
4.1.Map
4.1.1.µ”éĶ”ü’╝Ü
┬Ā Hazelcast Map(ÕŹ│IMap)ń╗¦µē┐java.util.MapÕ╝Ģńö©java.util.concurrent.ConcurrentMapµÄźÕÅŻ.ń«ĆÕŹĢµØźĶ»┤,Õ«āµś»java MapńÜäõĖĆń¦ŹÕłåÕĖāÕ╝ÅÕ«×ńÄ░.
┬Ā IMapńÜäõĖĆĶł¼µōŹõĮ£,µ»öÕ”éĶ»┤Ķ┐øĶĪīĶ»╗/ÕåÖµŚČ,õĖĵłæõ╗¼ÕĖĖĶ¦üńÜämapńÜäĶ»╗ÕåÖµ¢╣µ│ĢõĖƵĀĘ,IMapÕ«Üõ╣ēńÜäĶ»╗/ÕåÖµ¢╣µ│Ģõ╣¤õĖ║GetÕÆīPutµ¢╣µ│Ģ.
ÕłåÕĖāÕ╝ÅńÜäMapµś»µĆĵĀĘÕĘźõĮ£ńÜäÕæó’╝¤
┬Ā Hazelcastõ╝ÜÕ░åõĮĀńÜäMapķö«ÕĆ╝Õ»╣ķøåÕÉł,ÕĘ«õĖŹÕżÜÕ╣│ÕØćńÜäÕłåń”╗Ķć│µēƵ£ēńÜäHazelcastńÜ䵳ÉÕæśõĖŁ.µ»ÅõĖ¬µłÉÕæśµÉ║ÕĖ”Ķ┐æõ╝╝"(1/n * total-data) + backups",nõĖ║clusterõĖŁńÜäĶŖéńé╣µĢ░ķćÅ.
õĖ║õ║åÕĖ«ÕŖ®Õż¦Õ«Čµø┤ÕźĮńÜäńÉåĶ¦Ż,µÄźõĖŗµØźµłæõ╗¼ÕłøÕ╗║õĖĆõĖ¬Hazelcast Õ«×õŠŗ(ÕŹ│ĶŖéńé╣)ńäČÕÉÄÕłøÕ╗║õĖĆõĖ¬ÕÉŹõĖ║CapitalsńÜämap,ķö«ÕĆ╝Õ»╣ÕÅéĶĆāõ╗źõĖŗõ╗ŻńĀü:
┬Ā
public class FillMapMember {
public static void main( String[] args ) {
HazelcastInstance hzInstance = Hazelcast.newHazelcastInstance();
Map<String, String> capitalcities = hzInstance.getMap( "capitals" );
capitalcities.put( "1", "Tokyo" );
capitalcities.put( "2", "ParisŌĆØ );
capitalcities.put( "3", "Washington" );
capitalcities.put( "4", "Ankara" );
capitalcities.put( "5", "Brussels" );
capitalcities.put( "6", "Amsterdam" );
capitalcities.put( "7", "New Delhi" );
capitalcities.put( "8", "London" );
capitalcities.put( "9", "Berlin" );
capitalcities.put( "10", "Oslo" );
capitalcities.put( "11", "Moscow" );
...
...
capitalcities.put( "120", "Stockholm" )
}
}
┬Ā ┬ĀÕĮōõĮĀĶ┐ÉĶĪīĶ┐Öµ«Ąõ╗ŻńĀüńÜ䵌ČÕĆÖ,Õ░åõ╝ÜÕłøÕ╗║õĖĆõĖ¬ĶŖéńé╣Õ╣ČõĖöÕ£©µŁżĶŖéńé╣õĖŖÕłøÕ╗║õĖĆõĖ¬map,µŁżĶŖéńé╣Õ░åĶó½µĘ╗ÕŖĀĶć│ĶŖéńé╣ķøåÕÉł,Ķ»źķøåÕÉłõĖ║ÕłåÕĖāÕ╝ÅńÜä.
┬Ā õĖŗķØóĶ┐ÖÕ╣ģÕøŠÕÅ»õ╗źÕŠłÕĮóĶ▒ĪńÜäĶ»┤µśÄµŁżµ«Ąõ╗ŻńĀüńÜäĶ┐ÉĶĪīµĢłµ×£,ńÄ░Õ£©µłæõ╗¼µ£ēõ║åõĖĆõĖ¬ńŗ¼ń½ŗńÜäclusterĶŖéńé╣ÕĢ”!!
┬Ā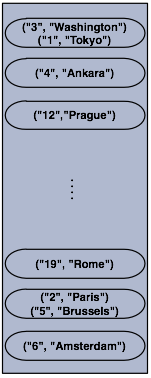
┬Ā
┬Ā ┬ĀNOTE:┬ĀPlease note that some of the partitions will not contain any data entries since we only have 120 objects and the partition count is 271 by default. This count is configurable and can be changed using the system property┬Ā
┬ĀNOTE:┬ĀPlease note that some of the partitions will not contain any data entries since we only have 120 objects and the partition count is 271 by default. This count is configurable and can be changed using the system property┬Āhazelcast.partition.count. Please see┬ĀAdvanced Configuration Properties.
