
еПВиАГиµДжЦЩпЉЪ
еЃШжЦєжЦЗж°£пЉЪhttp://mesos.apache.org/documentation¬†
дЄ≠жЦЗзњїиѓСпЉЪhttp://mesos.mydoc.io/¬†
GitHubпЉЪhttps://github.com/apache/mesos/tree/master¬†
иС£зЪДеНЪеЃҐпЉЪhttp://dongxicheng.org/category/apache-mesos/
еЃЙи£Е
дЄЛиљљmesos
еПВиАГпЉЪhttp://mesos.apache.org/documentation/latest/getting-started/¬†
дЄЛиљљжЬАжЦ∞зЙИжЬђпЉЪmesos-1.0.0пЉМзЙИжЬђи¶Бж±В:
- 64дљНlinuxжУНдљЬз≥їзїЯ
- еЖЕж†ЄзЙИжЬђе§ІдЇО3.10 зЙИжЬђ
- gccзЙИжЬђе§ІдЇО4.8.1еЃЙи£ЕдЊЭиµЦ
- еЃЙи£Еwget/tar¬†
- иОЈеПЦmavenзЪДrepoпЉЪ¬†
- wget http://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repo
- еЃЙи£Еepel repo(еЃЙи£ЕSVNењЕй°ї)пЉЪ¬†
- yum install -y epel-release
-
жЈїеК†SVN repoпЉЪ
-
еЬ®/etc/yum.repos.d/wandisco-svn.repoжЦЗдїґйЗМжЈїеК†пЉЪ
[WANdiscoSVN] 
name=WANdisco SVN Repo 1.9 
enabled=1 
baseurl=http://opensource.wandisco.com/centos/7/svn-1.9/RPMS// 
gpgcheck=1 
gpgkey=http://opensource.wandisco.com/RPM-GPG-KEY-WANdisco
-
-
жЫіжЦ∞systemdпЉЪ
- yum update systemd
-
еЃЙи£Еdevelopment tools
- yum groupinstall -y "Development Tools"
-
еЃЙи£ЕmesosдЊЭиµЦ
- sudo yum install -y apache-maven python-devel java-1.8.0-openjdk-devel zlib-devel libcurl-devel openssl-devel cyrus-sasl-devel cyrus-sasl-md5 apr-devel subversion-devel apr-util-devel
зЉЦиѓС
cd mesos
mkdir build
cd build
../configure
make(еПѓдї•дљњзФ®make -j NеК†ењЂзЉЦиѓСйАЯеЇ¶пЉМдЄНзДґзЉЦиѓСжЧґйЧійЭЮеЄЄйХњ)
make check
make installйЕНзљЃ
йїШиЃ§make installдЉЪеЃЙи£ЕеИ∞/user/local/sbinеЇХдЄЛпЉМйЕНзљЃжЦЗдїґеЬ®/usr/local/etcеЇХдЄЛпЉМеЬ®ињЩдЄ§дЄ™зЫЃељХдЄЛпЉМдЉЪжЬЙдЄАдЇЫжЦЗдїґиЈЯmaster/agentзЫЄеЕ≥
mesos-master
- mesos-start-masters.shпЉЪзФ®дЇОSSHзЩїељХеИ∞еРДдЄ™masterеєґдЄФињЫи°МstartжУНдљЬпЉМе¶ВжЮЬеНХжЬЇжЙІи°МпЉМеП™йЬАж≥®йЗКиЈЯSSHзЫЄеЕ≥жУНдљЬ(зЫіжО•йАЪињЗdaemon mesos-masterеРѓеК®)
