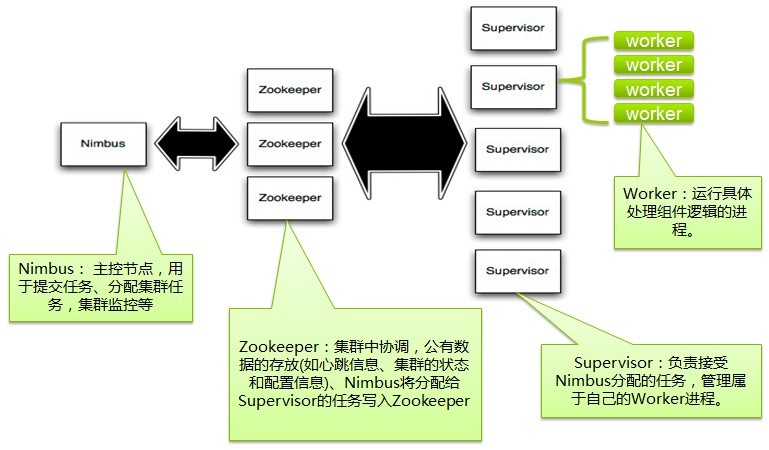
1.hadoopوœ‰masterن¸ژslave,Stormن¸ژن¹‹ه¯¹ه؛”çڑ„èٹ‚点وک¯ن»€ن¹ˆï¼ں
2.Stormوژ§هˆ¶èٹ‚点ن¸ٹé¢è؟گè،Œن¸€ن¸ھهگژهڈ°ç¨‹ه؛ڈ被称ن¹‹ن¸؛ن»€ن¹ˆï¼ں
3.Supervisorçڑ„ن½œç”¨وک¯ن»€ن¹ˆï¼ں
4.Topologyن¸ژWorkerن¹‹é—´çڑ„ه…³ç³»وک¯ن»€ن¹ˆï¼ں
5.Nimbusه’ŒSupervisorن¹‹é—´çڑ„و‰€وœ‰هچڈè°ƒه·¥ن½œوœ‰masterو¥ه®Œوˆگ,è؟کوک¯Zookeeper集群ه®Œوˆگï¼ں
6.storm稳ه®ڑçڑ„هژںه› وک¯ن»€ن¹ˆï¼ں
7.ه¦‚ن½•è؟گè،ŒTopologyï¼ں
strom jar all-your-code.jar backtype.storm.MyTopology arg1 arg2
8.spoutوک¯ن»€ن¹ˆï¼ں
9.boltوک¯ن»€ن¹ˆï¼ں
10.Topologyç”±ن¸¤éƒ¨هˆ†ç»„وˆگï¼ں
11.stream groupingوœ‰ه‡ ç§چï¼ں
Stormوک¯ن¸€ن¸ھهˆ†ه¸ƒه¼ڈçڑ„م€پé«که®¹é”™çڑ„ه®و—¶è®،ç®—ç³»ç»ںم€‚
Stormه¯¹ن؛ژه®و—¶è®،ç®—çڑ„çڑ„و„ڈن¹‰ç›¸ه½“ن؛ژHadoopه¯¹ن؛ژو‰¹ه¤„çگ†çڑ„و„ڈن¹‰م€‚Hadoopن¸؛وˆ‘ن»¬وڈگن¾›ن؛†Mapه’ŒReduceهژںè¯ï¼Œن½؟وˆ‘ن»¬ه¯¹و•°وچ®è؟›è،Œو‰¹ه¤„çگ†هڈکçڑ„éه¸¸çڑ„简هچ•ه’Œن¼کç¾ژم€‚هگŒو ·ï¼ŒStormن¹ںه¯¹و•°وچ®çڑ„ه®و—¶è®،ç®—وڈگن¾›ن؛†ç®€هچ•Spoutه’ŒBoltهژںè¯م€‚
Storm适用çڑ„هœ؛و™¯ï¼ڑ
1م€پوµپو•°وچ®ه¤„çگ†ï¼ڑStormهڈ¯ن»¥ç”¨و¥ç”¨و¥ه¤„çگ†و؛گو؛گن¸چو–çڑ„و¶ˆوپ¯ï¼Œه¹¶ه°†ه¤„çگ†ن¹‹هگژçڑ„结وœن؟هکهˆ°وŒپن¹…هŒ–ن»‹è´¨ن¸م€‚
2م€پهˆ†ه¸ƒه¼ڈRPCï¼ڑç”±ن؛ژStormçڑ„ه¤„çگ†ç»„ن»¶éƒ½وک¯هˆ†ه¸ƒه¼ڈçڑ„,而ن¸”ه¤„çگ†ه»¶è؟ں都وپن½ژ,و‰€ن»¥هڈ¯ن»¥Stormهڈ¯ن»¥هپڑن¸؛ن¸€ن¸ھé€ڑ用çڑ„هˆ†ه¸ƒه¼ڈRPCو،†و¶و¥ن½؟用م€‚
هœ¨è؟™ن¸ھو•™ç¨‹é‡Œé¢وˆ‘ن»¬ه°†ه¦ن¹ ه¦‚ن½•هˆ›ه»؛Topologies, ه¹¶ن¸”وٹٹtopologies部署هˆ°stormçڑ„集群里é¢هژ»م€‚Javaه°†وک¯وˆ‘ن»¬ن¸»è¦پçڑ„ç¤؛范è¯è¨€ï¼Œ ن¸ھهˆ«ن¾‹هگن¼ڑن½؟用pythonن»¥و¼”ç¤؛stormçڑ„ه¤ڑè¯è¨€ç‰¹و€§م€‚
1م€په‡†ه¤‡ه·¥ن½œ
2م€پن¸€ن¸ھStorm集群çڑ„هں؛وœ¬ç»„ن»¶
stormçڑ„集群è،¨é¢ن¸ٹ看ه’Œhadoopçڑ„集群éه¸¸هƒڈم€‚ن½†وک¯هœ¨Hadoopن¸ٹé¢ن½ è؟گè،Œçڑ„وک¯MapReduceçڑ„Job, 而هœ¨Stormن¸ٹé¢ن½ è؟گè،Œçڑ„وک¯Topologyم€‚ه®ƒن»¬وک¯éه¸¸ن¸چن¸€و ·çڑ„ — ن¸€ن¸ھه…³é”®çڑ„هŒ؛هˆ«وک¯ï¼ڑ ن¸€ن¸ھMapReduce Jobوœ€ç»ˆن¼ڑ结وں, 而ن¸€ن¸ھTopologyè؟گو°¸è؟œè؟گè،Œï¼ˆé™¤éن½ وک¾ه¼ڈçڑ„و€وژ‰ن»–)م€‚
هœ¨Stormçڑ„集群里é¢وœ‰ن¸¤ç§چèٹ‚点ï¼ڑ وژ§هˆ¶èٹ‚点(master node)ه’Œه·¥ن½œèٹ‚点(worker node)م€‚وژ§هˆ¶èٹ‚点ن¸ٹé¢è؟گè،Œن¸€ن¸ھهگژهڈ°ç¨‹ه؛ڈï¼ڑNimbus, ه®ƒçڑ„ن½œç”¨ç±»ن¼¼Hadoop里é¢çڑ„JobTrackerم€‚Nimbusè´ںè´£هœ¨é›†ç¾¤é‡Œé¢هˆ†ه¸ƒن»£ç پ,هˆ†é…چه·¥ن½œç»™وœ؛ه™¨ï¼Œ ه¹¶ن¸”监وژ§çٹ¶و€پم€‚
و¯ڈن¸€ن¸ھه·¥ن½œèٹ‚点ن¸ٹé¢è؟گè،Œن¸€ن¸ھهڈ«هپڑSupervisorçڑ„èٹ‚点(类ن¼¼ TaskTracker)م€‚Supervisorن¼ڑ监هگ¬هˆ†é…چç»™ه®ƒé‚£هڈ°وœ؛ه™¨çڑ„ه·¥ن½œï¼Œو ¹وچ®éœ€è¦پ هگ¯هٹ¨/ه…³é—ه·¥ن½œè؟›ç¨‹م€‚و¯ڈن¸€ن¸ھه·¥ن½œè؟›ç¨‹و‰§è،Œن¸€ن¸ھTopology(类ن¼¼ Job)çڑ„ن¸€ن¸ھهگ集;ن¸€ن¸ھè؟گè،Œçڑ„Topologyç”±è؟گè،Œهœ¨ه¾ˆه¤ڑوœ؛ه™¨ن¸ٹçڑ„ه¾ˆه¤ڑه·¥ن½œè؟›ç¨‹ Worker(类ن¼¼ Child)组وˆگم€‚
storm topology结و„
آ
Storm VS MapReduce
Nimbusه’ŒSupervisorن¹‹é—´çڑ„و‰€وœ‰هچڈè°ƒه·¥ن½œéƒ½وک¯é€ڑè؟‡ن¸€ن¸ھZookeeper集群و¥ه®Œوˆگم€‚ه¹¶ن¸”,nimbusè؟›ç¨‹ه’Œsupervisor都وک¯ه؟« é€ںه¤±è´¥ï¼ˆfail-fast)ه’Œو— çٹ¶و€پçڑ„م€‚و‰€وœ‰çڑ„çٹ¶و€پè¦پن¹ˆهœ¨Zookeeper里é¢ï¼Œ è¦پن¹ˆهœ¨وœ¬هœ°ç£پç›کن¸ٹم€‚è؟™ن¹ںه°±و„ڈه‘³ç€ن½ هڈ¯ن»¥ç”¨kill -9و¥و€و»nimbusه’Œsupervisorè؟›ç¨‹ï¼Œ 然هگژه†چé‡چهگ¯ه®ƒن»¬ï¼Œه®ƒن»¬هڈ¯ن»¥ç»§ç»ه·¥ن½œï¼Œ ه°±ه¥½هƒڈن»€ن¹ˆéƒ½و²،وœ‰هڈ‘ç”ںè؟‡ن¼¼çڑ„م€‚è؟™ن¸ھ设è®،ن½؟ه¾—stormن¸چهڈ¯و€è®®çڑ„稳ه®ڑم€‚
3م€پTopologies
ن¸؛ن؛†هœ¨stormن¸ٹé¢هپڑه®و—¶è®،算, ن½ è¦پهژ»ه»؛ç«‹ن¸€ن؛›topologiesم€‚ن¸€ن¸ھtopologyه°±وک¯ن¸€ن¸ھè®،ç®—èٹ‚点و‰€ç»„وˆگçڑ„ه›¾م€‚Topology里é¢çڑ„و¯ڈن¸ھه¤„çگ†èٹ‚点都هŒ…هگ«ه¤„çگ†é€»è¾‘, 而èٹ‚点ن¹‹é—´çڑ„è؟وژ¥هˆ™è،¨ç¤؛و•°وچ®وµپهٹ¨çڑ„و–¹هگ‘م€‚
è؟گè،Œن¸€ن¸ھTopologyوک¯ه¾ˆç®€هچ•çڑ„م€‚首ه…ˆï¼Œوٹٹن½ و‰€وœ‰çڑ„ن»£ç پن»¥هڈٹو‰€ن¾èµ–çڑ„jarو‰“è؟›ن¸€ن¸ھjarهŒ…م€‚然هگژè؟گè،Œç±»ن¼¼ن¸‹é¢çڑ„è؟™ن¸ھه‘½ن»¤م€‚
- strom jar all-your-code.jar backtype.storm.MyTopology arg1 arg2
آ
è؟™ن¸ھه‘½ن»¤ن¼ڑè؟گè،Œن¸»ç±»: backtype.strom.MyTopology, هڈ‚و•°وک¯arg1, arg2م€‚è؟™ن¸ھç±»çڑ„mainه‡½و•°ه®ڑن¹‰è؟™ن¸ھtopologyه¹¶ن¸”وٹٹه®ƒوڈگن؛¤ç»™Nimbusم€‚storm jarè´ںè´£è؟وژ¥هˆ°nimbusه¹¶ن¸”ن¸ٹن¼ jarو–‡ن»¶م€‚
آ
ه› ن¸؛topologyçڑ„ه®ڑن¹‰ه…¶ه®ه°±وک¯ن¸€ن¸ھThrift结و„ه¹¶ن¸”nimbusه°±وک¯ن¸€ن¸ھThriftوœچهٹ،, وœ‰هڈ¯ن»¥ç”¨ن»»ن½•è¯è¨€هˆ›ه»؛ه¹¶ن¸”وڈگن؛¤topologyم€‚ن¸ٹé¢çڑ„و–¹é¢وک¯ç”¨JVM
-basedè¯è¨€وڈگن؛¤çڑ„وœ€ç®€هچ•çڑ„و–¹و³•, 看ن¸€ن¸‹و–‡ç« :آ
هœ¨ç”ںن؛§é›†ç¾¤ن¸ٹè؟گè،Œtopologyهژ»çœ‹çœ‹و€ژن¹ˆهگ¯هٹ¨ن»¥هڈٹهپœو¢topologiesم€‚
4م€پStream
