
еҺҹж–Үй“ҫжҺҘпјҡhttp://blog.csdn.net/dm_vincent/article/details/41242565
В
жң¬ж–Үзҝ»иҜ‘иҮӘElasticsearchе®ҳж–№жҢҮеҚ—зҡ„distributed document storeдёҖз« гҖӮ
еҲҶеёғејҸж–ҮжЎЈеӯҳеӮЁ
еңЁдёҠдёҖз« дёӯпјҢжҲ‘们дёҖзӣҙеңЁд»Ӣз»Қзҙўеј•ж•°жҚ®е’ҢиҺ·еҸ–ж•°жҚ®зҡ„ж–№жі•гҖӮдҪҶжҳҜжҲ‘们зңҒз•ҘдәҶеҫҲеӨҡе…ідәҺж•°жҚ®жҳҜеҰӮдҪ•еңЁйӣҶзҫӨдёӯиў«еҲҶеёғ(Distributed)е’ҢиҺ·еҸ–(Fetched)зҡ„жҠҖжңҜз»ҶиҠӮгҖӮиҝҷе®һйҷ…дёҠжҳҜжңүж„Ҹдёәд№Ӣ - дҪ зңҹзҡ„дёҚйңҖиҰҒдәҶи§Јж•°жҚ®еңЁESдёӯжҳҜеҰӮдҪ•иў«еҲҶеёғзҡ„гҖӮе®ғиғҪе·ҘдҪңе°ұи¶іеӨҹдәҶгҖӮ
еңЁжң¬з« дёӯпјҢжҲ‘们е°Ҷдјҡж·ұе…ҘеҲ°иҝҷдәӣеҶ…йғЁжҠҖжңҜз»ҶиҠӮдёӯпјҢжқҘеё®еҠ©дҪ дәҶи§ЈдҪ зҡ„ж•°жҚ®жҳҜеҰӮдҪ•иў«еӯҳеӮЁеңЁдёҖдёӘеҲҶеёғејҸзі»з»ҹдёӯзҡ„гҖӮ
В
В
и·Ҝз”ұдёҖд»Ҫж–ҮжЎЈ(Document)еҲ°дёҖдёӘеҲҶзүҮ(Shard)
В
еҪ“дҪ зҙўеј•дёҖд»Ҫж–ҮжЎЈж—¶пјҢе®ғдјҡиў«дҝқеӯҳеҲ°дёҖдёӘдё»иҰҒеҲҶзүҮ(Primary Shard)дёҠгҖӮйӮЈд№ҲESжҳҜеҰӮдҪ•зҹҘйҒ“иҜҘж–ҮжЎЈеә”иҜҘиў«дҝқеӯҳеҲ°е“ӘдёӘеҲҶзүҮдёҠе‘ўпјҹеҪ“жҲ‘们еҲӣе»әдәҶдёҖд»Ҫж–°ж–ҮжЎЈпјҢESжҳҜеҰӮдҪ•зҹҘйҒ“е®ғ究з«ҹеә”иҜҘдҝқеӯҳеҲ°еҲҶзүҮ1жҲ–иҖ…еҲҶзүҮ2дёҠзҡ„е‘ўпјҹ
иҝҷдёӘиҝҮзЁӢдёҚиғҪжҳҜйҡҸжңәзҡ„пјҢеӣ дёәе°ҶжқҘжҲ‘们жҲ–и®ёиҝҳйңҖиҰҒиҺ·еҸ–иҜҘж–ҮжЎЈгҖӮе®һйҷ…дёҠпјҢиҝҷдёӘиҝҮзЁӢжҳҜйҖҡиҝҮдёҖдёӘйқһеёёз®ҖеҚ•зҡ„е…¬ејҸеҶіе®ҡзҡ„пјҡ
shard = hash(routing) % number_of_primary_shards
д»ҘдёҠзҡ„routingзҡ„еҖјжҳҜдёҖдёӘд»»ж„Ҹзҡ„еӯ—з¬ҰдёІпјҢе®ғй»ҳи®Өиў«и®ҫзҪ®жҲҗж–ҮжЎЈзҡ„_idеӯ—ж®өпјҢдҪҶжҳҜд№ҹеҸҜд»Ҙиў«и®ҫзҪ®жҲҗе…¶д»–жҢҮе®ҡзҡ„еҖјгҖӮиҝҷдёӘroutingеӯ—з¬ҰдёІдјҡиў«дј е…ҘеҲ°дёҖдёӘе“ҲеёҢеҮҪж•°(Hash Function)жқҘеҫ—еҲ°дёҖдёӘж•°еӯ—пјҢ然еҗҺиҜҘж•°еӯ—дјҡе’Ңзҙўеј•дёӯзҡ„дё»иҰҒеҲҶзүҮж•°иҝӣиЎҢжЁЎиҝҗз®—жқҘеҫ—еҲ°дҪҷж•°гҖӮиҝҷдёӘдҪҷж•°зҡ„иҢғеӣҙеә”иҜҘжҖ»жҳҜеңЁ0е’Ңnumber_of_primary_shards - 1д№Ӣй—ҙпјҢе®ғе°ұжҳҜдёҖд»Ҫж–ҮжЎЈиў«еӯҳеӮЁеҲ°зҡ„еҲҶзүҮзҡ„еҸ·з ҒгҖӮ
иҝҷе°ұи§ЈйҮҠдәҶдёәд»Җд№Ҳзҙўеј•дёӯзҡ„дё»иҰҒеҲҶзүҮж•°йҮҸеҸӘиғҪеңЁзҙўеј•еҲӣе»әж—¶иў«жҢҮе®ҡпјҢ并且е°ҶжқҘйғҪдёҚиғҪеңЁиў«жӣҙж”№пјҡеҰӮжһңдё»иҰҒеҲҶзүҮж•°йҮҸеңЁзҙўеј•еҲӣе»әеҗҺж”№еҸҳдәҶпјҢйӮЈд№Ҳд№ӢеүҚзҡ„жүҖжңүи·Ҝз”ұз»“жһңйғҪдјҡеҸҳзҡ„дёҚжӯЈзЎ®пјҢд»ҺиҖҢеҜјиҮҙж–ҮжЎЈдёҚиғҪиў«жӯЈзЎ®ең°иҺ·еҸ–гҖӮ
