
SparkBench简介
SparkBench是Spark的基准性能测试项目,由来自IBM Watson研究中心的五位研究者(Min Li, Jian Tan, Yandong Wang, Li Zhang, Valentina Salapura)发起,并贡献至开源社区。
SparkBench的测试项目覆盖了Spark支持的四种最主流的应用类型,即机器学习、图计算、SQL查询和流数据计算。每种类型的应用又选择了最常用的几个算法或者应用进行比对测试,测试结果从系统资源消耗、时间消耗、数据流特点等各方面全面考察,总体而言是比较全面的测试。
所有的研究结果以论文的形式公开发布,原文可在SparkBench的官方网站下载,测试相关的数据和代码也可下载供测试使用,本文将主要的研究结果呈现给大家。
SparkBench的目的
SparkBench最主要的目的是通过基准性能测试,研究Spark与传统计算平台的不同之处,为搭建Spark平台提供参考和通用指导原则。具体而言SparkBench可以在如下场景中发挥作用:
1、重点领域需要有参考数据和定量分析结果,包括:Spark缓存设置、内存管理优化、调度策略;
2、需要不同硬件、不同平台中运行Spark的性能参照数据;
3、寻找Spark集群规划指导原则,帮助定位资源配置中的瓶颈,通过合理的配置使资源竞争最小化;
4、需要从多个角度深入分析Spark平台,包括:负载类型、关键配置参数、扩展性和容错性等
SparkBench测试项目
SparkBench主要的的测试项目,按负载类型划分如下表所示:
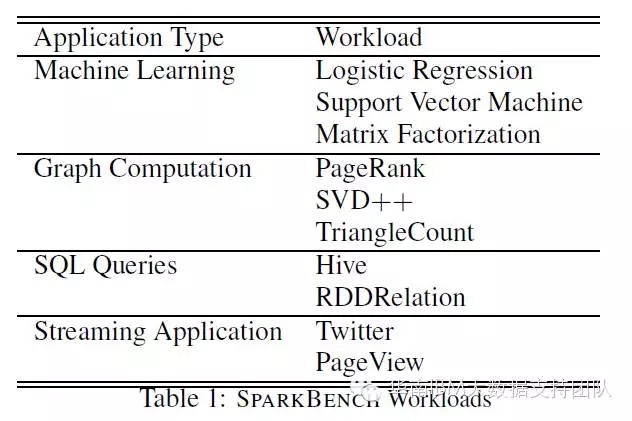
其中机器学习类型选择了最常用的逻辑回归、支持向量机和矩阵分解算法,这些是在进行数据归类或者构建推荐系统时最常用的机器学习算法,很有代表性。图计算类别中选取了最流行的三种图计算算法:PangeRank、SVD++和TriangleCount,各具特点。SQL查询类别同时测试了Hive on Spark和原生态的Spark SQL,测试覆盖最常用的三种SQL操作:select、aggregate和 join。流计算类别分别测试了Twitter数据接口Twitter4j的流数据和模拟用户访问网页的流数据(PageView)。
除了表中列出的测试项目,目前最新版本的SparkBench还包括很多其他负载类型的测试项目:KMeans,LinearRegression,DecisionTree,ShortestPaths, LabelPropagation, ConnectedComponent, StronglyConnectedComponent,PregelOperatio。
