
Kafka是分布式消息系统,需要处理海量的消息,Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强的存储能力,但实际上,使用硬盘并没有带来过多的性能损失
kafka主要使用了以下几个方式实现了超高的吞吐率
顺序读写
kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能
顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写
Kafka官方给出了测试数据(Raid-5,7200rpm):
顺序 I/O: 600MB/s
随机 I/O: 100KB/s
零拷贝
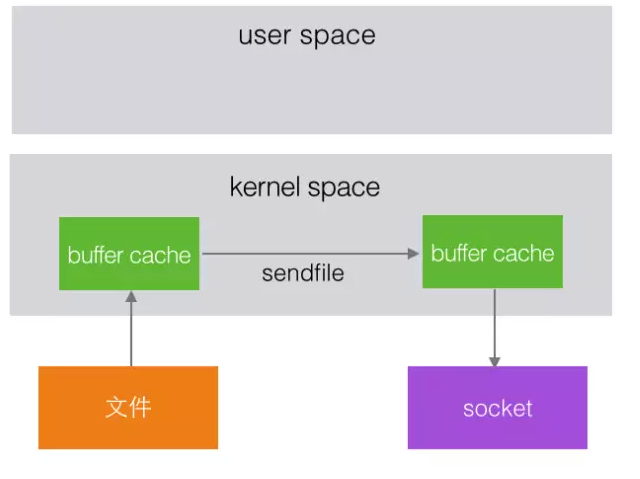
先简单了解下文件系统的操作流程,例如一个程序要把文件内容发送到网络
这个程序是工作在用户空间,文件和网络socket属于硬件资源,两者之间有一个内核空间
在操作系统内部,整个过程为:

在Linux kernel2.2 之后出现了一种叫做"零拷贝(zero-copy)"系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”
系统上下文切换减少为2次,可以提升一倍的性能
文件分段
kafka的队列topic被分为了多个区partition,每个partition又分为多个段segment,所以一个队列中的消息实际上是保存在N多个片段文件中
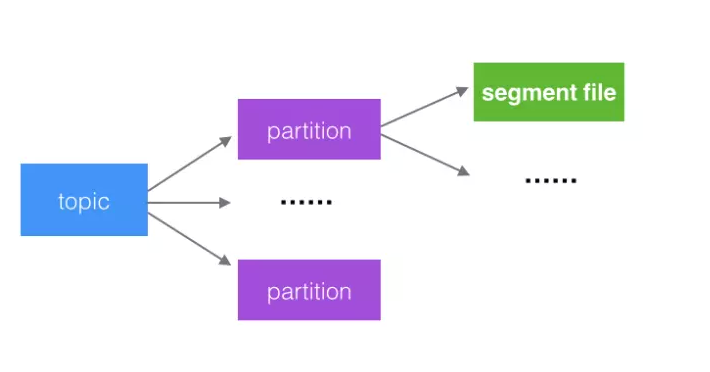
通过分段的方式,每次文件操作都是对一个小文件的操作,非常轻便,同时也增加了并行处理能力
批量发送
Kafka允许进行批量发送消息,先将消息缓存在内存中,然后一次请求批量发送出去
比如可以指定缓存的消息达到某个量的时候就发出去,或者缓存了固定的时间后就发送出去
如100条消息就发送,或者每5秒发送一次
这种策略将大大减少服务端的I/O次数
数据压缩
Kafka还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩
压缩的好处就是减少传输的数据量,减轻对网络传输的压力
Producer压缩之后,在Consumer需进行解压,虽然增加了CPU的工作,但在对大数据处理上,瓶颈在网络上而不是CPU,所以这个成本很值得
http://it.dataguru.cn/article-9855-1.html



相关推荐
由于它已经设计、优化并用于的服务器系统,每个流每秒产生超过 100 万个 I/O 密集型任务,其内部实现记录并发处理的实现高度优化,可以产生理想的吞吐量以最少的服务器数量,最大限度地提高资源利用率。入门/教程请...
Kafka 是一种高吞吐的分布式消息系统,能够替代传统的消息队列用于解耦合数据处理,缓存未处理消息等,同时具有更高的吞吐率,支持分区、多副本、冗余,因此被广泛用于大规模消息数据处理应用。 Kafka 的特点: 1....
而Apache Kafka则是一个高吞吐量的分布式发布订阅消息系统,常用于构建实时数据管道和流处理应用。将两者结合,可以构建出强大的实时数据处理平台。 **二、写入数据到Kafka** 在Storm-Kafka集成中,首先需要将数据...
