
问题:当我们要在ES中存储数据的时候,数据应该存储在主分片和复制分片中的哪一个中去;当我们在ES中检索数据的时候,又是怎么判断要查询的数据是属于哪一个分片。
-
数据存储到分片的过程是一定规则的,并不是随机发生的。
-
规则:shard = hash(routing) % number_of_primary_shards
-
Routing值可以是一个任意的字符串,默认情况下,它的值为存数数据对应文档 _id 值,也可以是用户自定义的值。Routing这个字符串通过一个hash的函数处理,并返回一个数值,然后再除以索引中主分片的数目,所得的余数作为主分片的编号,取值一般在0到number_of_primary_shards - 1的这个范围中。通过这种方法计算出该数据是存储到哪个分片中。
-
正是这种路由机制,导致了主分片的个数为什么在索引建立之后不能修改。对已有索引主分片数目的修改直接会导致路由规则出现严重问题,部分数据将无法被检索。
二、主分片与复制分片如何交互
为了说明这个问题,我用一个例子来说明。
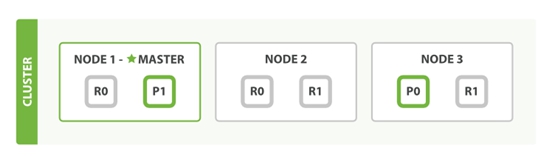
在上面这个例子中,有三个ES的node,其中每一个index中包含两个primary shard,每个primary shard拥有一个replica shard。下面从几种常见的数据操作来说明二者之间的交互情况。
1、索引与删除一个文档
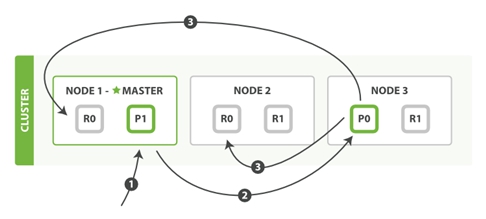
这两种过程均可以分为三个过程来描述:
阶段1:客户端发送了一个索引或者删除的请求给node 1。
阶段2:node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3在shard 0 的primary shard上执行请求。如果请求执行成功,它node 3将并行地将该请求发给shard 0的其余所有replica shard上,也就是存在于node 1和node 2中的replica shard。如果所有的replica shard都成功地执行了请求,那么将会向node 3回复一个成功确认,当node 3收到了所有replica shard的确认信息后,则最后向用户返回一个Success的消息。
2、更新一个文档

该过程可以分为四个阶段来描述:
阶段1:客户端向node 1发送一个文档更新的请求。
阶段2:同样的node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3从文档所在的primary shard中获取到它的JSON文件,并修改其中的_source中的内容,之后再重新索引该文档到其primary shard中。
阶段4:如果node 3成功地更新了文档,node 3将会把文档新的版本并行地发给其余所有的replica shard所在node中。这些node也同样重新索引新版本的文档,执行后则向node 3确认成功,当node 3接收到所有的成功确认之后,再向客户端发送一个更新成功的信息。
3、检索文档
CRUD这些操作的过程中一般都是结合一些唯一的标记例如:_index,_type,以及routing的值,这就意味在执行操作的时候都是确切的知道文档在集群中的哪个node中,哪个shard中。
而检索过程往往需要更多的执行模式,因为我们并不清楚所要检索的文档具体位置所在, 它们可能存在于ES集群中个任何位置。因此,一般情况下,检索的执行不得不去询问index中的每一个shard。
但是,找到所有匹配检索的文档仅仅只是检索过程的一半,在向客户端返回一个结果列表之前,必须将各个shard发回的小片的检索结果,拼接成一个大的已排好序的汇总结果列表。正因为这个原因,检索的过程将分为查询阶段与获取阶段(Query Phase and Fetch Phase)。
-
Query Phase
在最初的查询过程中,查询请求会广播到index中的每一个primary shard和replica shard中,每一个shard会在本地执行检索,并建立一个优先级队列(priority queue)。这个优先级队列是一个根据文档匹配度这个指标所排序列表,列表的长度由分页参数from和size两个参数所决定。例如:

下面从一个例子中说明这个过程:

Query Phase阶段可以再细分成3个小的子阶段:
子阶段1:客户端发送一个检索的请求给node 3,此时node 3会创建一个空的优先级队列并且配置好分页参数from与size。
子阶段2:node 3将检索请求发送给该index中个每一个shard(这里的每一个意思是无论它是primary还是replica,它们的组合可以构成一个完整的index数据)。每个shard在本地执行检索,并将结果添加到本地优先级队列中。
子阶段3:每个shard返回本地优先级序列中所记录的_id与sort值,并发送node 3。Node 3将这些值合并到自己的本地的优先级队列中,并做全局的排序。
-
Fetch Phase
Query Phase主要定位了所要检索数据的具体位置,但是我们还必须取回它们才能完成整个检索过程。而Fetch Phase阶段的任务就是将这些定位好的数据内容取回并返回给客户端。
同样也用一个例子来说明这个过程:

Fetch Phase过程可以分为三个子过程来描述:
子阶段1:node 3获取了所有待检索数据的定位之后,发送一个mget的请求给与数据相关的shard。
子阶段2:每个收到node 3的get请求的shard将读取相关文档_source中的内容,并将它们返回给node 3。
子阶段3:当node 3获取到了所有shard返回的文档后,node 3将它们合并成一条汇总的结果,返回给客户端。
http://my.oschina.net/galenz/blog/422189



