
python
Python中文转拼音代码(支持全拼和首字母缩写)
本文的代码,从https://github.com/cleverdeng/pinyin.py升级得来,针对原文的代码,做了以下升级:
代码很简单,直接读取了一个词典(字符和英文的映射),然后挨个替换中文中的拼音即可;
实例中main函数的代码输出结果

代码使用方法:
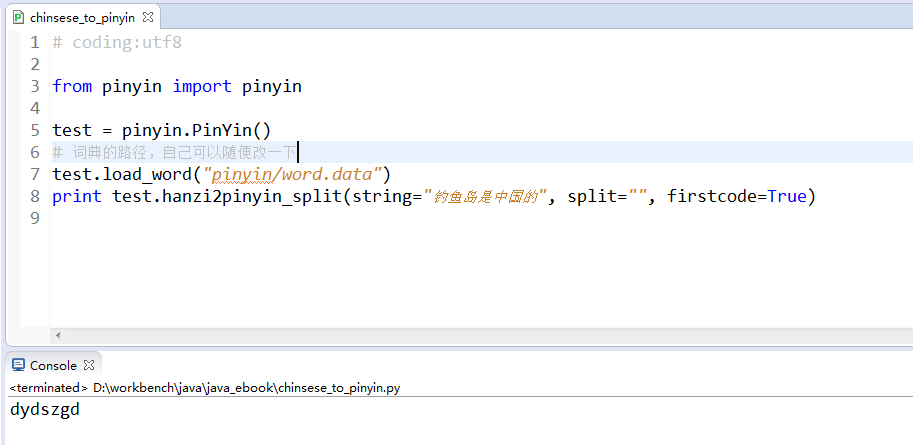
如果需要其他的提取,可以修改一下代码实现;
代码(包含词典)打包下载:
Python使用list字段模式或者dict字段模式读取文件的方法
Python用于处理文本数据绝对是个利器,极为简单的读取、分割、过滤、转换支持,使得开发者不需要考虑繁杂的流文件处理过程(相对于JAVA来说的,嘻嘻)。博主自己工作中,一些复杂的文本数据处理计算,包括在HADOOP上编写Streaming程序,均是用Python完成。
而在文本处理的过程中,将文件加载内存中是第一步,这就涉及到怎样将文件中的某一列映射到具体的变量的过程,最最愚笨的方法,就是按照字段的下标进行引用,比如这样子:
如果按照这种方式读取,一旦文件有顺序、增减列的变动,代码的维护是个噩梦,这种代码一定要杜绝。
本文推荐两种优雅的方式来读取数据,都是先配置字段模式,然后按照模式读取,而模式则有字典模式和列表模式两种形式;
读取文件,按照分隔符分割成字段数据列表
首先读取文件,按照分隔符分割每一行的数据,返回字段列表,以便后续处理。
代码如下:
使用yield关键字,每次抛出单个行的分割数据,这样在调度程序中可以用for fields in read_file_data(fpath)的方式读取每一行。
映射到模型之方法1:使用配置好的字典模式,装配读取的数据列表
这种方法配置一个{“字段名”: 字段位置}的字典作为数据模式,然后按照该模式装配读取的列表数据,最后实现用字典的方式访问数据。
所使用的函数:
有了该方法和之前的方法,可以用以下的方式读取数据:
输出结果:
映射到模型之方法2:使用配置好的列表模式,装配读取的数据列表
如果需要读取文件所有列,或者前面的一些列,那么配置字典模式优点复杂,因为需要给每个字段配置索引位置,并且这些位置是从0开始完后数的,属于低级劳动,需要消灭。
列表模式应命运而生,先将配置好的列表模式转换成字典模式,然后按字典加载就可以实现。
转换模式,以及用按列表模式读取的代码:
使用的时候,可以用列表的形式配置模式,不需要配置索引更加简洁:
运行结果和字典模式的完全一样。
file_util.py全部代码
以下是file_util.py中的全部代码,可以放在自己的公用类库中使用
本文地址:http://www.crazyant.net/1707.html
Python操作MySQL视频教程
给大家带来自己制作的Python操作MySQL视频教程。本教程分为三节:Python开发环境搭建以及支持MySQL开发的插件安装、Python访问MySQL数据库的标准API规范接口讲解、Python开发MySQL程序实战编码演示。通过课 程的学习,大家能够基本掌握用Python开发MySQL程序。
视频高清版百度链接: http://pan.baidu.com/s/1DB0qM 密码: ri1n
Python操作MySQL视频教程第一讲 – 开发环境搭建
推荐使用以下的开发环境搭配:
-
Eclipse + JDK7
- 插件:PyDev 3.8.0
-
