作者:张天雷
摘自:InfoQ
如何利用高性能分布式计算平台来解决现实问题一直是人们所关心的话题。近期,comSysto公司的Danial Bartl就分享了该公司研发团队利用Spark平台解决Kaggle竞赛问题的经历,为Spark等平台应用于数据科学领域提供了借鉴。
Danial提到,comSysto公司经常会举行一些讨论会,来评估未来的技术和共享以往的经验。在近期,大数据分析类的众包平台Kaggle的一道数据科学的挑战赛引起了他们的注意。
该挑战赛的内容十分有趣:AXA提供了一个包含5万个匿名驾驶员线路的数据集。本次竞赛的目的是根据路线研发出一个驾驶类型的算法类签名,来表征驾驶员的特征。例如,驾驶员是否长距离驾驶?短距离驾驶?高速驾驶?回头路?是否从某些站点急剧加速?是否高速转弯?所有这些问题的答案形成了表征驾驶员特征的独特标签。
面对此挑战,comSysto公司的团队想到了涵盖批处理、流数据、机器学习、图处理、SQL查询以及交互式定制分析等多种处理模型的Spark平台。他们正好以此挑战赛为契机来增强Spark方面的经验。为了对数据集进行分析并控制投入成本,他们搭建了一个包含只三个节点的集群——每个节点包含一个八核的i7处理器和16GB的内存。集群运行了携带Spark库的MR,可以有效存储运算的中间结果。接下来,本文就从数据分析、机器学习和结果等三个方面介绍comSysto团队解决以上问题的过程。
数据分析
作为解决问题的第一个步骤,数据分析起着非常关键的作用。然而,出乎comSysto公司团队意料的是,竞赛提供的原始数据非常简单。该数据集只包含了线路的若干匿名坐标对(x,y),如(1.3,4.4)、(2.1,4.8)和(2.9,5.2)等。如下图所示,驾驶员会在每条线路中出发并返回到原点(0,0),然后从原点挑选随机方向再出发,形成多个折返的路线。
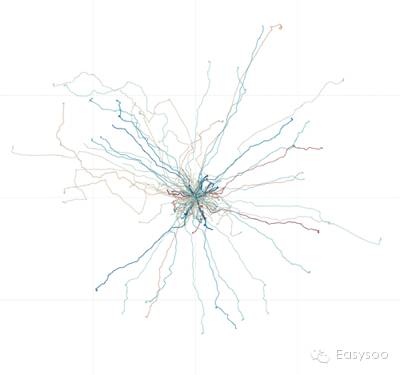
拿到数据后,comSysto公司的团队有些气馁:只看坐标很难表征一个驾驶员吧?!
信息指纹的定义
因此,在原始数据如此简单的情况,该团队面临的一个问题就是如何将坐标信息转换为有用的机器学习数据。经过认证思考,其采用了建立信息指纹库的方法,来搜集每一个驾驶员有意义和特殊的特征。为了获得信息指纹,团队首先定义了一系列特征:
其中,v为速度、r为曲线路径所形成圆的半径。半径计算需要用到当前点、之前和之后的若干个点的坐标信息。而,向心加速度是对驾驶员高速驾驶风格的体现:该值越大表明转弯的速度越快。
一个驾驶员所有线路的上述特征组成了其简历(信息指纹)。根据经验,城市道路和高速道路上的平均速度是不同的。因此,一个驾驶员在所有线路上的平均速度并没有很多意义。ecoSysto选择了城市道路、长距离高速道路和乡村道路等不同路线类型的平均速度和最大速度作为了研究对象。
数据统计:根据统计,本次竞赛的数据集中共包含了2700个驾驶员,共54000个线路的信息。所有的线路共包含3.6亿个X/Y坐标——以每秒记录一个坐标来算,共包含10万个小时的线路数据。
机器学习
在初步的数据准备和特征提取后,ecoSysto团队开始选择和测试用于预测驾驶员行为的机器学习模型。
聚类
机器学习的第一步就是把路线进行分类——ecoSysto团队选择k-means算法来对路线类型进行自动分类。这些类别根据所有驾驶员的所有路线推导得到,并不针对单个驾驶员。在拿到聚类结果后,ecoSysto团队的第一感觉就是,提取出的特征和计算得到的分类与路线长度相关。这表明,他们能够作为路线类型的一个指针。最终,根据交叉验证结果,他们选择了8种类型——每条路线指定了一种类型的ID,用于进一步分析。
预测
对于驾驶员行为预测,ecoSysto团队选择一个随机森林(random forest)算法来训练预测模型。该模型用于计算某个特定驾驶员完成给定路线的概率。首先,团队采用下述方法建立了一个训练集:选择一个驾驶员的约200条路线(标为“1”——匹配),再加随机选择的其他驾驶员的约200条路线(标为“0”——不匹配)。然后,这些数据集放入到随机森林训练算法中,产生每个驾驶员的随机森林模型。之后,该模型进行交叉验证,并最终产生Kaggle竞赛的提交数据。根据交叉验证的结果,ecoSysto团队选择了10棵树和最大深度12作为随机森林模型的参数。有关更多Spark机器学习库(MLib)中用于预测的集成学习算法的对比可参考Databrick的博客。
流水线
ecoSysto团队的工作流划分为了若干用Java应用实现的独立步骤。这些步骤可以通过“spark-submit”命令字节提交给Spark执行。流水线以Hadoop SequenceFile作为输入,以CSV文件作为输出。流水线主要包含下列步骤:

-
转换原始输入文件:将原有的55万个小的CSV文件转换为一个单独的Hadoop Sequen ceFile。
-
提取特征并计算统计数字:利用以上描述的定义计算特征值,并利用Spark RDD变换API计算平均值和方差等统计数字,写入到一个CSV文件中。
-
计算聚类结果:利用以上特征和统计值以及Spark MLlib的API来对路线进行分类。
-
随机森林训练:选取maxDepth和crossValidation等配置参数,结合每条线路的特征,开始随机森林模型的训练。对于实际Kaggle提交的数据,ecoSysto团队只是加载了串行化的模型,并预测每条线路属于驾驶员的概率,并将其以CSV格式保存在文件中。
结果
最终,ecoSysto团队的预测模型以74%的精度位列Kaggle排行榜的670位。该团队表示,对于只花2天之间就完成的模型而言,其精度尚在可接受范围内。如果再花费一定的时间,模型精度肯定可以有所改进。但是,该过程证明了高性能分布式计算平台可用于解决实际的机器学习问题。


分享到:




相关推荐
3. **Kaggle竞赛**:Kaggle是全球知名的机器学习和数据科学竞赛平台,参赛者需要利用提供的数据集,使用各种机器学习技术解决问题。在这个过程中,Spark MLlib的高效并行计算能力可以极大地提高数据处理速度,加速...
kaggle是全球知名的数据科学和机器学习竞赛平台,而天池则是阿里巴巴主办的数据科学竞赛平台,它们都提供了丰富的数据集和实战机会,有助于提升面试者的实战经验和解决问题的能力。 "海量数据中位数"是指在大数据...
Kaggle是一个全球知名的平台,汇聚了数据科学家和机器学习工程师,参与各种数据预测挑战。这些比赛通常涉及实际问题,如疾病诊断、图像识别、市场预测等。通过参加Kaggle比赛,不仅可以检验自己的模型性能,还能与...
标题 "Kaggle比赛日本股市数据" 涉及的是一个数据科学竞赛,该竞赛源自Kaggle平台,目标是对日本股市进行预测。这通常涉及到金融市场的数据分析、时间序列预测和机器学习技术。 描述中提到的"stock_prices.csv"是一...
【Kaggle十大案例精讲视频教程】是一套专注于数据科学实战的学习资源,旨在通过剖析Kaggle...通过这个教程,你可以不仅提升自己的编程能力,还能深入了解如何运用这些技术解决实际问题,提升你在数据科学领域的竞争力。
总的来说,PySpark 结合了 Spark 的高性能计算能力和 Python 的易用性,为数据科学家和工程师提供了高效处理大数据的强大工具。通过熟练掌握 PySpark,不仅可以加速数据处理流程,还能实现复杂的机器学习模型和数据...
随着人工智能技术的不断发展,数据科学家的角色变得越来越关键,他们利用机器学习算法来解决复杂问题,优化物流流程,提高效率。本项目通过对美国数据科学就业市场的深入分析,揭示了这个领域的就业趋势、人才需求...
标题中的“Sparkaggle_1”表明这是一个与Apache Spark相关的项目,主要目的是参与Kaggle竞赛,这是一项数据科学和机器学习领域的国际性比赛。Kaggle挑战通常涉及预测、分类或其他数据分析任务,参赛者使用自己的算法...
Outbrain点击率预估是Kaggle上一个著名的数据科学竞赛,主要目标是预测用户在Outbrain平台看到的推荐内容中是否会点击某个广告。这个竞赛不仅考验参赛者对机器学习模型的理解,还要求掌握大量的数据处理技巧。我们将...
找寻项目实践是提升技能的重要途径,可以尝试解决实际的安全问题。最后,掌握大数据处理技术,如Spark、Hadoop和Storm,以应对大规模的数据分析需求。 通过以上学习路径,你可以逐步建立起在安全数据科学领域的专业...
在数据科学与大数据技术相关的竞赛项目中,参与者可以通过实际问题锻炼技能,如Kaggle竞赛,涉及机器学习、数据可视化等多个方向。开源项目如GitHub上的各种数据分析项目,提供了丰富的学习资源和参与机会。 近3年...
在IT行业中,中风预测是一项重要的医疗数据分析任务,它涉及到机器学习、大数据处理以及人工智能等多个领域。...总之,"中风预测"项目结合了医学知识、数据科学和软件工程,旨在通过先进的信息技术改善公众健康。
例如,Kaggle是一个知名的数据科学竞赛平台,提供多种领域的公开数据集,适合进行机器学习模型的训练和比较。UCI Machine Learning Repository也是一个宝贵的资源库,包含大量用于教学和研究的小型数据集。 对于...
不断更新的数据科学Python笔记:深度学习(TensorFlow, Theano, Caffe), scikit-learn, Kaggle,大数据库(Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python 精粹 以及各种命令行技巧。
- `Python Exercises`:数据科学中Python是最常用的编程语言,可能包含使用Pandas、NumPy和Matplotlib等库解决实际问题的练习。 - `R Scripts`:R语言是另一个数据科学领域常用的语言,可能有使用R进行数据分析和...
在大数据领域,竞赛项目是提升技能和实践经验的重要途径。这些竞赛涵盖了Kaggle、阿里天池大数据、腾讯大数据、京东大数据以及DataCastle等知名平台,为...在实践中不断学习和迭代,是成为数据科学领域专家的必经之路。
Kaggle是数据科学竞赛的平台,它提供了丰富的数据集和问题,让参与者用各种技术,包括SQL,来解决问题并展示其分析能力。通过这种方式,你不仅可以检验自己的学习成果,还能积累实战经验,提升简历的含金量。 这个...
Kaggle是一个知名的竞赛平台,它聚集了全球的数据科学家和机器学习专家,以解决各种实际问题。在这个"Kaggle-Telematics"项目中,我们可以看到参与者们如何运用他们的技能来分析这些数据,从而提供有价值的洞察。 ...