
s
Druid is a high-performance, column-oriented, distributed data store.
OLAP、OLTP的介绍和比较
http://76287.blog.51cto.com/66287/885475
http://blog.csdn.net/zhangzheng0413/article/details/8271322/
OLTP与OLAP的介绍
数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
OLTP与OLAP之间的比较:

OLTP,也叫联机事务处理(Online Transaction Processing),表示事务性非常高的系统,一般都是高可用的在线系统,以小的事务以及小的查询为主,评估其系统的时候,一般看其每秒执行的Transaction以及Execute SQL的数量。在这样的系统中,单个数据库每秒处理的Transaction往往超过几百个,或者是几千个,Select 语句的执行量每秒几千甚至几万个。典型的OLTP系统有电子商务系统、银行、证券等,如美国eBay的业务数据库,就是很典型的OLTP数据库。
OLTP系统最容易出现瓶颈的地方就是CPU与磁盘子系统。
(1)CPU出现瓶颈常表现在逻辑读总量与计算性函数或者是过程上,逻辑读总量等于单个语句的逻辑读乘以执行次数,如果单个语句执行速度虽然很快,但是执行次数非常多,那么,也可能会导致很大的逻辑读总量。设计的方法与优化的方法就是减少单个语句的逻辑读,或者是减少它们的执行次数。另外,一些计算型的函数,如自定义函数、decode等的频繁使用,也会消耗大量的CPU时间,造成系统的负载升高,正确的设计方法或者是优化方法,需要尽量避免计算过程,如保存计算结果到统计表就是一个好的方法。
(2)磁盘子系统在OLTP环境中,它的承载能力一般取决于它的IOPS处理能力. 因为在OLTP环境中,磁盘物理读一般都是db file sequential read,也就是单块读,但是这个读的次数非常频繁。如果频繁到磁盘子系统都不能承载其IOPS的时候,就会出现大的性能问题。
OLTP比较常用的设计与优化方式为Cache技术与B-tree索引技术,Cache决定了很多语句不需要从磁盘子系统获得数据,所以,Web cache与Oracle data buffer对OLTP系统是很重要的。另外,在索引使用方面,语句越简单越好,这样执行计划也稳定,而且一定要使用绑定变量,减少语句解析,尽量减少表关联,尽量减少分布式事务,基本不使用分区技术、MV技术、并行技术及位图索引。因为并发量很高,批量更新时要分批快速提交,以避免阻塞的发生。
OLTP 系统是一个数据块变化非常频繁,SQL 语句提交非常频繁的系统。 对于数据块来说,应尽可能让数据块保存在内存当中,对于SQL来说,尽可能使用变量绑定技术来达到SQL重用,减少物理I/O 和重复的SQL 解析,从而极大的改善数据库的性能。
这里影响性能除了绑定变量,还有可能是热快(hot block)。 当一个块被多个用户同时读取时,Oracle 为了维护数据的一致性,需要使用Latch来串行化用户的操作。当一个用户获得了latch后,其他用户就只能等待,获取这个数据块的用户越多,等待就越明显。 这就是热快的问题。 这种热快可能是数据块,也可能是回滚端块。 对于数据块来讲,通常是数据库的数据分布不均匀导致,如果是索引的数据块,可以考虑创建反向索引来达到重新分布数据的目的,对于回滚段数据块,可以适当多增加几个回滚段来避免这种争用。
OLAP,也叫联机分析处理(Online Analytical Processing)系统,有的时候也叫DSS决策支持系统,就是我们说的数据仓库。在这样的系统中,语句的执行量不是考核标准,因为一条语句的执行时间可能会非常长,读取的数据也非常多。所以,在这样的系统中,考核的标准往往是磁盘子系统的吞吐量(带宽),如能达到多少MB/s的流量。
磁盘子系统的吞吐量则往往取决于磁盘的个数,这个时候,Cache基本是没有效果的,数据库的读写类型基本上是db file scattered read与direct path read/write。应尽量采用个数比较多的磁盘以及比较大的带宽,如4Gb的光纤接口。
在OLAP系统中,常使用分区技术、并行技术。
分区技术在OLAP系统中的重要性主要体现在数据库管理上,比如数据库加载,可以通过分区交换的方式实现,备份可以通过备份分区表空间实现,删除数据可以通过分区进行删除,至于分区在性能上的影响,它可以使得一些大表的扫描变得很快(只扫描单个分区)。另外,如果分区结合并行的话,也可以使得整个表的扫描会变得很快。总之,分区主要的功能是管理上的方便性,它并不能绝对保证查询性能的提高,有时候分区会带来性能上的提高,有时候会降低。
并行技术除了与分区技术结合外,在Oracle 10g中,与RAC结合实现多节点的同时扫描,效果也非常不错,可把一个任务,如select的全表扫描,平均地分派到多个RAC的节点上去。
在OLAP系统中,不需要使用绑定(BIND)变量,因为整个系统的执行量很小,分析时间对于执行时间来说,可以忽略,而且可避免出现错误的执行计划。但是OLAP中可以大量使用位图索引,物化视图,对于大的事务,尽量寻求速度上的优化,没有必要像OLTP要求快速提交,甚至要刻意减慢执行的速度。
