
散列表(也叫哈希表)是一种查找算法,与链表、树等算法不同的是,散列表算法在查找时不需要进行一系列和关键字(关键字是数据元素中某个数据项的值,用以标识一个数据元素)的比较操作。
散列表算法希望能尽量做到不经过任何比较,通过一次存取就能得到所查找的数据元素,因而必须要在数据元素的存储位置和它的关键字(可用key表示)之间建立一个确定的对应关系,使每个关键字和散列表中一个唯一的存储位置相对应。因此在查找时,只要根据这个对应关系找到给定关键字在散列表中的位置即可。这种对应关系被称为散列函数(可用h(key)示)。
根据设定的散列函数h(key)和处理冲突的方法将一组关键字key映像到一个有限的连续的地址区间上,并以关键字在地址区间中的像作为数据元素在表中的存储位置,这种表便被称为散列表,这一映像过程称为散列,所得存储位置称为散列地址。
关键字、散列函数以及散列表的关系如下图所示:
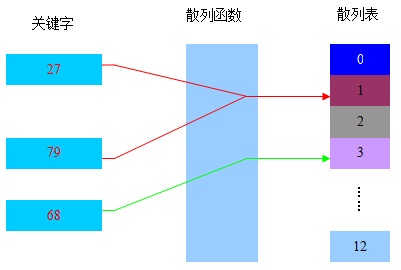
1、散列函数
散列函数是从关键字到地址区间的映像。
好的散列函数能够使得关键字经过散列后得到一个随机的地址,以便使一组关键字的散列地址均匀地分布在整个地址区间中,从而减少冲突。
常用的构造散列函数的方法有:
(1)、直接定址法
取关键字或关键字的某个线性函数值为散列地址,即:
h(key) = key 或 h(key) = a * key + b
其中a和b为常数。
(2)、数字分析法
(3)、平方取值法
取关键字平方后的中间几位为散列地址。
(4)、折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为散列地址。
(5)、除留余数法
取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址,即:
h(key) = key MOD p p ≤ m
(6)、随机数法
选择一个随机函数,取关键字的随机函数值为它的散列地址,即:
h(key) = random(key)
其中random为随机函数。
2、处理冲突
对不同的关键字可能得到同一散列地址,即key1 ≠ key2,而h(key1)= h(key2),这种现象称为冲突。具有相同函数值的关键字对该散列函数来说称作同义词。
在一般情况下,散列函数是一个压缩映像,这就不可避免地会产生冲突,因此,在创建散列表时不仅要设定一个好的散列函数,而且还要设定一种处理冲突的方法。
常用的处理冲突的方法有:
(1)、开放定址法
hi =(h(key) + di) MOD m i =1,2,…,k(k ≤ m-1)
其中,h(key)为散列函数,m为散列表表长,di为增量序列,可有下列三种取法:
1)、di = 1,2,3,…,m-1,称线性探测再散列;
2)、di = 12,-12,22,-22,32,…,±k2 (k ≤m/2),称二次探测再散列;
3)、di = 伪随机数序列,称伪随机探测再散列。
(2)、再散列法
hi = rhi(key) i = 1,2,…,k
rhi均是不同的散列函数。
(3)、链地址法
将所有关键字为同义词的数据元素存储在同一线性链表中。假设某散列函数产生的散列地址在区间[0,m-1]上,则设立一个指针型向量void *vec[m],其每个分量的初始状态都是空指针。凡散列地址为i的数据元素都插入到头指针为vec[i]的链表中。在链表中的插入位置可以在表头或表尾,也可以在表的中间,以保持同义词在同一线性链表中按关键字有序排列。
(4)、建立一个公共溢出区
ps:暂未找到java相关例子,稍后补上
转帖自:http://blog.csdn.net/npy_lp/article/details/7390378



相关推荐
根据给定文件的信息,我们可以推断出文档主要讨论了散列表的基本概念。下面将详细介绍散列表的相关知识点: ### 散列表的基本概念 #### 1. 定义与用途 散列表(Hash Table),也称为哈希表,是一种通过特殊的数据...
此外,学生还需要撰写一份详尽的课程设计报告,其中应包含对问题的描述、基本要求、测试数据、算法思路、模块划分、数据结构设计、源代码和测试结果等内容,全面反映学生对散列表概念的掌握及其应用能力。...
首先,我们要了解散列表(Hash Table)的基本概念。散列表是一种通过哈希函数将数据映射到数组中的数据结构,其核心优势在于快速查找和插入操作。它利用了“键-值”对的方式存储数据,通过计算键的哈希值确定元素在...
