
ÁģÄšĽč
FacebookÁöĄśēįśćģšĽďŚļďŚ≠ėŚā®Śú®ŚįϝᏌ§ßŚěčHadoop/HDFSťõÜÁ姄ÄāHiveśėĮFacebookŚú®Śá†ŚĻīŚČćšłďšłļHadoopśČďťÄ†ÁöĄšłÄś¨ĺśēįśćģšĽďŚļďŚ∑•ŚÖ∑„ÄāŚú®šĽ•ŚČćÔľĆFacebookÁöĄÁßĎŚ≠¶Śģ∂ŚíĆŚąÜśěźŚłąšłÄÁõīšĺ̝̆HiveśĚ•ŚĀöśēįśćģŚąÜśěź„ÄāšĹÜHivešĹŅÁĒ®MapReducešĹúšłļŚļēŚĪāŤģ°Áģóś°Üśě∂ԾƜėĮšłďšłļśČĻŚ§ĄÁźÜŤģĺŤģ°ÁöĄ„ÄāšĹÜťöŹÁĚÄśēįśćģŤ∂äśĚ•Ť∂䌧öԾƚĹŅÁĒ®HiveŤŅõŤ°ĆšłÄšł™ÁģÄŚćēÁöĄśēįśćģśü•ŤĮĘŚŹĮŤÉĹŤ¶ĀŤäĪŤīĻŚá†ŚąÜŚąįŚá†ŚįŹśó∂ԾƜėĺÁĄ∂šłćŤÉĹśĽ°Ť∂≥šļ§šļ팾Źśü•ŤĮĘÁöĄťúÄśĪā„ÄāFacebookšĻüŤįÉÁ†ĒšļÜŚÖ∂šĽĖśĮĒHiveśõīŚŅęÁöĄŚ∑•ŚÖ∑ԾƚĹÜŚģÉšĽ¨Ť¶ĀšĻąŚú®ŚäüŤÉĹśúČśČÄťôźŚą∂Ť¶ĀšĻąŚįĪŚ§™ÁģÄŚćēԾƚĽ•Ťá≥šļéśó†ś≥ēśďćšĹúFacebookŚļ쌧ßÁöĄśēįśćģšĽďŚļď„Äā
2012ŚĻīŚľÄŚßčŤĮēÁĒ®ÁöĄšłÄšļõŚ§ĖťÉ®ť°ĻÁõģťÉĹšłćŚźąťÄāԾƚĽĖšĽ¨ŚÜ≥ŚģöŤá™Ś∑ĪŚľÄŚŹĎԾƍŅôŚįĪśėĮPresto„Äā2012ŚĻīÁßčŚ≠£ŚľÄŚß茾ČŹĎÔľĆÁõģŚČćŤĮ•ť°ĻÁõģŚ∑≤ÁĽŹŚú®Ť∂ÖŤŅá 1000ŚźćFacebookťõáŚĎėšł≠šĹŅÁĒ®ÔľĆŤŅźŤ°ĆŤ∂ÖŤŅá30000šł™śü•ŤĮĘԾƜĮŹśó•śēįśćģŚú®1PBÁļߌąę„ÄāFacebookÁßįPrestoÁöĄśÄߍÉĹśĮĒHiveŤ¶ĀŚ•Ĺšłä10ŚÄ挧ö„Äā2013ŚĻīFacebookś≠£ŚľŹŚģ£ŚłÉŚľÄśļźPresto„Äā
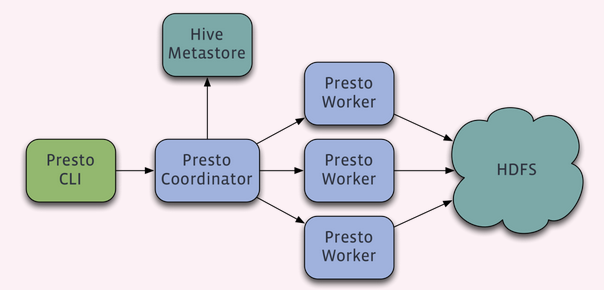
Prestośü•ŤĮĘŚľēśďéśėĮšłÄšł™Master-SlaveÁöĄśě∂śěĄÔľĆÁĒĪšłÄšł™CoordinatorŤäāÁāĻԾƚłÄšł™Discovery ServerŤäāÁāĻԾƌ§öšł™WorkerŤäāÁāĻÁĽĄśąźÔľĆDiscovery ServerťÄöŚłłŚÜÖŚĶĆšļéCoordinatorŤäāÁāĻšł≠„ÄāCoordinatorŤīüŤī£Ťß£śěźSQLŤĮ≠ŚŹ•ÔľĆÁĒüśąźśČߍ°ĆŤģ°ŚąíԾƌąÜŚŹĎśČߍ°ĆšĽĽŚä°ÁĽôWorkerŤäāÁāĻśČߍ°Ć„ÄāWorkerŤäāÁāĻŤīüŤī£ŚģěťôÖśČߍ°Ćśü•ŤĮĘšĽĽŚä°„ÄāWorkerŤäāÁāĻŚźĮŚä®ŚźéŚźĎDiscovery ServerśúćŚä°ś≥®ŚÜĆÔľĆCoordinatoršĽéDiscovery ServerŤé∑ŚĺóŚŹĮšĽ•ś≠£ŚłłŚ∑•šĹúÁöĄWorkerŤäāÁāĻ„ÄāŚ¶āśěúťÖćÁĹģšļÜHive ConnectorԾƝúÄŤ¶ĀťÖćÁĹģšłÄšł™Hive MetaStoreśúćŚä°šłļPrestośŹźšĺõHiveŚÖÉšŅ°śĀĮÔľĆWorkerŤäāÁāĻšłéHDFSšļ§šļíŤĮĽŚŹĖśēįśćģ„Äā
*ÁČĻÁāĻ
- ŚģĆŚÖ®ŚüļšļéŚÜÖŚ≠ėÁöĄŚĻ∂Ť°ĆŤģ°Áģó
- śĶĀśįīÁļŅ
- śú¨ŚúįŚĆĖŤģ°Áģó
- Śä®śÄĀÁľĖŤĮĎśČߍ°ĆŤģ°Śąí
- ŚįŹŚŅÉšĹŅÁĒ®ŚÜÖŚ≠ėŚíĆśēįśćģÁĽďśěĄ
- ÁĪĽBlinkDBÁöĄŤŅĎšľľśü•ŤĮĘ
- GCśéߌą∂
*śŹźšļ§śü•ŤĮĘ
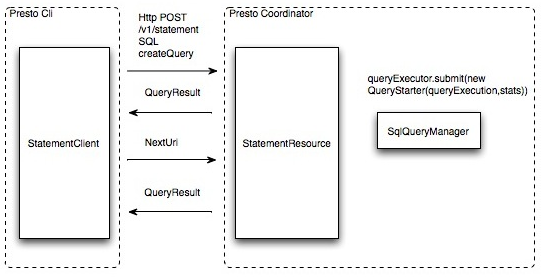
ÁĒ®śą∑šĹŅÁĒ®Presto CliśŹźšļ§šłÄšł™śü•ŤĮĘŤĮ≠ŚŹ•ŚźéÔľĆClišĹŅÁĒ®HTTPŚćŹŤģģšłéCoordinatorťÄöšŅ°ÔľĆCoordinatorśĒ∂Śąįśü•ŤĮĘŤĮ∑śĪāŚźéŤįÉÁĒ®SqlParserŤß£śěźSQLŤĮ≠ŚŹ•ŚĺóŚąįStatementŚĮĻŤĪ°ÔľĆŚĻ∂ŚįÜStatementŚįĀŤ£ÖśąźšłÄšł™QueryStarterŚĮĻŤĪ°śĒĺŚÖ•ÁļŅÁ®čśĪ†šł≠Á≠ČŚĺÖśČߍ°Ć„Äā
ÁéĮŚĘÉŤ¶ĀśĪā
Śüļśú¨Ť¶ĀśĪā:
- Linux or Mac OS X
- Java 8, 64-bit
- Python 2.4+
HADOOP / HIVE
Presto supports reading Hive data from the following versions of Hadoop:
- Apache Hadoop 1.x
- Apache Hadoop 2.x
- Cloudera CDH 4
- Cloudera CDH 5
- The following file formats are supported: Text, SequenceFile, RCFile, ORC
Additionally, a remote Hive metastore is required. Local or embedded mode is not supported. Presto does not use MapReduce and thus only requires HDFS.
CASSANDRA
Cassandra 2.x is required. This connector is completely independent of the Hive connector and only requires an existing Cassandra installation.
TPC-H
The TPC-H connector dynamically generates data that can be used for experiementing with and testing Presto. This connector has no external requirements.
