
дёҖ.е®үиЈ…hadoopеҲҶеёғејҸйӣҶзҫӨпјҡ
1 е®үиЈ…Vmware WorkStationиҪҜ件
жңүдәӣдәәдјҡй—®пјҢдёәдҪ•иҰҒе®үиЈ…иҝҷдёӘиҪҜ件пјҢиҝҷжҳҜдёҖдёӘVMе…¬еҸёжҸҗдҫӣзҡ„иҷҡжӢҹжңәе·ҘдҪңе№іеҸ°пјҢеҗҺйқўйңҖиҰҒеңЁиҝҷдёӘе№іеҸ°дёҠе®үиЈ…linuxж“ҚдҪңзі»з»ҹгҖӮе…·дҪ“е®үиЈ…иҝҮзЁӢзҪ‘дёҠжңүеҫҲеӨҡиө„ж–ҷпјҢиҝҷйҮҢдёҚдҪңиҝҮеӨҡзҡ„иҜҙжҳҺгҖӮ
В
2 еңЁиҷҡжӢҹжңәдёҠе®үиЈ…linuxж“ҚдҪңзі»з»ҹ
еңЁеүҚдёҖжӯҘзҡ„еҹәзЎҖд№ӢдёҠе®үиЈ…linuxж“ҚдҪңзі»з»ҹпјҢеӣ дёәhadoopдёҖиҲ¬жҳҜиҝҗиЎҢеңЁlinuxе№іеҸ°д№ӢдёҠзҡ„пјҢиҷҪ然зҺ°еңЁд№ҹжңүwindowsзүҲжң¬пјҢдҪҶжҳҜеңЁlinuxдёҠе®һж–ҪжҜ”иҫғзЁіе®ҡпјҢд№ҹдёҚжҳ“еҮәй”ҷпјҢеҰӮжһңеңЁwindowsе®үиЈ…hadoopйӣҶзҫӨпјҢдј°и®ЎеңЁе®үиЈ…иҝҮзЁӢдёӯйқўеҜ№зҡ„еҗ„з§Қй—®йўҳдјҡи®©дәәжӣҙеҠ еҙ©жәғпјҢе…¶е®һжҲ‘иҝҳжІЎеңЁwindowsдёҠе®үиЈ…иҝҮпјҢе‘өе‘ө~
еңЁиҷҡжӢҹжңәдёҠе®үиЈ…зҡ„linuxж“ҚдҪңзі»з»ҹдёәubuntu10.04пјҢиҝҷжҳҜжҲ‘е®үиЈ…зҡ„зі»з»ҹзүҲжң¬пјҢдёәд»Җд№ҲжҲ‘дјҡдҪҝз”ЁиҝҷдёӘзүҲжң¬е‘ўпјҢеҫҲз®ҖеҚ•пјҢеӣ дёәжҲ‘з”Ёзҡ„зҶҹ^_^е…¶е®һз”Ёе“ӘдёӘlinuxзі»з»ҹйғҪжҳҜеҸҜд»Ҙзҡ„пјҢжҜ”еҰӮпјҢдҪ еҸҜд»Ҙз”Ёcentos, redhat, fedoraзӯүеқҮеҸҜпјҢе®Ңе…ЁжІЎжңүй—®йўҳгҖӮеңЁиҷҡжӢҹжңәдёҠе®үиЈ…linuxзҡ„иҝҮзЁӢд№ҹеңЁжӯӨз•ҘиҝҮпјҢеҰӮжһңдёҚдәҶи§ЈеҸҜд»ҘеңЁзҪ‘дёҠжҗңжҗңпјҢжңүи®ёеӨҡиҝҷж–№йқўзҡ„иө„ж–ҷгҖӮ
В
3 еҮҶеӨҮ3дёӘиҷҡжӢҹжңәиҠӮзӮ№
е…¶е®һиҝҷдёҖжӯҘйӘӨйқһеёёз®ҖеҚ•пјҢеҰӮжһңдҪ е·Із»Ҹе®ҢжҲҗдәҶ第2жӯҘпјҢжӯӨж—¶дҪ е·Із»ҸеҮҶеӨҮеҘҪдәҶ第дёҖдёӘиҷҡжӢҹиҠӮзӮ№пјҢйӮЈз¬¬дәҢдёӘе’Ң第дёүдёӘиҷҡжӢҹжңәиҠӮзӮ№еҰӮдҪ•еҮҶеӨҮпјҹеҸҜиғҪдҪ е·Із»ҸжғіжҳҺзҷҪдәҶпјҢдҪ еҸҜд»ҘжҢү第2жӯҘзҡ„ж–№жі•пјҢеҶҚеҲҶеҲ«е®үиЈ…дёӨйҒҚlinuxзі»з»ҹпјҢе°ұеҲҶеҲ«е®һзҺ°дәҶ第дәҢгҖҒдёүдёӘиҷҡжӢҹжңәиҠӮзӮ№гҖӮдёҚиҝҮиҝҷдёӘиҝҮзЁӢдј°и®Ўдјҡи®©дҪ еҫҲеҙ©жәғпјҢе…¶е®һиҝҳжңүдёҖдёӘжӣҙз®ҖеҚ•зҡ„ж–№жі•пјҢе°ұжҳҜеӨҚеҲ¶е’ҢзІҳиҙҙпјҢжІЎй”ҷпјҢе°ұжҳҜеңЁдҪ еҲҡе®үиЈ…еҘҪзҡ„第дёҖдёӘиҷҡжӢҹжңәиҠӮзӮ№пјҢе°Ҷж•ҙдёӘзі»з»ҹзӣ®еҪ•иҝӣиЎҢеӨҚеҲ¶пјҢеҪўжҲҗ第дәҢе’Ң第дёүдёӘиҷҡжӢҹжңәиҠӮзӮ№гҖӮз®ҖеҚ•еҗ§пјҒ~~
