µ£»Ķ»ŁÕ«Üõ╣ē
| µ£»Ķ»Ł |
Ķŗ▒µ¢ć |
Ķ¦ŻķćŖ |
| ÕōłÕĖīń«Śµ│Ģ |
hash algorithm |
µś»õĖĆń¦ŹÕ░åõ╗╗µäÅÕåģÕ«╣ńÜäĶŠōÕģźĶĮ¼µŹóµłÉńøĖÕÉīķĢ┐Õ║”ĶŠōÕć║ńÜäÕŖĀջ嵢╣Õ╝Å’╝īÕģČĶŠōÕć║Ķó½ń¦░õĖ║ÕōłÕĖīÕĆ╝ŃĆé┬Ā
|
| ÕōłÕĖīĶĪ© |
hash table |
µĀ╣µŹ«Ķ«ŠÕ«ÜńÜäÕōłÕĖīÕćĮµĢ░H(key)ÕÆīÕżäńÉåÕå▓ń¬üµ¢╣µ│ĢÕ░åõĖĆń╗äÕģ│ķö«ÕŁŚµśĀĶ▒ĪÕł░õĖĆõĖ¬µ£ēķÖÉńÜäÕ£░ÕØĆÕī║ķŚ┤õĖŖ’╝īÕ╣Čõ╗źÕģ│ķö«ÕŁŚÕ£©Õ£░ÕØĆÕī║ķŚ┤õĖŁńÜäĶ▒ĪõĮ£õĖ║Ķ«░ÕĮĢÕ£©ĶĪ©õĖŁńÜäÕŁśÕé©õĮŹńĮ«’╝īĶ┐Öń¦ŹĶĪ©ń¦░õĖ║ÕōłÕĖīĶĪ©µł¢µĢŻÕłŚ’╝īµēĆÕŠŚÕŁśÕé©õĮŹńĮ«ń¦░õĖ║ÕōłÕĖīÕ£░ÕØƵł¢µĢŻÕłŚÕ£░ÕØĆŃĆé |
ń║┐ń©ŗõĖŹÕ«ēÕģ©ńÜäHashMap
ÕøĀõĖ║ÕżÜń║┐ń©ŗńÄ»ÕóāõĖŗ’╝īõĮ┐ńö©HashmapĶ┐øĶĪīputµōŹõĮ£õ╝ÜÕ╝ĢĶĄĘµŁ╗ÕŠ¬ńÄ»’╝īÕ»╝Ķć┤CPUÕł®ńö©ńÄćµÄźĶ┐æ100%’╝īµēĆõ╗źÕ£©Õ╣ČÕÅæµāģÕåĄõĖŗõĖŹĶāĮõĮ┐ńö©HashMapŃĆé
Õ”éõ╗źõĖŗõ╗ŻńĀü’╝Ü
01 |
final┬ĀHashMap<String, String> map =┬Ānew┬ĀHashMap<String, String>(2);
|
03 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀThread t =┬Ānew┬ĀThread(new┬ĀRunnable() {
|
05 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā@Override
|
07 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āpublic┬Āvoid┬Ārun() {
|
09 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āfor┬Ā(int┬Āi =┬Ā0; i <┬Ā10000; i++) {
|
11 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ānew┬ĀThread(new┬ĀRunnable() {
|
13 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā@Override
|
15 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āpublic┬Āvoid┬Ārun() {
|
17 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āmap.put(UUID.randomUUID().toString(),┬Ā"");
|
19 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā}
|
21 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā},┬Ā"ftf"┬Ā+ i).start();
|
23 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā}
|
25 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā}
|
27 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā},┬Ā"ftf");
|
29 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āt.start();
|
31 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āt.join();
|
µĢłńÄćõĮÄõĖŗńÜäHashTableÕ«╣ÕÖ©
┬Ā┬Ā┬Ā┬Ā┬ĀHashTableÕ«╣ÕÖ©õĮ┐ńö©synchronizedµØźõ┐ØĶ»üń║┐ń©ŗÕ«ēÕģ©’╝īõĮåÕ£©ń║┐ń©ŗń½×õ║ēµ┐ĆńāłńÜäµāģÕåĄõĖŗHashTableńÜäµĢłńÄćķØ×ÕĖĖõĮÄõĖŗŃĆéÕøĀõĖ║ÕĮōõĖĆõĖ¬ń║┐ń©ŗĶ«┐ķŚ«HashTableńÜäÕÉīµŁźµ¢╣µ│ĢµŚČ’╝īÕģČõ╗¢ń║┐ń©ŗĶ«┐ķŚ«HashTableńÜäÕÉīµŁźµ¢╣µ│ĢµŚČ’╝īÕÅ»ĶāĮõ╝ÜĶ┐øÕģźķś╗ÕĪ×µł¢ĶĮ«Ķ»óńŖȵĆüŃĆéÕ”éń║┐ń©ŗ1õĮ┐ńö©putĶ┐øĶĪīµĘ╗ÕŖĀÕģāń┤Ā’╝īń║┐ń©ŗ2õĖŹõĮåõĖŹĶāĮõĮ┐ńö©putµ¢╣µ│ĢµĘ╗ÕŖĀÕģāń┤Ā’╝īÕ╣ČõĖöõ╣¤õĖŹĶāĮõĮ┐ńö©getµ¢╣µ│ĢµØźĶÄĘÕÅ¢Õģāń┤Ā’╝īµēĆõ╗źń½×õ║ēĶČŖµ┐ĆńāłµĢłńÄćĶČŖõĮÄŃĆé
