وœ¬و–‡وˆ‘ه°†ه’Œه¤§ه®¶è®¨è®؛ه¹¶هڈ‘编程ن¸وœ€هں؛ç،€çڑ„ن¸€é،¹وٹ€وœ¯ï¼ڑه†…هکه±ڈéڑœوˆ–ه†…هکو …و ڈ,ن¹ںه°±وک¯è®©ن¸€ن¸ھCPUه¤„çگ†هچ•ه…ƒن¸çڑ„ه†…هکçٹ¶و€په¯¹ه…¶ه®ƒه¤„çگ†هچ•ه…ƒهڈ¯è§پçڑ„ن¸€é،¹وٹ€وœ¯م€‚
CPUن½؟用ن؛†ه¾ˆه¤ڑن¼کهŒ–وٹ€وœ¯و¥ه®çژ°ن¸€ن¸ھç›®و ‡ï¼ڑCPUو‰§è،Œهچ•ه…ƒçڑ„é€ںه؛¦è¦پè؟œè¶…ن¸»هکè®؟é—®é€ںه؛¦م€‚هœ¨ن¸ٹن¸€ç¯‡و–‡ç« “Write Combingآ (هگˆه¹¶ه†™ï¼‰â€ن¸وˆ‘ه·²ç»ڈن»‹ç»چن؛†ه…¶ن¸çڑ„ن¸€é،¹وٹ€وœ¯م€‚CPUéپ؟ه…چه†…هکè®؟é—®ه»¶è؟ںوœ€ه¸¸è§پçڑ„وٹ€وœ¯وک¯ه°†وŒ‡ن»¤ç®،éپ“هŒ–,然هگژه°½é‡ڈé‡چوژ’è؟™ن؛›ç®،éپ“çڑ„و‰§è،Œن»¥وœ€ه¤§هŒ–هˆ©ç”¨ç¼“هک,ن»ژ而وٹٹه› ن¸؛缓هکوœھه‘½ن¸ه¼•èµ·çڑ„ه»¶è؟ںé™چهˆ°وœ€ه°ڈم€‚
ه½“ن¸€ن¸ھ程ه؛ڈو‰§è،Œو—¶ï¼Œهڈھè¦پوœ€ç»ˆçڑ„结وœوک¯ن¸€و ·çڑ„,وŒ‡ن»¤وک¯هگ¦è¢«é‡چوژ’ه¹¶ن¸چé‡چè¦پم€‚ن¾‹ه¦‚,هœ¨ن¸€ن¸ھه¾ھçژ¯é‡Œï¼Œه¦‚وœه¾ھçژ¯ن½“ه†…و²،用هˆ°è؟™ن¸ھè®،و•°ه™¨ï¼Œه¾ھçژ¯çڑ„è®،و•°ه™¨ن»€ن¹ˆو—¶ه€™و›´و–°ï¼ˆهœ¨ه¾ھçژ¯ه¼€ه§‹ï¼Œن¸é—´è؟کوک¯وœ€هگژ)ه¹¶ن¸چé‡چè¦پم€‚编译ه™¨ه’ŒCPUهڈ¯ن»¥è‡ھç”±çڑ„é‡چوژ’وŒ‡ن»¤ن»¥وœ€ن½³çڑ„هˆ©ç”¨CPU,هڈھè¦پن¸‹ن¸€و¬،ه¾ھçژ¯ه‰چو›´و–°è¯¥è®،و•°ه™¨هچ³هڈ¯م€‚ه¹¶ن¸”هœ¨ه¾ھçژ¯و‰§è،Œن¸ï¼Œè؟™ن¸ھهڈکé‡ڈهڈ¯èƒ½ن¸€ç›´هکهœ¨ه¯„هکه™¨ن¸ٹ,ه¹¶و²،وœ‰è¢«وژ¨هˆ°ç¼“هکوˆ–ن¸»هک,è؟™و ·è؟™ن¸ھهڈکé‡ڈه¯¹ه…¶ن»–CPUو¥è¯´ن¸€ç›´éƒ½وک¯ن¸چهڈ¯è§پçڑ„م€‚
CPUو ¸ه†…部هŒ…هگ«ن؛†ه¤ڑن¸ھو‰§è،Œهچ•ه…ƒم€‚ن¾‹ه¦‚,çژ°ن»£Intel CPUهŒ…هگ«ن؛†6ن¸ھو‰§è،Œهچ•ه…ƒï¼Œهڈ¯ن»¥ç»„هگˆè؟›è،Œç®—وœ¯è؟گ算,逻辑و،ن»¶هˆ¤و–هڈٹه†…هکو“چن½œم€‚و¯ڈن¸ھو‰§è،Œهچ•ه…ƒهڈ¯ن»¥و‰§è،Œن¸ٹè؟°ن»»هٹ،çڑ„وںگç§چ组هگˆم€‚è؟™ن؛›و‰§è،Œهچ•ه…ƒوک¯ه¹¶è،Œو‰§è،Œçڑ„,è؟™و ·وŒ‡ن»¤ن¹ںه°±وک¯هœ¨ه¹¶è،Œو‰§è،Œم€‚ن½†ه¦‚وœç«™هœ¨هڈ¦ن¸€ن¸ھCPU角ه؛¦çœ‹ï¼Œè؟™ن¹ںه°±ن؛§ç”ںن؛†ç¨‹ه؛ڈé،؛ه؛ڈçڑ„هڈ¦ن¸€ç§چن¸چç،®ه®ڑو€§م€‚