python-2.7.8
- 插件:MySQL-python-1.2.4b4.win32-py2.7
-
MySQL服务器:使用wampserver2.5软件包自带的MySQL软件
- 需要安装:vcredist_x64
- Mysql-5.6.17
本视频在优酷的地址:http://v.youku.com/v_show/id_XODE3Nzk4MTEy.html
Python操作MySQL视频教程第二讲 – 标准接口规范
第二讲的视频教程讲解的主要内容是:
- Python官方针对操作数据库的标准规范
- Python建立和数据库的connect连接对象
- connection对象的构造函数,包括主机、端口、用户名、密码、编码等参数
- connection对象的方法,主要是关闭连接、获取游标、提交事务、回滚事务
- Python执行SQL语句的cursor对象
- 普通游标和字典游标的区别,以及字典游标优于普通游标的原因
- 游标执行SQL语句的方法
- 游标获取执行SQL语句结果集合的方法
- Python编写访问数据库程序的框架,主要包括以下步骤:
- 导入MySQLdb对象
- 获取connection对象
- 获取普通游标或者字典游标
- 执行SQL语句
- 从游标对象中取出数据,对数据做其他处理;
- 关闭连接
视频在优酷的地址:http://v.youku.com/v_show/id_XODIxNzQ1MjQ0.html
Python操作MySQL视频教程第三讲 – 实例代码演示
第三讲的视频教程讲解的主要内容是:
- Python编写MySQL程序的框架
- 引入模块:import MySQLdb
- 获取连接:conn = MySQLdb.connect()
- 获取游标:cursor = conn.cursor()
- 执行SQL:cursor.execute()
- 获取数据:curosr.fetchall()
- 关闭连接:conn.close()
- MySQL的Innodb和Myisam引擎的区别
- innodb支持事务,myisam不支持事务
- 如果访问的是innodb数据库,并执行了insert、delete、update语句,python代码中必须执行conn.commit()才能使得SQL执行生效
视频在优酷的地址:http://v.youku.com/v_show/id_XODI4MjE4Njgw.html
本文的代码和PPT在git上的地址:http://git.oschina.net/peishuaishuai/python-mysql-tutorial
本文的高清视频随后会发布在百度网盘,敬请期待。
本文地址:http://www.crazyant.net/1664.html ,转载请注明来源。
Python批量重命名文件的方法
用到了os的两个接口:
1、列出文件夹中的所有文件(也包含目录)
os.listdir(path)
Return a list containing the names of the entries in the directory given by path. The list is in arbitrary order. It does not include the special entries ‘.’ and ‘..’ even if they are present in the directory.Availability: Unix, Windows.
