
JDBC批量Insert深度优化(有事务)
环境:
MySQL 5.1
RedHat Linux AS 5
JavaSE 1.5
DbConnectionBroker 微型数据库连接池
测试的方案:
执行10万次Insert语句,使用不同方式。
A组:静态SQL,自动提交,没事务控制(MyISAM引擎)
1、逐条执行10万次
2、分批执行将10万分成m批,每批n条,分多种分批方案来执行。
B组:预编译模式SQL,自动提交,没事务控制(MyISAM引擎)
1、逐条执行10万次
2、分批执行将10万分成m批,每批n条,分多种分批方案来执行。
-------------------------------------------------------------------------------------------
C组:静态SQL,不自动提交,有事务控制(InnoDB引擎)
1、逐条执行10万次
2、分批执行将10万分成m批,每批n条,分多种分批方案来执行。
D组:预编译模式SQL,不自动提交,有事务控制(InnoDB引擎)
1、逐条执行10万次
2、分批执行将10万分成m批,每批n条,分多种分批方案来执行。
本次主要测试C、D组,并得出测试结果。
SQL代码
DROP TABLE IF EXISTS tuser;
CREATE TABLE tuser (
id bigint(20) NOT NULL AUTO_INCREMENT,
name varchar(12) DEFAULT NULL,
remark varchar(24) DEFAULT NULL,
createtime datetime DEFAULT NULL,
updatetime datetime DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE tuser (
id bigint(20) NOT NULL AUTO_INCREMENT,
name varchar(12) DEFAULT NULL,
remark varchar(24) DEFAULT NULL,
createtime datetime DEFAULT NULL,
updatetime datetime DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
C、D组测试代码:
package testbatch;
import java.io.IOException;
import java.sql.*;
/**
* JDBC批量Insert优化(下)
*
* @author leizhimin 2009-7-29 10:03:10
*/
public class TestBatch {
public static DbConnectionBroker myBroker = null;
static {
try {
myBroker = new DbConnectionBroker("com.mysql.jdbc.Driver",
"jdbc:mysql://192.168.104.163:3306/testdb",
"vcom", "vcom", 2, 4,
"c:\\testdb.log", 0.01);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 初始化测试环境
*
* @throws SQLException 异常时抛出
*/
public static void init() throws SQLException {
Connection conn = myBroker.getConnection();
conn.setAutoCommit(false);
Statement stmt = conn.createStatement();
stmt.addBatch("DROP TABLE IF EXISTS tuser");
stmt.addBatch("CREATE TABLE tuser (\n" +
" id bigint(20) NOT NULL AUTO_INCREMENT,\n" +
" name varchar(12) DEFAULT NULL,\n" +
" remark varchar(24) DEFAULT NULL,\n" +
" createtime datetime DEFAULT NULL,\n" +
" updatetime datetime DEFAULT NULL,\n" +
" PRIMARY KEY (id)\n" +
") ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8");
stmt.executeBatch();
conn.commit();
myBroker.freeConnection(conn);
}
/**
* 100000条静态SQL插入
*
* @throws Exception 异常时抛出
*/
public static void testInsert() throws Exception {
init(); //初始化环境
Long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
String sql = "\n" +
"insert into testdb.tuser \n" +
"\t(name, \n" +
"\tremark, \n" +
"\tcreatetime, \n" +
"\tupdatetime\n" +
"\t)\n" +
"\tvalues\n" +
"\t('" + RandomToolkit.generateString(12) + "', \n" +
"\t'" + RandomToolkit.generateString(24) + "', \n" +
"\tnow(), \n" +
"\tnow()\n" +
")";
Connection conn = myBroker.getConnection();
conn.setAutoCommit(false);
Statement stmt = conn.createStatement();
stmt.execute(sql);
conn.commit();
myBroker.freeConnection(conn);
}
Long end = System.currentTimeMillis();
System.out.println("单条执行100000条Insert操作,共耗时:" + (end - start) / 1000f + "秒!");
}
/**
* 批处理执行静态SQL测试
*
* @param m 批次
* @param n 每批数量
* @throws Exception 异常时抛出
*/
public static void testInsertBatch(int m, int n) throws Exception {
init(); //初始化环境
Long start = System.currentTimeMillis();
for (int i = 0; i < m; i++) {
//从池中获取连接
Connection conn = myBroker.getConnection();
conn.setAutoCommit(false);
Statement stmt = conn.createStatement();
for (int k = 0; k < n; k++) {
String sql = "\n" +
"insert into testdb.tuser \n" +
"\t(name, \n" +
"\tremark, \n" +
"\tcreatetime, \n" +
"\tupdatetime\n" +
"\t)\n" +
"\tvalues\n" +
"\t('" + RandomToolkit.generateString(12) + "', \n" +
"\t'" + RandomToolkit.generateString(24) + "', \n" +
"\tnow(), \n" +
"\tnow()\n" +
")";
//加入批处理
stmt.addBatch(sql);
}
stmt.executeBatch(); //执行批处理
conn.commit();
// stmt.clearBatch(); //清理批处理
stmt.close();
myBroker.freeConnection(conn); //连接归池
}
Long end = System.currentTimeMillis();
System.out.println("批量执行" + m + "*" + n + "=" + m * n + "条Insert操作,共耗时:" + (end - start) / 1000f + "秒!");
}
/**
* 100000条预定义SQL插入
*
* @throws Exception 异常时抛出
*/
public static void testInsert2() throws Exception { //单条执行100000条Insert操作,共耗时:40.422秒!