┬Ā
┬Ā µÄźõĖŗµØźµłæõ╗¼ÕłøÕ╗║ń¼¼õ║īõĖ¬clusterĶŖéńé╣.µŁżÕżäÕżćõ╗ĮńÜäµĢ░µŹ«õ╣¤õ╝ÜĶó½ÕłøÕ╗║.Ķ»Ęµ│©µäÅÕģ│õ║ÄÕżćõ╗ĮĶ┐Öķā©Õłåń¤źĶ»åµłæõ╗¼Õ░åÕ£©Hazelcast OverviewĶ┐ÖĶŖéĶ»”ń╗åĶ«▓Ķ¦Ż.
ÕźĮÕĢ”Ķ»ØõĖŹÕżÜĶ»┤,µłæõ╗¼Ķ┐ÉĶĪīÕłÜµēŹńÜäõ╗ŻńĀüĶ┐øĶĪīń¼¼õ║īõĖ¬ĶŖéńé╣ńÜäÕłøÕ╗║Õɦ.õĖŗķØ󵜻õĖżõĖ¬ĶŖéńé╣ńÜäńż║µäÅÕøŠ,Ķ»”ń╗åńÜäÕ▒Ģńż║õ║åµĢ░µŹ«õĖÄÕżćõ╗ĮµĢ░µŹ«ÕŁśÕé©ńÜäµ¢╣Õ╝Å,µśŠĶĆīµśōĶ¦üÕżćõ╗ĮµĢ░µŹ«µś»ÕłåÕĖāÕ╝ÅńÜäÕ¢ö~
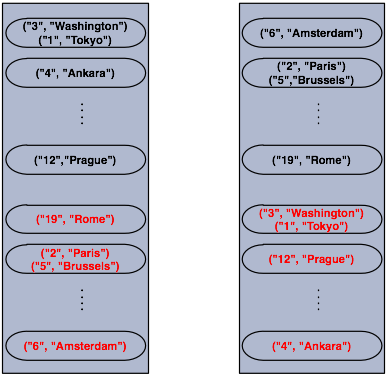
┬Ā Õ”éõĮĀµēĆĶ¦ü,ÕĮōõĖĆõĖ¬µ¢░µłÉÕæśÕŖĀÕģźclusterõĖŁµŚČ,Õ«āÕ░åõ╝ܵē┐µŗģķā©ÕłåµĢ░µŹ«ńÜäÕżćõ╗ĮĶ┤Żõ╗╗.µ£Ćń╗ł,Õ«āÕ░åµÉ║ÕĖ”Õż¦ń║”"(1/n┬Ā*┬Ātotal-data) + backups"ńÜäÕżćõ╗ĮµĢ░µŹ«,õ╗ÄĶĆīÕćÅÕ░æÕģČõ╗¢ĶŖéńé╣ńÜäĶ┤¤ĶĮĮ.
HazelcastInstance::getMapÕ«×ķÖģõĖŖÕ░åõ╝ÜĶ┐öÕø×õĖĆõĖ¬ń╗¦µē┐Ķć¬java.util.concurrent.ConcurrentMap┬ĀńÜäcom.hazelcast.core.IMapÕ«×õŠŗ.
┬Ā µ£ēõ║øµ¢╣µ│ĢÕāÅConcurrentMap.putIfAbsent(key,value)ŃĆüConcurrentMap.replace(key,value),ÕÅ»õ╗źńö©õ║ÄÕłåÕĖāÕ╝ÅmapõĖŁ,õĖŗķØóµłæõ╗¼ń£ŗõĖĆõĖ¬õŠŗÕŁÉ:
┬Ā
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import java.util.concurrent.ConcurrentMap;
HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance();
Customer getCustomer( String id ) {
ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap( "customers" );
Customer customer = customers.get( id );
if (customer == null) {
customer = new Customer( id );
customer = customers.putIfAbsent( id, customer );
}
return customer;
}
public boolean updateCustomer( Customer customer ) {
ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap( "customers" );
return ( customers.replace( customer.getId(), customer ) != null );
}
public boolean removeCustomer( Customer customer ) {
ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap( "customers" );
return customers.remove( customer.getId(), customer );
}
┬Ā ┬ĀµēƵ£ēConcurrentMapńÜäµōŹõĮ£,µ»öÕ”éĶ»┤putÕÆīremoveµōŹõĮ£,Õ£©keyĶó½ÕģČõ╗¢µ£¼Õ£░µł¢Ķ┐£ń½»JVMń║┐ń©ŗķöüõĮŵŚČķāĮÕ░åĶ┐øĶĪīńŁēÕŠģ,ÕÅ»µś»Õ«āõ╗¼ń╗łÕ░åĶ┐öÕø×µłÉÕŖ¤.┬ĀConcurrentMapµōŹõĮ£µ░ĖĶ┐£õĖŹõ╝ܵŖøÕć║java.util.ConcurrentModificationException.
┬Ā
Also see:
4.1.2.MapńÜäÕżćõ╗Į
┬Ā HazelcastÕ░åmapÕłåÕĖāÕ╝ÅńÜäÕŁśÕé©õ║ÄÕ»╣õĖ¬JVMõĖŖ(cluster members).µ»ÅõĖ¬JVMÕ░åõ╝ÜholdõĮÅõĖĆķā©ÕłåµĢ░µŹ«,ÕĮōJVMÕÅæńö¤Õ┤®µ║āµŚČ,µĢ░µŹ«Õ░åõĖŹõ╝ÜõĖóÕż▒.