з”ЁжҲ·жңүж—¶дјҡи®Өдёәе°Ҷдё»иҰҒеҲҶзүҮж•°йҮҸеӣәе®ҡдёӢжқҘдјҡи®©е°ҶжқҘеҜ№зҙўеј•зҡ„ж°ҙе№іжү©еұ•(Scale Out)еҸҳзҡ„еӣ°йҡҫгҖӮе®һйҷ…дёҠпјҢжңүдәӣжҠҖжңҜиғҪеӨҹи®©дҪ ж №жҚ®йңҖиҰҒж–№дҫҝең°иҝӣиЎҢж°ҙе№іжү©еұ•гҖӮжҲ‘们дјҡеңЁDesigning for scaleдёӯд»Ӣз»ҚиҝҷдәӣжҠҖжңҜгҖӮ
жүҖжңүзҡ„ж–ҮжЎЈAPI(get, index, delete, buli, updateе’Ңmget)йғҪжҺҘеҸ—дёҖдёӘroutingеҸӮж•°пјҢе®ғз”ЁжқҘе®ҡеҲ¶д»Һж–ҮжЎЈеҲ°еҲҶзүҮзҡ„жҳ е°„гҖӮдёҖдёӘзү№е®ҡзҡ„routingеҖјиғҪеӨҹзЎ®дҝқжүҖжңүзӣёе…іж–ҮжЎЈ - жҜ”еҰӮеұһдәҺзӣёеҗҢз”ЁжҲ·зҡ„жүҖжңүж–ҮжЎЈ - йғҪдјҡиў«еӯҳеӮЁеңЁзӣёеҗҢзҡ„еҲҶзүҮдёҠгҖӮжҲ‘们дјҡеңЁDesigning for scaleдёӯиҜҰз»Ҷд»Ӣз»Қдёәд»Җд№ҲдҪ еҸҜиғҪдјҡиҝҷж ·еҒҡгҖӮ
В
В
дё»иҰҒеҲҶзүҮ(Primary Shard)е’ҢеүҜжң¬еҲҶзүҮ(Replica Shard)жҳҜеҰӮдҪ•дәӨдә’зҡ„
В
дёәдәҶи§ЈйҮҠиҝҷдёӘй—®йўҳпјҢеҒҮи®ҫжҲ‘们жңүдёҖдёӘеҢ…еҗ«3дёӘиҠӮзӮ№(Node)зҡ„йӣҶзҫӨ(Cluster)гҖӮе®ғеҗ«жңүдёҖдёӘжӢҘжңү2дёӘдё»иҰҒеҲҶзүҮзҡ„еҗҚдёәblogsзҡ„зҙўеј•гҖӮжҜҸдёӘдё»иҰҒеҲҶзүҮжңү2дёӘеүҜжң¬еҲҶзүҮгҖӮжӢҘжңүзӣёеҗҢж•°жҚ®зҡ„дёӨдёӘеҲҶзүҮз»қдёҚдјҡиў«еҲҶй…ҚеҲ°еҗҢдёҖдёӘиҠӮзӮ№дёҠпјҢжүҖд»ҘиҝҷдёӘйӣҶзҫӨзҡ„жһ„жҲҗеҸҜиғҪдјҡеғҸдёӢеӣҫиҝҷж ·пјҡ
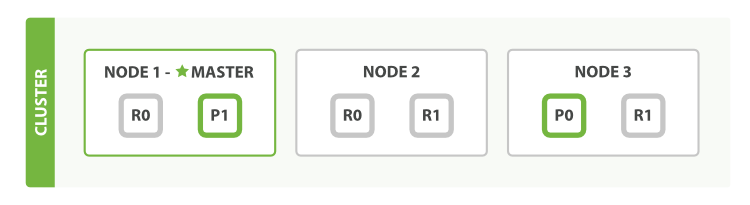
жҲ‘们еҸҜд»Ҙеҗ‘йӣҶзҫӨдёӯзҡ„д»»ж„ҸдёҖдёӘиҠӮзӮ№еҸ‘йҖҒиҜ·жұӮгҖӮжҜҸдёӘиҠӮзӮ№йғҪжңүи¶іеӨҹзҡ„иғҪеҠӣжқҘеӨ„зҗҶиҜ·жұӮгҖӮжҜҸдёӘиҠӮзӮ№йғҪзҹҘйҒ“йӣҶзҫӨдёӯзҡ„жҜҸд»Ҫж–ҮжЎЈзҡ„дҪҚзҪ®пјҢеӣ жӯӨиғҪеӨҹе°ҶиҜ·жұӮиҪ¬еҸ‘еҲ°зӣёеә”зҡ„иҠӮзӮ№гҖӮеңЁдёӢйқўзҡ„дҫӢеӯҗдёӯпјҢжҲ‘们дјҡе°ҶжүҖжңүзҡ„иҜ·жұӮйғҪеҸ‘йҖҒеҲ°иҠӮзӮ№1дёҠпјҢиҝҷдёӘиҠӮзӮ№иў«з§°дёәиҜ·жұӮиҠӮзӮ№(Requesting Node)гҖӮ
TIPВ еҪ“еҸ‘йҖҒиҜ·жұӮж—¶пјҢжңҖеҘҪйҮҮз”ЁдёҖз§ҚеҫӘзҺҜ(Round-robin)зҡ„ж–№ејҸжқҘе°ҶиҜ·жұӮдҫқж¬ЎеҸ‘йҖҒеҲ°жҜҸдёӘиҠӮзӮ№дёҠпјҢд»ҺиҖҢеҒҡеҲ°еҲҶжӢ…иҙҹиҪҪгҖӮ
В
В
ж–ҮжЎЈзҡ„еҲӣе»әпјҢзҙўеј•е’ҢеҲ йҷӨ
В
еҲӣе»әпјҢзҙўеј•е’ҢеҲ йҷӨзҡ„иҜ·жұӮйғҪжҳҜеҶҷж“ҚдҪң(Write Operations)пјҢе®ғ们йғҪеә”иҜҘйҰ–е…ҲеңЁдё»иҰҒеҲҶзүҮ(Primary Shard)дёҠжҲҗеҠҹе®ҢжҲҗпјҢ然еҗҺжүҚиғҪиў«жӢ·иҙқе…іиҒ”зҡ„еүҜжң¬еҲҶзүҮ(Replica Shard)дёҠгҖӮ
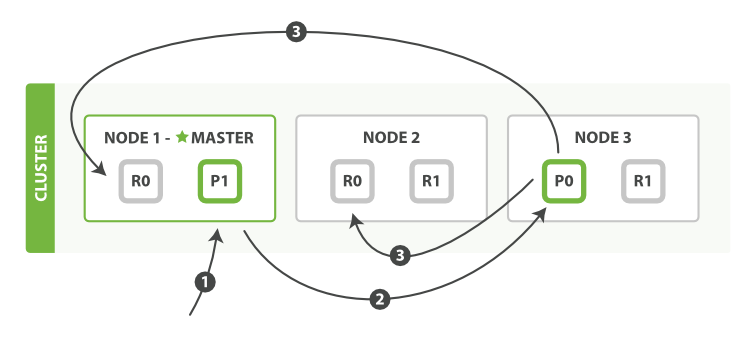
иҝҷдёӘиҝҮзЁӢеҰӮдёҠеӣҫжүҖзӨәгҖӮдёӢйқўжҲ‘们еҲ—дёҫеҮәеӣҫдёӯз”ЁжқҘе®ҢжҲҗеҲӣе»әпјҢзҙўеј•е’ҢеҲ йҷӨж–ҮжЎЈзҡ„жҜҸдёӘжӯҘйӘӨпјҡ
- е®ўжҲ·з«Ҝ(Client)еҗ‘иҠӮзӮ№1еҸ‘йҖҒдәҶдёҖдёӘз”ЁдәҺеҲӣе»әпјҢзҙўеј•жҲ–жҳҜеҲ йҷӨзҡ„иҜ·жұӮгҖӮ