Deployment
šłÄ„ÄĀŚģČŤ£ÖŚíƝɮÁĹ≤Presto
1„ÄĀŚģČŤ£ÖÁéĮŚĘÉ
1
|
# śďćšĹúÁ≥ĽÁĽü
CentOS release 6.5 (Final)
2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
# HadoopÁČąśú¨
Hadoop 2.4.0
# hiveÁČąśú¨
hive-0.13.1
#XXkÁČąśú¨
java version "1.8.0_45"
export PATH=.:$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
|
2„ÄĀprestośě∂śěĄ
šłäŚõ匏ĮšĽ•Áú茹įԾƝúÄŤ¶ĀšĺĚŤĶĖhivemetastorśúćŚä°ÔľĆŤģŅťóģhiveťáĆťĚĘÁöĄŤ°®ÔľĀśČÄšĽ•šłÄŚģöťúÄŤ¶ĀŚģČŤ£ÖhiveŚĻ∂šłĒŚźĮŚä®hivemetasotreśúćŚä°ÔľĀ
3„ÄĀŚģČŤ£Öpresto
1
|
https://prestodb.io/docs/current/installation.html
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.100/presto-server-0.100.tar.gz
#Ťß£Śéč
tar -zxvf presto-server-0.100.tar.gz
#ŚąõŚĽļŤĹĮŤŅěśé•
ln -s presto-server-0.100 presto
#Ťß£Śé茟éÁõģŚĹē
[root@itr-mastertest01 presto]# tree -L 2
.
|-- NOTICE
|-- README.txt
|-- bin
| |-- launcher
| |-- launcher.properties
| |-- launcher.py
| `-- procname
|-- lib
| |-- aether-api-1.13.1.jar
| |-- ………
`-- plugin
|-- cassandra
|-- example-http
|-- hive-cdh4
|-- hive-cdh5
|-- hive-hadoop1
|-- hive-hadoop2
|-- kafka
|-- ml
|-- mysql
|-- postgresql
|-- raptor
`-- tpch
Pluginšł≠ŚŹĮšĽ•Áú茹įśĒĮśĆĀhadoop1,hadoop2,cdh5,cdh4ŤŅôšļõśŹíšĽ∂ԾƚłčťĚĘśąĎšĽ¨ÁĒ®ŚąįÁöĄśėĮhive-hadoop2
|
4. ťÖćÁĹģ Presto
1
|
Śú®presto-server-0.100ťáĆťĚĘŚąõŚĽļetcÁõģŚĹēԾƌĻ∂ŚąõŚĽļšĽ•šłčśĖᚼ∂Ôľö
node.propertiesÔľöśĮŹšł™ŤäāÁāĻÁöĄÁéĮŚĘÉťÖćÁĹģ
jvm.configÔľöjvm ŚŹāśēį
config.propertiesÔľöťÖćÁĹģ Presto Server ŚŹāśēį
log.propertiesÔľöťÖćÁĹģśó•ŚŅóÁ≠ČÁļß
Catalog PropertiesÔľöCatalog ÁöĄťÖćÁĹģ
|
(1).etc/node.properties Á§ļšĺčťÖćÁĹģŚ¶āšłč
1
|
node.environment=production
node.id=5b47019c-a05c-42a5-9f9c-f17dbe27b42a #ŤŅôšł™ŚÄľŚŅÖť°ĽśėĮŚĒĮšłÄÁöĄ
node.data-dir=/usr/local/presto/data
ŚŹāśēįŤĮīśėéÔľö
node.environmentÔľöÁéĮŚĘÉŚźćÁßį„ÄāšłÄšł™ťõÜÁ姍äāÁāĻšł≠ÁöĄśČÄśúČŤäāÁāĻÁöĄŚźćÁßįŚļĒŤĮ•šŅĚśĆĀšłÄŤáī„Äā
node.idÔľöŤäāÁāĻŚĒĮšłÄś†áŤĮÜÁöĄŚźćÁßį„ÄāŤŅôťáĆšĹŅÁĒ®uuidgenÁĒüśąź„Äā
node.data-dirÔľöśēįśćģŚíĆśó•ŚŅóŚ≠ėśĒĺŤ∑ĮŚĺĄ„Äā
|
(2).etc/jvm.config Á§ļšĺčťÖćÁĹģŚ¶āšłč
1
|
-server
-Xmx16G
-XX:+UseConcMarkSweepGC
-XX:+ExplicitGCInvokesConcurrent
-XX:+CMSClassUnloadingEnabled
-XX:+AggressiveOpts
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill -9 %p
-XX:ReservedCodeCacheSize=150M
#-Xbootclasspath/p:/home/hsu/presto/lib/floatingdecimal-0.1.jar,1.7śČďpatch,1.8šłćŚú®ťúÄŤ¶ĀÔľĀ
-Djava.library.path=/opt/cloudera/parcels/CDH-5.2.0-1.cdh5.2.0.p0.36/lib/hadoop-0.20-mapreduce/lib/native/Linux-amd64-64
ťúÄŤ¶Āś≥®śĄŹÁöĄśėĮśúÄŚźéšł§Ť°ĆÔľö
/usr/local/presto/Linux-amd64-64ÔľöŤŅôśėĮšłļšļÜŚú®Prestošł≠śĒĮśĆĀLZO
|
(3).etc/config.properties
1
|
etc/config.propertiesŚĆÖŚźę Presto Server ÁõłŚÖ≥ÁöĄťÖćÁĹģԾƜĮŹšłÄšł™ Presto Server ŚŹĮšĽ•ŚźĆśó∂šĹúšłļ coordinator ŚíĆ worker šĹŅÁĒ®„ÄāšĹ†ŚŹĮšĽ•ŚįÜšĽĖšĽ¨ťÖćÁĹģŚú®šłÄšł™ŤäāÁāĻšłäԾƚĹÜśėĮԾƌú®šłÄšł™Ś§ßÁöĄťõÜÁ姚łäŚĽļŤģģŚąÜŚľÄťÖćÁĹģšĽ•śŹźťęėśÄߍÉĹ„Äā
coordinator ÁöĄśúÄŚįŹťÖćÁĹģÔľö
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=9090
task.max-memory=1GB
discovery-server.enabled=true
discovery.uri= http://itr-mastertest01:9090
worker ÁöĄśúÄŚįŹťÖćÁĹģÔľö
coordinator=false
http-server.http.port=9090
task.max-memory=1GB
discovery.uri= http://itr-mastertest01:9090
ŚŹĮťÄČÁöĄÔľĆšĹúšłļśĶčŤĮēԾƚņŚŹĮšĽ•Śú®šłÄšł™ŤäāÁāĻšłäŚźĆśó∂ťÖćÁĹģšł§ŤÄÖÔľö
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=9090
task.max-memory=1GB
discovery-server.enabled=true
discovery.uri=http://itr-mastertest01:9090
ŚŹāśēįŤĮīśėéÔľö
coordinatorÔľöPresto ŚģěšĺčśėĮŚź¶šĽ• coordinator ŚĮĻŚ§ĖśŹźšĺõśúćŚä°
node-scheduler.include-coordinatorÔľöśėĮŚź¶ŚÖĀŤģłŚú® coordinator šłäŤŅõŤ°ĆŤįÉŚļ¶šĽĽŚä°
http-server.http.portÔľöHTTP śúćŚä°ÁöĄÁęĮŚŹ£
task.max-memory=1GBÔľöśĮŹšłÄšł™šĽĽŚä°ÔľąŚĮĻŚļĒšłÄšł™ŤäāÁāĻšłäÁöĄšłÄšł™śü•ŤĮĘŤģ°ŚąíԾȜČÄŤÉĹšĹŅÁĒ®ÁöĄśúÄŚ§ßŚÜÖŚ≠ė
discovery-server.enabledÔľöśėĮŚź¶šĹŅÁĒ® Discovery service ŚŹĎÁéįťõÜÁ姚ł≠ÁöĄśĮŹšłÄšł™ŤäāÁāĻ„Äā
discovery.uriÔľöDiscovery server ÁöĄ url
|
(4).etc/log.properties
1
|
etc/log.properties ŚŹĮšĽ•ŤģĺÁĹģśüźšłÄšł™ java ŚĆÖÁöĄśó•ŚŅóÁ≠ČÁļßÔľö
com.facebook.presto=INFO
ŚÖ≥šļé Catalog ÁöĄťÖćÁĹģԾƝ¶ĖŚÖąťúÄŤ¶ĀŚąõŚĽļ etc/catalog ÁõģŚĹēÔľĆÁĄ∂Śźéś†ĻśćģšĹ†śÉ≥šĹŅÁĒ®ÁöĄŤŅěśé•Śô®śĚ•ŚąõŚĽļŚĮĻŚļĒÁöĄťÖćÁĹģśĖᚼ∂ԾƜĮĒŚ¶āԾƚņśÉ≥šĹŅÁĒ® jmx ŤŅěśé•Śô®ÔľĆŚąôŚąõŚĽļ jmx.propertiesÔľö
connector.name=jmx
Ś¶āśěúšĹ†śÉ≥šĹŅÁĒ® hive ÁöĄŤŅěśé•Śô®ÔľĆŚąôŚąõŚĽļ hive.propertiesÔľö
connector.name=hive-hadoop2
hive.metastore.uri=thrift://itr-mastertest02:9083 #šŅģśĒĻšłļ hive-metastore śúćŚä°śČÄŚú®ÁöĄšłĽśúļŚźćÁßįԾƍŅôťáĆśąĎśėĮŚģČŤ£ÖŚú® itr-mastertest02ŤäāÁāĻ
hive.config.resources=/usr/local/hadoop-2.4.0/etc/hadoop/core-site.xml, /usr/local/hadoop-2.4.0/etc/hadoop/hdfs-site.xml
hive.allow-drop-table=true #ŚÖĀŤģłŚą†ťô§hiveŤ°®
śõīŚ§öŚÖ≥šļéŤŅěśé•Śô®ÁöĄŤĮīśėéԾƍĮ∑ŚŹāŤÄÉ http://prestodb.io/docs/current/connector.html„Äā
ťÄöŤŅᚼ•šłäÁöĄŚõõś≠•ÔľĆCoordinatorŚ∑≤ÁĽŹŤģĺÁĹģŚģĆśĮē„Äā
|
(5).ťÖćÁĹģworkerŤäāÁāĻ
1
|
śČÄśúČÁöĄťÖćÁĹģÁöĄÁõģŚĹēÁĽďśěĄťÉĹśėĮšłÄś†∑ÁöĄÔľĆŚŹ™ťúÄŤ¶ĀšŅģśĒĻšłäŤŅįÁöĄšł§šł™śĖᚼ∂ŚįĪŚŹĮšĽ•ŤĺĺśąźWorkersšłäÁöĄÁĽüšłÄťÖćÁĹģÔľö
scp -rq presto* itr-node0x:/usr/local/
šŅģśĒĻÁ¨¨šłÄšł™śĖᚼ∂Ôľöconfig.propertiesÔľö
coordinator=false