Changed in version 2.3: On Windows NT/2k/XP and Unix, if path is a Unicode object, the result will be a list of Unicode objects. Undecodable filenames will still be returned as string objects
2、对文件进行重命名
os.rename(src, dst)
Rename the file or directory src to dst. If dst is a directory, OSError will be raised. On Unix, if dst exists and is a file, it will be replaced silently if the user has permission. The operation may fail on some Unix flavors if src and dst are on different filesystems. If successful, the renaming will be an atomic operation (this is a POSIX requirement). On Windows, if dst already exists, OSError will be raised even if it is a file; there may be no way to implement an atomic rename when dst names an existing file.Availability: Unix, Windows
其实就是用os.listdir读取里面所有的文件,然后用os.rename进行文件重命名即可实现。
python的os模块官方介绍:http://docs.python.org/2/library/os.html
转载请注明来源:http://www.crazyant.net/1397.html
Python内置函数map、reduce、filter在文本处理中的应用
文件是由很多行组成的,这些行组成一个列表,python提供了处理列表很有用的三个函数:map、reduce、filter。因此在文本处理中,可以使用这三个函数达到代码的更加精简清晰。
这里的map、reduce是python的内置函数,跟hadoop的map、reduce函数没有关系,不过使用的目的有点类似,map函数做预处理、reduce函数一般做聚合。
map、reduce、filter在文本处理中的使用
下面是一个文本文件的内容,第1列是ID,第4列是权重,我们的目标是获取所有ID是奇数的行,将这些行的权重翻倍,最后返回权重值的总和。
| ID | 键 | 值 | 权重 |
| 1 | name1 | value1 | 11 |
| 2 | name2 | value2 | 12 |
| 3 | name3 | value3 | 13 |
| 4 | name4 | value4 | 14 |
| 5 | name5 | value5 | 15 |
| 6 | name6 | value6 | 16 |
| 7 | name7 | value7 | 17 |
| 8 | name8 | value8 | 18 |
| 9 | name9 | value9 | 19 |
| 10 | name10 | value10 | 20 |
使用filter、map、reduce函数的代码如下;
运行结果:
map、reduce、filter函数的特点
- filter函数:以列表为参数,返回满足条件的元素组成的列表;类似于SQL中的where a=1
- map函数:以列表为参数,对每个元素做处理,返回这些处理后元素组成的列表;类似于sql中的select a*2
- reduce函数:以列表为参数,对列表进行累计、汇总、平均等聚合函数;类似于sql中的select sum(a),average(b)
这些函数官方的解释
map(function, iterable, …)
Apply function to every item of iterable and return a list of the results. If additional iterable arguments are passed, function must take that many arguments and is applied to the items from all iterables in parallel. If one iterable is shorter than another it is assumed to be extended with None items. If function is None, the identity function is assumed; if there are multiple arguments, map() returns a list consisting of tuples containing the corresponding items from all iterables (a kind of transpose operation). The iterable arguments may be a sequence or any iterable object; the result is always a list.
reduce(function, iterable[, initializer])
Apply function of two arguments cumulatively to the items of iterable, from left to right, so as to reduce the iterable to a single value. For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates ((((1+2)+3)+4)+5). The left argument, x, is the accumulated value and the right argument, y, is the update value from the iterable. If the optional initializer is present, it is placed before the items of the iterable in the calculation, and serves as a default when the iterable is empty. If initializer is not given and iterable contains only one item, the first item is returned. Roughly equivalent to:
def reduce(function, iterable, initializer=None):
it = iter(iterable)
if initializer is None:
try:
initializer = next(it)
except StopIteration:
raise TypeError(‘reduce() of empty sequence with no initial value’)
accum_value = initializer
for x in it:
accum_value = function(accum_value, x)
return accum_value
filter(function, iterable)
Construct a list from those elements of iterable for which function returns true. iterable may be either a sequence, a container which supports iteration, or an iterator. If iterable is a string or a tuple, the result also has that type; otherwise it is always a list. If function is None, the identity function is assumed, that is, all elements of iterable that are false are removed.
Note that filter(function, iterable) is equivalent to [item for item in iterable if function(item)] if function is not None and [item for item in iterable if item] if function is None.
See itertools.ifilter() and itertools.ifilterfalse() for iterator versions of this function, including a variation that filters for elements where the function returns false.
参考资料:
http://docs.python.org/2/library/functions.html
http://www.oschina.net/code/snippet_111708_16145
转载请注明来源: http://www.crazyant.net/1390.html
mysql根据A表更新B表的方法
最近遇到一个需求:mysql中A表和B表都有(id, age)字段,现在想读取B表的age字段,将其update到A表对应ID的age字段中去,我直接想到了一种方案:用Python读取B表,获得{id:age}形式的数据,然后根据每个ID和age的值依次update A表。
两个表分别定义和数据如下:
A表定义:
| id | int(11) | |
| name | varchar(20) | |
| age | int(11) |
数据:
1,name1,0
2,name2,0
3,name3,0
4,name4,0
5,name5,0
B表定义
| id | int(11) | |
| age | int(11) |
数据:
1,11
2,21
3,31
4,41
5,51
python代码来实现
# -*- encoding:utf8 -*-
'''
@author: crazyant.net
读取B表的(id, age)数据,然后依次更新A表;
'''
from common.DBUtil import DBdbUtil = DB('127.0.0.1',3306,'root','','test')
rs = dbUtil.query("SELECT id,age FROM table_b")
for row in rs:
(idv,age)=row
print (idv,age)
update_sql="update table_a set age='%s' where id='%s';"%(age,idv)
print update_sql
dbUtil.update(update_sql)print 'over'
其实一条SQL语句就可以搞定
看了看代码,实在是简单,于是网上搜了一下mysql能不能根据一个表更新另一个表,结果发现update本身就支持多个表更新的功能。
UPDATE table_a,table_b SET table_a.age=table_b.age WHERE table_a.id=table_b.id;
用python代码就显得是大炮打蚊子多次一举了。
转载请注明来源:链接
[织梦DEDE迁移]读取织梦MySQL生成所有文章链接
广告:本人承接迁移织梦到wordpress的业务.