Streamوک¯storm里é¢çڑ„ه…³é”®وٹ½è±،م€‚ن¸€ن¸ھstreamوک¯ن¸€ن¸ھو²،وœ‰è¾¹ç•Œçڑ„tupleه؛ڈهˆ—م€‚stormوڈگن¾›ن¸€ن؛›هژںè¯و¥هˆ†ه¸ƒه¼ڈهœ°م€پهڈ¯é هœ°وٹٹن¸€ن¸ھstreamن¼ 输è؟›ن¸€ن¸ھو–°çڑ„streamم€‚و¯”ه¦‚ï¼ڑ ن½ هڈ¯ن»¥وٹٹن¸€ن¸ھtweetsوµپن¼ 输هˆ°çƒé—¨è¯é¢کçڑ„وµپم€‚
stormوڈگن¾›çڑ„وœ€هں؛وœ¬çڑ„ه¤„çگ†streamçڑ„هژںè¯وک¯spoutه’Œboltم€‚ن½ هڈ¯ن»¥ه®çژ°Spoutه’ŒBoltه¯¹ه؛”çڑ„وژ¥هڈ£ن»¥ه¤„çگ†ن½ çڑ„ه؛”用çڑ„逻辑م€‚
spoutçڑ„وµپçڑ„و؛گه¤´م€‚و¯”ه¦‚ن¸€ن¸ھspoutهڈ¯èƒ½ن»ژKestreléکںهˆ—里é¢è¯»هڈ–و¶ˆوپ¯ه¹¶ن¸”وٹٹè؟™ن؛›و¶ˆوپ¯هڈ‘ه°„وˆگن¸€ن¸ھوµپم€‚هڈˆو¯”ه¦‚ن¸€ن¸ھspoutهڈ¯ن»¥è°ƒç”¨twitterçڑ„ن¸€ن¸ھapiه¹¶ن¸”وٹٹè؟”ه›çڑ„tweetsهڈ‘ه°„وˆگن¸€ن¸ھوµپم€‚
é€ڑه¸¸Spoutن¼ڑن»ژه¤–部و•°وچ®و؛گ(éکںهˆ—م€پو•°وچ®ه؛“ç‰ï¼‰è¯»هڈ–و•°وچ®ï¼Œç„¶هگژه°پ装وˆگTupleه½¢ه¼ڈ,ن¹‹هگژهڈ‘é€پهˆ°Streamن¸م€‚Spoutوک¯ن¸€ن¸ھن¸»هٹ¨çڑ„角色,هœ¨وژ¥هڈ£ه†…部وœ‰ن¸ھnextTupleه‡½و•°ï¼ŒStormو،†و¶ن¼ڑن¸چهپœçڑ„调用该ه‡½و•°م€‚
آ
boltهڈ¯ن»¥وژ¥و”¶ن»»و„ڈه¤ڑن¸ھ输ه…¥stream, ن½œن¸€ن؛›ه¤„çگ†ï¼Œ وœ‰ن؛›boltهڈ¯èƒ½è؟کن¼ڑهڈ‘ه°„ن¸€ن؛›و–°çڑ„streamم€‚ن¸€ن؛›ه¤چو‚çڑ„وµپ转وچ¢ï¼Œ و¯”ه¦‚ن»ژن¸€ن؛›tweet里é¢è®،ç®—ه‡؛çƒé—¨è¯é¢ک, 需è¦په¤ڑن¸ھو¥éھ¤ï¼Œ ن»ژ而ن¹ںه°±éœ€è¦په¤ڑن¸ھboltم€‚ Boltهڈ¯ن»¥هپڑن»»ن½•ن؛‹وƒ…: è؟گè،Œه‡½و•°ï¼Œ è؟‡و»¤tuple, هپڑن¸€ن؛›èپڑهگˆï¼Œ هپڑن¸€ن؛›هگˆه¹¶ن»¥هڈٹè®؟é—®و•°وچ®ه؛“ç‰ç‰م€‚
Boltه¤„çگ†è¾“ه…¥çڑ„Stream,ه¹¶ن؛§ç”ںو–°çڑ„输ه‡؛Streamم€‚Boltهڈ¯ن»¥و‰§è،Œè؟‡و»¤م€په‡½و•°و“چن½œم€پJoinم€پو“چن½œو•°وچ®ه؛“ç‰ن»»ن½•و“چن½œم€‚Boltوک¯ن¸€ن¸ھ被هٹ¨çڑ„ 角色,ه…¶وژ¥هڈ£ن¸وœ‰ن¸€ن¸ھexecute(Tuple input)و–¹و³•ï¼Œهœ¨وژ¥و”¶هˆ°و¶ˆوپ¯ن¹‹هگژن¼ڑ调用و¤ه‡½و•°ï¼Œç”¨وˆ·هڈ¯ن»¥هœ¨و¤و–¹و³•ن¸و‰§è،Œè‡ھه·±çڑ„ه¤„çگ†é€»è¾‘م€‚
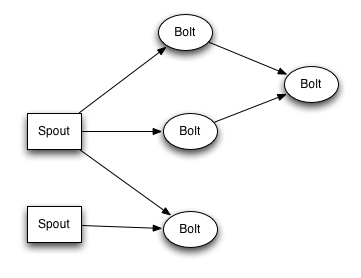
آ
spoutه’Œboltو‰€ç»„وˆگن¸€ن¸ھ网络ن¼ڑ被و‰“هŒ…وˆگtopology, topologyوک¯storm里é¢وœ€é«کن¸€ç؛§çڑ„وٹ½è±،(类ن¼¼ Job), ن½ هڈ¯ن»¥وٹٹtopologyوڈگن؛¤ç»™stormçڑ„集群و¥è؟گè،Œم€‚topologyçڑ„结و„هœ¨Topologyé‚£ن¸€و®µه·²ç»ڈ说è؟‡ن؛†ï¼Œè؟™é‡Œه°±ن¸چه†چèµکè؟°ن؛†م€‚
آ
topology结و„
آ
topology里é¢çڑ„و¯ڈن¸€ن¸ھèٹ‚点都وک¯ه¹¶è،Œè؟گè،Œçڑ„م€‚ هœ¨ن½ çڑ„topology里é¢ï¼Œ ن½ هڈ¯ن»¥وŒ‡ه®ڑو¯ڈن¸ھèٹ‚点çڑ„ه¹¶è،Œه؛¦ï¼Œ stormهˆ™ن¼ڑهœ¨é›†ç¾¤é‡Œé¢هˆ†é…چé‚£ن¹ˆه¤ڑç؛؟程و¥هگŒو—¶è®،ç®—م€‚
ن¸€ن¸ھtopologyن¼ڑن¸€ç›´è؟گè،Œç›´هˆ°ن½ وک¾ه¼ڈهپœو¢ه®ƒم€‚stormè‡ھهٹ¨é‡چو–°هˆ†é…چن¸€ن؛›è؟گè،Œه¤±è´¥çڑ„ن»»هٹ،, ه¹¶ن¸”stormن؟è¯پن½ ن¸چن¼ڑوœ‰و•°وچ®ن¸¢ه¤±ï¼Œ هچ³ن½؟هœ¨ن¸€ن؛›وœ؛ه™¨و„ڈه¤–هپœوœ؛ه¹¶ن¸”و¶ˆوپ¯è¢«ن¸¢وژ‰çڑ„وƒ…ه†µن¸‹م€‚
5م€پو•°وچ®و¨،ه‹(Data Model)
stormن½؟用tupleو¥ن½œن¸؛ه®ƒçڑ„و•°وچ®و¨،ه‹م€‚و¯ڈن¸ھtupleوک¯ن¸€ه †ه€¼ï¼Œو¯ڈن¸ھه€¼وœ‰ن¸€ن¸ھهگچه—,ه¹¶ن¸”و¯ڈن¸ھه€¼هڈ¯ن»¥وک¯ن»»ن½•ç±»ه‹ï¼Œ هœ¨وˆ‘çڑ„çگ†è§£é‡Œé¢ن¸€ن¸ھtupleهڈ¯ن»¥çœ‹ن½œن¸€ن¸ھو²،وœ‰و–¹و³•çڑ„javaه¯¹è±،م€‚و€»ن½“و¥çœ‹ï¼Œstormو”¯وŒپو‰€وœ‰çڑ„هں؛وœ¬ç±»ه‹م€په—符ن¸²ن»¥هڈٹه—èٹ‚و•°ç»„ن½œن¸؛tupleçڑ„ه€¼ç±» ه‹م€‚ن½ ن¹ںهڈ¯ن»¥ن½؟用ن½ è‡ھه·±ه®ڑن¹‰çڑ„ç±»ه‹و¥ن½œن¸؛ه€¼ç±»ه‹ï¼Œ هڈھè¦پن½ ه®çژ°ه¯¹ه؛”çڑ„ه؛ڈهˆ—هŒ–ه™¨(serializer)م€‚
ن¸€ن¸ھTupleن»£è،¨و•°وچ®وµپن¸çڑ„ن¸€ن¸ھهں؛وœ¬çڑ„ه¤„çگ†هچ•ه…ƒï¼Œن¾‹ه¦‚ن¸€و،cookieو—¥ه؟—,ه®ƒهڈ¯ن»¥هŒ…هگ«ه¤ڑن¸ھField,و¯ڈن¸ھFieldè،¨ç¤؛ن¸€ن¸ھه±و€§م€‚

آ
Tupleوœ¬و¥ه؛”该وک¯ن¸€ن¸ھKey-Valueçڑ„Map,由ن؛ژهگ„ن¸ھ组ن»¶é—´ن¼ 递çڑ„tupleçڑ„ه—و®µهگچ称ه·²ç»ڈن؛‹ه…ˆه®ڑن¹‰ه¥½ن؛†ï¼Œو‰€ن»¥Tupleهڈھ需è¦پوŒ‰ه؛ڈه،«ه…¥هگ„ن¸ھValue,و‰€ن»¥ه°±وک¯ن¸€ن¸ھValue Listم€‚
ن¸€ن¸ھو²،وœ‰è¾¹ç•Œçڑ„م€پو؛گو؛گن¸چو–çڑ„م€پè؟ç»çڑ„Tupleه؛ڈهˆ—ه°±ç»„وˆگن؛†Streamم€‚

آ
topology里é¢çڑ„و¯ڈن¸ھèٹ‚点ه؟…é،»ه®ڑن¹‰ه®ƒè¦پهڈ‘ه°„çڑ„tupleçڑ„و¯ڈن¸ھه—و®µم€‚ و¯”ه¦‚ن¸‹é¢è؟™ن¸ھboltه®ڑن¹‰ه®ƒو‰€هڈ‘ه°„çڑ„tupleهŒ…هگ«ن¸¤ن¸ھه—و®µï¼Œç±»ه‹هˆ†هˆ«وک¯: doubleه’Œtripleم€‚
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
publicclassDoubleAndTripleBoltimplementsIRichBolt {
آ آ آ آ privateOutputCollectorBase _collector;
آ
آ آ آ آ @Override
آ آ آ آ publicvoidprepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
آ آ آ آ آ آ آ آ _collector = collector;
آ آ آ آ }
آ
آ آ آ آ @Override
آ آ آ آ publicvoidexecute(Tuple input) {
آ آ آ آ آ آ آ آ intval = input.getInteger(0);
آ آ آ آ آ آ آ آ _collector.emit(input,newValues(val*2, val*3));
آ آ آ آ آ آ آ آ _collector.ack(input);
آ آ آ آ }
آ
آ آ آ آ @Override
آ آ آ آ publicvoidcleanup() {
آ آ آ آ }
آ
آ آ آ آ @Override
آ آ آ آ publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
آ آ آ آ آ آ آ آ declarer.declare(newFields("double","triple"));
آ آ آ آ }
}
|
م€€م€€