ConcurrentHashMapńÜäķöüÕłåµ«ĄµŖƵ£»
┬Ā┬Ā┬Ā┬Ā┬ĀHashTableÕ«╣ÕÖ©Õ£©ń½×õ║ēµ┐ĆńāłńÜäÕ╣ČÕÅæńÄ»ÕóāõĖŗĶĪ©ńÄ░Õć║µĢłńÄćõĮÄõĖŗńÜäÕĤÕøĀ’╝īµś»ÕøĀõĖ║µēƵ£ēĶ«┐ķŚ«HashTableńÜäń║┐ń©ŗķāĮÕ┐ģķĪ╗ń½×õ║ēÕÉīõĖƵŖŖķöü’╝īķéŻÕüćÕ”éÕ«╣ÕÖ©ķćīµ£ēÕżÜµŖŖķöü’╝īµ»ÅõĖƵŖŖķöüńö©õ║ÄķöüÕ«╣ÕÖ©ÕģČõĖŁõĖĆķā©ÕłåµĢ░µŹ«’╝īķéŻõ╣łÕĮōÕżÜń║┐ń©ŗĶ«┐ķŚ«Õ«╣ÕÖ©ķćīõĖŹÕÉīµĢ░µŹ«µ«ĄńÜäµĢ░µŹ«µŚČ’╝īń║┐ń©ŗķŚ┤Õ░▒õĖŹõ╝ÜÕŁśÕ£©ķöüń½×õ║ē’╝īõ╗ÄĶĆīÕÅ»õ╗źµ£ēµĢłńÜäµÅÉķ½śÕ╣ČÕÅæĶ«┐ķŚ«µĢłńÄć’╝īĶ┐ÖÕ░▒µś»ConcurrentHashMapµēĆõĮ┐ńö©ńÜäķöüÕłåµ«ĄµŖƵ£»’╝īķ”¢ÕģłÕ░åµĢ░µŹ«ÕłåµłÉõĖƵ«ĄõĖƵ«ĄńÜäÕŁśÕé©’╝īńäČÕÉÄń╗Öµ»ÅõĖƵ«ĄµĢ░µŹ«ķģŹõĖƵŖŖķöü’╝īÕĮōõĖĆõĖ¬ń║┐ń©ŗÕŹĀńö©ķöüĶ«┐ķŚ«ÕģČõĖŁõĖĆõĖ¬µ«ĄµĢ░µŹ«ńÜ䵌ČÕĆÖ’╝īÕģČõ╗¢µ«ĄńÜäµĢ░µŹ«õ╣¤ĶāĮĶó½ÕģČõ╗¢ń║┐ń©ŗĶ«┐ķŚ«ŃĆé
ConcurrentHashMapńÜäń╗ōµ×ä
µłæõ╗¼ķĆÜĶ┐ćConcurrentHashMapńÜäń▒╗ÕøŠµØźÕłåµ×ÉConcurrentHashMapńÜäń╗ōµ×äŃĆé
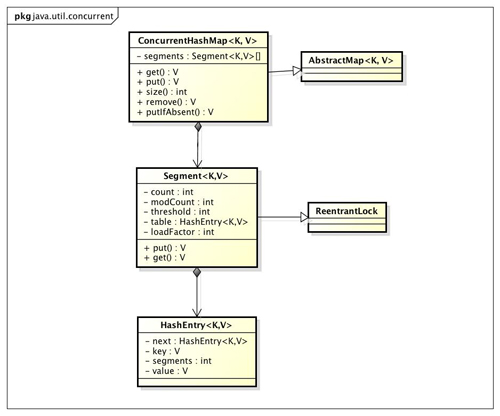
ConcurrentHashMapµś»ńö▒SegmentµĢ░ń╗äń╗ōµ×äÕÆīHashEntryµĢ░ń╗äń╗ōµ×äń╗䵳ÉŃĆéSegmentµś»õĖĆń¦ŹÕÅ»ķćŹÕģźķöüReentrantLock’╝īÕ£©ConcurrentHashMapķćīµē«µ╝öķöüńÜäĶ¦ÆĶē▓’╝īHashEntryÕłÖńö©õ║ÄÕŁśÕé©ķö«ÕĆ╝Õ»╣µĢ░µŹ«ŃĆéõĖĆõĖ¬ConcurrentHashMapķćīÕīģÕɽõĖĆõĖ¬SegmentµĢ░ń╗ä’╝īSegmentńÜäń╗ōµ×äÕÆīHashMapń▒╗õ╝╝’╝īµś»õĖĆń¦ŹµĢ░ń╗äÕÆīķōŠĶĪ©ń╗ōµ×ä’╝ī õĖĆõĖ¬SegmentķćīÕīģÕɽõĖĆõĖ¬HashEntryµĢ░ń╗ä’╝īµ»ÅõĖ¬HashEntryµś»õĖĆõĖ¬ķōŠĶĪ©ń╗ōµ×äńÜäÕģāń┤Ā’╝ī µ»ÅõĖ¬SegmentÕ«łµŖżĶĆģõĖĆõĖ¬HashEntryµĢ░ń╗äķćīńÜäÕģāń┤Ā,ÕĮōÕ»╣HashEntryµĢ░ń╗äńÜäµĢ░µŹ«Ķ┐øĶĪīõ┐«µö╣µŚČ’╝īÕ┐ģķĪ╗ķ”¢ÕģłĶÄĘÕŠŚÕ«āÕ»╣Õ║öńÜäSegmentķöüŃĆé
┬Ā
ConcurrentHashMapńÜäÕłØÕ¦ŗÕī¢
ConcurrentHashMapÕłØÕ¦ŗÕī¢µ¢╣µ│Ģµś»ķĆÜĶ┐ćinitialCapacity’╝īloadFactor, concurrencyLevelÕćĀõĖ¬ÕÅéµĢ░µØźÕłØÕ¦ŗÕī¢segmentsµĢ░ń╗ä’╝īµ«ĄÕüÅń¦╗ķćÅsegmentShift’╝īµ«ĄµÄ®ńĀüsegmentMaskÕÆīµ»ÅõĖ¬segmentķćīńÜäHashEntryµĢ░ń╗äŃĆé
ÕłØÕ¦ŗÕī¢segmentsµĢ░ń╗äŃĆéĶ«®µłæõ╗¼µØźń£ŗõĖĆõĖŗÕłØÕ¦ŗÕī¢segmentShift’╝īsegmentMaskÕÆīsegmentsµĢ░ń╗äńÜäµ║Éõ╗ŻńĀüŃĆé
01 |
if┬Ā(concurrencyLevel > MAX_SEGMENTS)
|
03 |
concurrencyLevel = MAX_SEGMENTS; |
11 |
while┬Ā(ssize < concurrencyLevel) {
|
19 |
segmentShift =┬Ā32┬Ā- sshift;
|
21 |
segmentMask = ssize -┬Ā1;
|
23 |
this.segments = Segment.newArray(ssize);
|
ńö▒õĖŖķØóńÜäõ╗ŻńĀüÕÅ»ń¤źsegmentsµĢ░ń╗äńÜäķĢ┐Õ║”ssizeķĆÜĶ┐ćconcurrencyLevelĶ«Īń«ŚÕŠŚÕć║ŃĆéõĖ║õ║åĶāĮķĆÜĶ┐ćµīēõĮŹõĖÄńÜäÕōłÕĖīń«Śµ│ĢµØźÕ«ÜõĮŹsegmentsµĢ░ń╗äńÜäń┤óÕ╝Ģ’╝īÕ┐ģķĪ╗õ┐ØĶ»üsegmentsµĢ░ń╗äńÜäķĢ┐Õ║”µś»2ńÜäNµ¼Īµ¢╣’╝łpower-of-two size’╝ē’╝īµēĆõ╗źÕ┐ģķĪ╗Ķ«Īń«ŚÕć║õĖĆõĖ¬µś»Õż¦õ║ĵł¢ńŁēõ║ÄconcurrencyLevelńÜäµ£ĆÕ░ÅńÜä2ńÜäNµ¼Īµ¢╣ÕĆ╝µØźõĮ£õĖ║segmentsµĢ░ń╗äńÜäķĢ┐Õ║”ŃĆéÕüćÕ”éconcurrencyLevelńŁēõ║Ä14’╝ī15µł¢16’╝īssizeķāĮõ╝ÜńŁēõ║Ä16’╝īÕŹ│Õ«╣ÕÖ©ķćīķöüńÜäõĖ¬µĢ░õ╣¤µś»16ŃĆéµ│©µäÅconcurrencyLevelńÜäµ£ĆÕż¦Õż¦Õ░ŵś»65535’╝īµäÅÕæ│ńØĆsegmentsµĢ░ń╗äńÜäķĢ┐Õ║”µ£ĆÕż¦õĖ║65536’╝īÕ»╣Õ║öńÜäõ║īĶ┐øÕłČµś»16õĮŹŃĆé
