è§£ن؛†sparkو€ژن¹ˆن½؟用JVMçڑ„ه†…هکن»¥هڈٹ集群ن¸ٹو‰§è،Œو§½وک¯ن»€ن¹ˆï¼Œç›®ه‰چن¸؛و¢è؟کو²،وœ‰è°ˆهˆ°taskçڑ„ن¸€ن؛›ç»†èٹ‚,è؟™ه°†هœ¨هڈ¦ن¸€ن¸ھو–‡ç« ن¸وڈگé«ک,هں؛وœ¬ن¸ٹه°±وک¯sparkçڑ„ن¸€ن¸ھه·¥ن½œهچ•ه…ƒï¼Œن½œن¸؛exectorçڑ„jvmè؟›ç¨‹ن¸çڑ„ن¸€ن¸ھç؛؟程و‰§è،Œï¼Œè؟™ن¹ںوک¯ن¸؛ن»€ن¹ˆsparkçڑ„jobهگ¯هٹ¨و—¶é—´ه؟«çڑ„هژںه› ,هœ¨jvmن¸هگ¯هٹ¨ن¸€ن¸ھç؛؟程و¯”هگ¯هٹ¨ن¸€ن¸ھهچ•ç‹¬çڑ„jvmè؟›ç¨‹ه—(هœ¨hadoopن¸و‰§è،Œmapreduceه؛”用ن¼ڑهگ¯هٹ¨ه¤ڑن¸ھjvmè؟›ç¨‹ï¼‰آ
ن¸‹é¢ه°†ه…³و³¨sparkçڑ„هڈ¦ن¸€ن¸ھوٹ½è±،ï¼ڑpartition, sparkه¤„çگ†çڑ„و‰€وœ‰و•°وچ®éƒ½ن¼ڑهˆ‡هˆ†وˆگpartion,ن¸€ن¸ھparitionوک¯ن»€ن¹ˆن»¥هڈٹو€ژن¹ˆç،®ه®ڑ,partitionçڑ„ه¤§ه°ڈه®Œه…¨ن¾èµ–و•°وچ®و؛گ,sparkن¸ه¤§éƒ¨هˆ†ç”¨ن؛ژ读هڈ–و•°وچ®çڑ„و–¹و³•éƒ½هڈ¯ن»¥وŒ‡ه®ڑç”ںوˆگçڑ„RDDن¸partitionçڑ„ن¸ھو•°ï¼Œه½“ن»ژhdfsن¸ٹ读هڈ–ن¸€ن¸ھو–‡ن»¶و—¶ï¼Œن¼ڑن½؟用Hadoopçڑ„InputFormatو¥ه¤„çگ†ï¼Œé»ک认وƒ…ه†µن¸‹InputFormatè؟”ه›و¯ڈن¸ھInputSplit都ن¼ڑوک ه°„RDDن¸çڑ„ن¸€ن¸ھPartition,ه¤§éƒ¨هˆ†هکه‚¨هœ¨HDFSن¸ٹçڑ„و–‡ن»¶و¯ڈن¸ھو•°وچ®ه—ن¼ڑç”ںوˆگن¸€ن¸ھInputSplit,و¯ڈن¸ھو•°وچ®ه—ه¤§ه°ڈن¸؛64mbه’Œ128mb,ه› ن¸؛HDFSن¸ٹé¢çڑ„و•°وچ®çڑ„ه—边界وک¯وŒ‰ه—èٹ‚و¥ç®—çڑ„(64mbن¸€ن¸ھه—),ن½†وک¯ه½“و•°وچ®è¢«ه¤„çگ†وک¯ï¼Œه®ƒهڈˆè¦پوŒ‰è®°ه½•è؟›è،Œهˆ‡هˆ†ï¼Œه¯¹ن؛ژو–‡وœ¬و–‡ن»¶و¥è¯´هˆ‡هˆ†çڑ„ه—符ه°±وک¯وچ¢è،Œç¬¦ï¼Œه¯¹ن؛ژsequenceو–‡ن»¶و¥è¯´ï¼Œن»–وک¯ه—结وں,ه¦‚وœوک¯هژ‹ç¼©و–‡ن»¶ï¼Œو•´ن¸ھو–‡ن»¶éƒ½è¢«هژ‹ç¼©ن؛†ï¼Œه®ƒن¸چ能وŒ‰è،Œè؟›è،Œهˆ‡هˆ†ن؛†ï¼Œو•´ن¸ھو–‡ن»¶هڈھوœ‰ن¸€ن¸ھinputsplit,è؟™و ·sparkن¸ن¹ںن¼ڑهڈھوœ‰ن¸€ن¸ھparition,هœ¨ه¤„çگ†çڑ„و—¶ه€™éœ€è¦پو‰‹هٹ¨çڑ„repatitionم€‚
آ آ [1]
آ
آ