┬Ā ÕłåÕĖāÕ╝ÅńÜäMapÕ£©õĖĆõĖ¬µłÉÕæśÕ┤®µ║āµŚČ,µŗźµ£ēõĖĆõĖ¬Ķ»źµłÉÕæśµĢ░µŹ«ńÜäÕżćõ╗Į,õ╗ÄĶĆī,µŁżµ¼ĪÕ┤®µ║āÕ░åõĖŹõ╝ÜÕ»╣µĢ░µŹ«õ║¦ńö¤õĖóÕż▒.Õżćõ╗ĮµōŹõĮ£µś»ÕÉīµŁźńÜä,ÕĮōmap.put(key, value)µōŹõĮ£Ķ┐öÕø×µŚČ,Õ«āÕ░åõ┐ØĶ»üµŁżµ¼ĪµōŹõĮ£õ╝ÜÕ£©ÕÅ”õĖĆõĖ¬ĶŖéńé╣õĖŖĶ┐øĶĪīķćŹÕżŹµōŹõĮ£,õ╗ÄĶĆīÕ£©ÕÅ”õĖĆõĖ¬ĶŖéńé╣õĖŖĶ┐øĶĪīµĢ░µŹ«ńÜäÕżćõ╗Į.Õ»╣õ║ÄĶ»╗ÕÅ¢µØźĶ»┤,Õ«āÕ░åõ┐ØĶ»ü┬Āmap.get(key)Ķ┐öÕø×µ£Ćµ¢░ńÜäķö«ÕĆ╝Õ»╣.Ķ»ĘĶ«░õĮÅÕłåÕĖāÕ╝ÅmapńÜäķö«ÕĆ╝Õ»╣µś»õĖźµĀ╝õĖĆĶć┤Õ£░.
┬Ā ÕÉīµŁźÕżćõ╗Į
┬Ā õĖ║õ║åõ┐ØĶ»üµĢ░µŹ«Õ«ēÕģ©,HazelcastÕģüĶ«ĖõĮĀµīćÕ«ÜÕżćõ╗ĮńÜäµĢ░ķćÅ.ÕĮōõĮĀµīćիܵĢ░ķćÅÕÉÄJVMÕ░åµĢ░µŹ«µŗĘĶ┤ØĶć│ÕģČõ╗¢ńÜäJVM,ÕģĘõĮōķģŹńĮ«Õżćõ╗ĮµĢ░ķćÅĶ»ĘõĮ┐ńö©backup-countµĀćńŁŠ.
┬Ā
<hazelcast>
<map name="default">
<backup-count>1</backup-count>
</map>
</hazelcast>
┬Ā ÕĮōµĢ░ķćŵś»1µŚČ,µäÅÕæ│ńØƵ£ēÕ«āńÜäµĢ░µŹ«Õżćõ╗ĮÕ£©ÕÅ”õĖĆõĖ¬clusterĶŖéńé╣õĖŖ.ÕĮōĶ«ŠńĮ«õĖ║2µŚČ,Õ«āńÜäµĢ░µŹ«Õżćõ╗ĮÕ£©ÕÅ”õĖżõĖ¬ĶŖéńé╣õĖŖ.ÕĮōńäČÕ«āõ╣¤ÕÅ»õ╗źĶ«ŠńĮ«õĖ║0,ÕĮōĶ«ŠńĮ«õĖ║0µŚČ,Õ░åõĖŹõ╝ÜÕżćõ╗ĮµĢ░µŹ«.
┬Ā
µ»öÕ”éĶ»┤,ÕĮōµĆ¦ĶāĮĶ”üµ▒éµ»öµĢ░µŹ«Õżćõ╗ĮĶ”üµ▒éķ½śµŚČ.µ£ĆÕż¦Õżćõ╗ĮµĢ░ķćÅõĖŖķÖɵś»6.
┬Ā Hazelcastµö»µīüÕÉīµŁźÕżćõ╗Įõ╣¤µö»µīüÕ╝鵣źÕżćõ╗Į.ń╝║ń£üńÜäÕżćõ╗Įµ¢╣Õ╝ÅõĖ║ÕÉīµŁźÕżćõ╗Įµ¢╣Õ╝Å.┬Ā(configured with┬Ābackup-count).Õ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ,Õżćõ╗ĮµōŹõĮ£Õ░åµē¦ĶĪīķś╗ÕĪ×µōŹõĮ£,ÕŹ│ÕŬµ£ēÕĮōõĖŖõĖĆõĖ¬Õżćõ╗ĮµōŹõĮ£Ķ┐öÕø×µłÉÕŖ¤õ┐Īµü»µŚČµēŹõ╝ܵē¦ĶĪīõĖŗõĖĆõĖ¬Õżćõ╗ĮµōŹõĮ£(µŁżÕżäÕłĀķÖżõ╣¤ÕÉīµĀĘķĆéńö©).ÕøĀµŁż,Õ£©putµōŹõĮ£µŚČ,õĮĀĶ”üńĪ«Ķ«żõĮĀńÜäÕżćõ╗ĮÕĘ▓ń╗ÅĶó½µø┤µ¢░.ÕĮōńäČ,ÕÉīµŁźÕżćõ╗ĮµōŹõĮ£ńÜäķś╗ÕĪ×ķŚ«ķóś,Õ░åÕĖ”µØźõĖĆõ║øµĮ£Õ£©ńÜäķŚ«ķóśÕÅŖµČłĶĆŚ.