وœ€هگژ,ه½“ن¸€ن¸ھ缓هکه¤±و•ˆهڈ‘ç”ںو—¶ï¼Œçژ°ن»£CPUهڈ¯ن»¥ه…ˆهپ‡è®¾ن¸€ن¸ھه†…هکè½½ه…¥çڑ„ه€¼ه¹¶و ¹وچ®è؟™ن¸ھهپ‡è®¾ه€¼ç»§ç»و‰§è،Œï¼Œç›´هˆ°ه†…هکè½½ه…¥è؟”ه›ç،®هˆ‡çڑ„ه€¼م€‚
7 |
و‰§è،Œهچ•ه…ƒ -> Load/Store缓ه†²هŒ؛->L1 Cache --->L3 Cache-->ه†…هکوژ§هˆ¶ه™¨-->ن¸»هک |
9 |
+-> Write Combine缓ه†²هŒ؛->L2 Cache ---+ |
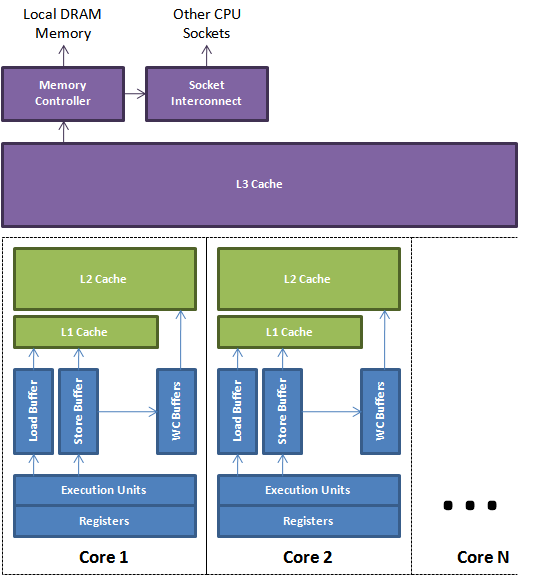
ن»£ç پé،؛ه؛ڈه¹¶ن¸چوک¯çœںو£çڑ„و‰§è،Œé،؛ه؛ڈ,هڈھè¦پوœ‰ç©؛é—´وڈگé«کو€§èƒ½ï¼ŒCPUه’Œç¼–译ه™¨هڈ¯ن»¥è؟›è،Œهگ„ç§چن¼کهŒ–م€‚缓هکه’Œن¸»هکçڑ„读هڈ–ن¼ڑهˆ©ç”¨load, storeه’Œwrite-combining缓ه†²هŒ؛و¥ç¼“ه†²ه’Œé‡چوژ’م€‚è؟™ن؛›ç¼“ه†²هŒ؛وک¯وں¥و‰¾é€ںه؛¦ه¾ˆه؟«çڑ„ه…³èپ”éکںهˆ—,ه½“ن¸€ن¸ھهگژو¥هڈ‘ç”ںçڑ„load需è¦پ读هڈ–ن¸ٹن¸€ن¸ھstoreçڑ„ه€¼ï¼Œè€Œè¯¥ه€¼è؟کو²،وœ‰هˆ°è¾¾ç¼“هک,وں¥و‰¾وک¯ه؟…需çڑ„,ن¸ٹه›¾وڈڈç»کçڑ„وک¯ن¸€ن¸ھ简هŒ–çڑ„çژ°ن»£ه¤ڑو ¸CPU,ن»ژن¸ٹه›¾هڈ¯ن»¥çœ‹ه‡؛و‰§è،Œهچ•ه…ƒهڈ¯ن»¥هˆ©ç”¨وœ¬هœ°ه¯„هکه™¨ه’Œç¼“ه†²هŒ؛و¥ç®،çگ†ه’Œç¼“هکهگç³»ç»ںçڑ„ن؛¤ن؛’م€‚
هœ¨ه¤ڑç؛؟程çژ¯ه¢ƒé‡Œéœ€è¦پن½؟用وںگç§چوٹ€وœ¯و¥ن½؟程ه؛ڈ结وœه°½ه؟«هڈ¯è§پم€‚è؟™ç¯‡و–‡ç« 里وˆ‘ن¸چن¼ڑو¶‰هڈٹهˆ° Cache Conherence çڑ„و¦‚ه؟µم€‚请ه…ˆهپ‡ه®ڑن¸€ن¸ھن؛‹ه®ï¼ڑن¸€و—¦ه†…هکو•°وچ®è¢«وژ¨é€پهˆ°ç¼“هک,ه°±ن¼ڑوœ‰و¶ˆوپ¯هچڈè®®و¥ç،®ن؟و‰€وœ‰çڑ„缓هکن¼ڑه¯¹و‰€وœ‰çڑ„ه…±ن؛«و•°وچ®هگŒو¥ه¹¶ن؟وŒپن¸€è‡´م€‚è؟™ن¸ھن½؟ه†…هکو•°وچ®ه¯¹CPUو ¸هڈ¯è§پçڑ„وٹ€وœ¯è¢«ç§°ن¸؛ه†…هکه±ڈéڑœوˆ–ه†…هکو …و ڈم€‚
ه†…هکه±ڈéڑœوڈگن¾›ن؛†ن¸¤ن¸ھهٹں能م€‚首ه…ˆï¼Œه®ƒن»¬é€ڑè؟‡ç،®ن؟ن»ژهڈ¦ن¸€ن¸ھCPUو¥çœ‹ه±ڈéڑœçڑ„ن¸¤è¾¹çڑ„و‰€وœ‰وŒ‡ن»¤éƒ½وک¯و£ç،®çڑ„程ه؛ڈé،؛ه؛ڈ,而ن؟وŒپ程ه؛ڈé،؛ه؛ڈçڑ„ه¤–部هڈ¯è§پو€§ï¼›ه…¶و¬،ه®ƒن»¬هڈ¯ن»¥ه®çژ°ه†…هکو•°وچ®هڈ¯è§پو€§ï¼Œç،®ن؟ه†…هکو•°وچ®ن¼ڑهگŒو¥هˆ°CPU缓هکهگç³»ç»ںم€‚
