
иљђ
иѓізЩљдЇЖпЉМ糥еЉХйЧЃйҐШе∞±жШѓдЄАдЄ™жЯ•жЙЊйЧЃйҐШгАВгАВгАВ
 
жХ∞жНЃеЇУ糥еЉХпЉМжШѓжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдЄ≠дЄАдЄ™жОТеЇПзЪДжХ∞жНЃзїУжЮДпЉМдї•еНПеК©ењЂйАЯжߕ胥гАБжЫіжЦ∞жХ∞жНЃеЇУи°®дЄ≠жХ∞жНЃгАВ糥еЉХзЪДеЃЮзО∞йАЪеЄЄдљњзФ®Bж†СеПКеЕґеПШзІНB+ж†СгАВ
еЬ®жХ∞жНЃдєЛе§ЦпЉМжХ∞жНЃеЇУз≥їзїЯињШзїіжК§зЭАжї°иґ≥зЙєеЃЪжЯ•жЙЊзЃЧж≥ХзЪДжХ∞жНЃзїУжЮДпЉМињЩдЇЫжХ∞жНЃзїУжЮДдї•жЯРзІНжЦєеЉПеЉХзФ®пЉИжМЗеРСпЉЙжХ∞жНЃпЉМињЩж†Је∞±еПѓдї•еЬ®ињЩдЇЫжХ∞жНЃзїУжЮДдЄКеЃЮзО∞йЂШзЇІжЯ•жЙЊзЃЧж≥ХгАВињЩзІНжХ∞жНЃзїУжЮДпЉМе∞±ж؃糥еЉХгАВ
䪯谮职皁糥еЉХи¶БдїШеЗЇдї£дїЈзЪДпЉЪдЄАжШѓеҐЮеК†дЇЖжХ∞жНЃеЇУзЪДе≠ШеВ®з©ЇйЧіпЉМдЇМжШѓеЬ®жПТеЕ•еТМдњЃжФєжХ∞жНЃжЧґи¶БиК±иієиЊГе§ЪзЪДжЧґйЧі(еۆ䪯糥еЉХдєЯи¶БйЪПдєЛеПШеК®)гАВ
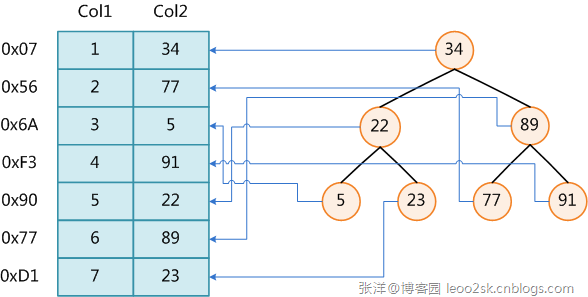
 
дЄКеЫЊе±Хз§ЇдЇЖдЄАзІНеПѓиГљзЪД糥еЉХжЦєеЉПгАВеЈ¶иЊєжШѓжХ∞жНЃи°®пЉМдЄАеЕ±жЬЙдЄ§еИЧдЄГжЭ°иЃ∞ељХпЉМжЬАеЈ¶иЊєзЪДжШѓжХ∞жНЃиЃ∞ељХзЪДзЙ©зРЖеЬ∞еЭАпЉИж≥®жДПйАїиЊСдЄКзЫЄйВїзЪДиЃ∞ељХеЬ®з£БзЫШдЄКдєЯеєґдЄНжШѓдЄАеЃЪзЙ©зРЖзЫЄйВїзЪДпЉЙгАВдЄЇдЇЖеК†ењЂCol2зЪДжЯ•жЙЊпЉМеПѓдї•зїіжК§дЄАдЄ™еП≥иЊєжЙАз§ЇзЪДдЇМеПЙжЯ•жЙЊж†СпЉМжѓПдЄ™иКВзВєеИЖеИЂеМЕеЀ糥еЉХйФЃеАЉеТМдЄАдЄ™жМЗеРСеѓєеЇФжХ∞жНЃиЃ∞ељХзЙ©зРЖеЬ∞еЭАзЪДжМЗйТИпЉМињЩж†Је∞±еПѓдї•ињРзФ®дЇМеПЙжЯ•жЙЊеЬ®O(log2n)зЪДе§НжЭВеЇ¶еЖЕиОЈеПЦеИ∞зЫЄеЇФжХ∞жНЃгАВ
 
еИЫ忯糥еЉХеПѓдї•е§Іе§ІжПРйЂШз≥їзїЯзЪДжАІиГљгАВ
зђђдЄАпЉМйАЪињЗеИЫеїЇеФѓдЄАжАІзіҐеЉХпЉМеПѓдї•дњЭиѓБжХ∞жНЃеЇУи°®дЄ≠жѓПдЄАи°МжХ∞жНЃзЪДеФѓдЄАжАІгАВ
зђђдЇМпЉМеПѓдї•е§Іе§ІеК†ењЂжХ∞жНЃзЪДж£А糥йАЯеЇ¶пЉМињЩдєЯжШѓеИЫ忯糥еЉХзЪДжЬАдЄїи¶БзЪДеОЯеЫ†гАВ
зђђдЄЙпЉМеПѓдї•еК†йАЯи°®еТМи°®дєЛйЧізЪДињЮжО•пЉМзЙєеИЂжШѓеЬ®еЃЮзО∞жХ∞жНЃзЪДеПВиАГеЃМжХіжАІжЦєйЭҐзЙєеИЂжЬЙжДПдєЙгАВ
зђђеЫЫпЉМеЬ®дљњзФ®еИЖзїДеТМжОТеЇПе≠РеП•ињЫи°МжХ∞жНЃж£А糥жЧґпЉМеРМж†ЈеПѓдї•жШЊиСЧеЗПе∞Сжߕ胥дЄ≠еИЖзїДеТМжОТеЇПзЪДжЧґйЧігАВ
зђђдЇФпЉМйАЪињЗдљњзԮ糥еЉХпЉМеПѓдї•еЬ®жߕ胥зЪДињЗз®ЛдЄ≠пЉМдљњзФ®дЉШеМЦйЪРиЧПеЩ®пЉМжПРйЂШз≥їзїЯзЪДжАІиГљгАВ¬†
 
