
Õ£©Õ╣ČĶĪīÕżäńÉåĶāĮÕŖøµ¢╣ķØó’╝īPythonńÜäÕŻ░ÕÉŹÕ╣ČõĖŹÕż¬ÕźĮŃĆéõĖŹĶĆāĶÖæÕģ│õ║Äń║┐ń©ŗÕÆīGIL’╝łÕżÜµĢ░µāģÕåĄõĖŗµś»ÕÉłńÉåńÜä’╝ēńÜäµĀćÕćåĶ«║µŹ«’╝īµłæĶ«żõĖ║PythonõĖŁÕģ│õ║ÄÕ╣ČĶĪīńÜäń£¤µŁŻķŚ«ķóśÕ╣ČõĖŹµś»õĖĆõĖ¬µŖƵ£»ķŚ«ķóś’╝īĶĆīµś»µĢÖÕŁ”ķŚ«ķóśŃĆéÕø┤ń╗ĢPythonń║┐ń©ŗÕÆīÕżÜĶ┐øń©ŗńÜäÕĖĖĶ¦üµĢÖń©ŗ’╝īõĖĆĶł¼ķāĮÕåÖÕŠŚõĖŹķöÖ’╝īõĮåõ╣¤õ╗żõ║║õ╣ÅÕæ│ - µ┐ĆńāłķØ×ÕćĪ’╝īÕ»╣µŚźÕĖĖń£¤µŁŻµ£ēńö©ńÜäõĖ£Ķź┐ÕŹ┤ÕŠłÕ░æµČēÕÅŖŃĆé
µ▓┐ĶóŁńÜäõŠŗÕŁÉ
Õ£©DuckDuckGo’╝łDDG’╝ēõĖŁµÉ£ń┤óŌĆ£PythonÕżÜń║┐ń©ŗµĢÖń©ŗŌĆØ’╝īń«ĆÕŹĢĶ░āµ¤źõĖĆõĖŗµÄÆÕ£©ÕēŹķØóńÜäń╗ōµ×£’╝īÕ░▒õ╝ÜÕÅæńÄ░Õ«āõ╗¼ń╗ÖÕć║ńÜäķāĮµś»ÕÉīµĀĘÕ¤║õ║ÄClass + QueueńÜäńż║õŠŗŃĆé
õ╗ŗń╗Źthreading/multiprocessingŃĆüńö¤õ║¦ĶĆģ/µČłĶ┤╣ĶĆģńÜäń£¤Õ«×ńż║õŠŗõ╗ŻńĀü’╝Ü
# coding: utf-8
# Example.py
'''
µĀćÕćåńÜäÕżÜń║┐ń©ŗńö¤õ║¦ĶĆģ/µČłĶ┤╣ĶĆģµ©ĪÕ╝Å
'''
import time
import threading
import Queue
class Consumer(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self._queue = queue
def run(self):
while True:
# queue.get() õ╝Üķś╗ÕĪ×ÕĮōÕēŹń║┐ń©ŗ’╝īńø┤Õł░ĶÄĘÕÅ¢Õł░õĖĆõĖ¬µĢ░µŹ«ķĪ╣
msg = self._queue.get()
# µŻĆµ¤źÕĮōÕēŹµČłµü»µś»ÕÉ”µś»õĖ¬ŌĆ£µ»ÆĶŹ»õĖĖŌĆØ
if isinstance(msg, str) and msg == 'quit':
# Õ”éµ×£µś»’╝īÕłÖķĆĆÕć║ÕŠ¬ńÄ»
break
# ŌĆ£ÕżäńÉåŌĆØ (Ķ┐Öķćīµś»µēōÕŹ░)õ╗Äķś¤ÕłŚõĖŁÕÅ¢Õć║ńÜäµĢ░µŹ«ķĪ╣
print "I'm a thread, and I received %s!!" % msg
# µłæÕ¦ŗń╗łµś»Ķ┐Öõ╣łńÜäÕÅŗÕźĮ
print 'Bye byes!'
def Producer():
# Queueńö©õ║ÄÕ£©ń║┐ń©ŗõ╣ŗķŚ┤Õģ▒õ║½µĢ░µŹ«ķĪ╣
queue = Queue.Queue()
# ÕłøÕ╗║õĖĆõĖ¬ÕĘźõĮ£Õ«×õŠŗ
worker = Consumer(queue)
# startµ¢╣µ│Ģõ╝ÜĶ░āńö©Õåģķā©ńÜärun()µ¢╣µ│ĢµØźÕ╝ĆÕÉ»ń║┐ń©ŗ
worker.start()
# ÕÅśķćÅ’╝īńö©õ║ÄĶ┐ĮĶĖ¬Õ╝ĆÕ¦ŗńÜ䵌ČķŚ┤
start_time = time.time()
# Õ£©5ń¦Æõ╣ŗÕåģ
while time.time() - start_time < 5:
# ŌĆ£ńö¤õ║¦ŌĆØõĖĆÕØŚÕĘźõĮ£’╝īµöŠÕģźķś¤ÕłŚõĖŁ’╝īńö▒µČłĶ┤╣ĶĆģµØźÕżäńÉå
queue.put('something at %s' % time.time())
# ńØĪń£ĀõĖĆõ╝ÜÕä┐’╝īõ╗źķü┐ÕģŹĶ┐ćÕżÜńÜäµČłµü»
time.sleep(1)
# Ķ┐Öµś»µØƵŁ╗ń║┐ń©ŗńÜäŌĆ£µ»ÆĶŹ»õĖĖŌĆص¢╣Õ╝Å
queue.put('quit')
# ńŁēÕŠģń║┐ń©ŗÕģ│ķŚŁ
worker.join()
if __name__ == '__main__':
Producer()
ÕŚ»...ķŚ╗ķŚ╗’╝īõ╗ŻńĀüõĖŁõĖĆĶéĪÕŁÉJavańÜäµ░öµü»ŃĆé