- иҠӮзӮ№дҪҝз”ЁиҜҘж–ҮжЎЈзҡ„_idеӯ—ж®өжқҘеҶіе®ҡдәҶе®ғеә”иҜҘеұһдәҺеҲҶзүҮ0гҖӮеӣ жӯӨиҜ·жұӮдјҡиў«иҪ¬еҸ‘еҲ°иҠӮзӮ№3пјҢеӣ дёәеҲҶзүҮ0зҡ„дё»иҰҒеҲҶзүҮзӣ®еүҚиў«еҲҶй…ҚеңЁиҠӮзӮ№3дёҠгҖӮ
- иҠӮзӮ№3дјҡеңЁж–ҮжЎЈеҜ№еә”зҡ„дё»иҰҒеҲҶзүҮдёҠжү§иЎҢиҝҷдёӘиҜ·жұӮгҖӮеҰӮжһңжү§иЎҢжҲҗеҠҹдәҶпјҢйӮЈд№Ҳе®ғдјҡе°ҶиҜҘиҜ·жұӮ并иЎҢең°иҪ¬еҸ‘еҲ°еҜ№еә”еүҜжң¬еҲҶзүҮжүҖеңЁзҡ„иҠӮзӮ№1е’ҢиҠӮзӮ№2дёҠгҖӮдёҖж—ҰжүҖжңүзҡ„еүҜжң¬еҲҶзүҮйғҪжҲҗеҠҹе®ҢжҲҗдәҶиҜҘиҜ·жұӮпјҢйӮЈд№ҲиҠӮзӮ№3е°ұдјҡеҗ‘иҜ·жұӮиҠӮзӮ№(Requesting Node)жҠҘе‘Ҡжү§иЎҢжҲҗеҠҹпјҢ然еҗҺиҠӮзӮ№3е°ұиғҪеӨҹеҗ‘е®ўжҲ·з«ҜеҸ‘йҖҒдёҖдёӘиҜ·жұӮжү§иЎҢжҲҗеҠҹзҡ„е“Қеә”дәҶгҖӮ
еҪ“е®ўжҲ·з«ҜжҺҘ收еҲ°дәҶжү§иЎҢжҲҗеҠҹзҡ„е“Қеә”ж—¶пјҢеңЁдё»иҰҒеҲҶзүҮе’Ңе…¶е…іиҒ”зҡ„жүҖжңүеүҜжң¬еҲҶзүҮдёӯпјҢеҸ‘йҖҒзҡ„ж–ҮжЎЈе·Із»Ҹиў«жҲҗеҠҹжӣҙж–°дәҶгҖӮиҮіжӯӨпјҢдҪ зҡ„дҝ®ж”№е°ұе®ҢжҲҗдәҶгҖӮ
еңЁиҝҷдёӘиҝҮзЁӢдёӯиҝҳеӯҳеңЁдёҖдәӣеҸҜйҖүзҡ„еҸӮж•°з”ЁжқҘеҜ№жӯӨиҝҮзЁӢиҝӣиЎҢи°ғж•ҙпјҢеҸҜиғҪең°еҰӮд»ҘзүәзүІж•°жҚ®е®үе…Ёзҡ„д»Јд»·жқҘеўһеҠ жҖ§иғҪгҖӮеӣ дёәESжң¬иә«е·Із»Ҹи¶іеӨҹеҝ«дәҶпјҢжүҖд»ҘиҝҷдәӣеҸҜйҖүеҸӮж•°еҫҲе°‘иў«дҪҝз”ЁпјҢдҪҶжҳҜдёәдәҶе®Ңж•ҙжҖ§иҝҳжҳҜдјҡеҜ№е®ғ们иҝӣиЎҢи§ЈйҮҠпјҡ
replication
replicationзҡ„й»ҳи®ӨеҖјжҳҜsyncгҖӮе®ғдјҡеҜјиҮҙдё»иҰҒеҲҶзүҮе°Ҷзӯүеҫ…еүҜжң¬еҲҶзүҮдёҠзҡ„жү§иЎҢжҲҗеҠҹе“Қеә”пјҢ然еҗҺжүҚдјҡе°Ҷжү§иЎҢжҲҗеҠҹе“Қеә”еҸ‘йҖҒеҲ°иҜ·жұӮиҠӮзӮ№гҖӮ еҰӮжһңдҪ е°Ҷreplicationи®ҫзҪ®жҲҗasyncпјҢйӮЈд№Ҳе®ғдјҡеҜјиҮҙжҲҗеҠҹе“Қеә”дјҡеңЁиҜ·жұӮеңЁдё»иҰҒеҲҶзүҮдёҠжҲҗеҠҹжү§иЎҢеҗҺе°ұдјҡиў«еҸ‘йҖҒеҲ°е®ўжҲ·з«ҜгҖӮе®ғд»Қ然дјҡе°ҶиҜ·жұӮиҪ¬еҸ‘еҲ°еүҜжң¬еҲҶзүҮжүҖеңЁзҡ„иҠӮзӮ№дёҠпјҢеҸӘжҳҜдҪ е°Ҷж— жі•еҫ—зҹҘиҜ·жұӮеңЁеүҜжң¬еҲҶзүҮдёҠжҳҜеҗҰиғҪжҲҗеҠҹжү§иЎҢгҖӮ жҸҗеҲ°иҝҷдёӘйҖүйЎ№зҡ„зӣ®зҡ„жҳҜдёәдәҶи®©дҪ дёҚиҰҒдҪҝз”Ёе®ғгҖӮй»ҳи®Өзҡ„syncеҖјиғҪеӨҹи®©ESеӨ„зҗҶеҗ„з§Қзі»з»ҹдёӯзҡ„ж•°жҚ®еҺӢеҠӣгҖӮиҖҢдҪҝз”ЁдәҶasyncеҸҜиғҪдјҡеӣ дёәеҸ‘йҖҒдәҶиҝҮеӨҡж— йңҖзӯүеҫ…е…¶е®ҢжҲҗзҡ„иҜ·жұӮиҖҢи®©ESеӨ„дәҺиҝҮиҪҪзҡ„зҠ¶жҖҒгҖӮ
consistency
й»ҳи®Өжғ…еҶөдёӢпјҢдё»иҰҒеҲҶзүҮйңҖиҰҒйҖҡиҝҮд»ІиЈҒ(Quorum)пјҢеҚізЎ®и®ӨеӨ§йғЁеҲҶеҲҶзүҮжӢ·иҙқ(еҲҶзүҮжӢ·иҙқеҸҜд»ҘдҪҝдё»иҰҒеҲҶзүҮжҲ–иҖ…еүҜжң¬еҲҶзүҮпјҢдёӨиҖ…еқҮеҸҜ)жңүж•Ҳж—¶пјҢжүҚдјҡеҸ‘иө·дёҖдёӘеҶҷж“ҚдҪңгҖӮиҝҷж ·еҒҡзҡ„зӣ®зҡ„жҳҜдёәдәҶйҳІжӯўе°Ҷж•°жҚ®еҶҷе…ҘеҲ°зҪ‘з»ңдёӯ"й”ҷиҜҜзҡ„дёҖдҫ§(Wrong Side)"гҖӮд»ІиЈҒзҡ„е®ҡд№үеҰӮдёӢпјҡ
int( (primary + number_of_replicas) / 2 ) + 1
