
概念:
Workers (JVMs): 在一个节点上可以运行一个或多个独立的JVM 进程。一个Topology可以包含一个或多个worker(并行的跑在不同的machine上), 所以worker process就是执行一个topology的子集, 并且worker只能对应于一个topology
Executors (threads): 在一个worker JVM进程中运行着多个Java线程。一个executor线程可以执行一个或多个tasks。但一般默认每个executor只执行一个task。一个worker可以包含一个或多个executor, 每个component (spout或bolt)至少对应于一个executor, 所以可以说executor执行一个compenent的子集, 同时一个executor只能对应于一个component。
Tasks(bolt/spout instances):Task就是具体的处理逻辑对象,每一个Spout和Bolt会被当作很多task在整个集群里面执行。每一个task对应到一个线程,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。你可以调用TopologyBuilder.setSpout和TopBuilder.setBolt来设置并行度 — 也就是有多少个task。
配置并行度
对于并发度的配置, 在storm里面可以在多个地方进行配置, 优先级为:defaults.yaml < storm.yaml < topology-specific configuration < internal component-specific configuration < external component-specific configuration
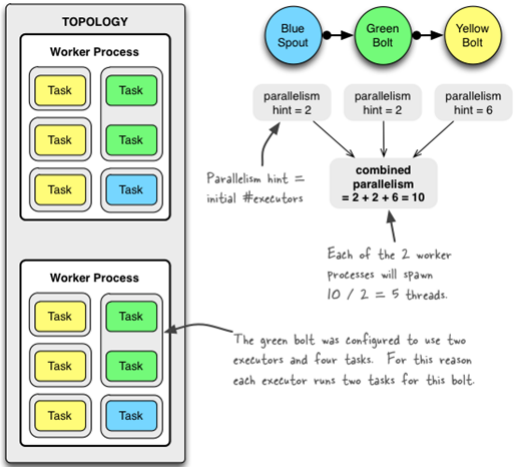
worker processes的数目, 可以通过配置文件和代码中配置, worker就是执行进程, 所以考虑并发的效果, 数目至少应该大亍machines的数目
executor的数目, component的并发线程数,只能在代码中配置(通过setBolt和setSpout的参数), 例如, setBolt("green-bolt", new GreenBolt(), 2)
tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过setNumTasks()配置
Topology的worker数通过config设置,即执行该topology的worker(java)进程数。它可以通过 storm rebalance 命令任意调整。
|
1
2
3
4
5
6
|
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2).setNumTasks(4).shuffleGrouping("blue-spout"); //set tasks number to 4
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6).shuffleGrouping("green-bolt");
StormSubmitter.submitTopology("mytopology", conf, topologyBuilder.createTopology());
|
动态的改变并行度
Storm支持在不 restart topology 的情况下, 动态的改变(增减) worker processes 的数目和 executors 的数目, 称为rebalancing. 通过Storm web UI,或者通过storm rebalance命令实现:
|
1
|
storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10 |
流分组策略----Stream Grouping
Stream Grouping,告诉topology如何在两个组件之间发送tuple
定义一个topology的其中一步是定义每个bolt接收什么样的流作为输入。stream grouping就是用来定义一个stream应该如果分配数据给bolts上面的多个tasks
Storm里面有7种类型的stream grouping,你也可以通过实现CustomStreamGrouping接口来实现自定义流分组
1. Shuffle Grouping
随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
2. Fields Grouping
按字段分组,比如,按"user-id"这个字段来分组,那么具有同样"user-id"的 tuple 会被分到相同的Bolt里的一个task, 而不同的"user-id"则可能会被分配到不同的task。
3. All Grouping
广播发送,对亍每一个tuple,所有的bolts都会收到
4. Global Grouping
全局分组,整个stream被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
5. None Grouping