ÕłØÕ¦ŗÕī¢segmentShiftÕÆīsegmentMaskŃĆéĶ┐ÖõĖżõĖ¬Õģ©Õ▒ĆÕÅśķćÅÕ£©Õ«ÜõĮŹsegmentµŚČńÜäÕōłÕĖīń«Śµ│Ģķćīķ£ĆĶ”üõĮ┐ńö©’╝īsshiftńŁēõ║Ässizeõ╗Ä1ÕÉæÕĘ”ń¦╗õĮŹńÜäµ¼ĪµĢ░’╝īÕ£©ķ╗śĶ«żµāģÕåĄõĖŗconcurrencyLevelńŁēõ║Ä16’╝ī1ķ£ĆĶ”üÕÉæÕĘ”ń¦╗õĮŹń¦╗ÕŖ©4µ¼Ī’╝īµēĆõ╗źsshiftńŁēõ║Ä4ŃĆésegmentShiftńö©õ║ÄÕ«ÜõĮŹÕÅéõĖÄhashĶ┐Éń«ŚńÜäõĮŹµĢ░’╝īsegmentShiftńŁēõ║Ä32ÕćÅsshift’╝īµēĆõ╗źńŁēõ║Ä28’╝īĶ┐Öķćīõ╣ŗµēĆõ╗źńö©32µś»ÕøĀõĖ║ConcurrentHashMapķćīńÜähash()µ¢╣µ│ĢĶŠōÕć║ńÜäµ£ĆÕż¦µĢ░µś»32õĮŹńÜä’╝īÕÉÄķØóńÜ䵥ŗĶ»ĢõĖŁµłæõ╗¼ÕÅ»õ╗źń£ŗÕł░Ķ┐Öńé╣ŃĆésegmentMaskµś»ÕōłÕĖīĶ┐Éń«ŚńÜäµÄ®ńĀü’╝īńŁēõ║ÄssizeÕćÅ1’╝īÕŹ│15’╝īµÄ®ńĀüńÜäõ║īĶ┐øÕłČÕÉäõĖ¬õĮŹńÜäÕĆ╝ķāĮµś»1ŃĆéÕøĀõĖ║ssizeńÜäµ£ĆÕż¦ķĢ┐Õ║”µś»65536’╝īµēĆõ╗źsegmentShiftµ£ĆÕż¦ÕĆ╝µś»16’╝īsegmentMaskµ£ĆÕż¦ÕĆ╝µś»65535’╝īÕ»╣Õ║öńÜäõ║īĶ┐øÕłČµś»16õĮŹ’╝īµ»ÅõĖ¬õĮŹķāĮµś»1ŃĆé
ÕłØÕ¦ŗÕī¢µ»ÅõĖ¬SegmentŃĆéĶŠōÕģźÕÅéµĢ░initialCapacityµś»ConcurrentHashMapńÜäÕłØÕ¦ŗÕī¢Õ«╣ķćÅ’╝īloadfactorµś»µ»ÅõĖ¬segmentńÜäĶ┤¤ĶĮĮÕøĀÕŁÉ’╝īÕ£©µ×äķĆĀµ¢╣µ│Ģķćīķ£ĆĶ”üķĆÜĶ┐ćĶ┐ÖõĖżõĖ¬ÕÅéµĢ░µØźÕłØÕ¦ŗÕī¢µĢ░ń╗äõĖŁńÜäµ»ÅõĖ¬segmentŃĆé
01 |
if┬Ā(initialCapacity > MAXIMUM_CAPACITY)
|
03 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀinitialCapacity = MAXIMUM_CAPACITY;
|
05 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Āint┬Āc = initialCapacity / ssize;
|
07 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Āif┬Ā(c * ssize < initialCapacity)
|
09 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā++c;
|
11 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Āint┬Ācap =┬Ā1;
|
13 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Āwhile┬Ā(cap < c)
|
15 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ācap <<=┬Ā1;
|
17 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Āfor┬Ā(int┬Āi =┬Ā0; i <┬Āthis.segments.length; ++i)
|
19 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āthis.segments[i] =┬Ānew┬ĀSegment<K,V>(cap, loadFactor);
|
õĖŖķØóõ╗ŻńĀüõĖŁńÜäÕÅśķćÅcapÕ░▒µś»segmentķćīHashEntryµĢ░ń╗äńÜäķĢ┐Õ║”’╝īÕ«āńŁēõ║ÄinitialCapacityķÖżõ╗źssizeńÜäÕĆŹµĢ░c’╝īÕ”éµ×£cÕż¦õ║Ä1’╝īÕ░▒õ╝ÜÕÅ¢Õż¦õ║ÄńŁēõ║ÄcńÜä2ńÜäNµ¼Īµ¢╣ÕĆ╝’╝īµēĆõ╗źcapõĖŹµś»1’╝īÕ░▒µś»2ńÜäNµ¼Īµ¢╣ŃĆésegmentńÜäÕ«╣ķćÅthreshold’╝Ø(int)cap*loadFactor’╝īķ╗śĶ«żµāģÕåĄõĖŗinitialCapacityńŁēõ║Ä16’╝īloadfactorńŁēõ║Ä0.75’╝īķĆÜĶ┐ćĶ┐Éń«ŚcapńŁēõ║Ä1’╝īthresholdńŁēõ║ÄķøČŃĆé
Õ«ÜõĮŹSegment