µłæõĖŹµā│Ķ«®Õż¦Õ«ČĶ¦ēÕŠŚÕźĮÕāŵłæĶ«żõĖ║ńö¤õ║¦ĶĆģ/µČłĶ┤╣ĶĆģµś»ÕżäńÉåń║┐ń©ŗ/ÕżÜĶ┐øń©ŗńÜäķöÖĶ»»µ¢╣Õ╝Å - ÕøĀõĖ║ńĪ«Õ«×õĖŹµś»ŃĆéÕ«×ķÖģõĖŖ’╝īÕ»╣ÕżÜń¦ŹķŚ«ķóśµØźĶ»┤’╝īĶ┐Öń¦Źµ¢╣Õ╝ÅķØ×ÕĖĖķĆéÕÉłŃĆéńäČĶĆī’╝īµłæĶ«żõĖ║’╝ÜÕ»╣õ║ĵŚźÕĖĖńÜäĶäܵ£¼ń©ŗÕ║ÅµØźĶ»┤’╝īĶ┐Öń¦Źµ¢╣Õ╝ÅÕ╣ČķØ×µś»µ£Ćµ£ēńö©ńÜäŃĆé
ķŚ«ķóś’╝łµłæĶ«żõĖ║ńÜä’╝ē
ÕģČõĖĆ’╝īõĖ║õ║åÕüÜńé╣µ£ēńö©ńÜäõ║ŗµāģ’╝īõĮĀÕŠŚµÉ×õĖĆõĖ¬Õģ¼Õ╝ÅÕī¢ńÜäń▒╗’╝øÕģČõ║ī’╝īõĮĀÕŠŚń╗┤µŖżõĖĆõĖ¬ķś¤ÕłŚ’╝łQueue’╝ē’╝īńö©õ║Äõ╝ĀķĆüÕ»╣Ķ▒Ī’╝øĶ┐Öõ║øķĮÉÕżćõ╣ŗÕÉÄ’╝īÕ£©ķś¤ÕłŚń«ĪķüōńÜäõĖżń½»Ķ┐śÕŠŚÕćåÕżćµ¢╣µ│ĢµØźÕüÜń£¤µŁŻńÜäÕĘźõĮ£’╝łÕ”éµ×£ÕĖīµ£øµ£ēõĖżń¦Źµ¢╣Õ╝ÅµØźķĆÜõ┐Īµł¢ĶĆģÕćåÕżćÕŁśÕé©ń╗ōµ×£’╝īÕÅ»ĶāĮĶ┐śÕŠŚÕ╝ĢÕģźÕÅ”õĖĆõĖ¬ķś¤ÕłŚ’╝ēŃĆé
µø┤ÕżÜńÜäÕĘźõĮ£ĶĆģ’╝īµø┤ÕżÜńÜäķŚ«ķóś
Õ¤║õ║ĵŁż’╝īõĖŗõĖĆõ╗ČõĮĀµā│Ķ”üÕüÜńÜäõ║ŗµāģÕ░▒µś»µÉ×õĖĆõĖ¬ÕĘźõĮ£ĶĆģń▒╗ńÜäµ▒Ā’╝īµØźÕŖĀķƤõĮĀńÜäPythonń©ŗÕ║ÅŃĆéÕ£©Õģ│õ║Äń║┐ń©ŗńÜäIBMµĢÖń©ŗõĖŁ’╝īń╗ÖÕć║õ║åõĖĆõĖ¬ńż║õŠŗõ╗ŻńĀü’╝īõ╗źõĖŗµś»ÕģČÕÅśń¦ŹŃĆéĶ┐Öµś»õĖĆõĖ¬ÕĖĖĶ¦üńÜäÕ║öńö©Õ£║µÖ» - Õ£©ÕżÜõĖ¬ń║┐ń©ŗõĖŖÕłåķģŹĶÄĘÕÅ¢ńĮæķĪĄńÜäõ╗╗ÕŖĪŃĆé
# coding: utf-8
# Example2.py
'''
õĖĆõĖ¬µø┤ÕŖĀÕ«×ķÖģńÜäń║┐ń©ŗµ▒Āńż║õŠŗ
'''
import time
import threading
import Queue
import urllib2
class Consumer(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self._queue = queue
def run(self):
while True:
content = self._queue.get()
if isinstance(content, str) and content == 'quit':
break
response = urllib2.urlopen(content)
print 'Bye byes!'
def Producer():
urls = [
'http://www.python.org', 'http://www.yahoo.com'
'http://www.scala.org', 'http://www.google.com'
# ńŁēńŁē...
]
queue = Queue.Queue()
worker_threads = build_worker_pool(queue, 4)
start_time = time.time()
# ÕŖĀÕģźÕŠģÕżäńÉåńÜäURL
for url in urls:
queue.put(url)
# ÕŖĀÕģźµ»ÆĶŹ»õĖĖ
for worker in worker_threads:
queue.put('quit')
for worker in worker_threads:
worker.join()
print 'Done! Time taken: {}'.format(time.time() - start_time)
def build_worker_pool(queue, size):
workers = []
for _ in range(size):
worker = Consumer(queue)
worker.start()
workers.append(worker)