- mesos-stop-master.shпЉЪзФ®дЇОSSHзЩїељХеИ∞еРДдЄ™masterпЉМеєґдЄФињЫи°МstopжУНдљЬпЉМе¶ВжЮЬеНХжЬЇжЙІи°МпЉМеП™йЬАж≥®йЗКSSHзЫЄеЕ≥жУНдљЬ(зЫіжО•жЙІи°Мkillall mesos-master)
- mesos-daemon.shпЉЪзФ®дЇОеРѓеК®mesos daemonпЉМйїШиЃ§дЉЪжЙІи°МдЄАдЇЫеК®дљЬ(иЃЊзљЃulimit -nдї•еПКеРѓеК®еѓєеЇФзЪДзОѓеҐГеПШйЗПиЃЊзљЃ/usr/local/etc/PROCNAME-env.sh)
- mesos-agentеЃЮйЩЕзЪДдЇМињЫеИґжЦЗдїґпЉМеПѓдї•йАЪињЗ--helpжЭ•жЯ•зЬЛеѓєеЇФеПВжХ∞пЉМеПВжХ∞еПВиАГпЉЪhttp://mesos.apache.org/documentation/latest/configuration/
-
/usr/local/etc/mesos/mesos-master-env.shпЉЪиЃЊзљЃmesosзОѓеҐГеПШйЗПпЉМеПШйЗПеСљеРНиІДеИЩдЄЇMESOS_еПВжХ∞пЉМеЕґдЄ≠{еПВжХ∞}дЄЇmesos-master --helpдЄ≠зЪДеПВжХ∞пЉМиЃЊзљЃе¶ВдЄЛпЉЪ
export MESOS_log_dir=/var/log/mesos/master # иЃЊзљЃжЧ•ењЧзЫЃељХ export MESOS_work_dir=/var/run/mesos/master # иЃЊзљЃworkзЫЃељХпЉМдЉЪе≠ШжФЊдЄАдЇЫињРи°Мдњ°жБѓ export MESOS_ip=127.0.0.1 # иЃЊзљЃIP # export MESOS_port=5050 # иЃЊзљЃPORTпЉМйїШиЃ§жШѓ5050 export MESOS_CLUSTER=mesos_test_cluster1 # иЃЊзљЃйЫЖзЊ§еРНзІ∞ export MESOS_hostname=127.0.0.1 # иЃЊзљЃmaster hostname export MESOS_logging_level=INFO # иЃЊзљЃжЧ•ењЧзЇІеИЂ export MESOS_offer_timeout=60secs # иЃЊзљЃofferзЪДиґЕжЧґжЧґйЧі # export MESOS_agent_ping_timeout=15 # иЃЊзљЃping иґЕжЧґжЧґйЧіпЉМйїШиЃ§15s # export MESOS_allocation_interval=1 # иЃЊзљЃиµДжЇР allocationйЧійЪФпЉМйїШиЃ§1s
ж≥®жДПпЉЪoffer_timeoutйЭЮеЄЄеЕ≥йФЃпЉМйїШиЃ§жШѓдЄНиґЕжЧґпЉМе¶ВжЮЬдЄАдЄ™offerеПСзїЩschedulerеРОschedulerдЄНеБЪдїїдљХе§ДзРЖ(acceptOffersжИЦиАЕdeclineOffer)пЉМйВ£дєИињЩдЄ™offerдЄАзЫідЉЪ襀ињЩдЄ™schedulerзїЩеН†зФ®дЇЖпЉМзЫіеИ∞schedulerиЗ™еЈ±зїУжЭЯињЫз®ЛжИЦиАЕйААеЗЇж≥®еЖМгАВжЙАдї•offer_timeoutдЄАиИђи¶БиЃЊзљЃпЉМзФ®дЇОйШ≤ж≠ҐзФ±дЇОschedulerиЗ™иЇЂзЪДйЧЃйҐШ(еБґеПСжАІhangдљПпЉМжИЦиАЕз®ЛеЇПйЧЃйҐШж≤°жЬЙе§ДзРЖoffer)еѓЉиЗіиµДжЇРжЧ†ж≥ХеИ©зФ®