дєЯиЃЄдЉЪжЬЙдЇЇи¶БйЧЃпЉЪеҐЮеʆ糥еЉХжЬЙе¶Вж≠§е§ЪзЪДдЉШзВєпЉМдЄЇдїАдєИдЄНеѓєи°®дЄ≠зЪДжѓПдЄАдЄ™еИЧеИЫеїЇдЄА䪙糥еЉХеСҐпЉЯеЫ†дЄЇпЉМеҐЮеʆ糥еЉХдєЯжЬЙиЃЄе§ЪдЄНеИ©зЪДжЦєйЭҐгАВ
зђђдЄАпЉМеИЫ忯糥еЉХеТМзїіжʧ糥еЉХи¶БиАЧиієжЧґйЧіпЉМињЩзІНжЧґйЧійЪПзЭАжХ∞жНЃйЗПзЪДеҐЮеК†иАМеҐЮеК†гАВ
зђђдЇМпЉМ糥еЉХйЬАи¶БеН†зЙ©зРЖз©ЇйЧіпЉМйЩ§дЇЖжХ∞жНЃи°®еН†жХ∞жНЃз©ЇйЧідєЛе§ЦпЉМжѓПдЄА䪙糥еЉХињШи¶БеН†дЄАеЃЪзЪДзЙ©зРЖз©ЇйЧіпЉМе¶ВжЮЬи¶БеїЇзЂЛиБЪз∞З糥еЉХпЉМйВ£дєИйЬАи¶БзЪДз©ЇйЧіе∞±дЉЪжЫіе§ІгАВ
зђђдЄЙпЉМељУеѓєи°®дЄ≠зЪДжХ∞жНЃињЫи°МеҐЮеК†гАБеИ†йЩ§еТМдњЃжФєзЪДжЧґеАЩпЉМ糥еЉХдєЯи¶БеК®жАБзЪДзїіжК§пЉМињЩж†Је∞±йЩНдљОдЇЖжХ∞жНЃзЪДзїіжК§йАЯеЇ¶гАВ
 
糥еЉХжШѓеїЇзЂЛеЬ®жХ∞жНЃеЇУи°®дЄ≠зЪДжЯРдЇЫеИЧзЪДдЄКйЭҐгАВеЬ®еИЫ忯糥еЉХзЪДжЧґеАЩпЉМеЇФиѓ•иАГиЩСеЬ®еУ™дЇЫеИЧдЄКеПѓдї•еИЫ忯糥еЉХпЉМеЬ®еУ™дЇЫеИЧдЄКдЄНиГљеИЫ忯糥еЉХгАВдЄАиИђжЭ•иѓіпЉМеЇФиѓ•еЬ®ињЩдЇЫеИЧдЄКеИЫ忯糥еЉХпЉЪеЬ®зїПеЄЄйЬАи¶БжРЬ糥зЪДеИЧдЄКпЉМеПѓдї•еК†ењЂжРЬ糥зЪДйАЯеЇ¶пЉЫеЬ®дљЬдЄЇдЄїйФЃзЪДеИЧдЄКпЉМеЉЇеИґиѓ•еИЧзЪДеФѓдЄАжАІеТМзїДзїЗи°®дЄ≠жХ∞жНЃзЪДжОТеИЧзїУжЮДпЉЫеЬ®зїПеЄЄзФ®еЬ®ињЮжО•зЪДеИЧдЄКпЉМињЩдЇЫеИЧдЄїи¶БжШѓдЄАдЇЫе§ЦйФЃпЉМеПѓдї•еК†ењЂињЮжО•зЪДйАЯеЇ¶пЉЫеЬ®зїПеЄЄйЬАи¶Бж†єжНЃиМГеЫіињЫи°МжРЬ糥зЪДеИЧдЄКеИЫ忯糥еЉХпЉМеۆ䪯糥еЉХеЈ≤зїПжОТеЇПпЉМеЕґжМЗеЃЪзЪДиМГеЫіжШѓињЮзї≠зЪДпЉЫеЬ®зїПеЄЄйЬАи¶БжОТеЇПзЪДеИЧдЄКеИЫ忯糥еЉХпЉМеۆ䪯糥еЉХеЈ≤зїПжОТеЇПпЉМињЩж†Јжߕ胥еПѓдї•еИ©зԮ糥еЉХзЪДжОТеЇПпЉМеК†ењЂжОТеЇПжߕ胥жЧґйЧіпЉЫеЬ®зїПеЄЄдљњзФ®еЬ®WHEREе≠РеП•дЄ≠зЪДеИЧдЄКйЭҐеИЫ忯糥еЉХпЉМеК†ењЂжЭ°дїґзЪДеИ§жЦ≠йАЯеЇ¶гАВ
 
еРМж†ЈпЉМеѓєдЇОжЬЙдЇЫеИЧдЄНеЇФиѓ•еИЫ忯糥еЉХгАВдЄАиИђжЭ•иѓіпЉМдЄНеЇФиѓ•еИЫ忯糥еЉХзЪДзЪДињЩдЇЫеИЧеЕЈжЬЙдЄЛеИЧзЙєзВєпЉЪ
зђђдЄАпЉМеѓєдЇОйВ£дЇЫеЬ®жߕ胥дЄ≠еЊИе∞СдљњзФ®жИЦиАЕеПВиАГзЪДеИЧдЄНеЇФиѓ•еИЫ忯糥еЉХгАВињЩжШѓеЫ†дЄЇпЉМжЧҐзДґињЩдЇЫеИЧеЊИе∞СдљњзФ®еИ∞пЉМеЫ†ж≠§жЬЙ糥еЉХжИЦиАЕж׆糥еЉХпЉМеєґдЄНиГљжПРйЂШжߕ胥йАЯеЇ¶гАВзЫЄеПНпЉМзФ±дЇОеҐЮеК†дЇЖ糥еЉХпЉМеПНиАМйЩНдљОдЇЖз≥їзїЯзЪДзїіжК§йАЯеЇ¶еТМеҐЮе§ІдЇЖз©ЇйЧійЬАж±ВгАВ
зђђдЇМпЉМеѓєдЇОйВ£дЇЫеП™жЬЙеЊИе∞СжХ∞жНЃеАЉзЪДеИЧдєЯдЄНеЇФиѓ•еҐЮеʆ糥еЉХгАВињЩжШѓеЫ†дЄЇпЉМзФ±дЇОињЩдЇЫеИЧзЪДеПЦеАЉеЊИе∞СпЉМдЊЛе¶ВдЇЇдЇЛи°®зЪДжАІеИЂеИЧпЉМеЬ®жߕ胥зЪДзїУжЮЬдЄ≠пЉМзїУжЮЬйЫЖзЪДжХ∞жНЃи°МеН†дЇЖи°®дЄ≠жХ∞жНЃи°МзЪДеЊИе§ІжѓФдЊЛпЉМеН≥йЬАи¶БеЬ®и°®дЄ≠жРЬ糥зЪДжХ∞жНЃи°МзЪДжѓФдЊЛеЊИе§ІгАВеҐЮеʆ糥еЉХпЉМеєґдЄНиГљжШОжШЊеК†ењЂж£А糥йАЯеЇ¶гАВ
зђђдЄЙпЉМеѓєдЇОйВ£дЇЫеЃЪдєЙдЄЇtext, imageеТМbitжХ∞жНЃз±їеЮЛзЪДеИЧдЄНеЇФиѓ•еҐЮеʆ糥еЉХгАВињЩжШѓеЫ†дЄЇпЉМињЩдЇЫеИЧзЪДжХ∞жНЃйЗПи¶БдєИзЫЄељУе§ІпЉМи¶БдєИеПЦеАЉеЊИе∞СгАВ
зђђеЫЫпЉМељУдњЃжФєжАІиГљињЬињЬе§ІдЇОж£А糥жАІиГљжЧґпЉМдЄНеЇФиѓ•еИЫ忯糥еЉХгАВињЩжШѓеЫ†дЄЇпЉМдњЃжФєжАІиГљеТМж£А糥жАІиГљжШѓдЇТзЫЄзЯЫзЫЊзЪДгАВељУеҐЮеʆ糥еЉХжЧґпЉМдЉЪжПРйЂШж£А糥жАІиГљпЉМдљЖжШѓдЉЪйЩНдљОдњЃжФєжАІиГљгАВељУеЗПе∞С糥еЉХжЧґпЉМдЉЪжПРйЂШдњЃжФєжАІиГљпЉМйЩНдљОж£А糥жАІиГљгАВеЫ†ж≠§пЉМељУдњЃжФєжАІиГљињЬињЬе§ІдЇОж£А糥жАІиГљжЧґпЉМдЄНеЇФиѓ•еИЫ忯糥еЉХгАВ
 