µŚóńäČConcurrentHashMapõĮ┐ńö©Õłåµ«ĄķöüSegmentµØźõ┐صŖżõĖŹÕÉīµ«ĄńÜäµĢ░µŹ«’╝īķéŻõ╣łÕ£©µÅÆÕģźÕÆīĶÄĘÕÅ¢Õģāń┤ĀńÜ䵌ČÕĆÖ’╝īÕ┐ģķĪ╗ÕģłķĆÜĶ┐ćÕōłÕĖīń«Śµ│ĢÕ«ÜõĮŹÕł░SegmentŃĆéÕÅ»õ╗źń£ŗÕł░ConcurrentHashMapõ╝Üķ”¢ÕģłõĮ┐ńö©Wang/Jenkins hashńÜäÕÅśń¦Źń«Śµ│ĢÕ»╣Õģāń┤ĀńÜähashCodeĶ┐øĶĪīõĖƵ¼ĪÕåŹÕōłÕĖīŃĆé
1 |
private┬Āstatic┬Āint┬Āhash(int┬Āh) {
|
3 |
h += (h <<┬Ā15) ^┬Ā0xffffcd7d; h ^= (h >>>┬Ā10);
|
5 |
h += (h <<┬Ā3); h ^= (h >>>┬Ā6);
|
7 |
h += (h <<┬Ā2) + (h <<┬Ā14);┬Āreturn┬Āh ^ (h >>>┬Ā16);
|
ÕåŹÕōłÕĖī’╝īÕģČńø«ńÜ䵜»õĖ║õ║åÕćÅÕ░æÕōłÕĖīÕå▓ń¬ü’╝īõĮ┐Õģāń┤ĀĶāĮÕż¤ÕØćÕīĆńÜäÕłåÕĖāÕ£©õĖŹÕÉīńÜäSegmentõĖŖ’╝īõ╗ÄĶĆīµÅÉķ½śÕ«╣ÕÖ©ńÜäÕŁśÕÅ¢µĢłńÄćŃĆéÕüćÕ”éÕōłÕĖīńÜäĶ┤©ķćÅÕĘ«Õł░µ×üńé╣’╝īķéŻõ╣łµēƵ£ēńÜäÕģāń┤ĀķāĮÕ£©õĖĆõĖ¬SegmentõĖŁ’╝īõĖŹõ╗ģÕŁśÕÅ¢Õģāń┤Āń╝ōµģó’╝īÕłåµ«Ąķöüõ╣¤õ╝ÜÕż▒ÕÄ╗µäÅõ╣ēŃĆ鵳æÕüÜõ║åõĖĆõĖ¬µĄŗĶ»Ģ’╝īõĖŹķĆÜĶ┐ćÕåŹÕōłÕĖīĶĆīńø┤µÄźµē¦ĶĪīÕōłÕĖīĶ«Īń«ŚŃĆé
1 |
System.out.println(Integer.parseInt("0001111",┬Ā2) &┬Ā15);
|
3 |
System.out.println(Integer.parseInt("0011111",┬Ā2) &┬Ā15);
|
5 |
System.out.println(Integer.parseInt("0111111",┬Ā2) &┬Ā15);
|
7 |
System.out.println(Integer.parseInt("1111111",┬Ā2) &┬Ā15);
|
Ķ«Īń«ŚÕÉÄĶŠōÕć║ńÜäÕōłÕĖīÕĆ╝Õģ©µś»15’╝īķĆÜĶ┐ćĶ┐ÖõĖ¬õŠŗÕŁÉÕÅ»õ╗źÕÅæńÄ░Õ”éµ×£õĖŹĶ┐øĶĪīÕåŹÕōłÕĖī’╝īÕōłÕĖīÕå▓ń¬üõ╝ÜķØ×ÕĖĖõĖźķ插╝īÕøĀõĖ║ÕŬĶ”üõĮÄõĮŹõĖƵĀĘ’╝īµŚĀĶ«║ķ½śõĮŹµś»õ╗Ćõ╣łµĢ░’╝īÕģČÕōłÕĖīÕĆ╝µĆ╗µś»õĖƵĀĘŃĆ鵳æõ╗¼ÕåŹµŖŖõĖŖķØóńÜäõ║īĶ┐øÕłČµĢ░µŹ«Ķ┐øĶĪīÕåŹÕōłÕĖīÕÉÄń╗ōµ×£Õ”éõĖŗ’╝īõĖ║õ║åµ¢╣õŠ┐ķśģĶ»╗’╝īõĖŹĶČ│32õĮŹńÜäķ½śõĮŹĶĪźõ║å0’╝īµ»ÅķÜöÕøøõĮŹńö©ń½¢ń║┐ÕłåÕē▓õĖŗŃĆé
1 |
0100’Į£0111’Į£0110’Į£0111’Į£1101’Į£1010’Į£0100’Į£1110
|
3 |
1111’Į£0111’Į£0100’Į£0011’Į£0000’Į£0001’Į£1011’Į£1000
|
5 |
0111’Į£0111’Į£0110’Į£1001’Į£0100’Į£0110’Į£0011’Į£1110
|
7 |
1000’Į£0011’Į£0000’Į£0000’Į£1100’Į£1000’Į£0001’Į£1010
|
ÕÅ»õ╗źÕÅæńÄ░µ»ÅõĖĆõĮŹńÜäµĢ░µŹ«ķāĮµĢŻÕłŚÕ╝Ćõ║å’╝īķĆÜĶ┐ćĶ┐Öń¦ŹÕåŹÕōłÕĖīĶāĮĶ«®µĢ░ÕŁŚńÜäµ»ÅõĖĆõĮŹķāĮĶāĮÕÅéÕŖĀÕł░ÕōłÕĖīĶ┐Éń«ŚÕĮōõĖŁ’╝īõ╗ÄĶĆīÕćÅÕ░æÕōłÕĖīÕå▓ń¬üŃĆéConcurrentHashMapķĆÜĶ┐ćõ╗źõĖŗÕōłÕĖīń«Śµ│ĢÕ«ÜõĮŹsegmentŃĆé
ķ╗śĶ«żµāģÕåĄõĖŗsegmentShiftõĖ║28’╝īsegmentMaskõĖ║15’╝īÕåŹÕōłÕĖīÕÉÄńÜäµĢ░µ£ĆÕż¦µś»32õĮŹõ║īĶ┐øÕłČµĢ░µŹ«’╝īÕÉæÕÅ│µŚĀń¼”ÕÅĘń¦╗ÕŖ©28õĮŹ’╝īµäŵĆصś»Ķ«®ķ½ś4õĮŹÕÅéõĖÄÕł░hashĶ┐Éń«ŚõĖŁ’╝ī (hash >>> segmentShift) & segmentMaskńÜäĶ┐Éń«Śń╗ōµ×£ÕłåÕł½µś»4’╝ī15’╝ī7ÕÆī8’╝īÕÅ»õ╗źń£ŗÕł░hashÕĆ╝µ▓Īµ£ēÕÅæńö¤Õå▓ń¬üŃĆé
1 |
final┬ĀSegment<K,V> segmentFor(int┬Āhash) {
|
3 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āreturn┬Āsegments[(hash >>> segmentShift) & segmentMask];
|
ConcurrentHashMapńÜägetµōŹõĮ£