init(); //初始化环境
Long start = System.currentTimeMillis();
String sql = "" +
"insert into testdb.tuser\n" +
" (name, remark, createtime, updatetime)\n" +
"values\n" +
" (?, ?, ?, ?)";
for (int i = 0; i < 100000; i++) {
Connection conn = myBroker.getConnection();
conn.setAutoCommit(false);
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, RandomToolkit.generateString(12));
pstmt.setString(2, RandomToolkit.generateString(24));
pstmt.setDate(3, new Date(System.currentTimeMillis()));
pstmt.setDate(4, new Date(System.currentTimeMillis()));
pstmt.executeUpdate();
conn.commit();
pstmt.close();
myBroker.freeConnection(conn);
}
Long end = System.currentTimeMillis();
System.out.println("单条执行100000条Insert操作,共耗时:" + (end - start) / 1000f + "秒!");
}
/**
* 批处理执行预处理SQL测试
*
* @param m 批次
* @param n 每批数量
* @throws Exception 异常时抛出
*/
public static void testInsertBatch2(int m, int n) throws Exception {
init(); //初始化环境
Long start = System.currentTimeMillis();
String sql = "" +
"insert into testdb.tuser\n" +
" (name, remark, createtime, updatetime)\n" +
"values\n" +
" (?, ?, ?, ?)";
for (int i = 0; i < m; i++) {
//从池中获取连接
Connection conn = myBroker.getConnection();
conn.setAutoCommit(false);
PreparedStatement pstmt = conn.prepareStatement(sql);
for (int k = 0; k < n; k++) {
pstmt.setString(1, RandomToolkit.generateString(12));
pstmt.setString(2, RandomToolkit.generateString(24));
pstmt.setDate(3, new Date(System.currentTimeMillis()));
pstmt.setDate(4, new Date(System.currentTimeMillis()));
//加入批处理
pstmt.addBatch();
}
pstmt.executeBatch(); //执行批处理
conn.commit();
// pstmt.clearBatch(); //清理批处理
pstmt.close();
myBroker.freeConnection(conn); //连接归池
}
Long end = System.currentTimeMillis();
System.out.println("批量执行" + m + "*" + n + "=" + m * n + "条Insert操作,共耗时:" + (end - start) / 1000f + "秒!");
}
public static void main(String[] args) throws Exception {
init();
Long start = System.currentTimeMillis();
System.out.println("--------C组测试----------");
testInsert();
testInsertBatch(100, 1000);
testInsertBatch(250, 400);
testInsertBatch(400, 250);
testInsertBatch(500, 200);
testInsertBatch(1000, 100);
testInsertBatch(2000, 50);
testInsertBatch(2500, 40);
testInsertBatch(5000, 20);
Long end1 = System.currentTimeMillis();
System.out.println("C组测试过程结束,全部测试耗时:" + (end1 - start) / 1000f + "秒!");
System.out.println("--------D组测试----------");
testInsert2();
testInsertBatch2(100, 1000);
testInsertBatch2(250, 400);
testInsertBatch2(400, 250);
testInsertBatch2(500, 200);
testInsertBatch2(1000, 100);
testInsertBatch2(2000, 50);
testInsertBatch2(2500, 40);
testInsertBatch2(5000, 20);
Long end2 = System.currentTimeMillis();
System.out.println("D组测试过程结束,全部测试耗时:" + (end2 - end1) / 1000f + "秒!");
}
}
import java.io.IOException;
import java.sql.*;
/**
* JDBC批量Insert优化(下)
*
* @author leizhimin 2009-7-29 10:03:10
*/