ж†єжНЃжХ∞жНЃеЇУзЪДеКЯиГљпЉМеПѓдї•еЬ®жХ∞жНЃеЇУиЃЊиЃ°еЩ®дЄ≠еИЫеїЇдЄЙзІН糥еЉХпЉЪеФѓдЄА糥еЉХгАБдЄїйԁ糥еЉХеТМиБЪйЫЖ糥еЉХгАВ
еФѓдЄА糥еЉХ¬†
 
еФѓдЄА糥еЉХжШѓдЄНеЕБиЃЄеЕґдЄ≠дїїдљХдЄ§и°МеЕЈжЬЙзЫЄеРМ糥еЉХеАЉзЪД糥еЉХгАВ
ељУзО∞жЬЙжХ∞жНЃдЄ≠е≠ШеЬ®йЗНе§НзЪДйФЃеАЉжЧґпЉМе§Іе§ЪжХ∞жХ∞жНЃеЇУдЄНеЕБиЃЄе∞ЖжЦ∞еИЫеїЇзЪДеФѓдЄА糥еЉХдЄОи°®дЄАиµЈдњЭе≠ШгАВжХ∞жНЃеЇУињШеПѓиГљйШ≤ж≠ҐжЈїеК†е∞ЖеЬ®и°®дЄ≠еИЫеїЇйЗНе§НйФЃеАЉзЪДжЦ∞жХ∞жНЃгАВдЊЛе¶ВпЉМе¶ВжЮЬеЬ®employeeи°®дЄ≠иБМеСШзЪДеІУ(lname)дЄКеИЫеїЇдЇЖеФѓдЄА糥еЉХпЉМеИЩдїїдљХдЄ§дЄ™еСШеЈ•йГљдЄНиГљеРМеІУгАВ
дЄїйԁ糥еЉХ
жХ∞жНЃеЇУи°®зїПеЄЄжЬЙдЄАеИЧжИЦеИЧзїДеРИпЉМеЕґеАЉеФѓдЄАж†ЗиѓЖи°®дЄ≠зЪДжѓПдЄАи°МгАВиѓ•еИЧзІ∞дЄЇи°®зЪДдЄїйФЃгАВ
еЬ®жХ∞жНЃеЇУеЕ≥з≥їеЫЊдЄ≠дЄЇи°®еЃЪдєЙдЄїйФЃе∞ЖиЗ™еК®еИЫеїЇдЄїйԁ糥еЉХпЉМдЄїйԁ糥еЉХжШѓеФѓдЄА糥еЉХзЪДзЙєеЃЪз±їеЮЛгАВ胕糥еЉХи¶Бж±ВдЄїйФЃдЄ≠зЪДжѓПдЄ™еАЉйГљеФѓдЄАгАВељУеЬ®жߕ胥дЄ≠дљњзФ®дЄїйԁ糥еЉХжЧґпЉМеЃГињШеЕБиЃЄеѓєжХ∞жНЃзЪДењЂйАЯиЃњйЧЃгАВ
иБЪйЫЖ糥еЉХ
еЬ®иБЪйЫЖ糥еЉХдЄ≠пЉМи°®дЄ≠и°МзЪДзЙ©зРЖй°ЇеЇПдЄОйФЃеАЉзЪДйАїиЊСпЉИ糥еЉХпЉЙй°ЇеЇПзЫЄеРМгАВдЄАдЄ™и°®еП™иГљеМЕеРЂдЄАдЄ™иБЪйЫЖ糥еЉХгАВ
е¶ВжЮЬжЯР糥еЉХдЄНжШѓиБЪйЫЖ糥еЉХпЉМеИЩи°®дЄ≠и°МзЪДзЙ©зРЖй°ЇеЇПдЄОйФЃеАЉзЪДйАїиЊСй°ЇеЇПдЄНеМєйЕНгАВдЄОйЭЮиБЪйЫЖ糥еЉХзЫЄжѓФпЉМиБЪйЫЖ糥еЉХйАЪеЄЄжПРдЊЫжЫіењЂзЪДжХ∞жНЃиЃњйЧЃйАЯеЇ¶гАВ
 
 
 
