
简ن»‹
وڈگن¾›ن؛†ن¸€ن¸ھهں؛ن؛ژFIFOéکںهˆ—,هڈ¯ن»¥ç”¨ن؛ژو„ه»؛é”پوˆ–者ه…¶ن»–相ه…³هگŒو¥è£…ç½®çڑ„هں؛ç،€و،†و¶م€‚该هگŒو¥ه™¨ï¼ˆن»¥ن¸‹ç®€ç§°هگŒو¥ه™¨ï¼‰هˆ©ç”¨ن؛†ن¸€ن¸ھintو¥è،¨ç¤؛çٹ¶و€پ,وœںوœ›ه®ƒèƒ½ه¤ںوˆگن¸؛ه®çژ°ه¤§éƒ¨هˆ†هگŒو¥éœ€و±‚çڑ„هں؛ç،€م€‚ن½؟用çڑ„و–¹و³•وک¯ç»§و‰؟,هگç±»é€ڑè؟‡ç»§و‰؟هگŒو¥ه™¨ه¹¶éœ€è¦په®çژ°ه®ƒçڑ„و–¹و³•و¥ç®،çگ†ه…¶çٹ¶و€پ,ç®،çگ†çڑ„و–¹ه¼ڈه°±وک¯é€ڑè؟‡ç±»ن¼¼acquireه’Œreleaseçڑ„و–¹ه¼ڈو¥و“چç؛µçٹ¶و€پم€‚然而ه¤ڑç؛؟程çژ¯ه¢ƒن¸ه¯¹çٹ¶و€پçڑ„و“چç؛µه؟…é،»ç،®ن؟هژںهگو€§ï¼Œه› و¤هگç±»ه¯¹ن؛ژçٹ¶و€پçڑ„وٹٹوڈ،,需è¦پن½؟用è؟™ن¸ھهگŒو¥ه™¨وڈگن¾›çڑ„ن»¥ن¸‹ن¸‰ن¸ھو–¹و³•ه¯¹çٹ¶و€پè؟›è،Œو“چن½œï¼ڑ
- java.util.concurrent.locks.AbstractQueuedSynchronizer.getState()
- java.util.concurrent.locks.AbstractQueuedSynchronizer.setState(int)
- java.util.concurrent.locks.AbstractQueuedSynchronizer.compareAndSetState(int, int)
هگç±»وژ¨èچگ被ه®ڑن¹‰ن¸؛è‡ھه®ڑن¹‰هگŒو¥è£…ç½®çڑ„ه†…部类,هگŒو¥ه™¨è‡ھè؛«و²،وœ‰ه®çژ°ن»»ن½•هگŒو¥وژ¥هڈ£ï¼Œه®ƒن»…ن»…وک¯ه®ڑن¹‰ن؛†è‹¥ه¹²acquireن¹‹ç±»çڑ„و–¹و³•و¥ن¾›ن½؟用م€‚该هگŒو¥ه™¨هچ³هڈ¯ن»¥ن½œن¸؛وژ’ن»–و¨،ه¼ڈن¹ںهڈ¯ن»¥ن½œن¸؛ه…±ن؛«و¨،ه¼ڈ,ه½“ه®ƒè¢«ه®ڑن¹‰ن¸؛ن¸€ن¸ھوژ’ن»–و¨،ه¼ڈو—¶ï¼Œه…¶ن»–ç؛؟程ه¯¹ه…¶çڑ„èژ·هڈ–ه°±è¢«éک»و¢ï¼Œè€Œه…±ن؛«و¨،ه¼ڈه¯¹ن؛ژه¤ڑن¸ھç؛؟程èژ·هڈ–都هڈ¯ن»¥وˆگهٹںم€‚
هگŒو¥ه™¨وک¯ه®çژ°é”پçڑ„ه…³é”®ï¼Œهˆ©ç”¨هگŒو¥ه™¨ه°†é”پçڑ„è¯ن¹‰ه®çژ°ï¼Œç„¶هگژهœ¨é”پçڑ„ه®çژ°ن¸èپڑهگˆهگŒو¥ه™¨م€‚هڈ¯ن»¥è؟™و ·çگ†è§£ï¼ڑé”پçڑ„APIوک¯é¢هگ‘ن½؟用者çڑ„,ه®ƒه®ڑن¹‰ن؛†ن¸ژé”پن؛¤ن؛’çڑ„ه…¬ه…±è،Œن¸؛,而و¯ڈن¸ھé”پ需è¦په®Œوˆگ特ه®ڑçڑ„و“چن½œن¹ںوک¯é€ڈè؟‡è؟™ن؛›è،Œن¸؛و¥ه®Œوˆگçڑ„(و¯”ه¦‚ï¼ڑهڈ¯ن»¥ه…پ许ن¸¤ن¸ھç؛؟程è؟›è،Œهٹ é”پ,وژ’除ن¸¤ن¸ھن»¥ن¸ٹçڑ„ç؛؟程),ن½†وک¯ه®çژ°وک¯ن¾و‰کç»™هگŒو¥ه™¨و¥ه®Œوˆگï¼›هگŒو¥ه™¨é¢هگ‘çڑ„وک¯ç؛؟程è®؟é—®ه’Œèµ„و؛گوژ§هˆ¶ï¼Œه®ƒه®ڑن¹‰ن؛†ç؛؟程ه¯¹èµ„و؛گوک¯هگ¦èƒ½ه¤ںèژ·هڈ–ن»¥هڈٹç؛؟程çڑ„وژ’éکںç‰و“چن½œم€‚é”په’ŒهگŒو¥ه™¨ه¾ˆه¥½çڑ„éڑ”离ن؛†ن؛Œè€…و‰€éœ€è¦په…³و³¨çڑ„领هںں,ن¸¥و ¼و„ڈن¹‰ن¸ٹ讲,هگŒو¥ه™¨هڈ¯ن»¥é€‚用ن؛ژ除ن؛†é”پن»¥ه¤–çڑ„ه…¶ن»–هگŒو¥è®¾و–½ن¸ٹ(هŒ…و‹¬é”پ)م€‚
هگŒو¥ه™¨çڑ„ه¼€ه§‹وڈگهˆ°ن؛†ه…¶ه®çژ°ن¾èµ–ن؛ژن¸€ن¸ھFIFOéکںهˆ—,那ن¹ˆéکںهˆ—ن¸çڑ„ه…ƒç´ Nodeه°±وک¯ن؟هکç€ç؛؟程ه¼•ç”¨ه’Œç؛؟程çٹ¶و€پçڑ„ه®¹ه™¨ï¼Œو¯ڈن¸ھç؛؟程ه¯¹هگŒو¥ه™¨çڑ„è®؟问,都هڈ¯ن»¥çœ‹هپڑوک¯éکںهˆ—ن¸çڑ„ن¸€ن¸ھèٹ‚点م€‚Nodeçڑ„ن¸»è¦پهŒ…هگ«ن»¥ن¸‹وˆگه‘کهڈکé‡ڈï¼ڑ
Node {
int waitStatus;
Node prev;
Node next;
Node nextWaiter;
Thread thread;
}
ن»¥ن¸ٹن؛”ن¸ھوˆگه‘کهڈکé‡ڈن¸»è¦پè´ںè´£ن؟هک该èٹ‚点çڑ„ç؛؟程ه¼•ç”¨ï¼ŒهگŒو¥ç‰ه¾…éکںهˆ—(ن»¥ن¸‹ç®€ç§°syncéکںهˆ—)çڑ„ه‰چ驱ه’Œهگژ继èٹ‚点,هگŒو—¶ن¹ںهŒ…و‹¬ن؛†هگŒو¥çٹ¶و€پم€‚
| ه±و€§هگچ称 | وڈڈè؟° |
| int waitStatus | è،¨ç¤؛èٹ‚点çڑ„çٹ¶و€پم€‚ه…¶ن¸هŒ…هگ«çڑ„çٹ¶و€پوœ‰ï¼ڑ
|
| Node prev | ه‰چ驱èٹ‚点,و¯”ه¦‚ه½“ه‰چèٹ‚点被هڈ–و¶ˆï¼Œé‚£ه°±éœ€è¦په‰چ驱èٹ‚点ه’Œهگژ继èٹ‚点و¥ه®Œوˆگè؟وژ¥م€‚ |
| Node next | هگژ继èٹ‚点م€‚ |
| Node nextWaiter | هکه‚¨conditionéکںهˆ—ن¸çڑ„هگژ继èٹ‚点م€‚ |
| Thread thread | ه…¥éکںهˆ—و—¶çڑ„ه½“ه‰چç؛؟程م€‚ |
èٹ‚点وˆگن¸؛syncéکںهˆ—ه’Œconditionéکںهˆ—و„ه»؛çڑ„هں؛ç،€ï¼Œهœ¨هگŒو¥ه™¨ن¸ه°±هŒ…هگ«ن؛†syncéکںهˆ—م€‚هگŒو¥ه™¨و‹¥وœ‰ن¸‰ن¸ھوˆگه‘کهڈکé‡ڈï¼ڑsyncéکںهˆ—çڑ„ه¤´ç»“点headم€پsyncéکںهˆ—çڑ„ه°¾èٹ‚点tailه’Œçٹ¶و€پstateم€‚ه¯¹ن؛ژé”پçڑ„èژ·هڈ–,请و±‚ه½¢وˆگèٹ‚点,ه°†ه…¶وŒ‚è½½هœ¨ه°¾éƒ¨ï¼Œè€Œé”پ资و؛گçڑ„转移(é‡ٹو”¾ه†چèژ·هڈ–)وک¯ن»ژه¤´éƒ¨ه¼€ه§‹هگ‘هگژè؟›è،Œم€‚ه¯¹ن؛ژهگŒو¥ه™¨ç»´وٹ¤çڑ„çٹ¶و€پstate,ه¤ڑن¸ھç؛؟程ه¯¹ه…¶çڑ„èژ·هڈ–ه°†ن¼ڑن؛§ç”ںن¸€ن¸ھ链ه¼ڈçڑ„结و„م€‚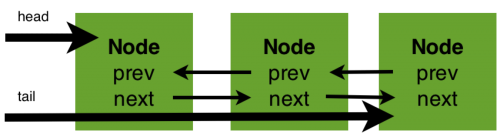
API说وکژ
ه®çژ°è‡ھه®ڑن¹‰هگŒو¥ه™¨و—¶ï¼Œéœ€è¦پن½؟用هگŒو¥ه™¨وڈگن¾›çڑ„getState()م€پsetState()ه’ŒcompareAndSetState()و–¹و³•و¥و“چç؛µçٹ¶و€پçڑ„هڈکè؟پم€‚
| و–¹و³•هگچ称 | وڈڈè؟° |
| protected boolean tryAcquire(int arg) | وژ’ه®ƒçڑ„èژ·هڈ–è؟™ن¸ھçٹ¶و€پم€‚è؟™ن¸ھو–¹و³•çڑ„ه®çژ°éœ€è¦پوں¥è¯¢ه½“ه‰چçٹ¶و€پوک¯هگ¦ه…پ许èژ·هڈ–,然هگژه†چè؟›è،Œèژ·هڈ–(ن½؟用compareAndSetStateو¥هپڑ)çٹ¶و€پم€‚ |
| protected boolean tryRelease(int arg)آ | é‡ٹو”¾çٹ¶و€پم€‚ |
| protected int tryAcquireShared(int arg) | ه…±ن؛«çڑ„و¨،ه¼ڈن¸‹èژ·هڈ–çٹ¶و€پم€‚ |