绑定变量真正的用途是在OLTP系统中,这个系统通常有这样的特点,用户并发数很大,用户的请求十分密集,并且这些请求的SQL 大多数是可以重复使用的。
对于OLAP系统来说,绝大多数时候数据库上运行着的是报表作业,执行基本上是聚合类的SQL 操作,比如group by,这时候,把优化器模式设置为all_rows是恰当的。 而对于一些分页操作比较多的网站类数据库,设置为first_rows会更好一些。 但有时候对于OLAP 系统,我们又有分页的情况下,我们可以考虑在每条SQL 中用hint。 如:
Select a.* from table a;
分开设计与优化
在设计上要特别注意,如在高可用的OLTP环境中,不要盲目地把OLAP的技术拿过来用。
如分区技术,假设不是大范围地使用分区关键字,而采用其它的字段作为where条件,那么,如果是本地索引,将不得不扫描多个索引,而性能变得更为低下。如果是全局索引,又失去分区的意义。
并行技术也是如此,一般在完成大型任务时才使用,如在实际生活中,翻译一本书,可以先安排多个人,每个人翻译不同的章节,这样可以提高翻译速度。如果只是翻译一页书,也去分配不同的人翻译不同的行,再组合起来,就没必要了,因为在分配工作的时间里,一个人或许早就翻译完了。
位图索引也是一样,如果用在OLTP环境中,很容易造成阻塞与死锁。但是,在OLAP环境中,可能会因为其特有的特性,提高OLAP的查询速度。MV也是基本一样,包括触发器等,在DML频繁的OLTP系统上,很容易成为瓶颈,甚至是Library Cache等待,而在OLAP环境上,则可能会因为使用恰当而提高查询速度。
对于OLAP系统,在内存上可优化的余地很小,增加CPU 处理速度和磁盘I/O 速度是最直接的提高数据库性能的方法,当然这也意味着系统成本的增加。
比如我们要对几亿条或者几十亿条数据进行聚合处理,这种海量的数据,全部放在内存中操作是很难的,同时也没有必要,因为这些数据快很少重用,缓存起来也没有实际意义,而且还会造成物理I/O相当大。 所以这种系统的瓶颈往往是磁盘I/O上面的。
对于OLAP系统,SQL 的优化非常重要,因为它的数据量很大,做全表扫描和索引对性能上来说差异是非常大的。
其他
Oracle 10g以前的版本建库过程中可供选择的模板有:
Data Warehouse (数据仓库)
General Purpose (通用目的、一般用途)
New Database
Transaction Processing (事务处理)
Oracle 11g的版本建库过程中可供选择的模板有:
一般用途或事务处理
定制数据库
数据仓库
个人对这些模板的理解为:
联机分析处理(OLAP,On-line Analytical Processing),数据量大,DML少。使用数据仓库模板
联机事务处理(OLTP,On-line Transaction Processing),数据量少,DML频繁,并行事务处理多,但是一般都很短。使用一般用途或事务处理模板。
决策支持系统(DDS,Decision support system),典型的操作是全表扫描,长查询,长事务,但是一般事务的个数很少,往往是一个事务独占系统。
Apache Kylin logoOLAP 分析引擎 Apache Kylin
http://www.oschina.net/p/kylin-olap
Kylin 是一个开源的分布式的 OLAP 分析引擎,来自 eBay 公司开发,基于 Hadoop 提供 SQL 接口和 OLAP 接口,支持 TB 到 PB 级别的数据量。
Kylin 是:
-
超级快的 OLAP 引擎,具备可伸缩性
-
为 Hadoop 提供 ANSI-SQL 接口
-
交互式查询能力
-
MOLAP Cube
-
可与其他 BI 工具无缝集成,如 Tableau,而 Microstrategy 和 Excel 将很快推出
其他值得关注的特性包括:
-
作业管理和监控
-
压缩和编码的支持
-
Cube 的增量更新
-
Leverage HBase Coprocessor for query latency
-
Approximate Query Capability for distinct Count (HyperLogLog)
-
易用的 Web 管理、构建、监控和查询 Cube 的接口
-
Security capability to set ACL at Cube/Project Level
-
支持 LDAP 集成
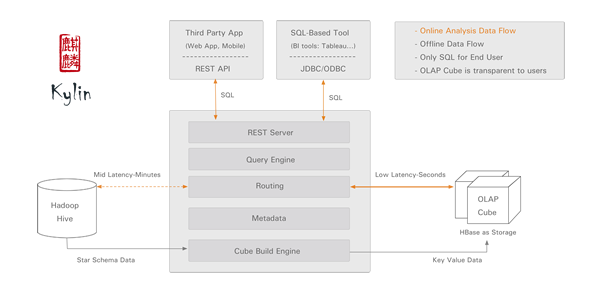
运行环境要求:
Hadoop
-
Hadoop: 2.2.0.2.0.6.0-61 or above
-
Hive: 0.12.0.2.0.6.0-61 or above
-
HBase: 0.96.0.2.0.6.0-61-hadoop2
Tested with Hortornworks distribution (HDP2.1.3), not tested with others yet.