е±АйГ®жАІеОЯзРЖдЄОз£БзЫШйҐДиѓї
 
зФ±дЇОе≠ШеВ®дїЛиі®зЪДзЙєжАІпЉМз£БзЫШжЬђиЇЂе≠ШеПЦе∞±жѓФдЄїе≠ШжЕҐеЊИе§ЪпЉМеЖНеК†дЄКжЬЇжҐ∞ињРеК®иАЧиієпЉМз£БзЫШзЪДе≠ШеПЦйАЯеЇ¶еЊАеЊАжШѓдЄїе≠ШзЪДеЗ†зЩЊеИЖеИЖдєЛдЄАпЉМеЫ†ж≠§дЄЇдЇЖжПРйЂШжХИзОЗпЉМи¶Бе∞љйЗПеЗПе∞Сз£БзЫШI/OгАВдЄЇдЇЖиЊЊеИ∞ињЩдЄ™зЫЃзЪДпЉМз£БзЫШеЊАеЊАдЄНжШѓдЄ•ж†ЉжМЙйЬАиѓїеПЦпЉМиАМжШѓжѓПжђ°йГљдЉЪйҐДиѓїпЉМеН≥дљњеП™йЬАи¶БдЄАдЄ™е≠ЧиКВпЉМз£БзЫШдєЯдЉЪдїОињЩдЄ™дљНзљЃеЉАеІЛпЉМй°ЇеЇПеРСеРОиѓїеПЦдЄАеЃЪйХњеЇ¶зЪДжХ∞жНЃжФЊеЕ•еЖЕе≠ШгАВињЩж†ЈеБЪзЪДзРЖиЃЇдЊЭжНЃжШѓиЃ°зЃЧжЬЇзІСе≠¶дЄ≠иСЧеРНзЪДе±АйГ®жАІеОЯзРЖпЉЪељУдЄАдЄ™жХ∞ж́襀зФ®еИ∞жЧґпЉМеЕґйЩДињСзЪДжХ∞жНЃдєЯйАЪеЄЄдЉЪй©ђдЄК襀䚜зФ®гАВз®ЛеЇПињРи°МжЬЯйЧіжЙАйЬАи¶БзЪДжХ∞жНЃйАЪеЄЄжѓФиЊГйЫЖдЄ≠гАВ
зФ±дЇОз£БзЫШй°ЇеЇПиѓїеПЦзЪДжХИзОЗеЊИйЂШпЉИдЄНйЬАи¶БеѓїйБУжЧґйЧіпЉМеП™йЬАеЊИе∞СзЪДжЧЛиљђжЧґйЧіпЉЙпЉМеЫ†ж≠§еѓєдЇОеЕЈжЬЙе±АйГ®жАІзЪДз®ЛеЇПжЭ•иѓіпЉМйҐДиѓїеПѓдї•жПРйЂШI/OжХИзОЗгАВ
йҐДиѓїзЪДйХњеЇ¶дЄАиИђдЄЇй°µпЉИpageпЉЙзЪДжХіеАНжХ∞гАВй°µжШѓиЃ°зЃЧжЬЇзЃ°зРЖе≠ШеВ®еЩ®зЪДйАїиЊСеЭЧпЉМз°ђдїґеПКжУНдљЬз≥їзїЯеЊАеЊАе∞ЖдЄїе≠ШеТМз£БзЫШе≠ШеВ®еМЇеИЖеЙ≤дЄЇињЮзї≠зЪДе§Іе∞ПзЫЄз≠ЙзЪДеЭЧпЉМжѓПдЄ™е≠ШеВ®еЭЧзІ∞дЄЇдЄАй°µпЉИеЬ®иЃЄе§ЪжУНдљЬз≥їзїЯдЄ≠пЉМй°µеЊЧе§Іе∞ПйАЪеЄЄдЄЇ4kпЉЙпЉМдЄїе≠ШеТМз£БзЫШдї•й°µдЄЇеНХдљНдЇ§жНҐжХ∞жНЃгАВељУз®ЛеЇПи¶БиѓїеПЦзЪДжХ∞жНЃдЄНеЬ®дЄїе≠ШдЄ≠жЧґпЉМдЉЪиІ¶еПСдЄАдЄ™зЉЇй°µеЉВеЄЄпЉМж≠§жЧґз≥їзїЯдЉЪеРСз£БзЫШеПСеЗЇиѓїзЫШдњ°еПЈпЉМз£БзЫШдЉЪжЙЊеИ∞жХ∞жНЃзЪДиµЈеІЛдљНзљЃеєґеРСеРОињЮзї≠иѓїеПЦдЄАй°µжИЦеЗ†й°µиљљеЕ•еЖЕе≠ШдЄ≠пЉМзДґеРОеЉВеЄЄињФеЫЮпЉМз®ЛеЇПзїІзї≠ињРи°МгАВ
B-/+Tree糥еЉХзЪДжАІиГљеИЖжЮР
еИ∞ињЩйЗМзїИдЇОеПѓдї•еИЖжЮРB-/+Tree糥еЉХзЪДжАІиГљдЇЖгАВ
дЄКжЦЗиѓіињЗдЄАиИђдљњзФ®з£БзЫШI/Oжђ°жХ∞иѓД俣糥еЉХзїУжЮДзЪДдЉШеК£гАВеЕИдїОB-TreeеИЖжЮРпЉМж†єжНЃB-TreeзЪДеЃЪдєЙпЉМеПѓзЯ•ж£А糥дЄАжђ°жЬАе§ЪйЬАи¶БиЃњйЧЃhдЄ™иКВзВєгАВжХ∞жНЃеЇУз≥їзїЯзЪДиЃЊиЃ°иАЕеЈІе¶ЩеИ©зФ®дЇЖз£БзЫШйҐДиѓїеОЯзРЖпЉМе∞ЖдЄАдЄ™иКВзВєзЪДе§Іе∞ПиЃЊдЄЇз≠ЙдЇОдЄАдЄ™й°µпЉМињЩж†ЈжѓПдЄ™иКВзВєеП™йЬАи¶БдЄАжђ°I/Oе∞±еПѓдї•еЃМеЕ®иљљеЕ•гАВдЄЇдЇЖиЊЊеИ∞ињЩдЄ™зЫЃзЪДпЉМеЬ®еЃЮйЩЕеЃЮзО∞B-TreeињШйЬАи¶БдљњзФ®е¶ВдЄЛжКАеЈІпЉЪ
жѓПжђ°жЦ∞еїЇиКВзВєжЧґпЉМзЫіжО•зФ≥иѓЈдЄАдЄ™й°µзЪДз©ЇйЧіпЉМињЩж†Је∞±дњЭиѓБдЄАдЄ™иКВзВєзЙ©зРЖдЄКдєЯе≠ШеВ®еЬ®дЄАдЄ™й°µйЗМпЉМеК†дєЛиЃ°зЃЧжЬЇе≠ШеВ®еИЖйЕНйГљжШѓжМЙй°µеѓєйљРзЪДпЉМе∞±еЃЮзО∞дЇЖдЄАдЄ™nodeеП™йЬАдЄАжђ°I/OгАВ
B-TreeдЄ≠дЄАжђ°ж£А糥жЬАе§ЪйЬАи¶Бh-1жђ°I/OпЉИж†єиКВзВєеЄЄй©їеЖЕе≠ШпЉЙпЉМжЄРињЫе§НжЭВеЇ¶дЄЇO(h)=O(logdN)гАВдЄАиИђеЃЮйЩЕеЇФзФ®дЄ≠пЉМеЗЇеЇ¶dжШѓйЭЮеЄЄе§ІзЪДжХ∞е≠ЧпЉМйАЪеЄЄиґЕињЗ100пЉМеЫ†ж≠§hйЭЮеЄЄе∞ПпЉИйАЪеЄЄдЄНиґЕињЗ3пЉЙгАВ
иАМзЇҐйїСж†СињЩзІНзїУжЮДпЉМhжШОжШЊи¶БжЈ±зЪДе§ЪгАВзФ±дЇОйАїиЊСдЄКеЊИињСзЪДиКВзВєпЉИзИґе≠РпЉЙзЙ©зРЖдЄКеПѓиГљеЊИињЬпЉМжЧ†ж≥ХеИ©зФ®е±АйГ®жАІпЉМжЙАдї•зЇҐйїСж†СзЪДI/OжЄРињЫе§НжЭВеЇ¶дєЯдЄЇO(h)пЉМжХИзОЗжШОжШЊжѓФB-TreeеЈЃеЊИе§ЪгАВ
 