http-server.http.port=9090
task.max-memory=1GB
discovery.uri=http://itr-mastertest01:9090
śąĎšĽ¨Áú茹įԾƚĹúšłļWorkerŤäāÁāĻԾƌ∑≤ÁĽŹŚįÜcoordinatorÁ¶ĀÁĒ®śéČÔľöcoordinator=falseÔľõ
PrestoServerÁöĄÁõĎŚź¨ŚúįŚĚÄԾƍŅėśėĮ9090ÁęĮŚŹ£Ôľõ
ŚćēšĽĽŚä°ŚÜÖŚ≠ėśēįŤŅėśėĮ1GBÔľõ
śĆጟϜąĎšĽ¨ÁöĄDiscoveryServerÔľödiscovery.uri= http://itr-mastertest01:9090
šŅģśĒĻÁ¨¨šļĆšł™śĖᚼ∂Ôľönode.properties
node.environment=production
node.id=c0550bd7-fcc2-407d-bfda-b1f26fb341b0
node.data-dir=/usr/local/presto/data
ťô§šļÜnode.idÁöĄťÖćÁĹģšŅģśĒĻŚ§ĖԾƌÖ∂ŚģÉťÉĹšŅĚśĆĀšłÄŤáīŚć≥ŚŹĮԾƍŅôšł™IDťúÄŤ¶ĀśĮŹšł™ŤäāÁāĻťÉĹšłćŚźĆԾƜČÄšĽ•ÔľĆŤŅôšł™šłćŤÉĹÁģÄŚćēÁöĄśč∑ŤīĚŚąįŚÖ∂ŚģÉWorkerŤäāÁāĻšłäԾƍÄĆŤ¶ĀŚú®śĮŹšł™ŤäāÁāĻšłäťÉĹšŅģśĒĻśąźšłÄšł™Á訚łÄśó†šļĆÁöĄŚÄľÔľĆśąĎŤŅôťáĆśėĮťÄöŤŅáuuidgenŤŅôšł™ŚĎĹšĽ§śĚ•ÁĒüśąźÁöĄŤŅôšł™šł≤„Äā
|
(6). ś∑ĽŚä†ŚĮĻLZOÁöĄśĒĮśĆĀ
1
|
1. śąĎšĽ¨ťúÄŤ¶ĀŚú®śĮŹšł™PrestoŤäāÁāĻšłäÁöĄŚĮĻŚļĒÁöĄśŹíšĽ∂ÁõģŚĹēšłčԾƜĒĺÁĹģhadoop-lzo.jarśĖᚼ∂ԾƚĽ•šĹŅŚÖ∂ŤŅźŤ°Ćśó∂ŚŹĮšĽ•Śä†ŤĹĹŚąįÁõłŚÖ≥ÁĪĽÔľö
cd /usr/local/presto/plugin/hive-hadoop2
scp -r hadoop-lzo.jar itr-node0x:/usr/local/presto/plugin/hive-hadoop
2. JVMŚźĮŚä®ŚŹāśēįšł≠ԾƜ∑ĽŚä†Ś¶āšłčŚŹāśēįÔľö
-Djava.library.path=/usr/local/presto/Linux-amd64-64
ŤŅôś†∑ÔľĆHDFSšł≠ÁöĄLZOśĖᚼ∂ŚįĪŚŹĮšĽ•ś≠£ŚłłŤģŅťóģŚąįšļÜ„Äā
|
(7). ŚÖ≥šļéśÄߍÉĹÁöĄšłÄšļõśĶčŤĮēÁĽŹť™Ć
1
|
Ś¶āśěúšłćÁ¶Āś≠ĘCoordinatoršłäŤŅźŤ°ĆšĽĽŚä°Ôľąnode-scheduler.include-coordinator=falseÔľČԾƝā£šĻąśÄߍÉĹÁöĄťôćšĹéšĻüťĚ쌳łśėéśėĺ„Äā
node-scheduler.include-coordinatorÔľöśėĮŚź¶ŚÖĀŤģłŚú®coordinatorśúćŚä°šł≠ŤŅõŤ°ĆŤįÉŚļ¶Ś∑•šĹú„ÄāŚĮĻšļ錧ߌěčÁöĄťõÜÁĺ§ÔľĆŚú®šłÄšł™ŤäāÁāĻšłäÁöĄPresto serverŚć≥šĹúšłļcoordinatorŚŹąšĹúšłļworkeŚįÜšľöťôćšĹéśü•ŤĮĘśÄߍÉĹ„ÄāŚõ†šłļŚ¶āśěúšłÄšł™śúćŚä°Śô®šĹúšłļworkeršĹŅÁĒ®ÔľĆťā£šĻąŚ§ßťÉ®ŚąÜÁöĄŤĶĄśļźťÉĹšłćšľöŤĘęworkerŚć†ÁĒ®ÔľĆťā£šĻąŚįĪšłćšľöśúČŤ∂≥Ś§üÁöĄŤĶĄśļźŤŅõŤ°ĆŚÖ≥ťĒģšĽĽŚä°ŤįÉŚļ¶„ÄĀÁģ°ÁźÜŚíĆÁõĎśéßśü•ŤĮĘśČߍ°Ć„Äā
|
5„ÄĀŤŅěśé•Śô®ťÖćÁĹģ
5.1 prestośĒĮśĆĀÁöĄŤŅěśé•Śô®
- (1). Black Hole Connector
- (2). Cassandra Connector
- (3)·. Hive Connector
- (4). JMX Connector
- (5). Kafka Connector
- (6). Kafka Connector Tutorial
- (7). MySQL Connector
- (8). PostgreSQL Connector
- (9). System Connector
- (10). TPCH Connector
5.2 hive
1
|
ŚÖ≥šļé Catalog ÁöĄťÖćÁĹģԾƝ¶ĖŚÖąťúÄŤ¶ĀŚąõŚĽļ etc/catalog ÁõģŚĹēÔľĆÁĄ∂Śźéś†ĻśćģšĹ†śÉ≥šĹŅÁĒ®ÁöĄŤŅěśé•Śô®śĚ•ŚąõŚĽļŚĮĻŚļĒÁöĄťÖćÁĹģśĖᚼ∂ԾƜĮĒŚ¶āԾƚņśÉ≥šĹŅÁĒ® jmx ŤŅěśé•Śô®ÔľĆŚąôŚąõŚĽļ jmx.propertiesÔľö
connector.name=jmx
Ś¶āśěúšĹ†śÉ≥šĹŅÁĒ® hive ÁöĄŤŅěśé•Śô®ÔľĆŚąôŚąõŚĽļ hive.propertiesÔľö
connector.name=hive-hadoop2
hive.metastore.uri=thrift://itr-mastertest02:9083 #šŅģśĒĻšłļ hive-metastore śúćŚä°śČÄŚú®ÁöĄšłĽśúļŚźćÁßįԾƍŅôťáĆśąĎśėĮŚģČŤ£ÖŚú® itr-mastertest02ŤäāÁāĻ
hive.config.resources=/usr/local/hadoop-2.4.0/etc/hadoop/core-site.xml, /usr/local/hadoop-2.4.0/etc/hadoop/hdfs-site.xml
hive.allow-drop-table=true #ŚÖĀŤģłŚą†ťô§hiveŤ°®
śõīŚ§öŚÖ≥šļéŤŅěśé•Śô®ÁöĄŤĮīśėéԾƍĮ∑ŚŹāŤÄÉ http://prestodb.io/docs/current/connector.html„Äā
|
5.3 mysql
1
|
$ cat mysql.properties
connector.name=mysql
connection-url=XXbc:mysql://localhost:3306
connection-user=root
connection-password=admin
$ /home/hsu/presto/bin/presto-cli --server serv01:9090 --catalog mysql --schema mysql;
presto:mysql> SHOW TABLES FROM mysql.hive;
presto:default> SHOW SCHEMAS;
presto:default> use hive;
presto:hive> show tables;
$ /home/hsu/presto-server-0.103/bin/presto-cli --server serv01:9090 --catalog mysql --schema airpal
presto:default> SHOW SCHEMAS;
Schema
--------------------
airpal
presto:default> show catalogs;
Catalog
---------
hive
system
jmx
mysql
(4 rows)
Ś¶āśěúťĀጹįśü•Áúčmysqlśēįśćģ
presto:airpal> select * from jobs;
Query 20150521_062342_00051_ueeai failed: No nodes available to run query
1„ÄĀś£Äśü•mysqlśėĮŚź¶Śú®prestoÁöĄšłĽŤäāÁāĻ
2„ÄĀś£Äśü•šłĽŤäāÁāĻťÖćÁĹģśĖᚼ∂cat config.propertiesśėĮŚź¶ťÖćÁĹģnode-scheduler.include-coordinator=falseԾƜČČć≥ŚŹĮŤß£ŚÜ≥
3„ÄĀÁ¶Āś≠ĘšļÜšłĽŤäāÁāĻworkerԾƝā£ŚįĪśó†ś≥ēŤĮĽŚŹĖŚąįmysqlśēįśćģÔľĀ
#ŚÜôśēįśćģmysqlŚąįhive
presto:default> show catalogs;
Catalog
---------
hive
system
jmx
tpch
mysql
(5 rows)
presto:default> create table hive.default.jobs as select * from mysql.airpal.jobs;
CREATE TABLE: 10 rows
Query 20150521_083025_00038_z2qr2, FINISHED, 2 nodes
Splits: 3 total, 3 done (100.00%)
0:03 [10 rows, 0B] [3 rows/s, 0B/s]
presto:default> select count(1) from jobs;
_col0
-------
10
(1 row)
|
5.4 kafka
ŤŅôťáĆšłĽŤ¶ĀŚŹāŤÄÉŚģėÁĹĎŚģěÁéįÔľöhttps://prestodb.io/docs/current/connector/kafka-tutorial.html
Step 1: Install Apache Kafka
1
|
ŚŹāŤÄÉkafkaŚģČŤ£ÖśĖáś°£
|
 
Step 2: Make the Kafka topics known to Presto
1
|
$ cat kafka.properties
connector.name=kafka
kafka.nodes=serv01:9092,serv02:9092,serv03:9092,serv04:9092,serv04:9092,serv06:9092,serv07:9092,serv08:9092,serv09:9092,serv10:9092
kafka.table-names=tpch.customer,tpch.orders,tpch.lineitem,tpch.part,tpch.partsupp,tpch.supplier,tpch.nation,tpch.region
kafka.hide-internal-columns=false
#ťúÄŤ¶Āťá挟ĮťõÜÁĺ§
|
 
Step 3: Load data
1
|
http://prestodb-china.com/docs/current/connector/kafka-tutorial.html
$ curl -o kafka-tpch https://repo1.maven.org/maven2/de/softwareforge/kafka_tpch_0811/1.0/kafka_tpch_0811-1.0.sh