еҫҲеӨҡдәәд№ҹи®ёдјҡй—®пјҢиҝҷдёүдёӘз»“зӮ№жңүд»Җд№Ҳз”ЁпјҢеҺҹзҗҶеҫҲз®ҖеҚ•пјҢжҢүз…§hadoopйӣҶзҫӨзҡ„еҹәжң¬иҰҒжұӮпјҢе…¶дёӯдёҖдёӘжҳҜmasterз»“зӮ№пјҢдё»иҰҒжҳҜз”ЁдәҺиҝҗиЎҢhadoopзЁӢеәҸдёӯзҡ„namenodeгҖҒsecondorynamenodeе’Ңjobtrackerд»»еҠЎгҖӮз”ЁеӨ–дёӨдёӘз»“зӮ№еқҮдёәslaveз»“зӮ№пјҢе…¶дёӯдёҖдёӘжҳҜз”ЁдәҺеҶ—дҪҷзӣ®зҡ„пјҢеҰӮжһңжІЎжңүеҶ—дҪҷпјҢе°ұдёҚиғҪз§°д№ӢдёәhadoopдәҶпјҢжүҖд»ҘжЁЎжӢҹhadoopйӣҶзҫӨиҮіе°‘иҰҒжңү3дёӘз»“зӮ№пјҢеҰӮжһңз”өи„‘й…ҚзҪ®йқһеёёй«ҳпјҢеҸҜд»ҘиҖғиҷ‘еўһеҠ дёҖдәӣе…¶е®ғзҡ„з»“зӮ№гҖӮslaveз»“зӮ№дё»иҰҒе°ҶиҝҗиЎҢhadoopзЁӢеәҸдёӯзҡ„datanodeе’Ңtasktrackerд»»еҠЎгҖӮ
жүҖд»ҘпјҢеңЁеҮҶеӨҮеҘҪиҝҷ3дёӘз»“зӮ№д№ӢеҗҺпјҢйңҖиҰҒеҲҶеҲ«е°Ҷlinuxзі»з»ҹзҡ„дё»жңәеҗҚйҮҚе‘ҪеҗҚпјҲеӣ дёәеүҚйқўжҳҜеӨҚеҲ¶е’ҢзІҳеё–ж“ҚдҪңдә§з”ҹеҸҰдёӨдёҠз»“зӮ№пјҢжӯӨж—¶иҝҷ3дёӘз»“зӮ№зҡ„дё»жңәеҗҚжҳҜдёҖж ·зҡ„пјүпјҢйҮҚе‘ҪеҗҚдё»жңәеҗҚзҡ„ж–№жі•пјҡ
Vim /etc/hostname
йҖҡиҝҮдҝ®ж”№hostnameж–Ү件еҚіеҸҜпјҢиҝҷдёүдёӘзӮ№з»“еқҮиҰҒдҝ®ж”№пјҢд»ҘзӨәеҢәеҲҶгҖӮ
д»ҘдёӢжҳҜжҲ‘еҜ№дёүдёӘз»“зӮ№зҡ„ubuntuзі»з»ҹдё»жңәеҲҶеҲ«е‘ҪеҗҚдёәпјҡmaster, node1, node2
В

В

В

В
еҹәжң¬жқЎд»¶еҮҶеӨҮеҘҪдәҶпјҢеҗҺйқўиҰҒе№Іе®һдәӢдәҶпјҢеҝғжҖҘдәҶеҗ§пјҢе‘өе‘өпјҢеҲ«зқҖжҖҘпјҢеҸӘиҰҒи·ҹзқҖжң¬дәәзҡ„жҖқи·ҜпјҢдёҖжӯҘдёҖдёӘи„ҡеҚ°ең°пјҢдёҖе®ҡиғҪжҲҗеҠҹеёғзҪІе®үиЈ…еҘҪhadoopйӣҶзҫӨзҡ„гҖӮ
иҝҷйҮҢйқўиҝҳжңүй—®йўҳзҪ‘з»ңй…ҚзҪ®пјҡ
иҷҡжӢҹжңәдёүз§ҚзҪ‘з»ңжЁЎејҸиҜҘеҰӮдҪ•дёҠзҪ‘жҢҮеҜј
иҷҡжӢҹжңәдёӢиҪҪең°еқҖпјҡ
VMware Workstation 10.0.0з®ҖдҪ“дёӯж–ҮжӯЈејҸзүҲе®ҳж–№дёӢиҪҪең°еқҖ
еҰӮжһңжҳҜйӣ¶еҹәзЎҖеҸҜд»ҘеҸӮиҖғпјҡ
йӣҶзҫӨжҗӯе»әеҝ…еӨҮпјҢдә‘жҠҖжңҜеҹәзЎҖпјҡLinuxеҸҠиҷҡжӢҹеҢ–зҹҘиҜҶеӯҰд№ жҢҮеҜјпјҲhadoopгҖҒopenstackпјү
В
е®үиЈ…иҝҮзЁӢдё»иҰҒжңүд»ҘдёӢеҮ дёӘжӯҘйӘӨпјҡ
дёҖгҖҒВ В В В В В В В й…ҚзҪ®hostsж–Ү件
дәҢгҖҒВ В В В В В В В е»әз«ӢhadoopиҝҗиЎҢеёҗеҸ·
дёүгҖҒВ В В В В В В В й…ҚзҪ®sshе…ҚеҜҶз Ғиҝһе…Ҙ
еӣӣгҖҒВ В В В В В В В дёӢиҪҪ并解еҺӢhadoopе®үиЈ…еҢ…
дә”гҖҒВ В В В В В В В й…ҚзҪ®namenode,дҝ®ж”№siteж–Ү件
е…ӯгҖҒВ В В В В В В В й…ҚзҪ®hadoop-env.shж–Ү件
дёғгҖҒВ В В В В В В В й…ҚзҪ®mastersе’Ңslavesж–Ү件
е…«гҖҒВ В В В В В В В еҗ‘еҗ„иҠӮзӮ№еӨҚеҲ¶hadoop
д№қгҖҒВ В В В В В В В ж јејҸеҢ–namenode
еҚҒгҖҒВ В В В В В В В еҗҜеҠЁhadoop
еҚҒдёҖгҖҒВ В В В з”ЁjpsжЈҖйӘҢеҗ„еҗҺеҸ°иҝӣзЁӢжҳҜеҗҰжҲҗеҠҹеҗҜеҠЁ
еҚҒдәҢгҖҒВ В В В йҖҡиҝҮзҪ‘з«ҷжҹҘзңӢйӣҶзҫӨжғ…еҶө
В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В