consistencyзҡ„еҖјеҸҜд»ҘжҳҜone(д»…дё»иҰҒеҲҶзүҮ)пјҢall(дё»иҰҒеҲҶзүҮе’ҢжүҖжңүеүҜжң¬еҲҶзүҮ)пјҢжҲ–иҖ…жҳҜй»ҳи®Өзҡ„quorumВ - еӨ§йғЁеҲҶеҲҶзүҮжӢ·иҙқгҖӮ
жіЁж„Ҹnumber_of_replicasжҳҜжҢҮе®ҡеңЁзҙўеј•и®ҫзҪ®дёӯзҡ„еүҜжң¬еҲҶзүҮзҡ„ж•°йҮҸпјҢдёҚжҳҜеҪ“еүҚеӨ„дәҺжҙ»еҠЁзҠ¶жҖҒзҡ„еүҜжң¬еҲҶзүҮж•°йҮҸгҖӮеҰӮжһңдҪ еңЁзҙўеј•дёӯжҢҮе®ҡдәҶжңү3дёӘеүҜжң¬еҲҶзүҮзҡ„иҜқпјҢйӮЈд№Ҳquorumзҡ„еҖје°ұжҳҜпјҡ
int( (primary + 3 replicas) / 2 ) + 1 = 3
йӮЈд№ҲеҪ“еҸӘеҗҜеҠЁдәҶдёӨдёӘиҠӮзӮ№ж—¶пјҢйӮЈд№Ҳе°ұж— жі•ж»Ўи¶іquorumпјҢд»ҺиҖҢеҜјиҮҙж— жі•зҙўеј•жҲ–иҖ…еҲ йҷӨд»»дҪ•ж–ҮжЎЈгҖӮ
timeout
еҰӮжһңжІЎжңүи¶іеӨҹзҡ„еҲҶзүҮжӢ·иҙқдјҡеҰӮдҪ•е‘ўпјҹESдјҡзӯүеҫ…пјҢеёҢжңӣжңүжӣҙеӨҡзҡ„еҲҶзүҮдјҡеҮәзҺ°гҖӮй»ҳи®Өе®ғдјҡзӯүеҫ…1еҲҶй’ҹгҖӮеҰӮжһңйңҖиҰҒеҸҜд»Ҙе°ҶиҝҷдёӘж—¶й—ҙи®ҫзҪ®зҡ„зҹӯдёҖдәӣпјҡ100иЎЁзӨәзҡ„жҳҜ100жҜ«з§’пјҢ30sиЎЁзӨәзҡ„жҳҜ30з§’гҖӮ
NOTEВ дёҖдёӘж–°зҡ„зҙўеј•й»ҳи®Өдјҡжңү1дёӘеүҜжң¬еҲҶзүҮпјҢйӮЈд№ҲдёәдәҶж»Ўи¶іquorumеҲҷйңҖиҰҒжңүдёӨдёӘжҙ»еҠЁзҡ„еҲҶзүҮжӢ·иҙқгҖӮдҪҶжҳҜпјҢеҪ“ESиҝҗиЎҢеңЁдёҖдёӘеҚ•дёҖиҠӮзӮ№зҡ„йӣҶзҫӨдёҠж—¶пјҢиҝҷдәӣй»ҳи®Өи®ҫзҪ®дјҡйҳ»жӯўз”ЁжҲ·еҒҡд»»дҪ•жңүз”Ёзҡ„ж“ҚдҪң(жҜ”еҰӮзҙўеј•зӯүеҶҷж“ҚдҪң)гҖӮдёәдәҶйҳІжӯўиҝҷдёӘй—®йўҳпјҢеҸӘжңүеҪ“number_of_replicasеӨ§дәҺ1ж—¶пјҢquorumжүҚйңҖиҰҒиў«ж»Ўи¶ігҖӮ
В
В
иҺ·еҸ–ж–ҮжЎЈ
В
ж–ҮжЎЈиғҪеӨҹйҖҡиҝҮдё»иҰҒеҲҶзүҮ(Primary Shard)жҲ–иҖ…д»»ж„ҸдёҖдёӘеүҜжң¬еҲҶзүҮ(Replica Shard)иҺ·еҸ–гҖӮ
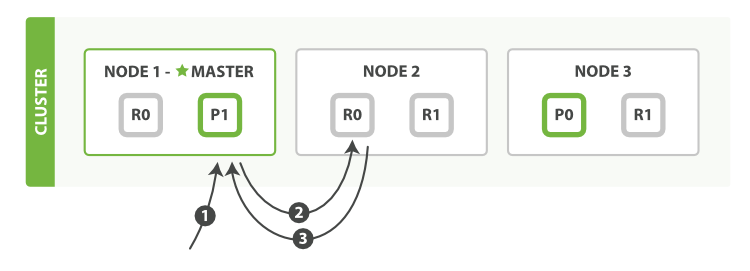
дёҠеӣҫеұ•зӨәдәҶиҺ·еҸ–ж–ҮжЎЈзҡ„иҝҮзЁӢпјҢжҜҸдёӘжӯҘйӘӨи§ЈйҮҠеҰӮдёӢпјҡ
- е®ўжҲ·з«Ҝ(Client)еҸ‘йҖҒдёҖдёӘиҜ·жұӮеҲ°иҠӮзӮ№1гҖӮ
- иҜҘиҠӮзӮ№еҲ©з”Ёж–ҮжЎЈзҡ„_idеӯ—ж®өжқҘеҲӨж–ӯиҜҘж–ҮжЎЈеұһдәҺеҲҶзүҮ0гҖӮеҲҶзүҮ0зҡ„еҲҶзүҮжӢ·иҙқ(дё»иҰҒеҲҶзүҮжҲ–иҖ…жҳҜеүҜжң¬еҲҶзүҮ)еӯҳеңЁдәҺжүҖжңүзҡ„3дёӘиҠӮзӮ№дёҠгҖӮиҝҷдёҖж¬ЎпјҢе®ғе°ҶиҜ·жұӮиҪ¬еҸ‘еҲ°дәҶиҠӮзӮ№2гҖӮ
- иҠӮзӮ№2е°Ҷж–ҮжЎЈиҝ”еӣһз»ҷиҠӮзӮ№1пјҢиҠӮзӮ№1йҡҸеҚіе°Ҷж–ҮжЎЈиҝ”еӣһз»ҷе®ўжҲ·з«ҜгҖӮ
еҜ№дәҺиҜ»иҜ·жұӮ(Read Request)пјҢиҜ·жұӮиҠӮзӮ№(Requesting Node)жҜҸж¬ЎйғҪдјҡйҖүжӢ©дёҖдёӘдёҚеҗҢзҡ„еҲҶзүҮжӢ·иҙқжқҘе®һзҺ°иҙҹиҪҪеқҮиЎЎ - еҫӘзҺҜдҪҝз”ЁжүҖжңүзҡ„еҲҶзүҮжӢ·иҙқгҖӮ