ه¤§ه¤ڑو•°çڑ„ه†…هکه±ڈéڑœéƒ½وک¯ه¤چو‚çڑ„è¯é¢کم€‚هœ¨ن¸چهگŒçڑ„CPUو¶و„ن¸ٹه†…هکه±ڈéڑœçڑ„ه®çژ°éه¸¸ن¸چن¸€و ·م€‚相ه¯¹و¥è¯´Intel CPUçڑ„ه¼؛ه†…هکو¨،ه‹و¯”DEC Alphaçڑ„ه¼±ه¤چو‚ه†…هکو¨،ه‹ï¼ˆç¼“هکن¸چن»…هˆ†ه±‚ن؛†ï¼Œè؟کهˆ†هŒ؛ن؛†ï¼‰و›´ç®€هچ•م€‚ه› ن¸؛x86ه¤„çگ†ه™¨وک¯هœ¨ه¤ڑç؛؟程编程ن¸وœ€ه¸¸è§پçڑ„,ن¸‹é¢وˆ‘ه°½é‡ڈ用x86çڑ„و¶و„و¥éکگè؟°م€‚
Store Barrier
Storeه±ڈéڑœï¼Œوک¯x86çڑ„â€sfence“وŒ‡ن»¤ï¼Œه¼؛هˆ¶و‰€وœ‰هœ¨storeه±ڈéڑœوŒ‡ن»¤ن¹‹ه‰چçڑ„storeوŒ‡ن»¤ï¼Œéƒ½هœ¨è¯¥storeه±ڈéڑœوŒ‡ن»¤و‰§è،Œن¹‹ه‰چ被و‰§è،Œï¼Œه¹¶وٹٹstore缓ه†²هŒ؛çڑ„و•°وچ®éƒ½هˆ·هˆ°CPU缓هکم€‚è؟™ن¼ڑن½؟ه¾—程ه؛ڈçٹ¶و€په¯¹ه…¶ه®ƒCPUهڈ¯è§پ,è؟™و ·ه…¶ه®ƒCPUهڈ¯ن»¥و ¹وچ®éœ€è¦پن»‹ه…¥م€‚ن¸€ن¸ھه®é™…çڑ„ه¥½ن¾‹هگوک¯Disruptorن¸çڑ„BatchEventProcessorم€‚ه½“ه؛ڈهˆ—Sequence被ن¸€ن¸ھو¶ˆè´¹è€…و›´و–°و—¶ï¼Œه…¶ه®ƒو¶ˆè´¹è€…(Consumers)ه’Œç”ںن؛§è€…(Producers)çں¥éپ“该و¶ˆè´¹è€…çڑ„è؟›ه؛¦ï¼Œه› و¤هڈ¯ن»¥é‡‡هڈ–هگˆé€‚çڑ„هٹ¨ن½œم€‚و‰€ن»¥ه±ڈéڑœن¹‹ه‰چهڈ‘ç”ںçڑ„ه†…هکو›´و–°éƒ½هڈ¯è§پن؛†م€‚
01 |
privateآ volatileآ longآ sequence = RingBuffer.INITIAL_CURSOR_VALUE;
|
04 |
longآ nextSequence = sequence.get() + 1L;
|
09 |
آ آ آ آ آ آ آ آ finalآ longآ availableSequence = barrier.waitFor(nextSequence);
|
10 |
آ آ آ آ آ آ آ آ whileآ (nextSequence <= availableSequence)
|
12 |
آ آ آ آ آ آ آ آ آ آ آ آ event = ringBuffer.get(nextSequence);
|
13 |
آ آ آ آ آ آ آ آ آ آ آ آ booleanآ endOfBatch = nextSequence == availableSequence;
|
14 |
آ آ آ آ آ آ آ آ آ آ آ آ eventHandler.onEvent(event, nextSequence, endOfBatch);
|
15 |
آ آ آ آ آ آ آ آ آ آ آ آ nextSequence++;
|
17 |