本文阐述了从织梦的Mysql数据库读取数据表,生成所有文章链接的方法。
本文中使用了封装了Mysql常用函数的一个模块DBUtil,代码见链接
1、确认链接的组成结构
这个信息记录在dede的分类表dede_arctype的namerule字段中;
执行SQL语句:SELECT namerule FROM dede_arctype;
会看到返回结果都是一个值(一般都没有修改):{typedir}/{Y}/{M}{D}/{aid}.html
这意思是,链接由以下字段组成:
- {typedir}:类型的目录,来源于dede_arctype的typedir字段;
- {Y}{M}{D}:文章发布的时间,来源于dede_archives表的pubdate字段;
- {aid}:文章ID,来源于dede_archives的ID字段;
2、读取Mysql,拼凑URL
大致过程:
- 读取mysql的dede_arctype表和dede_archives,得到所有链接信息(包括文章ID、类型名称、类型目录、标题、发布日期、自定义文件名)
- 对于每一个链接,根据第1步骤的介绍装备链接;
- 至此已经拿到了所有的链接ID、链接标题和链接URL。
其他模块可以访问该模块,采用dlinks.allLinks来访问所有的链接,其中的每个列表元素均包括链接ID、链接标题和链接URL。
转载请注明来源:织梦dede迁移读取织梦mysql生成所有文章链接
Python访问MySQL封装的常用类
python访问mysql比较简单,细节请参考我的另一篇文章:链接
自己平时也就用到两个mysql函数:查询和更新,下面是自己常用的函数的封装,大家拷贝过去直接可以使用。
文件名:DBUtil.py
使用方法为文件下面的main函数,使用query执行select语句并获取结果;或者使用update进行insert、delete等操作。
python执行shell的两种方法
有两种方法可以在Python中执行SHELL程序,方法一是使用Python的commands包,方法二则是使用subprocess包,这两个包均是Python现有的内置模块。
使用python内置commands模块执行shell
commands对Python的os.popen()进行了封装,使用SHELL命令字符串作为其参数,返回命令的结果数据以及命令执行的状态;
该命令目前已经废弃,被subprocess所替代;
使用python最新的subprocess模块执行shell
Python目前已经废弃了os.system,os.spawn*,os.popen*,popen2.*,commands.*来执行其他语言的命令,subprocesss是被推荐的方法;
subprocess允许你能创建很多子进程,创建的时候能指定子进程和子进程的输入、输出、错误输出管道,执行后能获取输出结果和执行状态。
也可以在Popen中指定stdin和stdout为一个变量,这样就能直接接收该输出变量值。
总结
在python中执行SHELL有时候也是很必须的,比如使用Python的线程机制启动不同的shell进程,目前subprocess是Python官方推荐的方法,其支持的功能也是最多的,推荐大家使用。
转载请注明来源:http://www.crazyant.net/1319.html
Python封装的常用日期函数
处理日志数据时,经常要对日期进行进行计算,比如日期加上天数、日期相差天数、日期对应的周等计算,本文收集了几个常用的python日期功能函数,一直更新中。
直接贴代码(文件名DateUtil.py),函数功能可以直接查看注释:
转载请注明来源:http://www.crazyant.net/1309.html



相关推荐
Python 编程案例教程答案 Python 是一种高级、解释性的编程语言,广泛应用于后端开发、数据科学、人工智能、网络爬虫等领域。Python 编程案例教程答案旨在为初学者和中级开发者提供详细的编程案例和答案,帮助他们...