هœ¨Sparkه†…部,هچ•ن¸ھexecutorè؟›ç¨‹ه†…RDDçڑ„هˆ†ç‰‡و•°وچ®وک¯ç”¨Iteratorوµپه¼ڈè®؟é—®çڑ„,Iteratorçڑ„hasNextو–¹و³•ه’Œnextو–¹و³•وک¯ç”±RDD lineageن¸ٹهگ„ن¸ھtransformationوگ؛ه¸¦çڑ„é—هŒ…ه‡½و•°ه¤چهگˆè€Œوˆگçڑ„م€‚该ه¤چهگˆIteratorو¯ڈè®؟é—®ن¸€ن¸ھه…ƒç´ ,ه°±ه¯¹è¯¥ه…ƒç´ ه؛”用相ه؛”çڑ„ه¤چهگˆه‡½و•°ï¼Œه¾—هˆ°çڑ„结وœه†چوµپه¼ڈهœ°èگ½هœ°ï¼ˆه¯¹ن؛ژshuffle stageوک¯èگ½هœ°هˆ°وœ¬هœ°و–‡ن»¶ç³»ç»ںç•™ه¾…هگژç»stageè®؟问,ه¯¹ن؛ژresult stageوک¯èگ½هœ°هˆ°HDFSوˆ–é€په›driver端ç‰ç‰ï¼Œè§†é€‰ç”¨çڑ„action而ه®ڑ)م€‚ه¦‚وœç”¨وˆ·و²،وœ‰è¦پو±‚Spark cache该RDDçڑ„结وœï¼Œé‚£ن¹ˆè؟™ن¸ھè؟‡ç¨‹هچ 用çڑ„ه†…هکوک¯ه¾ˆه°ڈçڑ„,ن¸€ن¸ھه…ƒç´ ه¤„çگ†ه®Œو¯•هگژه°±èگ½هœ°وˆ–و‰”وژ‰ن؛†ï¼ˆو¦‚ه؟µن¸ٹه¦‚و¤ï¼Œه®çژ°ن¸ٹوœ‰buffer),ه¹¶ن¸چن¼ڑé•؟ن¹…هœ°هچ 用ه†…هکم€‚هڈھوœ‰هœ¨ç”¨وˆ·è¦پو±‚Spark cache该RDD,ن¸”storage levelè¦پو±‚هœ¨ه†…هکن¸cacheو—¶ï¼ŒIteratorè®،ç®—ه‡؛çڑ„结وœو‰چن¼ڑ被ن؟留,é€ڑè؟‡cache managerو”¾ه…¥ه†…هکو± م€‚



相ه…³وژ¨èچگ
Apache Spark is an in-memory cluster-based parallel processing system that provides a wide range of functionalities such as graph processing, machine learning, stream processing, and SQL. This book ...
Apache Spark is an in-memory cluster based parallel processing system that provides a wide range of functionality like graph processing, machine learning, stream processing and SQL. It operates at ...
Turbocharge Spark with Alluxio, a distributed in-memory storage platform Deploy big data in the cloud using Cloudera Director Perform real-time data visualization and time series analysis using ...
Chapter 1, Machine Learning Review, ... In the detailed case study for both big data batch and real-time we select the UCI Covertype dataset and the machine learning libraries H2O, Spark MLLib and SAMOA.