┬Ā Õ╝鵣źÕżćõ╗Į
┬Ā Õ╝鵣źÕżćõ╗Į,õ╗ÄÕÅ”õĖƵ¢╣ķØóµØźĶ»┤,Õ«āÕ░åõĖŹõ╝ÜĶ┐øĶĪīķś╗ÕĪ×µōŹõĮ£.Õ╝鵣źÕżćõ╗ĮÕ░åõĖŹõ╝ÜĶ”üµ▒éĶ┐öÕø×ńĪ«Ķ«żõ┐Īµü»(Õżćõ╗ĮµōŹõĮ£Õ░åÕ£©õĖĆõ║øµŚČķŚ┤ńé╣µē¦ĶĪī).Õ╝鵣źÕżćõ╗ĮńÜäķģŹńĮ«,Ķ»ĘõĮ┐ńö©async-backup-countµĀćńŁŠ.
┬Ā
<hazelcast>
<map name="default">
<backup-count>0</backup-count>
<async-backup-count>1</async-backup-count>
</map>
</hazelcast>
┬Ā
┬Ā┬ĀNOTE:┬ĀBackups increase memory usage since they are also kept in memory. So for every backup, you double the original memory consumption.
┬ĀNOTE:┬ĀA map can have both sync and aysnc backups at the same time.
┬Ā Õżćõ╗ĮµĢ░µŹ«ńÜäĶ»╗ÕÅ¢ ┬Ā
┬Ā ń╝║ń£üµāģÕåĄõĖŗ,Hazelcastµŗźµ£ēõĖĆõ╗ĮÕÉīµŁźÕżćõ╗ĮµĢ░µŹ«.Õ”éµ×£Õżćõ╗ĮµĢ░ķćÅÕż¦õ║Ä1µŚČµ»ÅõĖ¬µłÉÕæśÕ░åõ┐ØÕŁśµ£¼Ķ║½ńÜäķö«ÕĆ╝µĢ░µŹ«õ╗źÕÅŖÕģČõ╗¢µłÉÕæśńÜäÕżćõ╗ĮµĢ░µŹ«.ÕøĀµŁżÕ»╣õ║ÄĶ░āńö©┬Āmap.get(key)┬Āµ¢╣µ│ĢµŚČ,Õ«āµ£ēÕÅ»ĶāĮĶ░āńö©Ķ»źµłÉÕæśÕ£©µ£¼µłÉÕæśõĖŁÕĘ▓ń╗ÅÕżćõ╗ĮńÜäkey,┬Āmap.get(key)┬ĀÕ░åõ╝ÜĶ»╗ÕÅ¢Õ«×ķÖģõĖŖµŗźµ£ēĶ»źķö«ńÜ䵳ÉÕæśńÜäÕĆ╝õ╗ÄĶĆīµØźõ┐ØĶ»üµĢ░µŹ«ńÜäõĖĆĶć┤µĆ¦.Õ”éµ×£Õ░å┬Āread-backup-data Ķ«ŠńĮ«õĖ║true,ķéŻõ╣łÕ«āµ£ēÕÅ»ĶāĮńø┤µÄźõ╗ĵ£¼µłÉÕæśõĖŁĶ»╗ÕÅ¢ÕģČõ╗¢µłÉÕæśÕżćõ╗ĮÕ£©µŁżÕżäńÜäµĢ░µŹ«.┬ĀõĖ║õ║åÕó×Õ╝║µĢ░µŹ«ńÜäõĖĆĶć┤µĆ¦,read-backup-datańÜäķ╗śĶ«żÕĆ╝µś»false.Õ░åµŁżÕĆ╝Ķ«ŠńĮ«õĖ║trueÕ░åÕó×Õ╝║Ķ»╗ÕÅ¢ńÜäµĆ¦ĶāĮ.
┬Ā
<hazelcast>
<map name="default">
<backup-count>0</backup-count>
<async-backup-count>1</async-backup-count>
<read-backup-data>true</read-backup-data>
</map>
</hazelcast>
┬ĀµŁżÕżäĶ»┤ńÜäńē╣µĆ¦,ÕĮōõĖöõ╗ģÕĮōµ£ēĶć│Õ░æ1õĖ¬ÕÉīµŁźµł¢Õ╝鵣źÕżćõ╗ĮńÜäµāģÕåĄõĖŗÕÅ»ńö©Õ¢ö.
4.1.3.ÕēöķÖż(Eviction)
┬Ā ķÖżķØ×õĮĀõ╗Ämapõ║║ÕĘźÕłĀķÖżµĢ░µŹ«µł¢õĮ┐ńö©ÕēöķÖżńŁ¢ńĢź,ÕÉ”ÕłÖõ╗¢õ╗¼Õ░åõ╝ÜķüŚńĢÖÕ£©mapõĖŁ.Hazelcastµö»µīüÕłåÕĖāÕ╝ÅmapńÜäÕ¤║õ║ÄńŁ¢ńĢźńÜäÕēöķÖż.õĖĆĶł¼ńÜäńŁ¢ńĢźõĖ║LRU(Least Recently Used)õ╗źÕÅŖLFU (Least Frequently Used).
õ╗źõĖŗµś»ÕÅ”Õż¢ńÜäõĖĆõ║øķģŹńĮ«ÕŻ░µśÄ’╝Ü
┬Ā
<hazelcast>
<map name="default">
...
