
Redis中支持的数据结构比Memcached要多的多啦,如基本的字符串、哈希表、列表、集合、可排序集,在这些基本数据结构上也提供了针对该数据结构的各种操作,这也是Redis之所以流行起来的一个重要原因,当然Redis能够流行起来的原因,远远不只这一个,如支持高并发的读写、数据的持久化、高效的内存管理及淘汰机制...
从Redis的git提交历史中,可以查到,2009/10/24在1.050版本,Redis开始支持可排序集,在该版本中,只提供了一条命令zadd,宏定义如下所示:
1 {"zadd",zaddCommand,4,REDIS_CMD_BULK|REDIS_CMD_DENYOOM},
那么什么是可排序集呢? 从Redis 1.0开始就给我们提供了集合(Set)这种数据结构,集合就跟数学上的集合概念是一个道理【无序性,确定性,互异性】,集合里的元素无法保证元素的顺序,而业务上的需求,可能不止是一个集合,而且还要求能够快速地对集合元素进行排序,于是乎,Redis中提供了可排序集这么一种数据结构,似乎也是合情合理,无非就是在集合的基础上增加了排序功能,也许有人会问,Redis中不是有Sort命令嘛,下面的操作不也是同样可以达到对无序集的排序功能嘛,是的,是可以,但是在这里我们一直强调的是快速这两个字,而Sort命令的时间复杂度为O(N+M*Log(M)),可排序集获取一定范围内元素的时间复杂度为O(log(N) + M)

root@bjpengpeng-VirtualBox:/home/bjpengpeng/redis-3.0.1/src# ./redis-cli 127.0.0.1:6379> sort set 1) "1" 2) "2" 3) "3" 4) "5" 127.0.0.1:6379> sort set desc 1) "5" 2) "3" 3) "2" 4) "1" 127.0.0.1:6379>
在了解可排序集是如何实现之前,需要了解一种数据结构跳表(Skip List),跳表与AVL、红黑树...等相比,数据结构简单,算法易懂,但查询的时间复杂度与平衡二叉树/红黑树相当,跳表的基本结构如下图所示
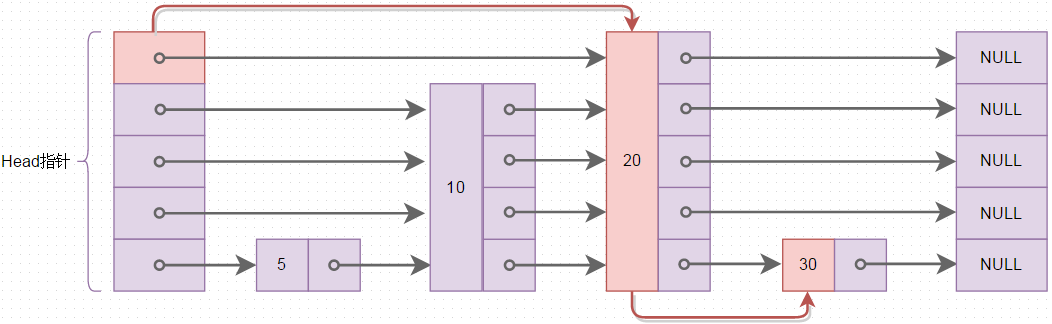
上图中整个跳表结构存放了4个元素5->10->20->30,图中的红色线表示查找元素30时,走的查找路线,从Head指针数组里最顶层的指针所指的20开始比较,与普通的链表查找相比,跳表的查询可以跳跃元素,上图中查询30,发现30比20大,则查找就是20开始,而普通链表的查询必须一个元素一个元素的比较,时间复杂度为O(n)
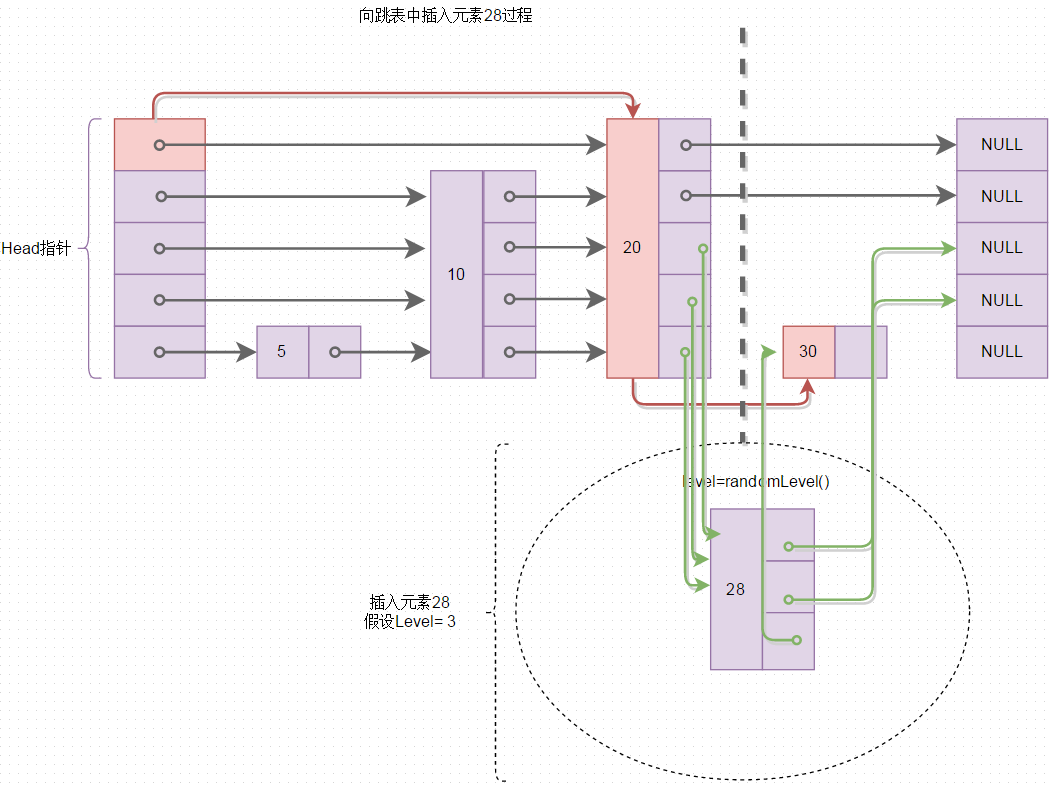
有了上图所示的跳表基本结构,再看看如何向跳表中插入元素,向跳表中插入元素,由于元素所在层级的随机性,平均起来也是O(logn),说白了,就是查找元素应该插入在什么位置,然后就是普通的移动指针问题,再想想往有序单链表的插入操作吧,时间复杂度是不是也是O(n),下图所示是往跳表中插入元素28的过程,图中红色线表示查找插入位置的过程,绿色线表示进行指针的移动,将该元素插入
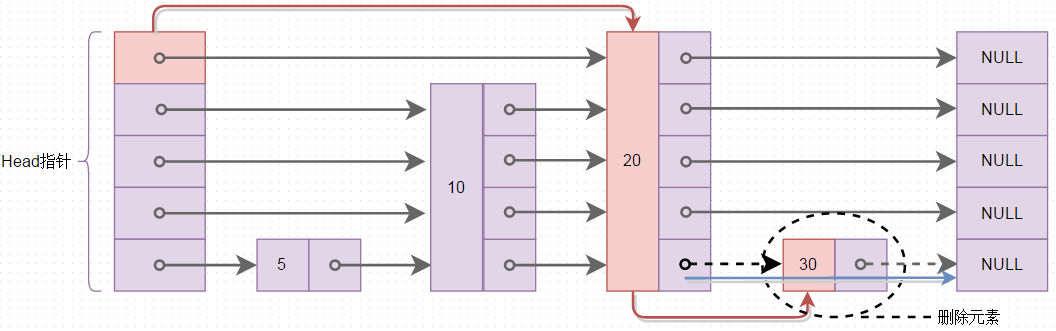
有了跳表的查找及插入那么就看看在跳表中如何删除元素吧,跳表中删除元素的个程,查找要删除的元素,找到后,进行指针的移动,过程如下图所示,删除元素30
有了上面的跳表基本结构图及原理,自已设计及实现跳表吧,这样当看到Redis里面的跳表结构时我们会更加熟悉,更容易理解些,【下面是对Redis中的跳表数据结构及相关代码进行精减后形成的可运行代码】,首先定义跳表的基本数据结构如下所示
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