《Python编程案例教程》教学设计思路总结 在《Python编程案例教程》中,我们可以看到,这门课程的设计思路是基于高等院校教育的要求,即强调“基础理论适度够用、加强实践环节、突出实际操作”。课程的设计目标是使...
本合集涵盖了Python的多个重要方面,旨在通过丰富的实战案例帮助读者深入理解和掌握Python的运用。 首先,基础部分是学习任何编程语言的基石。Python的基础包括变量、数据类型(如整型、浮点型、字符串、列表、元组...
《Python编程案例教程》是刘庆教授的一本深入浅出的Python编程教材,旨在通过丰富的实例和详尽的解析帮助初学者快速掌握Python语言。这本书的课件PPT、课后例题答案以及示例代码提供了全面的学习资源,让学生不仅...
python爬虫案例获取歌曲python爬虫案例获取歌曲python爬虫案例获取歌曲python爬虫案例获取歌曲python爬虫案例获取歌曲python爬虫案例获取歌曲python爬虫案例获取歌曲python爬虫案例获取歌曲python爬虫案例获取歌曲...
《Python项目案例开发从入门到实践》这个压缩包文件提供了丰富的Python编程实践资源,涵盖了从基础到高级的各种应用场景。以下是对各个子文件所涉及的知识点的详细解释: 1. **第6章 爬虫应用——抓取网站图片 ...
Python基础入门教程 Python语言编程导论 Python应用案例1 (共12页).ppt Python基础入门教程 Python语言编程导论 Python应用案例二 (共24页).ppt Python基础入门教程 Python语言编程导论 SciPy扩展库简介 (共53...
python编程案例教程课后答案-Python编程练习题学习汇总 数字计算;关于数轴和长整型数据类型的练习;平方数的操作练习;日期计算,编程练习
python爬虫案例Python爬虫小案例Python爬虫小案例Python爬虫小案例Python爬虫小案例Python爬虫小案例Python爬虫小案例Python爬虫小案例Python爬虫小案例Python爬虫小案例Python爬虫小案例Python爬虫小案例Python爬虫...
Python Web 案例 demo 主要关注的是使用 Python 语言构建 Web 应用程序的实践。在这个领域,Python 提供了多个强大的框架,其中最著名的是 Django 和 Flask。本示例可能涵盖了从基础到进阶的多种应用场景,旨在帮助...
Python python 案例 python 案例 python 案例 python 案例 python 案例
本资源“python案例集锦pdf文件.zip”提供了一系列的Python项目介绍,旨在为初学者和进阶者指明学习方向,了解当前Python领域的热门趋势。 1. Python基础:Python以其易读性强、语法简洁而受到欢迎。基础知识点包括...
1. **Python基础语法**:Python语言以其简洁明了的语法而闻名,包括变量声明、注释、字符串、数字、列表、元组、字典等基本数据类型。学习Python的基础语法是入门的第一步,了解如何创建、赋值、操作和组合这些元素...
【Python基础】 Python是一种高级编程语言,以其简洁明了的语法著称。在Python的基础部分,我们将学习如何使用内置函数、语法特性以及各种数据...通过学习这些实用的小案例,可以系统地提升Python技能,从入门到精通。
"课题 "Python典型案例-飞机大战 " "课时 "2课时(90 min) " "教学目标 "知识技能目标: " " "(1)掌握游戏开发的流程 " " "(2)学习pygame模块游戏开发案例 " " "思政育人目标: " " "(1)培养学生掌握信息的...
### selenium webdriver基于python源码案例 #### 一、Selenium简介与环境搭建 **1.1 Selenium概述** Selenium是一个强大的工具集,主要用于自动化Web应用的测试。它支持多种编程语言,如Java、C#、Python等,并能...
python项目各个案例,并且有非常详细的说明以及步骤,适合于新手以及编程经验不高的人。容易入门,容易看懂。
python python爬虫案例 python爬虫案例 python爬虫案例 python爬虫案例 python爬虫案例
在Python中,`sklearn.ensemble.RandomForestClassifier`和`sklearn.ensemble.RandomForestRegressor`是实现随机森林的常用工具。案例中可能会展示如何调整随机森林的参数,比如树的数量、特征的随机选择比例,以及...