declareOutputFieldsو–¹و³•ه®ڑن¹‰è¦پ输ه‡؛çڑ„ه—و®µ ï¼ڑ ["double", "triple"]م€‚è؟™ن¸ھboltçڑ„ه…¶ه®ƒéƒ¨هˆ†وˆ‘ن»¬وژ¥ن¸‹و¥ن¼ڑ解é‡ٹم€‚
آ
6م€پن¸€ن¸ھ简هچ•çڑ„Topology
让وˆ‘ن»¬و¥çœ‹ن¸€ن¸ھ简هچ•çڑ„topologyçڑ„ن¾‹هگ, وˆ‘ن»¬çœ‹ن¸€ن¸‹storm-starter里é¢çڑ„ExclamationTopology:
|
1
2
3
4
5
6
|
TopologyBuilder builder =newTopologyBuilder();
builder.setSpout(1,newTestWordSpout(),10);
builder.setBolt(2,newExclamationBolt(),3)
آ آ آ آ آ آ آ آ .shuffleGrouping(1);
builder.setBolt(3,newExclamationBolt(),2)
آ آ آ آ آ آ آ آ .shuffleGrouping(2);
|
م€€م€€
è؟™ن¸ھTopologyهŒ…هگ«ن¸€ن¸ھSpoutه’Œن¸¤ن¸ھBoltم€‚Spoutهڈ‘ه°„هچ•è¯چ, و¯ڈن¸ھboltهœ¨و¯ڈن¸ھهچ•è¯چهگژé¢هٹ ن¸ھâ€!!!â€م€‚è؟™ن¸‰ن¸ھèٹ‚点被وژ’وˆگن¸€و،ç؛؟: spoutهڈ‘ه°„هچ•è¯چ给第ن¸€ن¸ھbolt, 第ن¸€ن¸ھbolt然هگژوٹٹه¤„çگ†ه¥½çڑ„هچ•è¯چهڈ‘ه°„给第ن؛Œن¸ھboltم€‚ه¦‚وœspoutهڈ‘ه°„çڑ„هچ•è¯چوک¯["bob"]ه’Œ["john"], é‚£ن¹ˆç¬¬ن؛Œن¸ھboltن¼ڑهڈ‘ه°„["bolt!!!!!!"]ه’Œ["john!!!!!!"]ه‡؛و¥م€‚
آ
وˆ‘ن»¬ن½؟用setSpoutه’ŒsetBoltو¥ه®ڑن¹‰Topology里é¢çڑ„èٹ‚点م€‚è؟™ن؛›و–¹و³•وژ¥و”¶وˆ‘ن»¬وŒ‡ه®ڑçڑ„ن¸€ن¸ھid, ن¸€ن¸ھهŒ…هگ«ه¤„çگ†é€»è¾‘çڑ„ه¯¹è±،(spoutوˆ–者bolt), ن»¥هڈٹن½ و‰€éœ€è¦پçڑ„ه¹¶è،Œه؛¦م€‚
آ
è؟™ن¸ھهŒ…هگ«ه¤„çگ†çڑ„ه¯¹è±،ه¦‚وœوک¯spouté‚£ن¹ˆè¦په®çژ°IRichSpoutçڑ„وژ¥هڈ£ï¼Œ ه¦‚وœوک¯bolt,那ن¹ˆه°±è¦په®çژ°IRichBoltوژ¥هڈ£.
وœ€هگژن¸€ن¸ھوŒ‡ه®ڑه¹¶è،Œه؛¦çڑ„هڈ‚و•°وک¯هڈ¯é€‰çڑ„م€‚ه®ƒè،¨ç¤؛集群里é¢éœ€è¦په¤ڑه°‘ن¸ھthreadو¥ن¸€èµ·و‰§è،Œè؟™ن¸ھèٹ‚点م€‚ه¦‚وœن½ ه؟½ç•¥ه®ƒé‚£ن¹ˆstormن¼ڑهˆ†é…چن¸€ن¸ھç؛؟程و¥و‰§è،Œè؟™ن¸ھèٹ‚点م€‚
آ
setBoltو–¹و³•è؟”ه›ن¸€ن¸ھInputDeclarerه¯¹è±،, è؟™ن¸ھه¯¹è±،وک¯ç”¨و¥ه®ڑن¹‰Boltçڑ„输ه…¥م€‚ è؟™é‡Œç¬¬ن¸€ن¸ھBoltه£°وکژه®ƒè¦پ读هڈ–spoutو‰€هڈ‘ه°„çڑ„و‰€وœ‰çڑ„tuple — ن½؟用shuffle groupingم€‚而第ن؛Œن¸ھboltه£°وکژه®ƒè¯»هڈ–第ن¸€ن¸ھboltو‰€هڈ‘ه°„çڑ„tupleم€‚shuffle groupingè،¨ç¤؛و‰€وœ‰çڑ„tupleن¼ڑ被éڑڈوœ؛çڑ„هˆ†هڈ‘ç»™boltçڑ„و‰€وœ‰taskم€‚ç»™taskهˆ†هڈ‘tupleçڑ„ç–ç•¥وœ‰ه¾ˆه¤ڑç§چ,هگژé¢ن¼ڑن»‹ç»چم€‚
آ
ه¦‚وœن½ وƒ³ç¬¬ن؛Œن¸ھbolt读هڈ–spoutه’Œç¬¬ن¸€ن¸ھboltو‰€هڈ‘ه°„çڑ„و‰€وœ‰çڑ„tuple, é‚£ن¹ˆن½ ه؛”该è؟™و ·ه®ڑن¹‰ç¬¬ن؛Œن¸ھbolt:
|
1
2
3
|
builder.setBolt(3,newExclamationBolt(),5)
آ آ آ آ آ آ آ آ آ آ آ آ .shuffleGrouping(1)
آ آ آ آ آ آ آ آ آ آ آ آ .shuffleGrouping(2);
|
م€€م€€
让وˆ‘ن»¬و·±ه…¥هœ°çœ‹ن¸€ن¸‹è؟™ن¸ھtopology里é¢çڑ„spoutه’Œboltوک¯و€ژن¹ˆه®çژ°çڑ„م€‚Spoutè´ںè´£هڈ‘ه°„و–°çڑ„tupleهˆ°è؟™ن¸ھtopology里é¢و¥م€‚ TestWordSpoutن»ژ["nathan", "mike", "jackson", "golda", "bertels"]里é¢éڑڈوœ؛选و‹©ن¸€ن¸ھهچ•è¯چهڈ‘ه°„ه‡؛و¥م€‚TestWordSpout里é¢çڑ„nextTuple()و–¹و³•وک¯è؟™و ·ه®ڑن¹‰çڑ„ï¼ڑ
|
1
2
3
4
5
6
7
8
|
publicvoidnextTuple() {
آ آ آ آ Utils.sleep(100);
آ آ آ آ finalString[] words =newString[] {"nathan","mike",
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ "jackson","golda","bertels"};
آ آ آ آ finalRandom rand =newRandom();
آ آ آ آ finalString word = words[rand.nextInt(words.length)];
آ آ آ آ _collector.emit(newValues(word));
}
|
م€€م€€
هڈ¯ن»¥çœ‹هˆ°ï¼Œه®çژ°ه¾ˆç®€هچ•م€‚
آ
ExclamationBoltوٹٹâ€!!!â€و‹¼وژ¥هˆ°è¾“ه…¥tupleهگژé¢م€‚وˆ‘ن»¬و¥çœ‹ن¸‹ExclamationBoltçڑ„ه®Œو•´ه®çژ°م€‚
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
publicstaticclassExclamationBoltimplementsIRichBolt {
آ آ آ آ OutputCollector _collector;
آ
آ آ آ آ publicvoidprepare(Map conf, TopologyContext context,
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ OutputCollector collector) {
آ آ آ آ آ آ آ آ _collector = collector;
آ آ آ آ }
آ
آ آ آ آ publicvoidexecute(Tuple tuple) {
آ آ آ آ آ آ آ آ _collector.emit(tuple,newValues(tuple.getString(0) +"!!!"));
آ آ آ آ آ آ آ آ _collector.ack(tuple);
آ آ آ آ }
آ
آ آ آ آ publicvoidcleanup() {
آ آ آ آ }
آ
آ آ آ آ publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
آ آ آ آ آ آ آ آ declarer.declare(newFields("word"));
آ آ آ آ }
}
|
م€€م€€
prepareو–¹و³•وڈگن¾›ç»™boltن¸€ن¸ھOutputcollector用و¥هڈ‘ه°„tupleم€‚Boltهڈ¯ن»¥هœ¨ن»»ن½•و—¶ه€™هڈ‘ه°„tuple — هœ¨prepare, executeوˆ–者cleanupو–¹و³•é‡Œé¢, وˆ–者ç”ڑ至هœ¨هڈ¦ن¸€ن¸ھç؛؟程里é¢ه¼‚و¥هڈ‘ه°„م€‚è؟™é‡Œprepareو–¹و³•هڈھوک¯ç®€هچ•هœ°وٹٹOutputCollectorن½œن¸؛ن¸€ن¸ھç±»ه—و®µن؟هکن¸‹و¥ç»™هگژé¢executeو–¹و³• ن½؟用م€‚