зїЉдЄКжЙАињ∞пЉМзФ®B-TreeдљЬ䪯糥еЉХзїУжЮДжХИзОЗжШѓйЭЮеЄЄйЂШзЪДгАВ
 
 
еЇФиѓ•иК±жЧґйЧіе≠¶дє†B-ж†СеТМB+ж†СжХ∞жНЃзїУжЮД
=============================================================================================================
 
1пЉЙBж†С
Bж†СдЄ≠жѓПдЄ™иКВзВєеМЕеРЂдЇЖйФЃеАЉеТМйФЃеАЉеѓєдЇОзЪДжХ∞жНЃеѓєи±°е≠ШжФЊеЬ∞еЭАжМЗйТИпЉМжЙАдї•жИРеКЯжРЬ糥дЄАдЄ™еѓєи±°еПѓдї•дЄНзФ®еИ∞иЊЊж†СзЪДеПґиКВзВєгАВ
жИРеКЯжРЬ糥еМЕжЛђиКВзВєеЖЕжРЬ糥еТМж≤њжЯРдЄАиЈѓеЊДзЪДжРЬ糥пЉМжИРеКЯжРЬ糥жЧґйЧіеПЦеЖ≥дЇОеЕ≥йФЃз†БжЙАеЬ®зЪДе±Вжђ°дї•еПКиКВзВєеЖЕеЕ≥йФЃз†БзЪДжХ∞йЗПгАВ
 
еЬ®Bж†СдЄ≠жЯ•жЙЊзїЩеЃЪеЕ≥йФЃе≠ЧзЪДжЦєж≥ХжШѓпЉЪй¶ЦеЕИжККж†єзїУзВєеПЦжЭ•пЉМеЬ®ж†єзїУзВєжЙАеМЕеРЂзЪДеЕ≥йФЃе≠ЧK1,вА¶,kjжЯ•жЙЊзїЩеЃЪзЪДеЕ≥йФЃе≠ЧпЉИеПѓзФ®й°ЇеЇПжЯ•жЙЊжИЦдЇМеИЖжЯ•жЙЊж≥ХпЉЙпЉМиЛ•жЙЊеИ∞з≠ЙдЇОзїЩеЃЪеАЉзЪДеЕ≥йФЃе≠ЧпЉМеИЩжЯ•жЙЊжИРеКЯпЉЫеР¶еИЩпЉМдЄАеЃЪеПѓдї•з°ЃеЃЪи¶БжЯ•зЪДеЕ≥йФЃе≠ЧеЬ®жЯРдЄ™KiжИЦKi+1дєЛйЧіпЉМдЇОжШѓеПЦPiжЙАжМЗзЪДдЄЛдЄАе±В糥еЉХиКВзВєеЭЧзїІзї≠жЯ•жЙЊпЉМзЫіеИ∞жЙЊеИ∞пЉМжИЦжМЗйТИPiдЄЇз©ЇжЧґжЯ•жɌ姱賕гАВ
 
 
2пЉЙB+ж†С
 
B+ж†СйЭЮеПґиКВзВєдЄ≠е≠ШжФЊзЪДеЕ≥йФЃз†БеєґдЄНжМЗз§ЇжХ∞жНЃеѓєи±°зЪДеЬ∞еЭАжМЗйТИпЉМйЭЮдєЯиКВзВєеП™ж؃糥еЉХйГ®еИЖгАВжЙАжЬЙзЪДеПґиКВзВєеЬ®еРМдЄАе±ВдЄКпЉМеМЕеРЂдЇЖеЕ®йГ®еЕ≥йФЃз†БеТМзЫЄеЇФжХ∞жНЃеѓєи±°зЪДе≠ШжФЊеЬ∞еЭАжМЗйТИпЉМдЄФеПґиКВзВєжМЙеЕ≥йФЃз†БдїОе∞ПеИ∞е§Ій°ЇеЇПйУЊжО•гАВе¶ВжЮЬеЃЮйЩЕжХ∞жНЃеѓєи±°жМЙеК†еЕ•зЪДй°ЇеЇПе≠ШеВ®иАМдЄНжШѓжМЙеЕ≥йФЃз†Бжђ°жХ∞е≠ШеВ®зЪДиѓЭпЉМеПґиКВзВєзЪД糥еЉХењЕй°їж؃箆еѓЖ糥еЉХпЉМиЛ•еЃЮйЩЕжХ∞жНЃе≠ШеВ®жМЙеЕ≥йФЃз†Бжђ°еЇПе≠ШжФЊзЪДиѓЭпЉМеПґиКВзº糥еЉХжЧґз®АзЦП糥еЉХгАВ
 
