
我们兴奋地宣布,从今天开始,Apache Spark1.5.0的预览数据砖是可用的。我们的用户现在可以选择提供集群与Spark 1.5或先前的火花版本准备好几个点击。
正式,Spark 1.5预计将在数周内公布,和社区所做的QA测试的版本。鉴于火花的快节奏发展,我们觉得这是很重要的,使我们的用户尽快开发和利用新特性。与传统的本地软件部署,它可以需要几个月,甚至几年,从供应商收到软件更新。数据砖的云模型,我们可以在几小时内更新,让用户试他们的火花版本的选择。
What’s New?
The last few releases of Spark focus on making data science more accessible, through high-level programming APIs such as DataFrames, machine learning pipelines, and R language support. A large part of Spark 1.5, on the other hand, focuses on under-the-hood changes to improve Spark’s performance, usability, and operational stability.
Spark 1.5 delivers the first phase of Project Tungsten, a new execution backend for DataFrames/SQL. Through code generation and cache-aware algorithms, Project Tungsten improves the runtime performance with out-of-the-box configurations. Through explicit memory management and external operations, the new backend also mitigates the inefficiency in JVM garbage collection and improves robustness in large-scale workloads.
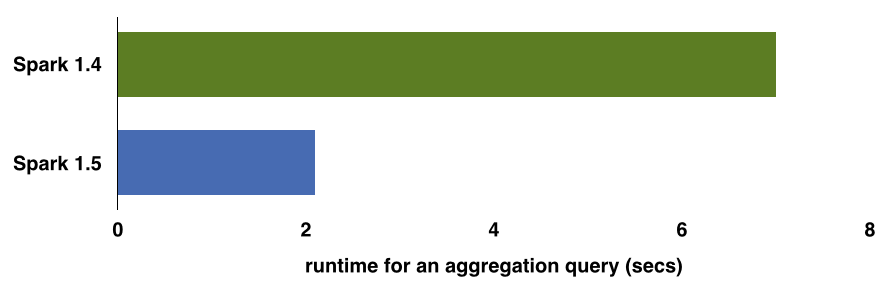
Over the next few weeks, we will be writing about Project Tungsten. To give you a sneak peek, the above chart compares the out-of-the-box (i.e. no configuration changes) performance of an aggregation query (16 million records and 1 million composite keys) using Spark 1.4 and Spark 1.5 on my laptop.
Streaming workloads typically run 24/7 and have stringent stability requirements. In this release, Typesafe has introduced Backpressure in Spark Streaming. With this feature, Spark Streaming can dynamically control the data ingest rates to adapt to unpredictable variations in processing load. This allows streaming applications to be more robust against bursty workloads and downstream delays.
Of course, Spark 1.5 is the work of more than 220 open source contributors from over 80 organizations, and includes a lot more than the above two. Some examples include:
- New machine learning algorithms: multilayer perceptron classifier, PrefixSpan for sequential pattern mining, association rule generation, etc.
- Improved R language support and GLMs with R formula.
- Better instrumentation and reporting of memory usage in web UI.
Stay tuned for future blog posts covering the release as well as deep dives into specific improvements.
How do I use it?
Launching a Spark 1.5 cluster is as easy as selecting Spark 1.5 experimental version in the cluster creation interface in Databricks.
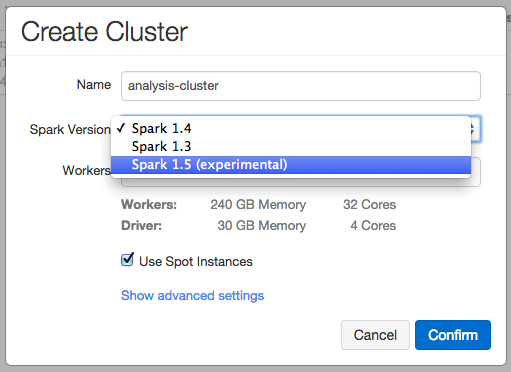
Once you hit confirm, you will get a Spark cluster ready to go with Spark 1.5.0 and start testing the new release. Multiple Spark version support in Databricks also enables users to run Spark 1.5 canary clusters side-by-side with existing production Spark clusters.
You can find the work-in-progress documentation for Spark 1.5.0 here. Please be aware that just like any other preview software, Spark 1.5.0 support is experimental. There will be bugs and quirks that we find and fix in the next couple of weeks. The good news is that you don’t have to worry about following the development or upgrading yourself. As we discover and fix bugs in the open source project, the Spark 1.5 option in Databricks will also be updated automatically. If you encounter a bug, please report it by filing a JIRA ticket.
To try Databricks, sign up for a free 30-day trial.