дёӢйқўжҲ‘们еҜ№д»ҘдёҠиҝҮзЁӢпјҢеҗ„дёӘеҮ»з ҙеҗ§пјҒ~~
дёҖгҖҒВ В В В В В В В й…ҚзҪ®hostsж–Ү件
е…Ҳз®ҖеҚ•иҜҙжҳҺдёӢй…ҚзҪ®hostsж–Ү件зҡ„дҪңз”ЁпјҢе®ғдё»иҰҒз”ЁдәҺзЎ®е®ҡжҜҸдёӘз»“зӮ№зҡ„IPең°еқҖпјҢж–№дҫҝеҗҺз»ӯ
masterз»“зӮ№иғҪеҝ«йҖҹжҹҘеҲ°е№¶и®ҝй—®еҗ„дёӘз»“зӮ№гҖӮеңЁдёҠиҝ°3дёӘиҷҡжңәз»“зӮ№дёҠеқҮйңҖиҰҒй…ҚзҪ®жӯӨж–Ү件гҖӮз”ұдәҺйңҖиҰҒзЎ®е®ҡжҜҸдёӘз»“зӮ№зҡ„IPең°еқҖпјҢжүҖд»ҘеңЁй…ҚзҪ®hostsж–Ү件д№ӢеүҚйңҖиҰҒе…ҲжҹҘзңӢеҪ“еүҚиҷҡжңәз»“зӮ№зҡ„IPең°еқҖжҳҜеӨҡе°‘пјҢеҸҜд»ҘйҖҡиҝҮifconfigе‘Ҫд»ӨиҝӣиЎҢжҹҘзңӢпјҢеҰӮжң¬е®һйӘҢдёӯпјҢmasterз»“зӮ№зҡ„IPең°еқҖдёәпјҡ
В В В В В В В <ignore_js_op style="word-wrap: break-word;">
В
еҰӮжһңIPең°еқҖдёҚеҜ№пјҢеҸҜд»ҘйҖҡиҝҮifconfigе‘Ҫд»Өжӣҙж”№з»“зӮ№зҡ„зү©зҗҶIPең°еқҖпјҢзӨәдҫӢеҰӮдёӢпјҡ
В В В В В В В <ignore_js_op style="word-wrap: break-word;">
В
йҖҡиҝҮдёҠйқўе‘Ҫд»ӨеҸҜд»Ҙе°ҶIPж”№дёә192.168.1.100гҖӮе°ҶжҜҸдёӘз»“зӮ№зҡ„IPең°еқҖи®ҫзҪ®е®ҢжҲҗеҗҺпјҢе°ұеҸҜд»Ҙй…ҚзҪ®hostsж–Ү件дәҶпјҢhostsж–Ү件и·Ҝеҫ„дёә;/etc/hostsпјҢжҲ‘зҡ„hostsж–Ү件й…ҚзҪ®еҰӮдёӢпјҢеӨ§е®¶еҸҜд»ҘеҸӮиҖғиҮӘе·ұзҡ„IPең°еқҖд»ҘеҸҠзӣёеә”зҡ„дё»жңәеҗҚе®ҢжҲҗй…ҚзҪ®
В
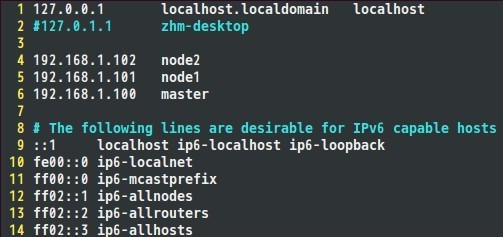
В
дәҢгҖҒВ В В В В В В В е»әз«ӢhadoopиҝҗиЎҢеёҗеҸ·
еҚідёәhadoopйӣҶзҫӨдё“й—Ёи®ҫзҪ®дёҖдёӘз”ЁжҲ·з»„еҸҠз”ЁжҲ·пјҢиҝҷйғЁеҲҶжҜ”иҫғз®ҖеҚ•пјҢеҸӮиҖғзӨәдҫӢеҰӮдёӢпјҡ
sudo groupadd hadoopВ В //и®ҫзҪ®hadoopз”ЁжҲ·з»„
sudo useradd вҖ“s /bin/bash вҖ“d /home/zhm вҖ“m zhm вҖ“g hadoop вҖ“G adminВ В //ж·»еҠ дёҖдёӘzhmз”ЁжҲ·пјҢжӯӨз”ЁжҲ·еұһдәҺhadoopз”ЁжҲ·з»„пјҢдё”е…·жңүadminжқғйҷҗгҖӮ
sudo passwd zhmВ В //и®ҫзҪ®з”ЁжҲ·zhmзҷ»еҪ•еҜҶз Ғ
su zhmВ В //еҲҮжҚўеҲ°zhmз”ЁжҲ·дёӯ
В
дёҠиҝ°3дёӘиҷҡжңәз»“зӮ№еқҮйңҖиҰҒиҝӣиЎҢд»ҘдёҠжӯҘйӘӨжқҘе®ҢжҲҗhadoopиҝҗиЎҢеёҗеҸ·зҡ„е»әз«ӢгҖӮ
В
дёүгҖҒВ В В В В В В В й…ҚзҪ®sshе…ҚеҜҶз Ғиҝһе…Ҙ
иҝҷдёҖзҺҜиҠӮжңҖдёәйҮҚиҰҒпјҢиҖҢдё”д№ҹжңҖдёәе…ій”®пјҢеӣ дёәжң¬дәәеңЁиҝҷдёҖжӯҘйӘӨиЈҒдәҶдёҚе°‘и·ҹеӨҙпјҢиө°дәҶдёҚе°‘ејҜ
и·ҜпјҢеҰӮжһңиҝҷдёҖжӯҘиө°жҲҗеҠҹдәҶпјҢеҗҺйқўзҺҜиҠӮиҝӣиЎҢзҡ„д№ҹдјҡжҜ”иҫғйЎәеҲ©гҖӮ
SSHдё»иҰҒйҖҡиҝҮRSAз®—жі•жқҘдә§з”ҹе…¬й’ҘдёҺз§Ғй’ҘпјҢеңЁж•°жҚ®дј иҫ“иҝҮзЁӢдёӯеҜ№ж•°жҚ®иҝӣиЎҢеҠ еҜҶжқҘдҝқйҡңж•°