SegmentńÜägetµōŹõĮ£Õ«×ńÄ░ķØ×ÕĖĖń«ĆÕŹĢÕÆīķ½śµĢłŃĆéÕģłń╗ÅĶ┐ćõĖƵ¼ĪÕåŹÕōłÕĖī’╝īńäČÕÉÄõĮ┐ńö©Ķ┐ÖõĖ¬ÕōłÕĖīÕĆ╝ķĆÜĶ┐ćÕōłÕĖīĶ┐Éń«ŚÕ«ÜõĮŹÕł░segment’╝īÕåŹķĆÜĶ┐ćÕōłÕĖīń«Śµ│ĢÕ«ÜõĮŹÕł░Õģāń┤Ā’╝īõ╗ŻńĀüÕ”éõĖŗ’╝Ü
1 |
public┬ĀV get(Object key) {
|
3 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āint┬Āhash = hash(key.hashCode());
|
5 |
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āreturn┬ĀsegmentFor(hash).get(key, hash);
|
getµōŹõĮ£ńÜäķ½śµĢłõ╣ŗÕżäÕ£©õ║ĵĢ┤õĖ¬getĶ┐ćń©ŗõĖŹķ£ĆĶ”üÕŖĀķöü’╝īķÖżķØ×Ķ»╗Õł░ńÜäÕĆ╝µś»ń®║ńÜäµēŹõ╝ÜÕŖĀķöüķćŹĶ»╗’╝īµłæõ╗¼ń¤źķüōHashTableÕ«╣ÕÖ©ńÜägetµ¢╣µ│Ģµś»ķ£ĆĶ”üÕŖĀķöüńÜä’╝īķéŻõ╣łConcurrentHashMapńÜägetµōŹõĮ£µś»Õ”éõĮĢÕüÜÕł░õĖŹÕŖĀķöüńÜäÕæó’╝¤ÕĤÕøĀµś»Õ«āńÜägetµ¢╣µ│ĢķćīÕ░åĶ”üõĮ┐ńö©ńÜäÕģ▒õ║½ÕÅśķćÅķāĮÕ«Üõ╣ēµłÉvolatile’╝īÕ”éńö©õ║Äń╗¤Ķ«ĪÕĮōÕēŹSegementÕż¦Õ░ÅńÜäcountÕŁŚµ«ĄÕÆīńö©õ║ÄÕŁśÕé©ÕĆ╝ńÜäHashEntryńÜävalueŃĆéÕ«Üõ╣ēµłÉvolatileńÜäÕÅśķćÅ’╝īĶāĮÕż¤Õ£©ń║┐ń©ŗõ╣ŗķŚ┤õ┐صīüÕÅ»Ķ¦üµĆ¦’╝īĶāĮÕż¤Ķó½ÕżÜń║┐ń©ŗÕÉīµŚČĶ»╗’╝īÕ╣ČõĖöõ┐ØĶ»üõĖŹõ╝ÜĶ»╗Õł░Ķ┐ćµ£¤ńÜäÕĆ╝’╝īõĮåµś»ÕŬĶāĮĶó½ÕŹĢń║┐ń©ŗÕåÖ’╝łµ£ēõĖĆń¦ŹµāģÕåĄÕÅ»õ╗źĶó½ÕżÜń║┐ń©ŗÕåÖ’╝īÕ░▒µś»ÕåÖÕģźńÜäÕĆ╝õĖŹõŠØĶĄ¢õ║ÄÕĤÕĆ╝’╝ē’╝īÕ£©getµōŹõĮ£ķćīÕŬķ£ĆĶ”üĶ»╗õĖŹķ£ĆĶ”üÕåÖÕģ▒õ║½ÕÅśķćÅcountÕÆīvalue’╝īµēĆõ╗źÕÅ»õ╗źõĖŹńö©ÕŖĀķöüŃĆéõ╣ŗµēĆõ╗źõĖŹõ╝ÜĶ»╗Õł░Ķ┐ćµ£¤ńÜäÕĆ╝’╝īµś»µĀ╣µŹ«javaÕåģÕŁśµ©ĪÕ×ŗńÜähappen beforeÕÄ¤ÕłÖ’╝īÕ»╣volatileÕŁŚµ«ĄńÜäÕåÖÕģźµōŹõĮ£Õģłõ║ÄĶ»╗µōŹõĮ£’╝īÕŹ│õĮ┐õĖżõĖ¬ń║┐ń©ŗÕÉīµŚČõ┐«µö╣ÕÆīĶÄĘÕÅ¢volatileÕÅśķćÅ’╝īgetµōŹõĮ£õ╣¤ĶāĮµŗ┐Õł░µ£Ćµ¢░ńÜäÕĆ╝’╝īĶ┐Öµś»ńö©volatileµø┐µŹóķöüńÜäń╗ÅÕģĖÕ║öńö©Õ£║µÖ»ŃĆé
1 |
transient┬Āvolatile┬Āint┬Ācount;
|
Õ£©Õ«ÜõĮŹÕģāń┤ĀńÜäõ╗ŻńĀüķćīµłæõ╗¼ÕÅ»õ╗źÕÅæńÄ░Õ«ÜõĮŹHashEntryÕÆīÕ«ÜõĮŹSegmentńÜäÕōłÕĖīń«Śµ│ĢĶÖĮńäČõĖƵĀĘ’╝īķāĮõĖĵĢ░ń╗äńÜäķĢ┐Õ║”ÕćÅÕÄ╗õĖĆńøĖõĖÄ’╝īõĮåµś»ńøĖõĖÄńÜäÕĆ╝õĖŹõĖƵĀĘ’╝īÕ«ÜõĮŹSegmentõĮ┐ńö©ńÜ䵜»Õģāń┤ĀńÜähashcodeķĆÜĶ┐ćÕåŹÕōłÕĖīÕÉÄÕŠŚÕł░ńÜäÕĆ╝ńÜäķ½śõĮŹ’╝īĶĆīÕ«ÜõĮŹHashEntryńø┤µÄźõĮ┐ńö©ńÜ䵜»ÕåŹÕōłÕĖīÕÉÄńÜäÕĆ╝ŃĆéÕģČńø«ńÜ䵜»ķü┐ÕģŹõĖżµ¼ĪÕōłÕĖīÕÉÄńÜäÕĆ╝õĖƵĀĘ’╝īÕ»╝Ķć┤Õģāń┤ĀĶÖĮńäČÕ£©SegmentķćīµĢŻÕłŚÕ╝Ćõ║å’╝īõĮåµś»ÕŹ┤µ▓Īµ£ēÕ£©HashEntryķćīµĢŻÕłŚÕ╝ĆŃĆé
1 |
hash >>> segmentShift) & segmentMask
|
3 |
int┬Āindex = hash & (tab.length -┬Ā1);
|
ConcurrentHashMapńÜäPutµōŹõĮ£
ńö▒õ║Äputµ¢╣µ│Ģķćīķ£ĆĶ”üÕ»╣Õģ▒õ║½ÕÅśķćÅĶ┐øĶĪīÕåÖÕģźµōŹõĮ£’╝īµēĆõ╗źõĖ║õ║åń║┐ń©ŗÕ«ēÕģ©’╝īÕ£©µōŹõĮ£Õģ▒õ║½ÕÅśķćŵŚČÕ┐ģķĪ╗ÕŠŚÕŖĀķöüŃĆéPutµ¢╣µ│Ģķ”¢ÕģłÕ«ÜõĮŹÕł░Segment’╝īńäČÕÉÄÕ£©SegmentķćīĶ┐øĶĪīµÅÆÕģźµōŹõĮ£ŃĆéµÅÆÕģźµōŹõĮ£ķ£ĆĶ”üń╗ÅÕÄåõĖżõĖ¬µŁźķ¬ż’╝īń¼¼õĖƵŁźÕłżµ¢Łµś»ÕÉ”ķ£ĆĶ”üÕ»╣SegmentķćīńÜäHashEntryµĢ░ń╗äĶ┐øĶĪīµē®Õ«╣’╝īń¼¼õ║īµŁźÕ«ÜõĮŹµĘ╗ÕŖĀÕģāń┤ĀńÜäõĮŹńĮ«ńäČÕÉĵöŠÕ£©HashEntryµĢ░ń╗äķćīŃĆé