mesos-agent
- mesos-start-agent.shпЉЪзФ®дЇОSSHзЩїељХеИ∞еРДдЄ™agentеєґдЄФињЫи°МstartжУНдљЬпЉМе¶ВжЮЬеНХжЬЇжЙІи°МпЉМеП™йЬАж≥®йЗКиЈЯSSHзЫЄеЕ≥жУНдљЬ(зЫіжО•йАЪињЗdaemon mesos-agentеРѓеК®)
- mesos-stop-agent.shпЉЪзФ®дЇОSSHзЩїељХеИ∞еРДдЄ™agentпЉМеєґдЄФињЫи°МstopжУНдљЬпЉМе¶ВжЮЬеНХжЬЇжЙІи°МпЉМеП™йЬАж≥®йЗКSSHзЫЄеЕ≥жУНдљЬ(зЫіжО•жЙІи°Мkillall mesos-agent)
- mesos-daemon.shпЉЪзФ®дЇОеРѓеК®mesos daemonпЉМйїШиЃ§дЉЪжЙІи°МдЄАдЇЫеК®дљЬ(иЃЊзљЃulimit -nдї•еПКеРѓеК®еѓєеЇФзЪДзОѓеҐГеПШйЗПиЃЊзљЃ/usr/local/etc/PROCNAME-env.sh)
- mesos-agentеЃЮйЩЕзЪДдЇМињЫеИґжЦЗдїґпЉМеПѓдї•йАЪињЗ--helpжЭ•жЯ•зЬЛеѓєеЇФеПВжХ∞пЉМеПВжХ∞еПВиАГпЉЪhttp://mesos.apache.org/documentation/latest/configuration/
-
/usr/local/etc/mesos/mesos-agent-env.shпЉЪиЃЊзљЃmesos-agentзОѓеҐГеПШйЗПпЉМеПШйЗПеСљеРНиІДеИЩдЄЇMESOS_еПВжХ∞пЉМеЕґдЄ≠{еПВжХ∞}дЄЇmesos-agent --helpдЄ≠зЪДеПВжХ∞пЉМиЃЊзљЃе¶ВдЄЛпЉЪ
# The mesos master URL to contact. Should be host:port for # non-ZooKeeper based masters, otherwise a zk:// or file:// URL. export MESOS_master=172.24.133.164:5050 # Other options you're likely to want to set: export MESOS_ip=172.24.133.164 export MESOS_port=5051 export MESOS_hostname=mesos_cl_agent164 export MESOS_log_dir=/var/log/mesos/agent export MESOS_work_dir=/var/run/mesos/agent export MESOS_logging_level=INFO export MESOS_isolation=cgroups
еРѓеК®
mesos-master
- жЙІи°Мsh mesos-start-masters.sh
- ps aux | grep mesos-master иГљзЬЛеИ∞masterињЫз®Л
- netstat -nltp | grep mesosпЉМиГљзЬЛеИ∞masterеЈ≤зїПзїСеЃЪ5050зЂѓеП£
- жЯ•зЬЛhttp://127.0.0.1:5050пЉМеПѓдї•зЬЛеИ∞ељУеЙНmesosйЫЖзЊ§зЪДдЄАдЇЫзКґжАБ
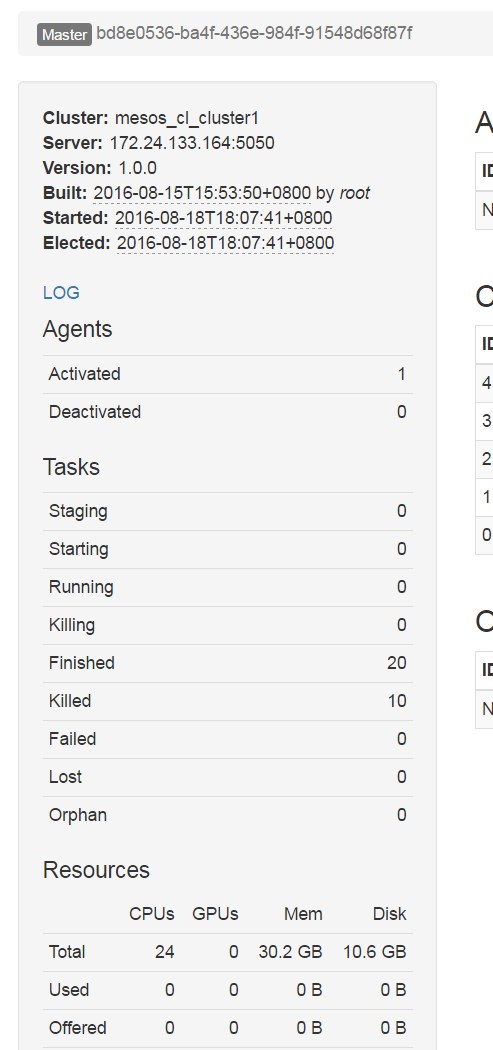
mesos-agent