| protected boolean tryReleaseShared(int arg) | ه…±ن؛«çڑ„و¨،ه¼ڈن¸‹é‡ٹو”¾çٹ¶و€پم€‚ |
| protected boolean isHeldExclusively() | هœ¨وژ’ه®ƒو¨،ه¼ڈن¸‹ï¼Œçٹ¶و€پوک¯هگ¦è¢«هچ 用م€‚ |
ه®çژ°è؟™ن؛›و–¹و³•ه؟…é،»وک¯ééک»ه،而ن¸”وک¯ç؛؟程ه®‰ه…¨çڑ„,وژ¨èچگن½؟用该هگŒو¥ه™¨çڑ„父类java.util.concurrent.locks.AbstractOwnableSynchronizerو¥è®¾ç½®ه½“ه‰چçڑ„ç؛؟程م€‚
ه¼€ه§‹وڈگهˆ°هگŒو¥ه™¨ه†…部هں؛ن؛ژن¸€ن¸ھFIFOéکںهˆ—,ه¯¹ن؛ژن¸€ن¸ھ独هچ é”پçڑ„èژ·هڈ–ه’Œé‡ٹو”¾وœ‰ن»¥ن¸‹ن¼ھç پهڈ¯ن»¥è،¨ç¤؛م€‚
èژ·هڈ–ن¸€ن¸ھوژ’ن»–é”پم€‚
while(èژ·هڈ–é”پ) {
if (èژ·هڈ–هˆ°) {
退ه‡؛whileه¾ھçژ¯
} else {
if(ه½“ه‰چç؛؟程و²،وœ‰ه…¥éکںهˆ—) {
é‚£ن¹ˆه…¥éکںهˆ—
}
éک»ه،ه½“ه‰چç؛؟程
}
}
é‡ٹو”¾ن¸€ن¸ھوژ’ن»–é”پم€‚
if (é‡ٹو”¾وˆگهٹں) {
هˆ 除ه¤´ç»“点
و؟€و´»هژںه¤´ç»“点çڑ„هگژ继èٹ‚点
}
ç¤؛ن¾‹
ن¸‹é¢é€ڑè؟‡ن¸€ن¸ھوژ’ه®ƒé”پçڑ„ن¾‹هگو¥و·±ه…¥çگ†è§£ن¸€ن¸‹هگŒو¥ه™¨çڑ„ه·¥ن½œهژںçگ†ï¼Œè€Œهڈھوœ‰وژŒوڈ،هگŒو¥ه™¨çڑ„ه·¥ن½œهژںçگ†و‰چ能ه¤ںو›´هٹ و·±ه…¥ن؛†è§£ه…¶ن»–çڑ„ه¹¶هڈ‘组ن»¶م€‚
وژ’ن»–é”پçڑ„ه®çژ°ï¼Œن¸€و¬،هڈھ能ن¸€ن¸ھç؛؟程èژ·هڈ–هˆ°é”پم€‚
class Mutex implements Lock, java.io.Serializable {
// ه†…部类,è‡ھه®ڑن¹‰هگŒو¥ه™¨
private static class Sync extends AbstractQueuedSynchronizer {
// وک¯هگ¦ه¤„ن؛ژهچ 用çٹ¶و€پ
protected boolean isHeldExclusively() {
return getState() == 1;
}
// ه½“çٹ¶و€پن¸؛0çڑ„و—¶ه€™èژ·هڈ–é”پ
public boolean tryAcquire(int acquires) {
assert acquires == 1; // Otherwise unused
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// é‡ٹو”¾é”پ,ه°†çٹ¶و€پ设置ن¸؛0
protected boolean tryRelease(int releases) {
assert releases == 1; // Otherwise unused
if (getState() == 0) throw new IllegalMonitorStateException();
setExclusiveOwnerThread(null);
setState(0);
return true;
}
// è؟”ه›ن¸€ن¸ھCondition,و¯ڈن¸ھcondition都هŒ…هگ«ن؛†ن¸€ن¸ھconditionéکںهˆ—
Condition newCondition() { return new ConditionObject(); }
}
// ن»…需è¦په°†و“چن½œن»£çگ†هˆ°Syncن¸ٹهچ³هڈ¯
private final Sync sync = new Sync();
public void lock() { sync.acquire(1); }
public boolean tryLock() { return sync.tryAcquire(1); }
public void unlock() { sync.release(1); }
public Condition newCondition() { return sync.newCondition(); }
public boolean isLocked() { return sync.isHeldExclusively(); }
public boolean hasQueuedThreads() { return sync.hasQueuedThreads(); }
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
public boolean tryLock(long timeout, TimeUnit unit)
throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}
}
هڈ¯ن»¥çœ‹هˆ°Mutexه°†Lockوژ¥هڈ£ه‡ن»£çگ†ç»™ن؛†هگŒو¥ه™¨çڑ„ه®çژ°م€‚
ن½؟用و–¹ه°†Mutexو„é€ ه‡؛و¥ن¹‹هگژ,调用lockèژ·هڈ–é”پ,调用unlockè؟›è،Œè§£é”پم€‚ن¸‹é¢ن»¥Mutexن¸؛ن¾‹هگ,详细هˆ†وگن»¥ن¸‹هگŒو¥ه™¨çڑ„ه®çژ°é€»è¾‘م€‚
ه®çژ°هˆ†وگ
public final void acquire(int arg)
该و–¹و³•ن»¥وژ’ن»–çڑ„و–¹ه¼ڈèژ·هڈ–é”پ,ه¯¹ن¸و–ن¸چو•ڈو„ں,ه®Œوˆگsynchronizedè¯ن¹‰م€‚
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
ن¸ٹè؟°é€»è¾‘ن¸»è¦پهŒ…و‹¬ï¼ڑ
1. ه°è¯•èژ·هڈ–(调用tryAcquireو›´و”¹çٹ¶و€پ,需è¦پن؟è¯پهژںهگو€§ï¼‰ï¼›
هœ¨tryAcquireو–¹و³•ن¸ن½؟用ن؛†هگŒو¥ه™¨وڈگن¾›çڑ„ه¯¹stateو“چن½œçڑ„و–¹و³•ï¼Œهˆ©ç”¨compareAndSetن؟è¯پهڈھوœ‰ن¸€ن¸ھç؛؟程能ه¤ںه¯¹çٹ¶و€پè؟›è،Œوˆگهٹںن؟®و”¹ï¼Œè€Œو²،وœ‰وˆگهٹںن؟®و”¹çڑ„ç؛؟程ه°†è؟›ه…¥syncéکںهˆ—وژ’éکںم€‚
2. ه¦‚وœèژ·هڈ–ن¸چهˆ°ï¼Œه°†ه½“ه‰چç؛؟程و„é€ وˆگèٹ‚点Nodeه¹¶هٹ ه…¥syncéکںهˆ—ï¼›
è؟›ه…¥éکںهˆ—çڑ„و¯ڈن¸ھç؛؟程都وک¯ن¸€ن¸ھèٹ‚点Node,ن»ژ而ه½¢وˆگن؛†ن¸€ن¸ھهڈŒهگ‘éکںهˆ—,类ن¼¼CLHéکںهˆ—,è؟™و ·هپڑçڑ„ç›®çڑ„وک¯ç؛؟程间çڑ„é€ڑن؟،ن¼ڑ被é™گهˆ¶هœ¨è¾ƒه°ڈ规و¨،(ن¹ںه°±وک¯ن¸¤ن¸ھèٹ‚点ه·¦هڈ³ï¼‰م€‚
3. ه†چو¬،ه°è¯•èژ·هڈ–,ه¦‚وœو²،وœ‰èژ·هڈ–هˆ°é‚£ن¹ˆه°†ه½“ه‰چç؛؟程ن»ژç؛؟程调ه؛¦ه™¨ن¸ٹو‘کن¸‹ï¼Œè؟›ه…¥ç‰ه¾…çٹ¶و€پم€‚
ن½؟用LockSupportه°†ه½“ه‰چç؛؟程unpark,ه…³ن؛ژLockSupportهگژç»ن¼ڑ详细ن»‹ç»چم€‚
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// ه؟«é€ںه°è¯•هœ¨ه°¾éƒ¨و·»هٹ
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