жҚ®зҡ„е®үе…ЁжҖ§е’ҢеҸҜйқ жҖ§пјҢе…¬й’ҘйғЁеҲҶжҳҜе…¬е…ұйғЁеҲҶпјҢзҪ‘з»ңдёҠд»»дёҖз»“зӮ№еқҮеҸҜд»Ҙи®ҝй—®пјҢз§Ғй’Ҙдё»иҰҒз”ЁдәҺеҜ№ж•°жҚ®иҝӣиЎҢеҠ еҜҶпјҢд»ҘйҳІд»–дәәзӣ—еҸ–ж•°жҚ®гҖӮжҖ»иҖҢиЁҖд№ӢпјҢиҝҷжҳҜдёҖз§ҚйқһеҜ№з§°з®—жі•пјҢжғіиҰҒз ҙи§ЈиҝҳжҳҜйқһеёёжңүйҡҫеәҰзҡ„гҖӮHadoopйӣҶзҫӨзҡ„еҗ„дёӘз»“зӮ№д№Ӣй—ҙйңҖиҰҒиҝӣиЎҢж•°жҚ®зҡ„и®ҝй—®пјҢиў«и®ҝй—®зҡ„з»“зӮ№еҜ№дәҺи®ҝй—®з”ЁжҲ·з»“зӮ№зҡ„еҸҜйқ жҖ§еҝ…йЎ»иҝӣиЎҢйӘҢиҜҒпјҢhadoopйҮҮз”Ёзҡ„жҳҜsshзҡ„ж–№жі•йҖҡиҝҮеҜҶй’ҘйӘҢиҜҒеҸҠж•°жҚ®еҠ и§ЈеҜҶзҡ„ж–№ејҸиҝӣиЎҢиҝңзЁӢе®үе…Ёзҷ»еҪ•ж“ҚдҪңпјҢеҪ“然пјҢеҰӮжһңhadoopеҜ№жҜҸдёӘз»“зӮ№зҡ„и®ҝй—®еқҮйңҖиҰҒиҝӣиЎҢйӘҢиҜҒпјҢе…¶ж•ҲзҺҮе°ҶдјҡеӨ§еӨ§йҷҚдҪҺпјҢжүҖд»ҘжүҚйңҖиҰҒй…ҚзҪ®SSHе…ҚеҜҶз Ғзҡ„ж–№жі•зӣҙжҺҘиҝңзЁӢиҝһе…Ҙиў«и®ҝй—®з»“зӮ№пјҢиҝҷж ·е°ҶеӨ§еӨ§жҸҗй«ҳи®ҝй—®ж•ҲзҺҮгҖӮ
В
В В В В В В OKпјҢеәҹиҜқе°ұдёҚиҜҙдәҶпјҢдёӢйқўзңӢзңӢеҰӮдҪ•й…ҚзҪ®SSHе…ҚеҜҶз Ғзҷ»еҪ•еҗ§пјҒ~~
(1)В В В В жҜҸдёӘз»“зӮ№еҲҶеҲ«дә§з”ҹе…¬з§ҒеҜҶй’ҘгҖӮ
й”®е…Ҙе‘Ҫд»Өпјҡ
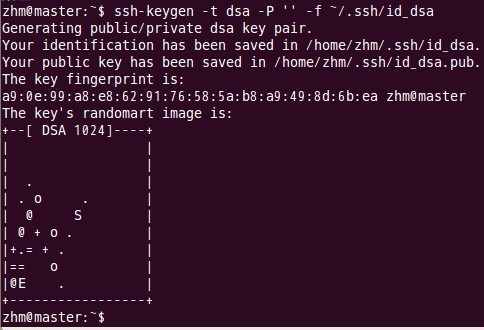
В
д»ҘдёҠе‘Ҫд»ӨжҳҜдә§з”ҹе…¬з§ҒеҜҶй’ҘпјҢдә§з”ҹзӣ®еҪ•еңЁз”ЁжҲ·дё»зӣ®еҪ•дёӢзҡ„.sshзӣ®еҪ•дёӯпјҢеҰӮдёӢпјҡ
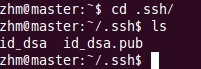
В
Id_dsa.pubдёәе…¬й’ҘпјҢid_dsaдёәз§Ғй’ҘпјҢзҙ§жҺҘзқҖе°Ҷе…¬й’Ҙж–Ү件еӨҚеҲ¶жҲҗauthorized_keysж–Ү件пјҢиҝҷдёӘжӯҘйӘӨжҳҜеҝ…йЎ»зҡ„пјҢиҝҮзЁӢеҰӮдёӢпјҡ

В
В
з”ЁдёҠиҝ°еҗҢж ·зҡ„ж–№жі•еңЁеү©дёӢзҡ„дёӨдёӘз»“зӮ№дёӯеҰӮжі•зӮ®еҲ¶еҚіеҸҜгҖӮ
В
(2)В В В В еҚ•жңәеӣһзҺҜsshе…ҚеҜҶз Ғзҷ»еҪ•жөӢиҜ•
еҚіеңЁеҚ•жңәз»“зӮ№дёҠз”ЁsshиҝӣиЎҢзҷ»еҪ•пјҢзңӢиғҪеҗҰзҷ»еҪ•жҲҗеҠҹгҖӮзҷ»еҪ•жҲҗеҠҹеҗҺжіЁй”ҖйҖҖеҮәпјҢиҝҮзЁӢеҰӮдёӢпјҡ
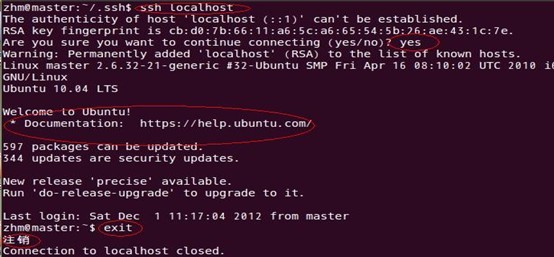
В
жіЁж„Ҹж ҮзәўеңҲзҡ„жҢҮзӨәпјҢжңүд»ҘдёҠдҝЎжҒҜиЎЁзӨәж“ҚдҪңжҲҗеҠҹпјҢеҚ•зӮ№еӣһзҺҜSSHзҷ»еҪ•еҸҠжіЁй”ҖжҲҗеҠҹпјҢиҝҷе°ҶдёәеҗҺз»ӯи·Ёеӯҗз»“зӮ№SSHиҝңзЁӢе…ҚеҜҶз Ғзҷ»еҪ•дҪңеҘҪеҮҶеӨҮгҖӮ
з”ЁдёҠиҝ°еҗҢж ·зҡ„ж–№жі•еңЁеү©дёӢзҡ„дёӨдёӘз»“зӮ№дёӯеҰӮжі•зӮ®еҲ¶еҚіеҸҜгҖӮ
В
(3)В В В В и®©дё»з»“зӮ№(master)иғҪйҖҡиҝҮSSHе…ҚеҜҶз Ғзҷ»еҪ•дёӨдёӘеӯҗз»“зӮ№пјҲslaveпјү
дёәдәҶе®һзҺ°иҝҷдёӘеҠҹиғҪпјҢдёӨдёӘslaveз»“зӮ№зҡ„е…¬й’Ҙж–Ү件дёӯеҝ…йЎ»иҰҒеҢ…еҗ«дё»з»“зӮ№зҡ„е…¬й’ҘдҝЎжҒҜпјҢиҝҷж ·