- жЙІи°Мsh mesos-start-agents.sh
- ps aux | grep mesos-agent иГљзЬЛеИ∞agentињЫз®Л
- netstat -nltp | grep mesosпЉМиГљзЬЛеИ∞agentеЈ≤зїПзїСеЃЪ5051зЂѓеП£
- жЯ•зЬЛhttp://127.0.0.1:5050пЉМеПѓдї•зЬЛеИ∞ељУеЙНmesosйЫЖзЊ§зЪДдЄАдЇЫзКґжАБпЉМеРМжЧґзЬЛеИ∞еѓєеЇФзЪДagent

жµЛиѓХFramework
-
жЙІи°МmesosиЗ™еЄ¶зЪДжµЛиѓХframeworkпЉИжµЛиѓХframeworkдЉЪиЗ™еК®дїїеК°жЙІи°МзїУжЭЯеРОиЗ™еК®йААеЗЇпЉЙ
# Run C++ framework (Exits after successfully running some tasks.). $ ./src/test-framework --master=127.0.0.1:5050 # Run Java framework (Exits after successfully running some tasks.). $ ./src/examples/java/test-framework 127.0.0.1:5050 # Run Python framework (Exits after successfully running some tasks.). $ ./src/examples/python/test-framework 127.0.0.1:5050 -
жЯ•зЬЛhttp://127.0.0.1:5050пЉМеПѓдї•зЬЛеИ∞frameworkдњ°жБѓеТМframeworkжЙІи°МзЪДtaskдњ°жБѓ

 
 
http://www.cnblogs.com/SailorXiao/p/5786781.html



зЫЄеЕ≥жО®иНР
### Sparkе≠¶дє†зђФиЃ∞ #### Apache SparkзЃАдїЛ Apache SparkжШѓдЄАжђЊдЄУдЄЇе§ІиІДж®°жХ∞жНЃе§ДзРЖиАМиЃЊиЃ°зЪДйЂШжАІиГљгАБйАЪзФ®зЪДиЃ°зЃЧеЉХжУОгАВеЃГзЪДж†ЄењГзЙєзВєеЬ®дЇОжПРдЊЫдЇЖеЉЇе§ІзЪДеЖЕе≠ШиЃ°зЃЧиГљеКЫпЉМдїОиАМжШЊиСЧжПРеНЗдЇЖжХ∞жНЃе§ДзРЖзЪДйАЯеЇ¶гАВSparkжЬАеИЭйЗЗзФ®Scala...
### Spring Microservices:жЮДеїЇеПѓжЙ©е±ХеЊЃжЬНеК° #### зЯ•иѓЖзВєж¶Вињ∞ жЬђдє¶гАКSpring Microservices: Build Scalable ...йАЪињЗе≠¶дє†ињЩдЇЫеЈ•еЕЈеТМжКАжЬѓпЉМеЉАеПСиАЕеПѓдї•жЫіе•љеЬ∞еЇФеѓєе§НжЭВзЪДеЇФзФ®з®ЛеЇПеЉАеПСжМСжИШпЉМжПРйЂШз≥їзїЯзЪДжАІиГљеТМз®≥еЃЪжАІгАВ
Spark-CoreжЦЗж°£жШѓжЬђдЇЇзїПдЄЙеєіжАїзїУзђФиЃ∞ж±ЗжАїиАМжЭ•пЉМеѓєдЇОиЗ™жИСе≠¶дє†Sparkж†ЄењГеЯЇз°АзЯ•иѓЖйЭЮеЄЄжЦєдЊњпЉМиµДжЦЩдЄ≠дЊЛдЄЊеЃМеЦДпЉМеЖЕеЃєдЄ∞еѓМгАВеЕЈдљУзЫЃељХе¶ВдЄЛпЉЪ зЫЃељХ зђђдЄАзЂ† SparkзЃАдїЛдЄОиЃ°зЃЧж®°еЮЛ 3 1 What is Spark 3 2 SparkзЃАдїЛ 3 3 Spark...