return workers
if __name__ == '__main__':
Producer()
ÕźÅµĢłõ║å’╝īõĮåµś»õĮĀń£ŗń£ŗĶ┐Öõ║øõ╗ŻńĀü’╝üÕćåÕżć’╝łsetup’╝ēµ¢╣µ│ĢŃĆüõĖĆń╗äĶ”üĶ┐ĮĶĖ¬ńÜäń║┐ń©ŗ’╝īµ£Ćń│¤ń│ĢńÜ䵜»’╝īĶŗźµ£ēõ╗╗õĮĢÕ£░µ¢╣µśōÕÅæńö¤µŁ╗ķöü’╝īÕ░▒õ╝Üõ║¦ńö¤õĖĆÕĀåńÜäjoinńŖȵĆüĶ»┤µśÄŃĆéĶ欵Łż’╝īõĖĆÕłćÕŬõ╝ܵø┤ÕżŹµØé’╝ü
Õł░ńø«ÕēŹõĖ║µŁó’╝īÕ«īµłÉõ║åõ║øõ╗Ćõ╣ł’╝¤ÕĢźķāĮµ▓Īµ£ēŃĆéõĖŖķØóńÜäõ╗ŻńĀüń║»ń▓╣ÕŬµś»µŖŖµēƵ£ēõĖ£Ķź┐ÕāÅńö©ń║Ėń│ŖĶĄĘµØźõĖƵĀĘ’╝łJust about everything in the above code is pure plumbing’╝īÕ”éõĮĢń┐╗Ķ»æ’╝¤’╝ēŃĆéĶ┐Öµś»ÕÅ”õĖĆń¦ŹÕģ¼Õ╝ÅÕī¢ńÜäÕåÖµ│Ģ’╝īõ╣¤µśōÕÅæńö¤ķöÖĶ»»’╝łÕś┐’╝īÕ£©ÕåÖĶ┐ÖõĖ¬õ╗ŻńĀüµŚČ’╝īµłæńöÜĶć│Õ┐śõ║åÕ£©ķś¤ÕłŚÕ»╣Ķ▒ĪõĖŖĶ░āńö©task_done()’╝łµłæµćÆÕŠŚÕÄ╗Ķ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóśńäČÕÉÄÕåŹµÉ×õĖ¬µł¬ÕøŠ’╝ē’╝ē’╝īõ╗śÕć║ÕŠłÕżÜ’╝īÕŠŚÕł░ńÜäÕŹ┤ÕŠłÕ░æŃĆéÕ╣ĖĶ┐ÉńÜ䵜»’╝īµłæõ╗¼µ£ēµø┤ÕźĮńÜäµ¢╣Õ╝ÅŃĆé
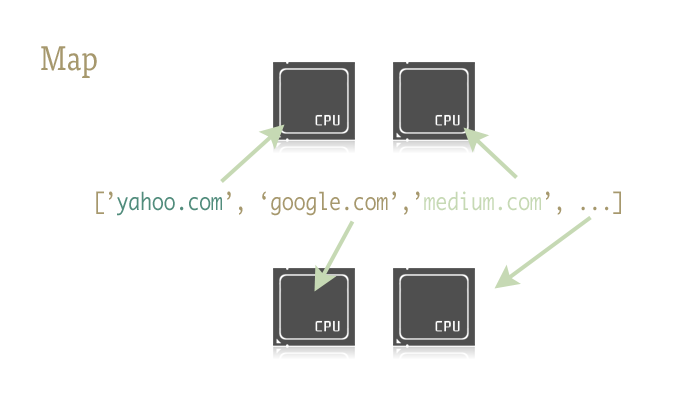
Õ╝ĢÕģź’╝ÜMap
Mapµś»õĖĆõĖ¬ķģĘķģĘńÜäÕ░ÅõĖ£Ķź┐’╝īõ╣¤µś»Õ£©Pythonõ╗ŻńĀüĶĮ╗µØŠÕ╝ĢÕģźÕ╣ČĶĪīńÜäÕģ│ķö«ŃĆéÕ»╣µŁżõĖŹń夵éēńÜäõ║║õ╝ÜĶ«żõĖ║mapµś»õ╗ÄÕćĮµĢ░Õ╝ÅĶ»ŁĶ©Ć’╝łÕ”éLisp’╝ēÕƤķē┤µØźńÜäõĖ£Ķź┐ŃĆémapµś»õĖĆõĖ¬ÕćĮµĢ░ - Õ░åÕÅ”õĖĆõĖ¬ÕćĮµĢ░µśĀÕ░äÕł░õĖĆõĖ¬Õ║ÅÕłŚõĖŖŃĆéõŠŗÕ”é’╝Ü
urls = ['http://www.yahoo.com', 'http://www.reddit.com']
results = map(urllib2.urlopen, urls)
Ķ┐Öµ«Ąõ╗ŻńĀüÕ£©õ╝ĀÕģźÕ║ÅÕłŚńÜäµ»ÅõĖ¬Õģāń┤ĀõĖŖÕ║öńö©µ¢╣µ│Ģurlopen’╝īÕ╣ČÕ░åµēƵ£ēń╗ōµ×£ÕŁśÕģźõĖĆõĖ¬ÕłŚĶĪ©õĖŁŃĆéÕż¦Ķć┤õĖÄõĖŗķØóĶ┐Öµ«Ąõ╗ŻńĀüńÜäķĆ╗ĶŠæńøĖÕĮō’╝Ü
results = []
for url in urls:
results.append(urllib2.urlopen(url))
Mapõ╝ÜõĖ║µłæõ╗¼ÕżäńÉåÕ£©Õ║ÅÕłŚõĖŖńÜäĶ┐Łõ╗Ż’╝īÕ║öńö©ÕćĮµĢ░’╝īµ£ĆÕÉÄÕ░åń╗ōµ×£ÕŁśÕģźõĖĆõĖ¬µ¢╣õŠ┐õĮ┐ńö©ńÜäÕłŚĶĪ©ŃĆé
Ķ┐ÖõĖ║õ╗Ćõ╣łķćŹĶ”üÕæó’╝¤ÕøĀõĖ║Õł®ńö©µü░ÕĮōńÜäÕ║ō’╝īmapĶ«®Õ╣ČĶĪīÕżäńÉåµłÉõĖ║Õ░Åõ║ŗõĖƵĪ®’╝ü
PythonµĀćÕćåÕ║ōõĖŁmultiprocessingµ©ĪÕØŚ’╝īõ╗źÕÅŖµ×üÕ░æõ║║ń¤źõĮåÕÉīµĀĘÕć║Ķē▓ńÜäÕŁÉµ©ĪÕØŚmultiprocessing.dummy’╝īµÅÉõŠøõ║åmapÕćĮµĢ░ńÜäÕ╣ČĶĪīńēłµ£¼ŃĆé
ķóśÕż¢Ķ»Ø’╝ÜĶ┐Öµś»ÕĢź’╝¤õĮĀõ╗ĵ£¬ÕɼĶ»┤Ķ┐ćĶ┐ÖÕÉŹõĖ║dummyńÜämulprocessingµ©ĪÕØŚńÜäń║┐ń©ŗÕģŗķÜåńēłµ£¼’╝¤µłæõ╣¤µś»µ£ĆĶ┐æµēŹń¤źķüōńÜäŃĆéÕ£©multiprocessingµ¢ćµĪŻķĪĄõĖŁõ╗ģµ£ēõĖĆÕÅźµÅÉÕł░Ķ┐ÖõĖ¬ÕŁÉµ©ĪÕØŚ’╝īĶĆīĶ┐ÖÕÅźĶ»ØÕ¤║µ£¼ÕÅ»õ╗źÕĮÆń╗ōõĖ║ŌĆ£Õō”’╝īµś»ńÜä’╝īÕŁśÕ£©Ķ┐ÖµĀĘõĖĆõĖ¬õĖ£Ķź┐ŌĆØŃĆéÕ«īÕģ©õĮÄõ╝░õ║åĶ┐ÖõĖ¬µ©ĪÕØŚńÜäõ╗ĘÕĆ╝’╝ü