ن¸ٹè؟°é€»è¾‘ن¸»è¦پهŒ…و‹¬ï¼ڑ
1. ن½؟用ه½“ه‰چç؛؟程و„é€ Nodeï¼›
ه¯¹ن؛ژن¸€ن¸ھèٹ‚点需è¦پهپڑçڑ„وک¯ه°†ه½“èٹ‚点ه‰چ驱èٹ‚点وŒ‡هگ‘ه°¾èٹ‚点(current.prev = tail),ه°¾èٹ‚点وŒ‡هگ‘ه®ƒï¼ˆtail = current),هژںوœ‰çڑ„ه°¾èٹ‚点çڑ„هگژ继èٹ‚点وŒ‡هگ‘ه®ƒï¼ˆt.next = current)而è؟™ن؛›و“چن½œè¦پو±‚وک¯هژںهگçڑ„م€‚ن¸ٹé¢çڑ„و“چن½œوک¯هˆ©ç”¨ه°¾èٹ‚点çڑ„设置و¥ن؟è¯پçڑ„,ن¹ںه°±وک¯compareAndSetTailو¥ه®Œوˆگçڑ„م€‚
2. ه…ˆè،Œه°è¯•هœ¨éکںه°¾و·»هٹ ï¼›
ه¦‚وœه°¾èٹ‚点ه·²ç»ڈوœ‰ن؛†ï¼Œç„¶هگژهپڑه¦‚ن¸‹و“چن½œï¼ڑ
(1)هˆ†é…چه¼•ç”¨TوŒ‡هگ‘ه°¾èٹ‚点;
(2)ه°†èٹ‚点çڑ„ه‰چ驱èٹ‚点و›´و–°ن¸؛ه°¾èٹ‚点(current.prev = tail);
(3)ه¦‚وœه°¾èٹ‚点وک¯T,那ن¹ˆه°†ه½“ه°¾èٹ‚点设置ن¸؛该èٹ‚点(tail = current,هژںهگو›´و–°ï¼‰ï¼›
(4)Tçڑ„هگژ继èٹ‚点وŒ‡هگ‘ه½“ه‰چèٹ‚点(T.next = current)م€‚
و³¨و„ڈ第3点وک¯è¦پو±‚هژںهگçڑ„م€‚
è؟™و ·هڈ¯ن»¥ن»¥وœ€çںè·¯ه¾„O(1)çڑ„و•ˆوœو¥ه®Œوˆگç؛؟程ه…¥éکں,وک¯وœ€ه¤§هŒ–ه‡ڈه°‘ه¼€é”€çڑ„ن¸€ç§چو–¹ه¼ڈم€‚
3. ه¦‚وœéکںه°¾و·»هٹ ه¤±è´¥وˆ–者وک¯ç¬¬ن¸€ن¸ھه…¥éکںçڑ„èٹ‚点م€‚
ه¦‚وœوک¯ç¬¬1ن¸ھèٹ‚点,ن¹ںه°±وک¯syncéکںهˆ—و²،وœ‰هˆه§‹هŒ–,那ن¹ˆن¼ڑè؟›ه…¥هˆ°enqè؟™ن¸ھو–¹و³•ï¼Œè؟›ه…¥çڑ„ç؛؟程هڈ¯èƒ½وœ‰ه¤ڑن¸ھ,وˆ–者说هœ¨addWaiterن¸و²،وœ‰وˆگهٹںه…¥éکںçڑ„ç؛؟程都ه°†è؟›ه…¥enqè؟™ن¸ھو–¹و³•م€‚
هڈ¯ن»¥çœ‹هˆ°enqçڑ„逻辑وک¯ç،®ن؟è؟›ه…¥çڑ„Node都ن¼ڑوœ‰وœ؛ن¼ڑé،؛ه؛ڈçڑ„و·»هٹ هˆ°syncéکںهˆ—ن¸ï¼Œè€Œهٹ ه…¥çڑ„و¥éھ¤ه¦‚ن¸‹ï¼ڑ
(1)ه¦‚وœه°¾èٹ‚点ن¸؛ç©؛,那ن¹ˆهژںهگهŒ–çڑ„هˆ†é…چن¸€ن¸ھه¤´èٹ‚点,ه¹¶ه°†ه°¾èٹ‚点وŒ‡هگ‘ه¤´èٹ‚点,è؟™ن¸€و¥وک¯هˆه§‹هŒ–ï¼›
(2)然هگژوک¯é‡چه¤چهœ¨addWaiterن¸هپڑçڑ„ه·¥ن½œï¼Œن½†وک¯هœ¨ن¸€ن¸ھwhile(true)çڑ„ه¾ھçژ¯ن¸ï¼Œç›´هˆ°ه½“ه‰چèٹ‚点ه…¥éکںن¸؛و¢م€‚
è؟›ه…¥syncéکںهˆ—ن¹‹هگژ,وژ¥ن¸‹و¥ه°±وک¯è¦پè؟›è،Œé”پçڑ„èژ·هڈ–,وˆ–者说وک¯è®؟é—®وژ§هˆ¶ن؛†ï¼Œهڈھوœ‰ن¸€ن¸ھç؛؟程能ه¤ںهœ¨هگŒن¸€و—¶هˆ»ç»§ç»çڑ„è؟گè،Œï¼Œè€Œه…¶ن»–çڑ„è؟›ه…¥ç‰ه¾…çٹ¶و€پم€‚而و¯ڈن¸ھç؛؟程都وک¯ن¸€ن¸ھ独立çڑ„ن¸ھن½“,ه®ƒن»¬è‡ھçœپçڑ„观ه¯ں,ه½“و،ن»¶و»،足çڑ„و—¶ه€™ï¼ˆè‡ھه·±çڑ„ه‰چ驱وک¯ه¤´ç»“点ه¹¶ن¸”هژںهگو€§çڑ„èژ·هڈ–ن؛†çٹ¶و€پ),那ن¹ˆè؟™ن¸ھç؛؟程能ه¤ں继ç»è؟گè،Œم€‚
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
ن¸ٹè؟°é€»è¾‘ن¸»è¦پهŒ…و‹¬ï¼ڑ
1. èژ·هڈ–ه½“ه‰چèٹ‚点çڑ„ه‰چ驱èٹ‚点;
需è¦پèژ·هڈ–ه½“ه‰چèٹ‚点çڑ„ه‰چ驱èٹ‚点,而ه¤´ç»“点و‰€ه¯¹ه؛”çڑ„هگ«ن¹‰وک¯ه½“ه‰چç«™وœ‰é”پن¸”و£هœ¨è؟گè،Œم€‚
2. ه½“ه‰چ驱èٹ‚点وک¯ه¤´ç»“点ه¹¶ن¸”能ه¤ںèژ·هڈ–çٹ¶و€پ,ن»£è،¨è¯¥ه½“ه‰چèٹ‚点هچ وœ‰é”پï¼›
ه¦‚وœو»،足ن¸ٹè؟°و،ن»¶ï¼Œé‚£ن¹ˆن»£è،¨èƒ½ه¤ںهچ وœ‰é”پ,و ¹وچ®èٹ‚点ه¯¹é”پهچ وœ‰çڑ„هگ«ن¹‰ï¼Œè®¾ç½®ه¤´ç»“点ن¸؛ه½“ه‰چèٹ‚点م€‚
3. هگ¦هˆ™è؟›ه…¥ç‰ه¾…çٹ¶و€پم€‚
ه¦‚وœو²،وœ‰è½®هˆ°ه½“ه‰چèٹ‚点è؟گè،Œï¼Œé‚£ن¹ˆه°†ه½“ه‰چç؛؟程ن»ژç؛؟程调ه؛¦ه™¨ن¸ٹو‘کن¸‹ï¼Œن¹ںه°±وک¯è؟›ه…¥ç‰ه¾…çٹ¶و€پم€‚
è؟™é‡Œé’ˆه¯¹acquireهپڑن¸€ن¸‹و€»ç»“ï¼ڑ
1. çٹ¶و€پçڑ„ç»´وٹ¤ï¼›
需è¦پهœ¨é”په®ڑو—¶ï¼Œéœ€è¦پç»´وٹ¤ن¸€ن¸ھçٹ¶و€پ(intç±»ه‹),而ه¯¹çٹ¶و€پçڑ„و“چن½œوک¯هژںهگه’Œééک»ه،çڑ„,é€ڑè؟‡هگŒو¥ه™¨وڈگن¾›çڑ„ه¯¹çٹ¶و€پè®؟é—®çڑ„و–¹و³•ه¯¹çٹ¶و€پè؟›è،Œو“چç؛µï¼Œه¹¶ن¸”هˆ©ç”¨compareAndSetو¥ç،®ن؟هژںهگو€§çڑ„ن؟®و”¹م€‚
2. çٹ¶و€پçڑ„èژ·هڈ–ï¼›
ن¸€و—¦وˆگهٹںçڑ„ن؟®و”¹ن؛†çٹ¶و€پ,ه½“ه‰چç؛؟程وˆ–者说èٹ‚点,ه°±è¢«è®¾ç½®ن¸؛ه¤´èٹ‚点م€‚
3. syncéکںهˆ—çڑ„ç»´وٹ¤م€‚
هœ¨èژ·هڈ–资و؛گوœھوœçڑ„è؟‡ç¨‹ن¸و،ن»¶ن¸چ符هگˆçڑ„وƒ…ه†µن¸‹(ن¸چ该è‡ھه·±ï¼Œه‰چ驱èٹ‚点ن¸چوک¯ه¤´èٹ‚点وˆ–者و²،وœ‰èژ·هڈ–هˆ°èµ„و؛گ)è؟›ه…¥ç،çœ çٹ¶و€پ,هپœو¢ç؛؟程调ه؛¦ه™¨ه¯¹ه½“ه‰چèٹ‚点ç؛؟程çڑ„è°ƒه؛¦م€‚
è؟™و—¶ه¼•ه…¥çڑ„ن¸€ن¸ھé‡ٹو”¾çڑ„é—®é¢ک,ن¹ںه°±وک¯è¯´ن½؟ç،çœ ن¸çڑ„Nodeوˆ–者说ç؛؟程èژ·ه¾—é€ڑçں¥çڑ„ه…³é”®ï¼Œه°±وک¯ه‰چ驱èٹ‚点çڑ„é€ڑçں¥ï¼Œè€Œè؟™ن¸€ن¸ھè؟‡ç¨‹ه°±وک¯é‡ٹو”¾ï¼Œé‡ٹو”¾ن¼ڑé€ڑçں¥ه®ƒçڑ„هگژ继èٹ‚点ن»ژç،çœ ن¸è؟”ه›ه‡†ه¤‡è؟گè،Œم€‚
ن¸‹é¢çڑ„وµپ程ه›¾هں؛وœ¬وڈڈè؟°ن؛†ن¸€و¬،acquireو‰€éœ€è¦پç»ڈهژ†çڑ„è؟‡ç¨‹ï¼ڑ
ه¦‚ن¸ٹه›¾و‰€ç¤؛,ه…¶ن¸çڑ„هˆ¤ه®ڑ退ه‡؛éکںهˆ—çڑ„و،ن»¶ï¼Œهˆ¤ه®ڑو،ن»¶وک¯هگ¦و»،足ه’Œن¼‘çœ ه½“ه‰چç؛؟程ه°±وک¯ه®Œوˆگن؛†è‡ھو—‹spinçڑ„è؟‡ç¨‹م€‚
public final boolean release(int arg)
هœ¨unlockو–¹و³•çڑ„ه®çژ°ن¸ï¼Œن½؟用ن؛†هگŒو¥ه™¨çڑ„releaseو–¹و³•م€‚相ه¯¹ن؛ژهœ¨ن¹‹ه‰چçڑ„acquireو–¹و³•ن¸هڈ¯ن»¥ه¾—ه‡؛调用acquire,ن؟è¯پ能ه¤ںèژ·هڈ–هˆ°é”پ(وˆگهٹںèژ·هڈ–çٹ¶و€پ),而releaseهˆ™è،¨ç¤؛ه°†çٹ¶و€پ设置ه›هژ»ï¼Œن¹ںه°±وک¯ه°†èµ„و؛گé‡ٹو”¾ï¼Œوˆ–者说ه°†é”پé‡ٹو”¾م€‚