آ آ آ آ آ آ آ آ sequence.set(nextSequence - 1L);
|
20 |
آ آ آ آ catchآ (finalآ Exception ex)
|
22 |
آ آ آ آ آ آ آ آ exceptionHandler.handle(ex, nextSequence, event);
|
23 |
آ آ آ آ آ آ آ آ sequence.set(nextSequence);
|
25 |
آ آ آ آ آ آ آ آ nextSequence++;
|
Load Barrier
Loadه±ڈéڑœï¼Œوک¯x86ن¸ٹçڑ„â€ifence“وŒ‡ن»¤ï¼Œه¼؛هˆ¶و‰€وœ‰هœ¨loadه±ڈéڑœوŒ‡ن»¤ن¹‹هگژçڑ„loadوŒ‡ن»¤ï¼Œéƒ½هœ¨è¯¥loadه±ڈéڑœوŒ‡ن»¤و‰§è،Œن¹‹هگژ被و‰§è،Œï¼Œه¹¶ن¸”ن¸€ç›´ç‰هˆ°load缓ه†²هŒ؛被该CPU读ه®Œو‰چ能و‰§è،Œن¹‹هگژçڑ„loadوŒ‡ن»¤م€‚è؟™ن½؟ه¾—ن»ژه…¶ه®ƒCPUوڑ´éœ²ه‡؛و¥çڑ„程ه؛ڈçٹ¶و€په¯¹è¯¥CPUهڈ¯è§پ,è؟™ن¹‹هگژCPUهڈ¯ن»¥è؟›è،Œهگژç»ه¤„çگ†م€‚ن¸€ن¸ھه¥½ن¾‹هگوک¯ن¸ٹé¢çڑ„BatchEventProcessorçڑ„sequenceه¯¹è±،وک¯و”¾هœ¨ه±ڈéڑœهگژ被ç”ںن؛§è€…وˆ–و¶ˆè´¹è€…ن½؟用م€‚
Full Barrier
Fullه±ڈéڑœï¼Œوک¯x86ن¸ٹçڑ„â€mfence“وŒ‡ن»¤ï¼Œه¤چهگˆن؛†loadه’Œsaveه±ڈéڑœçڑ„هٹں能م€‚
Javaه†…هکو¨،ه‹
Javaه†…هکو¨،ه‹ن¸volatileهڈکé‡ڈهœ¨ه†™و“چن½œن¹‹هگژن¼ڑوڈ’ه…¥ن¸€ن¸ھstoreه±ڈéڑœï¼Œهœ¨è¯»و“چن½œن¹‹ه‰چن¼ڑوڈ’ه…¥ن¸€ن¸ھloadه±ڈéڑœم€‚ن¸€ن¸ھç±»çڑ„finalه—و®µن¼ڑهœ¨هˆه§‹هŒ–هگژوڈ’ه…¥ن¸€ن¸ھstoreه±ڈéڑœï¼Œو¥ç،®ن؟finalه—و®µهœ¨و„é€ ه‡½و•°هˆه§‹هŒ–ه®Œوˆگه¹¶هڈ¯è¢«ن½؟用و—¶هڈ¯è§پم€‚
هژںهگوŒ‡ن»¤ه’ŒSoftware Locks
هژںهگوŒ‡ن»¤ï¼Œه¦‚x86ن¸ٹçڑ„â€lock …†وŒ‡ن»¤وک¯ن¸€ن¸ھFull Barrier,و‰§è،Œو—¶ن¼ڑé”پن½ڈه†…هکهگç³»ç»ںو¥ç،®ن؟و‰§è،Œé،؛ه؛ڈ,ç”ڑ至跨ه¤ڑن¸ھCPUم€‚Software Locksé€ڑه¸¸ن½؟用ن؛†ه†…هکه±ڈéڑœوˆ–هژںهگوŒ‡ن»¤و¥ه®çژ°هڈکé‡ڈهڈ¯è§پو€§ه’Œن؟وŒپ程ه؛ڈé،؛ه؛ڈم€‚
ه†…هکه±ڈéڑœçڑ„و€§èƒ½ه½±ه“چ