еҸҜиғҪеӯҳеңЁиҝҷз§Қжғ…еҶөпјҢеҪ“дёҖд»Ҫж–ҮжЎЈжӯЈеңЁиў«зҙўеј•ж—¶пјҢиҜҘж–ҮжЎЈеңЁдё»иҰҒеҲҶзүҮе·Із»Ҹе°ұз»ӘдәҶпјҢдҪҶжҳҜиҝҳжңӘиў«жӢ·иҙқеҲ°е…¶д»–еүҜжң¬еҲҶзүҮдёҠгҖӮжӯӨж—¶еүҜжң¬еҲҶзүҮжҲ–и®ёжҠҘе‘Ҡж–ҮжЎЈдёҚеӯҳеңЁ(иҜ‘жіЁпјҡжӯӨж—¶жңүиҜ»иҜ·жұӮжқҘиҺ·еҸ–иҜҘж–ҮжЎЈ)пјҢ然иҖҢдё»иҰҒеҲҶзүҮиғҪеӨҹжҲҗеҠҹиҝ”еӣһйңҖиҰҒзҡ„ж–ҮжЎЈ гҖӮдёҖж—Ұзҙўеј•иҜ·жұӮиҝ”еӣһз»ҷз”ЁжҲ·зҡ„е“Қеә”жҳҜжҲҗеҠҹпјҢйӮЈд№Ҳж–ҮжЎЈеңЁдё»иҰҒеҲҶзүҮд»ҘеҸҠжүҖжңүеүҜжң¬еҲҶзүҮдёҠйғҪжҳҜеҸҜз”Ёзҡ„гҖӮ
В
В
ж–ҮжЎЈзҡ„йғЁеҲҶжӣҙж–°(Partial Update)
В
update APIдјҡз»“еҗҲиҜ»е’ҢеҶҷжқҘе®ҢжҲҗдёҖж¬ЎйғЁеҲҶжӣҙж–°гҖӮ
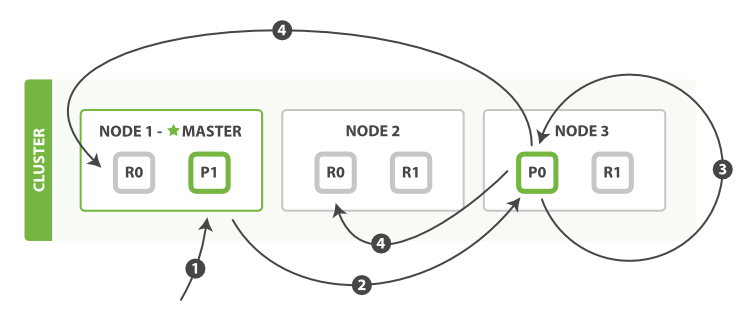
дёӢйқўеҜ№йғЁеҲҶжӣҙж–°зҡ„жӯҘйӘӨиҝӣиЎҢи§ЈйҮҠпјҡ
- е®ўжҲ·з«ҜеҸ‘йҖҒдёҖдёӘжӣҙж–°иҜ·жұӮеҲ°иҠӮзӮ№1гҖӮ
- иҠӮзӮ№1е°ҶиҜ·жұӮиҪ¬еҸ‘еҲ°иҠӮзӮ№3пјҢеӣ дёәдё»иҰҒеҲҶзүҮиў«еҲҶй…ҚеңЁиҜҘиҠӮзӮ№дёҠгҖӮ
- иҠӮзӮ№3д»Һдё»иҰҒеҲҶзүҮдёӯиҺ·еҸ–еҜ№еә”зҡ„ж–ҮжЎЈпјҢдҝ®ж”№JSONж–ҮжЎЈдёӯзҡ„_sourceеӯ—ж®өпјҢ然еҗҺиҜ•еӣҫеңЁиҜҘдё»иҰҒеҲҶзүҮдёӯеҜ№дҝ®ж”№еҗҺзҡ„ж–ҮжЎЈйҮҚж–°зҙўеј•(Reindex)гҖӮеҰӮжһңиҜҘж–ҮжЎЈе·Із»ҸеҸҰеӨ–дёҖдёӘиҝӣзЁӢз»ҷдҝ®ж”№дәҶпјҢйӮЈд№Ҳе®ғдјҡж №жҚ®
retry_on_conflictи®ҫзҪ®зҡ„ж¬Ўж•°йҮҚиҜ•гҖӮ - еҰӮжһңиҠӮзӮ№3иғҪеӨҹжҲҗеҠҹжӣҙж–°ж–ҮжЎЈпјҢе®ғдјҡе°Ҷж–°зүҲжң¬зҡ„ж–ҮжЎЈйҖҡиҝҮ并иЎҢзҡ„ж–№ејҸз»ҷиҪ¬еҸ‘еҲ°еүҜжң¬еҲҶзүҮжүҖеңЁзҡ„иҠӮзӮ№1е’ҢиҠӮзӮ№2дёҠпјҢд№ҹи®©е®ғ们иҝӣиЎҢйҮҚзҙўеј•зҡ„ж“ҚдҪңгҖӮдёҖж—ҰжүҖжңүзҡ„еүҜжң¬иҠӮзӮ№д№ҹжү§иЎҢжҲҗеҠҹпјҢиҠӮзӮ№3е°ұдјҡе°ҶиҝҷдёҖж¶ҲжҒҜеҸ‘йҖҒз»ҷиҜ·жұӮиҠӮзӮ№(Requesting NodeпјҢжӯӨеӨ„е°ұжҳҜиҠӮзӮ№1)гҖӮ然еҗҺиҜ·жұӮиҠӮзӮ№з»ҷе®ўжҲ·з«Ҝиҝ”еӣһе“Қеә”гҖӮ
update APIд№ҹиғҪеӨҹжҺҘеҸ—жҺҘеҸ—routingпјҢ'replication'пјҢ'consistency'е’Ң'timeout'еҸӮж•°гҖӮ
еҹәдәҺж–ҮжЎЈзҡ„еӨҚеҲ¶В еҪ“дёҖдёӘдё»иҰҒеҲҶзүҮе°Ҷдҝ®ж”№иҪ¬еҸ‘з»ҷе®ғзҡ„еүҜжң¬еҲҶзүҮж—¶пјҢе®ғдёҚдјҡиҪ¬иҫҫжӣҙж–°иҜ·жұӮгҖӮе®ғиҪ¬еҸ‘зҡ„жҳҜж–°зүҲжң¬зҡ„е®Ңж•ҙж–ҮжЎЈгҖӮйңҖиҰҒи®°дҪҸиҝҷдәӣиҪ¬еҸ‘еҲ°еүҜжң¬еҲҶзүҮзҡ„иҜ·жұӮжҳҜејӮжӯҘзҡ„пјҢд№ҹе°ұжҳҜиҜҙе®ғ们еҲ°иҫҫзҡ„йЎәеәҸе’ҢеҸ‘йҖҒзҡ„йЎәеәҸжҳҜдёҚзЎ®е®ҡзҡ„гҖӮеҰӮжһңESд»…д»…жҳҜиҪ¬еҸ‘дҝ®ж”№пјҢйӮЈд№Ҳиҝҷдәӣдҝ®ж”№е°ұеҸҜиғҪд»Ҙй”ҷиҜҜең°йЎәеәҸиў«жҺҘеҸ—пјҢд»ҺиҖҢеҜјиҮҙж•°жҚ®зҡ„жҚҹжҜҒгҖӮ
В
В
еӨҡж–ҮжЎЈжЁЎејҸ(Multi-Document Patterns)
В
mgetе’Ңbulk APIзҡ„иЎҢдёәжЁЎејҸе’ҢеҚ•дёӘзҡ„ж–ҮжЎЈж“ҚдҪңжҳҜзұ»дјјзҡ„гҖӮеҢәеҲ«дё»иҰҒеңЁдәҺиҜ·жұӮиҠӮзӮ№зҹҘйҒ“жҜҸд»Ҫж–ҮжЎЈиў«дҝқеӯҳеңЁйӮЈдёӘеҲҶзүҮдёҠпјҢеӣ жӯӨе°ұиғҪеӨҹе°ҶдёҖдёӘеӨҡж–ҮжЎЈиҜ·жұӮ(Multi-Document Request)з»ҷжӢҶеҲҶдёәй’ҲеҜ№жҜҸдёӘеҲҶзүҮзҡ„еӨҡж–ҮжЎЈиҜ·жұӮпјҢ然еҗҺ并иЎҢең°е°ҶиҝҷдәӣиҜ·жұӮиҪ¬еҸ‘еҲ°еҜ№еә”зҡ„иҠӮзӮ№дёҠгҖӮ