жЬђе≠¶дє†зђФиЃ∞е∞ЖжЈ±еЕ•жОҐиЃ®е¶ВдљХеИ©зФ®PySparkињЫи°МжХ∞жНЃе§ДзРЖеТМеИЖжЮРпЉМеЄЃеК©дљ†жОМжП°ињЩдЄАж†ЄењГжКАжЬѓгАВ й¶ЦеЕИпЉМPySparkжШѓApache SparkдЄОPythonзЪДзїУеРИпЉМеЕБиЃЄеЉАеПСиАЕзФ®PythonзЉЦеЖЩSparkеЇФзФ®з®ЛеЇПгАВеЃГжПРдЊЫдЇЖдЄ∞еѓМзЪДжХ∞жНЃе§ДзРЖжО•еП£пЉМеМЕжЛђRDD...
жЬђе≠¶дє†зђФиЃ∞е∞ЖжЈ±еЕ•жОҐиЃ®ињЩдЄ§дЄ™еЈ•еЕЈзЪДж†ЄењГж¶ВењµгАБеЇФзФ®еЬЇжЩѓдї•еПКе¶ВдљХе∞ЖеЃГдїђзїУеРИдљњзФ®гАВ **Hadoop** жШѓдЄАдЄ™еЉАжЇРж°ЖжЮґпЉМдЄїи¶БзФ®дЇОеИЖеЄГеЉПе≠ШеВ®еТМиЃ°зЃЧгАВеЃГзЪДж†ЄењГзїДдїґеМЕжЛђHDFSпЉИHadoop Distributed File SystemпЉЙеТМMapReduceгАВHDFS...
### Sparkе≠¶дє†зђФиЃ∞ #### Sparkж¶ВиІИ ##### 1. SparkзЃАдїЛ - **еЃЪдєЙ**пЉЪApache SparkжШѓдЄАзІНењЂйАЯдЄФйАЪзФ®зЪДе§ІиІДж®°жХ∞жНЃе§ДзРЖз≥їзїЯпЉМжЧ®еЬ®дЄЇе§ІиІДж®°жХ∞жНЃе§ДзРЖжПРдЊЫйЂШжХИзЪДжФѓжМБгАВ - **иµЈжЇР**пЉЪSparkжЬАеИЭзФ±зЊОеЫљеК†еЈЮе§Іе≠¶дЉѓеЕЛеИ©еИЖж†°зЪД...
жЬђзѓЗзђФиЃ∞дЄїи¶БжОҐиЃ®SparkдЄ≠зЪДеЕ±дЇЂеПШйЗПгАБRDDжМБдєЕеМЦгАБcheckpointжЬЇеИґгАБињРи°Мж®°еЉПдї•еПКдїїеК°и∞ГеЇ¶з≠ЙзЫЄеЕ≥зЯ•иѓЖзВєгАВ 1. **еЕ±дЇЂеПШйЗП** - **зіѓеК†еЩ®пЉИAccumulatorпЉЙ**пЉЪзіѓеК†еЩ®жШѓдЄАзІНеП™иГљеҐЮеК†дЄНиГљеЗПе∞СзЪДеЕ±дЇЂеПШйЗПпЉМеЄЄзФ®дЇОзїЯиЃ°дїїеК°дЄ≠...
е≠¶дє†зђФиЃ∞еМЕеРЂзЪДеЖЕеЃєеПѓиГљжґµзЫЦдЇЖSparkзЪДеЯЇжЬђж¶ВењµгАБж†ЄењГзїДдїґгАБжХ∞жНЃе§ДзРЖжµБз®Лдї•еПКеЃЮйЩЕеЇФзФ®ж°ИдЊЛз≠Йе§ЪдЄ™жЦєйЭҐгАВдї•дЄЛжШѓеѓєињЩдЇЫзЯ•иѓЖзВєзЪДиѓ¶зїЖиѓіжШОпЉЪ 1. **Sparkж¶Вињ∞**пЉЪSparkжШѓеЯЇдЇОеЖЕе≠ШиЃ°зЃЧзЪДе§ІжХ∞жНЃе§ДзРЖж°ЖжЮґпЉМеЃГжПРдЊЫдЇЖдЄАзІНењЂйАЯгАБ...
