
全文搜索引擎会用某种算法对要建索引的文档进行分析, 从文档中提取出若干Token(词元), 这些算法称为Tokenizer(分词器), 这些Token会被进一步处理, 比如转成小写等, 这些处理算法被称为Token Filter(词元处理器), 被处理后的结果被称为Term(词), 文档中包含了几个这样的Term被称为Frequency(词频)。 引擎会建立Term和原文档的Inverted Index(倒排索引), 这样就能根据Term很快到找到源文档了。 文本被Tokenizer处理前可能要做一些预处理, 比如去掉里面的HTML标记, 这些处理的算法被称为Character Filter(字符过滤器), 这整个的分析算法被称为Analyzer(分析器)。
整个分析过程,如下图所示:

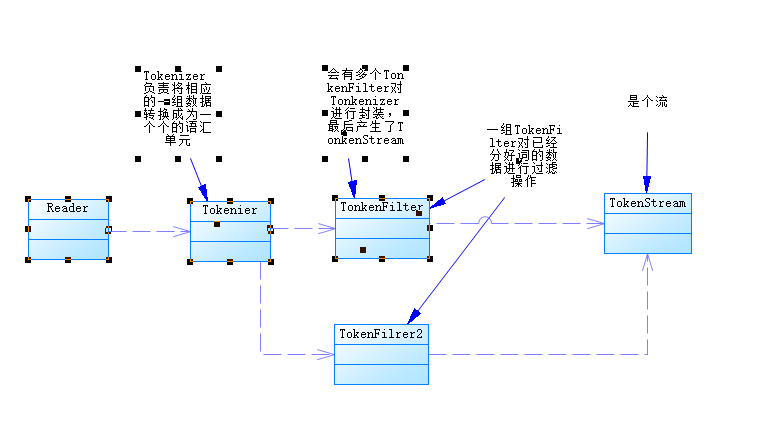
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
package org.lucene.test;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.core.SimpleAnalyzer;
import org.apache.lucene.analysis.core.StopAnalyzer;
import org.apache.lucene.analysis.core.WhitespaceAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.junit.Test;
import org.lucene.Util.AnalyzerUtils;
public class TestAnalyzer {
@Test
public void test01() throws Exception {
Analyzer a1 = new StandardAnalyzer();//标准分词器
Analyzer a2 = new StopAnalyzer();//停用分词器
Analyzer a3 = new SimpleAnalyzer();//简单分词器
Analyzer a4 = new WhitespaceAnalyzer();//空格分词器
String txt = "this is my house,I an come from yunnang zhaotong ,"+ "my qq is 6555@qq.com";
AnalyzerUtils.displayToken(txt, a1);
AnalyzerUtils.displayToken(txt, a2);
AnalyzerUtils.displayToken(txt, a3);
AnalyzerUtils.displayToken(txt, a4);
}
@Test
public void test02() throws Exception {
Analyzer a1 = new StandardAnalyzer();//标准分词器
Analyzer a2 = new StopAnalyzer();//停用分词器
Analyzer a3 = new SimpleAnalyzer();//简单分词器
Analyzer a4 = new WhitespaceAnalyzer();//空格分词器
String txt = "我来自遥远的哈尔滨,大东北帝国冰城皇家科技学院--黑龙江科技大学"; //可以发现对中文支持无效,不支持中文
AnalyzerUtils.displayToken(txt, a1);
AnalyzerUtils.displayToken(txt, a2);
AnalyzerUtils.displayToken(txt, a3);
AnalyzerUtils.displayToken(txt, a4);
}
} |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
package org.lucene.Util;
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class AnalyzerUtils {
public static void displayToken(String str,Analyzer a) throws Exception{
TokenStream stream = a.tokenStream("content", new StringReader(str));
stream.reset(); //在4.0以后的版本必须先reset一次
//创建一个属性,这个属性被添加到流中,随着这个TOkenStream增加,这个属性也增加
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class);
while (stream.incrementToken()) {
System.out.print(" [ "+cta+" ] ");
}
System.out.println();
}
} |



相关推荐
1. **选择合适的中文分词器**:根据应用场景和需求选择合适的分词器。 2. **配置Lucene**:在Lucene的配置文件中指定自定义的中文分词器。 3. **索引构建**:使用中文分词器构建索引。 4. **查询优化**:对查询语句...
总结来说,这个Lucene.NET中文分词器的出现,不仅解决了.NET开发者在处理中文文本时的痛点,也提供了一个实践和研究中文分词技术的实例。通过对最大向前匹配算法的运用,开发者可以在自己的项目中实现高效且相对准确...