<time-to-live-seconds>0</time-to-live-seconds>
<max-idle-seconds>0</max-idle-seconds>
<eviction-policy>LRU</eviction-policy>
<max-size policy="PER_NODE">5000</max-size>
<eviction-percentage>25</eviction-percentage>
...
</map>
</hazelcast>
┬ĀµÄźõĖŗµØź,µłæõ╗¼Ķ»┤µśÄõĖĆõĖŗÕÉäõĖ¬ķģŹńĮ«.
┬Ā
-
time-to-live: Maximum time in seconds for each entry to stay in the map. If it is not 0, entries that are older than and not updated for this time are evicted automatically. Valid values are integers between 0 andInteger.MAX VALUE. Default value is 0 and it means infinite. Moreover, if it is not 0, entries are evicted regardless of the set┬Āeviction-policy. -
max-idle-seconds: Maximum time in seconds for each entry to stay idle in the map. Entries that are idle for more than this time are evicted automatically. An entry is idle if no┬Āget,┬Āput┬Āor┬ĀcontainsKey┬Āis called. Valid values are integers between 0 and┬ĀInteger.MAX VALUE. Default value is 0 and it means infinite. -
eviction-policy: Valid values are described below.- NONE: Default policy. If set, no items will be evicted and the property┬Ā
max-size┬Āwill be ignored. Of course, you still can combine it with┬Ātime-to-live-seconds┬Āand┬Āmax-idle-seconds. - LRU: Least Recently Used.
- LFU: Least Frequently Used.
- NONE: Default policy. If set, no items will be evicted and the property┬Ā
-
max-size: Maximum size of the map. When maximum size is reached, map is evicted based on the policy defined. Valid values are integers between 0 and┬ĀInteger.MAX VALUE. Default value is 0. If you want┬Āmax-size┬Āto work,┬Āeviction-policy┬Āproperty must be set to a value other than NONE. Its attributes are described below.-
PER_NODE: Maximum number of map entries in each JVM. This is the default policy.<max-size policy="PER_NODE">5000</max-size> -
PER_PARTITION: Maximum number of map entries within each partition. Storage size depends on the partition count in a JVM. So, this attribute may not be used often. If the cluster is small it will be hosting more partitions and therefore map entries, than that of a larger cluster.<max-size policy="PER_PARTITION">27100</max-size> -
USED_HEAP_SIZE: Maximum used heap size in megabytes for each JVM.<max-size policy="USED_HEAP_SIZE">4096</max-size> -
USED_HEAP_PERCENTAGE: Maximum used heap size percentage for each JVM. If, for example, JVM is configured to have 1000 MB and this value is 10, then the map entries will be evicted when used heap size exceeds 100 MB.<max-size policy="USED_HEAP_PERCENTAGE">10</max-size>
-
-
eviction-percentage: When┬Āmax-size┬Āis reached, specified percentage of the map will be evicted. If 25 is set for example, 25% of the entries will be evicted. Setting this property to a smaller value will cause eviction of small number of map entries. So, if map entries are inserted frequently, smaller percentage values may lead to overheads. Valid values are integers between 0 and 100. Default value is 25.
┬Ā ÕēöķÖżķģŹńĮ«µĀʵ£¼
┬Ā
<map name="documents"> <max-size policy="PER_NODE">10000</max-size> <eviction -policy>LRU</eviction -policy> <max-idle-seconds>60</max-idle-seconds> </map>
Õ£©µŁżµĀʵ£¼õĖŁ,documents mapÕ░åÕ£©Õż¦Õ░ÅĶČģĶ┐ć10000µŚČÕ╝ĆÕ¦ŗÕēöķÖżµĢ░µŹ«µōŹõĮ£.ÕēöķÖżµōŹõĮ£Ķ┐øĶĪīÕēöķÖżńÜ䵜»µ£ĆÕ░æõĮ┐ńö©Õł░ńÜäµĢ░µŹ«.ÕģĘõĮōńÜ䵜»ÕēöķÖżĶČģĶ┐ć60ń¦Æµ£¬Ķó½õĮ┐ńö©ńÜäµĢ░µŹ«.
┬Ā
┬Ā ┬ĀÕēöķÖżķö«ÕĆ╝Õ»╣µĢ░µŹ«ńē╣µĆ¦
┬Ā ķĆÜĶ┐ćõĖŖĶ┐░ÕēöķÖżµö┐ńŁ¢ńÜäĶ¦ŻĶ»╗µłæõ╗¼ÕÅæńÄ░,ķĆÜĶ┐ćķģŹńĮ«ÕÅ»õ╗źķĆéńö©õ║ĵĢ┤õĖ¬mapńÜäµĢ░µŹ«.µ╗ĪĶČ│µØĪõ╗ČńÜäµĢ░µŹ«Õ░åõ╝ÜĶó½ÕēöķÖż.
┬Ā õĮåµś»ÕĮōõĮĀµā│ÕēöķÖżńē╣Õ«ÜńÜäµĢ░µŹ«µŚČõĮĀĶ»źµĆÄõ╣łÕŖ×Õæó’╝¤Õ£©Ķ┐ÖõĖ¬õŠŗÕŁÉõĖŁ,õĮĀÕÅ»õ╗źÕ£©Ķ░āńö©map.put()µ¢╣µ│ĢµŚČ,õĮ┐ńö©ttlõ╗źÕÅŖtimeunitÕÅéµĢ░µØźµēŗÕŖ©Ķ«ŠńĮ«Ķ┐ÖõĖ¬ķö«ÕĆ╝Õ»╣ńÜäÕēöķÖżµōŹõĮ£.õĖŗķØóń╗ÖÕć║µ£¼µōŹõĮ£ńÜäõ╗ŻńĀü.