дёҖж—Ұе®ғд»ҺжҜҸдёӘиҠӮзӮ№дёҠиҺ·еҫ—дәҶзӯ”жЎҲпјҢе®ғдјҡе°Ҷиҝҷдәӣзӯ”жЎҲж•ҙзҗҶжҲҗдёҖдёӘеҚ•зӢ¬зҡ„е“Қеә”并иҝ”еӣһз»ҷе®ўжҲ·з«ҜгҖӮ
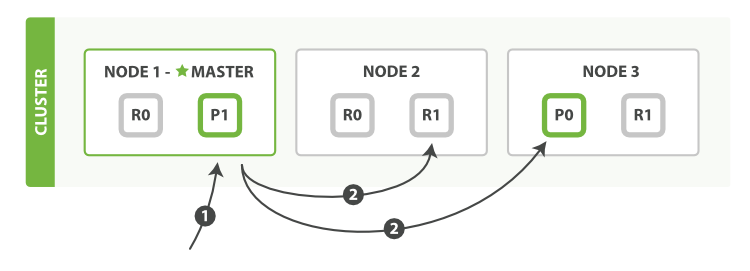
дҪҝз”ЁдёҖдёӘmgetиҜ·жұӮжқҘиҺ·еҸ–еӨҡд»Ҫж–ҮжЎЈзҡ„жӯҘйӘӨеҰӮдёӢпјҡ
- е®ўжҲ·з«ҜеҸ‘йҖҒдёҖдёӘmgetиҜ·жұӮеҲ°иҠӮзӮ№1гҖӮ
- иҠӮзӮ№1дёәжҜҸдёӘеҲҶзүҮ(еҸҜд»ҘжҳҜдё»иҰҒеҲҶзүҮжҲ–иҖ…еүҜжң¬еҲҶзүҮ)еҲӣе»әдёҖдёӘmgetиҜ·жұӮпјҢ然еҗҺе°Ҷе®ғ们并иЎҢең°иҪ¬еҸ‘еҲ°е…¶д»–еҲҶзүҮжүҖеңЁзҡ„иҠӮзӮ№гҖӮдёҖж—ҰиҠӮзӮ№1иҺ·еҫ—дәҶжүҖжңүзҡ„з»“жһңпјҢе°ұдјҡе°Ҷз»“жһңз»„иЈ…жҲҗе“Қеә”жңҖеҗҺиҝ”еӣһз»ҷе®ўжҲ·з«ҜгҖӮ
жҜҸд»Ҫж–ҮжЎЈйғҪеҸҜд»Ҙи®ҫзҪ®routingеҸӮж•°пјҢйҖҡиҝҮдј е…ҘдёҖдёӘdocsж•°з»„жқҘе®ҢжҲҗгҖӮ
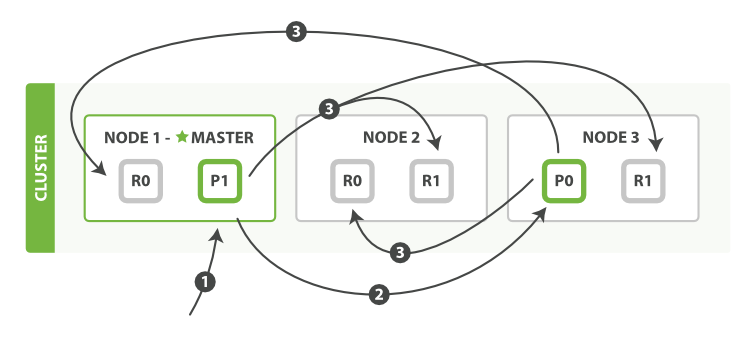
дҪҝз”ЁдёҖдёӘbulkиҜ·жұӮжқҘе®ҢжҲҗеҜ№еӨҡд»Ҫж–ҮжЎЈзҡ„еҲӣе»әпјҢзҙўеј•пјҢеҲ йҷӨеҸҠжӣҙж–°зҡ„жӯҘйӘӨеҰӮдёӢпјҡ
- е®ўжҲ·з«ҜеҸ‘йҖҒдёҖдёӘbulkиҜ·жұӮеҲ°иҠӮзӮ№1гҖӮ
- иҠӮзӮ№1дёәжҜҸдёӘеҲҶзүҮ(еҸӘиғҪжҳҜдё»иҰҒеҲҶзүҮ)еҲӣе»әдёҖдёӘbulkиҜ·жұӮпјҢ然еҗҺе°Ҷе®ғ们并иЎҢең°иҪ¬еҸ‘еҲ°е…¶д»–дё»иҰҒеҲҶзүҮжүҖеңЁзҡ„иҠӮзӮ№гҖӮ
- дё»иҰҒеҲҶзүҮдјҡйҖҗдёӘжү§иЎҢbulkиҜ·жұӮдёӯеҮәзҺ°зҡ„жҢҮд»ӨгҖӮеҪ“жҜҸдёӘжҢҮд»ӨжҲҗеҠҹе®ҢжҲҗеҗҺпјҢдё»иҰҒеҲҶзүҮдјҡе°Ҷж–°зҡ„ж–ҮжЎЈ(жҲ–иҖ…еҲ йҷӨзҡ„)并иЎҢең°иҪ¬еҸ‘еҲ°е®ғе…іиҒ”зҡ„жүҖжңүеүҜжң¬еҲҶзүҮдёҠпјҢ然еҗҺжү§иЎҢдёӢдёҖжқЎжҢҮд»ӨгҖӮдёҖж—ҰжүҖжңүзҡ„еүҜжң¬еҲҶзүҮеҜ№жүҖжңүзҡ„жҢҮд»ӨйғҪзЎ®е®ҡе…¶жҲҗеҠҹдәҶпјҢйӮЈд№ҲеҪ“еүҚиҠӮзӮ№е°ұдјҡеҗ‘иҜ·жұӮиҠӮзӮ№(Requesting Node)еҸ‘йҖҒжҲҗеҠҹзҡ„е“Қеә”пјҢжңҖеҗҺиҜ·жұӮиҠӮзӮ№дјҡж•ҙзҗҶжүҖжңүзҡ„е“Қеә”并жңҖз»ҲеҸ‘йҖҒе“Қеә”з»ҷе®ўжҲ·з«ҜгҖӮ
bulk APIд№ҹиғҪеӨҹеңЁж•ҙдёӘиҜ·жұӮзҡ„йЎ¶йғЁжҺҘеҸ—replicationе’ҢconsistencyеҸӮж•°пјҢеңЁжҜҸдёӘе…·дҪ“зҡ„иҜ·жұӮдёӯжҺҘеҸ—routingеҸӮж•°гҖӮ



зӣёе…іжҺЁиҚҗ
ElasticsearchжқғеЁҒжҢҮеҚ—-еҲҶеёғејҸж–ҮжЎЈеӯҳеӮЁ.pdf
ElasticSearchйҖҡиҝҮеҲҶзүҮпјҲshardingпјүе’ҢеӨҚеҲ¶пјҲreplicationпјүжңәеҲ¶пјҢжқҘе®һзҺ°ж•°жҚ®зҡ„еҲҶеёғејҸеӯҳеӮЁе’ҢжҹҘиҜўзҡ„иҙҹиҪҪеқҮиЎЎгҖӮеҲҶзүҮеҸҜд»Ҙе°Ҷж•°жҚ®еҲҶеёғеҲ°еӨҡдёӘиҠӮзӮ№дёҠпјҢиҖҢеӨҚеҲ¶еҲҷиғҪдҝқиҜҒй«ҳеҸҜз”ЁжҖ§е’Ңе®№й”ҷжҖ§гҖӮ е…Ёж–Үжҗңзҙўзі»з»ҹдёӯдёҖдёӘе…ій”®зҡ„з»„жҲҗйғЁеҲҶжҳҜ...