public class TestBatch {
public static DbConnectionBroker myBroker = null;
static {
try {
myBroker = new DbConnectionBroker("com.mysql.jdbc.Driver",
"jdbc:mysql://192.168.104.163:3306/testdb",
"vcom", "vcom", 2, 4,
"c:\\testdb.log", 0.01);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 初始化测试环境
*
* @throws SQLException 异常时抛出
*/
public static void init() throws SQLException {
Connection conn = myBroker.getConnection();
conn.setAutoCommit(false);
Statement stmt = conn.createStatement();
stmt.addBatch("DROP TABLE IF EXISTS tuser");
stmt.addBatch("CREATE TABLE tuser (\n" +
" id bigint(20) NOT NULL AUTO_INCREMENT,\n" +
" name varchar(12) DEFAULT NULL,\n" +
" remark varchar(24) DEFAULT NULL,\n" +
" createtime datetime DEFAULT NULL,\n" +
" updatetime datetime DEFAULT NULL,\n" +
" PRIMARY KEY (id)\n" +
") ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8");
stmt.executeBatch();
conn.commit();
myBroker.freeConnection(conn);
}
/**
* 100000条静态SQL插入
*
* @throws Exception 异常时抛出
*/
public static void testInsert() throws Exception {
init(); //初始化环境
Long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
String sql = "\n" +
"insert into testdb.tuser \n" +
"\t(name, \n" +
"\tremark, \n" +
"\tcreatetime, \n" +
"\tupdatetime\n" +
"\t)\n" +
"\tvalues\n" +
"\t('" + RandomToolkit.generateString(12) + "', \n" +
"\t'" + RandomToolkit.generateString(24) + "', \n" +
"\tnow(), \n" +
"\tnow()\n" +
")";
Connection conn = myBroker.getConnection();
conn.setAutoCommit(false);
Statement stmt = conn.createStatement();
stmt.execute(sql);
conn.commit();
myBroker.freeConnection(conn);
}
Long end = System.currentTimeMillis();
System.out.println("单条执行100000条Insert操作,共耗时:" + (end - start) / 1000f + "秒!");
}
/**
* 批处理执行静态SQL测试
*
* @param m 批次
* @param n 每批数量
* @throws Exception 异常时抛出
*/
public static void testInsertBatch(int m, int n) throws Exception {
init(); //初始化环境
Long start = System.currentTimeMillis();
for (int i = 0; i < m; i++) {
//从池中获取连接
Connection conn = myBroker.getConnection();
conn.setAutoCommit(false);
Statement stmt = conn.createStatement();
for (int k = 0; k < n; k++) {
String sql = "\n" +
"insert into testdb.tuser \n" +
"\t(name, \n" +
"\tremark, \n" +
"\tcreatetime, \n" +
"\tupdatetime\n" +
"\t)\n" +
"\tvalues\n" +
"\t('" + RandomToolkit.generateString(12) + "', \n" +
"\t'" + RandomToolkit.generateString(24) + "', \n" +
"\tnow(), \n" +
"\tnow()\n" +
")";
//加入批处理
stmt.addBatch(sql);
}
stmt.executeBatch(); //执行批处理
conn.commit();
// stmt.clearBatch(); //清理批处理
stmt.close();
myBroker.freeConnection(conn); //连接归池
}
Long end = System.currentTimeMillis();
System.out.println("批量执行" + m + "*" + n + "=" + m * n + "条Insert操作,共耗时:" + (end - start) / 1000f + "秒!");
}
/**
* 100000条预定义SQL插入
*
* @throws Exception 异常时抛出
*/
public static void testInsert2() throws Exception { //单条执行100000条Insert操作,共耗时:40.422秒!