┬Ā
myMap.put( "1", "John", 50, TimeUnit.SECONDS )
┬ĀµŁżÕżäÕ«×ńÄ░ńÜäµĢłµ×£µś»,ÕĮōķö«ŌĆ£1ŌĆصöŠÕģźmyMapµŚČ,Õ░åÕ£©50sÕÉÄĶó½ÕēöķÖż.
┬Ā
┬Ā ÕēöķÖżµēƵ£ēķö«ÕĆ╝Õ»╣
┬Ā Ķ░āńö©evictAll()µ¢╣µ│ĢÕ░åÕēöķÖżmapõĖŁķÖżõ║åõĖŖķöüńÜäķö«ÕĆ╝Õ»╣õ╗źÕż¢ńÜäµēƵ£ēķö«ÕĆ╝Õ»╣.Õ”éµ×£õĖĆõĖ¬mapõĖŁÕ«Üõ╣ēõ║åMapStore,ķéŻõ╣łĶ░āńö©evictAll()µ¢╣µ│ĢµŚČÕ░åõĖŹõ╝ÜĶ░āńö©deleteAllµ¢╣µ│Ģ.Õ”éµ×£õĮĀÕĖīµ£ødeleteAllµ¢╣µ│Ģ,Ķ»ĘĶ░āńö©clear()µ¢╣µ│Ģ.
┬Ā õĖŗķØóń╗ÖÕć║õĖĆõĖ¬õŠŗÕŁÉ~~’╝Ü
┬Ā┬Ā
public class EvictAll {
public static void main(String[] args) {
final int numberOfKeysToLock = 4;
final int numberOfEntriesToAdd = 1000;
HazelcastInstance node1 = Hazelcast.newHazelcastInstance();
HazelcastInstance node2 = Hazelcast.newHazelcastInstance();
IMap<Integer, Integer> map = node1.getMap(EvictAll.class.getCanonicalName());
for (int i = 0; i < numberOfEntriesToAdd; i++) {
map.put(i, i);
}
for (int i = 0; i < numberOfKeysToLock; i++) {
map.lock(i);
}
// should keep locked keys and evict all others.
map.evictAll();
System.out.printf("# After calling evictAll...\n");
System.out.printf("# Expected map size\t: %d\n", numberOfKeysToLock);
System.out.printf("# Actual map size\t: %d\n", map.size());
}
}
┬Āµē¦ĶĪīµĢłµ×£Õ”éõĖŗ’╝Ü
# After calling evictAll... # Expected map size : 4 # Actual map size : 4
┬Ā
┬ĀNOTE:┬ĀOnly EVICT_ALL event is fired for any registered listeners.
┬Ā
┬ĀÕÉÄń╗Łń½ĀĶŖéµĢ¼Ķ»ĘÕģ│µ│©.
┬ĀÕģ│õ║Äń┐╗Ķ»æńÜäõĖĆńé╣Ķ»┤µśÄ’╝Üõ╗ģõĮ£õĖ║ÕŁ”õ╣Āõ║żµĄüõ╣ŗńö©.Ք鵣ēķöÖĶ»»,Ķ»ĘÕż¦Õ«ČµīćÕć║,Ķ░óĶ░ó’╝ü
┬Ā---------------------------------------------------------------------------------------------------------------------------------------------
┬ĀĶŗ▒µ¢ćµ¢ćµĪŻ’╝Ühttp://docs.hazelcast.org/docs/3.3/manual/html-single/hazelcast-documentation.html
┬Ā
┬Ā



ńøĖÕģ│µÄ©ĶŹÉ
ÕīģÕɽń┐╗Ķ»æÕÉÄńÜäAPIµ¢ćµĪŻ’╝Ühazelcast-3.7.2-javadoc-APIµ¢ćµĪŻ-õĖŁµ¢ć(ń«ĆõĮō)ńēł.zip’╝ø MavenÕØɵĀć’╝Ücom.hazelcast:hazelcast:3.7.2’╝ø µĀćńŁŠ’╝ÜhazelcastŃĆüõĖŁµ¢ćµ¢ćµĪŻŃĆüjarÕīģŃĆüjava’╝ø õĮ┐ńö©µ¢╣µ│Ģ’╝ÜĶ¦ŻÕÄŗń┐╗Ķ»æÕÉÄńÜäAPIµ¢ćµĪŻ’╝īńö©µĄÅĶ¦łÕÖ©µēōÕ╝Ć...
ÕīģÕɽń┐╗Ķ»æÕÉÄńÜäAPIµ¢ćµĪŻ’╝Üshiro-hazelcast-1.4.0-javadoc-APIµ¢ćµĪŻ-õĖŁµ¢ć(ń«ĆõĮō)ńēł.zip’╝ø MavenÕØɵĀć’╝Üorg.apache.shiro:shiro-hazelcast:1.4.0’╝ø µĀćńŁŠ’╝ÜapacheŃĆüshiroŃĆühazelcastŃĆüõĖŁµ¢ćµ¢ćµĪŻŃĆüjarÕīģŃĆüjava’╝ø õĮ┐ńö©µ¢╣µ│Ģ’╝ÜĶ¦ŻÕÄŗ...