Kylin Server
-
Command hadoop, hive, hbase is workable on your hadoop cluster
-
JDK Runtime: JDK7 (OpenJDK or Oracle JDK)
-
Maven
-
Git
-
Tomcat
-
Mysql
Druid:一个用于大数据实时处理的开源分布式系统
http://www.infoq.com/cn/news/2015/04/druid-data/
Druid是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。尤其是当发生代码部署、机器故障以及其他产品系统遇到宕机等情况时,Druid仍能够保持100%正常运行。创建Druid的最初意图主要是为了解决查询延迟问题,当时试图使用Hadoop来实现交互式查询分析,但是很难满足实时分析的需要。而Druid提供了以交互方式访问数据的能力,并权衡了查询的灵活性和性能而采取了特殊的存储格式。
Druid功能介于PowerDrill和Dremel之间,它几乎实现了Dremel的所有功能,并且从PowerDrill吸收一些有趣的数据格式。Druid允许以类似Dremel和PowerDrill的方式进行单表查询,同时还增加了一些新特性,如为局部嵌套数据结构提供列式存储格式、为快速过滤做索引、实时摄取和查询、高容错的分布式体系架构等。从官方得知,Druid的具有以下主要特征:
- 为分析而设计——Druid是为OLAP工作流的探索性分析而构建,它支持各种过滤、聚合和查询等类;
- 快速的交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到;
- 高可用性——Druid的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失;
- 可扩展——Druid已实现每天能够处理数十亿事件和TB级数据。
Druid应用最多的是类似于广告分析创业公司Metamarkets中的应用场景,如广告分析、互联网广告系统监控以及网络监控等。当业务中出现以下情况时,Druid是一个很好的技术方案选择:
- 需要交互式聚合和快速探究大量数据时;
- 需要实时查询分析时;
- 具有大量数据时,如每天数亿事件的新增、每天数10T数据的增加;
- 对数据尤其是大数据进行实时分析时;
- 需要一个高可用、高容错、高性能数据库时。
一个Druid集群有各种类型的节点(Node)组成,每个节点都可以很好的处理一些的事情,这些节点包括对非实时数据进行处理存储和查询的Historical节点、实时摄取数据、监听输入数据流的Realtime节、监控Historical节点的Coordinator节点、接收来自外部客户端的查询和将查询转发到Realtime和Historical节点的Broker节点、负责索引服务的Indexer节点。
查询操作中数据流和各个节点的关系如下图所示:

如下图是Druid集群的管理层架构,该图展示了相关节点和集群管理所依赖的其他组件(如负责服务发现的ZooKeeper集群)的关系:

Druid已基于Apache License 2.0协议开源,代码托管在GitHub,其当前最新稳定版本是0.7.1.1。当前,Druid已有63个代码贡献者和将近2000个关注。Druid的主要贡献者包括广告分析创业公司Metamarkets、电影流媒体网站Netflix、Yahoo等公司。Druid官方还对Druid同Shark、Vertica、Cassandra、Hadoop、Spark、Elasticsearch等在容错能力、灵活性、查询性能等方便进行了对比说明。更多关于Druid的信息,大家还可以参考官方提供的入门教程、白皮书、设计文档等。
end



相关推荐
文章“基于Oracle的OLTP与OLAP数据库设计及实现”涉及了OLTP与OLAP系统设计的关键技术。首先,文章介绍了OLAP和OLTP的基本概念以及它们的不同应用点。OLTP系统由于需要处理大量的并发用户请求,因此在设计时更侧重于...
基于Oracle的OLTP与OLAP数据库内存设计和优化.pdf
《OLTP与OLAP:两种数据处理方式的深度解析》 在信息技术领域,OLTP(联机事务处理)和OLAP(联机分析处理)是两种核心的数据处理方式,它们各自服务于不同类型的业务需求,拥有截然不同的特性和应用场景。本文旨在...