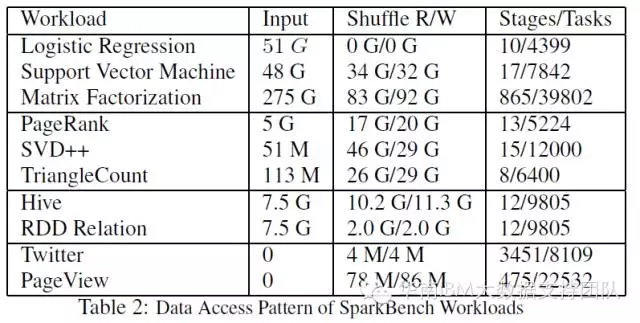
SparkBench的测试数据
SparkBench大部分测试数据由项目自带的数据生成器生成,其中SQL查询使用模拟生成的电子商务系统的订单数据,流计算使用的分别是Twitter数据(Twitter4j每60秒发布一次最热门的标签数据)和模拟生成的用户活动数据(用户点击、页面访问统计等等)。具体测试项目的数据量如下表所示:
SparkBench的研究方法
SparkBench基准测试通过每个测试项目指标的纵向对比,和多个测试项目指标的横向对比,来发现不同工作负载的规律,目前版本研究的主要指标是:任务执行时间、数据处理速度和对资源的消耗情况。在未来的版本中会陆续加入其它方面的指标进行研究,包括shuffle数据量, 输入输出数据量等。
SparkBench测试环境
公开发布的结果是基于IBM SoftLayer云计算平台的测试环境:总共11台虚拟主机,每台配置4核CPU,8GB的内存和2块100GB的虚拟硬盘(一块盘分配给HDFS,另一块做为Spark本地缓存使用),网络带宽1Gbps。11台虚拟主机中,只有1台作为管理节点,剩下的10台作为HDFS数据节点和Spark计算节点,每个Spark计算节点只设置1个executor并分配了6GB的最大内存。
可能会有人担心虚拟机测试结果会与物理环境测试结果相差过大,对于这一点论文指出,经过实际测试,在该虚拟环境中的测试结果与同等配置硬件环境的测试结果相比,相差不超过5%。
背景交代完毕,下面是最重要的内容:SparkBench测试结果及分析!
SparkBenc测结果和分析
任务运行时间对比
MapReduce作业分为Map和Reduce两个阶段,类似的Spark作业也可分为两部分:ShuffleMapTask和ResultTask。前者由Spark DAG生成,会在不同节点间分发数据,产生一系列高代价的操作:IO、数据序列化、反序列化等。按这两个阶段(分别显示为Shuffle Time和Regular Time)统计的运行时间占比如下:
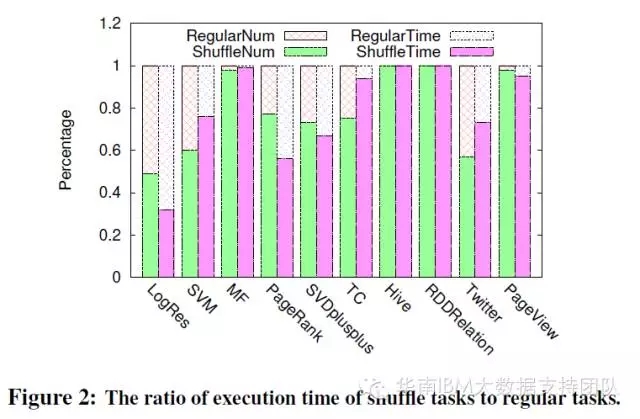
测试结果显示,除了逻辑回归测试项目中ShuffleMapTasks阶段运行时间占比小于一半,其他测试项目都超了过50%,其中HIVE SQL/Spark SQL和矩阵分解算法等这几个测试的ShuffleMapTasks时间占比接近100%! 论文中论述的原因是:SQL查询及矩阵分解算法都使用了大量的聚合和数据关联操作(RDD或表),比如矩阵分解算法中GroupBy操作就占用了约98%的时间,这样的操作会使Spark花费大量时间在不同Stage之间的协同和数据分发上。
测试项目的资源占比分析