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
ن¸ٹè؟°é€»è¾‘ن¸»è¦پهŒ…و‹¬ï¼ڑ
1. ه°è¯•é‡ٹو”¾çٹ¶و€پï¼›
tryRelease能ه¤ںن؟è¯پهژںهگهŒ–çڑ„ه°†çٹ¶و€پ设置ه›هژ»ï¼Œه½“然需è¦پن½؟用compareAndSetو¥ن؟è¯پم€‚ه¦‚وœé‡ٹو”¾çٹ¶و€پوˆگهٹںè؟‡ن¹‹هگژ,ه°†ن¼ڑè؟›ه…¥هگژ继èٹ‚点çڑ„ه”¤é†’è؟‡ç¨‹م€‚
2. ه”¤é†’ه½“ه‰چèٹ‚点çڑ„هگژ继èٹ‚点و‰€هŒ…هگ«çڑ„ç؛؟程م€‚
é€ڑè؟‡LockSupportçڑ„unparkو–¹و³•ه°†ن¼‘çœ ن¸çڑ„ç؛؟程ه”¤é†’,让ه…¶ç»§ç»acquireçٹ¶و€پم€‚
private void unparkSuccessor(Node node) {
// ه°†çٹ¶و€پ设置ن¸؛هگŒو¥çٹ¶و€پ
int ws = node.waitStatus;
if (ws < 0) compareAndSetWaitStatus(node, ws, 0); // èژ·هڈ–ه½“ه‰چèٹ‚点çڑ„هگژ继èٹ‚点,ه¦‚وœو»،足çٹ¶و€پ,那ن¹ˆè؟›è،Œه”¤é†’و“چن½œ // ه¦‚وœو²،وœ‰و»،足çٹ¶و€پ,ن»ژه°¾éƒ¨ه¼€ه§‹و‰¾ه¯»ç¬¦هگˆè¦پو±‚çڑ„èٹ‚点ه¹¶ه°†ه…¶ه”¤é†’ Node s = node.next; if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
ن¸ٹè؟°é€»è¾‘ن¸»è¦پهŒ…و‹¬ï¼Œè¯¥و–¹و³•هڈ–ه‡؛ن؛†ه½“ه‰چèٹ‚点çڑ„nextه¼•ç”¨ï¼Œç„¶هگژه¯¹ه…¶ç؛؟程(Node)è؟›è،Œن؛†ه”¤é†’,è؟™و—¶ه°±هڈھوœ‰ن¸€ن¸ھوˆ–هگˆçگ†ن¸ھو•°çڑ„ç؛؟程被ه”¤é†’,被ه”¤é†’çڑ„ç؛؟程继ç»è؟›è،Œه¯¹èµ„و؛گçڑ„èژ·هڈ–ن¸ژن؛‰ه¤؛م€‚
ه›é،¾و•´ن¸ھ资و؛گçڑ„èژ·هڈ–ه’Œé‡ٹو”¾è؟‡ç¨‹ï¼ڑ
هœ¨èژ·هڈ–و—¶ï¼Œç»´وٹ¤ن؛†ن¸€ن¸ھsyncéکںهˆ—,و¯ڈن¸ھèٹ‚点都وک¯ن¸€ن¸ھç؛؟程هœ¨è؟›è،Œè‡ھو—‹ï¼Œè€Œن¾وچ®ه°±وک¯è‡ھه·±وک¯هگ¦وک¯é¦–èٹ‚点çڑ„هگژ继ه¹¶ن¸”能ه¤ںèژ·هڈ–资و؛گï¼›
هœ¨é‡ٹو”¾و—¶ï¼Œن»…ن»…需è¦په°†èµ„و؛گè؟که›هژ»ï¼Œç„¶هگژé€ڑçں¥ن¸€ن¸‹هگژ继èٹ‚点ه¹¶ه°†ه…¶ه”¤é†’م€‚
è؟™é‡Œéœ€è¦پو³¨و„ڈ,éکںهˆ—çڑ„ç»´وٹ¤ï¼ˆé¦–èٹ‚点çڑ„و›´وچ¢ï¼‰وک¯ن¾é و¶ˆè´¹è€…(èژ·هڈ–و—¶ï¼‰و¥ه®Œوˆگçڑ„,ن¹ںه°±وک¯è¯´هœ¨و»،足ن؛†è‡ھو—‹é€€ه‡؛çڑ„و،ن»¶و—¶çڑ„ن¸€هˆ»ï¼Œè؟™ن¸ھèٹ‚点ه°±ن¼ڑ被设置وˆگن¸؛首èٹ‚点م€‚
protected boolean tryAcquire(int arg)
tryAcquireوک¯è‡ھه®ڑن¹‰هگŒو¥ه™¨éœ€è¦په®çژ°çڑ„و–¹و³•ï¼Œن¹ںه°±وک¯è‡ھه®ڑن¹‰هگŒو¥ه™¨ééک»ه،هژںهگهŒ–çڑ„èژ·هڈ–çٹ¶و€پ,ه¦‚وœé”پ该و–¹و³•ن¸€èˆ¬ç”¨ن؛ژLockçڑ„tryLockه®çژ°ن¸ï¼Œè؟™ن¸ھ特و€§وک¯synchronizedو— و³•وڈگن¾›çڑ„م€‚
public final void acquireInterruptibly(int arg)
该و–¹و³•وڈگن¾›èژ·هڈ–çٹ¶و€پ能هٹ›ï¼Œه½“然هœ¨و— و³•èژ·هڈ–çٹ¶و€پçڑ„وƒ…ه†µن¸‹ن¼ڑè؟›ه…¥syncéکںهˆ—è؟›è،Œوژ’éکں,è؟™ç±»ن¼¼acquire,ن½†وک¯ه’Œacquireن¸چهگŒçڑ„هœ°و–¹هœ¨ن؛ژه®ƒèƒ½ه¤ںهœ¨ه¤–ç•Œه¯¹ه½“ه‰چç؛؟程è؟›è،Œن¸و–çڑ„و—¶ه€™وڈگه‰چ结وںèژ·هڈ–çٹ¶و€پçڑ„و“چن½œï¼Œوچ¢هڈ¥è¯è¯´ï¼Œه°±وک¯هœ¨ç±»ن¼¼synchronizedèژ·هڈ–é”پو—¶ï¼Œه¤–界能ه¤ںه¯¹ه½“ه‰چç؛؟程è؟›è،Œن¸و–,ه¹¶ن¸”èژ·هڈ–é”پçڑ„è؟™ن¸ھو“چن½œèƒ½ه¤ںه“چه؛”ن¸و–ه¹¶وڈگه‰چè؟”ه›م€‚ن¸€ن¸ھç؛؟程ه¤„ن؛ژsynchronizedه—ن¸وˆ–者è؟›è،ŒهگŒو¥I/Oو“چن½œو—¶ï¼Œه¯¹è¯¥ç؛؟程è؟›è،Œن¸و–و“چن½œï¼Œè؟™و—¶è¯¥ç؛؟程çڑ„ن¸و–و ‡è¯†ن½چ被设置ن¸؛true,ن½†وک¯ç؛؟程ن¾و—§ç»§ç»è؟گè،Œم€‚
ه¦‚وœهœ¨èژ·هڈ–ن¸€ن¸ھé€ڑè؟‡ç½‘络ن؛¤ن؛’ه®çژ°çڑ„é”پو—¶ï¼Œè؟™ن¸ھé”پ资و؛گçھپ然è؟›è،Œن؛†é”€و¯پ,那ن¹ˆن½؟用acquireInterruptiblyçڑ„èژ·هڈ–و–¹ه¼ڈه°±èƒ½ه¤ں让该و—¶هˆ»ه°è¯•èژ·هڈ–é”پçڑ„ç؛؟程وڈگه‰چè؟”ه›م€‚而هگŒو¥ه™¨çڑ„è؟™ن¸ھ特و€§è¢«ه®çژ°Lockوژ¥هڈ£ن¸çڑ„lockInterruptiblyو–¹و³•م€‚و ¹وچ®Lockçڑ„è¯ن¹‰ï¼Œهœ¨è¢«ن¸و–و—¶ï¼ŒlockInterruptiblyه°†ن¼ڑوٹ›ه‡؛InterruptedExceptionو¥ه‘ٹçں¥ن½؟用者م€‚
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
// و£€وµ‹ن¸و–و ‡ه؟—ن½چ
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
ن¸ٹè؟°é€»è¾‘ن¸»è¦پهŒ…و‹¬ï¼ڑ
1. و£€وµ‹ه½“ه‰چç؛؟程وک¯هگ¦è¢«ن¸و–ï¼›
هˆ¤و–ه½“ه‰چç؛؟程çڑ„ن¸و–و ‡ه؟—ن½چ,ه¦‚وœه·²ç»ڈ被ن¸و–ن؛†ï¼Œé‚£ن¹ˆç›´وژ¥وٹ›ه‡؛ه¼‚ه¸¸ه¹¶ه°†ن¸و–و ‡ه؟—ن½چ设置ن¸؛falseم€‚
2. ه°è¯•èژ·هڈ–çٹ¶و€پï¼›
调用tryAcquireèژ·هڈ–çٹ¶و€پ,ه¦‚وœé،؛هˆ©ن¼ڑèژ·هڈ–وˆگهٹںه¹¶è؟”ه›م€‚
3. و„é€ èٹ‚点ه¹¶هٹ ه…¥syncéکںهˆ—ï¼›
èژ·هڈ–çٹ¶و€په¤±è´¥هگژ,ه°†ه½“ه‰چç؛؟程ه¼•ç”¨و„é€ ن¸؛èٹ‚点ه¹¶هٹ ه…¥هˆ°syncéکںهˆ—ن¸م€‚退ه‡؛éکںهˆ—çڑ„و–¹ه¼ڈهœ¨و²،وœ‰ن¸و–çڑ„هœ؛و™¯ن¸‹ه’ŒacquireQueuedç±»ن¼¼ï¼Œه½“ه¤´ç»“点وک¯è‡ھه·±çڑ„ه‰چ驱èٹ‚点ه¹¶ن¸”能ه¤ںèژ·هڈ–هˆ°çٹ¶و€پو—¶ï¼Œهچ³هڈ¯ن»¥è؟گè،Œï¼Œه½“然è¦په°†وœ¬èٹ‚点设置ن¸؛ه¤´ç»“点,è،¨ç¤؛و£هœ¨è؟گè،Œم€‚
4. ن¸و–و£€وµ‹م€‚
هœ¨و¯ڈو¬،被ه”¤é†’و—¶ï¼Œè؟›è،Œن¸و–و£€وµ‹ï¼Œه¦‚وœهڈ‘çژ°ه½“ه‰چç؛؟程被ن¸و–,那ن¹ˆوٹ›ه‡؛InterruptedExceptionه¹¶é€€ه‡؛ه¾ھçژ¯م€‚