散列表概念 散列表,又称哈希表,是一种基于数组结构的数据结构。它通过哈希函数将一组关键字映射到一个有限的连续地址集(即数组索引范围),并将这些关键字作为记录在表中的存储位置。哈希表能够实现对数据的...
电话号码查找系统是一种高效的数据检索工具,通过使用散列表(哈希表)来存储和查找用户信息,如电话号码、用户名和地址等。在C语言中实现这样的系统,需要掌握以下关键知识点: 1. **数据结构**:首先,我们需要一...
总的来说,通过"sanliebiao.rar_visual c_散列表_散列表实验",你不仅可以学习到散列表的基本概念,还能提升C++编程技能,特别是对于数据结构的实现和优化能力。这将对你未来在IT行业的职业生涯大有裨益。
散列表的工作基于“哈希”概念,即通过一个哈希函数将关键字转化为数组的索引。这个哈希函数应该设计得尽可能均匀分布,使得关键字能够平均地分布在数组的不同位置。理想的哈希函数能够避免或最小化冲突,即两个不同...
本报告主要聚焦于散列表的基本概念、哈希函数的设计、冲突解决策略以及实际应用中的操作细节。 问题描述:设哈希(Hash)表的地址范围为 0-17,哈希函数为:H(K) = K MOD 16。K 为关键字,用线性探测法再散列法处理...
散列表,又称哈希表,是一种在计算机科学中用于数据存储的数据结构,它通过使用哈希函数将键(key)映射到一个数组的特定位置,实现快速查找、插入和删除操作。在C++编程中,散列表常用于提高数据访问效率,因为它...
首先,我们需要理解散列表的基本原理。散列表通过散列函数将键(key)映射到数组的特定位置,使得我们能够以O(1)的平均时间复杂度进行操作。在这个电话查询系统中,键可能是电话号码,而值则可能包含联系人信息,如...
在IT领域,数据结构是计算机科学中的核心概念之一,它涉及到如何有效地组织和管理大量数据。散列表(Hash Table)是一种高效的数据结构,它通过哈希函数将数据映射到一个固定大小的数组中,实现了快速查找、插入和...
总的来说,这个实验旨在帮助你掌握图论的基本概念和散列表的实现原理,同时理解这些数据结构在实际问题中的性能表现。通过实际操作,你可以深化对这些理论知识的理解,并提高编程解决实际问题的能力。
首先,我们需要理解散列表的基本概念。散列表是一种基于键值对存储的数据结构,它通过散列函数将键映射到数组的特定位置,从而实现快速访问。在这个电话号码查询系统中,键可能是人的姓名或身份证号,而值则是对应的...
在IT领域,散列表(哈希表)是一种高效的数据结构,它通过散列函数将数据映射到一个固定大小的数组中,以实现快速的插入、查找和删除操作。在C语言中,我们可以手动设计并实现一个散列表,来满足各种应用场景的需求...
2)从键盘输入各记录,分别以电话号码和用户名为关键字建立散列表;3)采用一定的方法解决冲突; 4)查找并显示给定电话号码的记录;5)查找并显示给定用户名的记录。【进一步完成内容】 1)系统功能的完善; 2)设计不同的...
### Linux内核中链表和散列表的实现原理揭秘 #### 一、引言 Linux内核作为操作系统的核心部分,在其内部实现上广泛采用了多种高效的数据结构,如数组、链表和散列表等。其中,双向循环链表与散列表是内核中使用...
对于给定的一组整数和散列函数,分别采用线性探测法和拉链法处理冲突构造散列表,并在这两种方法构建的散列表中查找整数K,比较两种方法的时间和空间性能。
### 数据结构散列表电话号码查询系统课程设计 #### 一、设计目的 在本课程设计中,我们将使用散列表作为电话号码查询系统的核心数据结构。该系统的主要目标是实现高效的信息查询服务,包括但不限于根据电话号码...
Grasshopper运算器详解为设计师提供了一个关于Grasshopper中各种基础运算器功能的详细解读,这些运算器可用于参数化设计中,即设计师可以根据预先设定的逻辑或算法规则来控制设计的生成过程。 在了解Grasshopper...
本实验通过具体的编程实践,使学生深入理解了特殊矩阵和稀疏矩阵的存储与处理方法,以及散列表的基本概念和应用场景。这些知识点不仅有助于提高学生的理论知识水平,也为他们将来从事相关的软件开发工作打下了坚实的...