Dummyµś»multiprocessingµ©ĪÕØŚńÜäń▓ŠńĪ«ÕģŗķÜå’╝īÕö»õĖĆńÜäÕī║Õł½µś»’╝ÜmultiprocessingÕ¤║õ║ÄĶ┐øń©ŗÕĘźõĮ£’╝īĶĆīdummyµ©ĪÕØŚõĮ┐ńö©ń║┐ń©ŗ’╝łõ╣¤Õ░▒ÕĖ”µØźõ║åÕĖĖĶ¦üńÜäPythonķÖÉÕłČ’╝ēŃĆéÕøĀµŁż’╝īõ╗╗õĮĢõĖ£Ķź┐ÕÅ»ÕźŚńö©Õł░õĖĆõĖ¬µ©ĪÕØŚ’╝īõ╣¤Õ░▒ÕÅ»õ╗źÕźŚńö©Õł░ÕÅ”õĖĆõĖ¬µ©ĪÕØŚŃĆéÕ£©õĖżõĖ¬µ©ĪÕØŚõ╣ŗķŚ┤µØźÕø×ÕłćµŹóõ╣¤Õ░▒ńøĖÕĮōÕ«╣µśō’╝īÕĮōõĮĀõĖŹÕż¬ńĪ«Õ«ÜõĖĆõ║øµĪåµ×ČĶ░āńö©µś»IOÕ»åķøåÕ×ŗĶ┐śµś»CPUÕ»åķøåÕ×ŗµŚČ’╝īµā│ÕüܵÄóń┤óµĆ¦Ķ┤©ńÜäń╝¢ń©ŗ’╝īĶ┐ÖõĖĆńé╣õ╝ÜĶ«®õĮĀĶ¦ēÕŠŚķØ×ÕĖĖĶĄ×’╝ü
Õ╝ĆÕ¦ŗ
õĖ║õ║åĶ«┐ķŚ«mapÕćĮµĢ░ńÜäÕ╣ČĶĪīńēłµ£¼’╝īķ”¢Õģłķ£ĆĶ”üÕ»╝ÕģźÕīģÕɽիāńÜ䵩ĪÕØŚ’╝Ü
# õ╗źõĖŗõĖżĶĪīÕ╝ĢÕģźÕģČõĖĆÕŹ│ÕÅ»
from multiprocessing import Pool
from multiprocessing.dummy import Pool as ThreadPool
Õ╣ČÕ«×õŠŗÕī¢µ▒ĀÕ»╣Ķ▒Ī’╝Ü
# Ķ»æµ│©’╝ÜĶ┐ÖķćīÕģČÕ«×µś»õ╗źdummyµ©ĪÕØŚõĖ║õŠŗ
pool = ThreadPool()
Ķ┐ÖõĖĆÕÅźõ╗ŻńĀüÕżäńÉåõ║åexample2.pyõĖŁ7ĶĪīńÜäbuild_worker_poolÕćĮµĢ░Õ«īµłÉńÜäµēƵ£ēõ║ŗµāģŃĆéÕ”éÕÉŹµēĆńż║’╝īĶ┐ÖÕÅźõ╗ŻńĀüõ╝ÜÕłøÕ╗║õĖĆń╗äÕÅ»ńö©ńÜäÕĘźõĮ£ĶĆģ’╝īÕÉ»ÕŖ©Õ«āõ╗¼µØźÕćåÕżćÕĘźõĮ£’╝īÕ╣ČÕ░åÕ«āõ╗¼ÕŁśÕģźÕÅśķćÅõĖŁ’╝īµ¢╣õŠ┐Ķ«┐ķŚ«ŃĆé
poolÕ»╣Ķ▒ĪÕÅ»õ╗źµ£ēĶŗźÕ╣▓ÕÅéµĢ░’╝īõĮåńø«ÕēŹ’╝īÕŬķ£ĆÕģ│µ│©ń¼¼õĖĆõĖ¬’╝ÜĶ┐øń©ŗ/ń║┐ń©ŗµĢ░ķćÅŃĆéĶ┐ÖõĖ¬ÕÅéµĢ░ńö©õ║ÄĶ«ŠńĮ«µ▒ĀõĖŁńÜäÕĘźõĮ£ĶĆģµĢ░ńø«ŃĆéÕ”éµ×£ńĢÖń®║’╝īķ╗śĶ«żõĖ║µ£║ÕÖ©ńÜäCPUµĀĖµĢ░ŃĆé
õĖĆĶł¼µØźĶ»┤’╝īÕ”éµ×£õĖ║CPUÕ»åķøåÕ×ŗõ╗╗ÕŖĪõĮ┐ńö©Ķ┐øń©ŗµ▒Ā’╝łmultiprocessing pool’╝ē’╝īµø┤ÕżÜńÜäµĀĖńŁēõ║ĵø┤Õ┐½ńÜäķƤÕ║”’╝łõĮåµ£ēõĖĆõ║øµ│©µäÅõ║ŗķĪ╣’╝ēŃĆéńäČĶĆī’╝īÕĮōõĮ┐ńö©ń║┐ń©ŗµ▒Ā’╝łthreading’╝ēÕżäńÉåńĮæń╗£Õ»åķøåÕ×ŗõ╗╗ÕŖĪµŚČ’╝īµāģÕåĄÕ░▒ÕŠłõĖŹõĖƵĀĘõ║å’╝īÕøĀµŁżµ£ĆÕźĮĶ»Ģķ¬īõĖĆõĖŗµ▒ĀńÜäµ£ĆõĮ│Õż¦Õ░ÅŃĆé
pool = ThreadPool(4) # Õ░åµ▒ĀńÜäÕż¦Õ░ÅĶ«ŠńĮ«õĖ║4
Õ”éµ×£Ķ┐ÉĶĪīõ║åĶ┐ćÕżÜńÜäń║┐ń©ŗ’╝īÕ░▒õ╝ܵĄ¬Ķ┤╣µŚČķŚ┤Õ£©ń║┐ń©ŗÕłćµŹóõĖŖ’╝īĶĆīõĖŹµś»Õüܵ£ēńö©ńÜäõ║ŗµāģ’╝īµēĆõ╗źÕÅ»õ╗źµŖŖńÄ®µŖŖńÄ®ńø┤Õł░µēŠÕł░µ£ĆķĆéÕÉłõ╗╗ÕŖĪńÜäń║┐ń©ŗµĢ░ķćÅŃĆé
ńÄ░Õ£©µ▒ĀÕ»╣Ķ▒ĪÕłøÕ╗║ÕźĮõ║å’╝īń«ĆÕŹĢńÜäÕ╣ČĶĪīõ╣¤µś»Õ╝╣µīćõ╣ŗķŚ┤ńÜäõ║ŗµāģõ║å’╝īķéŻµØźķćŹÕåÖexample2.pyÕɦŃĆé