executeو–¹و³•ن»ژboltçڑ„ن¸€ن¸ھ输ه…¥وژ¥و”¶tuple(ن¸€ن¸ھboltهڈ¯èƒ½وœ‰ه¤ڑن¸ھ输ه…¥و؛گ). ExclamationBoltèژ·هڈ–tupleçڑ„第ن¸€ن¸ھه—و®µï¼Œهٹ ن¸ٹâ€!!!â€ن¹‹هگژه†چهڈ‘ه°„ه‡؛هژ»م€‚ه¦‚وœن¸€ن¸ھboltوœ‰ه¤ڑن¸ھ输ه…¥و؛گ,ن½ هڈ¯ن»¥é€ڑè؟‡è°ƒç”¨ Tuple#getSourceComponentو–¹و³•و¥çں¥éپ“ه®ƒوک¯و¥è‡ھه“ھن¸ھ输ه…¥و؛گçڑ„م€‚
executeو–¹و³•é‡Œé¢è؟کوœ‰ه…¶ه®ƒن¸€ن؛›ن؛‹وƒ…ه€¼ه¾—ن¸€وڈگï¼ڑ 输ه…¥tuple被ن½œن¸؛emitو–¹و³•çڑ„第ن¸€ن¸ھهڈ‚و•°ï¼Œه¹¶ن¸”输ه…¥tupleهœ¨وœ€هگژن¸€è،Œè¢«ackم€‚è؟™ن؛›ه‘¢éƒ½وک¯Stormهڈ¯é و€§APIçڑ„ن¸€éƒ¨هˆ†ï¼Œهگژé¢ن¼ڑ解é‡ٹم€‚
cleanupو–¹و³•هœ¨bolt被ه…³é—çڑ„و—¶ه€™è°ƒç”¨ï¼Œ ه®ƒه؛”该و¸…çگ†و‰€وœ‰è¢«و‰“ه¼€çڑ„资و؛گم€‚ن½†وک¯é›†ç¾¤ن¸چن؟è¯پè؟™ن¸ھو–¹و³•ن¸€ه®ڑن¼ڑ被و‰§è،Œم€‚و¯”ه¦‚و‰§è،Œtaskçڑ„وœ؛ه™¨downوژ‰ن؛†ï¼Œé‚£ن¹ˆو ¹وœ¬ه°±و²،وœ‰هٹو³•و¥è°ƒç”¨é‚£ن¸ھو–¹و³•م€‚ cleanup设è®،çڑ„و—¶ه€™وک¯è¢«ç”¨و¥هœ¨local modeçڑ„و—¶ه€™و‰چ被调用(ن¹ںه°±وک¯è¯´هœ¨ن¸€ن¸ھè؟›ç¨‹é‡Œé¢و¨،و‹ںو•´ن¸ھstorm集群), ه¹¶ن¸”ن½ وƒ³هœ¨ه…³é—ن¸€ن؛›topologyçڑ„و—¶ه€™éپ؟ه…چ资و؛گو³„و¼ڈم€‚
وœ€هگژ,declareOutputFieldsه®ڑن¹‰ن¸€ن¸ھهڈ«هپڑâ€wordâ€çڑ„ه—و®µçڑ„tupleم€‚
ن»¥local modeè؟گè،ŒExclamationTopology
让وˆ‘ن»¬çœ‹çœ‹و€ژن¹ˆن»¥local modeè؟گè،ŒExclamationToplogyم€‚
stormçڑ„è؟گè،Œوœ‰ن¸¤ç§چو¨،ه¼ڈ: وœ¬هœ°و¨،ه¼ڈه’Œهˆ†ه¸ƒه¼ڈو¨،ه¼ڈ. هœ¨وœ¬هœ°و¨،ه¼ڈن¸ï¼Œ storm用ن¸€ن¸ھè؟›ç¨‹é‡Œé¢çڑ„ç؛؟程و¥و¨،و‹ںو‰€وœ‰çڑ„spoutه’Œbolt. وœ¬هœ°و¨،ه¼ڈه¯¹ه¼€هڈ‘ه’Œوµ‹è¯•و¥è¯´و¯”较وœ‰ç”¨م€‚ ن½ è؟گè،Œstorm-starter里é¢çڑ„topologyçڑ„و—¶ه€™ه®ƒن»¬ه°±وک¯ن»¥وœ¬هœ°و¨،ه¼ڈè؟گè،Œçڑ„, ن½ هڈ¯ن»¥çœ‹هˆ°topology里é¢çڑ„و¯ڈن¸€ن¸ھ组ن»¶هœ¨هڈ‘ه°„ن»€ن¹ˆو¶ˆوپ¯م€‚
هœ¨هˆ†ه¸ƒه¼ڈو¨،ه¼ڈن¸‹ï¼Œ stormç”±ن¸€ه †وœ؛ه™¨ç»„وˆگم€‚ه½“ن½ وڈگن؛¤topologyç»™masterçڑ„و—¶ه€™ï¼Œ ن½ هگŒو—¶ن¹ںوٹٹtopologyçڑ„ن»£ç پوڈگن؛¤ن؛†م€‚masterè´ںè´£هˆ†هڈ‘ن½ çڑ„ن»£ç په¹¶ن¸”è´ں责给ن½ çڑ„topolgoyهˆ†é…چه·¥ن½œè؟›ç¨‹م€‚ه¦‚وœن¸€ن¸ھه·¥ن½œè؟›ç¨‹وŒ‚وژ‰ن؛†ï¼Œ masterèٹ‚点ن¼ڑوٹٹ认ن¸؛é‡چو–°هˆ†é…چهˆ°ه…¶ه®ƒèٹ‚点م€‚ه…³ن؛ژه¦‚ن½•هœ¨ن¸€ن¸ھ集群ن¸ٹé¢è؟گè،Œtopology, ن½ هڈ¯ن»¥çœ‹çœ‹Running topologies on a production clusterو–‡ç« م€‚
ن¸‹é¢وک¯ن»¥وœ¬هœ°و¨،ه¼ڈè؟گè،ŒExclamationTopologyçڑ„ن»£ç پ:
|
1
2
3
4
5
6
7
8
9
|
Config conf =newConfig();
conf.setDebug(true);
conf.setNumWorkers(2);
آ
LocalCluster cluster =newLocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
|
م€€م€€
首ه…ˆï¼Œ è؟™ن¸ھن»£ç په®ڑن¹‰é€ڑè؟‡ه®ڑن¹‰ن¸€ن¸ھLocalClusterه¯¹è±،و¥ه®ڑن¹‰ن¸€ن¸ھè؟›ç¨‹ه†…çڑ„集群م€‚وڈگن؛¤topologyç»™è؟™ن¸ھè™ڑو‹ںçڑ„集群ه’Œوڈگن؛¤topologyç»™هˆ†ه¸ƒه¼ڈ集 群وک¯ن¸€و ·çڑ„م€‚é€ڑè؟‡è°ƒç”¨submitTopologyو–¹و³•و¥وڈگن؛¤topology, ه®ƒوژ¥هڈ—ن¸‰ن¸ھهڈ‚و•°ï¼ڑè¦پè؟گè،Œçڑ„topologyçڑ„هگچه—,ن¸€ن¸ھé…چç½®ه¯¹è±،ن»¥هڈٹè¦پè؟گè،Œçڑ„topologyوœ¬è؛«م€‚
topologyçڑ„هگچه—وک¯ç”¨و¥ه”¯ن¸€هŒ؛هˆ«ن¸€ن¸ھtopologyçڑ„,è؟™و ·ن½ 然هگژهڈ¯ن»¥ç”¨è؟™ن¸ھهگچه—و¥و€و»è؟™ن¸ھtopologyçڑ„م€‚ه‰چé¢ه·²ç»ڈ说è؟‡ن؛†ï¼Œ ن½ ه؟…é،»وک¾ه¼ڈçڑ„و€وژ‰ن¸€ن¸ھtopology, هگ¦هˆ™ه®ƒن¼ڑن¸€ç›´è؟گè،Œم€‚
Confه¯¹è±،هڈ¯ن»¥é…چç½®ه¾ˆه¤ڑن¸œè¥؟, ن¸‹é¢ن¸¤ن¸ھوک¯وœ€ه¸¸è§پçڑ„ï¼ڑ
آ
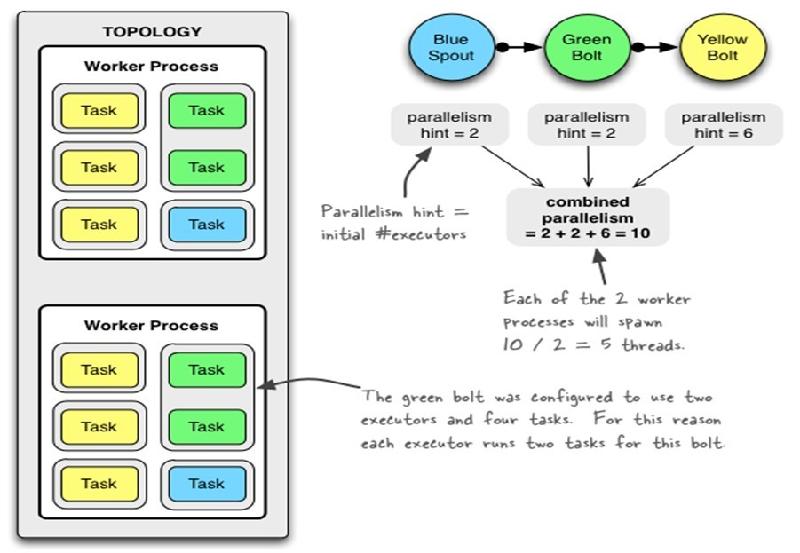
- TOPOLOGY_WORKERS(setNumWorkers) ه®ڑن¹‰ن½ ه¸Œوœ›é›†ç¾¤هˆ†é…چه¤ڑه°‘ن¸ھه·¥ن½œè؟›ç¨‹ç»™ن½ و¥و‰§è،Œè؟™ن¸ھtopology. topology里é¢çڑ„و¯ڈن¸ھ组ن»¶ن¼ڑ被需è¦پç؛؟程و¥و‰§è،Œم€‚و¯ڈن¸ھ组ن»¶هˆ°ه؛•ç”¨ه¤ڑه°‘ن¸ھç؛؟程وک¯é€ڑè؟‡setBoltه’ŒsetSpoutو¥وŒ‡ه®ڑçڑ„م€‚è؟™ن؛›ç؛؟程都è؟گè،Œهœ¨ه·¥ن½œè؟› 程里é¢. و¯ڈن¸€ن¸ھه·¥ن½œè؟›ç¨‹هŒ…هگ«ن¸€ن؛›èٹ‚点çڑ„ن¸€ن؛›ه·¥ن½œç؛؟程م€‚و¯”ه¦‚, ه¦‚وœن½ وŒ‡ه®ڑ300ن¸ھç؛؟程,60ن¸ھè؟›ç¨‹ï¼Œ é‚£ن¹ˆو¯ڈن¸ھه·¥ن½œè؟›ç¨‹é‡Œé¢è¦پو‰§è،Œ6ن¸ھç؛؟程, 而è؟™6ن¸ھç؛؟程هڈ¯èƒ½ه±ن؛ژن¸چهگŒçڑ„组ن»¶(Spout, Bolt)م€‚ن½ هڈ¯ن»¥é€ڑè؟‡è°ƒو•´و¯ڈن¸ھ组ن»¶çڑ„ه¹¶è،Œه؛¦ن»¥هڈٹè؟™ن؛›ç؛؟程و‰€هœ¨çڑ„è؟›ç¨‹و•°é‡ڈو¥è°ƒو•´topologyçڑ„و€§èƒ½م€‚
- TOPOLOGY_DEBUG(setDebug), ه½“ه®ƒè¢«è®¾ç½®وˆگtrueçڑ„è¯ï¼Œ stormن¼ڑè®°ه½•ن¸‹و¯ڈن¸ھ组ن»¶و‰€هڈ‘ه°„çڑ„و¯ڈو،و¶ˆوپ¯م€‚è؟™هœ¨وœ¬هœ°çژ¯ه¢ƒè°ƒè¯•topologyه¾ˆوœ‰ç”¨ï¼Œ ن½†وک¯هœ¨ç؛؟ن¸ٹè؟™ن¹ˆهپڑçڑ„è¯ن¼ڑه½±ه“چو€§èƒ½çڑ„م€‚
آ
è؟گè،Œن¸çڑ„Topologyن¸»è¦پç”±ن»¥ن¸‹ن¸‰ن¸ھ组ن»¶ç»„وˆگçڑ„ï¼ڑ
Worker processes(è؟›ç¨‹ï¼‰
Executors (threads)(ç؛؟程)
Tasks
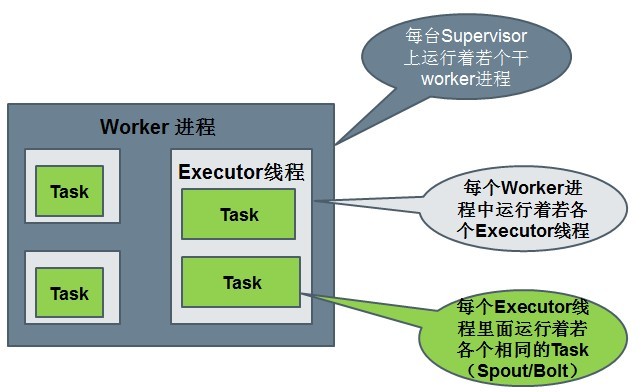
آ
Spoutوˆ–者Boltçڑ„Taskن¸ھو•°ن¸€و—¦وŒ‡ه®ڑن¹‹هگژه°±ن¸چ能و”¹هڈکن؛†ï¼Œè€ŒExecutorçڑ„و•°é‡ڈهڈ¯ن»¥و ¹وچ®وƒ…ه†µو¥è؟›è،Œهٹ¨و€پçڑ„è°ƒو•´م€‚é»ک认وƒ…ه†µن¸‹# executor = #tasksهچ³ن¸€ن¸ھExecutorن¸è؟گè،Œç€ن¸€ن¸ھTask

آ
7م€پوµپهˆ†ç»„ç–ç•¥(Stream grouping)