#include<stdio.h>#include<stdlib.h>#define ZSKIPLIST_MAXLEVEL 32#define ZSKIPLIST_P 0.25#include <math.h>//跳表节点typedef struct zskiplistNode {
int key;
int value;
struct zskiplistLevel {
struct zskiplistNode *forward;
} level[1];
} zskiplistNode;//跳表typedef struct zskiplist {
struct zskiplistNode *header;
int level;
} zskiplist; |
在代码中我们定义了跳表结构中保存的数据为Key->Value这种形式的键值对,注意的是skiplistNode里面内含了一个结构体,代表的是层级,并且定义了跳表的最大层级为32级,下面的代码是创建空跳表,以及层级的获取方式
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
//创建跳表的节点zskiplistNode *zslCreateNode(int level, int key, int value) {
zskiplistNode *zn = (zskiplistNode *)malloc(sizeof(*zn)+level*sizeof(zn->level));
zn->key = key;
zn->value = value;
return zn;
}//初始化跳表zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = (zskiplist *) malloc(sizeof(*zsl));
zsl->level = 1;//将层级设置为1
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,NULL,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
}
return zsl;
}//向跳表中插入元素时,随机一个层级,表示插入在哪一层int zslRandomLevel(void) {
int level = 1;
while ((rand()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
} |
在这段代码中,使用了随机函数获取过元素所在的层级,下面就是重点,向跳表中插入元素,插入元素之前先查找插入的位置,代码如下所示,代码中注意update[i]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
//向跳表中插入元素zskiplistNode *zslInsert(zskiplist *zsl, int key, int value) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i, level;
x = zsl->header;
//在跳表中寻找合适的位置并插入元素
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->key < key ||
(x->level[i].forward->key == key &&
x->level[i].forward->value < value))) {
x = x->level[i].forward;
}
update[i] = x;
}
//获取元素所在的随机层数
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