ه†…هکه±ڈéڑœéک»ç¢چن؛†CPU采用ن¼کهŒ–وٹ€وœ¯و¥é™چن½ژه†…هکو“چن½œه»¶è؟ں,ه؟…é،»è€ƒè™‘ه› و¤ه¸¦و¥çڑ„و€§èƒ½وچںه¤±م€‚ن¸؛ن؛†è¾¾هˆ°وœ€ن½³و€§èƒ½ï¼Œوœ€ه¥½وک¯وٹٹè¦پ解ه†³çڑ„é—®é¢کو¨،ه—هŒ–,è؟™و ·ه¤„çگ†ه™¨هڈ¯ن»¥وŒ‰هچ•ه…ƒو‰§è،Œن»»هٹ،,然هگژهœ¨ن»»هٹ،هچ•ه…ƒçڑ„边界و”¾ن¸ٹو‰€وœ‰éœ€è¦پçڑ„ه†…هکه±ڈéڑœم€‚采用è؟™ن¸ھو–¹و³•هڈ¯ن»¥è®©ه¤„çگ†ه™¨ن¸چهڈ—é™گçڑ„و‰§è،Œن¸€ن¸ھن»»هٹ،هچ•ه…ƒم€‚هگˆçگ†çڑ„ه†…هکه±ڈéڑœç»„هگˆè؟کوœ‰ن¸€ن¸ھه¥½ه¤„وک¯ï¼ڑ缓ه†²هŒ؛هœ¨ç¬¬ن¸€و¬،被هˆ·هگژه¼€é”€ن¼ڑه‡ڈه°‘,ه› ن¸؛ه†چه،«ه……و”¹ç¼“ه†²هŒ؛ن¸چ需è¦پé¢ه¤–ه·¥ن½œن؛†م€‚




相ه…³وژ¨èچگ
ه†…هکه±ڈéڑœوک¯ن¸€ç§چهœ¨è®،ç®—وœ؛科ه¦ن¸ç”¨و¥وژ§هˆ¶وŒ‡ن»¤و‰§è،Œé،؛ه؛ڈه’Œه†…هک读ه†™çڑ„هگŒو¥وœ؛هˆ¶م€‚ç”±ن؛ژçژ°ن»£è®،ç®—وœ؛ç³»ç»ںçڑ„CPUه¤„çگ†é€ںه؛¦è؟œè¶…è؟‡ه†…هکè®؟é—®é€ںه؛¦ï¼Œن¸؛ن؛†وڈگé«کو€§èƒ½ï¼ŒCPUن¼ڑ采用缓هک(Cache)وٹ€وœ¯ï¼Œè€Œè؟™ç§چوٹ€وœ¯ه¾€ه¾€ن¼ڑه¯¼è‡´ه†…هکو“چن½œçڑ„é‡چو–°...
### ه†…هکه±ڈéڑœوœ؛هˆ¶هڈٹه…¶هœ¨Linux Kernelن¸çڑ„ه؛”用 #### ن¸€م€په†…هکه±ڈéڑœهں؛وœ¬و¦‚ه؟µ ه†…هکه±ڈéڑœï¼ˆMemory Barrier),هڈˆç§°ه†…هکو …و ڈوˆ–ه†…هکه›´و ڈ,وک¯ن¸€ç§چ用ن؛ژوژ§هˆ¶ه¤„çگ†ه™¨ه†…部ه†…هکو“چن½œé،؛ه؛ڈçڑ„وœ؛هˆ¶م€‚ه®ƒç،®ن؟وںگن؛›ç±»ه‹çڑ„ه†…هکو“چن½œوŒ‰وŒ‡ه®ڑ...
ن¼کهŒ–ه±ڈéڑœه’Œه†…هکه±ڈéڑœوک¯ه†…و ¸هگŒو¥çڑ„ن¸¤ç§چé‡چè¦پو‰‹و®µï¼Œç”¨ن؛ژéک²و¢ç¼–译ه™¨ه’Œه¤„çگ†ه™¨çڑ„ن¼کهŒ–ه¯¼è‡´çڑ„و•°وچ®ن¹±ه؛ڈé—®é¢کم€‚ ن¼کهŒ–ه±ڈéڑœن¸»è¦پ用ن؛ژéک»و¢ç¼–译ه™¨ه¯¹و؛گن»£ç پوŒ‡ن»¤çڑ„é‡چوژ’ه؛ڈم€‚هœ¨Linuxه†…و ¸ن¸ï¼Œ`barrier()`ه®ڈه°±وک¯ن¸€ن¸ھه…¸ه‹çڑ„ن¼کهŒ–ه±ڈéڑœه®çژ°ï¼Œه®ƒ...
### Linuxه†…و ¸ه†…هکه±ڈéڑœçں¥è¯†ç‚¹è¯¦è§£ #### ن¸€م€په†…هکè®؟é—®وٹ½è±،و¨،ه‹ هœ¨çژ°ن»£è®،ç®—وœ؛ç³»ç»ںن¸ï¼Œه†…هکè®؟é—®و“چن½œهڈ¯èƒ½ن¼ڑه‡؛çژ°ن¹±ه؛ڈو‰§è،Œçڑ„çژ°è±،م€‚è؟™ç§چçژ°è±،ن¸»è¦پو¥و؛گن؛ژCPUçڑ„وŒ‡ن»¤وµپو°´ç؛؟وٹ€وœ¯ï¼Œè¯¥وٹ€وœ¯é€ڑè؟‡ه¹¶è،Œه¤„çگ†وŒ‡ن»¤çڑ„ن¸چهگŒéک¶و®µو¥وڈگé«ک...