еҪ“masterе°ұеҸҜд»ҘйЎәеҲ©е®үе…Ёең°и®ҝй—®иҝҷдёӨдёӘslaveз»“зӮ№дәҶгҖӮж“ҚдҪңиҝҮзЁӢеҰӮдёӢпјҡ

В
еҰӮдёҠиҝҮзЁӢжҳҫзӨәдәҶnode1з»“зӮ№йҖҡиҝҮscpе‘Ҫд»ӨиҝңзЁӢзҷ»еҪ•masterз»“зӮ№пјҢ并еӨҚеҲ¶masterзҡ„е…¬й’Ҙж–Ү件еҲ°еҪ“еүҚзҡ„зӣ®еҪ•дёӢпјҢиҝҷдёҖиҝҮзЁӢйңҖиҰҒеҜҶз ҒйӘҢиҜҒгҖӮжҺҘзқҖпјҢе°Ҷmasterз»“зӮ№зҡ„е…¬й’Ҙж–Ү件иҝҪеҠ иҮіauthorized_keysж–Ү件дёӯпјҢйҖҡиҝҮиҝҷжӯҘж“ҚдҪңпјҢеҰӮжһңдёҚеҮәй—®йўҳпјҢmasterз»“зӮ№е°ұеҸҜд»ҘйҖҡиҝҮsshиҝңзЁӢе…ҚеҜҶз ҒиҝһжҺҘnode1з»“зӮ№дәҶгҖӮеңЁmasterз»“зӮ№дёӯж“ҚдҪңеҰӮдёӢпјҡ

В
з”ұдёҠеӣҫеҸҜд»ҘзңӢеҮәпјҢnode1з»“зӮ№йҰ–ж¬ЎиҝһжҺҘж—¶йңҖиҰҒпјҢвҖңYESвҖқзЎ®и®ӨиҝһжҺҘпјҢиҝҷж„Ҹе‘ізқҖmasterз»“зӮ№иҝһжҺҘnode1з»“зӮ№ж—¶йңҖиҰҒдәәе·ҘиҜўй—®пјҢж— жі•иҮӘеҠЁиҝһжҺҘпјҢиҫ“е…ҘyesеҗҺжҲҗеҠҹжҺҘе…ҘпјҢзҙ§жҺҘзқҖжіЁй”ҖйҖҖеҮәиҮіmasterз»“зӮ№гҖӮиҰҒе®һзҺ°sshе…ҚеҜҶз ҒиҝһжҺҘиҮіе…¶е®ғз»“зӮ№пјҢиҝҳе·®дёҖжӯҘпјҢеҸӘйңҖиҰҒеҶҚжү§иЎҢдёҖйҒҚssh node1пјҢеҰӮжһңжІЎжңүиҰҒжұӮдҪ иҫ“е…ҘвҖқyesвҖқпјҢе°ұз®—жҲҗеҠҹдәҶпјҢиҝҮзЁӢеҰӮдёӢпјҡ
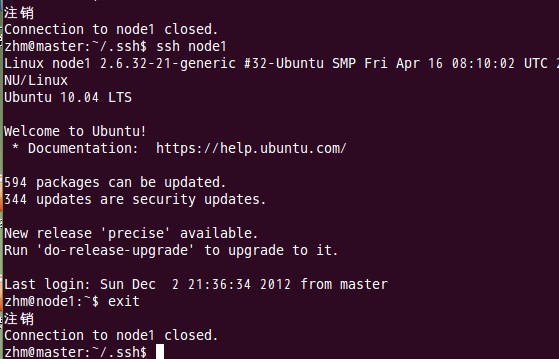
В
еҰӮдёҠеӣҫжүҖзӨәпјҢmasterе·Із»ҸеҸҜд»ҘйҖҡиҝҮsshе…ҚеҜҶз Ғзҷ»еҪ•иҮіnode1з»“зӮ№дәҶгҖӮ
В
еҜ№node2з»“зӮ№д№ҹеҸҜд»Ҙз”ЁеҗҢж ·зҡ„ж–№жі•иҝӣиЎҢпјҢеҰӮдёӢеӣҫпјҡ
Node2з»“зӮ№еӨҚеҲ¶masterз»“зӮ№дёӯзҡ„е…¬й’Ҙж–Ү件
В
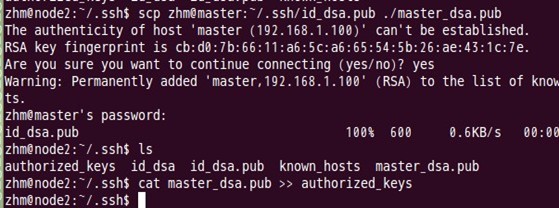
В
MasterйҖҡиҝҮsshе…ҚеҜҶз Ғзҷ»еҪ•иҮіnode2з»“зӮ№жөӢиҜ•пјҡ
第дёҖж¬Ўзҷ»еҪ•ж—¶пјҡ
В
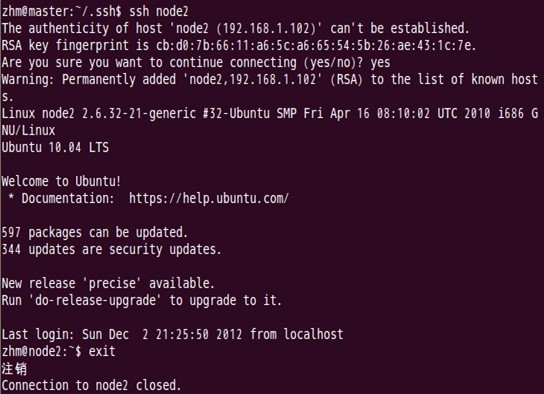
В
第дәҢж¬Ўзҷ»еҪ•ж—¶пјҡ
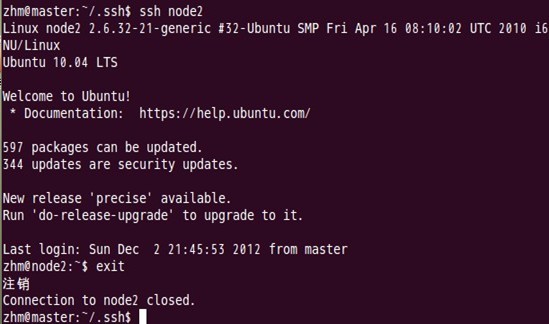
В
иЎЁйқўдёҠзңӢпјҢиҝҷдёӨдёӘз»“зӮ№зҡ„sshе…ҚеҜҶз Ғзҷ»еҪ•е·Із»Ҹй…ҚзҪ®жҲҗеҠҹпјҢдҪҶжҳҜжҲ‘们иҝҳйңҖиҰҒеҜ№дё»з»“зӮ№masterд№ҹиҰҒиҝӣиЎҢдёҠйқўзҡ„еҗҢж ·е·ҘдҪңпјҢиҝҷдёҖжӯҘжңүзӮ№и®©дәәеӣ°жғ‘пјҢдҪҶжҳҜиҝҷжҳҜжңүеҺҹеӣ зҡ„пјҢе…·дҪ“еҺҹеӣ зҺ°еңЁд№ҹиҜҙдёҚеӨӘеҘҪпјҢжҚ®иҜҙжҳҜзңҹе®һзү©зҗҶз»“зӮ№ж—¶йңҖиҰҒеҒҡиҝҷйЎ№е·ҘдҪңпјҢеӣ дёәjobtrackerжңүеҸҜиғҪдјҡеҲҶеёғеңЁе…¶е®ғз»“зӮ№дёҠпјҢjobtrackerжңүдёҚеӯҳеңЁmasterз»“зӮ№дёҠзҡ„еҸҜиғҪжҖ§гҖӮ
В
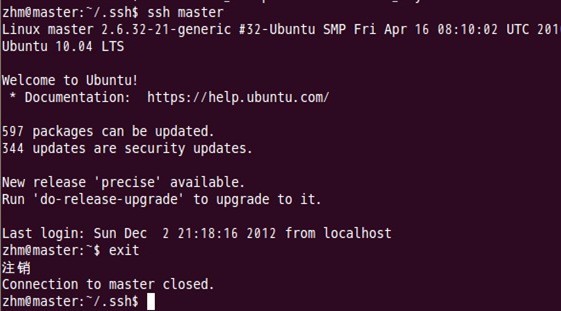
еҜ№masterиҮӘиә«иҝӣиЎҢsshе…ҚеҜҶз Ғзҷ»еҪ•жөӢиҜ•е·ҘдҪңпјҡ
В

В
В
В
иҮіжӯӨпјҢSSHе…ҚеҜҶз Ғзҷ»еҪ•е·Із»Ҹй…ҚзҪ®жҲҗеҠҹгҖӮ
В