update[i] = zsl->header;
}
zsl->level = level;
}
//为新创建的元素创建数据节点
x = zslCreateNode(level,key,value);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
}
return x;
} |
下面是代码中删除节点的操作,和插入节点类似
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
//跳表中删除节点的操作void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].forward = x->level[i].forward;
}
}
//如果层数变了,相应的将层数进行减1操作
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
}//从跳表中删除元素int zslDelete(zskiplist *zsl, int key, int value) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
//寻找待删除元素
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->key < key ||
(x->level[i].forward->key == key &&
x->level[i].forward->value < value))) {
x = x->level[i].forward;
}
update[i] = x;
}
x = x->level[0].forward;
if (x && key == x->key && x->value == value) {
zslDeleteNode(zsl, x, update);
//别忘了释放节点所占用的存储空间
free(x);
return 1;
} else {
//未找到相应的元素
return 0;
}
return 0;
} |
最后,附上一个不优雅的测试样例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
//将链表中的元素打印出来void printZslList(zskiplist *zsl) {
zskiplistNode *x;
x = zsl->header;
for (int i = zsl->level-1; i >= 0; i--) {
zskiplistNode *p = x->level[i].forward;
while (p) {
printf(" %d|%d ",p->key,p->value);
p = p->level[i].forward;
}
printf("\n");
}
}int main() {
zskiplist *list = zslCreate();
zslInsert(list,1,2);
zslInsert(list,4,5);
zslInsert(list,2,2);
zslInsert(list,7,2);
zslInsert(list,7,3);
zslInsert(list,7,3);
printZslList(list);
//zslDelete(list,7,2);
printZslList(list);
} |



相关推荐
### Redis介绍与内部实现机制详解 #### 一、Redis特性 **(一)存储结构** Redis,即Remote Dictionary Server的缩写,是一种基于字典结构的高性能键值存储系统。这种设计使得Redis能够高效地处理各种类型的数据...