ÕīģÕɽń┐╗Ķ»æÕÉÄńÜäAPIµ¢ćµĪŻ’╝Üshiro-hazelcast-1.4.0-javadoc-APIµ¢ćµĪŻ-õĖŁµ¢ć(ń«ĆõĮō)-Ķŗ▒Ķ»Ł-Õ»╣ńģ¦ńēł.zip’╝ø MavenÕØɵĀć’╝Üorg.apache.shiro:shiro-hazelcast:1.4.0’╝ø µĀćńŁŠ’╝ÜapacheŃĆüshiroŃĆühazelcastŃĆüõĖŁĶŗ▒Õ»╣ńģ¦µ¢ćµĪŻŃĆüjarÕīģŃĆüjava’╝ø ...
ÕīģÕɽń┐╗Ķ»æÕÉÄńÜäAPIµ¢ćµĪŻ’╝Ühazelcast-3.7.2-javadoc-APIµ¢ćµĪŻ-õĖŁµ¢ć(ń«ĆõĮō)-Ķŗ▒Ķ»Ł-Õ»╣ńģ¦ńēł.zip’╝ø MavenÕØɵĀć’╝Ücom.hazelcast:hazelcast:3.7.2’╝ø µĀćńŁŠ’╝ÜhazelcastŃĆüõĖŁĶŗ▒Õ»╣ńģ¦µ¢ćµĪŻŃĆüjarÕīģŃĆüjava’╝ø õĮ┐ńö©µ¢╣µ│Ģ’╝ÜĶ¦ŻÕÄŗń┐╗Ķ»æÕÉÄńÜäAPIµ¢ćµĪŻ...
2. **ÕłåÕĖāÕ╝Å Map**’╝ÜHazelcast ńÜäÕłåÕĖāÕ╝Å Map µö»µīüÕżÜĶŖéńé╣ķŚ┤ńÜäÕģ▒õ║½µĢ░µŹ«ÕŁśÕé©’╝īńĪ«õ┐صĢ░µŹ«ńÜäõĖĆĶć┤µĆ¦ÕÆīÕÅ»ńö©µĆ¦ŃĆé 3. **ÕłåÕĖāÕ╝Åķś¤ÕłŚÕÆīÕłŚĶĪ©**’╝ÜÕģüĶ«ĖÕ£©ķøåńŠżõĖŁńÜäõĖŹÕÉīĶŖéńé╣õ╣ŗķŚ┤ÕÉīµŁźµĢ░µŹ«’╝īÕ«×ńÄ░õ╗╗ÕŖĪĶ░āÕ║”ÕÆīµĢ░µŹ«Õģ▒õ║½ŃĆé 4. **ÕłåÕĖāÕ╝Åõ║ŗõ╗Č...
Hazelcastµś»õĖƵ¼ŠÕ╝Ƶ║ÉńÜäÕåģÕŁśµĢ░µŹ«ńĮæµĀ╝’╝īÕ«āµÅÉõŠøõ║åõĖĆõĖ¬ÕłåÕĖāÕ╝ÅÕåģÕŁśĶ«Īń«ŚÕ╣│ÕÅ░’╝īńö©õ║ÄÕżäńÉåÕż¦ķćŵĢ░µŹ«Õ╣ȵÅÉķ½śÕ║öńö©ń©ŗÕ║ÅńÜäµĆ¦ĶāĮŃĆéHazelcast Centerµś»ÕģČķģŹÕźŚńÜäń«ĪńÉåÕĘźÕģĘ’╝īÕÅ»õ╗źÕĖ«ÕŖ®ńö©µłĘńøæµÄ¦ŃĆüń«ĪńÉåÕÆīķģŹńĮ«Ķ┐ÉĶĪīõĖŁńÜäHazelcastÕ«×õŠŗŃĆéÕ£©õĮĀµÅÉõŠø...
1. **Hazelcast**: õ║åĶ¦Ż Hazelcast ńÜäµĀĖÕ┐āµ”éÕ┐Ą’╝īÕ”éÕłåÕĖāÕ╝ŵĢ░µŹ«ń╗ōµ×ä’╝łÕ”éÕłåÕĖāÕ╝ÅMapŃĆüQueueŃĆüTopicńŁē’╝ēŃĆüÕłåÕĖāÕ╝ÅĶ«Īń«ŚÕÆīń╝ōÕŁśµ£║ÕłČ’╝īõ╗źÕÅŖÕ”éõĮĢÕ£©ÕŠ«µ£ŹÕŖĪµ×ȵ×äõĖŁõĮ┐ńö©Õ«āµØźµÅÉķ½śÕÅ»õ╝Ėń╝®µĆ¦ÕÆīµĆ¦ĶāĮŃĆé 2. **STAX API**: ÕŁ”õ╣Ā STAX Ķ¦Żµ×É...