我们摘选几个关键测试项目的测试结果呈现如下:
逻辑回归测试:对CPU和内存的占用较为平均,分别为63%和5.2GB;对磁盘IO的占用峰值出现在测试开始阶段,后继占用逐渐减少。
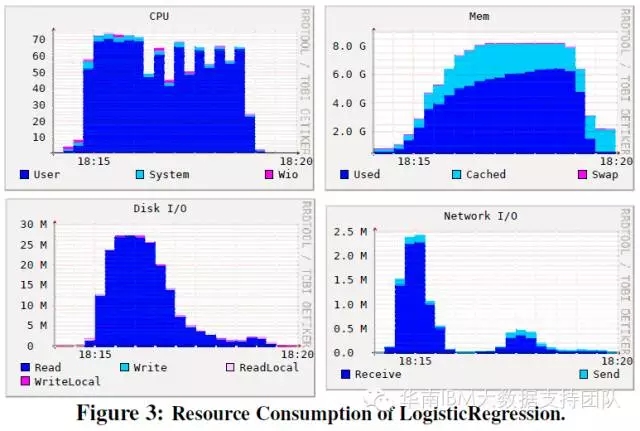
SVM测试项目:对CPU和IO的占用具有双峰的特点,分别在测试开始不久和测试结束前占用较多CPU和IO资源。
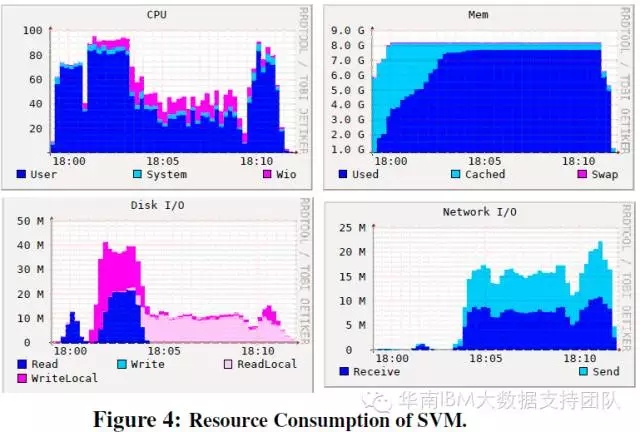
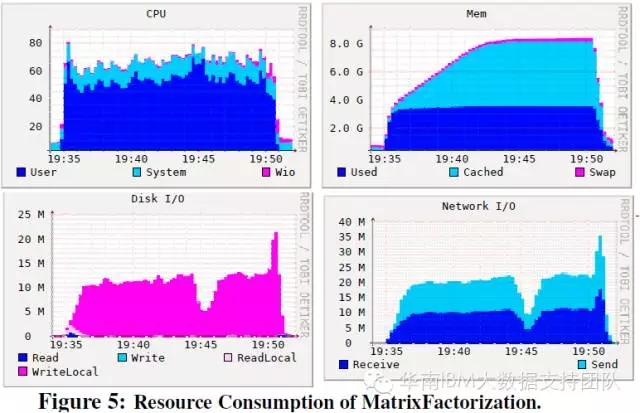
矩阵分解测试: 占用较高CPU和内存,对磁盘IO的占用特点是有大量的本地盘操作而不是HDFS操作,这是因为该工作负载产生大量的Shuffle数据,Shuffle是由本地盘的IO来完成的。
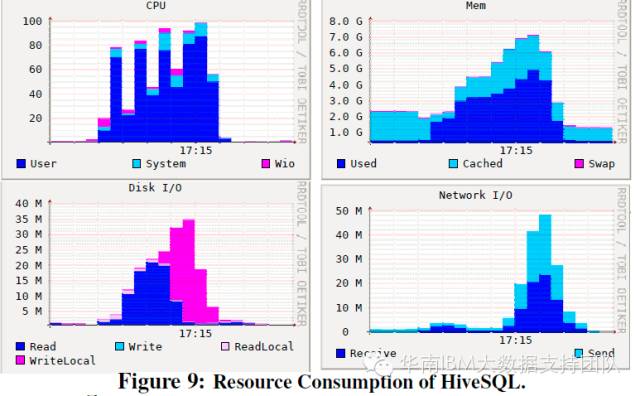
SQL查询测试项目:HIVE SQL和Spark Native SQL对资源的占用规律类似,都占用了将近100%的资源! 这与SQL计算中有大量的数据表关联有关。
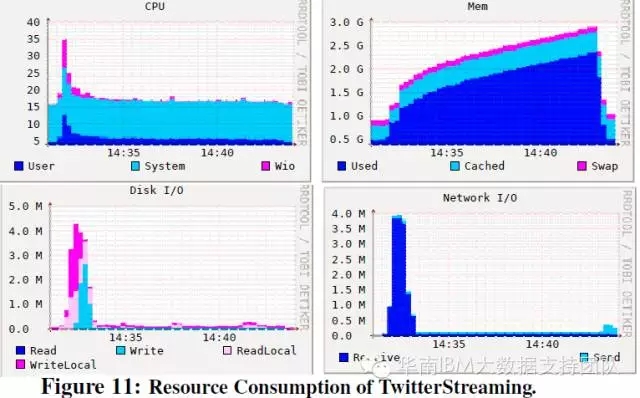
流计算测试项目:两个流计算测试项目的资源占用规律类似。与其他负载类型相比,除了内存占用逐渐变大,对其他资源(CPU/IO/网络)的占用率较低。
测试结果的指导意义
通过对四种工作负载、多个测试项目的结果分析,得到如下结论:
1. 内存资源对Spark尤为重要,因为所有类型的负载都需要在内存中保存大量RDD数据,因此系统配置时需要优先配置内存;
2. 进行优化时,Shuffle的优化异常重要,大部分负载超过50%的执行时间都用在Shuffle上。
有趣!只增加CPU可能会降低性能
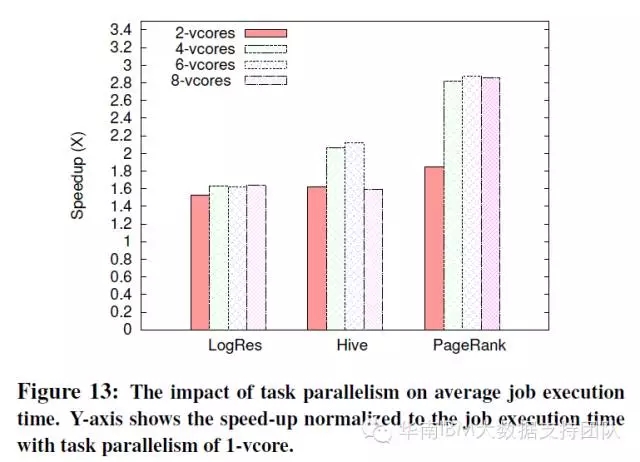
SparkBench测试还研究了增加CPU资源对负载性能的影响。测试中选用三种典型的负载(逻辑回归、PangeRank和Hive SQL),来研究线性增加CPU个数对任务执行时间的影响。
由于Spark中默认一个CPU Core分配一个Executor,只要系统CPU资源足够多,Spark会启动多个并行任务(Executor),因此增加CPU个数就是增加并发任务数量。而在现有环境中CPU核数从1增加到2,总体上都可以减少执行时间,成倍增加效率;但如果过度增加CPU可能不仅没能改善,反而会降低性能,参见HiveSQL测试结果:



相关推荐