Runs EverywhereпЉИиЈ®еє≥еП∞жАІпЉЙиЃ©SparkеПѓдї•еЬ®е§ЪзІНзОѓеҐГеТМеЯЇз°АиЃЊжЦљдЄКињРи°МпЉМеМЕжЛђHadoopгАБMesosгАБзЛђзЂЛйЫЖзЊ§пЉМзФЪиЗ≥дЇСзЂѓгАВSparkеПѓдї•жЧ†зЉЭжО•еЕ•еРДзІНжХ∞жНЃжЇРпЉМе¶ВHDFSгАБCassandraгАБHBaseгАБHiveеТМS3пЉМдЄЇжХ∞жНЃе§ДзРЖжПРдЊЫдЇЖжЮБе§ІзЪДзБµжіїжАІгАВ...
1. SparkеЃЙи£ЕдЄОйЕНзљЃпЉЪеМЕжЛђжЬђеЬ∞ж®°еЉПгАБйЫЖзЊ§ж®°еЉПпЉИе¶ВStandaloneгАБYARNгАБMesosпЉЙзЪДеЃЙи£ЕеТМйЕНзљЃжЦєж≥ХгАВ 2. Spark ShellдЄОPySparkпЉЪдїЛзїНе¶ВдљХдљњзФ®Spark ShellињЫи°МдЇ§дЇТеЉПзЉЦз®ЛпЉМдї•еПКPySparkзЪДдљњзФ®пЉМеЃГжШѓSparkеѓєPythonзЪДжО•еП£гАВ 3...
"Sparkе≠¶дє†.md"еЊИеПѓиГљжШѓдЄАдЄ™Markdownж†ЉеЉПзЪДе≠¶дє†зђФиЃ∞жИЦжХЩз®ЛпЉМMarkdownжШѓдЄАзІНиљїйЗПзЇІзЪДжЦЗжЬђж†ЉеЉПиѓ≠и®АпЉМйАЪеЄЄзФ®дЇОзЉЦеЖЩжКАжЬѓжЦЗж°£гАВињЩдЄ™жЦЗдїґеПѓиГљжґµзЫЦдЇЖSparkзЪДеЯЇз°Аж¶ВењµпЉМжѓФе¶ВRDDпЉИеЉєжАІеИЖеЄГеЉПжХ∞жНЃйЫЖпЉЙгАБDataFrameгАБDataSetпЉМ...
`sparkйЫЖзЊ§жР≠еїЇ.docx`еТМ`еНХдЄ™sparkйЫЖзЊ§жР≠еїЇ.docx`жЦЗдїґе∞ЖжґµзЫЦSparkйЫЖзЊ§зЪДеЃЙи£ЕеТМйЕНзљЃињЗз®ЛпЉМеМЕжЛђSpark StandaloneгАБMesosжИЦYARNз≠ЙдЄНеРМзЪДйГ®зљ≤ж®°еЉПгАВ 5. **Sqoop**пЉЪзФ®дЇОеЬ®HadoopеТМдЉ†зїЯзЪДеЕ≥з≥їеЮЛжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдєЛйЧіеѓЉеЕ•...
SparkзђФиЃ∞1.docx Spark жШѓдїАдєИпЉЯ Spark жШѓдЄАдЄ™еЯЇдЇОеЖЕе≠ШзЪДзїЯдЄАеИЖжЮРеЉХжУОпЉМзФ®дЇОе§ІиІДж®°жХ∞жНЃе§ДзРЖпЉМеМЕжЛђз¶їзЇњиЃ°зЃЧгАБеЃЮжЧґиЃ°зЃЧеТМењЂйАЯжߕ胥пЉИдЇ§дЇТеЉПжߕ胥пЉЙгАВеЃГеЕЈжЬЙењЂгАБжШУзФ®еТМйАЪзФ®з≠ЙзЙєзВєпЉМеПѓдї•ињЫи°Мз¶їзЇњиЃ°зЃЧгАБдЇ§дЇТеЉПжߕ胥гАБеЃЮжЧґ...