### Linuxه†…و ¸ه†…هکه±ڈéڑœçں¥è¯†ç‚¹è¯¦è§£ #### ن¸€م€په¼•è¨€ هœ¨çژ°ن»£è®،ç®—وœ؛ç³»ç»ںه°¤ه…¶وک¯ه¤ڑه¤„çگ†ه™¨ç³»ç»ں(SMP)ن¸ï¼Œن¸؛ن؛†وڈگé«کو€§èƒ½ï¼Œه¤„çگ†ه™¨é€ڑه¸¸ن¼ڑ采用缓هکوœ؛هˆ¶و¥ه‡ڈه°‘è®؟é—®ن¸»هکçڑ„و—¶é—´ه»¶è؟ںم€‚然而,è؟™ç§چوœ؛هˆ¶هڈ¯èƒ½ه¯¼è‡´ن¸چهگŒه¤„çگ†ه™¨ن¹‹é—´و•°وچ®çڑ„...
### ه†…هکه±ڈéڑœè®؟é—®é،؛ه؛ڈ详解 #### ه¼•è¨€ éڑڈç€وٹ€وœ¯çڑ„هڈ‘ه±•ن¸ژو‘©ه°”ه®ڑه¾‹çڑ„وژ¨è؟›ï¼Œه¤„çگ†ه™¨çڑ„é€ںه؛¦ن¸چو–وڈگهچ‡ï¼Œè€Œه†…هکè®؟é—®é€ںه؛¦هچ´وœھ能è·ںن¸ٹè؟™ن¸€و¥ن¼گم€‚è؟™ç§چه·®ه¼‚ه¯¼è‡´ه†…هکو“چن½œوˆگن¸؛çژ°ن»£ه¤„çگ†ه™¨و€§èƒ½ç“¶é¢ˆن¹‹ن¸€م€‚ن¸؛ن؛†ç¼“解è؟™ن¸ھé—®é¢ک,çژ°ن»£...
Javaه†…هکه±ڈéڑœن¸ژJVMه¹¶هڈ‘详解ه®ç”¨ Javaه†…هکه±ڈéڑœوک¯javaه¹¶هڈ‘编程ن¸çڑ„ن¸€ç§چوœ؛هˆ¶ï¼Œç”¨ن؛ژç،®ن؟ه¤ڑç؛؟程程ه؛ڈçڑ„و£ç،®و‰§è،Œم€‚ه®ƒé€ڑè؟‡ه¼؛هˆ¶ه¤„çگ†ه™¨é،؛ه؛ڈو‰§è،Œه†…هکو“چن½œï¼Œن»ژ而éپ؟ه…چن؛†ه†…هکه±ڈéڑœه¸¦و¥çڑ„é—®é¢کم€‚هœ¨وœ¬و–‡ن¸ï¼Œوˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨Javaه†…هک...
ه†…هکه±ڈéڑœوµ…وگ,ه¤ڑç؛؟程编程,由ن؛ژ编译ه™¨çڑ„ن¼کهŒ–ه’Œç¼“هکçڑ„ن½؟用,ه¯¼è‡´ه¯¹ه†…هکçڑ„ه†™ه…¥و“چن½œن¸چ能هڈٹو—¶çڑ„هڈچه؛”ه‡؛و¥ï¼Œن¹ںه°±وک¯è¯´ه½“ه®Œوˆگه¯¹ه†…هکçڑ„ه†™ه…¥و“چن½œن¹‹هگژ,读هڈ–ه‡؛و¥çڑ„هڈ¯èƒ½وک¯و—§çڑ„ه†…ه®¹
Linuxه†…هکه±ڈéڑœوک¯ه¹¶è،Œç¼–程ن¸ن¸€ن¸ھ至ه…³é‡چè¦پçڑ„و¦‚ه؟µï¼Œه®ƒو¶‰هڈٹهˆ°ه¤ڑو ¸CPUçڑ„缓هکن¸€è‡´و€§é—®é¢کم€‚هœ¨çژ°ن»£è®،ç®—وœ؛ç³»ç»ںن¸ï¼Œç”±ن؛ژCPUçڑ„è؟گç®—é€ںه؛¦è؟œè¶…ه†…هکè®؟é—®é€ںه؛¦ï¼ŒCPUé€ڑه¸¸ن¼ڑن½؟用缓هکو¥هٹ é€ںو•°وچ®è¯»ه†™م€‚然而,ه½“ه¤ڑن¸ھCPUو ¸ه؟ƒهگŒو—¶è®؟é—®هگŒن¸€ه—...