import urllib2
from multiprocessing.dummy import Pool as ThreadPool
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
# ńŁēńŁē...
]
# ÕłøÕ╗║õĖĆõĖ¬ÕĘźõĮ£ĶĆģń║┐ń©ŗµ▒Ā
pool = ThreadPool(4)
# Õ£©ÕÉäõĖ¬ń║┐ń©ŗõĖŁµēōÕ╝Ćurl’╝īÕ╣ČĶ┐öÕø×ń╗ōµ×£
results = pool.map(urllib2.urlopen, urls)
#close the pool and wait for the work to finish
# Õģ│ķŚŁń║┐ń©ŗµ▒Ā’╝īńŁēÕŠģÕĘźõĮ£ń╗ōµØ¤
pool.close()
pool.join()
ń£ŗń£ŗ’╝üń£¤µŁŻÕüÜõ║ŗµāģńÜäõ╗ŻńĀüõ╗ģµ£ē4ĶĪī’╝īÕģČõĖŁ3ĶĪīÕŬµś»ń«ĆÕŹĢńÜäĶŠģÕŖ®ÕŖ¤ĶāĮŃĆémapĶ░āńö©ĶĮ╗µØŠµÉ×Õ«Üõ║åõ╣ŗÕēŹńż║õŠŗ40ĶĪīõ╗ŻńĀüÕüÜńÜäõ║ŗµāģ’╝üĶ¦ēÕŠŚÕźĮńÄ®’╝īµłæÕ»╣õĖżń¦Źµ¢╣Õ╝ÅĶ┐øĶĪīõ║åµŚČķŚ┤µĄŗķćÅ’╝īÕ╣ČõĮ┐ńö©õ║åõĖŹÕÉīńÜäµ▒ĀÕż¦Õ░ÅŃĆé
# Ķ»æµ│©’╝ܵłæĶ¦ēÕŠŚõĖÄõĖ▓ĶĪīÕżäńÉåµ¢╣Õ╝ÅÕ»╣µ»öµäÅõ╣ēõĖŹÕż¦’╝īÕ║öĶ»źÕÆīķś¤ÕłŚńÜäµ¢╣Õ╝ÅĶ┐øĶĪīµĆ¦ĶāĮÕ»╣µ»ö
results = []
for url in urls:
result = urllib2.urlopen(url)
results.append(result)
# # ------- Õ»╣µ»ö ------- #
# # ------- µ▒ĀńÜäÕż¦Õ░ÅõĖ║4 ------- #
pool = ThreadPool(4)
results = pool.map(urllib2.urlopen, urls)
# # ------- µ▒ĀńÜäÕż¦Õ░ÅõĖ║8 ------- #
pool = ThreadPool(8)
results = pool.map(urllib2.urlopen, urls)
# # ------- µ▒ĀńÜäÕż¦Õ░ÅõĖ║13 ------- #
pool = ThreadPool(13)
results = pool.map(urllib2.urlopen, urls)
ń╗ōµ×£’╝Ü
ÕŹĢń║┐ń©ŗ: 14.4 ń¦Æ
µ▒ĀÕż¦Õ░ÅõĖ║4µŚČ’╝Ü3.1 ń¦Æ
µ▒ĀÕż¦Õ░ÅõĖ║8µŚČ’╝Ü1.4 ń¦Æ
µ▒ĀÕż¦Õ░ÅõĖ║13µŚČ’╝Ü1.3ń¦Æ
ń£¤µś»Õæ▒Õæ▒ÕŽÕĢŖ’╝üõ╣¤Ķ»┤µśÄõ║åĶ»Ģķ¬īõĖŹÕÉīńÜäµ▒ĀÕż¦Õ░ŵś»µ£ēÕ┐ģĶ”üńÜäŃĆéÕ£©µłæńÜäµ£║ÕÖ©õĖŖ’╝īµ▒ĀńÜäÕż¦Õ░ÅÕż¦õ║Ä9ÕÉÄõ╝ÜÕ»╝Ķć┤µĆ¦ĶāĮķĆĆÕī¢’╝łĶ»æµ│©’╝ÜÕÆ”’╝īń╗ōµ×£õĖŹµś»µśŠńż║13µ»ö8ńÜäµĆ¦ĶāĮĶ”üÕźĮõ╣ł’╝¤’╝ēŃĆé
ńÄ░Õ«×õĖŁńÜäExample 2
õĖ║ÕŹāÕ╝ĀÕøŠńēćÕłøÕ╗║ń╝®ńĢźÕøŠŃĆé
µØźÕüÜńé╣CPUÕ»åķøåÕ×ŗńÜäõ║ŗµāģ’╝üÕ»╣õ║ĵłæ’╝īÕ£©ÕĘźõĮ£õĖŁÕĖĖĶ¦üńÜäõ╗╗ÕŖĪµś»µōŹõĮ£Õż¦ķćÅńÜäÕøŠńēćńø«ÕĮĢŃĆéÕģČõĖŁõĖĆń¦ŹÕøŠńēćĶĮ¼µŹóµś»ÕłøÕ╗║ń╝®ńĢźÕøŠŃĆéĶ┐ÖķĪ╣ÕĘźõĮ£ķĆéõ║ÄÕ╣ČĶĪīÕżäńÉåŃĆé
Õ¤║µ£¼ńÜäÕŹĢĶ┐øń©ŗĶ«ŠńĮ«
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f)
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY))
images = get_image_paths(folder)
for image in images:
create_thumbnail(image)
ńż║õŠŗõ╗ŻńĀüõĖŁńö©õ║åõĖĆõ║øµŖĆÕʦ’╝īõĮåÕż¦õĮōõĖŖµś»’╝ÜÕÉæń©ŗÕ║Åõ╝ĀÕģźõĖĆõĖ¬ńø«ÕĮĢ’╝īõ╗Äńø«ÕĮĢõĖŁĶÄĘÕÅ¢µēƵ£ēÕøŠńēć’╝īńäČÕÉÄÕłøÕ╗║ń╝®ńĢźÕøŠ’╝īÕ╣ČÕ░åń╝®ńĢźÕøŠÕŁśµöŠÕł░ÕÉäĶć¬ńÜäńø«ÕĮĢõĖŁŃĆé
Õ£©µłæńÜäµ£║ÕÖ©õĖŖ’╝īĶ┐ÖõĖ¬ń©ŗÕ║ÅÕżäńÉåÕż¦ń║”6000Õ╝ĀÕøŠńēć’╝īĶŖ▒Ķ┤╣27.9ń¦ÆŃĆé
Õ”éµ×£õĮ┐ńö©õĖĆõĖ¬Õ╣ČĶĪīńÜämapĶ░āńö©µØźµø┐µŹóforÕŠ¬ńÄ»’╝Ü
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f)
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY))
images = get_image_paths(folder)
pool = Pool()
pool.map(create_thumbnail, images)
pool.close()
pool.join()
5.6ń¦Æ’╝ü
õ╗ģõ┐«µö╣ÕćĀĶĪīõ╗ŻńĀüÕ░▒ĶāĮÕŠŚÕł░ÕĘ©Õż¦ńÜäķƤÕ║”µÅÉÕŹćŃĆéĶ┐ÖõĖ¬ń©ŗÕ║ÅńÜäńö¤õ║¦ńÄ»Õóāńēłµ£¼ķĆÜĶ┐ćÕłćÕłåCPUÕ»åķøåÕ×ŗÕĘźõĮ£ÕÆīIOÕ»åķøåÕ×ŗÕĘźõĮ£Õ╣ČÕłåķģŹÕł░ÕÉäĶć¬ńÜäĶ┐øń©ŗÕÆīń║┐ń©ŗ’╝łķĆÜÕĖĖµś»µŁ╗ķöüõ╗ŻńĀüńÜäõĖĆõĖ¬ÕøĀń┤Ā’╝ē’╝īĶÄĘÕŠŚµø┤Õ┐½ńÜäķƤÕ║”ŃĆéńäČĶĆī’╝īńö▒õ║ÄmapµĆ¦Ķ┤©µĖģµÖ░µśÄńĪ«’╝īµŚĀķ£ĆµēŗÕŖ©ń«ĪńÉåń║┐ń©ŗ’╝īõ╗źÕ╣▓ÕćĆŃĆüÕÅ»ķØĀŃĆüµśōõ║ÄĶ░āĶ»ĢńÜäµ¢╣Õ╝ŵĘĘÕÉłÕī╣ķģŹõĖżĶĆģ’╝łĶ»æµ│©’╝ÜĶ┐ÖķćīńÜäŌĆ£õĖżĶĆģŌĆصś»µīćõ╗Ćõ╣ł’╝¤CPUÕ»åķøåÕ×ŗÕĘźõĮ£ÕÆīIOÕ»åķøåÕ×ŗÕĘźõĮ£’╝¤’╝ē’╝īõ╣¤µś»ńøĖÕĮōÕ«╣µśōńÜäŃĆé
Õ░▒µś»Ķ┐ÖµĀĘõ║åŃĆé’╝łÕćĀõ╣Ä’╝ēõĖĆĶĪīÕ╝ÅÕ╣ČĶĪīĶ¦ŻÕå│µ¢╣µĪłŃĆé┬Ā
┬Ā
http://blog.xiayf.cn/2015/09/11/parallelism-in-one-line/
Ķŗ▒µ¢ćÕĤµ¢ć’╝Ü
┬Āhttp://chriskiehl.com/article/parallelism-in-one-line/



ńøĖÕģ│µÄ©ĶŹÉ
ÕāÅparallel --pipe --roundrobinõĖƵĀĘ’╝īõĮåµś»Ķ┤¤ĶĮĮÕ╣│ĶĪĪµś»Õ¤║õ║ÄĶŠōÕģźĶĪīÕōłÕĖīµØźµē¦ĶĪīńÜäŃĆé Õ£©ÕŁÉĶ┐øń©ŗõĖŁµē¦ĶĪīķö«ĶüÜÕÉłµŚČ’╝īĶ┐ÖõĖĆńé╣Ķć│Õģ│ķćŹĶ”ü’╝īÕøĀõĖ║ķ鯵ŚČÕŬµ£ēõĖĆõĖ¬ÕłåńēćÕīģÕɽń╗ÖÕ«ÜńÜäķö«ŃĆé slb’╝ÜÕłåńēćńÜäĶ┤¤ĶĮĮÕ╣│ĶĪĪÕÖ©ń▒╗õ╝╝õ║Äparallel --pipe --...