жң¬ж–ҮжЎЈиҝҳжҢҮеҮәдәҶElasticsearchеңЁең°зҗҶиҰҒзҙ зҙўеј•еӯҳеӮЁж–№йқўзҡ„е…ій”®з ”з©¶гҖӮз”ұдәҺең°еҗҚең°еқҖж•°жҚ®е…·жңүзү№е®ҡзҡ„ең°зҗҶзү№жҖ§пјҢеӣ жӯӨйңҖиҰҒе°Ҷиҝҷдәӣж•°жҚ®иҝӣиЎҢжңүж•Ҳзҡ„зҙўеј•еӯҳеӮЁпјҢд»ҘдҫҝиғҪеӨҹеҝ«йҖҹеҮҶзЎ®ең°жЈҖзҙўеҲ°зӣёе…іж•°жҚ®гҖӮElasticsearchжҸҗдҫӣдәҶеӨҡз§Қең°зҗҶз©әй—ҙ...
3. **иҝ‘е®һж—¶жЈҖзҙў**пјҡElasticSearchж”ҜжҢҒиҝ‘е®һж—¶зҡ„ж–ҮжЎЈжЈҖзҙўпјҢиҝҷж„Ҹе‘ізқҖж–°зҙўеј•зҡ„ж–ҮжЎЈеҸҜд»ҘеңЁеҮ з§’й’ҹеҶ…еҸҳеҫ—еҸҜжЈҖзҙўгҖӮ #### дёүгҖҒFITSж•°жҚ®зҡ„зү№зӮ№еҸҠе…¶жҢ‘жҲҳ FITSж–Ү件主иҰҒз”ұж–Ү件еӨҙе’Ңж•°жҚ®зҹ©йҳөз»„жҲҗгҖӮж–Ү件еӨҙеҢ…еҗ«дәҶдёҖзі»еҲ—е…ғж•°жҚ®пјҢеҰӮ...
**ElasticsearchпјҡеҲҶеёғејҸжҗңзҙўдёҺеҲҶжһҗзҡ„еҲ©еҷЁ...жҖ»з»“жқҘиҜҙпјҢElasticsearchд»Ҙе…¶еҲҶеёғејҸгҖҒе®һж—¶гҖҒеҸҜжү©еұ•зҡ„зү№жҖ§пјҢжҲҗдёәзҺ°д»Јж•°жҚ®еҜҶйӣҶеһӢеә”з”Ёзҡ„зҗҶжғійҖүжӢ©пјҢи®©ж•°жҚ®дёҚеҶҚд»…д»…жҳҜеӯҳеӮЁзҡ„еҜ№иұЎпјҢиҖҢжҳҜиҪ¬еҸҳдёәжңүд»·еҖјзҡ„иө„жәҗпјҢй©ұеҠЁдёҡеҠЎзҡ„жҷәиғҪеўһй•ҝгҖӮ
**ElasticsearchеҲҶеёғејҸжҗңзҙўеј•ж“Һv8.12.2иҜҰи§Ј** ElasticsearchжҳҜдёҖдёӘејҖжәҗзҡ„е…Ёж–Үжҗңзҙўеј•ж“ҺпјҢеҹәдәҺLuceneеә“пјҢи®ҫи®ЎдёәеҲҶеёғејҸгҖҒеҸҜжү©еұ•дё”е®һж—¶зҡ„жҗңзҙўе’ҢеҲҶжһҗеј•ж“ҺгҖӮе®ғзҡ„ж ёеҝғзү№жҖ§еҢ…жӢ¬ејәеӨ§зҡ„е…Ёж–ҮжҗңзҙўгҖҒе®һж—¶еҲҶжһҗгҖҒй«ҳеҸҜз”ЁжҖ§е’Ңе®№й”ҷ...
Table of Contents generated with DocTocи·Ҝз”ұдёҖдёӘж–ҮжЎЈеҲ°дёҖдёӘеҲҶзүҮдёӯдё»еҲҶзүҮе’ҢеүҜжң¬еҲҶзүҮеҰӮдҪ•дәӨдә’ж–°е»әгҖҒзҙўеј•е’ҢеҲ йҷӨж–ҮжЎЈеҸ–еӣһдёҖдёӘж–ҮжЎЈеұҖ
1. еҲҶеёғејҸжһ¶жһ„пјҡElasticsearchзҡ„ж ёеҝғеңЁдәҺе®ғзҡ„еҲҶеёғејҸзү№жҖ§пјҢйҖҡиҝҮеҲҶзүҮпјҲShardsпјүе’ҢеүҜжң¬пјҲReplicasпјүжңәеҲ¶е®һзҺ°ж•°жҚ®зҡ„еҲҶж•ЈеӯҳеӮЁе’Ңй«ҳеҸҜз”ЁжҖ§гҖӮжәҗз ҒдёӯеҸҜд»ҘзңӢеҲ°еҰӮдҪ•е®һзҺ°иҝҷдәӣжңәеҲ¶пјҢеҢ…жӢ¬еҲҶзүҮеҲҶй…Қзӯ–з•ҘгҖҒеүҜжң¬еҗҢжӯҘд»ҘеҸҠиҠӮзӮ№й—ҙзҡ„йҖҡдҝЎгҖӮ...
ElasticsearchпјҲз®Җз§°ESпјүжҳҜдёҖж¬ҫејҖжәҗзҡ„е…Ёж–Үжҗңзҙўеј•ж“ҺпјҢеҹәдәҺLuceneжһ„е»әпјҢи®ҫи®Ўз”ЁдәҺеҲҶеёғејҸгҖҒе®һж—¶гҖҒеҸҜжү©еұ•зҡ„ж•°жҚ®еӯҳеӮЁе’ҢжҗңзҙўгҖӮе®ғдёҚд»…жҸҗдҫӣдәҶжҗңзҙўеҠҹиғҪпјҢиҝҳж”ҜжҢҒж•°жҚ®еҲҶжһҗе’ҢеҸҜи§ҶеҢ–пјҢе№ҝжіӣеә”з”ЁдәҺж—Ҙеҝ—еҲҶжһҗгҖҒзӣ‘жҺ§гҖҒеӨ§ж•°жҚ®еӨ„зҗҶзӯүйўҶеҹҹ...
ElasticsearchпјҲESпјүжҳҜдёҖз§ҚеҹәдәҺLuceneзҡ„ејҖжәҗе…Ёж–Үжҗңзҙўеј•ж“ҺпјҢдё“й—Ёи®ҫи®Ўз”ЁдәҺеӨ„зҗҶеӨ§и§„жЁЎж•°жҚ®зҡ„еҲҶеёғејҸгҖҒе®һж—¶жҗңзҙўе’ҢеҲҶжһҗеј•ж“ҺгҖӮе®ғи§ЈеҶідәҶдј з»ҹж•°жҚ®еә“еңЁеӨ§и§„жЁЎж•°жҚ®жЈҖзҙўж—¶зҡ„жҖ§иғҪй—®йўҳгҖӮ 1. **ж•°жҚ®еӯҳеӮЁ**пјҡElasticsearchйҮҮз”ЁеҲҶзүҮ...