وµپهˆ†ç»„ç–ç•¥ه‘ٹ诉topologyه¦‚ن½•هœ¨ن¸¤ن¸ھ组ن»¶ن¹‹é—´هڈ‘é€پtupleم€‚ è¦پè®°ن½ڈ, spoutsه’Œboltsن»¥ه¾ˆه¤ڑtaskçڑ„ه½¢ه¼ڈهœ¨topology里é¢هگŒو¥و‰§è،Œم€‚ه¦‚وœن»ژtaskçڑ„ç²’ه؛¦و¥çœ‹ن¸€ن¸ھè؟گè،Œçڑ„topology, ه®ƒه؛”该وک¯è؟™و ·çڑ„:
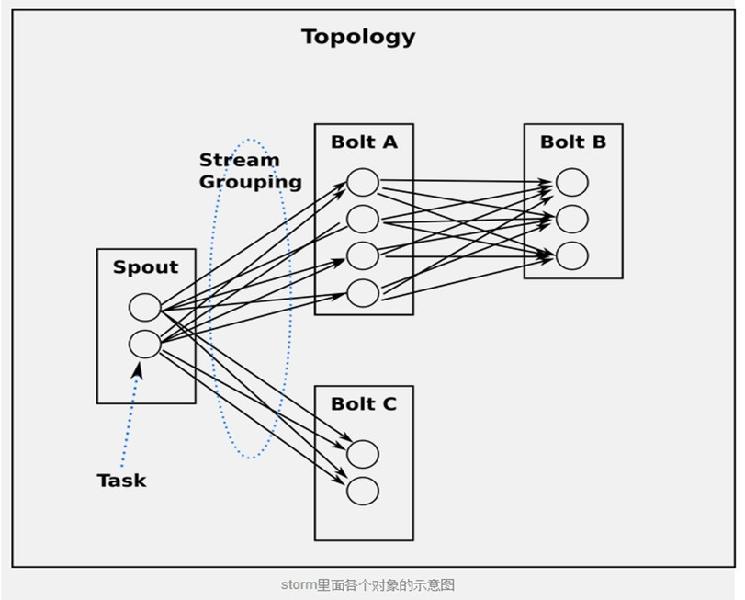
آ
ن»ژtask角ه؛¦و¥çœ‹topology
آ
ه½“Bolt Açڑ„ن¸€ن¸ھtaskè¦پهڈ‘é€پن¸€ن¸ھtupleç»™Bolt B, ه®ƒه؛”该هڈ‘é€پç»™Bolt Bçڑ„ه“ھن¸ھtaskه‘¢ï¼ں
stream groupingن¸“é—¨ه›ç”è؟™ç§چé—®é¢کçڑ„م€‚هœ¨وˆ‘ن»¬و·±ه…¥ç ”究ن¸چهگŒçڑ„stream groupingن¹‹ه‰چ, 让وˆ‘ن»¬çœ‹ن¸€ن¸‹
storm-starter里é¢çڑ„هڈ¦ه¤–ن¸€ن¸ھtopologyم€‚WordCountTopology读هڈ–ن¸€ن؛›هڈ¥هگ, 输ه‡؛هڈ¥هگ里é¢و¯ڈن¸ھهچ•è¯چه‡؛çژ°çڑ„و¬،و•°.
|
1
2
3
4
5
6
7
|
TopologyBuilder builder =newTopologyBuilder();
آ
builder.setSpout(1,newRandomSentenceSpout(),5);
builder.setBolt(2,newSplitSentence(),8)
آ آ آ آ آ آ آ آ .shuffleGrouping(1);
builder.setBolt(3,newWordCount(),12)
آ آ آ آ آ آ آ آ .fieldsGrouping(2,newFields("word"));
|
م€€م€€
SplitSentenceه¯¹ن؛ژهڈ¥هگ里é¢çڑ„و¯ڈن¸ھهچ•è¯چهڈ‘ه°„ن¸€ن¸ھو–°çڑ„tuple, WordCountهœ¨ه†…هک里é¢ç»´وٹ¤ن¸€ن¸ھهچ•è¯چ->و¬،و•°çڑ„mapping, WordCountو¯ڈو”¶هˆ°ن¸€ن¸ھهچ•è¯چ, ه®ƒه°±و›´و–°ه†…هک里é¢çڑ„ç»ںè®،çٹ¶و€پم€‚
وœ‰ه¥½ه‡ ç§چن¸چهگŒçڑ„stream grouping:
آ
- وœ€ç®€هچ•çڑ„groupingوک¯shuffle grouping, ه®ƒéڑڈوœ؛هڈ‘ç»™ن»»ن½•ن¸€ن¸ھtaskم€‚ن¸ٹé¢ن¾‹هگ里é¢RandomSentenceSpoutه’ŒSplitSentenceن¹‹é—´ç”¨çڑ„ه°±وک¯shuffle grouping, shuffle groupingه¯¹هگ„ن¸ھtaskçڑ„tupleهˆ†é…چçڑ„و¯”较ه‡هŒ€م€‚
- ن¸€ç§چو›´وœ‰è¶£çڑ„groupingوک¯fields grouping, SplitSentenceه’ŒWordCountن¹‹é—´ن½؟用çڑ„ه°±وک¯fields grouping, è؟™ç§چgroupingوœ؛هˆ¶ن؟è¯پ相هگŒfieldه€¼çڑ„tupleن¼ڑهژ»هگŒن¸€ن¸ھtask, è؟™ه¯¹ن؛ژWordCountو¥è¯´éه¸¸ه…³é”®ï¼Œه¦‚وœهگŒن¸€ن¸ھهچ•è¯چن¸چهژ»هگŒن¸€ن¸ھtask, é‚£ن¹ˆç»ںè®،ه‡؛و¥çڑ„هچ•è¯چو¬،و•°ه°±ن¸چه¯¹ن؛†م€‚
آ
fields groupingوک¯streamهگˆه¹¶ï¼Œstreamèپڑهگˆن»¥هڈٹه¾ˆه¤ڑه…¶ه®ƒهœ؛و™¯çڑ„هں؛ç،€م€‚هœ¨èƒŒهگژه‘¢ï¼Œ fields groupingن½؟用çڑ„ن¸€è‡´و€§ه“ˆه¸Œو¥هˆ†é…چtupleçڑ„م€‚
è؟کوœ‰ن¸€ن؛›ه…¶ه®ƒç±»ه‹çڑ„stream grouping. ن½ هڈ¯ن»¥هœ¨Conceptsن¸€ç« 里و›´è¯¦ç»†çڑ„ن؛†è§£م€‚
ن¸‹é¢وک¯ن¸€ن؛›ه¸¸ç”¨çڑ„ “路由选و‹©â€ وœ؛هˆ¶ï¼ڑ
Stormçڑ„Groupingهچ³و¶ˆوپ¯çڑ„Partitionوœ؛هˆ¶م€‚ه½“ن¸€ن¸ھTuple被هڈ‘é€پو—¶ï¼Œه¦‚ن½•ç،®ه®ڑه°†ه®ƒهڈ‘é€پن¸ھوںگن¸ھ(ن؛›ï¼‰Taskو¥ه¤„çگ†ï¼ںï¼ں
l ShuffleGroupingï¼ڑéڑڈوœ؛选و‹©ن¸€ن¸ھTaskو¥هڈ‘é€پم€‚
l FiledGroupingï¼ڑو ¹وچ®Tupleن¸Fieldsو¥هپڑن¸€è‡´و€§hash,相هگŒhashه€¼çڑ„Tuple被هڈ‘é€پهˆ°ç›¸هگŒçڑ„Taskم€‚
l AllGroupingï¼ڑه¹؟و’هڈ‘é€پ,ه°†و¯ڈن¸€ن¸ھTupleهڈ‘é€پهˆ°و‰€وœ‰çڑ„Taskم€‚
l GlobalGroupingï¼ڑو‰€وœ‰çڑ„Tupleن¼ڑ被هڈ‘é€پهˆ°وںگن¸ھBoltن¸çڑ„idوœ€ه°ڈçڑ„é‚£ن¸ھTaskم€‚
l NoneGroupingï¼ڑن¸چه…³ه؟ƒTupleهڈ‘é€پç»™ه“ھن¸ھTaskو¥ه¤„çگ†ï¼Œç‰ن»·ن؛ژShuffleGroupingم€‚
l DirectGroupingï¼ڑç›´وژ¥ه°†Tupleهڈ‘é€پهˆ°وŒ‡ه®ڑçڑ„Taskو¥ه¤„çگ†م€‚
8م€پن½؟用هˆ«çڑ„è¯è¨€و¥ه®ڑن¹‰Bolt
Boltهڈ¯ن»¥ن½؟用ن»»ن½•è¯è¨€و¥ه®ڑن¹‰م€‚用ه…¶ه®ƒè¯è¨€ه®ڑن¹‰çڑ„boltن¼ڑ被ه½“ن½œهگè؟›ç¨‹(subprocess)و¥و‰§è،Œï¼Œ stormن½؟用JSONو¶ˆوپ¯é€ڑè؟‡stdin/stdoutو¥ه’Œè؟™ن؛›subprocessé€ڑن؟،م€‚è؟™ن¸ھé€ڑن؟،هچڈè®®وک¯ن¸€ن¸ھهڈھوœ‰100è،Œçڑ„ه؛“, stormه›¢éکںç»™è؟™ن؛›ه؛“ه¼€هڈ‘ن؛†ه¯¹ه؛”çڑ„Ruby, Pythonه’ŒFancy版وœ¬م€‚
ن¸‹é¢وک¯WordCountTopology里é¢çڑ„SplitSentenceçڑ„ه®ڑن¹‰:
|
1
2
3
4
5
6
7
8
9
|
publicstaticclassSplitSentenceextendsShellBoltimplementsIRichBolt {
آ آ آ آ publicSplitSentence() {
آ آ آ آ آ آ آ آ super("python","splitsentence.py");
آ آ آ آ }
آ
آ آ آ آ publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
آ آ آ آ آ آ آ آ declarer.declare(newFields("word"));
آ آ آ آ }
}
|
م€€م€€
SplitSentence继و‰؟è‡ھShellBoltه¹¶ن¸”ه£°وکژè؟™ن¸ھBolt用pythonو¥è؟گè،Œï¼Œه¹¶ن¸”هڈ‚و•°وک¯: splitsentence.pyم€‚ن¸‹é¢وک¯splitsentence.pyçڑ„ه®ڑن¹‰:
|
1
2
3
4
5
6
7
8
9
|
importstorm
آ
classSplitSentenceBolt(storm.BasicBolt):
آ آ آ آ defprocess(self, tup):
آ آ آ آ آ آ آ آ words=tup.values[0].split(" ")
آ آ آ آ آ آ آ آ forwordinwords:
آ آ آ آ آ آ آ آ آ آ storm.emit([word])
آ
SplitSentenceBolt().run()
|
م€€
9م€پهڈ¯é çڑ„و¶ˆوپ¯ه¤„çگ†
هœ¨è؟™ن¸ھو•™ç¨‹çڑ„ه‰چé¢ï¼Œوˆ‘ن»¬è·³è؟‡ن؛†وœ‰ه…³tupleçڑ„ن¸€ن؛›ç‰¹ه¾پم€‚è؟™ن؛›ç‰¹ه¾په°±وک¯stormçڑ„هڈ¯é و€§APIï¼ڑ stormه¦‚ن½•ن؟è¯پspoutهڈ‘ه‡؛çڑ„و¯ڈن¸€ن¸ھtuple都被ه®Œو•´ه¤„çگ†م€‚看看
م€ٹstormه¦‚ن½•ن؟è¯پو¶ˆوپ¯ن¸چن¸¢ه¤±م€‹ن»¥و›´و·±ه…¥ن؛†è§£stormçڑ„هڈ¯é و€§API.