private boolean doAcquireNanos(int arg, long nanosTimeout) throws InterruptedException
该و–¹و³•وڈگن¾›ن؛†ه…·ه¤‡وœ‰è¶…و—¶هٹں能çڑ„èژ·هڈ–çٹ¶و€پçڑ„调用,ه¦‚وœهœ¨وŒ‡ه®ڑçڑ„nanosTimeoutه†…و²،وœ‰èژ·هڈ–هˆ°çٹ¶و€پ,那ن¹ˆè؟”ه›false,هڈچن¹‹è؟”ه›trueم€‚هڈ¯ن»¥ه°†è¯¥و–¹و³•çœ‹هپڑacquireInterruptiblyçڑ„هچ‡ç؛§ç‰ˆï¼Œن¹ںه°±وک¯هœ¨هˆ¤و–وک¯هگ¦è¢«ن¸و–çڑ„هں؛ç،€ن¸ٹه¢هٹ ن؛†è¶…و—¶وژ§هˆ¶م€‚
é’ˆه¯¹è¶…و—¶وژ§هˆ¶è؟™éƒ¨هˆ†çڑ„ه®çژ°ï¼Œن¸»è¦پ需è¦پè®،ç®—ه‡؛ç،çœ çڑ„delta,ن¹ںه°±وک¯é—´éڑ”ه€¼م€‚é—´éڑ”هڈ¯ن»¥è،¨ç¤؛ن¸؛nanosTimeout = هژںوœ‰nanosTimeout – now(ه½“ه‰چو—¶é—´ï¼‰+ lastTime(ç،çœ ن¹‹ه‰چè®°ه½•çڑ„و—¶é—´ï¼‰م€‚ه¦‚وœnanosTimeoutه¤§ن؛ژ0,那ن¹ˆè؟ک需è¦پن½؟ه½“ه‰چç؛؟程ç،çœ ï¼Œهڈچن¹‹هˆ™è؟”ه›falseم€‚
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
long lastTime = System.nanoTime();
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
if (nanosTimeout <= 0) return false; if (shouldParkAfterFailedAcquire(p, node) && nanosTimeout > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
long now = System.nanoTime();
//è®،ç®—و—¶é—´ï¼Œه½“ه‰چو—¶é—´ه‡ڈهژ»ç،çœ ن¹‹ه‰چçڑ„و—¶é—´ه¾—هˆ°ç،çœ çڑ„و—¶é—´ï¼Œç„¶هگژ被
//هژںوœ‰è¶…و—¶و—¶é—´ه‡ڈهژ»ï¼Œه¾—هˆ°ن؛†è؟که؛”该ç،çœ çڑ„و—¶é—´
nanosTimeout -= now - lastTime;
lastTime = now;
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
ن¸ٹè؟°é€»è¾‘ن¸»è¦پهŒ…و‹¬ï¼ڑ
1. هٹ ه…¥syncéکںهˆ—ï¼›
ه°†ه½“ه‰چç؛؟程و„é€ وˆگن¸؛èٹ‚点Nodeهٹ ه…¥هˆ°syncéکںهˆ—ن¸م€‚
2. و،ن»¶و»،足直وژ¥è؟”ه›ï¼›
退ه‡؛و،ن»¶هˆ¤و–,ه¦‚وœه‰چ驱èٹ‚点وک¯ه¤´ç»“点ه¹¶ن¸”وˆگهٹںèژ·هڈ–هˆ°çٹ¶و€پ,那ن¹ˆè®¾ç½®è‡ھه·±ن¸؛ه¤´ç»“点ه¹¶é€€ه‡؛,è؟”ه›true,ن¹ںه°±وک¯هœ¨وŒ‡ه®ڑçڑ„nanosTimeoutن¹‹ه‰چèژ·هڈ–ن؛†é”پم€‚
3. èژ·هڈ–çٹ¶و€په¤±è´¥ن¼‘çœ ن¸€و®µو—¶é—´ï¼›
é€ڑè؟‡LockSupport.unparkو¥وŒ‡ه®ڑه½“ه‰چç؛؟程ن¼‘çœ ن¸€و®µو—¶é—´م€‚
4. è®،ç®—ه†چو¬،ن¼‘çœ çڑ„و—¶é—´ï¼›
ه”¤é†’هگژçڑ„ç؛؟程,è®،ç®—ن»چ需è¦پن¼‘çœ çڑ„و—¶é—´ï¼Œè¯¥و—¶é—´è،¨ç¤؛ن¸؛nanosTimeout = هژںوœ‰nanosTimeout – now(ه½“ه‰چو—¶é—´ï¼‰+ lastTime(ç،çœ ن¹‹ه‰چè®°ه½•çڑ„و—¶é—´ï¼‰م€‚ه…¶ن¸now – lastTimeè،¨ç¤؛è؟™و¬،ç،çœ و‰€وŒپç»çڑ„و—¶é—´م€‚
5. ن¼‘çœ و—¶é—´çڑ„هˆ¤ه®ڑم€‚
ه”¤é†’هگژçڑ„ç؛؟程,è®،ç®—ن»چ需è¦پن¼‘çœ çڑ„و—¶é—´ï¼Œه¹¶و— éک»ه،çڑ„ه°è¯•ه†چèژ·هڈ–çٹ¶و€پ,ه¦‚وœه¤±è´¥هگژوں¥çœ‹ه…¶nanosTimeoutوک¯هگ¦ه¤§ن؛ژ0,ه¦‚وœه°ڈن؛ژ0,那ن¹ˆè؟”ه›ه®Œه…¨è¶…و—¶ï¼Œو²،وœ‰èژ·هڈ–هˆ°é”پم€‚ ه¦‚وœnanosTimeoutه°ڈن؛ژç‰ن؛ژ1000Lç؛³ç§’,هˆ™è؟›ه…¥ه؟«é€ںçڑ„è‡ھو—‹è؟‡ç¨‹م€‚é‚£ن¹ˆه؟«é€ںè‡ھو—‹ن¼ڑé€ وˆگه¤„çگ†ه™¨èµ„و؛گç´§ه¼ هگ—ï¼ں结وœوک¯ن¸چن¼ڑ,ç»ڈè؟‡وµ‹ç®—,ه¼€é”€çœ‹èµ·و¥ه¾ˆه°ڈ,ه‡ ن¹ژه¾®ن¹ژه…¶ه¾®م€‚Doug Leaه؛”该وµ‹ç®—ن؛†هœ¨ç؛؟程调ه؛¦ه™¨ن¸ٹçڑ„هˆ‡وچ¢é€ وˆگçڑ„é¢ه¤–ه¼€é”€ï¼Œه› و¤هœ¨çںو—¶1000ç؛³ç§’ه†…ه°±è®©ه½“ه‰چç؛؟程è؟›ه…¥ه؟«é€ںè‡ھو—‹çٹ¶و€پ,ه¦‚وœè؟™و—¶ه†چن¼‘çœ ç›¸هڈچن¼ڑ让nanosTimeoutçڑ„èژ·هڈ–و—¶é—´هڈکه¾—و›´هٹ ن¸چç²¾ç،®م€‚
ن¸ٹè؟°è؟‡ç¨‹هڈ¯ن»¥ه¦‚ن¸‹ه›¾و‰€ç¤؛ï¼ڑ
ن¸ٹè؟°è؟™ن¸ھه›¾ن¸هڈ¯ن»¥çگ†è§£ن¸؛هœ¨ç±»ن¼¼èژ·هڈ–çٹ¶و€پ需è¦پوژ’éکںçڑ„هں؛ç،€ن¸ٹه¢هٹ ن؛†ن¸€ن¸ھ超و—¶وژ§هˆ¶çڑ„逻辑م€‚و¯ڈو¬،超و—¶çڑ„و—¶é—´ه°±وک¯ه½“ه‰چ超و—¶ه‰©ن½™çڑ„و—¶é—´ه‡ڈهژ»ç،çœ çڑ„و—¶é—´ï¼Œè€Œهœ¨è؟™ن¸ھ超و—¶و—¶é—´çڑ„هں؛ç،€ن¸ٹè؟›è،Œن؛†هˆ¤و–,ه¦‚وœه¤§ن؛ژ0é‚£ن¹ˆç»§ç»ç،çœ ï¼ˆç‰ه¾…),هڈ¯ن»¥çœ‹ه‡؛è؟™ن¸ھ超و—¶ç‰ˆوœ¬çڑ„èژ·هڈ–çٹ¶و€پهڈھوک¯ن¸€ن¸ھè؟‘ن¼¼è¶…و—¶çڑ„èژ·هڈ–çٹ¶و€پ,ه› و¤ن»»ن½•هگ«وœ‰è¶…و—¶çڑ„调用هں؛وœ¬ç»“وœه°±وک¯è؟‘ن¼¼ن؛ژç»™ه®ڑ超و—¶م€‚
public final void acquireShared(int arg)
调用该و–¹و³•èƒ½ه¤ںن»¥ه…±ن؛«و¨،ه¼ڈèژ·هڈ–çٹ¶و€پ,ه…±ن؛«و¨،ه¼ڈه’Œن¹‹ه‰چçڑ„独هچ و¨،ه¼ڈوœ‰و‰€هŒ؛هˆ«م€‚ن»¥و–‡ن»¶çڑ„وں¥çœ‹ن¸؛ن¾‹ï¼Œه¦‚وœن¸€ن¸ھ程ه؛ڈهœ¨ه¯¹ه…¶è؟›è،Œè¯»هڈ–و“چن½œï¼Œé‚£ن¹ˆè؟™ن¸€و—¶هˆ»ï¼Œه¯¹è؟™ن¸ھو–‡ن»¶çڑ„ه†™و“چن½œه°±è¢«éک»ه،,相هڈچ,è؟™ن¸€و—¶هˆ»هڈ¦ن¸€ن¸ھ程ه؛ڈه¯¹ه…¶è؟›è،ŒهگŒو ·çڑ„读و“چن½œوک¯هڈ¯ن»¥è؟›è،Œçڑ„م€‚ه¦‚وœن¸€ن¸ھ程ه؛ڈهœ¨ه¯¹ه…¶è؟›è،Œه†™و“چن½œï¼Œé‚£ن¹ˆو‰€وœ‰çڑ„读ن¸ژه†™و“چن½œهœ¨è؟™ن¸€و—¶هˆ»ه°±è¢«éک»ه،,直هˆ°è؟™ن¸ھ程ه؛ڈه®Œوˆگه†™و“چن½œم€‚
ن»¥è¯»ه†™هœ؛و™¯ن¸؛ن¾‹ï¼Œوڈڈè؟°ه…±ن؛«ه’Œç‹¬هچ çڑ„è®؟é—®و¨،ه¼ڈ,ه¦‚ن¸‹ه›¾و‰€ç¤؛ï¼ڑ