$ mv kafka_tpch_0811-1.0.sh kafka_tpch
$ chmod 775 kafka_tpch
$ ./kafka_tpch load --brokers serv01:9092 --prefix tpch. --tpch-type tiny
|
 
Step 4: Basic data querying
1
|
$ ../bin/presto-cli --server serv01:9090 --catalog kafka --schema tpch
presto:tpch> show tables;
Table
----------
customer
lineitem
nation
orders
part
partsupp
region
supplier
(8 rows)
presto:tpch> DESCRIBE customer;
Column | Type | Null | Partition Key | Comment
-------------------+---------+------+---------------+---------------------------------------------
_partition_id | bigint | true | false | Partition Id
_partition_offset | bigint | true | false | Offset for the message within the partition
_segment_start | bigint | true | false | Segment start offset
_segment_end | bigint | true | false | Segment end offset
_segment_count | bigint | true | false | Running message count per segment
_key | varchar | true | false | Key text
_key_corrupt | boolean | true | false | Key data is corrupt
_key_length | bigint | true | false | Total number of key bytes
_message | varchar | true | false | Message text
_message_corrupt | boolean | true | false | Message data is corrupt
_message_length | bigint | true | false | Total number of message bytes
(11 rows)
presto:tpch> SELECT _message FROM customer LIMIT 2;
{"rowNumber":1,"customerKey":1,"name":"Customer#000000001","address":"IVhzIApeRb ot,c,E","nationKey":15,"phone":"25-989-741-2988","accountBalance":711.56,"marketSegment":"BUILDING","comment":"to the even, regular platelets. regular, ironic epitaphs nag e"}
{"rowNumber":3,"customerKey":3,"name":"Customer#000000003","address":"MG9kdTD2WBHm","nationKey":1,"phone":"11-719-748-3364","accountBalance":7498.12,"marketSegment":"AUTOMOBILE","comment":" deposits eat slyly ironic, even instructions. express foxes detect slyly. blithel
{"rowNumber":5,"customerKey":5,"name":"Customer#000000005","address":"KvpyuHCplrB84WgAiGV6sYpZq7Tj","nationKey":3,"phone":"13-750-942-6364","accountBalance":794.47,"marketSegment":"HOUSEHOLD","comment":"n accounts will have to unwind. foxes cajole accor"}
{"rowNumber":7,"customerKey":7,"name":"Customer#000000007","address":"TcGe5gaZNgVePxU5kRrvXBfkasDTea","nationKey":18,"phone":"28-190-982-9759","accountBalance":9561.95,"marketSegment":"AUTOMOBILE","comment":"ainst the ironic, express theodolites. express, even pinto bean
{"rowNumber":9,"customerKey":9,"name":"Customer#000000009","address":"xKiAFTjUsCuxfeleNqefumTrjS","nationKey":8,"phone":"18-338-906-3675","accountBalance":8324.07,"marketSegment":"FURNITURE","comment":"r theodolites according to the requests wake thinly excuses: pending‚ÄĚ}
presto:tpch> SELECT sum(cast(json_extract_scalar(_message, '$.accountBalance') AS double)) FROM customer LIMIT 10;
_col0
-------------------
6681865.590000002
|
 
Step 5: Add a topic decription file
1
|
etc/kafka/tpch.customer.json
$ cat tpch.customer.json
{
"tableName": "customer",
"schemaName": "tpch",
"topicName": "tpch.customer",
"key": {
"dataFormat": "raw",
"fields": [
{
"name": "kafka_key",
"dataFormat": "LONG",
"type": "BIGINT",
"hidden": "false"
}
]
},
"message": {
"dataFormat": "json",
"fields": [
{
"name": "row_number",
"mapping": "rowNumber",
"type": "BIGINT"
},
{
"name": "customer_key",
"mapping": "customerKey",
"type": "BIGINT"
},
{
"name": "name",
"mapping": "name",
"type": "VARCHAR"
},
{
"name": "address",
"mapping": "address",
"type": "VARCHAR"
},
{
"name": "nation_key",
"mapping": "nationKey",
"type": "BIGINT"
},
{
"name": "phone",
"mapping": "phone",
"type": "VARCHAR"
},
{
"name": "account_balance",
"mapping": "accountBalance",
"type": "DOUBLE"
},
{
"name": "market_segment",
"mapping": "marketSegment",
"type": "VARCHAR"
},
{
"name": "comment",
"mapping": "comment",
"type": "VARCHAR"
}
]
}
}
$ ťá挟ĮťõÜÁĺ§
$ presto/bin/presto-cli --server serv01:9090 --catalog kafka --schema tpch
presto:tpch> DESCRIBE customer;
Column | Type | Null | Partition Key | Comment
-------------------+---------+------+---------------+---------------------------------------------
kafka_key | bigint | true | false |
row_number | bigint | true | false |
customer_key | bigint | true | false |
name | varchar | true | false |
address | varchar | true | false |
nation_key | bigint | true | false |
phone | varchar | true | false |
account_balance | double | true | false |
market_segment | varchar | true | false |
comment | varchar | true | false |
_partition_id | bigint | true | false | Partition Id
_partition_offset | bigint | true | false | Offset for the message within the partition
_segment_start | bigint | true | false | Segment start offset
_segment_end | bigint | true | false | Segment end offset
_segment_count | bigint | true | false | Running message count per segment
_key | varchar | true | false | Key text
_key_corrupt | boolean | true | false | Key data is corrupt
_key_length | bigint | true | false | Total number of key bytes