init(); //初始化环境
Long start = System.currentTimeMillis();
String sql = "" +
"insert into testdb.tuser\n" +
" (name, remark, createtime, updatetime)\n" +
"values\n" +
" (?, ?, ?, ?)";
for (int i = 0; i < 100000; i++) {
Connection conn = myBroker.getConnection();
conn.setAutoCommit(false);
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, RandomToolkit.generateString(12));
pstmt.setString(2, RandomToolkit.generateString(24));
pstmt.setDate(3, new Date(System.currentTimeMillis()));
pstmt.setDate(4, new Date(System.currentTimeMillis()));
pstmt.executeUpdate();
conn.commit();
pstmt.close();
myBroker.freeConnection(conn);
}
Long end = System.currentTimeMillis();
System.out.println("单条执行100000条Insert操作,共耗时:" + (end - start) / 1000f + "秒!");
}
/**
* 批处理执行预处理SQL测试
*
* @param m 批次
* @param n 每批数量
* @throws Exception 异常时抛出
*/
public static void testInsertBatch2(int m, int n) throws Exception {
init(); //初始化环境
Long start = System.currentTimeMillis();
String sql = "" +
"insert into testdb.tuser\n" +
" (name, remark, createtime, updatetime)\n" +
"values\n" +
" (?, ?, ?, ?)";
for (int i = 0; i < m; i++) {
//从池中获取连接
Connection conn = myBroker.getConnection();
conn.setAutoCommit(false);
PreparedStatement pstmt = conn.prepareStatement(sql);
for (int k = 0; k < n; k++) {
pstmt.setString(1, RandomToolkit.generateString(12));
pstmt.setString(2, RandomToolkit.generateString(24));
pstmt.setDate(3, new Date(System.currentTimeMillis()));
pstmt.setDate(4, new Date(System.currentTimeMillis()));
//加入批处理
pstmt.addBatch();
}
pstmt.executeBatch(); //执行批处理
conn.commit();
// pstmt.clearBatch(); //清理批处理
pstmt.close();
myBroker.freeConnection(conn); //连接归池
}
Long end = System.currentTimeMillis();
System.out.println("批量执行" + m + "*" + n + "=" + m * n + "条Insert操作,共耗时:" + (end - start) / 1000f + "秒!");
}
public static void main(String[] args) throws Exception {
init();
Long start = System.currentTimeMillis();
System.out.println("--------C组测试----------");
testInsert();
testInsertBatch(100, 1000);
testInsertBatch(250, 400);
testInsertBatch(400, 250);
testInsertBatch(500, 200);
testInsertBatch(1000, 100);
testInsertBatch(2000, 50);
testInsertBatch(2500, 40);
testInsertBatch(5000, 20);
Long end1 = System.currentTimeMillis();
System.out.println("C组测试过程结束,全部测试耗时:" + (end1 - start) / 1000f + "秒!");
System.out.println("--------D组测试----------");
testInsert2();
testInsertBatch2(100, 1000);
testInsertBatch2(250, 400);
testInsertBatch2(400, 250);
testInsertBatch2(500, 200);
testInsertBatch2(1000, 100);
testInsertBatch2(2000, 50);
testInsertBatch2(2500, 40);
testInsertBatch2(5000, 20);
Long end2 = System.currentTimeMillis();
System.out.println("D组测试过程结束,全部测试耗时:" + (end2 - end1) / 1000f + "秒!");
}
}
执行结果:
--------C组测试----------
单条执行100000条Insert操作,共耗时:103.656秒!
批量执行100*1000=100000条Insert操作,共耗时:31.328秒!
批量执行250*400=100000条Insert操作,共耗时:31.406秒!
批量执行400*250=100000条Insert操作,共耗时:31.75秒!
批量执行500*200=100000条Insert操作,共耗时:31.438秒!
批量执行1000*100=100000条Insert操作,共耗时:31.968秒!
批量执行2000*50=100000条Insert操作,共耗时:32.938秒!
批量执行2500*40=100000条Insert操作,共耗时:33.141秒!
批量执行5000*20=100000条Insert操作,共耗时:35.265秒!
C组测试过程结束,全部测试耗时:363.656秒!
--------D组测试----------
单条执行100000条Insert操作,共耗时:107.61秒!
批量执行100*1000=100000条Insert操作,共耗时:32.64秒!