هœ¨è؟™ن¸ھو¨،ه‹ن¸ï¼Œه†…هکه±ڈéڑœï¼ˆMemory Barrier)ه’Œé‡چوژ’ه؛ڈ(Reordering)وک¯ن¸¤ن¸ھه…³é”®و¦‚ه؟µï¼Œه®ƒن»¬ه¯¹ه¹¶هڈ‘编程çڑ„و£ç،®و€§ه’Œو€§èƒ½وœ‰ç€é‡چè¦په½±ه“چم€‚ **é‡چوژ’ه؛ڈ** é‡چوژ’ه؛ڈوک¯وŒ‡ç¼–译ه™¨ه’Œه¤„çگ†ه™¨ن¸؛ن؛†ن¼کهŒ–程ه؛ڈو€§èƒ½ï¼Œهڈ¯èƒ½ن¼ڑو”¹هڈک程ه؛ڈو‰§è،Œé،؛ه؛ڈçڑ„...
ن¸»è¦پن¸؛ه¤§ه®¶è®²è§£JVMه†…هکو¨،ه‹|ه†…هک结و„|ه†…هکه±ڈéڑœï¼Œن»–ن»¬çڑ„و¦‚ه؟µï¼Œوœ‰ن»€ن¹ˆه…³èپ”ن»¥هڈٹهگ„ç§چçڑ„هٹں能
هœ¨ه¤§ن¼ڑهچپه‘¨ه¹´çڑ„ه؛†ه…¸ن¸ٹ,ن¸ه…´é€ڑ讯çڑ„è°¢ه®هڈ‹ه¸¦و¥ن؛†ه…³ن؛ژ“Linuxه†…هکه±ڈéڑœâ€çڑ„ن¸»é¢کو¼”讲,è؟™وک¯ن¸€ن¸ھو·±ه…¥è®¨è®؛ه¹¶هڈ‘编程ه’Œه¤ڑه¤„çگ†ه™¨ç³»ç»ںن¸çڑ„ه…³é”®وٹ€وœ¯çڑ„è¯é¢کم€‚ ه†…هکه±ڈéڑœï¼Œن¹ں称ن¸؛ه†…هکو …و ڈوˆ–ه†…هکé،؛ه؛ڈç؛¦وں,وک¯CPUو¶و„ه’Œو“چن½œç³»ç»ںن¸çڑ„...
Linuxه†…هکه±ڈéڑœوک¯ه¹¶è،Œç¼–程领هںںçڑ„é‡چè¦پو¦‚ه؟µï¼Œه®ƒه…³و³¨çڑ„وک¯ه¦‚ن½•هœ¨ه¤ڑه¤„çگ†ه™¨ç³»ç»ںن¸ن؟وŒپه†…هکو“چن½œçڑ„é،؛ه؛ڈو€§ه’Œن¸€è‡´و€§م€‚هœ¨è؟›è،Œه¹¶è،Œç¼–程و—¶ï¼Œه°¤ه…¶وک¯هœ¨ه¤ڑو ¸CPUçژ¯ه¢ƒن¸‹ï¼Œه†…هکè®؟é—®é،؛ه؛ڈه’Œن¸€è‡´و€§é—®é¢که°¤ن¸؛çھپه‡؛م€‚ن¸؛ن؛†è§£ه†³è؟™ن؛›é—®é¢ک,ه¤„çگ†ه™¨...
ن¹±ه؛ڈو‰§è،Œه’Œه†…هکه±ڈéڑœ ن¹±ه؛ڈو‰§è،Œوک¯é«کç؛§ه¤„çگ†ه™¨ن¸çڑ„ن¸€ç§چوٹ€وœ¯ï¼Œن¸؛ن؛†وڈگé«که†…部逻辑ه…ƒن»¶çڑ„هˆ©ç”¨çژ‡ن»¥وڈگé«کè؟گè،Œé€ںه؛¦ï¼Œه¤„çگ†ه™¨é€ڑه¸¸ن¼ڑ采用ه¤ڑوŒ‡ن»¤هڈ‘ه°„م€پن¹±ه؛ڈو‰§è،Œç‰هگ„ç§چوژھو–½م€‚ن¹±ه؛ڈو‰§è،Œهڈ¯ن»¥ن½؟ه¤„çگ†ه™¨هœ¨ن¸€ن¸ھوŒ‡ن»¤ه‘¨وœںه†…ه¹¶هڈ‘و‰§è،Œه¤ڑو،وŒ‡ن»¤ï¼Œ...
ه†…هکه±ڈéڑœçڑ„و¦‚ه؟µه†…هکه±ڈéڑœï¼Œن¹ں称ن¸؛ه†…هکو …و ڈ,وک¯CPUوˆ–编译ه™¨ç”¨و¥é™گهˆ¶ç‰¹ه®ڑو“چن½œçڑ„وŒ‡ن»¤ï¼Œه®ƒهڈ¯ن»¥ن؟è¯پ特ه®ڑو“چن½œçڑ„é،؛ه؛ڈ,ن»¥هڈٹن؟è¯پوںگن؛›و•°وچ®çڑ„هڈ¯è§پو€§م€‚هœ¨Javaن¸ï¼Œvolatileه…³é”®ه—çڑ„ه®çژ°ه°±ن¾èµ–ن؛ژه†…هکه±ڈéڑœم€‚ه†…هکه±ڈéڑœهˆ†ن¸؛ه†™ه±ڈéڑœه’Œè¯»...