Redis的内部实现机制基于内存,所有数据都存储在服务器的内存中,这确保了极高的读写速度。然而,纯内存存储会带来数据丢失的风险,因此Redis提供了持久化机制。有两种主要的持久化方式:RDB(快照)和AOF(Append ...
总的来说,《Redis深度历险:核心原理和应用实践》这本书涵盖了Redis的全面知识,无论对于初学者还是经验丰富的开发者,都能从中受益匪浅,深入理解Redis的内部工作机制,并学会如何在实际项目中有效利用Redis。...
总结,《Redis深度历险:核心原理和应用实践》这本书全面讲解了Redis的各个方面,不仅让读者理解其内部工作原理,更教会如何在实际项目中有效利用Redis,提升系统效率和稳定性。通过学习本书,开发者能够熟练掌握...
这本书深入剖析了Redis的内部工作机制,帮助读者理解其设计原理和实现细节。现在,我们有了一份与该书配套的Redis 3.0中文注释版源码,这将极大地便利开发者和学习者对Redis的理解。 Redis 3.0版本是一个重要的里程...
本资料“redis的设计与实现pdf”以及带注释的源码,将深入探讨Redis的内部工作机制和设计原理。 1. **Redis的数据结构** - **字符串**:基本的数据类型,可以存储简单的文本或二进制数据。 - **哈希**:用于存储...
### Redis设计与实现原理及运作机制 #### 一、内部数据结构 Redis 是一款高性能的键值存储系统,其高效性很大程度上得益于内部使用的多种高效数据结构。这些数据结构不仅支持Redis提供的各种复杂数据类型,同时也...
Redis原始注释 1. Redis中采用两种算法进行内存回收,引用计数算法以及LRU算法,在操作系统内存管理插件中,我们都学习过LRU算法...本篇博文紧随上篇Redis有序集内部实现原理分析,在此介绍博文里凡出现源码的地方
Redis 的源码分析是指对 Redis 的源代码进行深入的分析和研究,了解 Redis 的内部实现机制。通过源码分析,可以更好地理解 Redis 的原理和实现机制。 Redis 扩展学习 Redis 的扩展学习是指对 Redis 的深入学习和...
这本书《Redis设计与实现》由黄健宏撰写,深入浅出地介绍了Redis的核心原理和实际应用,对于理解Redis的内部机制和优化数据存储策略具有极大的帮助。 Redis的主要特性包括: 1. **内存存储**:Redis将所有数据存储...
本学习笔记基于GitHub上的项目“Redis-stud”,由JiangRRRen分享,旨在深入理解Redis的设计与实现原理。 一、Redis概述 Redis是Remote Dictionary Server的缩写,它是一个开源的、支持网络的、可持久化的键值存储...
本资料包包含了《Redis命令参考手册完整版.pdf》和《Redis设计与实现+第1版(黄健宏).pdf》,旨在帮助读者深入理解和掌握Redis的使用和设计原理。 《Redis命令参考手册完整版.pdf》是学习Redis操作的基础,涵盖了...
Redis的核心功能,如字符串、哈希、集合、有序集合等,都是基于`dict`来实现的。在本讨论中,我们将深入探讨Redis的`dict`结构、其特点、工作原理以及附带测试代码的意义。 首先,Redis的`dict`数据结构主要由两个...
【Redis学习笔记】基于《Redis设计与实现》的深度解析 Redis是一款高性能的键值存储...在学习过程中,参考《Redis设计与实现》这样的专业书籍,能够帮助我们深入理解Redis的内部原理,从而更好地驾驭这个强大的工具。
在深入学习部分,作者会剖析Redis的内部工作原理,包括数据结构实现、命令执行流程、网络模型等,这对于优化Redis的使用和性能调优至关重要。读者可以通过这部分内容理解Redis为何能实现毫秒级的响应时间,并学习...
- **Redis是什么**:Redis是一个内存中的数据结构存储系统,支持多种数据结构如字符串、哈希、列表、集合和有序集合。它通过持久化机制将内存中的数据保存到磁盘,以防止数据丢失,并提供了主从复制和集群功能以...