Elasticsearch еӯҰд№ ж–ҮжЎЈ Elasticsearch жҳҜдёҖдёӘеҹәдәҺ Lucene зҡ„жҗңзҙўжңҚеҠЎеҷЁпјҢжҸҗдҫӣдәҶдёҖдёӘеҲҶеёғејҸеӨҡз”ЁжҲ·иғҪеҠӣзҡ„е…Ёж–Үжҗңзҙўеј•ж“ҺпјҢеҹәдәҺ RESTful web жҺҘеҸЈгҖӮElasticsearch жҳҜз”Ё Java ејҖеҸ‘зҡ„пјҢ并дҪңдёә Apache и®ёеҸҜжқЎж¬ҫдёӢзҡ„ејҖж”ҫ...
еңЁжҖ§иғҪж–№йқўпјҢElasticsearch дҪҝз”ЁдәҶ B+Tree ж•°жҚ®з»“жһ„пјҢдҪҶдёҺдј з»ҹзҡ„ж•°жҚ®еә“дёҚеҗҢпјҢе®ғзҡ„ Term Index йғЁеҲҶеӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҢиҝҷеҠ еҝ«дәҶжҗңзҙўйҖҹеәҰпјҢдҪҶд№ҹеўһеҠ дәҶеҜ№еҶ…еӯҳиө„жәҗзҡ„йңҖжұӮгҖӮе°Ҫз®ЎеҰӮжӯӨпјҢElasticsearch зҡ„й«ҳжҖ§иғҪе’Ңжҳ“з”ЁжҖ§дҪҝе…¶жҲҗдёә...
е…·дҪ“жқҘиҜҙпјҢElasticsearchйҖҡиҝҮдёҖдёӘз®ҖеҚ•зҡ„е“ҲеёҢеҮҪж•°жқҘи®Ўз®—и·Ҝз”ұеҖјпјҢиҜҘеҖјеҶіе®ҡдәҶж–ҮжЎЈеә”еӯҳеӮЁеңЁе“ӘдёҖдёӘеҲҶзүҮдёҠпјҡ \[ \text{shard} = \text{hash}(\text{routing})\% \text{number_of_primary_shards} \] иҝҷйҮҢпјҢ`number_of_...
дёәжӮЁжҸҗдҫӣElasticSearchеҲҶеёғејҸжҗңзҙўеј•ж“ҺдёӢиҪҪпјҢElasticsearchжҳҜдёҖдёӘеҲҶеёғејҸзҡ„RESTfulйЈҺж јзҡ„жҗңзҙўе’Ңж•°жҚ®еҲҶжһҗеј•ж“ҺпјҢиғҪеӨҹи§ЈеҶіи¶ҠжқҘи¶ҠеӨҡзҡ„з”ЁдҫӢгҖӮдҪңдёәElastic Stackзҡ„ж ёеҝғпјҢе®ғйӣҶдёӯеӯҳеӮЁжӮЁзҡ„ж•°жҚ®пјҢеё®еҠ©жӮЁеҸ‘зҺ°ж„Ҹж–ҷд№Ӣдёӯд»ҘеҸҠж„Ҹж–ҷд№ӢеӨ–...
**ESеҲҶеёғејҸжҗңзҙўеј•ж“ҺиҜҰи§Ј** еңЁж•°еӯ—еҢ–дҝЎжҒҜж—¶д»ЈпјҢжҗңзҙўеј•ж“Һе·Із»ҸжҲҗдёәиҺ·еҸ–ж•°жҚ®зҡ„е…ій”®е·Ҙе…·гҖӮElasticsearchпјҲз®Җз§°ESпјүжҳҜдёҖж¬ҫеҹәдәҺLuceneзҡ„ејҖжәҗгҖҒе®һж—¶гҖҒеҲҶеёғејҸе…Ёж–Үжҗңзҙўеј•ж“ҺпјҢе®ғдёҚд»…жҸҗдҫӣдәҶжҗңзҙўеҠҹиғҪпјҢиҝҳиғҪиҝӣиЎҢж•°жҚ®еҲҶжһҗе’ҢеҸҜи§ҶеҢ–...
Elasticsearch жҳҜдёҖдёӘејҖжәҗзҡ„гҖҒй«ҳжү©еұ•зҡ„гҖҒеҲҶеёғејҸзҡ„гҖҒжҸҗдҫӣеӨҡз”ЁжҲ·иғҪеҠӣзҡ„е…Ёж–Үжҗңзҙўеј•ж“ҺпјҢд№ҹжҳҜдёҖдёӘеҹәдәҺ Lucene жҗңзҙўзҡ„жңҚеҠЎеҷЁпјҢеҸҜд»Ҙиҝ‘д№Һе®һж—¶ең°еӯҳеӮЁе’Ңжҗңзҙўж•°жҚ®гҖӮElasticsearch иғҪеҫҲж–№дҫҝең°з”ЁдәҺеҜ№еӨ§йҮҸж•°жҚ®иҝӣиЎҢжҗңзҙўе’ҢеҲҶжһҗпјҢе……еҲҶ...
Elasticsearchзҡ„еҲҶеёғејҸзү№жҖ§е…Ғи®ёе®ғеҸҜд»Ҙи·ЁеӨҡеҸ°жңҚеҠЎеҷЁеӯҳеӮЁе’Ңзҙўеј•ж•°жҚ®пјҢ并жҸҗдҫӣжҗңзҙўеҠҹиғҪгҖӮе…¶и®ҫи®Ўзӣ®ж ҮжҳҜеӨ„зҗҶе’ҢеҲҶжһҗеӨ§и§„жЁЎж•°жҚ®йӣҶпјҢжҸҗдҫӣе®һж—¶жҗңзҙўе’ҢеҲҶжһҗеҠҹиғҪгҖӮе®ғж”ҜжҢҒж°ҙе№іжү©еұ•пјҢиғҪеӨҹдҝқиҜҒж•°жҚ®зҡ„й«ҳеҸҜз”ЁжҖ§гҖӮ Elasticsearchзҡ„...
ж–ҮжЎЈAPIз”ЁдәҺеҜ№еӯҳеӮЁеңЁElasticSearchдёӯзҡ„ж•°жҚ®иҝӣиЎҢCRUDж“ҚдҪңгҖӮдё»иҰҒAPIеҢ…жӢ¬пјҡ - **Index API**пјҡз”ЁдәҺеҲӣе»әжҲ–жӣҙж–°зҙўеј•гҖӮ - **Get API**пјҡз”ЁдәҺйҖҡиҝҮIDиҺ·еҸ–зҙўеј•дёӯзҡ„ж–ҮжЎЈгҖӮ - **Delete API**пјҡз”ЁдәҺеҲ йҷӨжҢҮе®ҡзҡ„ж–ҮжЎЈгҖӮ - **Delete...
**Elasticsearch 7.11дёӯж–Үж–ҮжЎЈжҰӮи§Ҳ** ElasticsearchжҳҜдёҖж¬ҫејәеӨ§зҡ„ејҖжәҗжҗңзҙўеј•ж“ҺпјҢе№ҝжіӣеә”з”ЁдәҺж•°жҚ®жЈҖзҙўгҖҒеҲҶжһҗе’Ңе®һж—¶зӣ‘жҺ§гҖӮ7.11зүҲжң¬жҳҜе…¶зЁіе®ҡзүҲжң¬д№ӢдёҖпјҢжҸҗдҫӣдәҶиҜёеӨҡж”№иҝӣе’Ңж–°зү№жҖ§пјҢж—ЁеңЁжҸҗй«ҳжҗңзҙўжҖ§иғҪе’Ңз”ЁжҲ·дҪ“йӘҢгҖӮжң¬ж–Үе°Ҷж №жҚ®...