µś»ÕÉ”ķ£ĆĶ”üµē®Õ«╣ŃĆéÕ£©µÅÆÕģźÕģāń┤ĀÕēŹõ╝ÜÕģłÕłżµ¢ŁSegmentķćīńÜäHashEntryµĢ░ń╗䵜»ÕÉ”ĶČģĶ┐ćÕ«╣ķćÅ’╝łthreshold’╝ē’╝īÕ”éµ×£ĶČģĶ┐ćķśĆÕĆ╝’╝īµĢ░ń╗äĶ┐øĶĪīµē®Õ«╣ŃĆéÕĆ╝ÕŠŚõĖƵÅÉńÜ䵜»’╝īSegmentńÜäµē®Õ«╣Õłżµ¢Łµ»öHashMapµø┤µü░ÕĮō’╝īÕøĀõĖ║HashMapµś»Õ£©µÅÆÕģźÕģāń┤ĀÕÉÄÕłżµ¢ŁÕģāń┤Āµś»ÕÉ”ÕĘ▓ń╗ÅÕł░ĶŠŠÕ«╣ķćÅńÜä’╝īÕ”éµ×£Õł░ĶŠŠõ║åÕ░▒Ķ┐øĶĪīµē®Õ«╣’╝īõĮåµś»ÕŠłµ£ēÕÅ»ĶāĮµē®Õ«╣õ╣ŗÕÉĵ▓Īµ£ēµ¢░Õģāń┤ĀµÅÆÕģź’╝īĶ┐ÖµŚČHashMapÕ░▒Ķ┐øĶĪīõ║åõĖƵ¼ĪµŚĀµĢłńÜäµē®Õ«╣ŃĆé
Õ”éõĮĢµē®Õ«╣ŃĆéµē®Õ«╣ńÜ䵌ČÕĆÖķ”¢Õģłõ╝ÜÕłøÕ╗║õĖĆõĖ¬õĖżÕĆŹõ║ÄÕĤի╣ķćÅńÜäµĢ░ń╗ä’╝īńäČÕÉÄÕ░åÕĤµĢ░ń╗äķćīńÜäÕģāń┤ĀĶ┐øĶĪīÕåŹhashÕÉĵÅÆÕģźÕł░µ¢░ńÜäµĢ░ń╗äķćīŃĆéõĖ║õ║åķ½śµĢłConcurrentHashMapõĖŹõ╝ÜÕ»╣µĢ┤õĖ¬Õ«╣ÕÖ©Ķ┐øĶĪīµē®Õ«╣’╝īĶĆīÕŬջ╣µ¤ÉõĖ¬segmentĶ┐øĶĪīµē®Õ«╣ŃĆé
ConcurrentHashMapńÜäsizeµōŹõĮ£
Õ”éµ×£µłæõ╗¼Ķ”üń╗¤Ķ«ĪµĢ┤õĖ¬ConcurrentHashMapķćīÕģāń┤ĀńÜäÕż¦Õ░Å’╝īÕ░▒Õ┐ģķĪ╗ń╗¤Ķ«ĪµēƵ£ēSegmentķćīÕģāń┤ĀńÜäÕż¦Õ░ÅÕÉĵ▒éÕÆīŃĆéSegmentķćīńÜäÕģ©Õ▒ĆÕÅśķćÅcountµś»õĖĆõĖ¬volatileÕÅśķćÅ’╝īķéŻõ╣łÕ£©ÕżÜń║┐ń©ŗÕ£║µÖ»õĖŗ’╝īµłæõ╗¼µś»õĖŹµś»ńø┤µÄźµŖŖµēƵ£ēSegmentńÜäcountńøĖÕŖĀÕ░▒ÕÅ»õ╗źÕŠŚÕł░µĢ┤õĖ¬ConcurrentHashMapÕż¦Õ░Åõ║åÕæó’╝¤õĖŹµś»ńÜä’╝īĶÖĮńäČńøĖÕŖĀµŚČÕÅ»õ╗źĶÄĘÕÅ¢µ»ÅõĖ¬SegmentńÜäcountńÜäµ£Ćµ¢░ÕĆ╝’╝īõĮåµś»µŗ┐Õł░õ╣ŗÕÉÄÕÅ»ĶāĮń┤»ÕŖĀÕēŹõĮ┐ńö©ńÜäcountÕÅæńö¤õ║åÕÅśÕī¢’╝īķéŻõ╣łń╗¤Ķ«Īń╗ōµ×£Õ░▒õĖŹÕćåõ║åŃĆéµēĆõ╗źµ£ĆÕ«ēÕģ©ńÜäÕüܵ│Ģ’╝īµś»Õ£©ń╗¤Ķ«ĪsizeńÜ䵌ČÕĆÖµŖŖµēƵ£ēSegmentńÜäput’╝īremoveÕÆīcleanµ¢╣µ│ĢÕģ©ķā©ķöüõĮÅ’╝īõĮåµś»Ķ┐Öń¦ŹÕüܵ│ĢµśŠńäČķØ×ÕĖĖõĮĵĢłŃĆé
ÕøĀõĖ║Õ£©ń┤»ÕŖĀcountµōŹõĮ£Ķ┐ćń©ŗõĖŁ’╝īõ╣ŗÕēŹń┤»ÕŖĀĶ┐ćńÜäcountÕÅæńö¤ÕÅśÕī¢ńÜäÕćĀńÄćķØ×ÕĖĖÕ░Å’╝īµēĆõ╗źConcurrentHashMapńÜäÕüܵ│Ģµś»ÕģłÕ░ØĶ»Ģ2µ¼ĪķĆÜĶ┐ćõĖŹķöüõĮÅSegmentńÜäµ¢╣Õ╝ÅµØźń╗¤Ķ«ĪÕÉäõĖ¬SegmentÕż¦Õ░Å’╝īÕ”éµ×£ń╗¤Ķ«ĪńÜäĶ┐ćń©ŗõĖŁ’╝īÕ«╣ÕÖ©ńÜäcountÕÅæńö¤õ║åÕÅśÕī¢’╝īÕłÖÕåŹķććńö©ÕŖĀķöüńÜäµ¢╣Õ╝ÅµØźń╗¤Ķ«ĪµēƵ£ēSegmentńÜäÕż¦Õ░ÅŃĆé
ķéŻõ╣łConcurrentHashMapµś»Õ”éõĮĢÕłżµ¢ŁÕ£©ń╗¤Ķ«ĪńÜ䵌ČÕĆÖÕ«╣ÕÖ©µś»ÕÉ”ÕÅæńö¤õ║åÕÅśÕī¢Õæó’╝¤õĮ┐ńö©modCountÕÅśķćÅ’╝īÕ£©put , removeÕÆīcleanµ¢╣µ│ĢķćīµōŹõĮ£Õģāń┤ĀÕēŹķāĮõ╝ÜÕ░åÕÅśķćÅmodCountĶ┐øĶĪīÕŖĀ1’╝īķéŻõ╣łÕ£©ń╗¤Ķ«ĪsizeÕēŹÕÉĵ»öĶŠāmodCountµś»ÕÉ”ÕÅæńö¤ÕÅśÕī¢’╝īõ╗ÄĶĆīÕŠŚń¤źÕ«╣ÕÖ©ńÜäÕż¦Õ░ŵś»ÕÉ”ÕÅæńö¤ÕÅśÕī¢ŃĆé
ÕÅéĶĆāĶĄäµ¢Ö
- JDK1.6µ║Éõ╗ŻńĀüŃĆé
- ŃĆŖJavaÕ╣ČÕÅæń╝¢ń©ŗÕ«×ĶĘĄŃĆŗ
- JavaÕ╣ČÕÅæń╝¢ń©ŗõ╣ŗConcurrentHashMap
ĶĮ¼ĶĮĮĶ»Ęµ│©µśÄ’╝Ü┬ĀĶĮ¼ĶĮĮĶć¬Õ╣ČÕÅæń╝¢ń©ŗńĮæ ŌĆō ifeve.com




ńøĖÕģ│µÄ©ĶŹÉ
µ£¼µ¢ćÕ░åµĘ▒ÕģźÕłåµ×É`ConcurrentHashMap`ńÜäĶ«ŠĶ«ĪÕĤńÉåŃĆüµĆ¦ĶāĮńē╣ńé╣õ╗źÕÅŖÕĖĖĶ¦üõĮ┐ńö©Õ£║µÖ»’╝īÕĖ«ÕŖ®õĮĀµÅÉÕŹćJavaÕ╣ČÕÅæń╝¢ń©ŗńÜäµŖĆĶāĮŃĆé `ConcurrentHashMap`µś»`java.util.concurrent`ÕīģõĖŗńÜäõĖĆõĖ¬ń▒╗’╝īÕ«āÕ£©`HashMap`ńÜäÕ¤║ńĪĆõĖŖĶ┐øĶĪīõ║åõ╝śÕī¢’╝īõ╗źķĆéÕ║ö...