在上一次北京sparkmeetup技术分享会上,一个spark commiter就说他们忙着Spark 1.5(核心工作就说Tungsten),一个新的DataFrames / SQL执行后端。项目支持缓存通过代码生成算法,提高运行时性能与Tungsten的开箱即用配置。通过显式的内存管理和外部操作,新的后端也减轻了低效JVM的垃圾收集,提高了鲁棒性在大规模的工作负载
目前来看,spark1.5第一阶段目前是完成,估计后期应该有很多优化和代码修复,但可尝尝甜头,如果想了解1.5版本代码,看github spark1.5 branch,个人感觉 主要还是spark sql的提升吧,因为大多数公司都是 spark on yarn的方式,大多数任务提升希望在spark sql上面



相关推荐
Databricks是一个建立在Spark之上的平台,它为用户提供了一个云服务形式的Spark环境,使用户能够更方便地使用Spark进行数据分析和处理。 描述“life is short, you need spark!”是一个口号,形象地传达了掌握和...
reduceByKey方法通过在每个分区中先合并相同键的值,从而减少了网络传输,并允许Spark在Shuffle之前优化计算。而groupByKey方法则是先将所有键值对聚集到一个分区,然后再进行合并,这会增加网络负载和Shuffle过程中...
本次讲座通过99个问题的形式,深入探讨了Spark与Databricks之间的区别及其在实际应用中的优势和挑战。下面将基于提供的文件信息,总结和扩展相关的知识点。 #### 一、Spark与Databricks的关系及区别 - **关系**:...
官方的1.5.2版本spark,亲测可用,现提供低积分下载,只为帮助需要的人,如果可以,给个好评!
Databricks通过Spark平台帮助用户处理这些特性,提取隐藏在大数据中的价值。 2. "话说回来,Databricks到底是什么?" Databricks是基于Apache Spark构建的云平台,它提供了一个集成了数据湖、数据分析和机器学习的...
Apache Spark作为一种快速、通用且可扩展的数据处理引擎,已经得到了所有主要Hadoop发行版的支持,而Databricks作为Spark的主要推动者,致力于提供一个无缝的用户体验。 Databricks云平台的推出旨在解决企业在大...
Spark最佳实践 最佳实践 避免使用 GroupByKey 不要将大型 RDD 的所有元素拷贝到请求驱动者 常规故障处理 Job aborted due to stage failure: Task not serializable 缺失依赖 执行 start-all.sh 错误 - Connection ...
Spark纯净版安装包是一个用于安装Apache Spark的软件包,该软件包提供了Spark的基本功能和组件,但不包含任何额外的扩展或依赖项。纯净版安装包旨在提供一个轻量级、简单易用的Spark安装选项,适用于用户希望快速...
使用Apache Spark 1.5探索Web服务器日志 该数据集可从公开获得。 数据集来源: : 数据集描述: 此跟踪包含对萨斯喀彻温大学的WWW服务器的所有HTTP请求的七个月。 萨斯喀彻温大学位于加拿大萨斯喀彻温省萨斯卡通。...
spark Linux 版本安装包spark Linux 版本安装包spark Linux 版本安装包spark Linux 版本安装包spark Linux 版本安装包spark Linux 版本安装包spark Linux 版本安装包spark Linux 版本安装包spark Linux 版本安装包...
Spark的快速、通用和大规模数据处理能力,使其在批处理、实时流处理、机器学习和图计算等多个领域得到广泛应用。作为大数据处理的统一平台,Spark拥有一个快速的统一分析引擎,支持多种工作负载。 首先,Apache ...
spark.shuffle.blockTransferService netty shuffle过程中,传输数据的方式,两种选项,netty或nio,spark 1.2开始,默认就是netty,比较简单而且性能较高,spark 1.5开始nio就是过期的了,而且spark 1.6中会去除掉 ...
spark1.5版本 早期版本的assembly 包,大家快快来下载吧
作为一个由Apache Spark创始团队成员成立的公司,Databricks继续为开源Spark项目作出巨大贡献,并在全球范围内提供广泛的用户培训和企业支持。这表明了Databricks在推动Spark应用和促进大数据技术普及方面扮演着领导...
这些笔记本展示了如何在Databricks环境中使用Spark进行数据处理和分析,尤其强调了在Azure云环境下的应用。让我们深入探讨一下其中涉及的关键技术点。 1. **Apache Spark**:Spark是大数据处理领域的一个重要框架,...
Spark快速数据处理文档~ Spark集群 1.1 单机运行Spark 1.2 在EC2上运行Spark 1.3 在ElasticMapReduce上部署...1.5 在Mesos上部署Spark 1.6 在Yarn上部署Spark 1.7 通过SSH部署集群 1.8 链接和参考 1.9 小结
shuffle源码Databricks - Apache Spark:trade_mark: - 2X 认证开发人员 这个 repo 是我的认证准备笔记的集合。 如果您有任何建议,找到更正或想要欣赏,请发表评论:-) 关注我,,,, 指数 1. 一般影响链接 用于快速...
在这个"dataengineering-project"中,我们将深入探讨如何在Azure Databricks平台上使用Apache Spark处理和分析Yelp数据集,该数据集通常以Parquet格式存储,这是一种高效、列式存储的数据格式,非常适合大数据处理。...
Apress源代码 该存储库与Robert Ilijason(Apress,2020)一起。...发行版 版本v1.0对应于已出版书籍中的代码,没有更正或更新。 会费 请参阅文件Contributing.md,以获取有关如何为该存储库做出贡献的更多信息。