B+ж†СжЬЙ2дЄ™е§іжМЗйТИпЉМдЄАдЄ™жШѓж†СзЪДж†єиКВзВєпЉМдЄАдЄ™жШѓжЬАе∞ПеЕ≥йФЃз†БзЪДеПґиКВзВєгАВ
жЙАдї• B+ж†СжЬЙдЄ§зІНжРЬ糥жЦєж≥ХпЉЪ
дЄАзІНжШѓжМЙеПґиКВзВєиЗ™еЈ±жЛЙиµЈзЪДйУЊи°®й°ЇеЇПжРЬ糥гАВ
дЄАзІНжШѓдїОж†єиКВзВєеЉАеІЛжРЬ糥пЉМеТМBж†Сз±їдЉЉпЉМдЄНињЗе¶ВжЮЬйЭЮеПґиКВзВєзЪДеЕ≥йФЃз†Бз≠ЙдЇОзїЩеЃЪеАЉпЉМжРЬ糥庴дЄНеБЬж≠ҐпЉМиАМжШѓзїІзї≠ж≤њеП≥жМЗйТИпЉМдЄАзЫіжЯ•еИ∞еПґиКВзВєдЄКзЪДеЕ≥йФЃз†БгАВжЙАдї•жЧ†иЃЇжРЬ糥жШѓеР¶жИРеКЯпЉМйГље∞Жиµ∞еЃМж†СзЪДжЙАжЬЙе±ВгАВ
B+ ж†СдЄ≠пЉМжХ∞жНЃеѓєи±°зЪДжПТеЕ•еТМеИ†йЩ§дїЕеЬ®еПґиКВзВєдЄКињЫи°МгАВ
 
 
ињЩдЄ§зІНе§ДзРЖ糥еЉХзЪДжХ∞жНЃзїУжЮДзЪДдЄНеРМдєЛе§ДпЉЪ
aпЉМBж†СдЄ≠еРМдЄАйФЃеАЉдЄНдЉЪеЗЇзО∞е§Ъжђ°пЉМеєґдЄФеЃГжЬЙеПѓиГљеЗЇзО∞еЬ®еПґзїУзВєпЉМдєЯжЬЙеПѓиГљеЗЇзО∞еЬ®йЭЮеПґзїУзВєдЄ≠гАВиАМB+ж†СзЪДйФЃдЄАеЃЪдЉЪеЗЇзО∞еЬ®еПґзїУзВєдЄ≠пЉМеєґдЄФжЬЙеПѓиГљеЬ®йЭЮеПґзїУзВєдЄ≠дєЯжЬЙеПѓиГљйЗНе§НеЗЇзО∞пЉМдї•зїіжМБB+ж†СзЪДеє≥и°°гАВ
bпЉМеЫ†дЄЇBж†СйФЃдљНзљЃдЄНеЃЪпЉМдЄФеЬ®жХідЄ™ж†СзїУжЮДдЄ≠еП™еЗЇзО∞дЄАжђ°пЉМиЩљзДґеПѓдї•иКВзЬБе≠ШеВ®з©ЇйЧіпЉМдљЖдљњеЊЧеЬ®жПТеЕ•гАБеИ†йЩ§жУНдљЬе§НжЭВеЇ¶жШОжШЊеҐЮеК†гАВB+ж†СзЫЄжѓФжЭ•иѓіжШѓдЄАзІНиЊГе•љзЪДжКШдЄ≠гАВ
cпЉМBж†СзЪДжߕ胥жХИзОЗдЄОйФЃеЬ®ж†СдЄ≠зЪДдљНзљЃжЬЙеЕ≥пЉМжЬАе§ІжЧґйЧіе§НжЭВеЇ¶дЄОB+ж†СзЫЄеРМ(еЬ®еПґзїУзВєзЪДжЧґеАЩ)пЉМжЬАе∞ПжЧґйЧіе§НжЭВеЇ¶дЄЇ1(еЬ®ж†єзїУзВєзЪДжЧґеАЩ)гАВиАМB+ж†СзЪДжЧґеАЩе§НжЭВеЇ¶еѓєжЯРеїЇжИРзЪДж†СжШѓеЫЇеЃЪзЪДгАВ