ńö©õ║ÄKubernetesńÜäHazelcast DiscoveryµÅÆõ╗Č... ńēłµ£¼Õģ╝Õ«╣µĆ¦’╝Ü hazelcast-kubernetes 2.0+õĖÄhazelcast 4+Õģ╝Õ«╣hazelcast-kubernetes 1.3+õĖÄhazelcast 3.11.x’╝ī3.12.xÕģ╝Õ«╣Õ»╣õ║ÄĶŠāµŚ¦ńÜähazelcastńēłµ£¼’╝īµé©ķ£ĆĶ”üõĮ┐ńö©hazelcast-kub
Hazelcast µś»õĖƵ¼ŠµĄüĶĪīńÜäÕ╝Ƶ║ÉÕåģÕŁśµĢ░µŹ«ńĮæµĀ╝Ķ¦ŻÕå│µ¢╣µĪł’╝īÕ«āµÅÉõŠøÕłåÕĖāÕ╝Åń╝ōÕŁśŃĆüÕłåÕĖāÕ╝ÅMapŃĆüķś¤ÕłŚŃĆü topic ÕÆīÕģČõ╗¢Õ╣ČÕÅæµĢ░µŹ«ń╗ōµ×äŃĆéSpring µĪåµ×ȵś»JavaÕ╝ĆÕÅæõĖŁńÜäÕĖĖńö©õ╝üõĖÜń║¦Õ║öńö©µĪåµ×Č’╝īµÅÉõŠøõ║åõŠØĶĄ¢µ│©ÕģźŃĆüAOP’╝łķØóÕÉæÕłćķØóń╝¢ń©ŗ’╝ēńŁēÕŖ¤ĶāĮŃĆé...
Õ»╣õ║ÄPythonÕ╝ĆÕÅæĶĆģµØźĶ»┤’╝ī`hazelcast-python-client`µÅÉõŠøõ║åõĖÄHazelcastķøåńŠżķĆÜõ┐ĪńÜäµÄźÕÅŻ’╝īõĮ┐PythonÕ║öńö©ń©ŗÕ║ÅĶāĮÕż¤Õł®ńö©HazelcastńÜäÕ╝║Õż¦ÕŖ¤ĶāĮ’╝īÕ”éÕłåÕĖāÕ╝Åń╝ōÕŁśŃĆüÕłåÕĖāÕ╝ÅMapŃĆüķś¤ÕłŚŃĆüõĖ╗ķóśŃĆüõ║ŗõ╗ČŃĆüõ╗źÕÅŖµē¦ĶĪīÕłåÕĖāÕ╝Åõ╗╗ÕŖĪńŁēŃĆé...
2. **ÕłåÕĖāÕ╝Å Map**’╝ÜHazelcast ńÜäÕłåÕĖāÕ╝Å Map µś»Õģȵ£ĆÕĖĖńö©ńÜäµĢ░µŹ«ń╗ōµ×ä’╝īÕÅ»õ╗źÕ£©ķøåńŠżõĖŁÕŁśÕé©ķö«ÕĆ╝Õ»╣µĢ░µŹ«’╝īńĪ«õ┐صĢ░µŹ«ńÜäķ½śÕÅ»ńö©µĆ¦ÕÆīõĖĆĶć┤µĆ¦ŃĆé 3. **ÕłåÕĖāÕ╝Å List, Set, Queue, Topic**’╝ÜHazelcast Ķ┐śµÅÉõŠøõ║åÕģČõ╗¢ÕĖĖĶ¦üńÜäµĢ░µŹ«ń╗ōµ×ä’╝ī...
Hazelcastµś»õĖĆõĖ¬ÕåģÕŁśµĢ░µŹ«ńĮæµĀ╝’╝īĶāĮÕż¤ÕĖ«ÕŖ®µÅÉÕŹćÕ║öńö©ń©ŗÕ║ÅńÜäµĆ¦ĶāĮÕÆīÕÅ»µē®Õ▒ĢµĆ¦’╝īĶĆīHibernateµś»JavaķóåÕ¤¤Õ╣┐µ│øõĮ┐ńö©ńÜäÕ»╣Ķ▒ĪÕģ│ń│╗µśĀÕ░ä’╝łORM’╝ēµĪåµ×ČŃĆéĶ┐ÖõĖ¬ńēłµ£¼3.1.5ńÜäHazelcast-Hibernate3ķĆéķģŹÕÖ©õĮ┐ÕŠŚÕ╝ĆÕÅæĶĆģÕÅ»õ╗źÕł®ńö©HazelcastńÜäÕłåÕĖāÕ╝Å...
2. ÕłåÕĖāÕ╝ÅMap’╝ÜHazelcastńÜäÕłåÕĖāÕ╝ÅMapÕģüĶ«ĖÕ£©ķøåńŠżõĖŁńÜäµēƵ£ēĶŖéńé╣ķŚ┤Õģ▒õ║½µĢ░µŹ«ŃĆéÕ«āµö»µīüÕ╣ČÕÅæµōŹõĮ£’╝īµÅÉõŠøõ║åõĖĆĶć┤µĆ¦ÕōłÕĖīÕÆīÕłåÕī║ńŁ¢ńĢź’╝īńĪ«õ┐صĢ░µŹ«ńÜäÕłåÕĖāÕØćÕīĆÕÆīķ½śµĢłĶ«┐ķŚ«ŃĆé 3. QueueÕÆīTopic’╝ÜHazelcastńÜäÕłåÕĖāÕ╝ÅQueueÕ«×ńÄ░õ║åń║┐ń©ŗÕ«ēÕģ©ńÜä...
atmosphere-hazelcast-1.0.15-sources.jar
atmosphere-hazelcast-1.0.14-sources.jar
atmosphere-hazelcast-1.0.13-sources.jar
atmosphere-hazelcast-1.0.9-sources.jar
atmosphere-hazelcast-1.0.8-sources.jar
atmosphere-hazelcast-1.0.7-sources.jar