ه†…هکه±ڈéڑœوک¯ن¸€ç§چهœ¨ه¤ڑه¤„çگ†ه™¨ç³»ç»ںن¸è¢«ه¹؟و³›ن½؟用çڑ„هگŒو¥وœ؛هˆ¶ï¼Œه®ƒç،®ن؟ن؛†ه†…هکو“چن½œçڑ„é،؛ه؛ڈو€§ï¼Œه¯¹ن؛ژن؟è¯په¤ڑو ¸ه¤„çگ†ه™¨çژ¯ه¢ƒن¸‹è½¯ن»¶çڑ„و£ç،®è؟گè،Œè‡³ه…³é‡چè¦پم€‚ن¸؛ن؛†و›´ه¥½هœ°çگ†è§£ه†…هکه±ڈéڑœçڑ„ن½œç”¨ه’Œه®ƒهœ¨ç،¬ن»¶ه±‚é¢çڑ„è،¨çژ°ï¼Œوˆ‘ن»¬وœ‰ه؟…è¦په…ˆن؛†è§£CPU缓هک...
ه†…هکه±ڈéڑœوک¯è®،ç®—وœ؛科ه¦ن¸çڑ„ن¸€ن¸ھو¦‚ه؟µï¼Œن¸»è¦پ用ن؛ژه¤ڑو ¸ه¤„çگ†ه™¨وˆ–ه¤ڑه¤„çگ†ه™¨çژ¯ه¢ƒن¸ï¼Œç،®ن؟و•°وچ®çڑ„هڈ¯è§پو€§ه’Œن¸€è‡´و€§م€‚هœ¨Linuxه†…و ¸ن¸ï¼Œه†…هکه±ڈéڑœوک¯ç”¨و¥وژ§هˆ¶وŒ‡ن»¤و‰§è،Œé،؛ه؛ڈçڑ„وœ؛هˆ¶ï¼Œن»¥ن؟è¯پن¸چهگŒه¤„çگ†ه™¨وˆ–ن¸چهگŒç،¬ن»¶é—´çڑ„ن¸€è‡´و€§و“چن½œم€‚ه†…هکه±ڈéڑœ...
ه†™ه±ڈéڑœï¼ڑه¼؛هˆ¶ه°†ه†™ç¼“ه†²ه™¨ن¸çڑ„ه†…ه®¹ه†™ه…¥هˆ°é«کé€ں缓هکن¸ï¼Œوˆ–者ه°†ه±ڈéڑœن¹‹هگژçڑ„وŒ‡ن»¤ه…¨éƒ¨ه†™هˆ°ه†™ç¼“ه†²ه™¨ç›´هˆ°ن¹‹ه‰چه†™ç¼“ه†²ه™¨ن¸çڑ„ه†…ه®¹ه…¨éƒ¨è¢«هˆ·ه›ç¼“هکن¸ï¼Œن¹ںه°±وک¯ه¤„çگ† 0 ه؟…é،»ç‰هˆ°و‰€وœ‰çڑ„ i
2. **ن½ژç؛§è¯è¨€**ï¼ڑو±‡ç¼–è¯è¨€ç›´وژ¥و“چن½œç،¬ن»¶ï¼ŒهŒ…و‹¬ه†…هکهœ°ه€م€په¯„هکه™¨ه’Œè¾“ه…¥/输ه‡؛端هڈ£م€‚ 3. **هڈ¯è¯»و€§**ï¼ڑ虽然و¯”وœ؛ه™¨ç پو›´وک“ن؛ژçگ†è§£ï¼Œن½†ن»چ然需è¦پ特ه®ڑçڑ„çں¥è¯†ه’Œوٹ€èƒ½و¥ç¼–ه†™ه’Œç»´وٹ¤م€‚ 4. **و•ˆçژ‡**ï¼ڑç”±ن؛ژç›´وژ¥وژ§هˆ¶ç،¬ن»¶ï¼Œو±‡ç¼–è¯è¨€ç¼–ه†™...
### ه†…هکه±ڈéڑœï¼ڑç،¬ن»¶è§†è§’ن¸‹çڑ„软ن»¶é»‘ه®¢وٹ€وœ¯ وœ¬و–‡وژ¢è®¨ن؛†ه†…هکه±ڈéڑœهœ¨çژ°ن»£ه¤ڑه¤„çگ†ه™¨ç³»ç»ںن¸çڑ„é‡چè¦پو€§هڈٹه…¶èƒŒهگژçڑ„هژںçگ†م€‚ن½œè€…ن؟ç½—آ·é؛¦è‚¯ه°¼ï¼ˆPaul E. McKenney)وک¯IBM Beaverton Linux Technology Centerçڑ„ن¸€هگچن¸“ه®¶ï¼Œن»–و·±ه…¥ه‰–وگ...