JavaÕ╣ČÕÅæń╝¢ń©ŗõĖŁńÜäConcurrentHashMapµś»HashMapńÜäõĖĆõĖ¬ń║┐ń©ŗÕ«ēÕģ©ńēłµ£¼’╝īĶ«ŠĶ«Īńø«µĀ浜»Õ£©ķ½śÕ╣ČÕÅæÕ£║µÖ»õĖŗµÅÉõŠøķ½śµĢłńÜäµĢ░µŹ«Ķ«┐ķŚ«ŃĆéńøĖµ»öHashTable’╝īConcurrentHashMapķĆÜĶ┐ćķććńö©ķöüÕłåń”╗µŖƵ£»ÕÆīµø┤ń╗åń▓ÆÕ║”ńÜäķöüÕ«ÜńŁ¢ńĢźµØźµÅÉÕŹćµĆ¦ĶāĮŃĆéHashTable...
### µĘ▒ÕģźµÄóĶ«©ŃĆŖĶüŖĶüŖÕ╣ČÕÅæń│╗ÕłŚµ¢ćń½ĀŃĆŗ #### õĖĆŃĆüµĘ▒ÕģźÕłåµ×ÉVolatileńÜäÕ«×ńÄ░ÕĤńÉå **Õ╝ĢĶ©Ć** Õ£©ńÄ░õ╗ŻĶĮ»õ╗ČÕ╝ĆÕÅæõĖŁ’╝īńē╣Õł½µś»Õ£©ÕżÜń║┐ń©ŗń╝¢ń©ŗķóåÕ¤¤’╝īVolatileÕģ│ķö«ÕŁŚńÜäõĮ£ńö©õĖŹÕÅ»Õ┐ĮĶ¦åŃĆéõĮ£õĖ║õĖĆń¦ŹĶĮ╗ķćÅń║¦ńÜäÕÉīµŁźµ£║ÕłČ’╝īVolatileĶāĮÕż¤ńĪ«õ┐ØÕżÜ...
### ConcurrentHashMapµ║ÉńĀüÕłåµ×É #### õĖĆŃĆüµ”éĶ┐░ `ConcurrentHashMap`µś»JavaõĖŁńö©õ║ÄÕ«×ńÄ░ń║┐ń©ŗÕ«ēÕģ©ńÜäÕōłÕĖīĶĪ©ńÜäõĖĆń¦Źķ½śµĢłÕ«×ńÄ░µ¢╣Õ╝ÅŃĆéĶć¬Java 5Õ╝ĢÕģź`java.util.concurrent`ÕīģÕÉÄ’╝ī`ConcurrentHashMap`µłÉõĖ║õ║åÕżÜń║┐ń©ŗńÄ»ÕóāõĖŁµÄ©ĶŹÉ...
µ║ÉńĀüÕłåµ×ÉĶ¦üµłæÕŹÜµ¢ć’╝Ühttp://blog.csdn.net/wabiaozia/article/details/50684556
ŃĆɵ║ÉńĀüÕłåµ×ÉŃĆæµĘ▒ÕģźńÉåĶ¦Ż`ConcurrentHashMap`ńÜäÕĘźõĮ£ÕĤńÉå’╝īķ£ĆĶ”üµ¤źń£ŗÕģȵ║ÉńĀü’╝īńē╣Õł½µś»`put`ŃĆü`get`ŃĆü`resize`ńŁēÕģ│ķö«µōŹõĮ£’╝īõ╗źÕÅŖÕ£©õĖŹÕÉīńēłµ£¼õĖŁńÜäÕÅśÕī¢’╝īõŠŗÕ”éJava 8Õ╝ĢÕģźńÜäń║óķ╗æµĀæõ╝śÕī¢ŃĆé µĆ╗ń╗ō’╝ī`ConcurrentHashMap`µś»JavaÕ╣ČÕÅæń╝¢ń©ŗ...
JavaÕ╣ČÕÅæń│╗ÕłŚõ╣ŗConcurrentHashMapµ║ÉńĀüÕłåµ×É ConcurrentHashMapµś»JavaõĖŁõĖĆõĖ¬ķ½śµĆ¦ĶāĮńÜäÕōłÕĖīĶĪ©Õ«×ńÄ░’╝īÕ«āĶ¦ŻÕå│õ║åHashTableńÜäÕÉīµŁźķŚ«ķóś’╝īÕģüĶ«ĖÕżÜń║┐ń©ŗÕÉīµŚČµōŹõĮ£ÕōłÕĖīĶĪ©’╝īõ╗ÄĶĆīµÅÉķ½śµĆ¦ĶāĮŃĆé 1. ConcurrentHashMapńÜ䵳ÉÕæśÕÅśķćÅ’╝Ü ...
ŃĆÉJavaÕ╣ČÕÅæÕ«╣ÕÖ©õ╣ŗConcurrentHashMapŃĆæµś»Javań╝¢ń©ŗõĖŁńö©õ║Äķ½śµĢłÕ╣ČÕÅæµōŹõĮ£ńÜäķćŹĶ”üÕĘźÕģĘŃĆéńøĖµ»öõ║ÄHashMap’╝īConcurrentHashMapÕ£©ÕżÜń║┐ń©ŗńÄ»ÕóāõĖŗµÅÉõŠøõ║åń║┐ń©ŗÕ«ēÕģ©ńÜäõ┐ØĶ»ü’╝īķü┐ÕģŹõ║åÕøĀµē®Õ«╣Õ»╝Ķć┤ńÜäCPUĶĄäµ║ɵȳĶĆŚĶ┐ćķ½śķŚ«ķóśŃĆéõ╝Āń╗¤ńÜäń║┐ń©ŗÕ«ēÕģ©Ķ¦ŻÕå│...
### JavaÕ╣ČÕÅæń╝¢ń©ŗõ╣ŗConcurrentHashMap #### õĖĆŃĆüµ”éĶ┐░ `ConcurrentHashMap`µś»JavaÕ╣ČÕÅæń╝¢ń©ŗõĖŁńÜäõĖĆõĖ¬ķćŹĶ”üń╗äõ╗Č’╝īÕ«āµÅÉõŠøõ║åõĖĆń¦Źń║┐ń©ŗÕ«ēÕģ©ńÜäÕōłÕĖīĶĪ©Õ«×ńÄ░µ¢╣Õ╝ÅŃĆéõĖÄõ╝Āń╗¤ńÜä`Hashtable`µł¢`synchronized`Õģ│ķö«ÕŁŚńøĖµ»ö’╝ī`...