ن¸ٹه›¾ن¸ï¼Œç؛¢è‰²ن»£è،¨è¢«éک»ه،,ç»؟色ن»£è،¨هڈ¯ن»¥é€ڑè؟‡م€‚
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0) doAcquireShared(arg); } private void doAcquireShared(int arg) { final Node node = addWaiter(Node.SHARED); boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); if (p == head) { int r = tryAcquireShared(arg); if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
ن¸ٹè؟°é€»è¾‘ن¸»è¦پهŒ…و‹¬ï¼ڑ
1. ه°è¯•èژ·هڈ–ه…±ن؛«çٹ¶و€پï¼›
调用tryAcquireSharedو¥èژ·هڈ–ه…±ن؛«çٹ¶و€پ,该و–¹و³•وک¯ééک»ه،çڑ„,ه¦‚وœèژ·هڈ–وˆگهٹںهˆ™ç«‹هˆ»è؟”ه›ï¼Œن¹ںه°±è،¨ç¤؛èژ·هڈ–ه…±ن؛«é”پوˆگهٹںم€‚
2. èژ·هڈ–ه¤±è´¥è؟›ه…¥syncéکںهˆ—ï¼›
هœ¨èژ·هڈ–ه…±ن؛«çٹ¶و€په¤±è´¥هگژ,ه½“ه‰چو—¶هˆ»وœ‰هڈ¯èƒ½وک¯ç‹¬هچ é”پ被ه…¶ن»–ç؛؟程و‰€وٹٹوŒپ,那ن¹ˆه°†ه½“ه‰چç؛؟程و„é€ وˆگن¸؛èٹ‚点(ه…±ن؛«و¨،ه¼ڈ)هٹ ه…¥هˆ°syncéکںهˆ—ن¸م€‚
3. ه¾ھçژ¯ه†…هˆ¤و–退ه‡؛éکںهˆ—و،ن»¶ï¼›
ه¦‚وœه½“ه‰چèٹ‚点çڑ„ه‰چ驱èٹ‚点وک¯ه¤´ç»“点ه¹¶ن¸”èژ·هڈ–ه…±ن؛«çٹ¶و€پوˆگهٹں,è؟™é‡Œه’Œç‹¬هچ é”پacquireçڑ„退ه‡؛éکںهˆ—و،ن»¶ç±»ن¼¼م€‚
4. èژ·هڈ–ه…±ن؛«çٹ¶و€پوˆگهٹںï¼›
هœ¨é€€ه‡؛éکںهˆ—çڑ„و،ن»¶ن¸ٹ,ه’Œç‹¬هچ é”پن¹‹é—´çڑ„ن¸»è¦پهŒ؛هˆ«هœ¨ن؛ژèژ·هڈ–ه…±ن؛«çٹ¶و€پوˆگهٹںن¹‹هگژçڑ„è،Œن¸؛,而ه¦‚وœه…±ن؛«çٹ¶و€پèژ·هڈ–وˆگهٹںن¹‹هگژن¼ڑهˆ¤و–هگژ继èٹ‚点وک¯هگ¦وک¯ه…±ن؛«و¨،ه¼ڈ,ه¦‚وœوک¯ه…±ن؛«و¨،ه¼ڈ,那ن¹ˆه°±ç›´وژ¥ه¯¹ه…¶è؟›è،Œه”¤é†’و“چن½œï¼Œن¹ںه°±وک¯هگŒو—¶و؟€هڈ‘ه¤ڑن¸ھç؛؟程ه¹¶هڈ‘çڑ„è؟گè،Œم€‚
5. èژ·هڈ–ه…±ن؛«çٹ¶و€په¤±è´¥م€‚
é€ڑè؟‡ن½؟用LockSupportه°†ه½“ه‰چç؛؟程ن»ژç؛؟程调ه؛¦ه™¨ن¸ٹو‘کن¸‹ï¼Œè؟›ه…¥ن¼‘çœ çٹ¶و€پم€‚
ه¯¹ن؛ژن¸ٹè؟°é€»è¾‘ن¸ï¼Œèٹ‚点ن¹‹é—´çڑ„é€ڑçں¥è؟‡ç¨‹ه¦‚ن¸‹ه›¾و‰€ç¤؛ï¼ڑ
ن¸ٹه›¾ن¸ï¼Œç»؟色è،¨ç¤؛ه…±ن؛«èٹ‚点,ه®ƒن»¬ن¹‹é—´çڑ„é€ڑçں¥ه’Œه”¤é†’و“چن½œوک¯هœ¨ه‰چ驱èٹ‚点èژ·هڈ–çٹ¶و€پو—¶ه°±è؟›è،Œçڑ„,ç؛¢è‰²è،¨ç¤؛独هچ èٹ‚点,ه®ƒçڑ„被ه”¤é†’ه؟…é،»هڈ–ه†³ن؛ژه‰چ驱èٹ‚点çڑ„é‡ٹو”¾ï¼Œن¹ںه°±وک¯releaseو“چن½œï¼Œهڈ¯ن»¥çœ‹ه‡؛و¥ه›¾ن¸çڑ„独هچ èٹ‚点ه¦‚وœè¦پè؟گè،Œï¼Œه؟…é،»ç‰ه¾…ه‰چé¢çڑ„ه…±ن؛«èٹ‚点ه‡é‡ٹو”¾ن؛†çٹ¶و€پو‰چهڈ¯ن»¥م€‚而独هچ èٹ‚点ه¦‚وœèژ·هڈ–ن؛†çٹ¶و€پ,那ن¹ˆهگژç»çڑ„独هچ ه¼ڈèژ·هڈ–ه’Œه…±ن؛«ه¼ڈèژ·هڈ–ه‡è¢«éک»ه،م€‚
public final boolean releaseShared(int arg)
调用该و–¹و³•é‡ٹو”¾ه…±ن؛«çٹ¶و€پ,و¯ڈو¬،èژ·هڈ–ه…±ن؛«çٹ¶و€پacquireShared都ن¼ڑو“چن½œçٹ¶و€پ,هگŒو ·هœ¨ه…±ن؛«é”پé‡ٹو”¾çڑ„و—¶ه€™ï¼Œن¹ں需è¦په°†çٹ¶و€پé‡ٹو”¾م€‚و¯”ه¦‚说,ن¸€ن¸ھé™گه®ڑن¸€ه®ڑو•°é‡ڈè®؟é—®çڑ„هگŒو¥ه·¥ه…·ï¼Œو¯ڈو¬،èژ·هڈ–都وک¯ه…±ن؛«çڑ„,ن½†وک¯ه¦‚وœè¶…è؟‡ن؛†ن¸€ه®ڑçڑ„و•°é‡ڈ,ه°†ن¼ڑéک»ه،هگژç»çڑ„èژ·هڈ–و“چن½œï¼Œهڈھوœ‰ه½“ن¹‹ه‰چèژ·هڈ–çڑ„و¶ˆè´¹è€…ه°†çٹ¶و€پé‡ٹو”¾و‰چهڈ¯ن»¥ن½؟éک»ه،çڑ„èژ·هڈ–و“چن½œه¾—ن»¥è؟گè،Œم€‚
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
ن¸ٹè؟°é€»è¾‘ن¸»è¦په°±وک¯è°ƒç”¨هگŒو¥ه™¨çڑ„tryReleaseSharedو–¹و³•و¥é‡ٹو”¾çٹ¶و€پ,ه¹¶هگŒو—¶هœ¨doReleaseSharedو–¹و³•ن¸ه”¤é†’ه…¶هگژ继èٹ‚点م€‚
ن¸€ن¸ھن¾‹هگ
هœ¨ن¸ٹè؟°ه¯¹هگŒو¥ه™¨AbstractQueuedSynchronizerè؟›è،Œن؛†ه®çژ°ه±‚é¢çڑ„هˆ†وگن¹‹هگژ,وˆ‘ن»¬é€ڑè؟‡ن¸€ن¸ھن¾‹هگو¥هٹ و·±ه¯¹هگŒو¥ه™¨çڑ„çگ†è§£ï¼ڑ
设è®،ن¸€ن¸ھهگŒو¥ه·¥ه…·ï¼Œè¯¥ه·¥ه…·هœ¨هگŒن¸€و—¶هˆ»ï¼Œهڈھ能وœ‰ن¸¤ن¸ھç؛؟程能ه¤ںه¹¶è،Œè®؟问,超è؟‡é™گهˆ¶çڑ„ه…¶ن»–ç؛؟程è؟›ه…¥éک»ه،çٹ¶و€پم€‚
ه¯¹ن؛ژè؟™ن¸ھ需و±‚,هڈ¯ن»¥هˆ©ç”¨هگŒو¥ه™¨ه®Œوˆگن¸€ن¸ھè؟™و ·çڑ„设ه®ڑ,ه®ڑن¹‰ن¸€ن¸ھهˆه§‹çٹ¶و€پ,ن¸؛2,ن¸€ن¸ھç؛؟程è؟›è،Œèژ·هڈ–é‚£ن¹ˆه‡ڈ1,ن¸€ن¸ھç؛؟程é‡ٹو”¾é‚£ن¹ˆهٹ 1,çٹ¶و€پو£ç،®çڑ„范ه›´هœ¨[0,1,2]ن¸‰ن¸ھن¹‹é—´ï¼Œه½“هœ¨0و—¶ï¼Œن»£è،¨ه†چوœ‰و–°çڑ„ç؛؟程ه¯¹èµ„و؛گè؟›è،Œèژ·هڈ–و—¶هڈھ能è؟›ه…¥éک»ه،çٹ¶و€پ(و³¨و„ڈهœ¨ن»»ن½•و—¶ه€™è؟›è،Œçٹ¶و€پهڈکو›´çڑ„و—¶ه€™ه‡éœ€è¦پن»¥CASن½œن¸؛هژںهگو€§ن؟éڑœï¼‰م€‚ç”±ن؛ژ资و؛گçڑ„و•°é‡ڈه¤ڑن؛ژ1ن¸ھ,هگŒو—¶هڈ¯ن»¥وœ‰ن¸¤ن¸ھç؛؟程هچ وœ‰èµ„و؛گ,ه› و¤éœ€è¦په®çژ°tryAcquireSharedه’ŒtryReleaseSharedو–¹و³•ï¼Œè؟™é‡Œè°¢è°¢luoyuyouه’ŒهگŒن؛‹ه°ڈوکژوŒ‡و£ï¼Œه·²ç»ڈن؟®و”¹ن؛†ه®çژ°م€‚
public class TwinsLock implements Lock {
private final Sync sync = new Sync(2);
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = -7889272986162341211L;
Sync(int count) {
if (count <= 0) {