еӣӣгҖҒдёӢиҪҪ并解еҺӢhadoopе®үиЈ…еҢ…
е…ідәҺе®үиЈ…еҢ…зҡ„дёӢиҪҪе°ұдёҚеӨҡиҜҙдәҶпјҢдёҚиҝҮеҸҜд»ҘжҸҗдёҖдёӢзӣ®еүҚжҲ‘дҪҝз”Ёзҡ„зүҲжң¬дёәhadoop-0.20.2пјҢ
иҝҷдёӘзүҲжң¬дёҚжҳҜжңҖж–°зҡ„пјҢдёҚиҝҮеӯҰд№ еҳӣпјҢе…Ҳе…Ҙй—ЁпјҢеҗҺйқўзӯүзҶҹз»ғдәҶеҶҚз”Ёе…¶е®ғзүҲжң¬д№ҹдёҚжҖҘгҖӮиҖҢдё”гҖҠhadoopжқғеЁҒжҢҮеҚ—гҖӢиҝҷжң¬д№Ұд№ҹжҳҜй’ҲеҜ№иҝҷдёӘзүҲжң¬д»Ӣз»Қзҡ„гҖӮ
В В В В В В жіЁпјҡи§ЈеҺӢеҗҺhadoopиҪҜ件зӣ®еҪ•еңЁ/home/zhm/hadoopдёӢ
В
дә”гҖҒй…ҚзҪ®namenode,дҝ®ж”№siteж–Ү件
В В В В В В еңЁй…ҚзҪ®siteж–Ү件д№ӢеүҚйңҖиҰҒдҪңдёҖдәӣеҮҶеӨҮе·ҘдҪңпјҢдёӢиҪҪjavaжңҖж–°зүҲзҡ„JDKиҪҜ件пјҢеҸҜд»Ҙд»Һoracleе®ҳзҪ‘дёҠдёӢиҪҪпјҢжҲ‘дҪҝз”Ёзҡ„jdkиҪҜ件зүҲжң¬дёәпјҡjdk1.7.0_09пјҢжҲ‘е°Ҷjavaзҡ„JDKи§ЈеҺӢе®үиЈ…еңЁ/opt/jdk1.7.0_09зӣ®еҪ•дёӯпјҢжҺҘзқҖй…ҚзҪ®JAVA_HOMEе®ҸеҸҳйҮҸеҸҠhadoopи·Ҝеҫ„пјҢиҝҷжҳҜдёәдәҶж–№дҫҝеҗҺйқўж“ҚдҪңпјҢиҝҷйғЁеҲҶй…ҚзҪ®иҝҮзЁӢдё»иҰҒйҖҡиҝҮдҝ®ж”№home/xjnine/~/.bashrcж–Ү件жқҘе®ҢжҲҗпјҢеңЁprofileж–Ү件дёӯж·»еҠ еҰӮдёӢеҮ иЎҢд»Јз Ғпјҡ

В
然еҗҺжү§иЎҢпјҡ

В
и®©й…ҚзҪ®ж–Ү件з«ӢеҲ»з”ҹж•ҲгҖӮдёҠйқўй…ҚзҪ®иҝҮзЁӢжҜҸдёӘз»“зӮ№йғҪиҰҒиҝӣиЎҢдёҖйҒҚгҖӮ
В
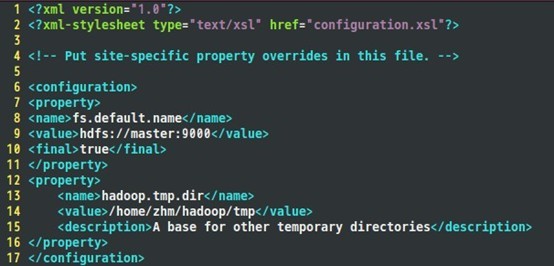
еҲ°зӣ®еүҚдёәжӯўпјҢеҮҶеӨҮе·ҘдҪңе·Із»Ҹе®ҢжҲҗпјҢдёӢйқўејҖе§Ӣдҝ®ж”№hadoopзҡ„й…ҚзҪ®ж–Ү件дәҶпјҢеҚіеҗ„з§Қsiteж–Ү件пјҢж–Ү件еӯҳж”ҫеңЁ/hadoop/confдёӢпјҢдё»иҰҒй…ҚзҪ®core-site.xmlгҖҒhdfs-site.xmlгҖҒmapred-site.xmlиҝҷдёүдёӘж–Ү件гҖӮ
Core-site.xmlй…ҚзҪ®еҰӮдёӢпјҡ
В
В
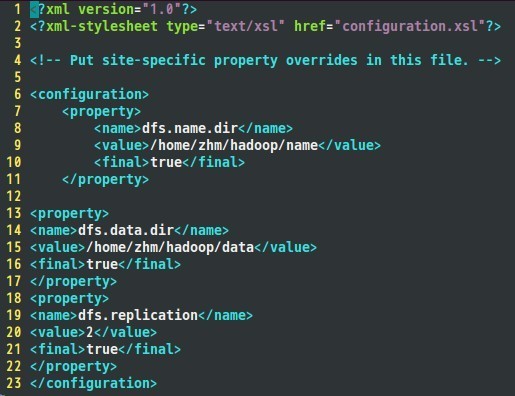
Hdfs-site.xmlй…ҚзҪ®еҰӮдёӢпјҡ
В
В
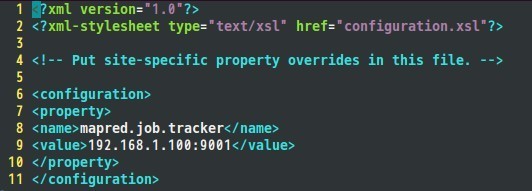
жҺҘзқҖжҳҜmapred-site.xmlж–Ү件пјҡ
В
В
е…ӯгҖҒй…ҚзҪ®hadoop-env.shж–Ү件
В
иҝҷдёӘйңҖиҰҒж №жҚ®е®һйҷ…жғ…еҶөжқҘй…ҚзҪ®гҖӮ

В
дёғгҖҒй…ҚзҪ®mastersе’Ңslavesж–Ү件
ж №жҚ®е®һйҷ…жғ…еҶөй…ҚзҪ®mastersзҡ„дё»жңәеҗҚпјҢеңЁжң¬е®һйӘҢдёӯпјҢmastersдё»з»“зӮ№зҡ„дё»жңәеҗҚдёәmaster,
дәҺжҳҜеңЁmastersж–Ү件дёӯеЎ«е…Ҙпјҡ
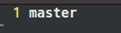
В
В В еҗҢзҗҶпјҢеңЁslavesж–Ү件дёӯеЎ«е…Ҙпјҡ
В
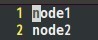
В
е…«гҖҒеҗ‘еҗ„иҠӮзӮ№еӨҚеҲ¶hadoop
еҗ‘node1иҠӮзӮ№еӨҚеҲ¶hadoopпјҡ
В

В
В В еҗ‘node2иҠӮзӮ№еӨҚеҲ¶hadoop:

В