µ£¼ĶŖ鵳æõ╗¼Õ░åµĘ▒ÕģźĶ¦Żµ×É`ConcurrentHashMap`ńÜä`put`ÕÆī`get`µ¢╣µ│Ģ’╝īõ╗źÕÅŖÕģČÕłØÕ¦ŗÕī¢Ķ┐ćń©ŗŃĆé ķ”¢Õģł’╝ī`ConcurrentHashMap`ńÜäÕłØÕ¦ŗÕī¢Ķ┐ćń©ŗÕ£©ń¼¼õĖƵ¼Ī`put`µōŹõĮ£µŚČĶ¦”ÕÅæ’╝īÕģȵĀĖÕ┐āÕ£©õ║Ä`initTable`µ¢╣µ│ĢŃĆéĶ┐ÖõĖ¬µ¢╣µ│ĢńĪ«õ┐ØÕ£©ÕżÜń║┐ń©ŗńÄ»ÕóāõĖŗÕ«ēÕģ©Õ£░...
ń©ŗÕ║ÅÕæśķØóĶ»ĢÕŖĀĶ¢¬Õ┐ģÕżć_ConcurrentHashMapÕ║ĢÕ▒éÕĤńÉåõĖĵ║ÉńĀüÕłåµ×ɵĘ▒ÕģźĶ»”Ķ¦Ż
ConcurrentHashMapµ║ÉńĀüÕłåµ×ɵ║ÉńĀüÕłåµ×É õ╗ŻńĀüĶ¦ŻķćŖķØ×ÕĖĖĶ»”ń╗å’╝ü’╝ü’╝ü’╝ü
õĖÄõ╝Āń╗¤ńÜä`Hashtable`ńøĖµ»ö’╝ī`ConcurrentHashMap`Õģʵ£ēµø┤ķ½śńÜäÕ╣ČÕÅæµĆ¦ĶāĮ’╝īĶ┐ÖõĖ╗Ķ”üÕŠŚńøŖõ║ÄÕ«āńÜäÕłåµ«ĄķöüµŖƵ£»ÕÆīķØ×ķś╗ÕĪ×ń«Śµ│ĢŃĆé #### õ║īŃĆü`ConcurrentHashMap`ńÜäÕ¤║µ£¼µ”éÕ┐Ą 1. **Õłåµ«ĄķöüµŖƵ£»**’╝Ü`ConcurrentHashMap`Õåģķā©ķććńö©õ║åÕłåµ«Ąķöü...
ķĆÜĶ┐ćÕ»╣ConcurrentHashMapńÜäµĘ▒ÕģźÕē¢µ×É’╝īµłæõ╗¼ÕÅ»õ╗źń£ŗÕł░Õ«āķĆÜĶ┐ćķöüÕłåµ«ĄµŖƵ£»µ×üÕż¦Õ£░µÅÉķ½śõ║åÕżÜń║┐ń©ŗńÄ»ÕóāõĖŗńÜäÕ╣ČÕÅæµĆ¦ĶāĮŃĆ鵣żÕż¢’╝īÕģČÕåģķā©Ķ«ŠĶ«ĪĶ┐śõĮōńÄ░õ║åÕ»╣µśōÕÅśµĆ¦ÕÆīõĖŹÕÅśµĆ¦ńÜäÕĘ¦Õ”ÖĶ┐Éńö©’╝īõ╗źÕÅŖķ½śµĢłńÜäÕ«ÜõĮŹÕÆīµē®Õ«╣µ£║ÕłČ’╝īĶ┐Öõ║øķāĮµś»ÕĆ╝ÕŠŚÕŁ”õ╣ĀńÜäÕģ│ķö«...
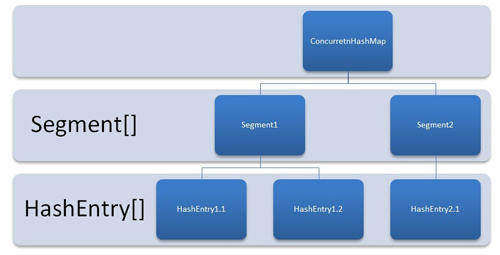
ConcurrentHashMapõĖ║õ║åµÅÉķ½śµ£¼Ķ║½ńÜäÕ╣ČÕÅæĶāĮÕŖø’╝īÕ£©Õåģķā©ķććńö©õ║åõĖĆõĖ¬ÕŽÕüÜSegmentńÜäń╗ōµ×ä’╝īõĖĆõĖ¬SegmentÕģČÕ«×Õ░▒µś»õĖĆõĖ¬ń▒╗HashTableńÜäń╗ōµ×ä’╝īSegmentÕåģķā©ń╗┤µŖżõ║åõĖĆõĖ¬ķōŠĶĪ©µĢ░ń╗ä’╝īµłæõ╗¼ńö©õĖŗķØóĶ┐ÖõĖĆÕ╣ģÕøŠµØźń£ŗõĖŗConcurrentHashMapńÜäÕåģķā©ń╗ōµ×ä...
ConcurrentHashMapµś»JavaõĖŁõĖĆõĖ¬ń║┐ń©ŗÕ«ēÕģ©ńÜäHashMapÕ«×ńÄ░’╝īõĖ╗Ķ”üńö©õ║ÄÕżÜń║┐ń©ŗ...Õ£©µĘ▒ÕģźńÉåĶ¦ŻConcurrentHashMapńÜäÕ¤║ńĪĆõĖŖ’╝īĶ┐śÕÅ»õ╗źĶ┐øõĖƵŁźńĀöń®ČÕģȵ║ÉńĀü’╝īµÄóń┤óJavaÕ╣ČÕÅæÕīģõĖŁÕģČõ╗¢ń║┐ń©ŗÕ«ēÕģ©ńÜäķøåÕÉłÕ«×ńÄ░’╝īõ╗źµø┤ÕźĮÕ£░ķĆéÕ║öÕżÜń║┐ń©ŗń╝¢ń©ŗńÜäµīæµłśŃĆé
µ£¼µ¢ćÕ░åń╗ōÕÉłJavaÕåģÕŁśµ©ĪÕ×ŗ’╝īÕłåµ×ÉJDKµ║Éõ╗ŻńĀü’╝īµÄóń┤óConcurrentHashMapķ½śÕ╣ČÕÅæńÜäÕģĘõĮōÕ«×ńÄ░µ£║ÕłČ’╝īÕīģµŗ¼ÕģČÕ£©JDKõĖŁńÜäÕ«Üõ╣ēÕÆīń╗ōµ×äŃĆüÕ╣ČÕÅæÕŁśÕÅ¢ŃĆüķćŹÕōłÕĖīÕÆīĶĘ©µ«ĄµōŹõĮ£’╝īÕ╣ČńØĆķćŹÕē¢µ×Éõ║åConcurrentHashMapĶ»╗µōŹõĮ£õĖŹķ£ĆĶ”üÕŖĀķöüÕÆīÕłåµ«Ąķöüµ£║ÕłČńÜäÕåģÕ£©...
javaµ£¼Õ£░ń╝ōÕŁśConcurrentHashMap