throw new IllegalArgumentException("count must large than zero.");
}
setState(count);
}
public int tryAcquireShared(int reduceCount) {
for (;;) {
int current = getState();
int newCount = current - reduceCount;
if (newCount < 0 || compareAndSetState(current, newCount)) {
return newCount;
}
}
}
public boolean tryReleaseShared(int returnCount) {
for (;;) {
int current = getState();
int newCount = current + returnCount;
if (compareAndSetState(current, newCount)) {
return true;
}
}
}
}
public void lock() {
sync.acquireShared(1);
}
public void lockInterruptibly() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public boolean tryLock() {
return sync.tryAcquireShared(1) >= 0;
}
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireSharedNanos(1, unit.toNanos(time));
}
public void unlock() {
sync.releaseShared(1);
}
@Override
public Condition newCondition() {
return null;
}
}
è؟™é‡Œوˆ‘ن»¬ç¼–ه†™ن¸€ن¸ھوµ‹è¯•و¥éھŒè¯پTwinsLockوک¯هگ¦èƒ½ه¤ںو£ه¸¸ه·¥ن½œه¹¶è¾¾هˆ°é¢„وœںم€‚
public class TwinsLockTest {
@Test
public void test() {
final Lock lock = new TwinsLock();
class Worker extends Thread {
public void run() {
while (true) {
lock.lock();
try {
Thread.sleep(1000L);
System.out.println(Thread.currentThread());
Thread.sleep(1000L);
} catch (Exception ex) {
} finally {
lock.unlock();
}
}
}
}
for (int i = 0; i < 10; i++) {
Worker w = new Worker();
w.start();
}
new Thread() {
public void run() {
while (true) {
try {
Thread.sleep(200L);
System.out.println();
} catch (Exception ex) {
}
}
}
}.start();
try {
Thread.sleep(20000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
ن¸ٹè؟°وµ‹è¯•ç”¨ن¾‹çڑ„逻辑ن¸»è¦پهŒ…و‹¬ï¼ڑ
​1. و‰“هچ°ç؛؟程
Workerهœ¨ن¸¤و¬،ç،çœ ن¹‹é—´و‰“هچ°è‡ھè؛«ç؛؟程,ه¦‚وœن¸€ن¸ھو—¶هˆ»هڈھ能وœ‰ن¸¤ن¸ھç؛؟程هگŒو—¶è®؟问,那ن¹ˆو‰“هچ°ه‡؛و¥çڑ„ه†…ه®¹ه°†وک¯وˆگه¯¹ه‡؛çژ°م€‚
​2. هˆ†éڑ”ç؛؟程
ن¸چهپœçڑ„و‰“هچ°وچ¢è،Œï¼Œèƒ½è®©Workerçڑ„输ه‡؛看起و¥و›´هٹ 直观م€‚
该وµ‹è¯•çڑ„结وœوک¯هœ¨ن¸€ن¸ھو—¶هˆ»ï¼Œن»…وœ‰ن¸¤ن¸ھç؛؟程能ه¤ںèژ·ه¾—هˆ°é”پ,ه¹¶ه®Œوˆگو‰“هچ°ï¼Œè€Œè،¨è±،ه°±وک¯و‰“هچ°çڑ„ه†…ه®¹وˆگه¯¹ه‡؛çژ°م€‚
آ
آ
http://ifeve.com/introduce-abstractqueuedsynchronizer/



相ه…³وژ¨èچگ
م€گJavaه¹¶هڈ‘ç³»هˆ—ن¹‹AbstractQueuedSynchronizerو؛گç پهˆ†وگ(独هچ و¨،ه¼ڈ)م€‘ AbstractQueuedSynchronizer(AQS)وک¯Javaه¹¶هڈ‘编程ن¸ن¸€ن¸ھé‡چè¦پçڑ„ه·¥ه…·ï¼Œه®ƒوک¯Javaه¹¶هڈ‘هŒ…`java.util.concurrent.locks`ن¸çڑ„و ¸ه؟ƒوٹ½è±،类,用ن؛ژو„ه»؛é”پ...
م€گ3.1.4.AQSه؛•ه±‚هژںçگ†هˆ†وگ1م€‘ هœ¨Javaه¹¶هڈ‘编程ن¸ï¼ŒAbstractQueuedSynchronizer(AQS)وک¯ن¸€ن¸ھو ¸ه؟ƒçڑ„هگŒو¥ç»„ن»¶ï¼Œç”¨ن؛ژو„ه»؛é”په’ŒهگŒو¥ه™¨çڑ„هں؛ç،€و،†و¶م€‚AQSوک¯ن¸€ن¸ھوٹ½è±،类,ه®ƒوڈگن¾›ن؛†ç؛؟程هگŒو¥çڑ„هں؛وœ¬وœ؛هˆ¶ï¼ŒهŒ…و‹¬ç؛؟程çڑ„وژ’éکںم€پç‰ه¾…ه’Œ...
6. **éک»ه،éکںهˆ—BlockingQueue**ï¼ڑ`14-éک»ه،éکںهˆ—BlockingQueueه®وˆکهڈٹه…¶هژںçگ†هˆ†وگن؛Œ-fox`讲解ن؛†éک»ه،éکںهˆ—çڑ„و¦‚ه؟µم€‚ BlockingQueueوک¯ن¸€ç§چ特و®ٹçڑ„éکںهˆ—,ه½“éکںهˆ—و»،و—¶ï¼Œç”ںن؛§è€…ç؛؟程ن¼ڑ被éک»ه،ï¼›éکںهˆ—ç©؛و—¶ï¼Œو¶ˆè´¹è€…ç؛؟程ن¼ڑ被éک»ه،م€‚è؟™ç§چ...
ن»ژه¹¶هڈ‘و¦‚ه؟µم€پهœ؛و™¯هˆ†وگه‡؛هڈ‘,ن¾و¬،ه¼•ه‡؛é”پم€پç‰ه¾…éکںهˆ—ç‰و¦‚ه؟µï¼Œç›´è‡³هˆ†وگو¸…و¥ڑjavaé”پوœ؛هˆ¶ه®çژ°çڑ„هژںçگ†م€‚ه¹¶ن»¥javaé”پوœ؛هˆ¶ه®çژ°هں؛ç±»AbstractQueuedSynchronizerçڑ„ه®çژ°ن¸؛ن¾‹ï¼Œن»ژ类(و ¸ه؟ƒه±و€§م€پو–¹و³•ï¼‰è®¾è®،و€è·¯ï¼Œهˆ°ه¯¹ه…³é”®ن»£ç پهپڑو³¨é‡ٹ...
ه¯¹ن؛ژjava.utilهŒ…ن¸‹çڑ„集هگˆو،†و¶ï¼Œو–‡و،£ن¸چن»…ن»‹ç»چن؛†هگ„ç§چ集هگˆç±»ï¼Œه¦‚Listم€پSetم€پMapçڑ„ن½؟用,è؟کهˆ†وگن؛†ه®ƒن»¬çڑ„ç؛؟程ه®‰ه…¨و¨،ه‹ه’Œهگ„è‡ھçڑ„特点م€‚ن¾‹ه¦‚,HashMapوک¯هں؛ن؛ژو•£هˆ—çڑ„,而HashTableهˆ™وک¯ç؛؟程ه®‰ه…¨çڑ„م€‚ ه¯¹ن؛ژه¹¶هڈ‘编程,و–‡و،£è¯¦ç»†...
SynchronousQueueçڑ„ه®çژ°هژںçگ†ن¸ژJavaه…¶ن»–éک»ه،éکںهˆ—(ه¦‚ArrayBlockingQueueم€پLinkedBlockingDeque)ن¸چهگŒï¼Œه®ƒه¹¶و²،وœ‰ن½؟用AQS(AbstractQueuedSynchronizer)و¥ه®çژ°ç؛؟程间çڑ„هچڈن½œï¼Œè€Œوک¯ç›´وژ¥هˆ©ç”¨CAS(Compare-And-Swap)و“چن½œ...