Õ£©Õż¦µĢ░µŹ«ÕżäńÉåķóåÕ¤¤’╝īMap-Reduceµ©ĪÕ×ŗÕĘ▓ń╗ŵłÉõĖ║õĖĆń¦ŹµĄüĶĪīńÜäń╝¢ń©ŗĶīāÕ╝Å’╝īÕ«āÕģüĶ«Ėń©ŗÕ║ÅÕæśķĆÜĶ┐ćµÅÅĶ┐░ÕÆīÕ«×µ¢ĮÕ╣ČĶĪīń©ŗÕ║ÅµØźÕżäńÉåÕż¦ķćŵĢ░µŹ«ķøåŃĆéõ╝Āń╗¤ńÜäMap-ReduceµĪåµ×ČķĆÜÕĖĖĶ┐ÉĶĪīÕ£©ńŗ¼ń½ŗńÜäĶ«Īń«ŚķøåńŠżõĖŖ’╝īĶĆīOracleµĢ░µŹ«Õ║ōķĆÜĶ┐ćÕģČńŗ¼ńē╣ńÜäńē╣µĆ¦ŌĆöŌĆö**...
ŃĆĆFourinoneÕ»╣õ║ÄÕłåÕĖāÕ╝ÅÕż¦µĢ░µŹ«ķćÅÕ╣ČĶĪīĶ«Īń«ŚńÜäĶ¦ŻÕå│µ¢╣µĪłõĖŹÕÉīõ║ÄÕżŹµØéńÜähadoop’╝īÕ«āõĖŹÕāÅhadoopńÜäõĖŁķŚ┤Ķ«Īń«Śń╗ōµ×£õŠØĶĄ¢õ║Ähdfs’╝īÕ«āõĮ┐ńö©õĖŹÕÉīõ║Ämap/reduceńÜäÕģ©µ¢░Ķ«ŠĶ«Īµ©ĪÕ╝ÅĶ¦ŻÕå│ķŚ«ķóśŃĆéFourinoneµ£ēŌĆ£ÕīģÕĘźÕż┤ŌĆØ’╝īŌĆ£Õ壵░æÕĘźŌĆØ’╝īŌĆ£µēŗÕĘźõ╗ōÕ║ōŌĆØńÜä...
Õ£©Ķ┐ÖõĖ¬õŠŗÕŁÉõĖŁ’╝īMapperµ»Åµ¼ĪµÄźµöČÕł░ńÜ䵜»õĖĆĶĪīµ¢ćµ£¼µĢ░µŹ«’╝īÕŹ│`"hellowww.aboutyun.comhelloworld"`ŃĆü`"hellohadoop"`ÕÆī`"hellomapreduce"`õĖŁńÜäõ╗╗µäÅõĖĆĶĪīŃĆé - Ķ»źÕÅéµĢ░ńÜäń▒╗Õ×ŗµś»`Text`’╝īĶ┐ÖµäÅÕæ│ńØĆÕ«āÕÅ»õ╗źµś»õĖĆõĖ¬ÕŁŚń¼”õĖ▓ŃĆéÕøĀµŁż’╝īÕ£©µ£¼...
ń¼¼õĖēõĖ¬ķŚ«ķ󜵜»ÕżäńÉå1GBÕż¦Õ░ÅńÜäĶ»Źµ¢ćõ╗Č’╝īµ»ÅĶĪīõĖĆõĖ¬Ķ»Ź’╝īńø«µĀ浜»µēŠÕć║ÕēŹNõĖ¬µ£Ćķóæń╣üńÜäĶ»ŹŃĆéĶ┐ÖõĖ¬ķŚ«ķóśÕÅ»õ╗źķĆÜĶ┐ćÕ╗║ń½ŗTrieµĀæµł¢ÕŁŚÕģĖµĀæµØźõ╝śÕī¢’╝īÕģłÕ»╣µēƵ£ēĶ»ŹĶ┐øĶĪīķóäÕżäńÉå’╝īńäČÕÉÄķĆÉĶ»Źµē½µÅŵ¢ćõ╗Č’╝īń╗¤Ķ«ĪĶ»ŹķóæŃĆéµ£ĆÕÉÄ’╝īķĆÜĶ┐ćÕĀåµÄÆÕ║ŵł¢ĶĆģĶ«ĪµĢ░µÄÆÕ║ÅńŁēµ¢╣µ│ĢµēŠ...
Õ£©Ķ┐ÖõĖ¬Ķ┐ćń©ŗõĖŁ’╝īMapķśČµ«ĄĶ┤¤Ķ┤ŻÕ░åõĖĆõĖ¬Õż¦ńÜäµĢ░µŹ«ķøåÕłåÕē▓õĖ║ńŗ¼ń½ŗńÜäÕØŚ’╝īÕ╣ČÕ£©µ»ÅõĖ¬ÕØŚõĖŖÕ╣ČĶĪīÕżäńÉå’╝īĶĆīReduceķśČµ«ĄÕłÖÕ»╣MapķśČµ«ĄńÜäń╗ōµ×£Ķ┐øĶĪīµ▒ćµĆ╗ŃĆéÕ£©µĢ░µŹ«µī¢µÄśķóåÕ¤¤’╝īMapReduceµ©ĪÕ×ŗÕÅ»õ╗źµ×üÕż¦µÅÉķ½śń«Śµ│ĢńÜäµē¦ĶĪīµĢłńÄć’╝īÕ░żÕģȵś»ķÆłÕ»╣ķéŻõ║øÕÅ»õ╗źĶó½ÕłåÕē▓...