_message | varchar | true | false | Message text
_message_corrupt | boolean | true | false | Message data is corrupt
_message_length | bigint | true | false | Total number of message bytes
(21 rows)
presto:tpch> SELECT * FROM customer LIMIT 5;
kafka_key | row_number | customer_key | name | address | nation_key | phone | account_balance | market_segment | comment
-----------+------------+--------------+--------------------+---------------------------------------+------------+-----------------+-----------------+----------------+---------------------------------------------------------------------------------------------------------
1 | 2 | 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tEgvwfmRchLXak | 13 | 23-768-687-3665 | 121.65 | AUTOMOBILE | l accounts. blithely ironic theodolites integrate boldly: caref
3 | 4 | 4 | Customer#000000004 | XxVSJsLAGtn | 4 | 14-128-190-5944 | 2866.83 | MACHINERY | requests. final, regular ideas sleep final accou
5 | 6 | 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx,LREYKUWAh yVn | 20 | 30-114-968-4951 | 7638.57 | AUTOMOBILE | tions. even deposits boost according to the slyly bold packages. final accounts cajole requests. furious
7 | 8 | 8 | Customer#000000008 | I0B10bB0AymmC, 0PrRYBCP1yGJ8xcBPmWhl5 | 17 | 27-147-574-9335 | 6819.74 | BUILDING | among the slyly regular theodolites kindle blithely courts. carefully even theodolites haggle slyly alon
9 | 10 | 10 | Customer#000000010 | 6LrEaV6KR6PLVcgl2ArL Q3rqzLzcT1 v2 | 5 | 15-741-346-9870 | 2753.54 | HOUSEHOLD | es regular deposits haggle. fur
(5 rows)
presto:tpch> SELECT sum(account_balance) FROM customer LIMIT 10;
_col0
-------------------
6681865.590000002
(1 row)
presto:tpch> SELECT kafka_key FROM customer ORDER BY kafka_key LIMIT 10;
kafka_key
-----------
0
1
2
3
4
5
6
7
8
9
(10 rows)
|
5.5 System Connector
1
|
presto:default> SHOW SCHEMAS FROM system;
Schema
--------------------
information_schema
metadata
runtime
presto:default> SHOW TABLES FROM system.runtime;
Table
---------
nodes
queries
tasks
presto:system> use system.runtime;
presto:runtime> show tables;
Table
---------
nodes
queries
tasks
|
6„ÄĀŚźĮŚä®Presto
1
|
[root@itr-mastertest01 presto]# bin/launcher start
bin/launcher start ‚Äďv
ŚźĮŚä®śä•ťĒôÔľö
Unsupported major.minor version 52.0ÔľĆXXkťúÄŤ¶Ā1.8+
tar -zxvf software/XXk-8u45-linux-x64.tar.gz
šłĽŤäāÁāĻŚźĮŚä®jpsÔľöbin/launcher start
PrestoServer
WorkerŚźĮŚä®Ôľöbin/launcher start
PrestoServer
|
7„ÄĀCommand Line Interface
1
|
śĶčŤĮē Presto CLI
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.100/presto-cli-0.100-executable.jar
Download presto-cli-0.100-executable.jarŚĻ∂ŚįÜŚÖ∂ťáćŚĎĹŚźćšłļ presto-cliÔľąšĹ†šĻüŚŹĮšĽ•ťáćŚĎĹŚźćšłļ prestoÔľČÔľĆÁĄ∂Śźéś∑ĽŚä†śČߍ°ĆśĚÉťôź„Äā
mv presto-cli-0.100-executable.jar presto
chmod +x presto
./presto --server itr-mastertest01:9090 --catalog hive --schema default
presto:default> show tables;
Table
--------------------
order_test
order_test_parquet
ŚŹĮšĽ•ŤŅźŤ°Ć --help ŚĎĹšĽ§śü•ÁúčśõīŚ§öŚŹāśēįԾƚĺ茶āšĹ†ŚŹĮšĽ•Śú®ŚĎĹšĽ§Ť°ĆÁõīśé•ŤŅźŤ°ĆšłčťĚĘŚĎĹšĽ§Ôľö
./presto --help
./presto --server itr-mastertest01:9090 --catalog hive --schema default --execute "show tables;"
ťĽėŤģ§śÉÖŚÜĶšłčÔľĆPresto ÁöĄśü•ŤĮĘÁĽďśěúśėĮšĹŅÁĒ® less Á®čŚļŹŚąÜť°ĶŤĺďŚáļÁöĄÔľĆšĹ†ŚŹĮšĽ•ťÄöŤŅášŅģśĒĻÁéĮŚĘÉŚŹėťáŹ PRESTO_PAGER ÁöĄŚÄľŚįÜŚÖ∂śĒĻšłļŚÖ∂šĽĖŚĎĹšĽ§ÔľĆŚ¶ā moreԾƜąĖŤÄÖŚįÜŚÖ∂ÁĹģšłļÁ©ļšĽ•Á¶Āś≠ĘŚąÜť°ĶŤĺďŚáļ„Äā
[hsu@serv01 ~]$ cat engines/presto-sql-cli.sh
/home/hsu/presto/bin/presto-cli --server serv01:9090 --catalog hive --schema default
|
8. śĶčŤĮē XXbc
1
|
https://repo1.maven.org/maven2/com/facebook/presto/presto-XXbc/0.100/presto-XXbc-0.100.jar
šĹŅÁĒ® XXbc ŤŅěśé• PrestoԾƝúÄŤ¶ĀšłčŤĹĹ XXbc ť©ĪŚä® presto-XXbc-0.100.jarŚĻ∂ŚįÜŚÖ∂Śä†ŚąįšĹ†ÁöĄŚļĒÁĒ®Á®čŚļŹÁöĄ classpath šł≠„Äā
śĒĮśĆĀšĽ•šłčŚá†Áßć XXBC URL ś†ľŚľŹÔľö
XXbc:presto://host:port
XXbc:presto://host:port/catalog
XXbc:presto://host:port/catalog/schema
ŤŅěśé• hive śēįśćģŚļďšł≠ sales ŚļďÔľĆÁ§ļšĺ茶āšłčÔľö
XXbc:presto: http://itr-mastertest01:9090/hive/sales
|
9. śÄĽÁĽď
1
|
śú¨śĖášłĽŤ¶ĀŤģįŚĹē Presto ÁöĄŚģČŤ£ÖťÉ®ÁĹ≤ŤŅáÁ®čԾƌĻ∂šĹŅÁĒ® hive-hadoop2 ŤŅěśé•Śô®ŤŅõŤ°ĆÁģÄŚćēśĶčŤĮē„ÄāšłčšłÄś≠•ÔľĆťúÄŤ¶ĀŚüļšļ隳ĚļõÁĒüšļßśēįśćģŚĀöšłÄšļõŚäüŤÉĹśĶčŤĮēšĽ•ŚŹäŚíĆ impala,spark-sql,hive ŚĀöšłÄšļõŚĮĻśĮĒśĶčŤĮē„Äā
ŤĶĄśĖôÔľöhttp://tech.meituan.com/presto.html
http://prestodb.io/
http://www.dw4e.com/?p=141
http://wangmeng.us/notes/Impala/ #Impala Presto wiki šłĽŤ¶ĀšĽčÁĽćšļÜ Presto ÁöĄśě∂śěĄ„ÄĀŚéüÁźÜŚíĆŚ∑•šĹúśĶĀÁ®čԾƚĽ•ŚŹäŚíĆ impala ÁöĄŚĮĻśĮĒ„Äā
|
šļĆ„ÄĀorcšľėÁßÄŚ≠ėŚā®ś†ľŚľŹ
https://code.facebook.com/posts/370832626374903/even-faster-data-at-the-speed-of-presto-orc/
orcÁöĄŤá™Śł¶ÔľĆšłćťúÄŤ¶Āś∑ĽŚä†jarŚĆÖ
https://github.com/klbostee/hadoop-lzo
ŤŅôšł™ÁľĖŤĮĎšļÜśĒ匹įpluginšłčťĚĘÁöĄŚĮĻŚļĒÁöĄhive-xxxÁõģŚĹēšłčťĚĘԾƌźĆś≠•šłčŚļĒŤĮ•ŚįĪŤÉĹÁĒ®šļÜ
ŤģĺÁĹģŤ°®ś†ľŚľŹ
1
|
set session hive.storage_format='RCBINARY'
set session hive.storage_format='RCTEXT'
set session hive.storage_format='ORC';
set session hive.storage_format='PARQUET';
|
šłČ„ÄĀPrestoŚÖ®ťĚ†šľėŚĆĖŚŹāśēį