зЫЄеЕ≥жО®иНР
жХ∞жНЃеЇУ糥еЉХиЃЊиЃ°дЄОдЉШеМЦжШѓжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдЄ≠иЗ≥еЕ≥йЗНи¶БзЪДдЄАдЄ™зОѓиКВпЉМеЃГзЫіжО•ељ±еУНеИ∞жХ∞жНЃжߕ胥...йАЪињЗе≠¶дє†гАКжХ∞жНЃеЇУ糥еЉХиЃЊиЃ°дЄОдЉШеМЦгАЛињЩж†ЈзЪДдЄУдЄЪдє¶з±НпЉМжИСдїђеПѓдї•жЈ±еЕ•зРЖиІ£ињЩдЇЫеОЯзРЖпЉМеєґе∞ЖеЕґеЇФзФ®дЇОеЃЮйЩЕеЈ•дљЬпЉМжПРеНЗжХ∞жНЃеЇУз≥їзїЯзЪДжХідљУжХИиГљгАВ
гАРMySQLжХ∞жНЃеЇУ糥еЉХеЃЮзО∞еОЯзРЖвАФвАФB+ж†СиІ£жЮРгАС еЬ®жХ∞жНЃеЇУйҐЖеЯЯпЉМMySQLдљЬдЄЇдЄїжµБзЪДжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯпЉМеЕґйЂШжХИзЪДжХ∞жНЃе≠ШеПЦжЬЇеИґз¶їдЄНеЉА糥еЉХзЪДжФѓжТСгАВ糥еЉХжШѓжХ∞жНЃеЇУз≥їзїЯдЉШеМЦжߕ胥йАЯеЇ¶зЪДеЕ≥йФЃпЉМеЃГйАЪињЗзЙєеЃЪзЪДжХ∞жНЃзїУжЮДеЃЮзО∞ењЂйАЯжЯ•жЙЊгАБжПТеЕ•еТМ...
"жХ∞жНЃеЇУ糥еЉХйВ£дЇЫдЇЛпЉИжХ∞жНЃеЇУ糥еЉХеОЯзРЖпЉЙ" жХ∞жНЃеЇУ糥еЉХжШѓжХ∞жНЃеЇУзЪДдЄАзІНеѓєи±°пЉМеЃГдњЭе≠ШжХ∞жНЃеЇУи°®дЄ≠дЄАеИЧжИЦе§ЪеИЧзїДеРИзЪДжОТеЇПгАВ糥еЉХжПРдЊЫжМЗеРСе≠ШеВ®еЬ®и°®зЪДжМЗеЃЪеИЧдЄ≠зЪДжХ∞жНЃеАЉзЪДжМЗйТИпЉМзДґеРОж†єжНЃжМЗеЃЪзЪДжОТеЇПй°ЇеЇПеѓєињЩдЇЫжМЗйТИжОТеЇПгАВжХ∞жНЃеЇУдљњзФ®...
еЬ®жЈ±еЕ•жОҐиЃ®SQLжХ∞жНЃеЇУ糥еЉХеОЯзРЖдєЛеЙНпЉМжИСдїђеЕИжЭ•зРЖиІ£дЄАдЄЛ糥еЉХзЪДеЯЇжЬђж¶ВењµгАВ糥еЉХпЉМз±їдЉЉдЇОдє¶з±НдЄ≠зЪДзЫЃељХпЉМжШѓжХ∞жНЃеЇУдЄ≠дЄАзІНзЙєжЃКзЪДжХ∞жНЃзїУжЮДпЉМзФ®дЇОењЂйАЯеЃЪдљНжХ∞жНЃгАВеЃГеєґдЄНе≠ШеВ®еЃЮйЩЕзЪДжХ∞жНЃпЉМиАМжШѓе≠ШеВ®дЇЖжХ∞жНЃи°МзЪДдљНзљЃдњ°жБѓпЉМдљњеЊЧжХ∞жНЃеЇУ...
жХ∞жНЃеЇУеОЯзРЖдЄОеЃЮзО∞з≥їеИЧ(1 of 8) - жХ∞жНЃеЇУз≥їзїЯеЃЮзО∞(зђђ...-Concepts and Techniques(1c,Morgan Kaufmann,1993), жХ∞жНЃеЇУ糥еЉХиЃЊиЃ°дЄОдЉШеМЦ, е§ІиІДж®°еИЖеЄГеЉПе≠ШеВ®з≥їзїЯпЉЪеОЯзРЖиІ£жЮРдЄОжЮґжЮДеЃЮжИШ, Foundations of Databases (жХ∞жНЃеЇУеЯЇз°А)
OracleжХ∞жНЃеЇУ糥еЉХеЃЮзО∞еОЯзРЖжШѓжХ∞жНЃеЇУзЃ°зРЖдЄОдЉШеМЦзЪДйЗНи¶БеЖЕеЃєпЉМзРЖиІ£ињЩдЇЫеОЯзРЖеПѓдї•еЄЃеК©жХ∞жНЃеЇУзЃ°зРЖеСШпЉИDBAпЉЙжЫіе•љеЬ∞зЃ°зРЖжХ∞жНЃпЉМжПРеНЗжߕ胥жХИзОЗпЉМдї•еПКињЫи°МењЕи¶БзЪДзїіжК§жУНдљЬгАВB-TreeжШѓOracleдЄ≠жЬАеЄЄзФ®зЪД糥еЉХз±їеЮЛпЉМеЕґж†ЄењГжШѓзїіжК§жХ∞жНЃзЪД...
ж†єжНЃжПРдЊЫзЪДдњ°жБѓпЉМжИСдїђеПѓдї•жО®жЦ≠еЗЇиѓ•жЦЗж°£дЄїи¶БжґЙеПКзЪДжШѓIBM InformixжХ∞жНЃеЇУз≥їзїЯзЪДжКАжЬѓзїЖиКВдЄОеЃЮзО∞еОЯзРЖгАВдЄЛйЭҐе∞ЖеЯЇдЇОињЩдЇЫдњ°жБѓе±ХеЉАпЉМиѓ¶зїЖдїЛзїНдЄОвАЬжХ∞жНЃеЇУеЃЮзО∞еОЯзРЖвАЭзЫЄеЕ≥зЪДзЯ•иѓЖзВєгАВ ### дЄАгАБIBM Informix ж¶Вињ∞ IBM Informix ...
### жХ∞жНЃеЇУдЄ≠糥еЉХеОЯзРЖжЈ±еЇ¶иІ£жЮР糥еЉХжШѓжХ∞жНЃеЇУдЄ≠зФ®дЇОеК†йАЯжХ∞жНЃж£А糥зЪДйЗНи¶БзїУжЮДпЉМеЃГз±їдЉЉдЇОдє¶з±НдЄ≠зЪДзЫЃељХпЉМиГље§ЯеЄЃеК©жХ∞жНЃеЇУзЃ°зРЖз≥їзїЯењЂйАЯеЃЪдљНеТМжПРеПЦжХ∞жНЃгАВжЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®жХ∞жНЃеЇУдЄ≠зЪД糥еЉХеОЯзРЖпЉМеМЕжЛђиБЪйЫЖ糥еЉХдЄОйЭЮиБЪйЫЖ糥еЉХзЪДж¶Вењµ...
жХ∞жНЃеЇУ糥еЉХеОЯзРЖжШѓжХ∞жНЃеЇУз≥їзїЯдЄ≠зЪДеЕ≥йФЃжКАжЬѓдєЛдЄАпЉМеЃГеѓєжХ∞жНЃж£А糥йАЯеЇ¶еТМз≥їзїЯжАІиГљжЬЙзЭАйЗНе§Іељ±еУНгАВеЬ®дЄ™дЇЇеЉАеПСињЗз®ЛдЄ≠пЉМжЈ±еЕ•зРЖиІ£еєґеЇФзФ®ињЩдЇЫеОЯзРЖиЗ≥еЕ≥йЗНи¶БгАВжЬђжЦЗе∞ЖеЫізїХжХ∞жНЃеЇУдЄ≠зЪД糥еЉХж¶ВењµгАБиБЪжЧП糥еЉХгАБдЄїйФЃдї•еПКжߕ胥дЉШеМЦињЫи°Миѓ¶ињ∞гАВ...