иҝҷж ·пјҢз»“зӮ№node1е’Ңз»“зӮ№node2д№ҹе®үиЈ…дәҶй…ҚзҪ®еҘҪзҡ„hadoopиҪҜ件дәҶгҖӮ
В
д№қгҖҒж јејҸеҢ–namenode
иҝҷдёҖжӯҘеңЁдё»з»“зӮ№masterдёҠиҝӣиЎҢж“ҚдҪңпјҡ
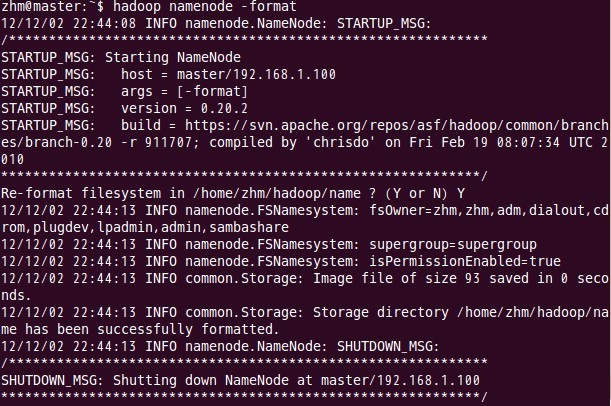
В
жіЁж„ҸпјҡдёҠйқўеҸӘиҰҒеҮәзҺ°вҖңsuccessfully formattedвҖқе°ұиЎЁзӨәжҲҗеҠҹдәҶгҖӮ
В
еҚҒгҖҒеҗҜеҠЁhadoop
иҝҷдёҖжӯҘд№ҹеңЁдё»з»“зӮ№masterдёҠиҝӣиЎҢж“ҚдҪңпјҡ
В
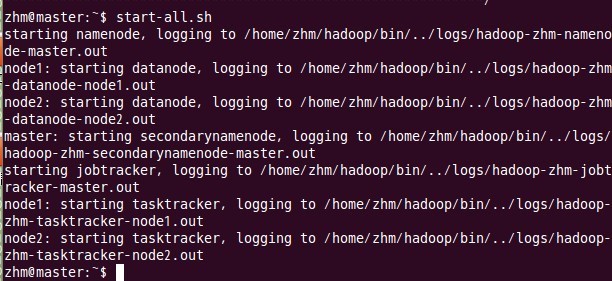
В
В
еҚҒдёҖгҖҒВ В з”ЁjpsжЈҖйӘҢеҗ„еҗҺеҸ°иҝӣзЁӢжҳҜеҗҰжҲҗеҠҹеҗҜеҠЁ
еңЁдё»з»“зӮ№masterдёҠжҹҘзңӢnamenode,jobtracker,secondarynamenodeиҝӣзЁӢжҳҜеҗҰеҗҜеҠЁгҖӮ
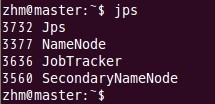
В
еҰӮжһңеҮәзҺ°д»ҘдёҠиҝӣзЁӢеҲҷиЎЁзӨәжӯЈзЎ®гҖӮ
В
еңЁnode1е’Ңnode2з»“зӮ№дәҶжҹҘзңӢtasktrackerе’ҢdatanodeиҝӣзЁӢжҳҜеҗҰеҗҜеҠЁгҖӮ
е…ҲжқҘnode1зҡ„жғ…еҶө:
В
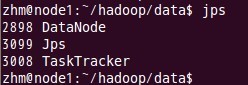
В
дёӢйқўжҳҜnode2зҡ„жғ…еҶөпјҡ
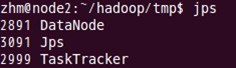
В
иҝӣзЁӢйғҪеҗҜеҠЁжҲҗеҠҹдәҶгҖӮжҒӯе–ң~~~
В
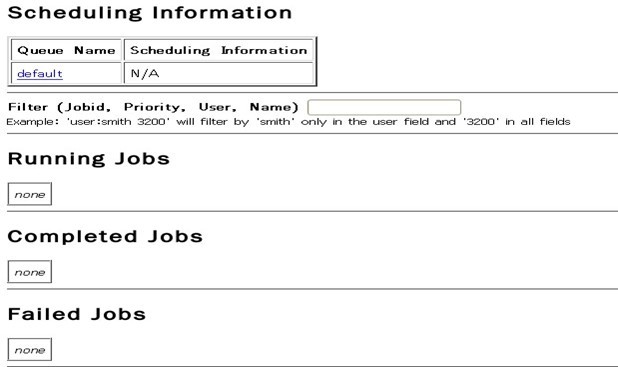
еҚҒдәҢгҖҒВ В йҖҡиҝҮзҪ‘з«ҷжҹҘзңӢйӣҶзҫӨжғ…еҶө
В В еңЁжөҸи§ҲеҷЁдёӯиҫ“е…Ҙпјҡhttp://192.168.1.100:50030пјҢзҪ‘еқҖдёәmasterз»“зӮ№жүҖеҜ№еә”зҡ„IPпјҡ
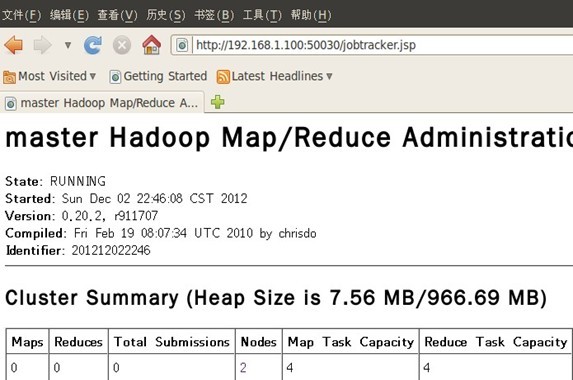
В
В
В
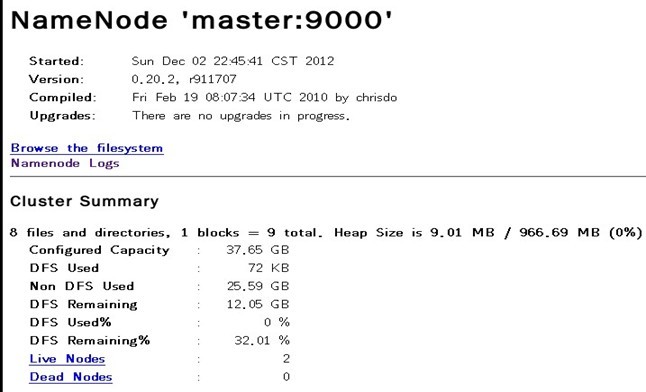
В В еңЁжөҸи§ҲеҷЁдёӯиҫ“е…Ҙпјҡhttp://192.168.1.100:50070пјҢзҪ‘еқҖдёәmasterз»“зӮ№жүҖеҜ№еә”зҡ„IPпјҡ
В
36.jpgВ
дёӢиҪҪйҷ„件  дҝқеӯҳеҲ°зӣёеҶҢ
В
В
иҮіжӯӨпјҢhadoopзҡ„е®Ңе…ЁеҲҶеёғејҸйӣҶзҫӨе®үиЈ…е·Із»Ҹе…ЁйғЁе®ҢжҲҗгҖӮ
дәҢпјҡй…ҚзҪ®eclipseејҖеҸ‘зҺҜеўғ
В



зӣёе…іжҺЁиҚҗ
еңЁEclipseзҡ„вҖңWindowвҖқиҸңеҚ•дёӯйҖүжӢ©вҖңPreferencesвҖқпјҢеңЁеј№еҮәзҡ„еҜ№иҜқжЎҶдёӯеҸҜд»ҘзңӢеҲ°ж–°еўһзҡ„Hadoopй…ҚзҪ®йҖүйЎ№пјҢз”ЁжҲ·еҸҜд»ҘеңЁиҝҷйҮҢи®ҫзҪ®HadoopйӣҶзҫӨзҡ„зӣёе…іеҸӮж•°пјҢеҰӮHadoopзҡ„е®үиЈ…и·Ҝеҫ„гҖҒJobTrackerе’ҢNameNodeзҡ„ең°еқҖзӯүгҖӮ еңЁе®һйҷ…ејҖеҸ‘иҝҮзЁӢ...
жҗӯе»әEclipseдёӢзҡ„Hadoop2.8.2ејҖеҸ‘зҺҜеўғжҳҜдёҖдёӘе…ій”®жӯҘйӘӨпјҢиҝҷе…Ғи®ёејҖеҸ‘иҖ…еңЁжң¬ең°зҺҜеўғдёӯзј–еҶҷгҖҒжөӢиҜ•е’Ңи°ғиҜ•Hadoop MapReduceзЁӢеәҸгҖӮд»ҘдёӢжҳҜеҜ№ж Үйўҳе’ҢжҸҸиҝ°дёӯжүҖиҝ°зҹҘиҜҶзӮ№зҡ„иҜҰз»ҶиҜҙжҳҺпјҡ 1. **JDKе®үиЈ…дёҺй…ҚзҪ®**пјҡйҰ–е…ҲпјҢдҪ йңҖиҰҒе®үиЈ…JDK 8...