وœ¬و–‡ه°†é€ڑè؟‡ه›¾هƒڈ解وگه’Œو؛گç پهˆ†وگ,و·±ه…¥وژ¢è®¨AQSçڑ„ه·¥ن½œوœ؛هˆ¶م€‚ ن¸€م€پAQSهں؛وœ¬ç»“و„ن¸ژهژںçگ† AQSçڑ„و ¸ه؟ƒوک¯ن¸€ن¸ھintç±»ه‹çڑ„stateه—و®µï¼Œه®ƒè،¨ç¤؛资و؛گçڑ„çٹ¶و€پم€‚ه½“stateن¸؛0و—¶ï¼Œè،¨ç¤؛资و؛گهڈ¯èژ·هڈ–ï¼›é0هˆ™è،¨ç¤؛ه·²è¢«هچ 用م€‚AQSç»´وٹ¤ن؛†ن¸€ن¸ھFIFOçڑ„...
هœ¨è؟™ç¯‡و–‡ç« ن¸ï¼Œوˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨AQSçڑ„هژںçگ†ه’Œه®çژ°وœ؛هˆ¶ï¼Œه¹¶ç»“هگˆو؛گç پهˆ†وگ,ن؛†è§£AQSوک¯ه¦‚ن½•ه·¥ن½œçڑ„م€‚ AQSçڑ„特点 1. ن½؟用Nodeه®çژ°FIFOéکںهˆ—,用ن؛ژو„ه»؛é”پوˆ–者ه…¶ن»–هگŒو¥è£…ç½®çڑ„هں؛ç،€و،†و¶م€‚ 2. هˆ©ç”¨volatile int stateè،¨ç¤؛çٹ¶و€پ,...
è؟کè¦پوژŒوڈ،ه¦‚ن½•é€ڑè؟‡JVMهڈ‚و•°è°ƒو•´ه†…هکé…چ置,ن»¥هڈٹه¦‚ن½•هˆ†وگه’Œè§£ه†³ه†…هکو³„و¼ڈé—®é¢کم€‚ é¢هگ‘ه¯¹è±،设è®،هژںهˆ™ه’Œè®¾è®،و¨،ه¼ڈوک¯é¢è¯•ن¸çڑ„é«کç؛§è¯é¢کم€‚ه¦‚هچ•ن¸€èپŒè´£هژںهˆ™م€په¼€é—هژںهˆ™م€پ里و°ڈو›؟وچ¢هژںهˆ™م€پن¾èµ–ه€’ç½®هژںهˆ™ç‰ï¼Œن»¥هڈٹه¸¸è§پçڑ„设è®،و¨،ه¼ڈ,ه¦‚ه·¥هژ‚...
* ThreadLocalهژںçگ†هˆ†وگ + ç؛؟程ه±€éƒ¨هڈکé‡ڈ * ç؛؟程و± çڑ„ه®çژ°هژںçگ† + و‰¹é‡ڈو‰§è،Œن»»هٹ، * ç؛؟程و± çڑ„ه‡ ç§چه®çژ°و–¹ه¼ڈ + CachedThreadPool + FixedThreadPool + ScheduledThreadPool ه››م€پé”پوœ؛هˆ¶ 1.4 é”پوœ؛هˆ¶ * ç؛؟程ه®‰ه…¨é—®é¢ک,...
ن؛†è§£ه¯¹è±،هˆ›ه»؛م€په†…هکه¸ƒه±€م€په†…هکو¨،ه‹م€پç±»هٹ è½½وœ؛هˆ¶ن»¥هڈٹهƒهœ¾و”¶é›†ç®—و³•ï¼ˆه¦‚هڈ¯è¾¾و€§هˆ†وگه’Œهƒهœ¾و”¶é›†ه™¨ï¼‰وک¯ه؟…ه¤‡çں¥è¯†م€‚JVMه¦‚ن½•هˆ¤و–ه¯¹è±،وک¯هگ¦ه·²و»ï¼Œن»¥هڈٹه¦‚ن½•è؟›è،Œه†…هکه›و”¶ï¼Œوک¯é¢è¯•ن¸çڑ„ه¸¸è§پé—®é¢کم€‚ هœ¨Android部هˆ†ï¼Œهں؛ç،€و¦‚ه؟µهŒ…و‹¬...
### ن؛Œم€پAQSهژںçگ†هˆ†وگ #### 2.1 AQSو¦‚è؟° AQSوڈگن¾›ن؛†ن¸€ن¸ھه†…部类Sync,该类继و‰؟è‡ھAQS,ه¹¶è´ںè´£ه¤„çگ†هگŒو¥ه™¨çڑ„و‰€وœ‰è°ƒç”¨م€‚ه®ƒه°†هگ„ç§چهگŒو¥ه™¨çڑ„è،Œن¸؛وٹ½è±،وˆگن¸€ç³»هˆ—و–¹و³•ï¼Œه¦‚tryAcquire()م€پtryRelease()ç‰ï¼Œè؟™ن؛›و–¹و³•هڈ¯ن»¥و ¹وچ®ه…·ن½“çڑ„...
7. **و»é”پم€پو´»é”پن¸ژ饥é¥؟**ï¼ڑهˆ†وگه¤ڑç؛؟程çژ¯ه¢ƒن¸‹هڈ¯èƒ½ه‡؛çژ°çڑ„ن¸‰ه¤§é—®é¢ک,ه¦‚ن½•è¯†هˆ«ه¹¶éپ؟ه…چه®ƒن»¬ï¼Œن»¥هڈٹJDKوڈگن¾›çڑ„و£€وµ‹ه’Œè°ƒè¯•ه·¥ه…·م€‚ 8. **ç؛؟程ه±€éƒ¨هڈکé‡ڈ**ï¼ڑن»‹ç»چThreadLocal类,ه®ƒوک¯ه¦‚ن½•ن¸؛و¯ڈن¸ھç؛؟程وڈگن¾›ç‹¬ç«‹çڑ„هڈکé‡ڈه‰¯وœ¬ï¼Œن»¥éپ؟ه…چو•°وچ®...
é€ڑè؟‡ن¸ٹè؟°هˆ†وگ,وˆ‘ن»¬هڈ¯ن»¥çœ‹ه‡؛AQSن¸؛هگ„ç§چهگŒو¥ه™¨وڈگن¾›ن؛†ن¸€ç§چé€ڑ用çڑ„و،†و¶ï¼Œن½؟ه¾—ه®çژ°ه¤چو‚çڑ„هگŒو¥é€»è¾‘هڈکه¾—و›´هٹ 简هچ•ه’Œé«کو•ˆم€‚هگŒو—¶ï¼Œé€ڑè؟‡`ReentrantLock`çڑ„ن¾‹هگ,وˆ‘ن»¬ن¹ں看هˆ°ن؛†AQSه¦‚ن½•ن¸ژه…·ن½“çڑ„هگŒو¥ه™¨ç›¸ç»“هگˆï¼Œه®çژ°ن؛†é«کو€§èƒ½م€پçپµو´»çڑ„...
هœ¨Javaه¹¶هڈ‘编程ن¸ï¼Œçگ†è§£ه’ŒوژŒوڈ،ه¹¶هڈ‘é”پçڑ„هژںçگ†ن¸ژه®çژ°è‡³ه…³é‡چè¦پ,ه› ن¸؛ه®ƒن»¬وک¯è§£ه†³ه¤ڑç؛؟程çژ¯ه¢ƒن¸‹çڑ„ن؛’و–¥ه’ŒهگŒو¥é—®é¢کçڑ„ه…³é”®م€‚وœ¬و–‡ه°†هں؛ن؛ژJDKو؛گç پ解وگJava领هںںن¸çڑ„ه¹¶هڈ‘é”پ,وژ¢è®¨AQSهں؛ç،€هگŒو¥ه™¨م€پLockSupportم€پConditionوژ¥هڈ£م€پLock...
11. **AQSو،†و¶**ï¼ڑ`AbstractQueuedSynchronizer`و،†و¶çڑ„هں؛ç،€هژںçگ†ï¼Œه¦‚ç‰ه¾…éکںهˆ—ه’Œç‹¬هچ و¨،ه¼ڈç‰م€‚ 12. **و»é”پو£€وµ‹ن¸ژ预éک²**ï¼ڑه¦‚ن½•و£€وµ‹و»é”پن»¥هڈٹه¸¸ç”¨çڑ„预éک²و»é”پçڑ„و–¹و³•م€‚ ### Springو،†و¶ #### ه…³é”®çں¥è¯†ç‚¹ï¼ڑ 1. **ن¾èµ–و³¨ه…¥**...
ن¸‹é¢وˆ‘ن»¬ه°†و·±ه…¥هˆ†وگ`ReentrantLock`çڑ„ه·¥ن½œهژںçگ†م€‚ #### 3. è½»é‡ڈç؛§é”پ`ReentrantLock` `ReentrantLock`وک¯ن¸€ç§چهڈ¯é‡چه…¥çڑ„ن؛’و–¥é”پ,و”¯وŒپه…¬ه¹³ه’Œéه…¬ه¹³ن¸¤ç§چو¨،ه¼ڈم€‚ه®ƒه†…部وœ‰ن¸€ن¸ھ`Sync`类,继و‰؟è‡ھ`AbstractQueuedSynchronizer`...
وœ¬و–‡ه°†هں؛ن؛ژç»™ه®ڑو–‡ن»¶وڈگن¾›çڑ„ن؟،وپ¯ï¼Œو·±ه…¥وژ¢è®¨J.U.Cو،†و¶çڑ„و ¸ه؟ƒو¦‚ه؟µن¹‹ن¸€â€”—`AbstractQueuedSynchronizer`(AQS),ه¹¶è¯¦ç»†ن»‹ç»چه…¶è®¾è®،هژںçگ†م€په؛”用هœ؛و™¯هڈٹو€§èƒ½ç‰¹ç‚¹م€‚ #### 1. AbstractQueuedSynchronizer (AQS) و¦‚è؟° `...
- **ه¹¶هڈ‘هژںè¯**ï¼ڑCASو“چن½œهڈٹه…¶ABAé—®é¢ک,ن»¥هڈٹAQS(AbstractQueuedSynchronizer)çڑ„ه®çژ°هژںçگ†م€‚ - **é”پوœ؛هˆ¶**ï¼ڑè‡ھو—‹é”پم€پéک»ه،é”پم€پن¹گ观é”پم€پو‚²è§‚é”پ,ن»¥هڈٹMCSé”په’ŒCLHé”پéکںهˆ—çڑ„ه؛”用م€‚ - **Javaç؛؟程و± **ï¼ڑç؛؟程و± çڑ„ه·¥ن½œهژںçگ†ï¼Œ...