基于Oracle的OLTP与OLAP数据库设计及实现 基于Oracle的OLTP与OLAP数据库设计及实现是关系型数据库管理系统中的重要组成部分。 在本文中,我们将介绍OLTP和OLAP数据库设计及实现的概念,并讨论基于Oracle的OLTP和...
### 性能分析:Linux 缓冲区缓存运行 Oracle OLTP 工作负载 #### 概述 本文档提供了一项针对 Linux 缓冲区缓存(Buffer Cache)在运行 Oracle OLTP(在线事务处理)工作负载时的性能分析研究。通过一系列测试收集...
Oracle则是全球知名的企业级数据库解决方案,与GaussDB一样,也广泛应用于OLTP场景。 在进行实验室环境搭建时,参考“美河学习在线eimhe.com_HCIP-GaussDB-OLTP V1.0实验室环境搭建指南(单机和主备版).docx”文档...
【HCIP-GaussDB-OLAP V1.0 培训教材】是华为认证的信息技术专家课程,专注于GaussDB-OLAP平台的详细学习。这个培训教材旨在帮助学员掌握GaussDB-OLAP的核心技术和应用,为大数据分析与处理提供专业能力。GaussDB是...
HCIP-GaussDB-OLTP(H13-921)教材V1.5.zip是一个针对华为认证的高级数据库管理课程的压缩包文件,它涵盖了GaussDB OLTP数据库的关键概念和技术。以下是对其中各个章节的详细解读: 1. **GaussDB OLTP概述**: ...
### OLTP与OLAP的区别精简总结 #### 当今数据处理分类 当今的数据处理领域大致可以分为两大类:联机事务处理(Online Transaction Processing,简称OLTP)与联机分析处理(Online Analytical Processing,简称OLAP...
### Oracle9i OLAP知识点详解 #### 一、Oracle9i OLAP简介 **Oracle9i OLAP**是Oracle公司推出的面向联机分析处理(Online Analytical Processing, OLAP)的功能模块之一,专为商业智能(Business Intelligence, ...
【OLTP与OLAP技术融合架构实践】 在线事务处理(OLTP)和在线分析处理(OLAP)是两种不同但互补的数据处理模式。OLTP主要关注于日常事务处理,如银行交易、电子商务订单等,强调高并发、低延迟和数据的一致性。而...
OLTP(在线事务处理)与OLAP(在线分析处理)是数据库领域的两项核心技术,它们分别服务于不同的业务需求场景。OLTP是面向交易的处理过程,强调的是快速响应用户操作,其特点包括数据量少、面向应用、并行事务处理、...
在GaussDB部分,HCIE-GaussDB-OLTP V1.0是针对华为分布式数据库GaussDB在在线事务处理(Online Transaction Processing)场景的专业认证。这个认证涵盖了GaussDB的理论知识、设计原则、实施方法以及故障排查技能,旨在...
作为Oracle数据库的一部分,Oracle OLAP与Oracle数据库的集成非常紧密,可以在同一数据库环境中同时管理OLTP和OLAP工作负载,简化了系统的管理和维护。 ### Oracle OLAP的应用场景 Oracle OLAP广泛应用于各种数据...
总结来说,腾讯广告的OLTP/OLAP实践涉及实时数据处理、存储优化、查询引擎优化等多个层面,通过一系列技术手段实现了高效、一致和可扩展的数据分析系统,为广告业务的运营和决策提供了强有力的支持。
Oracle OLAP 的出现是为了满足终端用户对数据库查询分析的需求,弥补传统关系数据库(OLTP)在数据分析方面的不足。 OLAP 技术背景 ---------------- 在 1960 年代,关系数据库之父 E.F.Codd 提出了关系模型,...
### OLTP与OLAP的区别详解 #### 一、引言 在现代信息技术领域,随着数据量的爆炸性增长以及业务需求的多样化发展,如何高效、准确地管理和利用这些数据成为了企业和组织关注的重点。在此背景下,两种重要的数据...
在数据处理领域,OLTP(在线事务处理)和OLAP(在线分析处理)是两种截然不同的系统类型,它们分别应对不同业务需求的挑战。OLTP作为传统关系型数据库的核心应用,它的存在与数据管理的历史紧密相连。随着系统数据...
该文档旨在帮助学员掌握GaussDB分布式数据库的安装、配置和管理技能,同时也涵盖了与PostgreSQL和Oracle数据库系统的对比,以深化对OLTP的理解。 1. GaussDB简介: GaussDB是华为自主研发的企业级分布式数据库,...
### Oracle Database 11g OLTP压缩总结 #### 压缩概述 Oracle Database 11g Release 1 (11gR1) 引入了一项重要的新特性——OLTP(Online Transaction Processing)表压缩。这一功能允许数据库在执行常规的数据维护...