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(如果可能的话)。
6. Direct Grouping
指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)
7. Local or shuffle grouping
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致。
消息的可靠处理机制
在storm中,可靠的信息处理机制是从spout开始的。一个提供了可靠的处理机制的spout需要记录他发射出去的tuple,当下游bolt处理tuple或者子tuple失败时spout能够重新发射。
Storm通过调用Spout的nextTuple()发送一个tuple。为实现可靠的消息处理,首先要给每个发出的tuple带上唯一的ID,并且将ID作为参数传递给SoputOutputCollector的emit()方法:collector.emit(new Values("value1","value2"), msgId); 给tuple指定ID告诉Storm系统,无论处理成功还是失败,spout都要接收tuple树上所有节点返回的通知。如果处理成功,spout的ack()方法将会对编号是msgId的消息应答确认;如果处理失败或者超时,会调用fail()方法。
bolt要实现可靠的信息处理机制包含两个步骤:1.当发射衍生的tuple时,需要锚定读入的tuple;2.当处理消息成功或失败时分别确认应答或者报错。
锚定一个tuple的意思是,建立读入tuple和衍生出的tuple之间的对应关系,这样下游的bolt就可以通过应答确认、报错或超时来加入到tuple树结构中。可以通过调用OutputCollector的emit()的一个重载函数锚定一个或一组tuple:collector.emit(tuple, new Values(word))
非锚定(collector.emit(new Values(word));)的tuple不会对数据流的可靠性起作用。如果一个非锚定的tuple在下游处理失败,原始的根tuple不会重新发送。
超时时间可以通过任务级参数Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS进行配置,默认超时值为30秒。
Storm 系统中有一组叫做"acker"的特殊的任务,它们负责跟踪DAG(有向无环图)中的每个消息。acker任务保存了spout消息id到一对值的映射。第一个值就是spout的任务id,通过这个id,acker就知道消息处理完成时该通知哪个spout任务。第二个值是一个64bit的数字,我们称之为"ack val", 它是树中所有消息的随机id的异或计算结果。ack val表示了整棵树的的状态,无论这棵树多大,只需要这个固定大小的数字就可以跟踪整棵树。当消息被创建和被应答的时候都会有相同的消息id发送过来做异或。
每当acker发现一棵树的ack val值为0的时候,它就知道这棵树已经被完全处理了。因为消息的随机ID是一个64bit的值,因此ack val在树处理完之前被置为0的概率非常小。假设你每秒钟发送一万个消息,从概率上说,至少需要50,000,000年才会有机会发生一次错误。即使如此,也只有在这个消息确实处理失败的情况下才会有数据的丢失!
有三种方法可以去掉消息的可靠性:
1、将参数Config.TOPOLOGY_ACKERS设置为0,通过此方法,当Spout发送一个消息的时候,它的ack方法将立刻被调用;
2、Spout发送一个消息时,不指定此消息的messageID。当需要关闭特定消息可靠性的时候,可以使用此方法;
3、最后,如果你不在意某个消息派生出来的子孙消息的可靠性,则此消息派生出来的子消息在发送时不要做锚定,即在emit方法中不指定输入消息。因为这些子孙消息没有被锚定在任何tuple tree中,因此他们的失败不会引起任何spout重新发送消息。
http://my.oschina.net/zc741520/blog/409949
http://www.it165.net/os/html/201502/11753.html



相关推荐
Storm应用的配置包括了内存分配、并行度设置、任务调度策略等,这些配置直接影响到Storm集群的性能。另外,Storm的监控也是必不可少的,因为监控可以帮助运维人员及时发现并解决问题,保持系统的稳定运行。 综上所...
**Storm 实时数据分析** 在大数据领域,实时数据处理已经成为一种重要的需求,Apache Storm 就是为了解决这一问题而设计的...在实践中,不断优化拓扑结构、调整并行度以及选择合适的分组策略,是提升Storm性能的关键。
5. 易于扩展:可以灵活调整spout和bolt的并行度来扩展处理能力。 Storm的拓扑结构是由spouts和bolts按照特定的顺序和逻辑连接而成的网络。数据流分组是拓扑设计中的一个关键点,它决定了数据如何在各个bolt之间流动...
通过阅读 `doc-0.8.1` 文件夹中的 HTML 文档,开发者可以详细了解 Storm 的 API 使用方法,包括创建和提交拓扑、定义 spouts 和 bolts、设置并行度以及处理容错等。这将有助于他们构建高效、可靠的实时数据处理系统...