1
|
presto:
ŚģėśĖĻťĽėŤģ§Ś≠ėŚā®ś†ľŚľŹśėĮRCFileś†ľŚľŹÁöĄÔľĆŚŹĮšĽ•ŤģĺÁĹģset session hive.storage_format='ORC';
XX:ŚģĘśą∑ÁęĮŚįĪŤ°ĆšļÜԾƌֹset session hive.storage_format='ORC';ÁĄ∂ŚźéŚĽļÁöĄŤ°®ŚįĪśėĮORCś†ľŚľŹÁöĄšļÜÔľĀ
XX:ÁĒüśąźorcśĖᚼ∂śēąÁéᜏźŚćጏāśēįÔľö
presto:test> set session task_writer_count='8';
XX:cat jvm.config śąĎšĽ¨ŤŅôŤĺĻ -Xmx120G
XX: ŚáļÁéįśēįśćģŚÄĺśĖúÔľö
optimize_hash_generation,ŤŅôšł™session ŚŹāśēįŤģĺÁĹģśąźtrueŤĮēšłč
presto:test> set session optimize_hash_generation='true';
PrestoÁĒüśąźorcŤ°®Ôľö
presto:default> set session hive.storage_format='PARQUET';
presto:default> create table test_parquet_test as select * from test_textfile;
presto:default> set session hive.storage_format='ORC';
presto:test> set session task_writer_count='8';
presto:test> create table test_orc_test_presto as select * from test_textfile;
hive (default)> show create table test;
#ÁĒüśąźšłćŚźĆś†ľŚľŹÁöĄŤ°®
set session hive.storage_format='RCBINARY'
set session hive.storage_format='RCTEXT'
set session hive.storage_format='PARQUET';
set session hive.storage_format='ORC';
|
Śõõ„ÄĀśĶčŤĮēŤŅáÁ®čťóģťĘė
1„ÄĀśüźšļõśü•ŤĮĘÁĽīŚļ¶šłćŚźąÁźÜŚĮľŤáīśēįśćģŚÄĺśĖúԾƜüźšļõŤäāÁāĻŤīüŤĹĹŤŅጧߍÄĆŚ§ĪŚéĽŤĀĒÁ≥ĽŚáļÁéįťóģťĘėÔľĀ
1
|
ŚÖ∑šĹ®ÁéįšłļÔľöQuery 20150507_013905_00017_3b8jn failed: Encountered too many errors talking to a worker node. The node may have crashed or be under too much load. This is probably a transient issue, so please retry your query in a few minutes.
select * from system.runtime.nodes;ŤĮ≠ŚŹ•ŚŹĎÁéįśüźšļõŤäāÁāĻŚíĆťõÜÁ姌§ĪŚéĽŤĀĒÁ≥ĽŚĮľŤáīŤĮÜŚąęÔľĀ
Ťß£ŚÜ≥ÔľöŚźąÁźÜÁöĄśü•ŤĮĘÁĽīŚļ¶ÔľĆŤįÉšľėŚŹāśēįset session optimize_hash_generation='true';
|
 
2„ÄĀorcśĖᚼ∂ś†ľŚľŹÁĒüśąźśēąÁéášĹéšłč
1
|
XX:ÁĒüśąźorcśĖᚼ∂śēąÁéᜏźŚćጏāśēįÔľö
presto:test> set session task_writer_count='8';
XXÁöĄÁĒüśąźorcŚįĪťĚ쌳łŚŅęÔľĆ15šł™nodeԾƍÄĆśąĎŤŅôťáĆŚįĪÁģóŤģĺÁĹģšļÜŤįÉšľėŚŹāśēįԾƝõÜÁ姍ŅėśėĮÁĒ®šļÜŚĺąťēŅśó∂ťóīÔľĀŚįĪŚú®Á°¨šĽ∂Áď∂ťĘąšłäťĚĘÔľĀšłćŚźĆś°Üśě∂ťÉĹśúȍᙌ∑ĪÁČĻŚģöšľėŚĆĖÁöĄś†ľŚľŹÔľĆťúÄŤ¶ĀŚõõÁĽĄśĶčŤĮēŚĮĻśĮĒÁúčԾƜČćŤÉĹÁú茹įŚéčÁľ©Á©ļťóīśÉÖŚÜĶÔľĀśó∂ťóīŚíĆÁ©ļťóīśėĮšł§ťöĺÁöĄśäČśč©ÔľĀXXÔľöśąĎšĽ¨ŤŅôŤĺĻ -Xmx120GÔľĆset session task_writer_count='8', task.max-memory=30GB
śĮŹšł™ŤäāÁāĻŚÜôÁļŅÁ®čŚĘěŚä†šłļ8šł™ÔľĆťĽėŤģ§śėĮ1šł™ÔľĀ
|
 
3„ÄĀprestoÁõģŚČćśó†ÁľďŚ≠ėŚäüŤÉĹ
1
|
śĖįÁČąśú¨ŚŹĮŤÉĹšľöśŹźšĺõԾƌ∑≤ÁĽŹśúČšļļŚú®ŚľÄŚŹĎś¨°ś®°ŚĚóŤŅėś≤°ŚźąŚĻ∂ŚąįŚģėśĖĻmasterÁČąśú¨šł≠ԾƍÄĆŚŹ™śėĮŚú®ŚąÜśĒĮšł≠!
|
 
4„ÄĀprestoŤģ°ÁģóŤäāÁāĻŚ§ĪŚéĽŤĀĒÁ≥Ľ,Ťģ°ÁģóÁöĄorcÁĽďśěúśĖᚼ∂ťĚ쌳łŚ∑®Ś§ß
1
|
presto:test> select count(1) from (SELECT a, b, c,row_number() OVER (PARTITION BY a,b ORDER BY a DESC) AS rnk FROM test_orc_test_presto) a where a.rnk=1;
Query 20150507_062202_00117_3b8jn, FAILED, 9 nodes
Splits: 18 total, 0 done (0.00%)
1:56 [88M rows, 1.27GB] [758K rows/s, 11.2MB/s]
Query 20150507_062202_00117_3b8jn failed: Encountered too many errors talking to a worker node. The node may have crashed or be under too much load. This is probably a transient issue, so please retry your query in a few minutes. (http://135.33.5.63:9090/v1/task/20150507_062202_00117_3b8jn.2.1/results/20150507_062202_00117_3b8jn.1.6/864 - requests failed for 84.18s)
presto:test> set session optimize_hash_generation='true';
SET SESSION
presto:test> set session optimize_hash_generation='false';
SET SESSION
ťíąŚĮĻorcś†ľŚľŹÁöĄŤ°®ŚÖ≥ťó≠šļÜś≠§ŤįÉšľėŚŹāśēįԾƝ°ļŚą©śČߍ°ĆÔľĀśéíśü•ŚŹĎÁéįorcśĖᚼ∂ŚĺąŚ§ß
ťúÄŤ¶Āśéߌą∂ÁĒüśąźśõīŚ§öśĮĒŤĺÉŚįŹÁöĄorcÁĽďśěúśĖᚼ∂ÔľĀśČĚłčŤŅôšł™patchÔľĆÁľĖŤĮĎšłčpresto-hiveť°ĻÁõģÁĄ∂Śźéśääpresto-hive-0.100.jarśõŅśćĘšļÜťá挟Įpresto
https://github.com/facebook/presto/pull/2655
----
ÁõģŚČ朹όłā0.100ÁČąśú¨ÔľĆŤÄĆŚú®0.101ÁČąśú¨ŚįĪŚ∑≤ÁĽŹšŅģšļÜś≠§ťóģťĘėšļÜÔľĀ
Á°ģŚģěÁĒ®hiveÁĒüśąźÁöĄorcŤ°®ŚŹĮšĽ•Ťß£ŚÜ≥ÔľĀťöĺťĀďśüźšļõŤäāÁāĻśĖᚼ∂Ś§™Ś§ßԾƌĮľŤáīŤģ°ÁģóŤäāÁāĻŚ§ĪŚéĽŤĀĒÁ≥ĽŚźóÔľüYESԾƍᙝóģŤá™Á≠ĒÔľĀ
QQÁ≠ĒÁĖĎÔľö
Ph-XX:
hiveÁĒüśąźÁöĄorcśĖᚼ∂śúȌ幌§öԾƍÄĆprestoÁĒüśąźÁöĄorcśĖᚼ∂śēįŚíĆworkeršłÄś†∑ÔľĀŚĮľŤáīśü•ŤĮĘorcÁöĄśó∂ŚÄôԾƜüźšļõŤäāÁāĻŚ§ĪŚéĽŤĀĒÁ≥ĽŤÄĆšĽĽŚä°Ś§ĪŤī•ÔľĀprestośü•ŤĮĘhiveÁĒüśąźÁöĄorcŤ°®ŚĺąŚŅęŚģĆśąźÔľĀśó†śä•ťĒôÔľĀśėĮ0.100ÁĒüśąźorcŤ°®ÁöĄÁ≠ĖÁē•ťóģťĘėŚźßÔľĀ@XX-AA
XX-AA 2015/5/13 9:34:40
šĹ†ŚŹĮšĽ•ŤģĺÁĹģtask_write_countŚŹāśēį
XX-AA 2015/5/13 9:35:17
ťĽėŤģ§śėĮ1ԾƚĻüŚįĪśėĮšłÄšł™ŤäāÁāĻŤĶ∑šłÄšł™writeÁļŅÁ®čԾƚĻüŚįĪśėĮšłÄšł™ŤäāÁāĻŚĹĘśąźšłÄšł™śĖᚼ∂Ծƌ¶āśěúŤŅôšł™ŚŹāśēįŤģĺÁĹģŚ§öšł™ÔľĆŚÜôÁöĄśĖᚼ∂šĻüšľöŚ§ö
XX-AA 2015/5/13 9:35:22
ŚÜôÁöĄśēąÁéášĻüťęė
|
 
5„ÄĀťíąŚĮĻhivešľėŚĆĖŚŹāśēį
1
|
hive.metastore-cache-ttl etc/catalog/hive.properties hiveŚÖÉśēįśćģÁľďŚ≠ėÁöĄŤŅáśúüśó∂ťóī default:1h
hive.metastore-refresh-interval etc/catalog/hive.properties hiveŚÖÉśēįśćģÁľďŚ≠ėÁöĄŚą∑śĖįśó∂ťóī default:1s
optimizer.optimize-hash-generation ŚŹ™ťúÄŚú®Coordinatoršłäetc/config.propertiesŤŅõŤ°ĆťÖćÁĹģ Ť°®Á§ļśėĮŚź¶ŚźĮÁĒ®ŚĮĻŚďąŚłĆŤĀöŚźąÁöĄšľėŚĆĖԾƌ¶āśěúŚźĮÁĒ®ŤĮ•ťÄČť°ĻԾƌįÜšľöśŹźŚćáCPUšĹŅÁĒ®Áéá default:FALSE
SET SESSION optimize_hash_generation = 'true';
SET SESSION hive.optimized_reader_enabled = 'true';
|
 
šļĒ„ÄĀWEBUIÁēĆťĚĘ
https://github.com/itweet/airpal
git clone https://github.com/itweet/airpal.git
./gradlew clean shadowJar
ťÖćÁĹģŚźéŚć≥ŚŹĮšĹŅÁĒ®ÔľĆŚŹāŤÄÉśĖáś°£ŤŅõŤ°ĆÔľĀ