内容概要:本文详细介绍了基于TMS320F系列芯片的C2000串口读写方案及其编程器——FlashPro2000的功能特点和支持的接口模式。文中不仅涵盖了硬件连接的具体步骤,还提供了代码实例来展示Flash擦除操作,并对比了JTAG和SCI-BOOT两种模式的优缺点。此外,针对不同型号的C2000系列芯片,给出了详细的适配指导以及避免烧录过程中可能出现的问题的方法。 适合人群:从事DSP开发的技术人员,尤其是对TI公司C2000系列芯片有一定了解并希望深入了解其编程和烧录细节的人群。 使用场景及目标:适用于实验室环境下的程序调试阶段,以及生产线上的批量烧录任务。主要目的是帮助开发者选择合适的编程工具和技术手段,提高工作效率,减少因误操作导致设备损坏的风险。 其他说明:文中提供的代码片段和命令行指令可以直接用于实际项目中,同时附带了一些实用技巧,如防止芯片变砖的小贴士和自动化重试脚本,有助于解决常见的烧录难题。
汉字字库存储芯片扩展实验 # 汉字字库存储芯片扩展实验 ## 实验目的 1. 了解汉字字库的存储原理和结构 2. 掌握存储芯片扩展技术 3. 学习如何通过硬件扩展实现大容量汉字字库存储 ## 实验原理 ### 汉字字库存储基础 - 汉字通常采用点阵方式存储(如16×16、24×24、32×32点阵) - 每个汉字需要占用32字节(16×16)到128字节(32×32)不等的存储空间 - 国标GB2312-80包含6763个汉字,需要较大存储容量 ### 存储芯片扩展方法 1. **位扩展**:增加数据总线宽度 2. **字扩展**:增加存储单元数量 3. **混合扩展**:同时进行位扩展和字扩展 ## 实验设备 - 单片机开发板(如STC89C52) - 存储芯片(如27C256、29C040等) - 逻辑门电路芯片(如74HC138、74HC373等) - 示波器、万用表等测试设备 - 连接线若干 ## 实验步骤 ### 1. 单芯片汉字存储实验 1. 连接27C256 EPROM芯片到单片机系统 2. 将16×16点阵汉字字库写入芯片 3. 编写程序读取并显示汉字 ### 2. 存储芯片字扩展实验 1. 使用地址译码器(如74HC138)扩展多片27C256 2. 将完整GB2312字库分布到各芯片中 3. 编写程序实现跨芯片汉字读取 ### 3. 存储芯片位扩展实验 1. 连接两片27C256实现16位数据总线扩展 2. 优化字库存储结构,提高读取速度 3. 测试并比较扩展前后的性能差异 ## 实验代码示例(单片机部分) ```c #include <reg52.h> #include <intrins.h> // 定义存储芯片控制引脚 sbit CE = P2^7; // 片选 sbit OE = P2^6; // 输出使能 sbit
测控装备干扰源快速侦测系统设计研究.pdf
嵌入式八股文面试题库资料知识宝典-【开发】嵌入式开源项目&库&资料.zip
嵌入式八股文面试题库资料知识宝典-百度2022年嵌入式面试题.zip