ń╗╝õĖŖµēĆĶ┐░’╝īÕ¤║õ║ÄMapReduceµŖƵ£»ńÜäÕ╣ČĶĪīķøåµłÉÕłåń▒╗ń«Śµ│Ģ’╝łEMapReduce’╝ēõĖ║ÕżäńÉåÕż¦Ķ¦äµ©ĪµĢ░µŹ«µÅÉõŠøõ║åõĖĆń¦Źµ£ēµĢłńÜäĶ¦ŻÕå│µ¢╣µĪłŃĆéĶ»źń«Śµ│ĢõĖŹõ╗ģÕģŗµ£Źõ║åõ╝Āń╗¤ń«Śµ│ĢÕ£©ÕżäńÉåÕż¦Ķ¦äµ©ĪµĢ░µŹ«µŚČńÜäÕ▒ĆķÖɵƦ’╝īĶ┐śÕ▒Ģńż║õ║åÕ£©µĢłńÄćÕÆīÕłåń▒╗ÕćåńĪ«µĆ¦µ¢╣ķØóńÜäõ╝śÕŖ┐ŃĆéµ£¬µØźńÜä...
- **ķŚ«ķóśµ”éĶ┐░**: µ£ēõĖĆõĖ¬1GBÕż¦Õ░ÅńÜäµ¢ćõ╗Č’╝īµ»ÅĶĪīµś»õĖĆõĖ¬Ķ»Ź’╝īĶ»ŹńÜäÕż¦Õ░ÅõĖŹĶČģĶ┐ć16ÕŁŚĶŖé’╝īÕåģÕŁśķÖÉÕłČÕż¦Õ░ÅõĖ║1MB’╝īĶ”üµ▒éĶ┐öÕø×ķóæµĢ░µ£Ćķ½śńÜä100õĖ¬Ķ»ŹŃĆé - **Ķ¦ŻÕå│µ¢╣µĪł**: - õĮ┐ńö©ÕōłÕĖīÕćĮµĢ░Õ░åÕŹĢĶ»ŹµśĀÕ░äÕł░5000õĖ¬Õ░ŵ¢ćõ╗ČõĖŁ’╝īµ»ÅõĖ¬µ¢ćõ╗Čń║”200KBŃĆé - ...
ThreadsX.jl ńÜäµĀĖÕ┐āńø«µĀ浜»õĖ║ Julia Õ╝ĆÕÅæĶĆģµÅÉõŠøõĖĆõĖ¬ń«Ćµ┤üõĖöķ½śµĢłńÜäÕ╣ČĶĪīń╝¢ń©ŗµÄźÕÅŻ’╝īõĮ┐ÕŠŚÕ╣ČĶĪīĶ«Īń«ŚÕÅśÕŠŚµø┤ÕŖĀń«ĆÕŹĢµśōĶĪīŃĆéÕ«āµē®Õ▒Ģõ║å Julia ńÜäµĀćÕćåÕ║ō’╝īńē╣Õł½µś»Õ£©Õ╣ČĶĪī Map, Reduce ÕÆīµÄÆÕ║Åń«Śµ│Ģµ¢╣ķØó’╝īµÅÉõŠøõ║åķóØÕż¢ńÜäõ╝śÕī¢ÕÆīÕĘźÕģĘŃĆé 1. **...
õĖ║µŁż’╝īń«Śµ│Ģ1’╝łGetFrequencySet_MR’╝ēÕ╝ĢÕģźMapReduce’╝īÕ░åµĢ░µŹ«ķøåµīēĶĪīÕåÖÕģźHadoopÕłåÕĖāÕ╝ŵ¢ćõ╗Čń│╗ń╗¤’╝īńö▒MapÕćĮµĢ░Õ░åńøĖÕÉīÕćåµĀćĶ»åń¼”Õ▒׵ƦńÜäÕģāń╗äÕłåń╗ä’╝īReduceÕćĮµĢ░ÕłÖĶ┤¤Ķ┤Żń╗¤Ķ«ĪÕÉäńŁēõ╗Ęń▒╗ńÜäķóæńÄć’╝īÕ«×ńÄ░ńŁēõ╗Ęń▒╗Ķ«Īń«ŚńÜäÕ╣ČĶĪīÕī¢’╝īõ╗ÄĶĆīµśŠĶæŚµÅÉÕŹć...
MapD CoreńÜäÕåģÕŁśÕłŚÕ╝ÅÕŁśÕ驵ś»ÕģČÕģ│ķö«ńē╣µĆ¦õ╣ŗõĖĆŃĆéõĖÄõ╝Āń╗¤ńÜäĶĪīÕ╝ÅÕŁśÕé©ńøĖµ»ö’╝īÕłŚÕ╝ÅÕŁśÕé©Õ£©ÕżäńÉåÕłåµ×ɵ¤źĶ»óµŚČÕģʵ£ēµśŠĶæŚõ╝śÕŖ┐ŃĆéńö▒õ║ÄÕłŚÕ╝ÅÕŁśÕé©Õ░åńøĖÕÉīń▒╗Õ×ŗńÜäµĢ░µŹ«ĶüÜķøåÕ£©õĖĆĶĄĘ’╝īĶ┐ÖõĮ┐ÕŠŚÕ»╣µ¤ÉõĖĆÕłŚńÜ䵤źĶ»óĶāĮÕż¤Õ┐½ķƤĶ«┐ķŚ«Õ╣ČÕżäńÉåµēĆķ£ĆńÜäµĢ░µŹ«’╝īÕćÅÕ░æõ║å...
Õ£©Ķ┐ÖõĖ¬õŠŗÕŁÉõĖŁ’╝īMapķśČµ«ĄÕ░åµ¢ćµ£¼µ¢ćõ╗ČõĖŁńÜäµ»ÅõĖĆĶĪīĶ¦åõĖ║õĖĆõĖ¬ķö«ÕĆ╝Õ»╣’╝īķö«õĖ║ń®║ÕŁŚń¼”õĖ▓’╝īÕĆ╝õĖ║µĢ┤ĶĪīÕåģÕ«╣ŃĆéMapperÕ░åµ»ÅõĖĆĶĪīÕåģÕ«╣µŗåÕłåµłÉÕŹĢĶ»Ź’╝īµ»ÅõĖ¬ÕŹĢĶ»ŹµłÉõĖ║µ¢░ńÜäķö«ÕĆ╝Õ»╣ńÜäķö«’╝īÕĆ╝õĖ║1ŃĆéReduceķśČµ«ĄÕłÖÕ░åµēƵ£ēÕÉīõĖĆõĖ¬ÕŹĢĶ»ŹńÜäķö«ÕĆ╝Õ»╣ĶüÜÕÉłÕ£©õĖĆĶĄĘ’╝ī...