еЬ®е≠¶дє†жХ∞жНЃеЇУз≥їзїЯеЃЮзО∞жЧґпЉМзРЖиІ£ињЩдЇЫеЯЇжЬђж¶ВењµеТМжКАжЬѓиЗ≥еЕ≥йЗНи¶БпЉМиАМињЩжЬђдє¶з±Не∞ЖеЄ¶йҐЖиѓїиАЕжЈ±еЕ•еИ∞жХ∞жНЃеЇУз≥їзїЯзЪДеЖЕйГ®пЉМжП≠з§ЇињЩдЇЫжЬЇеИґзЪДеЈ•дљЬеОЯзРЖгАВйАЪињЗйШЕиѓїгАКжХ∞жНЃеЇУз≥їзїЯеЃЮзО∞гАЛпЉМиѓїиАЕдЄНдїЕеПѓдї•дЇЖиІ£жХ∞жНЃеЇУиЃЊиЃ°зЪДзРЖиЃЇпЉМињШиГљжОМжП°еЃЮйЩЕ...
йАЪињЗйШЕиѓїгАКжХ∞жНЃеЇУз≥їзїЯеЃЮзО∞пЉИзђђдЇМзЙИпЉЙгАЛињЩжЬђдє¶пЉМдљ†е∞ЖдЄНдїЕиГље§ЯзРЖиІ£жХ∞жНЃеЇУз≥їзїЯзЪДеЈ•дљЬеОЯзРЖпЉМињШиГље≠¶дЉЪе¶ВдљХиІ£еЖ≥еЃЮйЩЕеЈ•дљЬдЄ≠йБЗеИ∞зЪДйЧЃйҐШгАВдє¶дЄ≠дЄ∞еѓМзЪДдЊЛе≠РеТМеЃЮиЈµж°ИдЊЛпЉМе∞ЖеЄЃеК©дљ†е∞ЖзРЖиЃЇзЯ•иѓЖиљђеМЦдЄЇеЃЮйЩЕжКАиГљпЉМжПРеНЗдљ†еЬ®жХ∞жНЃеЇУйҐЖеЯЯзЪД...
жЬђиѓЊз®ЛвАЬ0113-(жѓПзЙєжХЩиВ≤&жѓПзЙєе≠¶йЩҐ&иЪВиЪБиѓЊе†В)-4жЬЯ-жХ∞жНЃеЇУжКАжЬѓ-йЂШжАІиГљMySQL糥еЉХеЃЮзО∞еОЯзРЖдєЛеЃЮжИШжУНдљЬ糥еЉХвАЭиБЪзД¶дЇОMySQLзЪД糥еЉХеЃЮзО∞еОЯзРЖеТМеЃЮжИШеЇФзФ®пЉМжЧ®еЬ®жПРеНЗжХ∞жНЃеЇУжߕ胥жХИзОЗпЉМдїОиАМжПРйЂШжХідљУз≥їзїЯжАІиГљгАВ й¶ЦеЕИпЉМжИСдїђи¶БзРЖиІ£...
жЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®жХ∞жНЃеЇУ糥еЉХзЪДдљЬзФ®гАБеОЯзРЖдї•еПКдљХжЧґйАВеРИеИЫ忯糥еЉХгАВ й¶ЦеЕИпЉМ糥еЉХзЪДдљЬзФ®еЬ®дЇОйАЪињЗеЗПе∞СеЕ®и°®жЙЂжППзЪДжђ°жХ∞пЉМжШЊиСЧеК†ењЂжߕ胥йАЯеЇ¶гАВеЬ®ж≤°жЬЙ糥еЉХзЪДжГЕеЖµдЄЛпЉМжХ∞жНЃеЇУеЬ®жЙІи°МSQLжߕ胥жЧґпЉМйАЪеЄЄйЬАи¶БйБНеОЖжХідЄ™и°®жЭ•еѓїжЙЊзђ¶еРИжРЬ糥...
### MySQL Innodb 糥еЉХеОЯзРЖ...йАЪињЗеѓєжѓФдЄНеРМзЪДж†С嚥зїУжЮДпЉМжИСдїђдЇЖиІ£еИ∞B+ж†СдЄЇдљХжИРдЄЇжХ∞жНЃеЇУ糥еЉХзЪДзРЖжГ≥йАЙжЛ©гАВж≠§е§ЦпЉМињШиЃ®иЃЇдЇЖInnoDBдЄОMyISAMзЪДдЄїи¶БеЈЃеЉВпЉМдї•еПК糥еЉХзЪДжПТеЕ•еТМеИ†йЩ§жУНдљЬгАВеѓєдЇОзРЖиІ£еТМдЉШеМЦMySQLжХ∞жНЃеЇУзЪДжАІиГљиЗ≥еЕ≥йЗНи¶БгАВ
9. **жАІиГљдЉШеМЦ**пЉЪйАЪињЗ糥еЉХгАБжߕ胥дЉШеМЦгАБжХ∞жНЃеЇУйЗНжЮДеТМеИЖеМЇз≠ЙжЙЛжЃµжПРйЂШжХ∞жНЃеЇУзЪДжߕ胥йАЯеЇ¶еТМжХідљУжАІиГљгАВ 10. **жХ∞жНЃеЇУзЃ°зРЖз≥їзїЯпЉИDBMSпЉЙ**пЉЪеЃЮзО∞дЄКињ∞еКЯиГљзЪДиљѓдїґз≥їзїЯпЉМе¶ВOracleгАБMySQLгАБSQL ServerгАБPostgreSQLз≠ЙгАВ ...
гАКжХ∞жНЃеЇУз≥їзїЯеЃЮзО∞пЉИзђђдЇМзЙИпЉЙгАЛжШѓHector Garcia-MolinaгАБJeffrey D.UllmanеТМJennifer WidomдЄЙдљНиСЧеРНиЃ°зЃЧжЬЇзІСе≠¶еЃґзЪДиСЧдљЬпЉМзФ±жЭ®еЖђйЭТгАБеРіжДИйЭТз≠Йе≠¶иАЕзњїиѓСжИРдЄ≠жЦЗзЙИгАВињЩжЬђдє¶жЈ±еЕ•жОҐиЃ®дЇЖжХ∞жНЃеЇУз≥їзїЯзЪДеЖЕйГ®еЈ•дљЬеОЯзРЖпЉМжШѓе≠¶дє†...
еЕ®дє¶еИЖдЄЇжХ∞жНЃеЇУеЯЇз°АгАБеЇФзФ®з®ЛеЇПеЉАеПСгАБе≠ШеВ®дЄО糥еЉХгАБжߕ胥иѓДдЉ∞гАБдЇЛеК°зЃ°зРЖгАБжХ∞жНЃеЇУиЃЊиЃ°дЄОи∞ГжХігАБйЂШзЇІдЄїйҐШз≠ЙдЄГе§ІйГ®еИЖпЉМеѓєжХ∞жНЃеЇУзЪДиЃЊиЃ°дЄОдљњзФ®гАБжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯеЯЇжЬђеОЯзРЖдЄОеЃЮзО∞жКАжЬѓпЉМдї•еПКжХ∞жНЃеЇУз†Фз©ґзЪДжЦ∞ињЫе±ХеБЪдЇЖиѓ¶зїЖиЃЇињ∞гАВ...