少儿编程scratch项目源代码文件案例素材-空间站.zip
基于关联规则的商业银行个性化产品推荐.pdf
嵌入式八股文面试题库资料知识宝典-Linux基础使用.zip
内容概要:本文详细介绍了利用MATLAB进行轴棱锥生成贝塞尔高斯光束及环形光束光强图像的仿真研究。首先阐述了实验的背景与目标,强调了MATLAB在光学和计算科学领域的广泛应用。接着,具体描述了实验的方法与步骤,包括材料准备、仿真过程中的参数设定和光束生成代码编写。最后,对实验结果进行了深入分析,展示了贝塞尔高斯光束和环形光束的光强分布特点,验证了其光学性能的预期表现。文章还对未来的研究方向和技术改进提出了展望。 适合人群:从事光学、物理学及相关领域研究的专业人士,特别是对光束生成和光学性能分析感兴趣的科研工作者。 使用场景及目标:适用于需要进行光束生成和性能分析的实验室环境,旨在帮助研究人员更好地理解和优化光束特性和传播行为。 其他说明:本文不仅提供了详细的实验方法和步骤,还附有丰富的实验结果和数据分析,为后续研究提供了宝贵的参考资料。
内容概要:本文探讨了三电平NPC型有源电力滤波器(APF)的模型预测控制(MPC)中存在的开关频率过高问题及其解决方案。传统MPC方法会导致极高的开关频率,增加了系统的能耗和热量。通过引入滞环控制模块,可以在不大幅牺牲性能的情况下有效降低开关频率。具体来说,滞环控制通过在价值函数计算后增加一个判断条件,对状态切换进行惩罚,从而减少不必要的开关动作。实验结果显示,开关频率从4392Hz降至3242Hz,降幅达26.2%,虽然电流总谐波畸变率(THD)略有上升,但仍符合国家标准。此外,文中还提出了动态调整滞环宽度的方法,以进一步优化不同负载条件下的表现。 适合人群:从事电力电子、电力系统控制领域的研究人员和技术人员,特别是关注APF和MPC技术的人群。 使用场景及目标:适用于需要优化APF系统开关频率的研究和工程项目,旨在提高系统效率并降低成本。目标是在不影响系统性能的前提下,显著降低开关频率,减少能量损失和热管理难度。 其他说明:文章不仅提供了理论分析,还包括具体的实现代码片段,有助于读者理解和实践。同时,强调了在实际应用中需要注意的问题,如中点电位漂移等。
内容概要:本文介绍了三维POD DMD程序在处理原网格数据方面的独特优势和技术细节。首先阐述了该程序能读取结构化和非结构化网格数据及其拓扑关系,在生成模态数据过程中保持原始网格形态而不需要进行网格插值操作。接着展示了简化版本的Python代码片段,揭示了读取网格数据和生成模态数据的核心逻辑。最后提到提供的辅助学习资料如代码、视频教程、Word教程和实例数据,帮助用户深入理解并掌握该程序的应用。 适合人群:从事计算流体力学领域的研究人员和技术爱好者,尤其是那些希望提高数据处理效率的人群。 使用场景及目标:适用于需要处理复杂网格数据的研究项目,旨在简化数据处理流程,提升工作效率,同时保持数据的原始特性。 其他说明:文中不仅提供了理论性的讲解,还有具体的代码示例和丰富的学习资源,使读者可以边学边练,快速上手。