-
MysqlŚąõŚĽļŚļď
1mysql> select user,host from mysql.user\G; *************************** 1. row *************************** user: airpal host: % mysql> create database airpal; Query OK, 1 row affected (0.00 sec) mysql> grant all on airpal.* to 'airpal'@'%' identified by 'airpal'; Query OK, 0 rows affected (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) -
ťÖćÁĹģreferenceśĖᚼ∂
1[hsu@serv01 airpal]$ cat reference.yml # Logging settings logging: loggers: org.apache.shiro: INFO # The default level of all loggers. Can be OFF, ERROR, WARN, INFO, DEBUG, TRACE, or ALL. level: INFO # HTTP-specific options. server: applicationConnectors: - type: http port: 8081 idleTimeout: 10 seconds adminConnectors: - type: http port: 8082 shiro: iniConfigs: ["classpath:shiro_allow_all.ini"] dataSourceFactory: driverClass: com.mysql.XXbc.Driver user: airpal password: airpal url: XXbc:mysql://127.0.0.1:3306/airpal # The URL to the Presto coordinator. prestoCoordinator: http://serv01:9090 -
migragte your database
1[hsu@serv01 airpal]$ java -Duser.timezone=UTC -cp build/libs/airpal-0.1.0-SNAPSHOT-all.jar com.airbnb.airpal.AirpalApplication db migrate reference.yml INFO [2015-05-11 03:50:19,945] org.flywaydb.core.internal.command.DbMigrate: Successfully applied 5 migrations to schema `airpal` (execution time 00:01.568s). [hsu@serv01 airpal]$ java -server -Duser.timezone=UTC -cp build/libs/airpal-0.1.0-SNAPSHOT-all.jar com.airbnb.airpal.AirpalApplication server reference.yml
ŚÖ≠„ÄĀTPC-H
1
|
http://prestodb-china.com/docs/current/installation/benchmark-driver.html
https://repo1.maven.org/maven2/com/facebook/presto/presto-benchmark-driver/0.103/presto-benchmark-driver-0.103-executable.jar
$ mv presto-benchmark-driver-0.103-executable.jar presto-benchmark-driver
$ chmod +x presto-benchmark-driver
[hsu@serv01 test]$ ls
presto-benchmark-driver
$ cat suite.json
{
"file_formats": {
"query": ["single_.*", "tpch_.*"],
"schema": [ "tpch_sf(?<scale>.*)_(?<format>.*)_(?<compression>.*?)" ]
},
"legacy_orc": {
"query": ["single_.*", "tpch_.*"],
"schema": [ "tpch_sf(?<scale>.*)_(?<format>orc)_(?<compression>.*?)" ],
"session": {
"hive.optimized_reader_enabled": "false"
}
}
}
#ŚľÄŚßčśĶčŤĮēԾƜú®śúČśąźŚäü
[hsu@serv01 test]$ sh presto-benchmark-driver --server serv01:9090 --catalog tpch--schema default
https://prestodb.io/docs/current/connector/tpch.html
$ cat tpch.properties
connector.name=tpch
$ /home/hsu/presto/bin/presto-cli --server serv01:9090 --catalog tpch
presto:default> SHOW SCHEMAS FROM tpch;
Schema
--------------------
information_schema
sf1
sf100
sf1000
sf10000
sf100000
sf300
sf3000
sf30000
tiny
presto:default> use sf1;
presto:sf1> show tables;
Table
----------
customer
lineitem
nation
orders
part
partsupp
region
supplier
|
šłÉ„ÄĀŚáĹśēį
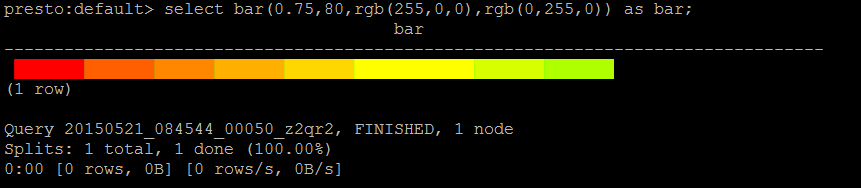
1
|
http://prestodb-china.com/docs/current/functions/color.html
|
 
- śó∂ťóīŚáĹśēį
1presto:default> select '2001-08-22 03:04:05',date_format(cast('2001-08-22 03:04:05' as timestamp),'%H%m') from default.event_type_jf limit 1; _col0 | _col1 ---------------------+------- 2001-08-22 03:04:05 | 0308 (1 row) http://prestodb-china.com/docs/current/functions/datetime.html presto:default> select '2001-08-22 03:04:05',date_format(cast('2001-08-22 03:04:05' as timestamp),'%Y%m%d') from default.event_type_jf limit 1; _col0 | _col1 ---------------------+---------- 2001-08-22 03:04:05 | 20010822 (1 row)
ŚÖę„ÄĀjoinśÄߍÉĹ
1
|
joinśó∂śúČŚ§ßŤ°®ÁöĄŤĮĚŚľÄŚźĮdistributed-joins-enabled=trueԾƌĻ∂ŚįÜŚ§ßŤ°®śĒĺŚú®joinÁöĄŚŹ≥šĺßԾƚľöśŹźťęėśÄߍÉĹ
śąĖŤÄÖŚĎĹšĽ§Ť°ĆťáĆťĚĘset session distributed_join='true';
ťÖćÁĹģśĖᚼ∂
# sample nodeId to provide consistency across test runs
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.environment=test
http-server.http.port=8080
discovery-server.enabled=true
discovery.uri=http://localhost:8080
exchange.http-client.max-connections=1000
exchange.http-client.max-connections-per-server=1000
exchange.http-client.connect-timeout=1m
exchange.http-client.read-timeout=1m
scheduler.http-client.max-connections=1000
scheduler.http-client.max-connections-per-server=1000
scheduler.http-client.connect-timeout=1m
scheduler.http-client.read-timeout=1m
query.client.timeout=5m
query.max-age=30m
plugin.bundles=\
../presto-raptor/pom.xml,\
../presto-hive-cdh4/pom.xml,\
../presto-example-http/pom.xml,\
../presto-kafka/pom.xml, \
../presto-tpch/pom.xml
presto.version=testversion
experimental-syntax-enabled=true
distributed-joins-enabled=true
|
ťėüŚąóÁõłŚÖ≥
https://prestodb.io/docs/current/admin/queue.html
SQLŤĮ≠ś≥ē
1.3 śėĺÁ§ļŚąÜŚĆļŤ°®
1
|
presto:bigdata> SHOW PARTITIONS FROM test_partitioned;
|
ŚŹāŤÄÉÔľöhttps://prestodb.io/
ŚéüŚąõśĖáÁę†ÔľĆŤĹ¨ŤĹĹŤĮ∑ś≥®śėéÔľö ŤĹ¨ŤĹĹŤá™sparkjvmÁöĄŚćöŚģĘ



ÁõłŚÖ≥śé®Ťćź
This is a plugin for Presto that allow you to use Oracle Jdbc Connection Presto-Connectors Member Connection Configuration Create new properties file inside etc/catalog dir: connector.name=oracle #...