1. **жҸ’件д»Ӣз»Қ**пјҡHadoop Eclipse PluginжҳҜдё“й—ЁдёәEclipseе®ҡеҲ¶зҡ„жү©еұ•пјҢе®ғе…Ғи®ёејҖеҸ‘иҖ…еңЁзҶҹжӮүзҡ„EclipseзҺҜеўғдёӢеҲӣе»әгҖҒзј–иҫ‘гҖҒиҝҗиЎҢе’Ңи°ғиҜ•MapReduceзЁӢеәҸпјҢжһҒеӨ§ең°з®ҖеҢ–дәҶHadoopеә”з”Ёзҡ„ејҖеҸ‘жөҒзЁӢгҖӮзүҲжң¬2.7.3дёҺHadoop 2.7.3зүҲжң¬е…је®№...
иҖҢ`hadoop-eclipse-plugin`еҲҷжҳҜдёәJavaйӣҶжҲҗејҖеҸ‘зҺҜеўғEclipseдё“й—Ёи®ҫи®Ўзҡ„дёҖдёӘжҸ’件пјҢе®ғжһҒеӨ§ең°з®ҖеҢ–дәҶHadoopеә”з”ЁзЁӢеәҸзҡ„ејҖеҸ‘е’Ңи°ғиҜ•иҝҮзЁӢгҖӮ **жҸ’件еҠҹиғҪ** 1. **йЎ№зӣ®еҲӣе»әдёҺз®ЎзҗҶ**пјҡдҪҝз”ЁжӯӨжҸ’件пјҢејҖеҸ‘иҖ…еҸҜд»ҘзӣҙжҺҘеңЁEclipseдёӯеҲӣе»ә...
еңЁејҖе§Ӣй…ҚзҪ® Eclipse дёҠзҡ„ Hadoop ејҖеҸ‘зҺҜеўғд№ӢеүҚпјҢзЎ®дҝқе·Із»Ҹе®ҢжҲҗдәҶ Hadoop иҝҗиЎҢзҺҜеўғзҡ„еҹәзЎҖжҗӯе»әгҖӮиҝҷйҖҡеёёеҢ…жӢ¬ Hadoop зҡ„е®үиЈ…дёҺй…ҚзҪ®гҖҒJava зҺҜеўғзҡ„и®ҫзҪ®зӯүгҖӮдёҖж—ҰиҝҷдәӣеҹәзЎҖе·ҘдҪңе®ҢжҲҗпјҢжҲ‘们е°ұеҸҜд»ҘзқҖжүӢеҮҶеӨҮејҖеҸ‘зҺҜеўғдәҶгҖӮ ##### 2....
10. **ејҖеҸ‘дёҺжөӢиҜ•е·Ҙе…·**пјҡдёәдәҶж–№дҫҝејҖеҸ‘е’ҢжөӢиҜ•пјҢеҸҜд»ҘдҪҝз”ЁHadoopжҸҗдҫӣзҡ„е‘Ҫд»ӨиЎҢе·Ҙе…·пјҢеҰӮ`hadoop fs`е‘Ҫд»ӨпјҢд»ҘеҸҠйӣҶжҲҗејҖеҸ‘зҺҜеўғпјҲIDEпјүдёӯзҡ„HadoopжҸ’件пјҢеҰӮEclipseзҡ„HadoopжҸ’件гҖӮ еңЁWindowsдёҠжҗӯе»әHadoopзҺҜеўғйңҖиҰҒиҖҗеҝғе’ҢеҜ№зі»з»ҹ...
жҖ»з»“жқҘиҜҙпјҢжң¬ж•ҷзЁӢиҜҰз»Ҷд»Ӣз»ҚдәҶеҰӮдҪ•еңЁvmwareиҷҡжӢҹжңәдёҠжҗӯе»әHadoopйӣҶзҫӨпјҢй…ҚзҪ®EclipseејҖеҸ‘зҺҜеўғпјҢеҲӣе»ә并иҝҗиЎҢHadoop MapReduceйЎ№зӣ®гҖӮйҖҡиҝҮйҒөеҫӘиҝҷдәӣжӯҘйӘӨпјҢеӯҰд№ иҖ…е°ҶиғҪеӨҹе»әз«ӢдёҖдёӘжңүж•Ҳзҡ„HadoopејҖеҸ‘зҺҜеўғпјҢд»ҺиҖҢжӣҙиҪ»жқҫең°иҝӣиЎҢеӨ§ж•°жҚ®...
еңЁ3.4.6зүҲжң¬дёӯпјҢе®ғжҸҗдҫӣдәҶзЁіе®ҡжҖ§е’ҢжҖ§иғҪзҡ„дјҳеҢ–пјҢдҪҝеҫ—еңЁWindowsзҺҜеўғдёӢжҗӯе»әе’ҢдҪҝз”ЁеҸҳеҫ—жӣҙеҠ ж–№дҫҝгҖӮ ZooKeeperзҡ„ж ёеҝғеҠҹиғҪеҢ…жӢ¬е‘ҪеҗҚжңҚеҠЎгҖҒй…ҚзҪ®з®ЎзҗҶгҖҒйӣҶзҫӨеҗҢжӯҘе’ҢеҲҶеёғејҸй”ҒзӯүпјҢе®ғйҖҡиҝҮдёҖдёӘз®ҖеҚ•зҡ„зұ»ZNodeзҡ„еұӮж¬Ўз»“жһ„жқҘеӯҳеӮЁж•°жҚ®пјҢ并...
ејҖеҸ‘зҺҜеўғжҗӯе»ә #### 1.1 JDKе®үиЈ… - **е®үиЈ…зЁӢеәҸ**: дҪҝз”Ё`jdk-7u55-windows-x64.exe`иҝӣиЎҢе®үиЈ…гҖӮ - **е®үиЈ…и·Ҝеҫ„**: дҫӢеҰӮ`D:\java\jdk1.7.0`гҖӮ - **е®үиЈ…жӯҘйӘӨ**: - иҝҗиЎҢе®үиЈ…зЁӢеәҸгҖӮ - и®ҫзҪ®е®үиЈ…и·Ҝеҫ„гҖӮ - е®ҢжҲҗJDKе®үиЈ…гҖӮ -...
1. е®үиЈ…е’Ңй…ҚзҪ®HBaseпјҡжҺҢжҸЎеңЁWindow10зҺҜеўғдёӢпјҢеҰӮдҪ•еңЁHadoopиҷҡжӢҹжңәдёҠжҗӯе»әHBaseзҡ„дјӘеҲҶеёғејҸйӣҶзҫӨгҖӮ 2. дҪҝз”ЁHBase ShellпјҡзҶҹжӮү并зҶҹз»ғиҝҗз”ЁHBaseжҸҗдҫӣзҡ„Shellе‘Ҫд»ӨпјҢеҰӮеҲӣе»әиЎЁгҖҒж·»еҠ ж•°жҚ®гҖҒжҹҘиҜўзӯүгҖӮ 3. еӯҰд№ HBaseжҰӮеҝөпјҡзҗҶи§ЈHBase...