Ķ░ʵŁīńÜäõĖēÕż¦Ķ«║µ¢ćŌĆöŌĆöŌĆ£ÕłåÕĖāÕ╝ŵ¢ćõ╗Čń│╗ń╗¤GFSŌĆØŃĆüŌĆ£Õż¦Ķ¦äµ©ĪµĢ░µŹ«ń«ĪńÉåBigtableŌĆØÕÆīŌĆ£Õ╣ČĶĪīĶ«Īń«Śµ©ĪÕ×ŗMapReduceŌĆØŌĆöŌĆöµś»Õż¦µĢ░µŹ«ÕżäńÉåķóåÕ¤¤ńÜäķćīń©ŗńóæÕ╝ÅÕĘźõĮ£’╝īÕ«āõ╗¼õĖ║ńÄ░õ╗Żõ║æĶ«Īń«ŚÕÆīÕż¦µĢ░µŹ«µŖƵ£»ÕźĀÕ«Üõ║åÕ¤║ńĪĆŃĆéĶ┐ÖõĖēń»ćĶ«║µ¢ćĶ»”ń╗åķśÉĶ┐░õ║åĶ░ʵŁīÕ”éõĮĢ...
Õ£©ŌĆ£MapReduceµ▒éĶĪīÕ╣│ÕØćÕĆ╝ŌĆØńÜäÕ£║µÖ»õĖŗ’╝īMapõ╗╗ÕŖĪÕÅ»ĶāĮķ£ĆĶ”üĶ»╗ÕÅ¢µ»ÅõĖĆĶĪīńÜäµĢ░µŹ«’╝īÕ░åµ»ÅĶĪīĶ¦åõĖ║õĖĆõĖ¬Ķ«░ÕĮĢ’╝īÕ░åĶ«░ÕĮĢńÜäµĢ░ÕĆ╝ķā©ÕłåµÅÉÕÅ¢Õć║µØź’╝īĶĮ¼Õī¢õĖ║`(key, value)`Õ»╣’╝īÕģČõĖŁkeyÕÅ»ĶāĮµś»ĶĪīÕÅʵł¢õ╗╗µäŵĀćĶ»å’╝īvalueµś»Ķ»źĶĪīńÜäµĢ░ÕĆ╝µĆ╗ÕÆīŃĆé...
MapReduceµś»õĖĆń¦Źń╝¢ń©ŗµ©ĪÕ×ŗ’╝īńö©õ║ÄÕżäńÉåÕż¦Ķ¦äµ©ĪµĢ░µŹ«ķøåńÜäÕ╣ČĶĪīĶ┐Éń«Ś’╝īÕ«āÕīģÕɽMap’╝łµśĀÕ░ä’╝ēÕÆīReduce’╝łÕĮÆń║”’╝ēõĖżõĖ¬Õģ│ķö«µōŹõĮ£ŃĆé ń│╗ń╗¤Ķ┐śõĮ┐ńö©õ║åZooKeeperµŖƵ£»µØźÕ╗║ń½ŗÕŁÉõ╗╗ÕŖĪÕżäńÉåÕÖ©õ╣ŗķŚ┤ńÜäÕŹÅĶ░āµ£║ÕłČŃĆéZooKeeperµś»õĖĆõĖ¬Õ╝Ƶ║ÉńÜäÕłåÕĖāÕ╝ÅÕŹÅĶ░āµ£ŹÕŖĪ...
- **µĢ░µŹ«µ©ĪÕ×ŗ**’╝ÜHBaseõĮ┐ńö©ĶĪ©µĀ╝ÕĮóÕ╝ÅÕŁśÕ驵Ģ░µŹ«’╝īµ»ÅÕ╝ĀĶĪ©ńö▒õĖĆń│╗ÕłŚĶĪīń╗䵳ɒ╝īµ»ÅõĖĆĶĪīńö▒ĶĪīķö«’╝łRow Key’╝ēÕö»õĖƵĀćĶ»åŃĆé - **ÕłåÕī║õĖÄÕŁśÕé©**’╝ÜHBaseĶć¬ÕŖ©Õ░åĶĪ©ÕłåµłÉÕżÜõĖ¬ÕłåÕī║’╝łRegion’╝ē’╝īµ»ÅõĖ¬ÕłåÕī║ÕÅ»õ╗źÕ£©õĖŹÕÉīńÜäĶŖéńé╣õĖŖÕŁśÕé©’╝īµö»µīüµ░┤Õ╣│µē®Õ▒ĢŃĆé...
Õ£©Ķ┐ÖõĖ¬Ķ┐ćń©ŗõĖŁ’╝īMapķśČµ«ĄÕ░åĶŠōÕģźµ¢ćõ╗ČÕłåÕē▓µłÉĶĪī’╝īńäČÕÉÄÕ»╣µ»ÅõĖĆĶĪīĶ┐øĶĪīÕŹĢĶ»ŹÕłćÕłå’╝īńö¤µłÉķö«ÕĆ╝Õ»╣’╝łÕŹĢĶ»Ź’╝ī1’╝ēŃĆéReduceķśČµ«ĄÕłÖĶ┤¤Ķ┤ŻĶüÜÕÉłĶ┐Öõ║øķö«ÕĆ╝Õ»╣’╝īÕ░åńøĖÕÉīÕŹĢĶ»ŹńÜäµēƵ£ēĶ«ĪµĢ░ÕĆ╝ńøĖÕŖĀ’╝īµ£Ćń╗łÕŠŚÕł░µ»ÅõĖ¬ÕŹĢĶ»ŹńÜäµĆ╗µĢ░ŃĆéĶ┐ÖõĖ¬õŠŗÕŁÉÕ▒Ģńż║õ║åMapReduce...
// ÕżäńÉåµ»ÅõĖĆĶĪīµĢ░µŹ« } ``` 3. **NIO’╝łķØ×ķś╗ÕĪ×I/O’╝ē**’╝ÜJavańÜäNIOÕ║ōµÅÉõŠøõ║å`Channels`ÕÆī`Buffers`ńÜäµ”éÕ┐Ą’╝īÕÅ»õ╗źńö©õ║ĵø┤ķ½śµĢłÕ£░Ķ»╗ÕåÖÕż¦µ¢ćõ╗ČŃĆé`FileChannel`ÕÅ»õ╗źõ╗ĵ¢ćõ╗ČõĖŁĶ»╗ÕÅ¢µĢ░µŹ«’╝īÕ╣ČõĖÄ`ByteBuffer`ķģŹÕÉłõĮ┐ńö©’╝īÕ«×ńÄ░ÕłåÕØŚĶ»╗ÕÅ¢ŃĆé...