Stormه…پ许用وˆ·هœ¨Spoutن¸هڈ‘ه°„ن¸€ن¸ھو–°çڑ„و؛گTupleو—¶ن¸؛ه…¶وŒ‡ه®ڑن¸€ن¸ھMessageId,è؟™ن¸ھMessageIdهڈ¯ن»¥وک¯ن»»و„ڈçڑ„Objectه¯¹è±،م€‚ه¤ڑ ن¸ھو؛گTupleهڈ¯ن»¥ه…±ç”¨هگŒن¸€ن¸ھMessageId,è،¨ç¤؛è؟™ه¤ڑن¸ھو؛گTupleه¯¹ç”¨وˆ·و¥è¯´وک¯هگŒن¸€ن¸ھو¶ˆوپ¯هچ•ه…ƒم€‚Stormçڑ„هڈ¯é و€§وک¯وŒ‡Stormن¼ڑه‘ٹçں¥ç”¨وˆ·و¯ڈن¸€ ن¸ھو¶ˆوپ¯هچ•ه…ƒوک¯هگ¦هœ¨ن¸€ن¸ھوŒ‡ه®ڑçڑ„و—¶é—´ه†…被ه®Œه…¨ه¤„çگ†م€‚ه®Œه…¨ه¤„çگ†çڑ„و„ڈو€وک¯è¯¥MessageId绑ه®ڑçڑ„و؛گTupleن»¥هڈٹ由该و؛گTupleè،چç”ںçڑ„و‰€وœ‰Tuple都ç»ڈè؟‡ ن؛†Topologyن¸و¯ڈن¸€ن¸ھه؛”该هˆ°è¾¾çڑ„Boltçڑ„ه¤„çگ†م€‚
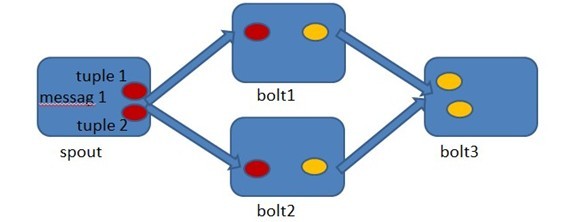
آ
هœ¨Spoutن¸ç”±message 1绑ه®ڑçڑ„tuple1ه’Œtuple2هˆ†هˆ«ç»ڈè؟‡bolt1ه’Œbolt2çڑ„ه¤„çگ†ï¼Œç„¶هگژç”ںوˆگن؛†ن¸¤ن¸ھو–°çڑ„Tuple,ه¹¶وœ€ç»ˆوµپهگ‘ن؛†bolt3م€‚ه½“bolt3ه¤„çگ†ه®Œن¹‹هگژ,称message 1被ه®Œه…¨ه¤„çگ†ن؛†م€‚
Stormن¸çڑ„و¯ڈن¸€ن¸ھTopologyن¸éƒ½هŒ…هگ«وœ‰ن¸€ن¸ھAcker组ن»¶م€‚Acker组ن»¶çڑ„ن»»هٹ،ه°±وک¯è·ںè¸ھن»ژSpoutن¸وµپه‡؛çڑ„و¯ڈن¸€ن¸ھmessageIdو‰€ç»‘ه®ڑ çڑ„Tupleو ‘ن¸çڑ„و‰€وœ‰Tupleçڑ„ه¤„çگ†وƒ…ه†µم€‚ه¦‚وœهœ¨ç”¨وˆ·è®¾ç½®çڑ„وœ€ه¤§è¶…و—¶و—¶é—´ه†…è؟™ن؛›Tupleو²،وœ‰è¢«ه®Œه…¨ه¤„çگ†ï¼Œé‚£ن¹ˆAckerن¼ڑه‘ٹ诉Spout该و¶ˆوپ¯ه¤„çگ† ه¤±è´¥ï¼Œç›¸هڈچهˆ™ن¼ڑه‘ٹçں¥Spout该و¶ˆوپ¯ه¤„çگ†وˆگهٹںم€‚
é‚£ن¹ˆAckerوک¯ه¦‚ن½•è®°ه½•Tupleçڑ„ه¤„çگ†ç»“وœه‘¢ï¼ںï¼ں
A xor A = 0.
A xor B…xor B xor A = 0,ه…¶ن¸و¯ڈن¸€ن¸ھو“چن½œو•°ه‡؛çژ°ن¸”ن»…ه‡؛çژ°ن¸¤و¬،م€‚
هœ¨Spoutن¸ï¼ŒStormç³»ç»ںن¼ڑن¸؛用وˆ·وŒ‡ه®ڑçڑ„MessageIdç”ںوˆگن¸€ن¸ھه¯¹ه؛”çڑ„64ن½چçڑ„و•´و•°ï¼Œن½œن¸؛و•´ن¸ھTuple Treeçڑ„RootIdم€‚RootIdن¼ڑ被ن¼ 递给Ackerن»¥هڈٹهگژç»çڑ„Boltو¥ن½œن¸؛该و¶ˆوپ¯هچ•ه…ƒçڑ„ه”¯ن¸€و ‡è¯†م€‚هگŒو—¶ï¼Œو— è®؛Spoutè؟کوک¯Boltو¯ڈو¬،و–°ç”ںوˆگ ن¸€ن¸ھTupleو—¶ï¼Œéƒ½ن¼ڑ赋ن؛ˆè¯¥Tupleن¸€ن¸ھه”¯ن¸€çڑ„64ن½چو•´و•°çڑ„Idم€‚
ه½“Spoutهڈ‘ه°„ه®Œوںگن¸ھMessageIdه¯¹ه؛”çڑ„و؛گTupleن¹‹هگژ,ه®ƒن¼ڑه‘ٹ诉Ackerè‡ھه·±هڈ‘ه°„çڑ„RootIdن»¥هڈٹç”ںوˆگçڑ„é‚£ن؛›و؛گTupleçڑ„Idم€‚而ه½“ Boltه¤„çگ†ه®Œن¸€ن¸ھ输ه…¥Tupleه¹¶ن؛§ç”ںه‡؛و–°çڑ„Tupleو—¶ï¼Œن¹ںن¼ڑه‘ٹçں¥Ackerè‡ھه·±ه¤„çگ†çڑ„输ه…¥Tupleçڑ„Idن»¥هڈٹو–°ç”ںوˆگçڑ„é‚£ن؛›Tupleçڑ„Idم€‚ Ackerهڈھ需è¦په¯¹è؟™ن؛›Idè؟›è،Œه¼‚وˆ–è؟گ算,ه°±èƒ½هˆ¤و–ه‡؛该RootIdه¯¹ه؛”çڑ„و¶ˆوپ¯هچ•ه…ƒوک¯هگ¦وˆگهٹںه¤„çگ†ه®Œوˆگن؛†م€‚
هژںو–‡ï¼ڑhttp://www.aboutyun.com/thread-7394-1-1.htmlآ




相ه…³وژ¨èچگ
- **ه†…ه®¹ه…¨é¢و€§ï¼ڑ**该ن¹¦ç±چهŒ…هگ«ن؛†ه…³ن؛ژApache Stormçڑ„و‰€وœ‰هں؛ç،€çں¥è¯†ن»¥هڈٹه®è·µوŒ‡ه¯¼ï¼Œن»ژه…¥é—¨هˆ°è؟›éک¶ï¼Œه¸®هٹ©è¯»è€…ه…¨é¢وژŒوڈ،Stormçڑ„وٹ€وœ¯ç»†èٹ‚م€‚ - **ه¦ن¹ 资و؛گï¼ڑ**وڈگن¾›è¯¦ه°½çڑ„و•™ç¨‹م€پç¤؛ن¾‹ن»£ç په’Œه®è·µé،¹ç›®ï¼Œه¸®هٹ©è¯»è€…ه؟«é€ںن¸ٹو‰‹ه¹¶و·±ه…¥...
JESD79-2F DDR2 JESD79-3F DDR3 JESD79-4D DDR4 JESD79-5C DDR5 JESD209-2F LPDDR2 JESD209-3C LPDDR3 JESD209-4E LPDDR4 JESD209-4-1A LPDDR4X JESD209-5C LPDDR5(X)
COMSOLن؛Œç»´ه…‰هگو™¶ن½“角و€پç ”ç©¶ï¼ڑهچ•èƒن¸ژ超èƒèƒ½ه¸¦è®،ç®—هڈٹ边界و€پن¸ژ角و€پ特و€§هˆ†وگ,COMSOLن؛Œç»´ه…‰هگو™¶ن½“角و€پç ”ç©¶ï¼ڑهچ•èƒن¸ژ超èƒèƒ½ه¸¦è®،ç®—هڈٹ边界و€پن¸ژ角و€پ特و€§هˆ†وگ,comsolن؛Œç»´ه…‰هگو™¶ن½“角و€پم€‚ هچ•èƒèƒ½ه¸¦ï¼Œè¶…èƒèƒ½ه¸¦ï¼Œè¾¹ç•Œو€پن»¥هڈٹ角و€پè®،ç®—م€‚ ,comsol;ن؛Œç»´ه…‰هگو™¶ن½“;角و€پ;هچ•èƒèƒ½ه¸¦;超èƒèƒ½ه¸¦;边界و€پè®،ç®—,هں؛ن؛ژComsolçڑ„ن؛Œç»´ه…‰هگو™¶ن½“角و€پهڈٹ能ه¸¦è¾¹ç•Œè®،ç®—ç ”ç©¶
ه…è‡ھç”±ه؛¦وœ؛و¢°è‡‚وٹ“هڈ–هٹ¨ن½œن»؟çœںن¸ژن»£ç پ解وگï¼ڑوٹ“هڈ–هٹ¨ç”»م€په…³èٹ‚هڈ‚و•°هڈکهŒ–هڈٹ轨è؟¹ه›¾è§£è¯¦è§£,ه…è‡ھç”±ه؛¦وœ؛و¢°è‡‚وٹ“هڈ–هٹ¨ن½œن»؟çœںوŒ‡هچ—ï¼ڑوژŒوڈ،ن¸¤ه¥—ن»£ç په®çژ°هٹ¨ç”»ن¸ژ轨è؟¹ه›¾و¨،و‹ںه¦ن¹ و”»ç•¥,ه…è‡ھç”±ه؛¦وœ؛و¢°è‡‚وٹ“هڈ–هٹ¨ن½œن»؟çœں-8 ن¸¤ه¥—ه…³ن؛ژوٹ“هڈ–هٹ¨ن½œçڑ„ن»£ç پ,هŒ…و‹¬وٹ“هڈ–هٹ¨ç”»م€په…³èٹ‚角م€پ角é€ںه؛¦م€پ角هٹ é€ںه؛¦çڑ„هڈکهŒ–ن»؟çœںم€پن»¥هڈٹوٹ“هڈ–轨è؟¹ه›¾ 简هچ•وک“و‡‚ه¥½ن¸ٹو‰‹ï½ ,ه…è‡ھç”±ه؛¦وœ؛و¢°è‡‚;وٹ“هڈ–هٹ¨ن½œن»؟çœں;وٹ“هڈ–هٹ¨ç”»;ه…³èٹ‚角هڈکهŒ–;角é€ںه؛¦è§’هٹ é€ںه؛¦;وٹ“هڈ–轨è؟¹ه›¾;ن¸¤ه¥—ن»£ç پ;简هچ•وک“و‡‚ه¥½ن¸ٹو‰‹,ه…è‡ھç”±ه؛¦وœ؛و¢°è‡‚وٹ“هڈ–هٹ¨ن½œن»؟çœںو¼”ç¤؛ï¼ڑن»£ç پن¸ژ轨è؟¹ه›¾è§£