融合双向路由注意力的多尺度X光违禁品检测.pdf
嵌入式八股文面试题库资料知识宝典-Linux_Shell基础使用.zip
嵌入式八股文面试题库资料知识宝典-联发科2021武汉嵌入式软件开发.zip
基于有限体积法Godunov格式的管道泄漏检测模型研究.pdf
嵌入式八股文面试题库资料知识宝典-ARM常见面试题目.zip
基于LWR问题的无证书全同态加密方案.pdf
嵌入式八股文面试题库资料知识宝典-符坤面试经验.zip
内容概要:本文详细探讨了三电平逆变器在带不平衡负载条件下的仿真研究。主要内容包括仿真环境的搭建、不同拓扑结构的选择(如T型、I型NPC和ANPC)、延时相消法(DSC)和双二阶广义积分器(DSOGI)的正负序分离控制策略、SVPWM或SPWM调制技术的应用、双闭环PI控制以及直流均压控制。文中通过具体的参数设置(交流电压220V,直流侧电压750V)进行了详细的仿真实验,并展示了各个控制策略的效果。最终,通过仿真实验验证了所提出方法的有效性,确保了交流侧三相电压波形的对称性和电流波形的自适应调节。 适合人群:从事电力电子、电机驱动、新能源发电等领域研究的技术人员和研究人员。 使用场景及目标:适用于需要理解和掌握三电平逆变器在复杂负载条件下控制策略的研究人员和技术人员。目标是提高对三电平逆变器及其控制策略的理解,优化实际应用中的性能。 其他说明:本文不仅提供了理论分析,还包含了具体的仿真步骤和代码实现,有助于读者更好地理解和应用相关技术。
内容概要:本文介绍了如何使用Matlab/Simulink软件构建一个14自由度的四轮驱动-四轮转向(4WID-4WIS)整车动力学模型。该模型涵盖了整车纵向、横向、横摆、车身俯仰、侧倾、垂向跳动及四轮旋转和垂向自由度等多个方面,旨在全面反映车辆在不同工况下的动态行为。文中详细描述了各子系统的建模方法,包括转向系统、整车系统、悬架系统、魔术轮胎pac2002、车轮系统和PI驾驶员模块。同时,提供了Simulink源码文件、建模说明文档及相关参考资料,便于用户理解和应用。 适用人群:主要面向汽车工程师、研究人员以及对汽车动力学和Simulink建模感兴趣的学习者。 使用场景及目标:①帮助用户深入了解车辆在各种工况下的动态行为;②为车辆控制策略的制定提供理论支持和技术手段;③作为学习和研究整车动力学建模的有效工具。 其他说明:该模型采用模块化建模方法,提高了模型的清晰度和可维护性,同时也提升了建模效率。