7.1 еЃЙи£ЕдЄОйГ®зљ≤пЉЪжґµзЫЦSparkзЪДеНХжЬЇж®°еЉПгАБйЫЖзЊ§ж®°еЉПеЃЙи£ЕпЉМдї•еПКYARNгАБMesosжИЦStandaloneз≠ЙиµДжЇРзЃ°зРЖеЩ®зЪДйЕНзљЃгАВ йАЪињЗдї•дЄКеЖЕеЃєпЉМдљ†е∞ЖеѓєSparkжЬЙеЕ®йЭҐзЪДдЇЖиІ£пЉМдїОеЯЇз°Аж¶ВењµеИ∞еЃЮжИШеЇФзФ®пЉМйАРж≠•жОМжП°SparkзЪДдљњзФ®жКАеЈІпЉМдЄЇдљ†зЪДжХ∞жНЃеИЖжЮР...
- **иІЖйҐСжХЩз®Л**пЉЪиІЖйҐСжХЩз®ЛеМЕеРЂдЇЖSparkзЪДеЯЇжЬђж¶ВењµгАБеЃЙи£ЕйЕНзљЃгАБж†ЄењГзїДдїґдїЛзїНз≠ЙеЖЕеЃєпЉМйАВеРИеИЭе≠¶иАЕеЕ•йЧ®гАВ - **зђФиЃ∞жЦЗж°£**пЉЪзђФиЃ∞жЦЗж°£иѓ¶зїЖиЃ∞ељХдЇЖе≠¶дє†ињЗз®ЛдЄ≠зЪДйЗНзВєйЪЊзВєпЉМжЬЙеК©дЇОеК†жЈ±зРЖиІ£еТМиЃ∞ењЖгАВ - **еЃЮиЈµй°єзЫЃ**пЉЪйАЪињЗеЃЮйЩЕ...
SparkеЬ®иЃЊиЃ°дЄКеЕЕеИЖеИ©зФ®дЇЖзО∞жЬЙжИРзЖЯзЪДжКАжЬѓж†ИпЉМдЊЛе¶ВAkkaеТМNettyзФ®дЇОйАЪдњ°пЉМдї•еПКYARNеТМMesosдљЬдЄЇиµДжЇРи∞ГеЇ¶жЬЇеИґгАВињЩдЇЫйАЙжЛ©дЄНдїЕдљУзО∞дЇЖSparkзЪДиЃЊиЃ°еУ≤е≠¶вАФвАФеН≥еЬ®еЈ≤жЬЙдЉШзІАжКАжЬѓеЯЇз°АдЄКжЮДеїЇжЫіеЉЇе§ІзЪДеЈ•еЕЈпЉМдєЯз°ЃдњЭдЇЖSparkзЪДеПѓйЭ†жАІеТМ...
4. еЕЉеЃєжАІпЉЪSpark еПѓдї•жЧ†зЉЭеѓєжО•HadoopзФЯжАБз≥їзїЯпЉМе¶ВHDFSгАБHiveз≠ЙпЉМеРМжЧґдєЯжФѓжМБYARNгАБMesosеТМKubernetesдљЬдЄЇиµДжЇРзЃ°зРЖеЩ®пЉМињЩжДПеС≥зЭАеЈ≤жКХиµДHadoopзЪДдЉБдЄЪжЧ†йЬАињБзІїжХ∞жНЃе∞±иГљеИ©зФ®SparkгАВSpark Standaloneж®°еЉПеИЩдЄЇзЛђзЂЛйГ®зљ≤жПРдЊЫ...
дЄА.SparkжЙІи°МжЬЇеИґ 1.жЙІи°МжЬЇеИґжАїиІИ SparkеЇФзФ®жПРдЇ§еРОзїПеОЖдЄАз≥їеИЧиљђеПШпЉМжЬАеРОжИРдЄЇtaskеЬ®еРДдЄ™иКВзВєдЄКжЙІи°М...SparkеЇФзФ®(application)жШѓзФ®жИЈжПРдЇ§зЪДеЇФзФ®з®ЛеЇПпЉМжЙІи°Мж®°еЉПжЬЙLocalпЉМStandaloneпЉМYARNпЉМMesosгАВж†єжНЃApplicationзЪДDriver