相关推荐
Elasticsearch是一个开源的全文搜索引擎,它以分布式、RESTful接口和实时性为特点,广泛应用于数据搜索、分析和监控。这个"elasticsearch服务器安装包"包含了一个用于部署Elasticsearch服务的jar包,以及可能的配置...
1. **分布式**:Elasticsearch设计为分布式系统,能够自动处理节点间的通信和数据分片,确保高可用性和容错性。 2. **实时性**:Elasticsearch支持实时索引和搜索,数据更新后几乎立即可见。 3. **RESTful API**:...
5. **分片(Shard)**:为了分散存储和提高查询效率,Elasticsearch将索引分成多个分片。分片可以在不同节点上,使得数据分布更均匀。 6. **副本(Replica)**:每个分片的副本用于提高数据可用性和容错性,当主分片...
6. **更友好的API**:Elasticsearch 6.x系列对RESTful API进行了大量优化,使得开发者更容易与Elasticsearch进行交互,6.6.0版本可能在此基础上进行了进一步的完善。 7. **更好的兼容性**:与其他生态工具(如...
- Elasticsearch基于Apache Lucene构建,采用分片和副本的概念,使得数据可以在多台机器上分布,提供高可用性和容错性。 - 分片允许数据横向扩展,每个分片可以独立地作为一个完整的搜索引擎工作,数据可以通过...
Elasticsearch 6.2.4 是一个流行的开源搜索引擎和分析引擎,主要用Java编写,广泛应用于大数据存储、搜索和分析。这个压缩包文件包含了运行和操作Elasticsearch 6.2.4版本所需的Java库。以下是关于Elasticsearch ...
如“elasticsearch-head”是一个Web界面插件,它提供了一个直观的方式来查看和管理Elasticsearch集群的状态,包括索引、节点、分片等信息。 在"elasticsearch.rar"这个压缩包中,可能包含了一个名为"elasticsearch-...
Elasticsearch是一个开源的全文搜索引擎,它在大数据分析和实时搜索领域扮演着重要角色。这款软件基于Apache Lucene构建,提供了分布式、RESTful风格的搜索和数据分析能力,广泛应用于日志分析、信息检索、网站搜索...
7. **分片(Shard)**:为了实现水平扩展,Elasticsearch将索引分割为多个分片。分片可以在集群内的不同节点上分布,使得大型数据集可以分散在多个机器上处理。 8. **副本(Replica)**:每个分片都可以有零个或多个...
1. **分布式架构**:Elasticsearch设计为分布式的,意味着它可以跨多个节点运行,并自动处理数据的分片和复制,以实现高可用性和容错性。在7.6.2版本中,它继续优化了节点间的通信和数据分布策略。 2. **RESTful ...
Elasticsearch-Head是一款强大的Elasticsearch管理工具,它提供了可视化的界面,使得用户能够方便地与Elasticsearch集群进行交互。"elasticsearch-head-5.0.0.zip"是这个工具的一个特定版本,适用于Elasticsearch的...
Go-vulcanizer支持动态更新集群设置,如分片数量、副本设置等,让这一过程变得简单且可控。 4. **查询和索引操作**:除了基础的增删改查功能,Go-vulcanizer还提供了丰富的查询选项,支持复杂的查询语句和过滤条件...
Elasticsearch是一款强大的分布式搜索和分析引擎,广泛应用于日志分析、全文检索、实时数据分析等领域。然而,作为一个命令行工具,它的操作并不直观,尤其是对于初学者而言。这时,就需要引入可视化界面来辅助管理...
- **复制与分片**:理解副本分片的概念,如何配置以提高数据冗余和可用性。 5. **Elastic Stack(ELK)** - **Logstash**:作为数据收集和预处理工具,Logstash如何与Elasticsearch配合实现日志管理和分析。 - *...
在导入过程中,可能需要调整Elasticsearch的设置,如分片数量、副本数量、映射配置等,以适应大数据量的导入,并确保查询性能。 通过以上步骤,我们可以实现从ArcGIS Shapefile到Elasticsearch的有效迁移。这样的...
Elasticsearch通过简单易用的RESTful API与外界交互,允许用户使用HTTP协议进行索引、搜索、分析等操作。这种方式使得集成到各种开发环境中变得非常便捷。 **4. 数据分析与可视化** Elasticsearch与Kibana结合,...
Elasticsearch是一个开源的全文搜索引擎,它以其高效、可扩展性以及实时分析能力而闻名。在Windows平台上,Elasticsearch提供了方便的安装包,便于在Windows操作系统上搭建和管理搜索和数据分析环境。此压缩包...
Elasticsearch是一个高度可扩展的开源全文搜索引擎,广泛应用于数据搜索、分析和实时监控场景。在Windows平台上,Elasticsearch的最新版本为8.1.1,专为64位操作系统设计。这个压缩包“elasticsearch-8.1.1-windows-...
Elasticsearch通过分片和复制机制实现了数据的分布存储,可以轻松处理大规模数据。 接着,源代码部分可能包含了如何设置和配置Elasticsearch集群的示例。这可能包括创建索引、映射字段、导入数据、搜索查询以及性能...