Kafka可以作为一个高吞吐量、持久化的消息队列,用于构建实时数据管道和流应用程序。 3. **emq_plugin_kafka 插件**: 这个插件是EMQ X Broker与Kafka之间的一个桥梁,它实现了EMQ到Kafka的数据转发。当EMQ X ...
以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输 支持Kafka Server间的消息分区,及分布式...
3. Kafka 高吞吐率实现 Kafka 的高吞吐率主要通过以下方式实现: * 顺序读写:Kafka 将消息写入到了分区 partition 中,而分区中消息是顺序读写的。 * 零拷贝:生产者、消费者对于 Kafka 中消息的操作是采用零拷贝...
Kafka 是一个高吞吐量、分布式的发布订阅消息系统。它由以下几个主要组件构成: - **Broker**: Kafka 集群的核心节点,负责存储和转发消息。 - **Topic**: 消息的分类,类似于数据库中的表,可以有多个分区...
Kafka的核心特性是它的高吞吐量和低延迟,使其成为实时数据处理和流数据管道的理想选择。 【核心特性】 1. **持久化与高可用性**:Kafka通过O(1)的磁盘数据结构实现高效的消息持久化,即使面对TB级别的数据也能...
#### 三、Kafka高吞吐率实现机制 Kafka通过一系列优化技术实现高吞吐率,主要包括: 1. **顺序读写**:Kafka将消息按顺序写入磁盘,利用了磁盘顺序读写的高效性。相比随机读写,顺序读写显著减少了磁盘寻道时间,...
Kafka是由LinkedIn开发并开源的一种高吞吐量、分布式的发布订阅消息系统,现在已经成为大数据领域不可或缺的一部分。以下是本书中可能涵盖的一些关键知识点: 1. **Kafka基本概念**:理解Kafka的核心概念,包括生产...
在分布式消息系统中,Kafka是一个广泛使用的高吞吐量、低延迟的开源消息队列。为了优化性能和提高效率,开发人员常常会利用连接池技术来管理Kafka生产者的连接。本文将深入探讨"Kafka生产者连接池"的概念、实现原理...
- **高吞吐量**:Kafka设计时考虑了大规模数据处理,能够处理每秒数十万条消息。 - **持久化**:消息默认会被持久化到磁盘,即使在服务器故障后也能恢复。 - **可扩展性**:通过添加更多的Broker节点,可以轻松...
Kafka是LinkedIn开发的一款高吞吐量、分布式的发布/订阅消息系统,目前已成为Apache软件基金会的顶级项目。在大规模数据处理和实时分析场景中,Kafka扮演着至关重要的角色。然而,为了确保Kafka服务的稳定性和高效...
**Kafka 的高吞吐率实现** Kafka 能够实现高吞吐率的原因有: 1. **顺序读写**: 消息在 partition 中按照顺序写入,提高硬盘读写效率。 2. **零拷贝**: 生产者和消费者直接通过操作系统内核空间进行消息传输,减少...
Kafka是一种高吞吐量、低延迟的分布式发布订阅消息系统,广泛应用于大数据实时处理和流数据处理场景。测试Kafka的性能和稳定性对于确保系统的可靠性和可扩展性至关重要。 要使用这个JMeter的Kafka扩展,首先需要将...
它由 Scala 和 Java 开发,被广泛应用于大数据领域,以其高吞吐量、可扩展性、容错性和持久化特性而著名。Kafka 的核心功能包括发布(write)与订阅(read)事件流、持久化事件存储以及事件流的实时处理。 Kafka 的...
#### 三、Kafka实现高吞吐率的关键技术 1. **顺序读写**:Kafka通过将消息追加到文件尾部的方式存储数据,利用磁盘顺序读写的特性,极大地提高了I/O效率。 - **性能对比**:顺序I/O的速度远高于随机I/O。例如,在...
8. **监控与日志**:为了确保系统健康,需要监控Kafka的性能指标,如CPU使用率、磁盘I/O、网络吞吐量等,并记录日志以便于问题排查。 9. **Kafka Connect**:Kafka Connect是一个用于数据集成的框架,可方便地将...
Kafka的核心特性包括高吞吐量、持久化、分区和复制,使其在大数据实时处理中具有很高的性能和可靠性。 **项目背景** 在互联网行业中,实时统计网页浏览数据是常见的需求,例如统计用户访问量、停留时间、页面点击率...
3. **性能调优**:通过Kafka-Manager提供的数据,你可以分析并调整Kafka的配置,以提高吞吐量、降低延迟或优化资源利用率。 总结,Kafka-Manager是Kafka管理员的得力助手,它通过可视化界面简化了集群的管理和监控...