Storm 提供了一个 ACK 框架来确保消息的可靠处理。当 Spout 发送一条消息时,它会等待来自 Bolt 的确认(ACK),只有收到 ACK 后才会丢弃该消息。如果在规定时间内没有收到 ACK,Spout 将重新发送该消息。这种方式...
3. Storm的高级特性:Storm不仅仅是一个简单的流处理工具,书中会对Storm的高级特性进行讲解,比如事务拓扑(Transactional Topologies)、可靠消息处理机制、状态管理等。 4. Storm的集群管理和部署:从零开始搭建...
而Trident是Storm的一个高级API,提供了可靠且精确一次的消息处理语义,常用于大规模实时数据处理任务,如日志分析、网站点击流分析、社交媒体数据处理等。本实战案例将重点介绍如何使用Storm Trident来计算网站的...
高并发度意味着更多的并行处理能力,但也可能增加资源消耗。 **1.4 Worker 与 Topology** - 每个 Worker 只属于一个 Topology,这意味着每个 Worker 中运行的所有 Task 都属于同一 Topology。 - 一个 Topology ...
4. **动态调整**:在运行时,可以动态调整拓扑的执行参数,如增加或减少工作节点,调整并行度等。 在"storm-test"这个文件中,很可能包含了示例代码、配置文件和必要的资源,帮助你实践上述的理论知识。通过阅读和...
根据提供的文件信息,本篇文章将围绕“2018年最新Java大数据基于Storm开发实时流处理器”的主题展开,深入解析Storm的基本概念、架构原理、在大数据处理中的应用场景以及如何使用Java进行开发等内容。 ### 一、...
Storm提供了多种分组方式,如**shuffle grouping**(随机分组)、**fields grouping**(按字段分组)、**global grouping**(全局分组)等,以满足不同类型的并行处理需求。 5. **容错机制**:Storm具有强大的容错...
- **理解Storm中的并行性**:Storm通过并行执行多个任务实例来提高处理能力。 - **调整拓扑以解决瓶颈**: - 在设计中解决固有的瓶颈。 - 针对数据流本身的瓶颈进行优化。 #### 五、总结 本书《Storm Applied》...
修改并行度实在是太容易了(当然对于实际情况来说,每个实例都会运行在单独的机器上)。 不过似乎有一个问题:单词is和great分别在每个WordCounter各计数一次。怎么会这样? 当你调用shuffleGrouping时,就决定了...
这些策略影响了数据在Bolts间的分布,从而影响到性能和并行度。 5. **容错机制** JStorm采用基于消息ID的完全一次处理模型(Exactly Once),保证数据不丢失且仅处理一次。`acker`组件负责确认消息处理状态,`...
最后,要充分利用Storm的能力,你需要深入理解数据流处理的实时性需求,以及如何优化处理性能,例如通过调整worker数量、parallism hint(并行度提示)等参数。同时,关注错误处理和容错机制,确保系统能够在出现...
为了提高性能,Spark Streaming提供了多种优化手段,包括减少网络传输、增加计算并行度、调整微批次大小等。 #### 四、实例演示 ##### 1. 网络数据处理 通过网络接口接收实时数据流,对其进行清洗、过滤和统计分析...
- Storm支持动态调整拓扑的并行度,以应对负载变化。 - 可与Hadoop YARN或Mesos集成,利用现有资源管理系统。 在"Real-Time-Analytics-with-Apache-Storm-master"这个项目中,可能包含了示例代码、教程文档以及...
15. **Storm并行处理**: - Storm可以根据设置的并行度,在集群中分配相应数量的工作线程(Executor)来执行任务组件。 16. **Storm的应用场景**: - Storm不仅可以用于实时数据处理,还可以用于实时分析、复杂事件...
- **Parallelism**: 调整Spout和Bolt的并行度可以优化性能,增加处理能力。 - **Shuffle Grouping**: 随机分发数据,有助于负载均衡。 - **Fields Grouping**: 基于字段的分组允许特定字段的数据在同一Bolt实例中...