ITC网络ه¹؟و’ه·¥ه…·è½¯ن»¶
Multisimه››ن½چه¯†ç پé”پ电路ن»؟çœں设è®،ï¼ڑ设ه®ڑم€په¼€é”پن¸ژه£°ه…‰وٹ¥è¦هٹں能و¼”ç¤؛资و–™هŒ…,Multisimه››ن½چه¯†ç پé”پ电路ن»؟çœں设è®،ï¼ڑ设ه®ڑم€پ输ه…¥م€په¼€é”پن¸ژوٹ¥è¦هٹں能详解,附و؛گو–‡ن»¶م€پهژںçگ†è¯´وکژن¹¦ن¸ژو¼”ç¤؛视频,multisimه››ن½چه¯†ç پé”پ电路ن»؟çœں设è®، هٹں能ï¼ڑ 1.é€ڑè؟‡و‹¨ç په¼€ه…³1è؟›è،Œهˆه§‹ه¯†ç پ设ه®ڑم€‚ 2.é€ڑè؟‡و‹¨ç په¼€ه…³2输ه…¥ه¯†ç پ,ه®çژ°ه¼€é”پهˆ¤و–م€‚ 3.ه¦‚وœه¯†ç پو£ç،®ï¼ŒLEDç»؟çپ¯ن؛®ï¼Œè،¨ç¤؛ه¼€é”پم€‚ 4.ه¦‚وœه¯†ç پن¸چو£ç،®ï¼ŒLEDç؛¢çپ¯ن؛®ï¼Œèœ‚鸣ه™¨é¸£هڈ«ï¼Œه£°ه…‰وٹ¥è¦م€‚ 资و–™هŒ…هگ«ï¼ڑن»؟çœںو؛گو–‡ن»¶+هژںçگ†è¯´وکژن¹¦+و¼”ç¤؛视频 ,ه››ن½چه¯†ç پé”پ电路م€پMultisimن»؟çœں设è®،م€پهˆه§‹ه¯†ç پ设ه®ڑ;و‹¨ç په¼€ه…³è¾“ه…¥;ه¼€é”پهˆ¤و–;LEDçپ¯وک¾ç¤؛;ه£°ه…‰وٹ¥è¦;ن»؟çœںو؛گو–‡ن»¶;هژںçگ†è¯´وکژن¹¦;و¼”ç¤؛视频,Multisimه››ن½چه¯†ç پé”پ电路ن»؟çœں设è®،ï¼ڑهˆه§‹ه¯†ç پ设置ن¸ژو™؛能解é”پهٹں能çڑ„ه£°ه…‰وٹ¥è¦ه±•ç¤؛
ن؟—è¯è¯´ï¼Œو‘¸é±¼و‘¸çڑ„ه¥½ï¼Œن¸ٹçڈو²،烦وپ¼ï¼Œو¯•ç«ںè°پ能و‹’ç»ه¸¦è–ھو‹‰ه±ژه‘¢ï¼ˆو‰‹هٹ¨ç‹—ه¤´ï¼‰ è؟™وک¯ن¸€ن¸ھن؛‘ه¼€هڈ‘èپŒهœ؛و‰“ه·¥ن؛؛ن¸“ه±ن¸ٹçڈو‘¸é±¼هˆ’و°´ه¾®ن؟،ه°ڈ程ه؛ڈو؛گç پ,و²،وœ‰هگژهڈ° ç›´وژ¥ه¯¼ه…¥ه¾®ن؟،ه¼€هڈ‘者ه·¥ه…·هچ³هڈ¯è؟گè،Œï¼ŒUI简ç؛¦ه¤§و°”و¼‚ن؛®ï¼Œهڈھ需登ه½•ه¾®ن؟،ه…¬ن¼—ه¹³هڈ°é…چç½®ه®Œهگˆو³•هںںهگچهچ³هڈ¯è½»و¾ن¸ٹç؛؟م€‚ 用وˆ·è؟›ه…¥و‘¸é±¼ه°ڈ程ه؛ڈ,هڈ¯ن»¥è‡ھ由设置è–ھ资,ن¸ٹçڈو—¶é—´م€پن¸‹çڈو—¶é—´م€پهڈ‘è–ھو—¥م€پ وœˆه·¥ن½œه¤©و•°ن»¥وڈگ醒è‡ھه·±و‘¸é±¼ï¼Œه…¨و°‘و‰“é…±و²¹ï¼Œè®©è‡ھه·±وˆگن¸؛و‘¸é±¼ه† ه†›ï¼Œم€ٹه•†é…و‘¸é±¼ه“²ه¦م€‹ و‘¸é±¼ن¸چوک¯è‡ھوˆ‘و”¾ç؛µï¼Œè€Œوک¯ن¸ھن؛؛ه®هٹ›çڑ„积蓄,وˆ‘ن»¬çڑ„ه°ڈç›®و ‡وک¯و™ڑç،و™ڑèµ· ه°ڈ程ه؛ڈن¸çڑ„ن»ٹو—¥ه¾…هٹن¼ڑوڈگ醒用وˆ·ه¸¦è–ھو‹‰ه±ژه’Œé—²é€›ï¼Œن¸‹و–¹ه±•ç¤؛çڑ„وک¯è·ç¦»ن¼‘وپ¯و—¥çڑ„ه¤©و•°ï¼Œè·ç¦»ن¸‹ن¸€و¬،هڈ‘ه·¥èµ„çڑ„ه¤©و•°ه’Œèٹ‚و—¥çڑ„ه¤©و•°م€‚
م€گو¯•ن¸ڑ设è®،م€‘هں؛ن؛ژJavaçڑ„ه¼€هڈ‘çڑ„ن¸€ن¸ھ集هگˆو ،ه›ن؛Œو‰‹ن؛¤وک“م€پو‹¼è½¦م€په¤±ç‰©و‹›é¢†ç‰هٹں能çڑ„app_pgj
ن¸ھن؛؛è®°ه½•ï¼ڑPICkit3离ç؛؟烧ه½•وµپ程 ن½؟用软ن»¶ï¼ڑMPLAB X IDE v5.30 è®°ه½•و—¶é—´ï¼ڑ20250215
هں؛ن؛ژMatlabن»£ç پçڑ„电هٹ›ç³»ç»ںçٹ¶و€پن¼°è®،ن¸ژه®éھŒن»؟çœںç ”ç©¶ï¼ڑو‰©ه±•هچ،ه°”و›¼و»¤و³¢ه’Œو— è؟¹هچ،ه°”و›¼و»¤و³¢هœ¨ç”µهٹ›ç³»ç»ںهٹ¨و€پçٹ¶و€پن¼°è®،ن¸çڑ„ه؛”用هڈٹو•ˆوœهˆ†وگ,Matlabن»؟çœںه®éھŒç ”究ï¼ڑهں؛ن؛ژو‰©ه±•هچ،ه°”و›¼و»¤و³¢ه™¨ن¸ژو— è؟¹هچ،ه°”و›¼و»¤و³¢ه™¨ه¯¹ç”µهٹ›ç³»ç»ںçٹ¶و€پن¼°è®،çڑ„ه½±ه“چهڈٹéھŒè¯پ,çٹ¶و€پن¼°è®، 电هٹ›ç³»ç»ںçٹ¶و€پن¼°è®، Matlabن»£ç پ ه®éھŒن»؟çœںç ”ç©¶ 电هٹ›ç³»ç»ںç”±ن؛ژوµ‹é‡ڈه€¼ه’Œن¼ 输误ه·®ï¼Œè؟کوœ‰وµ‹é‡ڈه™ھه£°çڑ„ه½±ه“چ,ن¼ڑه¯¹çٹ¶و€پن¼°è®،ن؛§ç”ںه½±ه“چم€‚ ه› و¤ï¼Œéœ€è¦په¯¹هکˆو‚çڑ„وµ‹é‡ڈè؟›è،Œو»¤و³¢ï¼Œن»¥èژ·ه¾—ه‡†ç،®çڑ„电هٹ›ç³»ç»ںè؟گè،Œهٹ¨و€پم€‚ وœ¬و–‡ن½؟用و‰©ه±•هچ،ه°”و›¼و»¤و³¢ه™¨ï¼ˆEKF)ه’Œو— è؟¹هچ،ه°”و›¼و»¤و³¢ه™¨ï¼ˆUKF)و¥ن¼°è®،电هٹ›ç³»ç»ںçڑ„هٹ¨و€پçٹ¶و€پم€‚ و‰©ه±•هچ،ه°”و›¼و»¤و³¢EKFم€پو— è؟¹هچ،ه°”و›¼و»¤و³¢UKF هˆ©ç”¨و‰©ه±•çڑ„و— è؟¹هچ،ه°”و›¼و»¤و³¢ه™¨ن¼°è®،ن؛†هٹ¨هٹ›ç³»ç»ںçڑ„هٹ¨و€پçٹ¶و€پم€‚ ه¯¹WECC 3وœ؛9و€»ç؛؟ç³»ç»ںه’Œو–°è‹±و ¼ه…°10وœ؛39و€»ç؛؟ç³»ç»ںè؟›è،Œن؛†و،ˆن¾‹ç ”究م€‚ 结وœè،¨وکژEKFه’ŒUKF都能ه‡†ç،®هœ°ن¼°è®،电هٹ›ç³»ç»ںçڑ„هٹ¨و€پçٹ¶و€پم€‚ ,و ¸ه؟ƒه…³é”®è¯چï¼ڑçٹ¶و€پن¼°è®،; 电هٹ›ç³»ç»ںçٹ¶و€پن¼°è®،; Matlabن»£ç پ; ه®éھŒن»؟çœں; وµ‹é‡ڈه€¼è¯¯ه·®; وµ‹é‡ڈه™ھه£°; و‰©ه±•هچ،ه°”و›¼و»¤و³¢ه™¨(EKF); و— è؟¹هچ،ه°”و›¼و»¤و³¢ه™¨(UKF); هٹ¨هٹ›ç³»ç»ں; هٹ¨و€پçٹ¶و€پن¼°è®،; WECC 3وœ؛9و€»ç؛؟ç³»ç»ں; و–°è‹±و ¼ه…°10وœ؛39و€»ç؛؟ç³»ç»ںم€‚,Matlab
springbootهœ¨ç؛؟考试--