批量执行250*400=100000条Insert操作,共耗时:32.641秒!
批量执行400*250=100000条Insert操作,共耗时:33.109秒!
批量执行500*200=100000条Insert操作,共耗时:32.859秒!
批量执行1000*100=100000条Insert操作,共耗时:33.547秒!
批量执行2000*50=100000条Insert操作,共耗时:34.312秒!
批量执行2500*40=100000条Insert操作,共耗时:34.672秒!
批量执行5000*20=100000条Insert操作,共耗时:36.672秒!
D组测试过程结束,全部测试耗时:378.922秒!
单条执行100000条Insert操作,共耗时:103.656秒!
批量执行100*1000=100000条Insert操作,共耗时:31.328秒!
批量执行250*400=100000条Insert操作,共耗时:31.406秒!
批量执行400*250=100000条Insert操作,共耗时:31.75秒!
批量执行500*200=100000条Insert操作,共耗时:31.438秒!
批量执行1000*100=100000条Insert操作,共耗时:31.968秒!
批量执行2000*50=100000条Insert操作,共耗时:32.938秒!
批量执行2500*40=100000条Insert操作,共耗时:33.141秒!
批量执行5000*20=100000条Insert操作,共耗时:35.265秒!
C组测试过程结束,全部测试耗时:363.656秒!
--------D组测试----------
单条执行100000条Insert操作,共耗时:107.61秒!
批量执行100*1000=100000条Insert操作,共耗时:32.64秒!
批量执行250*400=100000条Insert操作,共耗时:32.641秒!
批量执行400*250=100000条Insert操作,共耗时:33.109秒!
批量执行500*200=100000条Insert操作,共耗时:32.859秒!
批量执行1000*100=100000条Insert操作,共耗时:33.547秒!
批量执行2000*50=100000条Insert操作,共耗时:34.312秒!
批量执行2500*40=100000条Insert操作,共耗时:34.672秒!
批量执行5000*20=100000条Insert操作,共耗时:36.672秒!
D组测试过程结束,全部测试耗时:378.922秒!
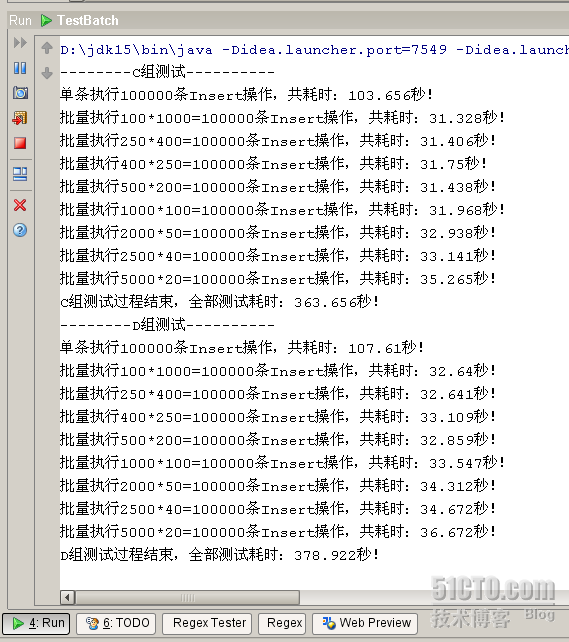
测试结果意想不到吧,最短时间竟然超过上篇。观察整个测试结果,发现总时间很长,原因是逐条执行的效率太低了。



相关推荐
总结来说,`logstash-output-jdbc`插件是Logstash连接关系型数据库的重要工具,通过它,你可以灵活地将日志和事件数据结构化并存入数据库,从而充分利用SQL的查询能力进行深度分析。在实际使用中,应根据具体需求...
《SQL Server 数据库连接驱动:sqljdbc4-4.0.jar 深度解析》 在信息化社会中,数据库管理系统的角色至关重要,SQL Server作为微软公司推出的强大关系型数据库管理系统,广泛应用于各种业务场景。而要与SQL Server...
2. **性能优化**:针对SQL Server进行了优化,如批量插入、预编译语句等功能,有效提高了数据处理速度。 3. **事务支持**:支持JDBC的事务管理,包括本地事务和分布式事务,确保数据的一致性和完整性。 4. **...