《Lucene中文分词技术详解》 在信息检索和自然语言处理领域,中文分词是至...同时,随着自然语言处理技术的发展,新的分词算法和工具不断涌现,持续关注并学习这些新技术,对于提升Lucene在中文环境下的性能至关重要。
对于开发者来说,理解这些分词器的工作原理和特性,有助于优化文本处理流程,提升系统的性能和用户体验。在实际应用中,根据具体业务场景,如搜索查询、情感分析或文本分类等,选择合适的分词器是至关重要的。
**Lucene 3.0 原理解析** Lucene 是一个开源的全文搜索引擎库,由 Apache 软件基金会...对于想要深入理解 Lucene 内部工作原理的开发者,深入学习《Lucene 3.0 原理与代码分析完整版.pdf》这份文档将是极有价值的。
总的来说,Lucene 2.1 的源码分析和中文分词技术为我们揭示了搜索引擎的核心原理和实现细节。通过深入研究这些源码,开发者不仅可以定制自己的搜索引擎,还可以学习到如何处理中文文本,提升自然语言处理能力。
运行这个程序,我们可以直观地看到分词效果,理解盘古分词的工作原理,并学习如何进行字典的管理和维护。 总的来说,了解并熟练掌握Lucene.NET 和盘古分词的集成,以及字典管理技巧,对于开发高效的中文全文搜索...
通过学习Lucene源码,我们可以定制自己的分词器、查询解析器,甚至优化搜索算法,以满足特定的搜索需求。例如,在中文环境下,可以使用IK Analyzer或者jieba分词库来增强对中文的支持。 总结,Lucene作为Java平台上...
本文将深入探讨Lucene的中文分词源码,帮助你理解其工作原理,以便更好地应用到自己的项目中。 首先,Lucene的分词过程主要涉及到两个关键组件:Analyzer和TokenStream。Analyzer是负责将输入的文本分解为一系列的...
《深入剖析Lucene中的中文分词算法源码》 在信息检索领域,Lucene作为一款强大的全文搜索引擎库,被...通过深入学习这些分词器的工作原理,开发者可以更好地调整分词策略,以适应特定的应用场景,提升系统的整体性能。
6. **测试用例**:源码包中通常会有测试类,如`IKAnalyzerTest`,这些测试用例可以用来验证分词器的正确性和效率,同时也是学习分词器工作原理的好材料。 深入研究IK分词器的源码,不仅可以了解中文分词的基本原理...
Solr5.5 搜索引擎之分词原理说明是指 Solr5.5 搜索引擎内部使用的分词原理,旨在帮助开发者自定义自己的分词器时掌握分词的基础知识。 1. 中文分词 中文分词是指将中文汉字序列切分成有意义的词的过程。中文分词是...
以下是对Lucene 3.0基本原理和关键过程的概述。 1. **全文检索的基本原理** 全文检索是针对非结构化数据(如文本)进行搜索的技术。它通过构建索引来实现快速查找。在Lucene中,这一过程包括分词、建立倒排索引和...
这个资料集可能包含了关于如何理解和使用Lucene的各种资源,特别是通过博主huanglz19871030在iteye上的博客文章链接,可以深入学习Lucene的核心概念和技术细节。 【标签】:“源码”和“工具”这两个标签暗示了这个...
### Lucene原理与代码分析概览 #### 一、全文检索基本原理 全文检索是一种能够检索文档中任意词语的信息检索技术...通过上述内容的学习,读者可以全面掌握Lucene的工作原理和技术细节,从而更好地应用于实际项目中。
通过对《Lucene 3.0 原理与代码分析完整版》的学习,开发者不仅可以理解Lucene的工作原理,还能掌握如何定制化Lucene以满足特定需求,从而在实际项目中充分利用其强大功能。这本书是深入研究和应用Lucene不可或缺的...
**Lucene学习指南** Lucene是一个高性能、全文检索库,由Apache软件基金会开发并维护,是Java编程语言中广泛使用的搜索引擎库。它提供了一个简单的API...通过深入学习和实践,你将能够利用Lucene构建高效的搜索系统。
综上所述,《C# Lucene.net原理与代码分析加强版》不仅提供了Lucene.net的工作原理,还深入分析了其实现细节,是学习和掌握全文检索技术不可或缺的资源。通过理解这些原理和机制,开发人员可以更好地优化和定制基于...
"庖丁解牛"分词器采用了先进的算法和技术来解决这个问题,包括基于词典的匹配、上下文信息分析以及统计学习方法等,使得它在处理中文文本时表现出了较高的准确性和效率。 "Lucene"是一个流行的开源全文搜索引擎库,...