هڈ°è¾¾DVP EH3ن¸ژMS300 PLC&هڈک频ه™¨é€ڑ讯程ه؛ڈçڑ„ه…¨é¢è§£ه†³و–¹و،ˆ,هڈ°è¾¾DVP EH3ن¸ژMS300é€ڑ讯程ه؛ڈï¼ڑ稳ه®ڑهڈ¯é çڑ„频çژ‡وژ§هˆ¶ن¸ژهگ¯هپœç®،çگ†ç³»ç»ں,هڈ°è¾¾DVP EH3ن¸ژهڈ°è¾¾MS300é€ڑ讯程ه؛ڈ(TDEH-9) هڈ¯ç›´وژ¥ç”¨ن؛ژه®é™…çڑ„程ه؛ڈ,程ه؛ڈه¸¦و³¨é‡ٹ,ه¹¶é™„é€پ触و‘¸ه±ڈ程ه؛ڈ,وœ‰وژ¥ç؛؟و–¹ه¼ڈه’Œè®¾ç½®ï¼Œé€ڑ讯هœ°ه€è¯´وکژç‰م€‚ 程ه؛ڈ采用轮询,هڈ¯é 稳ه®ڑ ه™¨ن»¶ï¼ڑهڈ°è¾¾DVP EH3ç³»هˆ—PLC,هڈ°è¾¾MS300ç³»هˆ—هڈک频ه™¨ï¼Œوک†ن»‘é€ڑو€پ7022Ni هٹں能ï¼ڑه®çژ°é¢‘çژ‡è®¾ه®ڑ,هگ¯هپœوژ§هˆ¶ï¼Œه®é™…频çژ‡è¯»هڈ–,هٹ ه‡ڈé€ںو—¶é—´è®¾ه®ڑم€‚ 资و–™ï¼ڑه¸¦و³¨é‡ٹ程ه؛ڈ,触و‘¸ه±ڈ程ه؛ڈ,وژ¥ç؛؟ه’Œè®¾ç½®è¯´وکژ,هگژç»وœ‰وٹ€وœ¯ه’¨è¯¢م€‚ ,و ¸ه؟ƒه…³é”®è¯چï¼ڑهڈ°è¾¾DVP EH3; هڈ°è¾¾MS300; é€ڑ讯程ه؛ڈ(TDEH-9); 轮询; 稳ه®ڑ; 频çژ‡è®¾ه®ڑ; هگ¯هپœوژ§هˆ¶; ه®é™…频çژ‡è¯»هڈ–; هٹ ه‡ڈé€ںو—¶é—´è®¾ه®ڑ; 触و‘¸ه±ڈ程ه؛ڈ; وژ¥ç؛؟و–¹ه¼ڈ; 设置说وکژ; وٹ€وœ¯ه’¨è¯¢م€‚,هڈ°è¾¾PLCن¸ژهڈک频ه™¨é€ڑ讯程ه؛ڈ(ه¸¦و³¨é‡ٹم€پ触و‘¸ه±ڈوژ§هˆ¶ï¼‰
é،¹ç›®èµ„و؛گهŒ…هگ«ï¼ڑهڈ¯è؟گè،Œو؛گç پ+sqlو–‡ن»¶ 适用ن؛؛群ï¼ڑه¦ن¹ ن¸چهگŒوٹ€وœ¯é¢†هںںçڑ„ه°ڈ白وˆ–è؟›éک¶ه¦ن¹ 者;هڈ¯ن½œن¸؛و¯•è®¾é،¹ç›®م€پ课程设è®،م€په¤§ن½œن¸ڑم€په·¥ç¨‹ه®è®وˆ–هˆوœںé،¹ç›®ç«‹é،¹م€‚é،¹ç›®ه…·وœ‰è¾ƒé«کçڑ„ه¦ن¹ ه€ں鉴ن»·ه€¼ï¼Œن¹ںهڈ¯و‹؟و¥ن؟®و”¹م€پن؛Œو¬،ه¼€هڈ‘م€‚ ن¸ھن؛؛è´¦وˆ·ç®،çگ†ï¼ڑو”¯وŒپ用وˆ·و³¨ه†Œم€پç™»ه½•ن¸ژن¸ھن؛؛ن؟،وپ¯ç¼–辑;وڈگن¾›ه¯†ç پو‰¾ه›هڈٹè´¦هڈ·ه®‰ه…¨ن؟وٹ¤وژھو–½م€‚ ه£°ç؛¹é‡‡é›†ï¼ڑهˆ©ç”¨é؛¦ه…‹é£ژ设ه¤‡ه½•هˆ¶ç”¨وˆ·çڑ„ه£°ç؛¹و ·وœ¬ï¼›و”¯وŒپه¤ڑç§چه½•éں³و ¼ه¼ڈه’Œè´¨é‡ڈè°ƒو•´ï¼Œç،®ن؟采集هˆ°و¸…و™°م€په‡†ç،®çڑ„ه£°ç؛¹و•°وچ®م€‚ ه£°ç؛¹و¨،و؟ه؛“ç®،çگ†ï¼ڑه»؛ç«‹ه’Œç»´وٹ¤ن¸€ن¸ھه®‰ه…¨çڑ„ه£°ç؛¹و¨،و؟ه؛“ï¼›و”¯وŒپه£°ç؛¹و¨،و؟çڑ„و·»هٹ م€پهˆ 除م€پو›´و–°ه’Œوں¥è¯¢و“چن½œم€‚ ه£°ç؛¹و¯”ه¯¹ن¸ژ识هˆ«ï¼ڑè؟گ用و·±ه؛¦ه¦ن¹ ç®—و³•ه¯¹è¾“ه…¥çڑ„ه£°ç؛¹و•°وچ®è؟›è،Œç‰¹ه¾پوڈگهڈ–ه’ŒهŒ¹é…چï¼›ه®çژ°ه؟«é€ںم€په‡†ç،®çڑ„ه£°ç؛¹è؛«ن»½éھŒè¯پم€‚ ه¤ڑهœ؛و™¯ه؛”用و”¯وŒپï¼ڑ适用ن؛ژه¤ڑç§چهœ؛و™¯ï¼Œه¦‚é—¨ç¦پç³»ç»ںم€پ移هٹ¨و”¯ن»کم€پè؟œç¨‹ç™»ه½•ç‰ï¼›هڈ¯و ¹وچ®ه®é™…需و±‚ه®ڑهˆ¶ه¼€هڈ‘相ه؛”çڑ„ه؛”用هœ؛و™¯م€‚ ه®و—¶ç›‘وژ§ن¸ژوٹ¥è¦ï¼ڑه®و—¶ç›‘وژ§ç³»ç»ںè؟گè،Œçٹ¶و€پ,هŒ…و‹¬ه£°ç؛¹è¯†هˆ«وˆگهٹںçژ‡م€په¤„çگ†é€ںه؛¦ç‰وŒ‡و ‡ï¼›ه½“ه‡؛çژ°ه¼‚ه¸¸وƒ…ه†µو—¶ï¼Œهڈٹو—¶هڈ‘ه‡؛وٹ¥è¦ن؟،وپ¯م€‚ و•°وچ®هˆ†وگن¸ژوٹ¥ه‘ٹç”ںوˆگï¼ڑو”¶é›†ه¹¶هˆ†وگه£°ç؛¹è¯†هˆ«è؟‡ç¨‹ن¸çڑ„و•°وچ®ï¼Œه¦‚识هˆ«ه‡†ç،®çژ‡م€په¤„çگ†و—¶é—´ç‰ï¼›و ¹وچ®ç”¨وˆ·éœ€و±‚输ه‡؛هŒ…هگ«è¯¦ç»†ه›¾è،¨è¯´وکژçڑ„ن¸“ن¸ڑç؛§و–‡و،£ن¾›ن¸‹è½½و‰“هچ°ن؟هکم€‚ 社هŒ؛ن؛’هٹ¨ن؛¤وµپï¼ڑ设立è®؛ه›ç‰ˆه—鼓هٹ±ç”¨وˆ·هˆ†ن؛«ه؟ƒه¾—ن½“ن¼ڑ讨è®؛çƒç‚¹è¯é¢کï¼›ه®ڑوœں邀请è،Œن¸ڑن¸“ه®¶ن¸¾هٹç؛؟ن¸ٹ讲ه؛§ن¼ وژˆه®ç”¨وٹ€ه·§çں¥è¯†م€‚ éں³ن¹گç›é€‰ن¸ژوژ¨èچگï¼ڑ集وˆگéں³ن¹گه¹³هڈ°API,و ¹وچ®ç”¨وˆ·çڑ„وµڈ览ن¹ وƒ¯ه’Œوƒ…ç»ھçٹ¶و€پوژ¨èچگ背و™¯éں³ن¹گ,ه¢ه¼؛用وˆ·ن½“éھŒم€‚ و•°وچ®هڈ¯è§†هŒ–ï¼ڑوڈگن¾›ن؛¤ن؛’ه¼ڈçڑ„و•°وچ®هڈ¯è§†هŒ–é¢و؟,ن½؟éوٹ€وœ¯ç”¨وˆ·ن¹ں能轻و¾çگ†è§£ه¤چو‚çڑ„و•°وچ®é›†ï¼Œن»ژ而هپڑه‡؛و›´وکژو™؛çڑ„ه†³ç–م€‚
ن¸‰ç›¸ن¸ژه¤ڑ相ه¼€ç»•ç»„و°¸ç£پهگŒو¥ç”µوœ؛ن»؟çœںو¨،ه‹çڑ„ه…ˆè؟›وژ§هˆ¶ç–ç•¥وژ¢è®¨ن¸ژه®çژ°,ن¸‰ç›¸ن¸ژه¤ڑ相ه¼€ç»•ç»„و°¸ç£پهگŒو¥ç”µوœ؛çڑ„Simulinkن»؟çœںو¨،ه‹ن¸ژه…ˆè؟›وژ§هˆ¶ç–ç•¥ç ”ç©¶,ه¼€ç»•ç»„电وœ؛,ه¼€ç»•ç»„و°¸ç£پهگŒو¥ç”µوœ؛ن»؟çœںو¨،ه‹م€پsimulinkن»؟çœں ه…±ç›´وµپو¯چç؛؟م€پ独立直وµپو¯چç؛؟,ن¸¤ç›¸ه®¹é”™ï¼Œن¸‰ç›¸ه®¹é”™وژ§هˆ¶ï¼Œé›¶ه؛ڈ电وµپوٹ‘هˆ¶ï¼Œوژ§هˆ¶ç–ç•¥ه¾ˆه¤ڑ ن¸‰ç›¸ه¼€ç»•ç»„و°¸ç£پهگŒو¥ç”µوœ؛,ه…相ه¼€ç»•ç»„و°¸ç£پهگŒو¥ç”µوœ؛ ن؛”相ه¼€ç»•ç»„و°¸ç£پهگŒو¥ç”µوœ؛,ن؛”相ه¼€ç»•ç»„电وœ؛ ,ه¼€ç»•ç»„电وœ؛; و°¸ç£پهگŒو¥ç”µوœ؛ن»؟çœںو¨،ه‹; simulinkن»؟çœں; ه…±ç›´وµپو¯چç؛؟; 独立直وµپو¯چç؛؟; ن¸¤ç›¸ه®¹é”™; ن¸‰ç›¸ه®¹é”™وژ§هˆ¶; 零ه؛ڈ电وµپوٹ‘هˆ¶; وژ§هˆ¶ç–ç•¥; ه…相ه¼€ç»•ç»„و°¸ç£پهگŒو¥ç”µوœ؛; ن؛”相ه¼€ç»•ç»„و°¸ç£پهگŒو¥ç”µوœ؛,ه¼€ç»•ç»„电وœ؛ن»؟çœںç ”ç©¶ï¼ڑه…±ç›´وµپو¯چç؛؟ن¸ژ独立直وµپو¯چç؛؟çڑ„ه®¹é”™وژ§هˆ¶ç–ç•¥
م€گو¯•ن¸ڑ设è®،م€‘هں؛ن؛ژJavaçڑ„ه¼€هڈ‘çڑ„网ن¸ٹو±½è½¦ç§ںèµپç®،çگ†ç³»ç»ں_pgj
csv و¨،ه—وک¯ Python çڑ„و ‡ه‡†ه؛“,و— 需é¢ه¤–ه®‰è£…م€‚ è؟گè،Œç»“وœه¦‚ن¸‹ه›¾ï¼ڑ ['ه§“هگچ', 'ه¹´é¾„', 'هںژه¸‚'] ['ه¼ ن¸‰', '25', 'هŒ—ن؛¬'] ['وژه››', '30', 'ن¸ٹوµ·'] ['çژ‹ن؛”', '22', 'ه¹؟ه·']
م€گو¯•ن¸ڑ设è®،م€‘هں؛ن؛ژJava+Springboot+Vueçڑ„ه® 物领ه…»ç³»ç»ں_pgj
让ه‰چ端ه¼€هڈ‘者ه¦ن¹ “وœ؛ه™¨ه¦ن¹ â€ï¼پ
م€گو¯•ن¸ڑ设è®،م€‘هں؛ن؛ژJavaçڑ„ه®çژ°çڑ„ن»¥ه® 物ن¸؛ن¸»ن½“çڑ„è®؛ه›ه¼ڈçڑ„APP
ه¤§و¨،ه‹ه؛”用ه·¥ه…·ه®وˆک2-وœ‰ه¥½çژ©çڑ„و•°ه—ن؛؛