presto oracle connector plugin.This is a plugin for Presto that allow you to use Oracle Jdbc Connection
usersync.tar.gz tagsync.tar.gz storm-plugin.tar.gz src.tar.gz sqoop-plugin.tar.gz solr_audit_conf.zip solr_audit_conf.tar.gz solr-plugin.tar.gz schema-registry-plugin.jar ranger-tools.tar.gz presto-...
this is a presto bigquery connector that can skip the license , and this is for demo only, can not use for ecommic env. You can use it to connect to bigquery without buying license
outline a selection of use cases that Presto supports at Facebook. We then describe its architecture and implementation, and call out features and performance optimizations that enable it to support ...
kubesql is a tool to use sql to query the resources of kubernetes. The resources of kubernetes such as nodes, pods and so on are handled as tables. For example, all pods are easily to list from api...
for the Presto-based Opera without using the remote server, nor is there likely to be. * Added option to not delete anonymous Firefox profile in .NET. This change adds an option to the .NET ...
router.Use(logMiddleware) // ŚŹ™ŚĮĻśüźšł™Ť∑ĮÁĒĪŚļĒÁĒ®ÁöĄŤļꚼŝ™ĆŤĮĀšł≠ťóīšĽ∂ router.POST("/protected", authMiddleware, protectResource) ``` Śú®Ś§ĄÁźÜJSONśēįśćģśó∂ÔľĆ"gopencils" śŹźšĺõšļÜśĖĻšĺŅÁöĄŚ∑•ŚÖ∑śĚ•Ťß£śěźŤĮ∑śĪāšĹďŚíƜ쥝ĆŚďćŚļĒ„Äā...
* Ťá™ŚģöšĻČŚÖ®ŚĪÄťÄöÁĒ®śďćšĹúÔľöśĒĮśĆĀŚÖ®ŚĪÄťÄöÁĒ®śĖĻś≥ēś≥®ŚÖ•ÔľąWrite once, use anywhereÔľČ * ŚÜÖÁĹģšĽ£Á†ĀÁĒüśąźŚô®ÔľöťááÁĒ®šĽ£Á†ĀśąĖŤÄÖ Maven śŹíšĽ∂ŚŹĮŚŅęťÄüÁĒüśąź Mapper „ÄĀModel „ÄĀService „ÄĀController ŚĪāšĽ£Á†ĀԾƜĒĮśĆĀś®°śĚŅŚľēśďéԾƜõīśúČŤ∂ÖŚ§öŤá™ŚģöšĻČ...
In order to use Presto to query an Iceberg table, make sure you have a working setup of Presto, Hive Metastore and Alluxio, and Presto can access data through Alluxio’s filesystem interface....
use Tuozhongedu\Mobile\Parser; $parser = new Parser(); $result = $parser->parse('13800138000'); echo $result['province'] . $result['city'] . $result['carrier']; ``` 4. **śēįśćģśõīśĖį**ÔľöśČčśúļŚŹ∑Á†ĀŚĹíŚĪěŚúį...
astro/wiki/Use/- dedisp https://github.com/ajameson/dedispiqrm_apollo https://gitlab.com/kmrajwade/iqrm_apollojupyterlab https://jupyter.org/PRESTO https://www.cv.nrao.edu/~sransom
śĖáś°£śúÄŚźéŚĆÖŚźęšļÜšłÄšļõś≥®śĄŹšļčť°ĻԾƜĮĒŚ¶ā‚ÄúNC=Not Connected‚ÄĚÔľąśú™ŤŅěśé•ÔľČŚíĆ‚ÄúDU=Dont‚Äôt Use‚ÄĚÔľąšłćŤ¶ĀšĹŅÁĒ®ÔľČԾƍŅôšļõśėĮŚĮĻÁČĻŚģöŚľēŤĄöÁä∂śÄĀÁöĄŤĮīśėéԾƜĆáŚĮľÁĒ®śą∑ś≠£Á°ģŤŅěśé•ŚíĆšĹŅÁĒ®Ś≠ėŚā®Śô®„Äā ### śÄĽÁĽď M27C256BśėĮšłÄś¨ĺÁĽŹŚÖłÁöĄÁīꌧĖÁļŅśď¶ťô§ŚŹĮ...
use Web Report System for java EasyReportśėĮšłÄšł™ÁģÄŚćēśėďÁĒ®ÁöĄWebśä•Ť°®Ś∑•ŚÖ∑,ŚģÉÁöĄšłĽŤ¶ĀŚäüŤÉĹśėĮśääSQLŤĮ≠ŚŹ•śü•ŤĮĘŚáļÁöĄśēįśćģŤĹ¨śćĘśąźśä•Ť°®ť°ĶťĚĘÔľĆ ŚźĆśó∂śĒĮśĆĀŤ°®ś†ľÁöĄŤ∑®Ť°Ć(RowSpan)šłéŤ∑®Śąó(ColSpan)ťÖćÁĹģ„Äā ŚźĆśó∂ŚģÉŤŅėśĒĮśĆĀśä•Ť°®ExcelŚĮľŚáļ„ÄĀ...
2. Batch / Stream (Spark/Flink/Presto/...)ÔľöHudi ŚŹĮšĽ•šłéŚ§öÁßćśēįśćģŚ§ĄÁźÜŚľēśďéťõÜśąźÔľĆśŹźšĺõťęėśēąÁöĄśēįśćģŚ§ĄÁźÜŤÉĹŚäõ„Äā 3. Source A/B/N delta...ÔľöHudi ŚŹĮšĽ•Ś§ĄÁźÜŚ§öÁßćśēįśćģśļźÔľĆśŹźšĺõťęėśēąÁöĄśēįśćģŚ§ĄÁźÜŤÉĹŚäõ„Äā Hudi API 1. Read/...
- **Opera**Ôľöśó©śúüšĹŅÁĒ®PrestoŚľēśďéÔľĆÁéįŚú®šĻüŤĹ¨ŚźĎBlink„Äā 4. **śĶŹŤßąŚô®ŚÖľŚģĻśÄß**Ôľö ÁĒĪšļ隳挟ĆÁöĄśĶŹŤßąŚô®ŚŹĮŤÉĹŚĮĻHTML„ÄĀCSSśąĖJavaScriptŚģěÁéįšłćŚģĆŚÖ®šłÄŤáīԾƌľÄŚŹĎŤÄÖťúÄŚÖ≥ś≥®Ť∑®śĶŹŤßąŚô®ŚÖľŚģĻśÄßťóģťĘė„ÄāťÄöŚłłŚÄüŚä©Can I UseÁĹĎÁęôśĚ•ś£Äśü•ÁČĻśÄß...
IE śĶŹŤßąŚô®ÁöĄŚÜÖś†łśėĮ TridentÔľĆMozilla ÁöĄ GeckoÔľĆChrome ÁöĄ BlinkÔľąWebKit ÁöĄŚąÜśĒĮÔľČÔľĆOpera ŚÜÖś†łŚéüšłļ PrestoÔľĆÁéįšłļ Blink„Äā šļĒ„ÄĀHTML5 śĖįÁČĻśÄߌíĆśĶŹŤßąŚô®ŚÖľŚģĻťóģťĘė HTML5 śĖįŚĘěšļÜŤģłŚ§öśĖįÁČĻśÄßԾƌ¶ā canvas„ÄĀvideo„ÄĀaudio„ÄĀ...