**JDBC MySQL:Java数据库连接的深度探索** 在Java编程领域,数据库操作是不可或缺的一部分,尤其是在构建企业级应用时。JDBC(Java Database Connectivity)作为Java标准API,为Java程序员提供了一个统一的接口来...
9. **优化JDBC操作**:包括预编译SQL(使用PreparedStatement)、批量操作、连接池和使用连接池管理器如C3P0、HikariCP等。 10. **MySQL特性和JDBC的结合**:MySQL提供了如存储过程、触发器、视图等特性,通过JDBC...
《Hibernate优化深度解析》 在Java企业级开发中,Hibernate作为一款强大的对象关系映射(ORM)框架,极大地简化了数据库操作。然而,随着项目的规模扩大,如何进行有效的Hibernate优化,提升系统的性能,成为了...
总体而言,RapidsDB通过其海量并行SQL能力,支持了大数据和深度学习的复杂分析任务,提供了灵活的联邦访问、高效的内存处理和查询优化机制,以及高性能的索引技术,是大数据处理和分析领域的重要工具。
- **队列深度**:合理设置队列深度,避免消息堆积。 - **持久化策略**:根据消息重要性选择不同的持久化策略,确保消息的可靠传递。 ##### 2. 消费者配置 - **消费者预取策略**:合理设置消费者预取消息的数量,以...
总结来说,大数据分析的关键技术在于如何根据业务需求选择合适的计算模式,如对于实时性要求高的场景选择流式计算,对于需要深度分析的历史数据则采用批量处理,而即席查询则在灵活查询和快速响应之间找到了平衡。...
大数据分析是现代信息技术领域的重要组成部分,它涉及到对海量数据的收集、存储、处理和分析,以便提取有价值的信息和洞察。...随着技术的不断进步,我们可以期待更多的创新工具和方法来提升大数据分析的效率和深度。
《银行管理系统的数据库连接技术——JDBC深度解析》 银行管理系统是现代金融机构信息化的重要组成部分,其稳定性和安全性直接影响到银行业务的正常运行。在银行管理系统中,数据存储和访问是核心功能之一,Java...
在本项目中,"J2EE 0.4—加入批量CRUD功能、加入框架页面、...总的来说,这个J2EE 0.4版本的更新,体现了开发者在Web应用开发中的深度理解和实践,包括后端数据处理的优化、前端用户体验的提升以及功能模块的集成能力。
"BasicKnowledge"可能包含了基本的Java语法和数据结构的代码实例,而"Learning"可能涵盖了更进阶的专题,如JDBC操作和多线程编程的实践案例。通过学习这些代码,你将能够提升你的Java编程技能,为今后的项目开发打下...
3. `hibernate.jdbc.batch_versioned_data`:开启后,Hibernate 为自动版本化的数据使用批量 DML,确保 JDBC executeBatch() 返回正确的行计数。 4. `hibernate.jdbc.factory_class`:允许指定自定义的 Batcher 类...
开启此选项,Hibernate将为自动版本化的数据使用批量DML,通常建议设置为`true`。 **16. hibernate.jdbc.factory_class** 选择自定义的Batcher类,用于处理批量操作,但大多数应用不需要。 **17. hibernate.jdbc....
如果设置为非零值,Hibernate 将使用 JDBC2 的批量更新。 hibernate.jdbc.batch_versioned_data Hibernate.jdbc.batch_versioned_data 属性用于控制 Hibernate 是否使用批量 DML。如果设置为 true,Hibernate 将...
3. **hibernate.jdbc.batch_versioned_data**:开启后,Hibernate会为自动版本化的数据使用批量DML操作。 4. **hibernate.jdbc.factory_class**:自定义的Batcher类,一般不常用,除非有特殊需求。 5. **hibernate...
- `hibernate.jdbc.batch_versioned_data`:开启后,Hibernate对自动版本化的数据使用批量DML操作。 - `hibernate.jdbc.factory_class`:自定义批处理器,一般情况下不需要设置。 - `hibernate.jdbc.use_...
15. **hibernate.jdbc.batch_versioned_data**: 开启后,Hibernate会在自动版本化的数据上使用批量DML,返回正确的行计数。 16. **hibernate.jdbc.factory_class**: 可以选择自定义的`Batcher`实现,但大多数情况下...